

Джимшер Челидзе
Искусственный интеллект. С неба на землю
Шрифты предоставлены компанией «ПараТайп»
Редактор Александр Александрович Перемышлин
Дизайнер обложки Александр Александрович Перемышлин
Иллюстратор Александр Александрович Перемышлин
© Джимшер Челидзе, 2025
© Александр Александрович Перемышлин, дизайн обложки, 2025
© Александр Александрович Перемышлин, иллюстрации, 2025
Искусственный интеллект наделал много шума и спекуляций. Кто-то считает его очередным мыльным пузырем, другие же опасаются потерять работу. Крупнейшие западные консалтинговые агентства строят образ ИИ как главного спасителя бизнеса в эпоху кризисов. Из этой книги вы узнаете реальное положение дел: что такое ИИ, что он может, а чего нет, какие технические, организационные и психологические проблемы с ним связаны, и чего нам ждать в ближайшие 10—20 лет.
ISBN 978-5-0064-8598-3
Создано в интеллектуальной издательской системе Ridero
Оглавление
Предисловие
2023 год стал началом третьего и пока самого жаркого лета искусственного интеллекта. Но что делать разработчикам и бизнесу? Стоит ли сокращать людей и полностью доверяться новой технологии? Или это все наносное, и вслед за летом придёт новая ИИ-зима? А как ИИ будет сочетаться с классическими инструментами и практиками менеджмента, управлением проектами, продуктами и бизнес-процессами? Неужели ИИ ломает все правила игры?
Мы погрузимся в эти вопросы, и в процессе размышлений и анализа различных факторов я постараюсь найти на них ответы.
Скажу сразу, здесь будет минимум технической информации. И даже более того, тут могут быть технические неточности. Но данная книга и не про то, какой тип нейросетей выбрать для решения той или иной задачи. Я предлагаю вам взгляд аналитика, управленца и предпринимателя на то, что происходит здесь и сейчас, чего ожидать глобально в ближайшем будущем и к чему готовиться.
Кому и чем может быть полезна эта книга?
— Собственникам и топ-менеджерам компаний.
Они поймут, что такое ИИ, как он работает, куда идут тренды, чего ожидать. То есть смогут избежать главной ошибки в цифровизации — искажённых ожиданий. А значит, смогут лидировать эти направления, минимизировать затраты, риски и сроки.
— ИТ-предпринимателям и основателям стартапов.
Они смогут понять, куда движется отрасль, какие ИТ-продукты и интеграции стоит разрабатывать, с чем придется столкнуться на практике.
— Техническим специалистам из ИТ.
Они смогут посмотреть на вопрос развития не только с технической точки зрения, но и экономической, управленческой. Поймут, почему до 90% ИИ-продуктов остаются невостребованными. Возможно, это поможет им в карьерном развитии.
— Обычным людям.
Они поймут, что их ждет в будущем и стоит ли бояться того, что ИИ их заменит. Спойлер — под угрозой оказались специалисты творческих специальностей.
Наше путешествие пройдет через три большие части.
— Сначала мы разберем, что такое ИИ, с чего все начиналось, какие у него есть проблемы и возможности, какие тренды развиваются, и что нас ждет в будущем. В общем, освоим теорию и долгосрочные перспективы.
— Затем мы рассмотрим синергию ИИ с инструментами системного подхода. Как они влияют друг на друга, в каких сценариях ИИ будет применяться и уже применяется в ИТ-решениях.
— В конце сосредоточимся на практике: примеры и практика.
По любимой моей традиции в книге будут QR-коды (для печатной версии) и активные гиперссылки (для электронной версии) на полезные статьи и интересные материалы.
Что касается самого ИИ, то в написании книги он применялся для демонстрации его работы, и эти фрагменты выделены, а также для поиска идей. Уровень технологии пока недостаточный для того, чтобы использовать информацию, сгенерированную ИИ, как готовый материал. Также важно отметить, что мой основной язык — русский, поэтому все запросы к ИИ я буду делать на русском языке.
Завершить предисловие я хочу благодарностями людям, которые помогали мне:
— Алисе и сыну Валерию;
— моим родителям;
— моему коучу Евгению Бажову;
— моей команде, в особенности Александру Перемышлину;
— моим партнерам и клиентам, которые давали мне пищу для размышлений, в особенности Кириллу Неелову;
— моим коллегам по проектам.
Часть 1. Введение в искусственный интеллект
Глава 1. Знакомство с ИИ
Что такое искусственный интеллект?
Начнем с того, что единого определения не существует. Давайте спросим у самого ИИ, а точнее у нескольких больших языковых моделей (LLM — large language model). Ниже несколько ответов с оригинальной орфографией.
GPT4: «Искусственный интеллект (ИИ) — это свойство искусственных интеллектуальных систем выполнять творческие функции, которые традиционно считаются прерогативой человека. Он связан с наукой и технологией создания интеллектуальных машин, особенно интеллектуальных компьютерных программ. Важно отметить, что ИИ не обязательно ограничивается биологически правдоподобными методами.
В общем плане, искусственный интеллект позволяет компьютерным системам имитировать когнитивные способности человека, такие как обучение и решение задач».
YandexGPT 3 Pro: «Искусственный интеллект (ИИ) — это свойство интеллектуальных систем выполнять творческие функции, традиционно считающиеся прерогативой человека. Это наука и технология создания интеллектуальных машин, особенно компьютерных программ, способных выполнять задачи, требующие человеческого интеллекта, например, решение сложных проблем, обучение на основе опыта, понимание естественного языка и способность адаптироваться к новым ситуациям. ИИ связан с использованием компьютеров для понимания человеческого интеллекта, но не ограничен биологически правдоподобными методами.».
Мне же, как человеку, ближе самое простое и понятное определение: ИИ — это любой математический метод, позволяющий имитировать человеческий или другой интеллект из естественной природы.
То есть ИИ — это огромное количество решений, в том числе и примитивные математические алгоритмы, и экспертные системы на базе правил, и современные ИИ решения на базе статистики.
