

автордың кітабын онлайн тегін оқу Объектно-ориентированный Python
Переводчик С. Черников
Стивен Лотт, Дасти Филлипс
Объектно-ориентированный Python, 4-е изд.. — СПб.: Питер, 2024.
ISBN 978-5-4461-1995-0
© ООО Издательство "Питер", 2024
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Об авторах
Стивен Лотт начинал программировать на больших, дорогих и мало кому доступных компьютерах. За десятилетия работы в индустрии высоких технологий он накопил богатый опыт в сфере разработки приложений.
На Python Стивен программирует с 1990-х годов. Он также пишет книги для издательства Pact Publishing. Его авторству принадлежат Mastering Object-Oriented, Modern Python Cookbook и Functional Python Programming.
Стивен живет на яхте, обычно швартуемой где-то на восточном берегу США, он постоянно в пути, постоянно на связи через Интернет. В жизни следует заповеди: «Не приходи домой, если тебе нечего рассказать».
Дасти Филлипс — разработчик программного обеспечения и автор нескольких книг, родом из Канады. В свое время создал стартап на пару с приятелем, теперь трудится над важными правительственными проектами, участвует в развитии крупнейшей социальной сети. Помимо этой книги, Дасти написал Creating Apps In Kivy, а на досуге сочиняет увлекательные рассказы.
Спасибо Стивену Лотту, что не покинул меня в моих начинаниях. Это бесценно… Желаю приятного чтения тем, кто приобретет эту книгу, и благодарю за все мою жену Джен Филлипс.
О научном редакторе
Бернат Габор родом из Трансильвании, работает старшим инженером-программистом в лондонской компании Bloomberg. В фокусе его профессиональных интересов — развитие конвейеров сбора данных на языке Python. На этом языке он работает уже более десяти лет, внося немалый вклад в развитие и опубликование открытого исходного кода языковых структур, преимущественно в области создания пакетов. Он разработал и поддерживает такие инструменты Python, как virtualenv, build и tox.
Чтобы узнать детали, перейдите на сайт https://bernat.tech/about.
Я благодарю Лизу, мою невесту. Она поддерживала меня каждый день! Люблю тебя!
Введение
Python — популярный язык, на нем часто пишут приложения и небольшие программы. Но для работы над более крупным проектом необходимо разбираться в проектировании программного обеспечения.
Эта книга об объектно-ориентированном подходе в Python. С ее помощью вы освоите нужную терминологию, последовательно познакомитесь с объектно-ориентированным программированием и проектированием. В книге приведено множество примеров. Мы расскажем, как правильно применять наследование и композицию, чтобы собирать программы из отдельных элементов. Каждый паттерн проектирования, описанный в книге, сопровождается конкретными примерами. В них будут использоваться встроенные исключения и структуры данных, а также стандартные библиотеки Python.
Вы также научитесь писать автоматизированные тесты и проверять, работает ли ваше приложение так, как задумано. Мы будем обращаться к разным библиотекам параллельного программирования на Python, чтобы создавать современные программы, использующие технологии многоядерности и многопоточности.
В дополнительном тематическом исследовании нам с вами предстоит рассмотреть несложный пример машинного обучения, проанализировать несколько альтернативных решений достаточно неординарных задач.
Для кого эта книга
Эта книга подойдет вам, если вы только начали изучать объектно-ориентированное программирование на Python, но при этом уже немного в курсе основных аспектов этого языка и имеете базовые навыки работы с кодом. Книга также будет полезна читателям с опытом программирования на других языках. В ней приводится много особенностей программирования на Python.
Python используется при исследовании и анализе данных, поэтому мы затронем и некоторые математические и статистические концепции. Усвоив их, вы сможете разрабатывать приложения еще лучше.
Структура издания
Книга состоит из четырех условных частей. Первые шесть глав описывают концепции и принципы объектно-ориентированного программирования (ООП), их реализацию на Python. Освоив этот материал, мы обратимся к встроенным особенностям языка Python и оценим их с учетом полученных знаний об ООП. Главы 10–12 cформируют ваше представление о паттернах проектирования, их воплощении с применением Python. И наконец, последняя часть охватывает две темы: тестирование и параллелизм.
Глава 1 «Объектно-ориентированное проектирование» познакомит с концепцией ООП. Вы узнаете о состояниях и действиях, атрибутах и методах, увидите, как из объектов получаются классы. Здесь мы разберем инкапсуляцию, наследование и композицию. Тематическое исследование, начатое в этой главе, поможет погрузиться в тему машинного обучения, и вы узнаете, как работает классификация методом ближайших соседей (k-NN).
В главе 2 «Объекты в Python» рассказывается о функционировании классов в языке Python. Будут рассмотрены аннотации типов, подсказки типов, классы, модули и пакеты. Мы поделимся практическими соображениями о классах и инкапсуляции. Вы познакомитесь с некоторыми классами, задействованными в классификаторе k-NN.
Материал главы 3 «Когда объекты одинаковы» поможет разобраться, как классы связаны друг с другом. Будут рассмотрены простое и множественное наследование. Также подробно поговорим о полиморфизме в классах. В тематическом исследовании будут разобраны разные подходы к проектированию для вычисления расстояния до ближайшего соседа.
Глава 4 «Ожидаемые неожиданности». В ней мы расскажем об исключениях и их обработке в Python, рассмотрим встроенную иерархию исключительных ситуаций. Научимся определять, связан ли сбой с отдельной областью или приложением в целом. В тематическом исследовании мы коснемся исключений, возникающих в процессе подтверждения (валидации) данных.
Глава 5 «Когда без ООП не обойтись». Вы познакомитесь с техниками проектирования. Разберетесь, как атрибуты превращаются в свойства Python. Будет рассмотрено управление коллекциями объектов в целом. В тематическом исследовании эти идеи найдут применение для продолжения работы с классификатором k-NN.
Глава 6 «Абстрактные классы и перезагрузка операторов». Читая ее, вы детально разберетесь в абстрактных классах Python, по крайней мере основных. Мы сравним утиную типизацию с формальными методами определения протокола, вникнем в техники перезагрузки встроенных операторов Python. Вы узнаете, что такое метаклассы и как они улучшают конструкцию классов. Тематическое исследование продемонстрирует, как переопределять некоторые существующие классы в абстрактные и как затем осторожно использовать абстракции для упрощения проектирования.
В главе 7 «Структуры данных Python» рассматриваются встроенные коллекции Python — кортежи, словари, списки и наборы. Вы освоите классы данных и именные кортежи, которые значительно упростят разработку. В тематическом исследовании мы пересмотрим определения некоторых классов и применим новые техники.
В главе 8 «Объектно-ориентированное и функциональное программирование» раскрываются особенности конструкций Python, не связанных с определениями классов. Python — объектно-ориентированный язык, но некоторые функциональные определения позволяют вызвать объект и без «костылей», не обязательно всегда использовать класс. Мы рассмотрим конструкцию контекстного менеджера и выражение with. В тематическом исследовании попробуем использовать вариант проекта без некоторых классов.
Глава 9 «Строки, сериализация и пути к файлам» покажет, как объекты сериализуются, как получить из строки объект. Будут описаны физические форматы, такие как Pickle, JSON и CSV. Тематическое исследование будет посвящено загрузке данных с последующей обработкой их классификатором k-NN.
В главе 10 «Паттерн Итератор» описана концепция итерации (повторения) в Python. Согласно ей, все встроенные коллекции воспроизводимы. Этот паттерн многофункционален, он один из основных в Python. Мы рассмотрим генератор списка в Python. В тематическом исследовании переработаем проект, применяя выражения генератора с целью разделить выборку на обучающие и тестовые данные.
В главе 11 «Общие паттерны проектирования» вы познакомитесь с основными паттернами проектирования: Декоратор, Наблюдатель, Стратегия, Команда, Состояние и Синглтон.
В главе 12 «Новые паттерны проектирования» продолжится рассмотрение паттернов проектирования: Адаптер, Фасад, Легковес, Абстрактная фабрика, Компоновщик и Шаблонный метод.
Глава 13 «Тестирование объектно-ориентированных программ». В ней будет рассказано, как использовать инструменты inittest и pytest, чтобы автоматизировать тестирование приложений на Python. Рассмотрим более «продвинутые» техники тестирования, например способы имитации объекта при модульном тестировании. В тематическом исследовании будут созданы тест-кейсы для вычисления расстояния до ближайшего соседа.
В главе 14 «Конкурентная обработка данных» вы узнаете, как быстрее и эффективнее производить вычисления, применяя возможности многоядерности и многопоточности компьютерной системы. Мы разберем, как они функционируют, а также познакомим вас с асинхронным модулем в Python. В тематическом исследовании попробуем применить эти техники в настройке параметров модели k-NN.
Какое ПО использовать
Все примеры из книги протестированы в среде Python версии 3.9.5 и mypy версии 0.812.
В некоторых случаях программы из примеров могут функционировать немного иначе в сравнении с описанным. Это зависит от особенностей интернет-соединения, используемого для сбора данных. Объем скачиваемых данных при этом невелик.
Иногда в примерах кода в книге используются библиотеки, которые не встроены в Python по умолчанию. В соответствующих главах мы рассмотрим их и расскажем, как устанавливать. Все подобные пакеты пронумерованы в соответствии с индексами PyPI на сайте https://pypi.org.
Файлы примеров
Файлы примеров, упоминаемые в книге, доступны на GitHub: https://github.com/PacktPublishing/Python-Object-Oriented-Programming---4th-edition.
Условные обозначения
В книге используются следующие обозначения.
Моноширинный шрифт: он применяется для написания фрагментов кода, имен БД, имен папок и файлов, пользовательского ввода. Например, так: вы можете подтвердить запуск Python, импортировав модуль antigravity в оболочке командной строки >>>.
Листинг выглядит так:
class Fizz:
def member(self, v: int) -> bool:
return v % 5 == 0
Если мы акцентируем внимание на строке кода, она выделяется полужирным шрифтом.
class Fizz:
def member(self, v: int) -> bool:
return v % 5 == 0
На сером фоне дается вывод в оболочке командной строки:
python -m pip install tox
Полужирным шрифтом выделены важные термины. Пример: объект — это коллекция данных и поведения.
Курсивом выделены определения и слова, на которых мы делаем акцент.
Рубленым шрифтом выделены URL-адреса, названия элементов интерфейса на экране, кнопок меню и диалоговых окон.

Предупреждения и важные идеи оформлены таким образом.

Советы и подсказки оформлены следующим образом.
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
На веб-сайте издательства www.piter.com вы найдете подробную информацию о наших книгах.
Глава 1. Объектно-ориентированное проектирование
В разработке программного обеспечения (ПО) проектирование часто упоминается как этап, предваряющий программирование. Это не так. В реальности анализ, проектирование и программирование взаимозависимы и связаны друг с другом. В книге будут приведены несколько листингов, где невозможно разделить программирование и проектирование. Одна из особенностей языка Python заключается в том, что он позволяет хорошо структурировать код.
В этой главе мы разберемся, как перейти от хорошей идеи к программированию как таковому. В процессе проектирования мы сформируем наглядные элементы, а именно диаграммы — они помогут продумать структуру кода, прежде чем приступать к его написанию. Итак, рассмотрим следующие темы.
• Что такое объектно-ориентированное проектирование.
• Различие между объектно-ориентированным проектированием и объектно- ориентированным программированием.
• Базовые принципы объектно-ориентированного проектирования.
• Базовые концепции унифицированного языка моделирования (UML) и когда его следует применять.
В тематическом исследовании этой главы рассмотрим архитектурную модель представления 4+1. Нам предстоит:
• кратко рассмотреть классическое приложение на основе машинного обучения, познакомиться с известной задачей классификации ирисов;
• изучить общее окружение (контекст) этого классификатора ирисов;
• набросать два представления иерархии классов, необходимых для решения задачи классификации ирисов.
Введение в объектно-ориентированное программирование
Все знают, что объекты — это предметы, которые можно потрогать, ощутить и использовать. Для детей объекты — игрушки. Деревянные кубики, пластиковые формочки, пазлы — первые объекты, с которыми человек сталкивается в жизни. Некоторые объекты выполняют строго определенные действия: колокольчик звенит, кнопка нажимается, рычаг передвигается.
