

автордың кітабын онлайн тегін оқу Terraform: инфраструктура на уровне кода
Научный редактор К. Русецкий
Переводчики О. Сивченко, С. Черников
Технические редакторы Н. Гринчик, Е. Рафалюк-Бузовская
Литературный редактор В. Байдук
Художники Н. Гринчик, В. Мостипан, Г. Синякина (Маклакова)
Корректоры Е. Павлович, Е. Рафалюк-Бузовская
Верстка О. Богданович
Евгений Брикман
Terraform: инфраструктура на уровне кода. — СПб.: Питер, 2021.
ISBN 978-5-4461-1590-7
© ООО Издательство "Питер", 2021
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Посвящается маме, папе, Лайле и Молли
Введение
Давным-давно в далеком-предалеком вычислительном центре древнее племя могущественных существ, известных как «сисадмины», вручную развертывало инфраструктуру. Каждый сервер, база данных (БД), балансировщик нагрузки и фрагмент сетевой конфигурации создавались и управлялись вручную. Это было мрачное и ужасное время: страх простоя, случайной ошибки в конфигурации, медленных и хрупких развертываний и того, что может произойти, если сисадмины перейдут на темную сторону (то есть возьмут отпуск). Но спешу вас обрадовать — благодаря движению DevOps у нас теперь есть замечательный инструмент: Terraform.
Terraform (https://www.terraform.io/) — это инструмент с открытым исходным кодом от компании HashiCorp. Он позволяет описывать инфраструктуру в виде кода на простом декларативном языке и развертывать ее/управлять ею в различных публичных облачных сервисах (скажем, Amazon Web Services, Microsoft Azure, Google Cloud Platform, DigitalOcean), а также частных облаках и платформах виртуализации (OpenStack, VMWare и др.) всего несколькими командами. Например, вместо того чтобы вручную щелкать кнопкой мыши на веб-странице или вводить десятки команд в консоль, вы можете воспользоваться следующим кодом и сконфигурировать сервер в AWS:
provider "aws" {
region = "us-east-2"
}
resource "aws_instance" "example" {
ami = "ami-0c55b159cbfafe1f0"
instance_type = "t2.micro"
}
Чтобы его развернуть, введите следующее:
$ terraform init
$ terraform apply
Благодаря своей простоте и мощи Terraform стал ключевым игроком в мире DevOps. Он позволяет заменить громоздкие, хрупкие и неавтоматизированные средства управления инфраструктурой на надежный автоматизированный инструмент, поверх которого вы можете объединить все остальные элементы DevOps (автоматическое тестирование, непрерывную интеграцию и непрерывное развертывание) и сопутствующий инструментарий (например, Docker, Chef, Puppet).
Прочитайте эту книгу, и вы сможете сразу приступить к работе с Terraform.
Начав с простейшего примера Hello, World, вы научитесь работать с полным стеком технологий (кластером серверов, балансировщиком нагрузки, базой данных), рассчитанным на огромные объемы трафика и крупные команды разработчиков, уже после прочтения лишь нескольких глав. Это практическое руководство не только научит принципам DevOps и инфраструктуры как кода (infrastructure as code, или IaC), но и проведет вас через десятки примеров кода, которые можно попробовать выполнить дома. Поэтому держите компьютер под рукой.
Дочитав книгу, вы будете готовы к работе с Terraform в реальных условиях.
Целевая аудитория книги
Книга предназначена для всех, кто отвечает за уже написанный код. Это относится к сисадминам, специалистам по эксплуатации, релиз-, SR-, DevOps-инженерам, разработчикам инфраструктуры, разработчикам полного цикла, руководителям инженерной группы и техническим директорам. Какой бы ни была ваша должность, если вы занимаетесь инфраструктурой, развертываете код, конфигурируете серверы, масштабируете кластеры, выполняете резервное копирование данных, мониторите приложения и отвечаете на вызовы в три часа ночи, эта книга для вас.
В совокупности эти обязанности обычно называют операционной деятельностью (или системным администрированием). Раньше часто встречались разработчики, которые умели писать код, но не разбирались в системном администрировании; точно так же нередко попадались сисадмины без умения писать код. Когда-то такое разделение было приемлемым, но в современном мире, который уже нельзя представить без облачных вычислений и движения DevOps, практически любому разработчику необходимы навыки администрирования, а любой сисадмин должен уметь программировать.
Для чтения этой книги не обязательно быть специалистом в той или иной области — поверхностного знакомства с языками программирования, командной строкой и серверным программным обеспечением (сайтами) должно хватить. Всему остальному можно научиться в процессе. Таким образом, по окончании чтения вы будете уверенно разбираться в одном из важнейших аспектов современной разработки и системного администрирования — в управлении инфраструктурой как кодом.
Вы не только научитесь управлять инфраструктурой в виде кода, используя Terraform, но и узнаете, как это вписывается в общую концепцию DevOps. Вот несколько вопросов, на которые вы сможете ответить по прочтении этой книги.
• Зачем вообще использовать IaC?
• Какая разница между управлением конфигурацией, оркестрацией, инициализацией ресурсов и шаблонизацией серверов?
• Когда следует использовать Terraform, Chef, Ansible, Puppet, Salt, CloudFormation, Docker, Packer или Kubernetes?
• Как работает система Terraform и как с ее помощью управлять инфраструктурой?
• Как создавать модули Terraform, подходящие для повторного использования?
• Как писать код для Terraform, который будет достаточно надежным для практического применения?
• Как тестировать свой код для Terraform?
• Как внедрить Terraform в свой процесс автоматического развертывания?
• Как лучше всего использовать Terraform в командной работе?
Вам понадобятся лишь компьютер (Terraform поддерживает большинство операционных систем), интернет-соединение и желание учиться.
Почему я написал эту книгу
Terraform — мощный инструмент, совместимый со всеми популярными облачными провайдерами. Он основан на простом языке, позволяет повторно использовать код, выполнять тестирование и управлять версиями. Это открытый проект с дружелюбным и активным сообществом. Но, надо признать, он еще не до конца сформирован.
Terraform — относительно новая технология. Несмотря на ее популярность, по состоянию на январь 2020 года все еще не вышла версия 1.0.0 (стабильная версия — 0.12.21. — Примеч. ред.). По-прежнему сложно найти книги и статьи или встретить специалистов, которые бы помогли вам овладеть этим инструментом. Официальная документация Terraform хорошо подходит для знакомства с базовым синтаксисом и возможностями, но в ней мало информации об идиоматических шаблонах, рекомендуемых методиках, тестировании, повторном использовании кода и рабочих процессах в команде. Это как пытаться овладеть французским языком с помощью одного лишь словаря, игнорируя грамматику и идиомы.
