Глава 1. Сбор и предобработка больших данных
Во всем есть своя мораль,
нужно только уметь ее найти!
Льюис Кэрролл «Алиса в стране чудес».
Введение
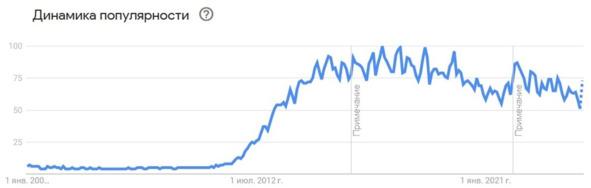
Технологии анализа больших данных — есть, оказывается и такое. И мы начнем рассматривать методы сбора и предобработки больших данных. Для начала посмотрим, как менялось количество запросов с ключевыми словами Big Data, см. рис.
Рис. Интерес публики к тематике больших данных
Можно видеть, что начиная примерно с 2012 года резко увеличился интерес к этой теме. Затем в течение нескольких лет мы вышли на «установившийся режим», на стабильный уровень интереса. И в последнее время интерес немного уменьшился в связи с тем, что публика уже насытилась первоначальной информацией по данному предмету. Картина очень напоминает «цикл хайпа» по Гартнеру. Сначала этого просто нет, затем оно появляется и мы видим первый всплеск, затем падение интереса, затем второй неторопливый рост и участок «плато». Но и это пройдёт, как написано в мудрых книгах.
Понятие и классификация больших данных
Для начала попробуем определить, что же такое «большие данные». В соответствии с названием это данные с большим «чем-то». Прежде всего, это большой размер, или объём, или проще говоря количество данных. И мнения здесь немного различаются, но в целом обычно имеется в виду такое количество данных, которое сложно или даже невозможно обработать традиционными методами. Такое количество данных, которое не умещается на обычном настольном компьютере. На самом деле, все эти технологии применимы к любым размерам выборки. Итак, первое свойство больших данных это объем.
На самом деле, в определении больших данных есть несколько слов, которые начинаются на английскую букву V. Их так и называют: три буквы V, пять букв V и так далее, см. рис.
Рис. Пять V в определении больших данных
Второе слово на букву V — это velocity, то есть скорость поступления данных. Имеется в виду, что данные поступают с очень большой скоростью. Данные создаются, обрабатываются, поступают, и их нужно либо хранить, либо обрабатывать на ходу. В этом случае используются технологии обработки потоков данных. Их так и называют — «потоковые данные».
Третье свойство больших данных — это различные типы, различные форматы. И это у нас третья буква V — variety, разнообразие. Имеется в виду данные, которые отличаются от того, что обычно хранится в реляционных базах данных в виде таблиц, связанных между собой по ключевому полю. Данные могут быть не только красиво структурированными в виде таблиц, но и не структурированными или частично структурированными. Примером может быть аудиозапись разговора или лекции. Здесь вообще никакой структуры нет. Частично структурированные данные — это могут быть документы с более или менее типовыми полями. Хотя работа с текстом — это отдельная проблема. Но тем не менее из текста можно попытаться извлечь отдельные свойства, которые более или менее повторяются.
Следующее свойство — достоверность. И здесь речь идет о том, что данные, которые собирают из различных источников, могут быть достоверными, а могут и не быть таковыми. И это значит, что то, что мы добываем из различных интернет-источников… с этим нужно что-то делать, определять качество данных и устанавливать степень нашего доверия к ним.
Наконец, еще одно свойство — Value. Тоже слово на букву V, условно это называют «ценностью». Здесь надо вспомнить основные определения из области информатики. Данные — это любые сведения, в том числе и те, в которых ничего полезного нет. А вот информацией называют то, что содержится в этих данных. То, что уменьшает неопределенность. То, что увеличивает наше понимание процесса или объекта. Следующим уровнем понимания в анализе данных является знание.
Итак, у нас есть данные на нижнем уровне, это любые сведения или факты. Далее идет информация, которая может представлять полезность или ценность. И следующий уровень — это понимание, знание или, как еще его называют, «инсайт». Это новое понимание, новые взаимосвязи, новые закономерности.
В качестве упражнения мы предлагаем вам подробнее познакомиться, в частности, с определениями того, что такое большие данные. Здесь нам может помочь «народная энциклопедия». Конечно, это не самый лучший и не самый надежный источник. Однако, это более или менее стабильный ресурс. Эти данные совершенно не обязательно являются качественными, правильными, полными, исчерпывающими и так далее (это мы намекаем на одно из свойств больших данных — см. выше). Рассматривайте это просто как упражнение и как пример того, как могут выглядеть те самые большие данные.
Больше информации находится в англоязычном варианте того же текста. Находим статью под названием Big Data. Если имеются трудности с пониманием английского языка, можно включить автоматический перевод. Такая функция доступна во многих современных инструментах. Достаточно нажать кнопочку «Перевести», и мы получаем достаточно приличный перевод.
Обратите внимание, что здесь говорится по поводу слов на букву V. Три слова на букву V, пять слов на букву V и так далее. Сколько всего здесь таких слов собрано. В принципе, это всё расширяет наше понимание самой концепции, что такое большие данные.
Ещё одно упражнение, которое нам предстоит выполнить. Посмотрите, что общего и чем отличаются технологии анализа больших данных и технологии бизнес-аналитики (или как её в настоящее время называют, BI-аналитика). Это прежде всего анализ информации, которая присутствует в корпоративных информационных системах. Для того, чтобы обобщить эти сведения и получить ответы на наши вопросы, вам предлагается не только заняться привычным поиском по ключевым словам, но и позвать на помощь наших интеллектуальных помощников. Заодно можно будет разобраться, как именно ими пользоваться.
