

автордың кітабын онлайн тегін оқу Release it! Проектирование и дизайн ПО для тех, кому не всё равно
М. Нейгард
Release it! Проектирование и дизайн ПО для тех, кому не всё равно
Переводчик И. Рузмайкина
Технический редактор Н. Суслова
Литературный редактор А. Жданов
Художники М. Кольцов, В. Шимкевич
Корректоры С. Беляева, Н. Викторова
Верстка Л. Панич
М. Нейгард
Release it! Проектирование и дизайн ПО для тех, кому не всё равно. — СПб.: Питер, 2015.
ISBN 978-5-496-01611-7
© ООО Издательство "Питер", 2015
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Предисловие
Вы больше года работали над сложным проектом. Наконец, кажется, все программные компоненты готовы, и даже модульное тестирование выполнено. Можно вздохнуть с облегчением. Вы закончили.
Или?
Означает ли «готовность программного компонента», что он готов к работе? Подготовлена ли ваша система к развертыванию? Смогут ли с ней справиться без вашей помощи обслуживающий персонал и толпы реальных пользователей? Нет ли у вас нехорошего предчувствия грядущих ночных звонков с паническими просьбами о помощи? Ведь разработка — это не только ввод всех необходимых программных компонентов.
Слишком часто работающая над проектом группа ставит своей целью не долгую беспроблемную эксплуатацию, а прохождение тестов контроля качества. То есть изрядная часть работы концентрируется вокруг грядущего тестирования. Однако тестирование, даже гибкое, практичное и автоматизированное, не является гарантией готовности программы к функционированию в реальных условиях. Возникающие в реальности нагрузки, обусловленные сумасшедшими пользователями, трафиком и хакерами из стран, о которых вы даже никогда не слышали, выходят за рамки условий, которые можно смоделировать в пределах теста.
Чтобы проследить за готовностью программы к реальным условиям, требуется соответствующая подготовка. Я хочу помочь вам выявить источник проблем и подсказать, как с ними бороться. Но прежде чем мы приступим к делу, хотелось бы осветить некоторые популярные заблуждения.
Во-первых, следует примириться с тем, что даже самое лучшее планирование не позволяет избежать некоторых нехороших вещей. Разумеется, их всегда по возможности следует предотвращать. Но мысль о том, что вы в состоянии предсказать и устранить все возможные проблемы, является роковой ошибкой. Вместо этого следует предпринять некие действия, сводящие на нет возможные риски, постаравшись при этом гарантировать работоспособность системы даже в случае непредвиденных тяжелых повреждений.
Во-вторых, следует понять, что «версия 1.0» — это не конец процесса разработки, а начало самостоятельного существования системы. Ситуация напоминает выросшего ребенка, который в первое время вынужден жить с родителями. Вряд ли вам захочется, чтобы ваш сын навсегда поселился в вашей квартире, особенно вместе со своей супругой, четырьмя детьми, двумя собаками и какаду.
Аналогичным образом все принятые на этапе разработки конструкторские решения окажут огромное влияние на вашу жизнь после выхода версии 1.0. Если вы не сумеете сконструировать систему, ориентированную на реальную производственную среду, ваша жизнь после ее выпуска будет полна волнений. И зачастую неприятных. В этой книге вы познакомитесь с важными компромиссами и узнаете, как их добиваться.
И наконец, несмотря на всеобщую любовь к технологиям, привлекательным новым методам и крутым системам, вам придется признать, что ничего из этого по большому счету не имеет значения. В мире бизнеса — а именно он заказывает музыку — все сводится к деньгам. Системы стоят денег. Чтобы компенсировать затраты на свое создание, они должны приносить деньги в виде прямого дохода или экономии средств. Дополнительная работа, как и простои, оборачивается дополнительными расходами. Неэффективный код дорого обходится, так как требует капитальных вложений и эксплуатационных затрат. Чтобы понять действующую систему, нужно думать в терминах выгоды. Чтобы остаться в деле, вы должны приносить деньги или хотя бы не терять их.
Я надеюсь, эта книга позволит изменить ситуацию и поможет вам и организации, в которой вы работаете, избежать огромных потерь и перерасхода средств — частой сопутствующей проблемы корпоративного программного обеспечения.
Для кого предназначена эта книга?
Я писал эту книгу для архитекторов, проектировщиков и разработчиков программного обеспечения корпоративного класса, в том числе сайтов, веб-служб и EAI-проектов. Для меня программное обеспечение корпоративного класса означает, что приложение должно работать, в противном случае компания потеряет деньги. В эту категорию попадают как коммерческие системы, напрямую связанные с получением дохода, например путем продаж, так и важные внутрикорпоративные системы, необходимые для выполнения рабочих обязанностей сотрудников. Если выход вашей программы из строя может на целый день оставить человека без работы, значит, эта книга предназначена для вас.
Структура книги
Книга разделена на четыре части, каждая из которых начинается с практического примера. В части I показано, как сохранить активность системы, обеспечив ее безотказную работу. Несмотря на обещанную надежность за счет избыточности, распределенные системы демонстрируют доступность, выражаемую скорее «двумя восьмерками», чем желанными «пятью девятками»1.
Необходимой предпосылкой для рассмотрения любых других вопросов является стабильность. Если ваша система рушится несколько раз в день, никто не будет рассматривать аспекты, связанные с отдаленным будущим. В такой среде доминируют краткосрочные исправления и, как следствие, краткосрочное мышление. Без стабильности не будет конкурентоспособного будущего, поэтому первым делом следует понять, каким образом вы можете гарантировать стабильность базовой системы, которая послужит основой для дальнейших работ.
Как только вы добьетесь стабильности, приходит время позаботиться о мощности системы. Этой теме посвящена часть II, в которой вы познакомитесь со способами измерения этого параметра, узнаете, что он на самом деле означает, и научитесь оптимизировать его в долгосрочной перспективе. Я покажу вам примеры паттернов и антипаттернов, иллюстрирующие хорошие и плохие проектные решения, и продемонстрирую потрясающее влияние, которое эти решения могут оказывать на вычислительную мощность (и, как следствие, на количество ночных телефонных звонков и сообщений).
В части III мы рассмотрим общие вопросы проектирования, которые архитектор должен учитывать при написании программ для центров обработки данных. За последнее десятилетие аппаратное обеспечение и проектирование инфраструктуры претерпели значительные изменения; к примеру, такая относительно редкая раньше практика, как виртуализация, сейчас распространена практически повсеместно. Сети стали куда сложнее — теперь они являются многоуровневыми и программируемыми. Обычным делом стали сети хранения данных. Разработка программного обеспечения должна учитывать и использовать эти новшества для обеспечения бесперебойной работы центров обработки данных.
В части IV существование системы рассматривается в рамках общей информационной экосистемы. Зачастую производственные системы напоминают кота Шрёдингера — они заперты в коробке без возможности наблюдать за их состоянием. Здоровью экосистемы это не способствует. Отсутствие информации делает невозможными целенаправленные улучшения2. В главе 17 обсуждаются факторы, технологии и процессы, которые следует изучать у работающих систем (это единственная ситуация, когда можно изучать определенные вещи). Выяснив показатели работоспособности и производительности конкретной системы, вы сможете действовать на основе этих данных. Более того, подобный подход является обязательным — действия нужно предпринимать только в свете полученной информации. Иногда это проще сказать, чем сделать, и в главе 18 мы рассмотрим препятствия на пути к изменениям и способы их уменьшения и преодоления.
Анализ примеров
Для иллюстрации основных концепций книги я привел несколько развернутых примеров. Они взяты из реальной жизни и описывают системные отказы, которым я был свидетелем. Эти отказы оказались крайне дорогостоящими — и компрометирующими — для тех, кто имел к ним отношение. Поэтому я опустил информацию, которая позволила бы идентифицировать конкретные компании и людей. Также я поменял названия систем, классов и методов. Но изменениям подверглись только «несущественные» детали. Во всех случаях я указал отрасль, последовательность событий, режим отказа, путь распространения ошибки и результат. Цена всех этих отказов не преувеличена. Это реальные потери реальных фирм. Я упомянул эти цифры в тексте, чтобы подчеркнуть серьезность материала. Отказ системы ставит под удар реальные деньги.
Благодарности
Идея книги появилась после моего выступления перед группой Object Technology. Поэтому я должен поблагодарить Кайла Ларсона (Kyle Larson) и Клайда Каттинга (Clyde Cutting) — благодаря им я вызвался сделать доклад, который они благосклонно приняли. Неоценимую поддержку мне оказали Том (Tom Poppendieck) и Мэри Поппендик (Mary Poppendieck), авторы двух фантастических книг о «бережливой разработке»3. Это они убедили меня, что я полностью готов к написанию собственной книги. Отдельное спасибо моему другу и коллеге Диону Стюарту (Dion Stewart), который постоянно оценивал написанные фрагменты.
Разумеется, было бы упущением не поблагодарить мою жену и дочерей. Первую половину своей жизни моя младшая дочь смотрела, как я работаю над книгой. Вы все так терпеливо ждали, когда я работал даже в выходные. Мари, Анна, Элизабет, Лаура и Сара, огромное вам спасибо.
1 То есть 88, а не 99,999% времени безотказной работы.
2 Случайные догадки порой могут приводить к улучшениям, но в подавляющем большинстве случаев хаос от них только возрастает.
3 Книги Lean Software Development и Implementing Lean Software Development. Последняя была переведена на русский язык издательством «Вильямс» и вышла под названием «Бережливое производство программного обеспечения. От идеи до прибыли».