Я написал эту книгу, чтобы помочь разработчикам изучить Terraform. Я пользуюсь этим инструментом четыре года из пяти с момента его создания — в основном в моей компании Gruntwork (http://www.gruntwork.io). Там он сыграл ключевую роль в создании библиотеки более чем из 300 000 строк проверенного временем инфраструктурного кода, готового к повторному использованию и уже применяемого сотнями компаний в промышленных условиях. Написание и поддержка такого большого объема инфраструктурного кода на таком длинном отрезке времени в таком огромном количестве разных компаний и сценариев применения позволили нам извлечь много непростых уроков. Я хочу поделиться ими с вами, чтобы вы могли сократить этот долгий процесс и овладеть Terraform в считаные дни.
Конечно, одним чтением этого не добьешься. Чтобы начать свободно разговаривать на французском, придется потратить какое-то время на общение с носителями языка, просмотр французских телепередач и прослушивание французской музыки. Чтобы овладеть Terraform, нужно написать для этой системы настоящий код, использовать его в реальном ПО и развернуть это ПО на настоящих серверах. Поэтому приготовьтесь к чтению, написанию и выполнению большого количества кода.
Структура издания
В книге освещается следующий список тем.
•Глава 1 «Почему Terraform». Как DevOps меняет наш подход к выполнению ПО; краткий обзор инструментов IaC, включая управление конфигурацией, шаблонизацию серверов, оркестрацию и инициализацию ресурсов; преимущества IaC; сравнение Terraform, Chef, Puppet, Ansible, SaltStack, OpenStack Heat и CloudFormation; как сочетать такие инструменты, как Terraform, Packer, Docker, Ansible и Kubernetes.
• Глава 2 «Приступаем к работе с Terraform». Установка Terraform; краткий обзор синтаксиса Terraform; обзор утилиты командной строки Terraform; как развернуть один сервер; как развернуть веб-сервер; как развернуть кластер веб-серверов; как развернуть балансировщик нагрузки; как очистить созданные вами ресурсы.
• Глава 3 «Как управлять состоянием Terraform». Что такое состояние Terraform; как хранить состояние, чтобы к нему имели доступ разные члены команды; как блокировать файлы состояния, чтобы предотвратить конкуренцию; как управлять конфиденциальными данными в Terraform; как изолировать файлы состояния, чтобы смягчить последствия ошибок; как использовать рабочие области Terraform; рекомендуемая структура каталогов для проектов Terraform; как работать с состоянием, доступным только для чтения.
• Глава 4 «Повторное использование инфраструктуры с помощью модулей Terraform». Что такое модули; как создать простой модуль; как сделать модуль конфигурируемым с помощью входных и выходных значений; локальные переменные; версионные модули; потенциальные проблемы с модулями; использование модулей для описания настраиваемых элементов инфраструктуры с возможностью повторного применения.
• Глава 5 «Работа с Terraform: циклы, условные выражения, развертывание и подводные камни». Циклы с параметром count, выражения for_each и for, строковая директива for; условный оператор с параметром count, выражениями for_each и for, строковой директивой if; встроенные функции; развертывание с нулевым временем простоя; часто встречающиеся подводные камни, связанные с ограничениями count и for_each, развертываниями без простоя; как хорошие планы могут провалиться, проблемы с рефакторингом и отложенная согласованность.
• Глава 6 «Код Terraform промышленного уровня». Почему проекты DevOps всегда развертываются дольше, чем ожидается; что характеризует инфраструктуру, готовую к промышленному использованию; как создавать модули Terraform для промышленных условий; готовые к выпуску модули; реестр модулей Terraform; «аварийные люки» в Terraform.
• Глава 7 «Как тестировать код Terraform». Ручное тестирование кода Terraform; тестовые среды и очистка; автоматизированное тестирование кода Terraform; Terrarest; модульные тесты; интеграционные тесты; сквозные тесты; внедрение зависимостей; параллельное выполнение тестов; этапы тестирования; пирамида тестирования; статический анализ; проверка свойств.
•Глава 8 «Как использовать Terraform в команде». Как внедрить Terraform в командную работу; как убедить начальство; рабочий процесс развертывания кода приложения; рабочий процесс развертывания инфраструктурного кода; управление версиями; золотое правило Terraform; разбор кода; рекомендации по оформлению кода; принятый в Terraform стиль; CI/CD для Terraform; процесс развертывания.
Эту книгу можно читать последовательно или сразу переходить к тем главам, которые вас больше всего интересуют. Имейте в виду, что все примеры последующих глав основаны на коде из предыдущих. Если вы листаете туда-сюда, используйте в качестве ориентира архив исходного кода (как описано в разделе «Примеры с открытым исходным кодом» далее). В приложении вы найдете список книг и статей о Terraform, системном администрировании, IaC и DevOps.
Что нового во втором издании
Первое издание вышло в 2017 году. В мае 2019-го я готовил второе издание и был очень удивлен тому, как все изменилось за пару лет! Эта книга по своему объему почти в два раза превосходит предыдущую и включает две полностью новые главы. Кроме того, существенно обновлены все оригинальные главы и примеры кода.
Если вы уже прочитали первое издание и хотите узнать, что изменилось, или вам просто интересно посмотреть, как эволюционировал проект Terraform, вот несколько основных моментов.
•Четыре крупных обновления Terraform. Когда вышла первая книга, стабильной версией Terraform была 0.8. Спустя четыре крупных обновления Terraform имеет версию 0.12. За это время появились некоторые поразительные новшества, о которых пойдет речь далее. Чтобы обновиться, пользователям придется попотеть!1
• Улучшения в автоматическом тестировании. Существенно эволюционировали методики и инструментарий написания автоматических тестов для кода Terraform. Тестированию посвящена новая глава, седьмая, которая затрагивает такие темы, как модульные, интеграционные и сквозные тесты, внедрение зависимостей, распараллеливание тестов, статический анализ и др.
• Улучшения в модулях. Инструментарий и методики создания модулей Terraform тоже заметно эволюционировали. В новой, шестой, главе вы найдете руководство по написанию испытанных модулей промышленного уровня с возможностью повторного использования — таких, которым можно доверить благополучие своей компании.
• Улучшения в рабочем процессе. Глава 8 была полностью переписана согласно тем изменениям, которые произошли в процедуре интеграции Terraform в рабочий процесс команд. Там, помимо прочего, можно найти подробное руководство о том, как провести прикладной и инфраструктурный код через все основные этапы: разработку, тестирование и развертывание в промышленной среде.
• HCL2. В Terraform 0.12 внутренний язык HCL обновился до HCL2. Это включает в себя поддержку полноценных выражений (чтобы вам не приходилось заворачивать все в ${…}!), развитые ограничители типов, условные выражения с отложенным вычислением, поддержку выражений null, for_each и for, вложенные блоки и др. Все примеры кода в этой книге были адаптированы для HCL2, а новые возможности языка подробно рассматриваются в главах 5 и 6.
• Переработанные механизмы хранения состояния. В Terraform 0.9 появилась концепция внутренних хранилищ. Это полноценный механизм хранения и разделения состояния Terraform со встроенной поддержкой блокирования. В Terraform 0.9 также были представлены окружения состояния, которые позволяют управлять развертываниями в разных средах; но уже в версии 0.10 им на смену пришли рабочие области. Все эти темы рассматриваются в главе 3.
