

автордың кітабын онлайн тегін оқу 100 ошибок Go и как их избежать
Переводчик Д. Строганов
Тейва Харшани
100 ошибок Go и как их избежать. — СПб.: Питер, 2023.
ISBN 978-5-4461-2058-1
© ООО Издательство "Питер", 2023
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Дэйву Харшани: продолжай оставаться тем, кто ты есть, братик. Твой потолок — звезды.
Милой Мелиссе.
Предисловие
В 2019 году я во второй раз начал профессионально заниматься работой на Go в качестве основного языка программирования. Тогда я заметил некоторые закономерности, связанные с ошибками написания кода на Go. Я подумал, что обобщение информации о таких частых ошибках было бы полезно для разработчиков.
В своем блоге я сделал пост «10 самых распространенных ошибок, с которыми я сталкивался в проектах на Go» («The Top 10 Most Common Mistakes I’ve Seen in Go Projects»). Пост стал популярным: его прочитали более 100 000 человек, он был выбран новостным бюллетенем Golang Weekly как один из лучших за 2019 год. Мне льстили положительные отзывы, которые я получал от сообщества Go.
Я понял, что обсуждение типичных ошибок — это мощный инструмент разработки. Сопровождаемый конкретными примерами, он поможет им эффективно осваивать новые навыки, облегчать запоминание как контекста, в котором эти ошибки встречаются, так и способов, позволяющих их избегать.
Около года я собирал примеры типичных ошибок: из профессиональных проектов других разработчиков, из репозиториев опенсорсных программ, из книг, блогов, исследований и обсуждений в сообществе Go. Могу сказать, что я и сам был «достойным источником информации» в плане подобных ошибок.
К концу 2020 года размер моей коллекции ошибок достиг 100 штук, и это показалось мне подходящим, чтобы предложить идею публикации какому-либо издательству. В результате я связался с Manning, которое считал высококлассным издательством, публиковавшим качественные книги, — для меня оно стало идеальным партнером. Потребовалось почти два года и бесчисленное количество итераций, чтобы четко сформулировать суть каждой из 100 ошибок вместе с релевантными примерами и несколькими решениями, где контекст — это ключевой фактор.
Очень надеюсь, что моя книга поможет вам избежать этих распространенных ошибок и улучшить владение языком Go.
Благодарности
Хочу выразить свою признательность многим людям. Моим родителям — за то, что поддержали меня в тот момент, когда во время учебы я ощутил себя так, как будто нахожусь в ситуации полного провала. Моему дяде Жан-Полю Демону (Jean-Paul Demont) за то, что помог увидеть свет в конце туннеля. Пьеру Готье (Pierre Gautier) за то, что был замечательным вдохновителем и помог мне поверить в себя. Дэмиену Шамбону (Damien Chambon) за то, что заставлял меня постоянно поднимать планку и подталкивал меня к лучшему. Лорану Бернару (Laurent Bernard) за то, что был образцом для подражания и привел меня к осознанию того, что навыки социального общения очень важны. Валентину Делепласу (Valentin Deleplace) за последовательность и логичность его исключительно полезных отзывов. Дугу Раддеру (Doug Rudder) за то, что обучил меня тонкому искусству передачи идей в письменной форме. Тиффани Тейлор (Tiffany Taylor) и Кэти Теннант (Katie Tennant) за высококачественное редактирование и корректуру текста, а также Тиму ван Дерзену (Tim van Deurzen) за глубину и качество профессионального рецензирования.
Хочу также поблагодарить Клару Шамбон (Clara Chambon) — мою любимую маленькую крестницу, Виржини Шамбон (Virginie Chambon) — милейшего человека на свете, всю семью Харшани, Афродити Катику (Afroditi Katika), Серхио Гарсеза (Sergio Garcez) и Каспера Бентсена (Kasper Bentsen) — замечательных инженеров-разработчиков, а также все сообщество Go.
Наконец, я хотел бы поблагодарить своих рецензентов: Адама Ванадамайкена (Adam Wanadamaiken), Алессандро Кампейса (Alessandro Campeis), Аллена Гуча (Allen Gooch), Андреса Сакко (Andres Sacco), Анупама Сенгупту (Anupam Sengupta), Борко Джурковича (Borko Djurkovic), Брэда Хоррокса (Brad Horrocks), Камала Какара (Camal Cakar), Чарльза М. Шелтона (Charles M. Shelton), Криса Аллана (Chris Allan), Клиффорда Тербера (Clifford Thurber), Козимо Дамиано Прете (Cosimo Damiano Prete), Дэвида Кронкайта (David Cronkite), Дэвида Джейкобса (David Jacobs), Дэвида Моравека (David Moravec), Фрэнсиса Сеташа (Francis Setash), Джанлуиджи Спаньоло (Gianluigi Spagnuolo), Джузеппе Максиа (Giuseppe Maxia), Хироюки Мушу (Hiroyuki Musha), Джеймса Бишопа (James Bishop), Джерома Майера (Jerome Meyer), Джоэля Холмса (Joel Holmes), Джонатана Р. Чоута (Jonathan R. Choate), Йорта Роденбурга (Jort Rodenburg), Кита Кима (Keith Kim), Кевина Ляо (Kevin Liao), Лева Вайде (Lev Veyde), Мартина Денерта (Martin Dehnert), Мэтта Велке (Matt Welke), Нираджа Шаха (Neeraj Shah), Оскара Утбулта (Oscar Utbult), Пейти Ли (Peiti Li), Филиппа Джанертка (Philipp Janertq), Роберта Веннера (Robert Wenner), Райана Барроуска (Ryan Burrowsq), Райана Хубера (Ryan Huber), Санкета Найка (Sanket Naik), Сатадру Ройя (Satadru Roy), Шона Д. Вика (Shon D. Vick), Тада Майера (Thad Meyer) и Вадима Туркова. Все ваши предложения и замечания помогли сделать эту книгу лучше.
Об этой книге
Книга «100 ошибок Go и как их избежать» содержит описание 100 распространенных ошибок, которые допускают Go-разработчики. Она в значительной степени сосредоточена на самом языке и его стандартной библиотеке, а не на внешних библиотеках или фреймворках. Обсуждения большинства ошибок сопровождаются конкретными примерами, иллюстрирующими те обстоятельства, когда такие ошибки могут совершаться. Эта книга — не какая-то догма. Каждое предлагаемое решение детализировано в той мере, чтобы передать контекст.
Для кого эта книга
Эта книга предназначена для разработчиков, уже знакомых с языком Go. В ней не рассматриваются его основные понятия — синтаксис или ключевые слова. Предполагается, что вы уже занимались реальным проектом на Go. Но прежде чем углубляться в большинство конкретных тем, удостоверимся, что некоторые базовые вещи понимаются ясно и четко.
Структура книги
Книга состоит из 12 глав:
Глава 1 «Go: просто научиться, но сложно освоить» объясняет, почему, несмотря на то что Go считается простым языком, его нелегко освоить досконально. В ней также приведены типы ошибок, которые мы рассмотрим в книге.
Глава 2 «Организация кода и проекта» содержит описание распространенных ошибок, которые могут помешать организовать программный код чистым, идиоматичным, удобным для дальнейшей обработки и поддержки образом.
В главе 3 «Типы данных» обсуждаются ошибки, связанные с основными типами, срезами и картами.
В главе 4 «Управляющие структуры» исследуются распространенные ошибки, связанные с циклами и другими управляющими структурами.
В главе 5 «Строки» рассматривается принцип представления строк и связанные с ним распространенные ошибки, приводящие к неточности или неэффективности кода.
В главе 6 «Функции и методы» обсуждаются распространенные проблемы, связанные с функциями и методами, такие как выбор типа получателя и предотвращение распространенных ошибок отложенного выполнения (defer).
В главе 7 «Обработка ошибок» рассматривается идиоматическая и точная обработка ошибок в Go.
В главе 8 «Конкурентность: основы» представлены основные концепции конкурентности. Мы разберем, почему конкурентность не всегда быстрее, в чем различия между конкурентностью и параллелизмом, а также обсудим типы рабочей нагрузки.
В главе 9 «Конкурентность: практика» рассмотрены примеры ошибок, связанных с конкурентностью при использовании каналов, горутин и других примитивов Go.
Глава 10 «Стандартная библиотека» содержит описание распространенных ошибок, допускаемых при использовании стандартной библиотеки с HTTP, JSON или (например) time API.
