

автордың кітабын онлайн тегін оқу Глоссариум по искусственному интеллекту и информационным технологиям
Александр Юрьевич Чесалов
Глоссариум по искусственному интеллекту и информационным технологиям
Шрифты предоставлены компанией «ПараТайп»
Иллюстратор Dzmitry Ryzhykau | Dreamstime
Дизайнер обложки Александр Юрьевич Чесалов
Редактор Хаджимурад Ахмедович Магомедов
© Александр Юрьевич Чесалов, 2024
© Dzmitry Ryzhykau | Dreamstime, иллюстрации, 2024
© Александр Юрьевич Чесалов, дизайн обложки, 2024
В этой небольшой, но, как мне кажется, очень полезной книге я хочу предложить вам краткий словарь из более чем 1000 терминов и определений по искусственному интеллекту и информационным технологиям (на русском и английском языках). Он поможет сориентироваться во всем многообразии новых терминов и определений в период активных цифровых трансформаций и применения технологий четвертой промышленной революции.
ISBN 978-5-0055-8957-6
Создано в интеллектуальной издательской системе Ridero
Оглавление
От Автора-составителя
Александр Юрьевич Чесалов
Доктор технических наук, Член-Корреспондент РАЕН,
Разработчик программы Центра искусственного интеллекта МГТУ им. Н. Э. Баумана, программы «Искусственный интеллект» и «Глубокая аналитика» проекта «Приоритет 2030» МГТУ им. Н. Э. Баумана в 2021—2022 годах.
Сертифицированный специалист: IBM Professional certificate foundations of AI, IBM Professional certificate Essential Technologies for Business и др.
Добрый день, дорогие друзья и коллеги!
2021 — 2022 годы выдались для меня не просто жаркими, но и щедрым на разные события, которые оказали на меня и мою повседневную работу огромное влияние.
Первое из них и, пожалуй, самое существенное событие — это мое участие в Конкурсе, проводимом Аналитическим Центром при Правительстве России по отбору получателей поддержки исследовательских центров в сфере искусственного интеллекта, в том числе в области «сильного» искусственного интеллекта, систем доверенного искусственного интеллекта и этических аспектов применения искусственного интеллекта, в качестве менеджера и специалиста перед которым была поставлена задача создать Центр разработки и внедрения сильного и прикладного искусственного интеллекта МГТУ им. Н. Э. Баумана, разработать и написать программу и план мероприятий Центра. Этому знаменательному событию я посвятил целую книгу «Как создать центр искусственного интеллекта за 100 дней». Информацию о ней вы можете найти на моем блоге chesalov.com и сайте ridero.ru.
Второе приятное событие — это мое ежегодное участие в Благотворительной ИТ-конференция «CISummIT Digital Hearts», которая проводится журналом «Современные Информационные Системы» и фондом Константина Хабенского. Конференция «CISummIT Digital Hearts» собирает самых активных участников ИТ-рынка, ведущих производителей и экспертов, чтобы собрать средства для помощи детям с заболеваниями головного мозга.

Третье — это Первый международный форум «Этика искусственного интеллекта: начало доверия», который состоялся 26 октября 2021 года. В рамках этого форума была организована церемония торжественного подписания Национального кодекса этики искусственного интеллекта, а также мне представилась возможность сделать доклад на тему «Роль искусственного интеллекта в образовании».

Как отмечается в самом документе: «Кодекс этики в сфере искусственного интеллекта (далее — Кодекс) устанавливает общие этические принципы и стандарты поведения, которыми следует руководствоваться участникам отношений в сфере искусственного интеллекта (далее — Акторы ИИ) в своей деятельности, а также механизмы реализации положений настоящего Кодекса». Форум стал первой в России специализированной площадкой, где около полутора тысяч разработчиков и пользователей технологий искусственного интеллекта обсудили в рамках пяти параллельных секций шаги по эффективному внедрению этики искусственного интеллекта в приоритетных отраслях экономики Российской Федерации. Вопросы, которые обсуждались на Форуме вызвали у меня, как и у многих других людей, самый что ни на есть живой интерес и, порой, было сложно выбрать кого из докладчиков на какой сессии слушать. На что я обратил свое особое внимание, так это на то, что не остался без внимания вопрос, связанный с религией и искусственным интеллектом.
В 2022 году я принял участие в работе собрания уполномоченных по этике искусственного интеллекта и присоединился к рабочей группе по созданию свода наилучших практик решения возникающих этических вопросов в жизненном цикле искусственного интеллекта.
Четвертое событие — это конечно же Международная конференция по искусственному интеллекту и анализу данных AI Journey, в рамках которой 10 ноября 2021 года компания «Программные системы Атлансис» (Atlansys Software) присоединилась к подписанию Национального Кодекса этики искусственного интеллекта. Число спикеров конференции поразило — их было более двухсот, а число онлайн-посещений сайта более сорока миллионов. Этому мероприятию и темам, которые были представлены докладчиками можно посвятить целую книгу, но я бы порекомендовал читателю ознакомиться с записями выступлений на сайте мероприятия: https://ai-journey.ru/media/broadcast.