• Вынос провайдеров из ядра Terraform. В Terraform 0.10 из ядра был вынесен код для всех провайдеров (то есть код для AWS, GCP, Azure и т. д.). Благодаря этому разработка провайдеров теперь ведется в отдельных репозиториях, в своем собственном темпе и с выпуском независимых версий. Однако теперь придется загружать код провайдера с помощью команды terraforminit каждый раз, когда вы начинаете работать с новым модулем. Об этом пойдет речь в главах 2 и 7.
• Большое количество новых провайдеров. В 2016 году проект Terraform официально поддерживал лишь несколько основных облачных провайдеров (AWS, GCP и Azure). Сейчас же их количество превысило 100, а провайдеров, разрабатываемых сообществом, и того больше2. Благодаря этому вы можете использовать код для работы не только с множеством разных облаков (например, теперь существуют провайдеры для Alicloud, Oracle Cloud Infrastructure, VMware vSphere и др.), но и с другими аспектами окружающего мира, включая системы управления версиями (GitHub, GitLab или BitBucket), хранилища данных (MySQL, PostreSQL или InfluxDB), системы мониторинга и оповещения (включая DataDog, New Relic или Grafana), платформы наподобие Kubernetes, Helm, Heroku, Rundeck или Rightscale и многое другое. Более того, сейчас у каждого провайдера намного лучше покрытие: скажем, провайдер для AWS охватывает большинство сервисов этой платформы, а поддержка новых сервисов часто появляется даже раньше, чем у CloudFormation!
• Реестр модулей Terraform. В 2017 году компания HashiCorp представила реестр модулей Terraform (registry.terraform.io) — пользовательский интерфейс, который облегчает просмотр и загрузку открытых универсальных модулей Terraform, разрабатываемых сообществом. В 2018 году была добавлена возможность запускать внутри своей организации закрытый реестр. В Terraform 0.11 появился полноценный синтаксис для загрузки модулей из реестра. Подробнее об этом читайте в разделе «Управление версиями» на с. 153.
• Улучшенная обработка ошибок. В Terraform 0.9 обновилась обработка ошибок состояния: если при записи состояния в удаленное хранилище обнаруживается ошибка, это состояние сохраняется локально, в файле errored.tfstate. В Terraform 0.12 механизм был полностью переработан. Теперь ошибки перехватываются раньше, а сообщения о них стали более понятными и содержат путь к файлу, номер строчки и фрагмент кода.
• Много других мелких изменений. Было сделано много менее значительных изменений, включая появление локальных переменных (см. раздел «Локальные переменные модулей» на с. 144), новые «аварийные люки» для взаимодействия с внешним миром с помощью скриптов (например, подраздел «Модули вне Terraform» на с. 242), выполнение plan в рамках команды apply (см. раздел «Развертывание одного сервера» на с. 64), исправление циклических проблем с create_before_destroy, значительное улучшение параметра count, которое позволяет ссылаться в нем на источники данных и ресурсы (см. раздел «Циклы» на с. 160), десятки новых встроенных функций, обновленное наследование provider и многое другое.
Чего нет в этой книге
Книга не задумывалась как исчерпывающее руководство по Terraform. Она не охватывает все облачные провайдеры, все ресурсы, которые поддерживаются каждым из них, или каждую команду, доступную в этой системе. За этими подробностями я отсылаю вас к документации по адресу https://www.terraform.io/docs/index.html.
Документация содержит множество полезной информации, но, если вы только знакомитесь с Terraform, концепцией «инфраструктура как код» или системным администрированием, вы попросту не знаете, какие вопросы задавать. Поэтому данная книга сосредоточена на том, чего нет в документации: как выйти за рамки вводных примеров и начать использовать Terraform в реальных условиях. Моя цель — быстро подготовить вас к работе с данной системой. Для этого мы обсудим, зачем вообще может понадобиться Terraform, как внедрить этот инструмент в рабочий процесс и какие методики и шаблоны проектирования обычно работают лучше всего.
Чтобы это продемонстрировать, я включил в книгу ряд примеров кода. Я пытался сделать так, чтобы вам было просто работать с ними в домашних условиях. Для этого минимизировал количество сторонних зависимостей. Именно поэтому везде используется лишь один облачный провайдер, AWS. Таким образом, вам нужно будет зарегистрироваться только в одном стороннем сервисе (к тому же AWS предлагает хороший бесплатный тариф, поэтому не придется ничего платить за выполнение примеров).
Примеры с открытым исходным кодом
Все доступные в этой книге примеры кода можно найти по адресу github.com/brikis98/terraform-up-and-running-code.
Перед чтением можете скопировать репозиторий, чтобы иметь возможность выполнять примеры на своем компьютере:
git clone https://github.com/brikis98/terraform-up-and-running-code.git
Примеры кода в этом репозитории разбиты по главам. Стоит отметить, что большинство из них демонстрирует состояние кода на момент завершения главы. Если вы хотите научиться как можно большему, весь код лучше писать самостоятельно, с нуля.
Программирование начинается в главе 2, где вы научитесь развертывать кластер веб-серверов с помощью Terraform от начала и до конца. После этого следуйте инструкциям в каждой последующей главе, развивая и улучшая этот пример.
Вносите изменения так, как указано в книге, пытайтесь писать весь код самостоятельно и используйте примеры из репозитория в GitHub только для того, чтобы свериться или прояснить непонятные моменты.

Версии
Все примеры в этой книге проверены на версии Terraform 0.12.x, которая на момент написания является последним крупным обновлением. Поскольку Terraform — относительно новый инструмент, который все еще не достиг версии 1.0.0, вполне вероятно, что будущие выпуски будут содержать обратно несовместимые изменения и некоторые из рекомендуемых методик со временем поменяются и эволюционируют.
Я попытаюсь выпускать обновления как можно чаще, но проект Terraform движется очень быстро. Чтобы не отставать, вам самим придется прилагать определенные усилия. Чтобы не пропустить последние новости, статьи и обсуждения, связанные с Terraform и DevOps, посещайте сайт этой книги по адресу http://www.terraformupandrunning.com/ и подпишитесь на информационную рассылку (http://www.terraformupandrunning.com/#newsletter)!
Использование примеров кода
Эта книга предназначена для того, чтобы помочь вам решать ваши задачи. Вы можете свободно использовать примеры кода в своих программах и документации. Если вы не воспроизводите существенную часть кода, не нужно с нами связываться. Это, скажем, касается ситуаций, когда вы включаете в свою программу несколько фрагментов кода, которые приводятся в книге. Однако продажа или распространение CD с примерами из книг издательства O’Reilly требует отдельного разрешения. Если вы цитируете эту книгу с примерами кода при ответе на вопрос, разрешение не требуется. Но нужно связаться с нами, если хотите включить существенную часть приводимого здесь кода в документацию своего продукта.