1 То есть 88, а не 99,999% времени безотказной работы.
2 Случайные догадки порой могут приводить к улучшениям, но в подавляющем большинстве случаев хаос от них только возрастает.
3 Книги Lean Software Development и Implementing Lean Software Development. Последняя была переведена на русский язык издательством «Вильямс» и вышла под названием «Бережливое производство программного обеспечения. От идеи до прибыли».
1. Введение
Современные учебные программы по разработке программного обеспечения являются до ужаса неполными. В их рамках рассматривается только то, как должна вести себя система. При этом не раскрывается обратный аспект — как системы не должны себя вести. А они не должны рушиться, зависать, терять данные, предоставлять несанкционированный доступ к информации, приводить к потере денег, разрушать вашу компанию или лишать вас заказчиков.
В этой книге мы рассмотрим способы планирования, проектирования и создания программного обеспечения — особенно распределенных систем — с учетом всех неприятных аспектов реального мира. Мы подготовимся к армии нелогичных пользователей, делающих сумасшедшие, непредсказуемые вещи. Атака на вашу программу начинается с момента ее выпуска. Программа должна быть устойчива к любому флэшмобу, слэшдот-эффекту или ссылкам на сайтах Fark и Digg. Мы непредвзято рассмотрим программы, не прошедшие тестирование, и найдем способы гарантировать их выживание при контакте с реальным миром.
Современная разработка программного обеспечения своей оторванностью от реальности напоминает ситуацию с разработкой автомобилей в начале 90-х годов. Модели автомобилей, придуманные исключительно в прохладном комфорте лабораторий, великолепно выглядели на чертежах и в системах автоматизированного проектирования. Идеальные изгибы машин блестели перед гигантскими вентиляторами, создающими ламинарный поток. Проектировщики, населявшие эти спокойные производственные помещения, выдавали конструкции, которые были элегантными, изящными, хорошо продуманными, но хрупкими, не соответствующими критериям прочности и в итоге имели весьма скромный ресурс. Построение и проектирование программного обеспечения по большей части происходит в таких же отдаленных от жизненных реалий стерильных условиях.
Нам же нужны автомобили, спроектированные для реального мира. Мы хотим, чтобы этим занимались люди, понимающие, что смена масла всегда происходит на 3000 миль позже, чем нужно; что шины на последней одной шестнадцатой дюйма протектора должны функционировать так же хорошо, как и на первой; что водитель рано или поздно может ударить по тормозам, держа в одной руке сэндвич с яйцом, а в другой сотовый телефон.
1.1. Правильный выбор цели
Большинство программ разрабатывается для исследовательской лаборатории или тестеров из отдела контроля качества. Они проектируются и строятся, чтобы проходить такие тесты, как, к примеру, «клиенту требуется ввести имя и фамилию и по желанию — отчество». То есть усилия направляются на выживание в вымышленном царстве отдела контроля качества, а не в реальном мире.
Можно ли быть уверенным, что прошедшая контроль качества система готова к использованию? Простое прохождение тестов ничего не говорит о стабильности системы в следующие три, а то и десять лет ее жизни. В результате может родиться Toyota Camry от программирования, способная на тысячи часов безотказной работы. А может получиться Chevy Vega, за несколько лет прогнивающий до дыр, или Ford Pinto, норовящий взорваться при каждом ударе в задний бампер. За несколько дней или недель тестирования невозможно понять, что принесут следующие несколько лет эксплуатации.
Проектировщики промышленных изделий долгое время придерживались политики подгонки «конструкции под технологичность изготовления». При таком подходе к разработке продуктов высокое качество должна сопровождать минимальная стоимость производства.
А еще раньше проектировщики и производители товаров вообще обитали в разных мирах. Нежелание проектировщиков участвовать в дальнейшем процессе приводило к появлению винтов в труднодоступных местах, деталей, которые легко было перепутать, и самопальных компонентов там, где могли бы применяться готовые комплектующие. Из всего этого неизбежно вытекало низкое качество и высокая стоимость производства.
Звучит знакомо, не так ли? Мы сейчас находимся в аналогичном положении. Мы постоянно опаздываем с выпуском новых систем, потому что время отнимают постоянные звонки с требованиями сопровождения недоделанных проектов, уже выпущенных нами в свет. Нашим аналогом подгонки «конструкции под технологичность изготовления» является подгонка «конструкции под эксплуатацию». Результаты своих трудов мы передаем не изготовителю, а тем, кто будет с ними работать. Мы должны проектировать индивидуальные программные системы и целый комплекс независимых систем, обеспечивая низкую стоимость и высокое качество своей продукции.
1.2. Важность интуиции
Решения, принятые на ранней стадии, оказывают сильное влияние на конечный вид системы. Чем раньше принимается решение, тем сложнее потом от него отказаться. От того, как вы определите границы системы и как разобьете ее на подсистемы, зависит структура рабочей группы, объем финансирования, структура сопровождения программного продукта и даже хронометраж работ. Распределение обязанностей внутри группы является первым наброском архитектуры (см. закон Конвея в разделе 7.2). Ирония состоит в том, что на ранней стадии решения принимаются в условиях минимальной информированности. Группа еще понятия не имеет о конечной структуре будущего программного продукта, но уже должна принимать необратимые решения.
Даже в случае «гибких» проектов4 для принятия решений лучше обладать даром предвидения. То есть проектировщик должен «пользоваться интуицией», чтобы заглянуть в будущее и выбрать наиболее надежный вариант. При одинаковых затратах на реализацию разные варианты могут иметь совершенно разную стоимость жизненного цикла, поэтому важно учесть, какой эффект каждое из решений окажет на доступность, вычислительную мощность и гибкость конечного продукта. Я продемонстрирую вам результаты десятков вариантов конструкции с примерами выгодных и вредных подходов. Все эти примеры я наблюдал в системах, с которыми мне довелось работать. И многое из этого стоило мне бессонных ночей.
1.3. Качество жизни
Версия 1.0 — это начало жизни вашей программы, но не конец проекта. И качество вашей жизни после предоставления версии 1.0 заказчикам зависит от решений, которые вы приняли в далеком прошлом.
И чем бы ни занимался ваш заказчик, он должен знать, что получает надежный, протестированный в условиях бездорожья и несокрушимый автомобиль, который повезет его бизнес вперед, а не хрупкую игрушку из стекла, которой суждено провести в магазине гораздо больше времени, чем на реальной дороге.
1.4. Охват проблемы
«Кризис программного обеспечения» начался более тридцати лет назад. Золотовладельцы считают, что программное обеспечение по-прежнему стоит слишком дорого. (Этой теме посвящена книга Тома де Марко WhyDoes Software Cost So Much?) А по мнению целевых доноров, его разработка занимает слишком много времени, несмотря на то что теперь она измеряется месяцами, а не годами. Судя по всему, достигнутая за последние тридцать лет продуктивность иллюзорна.
Эти термины появились в сообществе гибкого проектирования. Золотовладельцем (gold owner) называют того, кто платит за программное обеспечение, а целевым донором (goal donor) — того, чьи запросы это программное обеспечение призвано удовлетворять. Как правило, это два разных человека.
В то же время, возможно, реальный рост продуктивности выражается в том, что теперь мы можем решать более масштабные проблемы, а не в удешевлении и ускорении производства уже существующих программ. За последние десять лет сфера охвата наших программ выросла на несколько порядков.
В спокойные времена клиент-серверных систем информационная база могла охватывать сотни и тысячи пользователей, при этом одновременно с системой работали в лучшем случае несколько дюжин из них. Современные заказчики без смущения называют такие цифры, как «25 тысяч параллельно работающих пользователей» и «4 миллиона уникальных посетителей в день».
Возросли и требования к сроку эксплуатации. Если раньше «пять девяток» (99,999%) требовались только центральным серверам и обслуживающему их персоналу, то сейчас даже заурядным коммерческим сайтам нужна доступность 24 часа в сутки и 365 дней в году5. Очевидно, мы резко шагнули вперед в масштабах создаваемого программного обеспечения, но одновременно с этим появились новые варианты отказов, обстановка стала более неблагоприятной, а терпимость к дефектам снизилась.
Расширение границ задачи — быстро создавать программы, которые нравились бы пользователям и были простыми в обслуживании, — требует постоянного улучшения методик построения архитектуры и проектирования. При попытке применить вещи, подходящие для небольших сайтов, к системам с тысячами пользователей, к системам обработки транзакций, к распределенным системам, происходят самые разные отказы, часть из которых мы будем рассматривать подробно.
1.5. Миллионом больше, миллионом меньше
На карту ставится многое: успех вашего проекта, ваши права на акции или участие в прибылях, выживание вашей компании и даже ваше трудоустройство. Системы, ориентированные на прохождение тестов качества, часто так дороги в условиях эксплуатации, простоя и сопровождения, что никогда не становятся рентабельными, не говоря уже о выгоде, которая начинается после того, как прибыль от эксплуатации системы покрывает расходы на ее создание. Подобные системы демонстрируют низкий уровень эксплуатационной готовности, что приводит к прямым потерям в виде упущенной выгоды, а порой и непрямым потерям из-за ущерба, нанесенного торговой марке. Для многих моих клиентов цена простоя программного обеспечения превышает 100 000 долларов в час.
За год разница между 98% и 99,99% времени безотказной работы может дойти до 17 миллионов долларов6. Представьте себе эти 17 миллионов, которые к итоговой сумме можно было бы добавить, всего лишь улучшив проект!
