

автордың кітабын онлайн тегін оқу Грокаем машинное обучение
Переводчик Р. Чикин
Луис Серрано
Грокаем машинное обучение. — СПб.: Питер, 2024.
ISBN 978-5-4461-1923-3
© ООО Издательство "Питер", 2024
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Предисловие
Правда ли, что машинное обучение — это сложно и его трудно освоить? Конечно же, нет! Просто прочтите эту книгу!
Луис Серрано — настоящий волшебник, когда дело доходит до объяснения простыми словами. Я познакомился с ним, когда он преподавал машинное обучение на Udacity. Он заставлял наших студентов понять, что все машинное обучение так же просто, как сложение или вычитание. И самое главное, он делал материал интересным. Видеоролики, которые он создал для Udacity, были невероятно увлекательными и остаются одними из самых популярных материалов, предлагаемых на платформе.
Но эта книга еще лучше! Даже самые пугливые получат удовольствие от чтения, поскольку Серрано раскрывает некоторые из самых сокровенных секретов сообщества машинного обучения. Он шаг за шагом проведет вас через каждый важный алгоритм и метод в этой области. Вы можете стать фанатом машинного обучения, даже если вам не нравится математика. Серрано минимизирует математическую тарабарщину и вместо этого полагается на интуицию и практические объяснения.
Истинная цель книги — дать вам возможность самостоятельно овладеть этими методами. Так что книга полна забавных упражнений, в которых вы сможете сами опробовать эти загадочные (а теперь и разоблаченные) техники. Что бы вы предпочли — проглотить последнее телешоу Netflix или потратить время на применение машинного обучения к проблемам компьютерного зрения и понимания естественного языка? Если последнее, то эта книга для вас. Я не могу выразить, насколько это увлекательно — играть с новейшими разработками в области машинного обучения и видеть, как компьютер творит чудеса под вашим чутким руководством.
А поскольку машинное обучение едва ли не самая популярная технология последних лет, вы сможете использовать новообретенные навыки и в своей работе. Несколько лет назад газета New York Times объявила, что в мире насчитывается всего 10 000 экспертов по машинному обучению и миллионы открытых вакансий. Так обстоит дело и сегодня! Изучите эту книгу и станьте профессиональным инженером по машинному обучению. Вы гарантированно овладеете одним из самых востребованных в современном мире навыков.
В этой книге Луис Серрано проделал превосходную работу, объяснив сложные алгоритмы и сделав их доступными практически для всех. Но он сделал это не в ущерб глубине. Вместо этого он сфокусировался на расширении возможностей читателя с помощью цепочки понятных проектов и упражнений. В этом смысле это далеко не пассивное чтение. Чтобы в полной мере извлечь пользу из книги, вам придется потрудиться. У нас в Udacity есть поговорка: вы не похудеете, глядя за тем, как тренируются другие. Чтобы использовать машинное обучение, вы должны научиться применять его для решения реальных задач. Если вы готовы, то эта книга для вас — кем бы вы ни были!
Себастьян Тран, PhD, основатель Udacity, адъюнкт-профессор Стэнфордского университета
Вступление
Будущее уже здесь, и у этого будущего есть имя — машинное обучение. Благодаря его применению практически во всех отраслях, от медицины до банковского дела, от запуска беспилотных автомобилей до заказа кофе, интерес к нему растет лавинообразно. Но что такое машинное обучение?
Чаще всего, читая книгу или слушая лекцию по машинному обучению, я вижу либо море сложных формул, либо море строк кода. Долго я думал, что это и есть машинное обучение и что оно предназначено только для тех, кто обладает солидными знаниями как в математике, так и в информатике.
Однако позже я начал сравнивать машинное обучение с другими предметами, такими как музыка. Музыкальная теория и практика — сложные предметы. Но когда мы размышляем о музыке, то думаем не о партитурах и гаммах, а о песнях и мелодиях. И тогда я задался вопросом: а не может ли машинное обучение быть тем же самым? Действительно ли это лишь набор формул и кода или за этим есть мелодия?
Рис. В.1. Музыка — это не только гаммы и ноты. За техническими деталями скрывается мелодия. Точно так же машинное обучение — это не только формулы и код. Есть и мелодия, и в этой книге мы ее исполним
С этой мыслью я и отправился в путешествие с целью понять мелодию машинного обучения. Я месяцами пялился на формулы и код. Нарисовал множество диаграмм. Царапал рисунки на салфетках и показывал их своей семье, друзьям и коллегам. Я обучал модели на небольших и огромных наборах данных. Экспериментировал. Через некоторое время я начал слышать мелодию машинного обучения. Внезапно в моем сознании начали формироваться прекрасные образы. Я начал писать истории, которые соответствуют всем этим концепциям машинного обучения. Мелодии, картинки, истории — вот как мне нравится изучать любую тему, и именно этими мелодиями, картинками и историями я делюсь с вами в книге. Моя цель — сделать машинное обучение на 100 % понятным каждому, и эта книга — шаг в этом путешествии‚ шаг, который я счастлив делать вместе с вами!
Благодарности
Прежде всего я хотел бы поблагодарить моего редактора Марину Майклс, без которой книга не появилась бы на свет. Благодарю Марджан Бейс, Берта Бейтса и остальных членов команды издательства Manning за их поддержку, профессионализм, отличные идеи и терпение. Благодарю технических корректоров Ширли Яп и Карстена Стребека, редактора по развитию Криса Ати и рецензентов за то, что они дали отличные отзывы и исправили многие мои ошибки. Я благодарю выпускающего редактора Кери Хейлз, редактора Памелу Хант, графического редактора Дженнифер Хоул, корректора Джейсона Эверетта и всю производственную команду за отличную работу по воплощению этой книги в реальность. Благодарю Лауру Монтойю за ее помощь с инклюзивным языком и этикой искусственного интеллекта, Диего Эрнандеса — за ценные дополнения к коду и Кристиана Пикона — за огромную помощь с техническими аспектами репозитория и библиотек.
Я благодарен Себастьяну Трану за прекрасную работу по демократизации образования. Udacity была платформой, которая впервые подарила мне возможность учить мир, и я хотел бы поблагодарить замечательных коллег и студентов, которых там встретил. Алехандро Пердомо и команда Zapata Computing заслуживают благодарности за то, что познакомили меня с миром квантового машинного обучения. Спасибо многим замечательным руководителям и коллегам, с которыми я познакомился в Google и Apple, — они сыграли важную роль в моей карьере. Особая благодарность Роберто Чиприани и команде Paper Inc. за то, что позволили мне стать частью своей семьи, и за превосходную работу, которую они выполняют в образовательном сообществе.
Я хотел бы поблагодарить своих многочисленных университетских преподавателей, которые сформировали мою карьеру и мой образ мышления: Мэри Фальк де Лосада и ее команду на Колумбийских математических олимпиадах, где я полюбил математику и имел возможность встретиться с великими наставниками и завести дружбу, которая длилась всю жизнь; научного руководителя Сергея Фомина, который сыграл важную роль в моем математическом образовании и стиле преподавания; советника моего учителя Яна Гулдена; Нантель и Франсуа Бержерон, Брюса Сагана и Федерико Ардила, а также многих профессоров и коллег, с которыми я имел возможность работать, в частности, в университетах Ватерлоо, Мичигана, Квебека в Монреале и Йорке, и, наконец, Ричарда Хосино, команду и студентов университета Квест, которые помогли мне протестировать и улучшить материал этой книги.
Спасибо всем рецензентам: Элу Пежевски, Альберту Ногесу Сабатеру, Амиту Ламбе, Биллу Митчеллу, Борко Джурковичу, Даниэле Андреису, Эрику Саперу, Хао Лю, Джереми Р. Лошайдеру, Хуану Габриэлю Боно, Кей Энгельхардт, Кшиштофу Камычеку, Мэтью Марголису, Маттиасу Бушу, Майклу Брайту, Милладу Дагдони, Полине Кесельман, Тони Холдройд и Валери Парэм-Томпсон, ваши предложения помогли сделать эту книгу лучше.
Я хотел бы поблагодарить свою жену Каролину Лассо, которая всегда поддерживала меня; маму Сесилию Эрреру, которая воспитывала меня с любовью и поощряла следовать за своими мечтами; бабушку — она тот ангел, что смотрит на меня с небес; лучшего друга Алехандро Моралеса за то, что всегда был рядом, и друзей, которые осветили мой путь и скрасили мою жизнь. Я благодарю вас и люблю всем сердцем.
YouTube, блоги, подкасты и социальные сети дали мне возможность пообщаться с тысячами потрясающих людей по всему миру. Любознательные умы с бесконечной страстью к обучению, коллеги-преподаватели, которые щедро делятся своими знаниями и прозрениями, образуют электронное племя, которое вдохновляет меня каждый день и дает силы продолжать преподавать и учиться. Я благодарю всех, кто делится своими знаниями с миром или стремится учиться каждый день.
Я благодарю всех, кто стремится сделать этот мир более справедливым и мирным. Всех, кто борется за справедливость, мир, окружающую среду и за равные возможности для всех людей на Земле независимо от расы, пола, места рождения, условий и выбора, я благодарю от всего сердца.
И последнее, но, конечно, не менее важное: эта книга посвящается тебе, читатель. Ты выбрал путь обучения, путь совершенствования, путь ощущения комфорта в условиях дискомфорта, и это достойно восхищения. Я надеюсь, что эта книга станет важным шагом на пути к твоим мечтам и созданию лучшего мира.
О книге
Эта книга научит двум вещам: моделям машинного обучения и тому, как их использовать. Модели машинного обучения бывают разных типов. Некоторые из них возвращают детерминированный ответ, такой как «да» или «нет», а другие — ответ в виде вероятности. Одни из них используют уравнения, другие — операторы if. Их общая черта заключается в том, что все они возвращают ответ или прогноз. Отрасль машинного обучения, которая включает в себя модели, возвращающие прогноз, удачно названа прогностическим машинным обучением. На этом типе машинного обучения мы и сосредоточимся.
Как организована книга: дорожная карта
Типы глав
Эта книга состоит из глав двух типов. Большинство из них — главы 3, 5, 6, 8–12 — посвящены одному типу моделей машинного обучения. В каждой главе модель подробно разбирается, в том числе рассматриваются примеры, формулы, код и самостоятельные упражнения. А главы 4, 7 и 13 содержат полезные методы, которые можно использовать для обучения, оценки и улучшения моделей машинного обучения. В частности, в главе 13 сквозной пример исследуется на реальном наборе данных, здесь вы сможете применить все знания, полученные в предыдущих главах.
Рекомендуемые пути обучения
Вы можете работать с книгой двумя способами. Я рекомендую знакомиться с ней последовательно, глава за главой, потому что такое чередование моделей и методов их обучения весьма полезно. Другой путь заключается в том, чтобы сначала изучить все модели (главы 3, 5, 6, 8–12), а затем — методы их обучения (главы 4, 7 и 13). И, конечно же, поскольку все мы учимся по-разному, вы можете следовать собственному пути!
Приложения
Книга имеет три приложения. В приложении А опубликованы решения упражнений, описанных в каждой главе. Приложение Б содержит некоторые полезные формальные математические выводы, более технически сложные, чем остальная книга. Приложение В — это список литературы и ресурсов, с которыми я рекомендую ознакомиться, если вы хотите углубить свое понимание темы.
Требования и цели обучения
Книга даст вам прочную основу в области прогностического машинного обучения. Чтобы извлечь из нее максимальную пользу, вы должны обладать визуальным мышлением и хорошо разбираться в элементарной математике. Будет полезно (хотя и не обязательно) знать, как писать код, особенно на Python, потому что на протяжении всей книги вам предоставляется возможность реализовать и применить несколько моделей в реальных наборах данных. Прочитав эту книгу, вы сможете сделать следующее.
• Описать наиболее важные модели в прогностическом машинном обучении и то, как они работают, включая линейную и логистическую регрессию, наивный байесовский алгоритм, деревья решений, нейронные сети, машины опорных векторов и методы ансамблей.
• Определить их сильные и слабые стороны и параметры, которые они применяют.
• Определить, как эти модели используются в реальном мире, и сформулировать потенциальные способы применения машинного обучения к любой конкретной задаче, которую вы хотели бы решить.
• Узнать, как оптимизировать, сравнивать и улучшать эти модели, чтобы создавать лучшие из возможных моделей машинного обучения.
• Кодировать модели вручную или с помощью существующего пакета и использовать их для прогнозирования реальных наборов данных.
Если у вас на примете есть конкретный набор данных или проблема, я приглашаю вас подумать о том, как применить к ним то, что вы узнаете из этой книги, и использовать ее в качестве отправной точки для внедрения и экспериментов с вашими собственными моделями.
Я очень рад начать это путешествие вместе с вами и надеюсь, что вы рады не меньше!
Другие ресурсы
Данная книга самодостаточна. Это означает, что помимо требований, описанных ранее, в ней представлены все необходимые нам концепции. Тем не менее я включаю много ссылок, которые пригодятся, если вы захотите понять концепции более глубоко или изучить дополнительные темы. Все ссылки размещены в приложении В, а также здесь: http://serrano.academy/grokking-machine-learning.
Некоторые из моих собственных ресурсов тоже дополняют материалы этой книги. На странице в http://serrano.academy вы найдете множество материалов в форме видео, постов и кода. Видео есть и на моем канале YouTube www.youtube.com/c/LuisSerrano, с которым я рекомендую ознакомиться. И к большинству глав этой книги прилагается видео, которое стоит посмотреть во время чтения.
Мы будем писать код
Мы будем писать код на Python. Однако, если вы планируете изучать предложенные концепции без кода, можете игнорировать его. Тем не менее я рекомендую вам хотя бы взглянуть на него в ознакомительных целях.
Книга поставляется с репозиторием кода, и большинство глав дадут вам возможность кодировать алгоритмы с нуля или использовать некоторые распространенные пакеты Python для построения моделей, соответствующих заданным наборам данных. Репозиторий GitHub — это www.github.com/luisguiserrano/manning, и я указываю соответствующие блокноты по всей книге. В README репозитория вы найдете инструкции по установке пакетов для успешного запуска кода.
Основными пакетами Python, которые мы используем в книге, являются:
• NumPy — для хранения массивов и выполнения сложных математических вычислений;
• Pandas — для хранения, обработки и анализа больших наборов данных;
• Matplotlib — для построения графиков данных;
• Turi Create — для хранения и обработки данных, а также обучения моделей;
• Scikit-Learn — для обучения моделей машинного обучения;
• Keras (TensorFlow) — для обучения нейронных сетей.
О коде
Эта книга содержит много примеров исходного кода‚ внедренных в обычный текст. В обоих случаях исходный код форматируется таким моноширинным шрифтом, чтобы отделить его от обычного текста. Иногда код также обозначен жирным шрифтом, чтобы выделить код, который изменился по сравнению с предыдущими шагами в главе, например, когда новая функция добавляется к уже существующей строке кода.
Во многих случаях исходный код был переформатирован: мы добавили разрывы строк и переработали отступы, чтобы более полно использовать доступное пространство на страницах книги. Кроме того, комментарии, имеющиеся в исходном коде, часто удалялись, если код описывался в тексте. Многие листинги сопровождаются аннотациями к коду, уточняющими важные концепции.
Код примеров, приводимых в книге, доступен для скачивания на веб-сайте Manning (https://www.manning.com/books/grokking-machine-learning), а также с GitHub на www.github.com/luisguiserrano/manning.
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу comp@piter.com (издательство «Питер», компьютерная редакция). Мы будем рады узнать ваше мнение!
На веб-сайте издательства www.piter.com вы найдете подробную информацию о наших книгах.
Об авторе