Мы приветствуем, но не требуем отсылки на оригинал. Отсылка обычно состоит из названия, имени автора, издательства, ISBN. Например: «Terraform: инфраструктура на уровне кода», Евгений Брикман. Питер, 2020. 978-5-4461-1590-7.
Если вам кажется, что то, как вы обращаетесь с примерами кода, выходит за рамки добросовестного использования или условий, перечисленных выше, можете обратиться к нам по адресу permissions@oreilly.com.
Условные обозначения
В этой книге используются следующие типографические обозначения.
Курсив
Обозначает новые термины и важные моменты.
Рубленый
Обозначает URL, адреса электронной почты и элементы интерфейса.
Моноширинный шрифт
Используется в листингах кода, а также в тексте, обозначая такие программные элементы, как имена переменных и функций, базы данных, типы данных, переменные среды, операторы и ключевые слова, названия папок и файлов, а также пути к ним.
Жирный моноширинный шрифт
Обозначает команды или другой текст, который должен быть введен пользователем.
Курсивный моноширинный шрифт
Обозначает текст, вместо которого следует подставить пользовательские значения или данные, зависящие от контекста.

Этот значок обозначает примечание общего характера.

Этот значок обозначает предупреждение или предостережение.
Благодарности
Джош Падник
Без тебя эта книга не появилась бы. Ты тот, кто познакомил меня с Terraform, научил основам и помог разобраться со всеми сложностями. Спасибо, что поддерживал меня, пока я воплощал наши коллективные знания в книгу. Спасибо за то, что ты такой классный соучредитель. Благодаря тебе я могу заниматься стартапом и по-прежнему радоваться жизни. И больше всего я благодарен тебе за то, что ты хороший друг и человек.
O’Reilly Media
Спасибо за то, что выпустили еще одну мою книгу. Чтение и написание книг коренным образом изменили мою жизнь, и я горжусь тем, что вы помогаете мне делиться некоторыми из моих текстов с другими. Отдельная благодарность Брайану Андерсону за его помощь в подготовке первого издания в рекордные сроки и Вирджинии Уилсон, благодаря которой мне каким-то образом удалось поставить новый рекорд со вторым изданием.
Сотрудники Gruntwork
Не могу выразить, насколько я благодарен вам всем за то, что вы присоединились к нашему крошечному стартапу. Вы создаете потрясающее ПО! Спасибо, что удерживали компанию на плаву, пока я работал над вторым изданием этой книги. Вы замечательные коллеги и друзья.
Клиенты Gruntwork
Спасибо, что рискнули связаться с мелкой, неизвестной компанией и согласились стать подопытными кроликами для наших экспериментов с Terraform. Задача Gruntwork — на порядок упростить понимание, разработку и развертывание ПО. Нам не всегда это удается (в книге я описал многие из наших ошибок!), поэтому я благодарен за ваше терпение и желание принять участие в нашей дерзкой попытке улучшить мир программного обеспечения.
HashiCorp
Спасибо за создание изумительного набора инструментов для DevOps, включая Terraform, Packer, Consul и Vault. Вы улучшили мир DevOps, а заодно и жизни миллионов разработчиков.
Киф Моррис, Сет Варго, Маттиас Гис, Рокардо Феррейра, Акаш Махаян, Мориц Хейбер
Спасибо за вычитку первых черновиков книги и за большое количество подробных и конструктивных отзывов. Ваши советы улучшили эту книгу.
Читатели первого издания
Те из вас, кто купил первое издание, сделали возможным создание второго. Спасибо. Ваши отзывы, вопросы, предложения относительно исходного кода и постоянная жажда новостей послужили мотивацией примерно для 160 дополнительных страниц нового материала. Надеюсь, новый текст окажется полезным, и с нетерпением жду дальнейшего давления со стороны читателей.
Мама, папа, Лайла, Молли
Так получилось, что я написал еще одну книгу. Это, скорее всего, означает, что я проводил с вами меньше времени, чем мне бы хотелось. Спасибо за то, что отнеслись к этому с пониманием. Я вас люблю.
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
На веб-сайте издательства www.piter.com вы найдете подробную информацию о наших книгах.
1 Подробности ищите в руководствах по обновлению Terraform по адресу www.terraform.io/upgrade-guides/index.html.
2 Список провайдеров для Terraform можно найти на странице www.terraform.io/docs/providers/.
Список провайдеров для Terraform можно найти на странице www.terraform.io/docs/providers/.
Подробности ищите в руководствах по обновлению Terraform по адресу www.terraform.io/upgrade-guides/index.html.
•Четыре крупных обновления Terraform. Когда вышла первая книга, стабильной версией Terraform была 0.8. Спустя четыре крупных обновления Terraform имеет версию 0.12. За это время появились некоторые поразительные новшества, о которых пойдет речь далее. Чтобы обновиться, пользователям придется попотеть!1
• Большое количество новых провайдеров. В 2016 году проект Terraform официально поддерживал лишь несколько основных облачных провайдеров (AWS, GCP и Azure). Сейчас же их количество превысило 100, а провайдеров, разрабатываемых сообществом, и того больше2. Благодаря этому вы можете использовать код для работы не только с множеством разных облаков (например, теперь существуют провайдеры для Alicloud, Oracle Cloud Infrastructure, VMware vSphere и др.), но и с другими аспектами окружающего мира, включая системы управления версиями (GitHub, GitLab или BitBucket), хранилища данных (MySQL, PostreSQL или InfluxDB), системы мониторинга и оповещения (включая DataDog, New Relic или Grafana), платформы наподобие Kubernetes, Helm, Heroku, Rundeck или Rightscale и многое другое. Более того, сейчас у каждого провайдера намного лучше покрытие: скажем, провайдер для AWS охватывает большинство сервисов этой платформы, а поддержка новых сервисов часто появляется даже раньше, чем у CloudFormation!
1. Почему Terraform
Программное обеспечение (ПО) нельзя считать завершенным, если оно просто работает на вашем компьютере, проходит тесты и получает одобрение при обзоре кода (code review). ПО не готово, пока вы не доставите его пользователю.
Доставка ПО включает в себя множество задач, которые необходимо решить для того, чтобы сделать код доступным для клиента. Это подразумевает запуск кода на боевых (production) серверах, обеспечение его устойчивости к перебоям в работе и всплескам нагрузки, защиту от злоумышленников. Прежде чем погружаться в мир Terraform, стоит сделать шаг назад и поговорить о роли этого инструмента в большом деле доставки программного обеспечения.
В этой главе мы подробно обсудим следующие темы.
• Появление DevOps.
• Что такое инфраструктура как код.
• Как работает Terraform.
• Сравнение Terraform с другими инструментами для работы с инфраструктурой как с кодом.