В главе 11 «Тестирование» обсуждаются ошибки, которые делают тестирование и бенчмаркинг менее универсальными, эффективными и точными.
Глава 12 «Оптимизация» завершает книгу. В ней исследуются способы того, как оптимизировать приложение для повышения его производительности, — от понимания основ функционирования центрального процессора до конкретных тем, связанных с Go.
О коде в книге
Книга содержит множество примеров исходного кода как в нумерованных листингах, так и в тексте. В обоих случаях исходный код форматируется моноширинным шрифтом, в отличие от обычного текста. Иногда для кода также применяется жирный шрифт, чтобы выделить фрагменты, изменившиеся по сравнению с предыдущими шагами, — например, при добавлении новой функциональности в существующую строку кода.
Во многих случаях оригинальная версия исходного кода переформатируется; добавляются разрывы строк и измененные отступы, чтобы код помещался на странице. Иногда даже этого оказывается недостаточно и в листинги включаются маркеры продолжения строк (
Исполняемые фрагменты кода можно загрузить из версии liveBook (электронной) по адресу https://livebook.manning.com/book/100-go-mistakes-how-to-avoid-them. Полный код примеров книги доступен для загрузки на сайте Manning по адресу https://www.manning.com/books/100-go-mistakes-how-to-avoid-them и GitHub https://github.com/teivah/100-go-mistakes.
Форум liveBook
Приобретая книгу «100 ошибок Go и как их избежать», вы получаете бесплатный доступ к закрытому веб-форуму издательства Manning (на английском языке), на котором можно оставлять комментарии о книге, задавать технические вопросы и получать помощь от автора и других пользователей. Чтобы получить доступ к форуму, откройте страницу https://livebook.manning.com/book/100-go-mistakes-how-to-avoid-them/discussion. Информацию о форумах Manning и правилах поведения на них см. на https://livebook.manning.com/#!/discussion.
В рамках своих обязательств перед читателями издательство Manning предоставляет ресурс для содержательного общения читателей и авторов. Эти обязательства не подразумевают конкретную степень участия автора, которое остается добровольным (и неоплачиваемым). Задавайте автору хорошие вопросы, чтобы он не терял интереса к происходящему! Форум и архивы обсуждений доступны на веб-сайте издательства, пока книга продолжает издаваться.
Об авторе
ТЕЙВА ХАРШАНИ — старший инженер-программист в Docker. Работал в области страхования, транспорта и в отраслях, где критически важна безопасность, например в управлении воздушным движением. Увлечен языком Go и тем, как разрабатывать и реализовывать на нем надежные приложения.
Иллюстрация на обложке
На обложке книги — рисунок под названием «Femme de Buccari en Croatie» («Женщина из Бакара, Хорватия»).
Иллюстрация взята из вышедшего в 1797 году каталога национальных костюмов, составленного Жаком Грассе де Сен-Савьером. Каждая иллюстрация этого каталога тщательно прорисована и раскрашена от руки. В прежние времена по одежде человека можно было легко определить, где он живет и какова его профессия или положение. Manning отдает дань изобретательности и инициативности компьютерных технологий, используя для своих изданий обложки, демонстрирующие богатое вековое разнообразие региональных культур, оживающее на изображениях из собраний, подобных этому.
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
На веб-сайте издательства www.piter.com вы найдете подробную информацию о наших книгах.
1. Go: просто научиться, но сложно освоить
В этой главе:
• Что делает Go эффективным, масштабируемым и производительным языком
• Почему языку Go просто научиться, но овладеть им по-настоящему сложно
• Общее описание распространенных типов ошибок, допускаемых разработчиками
Ошибаться свойственно всем. Как сказал Альберт Эйнштейн:
Тот, кто никогда не совершал ошибок, тот никогда не пробовал что-то новое.
В конце концов, важно не количество совершенных ошибок, а наша способность учиться на них. Это утверждение относится и к программированию. Мастерство, которое мы приобретаем, — это не волшебство. Мы делаем множество ошибок и учимся на них. Это основная мысль книги. Мы рассмотрим и изучим 100 распространенных ошибок, которые допускаются во многих сферах использования языка Go, и это поможет вам стать более опытным программистом.
В главе 1 мы кратко расскажем, почему Go с годами стал одним из основных и стандартных инструментов работы. Мы обсудим, почему, несмотря на то что Go считается простым в изучении, овладение его нюансами может быть весьма сложным. Наконец, познакомимся с основными понятиями из этой книги.
1.1. Go: основные моменты
Если вы читаете нашу книгу, то, скорее всего, уже «подсели» на Go. Поэтому в этом разделе будет только краткий обзор, призванный напомнить, что делает Go таким мощным языком.
Отрасль разработки программного обеспечения (ПО) за последние десятилетия значительно изменилась. Большинство современных систем больше не создается одним человеком. Все они — результат работы команд, состоящих из многих программистов, а иногда даже из сотен, если не тысяч. Написанный программный код должен быть читабельным, выразительным, удобным в сопровождении, чтобы обеспечивать надежную работу системы на протяжении многих лет. С другой стороны, в нашем быстро меняющемся мире максимальное повышение гибкости и сокращение времени выхода на рынок очень важны для большинства компаний. Программирование тоже должно следовать этой тенденции, поэтому компании стремятся к тому, чтобы программисты работали максимально продуктивно при чтении, написании и сопровождении кода.
В ответ на эти вызовы и требования в 2007 году компания Google создала язык Go. С тех пор многие организации приняли его для использования в различных областях программирования: в API, автоматизации, базах данных, интерфейсах командной строки и т.д. Сегодня многие считают Go одним из основных языков для разработки облачных систем.
Что касается функциональности, то в Go нет наследования типов, исключений, макросов, частичных функций, поддержки ленивых вычислений или неизменяемости, перегрузки операторов, сопоставления шаблонов и т.д. Почему? Вот что об этом говорит официальный FAQ по Go (https://go.dev/doc/faq):
Почему в Go нет какой-то функции X? Ваша любимая функция может отсутствовать, поскольку не вписывается в логику или структуру языка, влияет на скорость компиляции или ясность дизайна кода либо просто потому, что сделала бы фундаментальную модель системы слишком сложной.
Оценка качества языка программирования на основании количества функций в нем, вероятно, некорректна. По крайней мере для Go эта метрика не главная. При оценке адекватности использования языка в масштабе какой-то организации используют несколько важных характеристик. К ним относятся:
• Стабильность. Несмотря на то что в Go вносятся частые изменения (направленные на улучшение самого языка и устранение уязвимостей с точки зрения безопасности), он остается достаточно стабильным языком. Некоторые считают это качество одной из лучших особенностей языка.
• Выразительность. Мы можем определить выразительность языка по тому, насколько написание и чтение кода отвечает представлениям о естественности и интуитивной понятности. Уменьшенное количество ключевых слов и ограниченные способы решения общих проблем делают Go выразительным языком для больших кодовых баз.
• Компиляция. Что может быть более раздражающим для разработчиков, чем долгое ожидание сборки для тестирования приложения? Стремление к быстрой компиляции всегда было сознательной целью разработчиков языка. А это основа высокой производительности.
• Безопасность. Go — надежный язык со статической типизацией. Следовательно, у него есть строгие правила времени компиляции, которые в большинстве случаев обеспечивают безопасность типов.
Go был создан с нуля с очень полезными функциями: с примитивами конкурентности, горутинами и каналами. Ему особо не нужно полагаться на внешние библиотеки для создания эффективных конкурентных приложений. Наблюдение за тем, насколько важна конкурентность в наши дни, также показывает, почему Go сейчас самый подходящий язык и будет оставаться им в обозримом будущем.
Некоторые считают Go простым языком, и отчасти это правда. Например, новичок может разобраться с его основными возможностями менее чем за один день. Возникает вопрос: зачем же изучать книгу, посвященную систематизации ошибок в Go, если он так прост?
1.2. Просто не означает легко
Между понятиями «просто» и «легко» есть тонкая разница. «Простой» применительно к технологии означает несложный для изучения или понимания. «Легкость» означает возможность добиваться чего угодно без особых усилий. Go прост в изучении, но не всегда легок в освоении.