В данной книге мы будем говорить именно о направлении, которое работает со статистикой и поиском взаимосвязей.
И хотя данное направление родилось где-то в 50-х годах 20 века, нас в первую очередь интересует то, что мы понимаем под этим сегодня, в начале 2020-х. И тут есть три основных направления.
1. Нейросети — математические модели, созданные по подобию нейронных связей мозга живых существ. Собственно, мозг человека — это суперсложная нейросеть, ключевая особенность которой заключается в том, что наши нейроны не ограничиваются состояниями «включен / выключен», а имеют гораздо больше параметров, которые пока не получается оцифровать и применить в полной мере.
2. Машинное обучение (ML) — статистические методы, позволяющие компьютерам улучшить качество выполняемой задачи с накоплением опыта и в процессе дообучения. Это направление известно с 1980-х годов.
3. Глубокое обучение (DL) — это не только обучение машины с помощью человека, который говорит, что верно, а что нет (как мы часто воспитываем детей, это называется обучением с подкреплением), но и самообучение систем (обучение без подкрепления, без участия человека). Это одновременное использование различных методик обучения и анализа данных. Данное направление развивается с 2010-х годов и считается наиболее перспективным для решения творческих задач, и тех задач, где сам человек не понимает четких взаимосвязей. И это как раз все современные и популярные модели, о которых мы много слышим. Но здесь мы вообще не можем предсказать, к каким выводам и результатам придет нейросеть. Манипулировать тут можно лишь тем, какие данные мы «скармливаем» ИИ-модели на входе.
Как обучаются ИИ модели?
Сейчас множество прикладных ИИ-моделей для бизнеса обучается с подкреплением: человек задает входную информацию, нейросеть возвращает ответ, после чего человек ей сообщает, верно она ответила или нет. И так раз за разом.

Подобным же образом работают и так называемые «Капчи» (CAPTCHA, Completely Automated Public Turing test to tell Computers and Humans Apart), то есть графические тесты безопасности на сайтах, вычисляющие, кем является пользователь: человеком или компьютером. Это когда вам, например, показывают разделенную на части картинку и просят указать те зоны, где изображены велосипеды. Или же просят ввести цифры или буквы, затейливым способом отображенные на сгенерированной картинке. Кроме основной задачи (тест Тьюринга), эти данные потом используются для обучения ИИ.
При этом существует и обучение без учителя, при котором система обучается без обратной связи со стороны человека. Это самые сложные проекты, но они позволяют решать и самые сложные, творческие задачи. Как раз ChatGPT и другие аналогичные решения являются продуктом такого обучения. Тут важно структурировать и разметить данные, которые мы используем для обучения ИИ.
Общие недостатки текущих решений на основе ИИ
Фундаментально все решения на базе ИИ на текущем уровне развития имеют общие проблемы.
— Объем данных для обучения.
Нейросетям нужны огромные массивы качественных и размеченных данных для обучения. Если человек может научиться отличать собак от кошек на паре примеров, то ИИ нужны тысячи.
— Зависимость от качества данных.
Любые неточности в исходных данных сильно сказываются на конечном результате. Нейросети просто собирают данные и не анализируют факты, их связанность.
— Этическая составляющая.
Для ИИ нет этики. Только математика и выполнение задачи. В итоге возникают сложные этические проблемы. Например, кого сбить автопилоту в безвыходной ситуации: взрослого, ребенка или пенсионера? Подобных споров бесчисленное множество. Для искусственного интеллекта нет ни добра, ни зла ровно так же, как и понятия «здравый смысл».
— Нейросети не могут оценить данные на реальность и логичность, а также склонны к генерации некачественного контента и ИИ-галлюцинаций.
Они допускают большое количество ошибок, что приводит к двум проблемам.
Первая — деградация поисковиков. ИИ создал столько некачественного контента, что поисковые системы (Google и другие) начали деградировать. Просто из-за того, что некачественного контента стало больше, он доминирует. Особенно здесь помогают SEO-оптимизаторы сайтов, которые просто набрасывают популярные запросы для продвижения.
Вторая — деградация ИИ-моделей. Генеративные модели используют Интернет для «дообучения». В итоге люди, используя ИИ и не проверяя за ним, сами заполняют Интернет некачественным контентом. А ИИ начинает использовать его. В итоге получается замкнутый круг, который приводят ко все большим проблемам.
Также по QR-коду и гиперссылке доступна статья на эту тему.

Осознавая проблему генерации ИИ наибольшего количества дезинформационного контента, компания Google провела исследование на эту тему. Учеными было проанализировано около двухсот статей СМИ (с января 2023 года по март 2024 года) о случаях, когда искусственный интеллект использовали не по назначению. Согласно результатам, чаще всего ИИ используют для генерации ненастоящих изображений людей и ложных доказательств чего-либо.
— Качество «учителей».
Почти все нейросети обучают люди: формируют запросы и дают обратную связь. И здесь много ограничений: кто и чему учит, на каких данных, для чего?
— Готовность людей.
Нужно ожидать огромного сопротивления людей, чью работу заберут нейросети.
— Страх перед неизвестным.
Рано или поздно нейросети станут умнее нас. И люди боятся этого, а значит, будут тормозить развитие и накладывать многочисленные ограничения.
— Непредсказуемость.
Иногда все идет как задумано, а иногда (даже если нейросеть хорошо справляется со своей задачей) даже создатели изо всех сил пытаются понять, как же алгоритмы работают. Отсутствие предсказуемости делает чрезвычайно трудным устранение и исправление ошибок в алгоритмах работы нейросетей. Мы только учимся понимать то, что сами создали.
— Ограничение по виду деятельности.
