

автордың кітабын онлайн тегін оқу Профессиональный бенчмарк: искусство измерения производительности
Переводчик А. Григорьева
Литературный редактор Н. Рощина
Художник В. Мостипан
Корректоры О. Андриевич, Е. Павлович, Е. Рафалюк-Бузовская
Андрей Акиньшин
Профессиональный бенчмарк: искусство измерения производительности. — СПб.: Питер, 2022.
ISBN 978-5-4461-1551-8
© ООО Издательство "Питер", 2022
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Об авторе

Андрей Акиньшин — старший разработчик в компании JetBrains. Там он трудится над Rider (кросс-платформенной средой разработки для .NET, основанной на платформе IntelliJ и ReSharper). Является мейнтейнером BenchmarkDotNet (самой популярной библиотеки для написания .NET-бенчмарков).
Андрей — программный директор конференции DotNext. На его счету более ста выступлений на различных мероприятиях для разработчиков, множество статей и постов. Кроме того, Андрей — обладатель звания Microsoft .NET MVP и серебряной медали Международной студенческой олимпиады по программированию ACM ICPC.
Автор имеет степень кандидата физико-математических наук и занимается научными проектами в сфере математической биологии и теории бифуркаций в Институте математики имени С.Л. Соболева Сибирского отделения Российской академии наук. Раньше он работал постдоком (postdoctoral research) в Институте имени Вейцмана.
О научных редакторах
Джон Гарленд — вице-президент по образовательным сервисам в компании Wintellect. Он профессионально разрабатывает программное обеспечение с 1990-х годов. Клиенты, которых он консультирует, — это и небольшие фирмы, и компании из списка Fortune 500. Его работа обсуждалась в основных тезисах и секциях конференций Microsoft. Он выступал на конференциях в Северной и Южной Америке и Европе. Джон живет в городе Камминге (штат Джорджия) с женой и дочерью. Он окончил Университет Флориды, получив степень бакалавра по вычислительной технике, написал книгу Windows Store Apps Succinctly («Краткий обзор приложений для Windows Store») и был соавтором книги Programming the Windows Runtime by Example («Программирование Windows Runtime в примерах»). На данный момент Джон работает над архитектурой облачного сервиса Microsoft Azure, является участником группы Microsoft Azure Insiders, ценным специалистом по Microsoft Azure, сертифицированным преподавателем Microsoft и сертифицированным членом общества разработчиков Microsoft Azure.

Саша Голдштейн — разработчик программного обеспечения в Google Research. Он работает над применением машинного обучения в различных продуктах Google, связанных с диалогами, классификацией текста, системами рекомендаций и т.д. До работы в Google Саша более десяти лет занимался отладкой программного обеспечения и оптимизацией производительности, вел курсы по всему миру и выступал на множестве международных конференций. Написал книгу Pro .NET Performance («Оптимизация приложений на платформе .NET») (Apress, 2012).

Благодарности
Я начал собирать материал для этой книги пять лет назад. На написание потратил около двух с половиной лет. Но, даже проработав над книгой тысячи часов, я все равно не смог бы закончить все главы в одиночку. Эта книга создана с помощью многих талантливых разработчиков.
Прежде всего я хотел бы поблагодарить Ивана Пащенко. Это человек, который вдохновил меня поделиться тем, что я знаю, и комментировал не только эту книгу, но и десятки моих ранних постов в блоге. Он поддерживал меня много лет и помог мне понять множество нюансов, необходимых для написания хорошей технической литературы. Спасибо, Иван!
Во-вторых, хочу поблагодарить всех моих неофициальных рецензентов: Ирину Ананьеву, Михаила Филиппова, Игоря Луканина, Адама Ситника, Карлена Симоняна, Стивена Тауба, Алину Смирнову, Федерико Андреса Луиса, Конрада Кокосу и Вэнса Моррисона. Они потратили немало времени на чтение черновиков и нашли кучу ошибок и опечаток на ранних стадиях написания. И дали много хороших советов, которые помогли мне значительно улучшить книгу.
В-третьих, я хочу поблагодарить команду издательства Apress: Джона Гарленда и Сашу Голдштейна (официальных технических рецензентов), Джоан Мюррей (рецензента издательства), Лору Берендсон (редактора-консультанта по аудитории), Нэнси Чен (редактора-координатора), Гвенан Спиринг (начального рецензента издательства) и остальных членов команды, которые помогли мне издать эту книгу. Прошу прощения за сорванные сроки и говорю вам спасибо за терпение. Благодаря этим людям из моих черновиков и заметок появилась реальная книга. Они помогли структурировать содержимое, представить мои идеи в понятной форме и исправить грамматические ошибки.
Далее я хочу поблагодарить всех разработчиков и пользователей BenchmarkDotNet. Я очень рад, что этот проект не только помогает программистам измерять производительность и анализировать результаты, но и популяризирует правильные подходы к бенчмаркингу, способствует дискуссиям о тонкостях бенчмаркинга и производительности. Я особенно благодарен Адаму Ситнику за огромный вклад в проект: без него эта библиотека не была бы такой замечательной.
Хочу также поблагодарить всех, с кем я обсуждал бенчмаркинг и производительность, кто пишет статьи на эти темы и выступает на конференциях. Я узнал много нового из личных бесед, постов в блогах, дискуссий на GitHub, обсуждений в Twitter и вопросов на StackOverflow (многие ссылки указаны в примечаниях и списке источников в конце книги). В особенности я хотел бы поблагодарить Мэтта Уоррена, Брендана Грегга, Дэниела Лейкенса, Джона Скита, Энди Эйерса, Агнера Фога, Реймонда Чена, Брюса Доусона, Дениса Бахвалова, Алексея Шипилева, Александра Мьютела, Бена Адамса и сотни других разработчиков, которые делятся своими знаниями и помогают создавать проекты с открытым исходным кодом. В книге можно найти много прекрасных практических примеров, существующих благодаря тем участникам сообщества, кому небезразлична производительность.
И наконец, я хочу поблагодарить свою семью и всех друзей и коллег, которые верили в меня, поддерживали и все время спрашивали: «Когда же наконец издадут твою книгу?»
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
На веб-сайте издательства www.piter.com вы найдете подробную информацию о наших книгах.
Введение
Нужно принять то, что вы не правы. Ваша цель — уменьшить степень неправоты.
Илон Маск
Я написал свой первый бенчмарк в 2004 году. Это было давно, поэтому точно не помню, что именно я измерял, но, думаю, исходный код выглядел примерно так:
var start = DateTime.Now;
// Что-то сделать
var finish = DateTime.Now;
Console.WriteLine(finish – start);
Я помню, что я думал в тот момент: мне казалось, что я теперь знаю все об измерении времени.
Спустя много лет разработки в области производительности я узнал немало нового. Оказалось, что измерение времени — это не так просто. В этой книге я хочу провести вас по захватывающему пути в чудесный мир бенчмаркинга, на котором можно узнать о том, как провести точные измерения производительности и избежать сотен возможных ошибок.
В современном мире очень важно писать программы, которые работают очень быстро. Возможно, именно из-за высокой скорости пользователи предпочтут ваш продукт продукту конкурентов, а из-за низкой — перестанут им пользоваться. Но что означает «быстро»? В каком случае можно сказать, что одна программа работает быстрее другой? Что делать, чтобы убедиться в том, что наш код будет везде работать достаточно быстро?
Если мы хотим создать быстрое приложение, прежде всего мы должны научиться измерять его скорость. И один из лучших способов для этого — бенчмаркинг. В Новом Оксфордском американском словаре бенчмарк определяется как «задача, созданная для оценки производительности компьютерной системы». Здесь хочется задать пару вопросов. Что означает производительность? Как ее можно оценить? Кто-то скажет, что это очень простые вопросы. Но на самом деле они настолько сложны, что я решил написать о них целую книгу.
Структура книги
В книге девять глав.
• Глава 1 «Введение в бенчмаркинг».
Здесь вы найдете базовую информацию о бенчмаркинге и других способах измерения производительности, а также о целях и требованиях бенчмаркинга. Мы обсудим пространства производительности и важность анализа результатов бенчмарка.
• Глава 2 «Подводные камни бенчмаркинга».
В этой главе вы найдете 15 примеров распространенных ошибок, обычно совершаемых разработчиками при бенчмаркинге. Все примеры маленькие и простые для понимания, но все они демонстрируют важные проблемы и объясняют, как их решать.
• Глава 3 «Как окружение влияет на производительность».
В ней объясняется, почему важно думать об окружении, и вводится много терминов, которые будут использоваться в последующих главах. Вы изучите 12 практических примеров, показывающих, как небольшие изменения в окружении могут значительно повлиять на производительность приложений.
• Глава 4 «Статистика для специалистов по производительности».
Здесь вы найдете важную информацию о статистике, необходимую при анализе производительности. Для каждого термина приведены практические рекомендации, которые помогут использовать статистические метрики при исследовании производительности. Также глава содержит несколько очень полезных для бенчмаркинга статистических подходов. В конце главы вы найдете описание того, как обмануть себя и окружающих с помощью бенчмаркинга. Эта информация поможет вам избежать неправильной интерпретации результатов.
• Глава 5 «Анализ и тестирование производительности».
В ней освещены темы, в которых нужно разбираться, если вы хотите контролировать уровень производительности крупного продукта автоматически. Вы узнаете о различных тестах производительности, об аномалиях производительности, которые можно наблюдать, и о том, как от них защититься. В конце этой главы найдете описание подхода «разработка через производительность» (performance-drive development) и общее обсуждение культуры производительности.
• Глава 6 «Инструменты для диагностики».
Содержит краткий обзор различных инструментов, которые могут пригодиться при анализе производительности.
• Глава 7 «Бенчмарки, ограниченные возможностями процессора».
В ней описаны 24 практических примера, показывающие различные подводные камни бенчмарков, ограниченных возможностями процессора. Мы обсудим некоторые характеристики, зависящие от среды выполнения кода, например переименование регистров, инлайнинг и интринзики (intrinsic), а также характеристики, зависящие от технического оборудования, — параллелизм на уровне команд, прогнозирование ветвлений и арифметические операции, в том числе IEEE 754.
• Глава 8 «Бенчмарки, ограниченные возможностями памяти».
Глава содержит 12 практических примеров, показывающих различные подводные камни бенчмарков, ограниченных возможностями памяти. Мы обсудим некоторые характеристики, зависящие от среды выполнения кода, связанные со сборкой мусора и ее настройками, а также характеристики, зависящие от технического оборудования, такие как кэш процессора и структура физической памяти.
• Глава 9 «Аппаратные и программные таймеры».
В этой главе вы найдете все, что нужно знать о таймерах. Мы обсудим основную терминологию, различные виды аппаратных таймеров, соответствующие API для замеров времени в различных операционных системах и самые распространенные подводные камни при их применении. В этой главе также содержится много дополнительных материалов, которые при бенчмаркинге не особо нужны, но могут заинтересовать тех, кто хочет больше узнать о таймерах.
Порядок глав имеет значение (например, в главе 3 вводится много терминов, используемых в последующих главах), но я старался сделать их максимально независимыми друг от друга. Если вас интересуют конкретные темы, можете прочитать только соответствующие главы: основная часть материала должна быть понятна, даже если пропустить первые главы.
Эта книга позволяет разобраться в основных понятиях и научит вас применять их для измерения производительности. Технологии меняются — каждый год выходят новые версии устройств, операционных систем и среды выполнения кода .NET, но основные понятия остаются неизменными. Изучив их, вы с легкостью сможете адаптировать их к новым технологическим веяниям.
Примеры
Непросто научиться бенчмаркингу без примеров. В книге их множество! Некоторые из них — это небольшие программы, иллюстрирующие теоретические понятия. Однако вы найдете и много примеров из реальной жизни.
Большинство из них основаны на моем личном опыте тестирования производительности в JetBrains (https://www.jetbrains.com/). Вы прочитаете про реальные задачи и их решения, которые возникали при разработке продуктов от JetBrains, таких как IntelliJ IDEA (https://www.jetbrains.com/idea/) (IDE на Java), ReSharper (https://www.jetbrains.com/resharper/) (плагин для Visual Studio) и Rider (https://www.jetbrains.com/rider/) (кросс-платформенная среда разработки для .NET, основанная на IntelliJ IDEA и ReSharper). Все эти продукты очень большие (исходный код Rider содержит более 20 млн строк кода) и включают в себя множество компонентов, важных для производительности. Сотни разработчиков каждый день вносят в них сотни изменений, поэтому сохранение производительности на приличном уровне — непростая задача. Надеюсь, что вы сочтете эти примеры и техники полезными и поймете, как применить их к собственным продуктам.