К последним, так сказать, приятным событиям я бы отнес свои выступления по направлению «искусственный интеллект» на таких мероприятиях, как Interpolitex и форум по цифровизации оборонно-промышленного комплекса России «ИТОПК».

Посещение первой в истории пленарной дискуссии «Особенности управления правами на результаты интеллектуальной деятельности в сфере технологий искусственного интеллекта», проводимой Министерством обороны Российской Федерации.

А также мой доклад на Международном военно-техническом форуме «Армия-2022» на тему: «Разработка программно-аппаратных комплексов для решения широкого круга прикладных задач с использованием технологий машинного обучения и доверенного искусственного интеллекта в Оборонно-промышленном комплексе РФ».

И последнее из всех — это участие в круглом столе «Информатизация профессиональной юридической деятельности: LegalTech и искусственный интеллект», проводимым Комитетом Совета Федерации по конституционному законодательству и государственному строительству совместно с Советом по развитию цифровой экономики при Совете Федерации.
Резюмируя всю свою активную работу за весь период с 2021 по 2022 годы, могу сказать, что где бы я не выступал с разными докладами по теме «искусственный интеллект», всегда возникали вопросы и жаркие споры среди участников мероприятий и ученых, относящиеся к терминам и определениям. Коллеги часто спорили, что же такое «искусственный интеллект», «сильный искусственный интеллект», что такое «Artificial general intelligence» и как переводить «general» — («сильный» или «общий», а может быть «прикладной»? Много было споров по определению термина «доверенный» искусственный интеллект и так далее.

Как следствием этого, я увидел необходимость в составлении (для себя лично) краткого словаря для помощи в выполнении повседневной работы, который назвал «Глоссариум» по аналогии с латинским словом «glossarium», что означает словарь узкоспециализированных терминов.
Первый вариант этой книги был опубликован в 2021 году и включал порядка 400 терминов. Второй вариант книги был готов уже летом 2022 года и в нее вошло более 1000 терминов и определений. В 2023 году я дополнил книгу новыми актуальными терминами и доработал некоторые старые.
Настоящий краткий словарь по искусственному интеллекту и информационным технологиям, в том числе, включает термины и определения из следующих документов:
— Стратегия развития информационного общества в Российской Федерации на 2017 — 2030 годы [[1]].
— Национальная стратегия развития искусственного интеллекта на период до 2030 года [[2]].
— Указ Президента Российской Федерации от 7 мая 2018 №204 «О национальных целях и стратегических задачах развития Российской Федерации на период до 2024 года» [[3]].
— Федеральный закон от 27.07.2006 N 152-ФЗ (ред. от 24.04.2020) «О персональных данных» [[4]].
— Национальная программа «Цифровая экономика Российской Федерации» [[5]].
— Кодекс этики ИИ [[6]].
— ГОСТы РФ. В том числе ГОСТ 59925 — 2021 «Информационные технологии. Большие данные. Техническое задание. Требования к содержанию и оформлению».
И многих других.
В том числе к ним добавились пара моих книг: «Цифровая трансформация» [[7]] и «Цифровая экосистема Института омбудсмена: концепция, технологии, практика» [[8]], и много других источников (смотри список литературы).
В этой небольшой, но как мне кажется, очень полезной книге я хочу предложить Вам краткий словарь из более чем 1000 терминов и определений по машинному обучению, искусственному интеллекту и информационным технологиям на русском и английском языках. Надеюсь, он поможет Вам сориентироваться во всем многообразии новых терминов и определений в период активных цифровых трансформаций и применения технологий четвертой промышленной революции.
Я, как автор-составитель, не претендую на авторство и уникальность представленных терминов и определений (конечно, коме тех, которые написал сам и сделал на них соответствующие ссылки). Тем не менее, я продолжаю работу в направлении по улучшению и наполнению этой книги новыми терминами и определениями, и, возможно, в ближайшее время, на суд читателя будет представлен более основательный труд.
Ссылки на первоисточники проставлены у оригинальных терминов и определений (т.е. если определение изначально было на английском языке из иностранного источника, то ссылка указывается возле него. Ссылка на тоже определение, переведенное или адаптированное на русский в этом издании не указывается. Это сделано с тем, чтобы не дублировать ссылки, не перегружать текст, не тратить, так сказать, бумагу, путая читателя).
Также, хочу сделать небольшое отступление и проинформировать уважаемого читателя о том, что эта книга является личным проектом автора и абсолютно свободным к распространению документом. Вы можете использовать эту книгу по-своему усмотрению, но ссылка на нее обязательна.