Луис Дж. Серрано — ученый-исследователь, работающий в области квантового искусственного интеллекта в Zapata Computing. Ранее он был инженером по машинному обучению в Google, ведущим преподавателем искусственного интеллекта в Apple и руководителем отдела контента в области искусственного интеллекта и науки о данных в Udacity. Луис получил докторскую степень по математике в Мичиганском университете, степень бакалавра и магистра математики в университете Ватерлоо и после этого работал исследователем в лаборатории комбинаторной и информационной математики Квебекского университета в Монреале. Луис ведет популярный YouTube-канал о машинном обучении с более чем 85 000 подписчиков и более чем 4 млн просмотров, часто выступает с докладами на конференциях по искусственному интеллекту и науке о данных.
1. Что такое машинное обучение? Это здравый смысл, проявляемый компьютером
В этой главе
• Что такое машинное обучение.
• Сложно ли машинное обучение (спойлер: нет).
• Чему мы научимся в этой книге.
• Что такое искусственный интеллект и чем он отличается от машинного обучения.
• Как мыслят люди и как можно внедрить эти идеи в машину.
• Некоторые базовые примеры машинного обучения из реальной жизни.

Я с радостью присоединяюсь к вам на пути к знаниям!
Приветствую вас на страницах этой книги! Я искренне рад присоединиться к вам на пути к пониманию машинного обучения. На высоком уровне машинное обучение — это процесс, в ходе которого компьютер решает проблемы и принимает решения. Почти как человек.
Через эту книгу я хочу донести до вас одну мысль: машинное обучение — это просто! Чтобы разобраться с ним‚ не нужно быть великим математиком или программистом. Базовая математика, конечно‚ понадобится, но основными составляющими послужат здравый смысл, хорошая визуальная интуиция и желание изучать и применять указанные методы ко всему, чем вы увлечены, и в области‚ где хотите что-то улучшить. Я получил огромное удовольствие от написания книги, так как мне понравилось углубляться в данную тему, и я надеюсь, что вы получите огромное удовольствие, прочитав ее и погрузившись в машинное обучение!
Машинное обучение повсюду
Машинное обучение можно встретить везде. Это утверждение с каждым днем кажется все более верным. Мне трудно представить себе хоть один аспект жизни, который нельзя было бы так или иначе улучшить с помощью машинного обучения. В любом деле, требующем повторения‚ анализа данных и сбора выходных данных‚ вам поможет машинное обучение. За последние несколько лет благодаря достижениям в области вычислительных мощностей и повсеместному сбору данных в сфере машинного обучения наблюдался поистине взрывной рост. Назову лишь несколько областей применения машинного обучения: системы рекомендаций, распознавание изображений, обработка текста, автопилот в автомобилях, выявление спама, постановка медицинских диагнозов… Список можно продолжать бесконечно. Возможно, у вас есть задача или область, в которой требуется ощутимый прогресс. Весьма вероятно, что машинное обучение вполне применимо в этой области — и именно это привело вас к этой книге. Давайте вместе с этим разберемся!
Нужен ли большой опыт в математике и программировании, чтобы понять машинное обучение?
Нет. Машинное обучение требует воображения, творческого подхода и визуального мышления. Оно заключается в том, чтобы улавливать закономерности, которые появляются в мире, и использовать их для прогнозирования событий будущего. Если вам нравится находить закономерности и выявлять корреляции, тогда машинное обучение — ваша область. Если бы я сказал вам, что бросил курить, стал есть больше овощей и занялся спортом, то что, согласно вашему прогнозу, произойдет с моим здоровьем через год? Возможно, оно улучшится. Если бы я сказал вам, что перехожу с красных свитеров на зеленые, то что‚ по-вашему, случится с моим здоровьем через год? Скорее всего, мало что изменится (может, случатся грандиозные перемены, но не из-за того, о чем я сообщил). Выявление таких корреляций и закономерностей — вот что такое машинное обучение. Единственное различие машинного обучения состоит в том, что здесь мы привязываем к этим шаблонам формулы и цифры, чтобы компьютеры могли их распознавать.
Для изучения машинного обучения необходимы некоторые знания математики и программирования, но экспертом быть вовсе не обязательно. Если вы уже эксперт в любой из этих областей (или даже в обеих), то эти навыки наверняка вам пригодятся. Но если пока это не так, вы все равно сможете изучить машинное обучение и восполнить пробелы в математике и программировании по ходу дела. В этой книге мы представим все необходимые математические концепции в тот момент, когда они нам понадобятся. Если говорить о кодировании, то объем кода‚ который потребуется в машинном обучении, зависит только от вас. В машинном обучении есть задания как для тех, кто программирует весь день напролет, так и для тех, кто не программирует вообще. Многие пакеты, API и инструменты помогают нам реализовать машинное обучение с минимальным объемом кода. С каждым днем машинное обучение становится все более общедоступным, и я рад, что вы не остались в стороне!
Формулы и код — это весело, если их рассматривать как язык
В большинстве книг по машинному обучению алгоритмы объясняются математически с использованием формул, производных и т.д. Хотя такие точные описания методов хорошо работают на практике, сама по себе формула может быть скорее запутанной, чем иллюстративной. Однако, подобно музыкальной партитуре, за запутанностью формулы может скрываться чудесная мелодия. Например, взглянем на формулу
А как насчет
Если вы действительно любите формулы, не волнуйтесь — в книге их достаточно. Но появляться они будут сразу после примера, который их иллюстрирует.
То же самое будет и с кодом. Если мы смотрим на код со стороны, он может казаться сложным, и бывает трудно поверить, что кто-то может уместить все это в своей голове. Однако код — это лишь последовательность шагов, и‚ как правило‚ каждый из них прост. В этой книге мы будем писать код, но разобьем его на простые шаги, каждый из которых подробно объясним на примерах либо с помощью иллюстраций. В первых нескольких главах мы будем кодировать свои модели с нуля, чтобы лучше понимать, как они работают. Однако в последующих главах модели усложнятся. Для них мы станем использовать такие пакеты, как Scikit-Learn, Turi Create или Keras, в которых точно и эффективно реализовано большинство алгоритмов машинного обучения.
Так что же такое машинное обучение?
Чтобы дать определение машинному обучению, сначала определим более общий термин — искусственный интеллект (ИИ).
Что такое искусственный интеллект
Это общий термин, который мы определяем так.
ИСКУССТВЕННЫЙ ИНТЕЛЛЕКТ — набор всех задач, в которых компьютер может принимать решения.
Во многих случаях компьютер принимает эти решения, имитируя принятие решения человеком. Также он может имитировать эволюционные, генетические или физические процессы. Но в целом каждый раз, когда мы видим, что компьютер решает проблему самостоятельно, будь то вождение автомобиля, поиск маршрута между двумя точками, постановка диагноза пациенту или рекомендация фильма, мы наблюдаем работу искусственного интеллекта.
Что такое машинное обучение
Машинное обучение похоже на искусственный интеллект, и часто их определения путают.
Машинное обучение (МО) является частью искусственного интеллекта, определяют его следующим образом.
МАШИННОЕ ОБУЧЕНИЕ — набор всех задач, в которых компьютер может принимать решения на основе данных.
Что это значит? Позвольте проиллюстрировать на рис. 1.1.
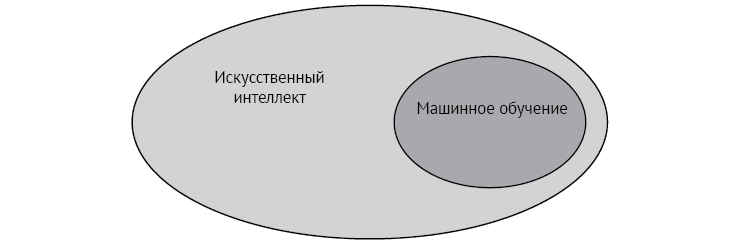
Рис. 1.1. Машинное обучение — это область искусственного интеллекта
Вернемся к рассмотрению того, как именно люди принимают решения. В общих чертах мы принимаем решения двумя путями:
• с помощью логики и рассуждений;
• задействуя собственный опыт.
Представьте, что мы принимаем решение о покупке автомобиля. Можно внимательно изучить его характеристики, такие как цена, расход топлива и навигация, после чего попытаться определить наилучшую комбинацию, которая соответствует нашему бюджету. Это использование логики и принятие разумного решения. Если же вместо этого мы спросим всех своих друзей, какими автомобилями они владеют и что им в них нравится или не нравится, составим список аргументов за и против‚ после чего с его помощью примем решение, то это будет применением опыта — в данном случае опыта друзей.
Машинное обучение представляет собой второй метод — принятие решений с использованием своего опыта. На компьютерном языке термин, обозначающий опыт, звучит как данные. Следовательно, при машинном обучении компьютеры принимают решения на основе данных. Таким образом, каждый раз, когда мы заставляем компьютер решать задачи или принимать решения с помощью только данных, мы занимаемся машинным обучением. Простыми словами машинное обучение можно описать так — это рассудительность, за исключением того факта, что проявляет ее компьютер.
Переход от решения проблем с использованием любых необходимых средств к решению проблем с применением только данных может показаться небольшим шагом для компьютера, но это огромный шаг для человечества (рис. 1.2). Когда-то давно, если мы хотели заставить компьютер выполнять какую-то задачу, нам нужно было писать программу, а именно целый набор инструкций, которым компьютер должен следовать. Этот процесс хорош для простых задач, но некоторые из них слишком сложны для подобной концепции. Например, рассмотрим задачу по определению того, есть ли на изображении яблоко. Начав писать компьютерную программу для решения этой задачи, мы быстро поймем, что это крайне сложно.