То же можно сказать про объекты в разработке ПО. Да, их нельзя потрогать, но и эти объекты делают что-то конкретное. Точное определение таково: объект — коллекция (набор) данных и поведения.
Так что же в таком случае значит «объектно-ориентированное программирование»? «Ориентированный» трактуется как «направленный», значит, объектно-ориентированное программирование — программирование, которое моделирует поведение реальных объектов. Это один из способов описать сложную систему. Она состоит из взаимодействующих объектов — каждый со своими данными и поведением.
Если вы знакомы с концепцией ООП, то знаете о существовании объектно-ориентированного анализа, объектно-ориентированного проектирования, объектно-ориентированного анализа и проектирования, а также объектно-ориентированного программирования. Это все отдельные части общей концепции объектно-ориентированного подхода. Фактически анализ, проектирование и программирование — различные стадии жизненного цикла разработки программного обеспечения.
В целях упрощения будем называть совокупность этих стадий объектно-ориентированным программированием.
Объектно-ориентированный анализ (ООА) — процесс изучения проблем, систем и задач программного обеспечения, а также определение объектов и взаимодействия между ними. На стадии анализа мы отвечаем на вопрос «Что мы хотим получить?».
Результат этой стадии процесса — четко сформулированные требования к программному обеспечению. Например, задачи должны быть сформулированы не в виде пользовательских историй: «Мне как ботанику нужен сайт, который помогает пользователям классифицировать растения. Так я смогу помочь корректно определить вид и род растений». А необходимо указать по шагам действия пользователей на сайте, как это сделано в перечне ниже; здесь курсив обозначает действия, а полужирный шрифт — объекты. Так, пользователь должен иметь возможность:
• посмотреть предыдущие загрузки;
• загрузить известный экземпляр;
• протестировать качество;
• посмотреть продукты;
• рассмотреть рекомендации.
Термин «анализ» неточен. Разве ребенок анализирует объекты? Вовсе нет — он исследует, пробует и открывает, что именно может получиться из кубиков и кусочков пазла. И правильнее говорить об «объектно-ориентированном исследовании». В разработке ПО формирование и анализ требований включают беседу с пользователями, изучение их поведения, отбор вариантов.
Объектно-ориентированное проектирование — процесс обработки полученных требований и составление спецификации. Проектировщик выделяет объекты и определяет их поведение, указывает, как одни объекты активизируют поведение других. На этой стадии мы отвечаем на вопрос «Как мы сделаем то, что хотим?».
Результат стадии проектирования — получение спецификации. Этот этап считается завершенным тогда, когда каждое требование, указанное в объектно-ориентированном анализе, представлено как класс и интерфейс, которые можно реализовать на любом объектно-ориентированном языке программирования (в идеальном случае).
Объектно-ориентированное программирование — процесс разработки программы, то есть реализация проекта в виде работающей программы, которая нужна заказчику.
Вот и все! И было бы прекрасно, если бы в реальной жизни мы работали строго по порядку, завершали один этап перед тем, как перейти к другому. Так, как нас научили проверенные учебники. На самом деле все гораздо сложнее. Независимо от того, как много усилий мы затратили, чтобы разделить фазы, — когда мы начнем проектировать, мы выясним, что требования нуждаются в дополнительном анализе. А когда начнем программировать, нам понадобится внести изменения в сам проект.
По мнению большинства разработчиков, в наши дни каскадная модель (некоторые называют ее «водопад») едва ли работает так однозначно. Часто приходится использовать итеративную модель разработки ПО. При итеративном подходе моделируются, разрабатываются и программируются небольшие части задач. Затем продукт в целом пересматривается, вносятся улучшения и корректировки, формулируются новые требования. Так качество продукта постепенно улучшается, и он обретает новые особенности в каждом очередном коротком цикле разработки.
Основная задача книги — разобрать ООП, и в данной главе мы рассмотрим его принципы и их роль в проектировании ПО. Это позволит понять концепцию еще до подробного изучения синтаксиса Python.
Объекты и классы
Объект — это данные с ассоциируемым поведением. Как различать объекты? Да просто: как яблоки и апельсины. Говорят, их нельзя сравнивать, но оба этих предмета — объекты. Яблоки и апельсины нечасто кодируются разработчиками, но, допустим, вы создаете приложение инвентаризации для фруктовой компании. Также предположим, что сбор яблок идет в бочки, а апельсинов в корзины.
Мы установили четыре типа объектов: яблоки, апельсины, бочки и корзины. В ООП тип объекта называется классом. Говоря технически, у нас имеется четыре класса объектов.
Важно различать понятия. Классы обозначают связанные объекты. Можно сказать, что класс — шаблон создания объектов. Представим, что перед вами на столе три апельсина. Каждый из них — отдельный объект, но все три имеют общие атрибуты и поведение — они представляют один класс, общий класс апельсинов.
Отношения между четырьмя классами в нашем приложении инвентаризации могут быть описаны на диаграмме классов языка UML (Unified Modeling Language — унифицированный язык моделирования). Все довольно просто (рис. 1.1).

Рис. 1.1. Диаграмма классов
Диаграмма показывает, что экземпляр класса Апельсин (проще говоря, апельсины) ассоциируется с Корзиной, а образец класса Яблоко (яблоки) — с Бочкой. Ассоциация отражает отношение экземпляров двух классов.
Синтаксис UML очевиден, не нужно читать специальные учебники для понимания языка. UML легко представить наглядно. Довольно часто для описания классов и их отношений мы рисуем квадраты и линии между ними. Разработчики используют подобные интуитивно понятные диаграммы, чтобы общаться с бизнес-аналитиками, менеджерами и между собой.
Обратите внимание, UML-диаграмма отображает классы Яблоко и Бочка, а не атрибуты объекта. Класс Яблоко и класс Бочка показывают, что данное яблоко находится в бочке. В UML возможно отобразить индивидуальные объекты, но в этом нет нужды. Достаточно знать, что каждый объект — представитель класса.
Часть разработчиков считает, что на создание UML-диаграмм не стоит тратить силы. По их мнению, формальные спецификации в виде UML-диаграмм до реализации проекта не требуются, а после реализации их официальное сопровождение бесполезно и становится только тратой времени.
Но ведь каждая команда разработчиков обсуждает проект, так что UML — полезный коммуникативный инструмент. Даже в компаниях, которые им пренебрегают, на совещаниях прибегают к упрощенной версии UML.
Кроме того, этот инструмент понадобится в будущем. Рано или поздно разработчику придется вспоминать: «Почему я сделал так, а не иначе?» Диаграммы помогут взглянуть на картину в целом и вспомнить забытое.
В этой главе нет инструкций по UML. Вы можете самостоятельно поискать в Интернете или приобрести книги на эту тему, если возникнет такая необходимость. Тема визуализации обширна: показывать приходится и диаграммы класса, и объекты, и варианты использования, и изменение состояний и действий. Мы остановимся только на диаграммах класса. Вы сможете выбрать подходящие вам конструкции из примеров и затем применить синтаксис UML в своих проектах.
Вернемся к нашей диаграмме с рис. 1.1. Ее задача не в том, чтобы разработчик знал, что яблоки находятся в бочках или сколько в каждой из них яблок. Диаграмма указывает только на связи. Визуализация связей между классами — то, ради чего мы используем подобные изображения. Основная цель — более точно выразить отношения между классами.
UML примечателен возможностью подбирать инструменты языка по мере необходимости. Нужно только понять, что именно необходимо. На планерке мы нарисуем только линии между квадратами, тогда как в формальном документе укажем больше деталей.
В примере с яблоками и бочками известно, что в одной бочке хранится много яблок. Чтобы не допустить ошибки и не посчитать, что в одной бочке находится одно яблоко, можно дополнить диаграмму новой деталью (рис. 1.2).
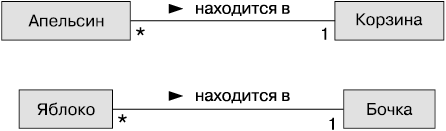
Рис. 1.2. Диаграмма классов детализированная
Диаграмма показывает, что апельсины находятся в корзинах, маленькая стрелка обозначает нахождение одного объекта в другом. Также речь идет о количестве объектов. Одна Корзина может содержать неограниченное количество (это обозначено на диаграмме символом *) объектов Апельсин, и каждый Апельсин находится только в одной Корзине. Это количество называют мощностью ассоциации (multiplicity of the object). Вы могли также слышать другое название — кардинальность (cardinality). Полезно, однако, понимать под кардинальностью некоторое число и диапазон, а под мощностью — обобщенное описание «число больше одного экземпляра».
Иногда можно забыть, с какой стороны линии находится число мощности. Мощность, ближайшая к классу, обозначает количество объектов класса, которые ассоциированы с каким-либо объектом с другой стороны линии. Так, для ассоциации яблок, находящихся в бочках: если читать слева направо, экземпляры класса Яблоко (объекты Яблоко) находятся в одной Бочке; и, наоборот, справа налево — только одна Бочка может быть ассоциирована с каким-либо числом Яблок.
Итак, мы уже знаем основы классов и уточнили взаимоотношения объектов. Теперь нужно разобрать атрибуты объекта, показатели состояния и поведение, которое связано с изменением состояния или взаимодействием с объектами.
Атрибуты и поведение
Еще раз о базовой терминологии ООП. Объекты — экземпляры класса, которые связаны между собой. Экземпляр класса — некоторый объект с определенными данными и поведением; апельсин на столе, перед нами, считается экземпляром общего класса апельсинов.
Апельсин имеет состояние: например, он спелый или неспелый; мы судим о состоянии объекта по его атрибутам. Также апельсин имеет некоторое поведение. Сам по себе он неподвижен, а вот его состояние может изменяться. Давайте разберем подробнее два термина — «состояние» и «поведение».
Данные — показатель состояния объекта
Обратимся к данным. Данные обозначают индивидуальные особенности объекта, его состояние, а класс — общие особенности, признаки, свойственные всем объектам класса. При этом каждый конкретный объект имеет свои значения данных для каждого признака. Например, три апельсина на столе (вы же еще не съели их, правда?) могут иметь разный вес. Класс Апельсин имеет атрибут Вес для представления этих данных. Все экземпляры класса Апельсин имеют атрибут Вес, но его значение для каждого апельсина индивидуально. Значение атрибутов, кстати, не обязательно уникально, два апельсина могут иметь одинаковый вес.
Атрибуты часто обозначаются как члены или свойства. Некоторые авторы разграничивают два термина — «атрибуты» и «свойства». Например, говорят, что значения атрибутов можно устанавливать, а свойства доступны только для чтения. Но на языке Python подобное разграничение бессмысленно: свойство можно перевести в режим «только для чтения», но его значения будут основаны на значении, которое в конечном счете доступно для записи. В тексте книги мы используем эти термины как синонимы. Кроме того, в главе 5 будет описан случай, когда ключевое слово «свойство» применяется в узком смысле для обозначения атрибутов специального типа.
В Python атрибут называют также экземпляром переменной, что помогает понять, как атрибут работает. Атрибуты — это переменные с уникальными значениями для каждого экземпляра класса. Python содержит и другие виды атрибутов, но для начала ограничимся этим упрощенным описанием.
В нашем приложении инвентаризации фруктов фермер может поинтересоваться: из какого сада апельсин? Когда он сорван? Сколько он весит? Также полезно знать, в какой корзине хранится апельсин. Яблоки могут иметь атрибут цвета, а бочки могут иметь разные размеры.
Некоторые атрибуты могут принадлежать нескольким классам (нам же интересно знать и о яблоках, когда они сорваны). Но пока, для первого примера, добавим в диаграмму только некоторые атрибуты (рис. 1.3).
В зависимости от того, насколько подробно нужно проработать структуру, может понадобиться указать тип каждого значения атрибута. В UML атрибуты типа имеют общепринятые названия, точно такие же, как в основных языках программирования: целое число, число с плавающей точкой, строка, байт или логический (булев) тип. Однако атрибуты могут также обозначать коллекции: списки, деревья и графы — и даже, что очень важно, неуниверсальные, специфические для данного приложения классы. Очевидно, что здесь налицо пересечение этапов проектирования и программирования. Различные примитивы и встроенные коллекции, доступные на одном языке программирования, могут не использоваться в другом.

