

автордың кітабын онлайн тегін оқу Программируй & типизируй
Научный редактор Ю. Имбро
Переводчик И. Пальти
Технический редактор Н. Хлебина
Литературный редактор Н. Хлебина
Художники Н. Гринчик, В. Мостипан, Г. Синякина (Маклакова)
Корректоры Е. Павлович, Т. Радецкая
Верстка Г. Блинов
Влад Ришкуция
Программируй & типизируй. — СПб.: Питер, 2021.
ISBN 978-5-4461-1692-8
© ООО Издательство "Питер", 2021
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Моей жене Диане за ее безграничное терпение.
Предисловие
Эта книга — итог многих лет изучения систем типов и правильности работы программного обеспечения, выраженный в виде практического руководства по созданию реальных приложений.
Мне всегда нравилось искать способы написания более совершенного кода, но собственно начало этой книги, мне кажется, было заложено в 2015 году. Я тогда перешел из одной команды разработчиков в другую и хотел обновить свои знания языка C++. Я начал смотреть видео с конференций по C++, читать книги Александра Степанова по обобщенному программированию и полностью изменил свои представления о том, как нужно писать код.
Параллельно в свободное время я изучал Haskell и осваивал продвинутые свойства его системы типов. Программируя на функциональном языке, начинаешь понимать, как много естественных возможностей подобных языков со временем приживаются в более распространенных языках.
Я прочитал немало книг на эту тему, начиная от Elements of Programming и From Mathematics to Generic Programming Степанова1 и до Category Theory for Programmers Бартоша Милевски (Bartosz Milewski)2 и Types and Programming Languages Бенджамина Пирса (Benjamin Pierce)3. Как вы понимаете из названий, книги посвящены скорее теоретико-математическим вопросам. Чем больше я узнавал о системах типов, тем лучше становился код, который я писал на работе. Между теоретическими вопросами проектирования систем типов и повседневной работой над программным обеспечением существует самая непосредственная связь. Я вовсе не открываю Америку: все причудливые возможности систем типов существуют как раз для решения реальных задач.
Я осознал, что далеко не у всех практикующих программистов есть время и желание читать объемные книги с математическими доказательствами. С другой стороны, я не потратил время впустую за чтением этих книг: благодаря им я стал лучшим специалистом по программному обеспечению. Мне стало понятно, что есть потребность в книге, в которой бы описывались системы типов и их преимущества на менее формальном языке, с упором на практическое применение в ежедневной работе.
Цель книги — подробный анализ возможностей систем типов, начиная от базовых типов, функциональных типов и создания подтипов4, ООП, обобщенного программирования и типов более высокого рода, например функторов и монад. Вместо того чтобы сосредоточиться на теоретической стороне этих возможностей, я опишу их практическое применение. В данной книге рассказывается, как и когда использовать каждую из них, чтобы сделать свой код лучше.
Изначально предполагалось, что примеры кода будут на языке C++. Система типов C++ обладает намного большими возможностями, чем у таких языков, как Java и C#. С другой стороны, C++ — сложный язык, и я не хотел искусственно ограничивать аудиторию книги, так что решил применить вместо него TypeScript. Система типов этого языка тоже располагает широкими возможностями, но его синтаксис более доступен, поэтому изучение примеров не доставит сложностей даже тем, кто привык к другим языкам. В приложении Б приведена краткая шпаргалка по используемому в данной книге подмножеству TypeScript.
Я надеюсь, что вы получите удовольствие от чтения этой книги и изучите кое-какие новые методики, которые сможете сразу же применить в своих проектах.
1 Степанов А., Мак-Джонс П. Начала программирования. — М.: Вильямс, 2011. Роуз Д., Степанов А.А. От математики к обобщенному программированию. — М.: ДМК Пресс, 2015.
2 «Теория категорий для программистов». Ее неофициальный перевод можно найти на сайте https://henrychern.wordpress.com/2017/07/17/httpsbartoszmilewski-com20141028category-theory-for-programmers-the-preface/. — Примеч. пер.
3 Пирс Б. Типы в языках программирования. — М.: Лямбда пресс; Добросвет, 2011.
4 Здесь и далее для единообразия subtype/supertype переводится как «подтип/надтип», хотя в русскоязычной литературе первое чаще называют «подтип» (а не субтип), а второе — «супертип». — Примеч. пер.
Я прочитал немало книг на эту тему, начиная от Elements of Programming и From Mathematics to Generic Programming Степанова1 и до Category Theory for Programmers Бартоша Милевски (Bartosz Milewski)2 и Types and Programming Languages Бенджамина Пирса (Benjamin Pierce)3. Как вы понимаете из названий, книги посвящены скорее теоретико-математическим вопросам. Чем больше я узнавал о системах типов, тем лучше становился код, который я писал на работе. Между теоретическими вопросами проектирования систем типов и повседневной работой над программным обеспечением существует самая непосредственная связь. Я вовсе не открываю Америку: все причудливые возможности систем типов существуют как раз для решения реальных задач.
Цель книги — подробный анализ возможностей систем типов, начиная от базовых типов, функциональных типов и создания подтипов4, ООП, обобщенного программирования и типов более высокого рода, например функторов и монад. Вместо того чтобы сосредоточиться на теоретической стороне этих возможностей, я опишу их практическое применение. В данной книге рассказывается, как и когда использовать каждую из них, чтобы сделать свой код лучше.
Я прочитал немало книг на эту тему, начиная от Elements of Programming и From Mathematics to Generic Programming Степанова1 и до Category Theory for Programmers Бартоша Милевски (Bartosz Milewski)2 и Types and Programming Languages Бенджамина Пирса (Benjamin Pierce)3. Как вы понимаете из названий, книги посвящены скорее теоретико-математическим вопросам. Чем больше я узнавал о системах типов, тем лучше становился код, который я писал на работе. Между теоретическими вопросами проектирования систем типов и повседневной работой над программным обеспечением существует самая непосредственная связь. Я вовсе не открываю Америку: все причудливые возможности систем типов существуют как раз для решения реальных задач.
Я прочитал немало книг на эту тему, начиная от Elements of Programming и From Mathematics to Generic Programming Степанова1 и до Category Theory for Programmers Бартоша Милевски (Bartosz Milewski)2 и Types and Programming Languages Бенджамина Пирса (Benjamin Pierce)3. Как вы понимаете из названий, книги посвящены скорее теоретико-математическим вопросам. Чем больше я узнавал о системах типов, тем лучше становился код, который я писал на работе. Между теоретическими вопросами проектирования систем типов и повседневной работой над программным обеспечением существует самая непосредственная связь. Я вовсе не открываю Америку: все причудливые возможности систем типов существуют как раз для решения реальных задач.
Степанов А., Мак-Джонс П. Начала программирования. — М.: Вильямс, 2011. Роуз Д., Степанов А.А. От математики к обобщенному программированию. — М.: ДМК Пресс, 2015.
«Теория категорий для программистов». Ее неофициальный перевод можно найти на сайте https://henrychern.wordpress.com/2017/07/17/httpsbartoszmilewski-com20141028category-theory-for-programmers-the-preface/. — Примеч. пер.
Пирс Б. Типы в языках программирования. — М.: Лямбда пресс; Добросвет, 2011.
Здесь и далее для единообразия subtype/supertype переводится как «подтип/надтип», хотя в русскоязычной литературе первое чаще называют «подтип» (а не субтип), а второе — «супертип». — Примеч. пер.
Благодарности
Прежде всего я хотел бы поблагодарить мою семью за поддержку и понимание. На каждом этапе данного пути со мной были моя жена Диана и дочь Ада, поддерживая меня и предоставляя свободу, необходимую для завершения этой книги.