В лихорадке разработки можно легко принять решение, которое оптимизирует затраты на проектирование за счет эксплуатационных расходов. С точки зрения команды разработчиков, которой выделен фиксированный бюджет и указана фиксированная дата сдачи проекта, это имеет смысл. А вот для заказавшей программное обеспечение организации это плохой выбор. Эксплуатируются системы куда дольше, чем разрабатываются, — по крайней мере, те, которыми не прекратили пользоваться. Значит, бессмысленно избегать разовых затрат, вводя в уравнение постоянные расходы на эксплуатацию. Более того, с финансовой точки зрения куда лучше противоположный подход. Потратив 5000 долларов на автоматизированную систему сборки и выпуска, позволяющую избежать простоя при переходе к новой версии, можно сэкономить 200 000 долларов7. Я думаю, что большинство финансовых директоров без колебаний санкционируют расходы, способные принести 4000% прибыли на инвестированный капитал.
Не избегайте разовых затрат на разработку, стараясь добиться снижения расходов на эксплуатацию.
Выбор структуры и архитектуры программы относится к финансовому решению. И его следует принимать с прицелом на стоимость внедрения и всех последующих затрат. Объединение технической и финансовой точек зрения относится к одной из наиболее важных тем, которые то и дело будут повторяться в этой книге.
1.6. Прагматичная архитектура
Термин архитектура применяется к двум разным видам деятельности. Один из них касается более высоких уровней абстракции, способствующих упрощению перехода с одной платформы на другую и большей независимости от аппаратного обеспечения и сетевого окружения. В крайних формах это превращается в «башню из слоновой кости» — населенную надменными гуру чистую комнату в стиле Кубрика, все стены которой украшены ящиками и стрелками. Оттуда исходят указания непрерывно работающим кодерам: «Используйте контейнерно-управляемое сохранение EJB-состояния!», «Для конструирования всех пользовательских интерфейсов используйте JSF!», «Все, что вам нужно, было нужно и когда-либо будет нужно, есть в Oracle!». Если в процессе написания кода по «корпоративным стандартам» вы когда-либо заикнетесь, что другая технология позволяет достичь нужного результата более простым путем, то станете жертвой архитектора, оторванного от реальности. И могу руку дать на отсечение, что архитектор, не слушающий кодеров из собственной рабочей группы, не станет прислушиваться и к пользователям. Думаю, результаты такого подхода вам доводилось видеть — это пользователи, которые бурно радуются падению системы, так как это позволяет им некоторое время от нее отдохнуть.
Другая порода архитекторов не только водит дружбу с кодерами, но может даже принадлежать к их числу. Такие архитекторы без колебаний понижают уровень абстракции и даже отказываются от него, если он не вписывается в общую картину. Эти прагматичные ребята, скорее всего, обсудят с вами такие вопросы, как использование памяти, требования процессора и пропускной способности, а также выгоды и недостатки гиперпоточности и объединения процессоров.
Архитектору из башни больше всего нравится представлять конечный результат в виде идеальных позванивающих кристаллов, в то время как прагматичный архитектор непрерывно учитывает динамику изменений. «Как выполнить развертывание, не заставляя всех перезагружаться?», «Какие параметры нам следует собрать, как они будут анализироваться?», «Какая часть системы больше всего нуждается в усовершенствованиях?». Выстроенная архитектором из башни система не допускает доработки; все ее части строго пригнаны друг к другу и адаптированы к своим задачам. У прагматичного архитектора все компоненты системы хорошо справляются с текущими нагрузками, и при этом он знает, что нужно поменять, если со временем нагрузка распределится по-иному.
Если вы относитесь к прагматичным архитекторам, у меня есть для вас целая книга полезной информации. Если же вы пока сидите в башне из слоновой кости, но не прекратили чтения, возможно, я смогу уговорить вас спуститься на несколько уровней абстракции — туда, где пересекаются аппаратная часть, программное обеспечение и пользователи: в мир эксплуатации. В результате ваши пользователи и фирма, на которую вы работаете (да и вы сами), станут намного счастливее, когда подойдет время выхода новой версии!
4 Честно признаюсь, что являюсь убежденным сторонником гибких методов. Акцент на раннем предоставлении и последовательных усовершенствованиях продукта способствует быстрому вводу программы в эксплуатацию. А так как только в процессе эксплуатации можно видеть реакцию программы на реальные воздействия, я выступаю за любые методы, позволяющие максимально быстро приступить к изучению ее поведения в реальных условиях.
5 Такая формулировка мне никогда не нравилась. Как инженер, я бы больше оценил выражение «24 на 365» или «24 на 7 и на 52».
6 Средняя стоимость 100 000 долларов за час простоя имеет место у поставщиков первого порядка.
7 Предполагается 10 000 долларов на версию (оплата работы плюс стоимость запланированных простоев), четыре версии в год в течение пяти лет. Большинство компаний предпочитают более пяти версий в год, но я консерватор.
4 Честно признаюсь, что являюсь убежденным сторонником гибких методов. Акцент на раннем предоставлении и последовательных усовершенствованиях продукта способствует быстрому вводу программы в эксплуатацию. А так как только в процессе эксплуатации можно видеть реакцию программы на реальные воздействия, я выступаю за любые методы, позволяющие максимально быстро приступить к изучению ее поведения в реальных условиях.
5 Такая формулировка мне никогда не нравилась. Как инженер, я бы больше оценил выражение «24 на 365» или «24 на 7 и на 52».
6 Средняя стоимость 100 000 долларов за час простоя имеет место у поставщиков первого порядка.
7 Предполагается 10 000 долларов на версию (оплата работы плюс стоимость запланированных простоев), четыре версии в год в течение пяти лет. Большинство компаний предпочитают более пяти версий в год, но я консерватор.
Часть I. Стабильность
2. Исключение, помешавшее работе авиакомпании
Вы когда-нибудь замечали, что большие проблемы часто начинаются с мелочей? Крошечная ошибка программиста превращается в катящийся с горы по склону снежный ком. И по мере ускорения его движения растет масштаб проблемы. Именно такой случай произошел в одной крупной авиакомпании. Тысячам пассажиров пришлось поменять свои планы, а компании это обошлось в сотни тысяч долларов. Вот как это случилось.
Все началось с запланированного перевода кластеров баз данных программы Core Facilities (CF) на резервную систему8. Авиакомпания переходила на сервис-ориентированную архитектуру, чтобы, как обычно бывает в таких случаях, повысить степень многократного использования, уменьшить время разработки и снизить производственные расходы. На тот момент применялась первая версия программы. Рабочая группа планировала поэтапное развертывание, обусловленное добавлением новых программных компонентов. План был вполне разумным, и, возможно, вы уже сталкивались с подобными вещами — в настоящий момент такое практикуется большинством крупных компаний.
Программа CF выполняла поиск рейсов — этот сервис часто встречается в приложениях для авиакомпаний. По дате, времени, коду аэропорта, номеру рейса или любой комбинации этих данных приложение ищет и возвращает данные с деталями рейса. Инцидент произошел, когда киоски самостоятельной регистрации, IVR-система и приложения «партнера по продажам» обновлялись для получения доступа к программе CF. Приложения партнера по продажам генерировали веб-каналы передачи данных для крупных сайтов бронирования. Голосовые сообщения и киоски регистрации отвечали за выделение пассажирам мест на борту. Были запланированы новые версии приложений для сопровождающих пассажиров и информационно-справочной службы, в результате которых поиск рейсов перекладывался на программу CF, но развертывание выполнить не успели, что, как вскоре выяснилось, было к лучшему.
Система предварительно записанных голосовых сообщений обозначается аббревиатурой IVR (Interactive Voice Response — интерактивный автоответчик).
Архитекторы программы CF прекрасно понимали ее важность. Они обеспечили высокую надежность. Программа работала на кластере серверов приложений J2EE с резервированием в базе данных Oracle 9i. Все данные хранились на большом внешнем RAID-массиве, дважды в день дублировались на внешний ленточный накопитель с копированием данных во второй массив хранения как минимум раз в пять минут.
В каждый момент времени сервер базы данных Oracle должен был работать на одном узле кластера, контролируемый продуктом Cluster Server на основе технологии Veritas, присваивающим виртуальные IP-адреса, и осуществляющий монтирование и размонтирование файловых систем в RAID-массиве. Пара резервных устройств распределителей нагрузки заблаговременно направляла входящий трафик на один из серверов приложений. Вызывающие приложения, например для киосков самостоятельной регистрации и IVR-системы, могли получать виртуальные IP-адреса через входной интерфейс. Ничто не предвещало проблем.
Если вы когда-либо имели дело с веб-сайтами или веб-службами, вам, скорее всего, будет знакомо то, что изображено на рис. 1. Это крайне распространенная архитектура с высоким уровнем надежности. У программы CF не было проблем, связанных с конкретным уязвимым звеном. Все аппаратное обеспечение дублировалось: процессоры, вентиляторы, накопители, сетевые карты, источники питания и сетевые коммутаторы. Каждый сервер стоял в собственной стойке на случай, если какая-нибудь из стоек получит повреждение. По сути, в случае пожара, наводнения, бомбардировки или падения метеорита за работу принимался второй комплект оборудования, расположенный в пятидесяти километрах от первого.
2.1. Авария
Как и в случае с большинством моих крупных клиентов, местная группа инженеров имела навыки работы с инфраструктурой аэропорта. Более того, большая часть работ выполнялась этой группой более трех лет. И вот однажды ночью местные инженеры вручную осуществляли переход от базы данных 1 приложения CF к базе данных 2. Перенос рабочей базы данных с одного хостинга на другой выполнялся при помощи технологии Veritas. Это требовалось для плановых работ на первом сервере. Совершенно обычных работ. В прошлом подобная процедура проводилась десятки раз.
