

автордың кітабын онлайн тегін оқу Машинное обучение для бизнеса и маркетинга
Х. Бринк, Дж. Ричардс, М. Феверолф
Машинное обучение
2017
Переводчик И. Рузмайкина
Технический редактор Н. Суслова
Литературный редактор А. Андриенко
Художники С. Заматевская , Р. Яцко
Корректоры Н. Викторова, В. Сайко
Верстка Л. Егорова
Х. Бринк, Дж. Ричардс, М. Феверолф
Машинное обучение. — СПб.: Питер, 2017.
ISBN 978-5-496-02989-6
© ООО Издательство "Питер", 2017
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Предисловие
В последние годы машинное обучение (ML — machine learning) превратилось в большой бизнес — фирмы используют его, чтобы заработать денег, прикладные исследования бурно развиваются как в индустриальной, так и в академической среде, а любопытные разработчики везде ищут возможность поднять свой уровень владения темой. Но возникший спрос намного превышает скорость появления хороших методик для изучения применяемых на практике техник. Наша книга призвана удовлетворить данный спрос.
Прикладное машинное обучение совмещает в себе равные доли математических принципов и полученных эмпирическим путем приемов, — другими словами, это настоящее искусство. Слишком сильная концентрация только на одном из этих аспектов в ущерб другому — проигрышная стратегия. Тут важен баланс.
Долгое время самым лучшим и единственным способом постижения машинного обучения было получение ученой степени в одной из областей, которые (по большей части независимо друг от друга) развивали статистические методы и техники оптимизации. Основной упор эти программы делали на ключевые алгоритмы, в том числе на их теоретические свойства и ограничения, а также на характерные особенности относящихся к данной сфере задач. Впрочем, параллельно не менее ценные знания накапливались неофициальным образом — в процессе неформального общения на конференциях, обмена информацией и сценариями обработки данных между коллегами из исследовательских лабораторий. Именно эти знания, по большому счету, и позволили установить, какие алгоритмы больше всего подходят в каждой ситуации, как обрабатывать данные на каждом этапе и как связать между собой различные этапы рабочего процесса.
Сейчас мы живем в эпоху открытого исходного кода, с готовыми к использованию высококачественными алгоритмами, доступными на сайте GitHub, и универсальными, хорошо спроектированными фреймворками, позволяющими связать все фрагменты друг с другом. Но даже среди этого изобилия неофициальные практические знания неизменно оказываются недоступными. Авторы данной книги оказывают вам большую услугу, сведя, наконец, эту скрытую информацию воедино; именно этого ключевого фрагмента не хватает для превращения машинного обучения из понятной лишь посвященным академической дисциплины в набор знаний и навыков по проектированию программного обеспечения.
Стоит подчеркнуть еще один момент. Большинство широко используемых сегодня методов машинного обучения далеки от совершенства и содержат ряд пробелов, которые можно было бы восполнить, будь мы в состоянии спроектировать идеальное решение. Современные методы имеют высокие требования к данным. Они, по большому счету, рады снабдить нас чрезмерно уверенными предсказаниями, если не принять необходимых мер. Небольшие изменения входных данных могут привести к крупным и странным изменениям в обнаруживаемых шаблонах. Получаемые результаты порой сложно интерпретировать и исследовать. Современная инженерия машинного обучения может рассматриваться как упражнение на сглаживание этих (и других) острых углов в методах оптимизации и статистического обучения.
В книге мы постепенно готовим читателя к упомянутым реалиям. Разговор начинается с типичных вариантов рабочего процесса, а затем мы переходим к более сложным примерам, демонстрирующим применение базовых знаний в реальных (читайте: запутанных) ситуациях. В книге крайне мало уравнений (потому что с ними можно ознакомиться где угодно, в том числе в классических учебниках), зато много неизвестных ранее сведений о подходах к реализации продуктов и решений на базе машинного обучения.
Без сомнения, сейчас самое лучшее время для изучения данной темы, и эта книга послужит существенным дополнением к изобилию повсеместно доступных математических и формальных сведений. Это принципиально новая книга, которую люди, давно работающие в данной области, хотели бы получить много лет назад.
Бо Кронин, директор по данным компании 21 Inc. Беркли, Калифорния
Вступление
Как студент, изучавший физику и астрономию, я много времени отдал работе с результатами измерений и моделирования, чтобы путем анализа, визуализации и дальнейшего моделирования извлечь из этих результатов полезную информацию. Я быстро сообразил, как мои навыки программирования могут помочь в решении повседневных задач. Первая же встреча с миром машинного обучения показала, что это не только потенциально крайне полезный новый инструмент, но и превосходная комбинация двух наиболее интересовавших меня дисциплин — теории анализа и обработки данных и программирования.
Машинное обучение стало важной частью моих исследований в области физики и привело меня на факультет астрономии Калифорнийского университета в Беркли, где статистики, физики и ученые, занимающиеся теорией и практикой вычислительных машин и систем, совместно работали над изучением Вселенной, используя ML как важный инструмент познания.
В центре исследования данных, меняющихся во времени (CTDI — Center for Time Domain Informatics), я встретил статистика и будущего соавтора этой книги Джозефа Ричардса. Мы ощутили не только возможность применения техник анализа данных и машинного обучения к научным исследованиям, но и возрастающий интерес к данной теме в компаниях и отраслях, не принадлежащих к академическим кругам. В результате совместно с Дамианом Идсом, Дэном Старром и Джошуа Блумом мы основали компанию Wise.io, предоставляющую машинное обучение в распоряжение бизнеса.
За последние четыре года Wise.io успела поработать над оптимизацией, расширением и автоматизацией посредством машинного обучения рабочих процессов многих компаний. Мы строили для наших клиентов масштабные прикладные платформы, делающие сотни миллионов предсказаний в месяц, и узнали, насколько запутанными и неупорядоченными зачастую являются реальные данные. Мы надеемся передать вам знания, позволяющие работать с такими данными и строить с помощью машинного обучения интеллектуальное программное обеспечение следующего поколения.
Наш третий соавтор, Марк Феверолф, — основатель и технический директор нескольких компаний в области систем управления и бизнес-аналитики, применяющих в работе традиционные статистические и количественные методы. При разработке систем измерения и оптимизации процессов нефтепереработки он и его группа поняли, что техники, пригодные для непрерывного производства, можно применить также к производительности баз данных, компьютерных систем и сетей. Их технологии управления распределенными системами встроены в ведущие инструменты управления. Следующие попытки были связаны с системами, отвечающими за изменения и оптимизацию телекоммуникаций и взаимодействие с клиентами.
Через несколько лет он увлекся конкурсами на платформе Kaggle и обратил внимание на машинное обучение. Он вел проект с рекомендациями для кабельного телевидения, попутно много узнав о больших данных, адаптации вычислительных алгоритмов для параллельных расчетов и вариантах реакции людей на рекомендации, данные машиной. В последние годы он дает консультации по применению машинного обучения и прогностического анализа к приложениям для цифровой рекламы, телекоммуникаций, производства полупроводников, систем управления и оптимизации пользовательского опыта.
Хенрик Бринк
Благодарности
Мы хотим поблагодарить издательство Manning Publications и всех, кто внес свой вклад в создание и публикацию этой книги, в частности редактора Сюзанну Клайн, которая терпеливо и последовательно консультировала нас в процессе работы.