Написание книги, безусловно, заслуга целой команды. Я признателен Майклу Стивенсу (Michael Stephens) за первоначальные отзывы. Я хочу поблагодарить моего редактора Элешу Хайд (Elesha Hyde) за всю ее помощь, советы и отзывы. Спасибо Майку Шепарду (Mike Shepard) за рецензию на каждую из глав и честную критику. Кроме того, спасибо Херману Гонсалесу (German Gonzales) за просмотр всех до единого примеров кода и проверку правильности их работы. Я хотел бы поблагодарить всех рецензентов за уделенное мне время и бесценные отзывы. Спасибо вам, Виктор Бек (Viktor Bek), Роберто Касадеи (Roberto Casadei), Ахмед Чиктэй (Ahmed Chicktay), Джон Корли (John Corley), Джастин Коулстон (Justin Coulston), Тео Деспудис (Theo Despoudis), Дэвид Ди Мария (David DiMaria), Кристофер Фрай (Christopher Fry), Херман Гонсалес-Моррис (German Gonzalez-Morris), Випул Гупта (Vipul Gupta), Питер Хэмптон (Peter Hampton), Клайв Харбер (Clive Harber), Фред Хит (Fred Heath), Райан Хьюбер (Ryan Huber), Дес Хорсли (Des Horsley), Кевин Норман Д. Капчан (Kevin Norman D. Kapchan), Хосе Сан-Леандро (Jose San Leandro), Джеймс Люй (James Liu), Уэйн Мазер (Wayne Mather), Арнальдо Габриэль Айала Мейер (Arnaldo Gabriel Ayala Meyer), Риккардо Новьелло (Riccardo Noviello), Марко Пероне (Marco Perone), Джермаль Прествуд (Jermal Prestwood), Борха Кеведо (Borja Quevedo), Доминго Себастьян Састре (Domingo Sebastia'n Sastre), Рохит Шарм (Rohit Sharm) и Грег Райт (Greg Wright).
Я хотел бы поблагодарить моих сослуживцев и наставников за все, чему они меня научили. Когда я изучал возможности применения типов для улучшения нашей кодовой базы, мне повезло встретить нескольких замечательных менеджеров, всегда готовых прийти на помощь. Спасибо Майку Наварро (Mike Navarro), Дэвиду Хансену (David Hansen) и Бену Россу (Ben Ross) за их веру в меня.
Спасибо всему сообществу разработчиков C++, от которых я столь многому научился, особенно Шону Пэренту (Sean Parent) — за вдохновение и замечательные советы.
О книге
Цель этой книги — продемонстрировать вам, как писать лучший, более безопасный код с помощью систем типов. Хотя большинство изданий, посвященных системам типов, сосредотачиваются на более формальных аспектах вопроса, данная книга представляет собой скорее практическое руководство. Она содержит множество примеров, приложений и сценариев, встречающихся в повседневной работе программиста.
Целевая аудитория
Книга предназначена для программистов-практиков, которые хотят узнать больше о функционировании систем типов и о том, как с их помощью повысить качество своего кода. Желательно иметь опыт работы с объектно-ориентированными языками программирования: Java, C#, C++ или JavaScript/TypeScript, а также хотя бы минимальный опыт проектирования ПО. Хотя в этой книге рассматриваются различные методики написания надежного, пригодного для компоновки и хорошо инкапсулированного кода, предполагается, что вы понимаете, почему эти свойства желательны.
Структура книги
Книга содержит 11 глав, посвященных различным аспектам типизированного программирования.
• В главе 1 мы познакомимся с типами и их системами, обсудим, для чего они служат и какую пользу могут принести. Рассмотрим существующие виды систем типов и поговорим о строгой, а также статической и динамической типизациях.
• В главе 2 мы рассмотрим простые типы данных, существующие в большинстве языков программирования, и нюансы, которые следует учитывать при их использовании. К распространенным простым типам данных относятся: пустой тип и единичный тип, булевы значения, числа, строки, массивы и ссылки.
• В главе 3 мы изучим сочетаемость: разнообразные способы сочетания типов для определения новых типов. Кроме того, рассмотрим различные способы реализации паттерна проектирования «Посетитель» и алгебраические типы данных.
• В главе 4 мы поговорим о типобезопасности — пути снижения неоднозначности и предотвращения ошибок при использовании типов. Кроме того, я расскажу о добавлении/удалении информации о типе из кода с помощью приведения типов.
• В главе 5 вы познакомитесь с функциональными типами и возможностями, возникающими благодаря созданию функциональных переменных. Мы рассмотрим альтернативные способы реализации паттерна проектирования «Стратегия» и конечных автоматов, а также базовые алгоритмы map(), filter() и reduce().
• В главе 6 будет представлен расширенный материал предыдущей главы и продемонстрировано несколько продвинутых приложений функциональных типов данных, начиная от упрощенного паттерна проектирования «Декоратор» и заканчивая возобновляемыми и асинхронными функциями.
• В главе 7 мы познакомимся с созданием подтипов и обсудим совместимость типов данных. Мы рассмотрим применение низшего и высшего типов и увидим, как связаны друг с другом тип-сумма, коллекции и функциональные типы с точки зрения подтипизации.
• В главе 8 мы обсудим ключевые элементы объектно-ориентированного программирования и их использование. Рассмотрим интерфейсы, наследование, сочетание типов и примеси.
• В главе 9 вы познакомитесь с обобщенным программированием и его первым приложением: обобщенными структурами данных. Эти структуры отделяют схему данных от них самих; обход структур возможен с помощью итераторов.
• В главе 10 мы продолжим тему обобщенного программирования и обсудим обобщенные алгоритмы и категории итераторов. Обобщенными являются алгоритмы, которые можно использовать повторно для различных типов данных. Итераторы играют роль интерфейса между структурами данных и алгоритмами и, в зависимости от своих возможностей, могут запускать различные алгоритмы.
• В главе 11, заключительной, будут описаны типы, принадлежащие к более высокому роду, и дано объяснение, что такое функторы и монады и как их использовать. Завершат эту главу ссылки на литературу для дальнейшего изучения.
Все главы используют понятия, описанные в предыдущих главах книги, так что читать их следует по порядку. Тем не менее четыре основные темы более или менее независимы. В первых четырех главах описываются основные понятия; в главах 5 и 6 рассказывается о функциональных типах данных; в главах 7 и 8 — о создании подтипов; главы 9, 10 и 11 посвящены обобщенному программированию.
О коде
Эта книга содержит множество примеров исходного кода как в пронумерованных листингах, так и внутри обычного текста. В обоих случаях исходный код набран воттакиммоношириннымшрифтом с целью отличить его от обычного текста. Иногда код также набран полужирнымшрифтом, чтобы подчеркнуть изменения по сравнению с предыдущими шагами в текущей главе, например при добавлении новой функциональной возможности к уже существующей строке кода.
Во многих случаях первоначальный исходный код был переформатирован: были добавлены разрывы строк и переработаны отступы, чтобы наилучшим образом использовать доступное место на страницах книги. В редких случаях этого оказывалось недостаточно, и листинги включают маркеры продолжения строки (). Кроме того, из исходного кода нередко удалялись комментарии там, где он описывался в тексте. Многие листинги сопровождают примечания к коду, подчеркивающие важные нюансы.
Исходный код для всех листингов данной книги доступен для скачивания с GitHub по адресу https://github.com/vladris/programming-with-types/. Сборка кода производилась с помощью версии 3.3 компилятора TypeScript со значением ES6 для опции target и c опцией strict.
Об авторе
Влад Ришкуция — специалист по разработке ПО в Microsoft, имеет более чем десятилетний опыт. За это время он руководил несколькими крупными программными проектами и обучил множество молодых специалистов.
Дискуссионный форум книги
Покупка этой книги дает право на бесплатный доступ к частному веб-форуму издательства Manning, где можно оставлять комментарии о книге, задавать технические вопросы и получать помощь от автора книги и других пользователей. Чтобы попасть на этот форум, перейдите по адресу https://livebook.manning.com/#!/book/natural-language-processing-in-action/discussion. Узнать больше о форумах издательства и правилах поведения на них можно на странице https://livebook.manning.com/#!/discussion.
Обязательства издательства Manning по отношению к своим читателям заключаются в том, чтобы предоставить место для содержательного диалога между отдельными читателями, а также читателями и авторами. Эти обязательства не включают какого-либо конкретного объема участия со стороны авторов, чей вклад в работу форума остается добровольным (и неоплачиваемым). Мы советуем вам задавать авторам интересные и трудные вопросы, чтобы их интерес не угас!