Рис. 1.2. Машинное обучение охватывает все задачи, в которых компьютеры принимают решения на основе данных
Давайте сделаем шаг назад и зададим себе вопрос: как мы, люди, узнали, как выглядит яблоко? Большинство слов мы выучили не благодаря тому, что кто-то объяснил нам, что они означают, а путем повторения. В детстве мы видели много предметов, и взрослые сообщали нам, что это за предметы. Прежде чем узнать, что такое яблоко, мы видели множество яблок на протяжении многих лет и слышали слово «яблоко», пока однажды в голове что-то не щелкнуло и мы не поняли, что такое яблоко. Это как раз то, что мы заставляем делать компьютер в рамках машинного обучения. Мы демонстрируем ему множество изображений и сообщаем, какие из них содержат яблоко (что составляет наши данные). Мы повторяем этот процесс до тех пор, пока компьютер не начнет улавливать верные формы и атрибуты, которые и составляют яблоко. В конце процесса, когда мы передаем компьютеру новое изображение, он уже может использовать эти шаблоны, чтобы определить, содержит ли изображение яблоко. То есть точно так же, как люди принимают решения на основе предыдущего опыта, компьютеры могут принимать решения на основе предыдущих данных. Конечно, нам все равно нужно запрограммировать компьютер так, чтобы он мог улавливать эти закономерности. В этом поможет ряд приемов, которым мы обучимся в книге.
Ну и раз уж мы сделали первый шаг — что такое глубокое обучение?
Точно так же, как машинное обучение является частью искусственного интеллекта, глубокое обучение — часть машинного обучения. В предыдущем разделе мы узнали, что в нашем распоряжении есть несколько методов, чтобы заставить компьютер учиться на основе данных. Один из этих методов работает настолько хорошо, что обзавелся собственной областью исследований, называемой глубоким обучением (ГО) (рис. 1.3), которую мы определяем следующим образом.
ГЛУБОКОЕ ОБУЧЕНИЕ — область машинного обучения, использующая объекты, называемые нейронными сетями.
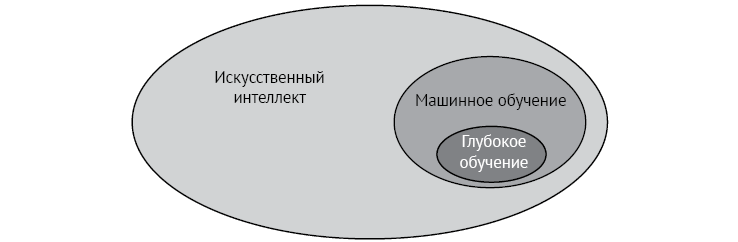
Рис. 1.3. Глубокое обучение является частью машинного обучения
Что такое нейронные сети? О них мы узнаем в главе 10. Глубокое обучение — это, возможно, наиболее часто используемый тип машинного обучения, потому что он действительно хорошо работает. Видя какое-то из передовых приложений, таких как распознавание изображений, генерация текста, игра в го или беспилотные автомобили, скорее всего, мы в той или иной степени наблюдаем глубокое обучение.
Другими словами, глубокое обучение — это часть машинного обучения, которое, в свою очередь, является частью искусственного интеллекта. Если бы эта книга была о транспорте, то ИИ был бы совокупностью транспортных средств, МО — автомобилями, а ГО — Ferrari.
Как заставить машины принимать решения с помощью данных? Концепция вспоминания — формулирования — прогнозирования
В предыдущем разделе говорилось, что машинное обучение состоит из набора методов, которые мы используем, чтобы заставить компьютер принимать решения на основе данных. В этом разделе узнаем, что подразумевается под принятием решений на основе данных и как работают некоторые из таких методов. Для этого еще раз проанализируем процесс, с помощью которого люди принимают решения, основанные на опыте. Это то, что называется концепцией вспоминания — формулирования — прогнозирования (рис. 1.4). Составляющие ее шаги сформулированы в следующем разделе. Цель машинного обучения состоит в том, чтобы научить компьютеры мыслить одинаково, следуя одним и тем же принципам.
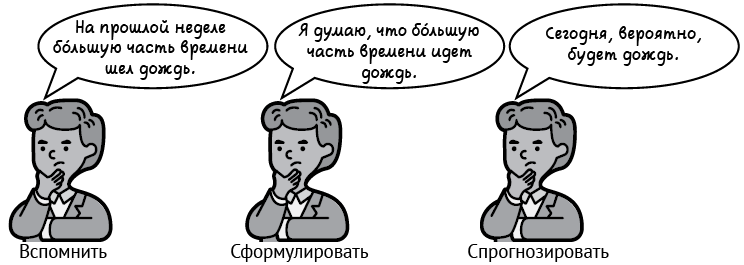
Рис. 1.4. Вспоминание — формулирование — прогнозирование — основная концепция, используемая в книге
Как мыслят люди?
Когда нам, людям, нужно принять решение, основанное на собственном опыте, мы обычно задействуем следующую концепцию.
1. Вспоминаем похожие ситуации в прошлом.
2. Формулируем общее правило.
3. Используем его, чтобы спрогнозировать то, что может произойти в будущем.
Например, если вопрос звучит так: «Будет ли сегодня дождь?», то процесс предсказания состоит в следующем.
1. Мы вспоминаем, что на прошлой неделе бóльшую часть времени шел дождь.
2. Мы формулируем правило о том‚ что в этом месте бóльшую часть времени идет дождь.
3. И прогнозируем, что сегодня будет дождь.
Мы можем быть правы или неправы, но по крайней мере пытаемся сделать максимально точный прогноз, основываясь на имеющейся информации.
Некоторые лингвомодели и алгоритмы машинного обучения
Прежде чем обратиться к дополнительным примерам, иллюстрирующим методы, используемые в машинном обучении, дадим определения кое-каких полезных терминов, которые будем применять на протяжении всей книги. Мы знаем, что при машинном обучении заставляем компьютер учиться решать проблему с помощью данных, используя их для построения модели. Что такое модель? Определим ее следующим образом.
МОДЕЛЬ — набор правил, которые представляют наши данные и могут быть задействованы для прогнозирования.
Мы можем думать о модели как о представлении реальности, использующем набор правил, максимально точно имитирующих существующие данные. В примере с дождем в предыдущем разделе нашим представлением реальности была модель, описывающая мир, где бóльшую часть времени идет дождь. Это простой мир с одним правилом: бóльшую часть времени идет дождь. Представление может быть точным, а может — нет, но, согласно нашим данным, это наиболее точное представление реальности, которое мы способны сформулировать. Позже мы применяем это правило для составления прогнозов на основе неявных данных.
Алгоритм — это процесс, который использовался для построения модели. В текущем примере он прост: мы посмотрели, сколько дней шел дождь, и поняли, что большинство. Конечно, алгоритмы машинного обучения могут быть намного сложнее, но в итоге они всегда состоят из набора шагов. Наше определение алгоритма таково.
АЛГОРИТМ — процедура или набор шагов, используемых для решения задачи или выполнения вычисления. Здесь цель алгоритма — построение модели.
Короче говоря, модель — это то, что мы применяем для прогнозирования, а алгоритм — то, с помощью чего строим модель. Эти два определения легко спутать, и часто они взаимозаменяемы, так что для ясности рассмотрим несколько примеров.
Примеры используемых людьми моделей
В этом разделе мы сосредоточимся на распространенном применении машинного обучения — обнаружении спама. В следующих примерах будем выявлять как спам‚ так и письма, им не являющиеся. Письма, не являющиеся спамом, называются также полезными1.
СПАМ И ПОЛЕЗНЫЕ ПИСЬМА
Спам — это общий термин для обозначения ненужной или нежелательной электронной почты, такой как письма-рассылки, рекламные акции и пр. Термин берет начало в скетче Монти Пайтона 1972 года, в котором каждый пункт меню ресторана содержал спам в качестве ингредиента. Разработчики используют термин «ветчина» (ham) для обозначения электронных писем, не являющихся спамом.
