

автордың кітабын онлайн тегін оқу SQL Server. Наладка и оптимизация для профессионалов
Переводчик С. Черников
Дмитрий Короткевич
SQL Server. Наладка и оптимизация для профессионалов. — СПб.: Питер, 2023.
ISBN 978-5-4461-2332-2
© ООО Издательство "Питер", 2023
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Предисловие
Прошло уже несколько лет с тех пор, как была издана моя предыдущая книга. За это время многое изменилось. Выпущено несколько новых версий SQL Server. Продукт стал более зрелым, кросс-платформенным, в нем появилась полноценная поддержка облачных технологий. Но я все равно не торопился публиковать новое издание книги «Pro SQL Server Internals» («Внутреннее устройство SQL Server для профессионалов»).
Тому было несколько причин. Как бы ни были хороши новые функции, они не меняли фундаментальных принципов работы продукта. Материал из моих старых книг по большей части подходит к SQL Server 2017, SQL Server 2019 и даже к свежему SQL Server 2022. Что еще более важно, я хотел написать книгу по-другому.
Наверное, стоит уточнить. Как некоторые из вас, возможно, знают, я уже много лет провожу курсы по SQL Server и использую собственные книги как методические пособия к этим курсам. Собственно, я и писать начал именно потому, что хотел представить материал в более структурированном формате, чем презентации PowerPoint. Я рад, что моим читателям это понравилось и книги оказались полезными.
Все мои курсы были посвящены внутреннему устройству SQL Server. Я всегда считал, что профессионал должен разбираться в своих инструментах, чтобы достичь успеха. Я рассказываю ученикам, как работает SQL Server, и помогаю им применять эти знания и создавать эффективные системы. Но в какой-то момент я обнаружил, что самой популярной темой на моих занятиях стали устранение неполадок и настройка производительности: ученикам интересно, когда я описываю конкретную проблему, а затем объясняю, почему она возникла.
Изменив методику преподавания, я решил изменить и методику написания книги. Прошло 18 месяцев — и результат перед вами. Лично мне нравится то, что получилось. Книга по-прежнему посвящена внутреннему устройству SQL Server, но теперь она лаконичнее и практичнее моих предыдущих работ1. Она научит вас эффективно обнаруживать и устранять типичные проблемы при работе с SQL Server, не перегружая лишней информацией. Книга также покажет, в каком направлении двигаться, если вы хотите узнать еще больше.
Здесь описана методология, которую используют многие консультанты мирового уровня по SQL Server. Вы научитесь собирать и анализировать данные, выявлять узкие места и очаги неэффективности. Что еще более важно, я покажу, как рассматривать систему целостно и «видеть лес за деревьями».
Содержание книги не привязано к какой-либо конкретной версии SQL Server. За немногими исключениями оно актуально для всех версий от SQL Server 2005 до SQL Server 2022 и последующих версий. Материал также подходит для управляемых служб SQL Server, работающих в облаке.
Для кого эта книга
Когда меня спрашивают, для кого предназначены мои книги, я всегда говорю, что пишу для специалистов по базам данных. Я намеренно использую такой термин, потому что считаю, что границы, разделяющие администраторов баз данных, разработчиков баз данных и даже разработчиков приложений, довольно условны. Сегодня невозможно добиться успеха в IT, если ограничиваться узкой специализацией и не расширять сферу своей компетенции и ответственности.
Владеть широким спектром технологий особенно важно в культуре DevOps, где команды разрабатывают и поддерживают решения сами для себя. Для разработчиков становится обычным делом устранять проблемы с производительностью, которые могут быть связаны с инфраструктурой или неэффективным кодом базы данных.
В общем, в какой бы роли вы ни работали с SQL Server, эта книга для вас. Я надеюсь, что вы найдете для себя полезную информацию независимо от того, как называется ваша должность.
Еще раз спасибо за ваше доверие, и я надеюсь, что вы прочтете эту книгу с таким же удовольствием, с каким я ее писал!
Структура книги
Книга состоит из 16 глав:
Глава 1 «Установка и настройка SQL Server» содержит принципы и лучшие методики того, как выбирать оборудование и настраивать экземпляры SQL Server.
Глава 2 «Модель выполнения SQL Server и статистика ожидания» описывает SQLOS — очень важный компонент SQL Server. Здесь же вы познакомитесь с таким распространенным методом устранения неполадок, как статистика ожидания. На эту главу опирается весь остальной материал книги.
Глава 3 «Производительность дисковой подсистемы» дает представление о том, как SQL Server взаимодействует с подсистемой ввода/вывода и как анализировать и оптимизировать ее производительность.
Глава 4 «Неэффективные запросы» демонстрирует несколько методов того, как выявлять неэффективные запросы и выбирать целевые объекты для оптимизации запросов.
Глава 5 «Хранение данных и настройка запросов» объясняет, как SQL Server работает с данными в базе данных, и дает рекомендации по настройке запросов.
Глава 6 «Загрузка процессора» рассматривает распространенные причины высокой загрузки ЦП и учит бороться с узкими местами на уровне процессора.
Глава 7 «Проблемы с оперативной памятью» посвящена настройкам SQL Server, относящимся к памяти, и описывает, как анализировать использование памяти и решать связанные с ней проблемы.
Глава 8 «Блокировки и конкурентный доступ» рассказывает о модели конкурентного доступа, используемой в SQL Server, и о том, как обращаться с блокировками в системе.
Глава 9 «Работа с базой данных tempdb и ее производительность» описывает использование системной базы данных tempdb и лучшие методики ее конфигурации. Кроме того, здесь содержатся рекомендации о том, как оптимально использовать вре́менные объекты и устранять распространенные узкие места в tempdb.
Глава 10 «Кратковременные блокировки» посвящена кратковременным блокировкам в SQL Server. Рассматриваются случаи, когда они вызывают проблемы, и способы решения этих проблем.
Глава 11 «Журнал транзакций» рассказывает о том, как устроен журнал транзакций в SQL Server и как избавиться от распространенных узких мест и ошибок в нем.
Глава 12 «Группы доступности AlwaysOn» рассматривает самую популярную технологию высокой доступности SQL Server и частые проблемы, с которыми можно столкнуться при ее использовании.
Глава 13 «Другие примечательные типы ожиданий» описывает несколько распространенных типов ожиданий, которые не рассматривались в прочих главах.
Глава 14 «Анализ схемы базы данных и индексов» дает ряд советов о том, как обнаруживать неэффективные участки структуры базы данных, а также оценивать использование индексов и их работоспособность.
Глава 15 «SQL Server в виртуализированных средах» рассказывает о передовых методах настройки виртуальных экземпляров SQL Server и устранении сопутствующих неполадок.
Глава 16 «SQL Server в облаке» описывает, как настраивать и использовать SQL Server в облачных виртуальных машинах. В ней также представлен обзор управляемых служб SQL Server, доступных в Microsoft Azure, Amazon Web Services (AWS) и Google Cloud Platform (GCP).
В конце каждой главы приведен контрольный список наиболее важных шагов по устранению неполадок, связанных с темой главы.
Наконец, приложение «Типы ожиданий» можно использовать как справочник по распространенным типам ожиданий и методам устранения основных неполадок для каждого типа.
Условные обозначения
В этой книге используются следующие условные обозначения.
Курсив
Курсивом выделены новые термины или важные понятия.
Моноширинный шрифт
Используется для листингов программного кода, а также внутри абзацев для обозначения таких элементов, как переменные и функции, базы данных, типы данных, переменные среды, операторы и ключевые слова.
Полужирный моноширинный
Показывает команды или другой текст, который пользователь должен ввести самостоятельно.
Моноширинный курсив
Показывает текст, который следует заменить значениями, полученными от пользователя или из контекста.
Шрифт без засечек
Используется для обозначения URL, адресов электронной почты, названий кнопок и других элементов интерфейса, каталогов, имен и расширений файлов.

Совет или предложение.

Общее примечание.

Предупреждение или предостережение.
Использование исходного кода примеров
Вспомогательные материалы (примеры кода, упражнения и т.д.) доступны для загрузки по адресу https://github.com/aboutsqlserver/code.
В папке Troubleshooting Scripts вы найдете записные книжки Azure Data Studio2 с использованными в книге сценариями диагностики и устранения неполадок. Примеры сценариев и приложений также есть в папке Companion Materials (Books).
Если не указано иное, сценарии будут работать во всех версиях SQL Server, начиная с SQL Server 2005. В старых версиях могут не поддерживаться некоторые столбцы динамических административных представлений, и вам придется закомментировать их.
Я планирую поддерживать и расширять библиотеку диагностических сценариев, так что проверяйте обновления в репозитории.
Если у вас возникнут вопросы технического характера по использованию примеров кода, направляйте их по электронной почте на адрес bookquestions@oreilly.com.
В общем случае все примеры кода из книги вы можете использовать в своих программах и в документации. Вам не нужно обращаться в издательство за разрешением, если вы не собираетесь воспроизводить существенные части программного кода. Если вы разрабатываете программу и используете в ней несколько фрагментов кода из книги, вам не нужно обращаться за разрешением. Но для продажи или распространения примеров из книги вам потребуется разрешение от издательства O’Reilly. Вы можете отвечать на вопросы, цитируя данную книгу или примеры из нее, но для включения существенных объемов программного кода из книги в документацию вашего продукта потребуется разрешение.
Мы рекомендуем, но не требуем добавлять ссылку на первоисточник при цитировании. Под ссылкой на первоисточник мы подразумеваем указание авторов, издательства и ISBN.
За получением разрешения на использование значительных объемов программного кода из книги обращайтесь по адресу permissions@oreilly.com.
Как связаться с автором
Вы можете написать мне по адресу dk@aboutsqlserver.com, если у вас есть вопросы по книге или по SQL Server в целом. Я всегда рад помочь, чем смогу.
Также загляните в мой блог по адресу https://aboutsqlserver.com. Обещаю писать туда чаще, раз уж книга наконец вышла!
Благодарности
Прежде всего, как и всегда, я хотел бы поблагодарить свою семью за постоянную помощь и поддержку. Писательство — это идеальное оправдание, чтобы избежать домашних обязанностей. Я до сих пор не понимаю, почему мне все сошло с рук!
Кроме того, я чрезвычайно благодарен Эрланду Соммарскогу (Erland Sommarskog), Томасу Грозеру (Thomas Grohser) и Уве Рикену (Uwe Ricken), которые проделали большую работу, рецензируя эту книгу. Благодаря им она стала значительно лучше и обрела окончательную форму.
Эрланд Соммарског работает с SQL Server уже тридцать лет и имеет статус Microsoft Data Platform MVP с 2001 года. Он работает независимым консультантом в Стокгольме (Швеция). Эрланд с удовольствием делится знаниями и опытом с сообществом. В свободное от SQL Server время он играет в бридж и путешествует.
Томас Грозер работает IT-специалистом более 35 лет и уже 12 лет является Microsoft Data Platform MVP. Он использует SQL Server с 1994 года и специализируется на архитектуре и реализации высокозащищенных, доступных, восстанавливаемых и эффективных баз данных, а также их базовой инфраструктуры. В свободное время Томас любит делиться знаниями, накопленными за десятилетия, с сообществом SQL Server и платформ данных, выступая в группах пользователей и на конференциях по всему миру.
Уве Рикен — Microsoft Data Platform MVP и Microsoft Certified Master (SQL Server 2008) из Франкфурта (Германия). Уве работает с SQL Server с 2007 года и специализируется на внутреннем устройстве баз данных и индексировании, а также на архитектуре и разработке баз данных. Он регулярно выступает на конференциях и мероприятиях по SQL Server и ведет блог http://www.sqlmaster.de.
Спасибо вам, Эрланд, Томас и Уве! Работать с вами было очень круто!