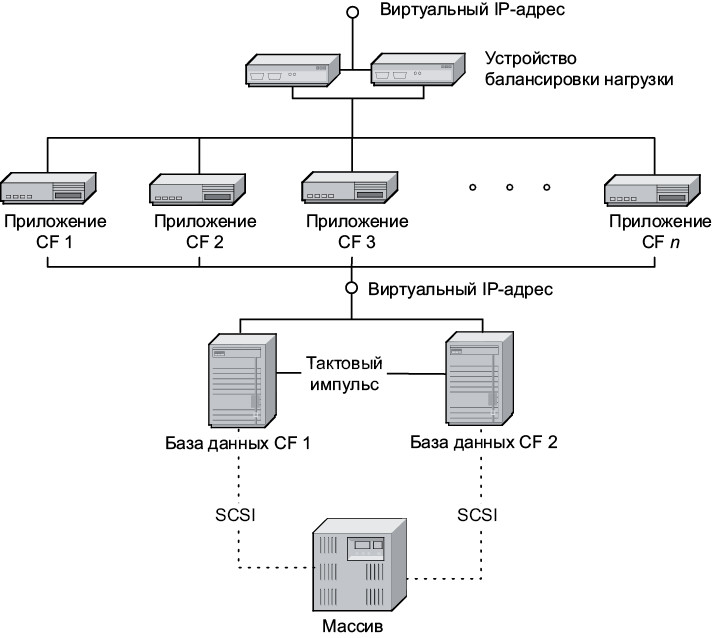
Рис. 1. Архитектура развертывания приложения CF
Перевод на другой ресурс осуществляло приложение Veritas Cluster Server. В течение минуты оно может остановить работу сервера Oracle с базой данных 1, размонтировать файловые системы с RAID-массива, повторно подключить их к базе данных 2, запустить там Oracle и назначить этой базе виртуальный IP-адрес. С точки зрения сервера приложений при этом вообще ничего не меняется, так как он настроен для соединения только с виртуальным IP-адресом.
Это конкретное изменение было запланировано на клиенте в четверг вечером, примерно в 11 часов по тихоокеанскому времени. Процессом руководил один из местных инженеров через центр управления. Все шло по плану. Рабочей была сделана база данных 2, после чего выполнили обновление базы данных 1. Дважды проверив корректность обновления, базу данных 1 снова сделали рабочей, а аналогичные изменения были внесены в базу данных 2. При этом регулярный мониторинг сайта показывал, что приложение все время оставалось доступным. В данном случае простой не планировался, поэтому его и не было. В половине первого ночи команда поставила на изменение метку «завершено успешно» и вышла из системы. Инженер пошел спать после 22-часовой смены. В конце концов, он и так уже держался только за счет кофе.
Следующие два часа прошли в обычном режиме.
Примерно в половине третьего утра все киоски самостоятельной регистрации на консоли мониторинга засветились красным — они прекратили свою работу одновременно по всей стране. Через несколько минут то же самое произошло с IVR-серверами. Ситуация была близка к катастрофе, ведь 2:30 по тихоокеанскому времени — это 5:30 по восточному времени, когда начинается основной поток регистраций на рейсы, летящие к Восточному побережью. Центр оперативного управления немедленно забил тревогу и собрал группу поддержки на телефонную конференцию.
При любых нештатных ситуациях я первым делом стараюсь восстановить обслуживание. Это куда важнее расследования причин. Возможность собрать данные для последующего анализа первопричины проблемы бесценна, но только в случае, если это не увеличивает время простоя системы. В экстренной ситуации полагаться на импровизацию не стоит. К счастью, давным-давно существуют сценарии, создающие дампы потоков и снимки баз данных. Подобный автоматизированный сбор данных идеально подходит к таким ситуациям. Исчезает необходимость действовать экспромтом, время простоя не увеличивается, но при этом накапливается информация, которую потом можно будет проанализировать. По инструкции центр оперативного управления немедленно запустил эти сценарии, одновременно попытавшись запустить один из серверов с приложением для киосков самостоятельной регистрации.
Получение дампов потоков
Любое Java-приложение генерирует дамп состояния любого потока в JVM при отправке сигнала 3 (SIGQUIT) в UNIX или нажатии комбинации клавиш Ctrl+Break в Windows.
При этом в операционной системе Windows вы должны пользоваться консолью с Java-приложением, запущенным в окне командной строки. Очевидно, что для входа с удаленного доступа вам потребуется система VNC или протокол Remote Desktop.
В операционной системе UNIX для отправки сигнала можно воспользоваться командой kill:
kill -3 18835
К сожалению, дампы потоков всегда отправляются на стандартное устройство вывода. Многие готовые запускающие сценарии не распознают стандартное устройство вывода или отправляют дамп в /dev/null. (Например, JBoss от Gentoo Linux по умолчанию отправляет отладочную информацию JBOSS_CONSOLE в /dev/null.) Файлы журналов, полученные при помощи библиотеки Log4J или пакета java.util.logging, дампы потоков не отображают. Поэкспериментируйте с запускающими сценариями вашего севера приложений, чтобы понять, каким образом создаются дампы потоков.
Вот небольшой фрагмент такого дампа.
"http-0.0.0.0-8080-Processor25" daemon prio=1 tid=0x08a593f0 \
nid=0x57ac runnable [a88f1000..a88f1ccc]
at java.net.PlainSocketImpl.socketAccept(Native Method)
at java.net.PlainSocketImpl.accept(PlainSocketImpl.java:353)
–locked <0xac5d3640> (a java.net.PlainSocketImpl)
at java.net.ServerSocket.implAccept(ServerSocket.java:448)
at java.net.ServerSocket.accept(ServerSocket.java:419)
at org.apache.tomcat.util.net.DefaultServerSocketFactory.\
acceptSocket(DefaultServerSocketFactory.java:60)
at org.apache.tomcat.util.net.PoolTcpEndpoint.\
acceptSocket(PoolTcpEndpoint.java:368)
at org.apache.tomcat.util.net.TcpWorkerThread.\
runIt(PoolTcpEndpoint.java:549)
at org.apache.tomcat.util.threads.ThreadPool$ControlRunnable.\
run(ThreadPool.java:683)
at java.lang.Thread.run(Thread.java:534)
"http-0.0.0.0-8080-Processor24" daemon prio=1 tid=0x08a57c30 \
nid=0x57ab in Object.wait() [a8972000..a8972ccc]
at java.lang.Object.wait(Native Method)
–waiting on <0xacede700> (a org.apache.tomcat.util.threads.\
ThreadPool$ControlRunnable)
at java.lang.Object.wait(Object.java:429)
at org.apache.tomcat.util.threads.ThreadPool$ControlRunnable.\
run(ThreadPool.java:655)
–locked <0xacede700> (a org.apache.tomcat.util.threads.\
ThreadPool$ControlRunnable)
at java.lang.Thread.run(Thread.java:534)
Дампы бывают крайне подробными.
Этот фрагмент демонстрирует два потока, имена которых выглядят примерно так: http-0.0.0.0-8080-ProcessorN. Номер 25 — запущенный поток, в то время как номер 24 заблокирован в методе Object.wait(). Этот дамп ясно показывает, что вы имеете дело с членами пула потоков, и ключом к решению могут оказаться некоторые классы в стеке с именами ThreadPool$ControlRunnable().
Для восстановления обслуживания важно правильно выбрать направление работ. Разумеется, всегда можно «перезагрузить мир», один за другим заново запуская все серверы. Эта стратегия почти всегда эффективна, но занимает много времени. В большинстве случаев причину проблем найти можно. В некотором смысле это как медицинская диагностика. Вы можете лечить пациента от всех существующих заболеваний, но это болезненно, дорого и долго. Вместо этого имеет смысл изучить симптомы и понять, что именно нужно лечить. Проблема в том, что отдельные симптомы недостаточно конкретны. Разумеется, порой симптом четко указывает на основную проблему, но это редкий случай. Чаще всего симптомы, например высокая температура, сами по себе ни о чем не говорят. Сотни заболеваний сопровождаются повышением температуры. И чтобы отличить одно от другого, нужны анализы или наблюдения.
В данном случае команда столкнулась с двумя наборами отказавших приложений. Они зависли практически одновременно, временной промежуток между этими событиями был настолько ничтожен, что вполне мог оказаться задержкой срабатывания инструментов слежения за киосками и IVR-приложениями. В подобном случае первым делом приходит на ум, что оба набора приложений зависят от некой третьей сущности, в работе которой произошел сбой. Но из рис. 2 следует, что единственным связующим звеном между киосками и IVR-системой была программа CF. Состоявшееся за три часа до инцидента переключение баз данных еще больше усиливало подозрения. Но мониторинг программы не выявил никаких проблем. Не дали результатов ни исследование журнала регистрации, ни проверка URL-адреса. При этом оказалось, что осуществлявшее мониторинг приложение попадало только на страницу состояния, поэтому информации о реальном состоянии серверов приложения CF было немного. Мы пометили, что позднее, когда появится действующий канал, эту ошибку нужно будет исправить.