Рис. 1.3. Диаграмма класса с атрибутами
На рис. 1.4 приведен пример диаграммы с использованием подсказок типов на языке Python.
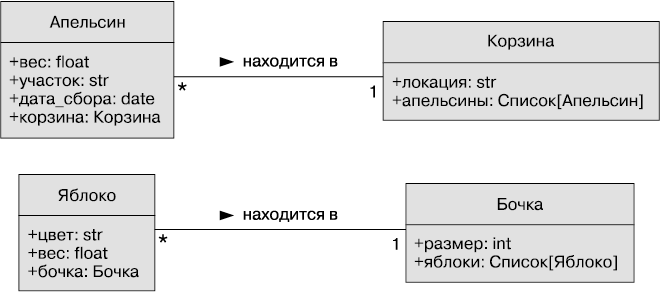
Рис. 1.4. Диаграмма класса с атрибутами и их типом
Обычно на этапе проектирования нет необходимости беспокоиться о точном определении типов данных, конкретная их реализация подбирается на этапе программирования. Достаточно оказывается общих имен. Поэтому можно просто назвать тип date (дата) вместо точного обозначения datetime.datetime. Если в нашем проекте требуется тип контейнера списка, Java-программисты при реализации могут выбрать связанный список (LinkedList) или списочный массив (ArrayList), а программисты на Python (да, это мы!) могут указать List[Apple] как подсказку типа и реализовать тип list.
В рассматриваемой сейчас фруктовой компании все описанные атрибуты — базовые примитивы. Но есть также неявные атрибуты, и дальше мы сможем их сделать явными — ассоциациями. Конкретный апельсин ссылается на корзину, в которой находится много апельсинов. Ссылка указывает на атрибут basket с подсказкой типа Basket.
Поведение — это действия
Выяснив, как данные определяют состояние объекта, разберем последний неизвестный термин — «поведение». Поведение — это действия, которые происходят с объектом. Поведение, которое определяется классом объекта, называется методами этого класса. На программном уровне методы сравнимы с функциями в структурном программировании, но, в отличие от последних, методы имеют доступ к атрибутам, в частности к переменным с данными, которые связаны с объектом. Так же как функции, методы принимают параметры и возвращают значение.
Параметры метода предоставляются ему как коллекция (набор) объектов, которые необходимо передать в метод. Аргументы — фактически переданные экземпляры объекта во время вызова метода. При этом передаваемые переменные связаны с переменными параметров в теле метода. Метод использует их независимо от того, для какого типа задач и достижения какой цели он оказывается вызван. Обычно результат выполнения метода — возвращаемые значения. Но возможна и другая ситуация: его действие направлено на изменение внутреннего состояния объекта.
Продолжим развитие нашего базового примера (пусть и несколько искусственного) — приложения инвентаризации. Посмотрим, будет ли работать это приложение как задумано. Одно действие, связанное с апельсинами, — собрать их. Это простое действие, реализуемое за два этапа.
1. Поместить апельсин в корзину и обновить атрибут Корзина в объекте Апельсин.
2. Добавить апельсин в список Апельсин в объекте Корзина.
При этом методу собрать нужно знать, в какую корзину кладется апельсин. Это выполняется, когда методу собрать передается параметр Корзина. Потом наша фруктовая ферма начнет продавать сок, нам нужно будет добавить метод выжать к классу Апельсин. Вызывая метод выжать, мы захотим получить обратно количество сока и при этом Апельсин удалить из Корзины.
Класс Корзина содержит метод продать. Когда корзина продана, наша система инвентаризации обновляет данные по объектам, которые еще не указаны нами, для расчета дохода. В другом случае корзина с апельсинами может еще до продажи оказаться испорченной, потому нужно добавить метод выбросить. Добавим эти методы на диаграмме (рис. 1.5).

Рис. 1.5. Диаграмма класса с атрибутами и методами
Добавление атрибутов и методов позволяет создать и описать систему взаимодействия между объектами. Каждый объект в системе — представитель определенного класса. Эти классы содержат типы данных объекта и вызываемые методы. Данные каждого объекта могут иметь разные состояния, отличаясь от состояний других экземпляров того же класса. Каждый объект реагирует на вызов метода по-своему, в зависимости от значений состояния.
Объектно-ориентированный анализ и объектно-ориентированное проектирование выявляют, что является объектом и как объекты взаимодействуют между собой. Каждый класс имеет свою зону ответственности и способы взаимодействия. В следующем разделе разберем, какие принципы делают такое взаимодействие простым и понятным.
И обратите внимание, что продажа корзины не является безусловной особенностью класса Корзина. Вполне возможно, что другие классы (здесь не указанные) ответственны за разные корзины и их перемещение. В каждом отдельном проекте часто присутствуют свои условия и ограничения. Резонно возникает вопрос, как именно ответственность распределена между разными классами. Не всегда очевидно единственно верное техническое решение разделения ответственности между классами, и часто приходится неоднократно вносить изменения в UML-диаграммы, чтобы исследовать разные варианты.
Сокрытие информации и создание общедоступного интерфейса
Ключевая задача моделирования объекта в объектно-ориентированном проектировании — определить, какой будет внешний интерфейс данного объекта. Интерфейс — коллекция, набор атрибутов и методов, доступных для взаимодействия с другими объектами. Особо стоит подчеркнуть, что свободный доступ извне к внутренней работе объекта не нужен, а в некоторых языках и запрещен.
Возьмем пример реального мира — телевизор. Пульт управления — наш интерфейс. Каждая кнопка пульта управления представляет метод, который мы вызываем, чтобы повлиять на объект «телевизор». Когда нажимаем кнопку, вызываем объект и обращаемся к методам, нам неинтересно, как именно телевизор получит сигнал — через кабель, спутник или Интернет. Нас не интересует, как идет электрический сигнал, когда мы увеличиваем громкость, неважно даже, будет ли звук передан в динамики или в наушники. Разбирая телевизор, чтобы что-либо починить внутри, например разделить выход на наушники и динамики, мы лишаемся гарантии.
Сокрытие внутренней реализации объекта называют сокрытием информации. Также об этом можно сказать, что информация инкапсулирована, хотя это более широкий термин. Инкапсулирование данных не обязательно означает сокрытие. Буквально «инкапсуляция» означает «помещение в капсулу» или «упаковку» атрибутов. Внешний корпус ТВ заключает в себя (инкапсулирует) состояние и поведение телевизора. Мы имеем доступ к внешнему экрану, динамикам и пульту управления. Но у нас нет доступа к связке усилителей или приемников ТВ.
При покупке компонента развлекательной системы мы изменяем уровень инкапсулированности и глубже вникаем во взаимодействие между компонентами. Если же мы внедряем IoT-устройство, нам оказывается важно понять, что внутри, какая именно начинка скрыта производителем.
Различие между инкапсуляцией и сокрытием информации не слишком важно в большинстве случаев, особенно на стадии проектирования. Во многих практических руководствах эти термины используют как взаимозаменяемые. Разработчикам Python не нужно скрывать информацию, создавая полностью приватные и недоступные переменные (мы обсудим это в главе 2), так что мы будем использовать термин «инкапсуляция» в широком смысле.
Общедоступность интерфейса, однако, крайне важна. В него будет трудно внести изменения, ведь именно через него одни классы общаются с другими. Каждое изменение интерфейса может лишить доступа к клиентским объектам, связанным с ним. Легко поменять то, что внутри, — улучшить производительность приложения или изменить права доступа по сети или локально: на клиентских объектах перемены отразятся несильно, взаимодействие останется неизменным при использовании ими внешнего интерфейса. Но если поменять интерфейс, будь то общедоступные имена атрибутов или порядок и типы аргументов у методов, то все клиентские классы также должны быть изменены. При проектировании внешнего интерфейса класса придерживайтесь однозначного правила: делайте его простым. Важнее простота в использовании интерфейса, чем заложенная в него при программировании замысловатость (это верно и для пользовательского интерфейса).
Здесь стоит отметить, что переменные Python с символом _ в начале имени — это переменные, не принадлежащие к внешнему интерфейсу.
Помните, программные объекты представляют реальные объекты, но не являются ими. Программные объекты — модели. Именно благодаря этому качеству они имеют право игнорировать все незначимые детали. Модель машины, которую один из авторов конструировал в детстве, была и вправду похожа на реальный «Форд Ти-бёрд» 1956 года, но не запускалась. Пока я был ребенком, это и не было так важно, сложные детали я не мог понять. Моя модель была абстракцией реального объекта.
Абстракция — еще один термин ООП, связанный с инкапсуляцией и сокрытием информации. Абстракция означает работу с частью информации соответствующей задачи. Так происходит разделение общедоступного интерфейса и внутренних механизмов. Водитель может повернуть руль, ускориться, затормозить. Для него не имеет значения, как работают двигатель, сцепление и тормоз. Зато это важно для механика, который решает свои задачи на другом уровне абстракции — настраивает двигатель или прокачивает тормоза. На рис. 1.6 изображены эти два уровня абстракции.
Теперь мы познакомились с основными терминами изучаемого подхода. Обобщим коротко то, что касается использования профессионального сленга: абстракция — процесс инкапсуляции информации на разных уровнях публичного интерфейса. Каждый частный элемент может быть скрыт. На UML-диаграмме используется знак – вместо +, чтобы показать, что этот элемент не является частью внешнего интерфейса.
Исходя из данных определений, сформулируем вывод: следует обеспечить, чтобы разрабатываемая модель была понятна другим объектам, ведь она должна с ними взаимодействовать. Для этого разработчику необходимо обращать пристальное внимание на детали.

Рис. 1.6. Уровни абстракции автомобиля
Проверяйте, чтобы методы и свойства имели осмысленные названия. На стадии анализа системы объекты по обыкновению существительные, а методы — глаголы. Атрибуты можно выразить как прилагательными, так и существительными. Называйте свои классы, атрибуты и методы в соответствии с сутью задачи.
При разработке полезно представить себя на месте объекта. Вам нужно понимать, за что именно вы отвечаете головой. Не позволяйте другим вмешиваться в работу, избавьтесь от информационного шума и потока данных, если считаете их лишними. Не позволяйте никому навешивать на вас лишние задачи, если вы считаете, что это не ваша обязанность.
Композиция
К этому моменту вы уже научились проектировать структуру своего ПО как систему взаимодействующих объектов с определенным представлением на соответствующем уровне абстракции. Но пока еще неизвестно, как задавать уровни абстракции. И в этом, надо сказать, существуют разные подходы. Паттерны проектирования мы обсудим ниже, в главах 10–12. Пока достаточно отметить, что большинство паттернов проектирования основаны на двух базовых принципах ООП: композиции и наследовании. Композиция проще, начнем с нее.
Композиция — процесс группировки объектов для создания нового объекта. Когда объект включен в другой, можно говорить о композиции. Мы уже сталкивались с этим понятием, когда говорили об автомобиле. Он состоит из двигателя, сцепления, фар, ветрового стекла и всех остальных частей. Двигатель, в свою очередь, содержит клапаны, коленчатый вал и поршень. В этом примере композиция, то есть составные части с внутренней вложенностью, определяет уровень абстракции. Объект Автомобиль имеет один уровень абстракции для водителя, другой уровень абстракции — тот, с которым работает механик. И конечно, можно выделить новые уровни абстракции на тот случай, когда механику понадобится более глубокое понимание принципов работы внутренних систем для ремонта машины.
Но пример машины хорош только для получения общего представления. С проектированием компьютерной системы все сложнее, и такого представления недостаточно. Физические объекты легко разбить на составные части, еще древние греки догадывались об атомах как мельчайших частицах материи (хотя и не создали ускоритель частиц). Компьютерная система включает более тонкие концепции, поэтому трудно разделить ее на компоненты так же, как мы делаем это с объектами реального мира, с поршнями и клапанами.
Объекты в объектно-ориентированной системе представляют иногда физические объекты: люди, книги, телефоны. Но чаще мы работаем с концепциями. Люди имеют имена, книги — названия, телефоны — телефонные номера. Телефонные номера, счета, имена, встречи, платежи не являются объектами реального мира, но они часто моделируются как компоненты в компьютерной системе.