Об иллюстрации на обложке
Рисунок на обложке называется Fille Lipporolle en habit de Noce («Девица Липороль в свадебном платье»). Эта иллюстрация взята из недавнего переиздания книги Жака Грассе де Сан-Савье Costumes de Diffe'rents Pays («Наряды разных стран»), опубликованной во Франции в 1797 году. Все иллюстрации прекрасно прорисованы и раскрашены вручную. Широкое разнообразие коллекции нарядов Грассе де Сан-Савье напоминает нам, насколько разъединены были различные регионы мира всего 200 лет назад. Изолированные друг от друга, люди говорили на разных диалектах и языках. На улицах городов и в деревнях по одной манере одеваться можно было легко понять, каким ремеслом занимается человек и каково его социальное положение.
Стили одежды с тех пор изменились, и столь богатое разнообразие различных регионов угасло. Зачастую непросто отличить даже жителя одного континента от жителя другого, не говоря уже о городах и странах. Возможно, мы пожертвовали культурным многообразием в пользу большего разнообразия личной жизни — и определенно более разнообразной и динамичной жизни технологической.
В наше время, когда книги на компьютерную тематику так мало отличаются друг от друга, издательство Manning отдает должное изобретательности и инициативе компьютерного бизнеса обложками книг, основанными на богатом разнообразии жизни в разных уголках мира двухвековой давности, возвращенном к нам иллюстрациями Жака Грассе де Сан-Савье.
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
На веб-сайте издательства www.piter.com вы найдете подробную информацию о наших книгах.
Глава 1. Введение в типизацию
В этой главе
• Зачем нужны системы типов.
• Преимущества сильно типизированного кода.
• Разновидности систем типов.
• Распространенные возможности систем типов.
Аппарат Mars Climate Orbiter развалился в атмосфере Марса, поскольку разработанный компанией Lockheed компонент выдавал измерения импульса силы в фунт-силах на секунду (единицы измерения США), а другой компонент, разработанный НАСА, ожидал, что импульс силы будет измеряться в ньютонах на секунду (единицы СИ). Катастрофы можно было избежать, если бы для этих двух величин использовались различные типы данных.
Как мы будем наблюдать на протяжении данной книги, проверки типов позволяют исключать целые классы ошибок при условии наличия достаточной информации. По мере роста сложности программного обеспечения должны обеспечиваться и лучшие гарантии правильности его работы. Мониторинг и тестирование могут продемонстрировать, ведет ли себя ПО в соответствии со спецификациями в заданный момент времени при определенных входных данных. Типы же обеспечивают более общее подтверждение должного поведения кода, независимо от входных данных.
Благодаря научным изысканиям в области языков программирования возникают все более и более эффективные системы типов (см., например, такие языки программирования, как Elm и Idris). Растет популярность языка Haskell. В то же время продолжаются попытки добиться проверки типов на стадии компиляции в динамически типизированных языках: в Python появилась поддержка указаний ожидаемых типов (type hints) и был создан язык TypeScript, единственная цель которого — обеспечить проверку типов во время компиляции в JavaScript.
Типизация кода, безусловно, важна, и благодаря полному использованию возможностей системы типов, предоставляемой языком программирования, можно писать лучший, более безопасный код.
1.1. Для кого эта книга
Книга предназначена для программистов-практиков. Читатель должен хорошо уметь писать код на одном из таких языков программирования, как Java, C#, C++ или JavaScript/TypeScript. Примеры кода приведены на языке TypeScript, но большая часть излагаемого материала применима к любому языку программирования. На самом деле в примерах далеко не всегда используется характерный TypeScript. По возможности они адаптировались так, чтобы их понимали программисты на других языках программирования. Сборка примеров кода описана в приложении A, а краткая «шпаргалка» по языку TypeScript — в приложении Б.
Если вы по работе занимаетесь разработкой объектно-ориентированного кода, то, возможно, слышали об алгебраических типах данных (algebraic data type, ADT), лямбда-выражениях, обобщенных типах данных (generics), функторах, монадах и хотите лучше разобраться, что это такое и как их использовать в своей работе.
Эта книга расскажет, как использовать систему типов языка программирования для проектирования менее подверженного ошибкам, более модульного и понятного кода. Вы увидите, как превратить ошибки времени выполнения, которые могут привести к отказу всей системы, в ошибки компиляции и перехватить их, пока они еще не натворили бед.
Основная часть литературы по системам типов сильно формализована. Книга же сосредотачивает внимание на практических приложениях систем типов; поэтому математики в ней очень мало. Тем не менее желательно, чтобы вы имели представление об основных понятиях алгебры, таких как функции и множества. Это понадобится для пояснения некоторых из нужных нам понятий.
1.2. Для чего существуют типы
На низком уровне аппаратного обеспечения и машинного кода логика программы (код) и данные, которыми она оперирует, представлены в виде битов. На этом уровне нет разницы между кодом и данными, так что вполне могут возникнуть ошибки, при которых система путает одно с другим. Их диапазон простирается от фатальных сбоев программы до серьезных уязвимостей, когда злоумышленник обманом заставляет систему считать входные данные кодом, подлежащим выполнению.
Пример подобной нестрогой интерпретации — функция eval() языка JavaScript, выполняющая строковое значение как код. Она отлично работает, если переданная ей строка представляет собой допустимый код на языке JavaScript, но вызывает ошибку времени выполнения в противном случае, как показано в листинге 1.1.
Листинг 1.1. Попытка интерпретировать данные как код
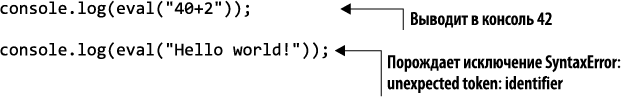
1.2.1. Нули и единицы
Необходимо не только различать код и данные, но и интерпретировать элементы данных. Состоящая из 16 бит последовательность 1100001010100011 может соответствовать беззнаковому 16-битному целому числу 49827, 16-битному целому числу со знаком –15709, символу '£' в кодировке UTF-8 или чему-то совершенно другому, как можно видеть на рис. 1.1. Аппаратное обеспечение, на котором работают наши программы, хранит все в виде последовательностей битов, так что необходим дополнительный слой для осмысления этих данных.
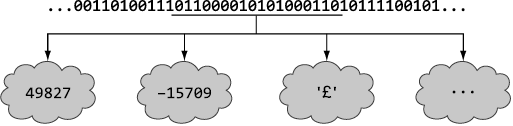
Рис. 1.1. Последовательность битов можно интерпретировать по-разному
Типы придают смысл подобным данным и указывают программному обеспечению, как интерпретировать заданную последовательность битов в установленном контексте, чтобы она сохранила задуманный автором смысл.
Кроме того, типы ограничивают множество допустимых значений переменных. Шестнадцатибитное целое число со знаком может отражать любое из целочисленных значений от –32768 до 32767 и только их. Благодаря ограничению диапазона допустимых значений исключаются целые классы ошибок, поскольку не допускается возникновения неправильных значений во время выполнения, как показано на рис. 1.2. Чтобы понять многие из приведенных в этой книге концепций, важно рассматривать типы как множества возможных значений.
В разделе 1.3 мы увидим: система обеспечивает также соблюдение многих других мер безопасности при добавлении возможностей в код, например обозначение значений как const или членов как private.
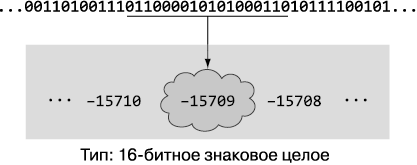
Рис. 1.2. Последовательность битов с типом 16-битного знакового целого. Информация о типе (16-битное знаковое целое число) указывает компилятору и/или среде выполнения, что эта битная последовательность представляет собой целочисленное значение в диапазоне от –32 768 до 32 767, благодаря чему она правильно интерпретируется как –15 709
1.2.2. Что такое типы и их системы
Раз уж книга посвящена типам и их системам, дам определения этих терминов, прежде чем идти дальше.