Другой источник опыта для меня — это BenchmarkDotNet. Я начал разрабатывать эту библиотеку в 2013 году как небольшой личный проект. Сегодня она стала самой популярной библиотекой для бенчмаркинга, которая используется практически во всех .NET-проектах, включая среду исполнения .NET. Работая с этим проектом, я участвовал в сотнях очень интересных обсуждений производительности. Некоторые из примеров в книге могут казаться искусственными, но почти все они взяты из реальной жизни.
Ожидания
Мы будем много обсуждать производительность, но не сможем обсудить все возможные темы. Вы не узнаете о том:
• как писать быстрый код;
• как оптимизировать медленный код;
• как профилировать приложения;
• как находить сложные места в приложениях.
И не найдете ответов на многие другие вопросы, связанные с производительностью.
Существует множество прекрасных книг и научных работ на эти темы. Вы можете найти некоторые из них в списке источников в конце книги. Повторю, что эта книга сосредоточена только на бенчмаркинге. Вы узнаете:
• как написать хороший бенчмарк;
• как выбрать релевантные метрики;
• как избежать подводных камней бенчмаркинга;
• как анализировать результаты бенчмарков.
И получите ответы на многие другие вопросы, связанные с бенчмаркингом.
Также следует помнить о том, что бенчмаркинг подходит не ко всем ситуациям. Вы не станете хорошим специалистом по производительности, если бенчмаркинг — ваш единственный навык. Однако это один из важнейших навыков. Приобретя его, вы станете лучше как разработчик программного обеспечения и сможете выполнять очень сложные исследования производительности.
1. Введение в бенчмаркинг
Проще оптимизировать правильный код, чем править оптимизированный код.
Билл Харлен, 1997 год
В этой главе мы обсудим концепцию бенчмаркинга, разницу между ним и другими видами исследований производительности, узнаем, какие задачи можно решить с помощью бенчмаркинга, как должен выглядеть хороший бенчмарк, как его написать и проанализировать его результаты. В частности, будут освещены следующие темы.
• Исследования производительности.
Как выглядит качественное исследование производительности? Почему так важно определить свои цели и задачи? Какие измерения, инструменты и подходы следует выбрать? Что нужно делать с показателями производительности, которые мы получаем?
• Цели бенчмаркинга.
Когда полезен бенчмаркинг? Как его можно использовать в анализе производительности или маркетинге? Как применять его для улучшения своих технических знаний или просто для развлечения?
• Требования к бенчмаркингу.
Каковы основные требования к бенчмаркингу? Почему так важно писать воспроизводимые, неразрушающие, верифицируемые, переносимые и честные бенчмарки с приемлемым уровнем точности?
• Пространства производительности.
Почему надо работать с многомерными пространствами производительности (и что это такое)? Почему важно построить качественную модель производительности? Как на нее влияют входные данные и окружение?
• Анализ.
Почему так важно анализировать результаты бенчмарка? Как их интерпретировать? Что такое узкие места и почему их нужно искать? Зачем нам знать статистику для бенчмаркинга?
В этой главе будут освещены основные теоретические концепции с помощью практических примеров. Если вы уже знаете, как измерять производительность, можете пропустить ее и перейти к главе 2.
Первый шаг к тому, чтобы узнать, как заниматься бенчмаркингом или другими видами измерения производительности, — создание хорошего плана.
Планирование измерения производительности
Хотите, чтобы ваш код работал быстро? Конечно, кто же этого не хочет! Однако поддерживать высокий уровень производительности не всегда просто. Жизненный цикл приложения включает в себя сложные бизнес-процессы, которые не обязательно сосредоточены на производительности. Когда вы внезапно замечаете, что функция работает слишком медленно, не всегда есть время вникнуть в проблему и ускорить приложение. Не всегда очевидно, как прямо сейчас написать такой код, который будет быстро работать в будущем.
Если вы хотите улучшить производительность, но понятия не имеете, что делать, — это нормально. Все, что вам нужно, лежит в пределах одного качественного исследования производительности.
Любое тщательное исследование требует хорошего плана с несколькими важными пунктами.
1. Определение проблемы и целей.
2. Подбор правильных метрик.
3. Выбор подхода и инструментов.
4. Проведение эксперимента и получение результатов.
5. Анализ и формулирование выводов.
Конечно, это лишь пример плана. В собственном плане вы можете выделить 20 пунктов или, наоборот, пропустить какие-то из них, потому что они для вас очевидны. Однако полное исследование производительности так или иначе включает в себя (явно или неявно) как минимум все эти пункты. Обсудим каждый из них подробнее.
Определение проблемы и целей
Этот пункт кажется очевидным, но многие его пропускают и сразу начинают что-то измерять или оптимизировать. Крайне важно задать себе несколько важных вопросов. Чем меня не устраивает нынешний уровень производительности? Чего я хочу достичь? Насколько быстро должен работать мой код?
Если вы просто начнете оптимизировать свою программу случайным образом, это будет пустой тратой времени. Лучше вначале определить проблемы и цели. Я даже рекомендую записать их на листике, держать этот листик на рабочем столе и посматривать на него во время работы.
Посмотрим несколько примеров проблем и целей, которые встречаются в реальной жизни.
• Проблема: нам нужна библиотека, поддерживающая сериализацию JSON, но мы не знаем, какая именно библиотека будет достаточно быстрой для нас.
Цель: сравнение двух библиотек (анализ производительности).
Мы нашли две подходящие библиотеки для JSON, у обеих есть все нужные характеристики. Важно выбрать более быструю, но их сложно сравнивать на примере общих случаев. Поэтому мы хотим проверить, какая из них быстрее в типичных для нас сценариях.
• Проблема: наши клиенты пользуются программным обеспечением наших конкурентов, потому что, по их мнению, оно работает быстрее.
Цель: наши клиенты должны узнать, что мы быстрее конкурентов (маркетинг).
На самом деле существующий уровень производительности достаточно высок, но необходимо донести до клиентов, что мы быстрее.
• Проблема: мы не знаем, какой архитектурный подход наиболее эффективен с точки зрения производительности.
Цель: улучшить уровень технической компетентности наших разработчиков (научный интерес).
Разработчики не всегда знают, как писать код эффективно. Иногда имеет смысл потратить время на исследования и найти полезные методики и архитектурные подходы, которые будут оптимальны для тех случаев, когда производительность играет важную роль.
• Проблема: разработчики устали от реализации скучной бизнес-логики.
Цель: сменить рабочую обстановку и решить несколько интересных задач (развлечение).
Организуйте соревнование по производительности между разработчиками, чтобы улучшить производительность вашего приложения. Выигрывает команда, добившаяся лучшей производительности.
Такие соревнования не обязательно помогают в решении проблем вашего бизнеса, но они могут улучшить атмосферу внутри организации и повысить продуктивность разработчиков в дальнейшем.
Как видите, определение проблемы может быть абстрактным предложением, описывающим цель высокого уровня. Следующий шаг — уточнить его, добавив детали. Их можно выразить с помощью метрик.
Подбор правильных метрик
Допустим, вы недовольны производительностью одного из фрагментов своего кода и хотите ускорить его в два раза1. Но для вас ускорение может означать одно, а для другого разработчика в команде — совсем другое. Работать с абстрактными понятиями невозможно. Если вам нужна четкая постановка проблем и определенные цели, необходимо подобрать правильно определенные метрики, отвечающие этим целям. Решение, какую метрику включить в список, не всегда очевидно, поэтому давайте обсудим несколько вопросов, которые помогут вам его принять.
• Что я хочу улучшить?
Возможно, вы хотите уменьшить период ожидания (latency) отдельного запроса (временной интервал между началом и окончанием) или увеличить пропускную способность (throughput) метода (сколько запросов мы можем выполнить за секунду). Часто люди думают, что эти величины взаимосвязаны и неважно, какую метрику они выберут, потому что все они одинаково коррелируют с производительностью приложения. Однако это не всегда так. Например, изменения в исходном коде могут уменьшить период ожидания, но сократить пропускную способность. Примерами других метрик могут служить количество случаев непопадания в кэш, утилизация процессорных ресурсов, объем кучи больших объектов в динамической памяти, время холодного запуска и многие другие. Не переживайте, если эти термины вам незнакомы, — мы объясним их в следующих главах.
• Уверен ли я,что точно знаю,что именно хочу улучшить?
Чаще всего ответ — нет. Необходимо быть гибкими и готовиться менять цели после получения результатов. Исследование производительности — процесс итеративный. На каждой стадии можно выбрать новые метрики. Например, вы начинаете работу с замеров периода ожидания операции. После первой стадии обнаруживаете, что программа тратит слишком много времени на сборку мусора. Тогда вы вводите другую метрику — объем выделяемой памяти в секунду. После второй стадии оказывается, что вы создаете много экземпляров int[] с коротким жизненным циклом. Следующей метрикой может быть количество созданных массивов int. После некоторой оптимизации (например, вы реализуете пул массивов и повторно используете копии массивов между операциями), возможно, захотите измерить эту же метрику снова. Конечно, можно использовать только первую метрику — период ожидания операции. Однако в этом случае вы будете работать не с изначальной проблемой, а с наведенными эффектами. Общая производительность — предмет сложный, который зависит от многих факторов. Не так-то просто отследить то, как изменения в конкретном месте влияют на длительность операции. Намного проще отслеживать конкретные характеристики целой системы.
• Каковы условия,в которых будет исполняться программа?
Допустим, вы выбрали метрику «пропускная способность» и хотите добиться 10 000 операций в секунду. Какая именно пропускная способность для вас важна? Вы хотите улучшить ее при средней или максимальной загрузке? Приложение однопоточное или многопоточное? Какой уровень параллельной обработки подходит в вашей ситуации? Сколько оперативной памяти на вашем сервере? Важно ли улучшить производительность во всех целевых окружениях, или у вас есть только одно окружение, которое известно заранее?
Не всегда очевидно, как выбрать правильные целевые условия и как они влияют на производительность. Тщательно продумывайте ограничения, подходящие для ваших метрик. Мы обсудим различные ограничения далее в этой книге.
• Как интерпретировать результаты?
Квалифицированный специалист по производительности всегда собирает информацию по одной и той же метрике много раз. С одной стороны, это хорошо, потому что так можно проверить статистические характеристики измеряемой метрики. С другой — плохо, потому что теперь мы должны проверять эти характеристики. Как их суммировать? Необходимо ли всегда выбирать среднее арифметическое? Или медиану? Допустим, мы хотим убедиться, что 95 % запросов могут выполниться быстрее, чем за N миллисекунд. В таком случае нам подходит 95-й процентиль. Мы подробно обсудим статистику и необходимость понимания того, что она важна не только для анализа результатов, но и для определения требуемых метрик. Всегда вдумчиво выбирайте те статистические характеристики, которые будут подходить для изначальной проблемы.
Таким образом, мы можем работать с различными метриками (от периода ожидания и пропускной способности до количества случаев непопадания в кэш и утилизации процессора) и различными условиями (например, средняя или максимальная загрузка) и агрегировать их разными способами (например, использовать среднее арифметическое, медиану или 95-й процентиль). Если вы не знаете, что применить, просто взгляните на бумажку, где записана проблема. Выбранные метрики всегда должны соответствовать вашей цели и определять детали на низком уровне проблемы. Нужно сделать так, чтобы улучшение выбранных метрик означало решение проблемы. В этом случае все будут довольны: и вы, и ваш начальник, и ваши пользователи.
После выбора правильных метрик наступает следующий этап — выбор способа сбора данных.
Выбор подхода и инструментов
В современном мире существует множество инструментов, подходов и методов измерения производительности. Выбирайте инструменты, подходящие для вашей ситуации. Проверяйте, обладает ли выбранный инструмент нужными характеристиками: точностью измерения, переносимостью, простотой использования и т.д.
Для принятия правильного решения нужно рассмотреть доступные варианты и выбрать те, которые лучше всего соответствуют заданной проблеме и метрикам. Давайте обсудим несколько самых популярных методов и соответствующие им инструменты.
• Изучение кода.