ИИ-помощники
Работа с интеллектуальными помощниками отличается от простого поиска в интернете и иногда бывает достаточно полезной. Хотя, опять же, качество ответов не всегда будет удовлетворительным. Поэтому здесь требуется проверять факты, руководствоваться здравым смыслом и заниматься тем, что называется «факт-чекинг». Fact Checking. Проверка правильности фактов.
Есть несколько источников, которые можно порекомендовать. Опять же, это не самые лучшие, не самые подробные сведения, но тем не менее, в достаточно доступном изложении. Ссылки приведены в конце главы.
Можно также предложить вводное описание технологии больших данных — обзор проблемы из серии «Для чайников»: Hurwitz (2013) Big Data For Dummies. «Большие данные для чайников», или «для сомневающихся», написана на достаточно популярном языке. Здесь на простых примерах объясняют основные проблемы и технологии.
Еще одна книга, которая посвящена данной проблеме: Лесковец (2016) Анализ больших наборов данных. В оригинале называется «Разведочный анализ», или «Дата майнинг». Книга основана на материалах университетского курса Стэнфорда. Желающие могут найти в открытом доступе и полный текст книги, и отдельные главы, и даже слайды для чтения лекций.
И здесь просматривается идея, которая продвигалась лет за 10—15 до всплеска интереса к большим данным. Это так называемый «дата майнинг» — разведочный анализ данных, или, как его ещё переводят, интеллектуальный анализ данных. Здесь более подробно описаны сами методы, сами технологии анализа. И меньше внимания выделяется облачным сервисам, которые служат для организации такой работы.
Отметим, что книга Лесковец доступна в университетской библиотечной системе. Если в вашей организации есть подписка, то вы совершенно свободно можете получить доступ к этой книге на русском языке.
Поскольку нас интересует литература по данной теме, попробуем составить такой список силами интеллектуальных помощников. В качестве упражнения попробуйте дать такое задание той системе, которая вам больше нравится. Мы будем рассматривать пример ИИ-помощника под названием perplexity, что переводится как «замешательство», или «запутанность». Видимо, он помогает эту «запутанность» распутать. Дальнейшие технические подробности мы обсуждаем в рамках лабораторной работы.
Мы формируем очень подробное задание, и оно звучит так. Вначале мы определяем роль. Мы говорим: «Твоя роль — опытный методолог онлайн-курсов». От того, как мы определим роль, будет зависеть поведение системы искусственного интеллекта. Дальше мы даём собственно задание: «Составь список из топ-10 книг на русском языке по методам и технологиям анализа больших данных».
Обычно большинство пользователей ограничивается этой фразой. Но мы пойдем немножко дальше. Мы определяем роль, даём задание, а дальше мы объясняем контекст. Можно явно вставить слово «контекст», либо указать, для кого будет предназначен ответ, это будущее произведение. Итак, мы говорим: «Твоя аудитория — слушатели курсов повышения квалификации с высшим образованием». Если бы мы сказали: «Твоя аудитория — школьники» или «Твоя аудитория — академики», ответ был бы совсем другим.
Дальше мы описываем формат вывода. Что именно мы хотим? Просто список? Или подробное описание книг? Или ссылки на сайты издательства? Или анализ цен? Или просто сводную табличку? Можно попросить всё, что угодно. В нашем случае мы говорим: «Выведи результаты в виде списка с заголовками». Значит, это должен быть текст, разбитый на абзацы с заголовками. Можно даже привести примеры того, что нам нужно, и сообщить, что это примеры.
Дальше мы уточняем: «Для каждой книги приведи краткое содержание в одном абзаце». И, наконец, мы просим, нам оформили ссылки на книги в соответствии с требованиями действующего государственного стандарта на библиографическое описание. Тогда можно будет использовать данный список практически один к одному, скопировать и вставить в список литературы, см рис.
При большом желании поэкспериментировать можно дополнительно указать «температуру». Этот параметр управляет вариативностью ответов и фантазией нашего помощника.
Рис. Пример подробного запроса (промпта)
Конечно, нам понадобится проверить факты и убедиться, что это не придуманные названия, что эти книги действительно существуют. И для этого у нас в рассматриваемом инструменте для каждого ответа приводятся ссылки на источники, которые всегда можно открыть и посмотреть. Как минимум, мы можем убедиться, что указанные источники существуют.
Для наших экспериментов мы создаем новый thread, то есть новую «нить», новую «ветку» или «беседу», в рамках которой будет поддерживаться определённый контекст, и интеллектуальная система будет помнить наши предыдущие запросы и ее ответы. Теперь мы вставляем наш запрос — так называемый промпт. Смотрим на него еще раз. У нас есть роль, у нас есть задание, у нас есть контекст, формат вывода и все прочее. Запускаем и удивляемся.
Предупреждаем, что результаты могут быть непредсказуемыми. Более того, если вы отправите один и тот же запрос несколько раз, вы можете получить совершенно разные ответы. Возможно, вы получите похожие книги или те же книги, но в другом порядке. Здесь есть такая вариативность ответов, ее обычно называют параметром «температура». Чем она «горячее», тем больше вариативность. И её тоже можно указать в своём запросе к нейросети. Теперь посмотрим на полученный ответ, см. рис.
Рис. Ответ системы — список книг с пояснениями
В ответе в начале указаны источники, которые можно открыть и увидеть, из каких текстов было собрано, обобщено то, что нам выведено на экран.
Просматриваем ответ. Пункт первый: «Революция в аналитике». Здесь идёт абзац текста с пояснением, о чём эта книга. И далее идет ссылка, очень похожая на требования стандарта. Здесь может быть указано количество страниц. Или не указано — в зависимости от