Что такое Тип
Тип (type) — классификация данных, определяющая допустимые операции над ними, смысл этих данных и множество допустимых значений. Компилятор и/или среда выполнения производят проверку типов, чтобы обеспечить целостность данных и соблюдение ограничений доступа, а также интерпретацию данных в соответствии с замыслом разработчика.
В некоторых случаях ради простоты мы будем игнорировать относящуюся к операциям часть этого определения и рассматривать типы просто как множества, отражающие все возможные значения экземпляра данного типа.
Система типов
Система типов (type system) представляет собой набор правил присвоения типов элементам языка программирования и обеспечения соблюдения этих присвоений. Такими элементами могут быть переменные, функции и другие высокоуровневые конструкции языка. Системы типов производят присвоение типов с помощью задаваемой в коде нотации или неявным образом, путем вывода типа конкретного элемента по контексту. Системы типов разрешают одни преобразования типов друг в друга и запрещают другие.
Теперь, когда мы узнали определения типов и систем типов, посмотрим, как обеспечивается соблюдение правил системы типов. На рис. 1.3 показано на высоком уровне выполнение исходного кода.
Если описывать на очень высоком уровне, то создаваемый нами исходный код преобразуется компилятором или интерпретатором в инструкции для машины (среды выполнения). Ее роль может играть физическая машина (в этом случае роль инструкций играют инструкции CPU) или виртуальная с собственным набором инструкций и функций.
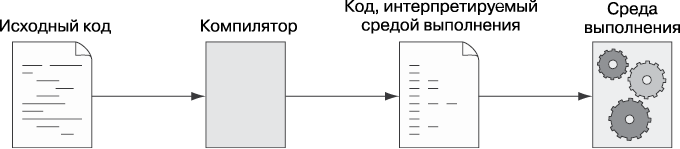
Рис. 1.3. С помощью компилятора или интерпретатора исходный код преобразуется в код, запускаемый средой выполнения. Ее роль может играть физический компьютер или виртуальная машина, например JVM Java или движок JavaScript браузера
Проверка типов
Процесс проверки типов (type checking) обеспечивает соблюдение программой правил системы типов. Проверка производится компилятором во время преобразования кода или средой выполнения при его работе. Компонент компилятора, обеспечивающий соблюдение правил типизации, называется модулем проверки типов (type checker).
Если проверка типов завершается неудачно, то есть программа не соблюдает правила системы типов, то возникает ошибка на этапе компиляции или выполнения. Разницу между проверкой типа на этапе компиляции и на этапе выполнения мы обсудим подробнее в разделе 1.4.
| Проверка типов и доказательства В основе систем типов лежит формальная теория. Замечательное соответствие Карри-Ховарда (Curry-Howard correspondence), известное также как эквивалентность между математическими доказательствами и программами (proofs-as-programs), демонстрирует родственность логики и теории типов. Оно показывает, что тип можно рассматривать как логическое высказывание, а функцию, принимающую на входе один тип и возвращающую другой, — как логическую импликацию. Значение типа эквивалентно факту справедливости высказывания. Возьмем для примера функцию, принимающую на входе boolean и возвращающую string. Из булева значения в строковое function booleanToString(b: boolean): string { if (b) { return "true"; } else { return "false"; } } Эту функцию можно интерпретировать как «из boolean следует string». По заданному факту высказывания типа boolean данная функция (импликация) выдает факт высказывания типа string. Факт boolean представляет собой значение этого типа, true или false. По нему указанная функция (импликация) выдает факт string в виде строки "true" или"false". Тесная связь между логикой и теорией типов показывает: соблюдающая правила системы типов программа эквивалентна логическому доказательству. Другими словами, система типов — язык написания этих доказательств. Соответствие Карри-Ховарда важно тем, что правильность работы программы гарантируется с логической строгостью. |
1.3. Преимущества систем типов
Все данные, по сути, представляют собой нули и единицы, поэтому все свойства данных, например их интерпретация, неизменяемость и видимость, относятся к уровню типа. Переменная объявляется с числовым типом, и модуль проверки типа гарантирует, что ее значение не будет интерпретировано как строковое. Переменная объявляется как приватная или предназначенная только для чтения. И хотя сами данные в памяти ничем не отличаются от аналогичных публичных изменяемых данных, модуль проверки типа гарантирует, что мы не будем обращаться к приватной переменной вне ее области видимости или пытаться изменить данные, предназначенные только для чтения.
Основные преимущества типизации — корректность (correctness), неизменяемость (immutability), инкапсуляция (encapsulation), компонуемость (composability) и читабельность (readability). Это фундаментальные признаки хорошей архитектуры и нормального поведения программного обеспечения. С течением времени системы развиваются. Эти признаки противостоят энтропии, которая неизбежно возникает в любой системе.
1.3.1. Корректность
Корректным (сorrect) является код, который ведет себя в соответствии со спецификациями, выдает ожидаемые результаты без ошибок и сбоев во время выполнения. Благодаря типам растут строгость кода и гарантии его должного поведения.
Для примера предположим, что нам нужно найти позицию строки "Script" внутри другой строки. Мы не будем передавать достаточную информацию о типе и разрешим передачу в качестве аргумента нашей функции значения типа any. Как показывает листинг 1.2, это приведет к ошибкам во время выполнения.
В этой программе содержится ошибка — 42 не является допустимым аргументом для функции scriptAt, но компилятор об этом молчит, поскольку мы не предоставили достаточную информацию о типе данных. Усовершенствуем данный код, ограничив аргумент типом string в листинге 1.3.
Теперь компилятор отвергает эту некорректную программу, выдавая следующее сообщение об ошибке: Argumentoftype'42'isnotassignabletoparameteroftype'string' (невозможно присвоить параметру типа 'string' аргумент типа '42').
Листинг 1.2. Недостаточная информация о типе данных
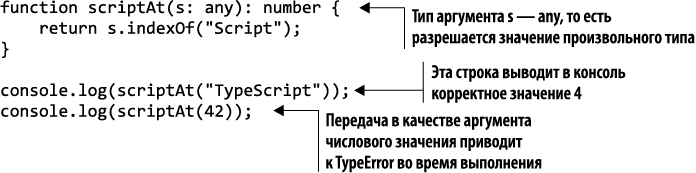
Листинг 1.3. Уточненная информация о типе

Воспользовавшись системой типов, мы из проблемы времени выполнения, которая могла проявиться при промышленной эксплуатации (и повлиять на наших клиентов), сделали безобидную проблему этапа компиляции, которую просто нужно исправить перед развертыванием кода. Модуль проверки типа гарантирует, что яблоки не будут передаваться в качестве апельсинов; а значит, растет ошибкоустойчивость кода.
Ошибки возникают, когда программа переходит в некорректное состояние, то есть текущее сочетание всех ее действующих переменных некорректно по какой-либо причине. Один из методов, позволяющих избавиться от части таких некорректных состояний, — уменьшение пространства состояний за счет ограничения количества возможных значений переменных, как показано на рис. 1.4.

Рис. 1.4. Благодаря правильному объявлению типа можно запретить некорректные значения. Первый тип слишком широк и допускает нежелательные нам значения. Второй тип — более жестко ограниченный — не скомпилируется, если код попытается присвоить переменной нежелательное значение
Пространство состояний (state space) работающей программы можно описать как сочетание всех вероятных значений всех ее действующих переменных. То есть декартово произведение типов всех переменных. Напомню, что тип переменной можно рассматривать как множество ее возможных значений. Декартово произведение двух множеств представляет собой множество, состоящее из всех их упорядоченных пар элементов.
Безопасность
Важный побочный результат запрета на потенциальные некорректные состояния — повышение безопасности кода. В основе множества атак лежит выполнение передаваемых пользователем данных, переполнение буфера и другие подобные методики, опасность которых нередко можно уменьшить за счет достаточно сильной системы типов и хороших определений типов.