Пример 1. Раздражающий друг
В этом примере мы встречаемся со своим другом Бобом‚ любителем отправлять электронные письма. Многие его письма — это спам в виде писем счастья. Они уже начинают раздражать. Сегодня суббота, и мы только что получили очередное уведомление по электронной почте от Боба. Можно ли угадать, спам ли это письмо, не глядя на него?
Попробуем использовать метод вспоминания — формулирования — прогнозирования. Во-первых, вспомним, скажем, последние десять электронных писем, полученных от Боба. Это наши данные. Мы помним, что шесть из них были спамом, а остальные четыре — полезными. Исходя из этой информации, можем сформулировать следующую модель.
Модель 1. Шесть из каждых десяти электронных писем от Боба — спам.
Это правило станет нашей моделью. Обратите внимание на то, что правило не обязательно должно быть истинным. Более того‚ оно может быть бессовестно неверным. Но, учитывая наши данные, это лучшее, что мы можем придумать, так что придется работать с тем‚ что есть. Далее в этой книге мы узнаем, как оценивать модели и улучшать их, когда это необходимо.
Теперь, когда у нас есть правило, можем использовать его, чтобы спрогнозировать, является ли электронное письмо спамом. Если шесть из десяти писем Боба — спам, то можно предположить, что новое электронное письмо с вероятностью 60 % будет спамом и с вероятностью 40 % — нет. Согласно этому правилу, с несколько большей вероятностью электронное письмо является спамом. Таким образом, прогнозируем, что электронное письмо — спам (рис. 1.5).
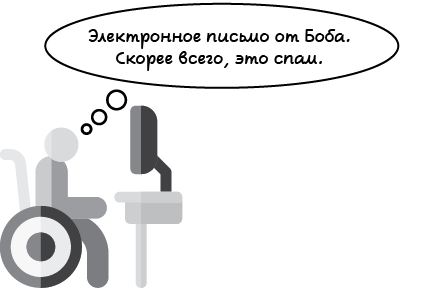
Рис. 1.5. Очень простая модель машинного обучения
Повторюсь, наше предсказание может оказаться неверным. Мы можем открыть электронное письмо и понять, что оно все-таки полезное. Но мы сделали прогноз на основе известных данных. Вот в чем суть машинного обучения! Возможно, вы уже думаете о том‚ можно ли внести в процесс какие-то улучшения. Мы оцениваем каждое электронное письмо от Боба сходным образом, но можно ли получить больше информации, которая поможет отделить спам? Попробуем немного глубже проанализировать эти электронные письма. Например, можно выяснить, когда именно Боб отправлял их‚ и попробовать выявить закономерность.
Пример 2. Раздражающий друг по расписанию
Давайте более внимательно рассмотрим электронные письма, которые Боб отправлял нам месяцем ранее. Точнее, посмотрим, в какой именно день он это делал. Вот электронные письма с названием дня недели и информацией о том, являются ли они спамом:
• понедельник — полезное;
• вторник — полезное;
• суббота — спам;
• воскресенье — спам;
• воскресенье — спам;
• среда — полезное;
• пятница — полезное;
• суббота — спам;
• вторник — полезное;
• четверг — полезное.
Все заиграло новыми красками‚ не так ли? Закономерность налицо! Похоже, что каждое электронное письмо, отправленное Бобом в течение недели, полезное, а отправленное в выходные — спам. В этом есть логика: возможно, в течение недели он отправляет нам рабочую электронную почту, а в выходные у него есть время для рассылки спама‚ и он решает ни в чем себе не отказывать. Итак, мы можем сформулировать более обоснованное правило или модель.
Модель 2. Каждое электронное письмо, которое Боб отправляет в течение недели, — это полезное письмо, а отправленное в выходные — спам.
Теперь посмотрим, какой сегодня день. Если воскресенье и мы только что получили электронное письмо от Боба, то с большой долей уверенности можем спрогнозировать, что это спам (рис. 1.6). Сделав прогноз, сразу отправляем его в мусорную корзину и продолжаем наш день.
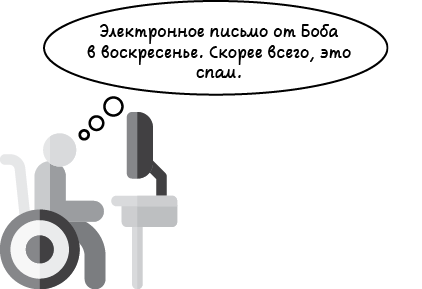
Рис. 1.6. Несколько более сложная модель машинного обучения
Пример 3. Все усложняется!
Теперь предположим, что мы продолжаем следовать этому правилу и однажды встречаем Боба на улице. Он спрашивает: «Почему ты не пришел на мой день рождения?» Мы понятия не имеем, о чем он говорит. Оказывается, в прошлое воскресенье он рассылал приглашения на свой день рождения, а мы его пропустили! Почему? Потому что он отправил письмо в выходной и мы предположили, что это спам. Похоже, нам требуется модель получше. Давайте вернемся к просмотру электронных писем Боба — тому шагу‚ когда мы вспоминаем, — и выясним, нет ли там других закономерностей:
• 1 Кбайт — полезное;
• 2 Кбайт — полезное;
• 16 Кбайт — спам;
• 20 Кбайт — спам;
• 18 Кбайт — спам;
• 3 Кбайт — полезное;
• 5 Кбайт — полезное;
• 25 Кбайт — спам;
• 1 Кбайт — полезное;
• 3 Кбайт — полезное.
Что же мы видим? Похоже, что объемные электронные письма обычно являются спамом, в то время как более мелкие — как правило, нет. Это вполне логично‚ потому что спам-письма часто содержат большие вложения.
Итак, мы можем сформулировать следующее правило.
Модель 3. Любое электронное письмо размером 10 Кбайт или больше — это спам, а менее 10 Кбайт — нет.
Теперь, когда правило сформулировано, можем сделать прогноз. Мы смотрим на электронное письмо, которое получили сегодня от Боба, видим, что его размер составляет 19 Кбайт, и закономерно приходим к выводу — это спам (рис. 1.7).
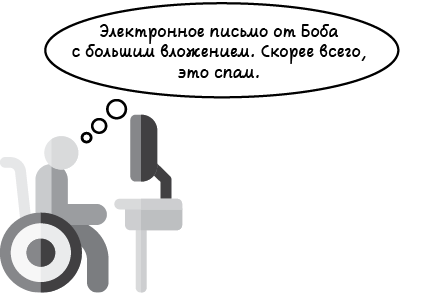
Рис. 1.7. Еще одна чуть более сложная модель машинного обучения
Ну что‚ задача решена? Как бы не так!
Прежде всего обратите внимание на то, что для составления прогнозов мы использовали день недели и размер электронного письма. Это примеры признаков — одного из самых важных понятий в книге.
ПРИЗНАК — любое свойство или характеристика данных, которые модель может применять для прогнозирования.
Легко догадаться, что существует еще множество признаков, которые могут указывать на то, является электронное письмо спамом или нет. Есть идеи? В следующих разделах мы выявим еще несколько.
Пример 4. Еще?
Наши два классификатора вполне рабочие, потому что исключают большие электронные письма и электронные письма, отправленные в выходные дни. Каждый из них использует только один из этих двух признаков. Но что, если нам нужно правило, которое работало бы с обоими признаками? Вполне допустимы правила, подобные следующим.
Модель 4. Если размер электронного письма более 10 Кбайт или оно было отправлено в выходные дни, то оно классифицируется как спам. В противном случае — как полезное.
Модель 5. Если электронное письмо отправлено в течение недели, то оно должно быть больше 15 Кбайт, чтобы попасть в категорию спама. Если оно отправлено в выходные дни, то должно быть больше 5 Кбайт, чтобы попасть в категорию спама. В противном случае оно классифицируется как полезное.
Можно усложнять и дальше.
Модель 6. Присвоим дням недели порядковые номера: понедельник — 0, вторник — 1, среда — 2, четверг — 3, пятница — 4, суббота — 5, воскресенье — 6. Если мы сложим номер дня и размер электронного письма (в килобайтах) и в результате получим 12 или более, то электронное письмо классифицируется как спам (рис. 1.8). В противном случае — как полезное.