Огромное спасибо моему коллеге Андре Фиано (Andre Fiano) — одному из самых знающих специалистов по инфраструктуре, которых я когда-либо встречал. Я многому научился у Андре, и он помог мне подготовить несколько наглядных примеров для этой книги.
И конечно же, я хотел бы поблагодарить всю команду O’Reilly и особенно Сару Грей (Sarah Grey), Элизабет Келли (Elizabeth Kelly), Кейт Дулли (Kate Dullea), Кристен Браун (Kristen Brown) и Одри Дойл (Audrey Doyle). Спасибо вам за то, что помогли привести мой английский в приемлемую форму и убедили меня, будто я умею рисовать диаграммы!
Эта книга посвящена SQL Server, и я хочу поблагодарить команду Microsoft за усердную работу над этим продуктом. Мне очень интересно, как он будет развиваться дальше.
И последнее, но не менее важное: отдельная благодарность — всем моим друзьям из сообщества #SQLFamily, которые поддерживали и подбадривали меня! Писать для такой замечательной аудитории — сплошное удовольствие!
Спасибо вам всем!
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
На веб-сайте издательства www.piter.com вы найдете подробную информацию о наших книгах.
Azure Data Studio можно скачать с сайта Microsoft: https://oreil.ly/zwwCf.
Название книги также изменилось. Теперь она называется «SQL Server Advanced Troubleshooting and Performance Tuning» («SQL Server. Наладка и оптимизация для профессионалов»). — Примеч. ред.
Изменив методику преподавания, я решил изменить и методику написания книги. Прошло 18 месяцев — и результат перед вами. Лично мне нравится то, что получилось. Книга по-прежнему посвящена внутреннему устройству SQL Server, но теперь она лаконичнее и практичнее моих предыдущих работ1. Она научит вас эффективно обнаруживать и устранять типичные проблемы при работе с SQL Server, не перегружая лишней информацией. Книга также покажет, в каком направлении двигаться, если вы хотите узнать еще больше.
В папке Troubleshooting Scripts вы найдете записные книжки Azure Data Studio2 с использованными в книге сценариями диагностики и устранения неполадок. Примеры сценариев и приложений также есть в папке Companion Materials (Books).
Глава 1. Установка и настройка SQL Server
Серверы баз данных функционируют не в безвоздушном пространстве. Они входят в экосистему одного или нескольких клиентских приложений. Базы данных приложений размещаются на одном или нескольких экземплярах SQL Server, а они, в свою очередь, развернуты на физическом или виртуальном оборудовании. Данные хранятся на дисках, чей ресурс обычно приходится делить с другими системами баз данных и не только. Наконец, всем компонентам нужна сеть, чтобы обмениваться данными и сохранять их.
Бороться с неполадками в базах данных непросто из-за сложности их экосистем и внутренних зависимостей. С точки зрения клиентов, большинство проблем касаются производительности: приложения работают медленно и не отвечают на запросы, время ожидания истекает, а иногда приложения вообще не подключаются к базе данных. Настоящая причина проблемы может скрываться где угодно. Может быть, аппаратное обеспечение неисправно или неправильно настроено, а может, в базе данных неэффективные индексы, схемы или код. Возможно, SQL Server перегружен, а может, клиентское приложение работает с ошибками или плохо спроектировано. Все это означает, что для поиска и устранения проблем нужно целостное представление обо всей системе.
Эта книга посвящена устранению неполадок в SQL Server. Но устранение неполадок всегда стоит начинать с анализа экосистемы приложения и среды SQL Server. В этой главе даны рекомендации о том, как выполнять этот анализ и обнаруживать наиболее распространенные проблемы в конфигурации SQL Server.
Сперва я расскажу о настройке оборудования и операционной системы. Затем пойдет речь об установке SQL Server и конфигурации базы данных. Далее мы коснемся темы консолидации SQL Server и дополнительных издержек, возникающих из-за средств мониторинга.
Аппаратное обеспечение и операционная система
Обычно устранять неполадки и настраивать производительность приходится в действующих системах, которые хранят много данных и работают под высокой нагрузкой. Тем не менее невозможно вовсе не говорить об аппаратной части. К тому же в ходе устранения неполадок может обнаружиться, что серверы просто не справляются с нагрузкой и нуждаются в обновлении.
Я не буду рекомендовать конкретных производителей или модели комплектующих, потому что аппаратное обеспечение быстро совершенствуется и к моменту публикации книги любой совет попросту устареет. Вместо этого я выскажу универсальные соображения, которые, надеюсь, еще долго будут актуальными.
Центральный процессор
Самая затратная часть системы — это, безусловно, лицензия на коммерческое ядро базы данных. Как правило, она значительно дороже оборудования, на котором предполагается разворачивать сервер БД. Поэтому рекомендую покупать самый мощный ЦП, какой позволит ваш бюджет, особенно если вы используете не версию SQL Server Enterprise Edition (эта версия не ограничивает количество доступных ядер).
Обратите внимание на модель процессора. Каждое новое поколение процессоров производительнее предыдущего. Можно получить прирост производительности на 10–15 %, просто поставив новый ЦП, даже если у него такая же тактовая частота, как у старого.
Иногда, когда стоимость лицензии — не главная проблема, приходится выбирать, что лучше: более медленный процессор с бо́льшим количеством ядер или более быстрый процессор с меньшим количеством ядер. В этом случае решение во многом зависит от загруженности системы. Для систем оперативной обработки транзакций (OLTP), особенно In-Memory OLTP, выгоднее будет одноядерный высокопроизводительный процессор. С другой стороны, для хранилищ данных и аналитических задач больше подойдет высокая степень параллелизма и большое количество ядер.
Оперативная память
В сообществе SQL Server бытует такая шутка:
— Сколько памяти нужно для SQL Server?
— Больше.
В этой шутке есть доля правды. Большой объем памяти позволяет SQL Server кэшировать больше данных. Это, в свою очередь, сокращает количество дисковых операций ввода/вывода (I/O) и положительно сказывается на производительности. Поэтому увеличение объема памяти сервера — зачастую самый дешевый и быстрый способ решить некоторые проблемы с производительностью.
Например, предположим, что система страдает от неоптимизированных запросов. Казалось бы, их влияние можно уменьшить, если добавить памяти и таким образом уменьшить чтение с физического диска для этих запросов. Но очевидно, что это не решает основную проблему и к тому же опасно, потому что данные могут разрастиcь до того, что перестанут помещаться в кэш. Тем не менее в качестве временного решения такой подход иногда годится.
У SQL Server Enterprise Edition объем используемой памяти не ограничен. У других версий есть ограничения. Standard Edition (SQL Server 2014 и более поздних версий) может использовать до 128 Гбайт ОЗУ для буферного пула, 32 Гбайт ОЗУ на каждую базу данных In-Memory OLTP и 32 Гбайт ОЗУ для хранения сегментов индекса columnstore. В Web Edition доступно вдвое меньше памяти, чем в Standard Edition. Учитывайте эти ограничения, когда собираете или обновляете экземпляры SQL Server, отличные от Enterprise Edition. Не забудьте выделить дополнительную память для других компонентов SQL Server, например кэша планов и менеджера блокировок.
Короче, добавьте столько памяти, сколько можете себе позволить. В наше время это дешево. Если ваши базы данных небольшие, то чрезмерное количество памяти ни к чему, однако учитывайте, что в будущем объем данных может вырасти.
Дисковая подсистема
Для хорошей производительности SQL Server необходима исправная и быстрая дисковая подсистема. SQL Server очень интенсивно занимается вводом/выводом, то есть постоянно считывает и записывает данные на диск.
Архитектуру дисковой подсистемы для SQL Server можно построить по-разному. Главное — добиться, чтобы задержка запросов ввода/вывода была минимальной. Для критически важных систем первого класса надежности я рекомендую, чтобы задержка чтения и записи данных не превышала 3–5 мс, а для записи журнала транзакций — 1–2 мс. К счастью, этих показателей легко достичь с помощью флеш-накопителей.
Но есть загвоздка: анализируя производительность ввода/вывода в SQL Server, нужно измерять время задержки на уровне самого́ SQL Server, а не на уровне хранилища. В SQL Server задержки могут оказаться значительно дольше, чем ключевые метрики производительности хранилища (KPI), потому что при интенсивном вводе/выводе могут возникать очереди. (В главе 3 мы рассмотрим, как собирать и анализировать данные о производительности ввода/вывода.)
Если ваша подсистема хранения поддерживает несколько уровней производительности, я рекомендую разместить на самом быстром диске базу данных tempdb, а на оставшихся — журнал транзакций и файлы данных. База данных tempdb — это общий ресурс на сервере, и для нее важна хорошая пропускная способность ввода/вывода.
Записи в файлы журнала транзакций выполняются синхронно. Для этих файлов важна низкая задержка записи. Записи в журнал транзакций также производятся последовательно; однако помните, что размещение нескольких файлов журналов и/или файлов данных на одном диске чревато режимом произвольного доступа сразу в нескольких базах данных.
Я рекомендую помещать файлы данных и журналов на разные физические диски, потому что при этом базу удобнее обслуживать и легче восстанавливать. Но стоит учитывать физическую конфигурацию хранилища. В некоторых случаях, когда в дисковых массивах недостаточно шпинделей, разделение массива на несколько LUN может снизить производительность всего массива.
В своих системах я не разбиваю кластеризованные и некластеризованные индексы по нескольким файловым группам, размещая их на разных дисках. От этого редко увеличивается производительность ввода/вывода, если только вы не разделяете полностью пути хранения по файловым группам. В то же время такая конфигурация может значительно усложнить аварийное восстановление.
Наконец, помните, что для некоторых технологий SQL Server важна хорошая эффективность последовательного ввода/вывода. Например, в In-Memory OLTP вообще не используется произвольный доступ, и ограничивающим фактором при запуске и восстановлении базы данных становится производительность последовательного чтения. Обход хранилища данных тоже зависит от последовательного ввода/вывода, когда B-деревья и индексы columnstore не сильно фрагментированы. У флеш-памяти разница между производительностью последовательного и произвольного ввода/вывода незначительна, а вот у магнитных дисков она довольно велика.
Сеть
SQL Server связывается с клиентами и другими серверами по сети. Очевидно, нужна достаточная пропускная способность сети, чтобы поддерживать эту связь. Остановлюсь на нескольких важных деталях.
Во-первых, при устранении неполадок, связанных с производительностью сети, необходимо анализировать топологию всей сети. Помните, что пропускная способность сети ограничена скоростью ее самого медленного компонента. Например, у вас может быть 10-гигабитный восходящий канал от сервера, но если где-то в сети оказался коммутатор на 1 Гбит/с, он ограничит общую пропускную способность. Это особенно важно для сетевых хранилищ: убедитесь, что пути доступа к дискам максимально эффективны.
Во-вторых, сложилась общепринятая практика выделять отдельную сеть для передачи тактового импульса в отказоустойчивых кластерах AlwaysOn и группах доступности AlwaysOn. Иногда стоит подумать о выделении отдельной сети для всего трафика группы доступности. Этот подход повышает надежность кластеров в простых конфигурациях, когда все кластерные узлы принадлежат одной подсети и могут использовать маршрутизацию уровня 2. Но в сложных конфигурациях с множеством подсетей наличие нескольких сетей может вызвать проблемы маршрутизации. Работая с такими конфигурациями, будьте осторожны и проверяйте, что связь между узлами сети налажена правильно, особенно в виртуальных средах, о которых я расскажу в главе 15.
Виртуализация добавляет еще один уровень сложности. Рассмотрим ситуацию, когда у вас есть виртуальный кластер SQL Server, узлы которого работают на разных хостах. Вам нужно будет убедиться, что хосты могут разделять и маршрутизировать трафик в кластерной сети отдельно от клиентского трафика. Если весь трафик локальной сети обслуживается через одну физическую сетевую карту, то тактовые импульсы теряют смысл.