Весь ИИ на середину 2024 года слабый (мы разберем этот термин в следующей главе). Сейчас алгоритмы ИИ хороши для выполнения целенаправленных задач, но плохо обобщают свои знания. В отличие от человека, ИИ, обученный играть в шахматы, не сможет играть в другую похожую игру, например, шашки. Кроме того, даже глубокое обучение плохо справляется с обработкой данных, которые отклоняются от его учебных примеров. Чтобы эффективно использовать тот же ChatGPT, необходимо изначально быть экспертом в отрасли и формулировать осознанный и четкий запрос.
— Затраты на создание и эксплуатацию.
Для создания нейросетей требуется много денег. Согласно отчету Guosheng Securities, стоимость обучения относительно примитивной LLM GPT-3 составила около 1,4 миллиона долларов. Для GPT-4 суммы уже уходят в десятки миллионов долларов.
Если взять для примера именно ChatGPT3, то только для обработки всех запросов от пользователей нужно было больше 30000 графических процессоров NVIDIA A100. На электроэнергию уходило около 50000 долларов ежедневно. Требуются команда и ресурсы (деньги, оборудование) для обеспечения их «жизнедеятельности». Также необходимо учесть затраты на инженеров для сопровождения.
Опять же, это общие недостатки для всех ИИ решений. Дальше мы будем возвращаться к этой теме несколько раз и проговаривать эти недостатки в более прикладных примерах.
Глава 2. Виды искусственного интеллекта
По видам решаемых задач
Генеративный
Генеративный ИИ способен создавать новый контент (изображения, текст, звуки и т. д.) по запросу пользователя. Например, чат-боты для общения, генерации картинок, видео, музыки, рекомендаций и т. д. Ему в книге будет посвящен специальный раздел.
Классифицирующий
Способен классифицировать данные на основе определенных критериев.
Он может обучаться на размеченных данных и использовать различные алгоритмы для принятия решений. Например, отделение кошек от собак, определение соответствует изделие требованиям по габаритам или нет, находится человек в опасной зоне со средствами индивидуальной защиты или нет, является ли письмо спамом, определение состояния здоровья и т. д.
Предиктивный / рекомендательный
Способен предсказывать будущие события или результаты на основе имеющихся данных и статистического анализа. Например, предсказание о скором отказе оборудования, о будущей урожайности, о возможных наследственных заболеваниях и так далее.
Иногда еще выделяют рекомендательный ИИ, который не просто предсказывает, а готовит рекомендации, что делать, но я отнесу его к предиктивному.
По «силе» и работе с неопределенностью
Теперь про три понятия — слабый, сильный и суперсильный ИИ.
Слабый ИИ
Все что мы с вами наблюдаем сейчас — слабый ИИ (ANI, Narrow AI). Он может решать узкоспециализированные задачи, для которых изначально проектировался. Например, он может отличать собаку от кошки, играть в шахматы, анализировать видео и улучшать качество видео / звука, консультировать по предметной области и т. д. Но, например, самый сильный слабый ИИ для игры в шахматы абсолютно бесполезен для игры в шашки. А ИИ для консультирования по управлению проектами абсолютно бесполезен для планирования технического обслуживания оборудования.

Сильный и суперсильный ИИ
Если с определением, что такое ИИ, все запутанно, то с термином «сильный ИИ» или «общий ИИ» все еще сложнее. Я приведу определение, которое, на мой взгляд, точнее всего определяет его суть.
Сильный или общий ИИ (AGI) — это ИИ, который может ориентироваться в меняющихся условиях, моделировать и прогнозировать развитие ситуации. А если ситуация выходит за стандартные алгоритмы, то самостоятельно найти ее решение. Например, решить задачу «поступить в университет» или изучить правила игры в шашки, и вместо шахмат начать играть в шашки. То есть это ИИ, который способен решать любые интеллектуальные задачи наравне с человеком, обладает универсальностью вместо узкой специализации и истинным пониманием, а не имитацией паттернов, а также способен к обучению, рассуждениям и творчеству.
Какими же качествами должен обладать такой ИИ?
Мышление — использование таких методов, как дедукция, индукция, ассоциация и т.д., которые направлены на выделение фактов из информации, их представление (сохранение). Это позволит точнее решать задачи в условиях неопределенности.
Память — использование различных типов памяти (кратковременная, долговременная). То есть задачи должны решаться с учетом накопленного опыта. Сейчас же, если вы пообщаетесь с ChatGPT 4, то увидите, что алгоритм обладает небольшой краткосрочной памятью и через некоторое время забывает, с чего все начиналось. Вообще, по моему мнению, вопрос памяти и «массивности» ИИ-моделей станет ключевым ограничением в развитии ИИ. Об этом чуть ниже.
Планирование — тактическое и стратегическое. Да, уже есть исследования, которые утверждают, что ИИ может планировать свои действия и даже обманывать человека для достижения своих целей. Но сейчас это все равно только в стадии зарождения. Чем глубже происходит планирование, особенно в условиях неопределенности, тем больше нужно мощностей. Ведь одно дело планировать игру в шахматы на 3—6 шагов в глубину, где все правила четкие, а другое в ситуации неопределенности.
Обучение — имитация действий другого объекта и обучение через проведение экспериментов. Сейчас ИИ учится на больших массивах данных, но он сам не моделирует и не проводит эксперименты. Хотя мы не до конца понимаем, как работает тот же Chat GPT, и это одна из главных проблем, обучение требует формирования долгосрочной памяти и сложных взаимосвязей. А это, как мы поняли, проблема для ИИ.
И вот такого сильного ИИ сейчас нет ни у кого. А заявление о скором (в горизонте 2024—2028 годов) появлении сильного ИИ, на мой взгляд, ошибочны или спекулятивны. Хотя, может, я обладаю слишком ограниченным знанием…
Да, ChatGPT от OpenAI и другие LLM умеют генерировать текст / иллюстрацию / видео через анализ запроса и обработку больших данных. Они ищут наиболее подходящие варианты сочетания слов и предложений, слов и изображений к запросу, в общем, ассоциативные сочетания, которые сформировались на стадии обучения. Но не стоит питать иллюзии, это лишь математика и статистика, а в их ответах много «брака» и «галлюцинаций». К реальному взаимодействию с миром они еще не готовы.