Возьмем, к примеру, конкурентность. В 2019 году было опубликовано исследование, посвященное ошибкам конкурентности: «Понимание реальных ошибок конкурентности в Go»1. Это исследование было первым систематическим анализом ошибок конкурентности. Оно опиралось на данные нескольких популярных репозиториев Go — Docker, gRPC и Kubernetes. Один из самых важных выводов заключается в том, что большинство блокирующих ошибок вызвано неточным использованием парадигмы передачи сообщений (message passing) по каналам, несмотря на убеждение, что передача сообщений легче обрабатывается и менее подвержена ошибкам, чем разделяемая память.
Какой должна быть реакция на такой вывод? Должны ли мы считать, что разработчики языка ошибались насчет передачи сообщений? Должны ли мы пересмотреть использование конкурентности в нашем проекте? Конечно нет.
Это не вопрос противопоставления передачи сообщений разделяемой памяти и выявления из них «победителя». Но разработчики Go должны хорошо понимать, как использовать конкурентность, каково ее влияние на современные процессоры, когда следует предпочесть один подход другому и как избежать при этом попадания в типичные ловушки. Этот пример подчеркивает, что хотя каналы и горутины могут быть простыми для изучения, на практике это совсем не просто.
Понятие «просто не значит легко» можно обобщить на многие аспекты Go, а не только на конкурентность. И чтобы стать опытными Go-разработчиками, нужно хорошо разбираться во всех его аспектах. А это требует времени, усилий и ошибок.
Цель книги — помочь ускорить наш путь к мастерству, рассмотрев 100 ошибок в Go.
1.3. 100 ошибок в Go
Почему следует прочитать эту книгу? Почему бы вместо этого не углубить знания с помощью «обычной» книги, которая достаточно подробно рассматривает разные темы?
В статье, опубликованной в 2011 году, нейробиологи доказали, что столкновение с ошибками — это лучшие моменты для развития способностей нашего мозга2. Все мы проходили через процесс обучения на какой-то ошибке, вспоминая этот случай через месяцы или даже годы, когда с ним был связан какой-то контекст. В статье Джанет Меткалф (Janet Metcalfe) говорится, что это происходит потому, что ошибки оказывают стимулирующее воздействие3. Суть в том, что мы можем помнить не только саму ошибку, но и ее контекст. И поэтому обучение на ошибках так эффективно.
Чтобы усилить этот эффект, в книге каждая рассматриваемая типичная ошибка подкреплена примерами из реальной практики. Эта книга не только о теории, она поможет избежать ошибок и принимать взвешенные, осознанные решения.
Скажи мне, и я забуду. Научи меня, и я запомню. Вовлеки меня, и я научусь.
Неизвестный автор
Здесь представлены семь основных категорий ошибок, которые можно классифицировать как:
• баги;
• излишнюю сложность;
• плохую читаемость;
• неоптимальную или неидиоматическую организацию;
• отсутствие удобства в API;
• неоптимизированный код;
• недостаточную производительность.
Далее я дам краткое описание каждой категории ошибок.
1.3.1. Баги
Первый и, возможно, самый очевидный тип — это ошибки в исходном коде. В 2020 году исследование, проведенное Synopsys, оценило стоимость багов в ПО только в США более чем в 2 триллиона долларов4.
Баги могут приводить и к трагическим последствиям. Вспомним случай с аппаратом для лучевой терапии Therac-25 производства компании Atomic Energy of Canada Limited (AECL). Из-за состояния гонки машина дала своим пациентам дозы облучения, которые в сотни раз превышали ожидаемые, что привело к смерти трех пациентов. Этот пример показывает, что баги могут повлечь за собой не только денежные потери. И мы, как разработчики, должны помнить, насколько важна наша работа.
Я рассмотрю множество случаев, которые могут привести к различным багам, включая гонки данных, утечки, логические ошибки и др. Хотя точные тесты и должны обнаруживать такие ошибки как можно раньше, иногда мы можем пропускать их из-за различных факторов, например из-за нехватки времени или их сложности. И разработчику важно убедиться, что для устранения таких багов сделано все возможное.
1.3.2. Излишняя сложность
Следующая категория ошибок связана с излишней сложностью. Значительная часть сложности ПО вызвана тем, что разработчики стремятся думать о своем воображаемом будущем. Вместо того чтобы решать конкретные задачи прямо сейчас, может возникнуть соблазн создать «эволюционирующее» ПО, которое будет пригодным для любого будущего варианта использования. В большинстве случаев это приводит к тому, что объем недостатков превышает число преимуществ, что делает код сложным для понимания и анализа.
Возвращаясь к Go, можно вспомнить множество примеров того, как у разработчиков возникает соблазн разработать абстрактные функции для будущего, например интерфейсы или дженерики. В этой книге обсуждаются примеры, когда следует проявлять особую осторожность, чтобы не переусложнить код.
1.3.3. Плохая читаемость
Как написал Роберт Мартин (Robert Martin) в книге «Clean Code: A Handbook of Agile Software Craftsmanship»5, соотношение времени, затрачиваемого на чтение и написание кода, значительно превышает 10 : 1. Большинство из нас начинали программировать в собственных проектах, где удобочитаемость не так важна. Но сегодняшняя разработка ПО — это программирование во временно́м измерении: нужно убедиться, что с приложением все еще можно работать и поддерживать его спустя месяцы, годы или, возможно, даже десятилетия после релиза.
При программировании на Go можно наделать много ошибок, которые затруднят читаемость кода. Среди таких ошибок может быть и вложенный код, и представления типов данных, а иногда и использование неименованных результирующих параметров. На протяжении этой книги мы будем учиться писать читаемый код и заботиться о его будущих читателях (в частности, о себе).
1.3.4. Неоптимальная или неидиоматическая организация
Другой тип ошибки — это неоптимальная или неидиоматическая организация кода и проекта. Такие проблемы могут затруднить анализ и дальнейшую поддержку проекта. В этой книге рассмотрены некоторые из распространенных ошибок такого рода. Например, мы увидим, как структурировать проект и обращаться с пакетами утилит или функциями инициализации. Рассмотрение этих ошибок поможет организовать код и проекты более эффективно и идиоматично.
1.3.5. Отсутствие удобства в API
Распространенные ошибки, снижающие удобство API для наших потребителей, — это еще один тип. Если API неудобен для пользователя, он будет менее выразительным и, следовательно, более трудным для понимания и более подверженным дальнейшим ошибкам.
Такие ошибки встречаются во многих ситуациях и могут заключаться в чрезмерном использовании типа any, в использовании неправильных порождающих паттернов при работе с опциями или в слепом применении стандартных методов объектно-ориентированного программирования, что влияет на удобство использования API. Мы рассмотрим распространенные ошибки, мешающие передавать в распоряжение наших пользователей удобные для них API.
1.3.6. Неоптимизированный код
Код, оптимизированный в недостаточной степени, — еще один тип ошибок разработчиков. Их можно сделать по разным причинам, например из-за непонимания особенностей языка или даже из-за отсутствия фундаментальных знаний. Недостаточная производительность — одно из наиболее очевидных последствий этой ошибки, но не единственное.
Оптимизация кода полезна и для точности. Например, в этой книге представлены некоторые распространенные методы, обеспечивающие высокую точность операций с плавающей точкой. Мы также рассмотрим множество случаев, которые могут негативно сказаться на производительности кода, например, из-за недостаточного распараллеливания задач, незнания того, как уменьшать использование ресурсов памяти, или влияния выравнивания данных. Поговорим о вопросах оптимизации под разными углами.
1.3.7. Недостаточная производительность
В большинстве случаев мы задаемся вопросом: какой язык лучше всего выбрать для конкретного нового проекта? Ответ: тот, с которым мы работаем наиболее продуктивно. Для достижения мастерства очень важно знать, как работает язык, и использовать его по максимуму.
Мы рассмотрим конкретные примеры, которые помогут стать продуктивными при работе на Go. Например, написание эффективных тестов для обеспечения работоспособности кода, использование стандартной библиотеки для повышения эффективности, а также извлечение максимальной пользы из инструментов профилирования и линтеров. Пришло время разобраться в этих 100 распространенных ошибках Go!
Итоги
• Go — это современный язык программирования, который позволяет повысить производительность разработчиков, что сегодня крайне важно для большинства компаний.
• Go прост в изучении, но нелегок в освоении. Поэтому важно углубить свои знания, чтобы использовать его наиболее эффективно.