Опытный разработчик с большим опытом может многое сказать о производительности и без измерений. Он может оценить асимптотическую сложность алгоритма, прикинуть накладные расходы на вызов определенных методов или заметить очевидно неэффективный фрагмент кода. Конечно, ничего нельзя сказать точно без измерений, но зачастую простые задачи, связанные с производительностью, можно решить, просто посмотрев на код и вдумчиво проанализировав его. Однако будьте осторожны, имейте в виду, что личные ощущения и интуиция легко могут вас подвести и даже самые опытные разработчики могут ошибиться. Не забывайте также о том, что технологии меняются и предыдущие предположения могут оказаться совершенно неправильными. Например, вы никогда не используете некоторый метод из-за того, что он очень медленный. В какой-то момент реализацию этого метода оптимизируют, и он становится супербыстрым. Но если вы не узнаете об этих улучшениях, то так и будете его избегать.
• Профилирование.
Что делать, если вы хотите оптимизировать приложение? С чего начать? Некоторые программисты начинают с первого же места, которое выглядит недостаточно оптимальным: «Я знаю, как оптимизировать этот фрагмент кода, сейчас этим и займусь!» Обычно подобный подход не очень полезен. Случайные оптимизации могут не оказать никакого влияния на производительность всего приложения. Если этот метод занимает 0,01 % от общего времени, вы, скорее всего, вообще не заметите никакого эффекта. Или, что хуже, можете принести больше вреда, чем пользы. Попытка писать слишком умный или быстрый код может увеличить его сложность и создать новые проблемы. В лучшем случае вы просто впустую потратите свое время.
Чтобы получить действительно ощутимую разницу, найдите место, где приложение тратит значительную часть времени. Лучший способ сделать это — профилирование. Некоторые добавляют измерение метрик прямо в приложение и получают какие-то цифры, но это не настоящее профилирование. Профилирование подразумевает, что вы берете профайлер, присоединяете его к приложению, делаете снимок состояния и смотрите на профиль. Существует множество инструментов для профилирования, мы обсудим их в главе 6. Единственное требование к ним довольно простое: они должны показывать горячие методы (те, которые часто вызывают) и узкие места в приложении. Хороший профайлер должен помочь вам быстро найти то место, которое нужно оптимизировать в первую очередь.
• Мониторинг.
Иногда невозможно профилировать приложение на локальном компьютере (многие проблемы могут воспроизводиться только на сервере). В этом случае мониторинг может помочь найти операцию, у которой явные проблемы с производительностью. Существуют разные подходы, но чаще всего разработчики применяют логирование или используют внешние инструменты (например, основанные на ETW). Когда появляются проблемы с производительностью, можно посмотреть на собранные данные и попытаться найти источник проблем.
• Тесты производительности.
Представьте, что вы только что написали очень эффективный алгоритм. Приложение стало супербыстрым, и вы хотите, чтобы оно таким и оставалось. Но затем кто-то (скорее всего, вы сами) случайно вносит изменения, которые портят это прекрасное состояние. Часто люди пишут модульные тесты, чтобы оценить корректность бизнес-логики. Однако в нашем случае недостаточно проверить только логику приложения. Если зафиксировать текущий уровень производительности действительно важно, то разумно написать специальные тесты — так называемые тесты производительности, проверяющие, что до и после изменений программа работает одинаково быстро. Эти тесты могут выполняться на сервере сборки приложений как часть процесса непрерывной интеграции (CI).
Писать такие тесты нелегко, поскольку обычно требуется одинаковое серверное окружение (аппаратные средства + программное обеспечение) для всех конфигураций, в которых будут выполняться тесты. Если производительность очень значима для вас, имеет смысл потратить время на создание инфраструктуры и разработку тестов производительности. Мы обсудим, как это правильно сделать, в главе 5.
• Бенчмаркинг.
Если вы спросите пять человек о том, что такое бенчмарк, то получите пять разных ответов. Мы называем так программу, которая измеряет характеристики производительности другой программы или фрагмента кода. Считайте бенчмарк научным экспериментом: он должен давать результаты, которые позволяют вам узнать что-то новое о вашей программе, о среде исполнения .NET, об операционной системе, о современных аппаратных средствах и мире вокруг нас. В идеале результаты подобного эксперимента возможно повторить, ими можно поделиться с коллегами, и они должны позволять нам принять правильное бизнес-решение, основанное на полученной информации.
Проведение эксперимента и получение результатов
Теперь пришло время эксперимента. В конце эксперимента или серии экспериментов вы получите результаты в форме чисел, формул, таблиц, графиков, снимков состояния и т.д. В простом эксперименте может использоваться один подход, а более сложные способны потребовать большего количества. Приведу пример. Вы начинаете ваш эксперимент с мониторинга, который помогает найти очень медленный пользовательский сценарий. Далее с помощью профилирования вы находите горячие методы и пишете для них бенчмарки. После этого вы оптимизируете приложение и убеждаетесь с помощью бенчмарков, что выбранные метрики действительно улучшились. Далее вы превращаете бенчмарки в тесты на производительность, чтобы не допустить деградаций в будущем. Как видите, одного волшебного решения не существует: у каждого подхода есть своя цель и свое применение. Важно всегда помнить о проблемах и метриках при проведении каждого исследования.
Анализ и формулирование выводов
Анализ — самая важная часть любого исследования производительности. Получив значения метрик, вы должны объяснить их и быть уверенными в том, что это объяснение правильное. Часто допускают такую ошибку — говорят что-то наподобие: «Профайлер показывает, что метод А быстрее метода Б. Давайте везде использовать А вместо Б!» Лучше сделать такой вывод: «Профайлер показывает, что метод А быстрее метода Б. У нас есть объяснение этому факту: метод А оптимизирован под те входные данные, которые мы использовали в этом эксперименте. Таким образом, мы понимаем, почему получили такие результаты профилирования. Однако следует продолжить исследования и проверить другие наборы входных данных, прежде чем решить, какой метод использовать в коде приложения. Возможно, в некоторых крайних случаях метод А будет значительно медленнее метода Б».
Многие необычные значения в замерах производительности связаны с ошибками в методологии измерений. Всегда старайтесь выдвинуть разумную теорию, объясняющую каждое число в полученных результатах. Если такой теории нет, вы можете принять неверное решение и ухудшить производительность. Выводы стоит делать только после тщательного анализа.
Цели бенчмаркинга
Теперь, обсудив основной план исследования производительности, сместим фокус на бенчмаркинг и шаг за шагом рассмотрим его важные аспекты. Начнем с самого начала — с целей бенчмаркинга и связанных с ними проблем.
Вы помните, что нужно сделать в начале любого исследования производительности? Определить проблему. Понять, какая у вас цель и почему важно решить эту проблему.
Бенчмаркинг не является универсальным подходом, полезным при любом исследовании производительности. Бенчмарки не могут сами оптимизировать код за вас или решить все проблемы с производительностью за вас. Они просто выдают набор цифр.
Поэтому, прежде чем начать, убедитесь, что эти цифры вам нужны и вы понимаете зачем. Множество людей просто начинают «бенчмаркать», не зная, как делать выводы из полученных данных. Бенчмаркинг — очень полезный подход, но только в том случае, если вы понимаете, когда и зачем его применять.
Пойдем дальше — узнаем о нескольких распространенных целях бенчмаркинга.
Анализ производительности
Одна из самых популярных целей бенчмаркинга — анализ производительности. Он имеет большое значение, если вам важна скорость вашего приложения, и может помочь со следующими проблемами и сценариями.
• Сравнение библиотек/платформ/алгоритмов.
Часто люди хотят использовать уже существующие решения проблемы и выбирают самое быстрое из доступных (если оно отвечает базовым требованиям). Иногда имеет смысл тщательно проверить, какое из решений работает быстрее всех, и сказать что-то в духе: «Я сделал несколько пробных прогонов, и мне кажется, что вторая библиотека быстрее всех». Однако нескольких измерений всегда недостаточно. Если необходимо выбрать самое быстрое решение, требуется выполнить рутинную работу по написанию бенчмарков, которые сравнивают варианты в различных состояниях и условиях и дают полную картину производительности. Кроме того, качественные измерения всегда служат мощным аргументом для убеждения ваших коллег!
• Настройка параметров.
В большинстве программ много магических констант. Некоторые из них, такие как объем кэша или степень параллелизма, могут повлиять на производительность. Трудно понять заранее, какие значения лучше всего подходят для вашего приложения, но бенчмаркинг поможет выбрать оптимальные значения для достижения достойного уровня производительности.
• Проверка возможностей.
Представьте, что вы ищете подходящий сервер для своего веб-приложения. Вам нужен максимально дешевый вариант, но при этом он должен делать N запросов в секунду (RPS). Было бы полезно иметь программу, которая может измерить максимальный RPS вашего приложения на различных устройствах.
• Проверка эффекта от изменений.
Вы реализовали прекрасную функцию, которая должна порадовать пользователей, но она работает довольно долго. Вы переживаете о том, как она повлияет на производительность приложения в целом. Чтобы оценить реальный эффект, вам понадобится измерить метрики производительности до и после того, как в продукт была добавлена эта функция.
• Проверка концепций.
У вас есть гениальная идея, которую вы хотите реализовать, но она влечет за собой множество изменений, и вы не уверены в том, как она повлияет на уровень производительности. В этом случае можете попытаться на скорую руку реализовать основную часть этой идеи и измерить ее влияние на производительность приложения.
• Анализ регрессии.
Вы хотите отследить, как производительность функции меняется с каждой модификацией, чтобы, если поступит жалоба вроде «В предыдущем релизе все работало гораздо быстрее», проверить, так ли это. Анализировать регрессию можно с помощью тестов производительности, но бенчмаркинг может быть применен и в этом случае.
Таким образом, анализ производительности является полезным подходом, позволяющим решить множество разных проблем. Однако это не единственная возможная цель бенчмаркинга.
Бенчмаркинг как инструмент маркетинга
Сотрудники отделов маркетинга и продаж любят публиковать статьи и записи в блогах, рекламирующие скорость нового продукта. Качественный отчет об исследовании производительности может им помочь. Мы, как программисты, обычно максимально фокусируемся только на исходном коде и технических аспектах разработки, но следует согласиться с тем, что маркетинг — это тоже важно. Отчеты о производительности, основанные на результатах бенчмаркинга, могут быть полезны при продвижении нового продукта. В отличие от ваших обычных целей бенчмаркинга, при написании отчета о производительности для других людей вы обобщаете все свои эксперименты, относящиеся к производительности. Вы рисуете графики, составляете таблицы и проверяете каждый аспект своего бенчмарка. Обдумываете вопросы, которые могут задать о вашем исследовании, пытаетесь заранее заготовить ответы, продумываете важные факты, которые надо сообщить. При рассказе о производительности отделу маркетинга слишком много измерений не бывает. Хороший отчет о производительности украсит работу отдела маркетинга, чему все будут рады. Необходимо также сказать пару слов о черном маркетинге — ситуации, когда человек представляет результаты бенчмарка, которые заведомо являются ложью, и докладчику это известно. Это неэтично, но о таких вещах следует знать. Есть несколько видов бенчмаркинга для черного маркетинга.
• Заголовки желтой прессы.
Проведение каких-либо измерений и неподтвержденные заявления, например: «Наша библиотека — самый быстрый инструмент». Многие люди все еще верят, что, если что-то написано в Интернете, это правда, даже если утверждение не подкреплено достоверными измерениями.
• Невоспроизводимое исследование.
Добавление технических деталей, которые невозможно воспроизвести. Никто не сможет собрать исходный код, запустить ваши бенчмарки или найти указанные аппаратные средства.
• Выборочные измерения.
Выбор отдельных измерений. Например, вы провели 1000 измерений производительности для своего приложения и столько же для приложения конкурентов. После этого выбираете лучшие результаты для себя и худшие — для конкурентов. Технически вы предоставляете верные результаты, которые можно воспроизвести, но на самом деле это всего лишь небольшой фрагмент истинной картины производительности.
• Выборочное окружение.
Выбор параметров, которые выгодны для вас. Например, если вы знаете, что приложение конкурентов работает быстро только на компьютерах с большим объемом оперативной памяти и SSD-диском, то выбираете устройство с малым объемом памяти и HDD-диском. Если знаете, что ваше приложение демонстрирует хорошие результаты только на Linux (а на Windows — плохие), то выбираете Linux. Возможно также найти конкретные входные данные, которые будут выгодны только для вас. Эти результаты будут верными и на 100 % воспроизводимыми, но необъективными.
• Выборочные сценарии.