Напоминаю, что главное в подобных ситуациях — восстановить работоспособность служб. В данном случае простой длился уже почти час, что в соответствии с соглашением об уровне обслуживания является максимально допустимым временем, поэтому рабочая группа решила перезагрузить все серверы приложения CF. Перезагрузка первого же сервера инициировала восстановление систем IVR. После загрузки остальных серверов информационно-справочная служба начала полностью функционировать, но киоски самостоятельной регистрации по-прежнему были выделены красным. По наитию главный инженер решил перезагрузить серверы их собственных приложений. Это помогло.
Всего на решение проблемы было потрачено чуть больше трех часов.
Соглашением об уровне обслуживания (Service Level Agreement, SLA) называется контракт между клиентом и поставщиком услуги, нарушение которого обычно ведет к значительным штрафам.
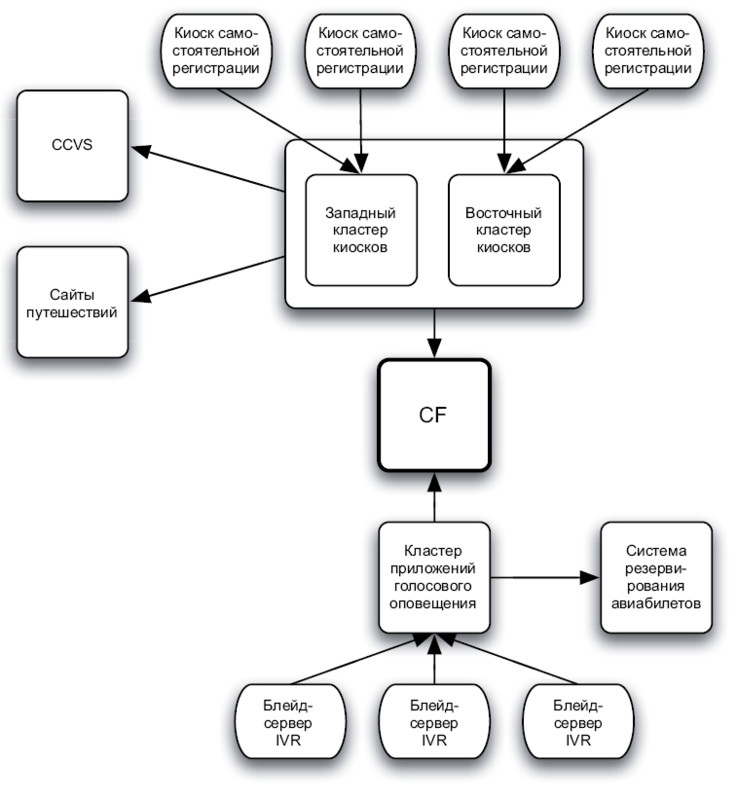
Рис. 2. Общие зависимости
2.2. Последствия
Может показаться, что три часа — это немного, особенно если вспомнить некоторые легендарные простои. (Например, в голову приходит отключение сайта ebay на целые сутки, происшедшее в 1999 году.) Но на работу авиакомпании этот инцидент влиял куда дольше. Сотрудников авиакомпании не хватало для обеспечения нормального функционирования в отсутствие приложений. Выход из строя киосков самостоятельной регистрации заставил руководство вызвать работников, у которых в этот день был выходной. Некоторые из них уже отработали свои 40 часов в неделю, то есть по трудовому соглашению это рассматривалось как сверхурочная работа. Но даже дополнительные сотрудники были всего лишь людьми. И к моменту, когда они оказались на рабочих местах, им пришлось иметь дело с задержкой. Ликвидировать ее последствия получилось только к трем часам дня.
Именно столько времени заняла регистрация на утренние рейсы. Осуществляющие эти рейсы самолеты все еще стояли у своих выходов на посадку. Они были заполнены наполовину. Многие путешественники в этот день не смогли вовремя улететь или прилететь. Оказалось, что четверг сопровождается массовыми перелетами компьютерщиков: консультанты возвращаются в родные города. А так как выходы на посадку были заняты неулетевшими самолетами, прилетающие самолеты перенаправлялись к незанятым выходам. То есть неудобства испытали даже те, кто успел пройти регистрацию. Им пришлось в спешном порядке переходить к новому выходу на посадку.
Материал об этом происшествии был показан в телепрограмме Доброе утро, Америка (дополненный видеосюжетом про трогательно беспомощных одиноких мам с детьми) и в информации для туристов телеканала Weather Channel.
Федеральное управление гражданской авиации США требует включения информации о своевременности прилетов и вылетов в годовую отчетность авиакомпаний. Сюда же включаются присылаемые в управление потребительские жалобы.
И именно от этой отчетности частично зависит зарплата генерального директора. Думаю, вы понимаете, что день, когда в центр управления врывается генеральный директор, чтобы узнать, по чьей вине он не может себе позволить провести отпуск на Виргинских островах, не предвещает ничего хорошего.
2.3. Анализ причин сбоя
В 10:30 утра по тихоокеанскому времени, через восемь часов после начала инцидента наш сотрудник по связям с клиентами Том9 пригласил меня для анализа причин сбоя. Так как отказ произошел вскоре после переключения баз и технического обслуживания, эти действия естественным образом попали под подозрение. В подобных случаях обычно исходят из посыла «после этого, значит, из-за этого»10. Это далеко не всегда так, но, по крайней мере, дает отправную точку для размышлений. Вообще говоря, когда Том мне позвонил, он попросил меня приехать, чтобы выяснить, почему переключение базы данных привело к сбою.
Оказавшись в воздухе, я достал свой ноутбук и принялся изучать сообщение о проблеме и предварительный отчет о происшествии.
Повестка дня была проста: произвести анализ причин сбоя и ответить на следующие вопросы:
Привело ли к сбою переключение базы данных? Если нет, что было его причиной?
Корректной ли была конфигурация кластера?
Корректно ли рабочая группа провела техническое обслуживание?
Как можно было выявить отказ до того, как он привел к отключению?
И, что самое важное, как мы можем гарантировать, что подобное никогда не повторится?
Разумеется, мое присутствие требовалось еще и затем, чтобы продемонстрировать клиенту, насколько серьезно мы относимся к происшедшему. Кроме того, мое расследование должно было снять опасения, что местная рабочая группа попытается замять инцидент. Разумеется, они не стали бы делать ничего подобного, но создать правильное впечатление после крупного сбоя порой так же важно, как и разобраться с самим сбоем.
Создать правильное впечатление после крупного сбоя так же важно, как и разобраться с самим сбоем.
Искать причины сбоя постфактум — это все равно что расследовать убийство. У вас есть ряд улик. Некоторые из них вполне надежны: например, журналы регистрации событий сервера, скопированные с момента сбоя. К некоторым стоит относиться скептически: например, к утверждениям свидетелей. Ведь люди склонны примешивать к результатам наблюдений собственные догадки и представлять гипотезы как факты. Вообще говоря, анализировать причины сбоя тяжелее, чем расследовать убийство. У вас нет тела для вскрытия, так как серверы возвращены в состояние, предшествующее сбою, и работают. Состояния, ставшего причиной отказа, больше не существует. Следы отказа могут обнаружиться в журналах регистрации или среди собранных в этот момент данных мониторинга, а могут и не обнаружиться. Найти улики бывает крайне тяжело.
Работая с уже имеющейся информацией, я наметил, какие данные следует собрать. С серверов приложений мне требовались журналы регистрации, дампы потоков и конфигурационные файлы. С серверов баз данных требовались конфигурационные файлы баз данных и сервера кластера. Я также пометил, что нужно сравнить текущие конфигурационные файлы с аналогичными файлами, полученными после ночного резервного копирования. Резервная копия была сделана до сбоя, а значит, я мог понять, были ли к моменту моего расследования внесены какие-либо изменения в конфигурацию. Другими словами, я узнал бы, не пытается ли кто-то скрыть ошибку.
К моменту прибытия в гостиницу мой организм говорил, что время уже позднее. Мне хотелось принять душ и завалиться в постель. Вместо этого меня поджидал менеджер с информацией об изменениях, происшедших, пока я был в воздухе. Мой рабочий день закончился только к часу ночи.
Утром, влив в себя изрядную порцию кофе, я закопался в конфигурации кластера базы данных и RAID-массива. Я искал следы наиболее распространенных проблем: недостаточное количество контрольных сигналов, прохождение контрольных сигналов через коммутаторы, по которым идет рабочий трафик, серверы настроены на работу с реальными IP-адресами вместо виртуальных, плохие зависимости между управляемыми пакетами и т.п. Контрольным списком я в тот раз не пользовался; просто припоминал проблемы, с которыми мне доводилось сталкиваться или о которых я слышал. Никаких неисправностей я не обнаружил. Группа инженеров отлично поработала с кластером базы данных. Надежный результат, хоть в учебник вставляй. Более того, казалось, что некоторые сценарии взяты непосредственно из учебных материалов фирмы Veritas.
Пришло время заняться конфигурацией серверов приложений. Инженеры скопировали все журналы регистрации серверов, обеспечивающих работу киосков, на время сбоя. Заодно я получил журналы регистрации серверов приложения CF. И все они содержали информацию, начиная с момента сбоя, ведь прошли всего одни сутки. И, что еще лучше, вместе с двумя наборами журналов в мои руки попали дампы потоков. Как человек, долгое время программирующий на языке Java, я обожаю пользоваться дампами потоков при отладке зависающих приложений.
Если вы умеете читать дампы, приложение становится открытой книгой. Вы можете многое узнать о приложении, кода которого никогда не видели. Вы узнаете, какими сторонними библиотеками оно пользуется, увидите его пулы потоков и количество потоков в каждом из них, выполняемые им фоновые задания. Обнаруженные в процессе трассировки стека каждого потока классы и методы скажут вам даже о том, какими протоколами пользуется приложение.