Рис. 1.8. Еще более сложная модель машинного обучения
Все это рабочие модели. Мы можем продолжать создавать все больше и больше моделей, добавляя уровни сложности или рассматривая все новые признаки. Теперь вопрос в том, какая же модель будет лучшей. Вот тут-то нам и понадобится помощь компьютера.
Примеры моделей, используемых машинами
Наша задача заключается в том, чтобы заставить компьютер думать так, как думаем мы, а именно применять структуру вспоминания — формулирования — прогнозирования. Если упростить, то вот что должен сделать компьютер на каждом из этапов.
• Вспомнить — обратиться к огромной таблице данных.
• Сформулировать — создать модели, просматривая множество правил и формул, и проверить, какая модель лучше всего соответствует данным.
• Спрогнозировать — использовать эту модель для прогнозирования будущих данных.
Этот процесс немногим отличается от того, что мы проделывали в предыдущем разделе. Улучшением здесь является то, что компьютер может быстро создавать модели, просматривая множество формул и комбинаций правил до тех пор, пока не обнаружит то, что хорошо соответствует имеющимся данным. Например, мы можем создать классификатор спама с такими признаками, как отправитель, дата и время суток, количество слов, количество орфографических ошибок и появление определенных слов, таких как «купить» или «выиграть». Модель вполне может выглядеть как следующее логическое утверждение.
Модель 7
• Если в электронном письме есть две орфографические ошибки или более, то оно классифицируется как спам.
• Если оно содержит вложение размером более 10 Кбайт, оно классифицируется как спам.
• Если отправителя нет в нашем списке контактов, письмо классифицируется как спам.
• Если в нем есть слова «купи» и «выиграй», оно классифицируется как спам.
• В противном случае оно классифицируется как полезное.
Все это можно записать следующей формулой.
Модель 8. Если (размер) + 10 (количество орфографических ошибок) – (количество появлений слова «мама») + 4 (количество появлений слова «купить») > 10, то мы классифицируем сообщение как спам (рис. 1.9). В противном случае классифицируем его как «ветчину».

Рис. 1.9. Гораздо более сложная модель машинного обучения, выработанная компьютером
Теперь вопрос: какое правило лучшее? Быстрый ответ: то, которое лучше всего соответствует данным. А настоящий ответ: то, которое лучше всего обобщает новые данные. В конце концов, мы можем прийти к сложному правилу, но компьютер способен сформулировать его и использовать для быстрого принятия решений. Следующий вопрос: как создать наилучшую модель? Именно об этом и пойдет речь в книге.
Резюме
• Машинное обучение — это просто! Любой желающий может изучить и применять его независимо от своего опыта. Все, что нужно, — это желание учиться и отличные идеи для реализации!
• Машинное обучение чрезвычайно полезно, поэтому используется в большинстве дисциплин. В науке‚ технологиях, социальной сфере и медицине оно оказывает значимое влияние и будет оказывать его впредь.
• Машинное обучение — это здравый смысл, реализуемый компьютером. Оно имитирует мышление людей, что позволяет принимать решения быстро и точно.
• Точно так же, как люди принимают решения на основе опыта, компьютеры способны принимать решения на основе предыдущих данных. Вот в чем суть машинного обучения!
• Машинное обучение использует структуру вспоминания — формулирования — прогнозирования следующим образом:
• вспомнить — обратиться к предыдущим данным;
• сформулировать — построить модель или правило на основе этих данных;
• спрогнозировать — применить эту модель для прогнозирования будущих данных.
1 В оригинале ham — антоним к слову spam. — Примеч. пер.
В этом разделе мы сосредоточимся на распространенном применении машинного обучения — обнаружении спама. В следующих примерах будем выявлять как спам‚ так и письма, им не являющиеся. Письма, не являющиеся спамом, называются также полезными1.
В оригинале ham — антоним к слову spam. — Примеч. пер.
2. Типы машинного обучения
В этой главе
• Три различных типа машинного обучения: контролируемое, неконтролируемое и обучение с подкреплением.
• Разница между размеченными и неразмеченными данными.
• Разница между регрессией и классификацией‚ а также их использованием.

Как мы узнали из главы 1, машинное обучение — это здравый смысл для компьютера. Принимая решения на основе предыдущих данных, он примерно имитирует процесс, посредством которого люди принимают решения на основе опыта. Естественно, программирование компьютеров для имитации процесса человеческого мышления — сложная задача, потому что компьютеры созданы для хранения и обработки чисел, а не для принятия решений. Ее и стремится решить машинное обучение. Оно делится на несколько ветвей в зависимости от типа принимаемого решения. В этой главе мы рассмотрим некоторые наиболее важные из них.
Машинное обучение нашло применение во многих областях, например таких, как:
• прогнозирование цен на жилье на основе размера дома, количества комнат и местоположения;
• прогнозирование сегодняшних цен на фондовом рынке на основе вчерашних цен и других рыночных факторов;
• обнаружение спама на основе слов, употребленных в электронном письме, и данных отправителя;
• распознавание изображений, например лиц или животных, на основе составляющих их пикселов;
• обработка длинных текстовых документов и создание их резюме;
• рекомендации пользователю видеороликов или фильмов, например, на YouTube или Netflix;
• создание чат-ботов, которые взаимодействуют с людьми и отвечают на вопросы;
• обучение автомобилей с автопилотом самостоятельно двигаться по городу;
• постановка диагноза людям и разделение их на больных и здоровых;
• сегментация рынка на аналогичные группы в зависимости от местоположения, покупательской способности и интересов;
• игры‚ подобные шахматам или го.
Попробуйте представить, как можно использовать машинное обучение в каждой из этих областей. Обратите внимание на то, что некоторые из этих применений отличаются друг от друга, но задачи могут решать аналогичные. Например, прогнозировать цены на жилье и на акции можно одинаковыми методами. Прогноз того, является ли электронное письмо спамом или является ли транзакция по кредитной карте мошеннической, также можно сделать с помощью сходных методов. А как насчет группировки пользователей приложения на основе их сходства? Это звучит иначе, чем прогнозирование цен на жилье, но выполнить это можно аналогично группировке газетных статей по темам. А как насчет игры в шахматы? Не похоже на все предыдущие приложения, но зато может иметь сходство с игрой в го.
Модели машинного обучения подразделяются на типы в зависимости от того, как они работают.
Итак‚ три основных семейства моделей машинного обучения:
• контролируемое обучение;
• неконтролируемое обучение;
• обучение с подкреплением.
В этой главе рассмотрим все три. Однако в рамках книги сосредоточимся только на контролируемом обучении, так как это самый естественный способ начать обучение и, возможно, наиболее широко используемый в настоящее время. О других типах можно самостоятельно узнать из литературы, потому что все они интересны и полезны! Среди ресурсов, собранных в приложении В, имеется несколько интересных ссылок, в том числе на несколько видеороликов, созданных автором.
В чем разница между размеченными и неразмеченными данными
Что такое данные
Мы говорили о данных в главе 1, но прежде чем двигаться дальше, дадим четкое определение того, что в этой книге подразумевается под данными. Данные — это всего лишь информация. Всегда, когда у нас есть таблица с информацией, у нас есть данные. Обычно каждая строка в таблице представляет собой точку данных. Допустим, у нас есть набор данных о домашних животных. В этом случае каждая строка представляет отдельного четвероногого. Каждое домашнее животное в таблице описывается определенными признаками.
Что же это за признаки
В главе 1 мы определили признаки как свойства или характеристики данных. Если наши данные содержатся в таблице, то признаками являются столбцы таблицы. В примере с домашним животным признаками могут быть размер, имя, тип или вес. Признаками могут служить даже цвета пикселов на изображении домашнего животного. Это то, что описывает наши данные. Однако некоторые признаки — особенные, мы называем их метками.
Метки?
Этот вариант чуть менее точен, так как зависит от контекста проблемы, которую мы пытаемся решить. Как правило, если мы хотим спрогнозировать определенный признак на основе других, этот признак служит меткой. Если пытаемся спрогнозировать тип домашнего животного (например, кошки или собаки) на основе информации о нем, то метка — это тип домашнего животного (кошка/собака). Если стремимся спрогнозировать, болен питомец или здоров, основываясь на симптомах и другой информации, то метка — это состояние здоровья (болен/здоров). Если пытаемся предсказать возраст питомца, то метка — это возраст (число).
Прогнозы
Мы уже использовали концепцию свободного прогнозирования, теперь давайте определим ее. Цель прогностической модели машинного обучения состоит в том, чтобы угадать метки в данных. Предположение, которое делает модель, называется прогнозом.
Теперь, зная, что такое метки, мы можем допустить, что существуют два основных типа данных: размеченные и неразмеченные.
Размеченные и неразмеченные данные
Размеченные данные — такие, которые поставляются с тегом или меткой (метка может быть как типом‚ так и числом). Неразмеченные данные — те, что поставляются без меток. Примером размеченных данных может служить набор данных, относящихся к электронным письмам, в котором есть столбец, где записано, является ли письмо спамом‚ или столбец, где указано, связано ли оно с работой. Пример неразмеченных данных — набор электронных писем, где нет конкретного столбца, который мы хотели бы спрогнозировать.
На рис. 2.1 мы видим три набора данных, содержащих изображения домашних животных. В первом наборе есть столбец с указанием типа домашнего животного, во втором — столбец, где приведен его вес. Это два примера размеченных данных. Третий набор состоит из изображений без меток, что делает его неразмеченными данными.

Рис. 2.1. Наборы данных: слева — размечен, меткой служит тип домашнего животного (собака/кошка); посередине — размечен, меткой служит вес (в килограммах); справа — не размечен
Конечно, это определение содержит некоторую двусмысленность, потому что в зависимости от проблемы мы определяем, подходит ли конкретный признак в качестве метки. Таким образом, определение того, размечены данные или нет, во многих случаях зависит от решаемой проблемы.
Размеченные и неразмеченные данные дают две ветви машинного обучения — контролируемое и неконтролируемое. Их определение мы найдем в следующих трех разделах.
Контролируемое обучение — раздел машинного обучения, который работает с размеченными данными
Мы можем обнаружить контролируемое обучение в некоторых наиболее распространенных современных приложениях, включая распознавание изображений, различные формы обработки текста и системы рекомендаций. Контролируемое обучение — это тип машинного обучения, при котором используются размеченные данные. Короче говоря, цель модели контролируемого обучения состоит в том, чтобы спрогнозировать (угадать) метки.
В примере на рис. 2.1 набор данных слева содержит изображения собак и кошек, а метки — «собака» и «кошка». Для этого набора данных модель машинного обучения будет использовать предыдущие данные и прогнозировать метки новых точек данных. Это означает, что, если мы введем новое изображение без метки, модель будет угадывать, кто это — собака или кошка, прогнозируя таким образом метку точки данных (рис. 2.2). Здесь точка данных соответствует собаке, и алгоритм контролируемого обучения обучается прогнозировать, что она действительно соответствует собаке.