Буду Вам благодарен за любые отзывы, предложения и уточнения. Направляйте их, пожалуйста, на aleksander.chesalov@yandex.ru
Подробно ознакомиться с моей работой и моими проектами в области цифровой экономики, искусственного интеллекта и создания различных ИТ-решений и систем Вы можете на моем персональном сайте chesalov.com.
Приятного Вам чтения и продуктивной работы!
Ваш, Александр Чесалов.
25.12.2021. Издание первое. 400 терминов.
27.06.2022. Издание второе. Дополнено до 1000 терминов.
29.04.2023. Издание третье. Дополнено. Корректировка ссылок.
Национальная программа «Цифровая экономика Российской Федерации». Министерство цифрового развития, связи и массовых коммуникаций Российской Федерации. [Электронный ресурс] // digital.gov.ru. URL: https://digital.gov.ru/ru/activity/directions/858/
Кодекс этики в сфере ИИ. [Электронный ресурс] // a-ai.ru URL: https://a-ai.ru/code-of-ethics/
Чесалов А. Ю. Цифровая трансформация. -М.: Ridero. 2020.-302c. URL: https://ridero.ru/books/cifrovaya_transformaciya_2/
Чесалов А. Ю. Цифровая экосистема Института омбудсмена: концепция, технологии, практика. -М.: Ridero. 2020.-320c. URL: https://ridero.ru/books/cifrovaya_ekosistema_instituta_ombudsmena_koncepciya_tekhnologii_praktika/
Указ Президента Российской Федерации от 09.05.2017 г. №203. О Стратегии развития информационного общества в Российской Федерации на 2017 — 2030 годы. [Электронный ресурс] // www.kremlin.ru. URL: http://kremlin.ru/acts/bank/41919
Указ Президента Российской Федерации от 10.10.2019 г. №490. О развитии искусственного интеллекта в Российской Федерации. [Электронный ресурс] // www.kremlin.ru. URL: http://www.kremlin.ru/acts/bank/44731
.Указ Президента Российской Федерации от 7 мая 2018 №204 «О национальных целях и стратегических задачах развития Российской Федерации на период до 2024 года».
Федеральный закон от 27.07.2006 N 152-ФЗ (ред. от 24.04.2020) «О персональных данных». [Электронный ресурс] // legalacts.ru URL: https://legalacts.ru/doc/152_FZ-o-personalnyh-dannyh/
Указ Президента Российской Федерации от 09.05.2017 г. №203. О Стратегии развития информационного общества в Российской Федерации на 2017 — 2030 годы. [Электронный ресурс] // www.kremlin.ru. URL: http://kremlin.ru/acts/bank/41919
Указ Президента Российской Федерации от 10.10.2019 г. №490. О развитии искусственного интеллекта в Российской Федерации. [Электронный ресурс] // www.kremlin.ru. URL: http://www.kremlin.ru/acts/bank/44731
.Указ Президента Российской Федерации от 7 мая 2018 №204 «О национальных целях и стратегических задачах развития Российской Федерации на период до 2024 года».
Федеральный закон от 27.07.2006 N 152-ФЗ (ред. от 24.04.2020) «О персональных данных». [Электронный ресурс] // legalacts.ru URL: https://legalacts.ru/doc/152_FZ-o-personalnyh-dannyh/
Национальная программа «Цифровая экономика Российской Федерации». Министерство цифрового развития, связи и массовых коммуникаций Российской Федерации. [Электронный ресурс] // digital.gov.ru. URL: https://digital.gov.ru/ru/activity/directions/858/
Кодекс этики в сфере ИИ. [Электронный ресурс] // a-ai.ru URL: https://a-ai.ru/code-of-ethics/
Чесалов А. Ю. Цифровая трансформация. -М.: Ridero. 2020.-302c. URL: https://ridero.ru/books/cifrovaya_transformaciya_2/
Чесалов А. Ю. Цифровая экосистема Института омбудсмена: концепция, технологии, практика. -М.: Ridero. 2020.-320c. URL: https://ridero.ru/books/cifrovaya_ekosistema_instituta_ombudsmena_koncepciya_tekhnologii_praktika/
КРАТКИЙ СЛОВАРЬ ПО ИСКУССТВЕННОМУ ИНТЕЛЛЕКТУ И ИНФОРМАЦИОННЫМ ТЕХНОЛОГИЯМ
«А»
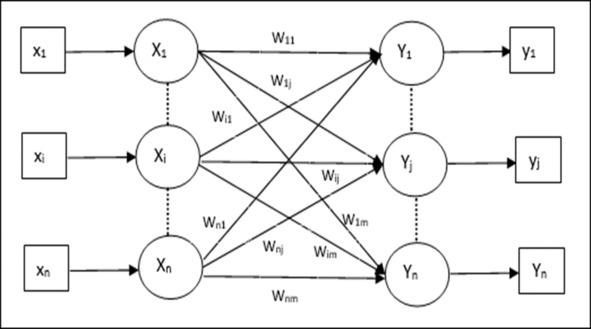
Автоассоциативная память (Auto Associative Memory) — это однослойная нейронная сеть, в которой входной обучающий вектор и выходные целевые векторы совпадают. Веса определяются таким образом, чтобы сеть хранила набор шаблонов. Как показано на следующем рисунке, архитектура сети автоассоциативной памяти имеет «n» количество входных обучающих векторов и аналогичное «n» количество выходных целевых векторов[1].