• Обучение на разборе ошибок и на конкретных примерах — это мощный способ овладеть языком. Книга на примерах разбора 100 распространенных ошибок ускорит путь к профессиональному мастерству.
1 T. Tu, X. Liu, et al. (с соавторами), Understanding Real-World Concurrency Bugs in Go, работа была представлена на ASPLOS 2019, April 13–17, 2019.
2 J.S. Moser, H.S. Schroder, с соавторами, “Mind Your Errors: Evidence for a Neural Mechanism Linking Growth Mindset to Adaptive Posterror Adjustments,” Psychological Science, vol. 22, no. 12, pp. 1484–1489, Dec. 2011.
3 J. Metcalfe, “Learning from Errors,” Annual Review of Psychology, vol. 68, pp. 465–489, Jan. 2017.
4 Synopsys, “The Cost of Poor Software Quality in the US: A 2020 Report.” 2020. https://news.synopsys.com/2021-01-06-Synopsys-Sponsored-CISQ-Research-Estimates-Cost-of-Poor-Software-Quality-in-the-US-2-08-Trillion-in-2020.
5 Мартин Р. «Чистый код: создание, анализ и рефакторинг». Санкт-Петербург, издательство «Питер».
Первый и, возможно, самый очевидный тип — это ошибки в исходном коде. В 2020 году исследование, проведенное Synopsys, оценило стоимость багов в ПО только в США более чем в 2 триллиона долларов4.
Возьмем, к примеру, конкурентность. В 2019 году было опубликовано исследование, посвященное ошибкам конкурентности: «Понимание реальных ошибок конкурентности в Go»1. Это исследование было первым систематическим анализом ошибок конкурентности. Оно опиралось на данные нескольких популярных репозиториев Go — Docker, gRPC и Kubernetes. Один из самых важных выводов заключается в том, что большинство блокирующих ошибок вызвано неточным использованием парадигмы передачи сообщений (message passing) по каналам, несмотря на убеждение, что передача сообщений легче обрабатывается и менее подвержена ошибкам, чем разделяемая память.
В статье, опубликованной в 2011 году, нейробиологи доказали, что столкновение с ошибками — это лучшие моменты для развития способностей нашего мозга2. Все мы проходили через процесс обучения на какой-то ошибке, вспоминая этот случай через месяцы или даже годы, когда с ним был связан какой-то контекст. В статье Джанет Меткалф (Janet Metcalfe) говорится, что это происходит потому, что ошибки оказывают стимулирующее воздействие3. Суть в том, что мы можем помнить не только саму ошибку, но и ее контекст. И поэтому обучение на ошибках так эффективно.
Как написал Роберт Мартин (Robert Martin) в книге «Clean Code: A Handbook of Agile Software Craftsmanship»5, соотношение времени, затрачиваемого на чтение и написание кода, значительно превышает 10 : 1. Большинство из нас начинали программировать в собственных проектах, где удобочитаемость не так важна. Но сегодняшняя разработка ПО — это программирование во временно́м измерении: нужно убедиться, что с приложением все еще можно работать и поддерживать его спустя месяцы, годы или, возможно, даже десятилетия после релиза.
J.S. Moser, H.S. Schroder, с соавторами, “Mind Your Errors: Evidence for a Neural Mechanism Linking Growth Mindset to Adaptive Posterror Adjustments,” Psychological Science, vol. 22, no. 12, pp. 1484–1489, Dec. 2011.
В статье, опубликованной в 2011 году, нейробиологи доказали, что столкновение с ошибками — это лучшие моменты для развития способностей нашего мозга2. Все мы проходили через процесс обучения на какой-то ошибке, вспоминая этот случай через месяцы или даже годы, когда с ним был связан какой-то контекст. В статье Джанет Меткалф (Janet Metcalfe) говорится, что это происходит потому, что ошибки оказывают стимулирующее воздействие3. Суть в том, что мы можем помнить не только саму ошибку, но и ее контекст. И поэтому обучение на ошибках так эффективно.
T. Tu, X. Liu, et al. (с соавторами), Understanding Real-World Concurrency Bugs in Go, работа была представлена на ASPLOS 2019, April 13–17, 2019.
Synopsys, “The Cost of Poor Software Quality in the US: A 2020 Report.” 2020. https://news.synopsys.com/2021-01-06-Synopsys-Sponsored-CISQ-Research-Estimates-Cost-of-Poor-Software-Quality-in-the-US-2-08-Trillion-in-2020.
J. Metcalfe, “Learning from Errors,” Annual Review of Psychology, vol. 68, pp. 465–489, Jan. 2017.
Мартин Р. «Чистый код: создание, анализ и рефакторинг». Санкт-Петербург, издательство «Питер».
2. Организация кода и проекта
В этой главе:
• Идиоматическая организация кода
• Эффективная работа с абстракциями: интерфейсы и дженерики
• Как структурировать проект: лучшие практики
Сделать текст кода в Go чистым, идиоматичным и удобным для сопровождения — непростая задача. Чтобы понять суть лучших практик, связанных с написанием кода и организацией проекта, потребуется накопить определенный опыт и набить шишки. Каких ловушек следует избегать (например, затенения переменных и злоупотребления вложенным кодом)? Как структурировать пакеты? Когда и где использовать интерфейсы или дженерики, функции инициализации и пакеты утилит? Рассмотрим распространенные ошибки в организации кода.
2.1. Ошибка #1: непреднамеренно затенять переменные
Область видимости переменной — это те места кода, в которых можно ссылаться на эту переменную, другими словами, та часть приложения, где действует привязка имени. В Go имя переменной, уже объявленное во внешней области видимости, может быть повторно объявлено во внутренней области видимости. Такая ситуация называется затенением переменной и может приводить к распространенным ошибкам.
В примере ниже показан непреднамеренный побочный эффект из-за наличия затененной переменной. В этом фрагменте кода HTTP-клиент создается двумя разными способами, в зависимости от булева значения tracing:

В этом примере в самом начале объявляется переменная client. Затем мы используем краткий оператор присваивания переменной (:=) в обоих внутренних блоках, чтобы присвоить результат вызова функции внутренним переменным client, а не внешней переменной client. В результате оказывается, что внешняя переменная всегда равна нулю.
ПРИМЕЧАНИЕ Этот код компилируется, поскольку внутренние переменные client используются в вызовах логирования. В противном случае появлялись бы ошибки компиляции: client declared and not used.
Как обеспечить присвоение значения именно исходной переменной client? Есть два варианта.

Здесь мы присваиваем результат временной переменной c, область видимости которой находится только в пределах блока if. Затем присваиваем его обратно переменной client. То же делаем для блока else.
Во втором варианте используется оператор присваивания (=) во внутренних блоках для непосредственного присвоения результатов функции переменной client. Но для этого нужно создать переменную error, поскольку оператор присваивания работает только в том случае, если имя переменной уже было объявлено. Например:

Чтобы не присваивать значение временной переменной, мы можем напрямую присвоить результат переменной client.
Оба способа вполне допустимы. Основное различие между ними заключается в том, что во втором варианте мы выполняем только одно присваивание, что можно считать более легким для чтения. Кроме того, со вторым вариантом можно объединить и реализовать обработку ошибок вне блоков операторов if/else, как показано в следующем примере:
if tracing {
client, err = createClientWithTracing()
} else {
client, err = createDefaultClient()
}
if err != nil {
// Типичная обработка ошибок
}
Затенение переменной происходит, когда ее имя повторно объявляется во внутренней области видимости, но мы видели, что эта практика чревата ошибками. Установка правила, запрещающего затененные переменные, зависит от личного вкуса. Иногда бывает удобно повторно использовать существующее имя, например err, для обозначения тех переменных, которые так или иначе связаны с ошибками. Но следует быть начеку, потому что теперь мы знаем, что можем столкнуться со сценарием, когда код компилируется, но переменная на самом деле получает значение, отличающееся от ожидаемого. Позже в этой главе мы рассмотрим, как обнаруживать затененные переменные.
В следующем разделе показано, почему важно не злоупотреблять вложенным кодом.
2.2. Ошибка #2: лишний вложенный код
Ментальная модель, относящаяся к конкретному программному продукту, представляет собой внутреннее мысленное представление о том, как ведет себя система. При программировании нужно придерживаться таких ментальных моделей (например, общих взаимодействий в коде и реализациях функций). Код считается удобочитаемым по множеству критериев: использование имен/названий, согласованность, соответствующее форматирование и т.д. Читабельный код требует меньше когнитивных усилий для понимания его соответствия ментальной модели, поэтому его легче читать и сопровождать.