Операционные системы и приложения
Как правило, я рекомендую использовать самую свежую версию операционной системы, которая поддерживает вашу версию SQL Server. Убедитесь, что и ОС, и SQL Server обновлены до последних версий, и наладьте регулярную установку обновлений.
Если вы используете старую версию SQL Server (до 2016), лучше устанавливать 64-разрядную ОС. В большинстве случаев 64-разрядная версия работает эффективнее 32-разрядной и лучше переносит масштабирование оборудования.
Начиная с SQL Server 2017, сервер баз данных можно развертывать и на Linux. С точки зрения производительности версии SQL Server для Windows и Linux очень похожи. Выбор ОС зависит от корпоративной экосистемы и от того, какую систему вам удобнее поддерживать. Имейте в виду, что для развертывания на Linux может потребоваться несколько иная стратегия высокой доступности (HA, High Availability) по сравнению с Windows. Например, для автоматического аварийного переключения, возможно, придется применять Pacemaker вместо Windows Server Failover Cluster (WSFC).
По возможности лучше использовать выделенный хост SQL Server. Помните, что проще и дешевле масштабировать серверы приложений и не тратить ценные ресурсы на хост базы данных.
В то же время не следует запускать на сервере несущественные процессы. Например, многие специалисты по базам данных запускают SQL Server Management Studio (SSMS) только на удаленных рабочих столах. Всегда лучше работать удаленно и не потреблять ресурсы сервера.
Наконец, если на сервере должно работать антивирусное ПО, то все папки баз данных нужно исключить из сканирования.
Виртуализация и облачные технологии
Современная IT-инфраструктура опирается на виртуализацию, которая обеспечивает дополнительную гибкость, упрощает управление и снижает затраты на оборудование. Поэтому чаще всего вам придется работать с виртуализированной инфраструктурой SQL Server.
Ничего плохого в этом нет. Грамотно реализованная виртуализация дает множество преимуществ при приемлемом снижении производительности. В случае VMware vSphere vMotion или Hyper-V Live Migration виртуализация добавляет еще один уровень высокой доступности. Виртуализация позволяет плавно обновлять аппаратное обеспечение и упрощает управление базой данных. Если вам не требуется выжимать максимум из оборудования, то экосистему SQL Server лучше виртуализировать.
На больших серверах с большим количеством ЦП накладные расходы на виртуализацию увеличиваются. Однако во многих случаях это оказывается вполне приемлемым.
Вместе с тем виртуализация добавляет лишний уровень сложности при устранении неполадок. Помимо показателей виртуальной машины, приходится обращать внимание на работоспособность и нагрузку хоста. Что еще хуже, влияние перегруженного хоста на производительность может быть незаметно по показателям в гостевой ОС.
Мы рассмотрим несколько подходов к устранению неполадок на уровне виртуализации в главе 15. Но для начала можно проконсультироваться у специалистов по инфраструктуре, не происходит ли на хосте избыточного резервирования ресурсов. Обратите внимание на количество физических ЦП и выделенных виртуальных ЦП на хосте, а также на физическую и выделенную память. Виртуальным машинам для критически важных экземпляров SQL Server нужно выделять достаточно ресурсов, чтобы их производительность не пострадала.
Если не брать в расчет уровень виртуализации, то на виртуализированных экземплярах SQL Server неполадки устраняются так же, как на обычных. То же самое относится и к облачным конфигурациям SQL Server на виртуальных машинах. В конце концов, облако — это всего лишь особый центр обработки данных, управляемый внешним провайдером.
Настройка SQL-сервера
Конфигурация по умолчанию, применяемая в процессе установки SQL Server, сама по себе неплоха и подходит для легких и даже умеренных нагрузок. Но и в ней есть параметры, которые необходимо проверить и отрегулировать.
Версия SQL Server и уровень обновления
SELECT @@VERSION — это первая команда, которую я запускаю во время проверки работоспособности SQL Server. Этому есть две причины. Во-первых, если знать версию, то легче продумывать стратегию отладки системы и предлагать улучшения. Во-вторых, это помогает понять, нет ли в системе уже известных проблем, характерных для этой версии.
Последняя причина очень важна. Клиенты не раз просили меня устранить неполадки, которые уже были устранены в пакетах исправлений и накопительных обновлениях. Всегда просматривайте примечания к выпуску обновлений, потому что может оказаться, что ваша проблема уже решена.
Советую обновляться до новейшей версии SQL Server. В каждой версии улучшаются производительность, функциональность и масштабируемость. Разница особенно заметна, если вы переходите на SQL Server 2016 или более позднюю версию с более старых. Выпуск SQL Server 2016 был важной вехой в истории продукта, и в этой версии появилось множество улучшений, влияющих на производительность. По моему опыту, само по себе обновление с SQL Server 2012 до 2016 или более поздней версии может повысить производительность на 20–40 % без дополнительных усилий.
Стоит также отметить, что, начиная с SQL Server 2016 SP1, многие функции, ранее предназначенные только для Enterprise Edition, появились и в более дешевых версиях. Некоторые из них — например, сжатие данных — позволяют SQL Server кэшировать больше данных в буферном пуле, что повышает производительность.
Очевидно, перед обновлением систему нужно протестировать: всегда существует вероятность, что после обновления она станет работать хуже. В случае небольших патчей такой риск невелик, но с крупными обновлениями лучше быть осторожнее. Некоторые риски можно снизить определенными настройками базы данных, как вы увидите далее в этой главе.
Мгновенная инициализация файлов
Каждый раз, когда SQL Server увеличивает размер файлов или журналов транзакций — будь то автоматически или в рамках команды ALTER DATABASE, — он заполняет свежевыделенную часть файла нулями. Этот процесс блокирует все сеансы, которые пытаются записывать в соответствующий файл, а в случае журнала транзакций в нем прекращается создание записей. Также при этом может произойти всплеск нагрузки на систему ввода/вывода.
Для файлов журналов транзакций это поведение нельзя изменить: SQL Server всегда заполняет их нулями. Однако для файлов данных его можно отключить, если активировать мгновенную инициализацию файлов (IFI, instant file initialization). Она ускоряет разрастание файла данных и сокращает время создания или восстановления баз данных.
Чтобы включить IFI, нужно предоставить стартовой учетной записи SQL Server разрешение SA_MANAGE_VOLUME_NAME, также известное как Perform Volume Maintenance Task (Выполнить обслуживание томов). Это можно сделать в приложении «Локальная политика безопасности» (Local Security Policy, secpol.msc). Чтобы изменения вступили в силу, нужно перезапустить SQL Server.
В SQL Server 2016 и более поздних версиях это разрешение также можно предоставить в процессе установки SQL Server, как показано на рис. 1.1.
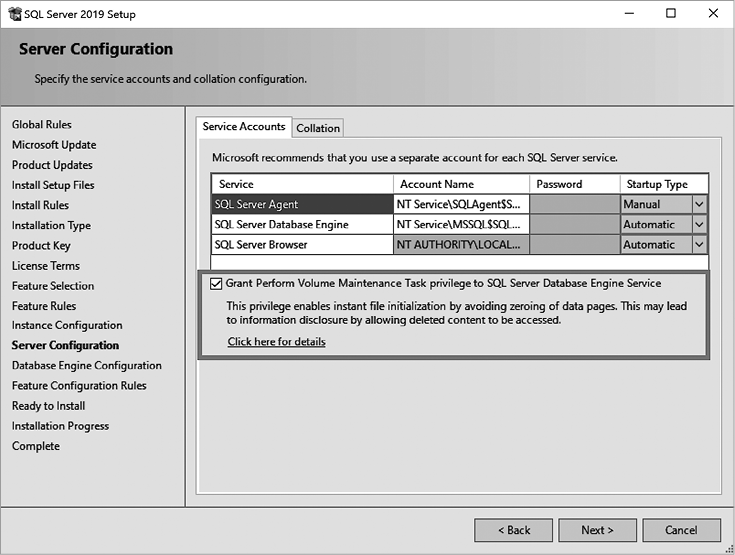
Рис. 1.1. Включение IFI во время установки SQL Server
Чтобы узнать, включена ли IFI, нужно посмотреть на столбец instant_file_initialization_enabled в динамическом представлении3 (DMV) sys.dm_server_services. Этот столбец доступен в SQL Server 2012 с пакетом обновления 4 (SP4), SQL Server 2016 с пакетом обновления 1 (SP1) и более поздних версиях. В старых версиях можно запустить код, показанный в листинге 1.1.
Листинг 1.1. Проверка того, включена ли мгновенная инициализация файлов (для старых версий SQL Server)
DBCC TRACEON(3004,3605,-1);
GO
CREATE DATABASE Dummy;
GO
EXEC sp_readerrorlog 0,1,N'Dummy';
GO
DROP DATABASE Dummy;
GO
DBCC TRACEOFF(3004,3605,-1);
GO
Если IFI не включена, то в журнале SQL Server будет написано, что SQL Server обнуляет файл данных .mdf и файл журнала .ldf (рис. 1.2). Когда IFI включена, обнуляется только файл журнала .ldf.
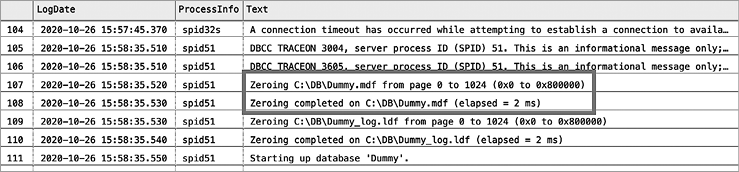
Рис. 1.2. Проверка настройки мгновенной инициализации файла
С этой настройкой связана небольшая угроза безопасности. Если IFI включена, то администраторы БД могут видеть данные из ранее удаленных файлов в ОС, просматривая свежевыделенные страницы в базе данных. Но для большинства систем это некритично.
Настройка базы tempdb
База tempdb — это системная база данных, предназначенная для хранения временных объектов, которые создают пользователи и сам SQL Server. Эта база очень активно используется и часто становится источником состязаний за ресурсы в системе. Как устранять проблемы, связанные с tempdb, я расскажу в главе 9, а пока поговорим о настройке.
Как уже упоминалось, базу данных tempdb стоит размещать на самом быстром диске. В общем случае этому диску не требуется резервное копирование или другие меры предохранения данных: tempdb создается заново при каждом запуске SQL Server, так что для нее вполне подойдет локальный SSD-накопитель или облачное хранилище. Но помните, что если база данных tempdb будет недоступна, то SQL Server перестанет работать.
Если у вас не Enterprise версия SQL Server и в системе больше памяти, чем он потребляет, то можно поместить tempdb на RAM-диск. Но с SQL Server Enterprise Edition так поступать не следует: вы добьетесь большей производительности, если используете эту память для буферного пула.
Предварительно выделяйте для файлов tempdb место, равное максимальному размеру RAM-диска, и создавайте дополнительные небольшие файлы данных и журналов на диске, чтобы предотвратить нехватку места. SQL Server не будет использовать небольшие файлы на диске, пока RAM-диск не заполнится.
В базе данных tempdb всегда должно быть несколько файлов данных. К сожалению, конфигурация по умолчанию, которая создается во время установки SQL Server, неоптимальна, особенно в старых версиях. В главе 9 я расскажу, как точно настроить количество файлов данных в tempdb, а пока можно опираться на эмпирические правила:
● Если на сервере восемь или меньше ядер ЦП, создайте такое же количество файлов данных, сколько и ядер.