Представление только выборочных сценариев бенчмаркинга. Вы можете честно выполнить бенчмаркинг при сравнении своего решения с решением конкурентов по пяти разным сценариям. Допустим, ваше решение оказывается лучше только при одном из них. В этом случае вы можете представить только этот сценарий, но сказать, что ваше решение быстрее во всех случаях.
Я надеюсь, все согласятся с тем, что методы черного маркетинга неэтичны и, что еще хуже, популяризируют плохие практики бенчмаркинга. В то же время белый маркетинг может стать хорошим инструментом для демонстрации результатов в области производительности. Если вы хотите легко выявлять удачные и неудачные исследования производительности, необходимо понимать их различия. Мы обсудим важные техники в этой области в главах 4 и 5.
Научный интерес
Бенчмарки могут помочь вам развить навыки разработки и разобраться во внутренностях вашего приложения. Они помогут вам понять все уровни своей программы, включая принципы работы среды выполнения кода, баз данных, хранилищ данных, процессора и т.д. Когда читаешь абстрактную теорию о том, как устроено оборудование, сложно понять, как эта информация соотносится с реальной жизнью. В этой книге мы будем в основном обсуждать академические бенчмарки с небольшими фрагментами кода. Сами по себе они чаще всего не очень полезны, но если вы хотите оценивать большие и сложные системы, для начала нужно научиться работать на самом простом уровне.
Бенчмаркинг ради развлечения
Многим моим друзьям нравятся игры, в которых нужно отгадывать загадки. Мои любимые загадки — это бенчмарки. Если много заниматься бенчмаркингом, часто встречаешь результаты измерений, которые не получается объяснить с первой попытки. Чтобы разобраться в ситуации, нужно обнаружить узкое место (bottleneck) и выполнить измерение снова. Однажды я провел несколько месяцев, пытаясь объяснить один запутанный код, который выдавал странные значения метрик производительности. После долгих недель мучений, найдя объяснение, я полчаса прыгал по офису от радости — это был момент истинного счастья и блаженства.
Возможно, вы когда-нибудь слышали о гольфе по производительности2. Вам дают простую задачу, которая решается легко, но необходимо найти самое быстрое и самое эффективное из решений. Если ваше решение быстрее решения вашего друга на несколько наносекунд, то, чтобы продемонстрировать различия, используется бенчмаркинг. При этом очень важно понимать, как грамотно работать с входными данными и окружением (ваше решение может быть самым быстрым только в определенных условиях). Бенчмаркинг для развлечения служит прекрасным способом развеяться после недели рутинной работы.
Теперь, когда вы знакомы с самыми распространенными целями бенчмаркинга, взглянем на требования к бенчмаркам, которые помогут нам достичь этих целей.
Требования к бенчмаркам
В целом любая программа, измеряющая длительность операции, может быть бенчмарком. Однако качественный бенчмарк должен отвечать определенным требованиям. Официального списка требований к бенчмаркам не существует, так что мы обсудим наиболее полезные рекомендации.
Повторяемость
Повторяемость — это самое важное требование. Если запустить бенчмарк дважды, он должен выдать один и тот же результат. Если запустить его трижды, он тоже должен выдать один и тот же результат. Если запустить его 1000 раз, он все равно должен выдать один и тот же результат. Конечно, невозможно получать абсолютно одинаковые результаты каждый раз, между измерениями всегда будут различия. Но они не должны быть значительными. Все результаты должны быть довольно близкими.
Нужно отметить, что выполнение одного и того же кода может очень сильно разниться по времени, особенно если он включает в себя дисковые или сетевые операции. Качественный бенчмарк — это не просто один эксперимент или одно число. Это распределение чисел. В качестве результата бенчмарка вы можете получить сложное распределение измерений с несколькими локальными максимумами.
Даже если измеряемый код зафиксирован и его нельзя изменить, вы все еще контролируете то, как запустить его итерации, какое будет исходное состояние системы на момент старта или какие будут входные данные. Вы можете написать бенчмарк множеством способов, но он должен выводить в качестве результата повторяемые данные.
Иногда достичь повторяемости невозможно, но необходимо к этому стремиться. В данной книге мы изучим методы и подходы, которые помогут стабилизировать результаты. Даже если ваш бенчмарк стабильно повторяем, это не значит, что больше ни о чем волноваться не нужно. Надо удовлетворить и другие требования.
Проверяемость и переносимость
Качественное исследование производительности проводится не в вакууме. Если вы хотите поделиться результатами с другими, убедитесь, что они смогут запустить программу на собственном устройстве. Попросите друзей, коллег или членов сообщества помочь вам улучшить результаты, но не забудьте подготовить соответствующий исходный код и убедиться, что бенчмарк доступен для проверки в других условиях.
Принцип невмешательства
Во время бенчмаркинга часто возникает эффект наблюдателя, то есть сам процесс наблюдения может повлиять на результат. Приведу два доступных примера из физики, откуда и взят этот термин.
• Электрическая цепь.
Чтобы измерить напряжение в электрической цепи, к ней подключают вольтметр, но тем самым в цепь вносятся изменения, которые могут повлиять на изначальное напряжение. Обычно дельта напряжения меньше погрешности измерения, так что это не составляет проблемы.
• Ртутный термометр.
Классический ртутный термометр при использовании поглощает какое-то количество тепловой энергии. В идеале это поглощение, влияющее на температуру тела, также необходимо измерить.
Похожие примеры существуют и в мире измерения продуктивности.
• Поиск горячих методов.
Вы хотите узнать, почему программа работает медленно или где находится проблемное место, но у вас нет доступа к профайлеру или другим инструментам для измерения. Поэтому вы решаете добавить логирование и выводить в файл текущее время перед каждым вызовом подозрительного метода и после него. К сожалению, цена дисковых операций высока и строчки с логированием легко могут стать новым узким местом. Станет невозможно найти изначальное проблемное место, поскольку вы потратили 90 % времени на запись данных на диск.
• Использование профайлера.
Применение профайлера может повлиять на измерение. Когда вы присоединяетесь к другому процессу, вы его замедляете. В некоторых режимах профайлера, например в режиме выборки (samping), эффект будет незначительным, но в других может оказаться огромным. Например, отслеживание (tracing) легко может удвоить изначальное время. Мы обсудим различные режимы профайлера в главе 6.
Запомните, что при измерении производительности приложений обычно возникает эффект наблюдателя, который может оказать заметное влияние на результаты замеров.
Приемлемый уровень точности
Однажды я исследовал необычное снижение производительности. После внесения изменений в Rider время одного из тестов увеличилось с 10 до 20 с. Я не вносил значительных изменений, так что это было похоже на мелкую ошибку. Ее было очень легко найти во время первой сессии профайлинга. Виновником оказался фрагмент бездумно скопированного кода. Я быстро все починил, но не торопился на этом останавливаться: нужно ведь убедиться, что все снова работает быстро. Как вы думаете, какой инструмент для измерения я использовал? Секундомер! И я не имею в виду System.Diagnostics.Stopwatch (который переводится как «секундомер»), я буквально использовал обычный секундомер, встроенный в мои старомодные наручные часы Casio 3298/F-105. У этого инструмента довольно низкая точность. Когда я получаю замер в 10 с, то на самом деле могло пройти 9 или 11 с. Однако точности моего секундомера хватило, чтобы обнаружить разницу между 10 и 20 с.
В любой ситуации есть инструменты, которые выполняют задачу, но ни один инструмент не годится для абсолютно всех ситуаций. Мои часы выполнили задачу, потому что измеряемая операция длилась около 10 с и мне была непринципиальна секундная погрешность. Когда операция длится 100 мс, ее определенно будет тяжело измерить с помощью физического секундомера. Понадобится специальная функция, которая умеет измерять время. Когда операция длится 100 мкс, то эта функция должна обладать высоким разрешением. Когда операция длится 100 нс, то простого использования такой функции может не хватить, чтобы корректно измерить длительность операции. Могут потребоваться дополнительные меры увеличения точности с многократным повторением операции.
Помните, что длительность операции — это не фиксированное число. Если измерить операцию десять раз, получится десять разных чисел. На современных компьютерах источники шума могут легко испортить измерения, увеличить разброс значений и в итоге повлиять на конечную точность.
К сожалению, идеальной точности добиться не получится, погрешности измерения будут всегда. Здесь важно знать свой уровень точности и иметь возможность удостовериться, что достигнутого уровня достаточно для решения изначальной задачи.
Честность
В идеальном мире каждый бенчмарк должен быть честным. Я всегда одобряю предоставление разработчиками полных и актуальных данных. В мире бенчмаркинга очень легко случайно обмануться. Если вы получили какие-то непонятные цифры, не прячьте их. Поделитесь ими с другими и признайтесь, что не знаете, откуда они взялись. Мы не сможем помочь друг другу улучшить бенчмарки, если во всех наших отчетах будут лишь идеальные результаты.
Пространства производительности
Говоря о производительности, мы имеем в виду не одно число. Обычно одного измеренного временнóго интервала недостаточно для того, чтобы сделать значимый вывод. В любом исследовании производительности мы работаем с многомерным пространством производительности. Важно помнить, что объектом изучения является пространство с большим количеством измерений, зависящее от многих переменных.
Основы
Что мы имеем в виду под термином «многомерное пространство производительности»? Разберемся на примере. Допустим, мы собираемся написать сайт книжного магазина. В частности, хотим создать страницу, показывающую все книги в категории, например все книги жанра фэнтези. Для простоты допустим, что обработка одной книги занимает 10 мс, а скорость всего остального (например, сетевой конфигурации, работы с базой данных, рендеринга HTML и т.д.) так высока, что временем, затрачиваемым на эти операции, можно пренебречь. Сколько времени займет загрузка этой страницы? Очевидно, это зависит от количества книг в категории. Положим, что нам понадобится 150 мс на загрузку 15 книг и 420 мс — на 42 книги. В общем, нужно 10N мс на N книг. Это очень простое одномерное пространство, выражаемое линейной моделью. Единственным измерением здесь является количество книг N. В каждой точке этого одномерного пространства есть число, описывающее производительность, — время, необходимое для загрузки страницы. Это пространство можно представить в виде двумерного графика (рис. 1.1).
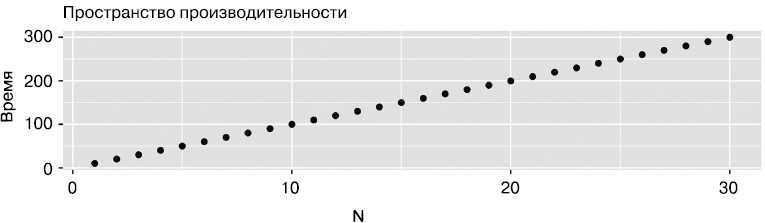
Рис. 1.1. Пример 1 простого пространства производительности
Теперь допустим, что на обработку одной книги нужно X мс (вместо константы 10 мс). Таким образом, наше пространство становится двумерным. Измерениями являются количество книг N и время обработки одной книги X. Общее время вычисляется по простой формуле Т = NX (рис. 1.2).
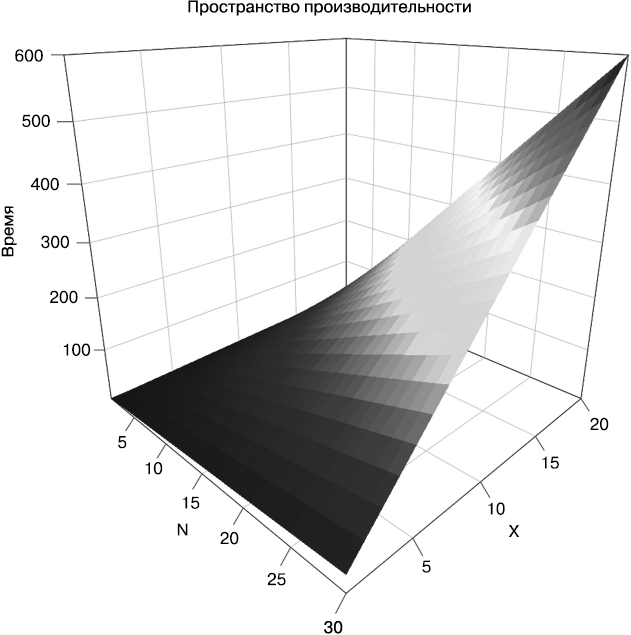
Рис. 1.2. Пример 2 простого пространства производительности
Конечно, в реальности общее время не может быть константой, даже если все параметры известны. Например, мы можем применить к нашей странице стратегию кэширования: иногда содержимое страниц находится в кэше и загрузка всегда занимает конкретное время, например 5 мс, а иногда не в кэше и загрузка длится NX мс. Таким образом, в каждой точке двухмерного пространства у нас не одно, а несколько временных значений.