Создадим гипотетическую модель, чтобы подробно изучить, как композиция работает. Допустим, стоит задача создать компьютерные шахматы. Создание программ для шахматных игр было довольно популярно в прошлом — в 80-е и 90-е годы. Разработчики всегда хотели научить машину обыгрывать гроссмейстера. Когда в 1997-м такая машина была создана (суперкомпьютер Deep Blue корпорации IBM победил чемпиона мира по шахматам Гарри Каспарова), интерес к подобным разработкам постепенно сошел на нет. Потомки Deep Blue всегда побеждают.
Итак, понятийный уровень для этой задачи таков. В шахматной игре играют два игрока на шахматной доске, где есть 64 клетки в сетке 8 на 8. У каждого игрока 16 фигур, которые двигаются поочередно за один ход. Каждая фигура может «съесть» фигуры противника. Доска обновляет свое изображение на экране компьютера после каждого хода.
Здесь полужирный шрифт обозначает методы, а курсив — объекты. Описание методов и объектов — первая задача в проектировании. На этом этапе уже важно подчеркнуть композицию: пока нас интересует доска, и поэтому можно не брать в расчет типы фигур и различия между игроками.
Создадим абстракцию высокого уровня. Есть два игрока, которые взаимодействуют с шахматами, перемещают фигуры, делая ход. Покажем это на диаграмме для данного уровня (рис. 1.7).

Рис. 1.7. Диаграмма объектов и экземпляров в шахматной игре
Выглядит не так, как диаграмма классов, и это действительно не она. На самом деле эта диаграмма — диаграмма объектов или экземпляров. Она нужна, чтобы описать состояние системы в конкретное время, определить экземпляры объектов, а не взаимодействие между классами. Напомним, что игроки — члены одного и того же класса, так что диаграмма класса будет выглядеть иначе (рис. 1.8).

Рис. 1.8. Диаграмма класса шахматной игры
Эта диаграмма показывает, что игроки взаимодействуют с шахматами. Причем один игрок передвигает фигуры только одного набора шахмат в каждый момент времени.
Но мы-то хотим подчеркнуть композицию, а не UML. Давайте подумаем, из чего состоят шахматы. Нас не интересуют особенности игроков на данный момент. У них есть сердце и голова, но в модели мы не будем обращать на это внимание. Да пусть наш игрок будет хоть самим Deep Blue — уж он точно не имеет ни сердца, ни головы.
Доска содержит 64 клетки. Набор шахмат состоит из доски и 32 фигур. Вы можете возразить, что шахматные фигуры могут быть взяты из другого набора, а значит, они не обязательно входят в этот. Хотя это невозможно для компьютерной версии шахмат, зато позволит нам сейчас проиллюстрировать еще одно понятие — агрегацию.
Агрегация подобна композиции. Различие лишь в том, что объекты агрегации могут существовать независимо друг от друга. Например, невозможно, чтобы клетка одной шахматной доски была связана с другой клеткой. Доска состоит из клеток. Но фигуры к ней прямого отношения не имеют и не связаны с ней. Фигуры могут принадлежать этой доске или другой, они, можно так сказать, временно агрегированы с доской в один набор шахмат.
Другой способ различать агрегацию и композицию — по сроку их жизни.
• Если объект составной, то внутренние объекты (части) создаются и удаляются только вместе — это композиция.
• Если объект связанный, то его подобъекты создаются и удаляются независимо друг от друга — это агрегация.
Запомните, что композиция и агрегация — это одно и то же, просто агрегация — более общая форма композиции. Каждое отношение композиции есть отношение агрегации, но не наоборот.
Опишем наш набор шахмат и добавим в диаграмму несколько атрибутов, выражающих отношение композиции (рис. 1.9).
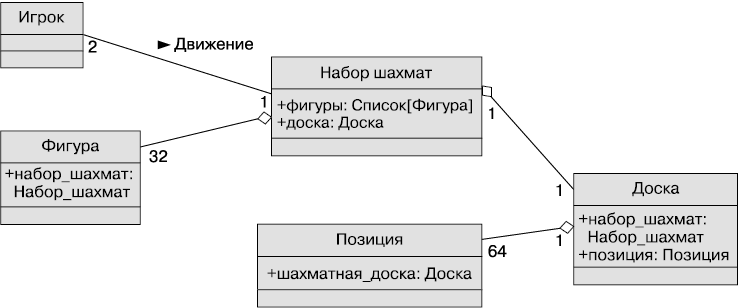
Рис. 1.9. Диаграмма классов для набора шахмат
Отношение композиции отмечается в UML черным ромбом. Белый ромб обозначает отношение агрегации. Обратите внимание, что доска и фигуры одновременно входят в Набор шахмат как части и содержат ссылку на атрибут набора. Это значит, что в конечном счете разграничение между агрегацией и композицией на стадии проектирования часто не имеет смысла. При реализации их действия одинаковы.
Пожалуй, учитывать смысловую разницу между ними нужно только тогда, когда вы обсуждаете с командой, как объекты между собой взаимодействуют. Например, может понадобиться назначить разные сроки жизни. И когда удаляется объект композиции (например, доска), удаляются и все его составные части. В агрегированных объектах такого нет.
Наследование
Итак, существует три вида отношений между объектами: ассоциация, композиция и агрегирование. И это еще не все, потому задержимся еще на некоторое время на примере с шахматами. Уже было сказано, что игрок может быть человеком или компьютерной машиной с искусственным интеллектом. Мы не вправе сказать, что игрок связан только с понятием «человек» или что искусственный интеллект представляет собой часть объекта «игрок». На самом деле и Deep Blue, и Гарри Каспаров тоже игроки.
Вот тут мы столкнулись с новым отношением — отношением наследования. Наследование — самое известное понятие ООП, используемое и к месту, и не к месту. Наследование всем понятно, каждый может вспомнить семейное генеалогическое дерево. Дасти Филлипс — один из авторов книги. Фамилия его деда была Филлипс, его отец унаследовал эту фамилию. Точно так же унаследовал ее Дасти. В ООП наследуются атрибуты и методы от других классов, как человек наследует физические черты или особенности характера от других.
Например, в нашем комплекте шахмат — 32 фигуры, но только шесть различных типов фигур (пешки, ладьи, слоны, кони, король и ферзь) со своим особым, отличающимся от других способом движения. Все эти классы имеют такие свойства, как цвет, принадлежность к шахматному комплекту и способ движения. Шесть типов фигур наследуют свойства общего класса Фигура.
На рис. 1.10 белая стрелка указывает, что отдельные классы наследуют свойства от класса Фигура. Все дочерние классы автоматически имеют атрибуты набор_шахмат и цвет. Все фигуры выглядят по-разному (внешний вид отображается на экране доски) и могут ходить по шахматной доске только определенным способом движения.
Понятно, что все дочерние классы класса Фигура должны иметь метод движение; иначе, когда мы попробуем передвинуть фигуру, выйдет ошибка. Также мы можем создать новую версию шахмат с новой фигурой (создадим фигуру Волшебник!). Наш текущий проект позволяет спроектировать фигуру без метода движение. И вновь мы потерпели бы неудачу, если бы захотели передвинуть подобную фигуру.
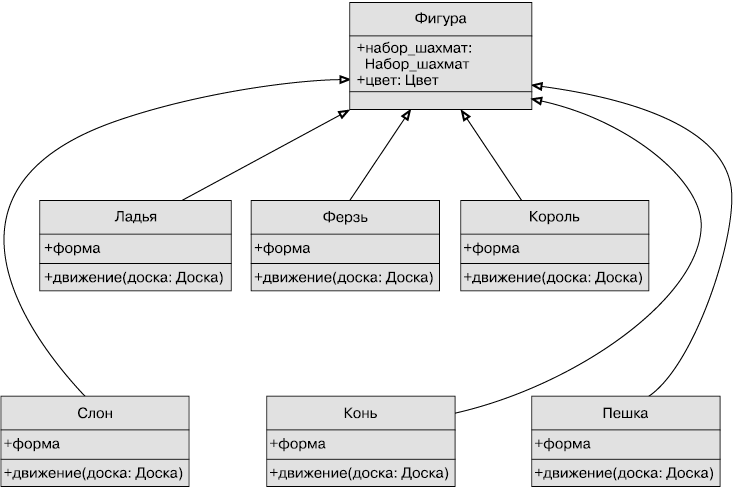
Рис. 1.10. Наследование в шахматных фигурах
Можно избежать этой ошибки, создав фиктивный метод в классе Фигура. Каждый дочерний класс затем может переопределить для себя этот метод. Пусть по умолчанию, например, этот метод отправляет сообщения, что эта фигура не может двигаться.
Переопределение методов в дочерних классах — очень мощный инструмент ООП. Например, если необходимо реализовать класс Игрок с искусственным интеллектом, то можно создать метод вычислить_движение, который будет принимать класс Доска с расстановкой фигур и, в зависимости от его значения, определять, куда сделать ход. Например, в базовом классе ход игрока будет определяться случайно, то есть передвинется случайная фигура в случайном направлении. Мы можем переписать этот метод в дочернем классе и реализовать поведение Deep Blue. Игра с первым, базовым игроком с ИИ подойдет любому новичку, а с Deep Blue будет трудно сразиться даже гроссмейстеру. При этом важно заметить, что другие методы класса не изменятся, например, метод, информирующий доску о совершенном движении, останется одним и тем же для обоих классов.
В случае шахматных фигур нет нужды определять значение по умолчанию методу движения для разных типов фигур. Пропишем реализацию метода движения в дочерних классах. Чтобы сделать так, создадим общий класс Фигура как абстрактный класс с методом движение как абстрактным методом. Абстрактные классы настойчиво требуют:
«Мы хотим, чтобы метод существовал в каждом неабстрактном классе, но заранее не была указана реализация для этого класса».
В принципе, можно создать абстракцию, которая не реализует никакого метода вообще. Такой класс говорит, что класс должен делать, но не дает совета, как поведение будет реализовано. В некоторых языках абстрактные классы называют интерфейсами. Возможно также создать класс только с абстрактными методами, но такие классы в Python встретишь нечасто.
Наследование — помощник абстракции
Что ж, теперь вы готовы узнать еще одно слово в профессиональном сленге ООП: полиморфизм. Концепция полиморфизма означает, что обращение к классу идет по-разному в зависимости от реализации дочернего класса. Вспоминаем, как реализовано передвижение фигур, описанное выше. Если посмотреть на проектирование детальнее: объект Доска принимает ход игрока и вызывает функцию движение фигуры. Доска не знает, с какой фигурой она сейчас имеет дело. Ее роль — только вызывать метод движение, а дочерний класс сам его реализует в зависимости от типа фигуры: Конь или Пешка.
Полиморфизм — крутой принцип, но в мире программирования Python используется редко. Python обращается с дочерним классом точно так же, как с родительским. Доска на Python реализует абсолютно любой объект с методом движение, будь то Слон, Автомобиль или Утка. Когда движение вызывается, Слон двигается диагонально, Автомобиль едет, а Утка плавает или летает в зависимости от настроения.
Полиморфизм на Python реализован как утиная типизация: если что-то выглядит как утка, плавает как утка и крякает как утка, то это, вероятно, и есть утка. Но действительно ли этот объект является уткой («действительно ли является» — ключевой вопрос в наследовании) — не так и важно; важнее здесь: объект плавает или ходит. Гуси и лебеди имеют такое же поведение, как и утка. Поэтому в будущем при проектировании можно создать новые виды птиц без точного формального наследования свойств от общего класса водоплавающих птиц. На примере шахмат мы видели формальное наследование, шахматные фигуры относятся к общему классу Фигура. Но утиная типизация предполагает больше возможностей для проектирования, программисты могут использовать классы так, как проектировщики заранее и не предполагали. Например, можно создать пингвина, который ходит и плавает, при этом нет необходимости указывать, что пингвин имеет общий с утками родительский класс.
Множественное наследование
Наследование в семье происходит от обоих родителей. Когда матери говорят, что у ее сына папины глаза, она отвечает: «Да, но у него мой нос».