● Если на сервере больше восьми ядер ЦП, создайте либо восемь файлов данных, либо четверть от числа ядер — в зависимости от того, что больше, — округляя до пакетов по четыре файла. Например, на 24-ядерном сервере нужно 8 файлов данных, а на 40-ядерном — 12 файлов.
Наконец, убедитесь, что у всех файлов данных tempdb одинаковый начальный размер и что параметры автоувеличения указаны в мегабайтах, а не в процентах. Это позволит SQL Server сбалансированно использовать файлы данных и уменьшить состязания за использование ресурсов в системе.
Флаги трассировки
Флаги трассировки в SQL Server позволяют активировать некоторые функции или изменить их поведение. В новых версиях SQL Server появляется все больше параметров конфигурации базы данных и сервера, но флаги трассировки по-прежнему широко используются. Вам нужно будет изучить, какие флаги есть в системе, и, возможно, включить некоторые из них.
Чтобы получить список включенных флагов трассировки, выполните команду DBCC TRACESTATUS. Флаги можно включить в диспетчере конфигурации SQL Server и/или с помощью параметра -T при запуске SQL Server.
Посмотрим на некоторые часто используемые флаги трассировки.
Т1118
Этот флаг запрещает использовать в SQL Server смешанные экстенты4. Это позволяет повысить пропускную способность tempdb в SQL Server 2014 и более ранних версиях, потому что уменьшается количество изменений и, следовательно, состязаний за ресурсы в системных каталогах tempdb. Этот флаг не нужен в SQL Server 2016 и более поздних версиях, где tempdb по умолчанию не использует смешанные экстенты.
Т1117
Если этот флаг установлен, то SQL Server автоматически увеличивает все файлы данных в файловой группе, когда в одном из файлов заканчивается место. Это позволяет более сбалансированно распределять ввод/вывод по файлам данных. В старых версиях SQL Server этот флаг стоит включить, чтобы улучшить пропускную способность tempdb, но лучше проверить, есть ли в базах данных пользователей файловые группы с несколькими файлами данных несбалансированного размера. Как и в случае с T1118, этот флаг не нужен в SQL Server 2016 и более поздних версиях, где tempdb по умолчанию автоматически увеличивает все файлы данных.
Т2371
По умолчанию SQL Server автоматически обновляет статистику только после того, как в индексе изменилось 20 % данных. Это означает, что для больших таблиц статистика редко обновляется автоматически. Флаг трассировки T2371 делает динамическим пороговое значение, при котором обновляется статистика: чем больше таблица, тем меньший процент изменений необходим для обновления статистики. Начиная с SQL Server 2016, это поведение также можно контролировать с помощью уровня совместимости базы данных. Тем не менее я все равно рекомендую включать этот флаг трассировки, если только у всех баз данных на сервере уровень совместимости не составляет 130 или выше.
Т3226
Когда этот флаг включен, SQL Server не заносит в журнал ошибок записи об успешном создании резервных копий базы данных. Это помогает уменьшить размер журналов, чтобы с ними было удобнее работать.
Т1222
Этот флаг заносит граф взаимных блокировок в журнал ошибок SQL Server. Он бывает полезен, но читать и анализировать журналы SQL Server становится сложнее. К тому же он избыточен, потому что граф взаимных блокировок при необходимости можно получить из сеанса расширенного события System_Health. Я обычно отключаю этот флаг.
Т4199
Этот флаг и параметр базы данных QUERY_OPTIMIZER_HOTFIXES (в SQL Server 2016 и более поздних версиях) управляют поведением исправлений оптимизатора запросов. Если флаг включен, то будут использоваться исправления из пакетов исправлений и накопительных обновлений. Это поможет устранить некоторые ошибки оптимизатора запросов и повысить производительность запросов, но увеличивает риск регрессии планов после исправлений. Обычно я не включаю этот флаг в промышленных экземплярах, если только нет возможности тщательно протестировать систему на предмет регрессий перед тем, как применять исправления.
Т7412
Этот флаг включает упрощенное профилирование инфраструктуры в SQL Server 2016 и 2017. Он позволяет собирать планы выполнения и множество метрик выполнения запросов, не перегружая ЦП. Я расскажу об этом подробнее в главе 5.
Резюмируем: в SQL Server 2014 и более ранних версиях включайте T1118, T2371 и, возможно, T1117. В SQL Server 2016 и более поздних версиях включайте T2371, кроме случаев, когда у всех баз данных на сервере уровень совместимости составляет 130 или выше. После этого посмотрите на все остальные флаги трассировки в системе и разберитесь, что они делают. Некоторые флаги устанавливаются без вашего ведома сторонними средствами и могут ухудшить производительность сервера.
Параметры сервера
У SQL Server есть множество параметров конфигурации. Я подробно опишу многие из них позже, но некоторые параметры рассмотрим сейчас.
Оптимизация для нерегламентированной рабочей нагрузки
Первый параметр конфигурации, о котором я расскажу, — Optimize for Ad-hoc Workloads (Оптимизировать для нерегламентированной рабочей нагрузки). От него зависит, как SQL Server кэширует планы выполнения нерегламентированных (непараметризованных) запросов. Когда этот параметр отключен (по умолчанию), SQL Server кэширует полные планы выполнения этих инструкций, отчего кэшу планов может понадобиться существенно больше памяти. Когда параметр включен, SQL Server сначала кэширует небольшую структуру (всего несколько сотен байтов) — так называемую заглушку плана, — а если запрос выполняется во второй раз, то заменяет заглушку полным планом выполнения.
В большинстве случаев нерегламентированные запросы выполняются однократно, поэтому имеет смысл включить Optimize for Ad-hoc Workloads. От этого может значительно сократиться использование памяти кэша планов — правда, изредка нерегламентированные запросы будут дополнительно перекомпилироваться. Очевидно, что этот параметр не влияет на кэширование параметризованных запросов и кода базы данных T-SQL.
Начиная с SQL Server 2019 и баз данных Azure SQL, параметр Optimize for Ad-hoc Workloads можно регулировать на уровне базы данных с помощью настройки OPTIMIZE_FOR_AD_HOC_WORKLOADS.
Максимальная память сервера
Второй важный параметр — Max Server Memory, который определяет, сколько памяти может потреблять SQL Server. Специалисты по базам данных любят спорить о том, как правильно настроить этот параметр, и существуют разные подходы к его вычислению. Многие даже предлагают оставить значение по умолчанию и разрешить SQL Server управлять им автоматически. На мой взгляд, лучше всего настроить его самостоятельно, но делать это нужно грамотно (подробнее в главе 7). Неудачно настроенный параметр может ухудшить быстродействие существеннее, чем значение по умолчанию.
На практике я часто сталкиваюсь с тем, что этому параметру уделяют недостаточно внимания. Иногда его забывают изменить после обновления оборудования или виртуальной машины, а иногда его неправильно рассчитывают в средах, где SQL Server работает на сервере совместно с другими приложениями. В обоих случаях, чтобы повысить производительность, можно для начала просто увеличить параметр Max Server Memory или даже перенастроить его на значение по умолчанию, а полноценным анализом заняться позже.
Маска соответствия
Стоит проверить процессорное соответствие SQL Server и, возможно, установить маску соответствия (affinity mask), если SQL Server работает на оборудовании с несколькими узлами неоднородного доступа к памяти (NUMA — non-uniform memory access). В современном аппаратном обеспечении каждый физический ЦП обычно становится отдельным узлом NUMA. Если вы разрешаете SQL Server использовать не все физические ядра, то нужно равномерно распределить процессоры SQL Server (или планировщики — см. главу 2) по NUMA.
Например, если SQL Server работает на сервере с двумя 18-ядерными процессорами Xeon и вы ограничиваете SQL Server до 24 ядер, то нужно установить маску привязки, которая задействует по 12 ядер от каждого физического ЦП. Производительность будет лучше, чем если бы SQL Server задействовал 18 ядер от первого процессора и 6 от второго.
В листинге 1.2 показано, как анализировать распределение планировщиков SQL Server (ЦП) между узлами NUMA. Обратите внимание на количество планировщиков для каждого столбца parent_node_id на выходе.
Листинг 1.2. Проверка распределения планировщиков узлов NUMA
SELECT
parent_node_id
,COUNT(*) as [Schedulers]
,SUM(current_tasks_count) as [Current]
,SUM(runnable_tasks_count) as [Runnable]
FROM sys.dm_os_schedulers
WHERE status = 'VISIBLE ONLINE'
GROUP BY parent_node_id;
Параллелизм
Важно проверить настройки параллельных операций в системе. Настройки по умолчанию, например MAXDOP = 0 и Cost Threshold for Parallelism = 5, в современных системах работают плохо. Как и в случае с максимальной памятью сервера, лучше подобрать параметры в соответствии с рабочей нагрузкой системы (в главе 6 обсудим это подробно). Могу предложить эмпирическое правило:
● Установите MAXDOP равным четверти количества доступных ЦП в OLTP и половине количества доступных ЦП в хранилище данных. На очень больших серверах OLTP оставьте MAXDOP равным 16 или ниже. Не превышайте количество планировщиков в узле NUMA.
● Cost Threshold for Parallelism установите равным 50.
Начиная с SQL Server 2016, и в серверных базах данных Azure SQL можно установить MAXDOP на уровне базы данных с помощью команды ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP. Это полезно, когда на одном сервере размещаются базы данных с разными рабочими нагрузками.
Параметры конфигурации
Как и в случае с флагами трассировки, проанализируйте и другие изменения параметров конфигурации, выполненные на сервере. Параметры конфигурации перечислены в представлении sys.configurations5. К сожалению, в SQL Server нельзя штатными средствами посмотреть параметры, заданные по умолчанию. Чтобы сравнить их с текущими параметрами, придется закодировать соответствующий список, как показано в листинге 1.3. Здесь для экономии места приведено лишь несколько параметров, но из сопутствующих материалов этой книги можно загрузить полную версию сценария.
Листинг 1.3. Поиск изменений в настройках конфигурации сервера
DECLARE
@defaults TABLE
(
name SYSNAME NOT NULL PRIMARY KEY,
def_value SQL_VARIANT NOT NULL
)
INSERT INTO @defaults(name,def_value)
VALUES('backup compression default',0);
INSERT INTO @defaults(name,def_value)
VALUES('cost threshold for parallelism',5);
INSERT INTO @defaults(name,def_value)
VALUES('max degree of parallelism',0);
INSERT INTO @defaults(name,def_value)
VALUES('max server memory (MB)',2147483647);
INSERT INTO @defaults(name,def_value)
VALUES('optimize for ad hoc workloads',0);
/* Прочие параметры опущены в этой книге */
SELECT
c.name, c.description, c.value_in_use, c.value
,d.def_value, c.is_dynamic, c.is_advanced
FROM
sys.configurations c JOIN @defaults d ON
c.name = d.name
WHERE
c.value_in_use <> d.def_value OR
c.value <> d.def_value
ORDER BY
c.name;
На рис. 1.3 приведен пример вывода предыдущего кода. Если столбцы value и value_in_use не совпадают, это указывает на заготовленные изменения конфигурации, которые вступят в силу после перезагрузки. Столбец is_dynamic показывает, можно ли изменить параметр конфигурации без перезапуска.

Рис. 1.3. Измененные параметры конфигурации сервера
Настройка баз данных
На следующем шаге надо проверить некоторые настройки базы данных и параметры конфигурации. Давайте изучим их.
Настройки базы данных
SQL Server позволяет регулировать многие настройки базы данных и управлять ее поведением в зависимости от нагрузки на систему и других требований. О многих из них мы поговорим позже в этой книге, но несколько настроек рассмотрим прямо сейчас.
Первый параметр — Auto Shrink (Автоматическое сжатие). Когда он включен, SQL Server периодически сжимает базу данных и возвращает высвободившееся пространство операционной системе. Этот параметр выглядит привлекательно и вроде бы позволяет оптимизировать использование дискового пространства, но он также может вызвать проблемы.