Это был простой пример. Однако я надеюсь, что вы поняли концепцию многомерного пространства производительности. На самом деле измерений сотни или даже тысячи. Работать с такими пространствами производительности очень нелегко, поэтому нужна модель производительности, описывающая, какие факторы нужно рассмотреть.
Модель производительности
Говорить о производительности и скорости программ всегда нелегко, потому что разные люди понимают эти термины по-разному. Иногда я вижу записи в блогах с заголовками вроде «Почему С++ быстрее, чем С#» или «Почему С# быстрее, чем С++». Как вы думаете, какой заголовок вернее? Ответ — оба неверны, потому что у языков программирования нет таких свойств, как скорость, быстрота, производительность и т.п.
Однако в повседневной речи вы можете сказать коллеге что-то в духе: «Думаю, в этом проекте нужно использовать язык Х вместо языка Y, потому что он будет быстрее». Это нормально, если вы оба одинаково понимаете глубинный смысл этой фразы и обсуждаете конкретный стек технологий (специальные версии исходного кода/компиляторов и т.д.), конкретную среду (например, операционную систему и аппаратные средства) и конкретное окружение (разработать определенный проект с известными вам требованиями). Однако фраза в целом будет неверна, поскольку язык программирования — это абстракция, у него нет производительности.
Таким образом, нам нужна модель производительности. Это модель, включающая в себя все важные для производительности факторы: исходный код, окружение, данные ввода и распределение производительности.
Исходный код
Исходный код — это первое, что вам следует рассмотреть, исходная точка исследования производительности. Также в этот момент можно начать говорить о производительности. Например, можно сделать асимптотический анализ и описать сложность вашего алгоритма с помощью индекса большого О3.
Допустим, у вас два алгоритма с коэффициентами сложности О(N) и О(N2). В некоторых случаях достаточно просто выбрать первый алгоритм без дополнительных измерений производительности. Однако следует помнить, что алгоритм О(N) не всегда быстрее, чем О(N2): во многих случаях ситуация противоположная для небольших значений N. Нужно понимать, что этот индекс описывает только предельный режим и обычно хорошо работает лишь с большими числами.
Если вы работаете не с академическим алгоритмом из институтской программы, вам может быть трудно подсчитать вычислительную сложность алгоритма. Даже если вы используете амортизационный анализ (который обсудим позже), ситуация не станет проще. Например, если в алгоритме, написанном на С#, создаете много объектов, появится неявное снижение производительности из-за сборщика мусора (GC).
Классический асимптотический анализ — это теоретическая деятельность. Она не учитывает характеристики современных устройств. Например, у вас может быть один алгоритм, работающий с кэшем процессора, и другой, не работающий с ним. При одинаковой сложности у них будут совершенно разные характеристики производительности.
Все сказанное не означает, что вам не следует пытаться анализировать производительность, основываясь только на исходном коде. Опытный разработчик часто может сделать множество верных предположений о производительности, бросив взгляд на код. Однако стоит помнить, что исходный код все еще является абстракцией. Строго говоря, мы не можем обсуждать скорость сырого исходного кода, не зная, как будем его запускать. Следующее, что нам нужно, — это окружение.
Окружение
Окружение — это набор внешних условий, влияющих на исполнение программы.
Допустим, мы написали код на C#. Что дальше? Дальше компилируем его с помощью компилятора C# и запускаем в среде выполнения .NET, использующей компилятор JIT, чтобы перевести код на промежуточном языке (Intermediate Language, IL) в команды архитектуры процессора4. Он будет выполняться на устройстве с определенным объемом оперативной памяти и определенной пропускной способностью сетевой конфигурации.
Заметили, сколько здесь неизвестных факторов? В реальности ваша программа всегда запускается в конкретном окружении. Вы можете использовать платформы х86, х64 или ARM. Можете использовать LegacyJIT или новый современный RyuJIT. Можете использовать различные реализации платформы .NET или версии общеязыковой среды выполнения (CLR). Вы можете запустить бенчмарк на платформе .NET Framework, .NET Core или Mono.
Не стоит экстраполировать результаты бенчмарка в одном окружении на все случаи. Например, если вы смените LegacyJIT на RyuJIT, это может значительно повлиять на результаты. LegacyJIT и RyuJIT используют разную логику для выполнения большинства оптимизаций (трудно сказать, что один из них лучше другого, — они просто разные). Если вы разработали приложение на .NET для Windows и .NET Framework и вдруг решили сделать его кросс-платформенным и запустить на Linux с помощью Mono или .NET Core, вас ждет много сюрпризов!
Конечно, проверить все возможные варианты окружения невозможно. Обычно вы работаете с одним окружением, установленным по умолчанию на вашем компьютере. Когда пользователи находят ошибку, можно услышать: «А на моем устройстве работает». Когда пользователи жалуются, что ПО работает медленно, можно услышать: «А на моем устройстве работает быстро». Иногда вы проверяете, как оно работает в нескольких других окружениях, например на х86 и х64 или в разных операционных системах. Однако существует множество конфигураций, которые никто не проверит. Только глубокое понимание внутренних элементов современного ПО и устройств может помочь вам догадаться, как все будет работать в другом производственном окружении. Мы обсудим окружения подробнее в главе 3.
Если вы можете проверить, как программа работает во всех нужных вам окружениях, — прекрасно. Однако есть еще один фактор, влияющий на производительность, — входные данные.
Входные данные
Входные данные — это набор переменных, обрабатываемый программой. Он может быть введен пользователем, содержаться в текстовом файле, быть аргументом метода и т.д.
Допустим, мы написали код на C# и выбрали нужное окружение. Теперь уже можно говорить о производительности или сравнивать два разных алгоритма, чтобы проверить, какой из них быстрее? Ответ — нет, потому что для разных входных данных мы можем наблюдать разную скорость алгоритма.
Например, нам нужно сравнить две программы с реализацией движка регулярных выражений. Как можно это сделать? Мы можем выполнить поиск по тексту с помощью регулярного выражения. Но какой текст и какое выражение использовать? И сколько пар «текст — выражение» взять? Если проверить только одну пару и окажется, что программа А быстрее программы Б, это вовсе не означает, что так происходит всегда. Если у вас есть две реализации, то часто можно наблюдать, что одна из них работает быстрее с одним типом входных данных, а другая — с другим. Полезно иметь набор эталонных входных данных, позволяющий сравнивать алгоритмы. Но создать его непросто: нужно включить в него разные наборы типовых входных данных и не забыть про крайние случаи.
Если вы хотите создать качественный набор эталонных данных, то должны понимать, что происходит во внутренней структуре вашего кода. Если работаете со структурой данных, проверьте разные паттерны доступа к памяти: последовательное считывание/запись, случайное считывание/запись и какие-нибудь регулярные паттерны. Если внутри ваших алгоритмов есть отдельная ветвь (обычный оператор if), проверьте разные шаблоны для следующих значений условий ветви: условие всегда верно, условие случайно, значения условия варьируются и т.д. (алгоритмы предсказания ветвления на современных устройствах творят просто волшебство, которое может значительно повлиять на производительность).
Распределение
Распределение производительности — это набор всех измеренных в ходе бенчмаркинга параметров.
Допустим, мы написали код на C#, выбрали нужное окружение и определили эталонный набор входных данных. Теперь-то мы можем сравнить два алгоритма и сказать: «Первый алгоритм в пять раз быстрее второго»? Ответ — все еще нет. Если запустить один и тот же код в одном и том же окружении с одними и теми же данными дважды, мы не получим одни и те же значения замеров. Между измерениями всегда есть разница. Иногда она незначительная, и мы ею пренебрегаем. Однако в реальности нельзя описать производительность с помощью одного числа — это всегда какое-то распределение. В простом случае оно выглядит нормальным и мы можем для сравнения алгоритмов использовать только средние значения.
Но может появиться и множество характеристик, усложняющих анализ. Например, огромный разброс значений или несколько локальных максимумов в распределении (типичная ситуация для больших компьютерных систем). В таких случаях очень сложно сравнивать алгоритмы и делать полезные выводы.
Например, взгляните на шесть распределений на рис. 1.3. У них у всех одно среднее значение — 100.
Можно отметить следующее:
• на графиках a и г изображены равномерные распределения;
• на б и д — нормальные распределения;
• разброс на графиках г и д гораздо больше, чем на a и б;
• у распределения в два локальных максимума, 50 и 150, и оно не содержит значений 100;
• у распределения е три локальных максимума, 50, 100 и 150, и оно содержит много значений 100.
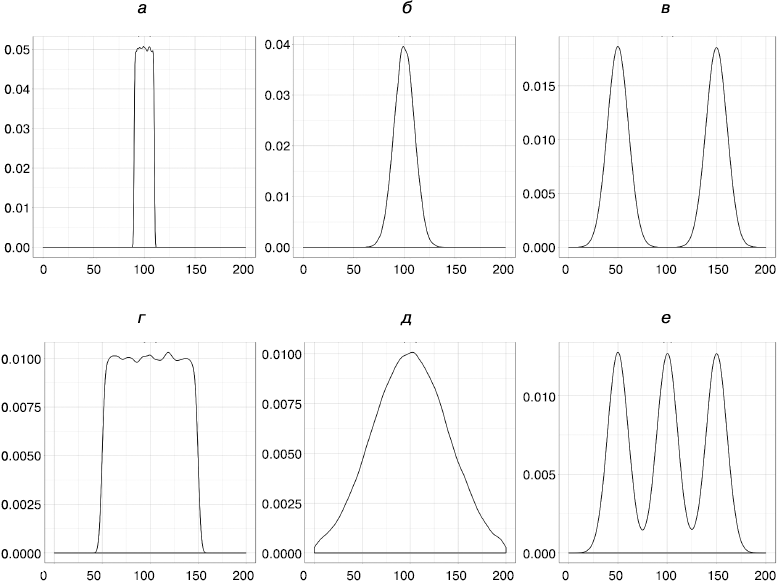
Рис. 1.3. Шесть различных распределений с одним средним значением
Очень важно различать разные виды распределений, потому что, если смотреть только на среднее значение, можно не заметить разницы между ними.
В ходе работы с более сложной логикой обычно появляются несколько локальных максимумов и большое стандартное отклонение. К счастью, в простых случаяхобычно можно игнорировать распределения, поскольку для базового анализа производительности достаточно среднего значения всех измерений. Однако иногда проверять статистические характеристики распределений полезно.
Теперь, когда мы обсудили важные составляющие модели производительности, пора собрать их вместе.
Пространство
Наконец мы можем говорить о пространстве производительности, которое помогает совместить исходный код, окружение и входные данные и проанализировать, как они влияют на распределение производительности. С математической точки зрения у нас есть функция от декартова произведения <ИсходныйКод>, <Окружение> и <ВходныеДанные> до <Распределение>:
(ИсходныйКод) х (Окружение) х (ВходныеДанные) --> (Распределение)
Это означает, что во всех ситуациях, в которых мы исполняем исходный код в определенном окружении с входными данными, мы получаем распределение измерений и функцию (в математическом смысле) с тремя аргументами: <ИсходныйКод>, <Окружение>, <ВходныеДанные>, которая выдает одно значение <Распределение>. Такая функция определяет пространство производительности. Когда мы исследуем производительность, то пытаемся понять внутреннюю структуру пространства, основанную на ограниченном наборе бенчмарков. В этой книге мы обсудим, какие факторы влияют на производительность, как проявляется это влияние и что нужно помнить при бенчмаркинге.
Итак, вы собрали эти функции и они выдают большое количество замеров, однако результаты еще нужно проанализировать. Поэтому обсудим анализ производительности.
Анализ
Анализ — это важнейший этап любого исследования производительности, поскольку результаты эксперимента без анализа представляют собой просто набор бессмысленных цифр. Давайте обсудим, что нужно делать, чтобы получить максимум пользы от сырых данных о производительности.
Плохой, непонятный и хороший
Иногда я называю бенчмарки плохими, но на самом деле они не могут быть ни хорошими, ни плохими (иногда бывают непонятными). Однако, раз уж мы используем эти слова в повседневной жизни и понимаем их значения, обсудим их в этом смысле.