Множественное наследование — одна из особенностей объектно-ориентированного проектирования, позволяющая наследовать функциональность от многих родительских классов. На практике реализация такого наследования — дело не из легких, а в некоторых языках категорически запрещена (например, в Java). Но множественное наследование используют в тех случаях, когда необходимо создать объект с двумя типами поведения. Скажем, нужно создать объект, который сканирует изображение и посылает его факсом. Такой объект можно получить путем наследования свойств от двух других объектов — сканера и факса.
Все будет в порядке, пока дочерний класс наследует поведение от двух родителей, имеющих разные интерфейсы. Но становится гораздо сложнее и запутаннее, если он наследует от двух родителей, интерфейсы которых совпадают. Со сканером и факсом нет никаких проблем, они выполняют разные задачи. Разберем другую ситуацию.
Допустим, есть мотоцикл и лодка, которые оба наследуют поведение от метода движение. Но что делать, если нужно создать машину-амфибию? Как результирующий класс будет знать, какое движение наследовать от метода движение? На уровне проектирования потребуется поломать голову. (И для одного из авторов, живущего на корабле, ответ на этот вопрос составляет почти жизненный интерес.)
В Python есть порядок разрешения методов (method resolution order, MRO), который помогает понять, какие альтернативные методы нужно использовать. Хотя порядок разрешения методов и прост сам по себе, но все-таки избежать совпадения или пересечения интерфейсов еще проще. Множественное наследование с техниками вроде «миксинов» (mix-in — «смешивания») оказывается полезным в случае объединения разных функций, но можно обойтись без него, если сразу проектировать составной объект.
Наследование — мощное средство для многократного использования кода. Этот замечательный инструмент демонстрирует преимущество ООП над более ранними парадигмами. Поэтому очень часто ООП-программисты хватаются за него в первую очередь. Однако, как говорят, молотком не превратишь шурупы в гвозди. Наследование следует применять, когда в задаче между объектами есть явное близкое отношение. Иначе структура кода становится грязной. Если такое случается, не стоит сразу утверждать, что этот проект плох, но нужно задуматься — почему он именно такой? Может, уместнее было бы использовать иные отношения или иной паттерн проектирования?
Тематическое исследование
Тематическое исследование растянется сразу на несколько глав. Мы с вами детально рассмотрим изучаемую проблему с разных точек зрения. Бывает полезно узнать разные методики и паттерны проектирования. И что важно: вы убедитесь, что нет единственного верного решения, их всегда несколько. Наша задача — проанализировать реальные примеры проблем с их внутренней глубиной и прочувствовать суть поиска сбалансированных решений. Мы хотим помочь читателям научиться применять ООП и концепции проектирования. Значит, мы должны показать практику выбора технических решений и рассмотрения альтернатив.
В этой части тематического исследования проанализируем трудности, возникающие при проектировании, и способы выхода из этих непростых ситуаций. Вам предстоит познакомиться с разными аспектами задачи проектирования, что, в свою очередь, послужит основой для выработки дальнейших решений в последующих главах. Мы рассмотрим UML-диаграммы, на которых отразим все элементы решаемой задачи. А при изучении материала других глав будут предложены альтернативные варианты, последовательности принятия проектных решений, способы внесения изменений в эти проектные решения.
Несомненно, как это часто бывает в ситуациях поиска выхода из реальных трудных положений, авторы имеют личные склонности и предпочтения. Последствия личных предпочтений разобраны в книге Technically Wrong Сары Вахтер-Бетчер.
Пользователям приложений нравится, когда автоматизирована работа по классификации. Именно эта операция служит основой формирования пользовательских предпочтений: последний раз покупатель купил продукт Х, и, возможно, он заинтересуется сходным продуктом Y. Мы соотнесли то, что покупатели приобретают, с определенным классом и предлагаем им купить продукты этого же класса. На самом деле такая выработка рекомендаций возможна только при использовании сложной организации данных.
Начнем ее изучение с небольшой и довольно простой задачи. Задача классификации продуктов потребительского спроса трудна, и всем понятно, что для освоения приемов классификации нужно сначала ограничиться приемлемым уровнем сложности. Так и поступим, а затем будем постепенно усложнять и переходить к тому, чтобы полностью соответствовать уровню запросов покупателей. В этом тематическом исследовании мы автоматизируем классификацию цветов ириса. Это хорошо проработанная классическая задача, решать ее можно по-разному, описанию подходов к ее решению посвящено немало книг и статей.
Прежде всего, понадобится экспериментальный набор данных, которые необходимы для точной классификации ириса. Как выглядит такой набор данных, будет подробно показано в следующем разделе.
Нам также предстоит создать несколько UML-диаграмм, которые будут наглядно изображать и обобщать структуру разрабатываемого приложения.
Исследуем задачу при помощи модели 4 + 1 представлений. Собственно, пять уровней представления таковы.
• Логический — представляет данные, статические атрибуты, отношения. Это основа объектно-ориентированного проектирования.
• Процессный — показывает, как данные обрабатываются. Здесь можно использовать разные формы подачи, включая модели состояния, диаграммы активности, диаграммы последовательностей.
• Программный — представление создания кода компонента. Здесь предстоит построить диаграмму, которая отразит программные компоненты и отношения между ними. Она послужит для демонстрации того, как определения классов собираются в программные модули и пакеты.
• Физический — отображение того, как приложение интегрируется и разворачивается. Если приложение использует общий паттерн проектирования, сложные диаграммы на этом уровне оказываются не нужны. В ином случае эта диаграмма окажется одной из ключевых, показывая, как компоненты интегрируются и разворачиваются во внешней по отношению к ним среде.
• Контекстный — на этом уровне мы показываем унифицированный контекст (окружение) для работы на других четырех уровнях представления. В этом представлении описывается, как пользователи взаимодействуют с системой, которую мы создаем. Кроме пользователей, на этом уровне представления отражаются автоматизированные интерфейсы и в целом ответ системы на воздействие со стороны любых внешних участников процесса.
Хороший тон — начинать с контекстного уровня, чтобы понять все другие уровни представления. По мере того как растет наше понимание пользователей и возникающих проблем, развивается и само контекстное представление.
Все представления модели 4 + 1 развиваются вместе. Изменение в одном неизбежно влечет за собой изменение в других. Ошибочно думать, что какое-то представление базовое, а другие представления всегда разрабатываются по этапам, как в классической каскадной системе.
Итак, приступим и сначала сформулируем задачу, ее условия, а уж затем попытаемся анализировать приложение или структуру кода программного обеспечения.
Введение и постановка задачи
Как выше уже было сказано, задача простейшая: классификация цветов. Для ее решения применим технику k-ближайшего соседа (k-nearest neighbors, или кратко k-NN). Нам понадобится обучающая выборка данных, в которой ирисы будут уже корректно классифицированы. Обучающая выборка обычно имеет несколько атрибутов, выраженных в числовых параметрах, и корректно классифицированные данные о каждом экземпляре, в данном случае о каждом цветке (то есть вид и род ириса). В примере каждый экземпляр данных входит в обучающую выборку, он имеет свои атрибуты — форму лепестка, размер; все атрибуты закодированы в числовой вектор, который является однозначной характеристикой именно этого ириса.
Остается только взять неизвестный ирис, выяснить его характеристики и сравнить расстояние до характеристик известных экземпляров цветов, ближайших соседей в векторном пространстве. Представьте, что мы проводим голосование среди небольшой группы ближайших соседей. Неизвестный образец принадлежит к классу, выбранному большинством ближайших соседей.
Если имеется только два измерения (сравниваемых атрибута), как в этом случае, можно построить диаграмму k-NN наподобие той, что показана на рис. 1.11.
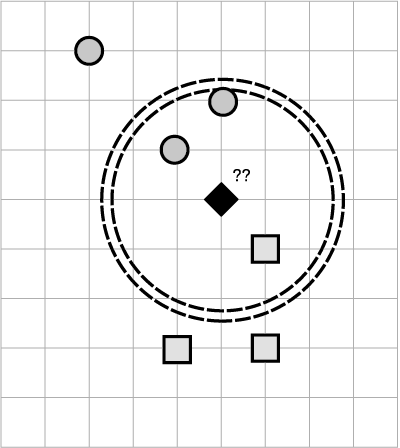
Рис. 1.11. k-ближайших соседей
Неизвестный образец помечен знаком ромба с текстом «??». Он находится в одном пространстве с разными известными образцами ириса, которые обозначены квадратом и кругом. Мы обозначили три ближайших соседа внутри круга, очерченного пунктирной линией. Проведя голосование, мы делаем вывод, что неизвестный образец, вероятнее всего, относится к «круглым» образцам.
В основе концепции k-NN лежит количественное измерение разных признаков. Не всегда просто перевести слова, адреса и любые непорядковые данные в порядковые числа. Но мы начнем работать с данными, которые уже переведены в числовые характеристики по точной шкале измерений.
Другая часть концепции — количество соседей, допущенных к голосованию. Это k-фактор, который определяет необходимое число k-ближайших соседей. У нас k-фактор равен трем, два соседа обозначены кругом, один — квадратом. Если принять k-фактор равным 5, то это изменит результаты голосования и большинством голосов победят «квадраты». Какой же k-фактор стоит выбрать? Определение наиболее подходящего k-фактора проводится на тестовом наборе данных, для которого известен правильный результат классификации: то есть проверяется работа алгоритма классификации для известного экземпляра. Очевидно, что в предыдущей диаграмме ромбом обозначен цветок, расположенный как раз посередине между двумя кластерами, то есть пример намеренно подчеркивает сложности задач классификации.
Научиться работать с классификацией можно, используя готовые данные классификации ириса. Дополнительная информация об этих данных доступна на сайтах https://archive.ics.uci.edu/ml/datasets/iris, https://www.kaggle.com/uciml/iris и множестве других.
Опытные читатели наверняка заметят противоречия в используемом подходе к тематическому исследованию по мере изучения ООА и проектирования. Так и задумано. Первичный анализ задачи приведет нас к новому этапу обучения, к новым решениям и к осознанным изменениям, которые придется вносить в результаты уже проведенной работы. По мере изучения теории будет эволюционировать и наш подход к тематическому исследованию. И если вы заметите противоречия и недоработки, попробуйте сформулировать собственные идеи проектирования и при прочтении следующих глав проверить их состоятельность.
Итак, необходимо рассмотреть несколько аспектов проблемы, продумать сценарии поведения и взаимодействия участников процесса с разрабатываемой системой. Начнем, как сказано выше, с уточнения представлений о контексте.
Представление контекста
На уровне контекста (окружения) приложения выделим участников двух типов.
• Ботаник, который предоставляет обучающие данные и тестовые данные с уже проведенной классификацией. Ботаник также разрабатывает тест-кейсы и устанавливает измеряемые параметры классификации. В простом случае он же решает, какое значение k-фактора установить для работы по методике k-NN.
• Пользователь, который классифицирует неизвестные образцы. Он измеряет параметры этих образцов и делает запрос с этими данными для отнесения нового объекта к какому-то классу с использованием классификатора. Имя «Пользователь» не самое точное обозначение роли участника процесса, но пока мы не готовы предложить что-то лучше. Оставим как есть и вернемся к нему, если что-то пойдет не так.
Обратимся к рис. 1.12. Это UML-диаграмма с обозначенными участниками процесса и тремя упомянутыми контекстными сценариями.
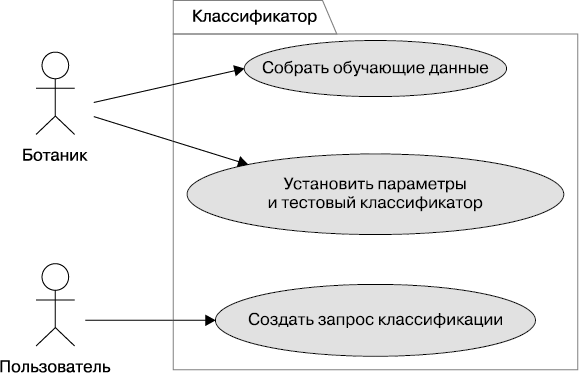
Рис. 1.12. UML-диаграмма контекста
Согласно правилам UML, каждая форма обозначения имеет свой смысл. Так, прямоугольник обозначает объекты, и система в целом изображена в виде прямоугольника. Действия каждого участника заключены в овал. Овал и круг зарезервированы для пользовательских историй, обычно они обозначают интерфейсы взаимодействия с разрабатываемой системой.