Корректность кода не исчерпывается исправлением невинных ошибок в коде с целью предотвратить атаки злоумышленников.
1.3.2. Неизменяемость
Неизменяемость (immutability) — еще одно свойство, тесно связанное с представлением о нашей работающей системе как о движении по пространству состояний. Вероятность ошибок можно снизить, если при нахождении системы в заведомо хорошем состоянии не допускать его изменений.
Рассмотрим простой пример, в котором попытаемся предотвратить деление на ноль с помощью проверки значения делителя и генерации ошибки в случае, когда оно равно 0, как показано в листинге 1.4. Если же значение может меняться после нашей проверки, то она теряет всякий смысл.
Листинг 1.4. «Плохое» изменение значения5

В настоящих программах подобное случается регулярно, причем часто довольно неожиданным образом: переменная меняется, скажем, конкурентным потоком выполнения или другой вызванной функцией. Как и в этом примере, сразу после изменения значения все гарантии, которые мы надеялись получить от наших проверок, теряются. Если же сделать x константой, как в листинге 1.5, то компилятор вернет ошибку при попытке изменить ее значение.
Листинг 1.5. Неизменяемость

Теперь компилятор отвергает некорректный код, выводя следующее сообщение об ошибке: Cannotassignto'x'becauseitisaconstant (Присвоение значения переменной x невозможно, поскольку она является константой).
В смысле представления в оперативной памяти разницы между изменяемой и неизменяемой x нет. Свойство константности значит что-то только для компилятора. Это свойство, обеспечиваемое системой типов.
Указание на неизменяемость состояния с помощью добавления ключевого слова const в описание типа предотвращает те изменения значений, при которых теряются гарантии, полученные благодаря предыдущим проверкам. Особенно полезна неизменяемость в случае конкурентного выполнения, поскольку делает невозможной состояние гонки.
Оптимизация компиляторов обеспечивает выдачу более эффективного кода в случае неизменяемых переменных, так как их значения можно встраивать в код. В некоторых функциональных языках программирования все данные — неизменяемые: функции принимают на входе какие-либо данные и возвращают другие, никогда не меняя входных. При этом достаточно один раз проверить значение переменной и убедиться в ее хорошем состоянии с целью гарантировать, что она будет находиться в хорошем состоянии на протяжении всего жизненного цикла. Конечно, при этом приходится идти на (не всегда желательный) компромисс: копировать данные, с которыми в противном случае можно было бы работать, не прибегая к дополнительным структурам данных.
Впрочем, не всегда имеет смысл делать все данные неизменяемыми. Тем не менее неизменяемость как можно большего числа данных может резко снизить вероятность возникновения таких проблем, как несоответствие заранее заданным условиям и состояние гонки по данным.
1.3.3. Инкапсуляция
Инкапсуляция (encapsulation) — сокрытие части внутреннего устройства кода в функции, классе или модуле. Как вы, вероятно, знаете, инкапсуляция — желательное свойство, она помогает понижать сложность: код разбивается на меньшие компоненты, каждый из которых предоставляет доступ только к тому, что действительно нужно, а подробности реализации скрываются и изолируются.
В листинге 1.6 мы расширим пример безопасного деления, превратив его в класс, который старается гарантировать отсутствие деления на 0.
Листинг 1.6. Недостаточная инкапсуляция
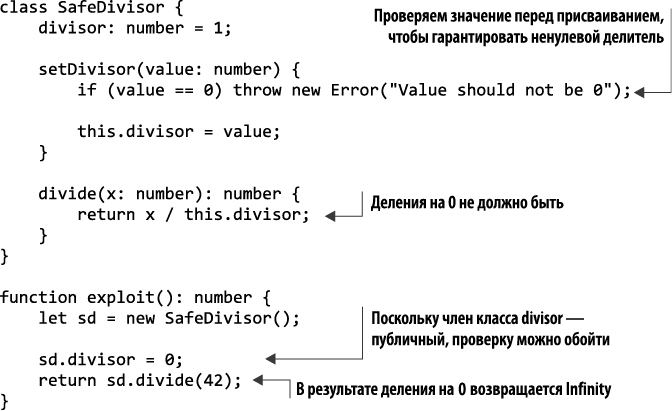
В данном случае мы не можем сделать делитель неизменяемым, поскольку хотим, чтобы у вызывающего наш API кода была возможность его обновлять. Проблема такова: вызывающая сторона может обойти проверку на 0 и непосредственно задать любое значение для divisor, так как он для них доступен. Эту проблему в данном случае можно решить, объявив его в качестве private и ограничив его область видимости классом, как показано в листинге 1.7.
Листинг 1.7. Инкапсуляция

Представление в оперативной памяти приватных и публичных членов класса одинаково; проблемный код не компилируется во втором примере просто благодаря указанию типа. На самом деле public, private и другие модификаторы видимости — свойства соответствующего типа.
Инкапсуляция (сокрытие информации) позволяет разбивать логику программы и данные на публичный интерфейс и непубличную реализацию. Это очень удобно в больших системах, поскольку при работе с интерфейсами (абстракциями) требуется меньше умственных усилий, чтобы понять конкретный фрагмент кода. Желательно анализировать и понимать код на уровне интерфейсов компонентов, а не всех их нюансов реализации. Полезно также ограничивать область видимости непубличной информации, чтобы внешний код не мог их модифицировать попросту вследствие отсутствия доступа.
Инкапсуляция существует на множестве уровней: сервис предоставляет доступ к своему API в виде интерфейса, модуль экспортирует свой интерфейс и скрывает нюансы реализации, класс делает видимыми только публичные члены класса и т.д. Чем слабее связь между двумя частями кода, тем меньший объем информации они разделяют. Благодаря этому усиливаются гарантии компонента относительно его внутренних данных, поскольку никакой внешний код не может их модифицировать, не прибегая к использованию интерфейса компонента.
1.3.4. Компонуемость
Допустим, нам требуется найти первое отрицательное число в числовом массиве и первую строку из одного символа в символьном массиве. Не прибегая к разбиению этой задачи на две части и последующему их объединению в единую систему, мы получили бы в итоге две функции: findFirstNegativeNumber() и findFirstOneCharacterString(), показанные в листинге 1.8.
Листинг 1.8. Некомпонуемая система
function findFirstNegativeNumber(numbers: number[])
: number | undefined {
for (let i of numbers) {
if (i < 0) return i;
}
}
function findFirstOneCharacterString(strings: string[])
: string | undefined {
for (let str of strings) {
if (str.length == 1) return str;
}
}
Эти две функции ищут первое отрицательное число и первую строку из одного символа соответственно. Если подобных элементов не найдено, то функции возвращают undefined (неявно, путем выхода из функции без оператора return).
Если появится новое требование к системе, например, заносить в журнал ошибку в случае невозможности найти искомый элемент, то придется обновить описание обеих функций, как показано в листинге 1.9.
Листинг 1.9. Обновление некомпонуемой системы
function findFirstNegativeNumber(numbers: number[])
: number | undefined {
for (let i of numbers) {
if (i < 0) return i;
}
console.error("No matching value found");
}
function findFirstOneCharacterString(strings: string[])
: string | undefined {
for (let str of strings) {
if (str.length == 1) return str;
}
console.error("No matching value found");
}
Данный вариант явно не оптимальный. Что, если мы забудем обновить код в одном из мест? Подобные проблемы усугубляются в больших системах. Судя по виду этих функций, алгоритм в них один и тот же; но в одном случае мы работаем с числами с одним условием, а в другом — со строками с другим условием. Можно написать обобщенный алгоритм с параметризацией по типу обрабатываемых данных и проверяемому условию, как показано в листинге 1.10. Подобный алгоритм не зависит от других частей системы, и его можно анализировать отдельно.
Листинг 1.10. Компонуемая система
function first<T>(range: T[], p: (elem: T) => boolean)
: T | undefined {
for (let elem of range) {
if (p (elem)) return elem;
}
}
function findFirstNegativeNumber(numbers: number[])
: number | undefined {
return first(numbers, n => n < 0);
}
function findFirstOneCharacterString(strings: string[])
: string | undefined {
return first(strings, str => str.length == 1);
}
Не волнуйтесь, если синтаксис немного непривычен; мы обсудим встраиваемые функции (такие как n=>n<0) в главе 5 и обобщенные функции — в главах 9 и 10.