Автоматизация (Automation) — это технология, с помощью которой процесс или процедура выполняется с минимальным участием человека.
Автоматизированная обработка персональных данных (Automated processing of personal data) — это обработка персональных данных с помощью средств вычислительной техники.
Автоматизированная система (Automated system) — это организационно-техническая система, которая гарантирует выработку решений, основанных на автоматизации информационных процессов во всевозможных отраслях деятельности.
Автоматизированная система управления (Automated control system) — это комплекс программных и программно-аппаратных средств, предназначенных для контроля за технологическим и (или) производственным оборудованием (исполнительными устройствами) и производимыми ими процессами, а также для управления такими оборудованием и процессами.
Автономное транспортное средство (Autonomous vehicle) — это вид транспорта, основанный на автономной системе управления. Управление автономным транспортным средством полностью автоматизировано и осуществляется без водителя при помощи оптических датчиков, радиолокации и компьютерных алгоритмов.
Автономные вычисления (Autonomic computing) — это способность системы к адаптивному самоуправлению собственными ресурсами для высокоуровневых вычислительных функций без ввода данных пользователем.
Автономный искусственный интеллект (Autonomous artificial intelligence) — это биологически инспирированная система, которая пытается воспроизвести устройство мозга, принципы его действия со всеми вытекающими отсюда свойствами.
Адаптивная система (Adaptive system) — это система, которая автоматически изменяет данные алгоритма своего функционирования и (иногда) свою структуру для поддержания или достижения оптимального состояния при изменении внешних условий.
Аддитивные технологии (Additive technologies) — это технологии послойного создания трехмерных объектов на основе их цифровых моделей («двойников»), позволяющие изготавливать изделия сложных геометрических форм и профилей.
Активное обучение/Стратегия активного обучения (Active Learning/Active Learning Strategy) — это особый способ полу управляемого машинного обучения, в котором обучающий агент может в интерактивном режиме запрашивать оракула для получения меток в новых точках данных. Подход к такому обучению основывается на самостоятельном выборе алгоритма некоторых данных из массы тех, на которых он учится. Активное обучение особенно ценно, когда помеченных примеров мало или их получение слишком затратно. Вместо слепого поиска разнообразных помеченных примеров алгоритм активного обучения выборочно ищет конкретный набор примеров, необходимых для обучения.
Алгоритм (Algorithm) — это точное предписание о выполнении в определенном порядке системы операций для решения любой задачи из некоторого данного класса (множества) задач. Термин «алгоритм» происходит от имени узбекского математика Мусы аль-Хорезми, который еще в 9 веке (ок. 820 г. н.э.) предложил простейшие арифметические алгоритмы. В математике и кибернетике класс задач определенного типа считается решенным, когда для ее решения установлен алгоритм. Нахождение алгоритмов является естественной целью человека при решении им разнообразных классов задач. Также, алгоритм — это набор правил или инструкций, данных ИИ, нейронной сети или другим машинам, чтобы помочь им учиться самостоятельно; классификация, кластеризация, рекомендация и регрессия — четыре самых популярных типа.
Алгоритм Q-обучения (Q-learning) — это алгоритм обучения, основанный на ценностях. Алгоритмы на основе значений обновляют функцию значений на основе уравнения (в частности, уравнения Беллмана). В то время как другой тип, основанный на политике, оценивает функцию ценности с помощью жадной политики, полученной из последнего улучшения политики. Табличное Q-обучение (при обучении с подкреплением) представляет собой реализацию Q-обучения с использованием таблицы для хранения Q-функций для каждой комбинации состояния и действия. «Q» в Q-learning означает качество. Качество здесь показывает, насколько полезно данное действие для получения вознаграждения в будущем[2].
Алгоритм любого времени (Anytime algorithm) — это алгоритм, который может дать частичный ответ, качество которого зависит от объема вычислений, которые он смог выполнить. Ответ, генерируемый алгоритмами anytime, является приближенным к правильному. Большинство алгоритмов выполняются до конца: они дают единственный ответ после выполнения некоторого фиксированного объема вычислений. Однако в некоторых случаях пользователь может захотеть завершить алгоритм до его завершения. Эта особенность алгоритмов anytime моделируется такой теоретической конструкцией, как предельная машина Тьюринга (Бургин, 1992; 2005)[3].
Алгоритмическая оценка (Algorithmic Assessment) — это техническая оценка, которая помогает выявлять и устранять потенциальные риски и непредвиденные последствия использования систем искусственного интеллекта, чтобы вызвать доверие и создать поддерживающие системы вокруг принятия решений ИИ.