Спасибо Бо Кронину за написанное им предисловие. Спасибо Валентину Креттасу за полную корректуру всех глав. И всем остальным, кто в рабочем порядке давал нам свои бесценные советы: Алену Куньо, Алессандрини Альфредо, Алексу Айверсону, Артуру Зубареву, Дэвиду Клементсу, Дину Айверсону, Якобу Кванту, Яну Гойвертсу, Костасу Пассадису, Лейфу Сингеру, Луи Луангзорну, Массимо Иларио, Майклу Лунду, Морану Корену, Пабло Доминику Вассели, Патрику Тухи, Равишанкару Раягопалану, Рэю Луго, Рэю Морхеду, Рису Моррисону, Ризвану Пателю, Роберту Диана и Урсину Стауссу.
Марк Феверолф благодарит Крэйга Кармайкла за их совместную одержимость идеей машинного обучения, а также свою жену Патрисию и дочь Эми за многолетнее терпение.
Хенрик Бринк хотел бы сказать спасибо основателям и всей команде проекта Wise.io за энтузиазм в применении машинного обучения к решению различных задач. Он благодарит своих родителей Эдит и Джонни, а также своего брата и сестру, которые передали ему страсть к знаниям и информации, и, что самое важное, свою жену Иду и своего сына Харальда за любовь и поддержку.
Джозеф Ричардс также хотел бы поблагодарить команду Wise.io за их общую увлеченность идеей машинного обучения и за бесконечную работоспособность и энергию, благодаря которым каждый рабочий день был истинным удовольствием. Особенно он хотел бы выразить благодарность своим родителям Сюзан и Карлу, которые научили его испытывать радость от возможности постоянно узнавать что-то новое, привили любовь к упорному труду и умение сопереживать. Кроме того, он благодарит свою жену Тришу за бесконечную любовь, сострадание и поддержку.
О книге
Книга «Машинное обучение на практике» предназначена для тех, кто хочет применять машинное обучение к решению различных задач. В ней описываются и объясняются процессы, алгоритмы и инструменты, относящиеся к основным принципам машинного обучения. Внимание акцентируется не на способах написания популярных алгоритмов, а на их практическом применении. Каждый этап построения и использования моделей машинного обучения иллюстрируется примерами, сложность которых варьируется от простого до среднего уровня.
Структура книги
Часть I «Последовательность действий при машинном обучении» знакомит с пятью этапами основной последовательности машинного обучения:
• В главе 1 «Что такое машинное обучение?» рассказывается, что представляет собой машинное обучение и для чего оно нужно.
• В главе 2 «Реальные данные» подробно рассматриваются характерные стадии подготовки данных для моделей с машинным обучением.
• Глава 3 «Моделирование и прогнозирование» обучает с помощью распространенных алгоритмов и библиотек созданию простых ML-моделей и генерированию прогнозов.
• В главе 4 «Оценка и оптимизация модели» ML-модели подробно рассматриваются с целью оценки и оптимизации их производительности.
• В главе 5 «Основы проектирования признаков» рассказывается о том, как увеличить количество необработанных данных, используя информацию из поставленной перед нами задачи.
В части II «Практическое применение» вводятся техники масштабирования моделей, а также техники извлечения признаков из текста, изображений и временных рядов, увеличивающие эффективность решения многих современных задач с машинным обучением. Эта часть содержит три главы с практическими примерами.
• Глава 6 «Пример: чаевые для таксистов» — первая, полностью посвященная рассмотрению примера. Мы попытаемся предсказать шансы таксиста на получение чаевых.
• Глава 7 «Усовершенствованное проектирование признаков» знакомит с более сложными техниками проектирования признаков, предназначенными для извлечения значений из текстов, изображений и временных рядов.
• В главе 8 «Пример обработки естественного языка» усовершенствованные техники проектирования признаков используются для предсказания тональности рецензий на фильмы.
• Глава 9 «Масштабирование процесса машинного обучения» знакомит с техниками, дающими ML-системам возможность работать с большими объемами данных, обеспечивающими более высокую скорость прогнозирования и уменьшающими время их ожидания.
• В главе 10 «Пример с цифровой рекламой» на большом объеме данных строится модель, предсказывающая вероятность перехода по рекламному баннеру.
Как читать эту книгу
Тех, кто пока не имеет опыта в области машинного обучения, главы с 1-й по 5-ю познакомят с процессами подготовки и исследования данных, проектированием признаков, моделированием и оценкой моделей. В примерах кода на языке Python используются такие популярные библиотеки, как pandas и scikit-learn. Главы с 6-й по 10-ю включают в себя три практических примера машинного обучения наряду с такими продвинутыми темами, как проектирование признаков и оптимизация. Так как основная вычислительная сложность инкапсулирована в библиотеках, приведенные фрагменты кода легко адаптировать к вашим собственным ML-приложениям.
Целевая аудитория
Эта книга позволит программистам, аналитикам данных, статистикам, специалистам по обработке данных и всем остальным применить машинное обучение к решению реальных задач или хотя бы просто понять, что оно собой представляет. Читатели, не прибегая к глубокому теоретическому изучению конкретных алгоритмов, получат практический опыт обработки реальных данных, моделирования, оптимизации и развертки систем машинного обучения. Для тех, кому интересна теория, мы обсуждаем математическую основу машинного обучения, объясняем некоторые алгоритмы и даем ссылки на материалы для дополнительного чтения. Основной акцент делается на практических результатах при решении поставленных задач.
Формат кода, загрузки и требования к ПО
Книга содержит множество примеров кода, как в виде листингов, так и в виде обычного текста. В обоих случаях код форматируется вот таким шрифтом, что позволяет легко отделить его от остального текста.
Представленные в листингах фрагменты кода написаны на языке Python с использованием библиотек pandas и scikit-learn. Записная книжка iPython с материалами книги доступна на сайте GitHub по адресу https://github.com/brinkar/real-world-machine-learning. Каждая глава помещена в отдельный ipynb-файл. Примеры данных добавлены в каталоги репозитория, так что все содержимое записных книжек можно запустить на выполнение, если вместе с интерактивной средой iPython вы установили необходимые библиотеки. Графики создавались с помощью модуля pyplot из библиотек matplotlib и Seaborn.
Часть графики, сгенерированной в записных книжках iPython, помещена в текст в виде рисунков. (Некоторые из них модифицированы для улучшения визуального восприятия в печатном издании и электронной книге.)
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу comp@piter.com (издательство «Питер», компьютерная редакция). Мы будем рады узнать ваше мнение!
На веб-сайте издательства www.piter.com вы найдете подробную информацию о наших книгах.
Об авторах
Хенрик Бринк — специалист по обработке и анализу данных и разработчик программного обеспечения, имеющий огромный практический опыт машинного обучения как в области производства, так и в сфере научной деятельности.
Джозеф Ричардс — старший научный сотрудник в области прикладной статистики и предсказательной аналитики. Хенрик и Джозеф совместно основали компанию Wise.io, которая занимается разработкой решений с машинным обучением для промышленности.
Марк Феверолф — основатель и президент компании Numinary Data Science, специализирующейся в области управления данными и предсказательной аналитики. Он работал статистиком и разработчиком аналитических баз данных в области социальных наук, химической инженерии, производительности информационных систем, планирования объема производства, кабельного телевидения и приложений для рекламы в Интернете.
Часть I. Последовательность действий при машинном обучении
Первая часть книги познакомит вас с основами процесса машинного обучения. В каждой главе рассматривается один из этапов.
Глава 1 рассказывает о предназначении машинного обучения и о том, зачем вам читать эту книгу.
В главе 2 будет детально рассмотрен этап обработки данных, а также распространенные способы их очистки и извлечения из них полезной информации.
В главе 3 вы приступите к созданию простых ML-моделей, попутно познакомившись с некоторыми алгоритмами и способами их применения в распространенных реализациях.
Глава 4 даст возможность пристально рассмотреть наши ML-модели с целью оценки и оптимизации их производительности.