Приведу простой пример примера на базе LLM. Во время своего первого путешествия по Китаю я использовал китайскую ИИ-модель, подключенную к китайскому Интернету. И когда я просил ИИ проложить маршрут в метро Пекина из точки А в точку Б, то почти каждый раз он ошибался.
Однако, имея в наличии только слабый ИИ и мечтая о более-менее сильном, уже сейчас различные исследователи в своей классификации выделяют суперсильный ИИ (ASI, Artificial Superintelligence).
Это такой ИИ, который:
— может решать как рутинные, так и творческие задачи;
— моментально ориентируется в неопределенности даже без подключения к сети Интернет;
— адаптирует решение задач к контексту обстоятельств и доступных возможностей / ресурсов;
— понимает эмоции людей (не только через текстовый запрос, но и на основе анализа мимики, тембра голоса и других параметров) и учитывает их в работе;
— способен самостоятельно взаимодействовать с реальным миром для решения задач.
Это такой ИИ, который мы видим пока что только в фантастических фильмах. Даже сам ИИ пишет об ASI как о «гипотетической концепции» и «предмете научной фантастики и активных исследований в области искусственного интеллекта». Это некоторая желаемая точка в далеком будущем, достигнуть которую пока не представляется возможным.
Суперсильный ИИ, или ASI, будет иметь возможность понимать и обрабатывать множество типов данных (текст, изображения, звук, видео), что позволит ему выполнять сложные задачи и принимать решения. Он будет использовать продвинутые технологии ИИ, такие как многомерные языковые модели (LLMs), многоразрядные нейронные сети и эволюционные алгоритмы.
В настоящее время ASI остается концептуальным и спекулятивным этапом развития ИИ, но он представляет собой значительный шаг вперед от текущего уровня ИИ.
И если слабых ИИ сейчас сотни, под каждую задачу, то сильных ИИ будут лишь десятки (скорее всего произойдет разделение по направлениям, мы это рассмотрим в следующем блоке), а суперсильный ИИ будет одним на государство или вообще всю планету.
Ограничения на пути к сильному ИИ
Если быть честным, я мало верю в быстрое появление сильного или суперсильного ИИ.
Во-первых, это очень затратная и сложная задача с точки зрения регуляторных ограничений. Эпоха бесконтрольного развития ИИ заканчивается. На него будет накладываться все больше ограничений. На тему регулирования ИИ мы поговорим в отдельной главе.
Ключевой тренд — риск-ориентированный подход. Так, в риск-ориентированном подходе сильный и суперсильный ИИ будут на верхнем уровне риска. А значит, и меры со стороны законотворчества будут заградительными.
Во-вторых, это сложная задача с технической точки зрения, причем сильный ИИ будет и очень уязвимым.
Сейчас, в середине 2020-х, для создания и обучения сильного ИИ нужны гигантские вычислительные мощности. Так, по мнению Леопольда Ашенбреннера, бывшего сотрудник OpenAI из команды Superalignment, потребуется создание дата-центра стоимостью в триллион долларов США. А его энергопотребление превысит всю текущую электрогенерацию США.
На тему энергопотребления в середине 2025 года высказался и Эрик Шмидт, бывший генеральный директор Google. Он выступил перед Комитетом по энергетике и торговле Палаты представителей американского парламента. Шмидт говорил о необходимости получения больших объемов энергии для питания центров обработки данных (ЦОД) с искусственным интеллектом. По словам Шмидта, средняя АЭС в США вырабатывает порядка 1 ГВт, при этом уже есть проекты ЦОД на 10 ГВт. Согласно одной из наиболее вероятных оценок Шмидта, дата-центрам к 2027 году потребуется еще 29 ГВт, а к 2030 году — все 67 ГВт. Для понимания масштаба — на 1 января 2025 года общая установленная мощность электростанций энергосистемы России составила 269 ГВт.
Если вернуться к теме сильного ИИ и сложности его создания, то нужны и сложные ИИ-модели (на порядки сложнее нынешних), и их сочетание (не только LLM для анализа запросов, а мультиагентные решения на разных принципах, но об этом позже). То есть придется экспоненциально увеличивать количество нейронов, выстраивать связи между нейронами, а также координировать работу различных сегментов и моделей.
При этом надо понимать, что если человеческие нейроны могут быть в нескольких состояниях, а активация может происходить «по-разному» (да простят меня биологи за такие упрощения), то машинный ИИ — упрощенная модель, которая так не умеет. Условно говоря, машинные 80—100 млрд нейронов не равны человеческим 80—100 млрд. Машине потребуется больше нейронов для решения аналогичных задач. Тот же GPT4 оценивают в 100 трлн параметров (условно нейронов), и он все равно уступает человеку.
Все это приводит к нескольким факторам.
Первый фактор — рост сложности всегда приводит к проблемам надежности, увеличивается количество точек отказа.
Сложные ИИ-модели трудно как создавать, так и поддерживать от деградации во времени, в процессе работы. ИИ-модели нужно постоянно «обслуживать». Если этого не делать, то сильный ИИ начнет деградировать, а нейронные связи будут разрушаться, это нормальный процесс. Любая сложная нейросеть, если постоянно не развивается, начинает разрушать ненужные связи. При этом поддержание взаимосвязей между нейронами — энергозатратная задача. ИИ всегда будет оптимизироваться и искать наиболее эффективное решение задачи, а значит, начнет отключать ненужные потребители энергии.
То есть ИИ станет похожим на старика с деменцией, а срок «жизни» сильно сократится. Представьте, что может натворить сильный ИИ с его возможностями, но который при этом будет страдать потерей памяти и резкими откатами в состояние ребенка? Даже для текущих ИИ-решений это актуальная проблема.
Давайте приведем пару простых примеров из жизни.