Алгоритмическая предвзятость (Biased algorithm) — это систематические и повторяющиеся ошибки в компьютерной системе, которые приводят к несправедливым результатам, например, привилегия одной произвольной группы пользователей над другими.
Алгоритмы машинного обучения (Machine learning algorithms) — это фрагменты кода, которые помогают пользователям исследовать и анализировать сложные наборы данных и находить в них смысл или закономерность. Каждый алгоритм — это конечный набор однозначных пошаговых инструкций, которые компьютер может выполнять для достижения определенной цели. В модели машинного обучения цель заключается в том, чтобы установить или обнаружить закономерности, с помощью которых пользователи могут создавать прогнозы либо классифицировать информацию. В алгоритмах машинного обучения используются параметры, основанные на учебных данных (подмножество данных, представляющее более широкий набор). При расширении учебных данных для более реалистичного представления мира с помощью алгоритма вычисляются более точные результаты. В различных алгоритмах применяются разные способы анализа данных. Они часто группируются по методам машинного обучения, в рамках которых используются: контролируемое обучение, неконтролируемое обучение и обучение с подкреплением. В наиболее популярных алгоритмах для прогнозирования целевых категорий, поиска необычных точек данных, прогнозирования значений и обнаружения сходства используются регрессия и классификация[4].
Анализ временных рядов (Time series analysis) — это раздел машинного обучения и статистики, который анализирует временные данные. Многие типы задач машинного обучения требуют анализа временных рядов, включая классификацию, кластеризацию, прогнозирование и обнаружение аномалий. Например, вы можете использовать анализ временных рядов, чтобы спрогнозировать будущие продажи зимних пальто по месяцам на основе исторических данных о продажах.
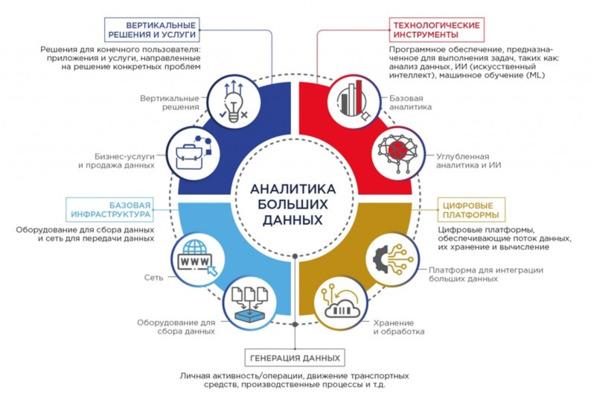
Аналитика больших данных — это методы, инструменты и приложения, которые используются для сбора и обработки больших наборов разнородных, быстро создаваемых данных и извлечения из них ценной информации. Эти данные могут поступать из самых разных источников: браузеров, мобильных приложений, электронной почты, социальных сетей и интеллектуальных сетевых устройств. Зачастую они генерируются с высокой скоростью и не обладают строго определенной формой: они могут быть полностью структурированными (таблицы баз данных или электронные таблицы Excel), частично структурированными (XML-файлы, веб-страницы) и неструктурированными (изображения, аудиофайлы)[5],[6].
Аналитика принятия решений (Decision intelligence) — это практическая дисциплина, используемая для улучшения процесса принятия решений путем четкого понимания и программной разработки того, как принимаются решения, и как итоговые результаты оцениваются, управляются и улучшаются с помощью обратной связи.
Аппаратное обеспечение (Hardware) — это система взаимосвязанных технических устройств, предназначенных для ввода (вывода), обработки и хранения данных.
Аппаратное обеспечение ИИ (AI hardware, AI-enabled hardware, AI hardware platform) — это аппаратное обеспечение ИИ, аппаратные средства ИИ, аппаратная часть инфраструктуры или системы искусственного интеллекта, ИИ-инфраструктуры.
Аппаратно-программный комплекс (Hardware-software complex) — это набор технических и программных средств, работающих совместно для выполнения одной или нескольких сходных задач.
Аппаратный акселератор (Hardware accelerator) — это устройство, выполняющее некоторый ограниченный набор функций для повышения производительности всей системы или отдельной её подсистемы. Например, purpose-built hardware accelerator — специализированный аппаратный ускоритель.
Аппаратный Сервер (аппаратное обеспечение) (Hardware Server) — это выделенный или специализированный компьютер для выполнения сервисного программного обеспечения (в том числе серверов тех или иных задач) без непосредственного участия человека. Одновременное использование как высокопроизводительных процессоров, так и FPGA позволяет обрабатывать сложные гибридные приложения.
Архитектура вычислительной машины (Architecture of a computer) — это концептуальная структура вычислительной машины, определяющая проведение обработки информации и включающая методы преобразования информации в данные и принципы взаимодействия технических средств и программного обеспечения.