Выявление проблемы в приложении CF не заняло много времени. Дампы потоков серверов, обеспечивающих работу приложений для киосков самостоятельной регистрации, показали именно то, что я ожидал увидеть по описанию поведения системы во время инцидента. Все сорок потоков, выделенных для обработки запросов от отдельных киосков, были заблокированы внутри метода SocketInputStream.socketRead0() — нативного метода библиотеки сокетов Java. Все они пытались прочитать ответ, которого не было.
Эти дампы потоков также позволили мне узнать точное имя класса и метода, который пытались вызывать потоки: FlightSearch.lookupByCity(). Чуть выше в стеке я с изумлением обнаружил ссылки на RMI- и EJB-методы. Программу CF всегда называли «веб-службой». Конечно, в наши дни определение «веб-служба» трактуется достаточно широко, но в случае сеансового объекта без сохранения состояния оно выглядит большой натяжкой. Интерфейс вызова удаленных методов (Remote Method Invocation, RMI) предоставляет технологии EJB способ вызова удаленной процедуры. EJB-вызовы передаются по одному из двух механизмов: CORBA или RMI. При всей моей любви к программной модели RMI пользоваться ею небезопасно из-за невозможности добавить к вызовам таймаут. А значит, вызывающая функция слабо защищена от проблем на удаленном сервере.
2.4. Бесспорное доказательство
На данном этапе результат моего анализа вполне соответствует симптомам сбоя: именно программа CF вызвала зависание как IVR-системы, так и киосков самостоятельной регистрации. Но остался самый главный вопрос: что случилось с программой CF?
Картина прояснилась, когда я исследовал дампы ее потоков. Сервер приложения CF для обработки EJB-вызовов и HTTP-запросов пользовался отдельными пулами потоков. Именно поэтому приложение CF могло отвечать приложению мониторинга даже во время сбоя. Практически все HTTP-потоки были бездействующими, что вполне согласуется с поведением EJB-сервера. Но при этом EJB-потоки были отданы под обработку вызовов метода FlightSearch.lookupByCity(). По сути, все потоки всех серверов приложений блокировались в одной и той же строке кода: при попытке проверить связь с базой данных из пула ресурсов.
Конечно, это было косвенное доказательство, но с учетом переключения базы данных перед сбоем создавалось впечатление, что я на верном пути.
Дальше начиналась неопределенность. Мне нужно было увидеть код, но центр управления не имел доступа к системе управления исходным кодом. В рабочей среде были развернуты только двоичные файлы.
Как правило, это хорошая мера предосторожности, но в данный момент она доставила мне некоторые неудобства. Спросив администратора, как мне получить доступ к исходному коду, я столкнулся с противодействием. Учитывая масштаб простоя, можно вообразить количество обвинений, носившихся в воздухе в поисках подходящей головы. Отношения между центром управления и разработчиками, никогда не отличавшиеся особой теплотой, были натянутыми сильнее, чем обычно. Каждый был настороже, опасаясь нацеленного в его сторону обвиняющего перста.
Так и не получив доступа к исходному коду, я сделал единственное, что мог: взял двоичные файлы из рабочего окружения и произвел их декомпиляцию11. Увидев код подозреваемого мной EJB-сервера, я понял, что нашел бесспорное доказательство. Вот этот сеансовый объект оказался единственным программным компонентом, который на данный момент реализовывала программа CF:
package com.example.cf.flightsearch;
...
public class FlightSearch implements SessionBean {
private MonitoredDataSource connectionPool;
public List lookupByCity(. . .) throws SQLException, RemoteException {
Connection conn = null;
Statement stmt = null;
try {
conn = connectionPool.getConnection();
stmt = conn.createStatement();
// Реализуем логику поиска
// возвращаем список результатов
} finally {
if (stmt != null) {
stmt.close();
}
if (conn != null) {
conn.close();
}
}
}
}
На первый взгляд метод сконструирован хорошо. Наличие блока try..finally указывает на желание автора вернуть системе ресурсы. Более того, такой блок фигурировал в некоторых учебниках по языку Java. К сожалению, у него был существенный недостаток.
Оказалось, что метод java.sql.Statement.close() может порождать исключение SQLException. Этого практически никогда не происходит. Драйвер Oracle поступает так, только обнаружив, что IOException пытается закрыть соединение, например при переходе базы данных на другой ресурс.
Предположим, JDBC-соединение создано до переключения. Использованный для создания соединения IP-адрес будет перенесен с одного хоста на другой, а вот текущее состояние TCP-соединений на хост второй базы данных переброшено не будет. При любой записи в сокет в конечном счете выбрасывается исключение IOException (после того, как операционная система и сетевой драйвер решают, что TCP-соединение отсутствует). Это означает, что любое JDBC-соединение в пуле ресурсов представляет собой мину замедленного действия.
Что поразительно, JDBC-соединение по-прежнему жаждет создавать запросы. Для этого объект соединения драйвера проверяет только собственное внутреннее состояние12. Если JDBC-соединение решает, что подключение никуда не делось, оно создает запрос. Выполнение этого запроса при сетевом вводе-выводе приводит к исключению SQLException. Но закрытие этого запроса дает аналогичный результат, так как драйвер попытается заставить сервер базы данных освободить связанные с запросом ресурсы.
Коротко говоря, драйвер хочет создать объект Statement, который не может быть использован. Это можно считать программной ошибкой. Разработчики из авиакомпании явно упирали именно на это. Но вы должны извлечь из этого главный урок. Если спецификация JDBC позволяет методу java.sql.Statement.close() выбрасывать исключение SQLException, ваш код должен его обрабатывать.
В показанном неверном коде исключение, выбрасываемое закрывающим запросом, приводило к тому, что соединение не закрывалось, а значит, возникала утечка ресурсов. После сорока подобных вызовов пул ресурсов истощался, и все последующие вызовы блокировались в методе connectionPool.getConnection(). Именно это я увидел в дампах потоков программы CF.
Работа авиакомпании, обслуживающей весь земной шар, с сотнями самолетов и десятками тысяч сотрудников была парализована совершенно школьной ошибкой: единственным необработанным исключением SQLException.
2.5. Легче предупредить, чем лечить?
Когда маленькая ошибка приводит к таким огромным убыткам, естественной реакцией становится фраза «Это никогда не должно повториться». Но как предотвратить подобные вещи? Экспертизой кода? Только при условии, что кто-то из экспертов знаком с особенностями JDBC-драйвера в Oracle или вся экспертная группа часами проверяет каждый метод. Дополнительным тестированием? Возможно. После обнаружения данной проблемы группа выполнила тестирование в условиях повышенной нагрузки и получила ту же самую ошибку. Но при обычном тестировании нагрузка на некорректный метод была недостаточной для возникновения проблемы. Другими словами, если заранее знать, где искать, то создать тест, обнаруживающий ошибку, очень просто.
Однако в конечном счете ожидания, что все до единой ошибки будут обнаружены и устранены на стадии тестирования, относятся скорее к мечтам. Неполадки будут возникать. А раз от них невозможно избавиться, нужно научиться минимизировать потери от них.
В данном случае хуже всего то, что ошибка в одной системе может распространиться на другие связанные с ней системы. Поэтому лучше задать другой вопрос: как сделать так, чтобы ошибки в одной системе не влияли ни на что другое? На каждом предприятии в наши дни имеется целая сеть взаимосвязанных и взаимозависимых систем. Они не могут — и не должны — допускать появления цепочек отказов. Поэтому мы рассмотрим паттерны проектирования, предотвращающие распространение подобных проблем.
8 Все названия, места и даты изменены.
9 Имя изменено.
10 Стандартная ошибка в логических выводах, заключающаяся в неверном представлении о том, что если событие Y следует сразу же за событием X, то X является причиной Y. Иногда это формулируется как «ты трогал это последним».
11 Моим любимым инструментом для декомпиляции Java-кода остается JAD. Он работает быстро и точно, хотя и с трудом разбирается с кодом, написанным на Java 5.
12 Это может быть особенностью, присущей только JDBC-драйверам в Oracle. Я проводил декомпиляцию только базы на Oracle.
8 Все названия, места и даты изменены.
9 Имя изменено.
10 Стандартная ошибка в логических выводах, заключающаяся в неверном представлении о том, что если событие Y следует сразу же за событием X, то X является причиной Y. Иногда это формулируется как «ты трогал это последним».
11 Моим любимым инструментом для декомпиляции Java-кода остается JAD. Он работает быстро и точно, хотя и с трудом разбирается с кодом, написанным на Java 5.
12 Это может быть особенностью, присущей только JDBC-драйверам в Oracle. Я проводил декомпиляцию только базы на Oracle.
3. Понятие стабильности
Новое программное обеспечение, как и свежий выпускник университета, появляется на свет полным оптимизма и внезапно сталкивается с суровыми жизненными реалиями. В реальном мире происходят вещи, которых обычно не бывает в лабораториях, и, как правило, вещи плохие. Лабораторные тесты придумываются людьми, знающими, какой ответ следует получить. Реальные тесты порой вообще не имеют ответов. Иногда они просто вызывают сбой вашего программного обеспечения.
Программное обеспечение предприятий должно быть скептически настроенным. Оно должно ожидать проблемы и никогда им не удивляться. Такое программное обеспечение не доверяет даже самому себе и ставит внутренние барьеры для защиты от сбоев. Оно отказывается вступать в слишком близкий контакт с другими системами, так как это может привести к повреждениям.