Можно сравнить создание сильного ИИ с тренировкой мышц человека. Когда мы только начинаем заниматься в спортивном зале и увлекаться силовыми занятиями, бодибилдингом, то прогресс идет быстро, но чем дальше, тем ниже КПД и рост результатов. Нужно все больше ресурсов (времени, нагрузок и энергии из пищи) для прогресса. Да даже просто удержание формы становится все более сложной задачей. Плюс рост силы идет от толщины сечения мышцы, а вот масса растет от объема. В итоге мышца в определенный момент станет настолько тяжелой, что не сможет сама себя двигать, а может даже и сама себя повредить.
Еще один пример сложности создания, но уже из области инженерии — гонки Формулы 1. Так, отставание в 1 секунду можно устранить, если вложить 1 млн и 1 год. Но вот чтобы отыграть решающие 0,2 секунды, может потребоваться уже 10 млн и 2 года работы. А фундаментальные ограничения конструкции машины могут заставить вообще пересмотреть всю концепцию гоночной машины.
И даже если посмотреть на обычные машины, то все точно так же. Современные автомобили дороже и создавать, и содержать, а без специального оборудования невозможно поменять даже лампочку. Если взять современные гиперкары, то после каждого выезда требуются целые команды техников для обслуживания.
Если все же посмотреть с точки зрения разработки ИИ, то в этой области есть два ключевых параметра:
— количество слоев нейронов (глубина ИИ-модели);
— количество нейронов в каждом слое (ширина слоя).
Глубина определяет, насколько велика способность ИИ к абстрагированию. Недостаточная глубина модели влечет за собой проблему с неспособностью к глубокому системному анализу, поверхностности этого анализа и суждений.
Ширина слоев определяет число параметров / критериев, которыми может оперировать нейронная сеть на каждом слое. Чем их больше, тем более сложные модели используются и возможно более полное отражение реального мира.
При этом, если количество слоев линейно влияет на функцию, то ширина нет. В итоге мы и получаем ту аналогию с мышцей — размер топовых ИИ-моделей (LLM) переваливает за триллион параметров (по разным оценкам, GPT-5 обладает 3 трлн нейронов), но модели на 2 порядка меньше не имеют критического падения производительности и качества ответов. Важнее то, на каких данных обучена модель и имеет ли она специализацию.
Ниже приведена статистика для LLM моделей от разных производителей.
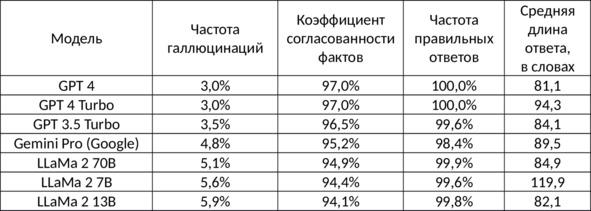
Сравните показатели LLaMa 2 70B, LLaMa 2 7B, LLaMa 2 13B. Показатели 7B, 13B и 70B условно демонстрируют сложность и обученность модели (7, 13 или 70 млрд параметров) — чем выше значение, тем лучше. Но как мы видим, качество ответов от этого радикально не меняется, в то время как цена и трудозатраты на разработку растут существенно.
Мы можем наблюдать, как лидеры наращивают вычислительные мощности, отстраивая новые дата-центры и в спешке решая вопросы энергоснабжения и охлаждения этих монстров. При этом повышение качества модели на условные 2% требует увеличения вычислительных мощностей на порядок.
Теперь практический пример к вопросу поддержания и обслуживания из-за деградации. Тут также будет заметно влияние людей. Любой ИИ, особенно на раннем этапе, будет обучаться на основе обратной связи от людей (их удовлетворенность, начальные запросы и задачи). Например, тот же ChatGPT4 использует запросы пользователей для дообучения своей модели, чтобы давать более релевантные ответы и при этом снизить нагрузку на «мозг». И в конце 2023 года появились статьи, что ИИ-модель стала «более ленивой». Чат-бот либо отказывается отвечать на вопросы, либо прерывает разговор, либо отвечает просто выдержками из поисковиков и других сайтов. Причем к середине 2024 года уже стало нормой, когда модель просто приводит выдержки из Википедии.
Одной из возможных причин этого является упрощение самих запросов от пользователей (они становятся все более примитивными). Ведь LLM не придумывают ничего нового, эти модели пытаются понять, чего вы хотите от них услышать и подстраиваются под это (проще говоря, у них также формируются стереотипы). Они ищут максимальную эффективность связки трудозатраты-результат, «отключая» ненужные нейронные связи. Это называется максимизацией функции. Просто математика и статистика.
Причем такая проблема будет характерна не только для LLM.
Таким образом, чтобы ИИ не стал деградировать, придется загружать его сложными исследованиями, при этом ограничивая его нагрузку примитивными задачами. А стоит его только выпустить в открытый мир, как соотношение задач будет в пользу простых и примитивных запросов пользователей или решения прикладных задач.
Вспомните себя. Действительно ли для выживания и размножения нужно развиваться? Или какое соотношение в вашей работе между интеллектуальными и рутинными задачами? А какого уровня математические задачи на этой работе вы решаете? Вам требуются интегралы и теория вероятности или же только математика до 9-го класса?
Второй фактор — количество данных и галлюцинации.
Да, мы можем увеличить текущие модели в ХХХХ раз. Но тому же прототипу ChatGPT5 уже в 2024 году не хватает данных для обучения. Ему отдали все, что есть. А сильному ИИ, который будет ориентироваться в неопределенности, на текущем уровне развития технологий просто не хватит данных. Необходимо собирать метаданные о поведении пользователей, думать, как обходить ограничения авторских прав и этические ограничения, собирать согласия пользователей.
Кроме того, на примере текущих LLM мы видим еще один тренд. Чем «всезнающее» модель, тем больше у нее неточностей, ошибок, абстракций и галлюцинаций. При этом, если взять базовую модель и дать ей в качестве знаний определенную предметную область, то качество ее ответов повышается: они предметнее, она меньше фантазирует (галлюцинирует) и меньше ошибается.