Важнейший аспект удобочитаемости — это фактор количества вложенных уровней. Предположим, что мы работаем над новым проектом и нужно понять, что делает следующая функция join:

} else {
if len(concat) > max {
return concat[:max], nil
} else {
return concat, nil
}
}
}
}
}
func concatenate(s1 string, s2 string) (string, error) {
// ...
}
Эта функция join объединяет две строки и возвращает подстроку, если длина больше максимальной. Кроме того, она обрабатывает проверки s1 и s2 и проверяет, возвращает ли вызов concatenate ошибку.
С точки зрения реализации функциональности все сделано правильно. Но выстраивание ментальной модели, охватывающей все различные случаи, скорее всего, будет непростой задачей. Почему? Из-за количества вложенных уровней.
Посмотрим на код, выполняющий ту же функцию, но реализованный по-другому:
func join(s1, s2 string, max int) (string, error) {
if s1 == "" {
return "", errors.New("s1 is empty")
}
if s2 == "" {
return "", errors.New("s2 is empty")
}
concat, err := concatenate(s1, s2)
if err != nil {
return "", err
}
if len(concat) > max {
return concat[:max], nil
}
return concat, nil
}
func concatenate(s1 string, s2 string) (string, error) {
// ...
}
Вы, наверное, заметили, что выстраивание ментальной модели в этой новой версии кода требует меньше когнитивного напряжения, хотя код выполняет то же самое, что и раньше. Здесь есть только два вложенных уровня. Как упомянул Мэт Райер (Mat Ryer), эксперт, участвующий в дискуссии подкаста Go Time (https://medium.com/@matryer/line-of-sight-in-code-186dd7cdea88):
Выровняйте «счастливый путь» (happy path) по левому краю — так вы сможете быстро просмотреть, что происходит ниже на каком-то одном уровне и увидеть, что на нем ожидаемо выполняется.
В первой версии выполнения этого упражнения было сложно определить, что из ожидаемого выполняется, из-за вложенных операторов if/else. И наоборот, вторая версия требует просмотра вниз первого уровня, чтобы увидеть поток выполняемых действий, и второго уровня, чтобы увидеть, как обрабатываются пограничные случаи, как показано на рис. 2.1.

Рис. 2.1. Чтобы понять, что входит в ожидаемый поток выполняемых действий, нужно просмотреть столбец «счастливого пути»
Как правило, чем больше вложенных уровней требует функция, тем сложнее ее читать и понимать. Рассмотрим несколько различных применений этого правила, чтобы оптимизировать код для удобства чтения:
• Когда происходит возврат из блока if, следует во всех случаях опускать блок else. Например, мы не должны писать:
if foo() {
// ...
return true
} else {
// ...
}
Вместо этого следует опустить блок else, как показано здесь:
if foo() {
// ...
return true
}
// ...
Во второй версии этого фрагмента код, находившийся в блоке else, перемещается на верхний уровень, что упрощает его чтение.
• Можно следовать этой логике в случае с путем, не являющимся «счастливым»:
if s != "" {
// ...
} else {
return errors.New("empty string")
}
Здесь пустая переменная s определяет путь, не являющимся «счастливым». Поэтому нужно изменить это условие так:
if s == "" {
return errors.New("empty string")
}
// ...
Эту версию кода читать легче, потому что она показывает «счастливый» путь на левом краю и уменьшает количество блоков.
Написание читаемого кода — важная задача для каждого разработчика. Стремление уменьшить количество вложенных блоков, выравнивание счастливого пути по левому краю и возврат как можно раньше — это конкретные средства для улучшения читабельности кода.
Далее обсудим типичные ошибки в проектах Go, связанные с неправильным использованием функции инициализации.
2.3. Ошибка #3: неправильно использовать функцию инициализации
Иногда в приложениях Go неправильно используются функции инициализации. Потенциальные последствия — трудности в отслеживании и обработке ошибок или сложный в понимании код. Освежим наше представление о том, что такое функция инициализации, а затем рассмотрим, когда ее использование уместно.
2.3.1. Концепция
Функция инициализации (init) — это функция, используемая для инициализации состояния приложения. Она не имеет аргументов и не возвращает результата (функция func()). Когда пакет инициализируется, оцениваются все объявления констант и переменных в пакете. Затем выполняются функции инициализации. Вот пример инициализации пакета main:
package main
import "fmt"
var a = func() int {
fmt.Println("var")
return 0
}()
func init() {
fmt.Println("init")
}
func main() {
fmt.Println("main")
}
Исполнение кода этого примера выведет следующее:
var
init
main
Функция init выполняется при инициализации пакета. В следующем примере мы определяем два пакета — main и redis, где main зависит от redis. Сначала main.go из основного пакета:
package main
import (
"fmt"
"redis"
)
func init() {
// ...
}
func main() {
err := redis.Store("foo", "bar")
// ...
}
А затем redis.go из пакета redis:
package redis
// imports
func init() {
// ...
}
func Store(key, value string) error {
// ...
}
Поскольку main зависит от redis, сначала выполняется функция инициализации в пакете redis, затем — в основном пакете, а затем сама функция main. На рис. 2.2 показана эта последовательность.
Мы можем определить несколько функций инициализации init для каждого пакета. В таком случае последовательность выполнения функции инициализации внутри пакета задается алфавитным порядком исходных файлов. Например, если пакет содержит файл a.go и файл b.go и в обоих содержится функция инициализации, то первой выполняется та из них, что находится в a.go.
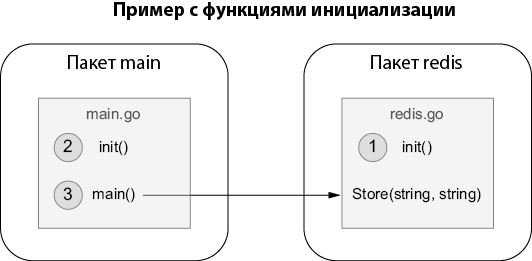
Рис. 2.2. Сначала выполняется функция инициализации init из пакета redis, затем функция инициализации init из пакета main и, наконец, сама функция main
Не следует слишком сильно полагаться на такой порядок выполнения функций инициализации внутри пакета — это может быть опасно, ведь исходные файлы могут быть переименованы и это может повлиять на порядок выполнения функций init.
Мы также можем определить несколько функций init в одном исходном файле. Например, такой код вполне допустим:
package main
import "fmt"
func init() {
fmt.Println("init 1")
}
func init() {
fmt.Println("init 2")
}
func main() {
}
Первая выполненная функция init является первой в исходном порядке. Вот вывод этого кода:
init 1
init 2
Мы также можем использовать функции инициализации init для реализации побочных эффектов. В следующем примере мы определяем пакет main, который не имеет сильной зависимости от foo (например, нет прямого использования публичной функции — public function). Но в примере требуется, чтобы пакет foo был инициализирован. Мы можем сделать это, используя оператор _:
package main
import (
"fmt"
_ "foo"
)
func main() {
// ...
}
В этом случае пакет foo инициализируется перед main. Следовательно, функции инициализации (init) в foo выполняются.
Другой аспект функции init в том, что ее нельзя вызвать напрямую, как в следующем примере:
package main
func init() {}
func main() {
init().
}
Этот код выдаст ошибку компиляции:
$ go build .
./main.go:6:2: undefined: init
Теперь, когда мы освежили в памяти представление о работе функций init, посмотрим, когда следует их использовать.
2.3.2. Когда использовать функции init
Рассмотрим пример уместного использования: удержание пула соединений с базой данных. В функции init открывается база данных с помощью sql.Open. Мы задаем эту базу данных как глобальную переменную, которую позже могут использовать другие функции:
var db *sql.DB
func init() {
dataSourceName :=
os.Getenv("MYSQL_DATA_SOURCE_NAME")
d, err := sql.Open("mysql", dataSourceName)
if err != nil {
log.Panic(err)
}
err = d.Ping()
if err != nil {
log.Panic(err)
}
db = d
}
Мы открываем базу данных, проверяем, можем ли ее пропинговать, а затем связываем ее с глобальной переменной. Что можно сказать о такой реализации? Опишем три ее основных недостатка.