Алгоритм сжатия базы данных работает на физическом уровне. Он находит пустое пространство в начале файла и переносит размещенные экстенты из конца файла в это пустое пространство, не учитывая, кто владелец экстента. Это создает заметную нагрузку и приводит к существенной фрагментации индекса. Более того, во многих случаях сжатие бесполезно: файлы рано или поздно все равно увеличатся снова. Всегда лучше управлять файловым пространством вручную и отключать автоматическое сжатие.
Параметр Auto Close (Автоматическая очистка) управляет тем, как SQL Server кэширует данные из базы данных. Когда он включен, SQL Server удаляет страницы данных из буферного пула и планы выполнения из кэша планов, если нет активных подключений к базе. Это снижает производительность новых сеансов, когда данные нужно опять кэшировать, а запросы — компилировать заново.
Как правило, Auto Close следует отключать. Но бывают исключения: например, экземпляры, на которых размещено большое количество редко используемых баз данных. Хотя даже в этом случае я бы подумал о том, чтобы оставить эту настройку отключенной и разрешить SQL Server очищать кэш обычным способом.
Убедитесь, что для параметра Page Verify (Верификация страниц) установлено значение CHECKSUM. Это позволяет эффективнее обнаруживать ошибки согласованности и исправлять повреждения базы данных.
Обратите внимание на модель восстановления базы данных (database recovery model). Если используется режим восстановления SIMPLE, то в случае аварии будет невозможно восстановить базу из резервных копий, сделанных позже, чем последняя полная (FULL) копия. Если вы обнаружили, что база работает в таком режиме, немедленно обсудите это с заинтересованными сторонами и убедитесь, что они понимают риски потери данных.
Параметр Database Compatibility Level (Уровень совместимости БД) управляет совместимостью и поведением SQL Server на уровне базы данных. Например, если вы используете SQL Server 2019 и у вас есть база данных с уровнем совместимости 130 (SQL Server 2016), то SQL Server будет вести себя так, как если бы база работала на SQL Server 2016. Если держать базы данных на более низких уровнях совместимости, то SQL Server будет проще обновлять, не опасаясь уменьшения производительности. Однако при этом также не будут доступны некоторые новые функции и улучшения.
Как правило, базу данных лучше запускать на последнем уровне совместимости, соответствующем версии SQL Server. Изменяйте уровень с осторожностью, потому что это, как любая смена версии, может снизить производительность. Перед изменениями протестируйте систему и убедитесь, что при необходимости вы сможете откатить изменение, особенно если база данных имеет уровень совместимости 110 (SQL Server 2012) или ниже. На уровне совместимости 120 (SQL Server 2014) или выше включается новая модель оценки количества элементов и могут существенно измениться планы выполнения запросов. Тщательно протестируйте систему, чтобы понять, к чему приведут изменения.
Чтобы SQL Server использовал устаревшие модели оценки количества элементов с новыми уровнями совместимости базы данных, в SQL Server 2016 и более поздних версиях установите для параметра базы данных LEGACY_CARDINALITY_ESTIMATION значение ON, а в SQL Server 2014 включите флаг трассировки на уровне сервера T9481. Этот подход позволит внедрять обновления или менять уровни совместимости поэтапно, сглаживая влияние на систему. (В главе 5 мы подробнее рассмотрим оценку количества элементов и обсудим, как снизить риски при обновлении SQL Server и изменениях уровня совместимости базы данных.)
Настройки журнала транзакций
SQL Server ведет журнал с опережающей записью, сохраняя информацию обо всех изменениях базы данных в журнале транзакций. SQL Server обрабатывает журналы транзакций последовательно, по принципу карусели. В большинстве случаев нет нужды заводить сразу несколько файлов журналов в системе: при этом администрировать базу данных становится сложнее, а производительность не растет.
На внутреннем уровне SQL Server разбивает журналы транзакций на фрагменты, называемые виртуальными файлами журнала (VLF — Virtual Log Files), и управляет ими как цельными единицами. Например, SQL Server не может усечь и повторно использовать VLF, если он содержит только одну активную запись журнала. Следите за количеством VLF в базе данных. При слишком малом количестве очень больших VLF управление журналом и его усечение будут неоптимальными. При слишком большом количестве небольших VLF снизится производительность операций с журналом транзакций. Стремитесь, чтобы в промышленных системах накапливалось не больше нескольких сотен VLF.
Количество VLF, которые SQL Server добавляет при увеличении журнала, зависит от версии SQL Server и размера увеличения. В большинстве случаев создается 8 VLF, если увеличение составляет от 64 Мбайт до 1 Гбайт, или 16 VLF, если увеличение превышает 1 Гбайт. Не следует полагаться на автоматическую настройку, основанную на проценте от увеличения, потому что при этом генерируется множество VLF неравномерного размера. Вместо этого измените параметр автоувеличения журнала, чтобы файл увеличивался пошагово. Я обычно использую шаги по 1024 Мбайт, что дает 128 Мбайт VLF, если только мне не нужен очень большой журнал транзакций.
В SQL Server 2016 и более поздних версиях можно подсчитать число VLF в базе данных с помощью представления sys.dm_db_log_info. В более старых версиях SQL Server эту информацию можно получить командой DBCC LOGINFO. Если журнал транзакций настроен неправильно, его имеет смысл перестроить. Для этого можно сократить журнал до минимального размера и увеличивать его шагами от 1024 Мбайт до 4096 Мбайт.
Не сжимайте файлы журналов транзакций автоматически. Они снова вырастут и снизят производительность, когда SQL Server обнулит файл. Лучше заранее выделить место и управлять размером файла журнала вручную. Однако не ограничивайте максимальный размер и автоувеличение (autogrowth), иначе журналы не смогут автоматически увеличиваться в случае чрезвычайных ситуаций. (В главе 11 мы подробнее поговорим о том, как устранять проблемы с журналом транзакций.)
Файлы данных и файловые группы
По умолчанию SQL Server создает новые базы данных, используя файловую группу PRIMARY, состоящую из одного файла, и один файл журнала транзакций. К сожалению, эта конфигурация неоптимальна с точки зрения производительности, управления базами данных и доступности.
SQL Server отслеживает, как файлы данных используют дисковое пространство, с помощью системных страниц, называемых картами распределения. В системах с очень изменчивыми данными карты распределения могут становиться источником состязания за ресурсы: SQL Server обеспечивает строго последовательный доступ к ним во время модификации (подробнее об этом в главе 10). У каждого файла данных есть собственный набор страниц карт распределения, и вы можете уменьшить состязания, если создадите несколько файлов в файловой группе с активно изменяемыми данными.
Убедитесь, что данные равномерно распределены по всем файлам в каждой файловой группе. В SQL Server используется алгоритм пропорционального заполнения, который записывает большую часть данных в файл, в котором больше свободного места. Файлы данных одинакового размера позволяют сбалансировать эти операции записи, уменьшив состязания карт распределения. Поэтому проверьте, что у всех файлов данных в файловой группе одинаковый размер и шаг автоматического увеличения, указанный в мегабайтах.
Также вы можете включить параметр файловой группы AUTOGROW_ALL_FILES (доступен в SQL Server 2016 и более поздних версиях), который запускает автоувеличение для всех файлов в файловой группе одновременно. В предыдущих версиях SQL Server для этого можно использовать флаг трассировки T1117, однако имейте в виду, что он устанавливается на уровне сервера и влияет на все базы данных и файловые группы в системе.
Изменять структуру существующих баз данных обычно нецелесообразно или невозможно. Но может потребоваться создавать новые файловые группы и перемещать данные, чтобы оптимизировать производительность. Приведем несколько советов, как делать это эффективно:
● Создайте несколько файлов данных в файловых группах с изменчивыми данными. Обычно я начинаю с четырех файлов и увеличиваю их количество, если вижу проблемы с кратковременной блокировкой (см. главу 10). Убедитесь, что у всех файлов данных одинаковый размер и параметры автоувеличения; включите параметр AUTOGROW_ALL_FILES. Для файловых групп, данные в которых предназначены только для чтения, обычно достаточно одного файла данных.
● Не разбивайте кластеризованные индексы, некластеризованные индексы или большие объекты (LOB) по разным файловым группам. Это редко помогает повысить производительность, зато может привести к проблемам в случае повреждения базы данных.
● Помещайте связанные сущности (например, Orders и OrderLineItems) в одну и ту же файловую группу. Это упростит управление базой данных и аварийное восстановление.
● По возможности оставляйте пустой файловую группу PRIMARY.
На рис 1.4 показан пример структуры базы данных для гипотетической системы электронной коммерции. Данные разбиты на секции и распределены по нескольким файловым группам, чтобы свести к минимуму время простоя и получить возможность использовать хотя бы часть базы данных в случае аварии6. Это также позволяет улучшить стратегию резервного копирования: можно копировать базу данных по частям и исключить из полных резервных копий данные, предназначенные только для чтения.
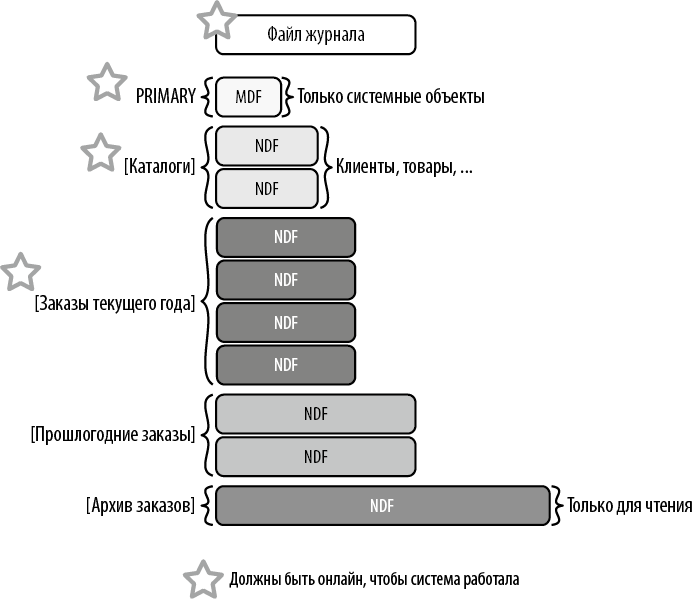
Рис. 1.4. Структура базы данных для системы электронной коммерции
Анализ журнала ошибок SQL Server
Журнал ошибок SQL Server — еще одно место, куда я обязательно заглядываю в начале устранения неполадок. Ошибки, зафиксированные в этом журнале, часто указывают на конкретные очаги проблем. Например, ошибки 823 и 824 могут свидетельствовать о проблемах с дисковой подсистемой и/или повреждением базы данных.
Просмотреть содержимое журнала ошибок можно средствами SSMS. Его также можно получить программно с помощью системной хранимой процедуры xp_readerrorlog. Проблема здесь заключается в количестве данных в журнале: полезные данные могут затеряться среди множества информационных сообщений.
Код в листинге 1.4 помогает решить эту проблему. Он отфильтровывает ненужный шум и позволяет сосредоточиться на сообщениях об ошибках. Управлять поведением кода можно с помощью следующих переменных:
@StartDate и @EndDate
Задают диапазон времени для анализа.
@NumErrorLogs
Указывает количество файлов журналов для чтения, если SQL Server переключается на файлы продолжения.
@ExcludeLogonErrors
Опускает сообщения аудита входа в систему.
@ShowSurroundingEvents и @ExcludeLogonSurroundingEvents
Позволяют получать информационные сообщения в ближайшей окрестности записей об ошибках из журнала. Временно́е окно для этих сообщений управляется переменными @SurroundingEventsBeforeSeconds и @SurroundingEventsAfterSeconds.