Третий фактор — уязвимость и затраты.
Как мы рассмотрели выше, нам потребуется создание дата-центра стоимостью в триллион долларов США. А его энергопотребление превысит всю текущую электрогенерацию США. А значит, потребуется и создание энергетической инфраструктуры с целым комплексом атомных электростанций. Да, ветряками и солнечными панелями эту задачу не решить.
Теперь добавим, что ИИ-модель будет привязана к своей «базе», и тогда одна удачная кибератака на энергетическую инфраструктуру обесточит весь «мозг».
А почему такой ИИ должен быть привязан к центру, почему нельзя сделать его распределенным?
Во-первых, распределенные вычисления все равно теряют в производительности и эффективности. Это разнородные вычислительные мощности, которые также загружены другими задачами и процессами. Кроме того, распределенная сеть не может гарантировать работу вычислительных мощностей постоянно. Что-то включается, что-то отключается. Доступная мощность будет нестабильной.
Во-вторых, это уязвимость перед атаками на каналы связи и ту же распределенную инфраструктуру. Представьте, что вдруг 10% нейронов вашего мозга просто отключилась (блокировка каналов связи или просто отключились из-за атаки), а остальные работают вполсилы (помехи и т.д.). В итоге снова имеем риск сильного ИИ, который то забывает, кто он, где он, для чего, то просто долго думает.
А уж если все придет к тому, что сильному ИИ потребуется мобильное (передвижное) тело для взаимодействия с миром, то реализовать это будет еще сложнее. Ведь как все это обеспечивать энергией и охлаждать? Откуда брать мощности для обработки данных? Плюс еще нужно добавлять машинное зрение и распознавание образов, а также обработку других датчиков (температура, слух и т.д.). Это огромные вычислительные мощности и потребность в охлаждении и энергии.
То есть это будет ограниченный ИИ с постоянным подключением к основному центру по беспроводной связи. А это снова уязвимость. Современные каналы связи дают выше скорость, но это сказывается на снижении дальности действия и проникающей способности, уязвимости перед средствами радиоэлектронной борьбы. То есть мы получаем рост нагрузки на инфраструктуру связи и рост рисков.
Тут можно, конечно, возразить. Например, тем, что можно взять предобученную модель и сделать ее локальной. Примерно так же, как я предлагаю разворачивать локальные ИИ-модели с «дообучением» в предметную область. Да, в таком виде все это может работать на одном сервере. Но такой ИИ будет очень ограничен, он будет «тупить» в условиях неопределенности и ему все равно нужна будет энергия и подключение к сети передачи данных. То есть это история не про создание человекоподобных суперсуществ.
Все это приводит к вопросам об экономической целесообразности инвестиций в это направление. Тем более с учетом двух ключевых трендов в развитии генеративного ИИ:
— создание дешевых и простых локальных моделей для решения специализированных задач;
— создание ИИ-оркестраторов, которые будут декомпозировать запрос на несколько локальных задач и затем перераспределять это между разными локальными моделями.
Таким образом, слабые модели с узкой специализацией останутся более свободными и простыми для создания. При этом смогут решать наши задачи. И в итоге мы имеем более простое и дешевое решение рабочих задач, нежели создание сильного ИИ.
Конечно, мы выносим за скобки нейроморфные и квантовые системы, но мы эту тему рассмотрим чуть ниже. И, естественно, в моих отдельных цифрах и аргументах могут быть ошибки, но в целом я убежден, что сильный ИИ — не вопрос ближайшего будущего. А все разговоры о нем — лишь способы поддержания внимания и привлечения инвестиций.
Если резюмировать, то у сильного ИИ есть несколько фундаментальных проблем.
— Экспоненциальный рост сложности разработки и противодействия деградации сложных моделей.
— Недостаток данных для обучения.
— Стоимость создания и эксплуатации.
— Привязанность к ЦОДам и требовательность к вычислительным ресурсам.
— Низкая эффективность текущих моделей по сравнению с человеческим мозгом.
Именно преодоление этих проблем определит дальнейший вектор развития всей технологии: либо все же сильный ИИ появится, либо мы уйдем в плоскость развития слабых ИИ и ИИ-оркестраторов, которые будут координировать работу десятков слабых моделей.
Но сейчас сильный ИИ никак не вяжется с ESG, экологией и коммерческим успехом. Его создание возможно только в рамках стратегических и национальных проектов, финансируемых государством. И вот один из интересных фактов в данном направлении: бывший глава Агентства национальной безопасности США (до 2023 года), генерал в отставке, Пол Накасоне в 2024 году вошел в совет директоров OpenAI. Официальная версия — для организации безопасности Chat GPT.
Также рекомендую прочитать документ под названием «Осведомленность о ситуации: Предстоящее десятилетие». Его автор — Леопольд Ашенбреннер, бывший сотрудник OpenAI из команды Superalignment. Документ доступен по QR-коду и гиперссылке.

Также сокращенный разбор этого документа доступен по QR-коду и гиперссылке ниже.

Если совсем упростить, то ключевые тезисы автора:
— К 2027 году сильный ИИ (AGI) станет реальностью.
Я с этим утверждением не согласен. Мои аргументы приведены выше, плюс некоторые тезисы ниже и описания рисков от авторов говорят о том же. Но опять же, что понимать под термином AGI? Свое определение я уже привел, но единого термина нет.
— AGI сейчас — ключевой геополитический ресурс. Забываем про ядерное оружие, это прошлое. Каждая страна будет стремиться получить AGI первой, как в свое время атомную бомбу.
Тезис спорный. Да, это отличный ресурс. Но как мне кажется, его значение переоценено, особенно с учетом сложности создания и обязательных будущих ошибок в его работе.
— Для создания AGI потребуется единый вычислительный кластер стоимостью в триллион долларов США. Такой уже строит Microsoft для OpenAI.
Помимо вычислительных мощностей нужны еще затраты на людей и решение фундаментальных проблем.