Прежде всего, обработка ошибок в функции инициализации носит ограниченный характер. Действительно, поскольку функция инициализации не выдает сообщения об ошибках, единственный способ сообщить о возможной ошибке — вызвать прерывание по panic, что приведет к остановке выполнения приложения. В нашем примере остановить приложение можно в любом случае, если не удается открыть базу данных. Но решение о такой остановке не обязательно должно приниматься самим пакетом. Возможно, вызывающая сторона предпочла бы реализовать повторную попытку или использовать резервный механизм. В этом случае открытие базы данных в функции инициализации не позволяет клиентским пакетам реализовать свою логику обработки ошибок.
Другой важный недостаток связан с тестированием. Если мы добавим в этот файл тесты, функция инициализации будет выполняться перед запуском тестовых случаев, что не обязательно будет тем, что нужно (например, если добавить юнит-тесты в служебную функцию, которая не требует создания такой связи). Поэтому функция init в этом примере усложняет написание юнит-тестов.
Последний недостаток заключается в том, что в примере требуется присвоить пул соединений базы данных глобальной переменной. Глобальные переменные имеют ряд серьезных недостатков, например:
• Внутри пакета глобальные переменные могут изменяться любыми функциями.
• Юнит-тесты могут быть более сложными, поскольку функция, зависящая от глобальной переменной, больше не будет изолирована.
В большинстве случаев следует инкапсулировать переменную, а не сохранять ее глобальной.
По этим причинам предыдущую инициализацию, скорее всего, лучше будет обрабатывать как часть простой старой функции, например:

Используя эту функцию, мы устранили основные недостатки, о которых говорили ранее, следующим образом:
• Ответственность за обработку ошибок возлагается на вызывающую функцию.
• Появляется возможность создать интеграционный тест для проверки, работает ли эта функция.
• Пул соединений/связей инкапсулирован внутри этой функции.
Нужно ли любой ценой избегать функций инициализации? Не совсем. Есть случаи, когда эти функции могут быть полезны. Например, официальный блог Go (http://mng.bz/PW6w) использует функцию инициализации для настройки статической конфигурации HTTP:
func init() {
redirect := func(w http.ResponseWriter, r *http.Request) {
http.Redirect(w, r, "/", http.StatusFound)
}
http.HandleFunc("/blog", redirect)
http.HandleFunc("/blog/", redirect)
static := http.FileServer(http.Dir("static"))
http.Handle("/favicon.ico", static)
http.Handle("/fonts.css", static)
http.Handle("/fonts/", static)
http.Handle("/lib/godoc/", http.StripPrefix("/lib/godoc/",
http.HandlerFunc(staticHandler)))
}
В этом примере функция инициализации не может стать причиной сбоя (http.HandleFunc может вызвать panic, но только если обработчик равен nil, чего в данном случае нет). При этом нет необходимости создавать какие-либо глобальные переменные, и функция не повлияет на возможные юнит-тесты. Таким образом, этот фрагмент кода представляет собой хороший пример того, где функции инициализации могут оказаться полезны. Подводя итог, мы увидели, что функции инициализации могут привести к некоторым проблемам:
• Они могут ограничивать возможности по обработке ошибок.
• Они могут усложнить реализацию тестов (например, понадобится устанавливать внешнюю зависимость, которая в рамках юнит-тестов может и не потребоваться).
• Если инициализация требует, чтобы мы определили какое-то состояние, то это нужно будет сделать через использование глобальных переменных.
Использовать функции инициализации нужно очень внимательно. Но они могут быть полезны в некоторых ситуациях, например при определении статической конфигурации, как мы увидели в этом разделе. В противном случае, как и просто в большинстве случаев, инициализацию следует обрабатывать с помощью специальных функций.
2.4. Ошибка #4: злоупотреблять геттерами и сеттерами
Инкапсуляция данных в программировании означает сокрытие значений или состояния объекта. Геттеры и сеттеры — это средства для включения инкапсуляции путем предоставления экспортированных методов поверх неэкспортированных полей объектов.
В Go нет автоматической поддержки геттеров и сеттеров, как в других языках. Не считается обязательным или идиоматичным использование геттеров и сеттеров для доступа к полям структуры (struct). Например, стандартная библиотека реализует структуры, где некоторые поля доступны напрямую, как структура time.Timer:
timer := time.NewTimer(time.Second)
<-timer.C.
Мы могли бы даже модифицировать C напрямую, хотя это и не рекомендуется (больше не будем получать события). Но этот пример показывает, что стандартная библиотека Go не требует использования геттеров и/или сеттеров, даже когда не надо изменять поле.
С другой стороны, использование геттеров и сеттеров дает некоторые преимущества:
• Они инкапсулируют поведение, связанное с получением данных какого-то поля или присвоением ему значения, что позволяет добавлять новые функции позднее (например, проверку поля, возврат вычисленного значения или обертывание доступа к полю вокруг мьютекса).
• Они скрывают внутреннее представление, давая больше гибкости в определении того, что мы раскрываем.
• Они дают точку перехвата при отладке, когда свойство изменяется во время исполнения, что упрощает отладку.
Если мы сталкиваемся с такими случаями или предвидим возможный вариант использования, гарантируя прямую совместимость, использование геттеров и сеттеров может принести некоторую пользу. Например, если мы используем их с полем Balance, мы должны следовать вот этим соглашениям о наименованиях:
• Метод геттера должен называться Balance (а не GetBalance).
• Метод сеттера должен называться SetBalance.
Пример:
currentBalance := customer.Balance().
if currentBalance < 0 {
customer.SetBalance(0).
}
Не следует перегружать код геттерами и сеттерами в структурах, если они не приносят никакой пользы. Будьте прагматиками и ищите баланс между эффективностью и соблюдением идиом, которые в других парадигмах программирования иногда считаются непререкаемыми.
Помните, что Go — уникальный язык, созданный исходя из целей достижения многих характеристик, включая простоту. Но если возникнет потребность в геттерах и сеттерах или эта потребность предвидится в будущем, гарантируя при этом «совместимость вперед», в их использовании нет ничего плохого.
Далее обсудим проблему злоупотребления интерфейсами.
2.5. Ошибка #5: загрязнять интерфейсы
Интерфейсы — это один из краеугольных камней языка Go при разработке и структурировании кода. Но как и со многими другими инструментами или концепциями, излишнее их использование становится недостатком. Загрязнение интерфейса (interface pollution) — это перегруз кода ненужными абстракциями, затрудняющими понимание. Это распространенная ошибка разработчиков, переходящих на Go с других языков и имеющих другие привычки. Прежде чем углубиться в тему, освежим знания об интерфейсах в Go. Затем посмотрим, когда использование интерфейсов уместно, а когда это становится загрязнением кода.
2.5.1. Концепции
Интерфейс предоставляет способ задать поведение объекта. Мы используем интерфейсы для создания общих абстракций, которые могут быть реализованы несколькими объектами. Интерфейсы в Go реализуются неявно. В языке нет явного ключевого слова (например, implements), которое бы показывало, что объект X реализует интерфейс Y.
Чтобы понять, что делает интерфейсы такими мощными инструментами, рассмотрим два популярных интерфейса из стандартной библиотеки: io.Reader и io.Writer. Пакет io предоставляет абстракции для примитивов ввода/вывода. Среди этих абстракций io.Reader относится к чтению данных из источника данных, а io.Writer — к записи данных в нужное место, как показано на рис. 2.3.
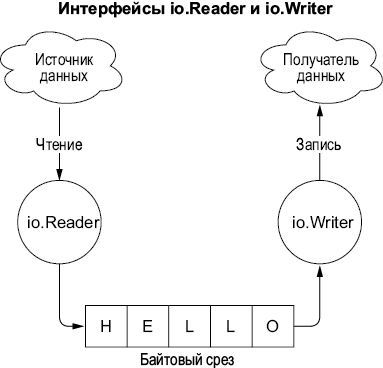
Рис. 2.3. io.Reader читает из источника данных и заполняет байтовый срез, а io.Writer записывает из байтового среза в нужное место
io.Reader содержит в себе только метод Read:
type Reader interface {
Read(p []byte) (n int, err error)
}
Пользовательские реализации интерфейса io.Reader должны принимать байтовый срез, заполняя его своими данными и возвращая либо количество прочитанных байтов, либо ошибку.