Глава 5 посвящена основам проектирования признаков. Извлечение признаков из данных является крайне важной частью построения и оптимизации производительности любой ML-системы.
1. Что такое машинное обучение?
В этой главе:
• основы машинного обучения;
• преимущества машинного обучения перед традиционными методами;
• базовые этапы машинного обучения;
• усовершенствованные методы повышения эффективности моделей.
В 1959 г. специалист по вычислительной технике из компании IBM Артур Самуэль написал компьютерную программу для игры в шашки. Каждому положению на доске присваивался некий вес, базирующийся на вероятности выигрыша. Изначально вероятность определялась по формуле, в которой учитывались такие факторы, как количество шашек на каждой стороне и количество дамок. Подход работал, но Самуэль придумал, каким образом можно повысить его эффективность. Сыграв с программой тысячу партий, он использовал их результаты для уточнения позиционных весов. К середине 1970-х гг. программа достигла уровня хорошо подготовленного непрофессионального игрока.1
Самуэль написал компьютерную программу, которая могла по мере накопления опыта улучшать собственные результаты. Программа училась — так зародилось машинное обучение (ML — machine learning).
Мы не собираемся вдаваться в запутанные и сложные математические подробности алгоритмов машинного обучения (хотя и «снимем несколько верхних листьев с этого капустного кочана», чтобы дать вам представление о функционировании наиболее распространенных алгоритмов). Но, по сути, основной целью книги является предоставление неспециалистам информации о важных аспектах и распространенных проблемах, с которыми приходится сталкиваться при интеграции машинного обучения в приложения и конвейеры данных. В этой главе мы рассмотрим реальную экономическую задачу — обзор кредитных заявок, которая покажет преимущество машинного обучения перед большинством существующих альтернатив.
1.1. Как обучаются машины
У людей мы различаем механическое заучивание и интеллектуальное осмысление. Зазубривание телефонных номеров или инструкций, без сомнения, тоже относится к процессу обучения. Но, как правило, под этим понятием мы подразумеваем кое-что другое.
Ребенок, играющий с друзьями, наблюдает реакцию других членов группы на свои действия. Этот опыт влияет на его будущее поведение в социуме. Но он не вспоминает и не проигрывает заново свое прошлое, а опирается на определенные, легко опознаваемые характеристики прошлых взаимодействий: детская площадка, класс, мама, папа, сестры и братья, друзья, незнакомцы, взрослые, дети, в помещении или на улице. Оценка новой ситуации базируется на признаках, с которыми ему доводилось сталкиваться раньше. Обучение при этом является не просто сбором информации. Формируется то, что можно назвать аналитической оценкой.
Представьте, как вы по картинкам учите ребенка отличать собаку от кошки. Показанная картинка кладется в одну из двух стопок, в зависимости от правильности полученного ответа. Чем дольше продолжается процесс, тем выше эффективность распознавания. Что интересно, нет необходимости специально учить ребенка отличать собаку от кошки. Человеческое сознание обладает встроенными механизмами классификации. Ему требуются только образцы. Научившись работать с картинками, ребенок сможет опознать практически любое изображение кошки или собаки, не говоря уже о реальных животных. Эта способность обобщать, применяя полученные в процессе тренировок знания к новым, ранее не встречавшимся образцам, является ключевой характеристикой как человеческого, так и машинного обучения.
Разумеется, процесс получения знаний человеком превосходит своей сложностью самые совершенные алгоритмы машинного обучения, но у компьютера есть преимущество в виде большей емкости для запоминания, извлечения и обработки данных. Накапливаемый им опыт представлен в форме данных за длительный период времени, обработанных с помощью описанных в этой книге техник, причем это представление позволяет получать и оптимизировать алгоритмы, реализующие если не аналитическую оценку, то хотя бы способность к обобщениям.
Аналогия между человеческим и машинным обучением закономерно заставляет вспомнить такое явление, как искусственный интеллект (AI — artificial intelligence). При этом естественным образом возникает вопрос: «Чем искусственный интеллект отличается от машинного обучения?». По этому вопросу нет единого мнения, но большинство соглашается с тем, что ML — это одна из форм AI, так как AI представляет собой куда более обширную область, включающую в числе прочего робототехнику, обработку лингвистической информации и системы машинного зрения. Неоднозначность терминологии усиливает тот факт, что машинное обучение все чаще применяется во многих сопутствующих областях AI. Можно сказать, что такая дисциплина, как машинное обучение, относится к специализированной совокупности знаний и связанным с ней техникам. Легко определить, что относится, а что не относится к машинному обучению, в то время как в случае искусственного интеллекта далеко не всегда можно провести такую же четкую границу. Перефразируя часто цитируемое определение Тома Митчелла, скажем, что компьютерная программа обучается, если ее производительность при выполнении определенной задачи, выраженная в измеряемых единицах, увеличивается по мере накопления опыта.2
Компания Kaggle объявила конкурс на алгоритм, максимально точно отличающий собак от кошек.3 Для тренировки участникам предоставили 25 000 изображений с метками, указывающими, кто именно изображен на картинке. После обучения каждый алгоритм должен был классифицировать 12 500 не имеющих меток тестовых изображений.
Те, кому мы рассказывали об этом конкурсе, зачастую задумывались о признаках, по которым можно отличить собаку от кошки. У кошек треугольные и стоячие уши, а у собак они висят, но бывают и исключения. Представьте, что вы должны, не прибегая к иллюстрациям, объяснить разницу между кошкой и собакой человеку, который никогда не видел ни того ни другого животного.
Для обучения и обобщения люди используют различные данные из примеров, включая формы, цвета, текстуры, пропорции и другие характеристики. Машинное обучение также применяет множество стратегий в различных комбинациях в зависимости от поставленной задачи.
Эти стратегии нашли свое воплощение в наборе алгоритмов, разработанных в течение последних десятилетий как учеными, так и практиками в самых разных дисциплинах — от статистики, компьютерной науки, робототехники и прикладной математики до поиска в Интернете, развлекательной сферы, цифровой рекламы и переводов с одного языка на другой. Алгоритмы крайне разнообразны и имеют свои сильные и слабые стороны. Некоторые относят объекты к определенному классу, другие предсказывают числовые значения. Существуют и алгоритмы, определяющие сходства и различия допускающих сравнение сущностей (например, людей, машин, процессов, кошек, собак). При этом все алгоритмы обучаются на примерах (опыте) и умеют применять полученные знания к новым, ранее не встречавшимся случаям, то есть способны к обобщению.
Заявленные на конкурс «Собаки против кошек» программы на этапе обучения раз за разом пытались корректно выполнить классификацию, используя множество алгоритмов. На каждой из миллионов обучающих итераций программа производила классификацию, измеряла полученный результат и затем хотя бы немного корректировала процесс в поисках постепенного улучшения. Победитель смог корректно распознать 98,914% ранее не демонстрировавшихся тестовых изображений. Это замечательный результат, если учесть, что у людей частота появления ошибки составляет примерно 7%. Процедура показана на илл. 1.1. Процесс машинного обучения анализирует изображения с метками и строит модель, которая в свою очередь используется процессом воспроизведения (предсказания) для классификации новых изображений. В примере вы видите, что одно изображение с кошкой было распознано некорректно.
Обратите внимание, что в данном случае мы рассматриваем так называемое обучение с учителем (supervised machine learning), но существуют и другие типы машинного обучения. Позже мы поговорим и о них.