Плохой.Плохой бенчмарк дает ненадежные, неясные результаты. Когда вы пишете программу, выдающую какие-то значения производительности, они всегда что-то означают, но, возможно, не то, чего вы ожидали. Вот несколько примеров.
• Вы хотите измерить производительность жесткого диска, а бенчмарк измеряет производительность файловой системы.
• Вы хотите узнать, сколько времени занимает рендеринг веб-страницы, а бенчмарк измеряет производительность базы данных.
• Вы хотите понять, насколько быстро процессор может обработать арифметические выражения, а бенчмарк измеряет, насколько эффективно компилятор оптимизирует эти выражения.
Плохо, когда бенчмарки не выдают надежной информации о пространстве производительности. Если вы написали ужасный бенчмарк, то все равно можете проанализировать его правильно и объяснить, откуда взялись такие цифры. А написав «лучший бенчмарк в мире», можете ошибиться в анализе. Использование сверхнадежной библиотеки для бенчмаркинга не гарантирует того, что вы непременно придете к правильным выводам. Если вы написали плохой бенчмарк в десять строк, основанный на простом цикле с применением DateTime.Now, это не значит, что результаты неверны: если вы прекрасно понимаете, что происходит внутри вашей программы, то сможете извлечь много полезной информации из полученных результатов.
Непонятный.Непонятный бенчмарк выдает результаты, которые трудно проверить. Это не означает их правильность или неправильность, просто им нельзя доверять. Если вы игнорируете хорошие практики бенчмаркинга и пишете запутанный код, то не можете быть уверены в том, что получили правильные результаты.
Представьте плохо написанный фрагмент кода. Никто не понимает, как он работает, но он работает и выполняет определенную задачу. Вы можете целый день распинаться об ужасном форматировании, непонятных названиях переменных и неконсистентном стиле, но программа продолжит работать корректно. То же самое происходит и в мире бенчмарков: непонятно написанный бенчмарк может выдавать правильные результаты, если вы правильно его анализируете. Поэтому вы не можете сказать, что их результаты непонятного бенчмарка неверны из-за того, что код написан слишком сложно, стадия прогрева пропущена, выполнено недостаточное количество итераций. Но можете назвать эти результаты ненадежными и потребовать дополнительного анализа.
Хороший.Хороший бенчмарк — это тот, который соответствует следующим критериям.
• Исходный код выглядит надежным. Он придерживается хороших практик бенчмаркинга и не содержит распространенных ошибок, которые могут запросто испортить результаты.
• Результаты правильные. Он измеряет то, что должен измерять, с высоким уровнем точности.
• Представлены выводы. Он объясняет контекст результатов и дает новую информацию о пространстве производительности на основе сырых значений измеренных метрик.
• Результаты объясняются и подтверждаются. Предоставляется дополнительная информация о результатах и о том, почему им можно доверять.
Хорошее исследование производительности всегда включает в себя анализ. Сырых цифр после измерений недостаточно. Главным результатом является вывод, основанный на анализе этих цифр.
В Интернете можно найти фрагменты кода, основанного на Stopwatch, которые содержат примеры результата без комментариев («Посмотрите, какой прекрасный бенчмарк» не считается). Если у вас есть значения производительности, их надо интерпретировать и объяснить, почему вы получили именно эти значения. Нужно объяснить, почему мы можем экстраполировать выводы и использовать их в других программах (вспомните, насколько сложными могут быть пространства производительности).
Конечно, этого недостаточно. Бенчмарк всегда должен включать в себя стадию проверки, если вы пытаетесь доказать, что его результаты верны.
Поиск узкого места
При анализе результатов бенчмарка всегда задавайтесь вопросом, почему он не работает быстрее. Обычно у него есть ограничивающий фактор, или узкое место, которое важно найти по следующим причинам.
• Если вы не знаете об узком месте, сложно объяснить результат бенчмарка.
• Только информация об ограничивающем факторе позволяет проверить набор параметров. Вы уверены, что использованные параметры соответствуют вашей проблеме? Это довольно типичная ситуация, когда разработчик пытается измерить полное время исполнения бенчмарка, а лучше измерять конкретные метрики, такие как количество неудачных обращений в кэш или объем потраченной памяти.
• Понимание того, где находится узкое место, позволит вам разработать более качественный бенчмарк и исследовать пространство производительности в правильном направлении.
• Многие разработчики, пытаясь что-то оптимизировать, используют бенчмаркинг в качестве первой стадии, но, не зная ограничивающего фактора, они не поймут, что конкретно нужно делать с его результатами и как их правильно использовать.
Принцип Парето, известный также как правило «80/20», описывает неравное распределение, например: 20 % затраченных усилий дают 80 % результатов, 20 % опасностей приводят к 80 % травм, 20 % ошибок вызывают 80 % поломок и т.д. Можно применить принцип Парето к узким местам (назовем это правилом бутылочного горлышка5) и сказать, что 20 % кода потребляют 80 % ресурсов. Если пойти дальше и попытаться найти проблему, используя эти 20 %, можно снова применить принцип Парето и получить принцип Парето второго порядка (Парето-2). В этом случае получится 4 % кода (4 % = 20 % · 20 %) и 64 % ресурсов (64 % = 80 % · 80 %). В больших приложениях со сложной многоуровневой архитектурой можно пойти еще дальше и сформулировать принцип Парето третьего порядка (Парето-3). В этом случае мы получим 0,8 % кода (0,8 % = 20 % · 20 % · 20 %) и 51,2 % ресурса (51,2 % = 80 % · 80 % · 80 %). Таким образом, имеются следующие правила бутылочного горлышка:
• Парето-1: 20 % кода потребляет 80 % ресурсов;
• Парето-2: 4 % кода потребляет 64 % ресурсов;
• Парето-3: 0,8 % кода потребляет 51,2 % ресурсов.
Здесь мы используем термин «ресурс» как абстрактный, но важно помнить, какие ресурсы ограничивают производительность и как они соотносятся с различными видами узких мест. В этой книге мы узнаем, что у каждого вида есть свои подводные камни и ограничивающие факторы, о которых важно помнить (см. главы 7 и 8). Понимание этого позволит сфокусироваться на более важных аспектах конкретной ситуации.
Статистика
Хотелось бы, чтобы каждый бенчмарк выдавал одно и то же значение каждый раз, но в реальности у измерений производительности странные и пугающие распределения. Конечно, это зависит от выбора параметров, но стоит быть готовыми к распределению необычной формы, особенно если вы измеряете время по настенным часам. Если вы хотите проанализировать результаты бенчмарка как следует, то должны знать основные принципы статистики, например разницу между средним арифметическим и медианой, а также значение слов «выброс», «стандартная ошибка» и «процентиль». Полезно также знать о центральной предельной теореме и мультимодальных распределениях. Совсем хорошо, если знаете, как проводить тесты на статистическую значимость, не пугаетесь словосочетания «нулевая гипотеза» и можете рисовать красивые и непонятные статистические графики. Не переживайте, если вы что-то из этого не знаете, мы все обсудим в главе 4.
Надеюсь, теперь вы понимаете, почему так важно потратить время на анализ. А сейчас давайте подытожим все, что узнали в этой главе.
Выводы
Вы кратко ознакомились с основными темами, важными для разработчика, желающего писать бенчмарки.
• Качественное исследование производительности и его этапы.
• Типичные цели бенчмаркинга и то, как они могут помочь создавать более быстрые программы и совершенствовать ваши навыки.
• Распространенные требования к бенчмаркам и разница между хорошими и плохими бенчмарками.
• Пространства производительности, а также почему важно учитывать исходный код, окружение и входные данные.
• Почему анализ так важен и как делать правильные выводы.
В последующих главах рассмотрим эти темы подробнее.
1 Конечно, это плохое определение проблемы. Если вы собираетесь провести оптимизацию, нужны более веские причины, чем недовольство. В данный момент мы говорим о метриках, поэтому допустим, что у нас есть определенные требования к производительности, а наше программное обеспечение не отвечает целям бизнеса (здесь неважно, какие они).
2 Примеры можно найти по адресу https://mattwarren.org/2016/05/16/adventures-in-benchmarking-performance-golf/.
3 Мы обсудим асимптотический анализ и индекс большого О в главе 4.
4 Мы обсудим эти термины в главе 3.
5 Правило бутылочного горлышка придумал Федерико Луис. Вы можете посмотреть его прекрасную лекцию на эту тему и другие темы, связанные с производительностью, на YouTube: www.youtube.com/watch?v=7GTpwgsmHgU.
Конечно, это плохое определение проблемы. Если вы собираетесь провести оптимизацию, нужны более веские причины, чем недовольство. В данный момент мы говорим о метриках, поэтому допустим, что у нас есть определенные требования к производительности, а наше программное обеспечение не отвечает целям бизнеса (здесь неважно, какие они).
Примеры можно найти по адресу https://mattwarren.org/2016/05/16/adventures-in-benchmarking-performance-golf/.
Мы обсудим асимптотический анализ и индекс большого О в главе 4.
Мы обсудим эти термины в главе 3.
Правило бутылочного горлышка придумал Федерико Луис. Вы можете посмотреть его прекрасную лекцию на эту тему и другие темы, связанные с производительностью, на YouTube: www.youtube.com/watch?v=7GTpwgsmHgU.
Принцип Парето, известный также как правило «80/20», описывает неравное распределение, например: 20 % затраченных усилий дают 80 % результатов, 20 % опасностей приводят к 80 % травм, 20 % ошибок вызывают 80 % поломок и т.д. Можно применить принцип Парето к узким местам (назовем это правилом бутылочного горлышка5) и сказать, что 20 % кода потребляют 80 % ресурсов. Если пойти дальше и попытаться найти проблему, используя эти 20 %, можно снова применить принцип Парето и получить принцип Парето второго порядка (Парето-2). В этом случае получится 4 % кода (4 % = 20 % · 20 %) и 64 % ресурсов (64 % = 80 % · 80 %). В больших приложениях со сложной многоуровневой архитектурой можно пойти еще дальше и сформулировать принцип Парето третьего порядка (Парето-3). В этом случае мы получим 0,8 % кода (0,8 % = 20 % · 20 % · 20 %) и 51,2 % ресурса (51,2 % = 80 % · 80 % · 80 %). Таким образом, имеются следующие правила бутылочного горлышка:
Допустим, вы недовольны производительностью одного из фрагментов своего кода и хотите ускорить его в два раза1. Но для вас ускорение может означать одно, а для другого разработчика в команде — совсем другое. Работать с абстрактными понятиями невозможно. Если вам нужна четкая постановка проблем и определенные цели, необходимо подобрать правильно определенные метрики, отвечающие этим целям. Решение, какую метрику включить в список, не всегда очевидно, поэтому давайте обсудим несколько вопросов, которые помогут вам его принять.
Допустим, мы написали код на C#. Что дальше? Дальше компилируем его с помощью компилятора C# и запускаем в среде выполнения .NET, использующей компилятор JIT, чтобы перевести код на промежуточном языке (Intermediate Language, IL) в команды архитектуры процессора4. Он будет выполняться на устройстве с определенным объемом оперативной памяти и определенной пропускной способностью сетевой конфигурации.
Исходный код — это первое, что вам следует рассмотреть, исходная точка исследования производительности. Также в этот момент можно начать говорить о производительности. Например, можно сделать асимптотический анализ и описать сложность вашего алгоритма с помощью индекса большого О3.
Возможно, вы когда-нибудь слышали о гольфе по производительности2. Вам дают простую задачу, которая решается легко, но необходимо найти самое быстрое и самое эффективное из решений. Если ваше решение быстрее решения вашего друга на несколько наносекунд, то, чтобы продемонстрировать различия, используется бенчмаркинг. При этом очень важно понимать, как грамотно работать с входными данными и окружением (ваше решение может быть самым быстрым только в определенных условиях). Бенчмаркинг для развлечения служит прекрасным способом развеяться после недели рутинной работы.
2. Подводные камни бенчмаркинга
Если вы изучали результат бенчмарка меньше недели, скорее всего, он неверный.
Брендан Грегг, автор книги Systems Performance: Enterprise and the Cloud (Prentice Hall, 2013)
В этой главе мы обсудим самые распространенные ошибки, совершаемые при попытках измерить производительность. Если вы хотите писать бенчмарки, вам необходимо смириться с фактом, что в большинстве случаев вы будете ошибаться. К сожалению, универсального надежного способа удостовериться в том, что вы получите те измерения производительности, которые хотели, не существует. Подводные камни появляются на разных уровнях: компилятор C#, среда исполнения .NET, процессор и т.д. Вы также узнаете о подходах и техниках, которые помогут писать надежные и корректные бенчмарки.