Сценарий выдает два результата. Первый — записи из журнала ошибок, которые содержат слово error. Когда параметр @ShowSurroundingEvents включен, сценарий также выводит записи журнала в ближайшей окрестности этих error-строк. Некоторые записи, содержащие слово error, можно исключить из вывода, если вставить их в таблицу @ErrorsToIgnore.
Листинг 1.4. Анализ журнала ошибок SQL Server
IF OBJECT_ID('tempdb..#Logs',N'U') IS NOT NULL DROP TABLE #Logs;
IF OBJECT_ID('tempdb..#Errors',N'U') IS NOT NULL DROP TABLE #Errors;
GO
CREATE TABLE #Errors
(
LogNum INT NULL,
LogDate DATETIME NULL,
ID INT NOT NULL identity(1,1),
ProcessInfo VARCHAR(50) NULL,
[Text] NVARCHAR(MAX) NULL,
PRIMARY KEY(ID)
);
CREATE TABLE #Logs
(
[LogDate] DATETIME NULL,
ProcessInfo VARCHAR(50) NULL,
[Text] NVARCHAR(MAX) NULL
);
DECLARE
@StartDate DATETIME = DATEADD(DAY,-7,GETDATE())
,@EndDate DATETIME = GETDATE()
,@NumErrorLogs INT = 1
,@ExcludeLogonErrors BIT = 1
,@ShowSurroundingEvents BIT = 1
,@ExcludeLogonSurroundingEvents BIT = 1
,@SurroundingEventsBeforeSecond INT = 5
,@SurroundingEventsAfterSecond INT = 5
,@LogNum INT = 0;
DECLARE
@ErrorsToIgnore TABLE
(
ErrorText NVARCHAR(1024) NOT NULL
);
INSERT INTO @ErrorsToIgnore(ErrorText)
VALUES
(N'Registry startup parameters:%'),
(N'Logging SQL Server messages in file%'),
(N'CHECKDB for database%finished without errors%');
WHILE (@LogNum <= @NumErrorLogs)
BEGIN
INSERT INTO #Errors(LogDate,ProcessInfo,Text)
EXEC [master].[dbo].[xp_readerrorlog]
@LogNum, 1, N'error', NULL, @StartDate, @EndDate, N'desc';
IF @@ROWCOUNT > 0
UPDATE #Errors SET LogNum = @LogNum WHERE LogNum IS NULL;
SET @LogNum += 1;
END;
IF @ExcludeLogonErrors = 1
DELETE FROM #Errors WHERE ProcessInfo = 'Logon';
DELETE FROM e
FROM #Errors e
WHERE EXISTS
(
SELECT *
FROM @ErrorsToIgnore i
WHERE e.Text LIKE i.ErrorText
);
-- Только ошибки
SELECT * FROM #Errors ORDER BY LogDate DESC;
IF @@ROWCOUNT > 0 AND @ShowSurroundingEvents = 1
BEGIN
DECLARE
@LogDate DATETIME
,@ID INT = 0
WHILE 1 = 1
BEGIN
SELECT TOP 1 @LogNum = LogNum, @LogDate = LogDate, @ID = ID
FROM #Errors
WHERE ID > @ID
ORDER BY ID;
IF @@ROWCOUNT = 0
BREAK;
SELECT
@StartDate = DATEADD(SECOND, -@SurroundingEventsBeforeSecond, @LogDate)
,@EndDate = DATEADD(SECONd, @SurroundingEventsAfterSecond, @LogDate);
INSERT INTO #Logs(LogDate,ProcessInfo,Text)
EXEC [master].[dbo].[xp_readerrorlog]
@LogNum, 1, NULL, NULL, @StartDate, @EndDate;
END;
IF @ExcludeLogonSurroundingEvents = 1
DELETE FROM #Logs WHERE ProcessInfo = ‚Logon';
DELETE FROM e
FROM #Logs e
WHERE EXISTS
(
SELECT *
FROM @ErrorsToIgnore i
WHERE e.Text LIKE i.ErrorText
);
SELECT * FROM #Logs ORDER BY LogDate DESC;
END
Я не привожу здесь полный список возможных ошибок, потому что он может быть очень длинным и во многих случаях зависит от конкретной системы. Но вам стоит проанализировать любые подозрительные результаты на выходе этого сценария и разобраться, как они могут повлиять на систему.
Наконец, я предлагаю настроить оповещения об ошибках с высоким уровнем серьезности в SQL Server Agent, если вы еще их не настроили. Как это сделать, можно узнать из документации Microsoft7.
Консолидация экземпляров и баз данных
Невозможно говорить об устранении неполадок SQL Server, не затронув вопросы консолидации баз данных и экземпляров SQL Server. Консолидация часто снижает затраты на оборудование и лицензии, но она тоже имеет свою цену, и вам нужно проанализировать, как консолидация может ухудшить текущую или будущую производительность системы.
Не существует универсальной стратегии консолидации, которая подошла бы к любому проекту. Принимая решение о консолидации, нужно учесть объем данных, нагрузку, конфигурацию оборудования, а также требования бизнеса и безопасности. Однако в общем случае следует избегать консолидации баз данных OLTP и хранилища данных/отчетов на одном сервере, если они работают под большой нагрузкой. (А если они уже консолидированы, их стоит разделить.) Запросы к хранилищу данных обычно оперируют большими объемами данных, что приводит к интенсивному вводу/выводу и сбросу содержимого буферного пула. В совокупности это негативно сказывается на производительности других систем.
Кроме того, при консолидации баз данных следует проанализировать требования к безопасности. Некоторые функции безопасности, такие как аудит, затрагивают весь сервер и ограничивают производительность всех баз данных на сервере. Еще один пример — прозрачное шифрование данных (TDE, Transparent Data Encryption). Хотя TDE — функция уровня базы данных, тем не менее SQL Server шифрует tempdb, если TDE включено хотя бы на одной базе. Это ограничивает производительность всех остальных систем.
Как правило, на одном и том же экземпляре SQL Server не стоит хранить базы данных с разными требованиями к безопасности. Следует проанализировать тенденции и выбросы в показателях и при необходимости отделить базы друг от друга. (Позже в этой книге я покажу код, который поможет проанализировать использование ЦП, операции ввода/вывода и затраты памяти для каждой базы данных.)
Я предлагаю использовать виртуализацию и консолидировать несколько виртуальных машин на одном или нескольких хостах вместо того, чтобы размещать несколько независимых и активных баз данных на одном экземпляре SQL Server. Такой подход обеспечивает гораздо бо́льшую гибкость, управляемость и взаимную изоляцию систем, особенно если несколько экземпляров SQL Server работают на одном сервере. Используя виртуализацию, гораздо проще контролировать потребление ими ресурсов.
Эффект наблюдателя
Для промышленного развертывания всякой серьезной системы SQL Server нужно внедрить стратегию мониторинга. Это могут быть либо сторонние средства мониторинга, либо код, созданный на основе стандартных технологий SQL Server, либо и то и другое.
Хорошая стратегия мониторинга жизненно важна для полноценной поддержки SQL Server. Мониторинг позволяет действовать на упреждение, сокращая количество инцидентов и время восстановления работоспособности. К сожалению, даром ничего не дается, и любой мониторинг увеличивает нагрузку на систему. В некоторых случаях эти накладные расходы оказываются незначительными и приемлемыми, но иногда они существенно влияют на производительность сервера.
За свою карьеру консультанта по SQL Server я видел множество примеров неэффективного мониторинга. Например, один клиент использовал инструмент, который предоставлял информацию о фрагментации индекса, вызывая функцию sys.dm_db_index_physical_stats в режиме DETAILED каждые четыре часа для каждого индекса в базе данных. Это приводило к огромным пикам ввода/вывода и очистке буферного пула, что сильно било по производительности. Другой клиент применял инструмент, который постоянно опрашивал различные DMV, значительно увеличивая нагрузку ЦП на сервере.
К счастью, во время устранения неполадок в системе такие запросы часто удается проанализировать, чтобы оценить их влияние. Но с другими технологиями это не всегда получается. Пример такого случая — мониторинг на основе расширенных событий (xEvents — Extended Events). Extended Events — это отличная технология, которая позволяет устранять сложные проблемы в SQL Server, но она плохо подходит в качестве инструмента профилирования. Некоторые события весьма тяжеловесны и ведут к большим накладным расходам в загруженных средах.
Рассмотрим пример кода, который создает сеанс расширенных событий. Этот сеанс фиксирует запросы, выполняемые в системе, см. листинг 1.5.
Листинг 1.5. Создание сеанса расширенных событий для захвата запросов в системе
CREATE EVENT SESSION CaptureQueries ON SERVER
ADD EVENT sqlserver.rpc_completed
(
SET collect_statement=(1)
ACTION
(
sqlos.task_time
,sqlserver.client_app_name
,sqlserver.client_hostname
,sqlserver.database_name
,sqlserver.nt_username
,sqlserver.sql_text
)
),
ADD EVENT sqlserver.sql_batch_completed
(
ACTION
(
sqlos.task_time
,sqlserver.client_app_name
,sqlserver.client_hostname
,sqlserver.database_name
,sqlserver.nt_username
,sqlserver.sql_text
)
),
ADD EVENT sqlserver.sql_statement_completed
ADD TARGET package0.event_file
(SET FILENAME=N'C:\PerfLogs\LongSql.xel',MAX_FILE_SIZE=(200))
WITH
(
MAX_MEMORY =4096 KB
,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS
,MAX_DISPATCH_LATENCY=5 SECONDS
);
Попробуйте выполнить этот код на сервере, который работает под большой нагрузкой с большим количеством одновременных запросов. Измерьте пропускную способность системы с запущенным сеансом расширенных событий и без него. Конечно же, будьте осторожны и не запускайте код на рабочем сервере!
На рис. 1.5 показана загрузка ЦП и количество пакетных запросов в секунду в обоих сценариях на одном из моих серверов. Как видите, включение сеанса расширенных событий уменьшило пропускную способность примерно на 20 %. Что еще хуже, обнаружить само существование этого сеанса на сервере довольно сложно.
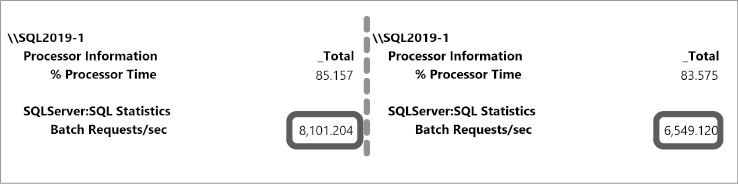
Рис. 1.5. Пропускная способность сервера с активным сеансом расширенных событий и без него
Очевидно, степень воздействия будет зависеть от рабочей нагрузки системы. В любом случае, при устранении неполадок следует проверить, нет ли в системе ненужных инструментов мониторинга или сбора данных.
В общем, оценивайте стратегию мониторинга и, в частности, ее накладные расходы, особенно когда на сервере размещено несколько баз данных. Например, расширенные события работают на уровне сервера. Хотя можно фильтровать события на основе поля database_id, эта фильтрация происходит после запуска события, так что расширенные события все равно влияют на все базы данных на сервере.
Резюме
Устранение неполадок в системе — это целостный процесс, требующий анализа всей экосистемы. Нужно проанализировать аппаратное обеспечение, ОС и уровни виртуализации, а также настройку SQL Server и баз данных.
У SQL Server есть множество параметров, которые позволяют тонко подстроить функционирование сервера под рабочие нагрузки системы. Существуют общие рекомендации, применимые к большинству систем: например, включить IFI и оптимизацию для нерегламентированных рабочих нагрузок, увеличить количество файлов в базе данных tempdb, включить определенные флаги трассировки, отключить автоматическое сжатие и настроить правильные параметры автоувеличения файлов базы данных.