Машинное обучение применяется к широкому кругу экономических задач — от обнаружения мошенничества до выбора целевой аудитории и рекомендаций товара, наблюдения за производством в реальном времени, анализа тональности текстов и медицинской диагностики. Оно может взять на себя задачи, которые невозможно выполнить вручную из-за огромного количества подлежащих обработке данных. В случае больших наборов данных машинное обучение иногда обнаруживает неочевидные зависимости, которые невозможно распознать при сколь угодно скрупулезном ручном рассмотрении. При этом комбинация множества таких «слабых» соотношений дает прекрасно работающие механизмы прогнозирования.
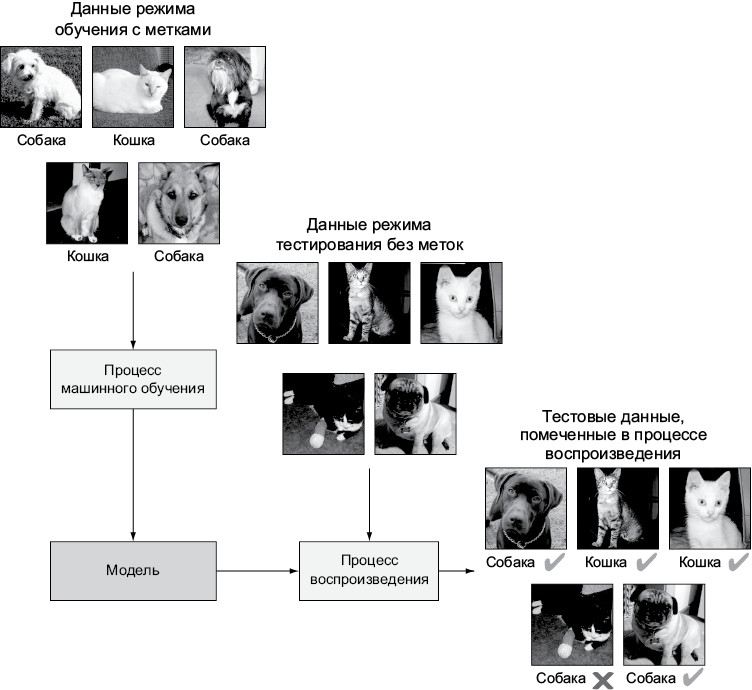
Илл. 1.1. Процесс машинного обучения для алгоритма, отличающего кошку от собаки
Процесс обучения на основе данных и последующего применения полученных знаний для обоснования будущих решений — чрезвычайно мощный инструмент. Машинное обучение быстро превращается в двигатель современной экономики, управляемой данными.
В табл. 1.1 перечислены широко распространенные техники машинного обучения с учителем и варианты их практического применения. Список далеко не исчерпывающий, так как потенциальные варианты использования могут занять несколько страниц.
Таблица 1.1. Варианты применения машинного обучения с учителем, систематизированные по типам задач
Задача
Описание
Пример применения
Классификация
На основе данных определяется дискретный класс для каждого объекта
Фильтрация спама, анализ тональности текстов, обнаружение мошенничества, рассылка целевых рекламных объявлений, прогнозирование оттока клиентов, обработка заявок на техническую поддержку, персонализация контента, выявление производственных дефектов, сегментация потребителей, обнаружение событий, изучение геномов и эффективности лекарственных средств
Регрессия
На основе данных предсказывается фактическое значение параметра
Прогнозы на рынке ценных бумаг, прогноз спроса, прогноз цены, оптимизация аукциона реальных объявлений, управление рисками, управление активами, прогнозы погоды, спортивные предсказания
Рекомендация
Предсказывается альтернатива, которую предпочтет пользователь
Предложения продуктов, подбор персонала, конкурс Netflix Prize, онлайн-знакомства, предложение контента
Заполнение пропусков
Вывод значений отсутствующих входных данных
Неполные истории болезни, отсутствующая информация о клиентах, данные переписей
1.2. Принятие решений на основе данных
В качестве примера рассмотрим реальную экономическую задачу, решение которой упрощается с помощью машинного обучения. Мы перечислим распространенные альтернативы и покажем преимущества ML-подхода.
Представьте, что вы сотрудник организации, которая предоставляет кредиты физическим лицам для открытия малого бизнеса в неблагоприятных районах. На начальном этапе вы получали несколько заявлений в неделю, поэтому могли вручную прочитать каждое и выполнить все проверки для принятия решения об одобрении кредита. Этот процесс схематично представлен на илл. 1.2. Заемщиков устраивала скорость
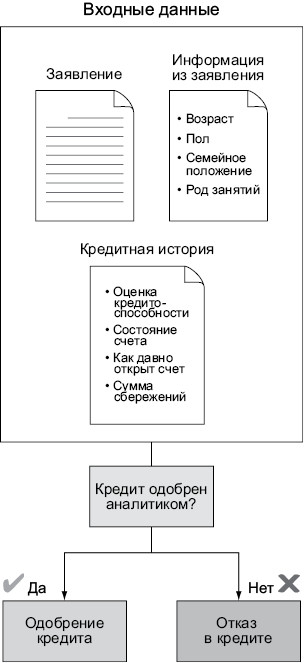
Илл. 1.2. Схема одобрения кредита в микрофинансовой организации
вашей работы и индивидуальный подход, и они везде рекомендовали вашу фирму.
По мере роста популярности фирмы количество заявлений увеличивается, их уже сотни в неделю. Даже сверхурочная работа не позволяет справиться с таким наплывом, клиенты устают ждать и отправляются в конкурирующую фирму. Очевидно, что обрабатывать заявления вручную нерационально, к тому же вы начинаете испытывать сильный стресс из-за отставания от графика.
Как выйти из этой ситуации? Сейчас мы рассмотрим несколько способов, позволяющих ускорить процесс анализа заявлений, к которым обычно прибегают в подобных случаях.
1.2.1. Традиционные подходы
Исследуем два традиционных подхода к анализу данных при рассмотрении заявлений — анализ вручную и бизнес-правила. Внимательно изучим реализацию обеих техник и покажем, что именно мешает расширению бизнеса.
Увеличение штата
Вы нанимаете для работы с заявлениями еще одного аналитика. Тот факт, что часть прибыли придется потратить на зарплату нового сотрудника, не вызывает особого восторга, зато вдвоем можно за то же время сделать в два раза больше. В результате за неделю вы справляетесь с очередью заявок.
Пару недель ваш дуэт успевает за спросом. Но количество потенциальных клиентов продолжает расти и в следующем месяце достигает 1000 в неделю. Чтобы справиться с нагрузкой, нужны еще два аналитика. Вы делаете вывод, что в долгосрочной перспективе такая схема не работает: доход от новых заемщиков пойдет на зарплату новым сотрудникам, а не в фонд кредитования. Увеличение штата по мере роста спроса препятствует развитию бизнеса. Более того, сам процесс найма — длительное и дорогое развлечение, лишающее бизнес изрядной части дохода. Наконец, новый сотрудник имеет меньше опыта и обрабатывает заявки медленнее, а вы начинаете чувствовать стресс из-за необходимости управлять рабочей группой.
Кроме такого явно негативного фактора, как рост издержек, вы столкнетесь с тем, что люди добавляют в процесс принятия решений собственные сознательные и подсознательные представления. Для обеспечения согласованности потребуется детально проработать всю процедуру одобрения, а также придумать обширную программу обучения для новых аналитиков, но это еще больше увеличит издержки и вовсе не факт, что решит проблему.
Использование бизнес-правил
Представим, что из 1000 кредитов с просроченной датой погашения только 70% погашены вовремя. Эта ситуация представлена на илл. 1.3.