Появление DevOps
Если бы в недалеком прошлом вы захотели создать компанию — разработчик ПО, вам бы пришлось иметь дело с большим количеством оборудования. Для этого нужно было бы подготовить шкафы и стойки, поместить в них серверы, подключить кабели и провода, установить систему охлаждения, предусмотреть резервные системы питания и т. д. В те дни было логично разделять работников на две команды: разработчиков (developers, Devs), которые занимались написанием программ, и системных администраторов (operations, Ops), в чьи обязанности входило управление этим оборудованием.
Типичная команда разработчиков собирала свое приложение и «перебрасывала его через стену» команде сисадминов. Последние должны были разобраться с тем, как его развертывать и запускать. Большая часть этого процесса выполнялась вручную. Отчасти потому, что это неизбежно требовало подключения физического аппаратного обеспечения (например, расстановки серверов по стойкам и разводки сетевых кабелей). Но программные аспекты работы системных администраторов, такие как установка приложений и их зависимостей, часто выполнялись вручную путем выполнения команд на сервере.
До поры до времени этого было достаточно, но по мере роста компании начинали возникать проблемы. Обычно выглядело так: поскольку ПО доставлялось вручную, а количество серверов увеличивалось, выпуск новых версий становился медленным, болезненным и непредсказуемым. Команда сисадминов иногда допускала ошибки, и в итоге некоторые серверы требовали немного других настроек по сравнению со всеми остальными (это проблема, известная как дрейф конфигурации). Поэтому росло число программных ошибок. Разработчики пожимали плечами и отвечали: «У меня на компьютере все работает!» Перебои в работе становились все более привычными.
Команда администраторов, уставшая от вызовов в три часа ночи после каждого выпуска, решала снизить частоту выпуска новых версий до одного в неделю. Затем происходил переход на месячный и в итоге на полугодовой цикл. За несколько недель до полугодового выпуска команды пытались объединить все свои проекты, что приводило к большой неразберихе с конфликтами слияния. Никому не удавалось стабилизировать основную ветку. Команды начинали винить друг друга. Возникало недоверие. Работа в компании останавливалась.
В наши дни ситуация меняется коренным образом. Вместо обслуживания собственных вычислительных центров многие компании переходят в облако, пользуясь преимуществами таких сервисов, как Amazon Web Services (AWS), Microsoft Azure и Google Cloud Platform (GCP). Вместо того чтобы тесно заниматься оборудованием, многие команды системных администраторов проводят все свое время за работой с программным обеспечением, используя инструменты вроде Chef, Puppet, Terraform и Docker. Вместо расставления серверов по стойкам и подключения сетевых кабелей многие сисадмины пишут код.
В итоге обе команды, Dev и Ops, в основном занимаются работой с ПО, и граница между ними постепенно размывается. Возможно, наличие отдельных команд, отвечающих за прикладной и инфраструктурный код, все еще имеет смысл, но уже сейчас очевидно, что обе они должны работать вместе более тесно. Вот где берет начало движение DevOps.
DevOps не название команды, должности или какой-то определенной технологии. Это набор процессов, идей и методик. Каждый понимает под DevOps что-то свое, но в этой книге я буду использовать следующее определение: цель DevOps — значительно повысить эффективность доставки ПО.
Вместо многодневного кошмара со слиянием веток вы постоянно интегрируете свой код, поддерживая его в развертываемом состоянии. Вместо ежемесячных развертываний вы можете доставлять свой код десятки раз в день или даже после каждой фиксации. Вместо того чтобы иметь дело с постоянными простоями и перебоями в работе, вы сможете создавать устойчивые системы с автоматическим восстановлением, используя мониторинг и оповещения для обнаружения проблем, которые требуют ручного вмешательства.
Компании, прошедшие через подобные трансформации, показывают изумительные результаты. Например, после применения в своей организации методик DevOps компания Nordstrom сумела удвоить количество выпускаемых ежемесячно функций, уменьшить число дефектов на 50 %, сократить сроки реализации идей в промышленных условиях на 60 % и снизить частоту сбоев в процессе эксплуатации ПО на 60–90 %. После того как в подразделении LaserJet Firmware компании HP стали использовать методики DevOps, доля времени, затрачиваемого на разработку новых возможностей, увеличилась с 5 до 40 %, а общая стоимость разработки была снижена на 40 %. До внедрения DevOps доставка кода в компании Etsy была нечастым процессом, сопряженным со стрессом и многочисленными перебоями в работе. Теперь развертывания выполняются по 25–50 раз в день с куда меньшим количеством проблем3.
Движение DevOps основано на четырех принципах: культуре, автоматизации, измерении и разделении (в англ. языке иногда используется аббревиатура CASM (http://bit.ly/2GS3CR3) — culture, automation, sharing, measurement). Эта книга не задумывалась как комплексный обзор DevOps (рекомендуемая литература приводится в приложении), поэтому сосредоточусь лишь на одном из указанных принципов: автоматизации.
Наша задача — автоматизировать как можно больше аспектов процесса доставки программного обеспечения. Это означает, что вы будете управлять своей инфраструктурой через код, а не с помощью веб-страницы или путем ввода консольных команд. Такую концепцию обычно называют «инфраструктура как код» (infrastructure as code, или IaC).
Что такое инфраструктура как код
Идея, стоящая за IaC, заключается в том, что для определения, развертывания, обновления и удаления инфраструктуры нужно писать и выполнять код. Это важный сдвиг в образе мышления, когда все аспекты системного администрирования воспринимаются как программное обеспечение — даже те, которые представляют оборудование (например, настройка физических серверов). Ключевым аспектом DevOps является то, что почти всем можно управлять внутри кода, включая серверы, базы данных, сети, журнальные файлы, программную конфигурацию, документацию, автоматические тесты, процессы развертывания и т. д.
Инструменты IaC можно разделить на пять общих категорий:
• специализированные скрипты;
• средства управления конфигурацией;
• средства шаблонизации серверов;
• средства оркестрации;
• средства инициализации ресурсов.
Рассмотрим каждую из них.
Специализированные скрипты
Самый простой и понятный способ что-либо автоматизировать — написать для этого специальный скрипт. Вы берете задачу, которая выполняется вручную, разбиваете ее на отдельные шаги, описываете каждый шаг в виде кода, используя любимый скриптовый язык, и выполняете получившийся скрипт на своем сервере, как показано на рис. 1.1.

Рис. 1.1. Выполнение специализированного скрипта на сервере
Например, ниже показан bash-скрипт setup-webserver.sh, который конфигурирует веб-сервер, устанавливая зависимости, загружая код из Git-репозитория и запуская Apache:
# Обновляем кэш apt-get
sudo apt-get update
# Устанавливаем PHP и Apache
sudo apt-get install -y php apache2
# Копируем код из репозитория
sudo git clone https://github.com/brikis98/php-app.git /var/www/html/app
# Запускаем Apache
sudo service apache2 start
Крайне удобной особенностью специализированных скриптов (и их огромным недостатком) является то, что код можно писать как угодно и с использованием популярных языков программирования общего назначения.