Сначала мы получаем обучающие корректно отсортированные данные. Точнее даже сказать так: нам нужны обучающие и тестовые данные. Очень часто мы говорим «обучающие данные» для краткости вместо более длинного, но и более точного выражения «обучающие и тестовые данные».
Ботаник определяет настроечные параметры и оценивает результаты тестовой классификации на проверенных обучающих данных, чтобы выяснить, работает ли классификатор. Настройке могут подлежать параметры двух видов:
• вычисляемое расстояние;
• количество ближайших голосующих соседей.
Подробнее они будут описаны ниже, в разделе, посвященном уровню «представление процесса». А еще позже, на последующих стадиях работы с тематическим исследованием, мы повторно проанализируем все свои наработки. Но на проблеме вычисления расстояния остановимся сейчас, это интересно.
Работая с тестовым набором данных, можно сводить результаты вычисления параметров в таблицу, методично заполняя ее ячейки для каждого варианта расчетов. Наилучшая комбинация параметров, которая даст результаты, более всего соответствующие известным для тестового набора расчетам, и станет рекомендацией Ботаника. В простом случае таблица будет двухмерной, такой как приведенная далее. В случае более сложного алгоритма таблица превратится в многомерную.
| Значение k-фактора |
||||
| k = 3 |
k = 5 |
k = 7 |
||
| Алгоритм вычисления расстояния |
Евклидов |
Результаты теста |
||
| Манхэттенское |
||||
| Чебышева |
||||
| Сёренсена |
||||
| Другие? |
||||
Затем Пользователь делает запрос. Неизвестные данные попадают к обученному классификатору, тот расправляется с ними и выдает результат классификации, то есть относит данные запроса к какому-то классу. Если смотреть в целом, Пользователь не всегда человек, обмен информацией может происходить между движком сайта с каталогом товаров и движком рекомендаций на основе нашего умного классификатора.
Оформляем каждый сценарий в виде пользовательской истории, то есть одного предложения от имени пользователя.
• Как Ботаник я хочу сгруппировать обучающие и тестовые данные, чтобы пользователи могли определить вид растения.
• Как Ботаник я хочу исследовать результаты теста классификатора, чтобы быть уверенным, что новые экземпляры будут правильно классифицированы.
• Как Пользователь я хочу сделать ключевые измерения с помощью классификатора и определить вид ириса.
Существительные и глаголы пользовательских историй послужат для представления логического уровня, данные которого будут в дальнейшем обработаны приложением.
Логическое представление
Еще раз посмотрим на диаграмму контекста: начнем с обучающих и тестовых данных. Уже проклассифицированные данные служат для тестирования нашего алгоритма классификации. Диаграмма на рис. 1.13 показывает один из способов отображения класса, содержащего обучающие и тестовые данные.

Рис. 1.13. Диаграмма класса обучения и тестирования
Итак, класс ОбучающиеДанные: каждый его объект имеет атрибуты. Объекту класса ОбучающиеДанные назначается имя и дата загрузки и тестирования. Затем каждому объекту обучающих данных назначается будто бы свой индивидуальный параметр k, он будет использоваться для работы алгоритма классификатора k-NN. Экземпляры можно разделить на выборку обучающих данных и тестированных данных.
Каждый класс объектов заключен в прямоугольник, ему присвоен индивидуальный номер секции.
• Вверху секции пишется имя класса объектов. Укажем там же подсказку типа, Список[Выборка]. Общий класс, Список, подсказывает, что данные списка относятся к объектам Выборка.
• Следующая секция прямоугольника класса содержит атрибуты объекта, другое название которых — переменные класса.
• В секции ниже позже будут добавлены методы для экземпляров класса.
Каждый объект класса Выборка имеет набор атрибутов: четыре значения измерений типа с плавающей точкой и строковое значение; все это в целом и есть кодировка классификации, присвоенная выборке Ботаником. В данном случае мы называем атрибут классом, потому что так сделано в исходных данных.
Стрелки на UML-диаграмме демонстрируют два вида отношений: они обозначены черным и белым ромбом. Черный показывает композицию: объект ОбучающиеДанные состоит из двух коллекций. Белый ромб показывает агрегацию: Список[Выборка] агрегирует элементы Выборка.
Подведем итоги.
• Композиция — отношение, где объекты существуют неразрывно. Нет обучающих данных без объектов Список[Выборка], и, наоборот, Список[Выборка] нельзя использовать без обучающих данных.
• Агрегация — отношение, где объекты независимы друг от друга. В этой диаграмме объект Выборка может входить или не входить в Список[Выборка].
Кто знает, важно ли нам знать отношение агрегации между объектами Выборка и объектом Список. Может быть, эта деталь проекта неважна. В таком случае лучше пропустить это отношение, пока не станет ясно, что без него не обойтись. Реализация в первую очередь должна отвечать ожиданиям пользователя.
Мы видим, что Список[Выборка] — отдельный класс объектов, иначе говоря, класс объектов Выборка в списке Python. Пропустим подробности и обобщим отношения на диаграмме (рис. 1.14).
Надо отметить, что такая простая диаграмма полезна для анализа, где структура данных неважна. И в то же время подобное сокращение затруднит проектирование, когда будет нужно иметь подробную информацию о классах Python.
А теперь попробуем сравнить представление на логическом уровне и три сценария диаграммы контекста (см. рис. 1.12). Мы же не хотим, чтобы какие-либо данные и процессы из пользовательских историй оказались потеряны и им не было отведено определенное место в классах, атрибутах или методах диаграммы.
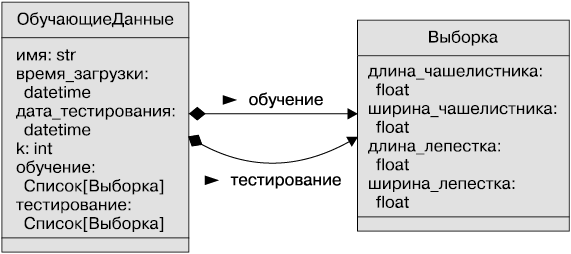
Рис. 1.14. Упрощенная диаграмма класса
Но пока решить эту задачу будет трудно по двум причинам.
• Непонятно, как на диаграмме показать тестовые и настраиваемые параметры. Хотелось бы видеть подходящий k-фактор. Но на ней нет значимых результатов теста, которые показывают разные варианты использования k-фактора.
• Пользователь на логическом уровне вовсе не показан. Нет запроса, нет ответа пользователя. Нет классов, связанных с пользователем.
Что ж, стоит признать, что первую проблему нужно постараться решить на логическом уровне. Перечитаем пользовательские истории и пропишем подробнее представление этого уровня. Вторая проблема — вопрос ограничений, которые мы себе назначим. Пока займемся описанием классификации и алгоритма k-NN, это возможно сделать, несмотря на то что неизвестны все детали запроса и ответа. Веб-сервисы для обработки запроса пользователя — один из вариантов решения, мы разберем его позже и пока оставим в стороне.
Пришло время перейти к представлению процессов обработки данных. Воспользуемся заведенным порядком создания приложения — начнем с его описания. Данные — основа приложения. Они не часто меняются, чего не скажешь об их обработке. Обработкой данных займемся во вторую очередь, именно потому, что она зависит от контекста, опыта пользователя и изменения в его предпочтениях.
Представление процессов
Итак, три пользовательские истории. Конечно, нам не нужны именно три диаграммы процесса. Хотя порой количество диаграмм процесса больше, чем число пользовательских историй. В других случаях достаточно одной тщательно проработанной диаграммы.
Но нужно держать в фокусе три процесса. Эти процессы ключевые для разрабатываемого приложения.
• Загрузка исходных данных выборки, обучающих данных.
• Запуск теста классификатора при данном значении k.
• Создание запроса классификации с новым объектом выборки.
Нарисуем диаграмму действий для этих процессов — она будет изображать изменение состояний (рис. 1.15).
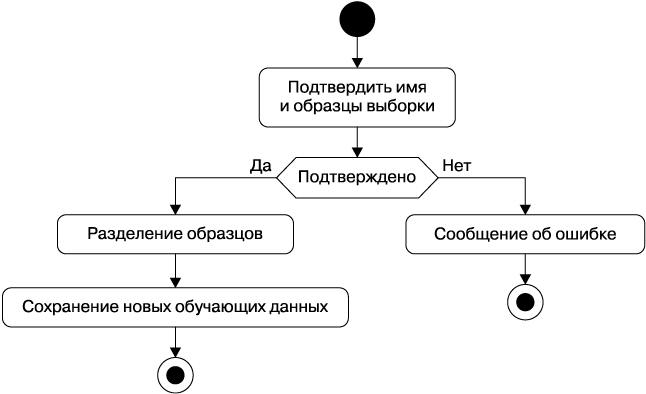
Рис. 1.15. Диаграмма действий
Процесс начинается с исходного пункта и завершается в конечном. В приложениях с транзакциями, например в веб-сервисах, допустимо не брать в расчет механизм работы веб-сервера. Лишние подробности только запутывают. Особенности HTTP, стандарты заголовка, cookie и безопасность опускаются. Мы принимаем к рассмотрению только ключевые процессы. Следим, чтобы каждому запросу соответствовал ответ.
Действия заключены в прямоугольники с закругленными углами. Когда необходимо отобразить класс объектов или компонент, связываем их с действием.
При этом важно обновлять представление на логическом уровне по мере работы на уровне процессов. Это типичная ситуация: представления не изолированы друг от друга. Приходится постепенно вносить изменения в каждое представление во время работы над каким-то одним. Иногда может потребоваться ввести дополнительные данные пользователя. Такие изменения развивают наши представления об исследовании.
Посмотрим на ответ системы, когда Ботаник вводит обучающие данные. На рис. 1.15 показан первый пример диаграммы действий.
Коллекция значений ИзвестнаяВыборка разделяется на обучающие и тестовые данные. Но строгих рекомендаций, как разбивать данные на обучающие и тестовые, нет. Мы пропустили это при описании нашей пользовательской истории. Возможно, даже наше логическое представление нуждается в доработке. Но сейчас примем в качестве рабочей гипотезы, что 75 % данных будут рассматриваться как обучающие, а 25 % — как тестовые.
Такие диаграммы уточняют каждую пользовательскую историю. Очень важно обращать внимание, чтобы каждый класс был связан с действием, и отслеживать, как изменяется его состояние с каждым шагом.
На диаграмме обозначен процесс Разделение. Это отглагольное существительное, и оно намекает на то, что нам потребуется ввести метод Разделить. То есть необходимо вернуться к классам и внести корректировку.
Разберем теперь построение компонентов. Мы проделали немало работы по проектированию, и пришло время создать определения классов.
Представление разработки
Существует хрупкий баланс между предстоящим разворачиванием проекта и разработкой компонентов. В исключительно редких случаях есть пара ограничений, обычно компоненты разрабатываются без их учета. По большому счету, уже в рамках целевой архитектуры элементы физического представления строго определены. Но физическое представление зависит от предпочтений в разработке, и его вид может оказаться любым.
Например, можно реализовать наш классификатор как часть внешних приложений. Или он будет встроен в программу на ПК, мобильное приложение или находиться на сайте. Поскольку все компьютеры связаны с сетью, разработчики обычно создают сайт, который связан с приложениями на компьютере и телефоне.
В веб-серверной архитектуре запрос идет на сервер, а ответ представляет собой HTML-страницу в браузере или JSON-документ, который выводится в мобильном приложении. Некоторые запросы требуют новых обучающих данных. Другие запросы будут связаны с классификацией неизвестных образцов. Ниже мы уточним архитектуру на физическом уровне представления. Например, мы захотим построить веб-сервер с помощью фреймворка Flask. Подробную информацию о Flask можно найти в книгах Mastering Flask Web Development1 и Learning Flask Framework2.
Диаграмма на рис. 1.16 отображает некоторые компоненты, требуемые для Flask-приложения.