Архитектура вычислительной системы (Architecture of a computing system) — это конфигурация, состав и принципы взаимодействия (включая обмен данными) элементов вычислительной системы.
Архитектура механизма обработки матриц (MPE) (Matrix Processing Engine Architecture) — это многомерный массив обработки физических матриц цифровых устройств с умножением (MAC), который вычисляет серию матричных операций сверточной нейронной сети.
Архитектура системы (Architecture of a system) — это принципиальная организация системы, воплощенная в её элементах, их взаимоотношениях друг с другом и со средой, а также принципы, направляющие её проектирование и эволюцию.
Архитектура фон Неймана (модель фон Неймана, Принстонская архитектура) (Von Neumann architecture) — это широко известный принцип совместного хранения команд и данных в памяти компьютера. Вычислительные машины такого рода часто обозначают термином «машина фон Неймана», однако соответствие этих понятий не всегда однозначно. В общем случае, когда говорят об архитектуре фон Неймана, подразумевают принцип хранения данных и инструкций в одной памяти[7].
Архитектурная группа описаний (Architectural description group, Architectural view) — это представление системы в целом с точки зрения связанного набора интересов.
Архитектурный фреймворк (Architectural frameworks) — это высокоуровневые описания организации как системы; они охватывают структуру его основных компонентов на разных уровнях, взаимосвязи между этими компонентами и принципы, определяющие их эволюцию[8].
Асинхронные межкристальные протоколы (Asynchronous inter-chip protocols) — это протоколы для обмена данных в низкоскоростных устройствах; для управления обменом данными используются не кадры, а отдельные символы.
Ассоциация по развитию искусственного интеллекта (Association for the Advancement of Artificial Intelligence) — это международное научное сообщество, занимающееся продвижением исследований и ответственным использованием искусственного интеллекта. AAAI также стремится повысить общественное понимание искусственного интеллекта (ИИ), улучшить обучение и подготовку специалистов, занимающихся ИИ, и предоставить рекомендации для планировщиков исследований и спонсоров относительно важности и потенциала текущих разработок ИИ и будущих направлений.
«Б»
Байесовский классификатор в машинном обучении (Bayesian classifier in machine learning) — это семейство простых вероятностных классификаторов, основанных на использовании теоремы Байеса и «наивном» предположении о независимости признаков классифицируемых объектов. Анализ на основе байесовской классификации активно изучался и использовался начиная с 1950-х годов в области классификации документов, где в качестве признаков использовались частоты слов. Алгоритм является масштабируемым по числу признаков, а по точности сопоставим с другими популярными методами, такими как машины опорных векторов. Как и любой классификатор, байесовский присваивает метки классов наблюдениям, представленным векторами признаков. При этом предполагается, что каждый признак независимо влияет на вероятность принадлежности наблюдения к классу. Например, объект можно считать яблоком, если он имеет округлую форму, красный цвет и диаметр около 10 см. Наивный байесовский классификатор «считает», что каждый из этих признаков независимо влияет на вероятность того, что этот объект является яблоком, независимо от любых возможных корреляций между характеристиками цвета, формы и размера. Простой байесовский классификатор строится на основе обучения с учителем. Несмотря на мало реалистичное предположение о независимости признаков, простые байесовские классификаторы хорошо зарекомендовали себя при решении многих практических задач. Дополнительным преимуществом метода является небольшое число примеров, необходимых для обучения[9].
Башня (Tower) — это компонент глубокой нейронной сети, которая сама по себе является глубокой нейронной сетью без выходного слоя. Как правило, каждая башня считывает данные из независимого источника. Башни независимы до тех пор, пока их выходные данные не будут объединены в последнем слое.
Безопасность критической информационной инфраструктуры (Security of a critical information infrastructure) — это состояние защищенности критической информационной инфраструктуры, обеспечивающее ее устойчивое функционирование при проведении в отношении ее компьютерных атак.
Бенчмаркинг (Benchmarking) — это набор методик, которые позволяют изучить опыт конкурентов и внедрить лучшие практики в своей компании.
Библиотека Keras (Keras Library) — это библиотека Python, используемая для глубокого обучения и создания искусственных нейронных сетей. Выпущенный в 2015 году, Keras предназначен для быстрого экспериментирования с глубокими нейронными сетями. Keras предлагает несколько инструментов, которые упрощают работу с изображениями и текстовыми данными. Помимо стандартных нейронных сетей, Keras также поддерживает сверточные и рекуррентные нейронные сети. В качестве бэкэнда Keras обычно использует TensorFlow, Microsoft Cognitive toolkit или Theano. Он удобен для пользователя и требует минимального кода для выполнения функций и команд. Keras имеет модульную структуру и имеет несколько методов предварительной обработки данных.
Библиотека Matplotlib (Matplotlib) — это комплексная, популярная библиотека Python с открытым исходным кодом для создания визуализаций «качества публикации». Визуализации могут быть статическими, анимированными или интерактивными. Он был эмулирован из MATLAB и, таким образом, содержит глобальные стили, очень похожие на MATLAB, включая иерархию объектов.