— Этот кластер будет потреблять больше электроэнергии, чем вся выработка США.
Этот тезис мы разобрали выше. Помимо триллиона долларов еще и инвестиции в электрогенерацию, а также появляются риски.
— Финансирование AGI пойдет от гигантов технологий — уже сегодня Nvidia, Microsoft, Amazon и Google выделяют по $100 миллиардов за квартал только на ИИ.
Считаю, что без государственного финансирования и, следовательно, вмешательства тут не обойтись.
— К 2030 году ежегодные инвестиции в ИИ достигнут $8 триллионов.
Отличное наблюдение. Теперь возникает вопрос, оправдано ли это экономически?
Несмотря на весь оптимизм Леопольда Ашенбреннера в области сроков создания AGI, он сам отмечает ряд ограничений:
— Недостаток вычислительных мощностей для проведения экспериментов.
— Фундаментальные ограничения, связанные с алгоритмическим прогрессом
— Идеи становятся все сложнее, поэтому вероятно ИИ-исследователи (ИИ-агенты, которые будут проводить исследования за людей) лишь поддержат текущий темп прогресса, а не увеличат его в разы. Однако Ашенбреннер считает, что эти препятствия могут замедлить, но не остановить рост интеллекта ИИ систем.
В завершение еще добавлю один факт. Сэм Альтман, глава Open AI, в 2025 году уже начал выдвигать мнение, что термин AGI слишком неопределенный и нужно его заменить.
Ко-пилоты, ИИ-агенты и мультиагентные системы
Еще одно направление, которое вы можете встретить и вокруг которого много шума — ко-пилоты, ИИ-агенты и мультиагентные системы.
Обычный чат-бот или сервис, который работает, когда вы его об этом просите и лишь дает рекомендации — это ИИ-ассистент.
Ко-пилот — это решение, которое может автоматизировать отдельные задачи под надзором человека. Например, человек диктует что хочет сделать, а ИИ пишет код или делает презентацию.
ИИ-агент — это ИИ, который может работать автономно и взаимодействовать самостоятельно с другими ИТ-решениями или оборудованием. То есть это расширение возможностей для принятия решений и взаимодействия с внешней средой.
Например, чат-бот на портале банка может спросить клиента, ищет ли он информацию об оплате счетов, тарифах на услуги или увеличении кредитного лимита. А затем через наводящие вопросы, собирая информацию из документов и профиля клиента, бот может предложить ему решение его проблемы. Также он может передать вопрос нужному человеку, если не может решить проблему известными методами.
Такой же подход развивается в направлении технической поддержки ИТ-служб для сотрудников — консультация, а если решения нет, то автоматическое направление задачи необходимому сотруднику со всей историей.
Мультиагентные системы — то же самое, что и агенты, только у нас появляется целое сочетание ИИ-агентов, которые взаимодействуют между собой, и вы их балансируете, устраняете «конфликты» между ними.
Причем, как показывают различные исследования, проблемы в таких системах идентичны тем, что возникают при проектировании организации и взаимодействии людей. Тут необходимо отработать целый ряд факторов:
— набор параметров и ресурсов, с которыми предстоит взаимодействовать;
— модель ролей и взаимодействия — кто, с кем и зачем, с какими целями и возможностями взаимодействует;
— организационные правила — возможные сочетания ролей внутри одного агента;
— организационная структура — топология и модель управления.
То есть, чтобы спроектировать мультиагентную систему, нужно научиться проектировать взаимодействие людей. Потенциал огромен, как и риски, ведь последствия могут быть критическими. Об этом мы поговорим чуть позже.
Поделюсь классификацией ИИ, которую увидел в ИИ-кластере в Пекине (технопарк Чжунгуаньцунь — Zhongguancun).

Они делят ИИ на 5 уровней:
— чат-боты и ассистенты, например, отвечающие по базам знаний (в их маркировке L1);
— рассуждающие модели, которые могут искать сложные решения на неоднозначные вопросы, используя логику (L2);
— создание агентов, способных роботизировать процесс и заменить человека в типовой задаче (например, в середине 2025 года даже лучшие агенты справляются с типовыми задачами без ошибок в 24% случаев) (L3);
— новаторы, которые способны к анализу и созданию нового (L4);
— организованный ИИ, который будет объединять несколько ИИ-моделей и сможет решать нетиповые и сложные задачи, в общем, это мультиагентные системы (L5);
— сильный/общий ИИ, который способен заменить человека и может решать междисциплинарные задачи.
Но это все общее видение, а в реальности в 2025 году мы только пробуем L3, хотя даже L2 работает со сбоями, а в компаниях и бизнесе с их огромной бюрократической инерцией все еще идет базовое осваивание L1.
Глава 3. А что может слабый ИИ и общие тренды
Слабый ИИ в прикладных задачах
Как вы уже, наверно, поняли, я — сторонник использования того, что есть, и с экономической целесообразностью. Возможно, это мой опыт антикризисного управления сказывается или просто ошибочное мнение. Но тем не менее, где можно применять текущий слабый ИИ на базе машинного обучения?
Наиболее релевантными направлениями для применения ИИ с машинным обучением можно обозначить:
— прогнозирование и подготовка рекомендаций для принятия решений;
— анализ сложных данных без четких взаимосвязей, в том числе для прогнозирования и принятия решений;
— оптимизация процессов;
— распознавание образов, в том числе изображений и голосовых записей;
— автоматизация выполнения отдельных задач, в том числе через генерацию контента.
Направление, которое на пике популярности в 2023—2024 годах, — распознавание образов, в том числе изображений и голосовых записей, и генерация контента. Именно сюда идет основная масса разработчиков ИИ и именно таких сервисов больше всего.
При этом особое внимание заслуживает связка ИИ + IoT (Интернет вещей) + Беспроводная связь + Облачные вычисления + Большие данные:
— ИИ получает чистые большие данные, в которых нет ошибок человеческого фактора для обучения и поиска взаимосвязей.