В следующей главе я расскажу об одном из наиболее важных компонентов SQL Server под названием SQLOS и устранении неполадок с помощью статистики ожидания.
Чек-лист устранения неполадок
□ Выполнить высокоуровневый анализ оборудования, сети и дисковой подсистемы.
□ В виртуализированных средах — обсудить со специалистами по инфраструктуре конфигурацию хоста и нагрузку.
□ Изучить версии ОС и SQL Server, номер выпуска и установленные исправления.
□ Проверить, включена ли мгновенная инициализация файла.
□ Проанализировать флаги трассировки.
□ Включить оптимизацию для нерегламентированных рабочих нагрузок.
□ Проверить настройки памяти и параллелизма на сервере.
□ Изучить настройки tempdb (включая количество файлов); в версиях SQL Server до 2016 года проверить флаг трассировки T1118 и, возможно, T1117.
□ Отключить автоматическое сжатие баз данных.
□ Проверить настройки файлов журнала данных и транзакций.
□ Проверить число VLF в файлах журнала транзакций.
□ Проверить ошибки в журнале SQL Server.
□ Проверить наличие ненужного мониторинга в системе.
https://oreil.ly/AntEt
https://oreil.ly/58Vd7
https://oreil.ly/CnPxm
https://oreil.ly/nsLMW
Чтобы глубже погрузиться в стратегии разбиения данных и аварийного восстановления, читайте мою книгу «Pro SQL Server Internals, Second Edition» (Apress, 2016).
На рис 1.4 показан пример структуры базы данных для гипотетической системы электронной коммерции. Данные разбиты на секции и распределены по нескольким файловым группам, чтобы свести к минимуму время простоя и получить возможность использовать хотя бы часть базы данных в случае аварии6. Это также позволяет улучшить стратегию резервного копирования: можно копировать базу данных по частям и исключить из полных резервных копий данные, предназначенные только для чтения.
Чтобы узнать, включена ли IFI, нужно посмотреть на столбец instant_file_initialization_enabled в динамическом представлении3 (DMV) sys.dm_server_services. Этот столбец доступен в SQL Server 2012 с пакетом обновления 4 (SP4), SQL Server 2016 с пакетом обновления 1 (SP1) и более поздних версиях. В старых версиях можно запустить код, показанный в листинге 1.1.
Как и в случае с флагами трассировки, проанализируйте и другие изменения параметров конфигурации, выполненные на сервере. Параметры конфигурации перечислены в представлении sys.configurations5. К сожалению, в SQL Server нельзя штатными средствами посмотреть параметры, заданные по умолчанию. Чтобы сравнить их с текущими параметрами, придется закодировать соответствующий список, как показано в листинге 1.3. Здесь для экономии места приведено лишь несколько параметров, но из сопутствующих материалов этой книги можно загрузить полную версию сценария.
Наконец, я предлагаю настроить оповещения об ошибках с высоким уровнем серьезности в SQL Server Agent, если вы еще их не настроили. Как это сделать, можно узнать из документации Microsoft7.
Этот флаг запрещает использовать в SQL Server смешанные экстенты4. Это позволяет повысить пропускную способность tempdb в SQL Server 2014 и более ранних версиях, потому что уменьшается количество изменений и, следовательно, состязаний за ресурсы в системных каталогах tempdb. Этот флаг не нужен в SQL Server 2016 и более поздних версиях, где tempdb по умолчанию не использует смешанные экстенты.
Глава 2. Модель выполнения SQL Server и статистика ожидания
Невозможно устранять неполадки в SQL Server, не разбираясь в его модели выполнения. Чтобы обнаруживать узкие места в системе, нужно знать, как SQL Server выполняет задачи и управляет ресурсами. Этим темам посвящена данная глава.
В начале главы пойдет речь об архитектуре и основных компонентах SQL Server. Затем мы изучим модель выполнения SQL Server и представим популярный метод устранения неполадок, который называется статистикой ожидания. Также рассмотрим несколько динамических административных представлений, которые обычно используются при устранении неполадок. Завершит главу обзор регулятора ресурсов, с помощью которого можно разделять рабочие нагрузки в системе.
SQL Server: высокоуровневая архитектура
Как известно, SQL Server — это очень сложный продукт, состоящий из десятков компонентов и подсистем, которые невозможно полноценно охватить в одной книге. В этом разделе приведем их обзор на самом общем уровне. Для удобства я разделю эти компоненты и подсистемы на несколько категорий, как показано на рис. 2.1. Давайте поговорим о них.
Уровень протокола обеспечивает связь между SQL Server и клиентскими приложениями. Этот уровень использует внутренний формат Tabular Data Stream (TDS, Поток табличных данных), чтобы передавать данные через сетевые протоколы, такие как TCP/IP или именованные каналы. Если клиентское приложение и SQL Server работают на одном компьютере, можно использовать другой протокол — Shared Memory (Общая память).
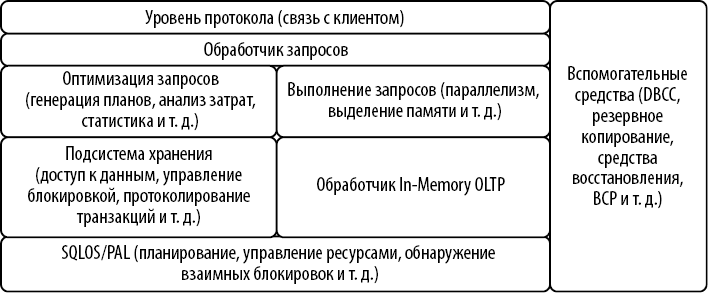
Рис. 2.1. Основные компоненты SQL Server
Устраняя проблемы, касающиеся соединения между клиентом и сервером, стоит проверить, какие протоколы включены. В некоторых версиях SQL Server, например Express и Developer, TCP/IP и именованные каналы по умолчанию отключены, так что сервер не принимает удаленных клиентских подключений, пока вы не включите сетевые протоколы в Диспетчере конфигурации (Configuration Manager) SQL Server.
Уровень обработчика запросов (Query Processor) отвечает за оптимизацию и выполнение запросов. Он осуществляет синтаксический анализ, оптимизирует запросы и управляет скомпилированными планами запросов, а также координирует все аспекты выполнения запросов.
Подсистема хранения (Storage Engine) отвечает за доступ к данным и их обработку в SQL Server. Она взаимодействует с данными на диске, управляет журналами транзакций и обрабатывает транзакции, блокировки и конкурентный доступ, а также выполняет некоторые другие задачи.
Обработчик In-Memory OLTP (In-Memory OLTP Engine) поддерживает In-Memory OLTP в SQL Server. Он работает с таблицами, оптимизированными для памяти, и отвечает за управление данными и доступ к этим таблицам, компиляцию в собственном коде, сохраняемость данных и прочие аспекты этой технологии.
Между компонентами существуют уровни абстракции. Например, Взаимодействие с запросами (Query Interop) (не показанное на рис. 2.1) позволяет обработчику запросов работать как с таблицами на основе строк, так и с таблицами, оптимизированными для памяти: запросы прозрачно перенаправляются либо в хранилище, либо в обработчик In-Memory OLTP.
Самый важный уровень абстракции — операционная система SQL Server (SQLOS), которая изолирует другие компоненты SQL Server от нижележащих операционных систем и занимается планированием, управлением ресурсами и их мониторингом, обработкой исключений и многими другими аспектами работы SQL Server. Например, когда для какого-нибудь компонента SQL Server требуется выделить память, он не вызывает функции API ОС напрямую, а запрашивает память у SQLOS. Это позволяет SQL Server детально контролировать выполнение задач и использование внутренних ресурсов, не полагаясь на ОС.
Наконец, с появлением поддержки Linux в SQL Server 2017 возник еще один компонент под названием Platform Abstraction Layer (PAL, Уровень платформенной абстракции) — прослойка между SQLOS и операционными системами. За исключением отдельных ситуаций, критичных для производительности, SQLOS не обращается напрямую к API ОС, а работает через PAL. При этом код самого SQL Server под Linux практически идентичен коду под Windows, что значительно ускоряет разработку и усовершенствование продукта.
С точки зрения устранения неполадок разница между SQL Server в Windows и Linux невелика. Конечно, приходится по-разному анализировать экосистему SQL Server и конфигурацию ОС. Но когда дело касается проблем внутри SQL Server, обе платформы ведут себя одинаково, поэтому в этой книге я не буду останавливаться на различиях между ними.
Давайте подробнее поговорим о SQLOS.
SQLOS и модель выполнения
Серверы баз данных должны обрабатывать большое количество пользовательских запросов, и SQL Server — не исключение. На верхнем уровне он распределяет запросы по отдельным потокам, чтобы запросы выполнялись одновременно. Если сервер не простаивает, количество активных потоков больше, чем количество ЦП в системе. Эффективное планирование — залог высокой производительности сервера.
В ранних версиях SQL Server использовался планировщик Windows. К сожалению, Windows (и Linux) — это операционные системы общего назначения, а значит, в них используется вытесняющее планирование. Это значит, что ОС выделяет на выполнение потока определенный временной интервал, или квант времени, а когда он истекает, переключается на другие потоки. Это затратная операция: она требует переключаться между пользовательским режимом и режимом ядра, что отрицательно сказывается на производительности.
В SQL Server 7.0 Microsoft представила первую версию планировщика пользовательского режима (UMS, User Mode Scheduler): это был тонкий слой между Windows и SQL Server, отвечающий за планирование. В нем использовалось совместное планирование: потоки SQL Server были запрограммированы так, чтобы добровольно уступать управление каждые 4 мс, давая другим потокам возможность поработать. Такой подход значительно сократил затраты на переключение режимов.
Отдельные процессы SQL Server, такие как расширенные хранимые процедуры, подпрограммы CLR, внешние языки и некоторые другие процессы, по-прежнему могут выполняться в режиме вытесняющего планирования.
Microsoft продолжила совершенствовать UMS в SQL Server 2000, а в SQL Server 2005 переработала его, создав более надежную систему SQLOS. В последующих версиях SQL Server SQLOS стала отвечать за планирование, управление памятью и вводом/выводом, обработку исключений, интеграцию с CLR и внешними языками, а также некоторые другие задачи.
Когда вы запускаете процесс SQL Server, SQLOS создает набор планировщиков, которые распределяют рабочую нагрузку между процессорами. Количество планировщиков совпадает с количеством логических ЦП в системе, и еще один планировщик создается для выделенного административного соединения (DAC, Dedicated Admin Connection). Например, если у вас два четырехъядерных физических процессора с гиперпоточностью, то SQL Server создаст 17 планировщиков. На практике можно считать, что планировщик — то же самое, что процессор, и я буду использовать эти термины взаимозаменяемо на протяжении всей книги.
DAC — это крайняя мера устранения неполадок подключения. Оно позволяет получить доступ к SQL Server, если он перестал отвечать и не принимает обычные соединения. Я расскажу об этом подробнее в главе 13.
Каждый планировщик может находиться в состоянии ONLINE или OFFLINE в зависимости от настроек маски соответствия и модели лицензирования на основе ядер. Планировщики обычно не перемещаются с одного процессора на другой, хотя такая миграция возможна, особенно при большой нагрузке. Чаще всего это не влияет на процесс устранения неполадок.
Планировщики управляют набором рабочих потоков, которые также называются исполнителями (workers). Максимальное количество исполнителей в системе определяется параметром конфигурации Max Worker Thread. Значение по умолчанию равно нулю, и при этом SQL Server вычисляет максимальное количество исполнителей, исходя из количества планировщиков в системе. Обычно менять значение по умолчанию не требуется да и не рекомендуется, если только вы не знаете точно, что делаете.