Библиотека Numpy (Numpy) — это библиотека Python, представленная в 2006 году для поддержки многомерных массивов и матриц. Библиотека также позволяет программистам выполнять высокоуровневые математические вычисления с массивами и матрицами. Можно сказать, что это объединение своих предшественников — The Numeric и Numarray. NumPy является неотъемлемой частью Python и по существу предоставляет программе математические функции типа MATLAB. По сравнению с обычными списками Python, он занимает меньше памяти, удобен в использовании и имеет более быструю обработку. При интеграции с другими библиотеками, такими как SciPy и / или Matplotlib, его можно эффективно использовать для целей анализа данных и анализа данных[10].
Библиотека Pytorch & Torch (Pytorch & Torch) — это библиотека машинного обучения, которая в основном используется для приложений обработки естественного языка и компьютерного зрения. Разработанная исследовательской лабораторией искусственного интеллекта и выпущенная в сентябре 2016 года, это библиотека с открытым исходным кодом, основанная на библиотеке Torch для научных вычислений и машинного обучения. PyTorch предоставляет операции с объектом n-мерного массива, аналогичные NumPy, однако, кроме того, он предлагает более быстрые вычисления за счет интеграции с графическим процессором. PyTorch автоматически различает построение и обучение нейронных сетей. PyTorch — это внесла свой вклад в разработку нескольких программ глубокого обучения — Tesla Autopilot, Uber’s Pyro, PyTorch Lighten и т. д.
Библиотека Scikit-learn (Scikit-learn Library) — это простая в освоении библиотека Python с открытым исходным кодом для машинного обучения, построенная на NumPy, SciPy и matplotlib. Его можно использовать для классификации данных, регрессии, кластеризации, уменьшения размерности, выбора модели и предварительной обработки.
Библиотека SciPy (SciPy Library) — это библиотека Python с открытым исходным кодом для выполнения научных и технических вычислений на Python. Она была разработана открытым сообществом разработчиков, которое также поддерживает его поддержку и спонсирует разработки. SciPy предлагает несколько пакетов алгоритмов и функций, которые поддерживают научные вычисления: константы, кластер, fft, fftpack, интегрировать и т. д. SciPy по сути является частью стека NumPy и использует многомерные массивы в качестве структур данных, предоставляемых модулем NumPy. Первоначально выпущенный в 2001 году, она распространялась по лицензии BSD с репозиторием на GitHub.
Библиотека Seaborn (Seaborn Library) — это библиотека визуализации данных Python для построения «привлекательных и информативных» статистических графиков. Seaborn основан на Matplotlib. Он включает в себя множество визуализаций на выбор, включая временные ряды и совместные графики.
Библиотека Theano (Theano Library) — это библиотека Python, используемая для компиляции, определения, оптимизации и оценки математических выражений, содержащих многомерные массивы. Она была разработана Монреальским институтом алгоритмов обучения (MILA) при Монреальском университете и выпущена в 2007 году. Это библиотека с открытым исходным кодом под лицензией BSD. Библиотека построена поверх NumPy и имеет аналогичный интерфейс. Наряду с процессором он позволяет использовать графический процессор для ускорения вычислений. Theano вносит значительный вклад в крупномасштабные научные вычисления и связанные с ними исследования и поддерживается специальной группой из 13 разработчиков.
Бинарное дерево (Binary tree) — это иерархическая структура данных, в которой каждый узел имеет значение (оно же является в данном случае и ключом) и ссылки на левого и правого потомка. Как правило, первый называется родительским узлом, а дети называются левым и правым наследниками. Двоичное дерево не является упорядоченным ориентированным деревом[11].
Биоконсерватизм (Bioconservatism) — это позиция нерешительности и скептицизма в отношении радикальных технологических достижений, особенно тех, которые направлены на изменение или улучшение условий жизни человека. Биоконсерватизм характеризуется верой в то, что технологические тенденции в современном обществе рискуют поставить под угрозу человеческое достоинство, а также противодействием движениям и технологиям, включая трансгуманизм, генетическую модификацию человека, «сильный» искусственный интеллект и технологическую сингулярность. Многие биоконсерваторы также выступают против использования таких технологий, как продление жизни и преимплантационный генетический скрининг[12],[13].
Биометрия (Biometrics) — это система распознавания людей. по одному или более физическим или поведенческим чертам.
Блок IFU (Instruction Fetch Unit IFU) — это блок предвыборки команд, который выстраивает в единую очередь команды, считываемые из внутренней или внешней памяти системы по шине EIB в соответствии с адресом, выставляемым по шине IAB.
Блок обработки изображений (Vision Processing Unit VPU) — это новый класс специализированных микропроцессоров, являющихся разновидностью ИИ -ускорителей, предназначенных для аппаратного ускорения работы алгоритмов машинного зрения.