Бóльшая часть подводных камней особенно неприятна в случае микробенчмарков с очень коротким временем работы (такие методы могут длиться миллисекунды, микросекунды и даже наносекунды). То, что мы обсудим, относится не только к микробенчмаркам, но и ко всем прочим видам бенчмарков. Однако сосредоточимся в основном на микробенчмарках по следующим причинам.
• Простейшие микробенчмарки состоят всего из нескольких строчек кода. Чтобы понять, что происходит в каждом примере, обычно требуется не больше одной минуты. Однако простота обманчива. Вы увидите, как сложно проводить измерения даже на очень простых фрагментах кода.
• Микробенчмарки обычно становятся первым шагом в мир бенчмаркинга, который совершают разработчики. Если хотите писать качественные бенчмарки в реальной жизни, нужно научиться писать микробенчмарки. Стандартные действия одинаковы в обоих случаях, а учиться гораздо проще на небольших примерах.
В этой главе мы рассмотрим некоторые из самых распространенных ошибок при микробенчмаркинге. В каждом примере вы увидите подраздел «Плохой бенчмарк». В нем описывается бенчмарк, который может показаться нормальным некоторым разработчикам, особенно если у них нет опыта в данной области, но он выдает плохие результаты. После этого будет представлен «бенчмарк получше». Обычно он все еще неидеален, у него есть определенные недостатки, но он демонстрирует, в каком направлении двигаться, чтобы улучшить ваши бенчмарки. Можно сказать, что если в плохом бенчмарке N ошибок, то в бенчмарке получше — максимум N – 1 ошибка. Надеюсь, такие примеры помогут понять, как избегать подобных ошибок.
И еще одно: если вы хотите получить не просто знания, но и навыки бенчмаркинга, не стоит бездумно пролистывать примеры. Запускайте каждый из них на своем компьютере. Поиграйте с исходным кодом: проверьте его в разных окружениях или поменяйте что-нибудь в коде. Посмотрите на результат и попытайтесь объяснить его для себя прежде, чем прочтете объяснение в книге. Навыки бенчмаркинга можно получить только опытным путем.
Общие подводные камни
Мы начнем с общих подводных камней. Все примеры будут представлены на C#, но соответствующие проблемы относятся не только к .NET, но и ко всем языкам и любой среде исполнения.
Неточные замеры времени
Прежде чем начать изучать подводные камни, поговорим об основах бенчмаркинга. Прежде всего нужно научиться замерять время.
Как измеряется время операции? Ответ на этот вопрос может показаться очевидным. Необходимо получить текущее время перед операцией (спросить у компьютера: «Который час?»), произвести операцию и получить текущее время еще раз. Затем вычесть первое значение из второго и получить затраченное время! Псевдокод может выглядеть примерно так (мы используем var, потому что тип отметки зависит от используемого API):
var startTimestamp = GetTimestamp();
// Что-то сделать
var endTimestamp = GetTimestamp();
var totalTime = endTimestamp – startTimestamp;
Но как именно следует ставить эти отметки времени? Платформа .NET предлагает несколько API для этих целей. Многие разработчики, начинающие писать бенчмарки, используют DateTime.Now:
DateTime start = DateTime.Now;
// Что-то сделать
DateTime end = DateTime.Now;
TimeSpan elapsed = end – start;
Для некоторых сценариев это работает нормально. Однако у DateTime.Now довольно много недостатков.
• Существует огромное количество не особо очевидных вещей, связанных с тем, как компьютер работает со временем. Например, правильное в настоящий момент время может вдруг измениться из-за перехода на зимнее время. Чтобы побороться с этой проблемой, можно использовать DateTime.UtcNow вместо DateTime.Now. Также DateTime.UtcNow работает быстрее, потому что ему не нужно высчитывать часовые пояса.
• Текущее время может быть синхронизировано с Интернетом в случайный момент. Синхронизация происходит довольно часто и запросто может привести к погрешности в несколько секунд.
• Точность DateTime.Now и DateTime.UtcNow невысока. Если ваш бенчмарк выполняется в течение нескольких минут или часов, это может быть не страшно, но если метод занимает меньше 1 мс, это совершенно неприемлемо.
Есть и много других проблем, связанных со временем. Мы их обсудим в главе 9. К счастью, существует другой системный класс System.Diagnostics.Stopwatch. Он разработан для измерения затраченного времени с наилучшим разрешением из возможных. Это лучшее из решений на платформе .NET для замеров времени. Вот пример его использования:
Stopwatch stopwatch = Stopwatch.StartNew();
// Что-то сделать
stopwatch.Stop();
TimeSpan elapsedTime = stopwatch.Elapsed;
Использование методов StartNew() и Stop() — самый удобный способ применения Stopwatch. Внутри они просто вызывают Stopwatch.GetTimestamp() дважды и считают разницу. GetTimestamp() выдает текущее количество тиков времени (абстрактная единица времени, используемая Stopwatch и другими подобными API), которое можно перевести в реальное время с помощью поля Stopwatch.Frequency6. Обычно в этом нет необходимости, но значение количества тиков может пригодиться при микробенчмаркинге (подробнее об этом — в главе 9). Вот пример применения:
long startTicks = Stopwatch.GetTimestamp();
// Что-то сделать
long endTicks = Stopwatch.GetTimestamp();
double elapsedSeconds = (endTicks - startTicks)
* 1.0 / Stopwatch.Frequency;
Со Stopwatch также могут быть проблемы, особенно на старых компьютерах, но это все же лучший API для замеров времени. Когда вы пишете микробенчмарк, полезно знать, как работает логика замеров времени внутри. У вас должны быть ответы на следующие вопросы:
• Каковы точность/разрешение выбранного API?
• Какова возможная разница между двумя последовательными замерами времени? Может ли она быть равна нулю? А намного больше разрешения? А меньше нуля?
• Сколько времени занимает получение одного замера?
Все эти темы и многие детали реализации освещены в главе 9. Не страшно, если вы не помните детали внутреннего устройства Stopwatch, но у вас должны быть ответы на данные вопросы для выбранного вами окружения.
А теперь настало время примеров!
Плохой бенчмарк
Допустим, мы хотим измерить, сколько времени требуется на сортировку списка из 10 000 элементов. Так выглядит плохой бенчмарк, основанный на DateTime:
var list = Enumerable.Range(0, 10000).ToList();
DateTime start = DateTime.Now;
list.Sort();
DateTime end = DateTime.Now;
TimeSpan elapsedTime = end - start;
Console.WriteLine(elapsedTime.TotalMilliseconds);
Этот бенчмарк ужасен: в нем куча проблем, и ему попросту нельзя доверять. Позже мы узнаем, почему он так плох и как исправить все проблемы. Сейчас же смотрим только на разрешение замеров времени.
Займемся вычислениями. На Windows 10 частота обновлений DateTime по умолчанию 64 Гц. Это означает, что мы получаем новое значение один раз в 15,625 мс. Некоторые приложения, например браузер или плеер, могут увеличить эту частоту до 2000 Гц (0,5 мс). Сортировка 10 000 элементов — это довольно быстрая операция на современных компьютерах. Обычно она выполняется быстрее чем за 0,5 мс. Поэтому, если вы используете Windows и закрыли все несистемные приложения, бенчмарк выдаст 0 или ~ 15,625 мс (зависит от вашего везения). Очевидно, что такой бенчмарк бесполезен — эти значения нельзя использовать для оценки производительности метода List.Sort().
Бенчмарк получше
Можно переписать наш пример с помощью Stopwatch:
var list = Enumerable.Range(0, 10000).ToList();
var stopwatch = Stopwatch.StartNew();
list.Sort();
stopwatch.Stop();
TimeSpan elapsedTime = stopwatch.Elapsed;
Console.WriteLine(elapsedTime.TotalMilliseconds);
Такой бенчмарк все еще плох и нестабилен (если запустить его несколько раз, будет большая разница между измерениями), но теперь у нас есть хорошее разрешение замеров времени. Типичное разрешение Stopwatch в Windows — 300–500 нс. Этот код выдает результат 0,05–0,5 мс в зависимости от устройства и среды исполнения, что гораздо ближе к реальному времени сортировки.
Совет
Выбирайте Stopwatch вместо DateTime.
В 99 % случаев основным инструментом для проставления отметок времени должен быть Stopwatch. Конечно, могут возникнуть крайние случаи, требующие других инструментов (мы обсудим их позже), но в простых случаях вам больше ничего не понадобится. Этот совет прост и не требует дополнительных строчек кода. DateTime может пригодиться, только если вам действительно нужно знать текущее время (и в этом случае, скорее всего, следует заняться мониторингом, а не бенчмаркингом). Если реальное текущее время не требуется, используйте правильный API: Stopwatch.
Теперь вы знаете, как написать простой бенчмарк с помощью Stopwatch. Пора узнать, как его запустить.
Неправильный запуск бенчмарка
Вам также нужно знать, как выполнять бенчмарк. Это может казаться совершенно очевидным, но многие разработчики страдают из-за неверных результатов бенчмарка, испорченных из-за того, что программа была неправильно запущена.
Плохой бенчмарк
Откройте свою любимую интерактивную среду разработки, создайте новый проект и напишите следующую простую программу:
var stopwatch = Stopwatch.StartNew();
for (int i = 0; i < 100000000; i++)
{
}
stopwatch.Stop();
Console.WriteLine(stopwatch.ElapsedMilliseconds);
Она ничего полезного не измеряет. Это просто пустой цикл. Результаты такого замера не имеют практической ценности, мы будем использовать его лишь для демонстрации некоторых проблем.
Давайте запустим эту программу. На моем ноутбуке она выдает значения около 400 мс (Windows, .NET Framework 4.6)7. Так в чем же тут главная проблема? По умолчанию каждый новый проект использует конфигурацию отладки (debug mode). Она предназначена для отладки, а не для бенчмаркинга. Многие забывают ее сменить, измеряют производительность сборок для отлаживания и получают неверный результат.
Бенчмарк получше
Переключим в режим релиза (release mode) и запустим этот код еще раз. На моем ноутбуке в этом режиме бенчмарк показывает ~ 40 мс. Разница примерно в десять раз!
Теперь ваша очередь. Запустите пустой цикл в обеих конфигурациях на своем устройстве и сравните результаты.
Совет
Используйте режим релиза без присоединенной программы отладки в стерильном окружении.
У меня есть для вас несколько небольших подсказок. Давайте обсудим все хорошие практики, которых стоит придерживаться, если вам нужны надежные результаты.
• Используйте режим релиза,а не отладки.
При создании нового проекта у вас обычно есть две конфигурации: отладка (debug) и релиз (release). Режим релиза означает, что в файле .csproj значится <Optimize>true</Optimize> или вы применяете /optimize в csc.
Иногда (особенно в случае микробенчмарков) в режиме отладки выбранный вами метод может запускаться в 100 раз медленнее! Никогда не используйте отладочную сборку для бенчмаркинга.
Порой я нахожу в Интернете отчеты о производительности приложений с отдельными результатами для конфигураций: debug и release. Не делайте так! Результаты в режиме отладки не показывают ничего полезного. Компилятор Roslyn добавляет в скомпилированную сборку много дополнительных IL-команд с одной целью — упростить отладку. Оптимизации Just-In-Time (JIT) в режиме отладки тоже недоступны. Производительность отладочной сборки может быть интересна, только если вы разрабатываете инструменты для отладки. В остальных случаях всегда используйте режим релиза.
• Не используйте присоединенную программу для отладки или профайлер.
Советую никогда не применять при бенчмарке присоединенную программу для отладки, например встроенную в среду разработки или внешнюю, такую как WinDbg или gdb. Присоединенный отладчик обычно замедляет ваше приложение. Не в десять раз, как просто в режиме отладки, но все равно результаты могут заметно испортиться. Кстати, если вы используете программу для отладки Visual Studio (нажатием F5), она по умолчанию выключает оптимизацию JIT даже в режиме релиза (эту функцию можно отключить, но по умолчанию она включена). Лучше всего создать бенчмарк в режиме релиза и запустить его в командной строке (например, cmd в Windows).
Другие присоединенные приложения, например профайлеры производительности или памяти, также могут легко испортить общую картину производительности. В случае применения присоединенного профайлера эффект зависит от вида профилирования (например, tracing влияет на скорость сильнее, чем sampling), но он всегда значительнее.