Если инструменты, специально созданные для IaC, предоставляют лаконичный API для выполнения сложных задач, языки программирования общего назначения подразумевают написание своего кода в каждом отдельно взятом случае. Более того, средства IaC обычно навязывают определенную структуру кода, тогда как в специализированных скриптах каждый разработчик использует собственный стиль и делает вещи по-своему. Если речь идет о скрипте из восьми строк, который устанавливает Apache, обе проблемы можно считать незначительными, но, если вы попытаетесь применить тот же подход к управлению десятками серверов, базами данных, балансировщиками нагрузки и сетевой конфигурацией, все пойдет наперекосяк.
Если вам когда-либо приходилось поддерживать большой репозиторий bash-скриптов, вы знаете, что это почти всегда превращается в «кашу» из плохо структурированного кода. Специализированные скрипты отлично подходят для небольших одноразовых задач, но, если вы собираетесь управлять всей своей инфраструктурой в виде кода, следует использовать специально предназначенный для этого инструмент IaC.
Средства управления конфигурацией
Chef, Puppet, Ansible и SaltStack являются средствами управления конфигурацией. Это означает, что они предназначены для установки и администрирования программного обеспечения на существующих серверах. Например, ниже показана роль Ansible под названием web-server.yml, которая настраивает тот же веб-сервер Apache, что и скрипт setup-webserver.sh:
- name: Update the apt-get cache
apt:
update_cache: yes
- name: Install PHP
apt:
name: php
- name: Install Apache
apt:
name: apache2
- name: Copy the code from the repository
git: repo=https://github.com/brikis98/php-app.git dest=/var/www/html/app
- name: Start Apache
service: name=apache2 state=started enabled=yes
Этот код похож на bash-скрипт, но использование такого инструмента, как Ansible, дает ряд преимуществ.
•Стандартизированное оформление кода. Ansible требует, чтобы код имел предсказуемую структуру. Это касается документации, структуры файлов и каталогов, параметров с понятными именами, управления конфиденциальными данными и т. д. Если каждый разработчик организует свои специализированные скрипты по-разному, то большинство средств управления конфигурацией имеют набор правил и соглашений, которые упрощают навигацию по коду.
• Идемпотентность4. Написать рабочий специализированный скрипт не так уж и трудно. Намного сложнее написать скрипт, который будет работать корректно вне зависимости от того, сколько раз вы его запустите. Каждый раз, когда вы создаете в своем скрипте папку, нужно убедиться, что ее еще не существует. Всякий раз, когда вы добавляете строчку в конфигурационный файл, необходимо проверить, существует ли эта строчка. И всегда, когда вы хотите запустить программу, надо определить, выполняется ли она в данный момент.
Код, который работает корректно независимо от того, сколько раз вы его запускаете, называется идемпотентным. Чтобы сделать идемпотентным bash-скрипт из предыдущего раздела, придется добавить много строчек кода, включая уйму условных выражений. Для сравнения: большинство функций Ansible идемпотентно по умолчанию. Например, роль Ansible web-server.yaml установит сервер Apache только в случае, если он еще не установлен, и попытается его запустить лишь при условии, что он еще не выполняется.
• Распределенность. Специализированные скрипты предназначены для выполнения на одном локальном компьютере. Ansible и другие средства управления конфигурацией специально «заточены» под работу с большим количеством удаленных серверов, как показано на рис. 1.2.
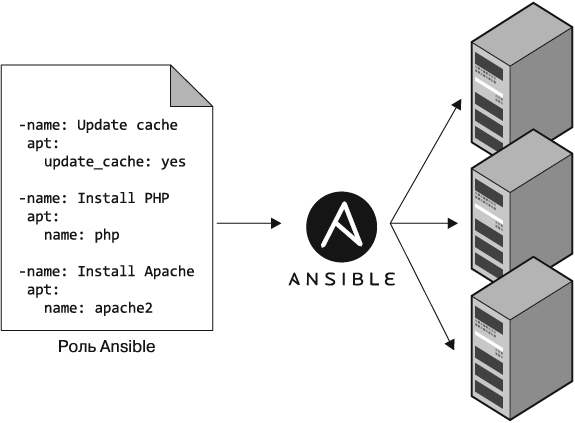
Рис. 1.2. Такие средства управления конфигурацией, как Ansible, способны выполнять ваш код на большом количестве серверов
Например, чтобы применить роль web-server.yml к пяти серверам, нужно сначала создать файл под названием hosts, который содержит IP-адреса этих серверов:
[webservers]
11.11.11.11
11.11.11.12
11.11.11.13
11.11.11.14
11.11.11.15
Далее следует определить такой плейбук (playbook) Ansible:
- hosts: webservers
roles:
- webserver
И в конце этот плейбук выполняется:
ansible-playbook playbook.yml
Это заставит Ansible параллельно сконфигурировать все пять серверов. В качестве альтернативы в плейбуке можно указать параметр под названием serial. Это позволит выполнить скользящее развертывание, которое обновит серверы пакетным образом. Например, если присвоить serial значение 2, Ansible будет обновлять сразу по два сервера, пока не будут обновлены все пять. Дублирование любой части этой логики в специализированных скриптах потребовало бы написания десятков или даже сотен строчек кода.
Средства шаблонизации серверов
Альтернативой управлению конфигурацией, набирающей популярность в последнее время, являются средства шаблонизации серверов, такие как Docker, Packer и Vagrant. Вместо того чтобы вводить кучу серверов и настраивать их, запуская на каждом один и тот же код, средства шаблонизации создают образ сервера, содержащий полностью самодостаточный «снимок» операционной системы (ОС), программного обеспечения, файлов и любых других важных деталей. Затем, как показано на рис. 1.3, этот образ можно будет установить на все ваши серверы, используя другие инструменты IaC.
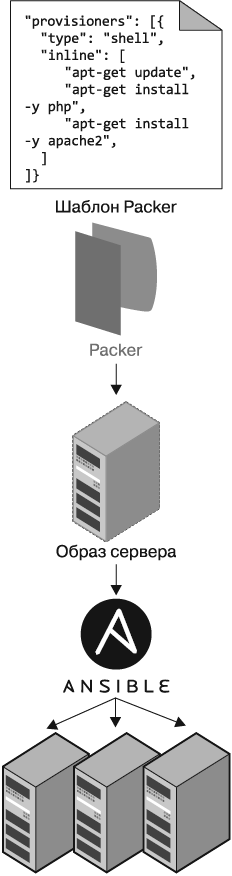
Рис. 1.3. С помощью таких средств шаблонизации, как Packer, можно создавать самодостаточные образы серверов. Затем, используя другие инструменты, такие как Ansible, эти образы можно установить на все ваши серверы

Рис. 1.4. Существует два вида образов: ВМ (слева) и контейнеры (справа). ВМ виртуализируют оборудование, тогда как контейнеры — только пользовательское пространство
Как видно на рис. 1.4, средства для работы с образами можно разделить на две общие категории.