Программа Core Facilities, о которой шла речь в предыдущей главе, была недостаточно скептической. Как это часто бывает, рабочая группа слишком восхищалась новыми технологиями и усовершенствованной архитектурой. Сотрудники могли бы сказать много восторженных слов об использовании заемных средств и суммирующем воздействии нескольких факторов. Ослепленные денежными знаками, они не увидели, что пора остановиться, и свернули не в ту сторону.
Слабая стабильность приводит к значительным убыткам. К убыткам относится и упущенная выгода. Поставщики, которых я упоминал в главе 1, теряют за час простоя 100 000 долларов, причем даже не в разгар сезона. Торговые системы могут потерять такую сумму из-за одной не прошедшей транзакции!
Эмпирическое правило гласит, что привлечение одного клиента обходится интернет-магазину в 25–50 долларов. Представьте, что он теряет 10% из 5000 уникальных посетителей в час. Это означает, что на привлечение клиентов было впустую потрачено 12 500–25 000 долларов.
Потеря репутации менее осязаема, но не становится от этого менее болезненной. Ущерб от появившегося на бренде пятна проявляется не так быстро, как урон от потери клиентов, но попробуйте опубликовать в журнале BusinessWeek отчет о проблемах при работе с вашей фирмой в горячий сезон. Потраченные на рекламу образа миллионы долларов — рекламу ваших услуг в Интернете — могут за несколько часов превратиться в пыль из-за нескольких некачественных жестких дисков.
Нужная вам стабильность вовсе не обязательно должна стоить дорого. В процессе построения архитектуры, дизайна и даже низкоуровневой реализации системы существует масса моментов принятия решения, от которых будет зависеть окончательная стабильность системы. В такие моменты порой оказывается, что функциональным требованиям удовлетворяют два варианта (с упором на прохождение тестов контроля качества). Но при этом один приведет к ежегодным часам простоя системы, а второй нет. И что самое интересное, реализация стабильного проекта стоит столько же, сколько реализация нестабильного.
Реализация стабильного проекта стоит столько же, сколько реализация нестабильного.
3.1. Определение стабильности
Прежде всего я хотел бы дать определение некоторым терминам. Транзакцией (transaction) называется выполненная системой абстрактная часть работы. Это не имеет отношения к транзакциям в базах данных. Одна часть работы может включать в себя несколько транзакций в базе данных. Например, в интернет-магазинах распространен тип транзакции «заказ, сделанный клиентом». Такая транзакция занимает несколько страниц, зачастую включая в себя интеграцию с внешними сервисами, такими как проверка кредитных карт. Системы создаются именно для проведения транзакций. Если система обрабатывает транзакции только одного типа, она называется выделенной. Смешанной нагрузкой (mixed workload) называется комбинация различных типов транзакций, обрабатываемых системой.
Слово система я использую для обозначения полного, независимого набора аппаратного обеспечения, приложений и служб, необходимого, чтобы обработать транзакции для пользователей. Система может быть совсем небольшой, например состоящей из единственного приложения. А может быть огромной, многоуровневой сетью из приложений и серверов. Еще я обозначаю этим термином набор хостов, приложений, сетевых сегментов, источников питания и пр., обрабатывающий транзакцию от одного узла до другого.
Отказоустойчивая система продолжает обрабатывать транзакции, даже когда импульсные помехи, постоянная нагрузка или неисправность отдельных узлов нарушают нормальный процесс обработки. Именно такое поведение большинство подразумевает под словом стабильность (stability). Серверы и приложения не только продолжают функционировать, но и дают пользователю возможность закончить работу.
Термины импульс (impulse) и нагрузка (stress) пришли из машиностроения. Импульс подразумевает резкую встряску системы. Как будто по ней ударили молотком. Нагрузка же, наоборот, представляет собой силу, прикладываемую к системе длительное время.
Огромное число посещений страницы с информацией об игровой приставке Xbox 360, случившееся после слухов о распродаже, вызвало импульс. Десять тысяч новых сеансов в течение одной минуты выдержать трудно. Мощный всплеск посещаемости сайта является импульсом. Выгрузка в очередь 12 миллионов сообщений ровно в полночь 21 ноября — это тоже импульс. Подобные вещи ломают систему в мгновение ока.
В то же время медленный ответ от процессинговой системы кредитных карт, производительности которой не хватает на работу со всеми клиентами, означает нагрузку на систему. В механической системе материал под нагрузкой меняет свою форму. Это изменение формы называется деформацией (strain). Напряжение вызывает деформацию. То же самое происходит с компьютерными системами. Напряжение, возникающее из-за процессинга кредитных карт, приводит к тому, что деформация распространяется на другие части системы, что может приводить к странным последствиям, например увеличению расхода оперативной памяти на веб-серверах или превышению допустимой частоты ввода-вывода на сервере базы данных.
продление срока службы
Основные опасности для долговечности вашей системы — это утечки памяти и рост объемов данных. Обе эти вещи убивают систему в процессе эксплуатации. И обе практически не обнаруживаются при тестировании.
Тестирование выявляет проблемы, что дает вам возможность их решить (вот почему я всегда благодарю тестеров моих программ, когда они обнаруживают очередную ошибку). Но по закону Мерфи случаются именно те вещи, на которые программа не тестировалась. То есть если вы не проверили, не падает ли программа сразу после полуночи или не возникает ли ошибка из-за нехватки памяти на сорок девятый час безотказной работы, именно тут вас подстерегает опасность. Если вы не проверяли наличие утечек памяти, проявляющихся только на седьмой день, через семь дней вас ждет утечка памяти.
Проблема в том, что в среде разработки приложения никогда не выполняются так долго, чтобы можно было обнаружить ошибки, проявляющиеся со временем. Сколько времени сервер приложений обычно функционирует у вас в среде разработки? Могу поклясться, что среднее время не превосходит продолжительности ситкома13. При тестировании качества он может поработать подольше, но, скорее всего, будет перезагружаться по крайней мере раз в день, если не чаще. Но даже запущенное и работающее приложение не испытывает непрерывной нагрузки. В подобных средах продолжительные тесты — например, работа сервера в течение месяца с ежедневным трафиком — невозможны.
Впрочем, ошибки такого сорта во время нагрузочного тестирования, как правило, все равно не выявляются. Нагрузочный тест проводится некоторое время, а затем программа прекращает работу. Час нагрузочного тестирования стоит изрядную сумму, поэтому никто не просит провести недельную проверку. Команда разработчиков обычно пользуется общей корпоративной сетью, поэтому вы не можете каждый раз лишать всех сотрудников фирмы доступа к таким жизненно необходимым вещам, как электронная почта и Интернет.
Каким же образом выяснить ошибки данного типа? Единственное, что вы можете сделать до того, как они причинят вам проблемы при эксплуатации, — это собственноручно провести испытания на долговечность. По возможности выделите для разработчика отдельную машину. Запустите на ней JMeter, Marathon или другой инструмент нагрузочного тестирования. Не делайте ничего экстремального, просто все время выполняйте запросы. Также обязательно сделайте несколько часов временем бездействия сценариев, имитируя отсутствие нагрузки ночью. Это позволит протестировать таймауты пула соединений и фаервола.
Иногда создать полноценную среду тестирования не удается по экономическим причинам. В этом случае попытайтесь проверить хотя бы самые важные части. Это все равно лучше, чем ничего.
В крайнем случае среда для тестирования долговечности программы сама собой возникнет в процессе ее эксплуатации. Ошибки в программе обязательно проявятся, но это не тот рецепт, который обеспечит вам счастливую жизнь.
Долговечная система способна обрабатывать транзакции долгое время. Какой период попадает под это определение? Зависит от конкретной ситуации. В качестве точки отсчета имеет смысл взять время между развертываниями кода. Если каждую неделю в производство вводится новый код, не имеет значения, сможет ли система проработать два года без перезагрузки. В то же время центры сбора данных в западной части штата Монтана не нуждаются в том, чтобы их вручную перезагружали раз в неделю.
Проведите тестирование срока службы. Это единственный способ обнаружить ошибки, проявляющиеся со временем.
3.2. Режимы отказов
К катастрофическому отказу могут привести как внезапные импульсы, так и чрезмерная нагрузка. Но в любом случае какой-то компонент системы начинает отказывать раньше, чем все остальное. В своей книге Inviting Disaster Джеймс Р. Чайлз называет это трещинами (cracks) системы. Он сравнивает сложную систему, находящуюся на грани отказа, со стальной пластинкой с микроскопической трещиной. Под нагрузкой эта трещина может начать расти быстрее и быстрее. В конечном счете скорость распространения дефекта превысит скорость звука, и металл с резким треском сломается. Фактор, послуживший триггером, а также способ распространения дефекта в системе вместе с результатом повреждения называют режимом отказа (failure mode).
В ваших системах в любом случае будут присутствовать различные режимы отказов. Отрицая неизбежность сбоев, вы лишаете себя возможности контролировать и сдерживать их. А признание неизбежности сбоев позволяет спроектировать реакцию системы в случае их возникновения. И как проектирующие автомобили инженеры создают зоны деформации — области, спроектированные специально, чтобы защитить пассажиров, поглотив в процессе своего разрушения силу удара, — вы можете реализовать безопасные режимы отказов, обеспечивающие защиту остальной части системы. Самозащита такого вида определяет надежность системы в целом.
Чайлз называет эти защитные меры ограничителями трещин (crackstoppers). Подобно тому как встраивание в автомобиль зон деформации поглощает импульс и сохраняет жизнь пассажирам, вы можете решить, какие программные компоненты системы не должны отключаться, и реализовать такие режимы отказов, которые защищают эти компоненты от выхода из строя. В противном случае однажды можно столкнуться с непредсказуемыми и, как правило, опасными вещами.