Каждый раз, когда появляется задача, она назначается свободному исполнителю. Если таких исполнителей нет, планировщик создает нового. Он также уничтожает простаивающих исполнителей через 15 минут бездействия или когда не хватает памяти. Каждый исполнитель занимает область в памяти, выделенной для стека потоков: 512 Кбайт в 32-разрядной версии и 2 Мбайт в 64-разрядной версии SQL Server. Исполнителей можно рассматривать как логическое представление потоков в ОС, а задачи — как единицы работы, выполняемые этими потоками.
Исполнители не перемещаются от одного планировщика к другому, а задачи не перемещаются между исполнителями. Однако SQLOS может создавать дочерние задачи и назначать их разным исполнителям, например в случае параллельного плана выполнения. Это объясняет ситуации, когда некоторые планировщики нагружены сильнее других: отдельные рабочие процессы могут время от времени получать более ресурсоемкие задачи.
По умолчанию SQL Server назначает задачи исполнителям, обходя узлы NUMA в циклическом режиме и не учитывая количество планировщиков в этих узлах. Неравномерное распределение планировщиков по узлам NUMA приводит к тому, что работа рассредоточивается между планировщиками несбалансированно (я покажу пример такой ситуации в главе 15).
Чаще всего при устранении неполадок мы исследуем именно задачи. Но бывают исключения, когда задача находится в состоянии PENDING, то есть она создана и ожидает доступного исполнителя. Это нормальное явление, и обычно исполнители быстро забирают задачи. Однако это также может сигнализировать о весьма опасном состоянии, когда в системе не хватает рабочих процессов для обработки запросов. В главе 13 я расскажу, как обнаруживать и решать эту проблему.
Помимо PENDING, задача может находиться в пяти других состояниях:
RUNNING
Задача в данный момент выполняется в планировщике.
RUNNABLE
Задача ожидает, пока планировщик ее запустит.
SUSPENDED
Задача ожидает внешнего события или ресурса.
SPINLOOP
Задача обрабатывает спин-блокировку. Спин-блокировки — это объекты синхронизации, служащие для защиты некоторых внутренних объектов. SQL Server может использовать спин-блокировки, когда предполагается, что доступ к объекту будет предоставлен очень быстро, без переключения контекста для исполнителей.
DONE
Задача завершена.
Первые три состояния — самые важные и распространенные. У каждого планировщика единовременно может быть не более одной задачи в состоянии RUNNING. Кроме того, у него есть две разные очереди: одна — для задач в состоянии RUNNABLE и одна — для задач в состоянии SUSPENDED. Когда задаче в состоянии RUNNING требуются ресурсы — например, страница данных с диска, — она подает запрос ввода/вывода и переходит в состояние SUSPENDED. Задача находится в очереди SUSPENDED до тех пор, пока запрос не будет выполнен и страница не будет прочитана. После этого, когда задача готова выполняться дальше, она перемещается в очередь RUNNABLE.
Возможно, ближайшая аналогия этого процесса из реальной жизни — общая очередь на кассовом узле в магазине. Здесь кассиры — это планировщики, а покупатели — задачи в очереди RUNNABLE. Покупатель, которого в данный момент обслуживают на кассе, аналогичен задаче в состоянии RUNNING.
Если на товаре нет штрихкода, кассир посылает работника магазина проверить цену. Кассир приостанавливает обслуживание текущего покупателя и просит его отойти в сторону (в очередь SUSPENDED). Когда работник возвращается с информацией о цене, покупатель переходит в конец очереди на кассе (то есть конец очереди RUNNABLE).
Конечно, на SQL Server эти процедуры выполняются намного эффективнее, чем в реальном магазине, где клиентам приходится терпеливо ждать в стороне, пока проверяют цену. (Наверное, покупатель в конце очереди RUNNABLE мечтал бы о таком же быстродействии, как в SQL Server!)
Статистика ожидания
Если не считать процедур инициализации и утилизации, задача на протяжении своего жизненного цикла переключается между состояниями RUNNING, SUSPENDED и RUNNABLE, как показано на рис. 2.2. Общее время выполнения складывается из трех компонентов: время в состоянии RUNNING, когда задача фактически выполняется, время в состоянии RUNNABLE, когда задача ожидает, пока планировщик (ЦП) ее запустит, и время в состоянии SUSPENDED, когда задача ожидает ресурсов.
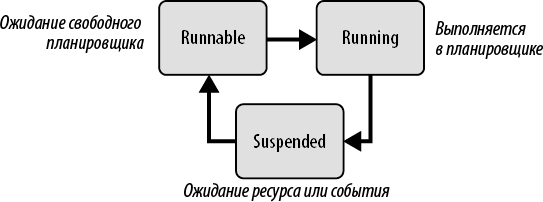
Рис. 2.2. Жизненный цикл задачи
В целом главная задача настройки производительности — в том, чтобы повысить пропускную способность системы, сократив время выполнения запросов. Этого можно добиться, если уменьшить время нахождения задач запросов в любом из трех перечисленных состояний.
Время запроса в состоянии RUNNING можно сократить, если модернизировать аппаратное обеспечение и перейти на более быстрые ЦП, а также если уменьшить объем задач благодаря оптимизации запросов. Чтобы сократить время RUNNABLE, можно добавить больше ресурсов ЦП или снизить нагрузку на систему. Но наибольшей экономии обычно удается достичь, если оптимизировать время, когда задача находится в состоянии SUSPENDED, ожидая ресурсов.
SQL Server отслеживает совокупное время, которое задачи проводят в состоянии SUSPENDED для различных типов ожидания. Эти данные можно просмотреть в представлении sys.dm_os_wait_stats8, чтобы получить общую картину узких мест в системе и уточнить стратегию устранения неполадок.
В коде листинга 2.1 показаны типы ожидания, которые занимают больше всего времени. (Опущены некоторые безобидные типы, в основном связанные с внутренними процессами SQL Server, которые проводят бо́льшую часть времени в ожидании.) Данные собираются с момента последнего перезапуска SQL Server или с момента последней очистки с помощью команды DBCC SQLPERF('sys.dm_os_wait_stats', CLEAR). В каждой новой версии SQL Server появляются новые типы ожидания. Одни из них полезны для устранения неполадок, а другие не имеет смысл учитывать9.
Листинг 2.1. Получение основных типов ожидания в системе (SQL Server 2012 и более поздние версии)
;WITH Waits
AS
(
SELECT
wait_type, wait_time_ms, waiting_tasks_count,signal_wait_time_ms
,wait_time_ms – signal_wait_time_ms AS resource_wait_time_ms
,100. * wait_time_ms / SUM(wait_time_ms) OVER() AS Pct
,100. * SUM(wait_time_ms) OVER(ORDER BY wait_time_ms DESC) /
NULLIF(SUM(wait_time_ms) OVER(), 0) AS RunningPct
,ROW_NUMBER() OVER(ORDER BY wait_time_ms DESC) AS RowNum
FROM sys.dm_os_wait_stats WITH (NOLOCK)
WHERE
wait_type NOT IN /* Исключаем не интересующие нас системные ожидания */
(N'BROKER_EVENTHANDLER',N'BROKER_RECEIVE_WAITFOR',N'BROKER_TASK_STOP'
,N'BROKER_TO_FLUSH',N'BROKER_TRANSMITTER',N'CHECKPOINT_QUEUE',N'CHKPT'
,N'CLR_SEMAPHORE',N'CLR_AUTO_EVENT',N'CLR_MANUAL_EVENT'
,N'DBMIRROR_DBM_EVENT',N'DBMIRROR_EVENTS_QUEUE',N'DBMIRROR_WORKER_QUEUE'
,N'DBMIRRORING_CMD',N'DIRTY_PAGE_POLL',N'DISPATCHER_QUEUE_SEMAPHORE'
,N'EXECSYNC',N'FSAGENT',N'FT_IFTS_SCHEDULER_IDLE_WAIT',N'FT_IFTSHC_MUTEX'
,N'HADR_CLUSAPI_CALL',N'HADR_FILESTREAM_IOMGR_IOCOMPLETION'
,N'HADR_LOGCAPTURE_WAIT',N'HADR_NOTIFICATION_DEQUEUE'
,N'HADR_TIMER_TASK',N'HADR_WORK_QUEUE',N'KSOURCE_WAKEUP',N'LAZYWRITER_SLEEP'
,N'LOGMGR_QUEUE',N'ONDEMAND_TASK_QUEUE'
,N'PARALLEL_REDO_WORKER_WAIT_WORK',N'PARALLEL_REDO_DRAIN_WORKER'
,N'PARALLEL_REDO_LOG_CACHE',N'PARALLEL_REDO_TRAN_LIST'
,N'PARALLEL_REDO_WORKER_SYNC',N'PREEMPTIVE_SP_SERVER_DIAGNOSTICS'
,N'PREEMPTIVE_OS_LIBRARYOPS',N'PREEMPTIVE_OS_COMOPS', N'PREEMPTIVE_OS_PIPEOPS'
,N'PREEMPTIVE_OS_GENERICOPS',N'PREEMPTIVE_OS_VERIFYTRUST'
,N'PREEMPTIVE_OS_FILEOPS',N'PREEMPTIVE_OS_DEVICEOPS'
,N'PREEMPTIVE_OS_QUERYREGISTRY',N'PREEMPTIVE_XE_CALLBACKEXECUTE'
,N'PREEMPTIVE_XE_DISPATCHER',N'PREEMPTIVE_XE_GETTARGETSTATE'
,N'PREEMPTIVE_XE_SESSIONCOMMIT',N'PREEMPTIVE_XE_TARGETINIT'
,N'PREEMPTIVE_XE_TARGETFINALIZE',N'PWAIT_ALL_COMPONENTS_INITIALIZED'
,N'PWAIT_DIRECTLOGCONSUMER_GETNEXT',N'PWAIT_EXTENSIBILITY_CLEANUP_TASK'
,N'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP',N'QDS_ASYNC_QUEUE'
,N'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP'
,N'REQUEST_FOR_DEADLOCK_SEARCH',N'RESOURCE_QUEUE',N'SERVER_IDLE_CHECK'
,N'SLEEP_BPOOL_FLUSH',N'SLEEP_DBSTARTUP',N'SLEEP_DCOMSTARTUP'
,N'SLEEP_MASTERDBREADY',N'SLEEP_MASTERMDREADY',N'SLEEP_MASTERUPGRADED'
,N'SLEEP_MSDBSTARTUP',N'SLEEP_SYSTEMTASK',N'SLEEP_TASK'
,N'SLEEP_TEMPDBSTARTUP',N'SNI_HTTP_ACCEPT',N'SOS_WORK_DISPATCHER'
,N'SP_SERVER_DIAGNOSTICS_SLEEP',N'SQLTRACE_BUFFER_FLUSH'
,N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP',N'SQLTRACE_WAIT_ENTRIES'
,N'STARTUP_DEPENDENCY_MANAGER',N'WAIT_FOR_RESULTS'
,N'WAITFOR',N'WAITFOR_TASKSHUTDOWN',N'WAIT_XTP_HOST_WAIT'
,N'WAIT_XTP_OFFLINE_CKPT_NEW_LOG',N'WAIT_XTP_CKPT_CLOSE',N'WAIT_XTP_RECOVERY'
,N'XE_BUFFERMGR_ALLPROCESSED_EVENT',N'XE_DISPATCHER_JOIN',N'XE_DISPATCHER_WAIT'
,N'XE_LIVE_TARGET_TVF',N'XE_TIMER_EVENT')
)
SELECT
w1.wait_type AS [Wait Type]
,w1.waiting_tasks_count AS [Wait Count]
,CONVERT(DECIMAL(12,3), w1.wait_time_ms / 1000.0) AS [Wait Time]



