Рис. 2.2. Модель контролируемого обучения прогнозирует метку новой точки данных
Если вы помните из главы 1, основа для принятия решения — это принцип вспоминания — формулирования — прогнозирования. Именно так работает контролируемое обучение. Модель сначала вспоминает набор данных о собаках и кошках. Затем формулирует модель или правило для всего, что, по ее мнению, представляет собой собаку и кошку. Наконец, когда появляется новое изображение, модель делает прогноз о том, что, по ее мнению, является меткой изображения — собака или кошка (рис. 2.3).

Рис. 2.3. Модель контролируемого обучения соответствует схеме вспоминания — формулирования — прогнозирования
Теперь обратите внимание на то, что на рис. 2.1 два типа размеченных наборов данных. В том, что в середине, каждая точка данных размечена весом животного. Здесь метки представляют собой числа. В наборе данных слева каждая точка данных размечена типом животного — собака или кошка. В нем метки — это состояния. Числа и состояния — это два типа данных, с которыми мы столкнемся в моделях контролируемого обучения. Первый тип называется числовыми данными, второй — категориальными.
ЧИСЛОВЫЕ ДАННЫЕ — это любой тип данных, в которых используются такие числа, как 4, 2,35 или –199. Примерами числовых данных могут служить цены, размеры или веса.
КАТЕГОРИАЛЬНЫЕ ДАННЫЕ — это любой тип данных, который использует категории или состояния, такие как «мужчина/женщина» или «кошка/собака/птица». Для этого типа данных у нас имеется конечный набор категорий, которые нужно связать с каждой из точек данных.
Это приводит к появлению следующих двух типов моделей контролируемого обучения.
РЕГРЕССИОННЫЕ МОДЕЛИ — это типы моделей, которые прогнозируют числовые данные. Результатом регрессионной модели выступает число, такое как вес животного.
КЛАССИФИКАЦИОННЫЕ МОДЕЛИ — это типы моделей, которые прогнозируют категориальные данные. Результатом классификационной модели служит категория или состояние, например тип животного — кошка или собака.
Рассмотрим два примера моделей контролируемого обучения: одну регрессию и одну классификацию.
Модель 1. Модель прогнозирования цен на жилье (регрессия). Здесь каждая точка данных представляет собой дом. Метка каждого дома — это его цена. Наша цель — добиться того, чтобы, когда на рынке появится новый дом (точка данных), мы могли бы спрогнозировать его метку, то есть цену.
Модель 2. Модель обнаружения спама в электронной почте (классификация). Здесь каждая точка данных представляет собой электронное письмо. Метка каждого из них — является ли оно спамом. Наша цель в том, чтобы при поступлении нового электронного письма (точки данных) мы могли спрогнозировать его метку, а именно, является ли оно спамом.
Обратите внимание на разницу между моделями 1 и 2.
• Модель прогнозирования цен на жилье может возвращать число из множества возможных значений, таких как 100 долларов, 250 000 долларов или 3 125 672,33 доллара. Это делает ее регрессионной моделью.
• Модель обнаружения спама может возвращать только два значения: спам или «ветчина». Таким образом, это классификационная модель.
В следующих подразделах мы подробнее остановимся на регрессии и классификации.
Регрессионные модели прогнозируют числа
Как говорилось ранее, регрессионные модели — это те, где метка, которую мы хотим получить, представляет собой число. Оно прогнозируется на основе признаков. В примере с жильем признаками могут быть любые характеристики, описывающие дом: размер, количество комнат, расстояние до ближайшей школы или уровень преступности в районе.
Далее приведены другие области, где можно использовать регрессионные модели.
• Фондовый рынок — прогнозирование цены определенной акции на основе других цен на акции и иных рыночных сигналов.
• Медицина — прогнозирование ожидаемой продолжительности жизни пациента или ожидаемого времени выздоровления на основе симптомов и истории болезни.
• Продажи — прогнозирование ожидаемой суммы, которую потратит клиент, на основе его демографических данных и поведения при покупках в прошлом.
• Рекомендации видео — прогнозирование ожидаемого количества времени, в течение которого пользователь будет смотреть видео, на основе демографических данных пользователя и других просмотренных им видео.
Наиболее распространенным методом регрессии выступает линейная регрессия. Для составления прогнозов в ней применяются линейные функции (прямые или аналоги) на основе признаков. Мы изучим линейную регрессию в главе 3. Другими популярными методами, с помощью которых выполняется регрессия, выступают регрессия дерева решений (ее мы изучим в главе 9) и несколько методов ансамбля, таких как случайные леса, AdaBoost, деревья с градиентным усилением и XGBoost (см. главу 12).
Классификационные модели предсказывают состояние
Классификационные модели — это модели, в которых метка, которую мы хотим спрогнозировать, представляет собой состояние, принадлежащее конечному набору состояний. Наиболее распространенные модели классификации выдают прогноз в виде «да» или «нет», но многие другие модели используют и больший набор состояний. На рис. 2.3 мы видели пример классификации, поскольку он предсказывает тип домашнего животного — кошка или собака.
В примере распознавания спама среди электронной почты модель предсказывает состояние электронного письма (а именно спам или «ветчина») на основе его признаков. В этом случае особенностями электронного письма могут быть содержащиеся в нем слова, количество орфографических ошибок, отправитель или что-либо еще, что его характеризует.
Другим распространенным применением классификации выступает распознавание изображений. Наиболее популярные модели распознавания изображений принимают в качестве входных данных пикселы изображения и выдают прогноз о том, что на нем представлено. Два наиболее известных набора данных для распознавания изображений — это MNIST и CIFAR-10. MNIST содержит приблизительно 60 000 черно-белых изображений размером 28 × 28 пикселов с написанными от руки цифрами, которые размечены как 0–9. Изображения взяты из нескольких источников, включая Американское бюро переписи населения и хранилище рукописных цифр (их авторы — американские старшеклассники). Набор данных MNIST можно найти по ссылке http://yann.lecun.com/exdb/mnist/. Набор данных CIFAR-10 содержит 60 000 цветных изображений различных объектов размером 32 × 32 пиксела. Они размечены десятью различными объектами (это объясняет число 10 в его названии): самолетами, автомобилями, птицами, кошками, оленями, собаками, лягушками, лошадьми, кораблями и грузовиками. Эта база данных поддерживается Канадским институтом перспективных исследований (CIFAR), ее можно найти по ссылке https://www.cs.toronto.edu/~kriz/cifar.html.
Далее приведены дополнительные полезные применения классификационных моделей.
• Анализ настроений — прогнозирование того, будет ли рецензия на фильм положительной или отрицательной, на основе имеющихся в ней слов.
• Посещаемость сайта — прогнозирование того, нажмет пользователь на ссылку или нет, на основе его демографических данных и взаимодействия с сайтом в прошлом.
• Социальные сети — прогнозирование того, будет ли пользователь дружить или взаимодействовать с другим пользователем, на основе их демографии, истории и общих друзей.
• Рекомендации по видео — прогнозирование того, будет ли пользователь смотреть видео, на основе демографических данных и других просмотренных видео.
Основная часть книги (главы 5, 6, 8–12) охватывает классификационные модели. В них мы изучаем персептроны (глава 5), логистические классификаторы (глава 6), наивный байесовский алгоритм (глава 8), деревья решений (глава 9), нейронные сети (глава 10), машины опорных векторов (глава 11) и методы ансамбля (глава 12).
Неконтролируемое обучение: раздел машинного обучения, который работает с неразмеченными данными
Неконтролируемое обучение помимо прочего является распространенным типом машинного обучения. От контролируемого обучения его отличает то, что данные для него не размечены. Другими словами, цель модели машинного обучения состоит в том, чтобы извлечь как можно больше информации из набора данных, который не имеет меток или целей для прогнозирования.
Каким может быть такой набор данных и что мы можем с ним делать? В целом несколько меньше, чем с размеченным набором, так как у нас нет меток для прогнозирования. Однако мы способны извлечь достаточно информации и из неразмеченного набора данных. Вернемся к примеру с кошками и собаками в крайнем правом наборе данных на рис. 2.1. Он состоит из изображений кошек и собак, но в нем нет меток. Поэтому мы не знаем, какой тип домашнего животного представляет каждое изображение, и не можем спрогнозировать, соответствует новое изображение собаке или кошке. Однако можем выполнять другие задачи, например, определять, похожи ли две картинки друг на друга. Это то, на что способны алгоритмы неконтролируемого обучения. Такой алгоритм может группировать изображения на основе сходства, даже не зная, что представляет собой каждая группа (рис. 2.4). Если все сделано правильно, алгоритм сможет отделить изображения собак от изображений кошек и даже сгруппировать их по породам!