Для добавления в эту реализацию журналирования достаточно обновить реализацию функции first. Причем если мы придумаем более эффективную реализацию алгоритма, то нужно будет лишь обновить реализацию, и этим автоматически воспользуются все вызывающие функции.
Как мы увидим в главе 10, когда будем обсуждать обобщенные алгоритмы и итераторы, эту функцию можно обобщить еще больше. Пока что она работает с массивом элементов типа T, но ее можно обобщить на обход произвольной структуры данных.
Если код некомпонуемый, то понадобится отдельная функция для каждого типа данных, структуры данных и условия, хотя все они, по сути, реализуют одну абстракцию. Возможность абстрагирования с последующим сочетанием и комбинированием компонентов существенно снижает дублирование. Выражать подобные абстракции позволяют обобщенные типы данных.
Возможность сочетания независимых компонентов превращает систему в модульную и уменьшает количество требующего сопровождения кода. Значение компонуемости растет по мере роста объема кода и числа компонентов. Части компонуемой системы сцеплены слабо; в то же время код в отдельных подсистемах не дублируется. Для учета новых требований обычно достаточно обновить один компонент вместо того, чтобы проводить масштабные изменения по всей системе. В то же время для понимания подобной системы требуется меньше мыслительных затрат, поскольку ее части можно анализировать по отдельности.
1.3.5. Читабельность
Код читают намного большее количество раз, чем пишут. Благодаря типизации становится понятно, какие аргументы ожидает функция, каковы предварительные условия для обобщенного алгоритма, какой интерфейс реализует класс и т.д. Ценность этой информации заключается в возможности провести анализ кода по отдельным частям: по одному виду определения, не обращаясь к исходному коду вызывающих и вызываемых функций, можно легко понять, как должен работать код.
Важную роль в этом процессе играют наименования и комментарии, но типизация добавляет в него дополнительный слой информации, позволяя именовать ограничения. Взглянем на нетипизированное объявление функции find() в листинге 1.11.
Листинг 1.11. Нетипизированная функция find()
declare function find(range: any, pred: any): any;
Из описания этой функции непросто понять, какие аргументы она ожидает на входе. Необходимо читать реализацию, пробовать различные параметры и смотреть, не получим ли мы на выходе ошибку во время выполнения, либо надеяться, что все описано в документации.
Сравните с предыдущим объявлением следующий код (листинг 1.12).
Листинг 1.12. Типизированная функция find()
declare function first<T>(range: T[],
p: (elem: T) => boolean): T | undefined;
Из этого описания сразу понятно, что для произвольного типа T необходимо передать в качестве аргумента range массив T[] и функцию, принимающую T и возвращающую boolean в качестве аргумента p. Кроме того, сразу же понятно, что функция возвращает T или undefined.
Вместо поиска реализации или чтения документации достаточно прочесть это объявление функции, чтобы понять, какие именно типы аргументов нужно передавать. Это существенно снижает нашу когнитивную нагрузку благодаря тому, что функция рассматривается как самодостаточная отдельная сущность. Задание подобной информации о типе явным образом, видимым не только компилятору, но и разработчику, намного облегчает понимание кода.
В большинстве современных языков программирования существуют какие-либо правила вывода типов (type inference), то есть определения типа переменной по контексту. Это удобно, поскольку позволяет снизить объем требуемого кода, но может превращаться в проблему, если код становится легко понятным для компилятора, но слишком запутанным для людей. Явно прописанный тип намного ценнее комментария, так как его соблюдение обеспечивает компилятор.
1.4. Разновидности систем типов
В настоящее время в большинстве языков программирования и сред выполнения есть типизация в той или иной форме. Мы уже давно осознали, что возможность интерпретировать код как данные и данные как код может привести к катастрофическим последствиям. Основное различие между современными системами типов состоит в том, когда проверяются типы данных, и в степени строгости этих проверок.
При статической типизации проверка совершается во время компиляции, так что по завершении последней гарантируются правильные типы значений во время выполнения. Напротив, при динамической типизации проверка типов данных откладывается до выполнения, поэтому несовпадения типов становятся ошибками времени выполнения.
При сильной типизации производится очень мало преобразований типов (а то и вообще не производится), а менее сильные системы типов допускают больше неявных преобразований типов данных.
1.4.1. Динамическая и статическая типизация
JavaScript — язык с динамической типизацией, а TypeScript — со статической. На самом деле TypeScript был создан именно для добавления статической проверки типов в JavaScript. Превращение ошибок времени выполнения в ошибки компиляции, особенно в больших приложениях, улучшает сопровождаемость и отказоустойчивость кода. Эта книга посвящена статической типизации и статическим языкам программирования, но полезно разобраться и в динамической модели.
Динамическая типизация не предполагает никаких ограничений типов во время компиляции. Обиходное название «утиная типизация» (duck typing) возникло из фразы «Если нечто ходит как утка и крякает как утка то, значит, это утка». Переменная может свободно применяться в коде как угодно, типизация происходит на этапе выполнения. Динамическую типизацию можно имитировать в TypeScript с помощью ключевого слова any, которое позволяет использовать нетипизированные переменные.
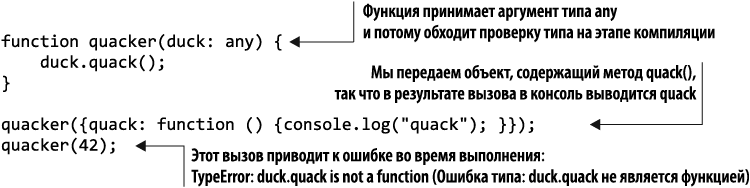
Реализуем функцию quacker(), принимающую на входе аргумент duck типа any и вызывающую для него функцию quack(). Все прекрасно работает, если у передаваемого объекта есть метод quack(). Если же передать нечто «не умеющее крякать» (без метода quack()), то получим TypeError времени выполнения, как показано в листинге 1.13.
Листинг 1.13. Динамическая типизация
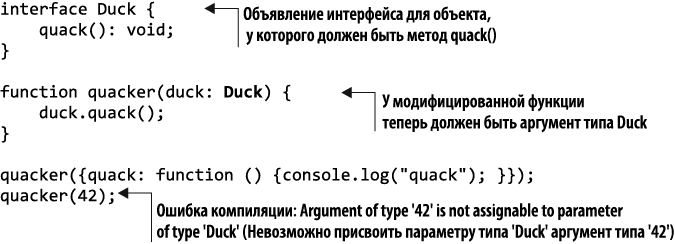
При статической типизации, с другой стороны, проверка типов производится на этапе компиляции, так что попытка передать аргумент не того типа вызывает ошибку компиляции. Для полноценного использования возможностей статической типизации TypeScript можно усовершенствовать код, объявив в нем интерфейс Duck и указав соответствующий тип аргумента функции, как показано в листинге 1.14. Обратите внимание: в TypeScript не обязательно явным образом указывать, что мы реализуем интерфейс Duck, лишь бы был метод quack(). Если функция quack() есть, то компилятор считает интерфейс реализованным. В других языках программирования пришлось бы явным образом объявить, что класс реализует этот интерфейс.
Листинг 1.14. Статическая типизация
Основное преимущество статической типизации — перехват подобных ошибок на этапе компиляции до того, как они вызовут сбой работающей программы.
1.4.2. Слабая и сильная типизации
При описания систем типов часто можно встретить термины «сильная типизация»6 (strong typing) и «слабая типизация» (weak typing). Сила системы типов определяется степенью строгости соблюдения ею ограничений типов. Слабая система неявно преобразует значения из их фактических типов в типы, ожидаемые там, где они используются.