Иногда можно использовать внутренние инструменты для диагностики среды исполнения программы. Например, если запустить mono с аргументами --profile=log:sample, будет создан файл .mlpd с информацией о профиле производительности приложения. Он может пригодиться для анализа относительной производительности (при поиске горячих методов), но абсолютная производительность будет сильно искажена из-за влияния профайлера.
Использовать отладочную сборку со встроенным отладчиком или профайлером нормально, только если вы отлаживаете или профилируете код. Не используйте ее для финального сбора измерений производительности, которые нужно будет анализировать.
• Выключите другие приложения.
Выключите все приложения, кроме процесса бенчмарка и стандартных процессов ОС. Если вы запускаете бенчмарк и в то же время используете среду разработки, это может отрицательно повлиять на результаты бенчмарка. Кто-то может сказать, что в реальной жизни наше приложение будет работать параллельно с другими, поэтому следует измерять производительность в реалистичных условиях. Но у этих условий есть один недостаток: их влияние невозможно предсказать. Если вы хотите работать в реалистичных условиях, нужно как следует проверить, как каждое из сторонних приложений может повлиять на производительность, что не так-то просто (мы обсудим множество полезных инструментов для этого в главе 6). Гораздо лучше проверять производительность в идеальных условиях, когда вас не беспокоят другие приложения.
Когда вы разрабатываете бенчмарк, нормально проводить пробные прогоны напрямую из любимой среды разработки. Но когда собираете конечные результаты, лучше среду разработки отключить и запустить бенчмарк из терминала.
Некоторые бенчмарки выполняются несколько часов. Дожидаться окончания скучно, поэтому многие разработчики любят делать что-то еще во время бенчмаркинга: играть, рисовать смешные картинки в Photoshop или писать новый код. Однако это не лучшая идея. Это может быть нормально, если вы четко понимаете, какие результаты хотите получить и как это может на них повлиять. Например, если вы проверяете гипотезу о том, что один метод работает в 1000 раз медленнее другого, выводы будет трудно испортить сторонними приложениями. Но если вы занимаетесь микробенчмаркингом, чтобы проверить предположение о разнице 5 %, запуск сложных фоновых процессов нежелателен: эксперимент перестанет быть стерильным и его результатам нельзя будет доверять. Конечно, вам может повезти и вы получите правильные результаты. Но вы не можете быть в этом уверены.
Будьте внимательны. Даже если вы отключите все приложения, которые можно завершить, в операционной системе все равно могут работать какие-то сервисы, потребляющие ресурсы процессора. Типичным примером является Защитник Windows (Windows Defender), который может решить произвести какую-нибудь сложную операцию в любой момент. На рис. 2.1 виден типичный шум от процессора в Windows8. Обычно системные процессы не настолько агрессивны, чтобы совсем испортить бенчмарк, но будьте готовы к тому, что некоторые из измерений окажутся намного больше других из-за шума на уровне процессора.
Рис. 2.1. Типичный шум ЦП в Windows
Чтобы избежать подобных ситуаций, следует запускать бенчмарк много раз и собирать все результаты. Процессорный шум может появиться в случайно выбранный момент, поэтому он обычно портит не все измерения, а лишь некоторые. Вы можете удостовериться в том, что окружение стерильно, с помощью дополнительных инструментов, которые отслеживают использование ресурсов. В некоторых случаях подобные инструменты тоже могут повлиять на результаты, поэтому вам все равно нужно выполнять стерильные запуски бенчмарка, а мониторинг применять при дополнительных проверках.
• Используйте режим энергопотребления «высокая производительность».
Если вы занимаетесь бенчмаркингом на ноутбуке, не отключайте его от сети и работайте в режиме максимальной производительности. Давайте снова поиграем с бенчмарком в виде пустого цикла. Отключите питание ноутбука, выберите режим Сохранение энергии и подождите, пока не останется 10 % от заряда батареи. Запустите бенчмарк. Затем подключите питание, выберите режим Высокая производительность и запустите его снова. Сравните результаты. На моем ноутбуке производительность выросла с ~ 140 до ~ 40 мс. Похожая ситуация складывается не только с микробенчмарками, но и с любыми другими приложениями. Попробуйте проверить это на своих любимых программах: сколько времени занимает выполнение различных операций. Надеюсь, что после этого эксперимента вы не станете запускать бенчмарки на ноутбуке с отключенным питанием.
К сожалению, даже если вы запустили бенчмарк правильно, это все равно не означает, что вы получите хорошие результаты. Давайте продолжим рассматривать различные подводные камни микробенчмарков.
Естественный шум
Даже если вы создадите суперстерильное окружение и запустите бенчмарк по всем правилам, от естественного шума все равно никуда не деться. Если запустить бенчмарк дважды, вы почти никогда не получите двух одинаковых результатов. Почему? Существует много источников шума.
• Всегда существуют другие процессы,соревнующиеся за ресурсы компьютера.
Даже если вы остановите все пользовательские процессы, останется много процессов операционной системы (каждый со своим приоритетом), которые нельзя отключить. Вы всегда будете делить с ними ресурсы. И поскольку вы не можете предсказать, что происходит в других процессах, невозможно прогнозировать и их воздействие на ваш бенчмарк.
• Распределение ресурсов недетерминировано.
Операционная система всегда контролирует выполнение вашей программы. Поскольку мы всегда работаем в многопроцессном и многопоточном окружении, невозможно предсказать, как ОС распределит ресурсы. К этим ресурсам относятся процессор, видеокарточка, сеть, диски и т.д. Количество переключений контекста процессов также непредсказуемо, а каждое из них будет ощутимо отражаться на измерениях.
• Структура памяти и случайный порядок распределения адресного пространства.
В момент запуска программы ей выделяется новый фрагмент глобального адресного пространства. Среда исполнения .NET может выделять память в разных местах с различными промежутками между одними и теми же объектами. Это может повлиять на производительность на разных уровнях. Например, выровненный и невыровненный доступ к данным работает за разное время; разные паттерны расположения данных создают различные ситуации в кэше процессора; процессор может использовать смещения объектов в памяти в качестве факторов в эвристических алгоритмах низкого уровня и т.д.
Еще одна интересная функция для обеспечения безопасности в современных операционных системах — это случайный порядок распределения адресного пространства (address space layout randomization, ASLR). Он защищает от вредоносных программ, которые могут эксплуатировать переполнение буфера. Это хорошо с точки зрения безопасности, но вот стабильность замеров времени от этого страдает9.
• Увеличение и ускорение частоты ЦП.
Современный процессор может динамически менять внутреннюю частоту в зависимости от состояния системы. К сожалению, этот процесс также недетерминирован — невозможно предугадать, когда и как изменится частота.
• Внешнее окружение тоже важно.
Я говорю не о версии .NET Framework или вашей операционной системе, а именно о факторах внешней среды, таких как температура. Однажды у моего ноутбука были проблемы с кулером. Он почти сломался, и температура процессора постоянно была повышена. Во время работы ноутбук издал громкий звук и через 10 мин выключился, потому что процессор перегрелся. К счастью, на дворе была зима, а жил я тогда в Сибири. Поэтому я открыл окно, сел на подоконник и работал в куртке, шапке и перчатках. Стоит ли здесь говорить о производительности? Из-за постоянного перегрева все работало очень медленно. И самое главное, скорость была непредсказуемой. Было невозможно запускать бенчмарки, потому что дисперсия значений оказывалась очень высокой.
Конечно же, это была исключительная ситуация, обычно таких ужасных условий не возникает. Вот еще один пример, с которым можно столкнуться в реальной жизни: запуск бенчмарков на облачном сервере. Это вполне нормальные условия для бенчмаркинга, если вас интересует именно производительность в реальных условиях. Важны условия в центре обработки данных провайдера вашего облачного сервиса. Внешних факторов очень много: окружающая температура, механические вибрации и т.д. Мы подробнее обсудим их в главе 3.
Таким образом, разница между похожими измерениями — это нормально, но необходимо всегда помнить о том, насколько значительными могут быть ошибки. В этом разделе мы рассмотрим пример, где естественный шум имеет значение.
Плохой бенчмарк
Допустим, мы хотим проверить, является ли число простым. Попробуем несколько способов и сравним производительность. На данный момент у нас есть только реализация IsPrime, и нам прямо сейчас нужна инфраструктура для бенчмаркинга. Поэтому мы сравниваем производительность двух одинаковых вызовов, чтобы убедиться, что бенчмаркинг работает правильно:
// Это не самый быстрый метод,
// но мы оптимизируем его позже
static bool IsPrime(int n)
{
for (int i = 2; i <= n - 1; i++)
if (n % i == 0)
return false;
return true;
}
static void Main()
{
var stopwatch1 = Stopwatch.StartNew();
IsPrime(2147483647);
stopwatch1.Stop();
var stopwatch2 = Stopwatch.StartNew();
IsPrime(2147483647);
stopwatch2.Stop();
Console.WriteLine(stopwatch1.ElapsedMilliseconds + " vs. " +
stopwatch2.ElapsedMilliseconds);
if (stopwatch1.ElapsedMilliseconds < stopwatch2.ElapsedMilliseconds)
Console.WriteLine("Первый метод быстрее");
else
Console.WriteLine("Второй метод быстрее");
}
Проверьте этот фрагмент у себя на компьютере, запустите его несколько раз.
Я уже проверил, как он работает на моем ноутбуке:
5609 против 5667
Первый метод быстрее.
И запустил его еще раз:
5573 vs. 5490
Второй метод быстрее
Таким образом, получены два показателя производительности для одной и той же программы с разными выводами. Наша основная проблема: мы забыли об ошибках! Если между двумя измерениями есть разница, это не значит, что один метод работает быстрее другого. Стоит проверить, превышает ли разница естественный шум. К сожалению, оценить размеры подобных ошибок непросто. Также непросто их минимизировать (в этой книге вы найдете множество полезных примеров). Обычно они составляют 5–20 % для примитивного бенчмарка, но иногда могут достигать 200–500 %! Поэтому будьте внимательны при сравнении производительности двух методов!
Теперь пора улучшить бенчмарк IsPrime.
Бенчмарк получше
Итак, у нас есть следующие требования.
1. Результаты должны быть стабильными, а выводы каждый раз одинаковыми.
2. Если методы занимают примерно одно и то же время, мы должны получать соответствующее сообщение.
Как это можно реализовать? Мы можем ввести максимально приемлемую ошибку (например, 20 %10 от среднего значения двух измерений) и использовать ее при сравнении:
var error = ((stopwatch1.ElapsedMilliseconds +
stopwatch2.ElapsedMilliseconds) / 2) * 0.20;
if (Math.Abs(stopwatch1.ElapsedMilliseconds -
stopwatch2.ElapsedMilliseconds) < error)
Console.WriteLine("Значительной разницы между методами нет");
else if (stopwatch1.ElapsedMilliseconds < stopwatch2.ElapsedMilliseconds)
Console.WriteLine("Первый метод быстрее");
else
Console.WriteLine("Второй метод быстрее");
Поправьте это в своем фрагменте и попробуйте запустить. Вот мой результат:
542 против 523
Значительной разницы между методами нет
Ура, мы получили правильный результат!
Однако повторю еще раз: это неидеальное решение. С помощью такого кода нельзя определить отклонение в производительности на 5–10 %: если один метод на самом деле работает на 7 % дольше другого, вы этого не заметите. Но он подходит, если разница в производительности двух- или трехкратная и очевидно, какой метод быстрее. Будьте внимательны: он годится не всегда, естественный шум иногда бывает очень сильным.
Совет
Всегда анализируйте случайные ошибки.
Мы не можем предотвратить естественный шум и случайные ошибки, поэтому лучшее, что можем сделать, — правильный анализ. Проведите много итераций бенчмарка, посмотрите на разброс и запомните порядок этих случайных ошибок. Если у вас два разных значения производительности для двух разных методов (в нашем жестоком мире всегда получаются разные цифры), сравните разницу с оценкой естественного шума для каждого метода, прежде чем делать выводы о том, какой метод быстрее (есть ли между ними значительная разница). Мы обсудим статистические методы сравнения распределений в главе 4.
В следующем разделе поговорим о других сюрпризах, наблюдающихся в распределениях измерений.
Сложные распределения
В предыдущих разделах мы обсудили, как достичь стабильных результатов бенчмарка. К сожалению, производительность кода не всегда можно описать с помощью одного числа.
Плохой бенчмарк
Рассмотрим с



