Со своей стороны, io.Writer определяет единственный метод — Write:
type Writer interface {
Write(p []byte) (n int, err error)
}
Пользовательские реализации io.Writer должны записывать данные, поступающие из среза, в их получатель и возвращать либо количество записанных байтов, либо ошибку. Поэтому оба интерфейса представляют собой фундаментальные абстракции:
• io.Reader считывает данные из источника.
• io.Writer записывает данные в их получатель.
В чем смысл наличия этих двух интерфейсов в языке? Какой смысл в создании этих абстракций?
Предположим, нужно реализовать функцию, которая должна копировать содержимое одного файла в другой. Можно создать специальную функцию, которая бы в качестве входных данных принимала два файла *os.Files. Или создать более общую функцию, используя абстракции io.Reader и io.Writer:
func copySourceToDest(source io.Reader, dest io.Writer) error {
// ...
}
Эта функция будет работать с параметрами *os.File (поскольку *os.File реализует как io.Reader, так и io.Writer) и любым другим типом, реализующим эти интерфейсы. Например, мы могли бы создать свой собственный io.Writer, который пишет в базу данных, и код остался бы прежним. Это увеличивает универсальность функции, и следовательно, возможность ее повторного использования.
Кроме того, написание юнит-теста для этой функции проще, потому что вместо обработки файлов можно использовать пакеты строк и байтов, которые предоставляют полезные реализации:

В этом примере источником (source) является *strings.Reader, а назначением (dest) — *bytes.Buffer. Мы тестируем поведение функции copySourceToDest без создания каких-либо файлов.
При проектировании интерфейсов помните о степени детализации (то есть сколько методов содержится в интерфейсе). Известная среди Go-разработчиков присказка (https://www.youtube.com/watch?v=PAAkCSZUG1c&t=318s) говорит, насколько большим должен быть интерфейс:
Чем больше интерфейс, тем слабее абстракция.
Роб Пайк (Rob Pike)
Добавление методов к интерфейсу может снизить возможности по его повторному использованию.
io.Reader и io.Writer — мощные абстракции, поскольку их невозможно сделать еще проще. Кроме того, можно комбинировать детализированные интерфейсы для создания абстракций более высокого уровня. Так обстоит дело с io.ReadWriter, который сочетает в себе функции чтения и записи:
type ReadWriter interface {
Reader
Writer
}
ПРИМЕЧАНИЕ Как сказал Эйнштейн, «все нужно делать как можно проще, но не проще этого». Применительно к интерфейсам это означает, что поиск идеальной детализации интерфейса не обязательно должен быть простым процессом.
Рассмотрим распространенные случаи, когда использование интерфейсов уместно.
2.5.2. Когда использовать интерфейсы
Когда следует создавать интерфейсы в Go? Рассмотрим три конкретных сценария, когда считается, что интерфейсы могут быть полезны. Обратите внимание, что цель состоит не в том, чтобы дать исчерпывающие рекомендации: чем больше примеров я бы добавил, тем в большей степени они зависели бы от контекста. Но эти три случая дают общее представление о вопросе:
• Общее поведение.
• Снижение связанности.
• Ограничение поведения.
Общее поведение
Первый вариант, который мы обсудим, — это использование интерфейсов, когда несколько типов реализуют общее поведение. Тогда можно заключить это поведение внутрь какого-то интерфейса. В стандартной библиотеке много таких примеров. Например, сортировка какой-либо коллекции может быть разложена на три действия:
• Получение данных о количестве элементов в коллекции.
• Сообщение о том, должен ли один элемент быть размещен перед другим.
• Перестановка двух элементов.
В пакет sort добавляется следующий интерфейс:
type Interface interface {
Len() int
Less(i, j int) bool
Swap(i, j int)
}
Этот интерфейс имеет большой потенциал для переиспользования, поскольку включает в себя общее поведение для сортировки любой проиндексированной коллекции.
Можно найти десятки реализаций пакета sort. Если в какой-то момент мы имеем дело, например, с набором целых чисел и хотим его отсортировать, будет ли нас интересовать то, как это может быть реализовано? Важен ли алгоритм сортировки: сортировка слиянием или быстрая сортировка? Во многих случаях это неважно. От способа сортировки можно абстрагироваться, и здесь мы зависим только от sort.Interface.
Нахождение правильной абстракции для факторизации поведения также может принести много пользы. Так, в пакете sort предоставляются служебные функции, которые используют sort.Interface: например, проверка того, была ли коллекция уже отсортирована. Например,
func IsSorted(data Interface) bool {
n := data.Len()
for i := n — 1; i > 0; i-- {
if data.Less(i, i-1) {
return false
}
}
return true
}
sort.Interface — правильный уровень абстракции, и это делает его очень ценным.
Рассмотрим следующий случай, когда полезно использование интерфейсов.
Снижение связанности (decoupling)
Еще один важный сценарий — отделение кода от его реализации. Если мы полагаемся на абстракцию вместо конкретной реализации, сама реализация может быть заменена на другую без необходимости менять код. Это и есть принцип подстановки Лисков (буква L в принципах SOLID Роберта Мартина).
Одно из преимуществ снижения связанности может относиться к юнит-тестам. Предположим, мы хотим реализовать метод CreateNewCustomer, который создает нового потребителя и сохраняет его. Мы решили полагаться непосредственно на конкретную реализацию (скажем, на структуру mysql.Store):
type CustomerService struct {
store mysql.Store
}
func (cs CustomerService) CreateNewCustomer(id string) error {
customer := Customer{id: id}
return cs.store.StoreCustomer(customer)
}
А что будет, если мы захотим протестировать этот метод? Поскольку customerService использует реальную реализацию для хранения Customer, нужно протестировать его с помощью интеграционных тестов, что требует запуска экземпляра MySQL (если только мы не используем альтернативный метод go-sqlmock, но эта тема выходит за рамки данного раздела). Хотя интеграционные тесты полезны, это не всегда то, что мы хотим делать. Для большей гибкости нужно отвязать CustomerService от фактической реализации. Сделать это можно через интерфейс:
type customerStorer interface {
StoreCustomer(Customer) error
}
type CustomerService struct {
storer customerStorer
}
func (cs CustomerService) CreateNewCustomer(id string) error {
customer := Customer{id: id}
return cs.storer.StoreCustomer(customer)
}
Сохранение созданного потребителя в базе теперь осуществляется через интерфейс, что дает бо́льшую гибкость в тестировании метода. Например, мы можем:
• использовать конкретную реализацию в интеграционных тестах;
• применять в юнит-тестах имитации (моки) или любые другие тестовые дублеры;
• делать и то и другое.
Обсудим третий сценарий: ограничение поведения.
Ограничение поведения
Третий сценарий на первый взгляд может показаться контринтуитивным. Речь идет об ограничении типа определенным поведением. Представим, что мы реализуем пользовательский конфигурационный пакет для работы с динамической конфигурацией. Мы создаем специальный контейнер для конфигураций int с помощью структуры IntConfig, в которой определены два метода: Get и Set. Вот как будет выглядеть такой код:
type IntConfig struct {
// ...
}
func (c *IntConfig) Get() int {
// Получить конфигурацию
}
func (c *IntConfig) Set(value int) {
// Обновить конфигурацию
}
Теперь предположим, что мы получили IntConfig, который содержит в себе определенную конфигурацию, например какое-то пороговое значение. Но в нашем коде нас интересует только получение значения этой конфигурации, и мы хотим предотвратить его обновление. Как мы можем обеспечить, чтобы семантически эта конфигурация была доступна только для чтения, если мы не хотим изменять пакет конфигурации? Ответ: создав абстракцию, которая ограничивает поведение только получением значения конфигурации:
type intConfigGetter interface {
Get() int
}
Тогда в коде можно указать только intConfigGetter вместо конкретной реализации:
type Foo struct {
threshold intConfigGetter
}
func NewFoo(threshold intConfigGetter) Foo {
return Foo{threshold: threshold}
}
func (f Foo) Bar() {
threshold := f.threshold.Get()
// ...
}
В этом примере геттер конфигурации внедряется в фабричный метод NewFoo. Он не влияет на потребителя этой функции, поскольку он по-прежнему может передавать структуру IntConfig по мере реализации intConfigGetter. Затем в методе Bar можно только прочитать конфигурацию, но не изменить ее. Поэтому мы также можем использовать интерфейсы, чтобы ограничить тип определенным поведением, например, если нужно соблюсти семантику.