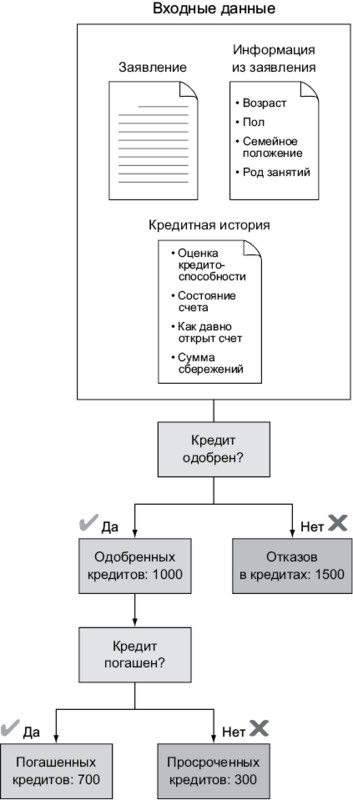
Илл. 1.3. За несколько месяцев работы из 2500 заявлений на кредит одобрена 1000. Из них 700 заявителей погасили кредит вовремя, а остальные 300 просрочили погашение. Этот исходный набор данных крайне важен для автоматизации процесса одобрения кредита
Теперь можно приступить к поиску связей между данными заявителя и количеством погашенных кредитов. В частности, ищется набор правил фильтрации, которые на выходе дают подмножество «хороших» кредитов, оплаченных преимущественно вовремя. Вручную проанализировав сотни заявок, вы приобретете огромный опыт, позволяющий отличать хорошую заявку от плохой.4 После проверки накопившихся данных о погашениях кредитов вы обнаружите в процедуре проверки кредитной надежности определенные тенденции:5
• большинство заемщиков с лимитом кредитования более $7500 не выполняли своих обязательств по кредиту;
• большинство заемщиков, не имеющих контокоррентного счета, погашали кредит в срок.
Теперь можно спроектировать механизм фильтрации, который уменьшит количество заявлений, вручную проверяемых по двум вышеуказанным критериям.
Первый фильтр будет автоматически отказывать всем заемщикам с лимитом кредитования более $7500. Ведь накопленные данные показали, что 44 из 86 заемщиков, взявших кредит, превышающий $7500, просрочили дату его погашения. Примерно 51% из просивших максимально возможный кредит не выполнили своих обязательств по сравнению с остальными 28%. Этот фильтр кажется хорошим способом отсечения заемщиков с высоким риском невозврата. Но следует учесть, что о столь крупном кредите шла речь только в 8,6% (86 из 1000) одобренных заявок. Это значит, что более 90% анкет вам все равно придется обрабатывать вручную. То есть требуется дополнительная фильтрация.
Второй фильтр автоматически принимает любого заявителя, у которого отсутствует контокоррентный счет. Это кажется отличным решением, так как вовремя погасило свой кредит 348 из 394 (88%) заемщиков, не имеющих контокоррентного счета. Добавление этого фильтра увеличивает количество автоматически принимаемых или отклоняемых заявлений до 45%. Соответственно, вручную остается обработать чуть больше половины анкет. Иллюстрация 1.4 демонстрирует эти правила фильтрации в виде схемы.
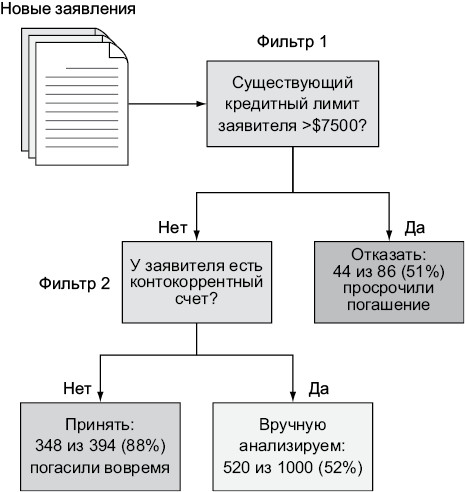
Илл. 1.4. Фильтрация по двум бизнес-правилам позволяет уменьшить количество проверяемых вручную заявок до 52%
Два бизнес-правила почти в два раза увеличивают количество обрабатываемых заявок без найма второго аналитика, так как вручную решение принимается только по 52% новых заемщиков. Кроме того, имея данные по 1000 заявок с известным результатом, вы предвидите, что механизм фильтрации будет ошибочно отклонять 42 заявки из каждой 1000 (4,2%) и ошибочно принимать 46 из каждой 1000 (4,6%).
По мере роста бизнеса хотелось бы, чтобы система автоматически принимала или отклоняла все больше заявок, не приводя к росту убытков из-за нарушения долговых обязательств. Для этого потребуются новые бизнес-правила. И скоро начнутся проблемы:
• По мере усложнения системы фильтрации все сложнее находить эффективные фильтры.
• Бизнес-правила становятся настолько запутанными, что их отладка и удаление устаревших, ставших малозначительными правил превращается в практически нереальную задачу.
• Формирование таких правил не является статистически строгим. Вам кажется, что путем более тщательного изучения данных можно найти лучшие «правила», но не факт, что они на самом деле существуют.
• Признаки возвращаемого кредита со временем изменяются — например, из-за изменения контингента заемщиков, — но система к этому не адаптируется. Для поддержания актуального состояния ее нужно постоянно редактировать.
Все эти затруднения можно свести к одному критическому недостатку в самом подходе с применением бизнес-правил: система автоматически не учится на предоставляемых ей данных.
Системы, управляемые данными, от простых статистических моделей до более проработанных обучающихся рабочих процессов, позволяют избежать проблем такого рода.
1.2.2. Подход с машинным обучением
Наконец, вы решили сделать процесс рассмотрения кредитных заявок полностью автоматизированным и управляемым данными. Машинное обучение прекрасно подходит для таких случаев, ведь сама его природа позволяет поддерживать нужный темп, как бы быстро ни возрастал приток новых заявлений. Более того, система извлекает оптимальные решения непосредственно из поступающих данных, не заставляя заранее жестко программировать произвольным образом выбираемые бизнес-правила. Такой переход от процесса анализа на основе бизнес-правил к машинному обучению означает, что точность решений не только возрастет, но и будет увеличиваться по мере выдачи новых кредитов. Вы будете полностью уверены, что ML-система дает оптимальный результат практически без вашего вмешательства.
При машинном обучении данные служат основой для более глубокого представления о проблеме. Чтобы определить наилучший порядок действий по отношению к каждой новой кредитной заявке, ML-система использует данные за прошлые периоды, на которых она обучалась. Для запуска машинного обучения системы одобрения кредитов берутся данные о 1000 выданных кредитов. Это сведения из заявлений заемщиков и информация о возврате кредита. Сведения из заявлений в свою очередь состоят из набора признаков (features) — численных или категориальных показателей, фиксирующих значимые характеристики каждого заявления. К признакам относятся, к примеру, оценка кредитоспособности заявителя, его пол и род занятий.
Иллюстрация 1.5 показывает схему обучения модели на основе данных за прошедший период. При поступлении новой заявки на кредит вероятность будущего корректного погашения мгновенно вычисляется по указанным в заявке сведениям.