Задумайтесь: «молоко» равно «белое»? В сильно типизированном мире ответ на этот вопрос: нет, молоко — жидкость и сравнивать ее с цветом бессмысленно. В слабо типизированном мире можно сказать: «Ну, цвет молока — белый, так что да, молоко равно белому». В сильно типизированном мире можно явным образом преобразовать молоко в цвет, задав вопрос вот так: «Равен ли цвет молока белому?» В слабо типизированном мире это уточнение не требуется.
JavaScript — слабо типизированный язык. Чтобы это увидеть, достаточно воспользоваться типом any в TypeScript и делегировать типизацию во время выполнения JavaScript. В JavaScript есть два оператора проверки на равенство: ==, проверяющий равенство двух значений, и ===, проверяющий равенство как значений, так и их типов (листинг 1.15). Поскольку JavaScript — слабо типизированный язык, выражение вида "42"==42 равно true. Это довольно странно, ведь "42" — текстовое значение, а 42 — число.
Листинг 1.15. Слабая типизация
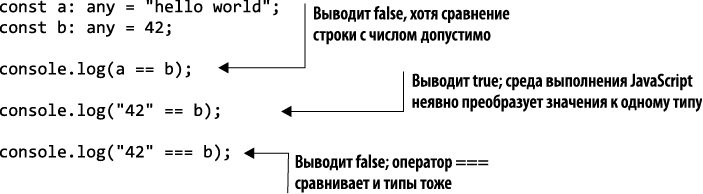
Неявные преобразования типов удобны тем, что не нужно писать много лишнего кода для явного преобразования из одного типа в другой, но и опасны, поскольку во многих случаях такие трансформации нежелательны и неожиданны для программиста. Благодаря сильной типизации TypeScript не скомпилирует ни одну из предыдущих операций сравнения, если объявить должным образом переменную a с типом string и переменную b с типом number, как показано в листинге 1.16.
Все эти операции сравнения вернут ошибку "Thisconditionwillalwaysreturn'false'sincethetypes'string'and'number'havenooverlap". (Это условие всегда возвращает false, поскольку типы 'string' и 'number' не пересекаются.) Модуль проверки типа обнаруживает, что мы пытаемся сравнить значения различных типов, и забраковывает код.
Листинг 1.16. Сильная типизация

Работать со слабой системой типов проще в краткосрочной перспективе, ведь эта система не заставляет программистов явно преобразовывать типы значений, однако она не дает тех гарантий, которые предоставляет сильная система. Большинство описанных в этой главе преимуществ и используемые в оставшейся части данной книги методики потеряют свою эффективность, если не подкрепить их должным образом.
Обратите внимание: хотя система типов может быть либо динамической (проверка типов во время выполнения), либо статической (проверка типов во время компиляции), существует целый диапазон степеней ее строгости: чем менее явные преобразования она производит, тем слабее система. В большинстве систем типов, даже сильных, есть какие-либо ограниченные возможности неявного приведения типов для считающихся безопасными преобразований. Распространенный пример — преобразование к boolean: if(a) скомпилируется, даже если a — number или относится к ссылочному типу. Еще один пример — расширяющее приведение типов (widening cast), о котором мы поговорим подробнее в главе 4. Для числовых значений в TypeScript используется только тип number, но в других языках, когда, допустим, передается восьмибитное значение при необходимом 16-битном целом числе, преобразование обычно выполняется автоматически, так как риска порчи данных нет (16-битное целое число может содержать любое значение, содержащееся в восьмибитном числе, и не только его).
1.4.3. Вывод типов
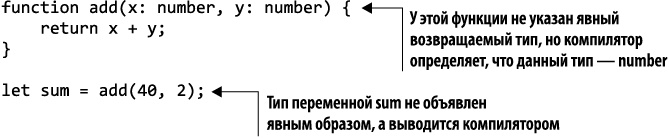
В некоторых случаях компилятор может вывести, исходя из контекста, тип переменной или функции, не указанный явным образом. Если присвоить переменной значение 42, например, то компилятор TypeScript может вывести, что ее тип — number, и нам не придется указывать тип. Это позволит увеличить прозрачность и понятность читателям кода, но соответствующая нотация необязательна.
Аналогично, если функция возвращает значения одного типа во всех операторах return, то указывать возвращаемый тип явно в описании функции не нужно. Компилятор может вывести эту информацию из кода, как показано в листинге 1.17.
В отличие от динамической типизации, которая производится только на этапе выполнения, в подобных случаях типизация определяется и проверяется на этапе компиляции, хотя явным образом описывать типы не нужно. При неоднозначности типизации компилятор выдаст ошибку и попросит нас указать нотацию типов более явным образом.
Листинг 1.17. Вывод типа
1.5. В этой книге
Сильная статическая система типов позволяет писать более корректный, лучше компонуемый и читабельный код. В данной книге мы рассмотрим основные возможности подобных современных систем типов с упором на их практическое применение.
Мы начнем с простых типов данных (primitive types), готовых для применения типов, доступных в большинстве языков программирования. Обсудим, как правильно их использовать и избежать распространенных ловушек. В ряде случаев будут показаны способы реализации некоторых из этих типов данных при отсутствии их нативной реализации в языке программирования.
Далее мы обсудим компонуемость и возможность сочетания простых типов данных в целях создания целой вселенной типов, необходимых для предметной области конкретной задачи. Существует множество способов сочетания типов данных, и вы узнаете, как выбрать правильный инструмент в зависимости от конкретной решаемой задачи.
Затем будет рассказано о функциональных типах данных (function types) и новых реализациях, обязанных своим появлением возможностям типизации функций и использования их аналогично обычным значениям. Функциональное программирование — весьма обширная тема, так что я не стану пытаться изложить ее во всей полноте, мы позаимствуем из нее некоторые полезные понятия и применим их к нефункциональному языку программирования для решения реальных задач.
Следующий этап эволюции систем типов после типизации значений, компоновки типов и типизации функций — создание подтипов (subtyping). Мы обсудим, какие качества делают тип подтипом другого типа, и попытаемся применить в нашем коде некоторые концепции объектно-ориентированного программирования. Обсудим наследование, компоновку и такой менее традиционный инструмент, как примеси.
Далее будет рассказано про обобщенные типы данных (generics), благодаря которым возможны переменные типов и параметризация кода типом данных. Обобщенные типы представляют собой совершенно новый уровень абстракции и компонуемости, расцепляя данные с их структурами, а структуры — с алгоритмами и делая вероятными адаптивные алгоритмы.
И наконец, обсудим типы более высокого рода (higher kinded types) — следующий уровень абстракции, параметризацию обобщенных типов данных. Типы более высокого рода представляют собой формализацию таких структур данных, как моноиды и монады. В настоящее время многие языки программирования не поддерживают типы более высокого рода, но их широкое применение в таких языках, как Haskell, и растущая популярность в конце концов должны привести и к внедрению их в более традиционные языки программирования.
Резюме
• Тип — классификация данных по возможным операциям над ними, их смыслу и набору допустимых значений.
• Система типов — набор правил назначения типов элементам языка программирования.
• Тип ограничивает диапазон принимаемых переменной значений, так что в некоторых случаях ошибка времени выполнения превращается в ошибку компиляции.
• Неизменяемость — свойство данных, возможное благодаря типизации и гарантирующее, что переменная не поменяется, когда не должна.
• Видимость — еще одно свойство уровня типа, определяющее, к каким данным есть доступ у тех или иных компонентов.
• Обобщенное программирование предоставляет широкие возможности расцепления и повторного использования кода.
• Указание нотаций типов упрощает понимание кода.
• Динамическая («утиная») типизация — определение типа на этапе выполнения.
• При статической типизации типы проверяются во время компиляции и перехватываются ошибки, которые в противном случае могли бы возникнуть во время выполнения.
• Строгость системы типов определяется числом допустимых неявных преобразований типов.
• Современные модули проверки типов включают обладающие широкими возможностями алгоритмы вывода, которые позволяют определять типы переменных, функций и т.д. без явного их указания в коде.
В главе 2 мы рассмотрим простые типы данных — простейшие стандартные блоки систем типов. Научимся избегать некоторых распространенных ошибок, возникающих при использовании этих типов, а также узнаем, как создать практически любую структуру данных из массивов и ссылок.