Рис. 2.4. Алгоритм неконтролируемого обучения вполне может извлекать информацию из данных. Например, он способен группировать похожие элементы
На самом деле, даже если метки есть, мы все равно можем использовать методы неконтролируемого обучения для своих данных, чтобы предварительно обработать их и более эффективно задействовать методы контролируемого обучения.
Основные направления неконтролируемого обучения — это кластеризация, понижение размерности и генеративное обучение.
АЛГОРИТМЫ КЛАСТЕРИЗАЦИИ — алгоритмы‚ которые группируют данные в кластеры на основе сходства.
АЛГОРИТМЫ ПОНИЖЕНИЯ РАЗМЕРНОСТИ — алгоритмы, которые упрощают данные и достоверно описывают их с меньшим количеством признаков.
ГЕНЕРАТИВНЫЕ АЛГОРИТМЫ — алгоритмы, которые способны генерировать новые точки данных, похожие на существующие.
В следующих трех подразделах мы более подробно изучим эти три ответвления.
Алгоритмы кластеризации разбивают набор данных на группы похожих элементов
Как говорилось ранее, алгоритмы кластеризации — это алгоритмы, которые разбивают набор данных на группы схожих элементов. Чтобы проиллюстрировать это, вернемся к двум наборам данных, упомянутых в разделе «Контролируемое обучение…», — о жилье и спаме. Но теперь представьте, что у них нет меток. Это означает, что в наборе данных о жилье нет цен, а в наборе данных о почте нет информации о том, что электронные письма являются спамом. Начнем с набора данных о жилье. Что можно с ним сделать? Вот вам одна идея: мы могли бы каким-то образом сгруппировать дома по сходству. Например, можно сгруппировать их по местоположению, цене, размеру или сочетанию этих факторов. Такой процесс называется кластеризацией. Кластеризация — это ответвление неконтролируемого машинного обучения, занимающееся задачами группировки элементов в наборе данных, разбивая их на кластеры, где все точки данных похожи.
Теперь рассмотрим второй пример — набор данных электронных писем. Поскольку он не размечен, мы не знаем, является ли то или иное электронное письмо спамом. Однако можем выполнить кластеризацию набора. Алгоритм кластеризации разбивает изображения на несколько групп в зависимости от различных признаков электронного письма. Ими могут быть слова, использованные в сообщении, отправитель, количество и размер вложений или типы ссылок внутри письма. После кластеризации набора данных человек (или совместно человек и алгоритм контролируемого обучения) может обозначить эти кластеры такими категориями, как «Личные», «Социальные» и «Рекламные акции».
В качестве примера рассмотрим набор данных, содержащий девять электронных писем, которые нужно сгруппировать (табл. 2.1). Признаки набора данных — размер электронного письма и количество получателей.
Таблица 2.1. Таблица электронных писем с указанием их размера и количества получателей
| Электронная почта |
Размер |
Получатели |
| 1 |
8 |
1 |
| 2 |
12 |
1 |
| 3 |
43 |
1 |
| 4 |
10 |
2 |
| 5 |
40 |
2 |
| 6 |
25 |
5 |
| 7 |
23 |
6 |
| 8 |
28 |
6 |
| 9 |
26 |
7 |
Сразу становится очевидно, что мы могли бы сгруппировать электронные письма по количеству получателей. Это создаст два кластера: один с электронными письмами, у которых два или менее получателей, и один с электронными письмами, у которых пять или более получателей. Мы могли бы также попытаться сгруппировать их в три группы по размеру. Но по мере того, как таблица будет становиться все больше, следить за группами станет все труднее и труднее. А что если построить график? Представим электронные письма в виде графика, где на горизонтальной оси указан размер, а на вертикальной — количество получателей. В итоге получим график, приведенный на рис. 2.5.
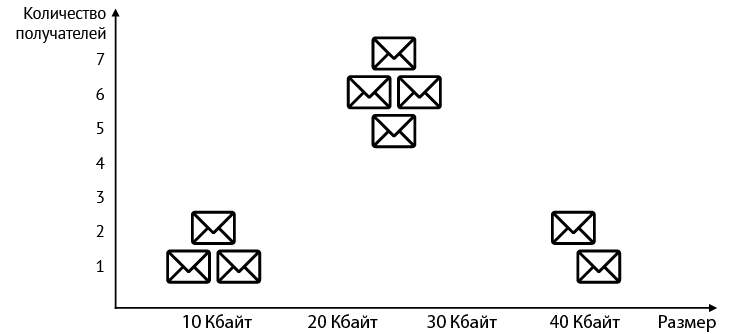
Рис. 2.5. График набора данных электронной почты
Здесь мы видим три четко определенных кластера (рис. 2.6).

Рис. 2.6. Можно сгруппировать электронные письма в три категории в зависимости от размера и количества получателей
Этот последний шаг отражает всю суть кластеризации. Конечно, нам, людям, легко работать с тремя группами, если они представлены графически. Но для компьютера эта задача не из легких. Кроме того, представьте, что данные содержат миллионы точек с сотнями или тысячами признаков. При наличии более чем трех объектов люди уже не смогут увидеть скопления, потому что будут не в силах визуализировать их размеры. К счастью, компьютеры могут выполнять такой тип кластеризации для огромных наборов данных с несколькими строками и столбцами.
Другие области применения кластеризации.
• Сегментация рынка — разделение покупателей на группы на основе демографических данных и предыдущего покупательского поведения для создания различных групповых маркетинговых стратегий.
• Генетика — объединение видов в группы на основе сходства генов.
• Медицинская визуализация — разделение изображения на части для изучения различных типов тканей.
• Рекомендации по видео — разделение пользователей на группы на основе демографических данных и просмотренных ранее видео и применение этого приема для рекомендации пользователю роликов, которые смотрели другие члены их группы.
Подробнее о моделях неконтролируемого обучения
В дальнейшем мы не будем рассматривать неконтролируемое обучение. Однако я настоятельно рекомендую изучить эту сферу самостоятельно. Вот некоторые из наиболее важных алгоритмов кластеризации. В приложении В перечислены другие ресурсы, включая несколько моих видеороликов, с помощью которых вы можете подробно изучить эти алгоритмы.
• Кластеризация K-средних. Этот алгоритм группирует точки, выбирая некоторые случайные центры масс и перемещая их все ближе и ближе к точкам, пока они не окажутся в нужных местах.
• Иерархическая кластеризация. Алгоритм начинается с группировки ближайших точек и продолжает работу, пока не получится нескольких четко определенных групп.
• Пространственная кластеризация на основе плотности (DBSCAN). Этот алгоритм начинает группировать точки в местах с высокой плотностью, помечая изолированные точки как шум.
• Гауссовы модели смешения. Алгоритм не присваивает точку одному кластеру, а присваивает доли точки каждому из существующих кластеров. Например, если есть три кластера, A, B и C, то алгоритм может определить, что 60 % точки принадлежит группе A, 25 % — группе B и 15 % — группе C.
Понижение размерности упрощает обработку данных без потери слишком большого объема информации
Понижение размерности — это полезный шаг в ходе предварительной обработки данных, который можно применять для их значительного упрощения, прежде чем переходить к другим методам. В качестве примера вернемся к набору данных о жилье. Представим, что в наборе присутствуют следующие признаки:
• размер;
• количество спален;
• количество ванных комнат;
• уровень преступности в районе;
• расстояние до ближайшей школы.
Этот набор данных состоит из пяти столбцов. А если нам требуется превратить его в более простой, с меньшим количеством столбцов, не теряя при этом большого количества информации? Давайте проделаем это, руководствуясь здравым смыслом. Присмотритесь повнимательнее к этим пяти признакам. Виден ли какой-то способ упрощения — возможно, способ объединить более мелкие категории в более общие?
При внимательном рассмотрении становится ясно, что первые три характеристики схожи, так как связаны с размером дома. Аналогично, четвертый и пятый признаки похожи друг на друга, поскольку связаны с качеством жизни в районе. Мы могли бы объединить первые три признака в больший признак «размер», а четвертый и пятый — в «благополучие района». Как же уплотнить признаки‚ касающиеся размера? Мы могли бы опустить данные о комнатах и спальнях и учитывать только размер или, возможно, взять какую-то другую комбинацию этих трех признаков. Таким же образом можно сжать признаки‚ касающиеся благополучия района. Алгоритмы понижения размерности ищут эффективные способы уплотнить первичные признаки (рис. 2.7, слева), потеряв при этом как можно меньше информации, сохранив данные как можно более нетронутыми и одновременно сумев упростить их для обработки и хранения (рис. 2.7, справа).
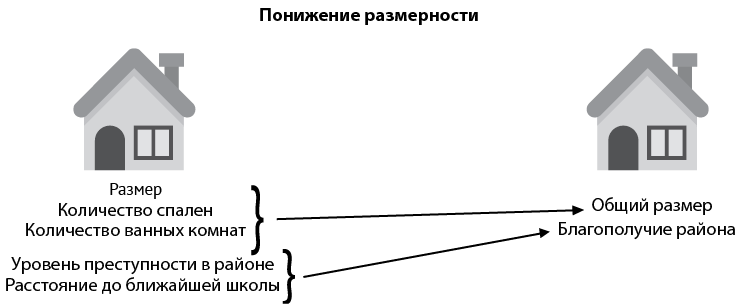
Рис. 2.7. Алгоритмы понижения размерности помогают упрощать данные
Почему этот процесс называется понижением размерности, если мы всего лишь уменьшаем количество столбцов в данных? Модное словцо для обозначения количества столбцов в наборе данных — измерение. Подумайте вот о чем: если данные состоят из одного столбца, то каждая точка данных представляет собой одно число. Набор чисел может быть нанесен на график как набор точек на линии, которая имеет ровно одно измерение. Если данные состоят из двух столбцов, то каждая точка данных формируется парой чисел. Мы можем представить набор пар чисел как набор точек в городе, где первое число — это номер улицы, а второе — номер дома. Адреса на карте являются двумерными, потому что располагаются на плоскости. Что происходит, когда наши данные состоят из трех столбцов? В этом случае каждая точка данных формируется тремя числами. Мы можем представить, что если каждый адрес в городе — это здание, то первое и второе числа — это улица и номер здания, а третье — этаж. Это больше похоже на трехмерный город. Можно продолжать и дальше. А как насчет четырех чисел? Мы не можем по-настоящему это визуализировать, но если бы могли, то набор точек выглядел бы как набор мест в четырехмерном городе и т.д. Лучший способ представить себе четырехмерный город — это представить таблицу с четырьмя столбцами. А как насчет 100-мерного города? Это будет таблица со 100 столбцами, в которой у каждого человека есть адрес, состоящий из 100 значений. Картина, которую можно было бы вообразить, думая о более высоких измерениях, показана на рис. 2.8. Это придуманный город, в котором адреса имеют столько координат, сколько нам нужно. Поэтому, перейдя от пяти измерений к двум, мы превратили наш пятимерный город в двумерный. Вот почему это называется понижением размерности.