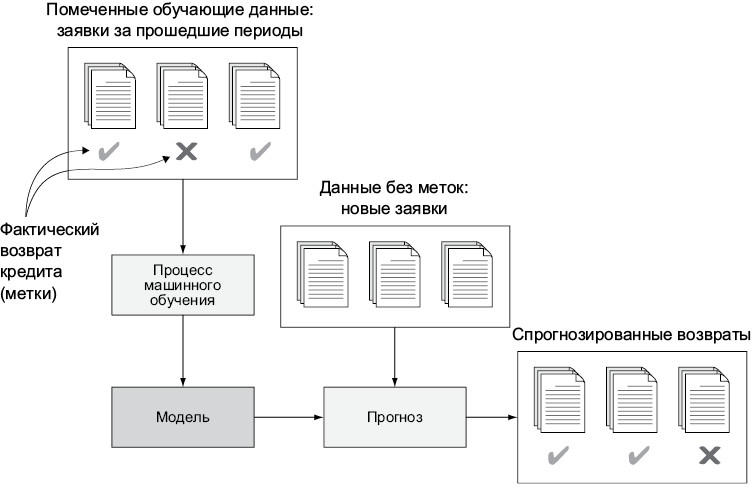
Илл. 1.5. Базовая схема машинного обучения на примере выдачи кредитов
После этого модель с машинным обучением определяет, как можно использовать данные каждого заявления для наилучшего прогнозирования ситуации. Обнаруживая в наборе обучающих данных закономерности и применяя их, процедура машинного обучения создает модель (пока ее можно рассматривать как черный ящик), прогнозирующую поведение каждого заемщика на основе предоставленной им информации.
Следующим шагом является выбор алгоритма. Виды машинного обучения варьируются от простых статистических моделей до нетривиальных подходов. Мы сравним два примера: простую параметрическую модель и непараметрический ансамбль деревьев классификации. Не стоит пугаться сложной терминологии. Скоро вы увидите, что в машинном обучении используется множество алгоритмов и множество способов их категоризации.
Большинство традиционных статистических экономических моделей попадает в первую категорию. В параметрических моделях соотношение между результатом и входными данными выражается через простые фиксированные уравнения. Данные применяются для определения оптимальных значений неизвестных частей уравнения. В эту категорию попадают: модель линейной регрессии, модель логистической регрессии и модель авторегрессии с лаговым оператором L. Все они будут подробно рассматриваться в главе 3.
В нашем примере для моделирования процесса одобрения кредита возьмем логистическую регрессию. В ней логарифм отношения шансов (log odds) каждого конкретного кредита на погашение рассматривается как линейная функция входных признаков. К примеру, если каждая новая заявка содержит три значимых признака: кредитный лимит заявителя (Credit_Line), уровень его образования (Education_Level) и возраст (Age), — логистическая регрессия попытается предсказать логарифм отношения шансов на невозврат кредита (мы обозначим его y) при помощи следующего уравнения:
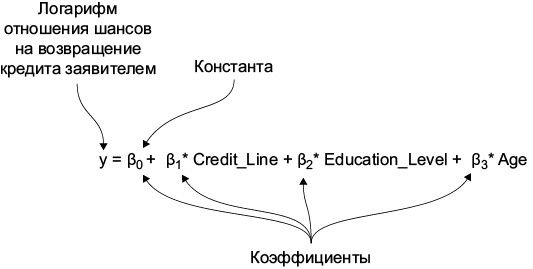
логарифм отношения шансов
Отношение шансов — это один из способов выражения вероятности. Вам, без сомнения, доводилось слышать такие выражения, как «шансы любимой команды на выигрыш 3 к 1». Отношением (odds) называется вероятность успеха (например, выигрыша), поделенная на вероятность неудачи (проигрыша). Математически это выражается следующим образом:
Odds(A) = P(A) / P(~A) = вероятность A, поделенная на вероятность не A
Соответственно, отношение 3 к 1 эквивалентно 0,75 / 0,25 = 3, а log(3) = 0,47712…
Если в качестве события A рассмотреть броски симметричной монеты, отношение шансов на выпадение «орла» составит 0,5 / 0,5 = 1. Log(1) = 0. Получается, выражение log(Odds) может иметь любое вещественное значение. Логарифм отношения шансов, стремящийся к –∞, означает практически невероятное событие. Значение ∞ указывает на практически гарантированное наступление события, в то время как log(1) = 0 соответствует равной вероятности как одного, так и другого варианта. Применение логарифма отношения шансов вместо обычной вероятности — всего лишь математический прием, облегчающий некоторые вычисления, так как, в отличие от вероятности, логарифм не ограничен значениями от 0 до 1.
Оптимальное значение всех коэффициентов уравнения (в рассматриваемом случае это β0, β1, β2 и β3) определено на основе 1000 примеров обучающих данных.
Когда соотношение между входными данными и результатом удается выразить формулой, результат (y) можно легко предсказать по значениям признаков (кредитный лимит, уровень образования и возраст). Остается только определить, какие значения β1, β2 и β3 дают наилучший результат, воспользовавшись данными за прошедшие периоды.
Но при более сложных зависимостях между входными данными и результатом такие алгоритмы, как логистическая регрессия, показывают свою ограниченность. В качестве примера рассмотрим набор данных из левой части илл. 1.6. Есть два исходных признака, и нужно отнести каждую точку на графике к одному из двух классов. В двумерном пространстве признаков эти классы разделены кривой, которую невозможно описать линейными уравнениями. Она называется решающей границей (decision boundary). Центральная часть рисунка демонстрирует результат, который дает для предоставленных данных модель на базе алгоритма логистической регрессии. Мы получаем две области, разделенные прямой линией, что ведет к многочисленным ошибкам классификации (точки попадают не в ту область).
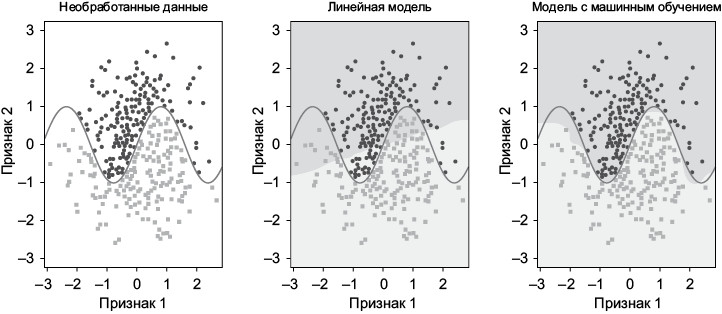
Илл. 1.6. В данной классификации отдельные элементы данных могут попасть в класс окружностей или в класс квадратов. Все представленные данные находятся в двумерном пространстве признаков с нелинейной решающей границей, обозначенной кривой линией. В то время как простая статистическая модель практически не в состоянии точно классифицировать данные (в центре), ML-модель (справа) дает возможность без особых усилий найти реальную границу между классами
В данном случае проблема в том, что на центральном рисунке мы попытались объяснить сложное нелинейное явление с помощью простой параметрической модели. Формальное определение параметрических и непараметрических моделей требует слишком сложных для данной книги математических формул. Суть же состоит в том, что параметрические модели прекрасно применимы только в случаях, когда заранее примерно известно соотношение между входными данными и прогнозируемым результатом. При наличии достаточного количества сведений о нелинейном соотношении иногда можно преобразовать входные данные или результат таким образом, что параметрическая модель будет работать. Скажем, если частота наблюдения некоего заболевания среди населения выше у пожилых людей, вы можете обнаружить линейное соотношение между вероятностью заражения и квадратом возраста. Но в реальности, как правило, приходится иметь дело с задачами, для которых предсказать подобные закономерности практически невозможно.
Нам требуются более гибкие модели, умеющие автоматически выявлять в данных сложные тенденции и структуры без предварительной информации о виде будущего шаблона. Именно здесь на помощь приходят непараметрические алгоритмы машинного обучения. В правой части илл. 1.6 вы видите результат применения к задаче непараметрического обучающего алгоритма (в данном случае это классификатор на базе алгоритма «случайный лес»). Очевидно, что предсказанная решающая кривая намного лучше совпадает с настоящей границей раздела, а значит, точность классификации намного выше, чем у параметрической модели.