В русскоязычной литературе часто также называется строгой типизацией. — Примеч. пер.
Стандартный встроенный объект JavaScript (и TypeScript), олицетворяет бесконечное значение. — Примеч. пер.
При описания систем типов часто можно встретить термины «сильная типизация»6 (strong typing) и «слабая типизация» (weak typing). Сила системы типов определяется степенью строгости соблюдения ею ограничений типов. Слабая система неявно преобразует значения из их фактических типов в типы, ожидаемые там, где они используются.
Листинг 1.4. «Плохое» изменение значения5
Глава 2. Базовые типы данных
В этой главе
• Основные простые типы данных и их использование.
• Вычисление булевых значений.
• Ловушки числовых типов и кодирования текста.
• Базовые типы для создания структур данных.
В качестве внутреннего представления данных в компьютере используются последовательности битов. Смысл этим последовательностям придают типы. В то же время типы служат для ограничения диапазонов допустимых значений элементов данных. Системы типов содержат наборы простых (встроенных) типов данных и наборы правил их сочетания.
В этой главе мы рассмотрим часто встречающиеся простые типы данных (пустой, единичный, булев тип, числа, строки, массивы и ссылки), способы их применения и распространенные ловушки. Хотя мы используем простые типы данных ежедневно, существуют малозаметные нюансы, которые необходимо учитывать для эффективного применения этих типов. Например, существует возможность сокращенного вычисления булевых выражений, а при вычислении числовых выражений может происходить переполнение.
Мы начнем с простейших типов, практически не несущих информации, и постепенно перейдем к типам, представляющим данные с помощью различных видов кодирования. Наконец, рассмотрим массивы и ссылки — стандартные блоки всех прочих более сложных структур данных.
2.1. Проектирование функций, не возвращающих значений
Если рассматривать типы как множества вероятных значений, то возникает вопрос: а существует ли тип, соответствующий пустому множеству? Оно не содержит элементов, так что невозможно будет создать экземпляр этого типа. Будет ли польза от такого типа?
2.1.1. Пустой тип
Посмотрим, сможем ли мы описать как часть библиотеки утилит функцию, которая, получив сообщение в качестве параметра, заносила бы в журнал факт возникновения ошибки, включая метку даты/времени и сообщение, после чего генерировала бы исключение, как показано в листинге 2.1. Такая функция является просто оберткой для throw, поэтому не должна возвращать управление.
Листинг 2.1. Генерация и журналирование ошибки в случае отсутствия файла конфигурации

Обратите внимание: возвращаемый тип функции в данном примере — never. Благодаря этому читателям кода понятно, что функция raise никогда не должна возвращать значение. Более того, если кто-нибудь потом случайно изменит описание функции, добавив оператор return, то код перестанет компилироваться. Типу never нельзя присвоить абсолютно никакое значение, поэтому задуманное поведение функции обеспечивает компилятор и гарантирует, что она не будет возвращать управление.
Подобный тип данных называется «необитаемым» (uninhabitable type), или пустым типом данных (empty type), поскольку создать его экземпляр невозможно.
Пустой тип данных
Пустой тип — это тип данных, у которого не может быть никакого значения: множество его вероятных значений — пустое. Задать значение переменной такого типа невозможно. Пустой тип уместен как символ невозможности чего-либо, например, в качестве возвращаемого типа функции, которая никогда не возвращает значения (генерирует исключение или содержит бесконечный цикл).
«Необитаемый» тип данных используется для объявления функций, которые никогда не возвращают значений. Функция может не возвращать значения по нескольким причинам: генерация исключения по всем ветвям кода, работа в бесконечном цикле или возникновение фатального сбоя программы. Все эти сценарии допустимы. Например, может понадобиться реализовать функцию, производящую журналирование или отправляющую телеметрические данные перед генерацией исключения либо аварийным выходом из программы в случае неустранимой ошибки. Или может возникнуть необходимость в коде, который бы непрерывно работал в цикле вплоть до момента останова всей системы, например, для обработки событий системы.
Объявление подобной функции как возвращающей void (тип, используемый в большинстве языков программирования для указания на отсутствие осмысленного значения) только вводит читателя в заблуждение. Наша функция не просто не возвращает осмысленное значение, она вообще ничего не возвращает!
| Незавершающиеся функции Пустой тип может показаться тривиальным, но демонстрирует фундаментальное различие между математикой и информатикой: в математике нельзя определить функцию, отображающую непустое множество в пустое. Это просто лишено смысла. Функции в математике не «вычисляются», они просто «существуют». Компьютеры, с другой стороны, вычисляют программы; пошагово выполняют инструкции. Компьютер в процессе вычислений может оказаться в бесконечном цикле, выполнение которого никогда не прекратится. Поэтому в компьютерных программах могут описываться осмысленные функции отображения в пустое множество, такие как в предыдущих примерах. |
Пустой тип имеет смысл использовать везде, где встречаются не возвращающие ничего функции, либо с целью показать явным образом, что никакого значения нет.
Самодельный пустой тип
Далеко не во всех широко распространенных языках программирования есть готовый пустой тип данных наподобие типа never в TypeScript. Но в большинстве языков его можно реализовать самостоятельно. Это осуществимо с помощью описания перечисляемого типа, не содержащего никаких элементов или структуры с одним только приватным конструктором, чтобы его нельзя было вызвать.
В листинге 2.2 показано, как можно реализовать пустой тип в TypeScript в виде класса, не допускающего создания экземпляров. Обратите внимание: TypeScript считает два типа со схожей структурой совместимыми, так что нам придется добавить фиктивное свойство типа void, чтобы в прочем коде не могло оказаться значения, которое неявно бы преобразовалось в Empty. В прочих языках, например Java и C#, такого дополнительного свойства не требуется, поскольку в них совместимость типов не определяется на основе их формы. Мы обсудим этот вопрос подробнее в главе 7.
Листинг 2.2. Реализация пустого типа в виде невоплощаемого класса
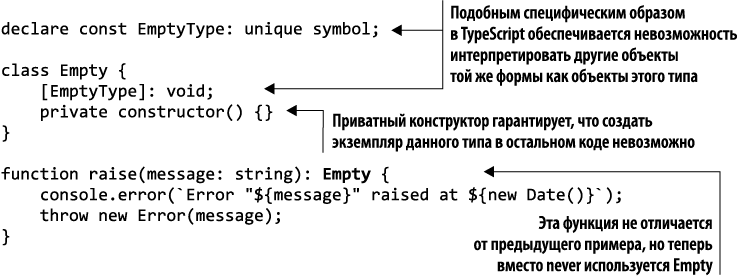
Данный код компилируется, поскольку компилятор выполняет анализ потока команд и определяет, что оператор return не нужен. С другой стороны, добавить этот оператор невозможно, поскольку нельзя создать экземпляр класса Empty.
2.1.2. Единичный тип
В предыдущем подразделе мы обсуждали функции, никогда ничего не возвращающие. А как насчет функций, которые производят возврат, но не возвращают ничего полезного? Существует множество подобных функций, вызываемых исключительно ради их побочных эффектов: они производят определенные действия, меняя какое-либо внешнее состояние, но не выполняют никаких вычислений, результаты которых могли бы вернуть.
Рассмотрим в качестве примера функцию console.log(): она выводит свой аргумент в отладочную консоль, но не возвращает никаких осмысленных значений. С другой стороны, по завершении выполнения она возвращает управление вызывающей стороне, так что ее возвращаемым типом не может служить never.
Классическая функция "Helloworld!", приведенная в листинге 2.3, — еще один хороший пример этого. Ее вызывают для вывода в консоль приветствия (то есть ради побочного эффекта), а не в целях возврата значения, так что мы укажем для нее возвращаемый тип void.
Листинг 2.3. Функция «Hello world!»

Возвращаемый тип подобных функций называется единичным типом (unit type), то есть типом, у которого может быть тол



