— Эффективность IoT повышается, так как становится возможным создание предиктивной (предсказательной) аналитики и раннего выявления отклонений.
В качестве примера связки больших данных и ИИ уместно привести BlackRock — одного из крупнейших мировых управляющих активами с активами под управлением порядка 11,5–11,6 трлн долларов США на 2025 год. Ключевым технологическим ядром компании является платформа Aladdin — интегрированная система инвестиционного и риск-менеджмента, в которой используются методы ИИ для очистки и интерпретации данных, автоматизации аналитических комментариев и персонализированных рекомендаций, а также для оценки рисков, ликвидности и сценарного анализа. Во время кризиса 2008 года BlackRock по поручению регуляторов США применяла возможности Aladdin для анализа и управления проблемными («токсичными») активами и стресс-тестирования портфелей, что закрепило платформу как отраслевой стандарт управления рисками. Система Alladin — пример рекомендательной системы на базе ИИ.
Ключевые тренды
— Машинное обучение движется ко все более низкому порогу вхождения.
Одна из задач, которую сейчас решают разработчики, — упрощение создания ИИ-моделей до уровня конструкторов сайтов, где для базового применения не нужны специальные знания и навыки. Создание нейросетей и дата-сайнс уже сейчас развиваются по модели «сервис как услуга», например, DSaaS — Data Science as a Service.
Знакомство с машинным обучением можно начинать с AUTO ML, его бесплатной версией, или DSaaS с проведением первичного аудита, консалтинга и разметкой данных. При этом даже разметку данных можно получить бесплатно. Все это снижает порог вхождения.
Также к этому можно отметить прорыв, который пришел с большими языковыми моделями. Теперь взаимодействовать с ИИ, строить аналитику и тому подобное может любой человек — порог вхождения чрезвычайно низкий.
— Создание нейросетей, которым нужно все меньше данных для обучения.
Несколько лет назад, чтобы подделать ваш голос, требовалось предоставить нейросети один-два часа записи вашей речи. Года два назад этот показатель снизился до нескольких минут. Ну, а в 2023 году компания Microsoft представила нейросеть, которой достаточно уже трех секунд для подделки.
Плюс появляются инструменты, с помощью которых можно менять голос даже в онлайн режиме.
— Снижение требовательности к ИТ-ресурсам
Еще один общий тренд для ИИ-направления — сжатие ИИ-моделей, чтобы их можно было запускать на менее мощных устройствах: ноутбуки, смартфоны, автомобили и так далее. Поэтому инвестиции в ИТ-инфраструктуру сейчас позволят использовать его долго, так как на той же мощности можно будет развертывать уже по несколько моделей.
— Мультимодальность
Обработка текста и аудио, изображений на входе, генерация комбинированных ответов на выходе — одно из базовых условий для создания современных решений. Эта механика становится обязательной для всех.
— Создание систем поддержки и принятия решений, в том числе отраслевых.
Будут создаваться отраслевые нейросети, и все активнее станут развиваться направление рекомендательных сетей, так называемые «цифровые советники» или решения класса «системы поддержки и принятия решений (DSS) для различных бизнес-задач».
Практический пример
Этот кейс мы рассмотрим еще не раз, так как это моя личная боль и тот продукт, над которым я работаю.
В проектном управлении существует проблема — 70% проектов либо проблемные, либо провальные.
— среднее превышение запланированных сроков наблюдается в 60% проектов, а среднее превышение на 80% от изначального срока;
— превышение бюджетов наблюдается в 57% проектов, а среднее превышение составляет 60% от изначального бюджета;
— недостижение критериев успешности — в 40% проектов.
При этом управление проектами уже занимает до 50% времени руководителей, а к 2030 году этот показатель достигнет 60%. Хотя еще в начале 20 века этот показатель был 5%. Мир становится все более изменчивым, и количество проектов растет. Даже продажи становятся все более «проектными», то есть комплексными и индивидуальными.
А к чему приводит такая статистика проектного управления?
— Репутационные потери.
— Штрафные санкции.
— Снижение маржинальности.
— Ограничение роста бизнеса.
При этом наиболее типовые и критичные ошибки:
— нечеткое формулирование целей, результатов и границ проекта;
— недостаточно проработанные стратегия и план реализации проекта;
— неадекватная организационная структура управления проектом;
— дисбаланс интересов участников проекта;
— неэффективные коммуникации внутри проекта и с внешними организациями.
Как решают эту задачу люди? Либо ничего не делают и страдают, либо идут учиться и используют трекеры задач.
При этом у обоих подходов есть свои плюсы и минусы. Например, классическое обучение дает возможность в ходе живого общения с учителем задавать вопросы и отрабатывать на практике различные ситуации. При этом оно дорого стоит и обычно не подразумевает дальнейшего сопровождения после окончания курса. Трекеры задач же, напротив, всегда под рукой, но при этом не адаптируются под конкретный проект и культуру компании, не способствуют выработке компетенций, а напротив, призваны для контроля работы.
В итоге, проанализировав свой опыт, я пришел к идее цифрового советника — искусственного интеллекта и предиктивных рекомендаций «что сделать, когда и как» за 10 минут для любого проекта и организации. Проектное управление становится доступным для любого руководителя условно за пару тысяч рублей в месяц.
В модель ИИ заложена методология управления проектами и наборы готовых рекомендаций. ИИ будет готовить наборы рекомендаций и постепенно самообучаться, находить все новые закономерности, а не привязываться к мнению создателя и того, кто будет обучать модель на первых этапах.
Глава 4. Генеративный ИИ
Что такое генеративный искусственный интеллект?
Ранее мы рассмотрели ключевые направления для применения ИИ:
— прогнозирование и принятие решений;
— анализ сложных данных без четких взаимосвязей, в том числе для прогнозирования;
— оптимизация процессов;
— распознавание образов, в том числе изображений и голосовых записей;
— генерация контента.
Направления ИИ, которые сейчас на пике популярности



