3.3. Распространение трещин
Применим вышесказанное к случаю в авиакомпании, о котором шла речь в предыдущей главе. В проекте Core Facilities режимы отказов отсутствовали. Проблема началась с необработанного исключения SQLException, но работа системы могла остановиться и по ряду других причин. Рассмотрим несколько примеров от низкоуровневых деталей до высокоуровневой архитектуры.
Так как пул был настроен таким образом, что блокировал потоки с запросами в отсутствие ресурсов, в конечном счете он заблокировал все обрабатывающие запросы потоки. (Это произошло независимо друг от друга на всех экземплярах серверов приложений.) Можно было настроить пул на открытие новых соединений в случае его истощения или после проверки всех соединений на блокировку вызывающих потоков на ограниченное время, а не навсегда. Любой из этих вариантов остановил бы распространение трещины. На следующем уровне проблема с единственным вызовом в программе CF привела к сбою вызывающих приложений на остальных хостах. Так как службы для CF построены на технологии Enterprise JavaBeans (EJB), для них используется RMI. А по умолчанию вызовы этого интерфейса лишены таймаута. Другими словами, вызывающие потоки блокировались в ожидании, пока будут прочитаны их ответы от EJB-компонентов программы CF. Первые двадцать потоков для каждого экземпляра получили исключения, точнее SQLException, в оболочке исключения InvocationTargetException, которое в свою очередь располагалось в оболочке исключения RemoteException. И после этого вызовы начали блокироваться.
Можно было написать клиент с таймаутами на RMI-сокетах14. В определенный момент времени можно было принять решение строить веб-службы для CF на основе HTTP, а не EJB. После этого осталось бы задать на клиенте таймаут на HTTP-запросы15. Еще вызовы клиентов можно было настроить таким образом, чтобы блокированные потоки отбрасывались, вместо того чтобы заставлять обрабатывающий запрос поток делать внешний интеграционный вызов. Ничего из этого не было сделано, и сбой в программе CF распространился на все использующие эту программу системы.
В еще большем масштабе серверы программы CF можно было разбить на несколько групп обслуживания. В этом случае проблема с одной из групп не прекращала бы работу всех пользователей программы. (В рассматриваемой ситуации все группы обслуживания вышли бы из строя одним и тем же способом, но такое происходит далеко не всегда.) Это еще один способ остановить распространение сбоя на все предприятие.
Если взглянуть на вопросы архитектуры еще более масштабно, то программу CF можно было построить с применением очередей сообщений запрос-ответ. При этом вызывающая сторона в курсе, что ответа может и не быть. И ее действия в этом случае являются частью обработки самого протокола. Можно поступить еще более радикально, заставив вызывающую сторону искать рейсы, отбирая в пространстве кортежей записи, совпадающие с критерием поиска. А программа CF заполняла бы пространство кортежей записями с информацией о рейсах. Чем сильнее связана архитектура, тем выше шанс, что ошибка в коде распространится по системе. И наоборот, менее связанная архитектура действует как амортизатор, уменьшая влияние ошибки, а не увеличивая его.
Любой из перечисленных подходов мог прервать распространение проблемы с исключением SQLException на остальную часть системы аэропорта. К сожалению, проектировщики при создании общих служб не учли возможность появления «трещин».
3.4. Цепочка отказов
В основе любого сбоя в работе системы лежит такая же цепочка событий. Одна небольшая вещь ведет к другой, которая в свою очередь вызывает нечто третье. При рассмотрении такой цепочки отказов постфактум отказ кажется неизбежным. Но если попытаться оценить вероятность последовательного возникновения именно таких событий, ситуация покажется потрясающе неправдоподобной. Однако неправдоподобие возникает лишь потому, что мы рассматриваем все события независимо друг от друга. Монетка не обладает памятью; результат каждого ее броска выпадает с той же самой вероятностью, что и любого из предыдущих бросков. Комбинация же событий, приведших к отказу, независимой не является. Отказ в одной точке или слое повышает вероятность остальных отказов. Если база данных начинает работать медленно, повышается вероятность того, что серверам приложений не хватит памяти. Так как все слои связаны друг с другом, происходящие на них события не являются независимыми.
На каждом шаге цепочки отказов формирование трещины можно ускорить, замедлить или остановить. Высокий уровень сложности дает дополнительные направления распространению трещины.
Сильная взаимозависимость ускоряет распространение трещин. К примеру, сильная взаимозависимость EJB-вызовов привела к тому, что проблема истощения ресурсов в CF-программе создала еще большие проблемы в вызывающих эту программу компонентах. В рамках подобных систем объединение потоков, занимающихся обработкой запросов, с вызовами внешних, интегрированных служб приводит к проблемам с удаленным доступом, которые, в свою очередь, приводят к простоям.
Одним из способов подготовки ко всем возможным отказам является учет всех внешних вызовов, всех операций ввода-вывода, всех использований ресурсов и всех ожидаемых результатов в поиске ответа на вопрос, какими способами может возникнуть сбой? Вспомните все возможные типы импульсов и напряжений:
Что, если не удастся установить начальное соединение?
Что, если установка соединения займет десять минут?
Что, если после установки соединения произойдет разрыв связи?
Что, если, установив соединение, я все равно не получу ответа?
Что, если ответ на мой запрос займет две минуты?
Что, если одновременно придут 10 000 запросов?
Что, если мой диск переполнится в момент, когда я пытаюсь записать сообщение об ошибке SQLException, возникшей потому, что работа сети парализована вирусной программой?
Я уже устал писать вопросы, а ведь это только небольшая часть возможных вариантов. Следовательно, изнурительный перебор нецелесообразен, если только речь не идет о жизненно важных системах. А как быть, если программа должна быть готова еще в этом десятилетии? Нужно искать готовые паттерны, которые позволят вам создать амортизаторы, смягчающие все эти нагрузки.
3.5. Паттерны и антипаттерны
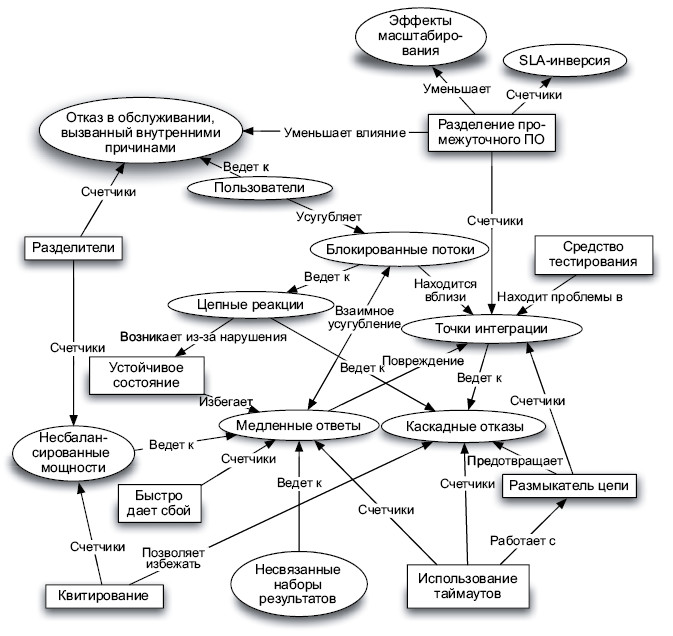
Мне пришлось иметь дело с сотнями эксплуатационных отказов. Каждый из них был по-своему уникален. (В конце концов, я ведь старался, чтобы однажды возникший отказ больше никогда не повторялся!) Я не могу вспомнить ни одной пары инцидентов с одинаковыми цепочками отказов: с одними и теми же триггерами, одними и теми же повреждениями и одним и тем же распространением. Но со временем я заметил наличие неких паттернов. Определенная уязвимость, тенденция определенной проблемы разрастаться определенным образом. С точки зрения стабильности эти паттерны отказов являются антипаттернами. Паттерны отказов рассматриваются в главе 4.
Наличие систематических закономерностей отказов заставляет предположить наличие распространенных решений. Предположив это, вы будете совершенно правы. Паттернам проектирования и архитектуры, позволяющим бороться с антипаттернами, посвящена глава 5. Разумеется, они не могут предотвратить трещины в системе. Подобного средства пока попросту не существует. Всегда будут некие условия, приводящие к сбою. Но эти паттерны останавливают распространение сбоя. Они помогают сдержать разрушения и сохранить частичную функциональность.
Вполне логично, что эти паттерны и антипаттерны взаимодействуют. Последние имеют тенденцию усиливать действие друг друга. И подобно набору из чеснока, серебра и огня для борьбы с соответствующими киношными монстрами16, каждый из паттернов облегчает последствия возникновения определенных проблем. Следующий рисунок демонстрирует наиболее важные из этих взаимодействий. А мы перейдем к рассмотрению антипаттернов — распространенного источника отказов.
13 Если пропустить рекламу, а также начальные и конечные титры, оно составит примерно 21 минуту.
14 Например, установив фабрику сокетов, вызывающую для всех создаваемых ею сокетов метод Socket.setSoTimeout().
15 При условии, что там не используются компоненты java.net.URL и java.net.URLConnection. До появления Java 5 задать таймаут на HTTP-вызовы, осуществляемые средствами стандартной библиотеки Java, было невозможно.
16 Это вампиры, оборотни и Франкенштейн.
...


