Непараметрические ML-модели дают высокий уровень точности при работе со сложными многомерными реальными наборами данных. Именно поэтому они выбираются для решения множества управляемых данными задач. В их число попадают такие широко используемые методы машинного обучения, как, к примеру, метод k-ближайших соседей, ядерное сглаживание, метод опорных векторов, деревья принятия решений и композиционное обучение. Все эти подходы будут подробно рассмотрены в следующих главах, кроме того, в приложении вы найдете обзор важнейших алгоритмов. Привлекательность же линейных алгоритмов связана с совсем другими свойствами. Их проще интерпретировать, они быстрее обсчитываются и проще масштабируются при увеличении набора данных.
Рекомендуемая литература
Учебник Г. Джеймса «An Introduction to Statistical Learning»6 детально знакомит с наиболее распространенными подходами к машинному обучению на уровне, доступном читателям без специальной подготовки в области математики и статистики. Английский вариант книги с согласия издательства доступен для скачивания в формате PDF на сайте авторов (http://www-bcf.usc.edu/~gareth/ISL/ISLR%20First%20Printing.pdf).
Но вернемся к задаче масштабирования микрофинансовой организации. В этом случае больше всего подойдет непараметрическая ML-модель. Она может обнаружить правила, которые вы вывели вручную, хотя, возможно, они будут выглядеть немного иначе для оптимизации статистических преимуществ. Скорее всего, модель самостоятельно выведет другую, более глубокую корреляцию входных параметров и желаемого результата, которую вы не могли даже представить.
Вы можете не только автоматизировать рабочий процесс, но и увеличить его точность, из чего непосредственно вытекает рост коммерческой стоимости. Предположим, непараметрическая ML-модель дает прогноз с точностью на 25% большей, чем у алгоритма логистической регрессии. Это означает, что при обработке новых заявок будет допущено меньше ошибок: вы одобрите меньше недобросовестных заемщиков и откажете меньшему числу добросовестных клиентов. В результате возрастет средняя доходность по кредитам, что позволит выдать больше кредитов и получить более высокий доход.
Надеемся, что вы уже поняли, насколько мощным инструментом является машинное обучение. Но перед определением основ рабочего процесса ML рассмотрим его преимущества, а заодно расскажем об ожидающих вас трудностях.
1.2.3. Пять преимуществ машинного обучения
Перед завершающей стадией нашего примера рассмотрим самые существенные преимущества систем с машинным обучением в сравнении с общепринятыми альтернативами, такими как ручной анализ, жестко запрограммированные бизнес-правила и простые статистические модели. Вот они:
• Точность. Машинное обучение использует данные для создания принимающей решение программы, оптимизированной под поставленную задачу. По мере накопления данных автоматически возрастает точность прогнозов.
• Автоматизация. По мере подтверждения и отбрасывания ответов ML-модель может автоматически обнаруживать новые шаблоны. Это позволяет встраивать машинное обучение непосредственно в автоматизированные рабочие процессы.
• Скорость. Машинное обучение дает ответы за доли секунды после поступления новой информации, позволяя системам реагировать в реальном времени.
• Возможность настройки. Многие задачи, управляемые данными, можно решить с помощью машинного обучения. Модели строятся на базе ваших собственных данных и допускают настройку под любую систему мер, принятую в вашем бизнесе.
• Масштабируемость. При росте бизнеса ML-модель легко приспосабливается к увеличивающимся объемам данных. Некоторые алгоритмы можно использовать для обработки множества данных на разных вычислительных машинах в облаке.
1.2.4. Сложности
Естественно, что для получения вышеперечисленных преимуществ требуется разобраться с рядом сложностей. Они зависят от параметров стоящей перед вами задачи и могут как преодолеваться элементарным образом, так и требовать колоссальных усилий.
Чаще всего требуется получить данные в годной к употреблению форме. Было подсчитано, что специалисты по работе с данными тратят на их подготовку 80% времени.7 Без сомнения, вы слышали, что при коммерческой деятельности в настоящее время фиксируется намного больше данных, чем когда-либо раньше, и это действительно так. Возможно, вам доводилось слышать и то, что эти данные называют «выхлопом» бизнес-процессов. Другими словами, драгоценные сведения нельзя напрямую использовать в качестве входных данных для ML-систем. Для извлечения из этих массивов полезной информации требуется кропотливая и нудная работа.
Фактически наша задача — сформулировать проблему таким образом, чтобы к ней можно было применить методы машинного обучения и получить имеющие практическую ценность и измеримые результаты. В рассматриваемом примере цель очевидна — предсказать, кто выплатит кредит вовремя, а кто нет. Классификация легко применима, а результат легко измерим. К счастью, реальные проблемы иногда бывают настолько же простыми. Например, предсказать, исходя из всех имеющихся у нас сведений о потенциальных покупателях (а их очень много), приобретут ли они наш товар. Такие задачи решаются без труда.
Вот более сложный пример — найти оптимальное сочетание средств массовой информации и комбинацию рекламных блоков для повышения узнаваемости торговой марки новой линии продуктов. Сама постановка задачи требует найти способ измерения узнаваемости торговой марки, получить информацию о вариантах выбора рекламных средств и подобрать данные, отражающие релевантный опыт с альтернативами и связанными с ними результатами.
Когда нужен сложный результат, выбор алгоритма и способа его применения сам по себе начинает требовать гигантских усилий. Исследователи, работающие в области кардиологии над прогнозами вероятности послеоперационных осложнений, обладают умопомрачительным количеством данных на каждого пациента, но для ML-алгоритмов бесполезны необработанные данные электрокардиографии (ЭКГ) и результаты секвенирования ДНК. Проектирование признаков (feature engineering) представляет собой процесс преобразования таких входных данных в подходящие для предсказывающей модели признаки.
Нельзя не упомянуть и проклятие всех, кто занимается созданием прогнозирующих моделей, — модель, которая идеально работает на обучающих данных, но демонстрирует полную неспособность к достоверным прогнозам на основании неизвестных ранее данных. Причиной в большинстве случаев становится переобучение (overfitting).
Вы убедитесь, что машинное обучение позволяет решить множество проблем, иногда кардинально упрощая процесс поиска решения. Хотя имеет смысл отметить, что полезность решения далеко не всегда соответствует усилиям, затраченным на его получение. Более того, машинное обучение не является панацеей от всех бед. Но после прочтения этой книги вы увидите, насколько хорошо оно справляется с множеством определяемых данными задач.
1.3. Рабочий процесс: от данных до внедрения
В этом разделе мы рассмотрим базовый процесс интеграции моделей машинного обучения в приложения или конвейеры данных. Его можно разбить на пять стадий: подготовка данных, построение модели, оценка, оптимизация и прогноз на новых данных. Этапы следуют друг за другом в определенном порядке, но большинство реальных приложений с машинным обучением требует множественного повторения каждого этапа в процессе последовательных приближений. Они подробно описываются в главах со 2-й по 4-ю, пока же мы дадим общее описание, чтобы показать, с чем вам предстоит иметь дело. Схема рабочего процесса представлена на илл. 1.7, и в следующих разделах мы детально разберем все упомянутые концепции. Этот рисунок будет то и дело попадаться в книге при рассмотрении различных этапов рабочего процесса ML.