Мы рассмотрели три возможных сценария использования интерфейсов, в которых они считаются полезными: выделение общего поведения, некоторое снижение связанности и ограничение типа определенным поведением. Это не исчерпывающий список, но он дает общее представление о том, когда интерфейсы в Go полезны.
Закончим этот раздел обсуждением проблем загрязнения интерфейса.
2.5.3. Загрязнение интерфейса
Злоупотребление интерфейсами в проектах на Go — частое явление. Возможно, у разработчика, который этим грешит, был опыт работы с C# или с Java и он счел естественным создавать интерфейсы, а не конкретные типы. Но в Go все должно работать не так.
Интерфейсы полезны для создания абстракций. И главное предостережение при знакомстве программиста с абстракциями — это помнить, что абстракции нужно открывать, а не создавать. Это означает, что мы не должны начинать создавать абстракции в коде, если для этого нет веской причины. Нужно не конструировать интерфейсы, а ждать возникновения конкретной потребности в них. Иными словами, создавайте интерфейс только тогда, когда он действительно нужен, а не тогда, когда возникает лишь ощущение, что он может понадобиться.
В чем основная проблема, связанная с чрезмерным использованием интерфейсов? Они делают поток кода менее ясным и более сложным. Добавление бесполезного косвенного уровня не приносит никакой пользы, а лишь создает бесполезную абстракцию, затрудняющую чтение, понимание и осмысление кода. Если нет веской причины для добавления интерфейса и неясно, как этот интерфейс делает код лучше, нужно поставить под сомнение цель создания такого интерфейса. Почему бы не вызвать реализацию какого-либо действия напрямую?
ПРИМЕЧАНИЕ При вызове метода через интерфейс мы можем столкнуться с оверхедом производительности. Требуется поиск в структуре данных хеш-таблицы, чтобы найти конкретный тип, на который указывает интерфейс. Но это не проблема во многих контекстах, поскольку оверхед минимален.
Следует быть очень осторожными при создании абстракций в коде: их следует обнаруживать, а не создавать. Для разработчиков характерно чрезмерно усложнять код в попытках угадать идеальный уровень абстракции. Этого следует избегать, поскольку в большинстве случаев в результате код «загрязняется» ненужными абстракциями и становится сложным для чтения.
Не программируйте интерфейсы, открывайте их.
Роб Пайк
Не будем пытаться решить проблемы абстрактно, будем решать только то, что нужно сейчас. И последнее, но не менее важное: если вы не понимаете, как какой-то интерфейс улучшает код, то следует подумать о его удалении для упрощения кода.
В следующем разделе продолжим эту тему и рассмотрим связанную с интерфейсами распространенную ошибку: создание интерфейсов на стороне производителя (producer).
2.6. Ошибка #6: интерфейсы на стороне производителя
В предыдущем разделе мы поговорили о том, когда использование интерфейсов оправданно. Но Go-разработчики часто неправильно понимают другой вопрос: где должен жить интерфейс?
Прежде чем углубиться в эту тему, удостоверимся, что термины этого раздела вам понятны:
• Сторона производителя (Producer) — интерфейс, определенный в том же пакете, что и конкретная реализация (рис. 2.4).
• Сторона потребителя (Consumer) — интерфейс, определенный во внешнем пакете, где он используется (рис. 2.5).
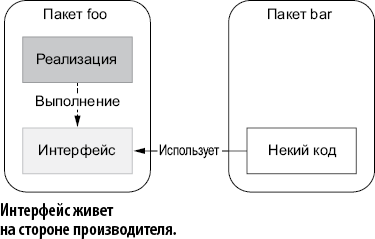
Рис. 2.4. Интерфейс определяется вместе с конкретной реализацией пакета

Рис. 2.5. Интерфейс определяется там, где он и используется
Часто можно увидеть, как разработчики создают интерфейсы на стороне производителя наряду с конкретной реализацией. Этот программный дизайн привычен для разработчиков, имеющих опыт работы с C # или с Java. Но в Go в большинстве случаев так делать не следует.
Обсудим пример: создадим специальный пакет для хранения и извлечения данных о потребителях. Мы решаем, что все вызовы в том же пакете должны проходить через следующий интерфейс:
package store
type CustomerStorage interface {
StoreCustomer(customer Customer) error
GetCustomer(id string) (Customer, error)
UpdateCustomer(customer Customer) error
GetAllCustomers() ([]Customer, error)
GetCustomersWithoutContract() ([]Customer, error)
GetCustomersWithNegativeBalance() ([]Customer, error)
}
Можно подумать, что есть веские причины для создания этого интерфейса и предоставления доступа к нему на стороне производителя. Возможно, это хороший способ отвязать код потребителя от фактической реализации. Или, возможно, мы стараемся предвидеть, что это поможет потребителям в создании тестовых дублеров. Какой бы ни была причина, в Go это не лучшая практика.
Интерфейсы в Go реализованы неявно, что обычно меняет правила игры по сравнению с языками с явной реализацией. В большинстве случаев подход, которому стоит следовать, аналогичен тому, что мы описали в предыдущем разделе: абстракции следует открывать, а не создавать. Это означает, что производитель не должен навязывать определенную абстракцию всем потребителям. Вместо этого потребитель должен решить, нужна ли ему какая-либо форма абстракции, а затем определить наилучший уровень абстракции для своих нужд.
В предыдущем примере один из потребителей не будет заинтересован в отвязывании своего кода. Возможно, другой потребитель захочет отвязать свой код, но его интересует только метод GetAllCustomers. Тогда он может создать интерфейс только одним методом, ссылаясь на структуру Customer из внешнего пакета:
package client
type customersGetter interface {
GetAllCustomers() ([]store.Customer, error)
}
Исходя из организации пакетов, результат этого показан на рис. 2.6. Несколько замечаний:
• Поскольку интерфейс customersGetter используется только в пакете client, он может остаться неэкспортированным.
• На рисунке это выглядит как циклические зависимости. Но зависимости от store к client нет, поскольку интерфейс реализован неявно. Поэтому такой подход не всегда возможен в языках с явной реализацией.
Суть состоит в том, что пакет client теперь может определить для своих нужд наиболее точную абстракцию (в этом примере есть только один метод). Это связано с концепцией принципа разделения интерфейса (I — ISP — в SOLID), которая гласит, что ни один потребитель не должен зависеть от методов, которые он не использует. И в этом случае лучший подход — разместить конкретную реализацию на стороне производителя, дать к ней доступ и позволить потребителю решить, как ее использовать и нужна ли вообще здесь абстракция.
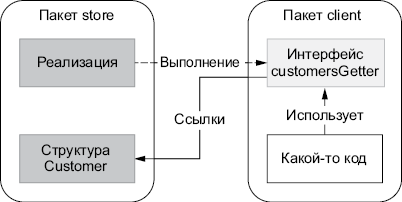
Рис. 2.6. Пакет client определяет необходимую ему абстракцию, создавая собственный интерфейс
Для полноты изложения отметим, что подход интерфейсов на стороне производителя иногда используется в стандартной библиотеке. Например, пакет encoding определяет интерфейсы, реализованные другими субпакетами, такими как encoding/json или encoding/binary. Является ли пакет encoding неверным с этой точки зрения? Точно нет. В этом случае абстракции, определенные в пакете encoding, используются во всей стандартной библиотеке, и разработчики языка знали, что предварительное создание этих абстракций полезно. Мы вернулись к обсуждению предыдущего раздела: не создавайте абстракцию, если вы просто думаете, что она может быть полезна в будущем, или не можете доказать, что она будет действительно нужна.
В большинстве случаев интерфейс должен жить на стороне потребителя. Но в определенных контекстах (например, когда мы твердо знаем, а не просто предвидим, что абстракция будет полезна для потребителей) можно сделать его на стороне производителя. В этом случае мы должны стремиться к тому, чтобы она была минимальной, что увеличивало бы потенциал ее переиспользования и делало ее легко компонуемой.
Продолжим обсуждение интерфейсов в контексте сигнатур функций.
2.7. Ошибка #7: возврат интерфейсов
При разработке сигнатуры функции может потребоваться вернуть либо интерфейс, либо конкретную реализацию. Разберемся, п