•Виртуальные машины эмулируют весь компьютер, включая аппаратное обеспечение. Для виртуализации (то есть симуляции) процессора, памяти, жесткого диска и сети запускается гипервизор, такой как VMWare, VirtualBox или Parallels. Преимущество подхода — любой образ ВМ, который работает поверх гипервизора, может видеть только виртуальное оборудование, поэтому он полностью изолирован от физического компьютера и любых других образов ВМ. И он выполняется аналогично во всех средах (например, на вашем компьютере, сервере проверки качества и боевом сервере). Недостаток в том, что виртуализация всего этого оборудования и запуск совершенно отдельной ОС для каждой ВМ требует большого количества ресурсов процессора и памяти, что влияет на время запуска. Образы ВМ можно описывать в виде кода, применяя такие инструменты, как Packer и Vagrant.
•Контейнеры эмулируют пользовательское пространство ОС5. Для изоляции процессов, памяти, точек монтирования и сети запускается среда выполнения контейнеров, такая как Docker, CoreOS rkt или cri-o. Преимущество этого подхода в том, что любой контейнер, который выполняется в данной среде, может видеть только собственно пользовательское пространство, поэтому он изолирован от основного компьютера и других контейнеров. При этом он ведет себя одинаково в любой среде (например, на вашем компьютере, сервере проверки качества, боевом сервере и т. д.). Но есть и недостаток: все контейнеры, запущенные на одном сервере, одновременно пользуются ядром его ОС и его оборудованием, поэтому достичь того уровня изоляции и безопасности, который вы получаете в ВМ, намного сложнее6. Поскольку применяются общие ядро и оборудование, ваши контейнеры могут загружаться в считаные миллисекунды и практически не будут требовать дополнительных ресурсов процессора или памяти. Образы контейнеров можно описывать в виде кода, используя такие инструменты, как Docker и CoreOS rkt.
Например, ниже представлен шаблон Packer под названием web-server.json, создающий Amazon Machine Image (AMI) — образ ВМ, который можно запускать в AWS:
{
"builders": [{
"ami_name": "packer-example",
"instance_type": "t2.micro",
"region": "us-east-2",
"type": "amazon-ebs",
"source_ami": "ami-0c55b159cbfafe1f0",
"ssh_username": "ubuntu"
}],
"provisioners": [{
"type": "shell",
"inline": [
"sudo apt-get update",
"sudo apt-get install -y php apache2",
"sudo git clone https://github.com/brikis98/php-app.git /var/www/html/app"
],
"environment_vars": [
"DEBIAN_FRONTEND=noninteractive"
]
}]
}
Шаблон Packer настраивает тот же веб-сервер Apache, который мы видели в файле setup-webserver.sh, и использует тот же код на bash7. Единственное отличие от предыдущего кода в том, что Packer не запускает веб-сервер Apache (с помощью команды вроде sudoserviceapache2start). Дело в том, что шаблоны серверов обычно применяются для установки ПО в образах, а запуск этого ПО должен происходить во время выполнения образа (например, когда он будет развернут на сервере).
Вы можете создать AMI из этого шаблона, запустив команду packerbuildwebserver.json. Когда сборка завершится, полученный образ AMI можно будет установить на все ваши серверы в AWS и сконфигурировать Apache для запуска во время загрузки компьютера (пример этого см. в подразделе «Средства оркестрации» на с. 35). В результате все они будут запущены абсолютно одинаково.
Имейте в виду, что разные средства шаблонизации серверов имеют различное назначение. Packer обычно используется для создания образов, выполняемых непосредственно поверх боевых серверов, таких как AMI (доступных для работы в вашей промышленной учетной записи). Образы, созданные в Vagrant, обычно запускаются на компьютерах для разработки. Это, к примеру, может быть образ VirtualBox, который работает на вашем ноутбуке под управлением Mac или Windows. Docker обычно делает образы для отдельных приложений. Их можно запускать на промышленных или локальных компьютерах при условии, что вы сконфигурировали на них Docker Engine, используя какой-то другой инструмент. Например, с помощью Packer часто создают образы AMI, у которых внутри установлен Docker Engine; дальше эти образы развертываются на кластере серверов в вашей учетной записи AWS, и затем в этот кластер доставляются отдельные контейнеры Docker для выполнения ваших приложений.
Шаблонизация серверов — это ключевой аспект перехода на неизменяемую инфраструктуру. Идея навеяна функциональным программированием, которое предполагает наличие «неизменяемых переменных». То есть после инициализации переменной ее значение больше нельзя изменить. Если нужно что-то обновить, вы создаете новую переменную. Благодаря этому код становится намного более понятным.
Неизменяемая инфраструктура работает по тому же принципу: если сервер уже развернут, в него больше не вносятся никакие изменения. Если нужно что-то обновить (например, развернуть новую версию кода), вы создаете новый образ из своего шаблона и развертываете его на новый сервер. Поскольку серверы никогда не меняются, вам намного проще следить за тем, что на них развернуто.
Средства оркестрации
Средства шаблонизации серверов отлично подходят для создания ВМ и контейнеров, но как ими после этого управлять? В большинстве реальных сценариев применения вам нужно выбрать какой-то способ выполнения следующих действий.
• Развертывать ВМ и контейнеры с целью эффективного использования ресурсов оборудования.
• Выкатывать обновления для своих многочисленных ВМ и контейнеров, используя такие стратегии, как скользящие, «сине-зеленые» и канареечные развертывания.
• Следить за работоспособностью своих ВМ и контейнеров, автоматически заменяя неисправные (автовосстановление).
• Масштабировать количество ВМ и контейнеров в обе стороны в зависимости от нагрузки (автомасштабирование).
• Распределять трафик между своими ВМ и контейнерами (балансировка нагрузки).
• Позволять своим ВМ и контейнерам находить друг друга и общаться между собой по сети (обнаружение сервисов).
Выполнение этих задач находится в сфере ответственности средств оркестрации, таких как Kubernetes, Marathon/Mesos, Amazon Elastic Container Service (Amazon ECS), Docker Swarm и Nomad. Например, Kubernetes позволяет описывать и администрировать контейнеры Docker в виде кода. Вначале развертывается кластер Kubernetes, который представляет собой набор серверов для выполнения ваших контейнеров Docker. У большинства облачных провайдеров есть встроенная поддержка развертывания управляемых кластеров Kubernetes: вроде Amazon Elastic Container Service for Kubernetes (Amazon EKS), Google Kubernetes Engine (GKE) и Azure Kubernetes Service (AKS).