Блокчейн (Blockchain) — это алгоритмы и протоколы децентрализованного хранения и обработки транзакций, структурированных в виде последовательности связанных блоков без возможности их последующего изменения.
Большие данные (Big data) — Большие данные представляют собой массивы информации, характеризующиеся колоссальными объемами, стремительно растущей скоростью накопления, разнообразием их формата представления как в виде структурированной, так и неструктурированной информации. Big Data также включают в себя комплекс инновационных методов и способов хранения и обработки информации с целью автоматизации, оптимизации бизнес-процессов, обеспечения принятия наиболее эффективных решений на основе накопленной информации. Согласно ГОСТ 59925 — 2021 «Информационные технологии. Большие данные. Техническое задание. Требования к содержанию и оформлению», большие массивы данных, отличающиеся главным образом такими характеристиками, как объем, разнообразие, скорость обработки и/или вариативность, которые требуют использования технологии масштабирования для эффективного хранения, обработки, управления и анализа[14],[15].
Булевая нейронная сеть (невесомая нейронная сеть) (Boolean neural network) –это многослойная нейронная сеть, состоящая из модуля самоорганизующейся нейронной сети для извлечения признаков, за которым следует модуль нейронной сети и модуль классификации нейронной сети, который прошел самостоятельную подготовку.
Бытовой искусственный интеллект (Consumer artificial intelligence) — это специализированные программы искусственного интеллекта, внедрённые в бытовые устройства и процессы.
«В»
Векторный процессор или массивный процессор (Vector processor or array processor) — это центральный процессор (ЦП), который реализует набор инструкций, где его инструкции предназначены для эффективной и действенной работы с большими одномерными массивами данных, называемыми векторами. Это отличается от скалярных процессоров, чьи инструкции работают только с отдельными элементами данных, и от некоторых из тех же скалярных процессоров, имеющих дополнительные арифметические блоки с одной инструкцией, несколькими данными (SIMD) или SWAR. Векторные процессоры могут значительно повысить производительность при определенных рабочих нагрузках, особенно при численном моделировании и подобных задачах. Методы векторной обработки также работают в оборудовании игровых приставок и графических ускорителях[16].
Видео аналитика (Video analytics) — это технология, использующая методы компьютерного зрения для автоматизированного использования различных данных, на основании анализа отслеживающих изображений, поступающих с видеокамер в режиме реального времени или из архивных записей.
Виртуализация (Virtualization) — это предоставление набора вычислительных ресурсов или их логическое объединение, абстрагированное от аппаратной реализации, и обеспечивающее при этом логическую изоляцию друг от друга вычислительных процессов, выполняемых на одном физическом ресурсе.
Виртуальный помощник (Virtual assistant) — это программный агент, который может выполнять задачи для пользователя на основе информации, введенной пользователем.
Внедрение технологий и/или средств (решений) для оперирования большими данными — это стадия жизненного цикла технологий и/или средств (решений) для оперирования большими данными, на которой осуществляется подготовка к их эксплуатации[17].
Восприятие речи (Speech perception) — это процесс, посредством которого звуки языка слышатся, интерпретируются и понимаются. Изучение восприятия речи тесно связано с областями фонологии и фонетики в лингвистике и когнитивной психологии и восприятием в психологии. Исследования в области восприятия речи направлены на то, чтобы понять, как люди-слушатели распознают звуки речи и используют эту информацию для понимания разговорной речи. Исследования восприятия речи находят применение в создании компьютерных систем, способных распознавать речь, в улучшении распознавания речи для слушателей с нарушениями слуха и языка, а также в обучении иностранному языку[18].
Временная сложность (Time complexity) — это вычислительная сложность, описывающая время, необходимое для выполнения алгоритма. Временная сложность обычно оценивается путем подсчета количества элементарных операций, выполняемых алгоритмом, при условии, что выполнение каждой элементарной операции занимает фиксированное количество времени. Таким образом, время и количество элементарных операций, выполняемых алгоритмом, различаются не более чем на постоянный множитель[19].
Временной ряд (Time Series) — это последовательность точек данных, записанных в определенное время и проиндексированных в соответствии с порядком их появления.
Временные данные (Temporal data) — это зафиксированные данные, показывающие состояние во времени.
Вспомогательный интеллект (Assistive intelligence) — это системы на основе ИИ, которые помогают принимать решения или выполнять действия.
Встраивание слов (Word embedding, Vector representation of words) — это термин (в обработке естественного языка — natural language processing), используемый для представления слов для анализа текста, обычно в форме вектора с действительным знаком, который кодирует значение слова таким образом, что слова, которые находятся ближе в векторном пространстве, становятся ближе по смыслу. Вложения слов можно получить с помощью набора методов языкового моделирования и изучения признаков, в которых слова или фразы из словаря сопоставляются с векторами действи



