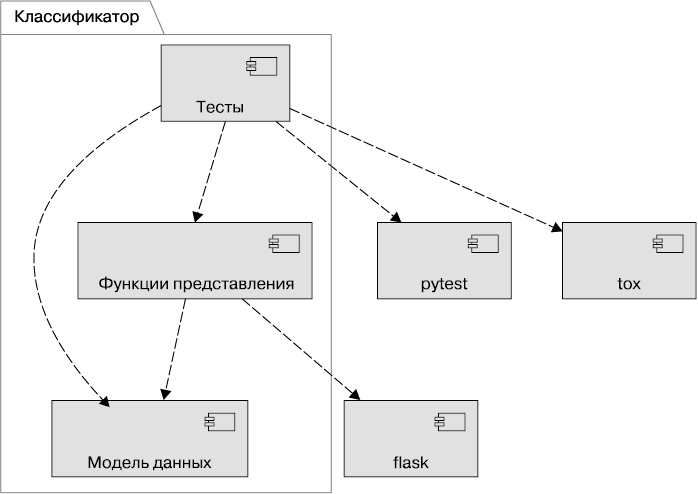
Рис. 1.16. Компоненты приложения
На диаграмме показано, что пакет Python, Classifier, содержит модули. Здесь указаны три модуля верхнего уровня.
• Модель данных (пока на уровне анализа нет ничего специфичного для Python, подробно разберем его использование в следующих главах). Разделим классы, ответственные за проблемные области, на модули. Это пригодится, когда придет время протестировать отдельные части приложения с этими классами. Нам еще предстоит обсудить это, потому что такой подход является фундаментальным.
• Функции представления (это условное имя на стадии анализа, а не как принято называть в Python). В этом модуле мы создаем образец класса Flask, определяем функции, которые обрабатывают запрос и создают ответ. Ответы затем отображаются в мобильном приложении или браузере. Сейчас не будем останавливаться на компонентах в нашем тематическом исследовании.
• Тесты. Здесь мы будем создавать юнит-тесты нашей модели и функции представления. Тесты нужно проводить, чтобы избежать непредвиденных ошибок, мы разберем их в главе 13.
Зависимости отмечены на диаграмме пунктирными стрелками. Они отмечаются флагом «импорт», чтобы уточнить связь пакетов и модулей.
Подробнее мы расскажем по мере изучения проектирования в других главах. Теперь же, когда мы знаем, что именно нужно разработать, посмотрим, как систему разворачивать на физическом уровне. Здесь важно не попасть впросак, не нарушить хрупкие связи между разработкой и разворачиванием. Иногда их лучше проектировать одновременно.
Физическое представление
Физический уровень показывает, как программа будет установлена на «железо». Когда имеем дело с веб-сервисами, мы говорим о постоянной интеграции и постоянном разворачивании. Проверенные юнит-тестами изменения интегрируются с существующими приложениями, мы тестируем целиком, а затем переходим к разворачиванию приложения для работы пользователей.
Хотя обычно мы разворачиваем сайты, иногда можно разворачивать консольное приложение. Код запускается на компьютере или в облаке. Может, даже мы захотим наш классификатор построить как веб-приложение.
На диаграмме на рис. 1.17 изображено представление веб-приложения сервера.

Рис. 1.17. Диаграмма приложения сервера
Диаграмма состоит из клиента и сервера с тремя «коробочками» компонентов, которые мы устанавливаем. Всего три компонента.
• Сторона клиента, где запускается приложение клиента. Это приложение связано с классификатором на стороне веб-сервера и генерирует RESTFUL-запросы. Иногда это может быть сайт, написанный на JavaScript, или мобильное приложение на Kotlin или Swift. Независимо от конкретной реализации фронтенд соединяется через HTTPS с веб-сервером. Данное соединение потребует некоторых настроек сертификатов и ключей шифрования для обеспечения безопасности.
• Веб-сервер GUnicorn. Веб-сервер обрабатывает разные запросы и, конечно же, наш HTTPS-протокол. Подробнее по ссылке: https://docs.gunicorn.org/en/stable/index.html.
• Само приложение Классификатор. Пока не будем анализировать все в деталях, пакет Classifier можно представить как небольшой компонент в фреймворке веб-сервиса Flask. Будем строить наше приложение, используя фреймворк Flask.
Здесь клиентская часть не связана с разработкой классификатора. Она упомянута в числе компонентов, чтобы можно было оценить окружение нашей программы. Связь приложения Classifier с веб-сервером показана пунктирной стрелкой. GUnicorn импортирует наш объект веб-сервера и отвечает на запросы.
Наконец разрабатываемое приложение рассмотрено со всех сторон на уровне 4 + 1. Пришло время подумать, как писать код. Пока будем программировать, диаграммы будут обновляться, видоизменяться. Относитесь к ним как к дорожной карте в беспросветном мире кода.
Заключение
Обобщим основные уроки, извлеченные на этом этапе тематического исследования.
1. Приложение будет запутанным. Но хорошая новость: пять представлений помогут изобразить и проанализировать всех пользователей, данные, процессы, компоненты, то есть все, что нужно разрабатывать и разворачивать.
2. Ошибки неизбежны. Не бывает идеальных решений — то и дело случаются промахи. Надо принять решение идти вперед, имея даже несовершенные частичные решения. Одно из преимуществ Python — быстрота разработки. Здесь не надо надолго увязать в плохом коде, проще и быстрее его удалить и заменить лучшим.
3. Стоит принять на вооружение разработку от частного к общему, постепенно расширяя проект и совершенствуя постановку задачи. После проектирования становится очевидно, что определение k-фактора — непростое занятие. Но настройку параметров классификации можно автоматизировать с помощью алгоритма поиска по таблице.
4. Подумайте, за что отвечает каждый класс. Иногда это получается, иногда ответственность класса оказывается сформулирована нечетко или полностью пропущена. Мы вернемся к проблеме определения ответственности класса позже, когда будем работать над анализом детальнее.
Итак, вернемся к этим темам в последующих главах. Основная задача — показать реальную работу; что-то переделывать, дополнять — в порядке вещей. Некоторые техники проектирования будут пересмотрены, когда мы познакомимся с ООП на Python. Нам еще предстоит разобраться, как выбирать разные паттерны проектирования. Переделывать уже выполненную работу с учетом полученных уроков — это и есть гибкий подход к разработке.
Ключевые моменты
Вспомним пройденное. В этой главе вы:
• узнали, как анализировать требования в объектно-ориентированном контексте;
• научились строить UML-диаграммы, чтобы понять взаимодействие элементов системы;
• освоили построение объектно-ориентированных систем, познакомились с терминологией и языком;
• научились различать классы, объекты, атрибуты и действия;
• узнали, как применять некоторые техники объектно-ориентированного проектирования.
В тематическом исследовании подробно разобрали:
• инкапсуляцию некоторой функциональности в класс;
• наследование в классах для расширения их возможностей;
• композицию класса для создания класса из объектов.
Упражнения
Книга, которую вы держите в руках, — это руководство. Мы не планируем описывать максимальное количество проблем и задач объектно-ориентированного анализа и проектировать что-либо вместо вас. Наша задача проста — поделиться идеями, которые вы затем сможете применять в своих проектах. Если вы уже имели опыт в ООП, вам не потребовалось затратить много усилий, читая эту главу. Однако если вы программируете на Python, но никогда не думали серьезно о структуре классов в целом, вам полезно проработать ее тщательно. Можете также сделать несколько упражнений.
Прежде всего подумайте о программировании какого-то уже завершенного вами проекта. Какие объекты там есть? Вспомните, какие атрибуты эти объекты имеют. Цвет? Вес? Прибыль? Стоимость? Имя? Артикул? Цена? Стиль?
Подумайте об атрибуте типов. Примитивы или классы? Может, некоторые атрибуты на самом деле — скрытое действие? Иногда данные фактически являются результатом вычисления, основываются на других данных. Может, правильнее использовать методы? Какие еще есть методы и действия у объекта? К какому объекту подходят методы? В каком отношении они находятся с объектом?
Теперь подумайте о проекте в целом. Неважно, для чего он предназначен — для развлечения или бизнеса с многомиллионными контрактами. И даже не обязательно, чтобы он был полноценным приложением — может, вы разработали одну из подсистем. Определите требования проекта и взаимодействующие объекты. Нарисуйте диаграмму класса на высшем уровне абстракции. Определите основные и второстепенные объекты. Напишите атрибуты и методы в самых значимых объектах. Попробуйте рассмотреть объекты на разных уровнях абстракции. Где вы использовали наследование и композицию? А где вы намеренно избежали наследования?
Основная задача — не спроектировать систему (хотя, если вы имеете достаточно времени, желаете развиваться в этой области, то почему бы и не попробовать сделать это). Основная цель — научиться думать об объектно-ориентированном проектировании. Размышляя о проекте, вы думаете о будущем, упрощаете свою дальнейшую работу.
И последнее: найдите инструкции по UML. В них можно заблудиться, найдите ту, что подойдет именно вам. Нарисуйте некоторые диаграммы класса или диаграммы последовательностей. Не нужно запоминать синтаксис (если понадобится, вы легко найдете его), нужно прочувствовать язык. Все равно что-то отложится в памяти, и вам будет проще рисовать диаграммы, когда будете обсуждать ООП.
Резюме
В этой главе вы познакомились c терминологией объектно-ориентированной парадигмы. Научились разделять объекты на классы, описывать атрибуты и действия объектов. Вы узнали о таких понятиях, как абстракция, инкапсуляция, сокрытие информации, поняли, что существуют различные отношения между объектами (ассоциация, композиция, наследование). UML-синтаксис помог в нашей совместной работе. Он оказался полезным и способным распутать самый запутанный разговор на планерке.
В следующей главе вы научитесь создавать классы и методы на Python.
В веб-серверной архитектуре запрос идет на сервер, а ответ представляет собой HTML-страницу в браузере или JSON-документ, который выводится в мобильном приложении. Некоторые запросы требуют новых обучающих данных. Другие запросы будут связаны с классификацией неизвестных образцов. Ниже мы уточним архитектуру на физическом уровне представления. Например, мы захотим построить веб-сервер с помощью фреймворка Flask. Подробную информацию о Flask можно найти в книгах Mastering Flask Web Development1 и Learning Flask Framework2.
В веб-серверной архитектуре запрос идет на сервер, а ответ представляет собой HTML-страницу в браузере или JSON-документ, который выводится в мобильном приложении. Некоторые запросы требуют новых обучающих данных. Другие запросы будут связаны с классификацией неизвестных образцов. Ниже мы уточним архитектуру на физическом уровне представления. Например, мы захотим построить веб-сервер с помощью фреймворка Flask. Подробную информацию о Flask можно найти в книгах Mastering Flask Web Development1 и Learning Flask Framework2.
https://www.packtpub.com/product/mastering-flask-webdevelopment-second-edition/9781788995405.
https://www.packtpub.com/product/learning-flask-framework/9781783983360.
Глава 2. Объекты в Python
Проект готов! Его можно превращать в рабочую программу. В книге представлено большое количество примеров и советов по созданию качественного ПО, но основное внимание уделено объектно-ориентированному программированию (ООП). Итак, приступим к освоению синтаксиса Python, позволяющего создавать объектно-ориентированное ПО.
В этой главе рассмотрим следующие темы.
• Подсказки типов в Python.
• Создание классов и экземпляров объектов в Python.
• Организация классов в пакеты и модули.
• Как убедить разработчиков не удалять данные.
• Работа со сторонними пакетами, доступными из индекса пакетов Python Package Index, PyPI.
Ну и, конечно, вы приобретете навыки создания классов.
Подсказки типов
Перед тем как создать класс, выясним, что такое класс и как его использовать. Основная идея заключается в том, что все в Python является объектами.
Например, строка "Hello, world!" или число 42 — это фактически экземпляры встроенных классов. Можно запустить интерактивный Python и использовать встроенную функцию type() для класса, определяющего свойства этих объектов:
>>> type("Hello, world!")
<class 'str'>
>>> type(42)
<class 'int'>
Идея ООП заключается в решении задач посредством взаимодействия объектов. Выражение умножения двух объектов, 6*7, обрабатывается методом встроенного класса int. Для более сложного поведения, как правило, приходится создавать уникальные классы.
Итак, два первых основных правила работы объектов Python:
• в Python все является объектами;
• каждый объект определяется как экземпляр хотя бы одного класса.