Рис. 2.8. Представление пространства более высоких измерений
Другие способы упрощения данных. Матричная факторизация и разложение по сингулярным значениям
Кажется, что кластеризация и понижение размерности совсем не похожи друг на друга, но на деле они не так уж сильно различаются. Предположим‚ у нас имеется таблица, полная данных, каждая строка соответствует точке данных, а каждый столбец — признаку. Следовательно, мы можем использовать кластеризацию для уменьшения количества строк в наборе данных (рис. 2.9), а понижение размерности — для уменьшения количества столбцов (рис. 2.10).
Возможно, вам интересно, есть ли способ, которым можно сократить количество строк и столбцов одновременно? И ответом будет — да! Два распространенных способа это проделать — разложение матрицы на множители и разложение по сингулярным значениям. Эти два алгоритма преобразуют большую матрицу данных в произведение меньших матриц.
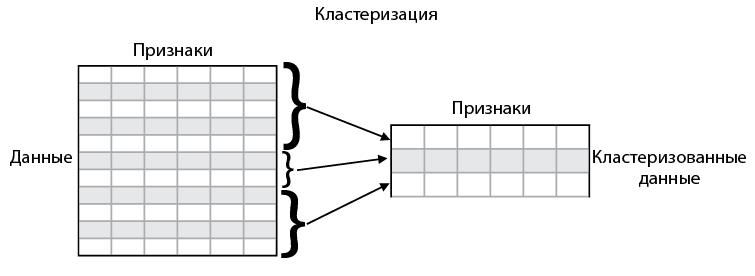
Рис. 2.9. Кластеризация может быть использована для упрощения данных за счет уменьшения количества строк в наборе данных путем группировки нескольких строк в одну

Рис. 2.10. Понижение размерности можно применять для упрощения данных за счет сокращения количества столбцов в наборе данных
Такие компании, как Netflix, широко задействуют матричную факторизацию для выработки рекомендаций. Представьте себе большую таблицу, где каждая строка соответствует пользователю, каждый столбец — фильму, а каждая запись в матрице — это рейтинг, который пользователь дал фильму. С помощью матричной факторизации можно извлечь определенные признаки, такие как тип фильма, актеры, появляющиеся в нем, и др., а также предсказать рейтинг, который пользователь даст ленте, на основе этих признаков.
При сжатии изображений применяется разложение по сингулярным значениям. Например, черно-белое изображение можно рассматривать как большую таблицу данных, где каждая запись содержит интенсивность соответствующего пиксела. Разложение по сингулярным значениям использует методы линейной алгебры для упрощения этой таблицы данных, что позволяет нам упростить изображение и сохранить его облегченную версию с помощью меньшего количества записей.
Генеративное машинное обучение
Генеративное машинное обучение — одна из самых удивительных областей машинного обучения. Если вы видели ультрареалистичные лица, изображения или видео, созданные компьютерами, значит, вы видели генеративное машинное обучение в действии.
Область генеративного обучения состоит из моделей, которые, учитывая набор данных, могут выводить новые точки данных, выглядящие как образцы из исходного набора. Эти алгоритмы изучают, как выглядят данные, после чего создают аналогичные точки данных. Например, если набор данных содержит изображения лиц, то алгоритм будет создавать реалистично выглядящие лица. Генеративные алгоритмы способны создавать чрезвычайно реалистичные изображения, картины и т.д. Они также создают видео, музыку, рассказы, стихи и много других замечательных штук. Наиболее популярный генеративный алгоритм — это генеративные состязательные сети (GAN), разработанные Яном Гудфеллоу с соавторами. Другие полезные и популярные генеративные алгоритмы: вариационные автокодеры, созданные Кингмой и Веллингом, и ограниченные машины Больцмана (RBMs), разработанные Джеффри Хинтоном.
Вы наверняка уже поняли, что генеративное обучение — довольно сложная штука. Человеку гораздо легче определить, изображена ли на картинке собака, чем нарисовать ее. Эта задача не менее трудна и для компьютеров. Так что алгоритмы генеративного обучения сложны, и для их эффективной работы требуется много данных и значительные вычислительные мощности. Поскольку наша книга посвящена контролируемому обучению, мы не будем подробно останавливаться на генеративном обучении, но в главе 10 получим представление о том, как работают некоторые из таких алгоритмов, поскольку они, как правило, используют нейронные сети. Приложение В содержит рекомендации по ресурсам, включая видео автора, которые помогут вам, если вы захотите продолжить изучение этой темы.
Что такое обучение с подкреплением
Обучение с подкреплением — это еще один тип машинного обучения, при котором изначально данные не передаются и мы должны заставить компьютер выполнить задачу. Вместо данных модель получает среду и агента, который должен в ней перемещаться. У агента есть цель или набор целей.
В окружающей среде есть награды и наказания, которые помогают агенту принимать правильные решения для достижения цели. Все это звучит несколько абстрактно, так что давайте рассмотрим пример.
Сетчатый мир
На рис. 2.11 мы видим сетчатый мир с роботом в левом нижнем углу. Это наш агент. Его цель состоит в том, чтобы добраться до сундука с сокровищами, расположенного в правом верхнем углу сетки. В ней также имеется гора. Это означает, что робот не сможет пройти через этот квадрат, потому что не способен взбираться на горы. Мы также видим дракона, который нападет на робота, если тот осмелится остановиться на его позиции. Это значит, что часть цели состоит в том, чтобы там не останавливаться. Вот и вся игра. И чтобы дать роботу информацию о том, как действовать дальше, мы отслеживаем результат. Счет начинается с нуля. Если робот доберется до сундука с сокровищами, то мы наберем 100 очков. Если он доберется до дракона, то потеряем 50 очков. И чтобы наш робот двигался быстро, мы можем задать условие, что за каждый шаг, который делает робот, мы теряем 1 очко, потому что он теряет энергию при ходьбе.

Рис. 2.11. Сетчатый мир, агентом в котором выступает робот
Если кратко‚ то способ обучения такого алгоритма следующий: робот начинает ходить, записывая свой результат и запоминая, какие шаги он сделал. Через какое-то время он может встретиться с драконом и потерять много очков. Таким образом он учится ассоциировать квадрат дракона и близкие к нему квадраты с понижением счета. В какой-то момент он может наткнуться на сундук с сокровищами и научится связывать этот квадрат и соседние с ним с высокой наградой. Поиграв в эту игру в течение длительного времени, робот получит хорошее представление о том, насколько ценен каждый квадрат. После чего он сможет пройти путь по квадратам‚ дойдя до сундука с сокровищами. На рис. 2.12 показан возможный путь. Он не идеален, поскольку проходит слишком близко к дракону. Сможете проложить путь получше?
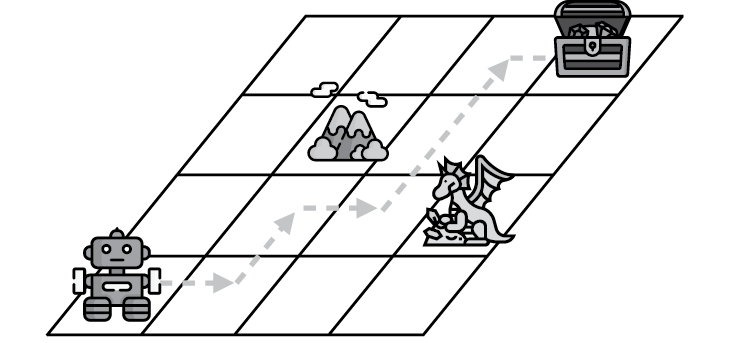
Рис. 2.12. Путь, по которому робот мог бы пройти, чтобы найти сундук с сокровищами
Конечно, это очень краткое объяснение, обучение с подкреплением — это нечто гораздо большее. В приложении В представлены некоторые ресурсы для дальнейшего изучения, включая видео про обучение с глубоким подкреплением.
Обучение с подкреплением применяется во множестве передовых областей. В их числе:
• игры. Компьютеры научились побеждать в таких играх‚ как го или шахматы, с помощью именно обучения с подкреплением. Кроме того, агентов научили побеждать в играх Atari, таких как Breakout или Super Mario;
• робототехника. Обучение с подкреплением широко используется, чтобы помочь роботам выполнять такие задачи, как сбор коробок, уборка комнаты или даже танцы;
• беспилотные автомобили. Методы обучения с подкреплением применяются для того, чтобы помочь автомобилю выполнять задачи планирования маршрута или поведения в определенных условиях.
Резюме
• Существует несколько типов машинного обучения, включая контролируемое обучение, неконтролируемое обучение и обучение с подкреплением.
• Данные могут быть размеченными или неразмеченными. Размеченные данные содержат специальный признак, или метку, который мы стремимся предсказать. Неразмеченные данные не содержат этого признака.
• Контролируемое обучение используется для размеченных данных и заключается в построении моделей, предсказывающих метки для неявных данных.
• Неконтролируемое обучение применяется для неразмеченных данных и состоит из алгоритмов, которые упрощают данные без потери большого количества информации. Неконтролируемое обучение часто служит этапом предварительной обработки.
• Два распространенных типа алгоритмов контролируемого обучения называются регрессией и классификацией.
• Регрессионные модели — это те, в которых ответом служит любое число.
• Классификационные модели — те, в которых ответ относится к типу или классу.
• Два распространенных типа алгоритмов неконтролируемого обучения — это кластеризация и понижение размерности.
• Кластеризация используется для группировки похожих данных в кластеры для извлечения информации или упрощения ее обработки.
• Понижение размерности — это способ упростить данные, объединив некоторые схожие признаки и потеряв как можно меньше информации.
• Матричная факторизация и разложение по сингулярным значениям — это дополнительные алгоритмы, способные упростить данные за счет уменьшения количества строк и столбцов.
• Генеративное машинное обучение — это инновационный тип неконтролируемого обучения, заключающийся в генерации данных, аналогичных исходному набору данных. Генеративные модели способны рисовать реалистичные лица, сочинять музыку и писать стихи.
• Обучение с подкреплением — это тип машинного обучения, при котором агент вынужден ориентироваться в среде и достигать цели. Оно широко используется во многих передовых приложениях.
Упражнения
Упражнение 2.1
Примером контролируемого или неконтролируемого обучения является каждый из следующих сценариев? Объясните свои ответы. В случае неоднозначности ответа выберите один из вариантов и объясните, почему выбрали именно его.
А. Система рекомендаций в социальной сети, которая предлагает пользователю потенциальных друзей.
Б. Система на новостном сайте, которая разделяет новости на темы.
В. Функция автоматического завершения предложений в Google.
Г. Система рекомендаций в интернет-магазине, которая формирует рекомендации, основываясь на истории покупок.
Д. Система в компании, выпускающей кредитные карты, которая фиксирует мошеннические транзакции.
Упражнение 2.2
Регрессию или классификацию необходимо использовать для любого из следующих применений машинного обучения? Объясните свои ответы. В случае неоднозначности ответа выберите один из вариантов и объясните, почему выбрали именно его.
А. Интернет-магазин, предсказывающий, сколько денег пользователь потратит на сайте.
Б. Голосовой помощник, декодирующий голос и превращающий его в текст.
В. Продажа или покупка акций определенной компании.
Г. Рекомендации видео от YouTube.
Упражнение 2.3
Ваша задача — построить беспилотный автомобиль. Приведите по крайней мере три примера задач машинного обучения, которые вам пришлось бы при этом решить. В каждом примере объясните, какое обучение вы используете, контролируемое или неконтролируемое. Если контролируемое, то применяете регрессию или классификацию? Если используете другие типы машинного обучения, объясните, какие и почему.



