Подготовив рабочий кластер, вы можете описать развертывание своего контейнера Docker в виде кода внутри YAML-файла:
apiVersion: apps/v1
# Используем объект Deployment для развертывания нескольких реплик вашего
# Docker-контейнера (возможно, больше одного) и декларативного выкатывания
# обновлений для него
kind: Deployment
# Метаданные этого развертывания, включая его имя
metadata:
name: example-app
# Спецификация, которая конфигурирует это развертывание
spec:
# Благодаря этому развертывание знает, как искать ваш контейнер
selector:
matchLabels:
app: example-app
# Приказываем объекту Deployment развернуть три реплики Docker-контейнера
replicas: 3
# Определяет способ обновления развертывания. Здесь указываем скользящие обновления
strategy:
rollingUpdate:
maxSurge: 3
maxUnavailable: 0
type: RollingUpdate
# Этот шаблон описывает, какие контейнеры нужно развернуть
template:
# Метаданные контейнера, включая метки
metadata:
labels:
app: example-app
# Спецификация контейнера
spec:
containers:
# Запускаем Apache на порту 80
- name: example-app
image:
ports:
- containerPort: 80
Этот файл говорит Kubernetes, что нужно создать развертывание, которое декларативно описывает следующее.
• Один или несколько контейнеров Docker для совместного запуска. Эта группа контейнеров называется подом, или под-оболочкой. Под, описанный в приведенном выше коде, содержит единственный контейнер, который запускает Apache.
• Настройки каждого контейнера Docker в под-оболочке. В нашем примере под-оболочка настраивает Apach для прослушивания порта 80.
• Сколько копий (реплик) под-оболочки должно быть в вашем кластере. У нас указано три реплики. Kubernetes автоматически определяет, в какой области кластера их следует развернуть, используя алгоритм планирования для выбора оптимальных серверов с точки зрения высокой доступности (например, каждая под-оболочка может оказаться на отдельном сервере, чтобы сбой на одном из них не остановил работу всего приложения), ресурсов (скажем, выбираются серверы с доступными портами, процессором, памятью и другими ресурсами, необходимыми вашему контейнеру), производительности (в частности, выбираются наименее загруженные серверы) и т. д. Кроме того, Kubernetes постоянно следит за тем, чтобы в кластере всегда было три реплики. Для этого автоматически заменяется любая под-оболочка, вышедшая из строя или переставшая отвечать.
• Как развертывать обновления. Когда выходит новая версия контейнера Docker, наш код выкатывает три новые реплики, ждет, когда они станут работоспособными, и затем удаляет три старые копии.
Так много возможностей всего в нескольких строчках на YAML! Чтобы развернуть свое приложение в Kubernetes, нужно выполнить команду kubectlapply-fexample-app.yml. Чтобы выкатить обновления, вы можете отредактировать YAML-файл и снова запустить kubectlapply.
Средства инициализации ресурсов
В отличие от инструментов для управления конфигурацией, шаблонизации серверов и оркестрации, код которых выполняется на каждом сервере, средства инициализации ресурсов, такие как Terraform, CloudFormation и OpenStack Heat, отвечают за создание самих серверов. С их помощью можно создавать не только серверы, но и базы данных, кэши, балансировщики нагрузки, очереди, системы мониторинга, настройки подсетей и брандмауэра, правила маршрутизации, сертификаты SSL и почти любой другой аспект вашей инфраструктуры (рис. 1.5).
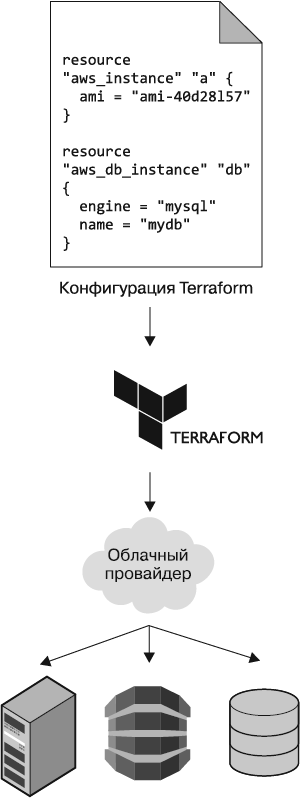
Рис. 1.5. Средства инициализации ресурсов можно использовать в связке с вашим облачным провайдером, чтобы создавать серверы, базы данных, балансировщики нагрузки и любые другие элементы вашей инфраструктуры
Например, следующий код развертывает веб-сервер с помощью Terraform:
resource "aws_instance" "app" {
instance_type = "t2.micro"
availability_zone = "us-east-2a"
ami = "ami-0c55b159cbfafe1f0"
user_data = <<-EOF
#!/bin/bash
sudo service apache2 start
EOF
}
Не нужно волноваться, если вам непонятны какие-то элементы данного синтаксиса. Пока что сосредоточьтесь на двух параметрах.
•ami определяет идентификатор образа AMI, который нужно развернуть на сервере. Вы можете присвоить ему ID образа, собранного из шаблона Packer web-server.json в подразделе «Средства оркестрации» на с. 35. В нем содержатся PHP, Apache и исходный код приложения.
•user_data. Этот bash-скрипт выполняется при загрузке веб-сервера. В предыдущем примере этот скрипт используется для запуска Apache.
Иными словами, это демонстрация того, как объединить инициализацию ресурсов и шаблонизацию серверов, что является распространенной практикой в неизменяемой инфраструктуре.
Преимущества инфраструктуры как кода
Теперь, когда вы познакомились со всевозможными разновидностями IaC, можно задаться вопросом: зачем нам это нужно? Зачем изучать целую кучу новых языков и инструментов, обременяя себя еще большим количеством кода, который нужно поддерживать?
Дело в том, что код довольно мощный. Усилия, которые идут на преобразование ручных процессов в код, вознаграждаются огромным улучшением ваших возможностей по доставке ПО. Согласно докладу о состоянии DevOps за 2016 год (bit.ly/31kCUYX), организации, применяющие такие методики, как IaC, развертывают код в 200 раз чаще и восстанавливаются после сбоев в 24 раза быстрее, а на реализацию новых функций уходит в 2555 раз меньше времени.
Когда ваша инфраструктура определена в виде кода, можно существенно улучшить процесс доставки ПО, используя широкий диапазон методик из мира программирования. Это дает преимущества.
•Самообслуживание. В большинстве команд, которые развертывают код вручную, мало сисадминов (часто один), и только они знают все магические заклинания для выполнения развертывания и имеют доступ к промышленной среде. Это становится существенным препятствием на пути роста компании. Если же ваша инфраструктура определена в виде кода, весь процесс развертывания можно автоматизировать, благодаря чему разработчики смогут доставлять свой код тогда, когда им это нужно.
• Скорость и безопасность. Автоматизация значительно ускоряет процесс развертывания, потому что компьютер может выполнить все его этапы куда быстрее человека. При этом повышается безопасность, так как автоматический процесс будет более последовательным, воспроизводимым и устойчивым к ошибкам с человеческим фактором.
• Документация. Вместо того чтобы держать состояние инфраструктуры в голове одного сисадмина, вы можете описать его в исходном файле, который каждый сможет прочитать. Иными словами, IaC играет роль документации, позволяя любому работнику компании понять, как все работает, даже если сисадмин уходит в отпуск.
• Управление версиями. Исходные файлы IaC можно хранить в системе управления версиями, благодаря чему в журнале фиксаций кода будет записана вся история вашей инфраструктуры. Это очень помогает при отладке, та



