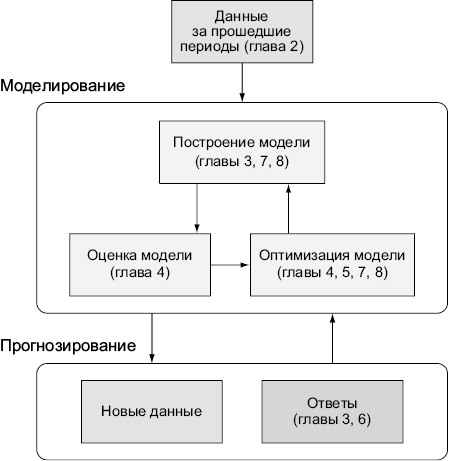
Илл. 1.7. Рабочий процесс реальных систем с машинным обучением. Данные за прошедшие периоды позволяют построить модель на базе ML-алгоритма. После этого нужно оценить производительность модели и оптимизировать ее точность и масштабируемость в соответствии с выдвинутыми требованиями. Готовая модель дает прогнозы для новых данных
1.3.1. Сбор и подготовка данных
Сбор и подготовка данных для систем с машинным обучением обычно влечет за собой их представление в виде таблицы, если изначально они имеют другую форму. Представьте, что данные распределены по строкам и столбцам, причем каждая строка соответствует изучаемому экземпляру (instance), а столбец — значению этого экземпляра. Существует несколько исключений, но можно смело утверждать, что большинство алгоритмов машинного обучения требует данных именно в таком формате. По поводу исключений мы пока беспокоиться не будем. Рассмотрим илл. 1.8, на которой простой набор данных представлен в виде таблицы.

Илл. 1.8. В наборе данных, представленном в виде таблицы, строки называются экземплярами, а столбцы представляют собой признаки
При взгляде на таблицу первым делом бросается в глаза, что столбцы, как правило, содержат данные одного типа, в то время как данные в строках принадлежат разным типам. На илл. 1.8 мы встречаемся с данными четырех типов: строковая переменная Name, целочисленная переменная Age, вещественная переменная Income и категориальная переменная Marital status (принимающая дискретное число значений). Такой набор данных называют гетерогенным (в отличие от гомогенного), и в главе 2 мы поговорим о том, как и зачем выполняется приведение некоторых типов данных к другим типам в зависимости от конкретного алгоритма машинного обучения.
Реальные данные могут быть «запутаны» разными способами. Представьте, что на этапе сбора данных измерить какое-то значение не представляется возможным. Нельзя и вернутся назад, чтобы отыскать недостающий фрагмент информации. В подобных случаях некоторые ячейки таблицы останутся незаполненными, что усложнит как построение модели, так и последующее прогнозирование. Иногда сбор данных осуществляется вручную, а мы все знаем, как легко делаются ошибки при выполнении повторяющихся задач. В результате часть сведений оказывается некорректной. Вы должны уметь работать с подобными сценариями или, по крайней мере, знать, как конкретный алгоритм ведет себя при наличии недостоверных данных. Подробно методы работы с отсутствующими и недостоверными данными будут рассматриваться в главе 2.
1.3.2. Обучение модели на данных
Первый этап построения успешной системы с машинным обучением — это формулировка вопроса, ответ на который должны дать наши данные. Например, наша простая таблица с личными данными позволяет построить ML-модель, предсказывающую семейное положение заявителя. Такая информация может пригодиться, например, при выборе демонстрируемой пользователю рекламы.
При этом переменная Marital status будет использоваться как целевая (target) или как метка (label), а все прочие переменные станут признаками (features). Наш ML-алгоритм должен понять, каким образом набор входных признаков позволяет успешно предсказывать значение целевой переменной. После этого вы сможете пользоваться построенной моделью для предсказания семейного положения заявителя, когда оно по каким-то причинам не указано. Иллюстрация 1.9 демонстрирует этот процесс на примере нашего небольшого набора данных.
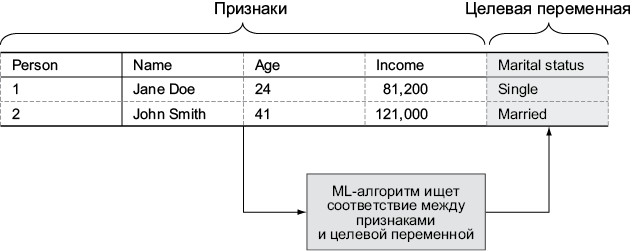
Илл. 1.9. Процесс моделирования с машинным обучением
На данном этапе ML-алгоритм можно представить в виде волшебной коробочки, которая выполняет отображение входных признаков на выходные данные. Но для построения работающей модели нужно более двух рядов. Одним из преимуществ алгоритмов машинного обучения в сравнении с другими распространенными методами является умение обрабатывать множество признаков. Иллюстрация 1.9 демонстрирует только четыре признака, из которых идентификатор заявителя и его имя никак не помогут предсказать его семейное положение. Некоторые алгоритмы в достаточной степени невосприимчивы к неинформативным признакам, в то время как другие дают более точные предсказания, когда такие признаки убираются из рассмотрения. Более подробно различные типы алгоритмов и их производительность в случае разных задач и наборов данных рассматриваются в главе 3.
Впрочем, ценные сведения порой могут быть извлечены и из неинформативных на первый взгляд признаков. Например, такой признак, как местоположение, сам по себе кажется бесполезным, но он может дать информацию о плотности населения. Такой вариант усовершенствования данных, называемый извлечением признаков (feature extraction), крайне важен в реальных ML-проектах и будет рассматриваться в главах 5 и 7.
Построив ML-модель, вы можете делать прогнозы для новых данных с неизвестной целевой переменной. Этот процесс показан на илл. 1.10.
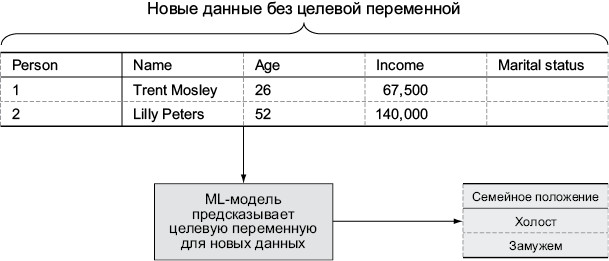
Илл. 1.10. Применение модели для предсказания новых данных
Предсказанная целевая переменная возвращается в той форме, в которой она фигурировала во взятых для обучения модели исходных данных. Прогнозирование с помощью модели, по сути, является заполнением пустого столбца новыми значениями. Некоторые ML-алгоритмы также включают в результат своей работы связанные с каждым классом вероятности. В рассматриваемом примере вероятностная ML-модель выдает для каждого нового заявителя два значения: вероятность, что человек состоит в браке, и вероятность того, что он свободен.
Мы опустили некоторые детали, но, в принципе, вы только что наблюдали за проектированием ML-системы. Любая система, связанная с машинным обучением, занимается созданием моделей и их применением для получения прогнозов. Представим базовый рабочий процесс ML в виде псевдокода, чтобы вы еще раз убедились, насколько он прост.
Листинг 1.1. Исходная структура программы с рабочим процессом ML
данные = загрузка_данных("данные/люди.csv")
модель = строим_модель(данные, цель="Семейное положение")
новые_данные = загрузка_данных("данные/новые_люди.csv")
прогнозы = модель.предсказывает(новые_данные)
Ни одна из этих функций пока не запрограммирована, мы показали только базовую структуру. К главе 3 вы поймете, что представляют собой все эти этапы. Остальная часть книги (главы с 4-й по 10-ю) учит строить модели, наилучшим образом подходящие для решения конкретных задач.
1.3.3. Оценка производительности модели
Системы с машинным обучением практически никогда не используются, пока не будет проверена их производительность. В этой главе мы для простоты опускаем многие детали, поэтому просто представим, что вы уже знаете, как строить модели и получать прогнозы с их помощью. И теперь нужен хитрый прием, который позволит понять, насколько готовая модель справляется со стоящими перед ней задачами.
Возьмем набор данных и представим, что целевая переменная неизвестна. Построим на их основе модель и используем их в качестве тестовых данных для нескольких прогнозов. Процесс тестирования схематично показан на илл. 1.11.



