Эти правила имеют интересные следствия. Оператор class создает новое определение класса. При создании экземпляра класса объект класса будет использоваться для создания и инициализации объекта-экземпляра.
В чем разница между классом и типом? Оператор class позволяет определять новые типы. Поскольку мы используем оператор class, далее будем называть эти типы классами. Для получения более подробной информации вы можете прочитать статью Python objects, types, classes, and instances — a glossary («Объекты, типы, классы и экземпляры Python — глоссарий»)3 Эли Бендерски. В ней можно найти следующее высказывание: «Термины “класс” и “тип” — синонимы, относящиеся к одному и тому же».
С помощью подсказок типов можно аннотировать переменные и функции типами.
Существует еще одно важное правило: переменная — это ссылка на объект. В качестве примера представьте стикер желтого цвета с написанным на нем названием, который можно наклеить на предмет, тем самым определяя этот предмет.
На самом деле это круто. Это означает, что информация о типе — описание этого объекта — определяется классом (-ами), связанным (-ми) с объектом.
Информация о типе никак не привязана к переменной. Таким образом, код наподобие следующего валиден, хоть и очень запутан:
>>> a_string_variable = "Hello, world!"
>>> type(a_string_variable)
<class 'str'>
>>> a_string_variable = 42
>>> type(a_string_variable)
<class 'int'>
Сначала создали объект, используя встроенный класс str, и присвоили объекту длинное имя a_string_variable. Затем создали объект, используя другой встроенный класс, int, и присвоили этому объекту такое же имя. При этом ссылка на предыдущий строковый объект окажется потерянной, и объект вообще перестанет существовать.
На рис. 2.1 показано, как переменная перемещается от объекта к объекту.
Рис. 2.1. Имена переменных и объекты
Различные свойства относятся к объекту, а не к переменной. При проверке типа переменной с помощью функции type() можно узнать тип объекта, на который в данный момент ссылается переменная. Переменная не имеет собственного типа, это лишь имя. Точно так же функция id() переменной определяет идентификатор объекта, на который ссылается переменная. Очевидно, что имя a_string_variable может ввести в заблуждение, если присвоить его целочисленному объекту.
Проверка типа
Переместимся на один уровень глубже в рассмотрении взаимосвязи между объектом и типом: проанализируем еще несколько следствий из указанных правил. Вот, скажем, определение функции:
>>> def odd(n):
... return n % 2 != 0
>>> odd(3)
True
>>> odd(4)
False
Функция выполняет некоторые вычисления, используя параметр-переменную, n. В примере вычисляется остаток после деления по модулю. Если нечетное число разделить на 2, в остатке остается 1. Если разделить четное число на 2, в остатке остается 0. То есть функция возвращает истинное значение для всех нечетных чисел.
Что произойдет, если мы не сможем предоставить число? Чтобы узнать, попробуем и проанализируем результат (распространенный способ изучения Python!). Введя код в интерактивной подсказке, получаем следующее:
>>> odd("Hello, world!")
Traceback (most recent call last):
File "<doctestexamples.md[9]>", line 1, in <module>
odd("Hello, world!")
File "<doctestexamples.md[6]>", line 2, in odd
return n % 2 != 0
TypeError: not all arguments converted during string formatting
Это важное следствие сверхгибких правил Python: ничто не мешает нам совершить ошибку, которая вызовет исключение. А вот и важная подсказка.
Python позволяет использовать несуществующие методы объектов.
В примере оператор %, предоставляемый классом str, работает не так, как оператор %, предоставляемый классом int, вызывая исключение. Для строк оператор % используется не очень часто, но он выполняет следующую интерполяцию: в результате вычисления выражения "a=%d"%113 возвращается строка 'a=113'. Если в левой части отсутствует спецификация формата %d, то будет вызвано исключение TypeError. Для целых чисел оператор предоставит остаток от деления: выражение 355%113 возвращает целое число 16.
Подобная гибкость позволяет обеспечить простоту использования имен переменных и одновременно предотвращать потенциальные проблемы. Ведь разработчик может использовать имя переменной, не особенно задумываясь.
Внутренние операторы Python сами проверяют соответствие операндов требованиям оператора. Однако созданное выше определение функции не включает проверку типов во время выполнения. Кроме того, не хотелось бы для реализации подобной проверки добавлять программный код. Вместо этого можно использовать инструменты проверки кода в рамках тестирования. Реально также предоставлять аннотации, называемые подсказками типов, и использовать инструменты проверки разрабатываемого кода на соответствие подсказкам типов.
В первую очередь рассмотрим, что представляют собой аннотации. В некоторых случаях за именем переменной следует двоеточие (:) и имя типа. Так можно делать для параметров функций (и методов), для операторов присваивания. Кроме того, мы также можем добавить синтаксис -> к определению функции (или метода класса), чтобы описать ожидаемый тип возвращаемого значения.
Ниже показано, как выглядят подсказки типов в обоих случаях:
>>> def odd(n: int) -> bool:
... return n % 2 != 0
Здесь мы добавили две подсказки типа в определение нашей небольшой функции odd(). Мы указали, что значения аргументов для параметра n должны быть целыми числами, а результатом будет логическое значение.
Хотя подсказки занимают некоторое пространство памяти, они не влияют на время выполнения кода. Python их игнорирует, то есть они необязательны. Однако разработчикам, которым придется работать с вашим кодом, они окажутся очень полезны. Это отличный способ сообщить другим разработчикам о ваших намерениях. На время изучения языка такие конструкции можно опускать, однако они пригодятся, когда вы в следующий раз решите вернуться к коду.
Инструмент mypy обычно используется для проверки подсказок на согласованность. Он не встроен в Python и требует отдельной загрузки и установки. О виртуальных средах и установке инструментов мы поговорим позже, в разделе «Сторонние библиотеки». На данный момент для их установки вы можете использовать команду python -m pip install mypy или conda install mypy, если используете инструмент conda.
Предположим, в каталоге src содержится файл bad_hints.py с этими двумя функциями и несколькими строками для вызова функции main():
def odd(n: int) -> bool:
return n % 2 != 0
def main():
print(odd("Hello, world!"))
if __name__ == "__main__":
main()
Запуск команды mypy в командной строке терминала ОС выглядит следующим образом:
% mypy –strict src/bad_hints.py
Инструмент mypy обнаружит в этом коде множество потенциальных проблем, включая по крайней мере следующие:
src/bad_hints.py:12: error: Function is missing a return type
annotation
src/bad_hints.py:12: note: Use "-> None" if function does not return
a value
src/bad_hints.py:13: error: Argument 1 to "odd" has incompatible type
"str"; expected "int"
Оператор def main(): находится в строке 12 примера, так как в нашем файле содержится большое количество комментариев, не отображенных в коде выше. Для вашей версии кода ошибка может находиться в строке 1.
Остановимся на двух выявленных проблемах.
• Функция main() не имеет возвращаемого типа. Инструмент mypy предлагает включить синтаксис -> None, чтобы более явно показать, что нет возвращаемого значения.
• Более важной является строка 13: код попытается вычислить функцию odd(), используя значение str. Это не соответствует подсказке типа для odd() и указывает на еще одну возможную ошибку.
Большинство примеров в книге содержат подсказки типов. Мы считаем, что они всегда полезны, особенно во время обучения, даже если необязательны по требованиям языка. Поскольку большая часть языка Python является очень гибкой в работе с типами, могут возникнуть ситуации, когда поведение Python трудно описать простыми словами. В книге мы постараемся избегать подобного.
База Python Enhancement Proposal (PEP) 585 содержит некоторые новые языковые функции, что позволяет упростить работу с подсказками. Для тестирования всех примеров в книге мы использовали инструмент mypy версии 0.812. Если вы станете работать с любой более старой версией, то столкнетесь с проблемами применения некоторых новых методов синтаксиса и аннотаций.
Теперь, когда мы показали, как параметры и атрибуты описываются с помощью подсказок типов, создадим несколько классов.
Создание классов в Python
Нет необходимости писать большой код, чтобы понять, что Python — очень чистый язык. Когда нужно выполнить поставленную задачу, мы просто берем и делаем это, не тратя время на настраивание предварительного кода. Реализация стандартного Hello, world в Python, как вы уже поняли, содержит всего одну строку.
Создание простого класса в Python 3 выглядит следующим образом, тоже очень коротко:
class MyFirstClass:
pass
Итак, первая объектно-ориентированная программа написана! Определение класса начинается с ключевого слова class. За ним следует имя (которое мы сами выберем), идентифицирующее класс, и строка завершается двоеточием.
Имя класса должно соответствовать общепринятым правилам именования переменных Python (оно должно начинаться с буквы или знака подчеркивания и может состоять только из букв, знаков подчеркивания или цифр). Еще одно замечание: руководством по стилю Python (его можно найти в Сети как PEP 8) рекомендуется, чтобы классы именовались с использованием так называемой нотации CapWords: имя должно начинаться с заглавной буквы, любые последующие слова также должны начинаться с заглавной буквы.
За строкой определения класса всегда следует содержимое класса (для удобства чтения кода рекомендуется использовать отступы). В Python для разграничения блоков кода применяются отступы, а не фигурные скобки, ключевые слова или квадратные скобки, используемые во многих других языках. Как правило, в соответствии с руководством по стилю рекомендуется на каждый уровень отступа ставить четыре пробела. Конечно, кроме тех случаев, когда можно обосновать другой подход (например, если возникает необходимость в качестве отступов использовать табуляцию, чтобы соответствовать чужому коду).
Поскольку наш первый класс не добавляет никаких данных и не выполняет никаких действий, мы просто во второй строке в качестве «заполнителя» использовали ключевое слово pass, чтобы указать, что никаких дальнейших действий не требуется.
Поначалу может показаться, что такой базовый класс мало для чего пригоден, но на самом деле он позволяет создавать экземпляры объектов этого класса. Чтобы начать работу с ним, следует загрузить класс в интерпретатор Python 3. Для этого сохраните определение класса в файле first_class.py, а затем выполните команду python -i first_class.py. Аргумент -i указывает Python запустить код, а затем перейти к интерактивному интерпретатору. Следующий сеанс интерпретатора демонстрирует базовое взаимодействие с этим классом:
>>> a = MyFirstClass()
>>> b = MyFirstClass()
>>> print(a)
<__main__.MyFirstClass object at 0xb7b7faec>
>>> print(b)
<__main__.MyFirstClass object at 0xb7b7fbac>
Этот код создает экземпляры двух объектов из нового класса, присваивая переменным объекта имена a и b. Создание экземпляра класса — это именно ввод имени класса, за которым следуют круглые скобки. Очень похоже на вызов функции. При вызове класса создастся новый объект. При выводе результата будут отображаться два объекта, класс, к которому они относятся, и их адрес в памяти. Адреса памяти редко используются в коде Python, но в данном случае они демонстрируют, что задействованы два разных объекта.
Используя оператор is, можно убедиться, что это действительно разные объекты:
>>> a is b
False
Это поможет не запутаться, так как иногда приходится создавать большое количество объектов и присваивать им разные имена переменных.
Добавление атрибутов
Теперь у нас есть базовый класс, однако он не содержит никаких данных и не выполняет никаких действий. Каким же образом можно присвоить атрибут данному объекту? На самом деле, чтобы добавить атрибуты, ничего особенного делать не надо. Для экземпляра объекта установим произвольные атрибуты, используя точечную нотацию. Например, так:
class Point:
pass
p1 = Point()
p2 = Point()
p1.x = 5
p1.y = 4
p2.x = 3
p2.y = 6
print(p1.x, p1.y)
print(p2.x, p2.y)
После запуска кода операторы print отобразят новые значения атрибутов:
5 4
3 6
Пример кода создает пустой класс Point без каких-либо данных или определенного поведения. Затем он создает два экземпляра этого класса и присваивает каждому из экземпляров координаты x и y для идентификации точки в системе координат двумерного пространства. Чтобы присвоить значение атрибуту объекта, будем использовать синтаксис <object>.<attribute>=<value>. Данный синтаксис иногда называют точечной нотацией. Значение может быть любым: примитив Python, встроенный тип данных или другой объект. Это может быть даже функция или другой класс!
Создание подобных атрибутов может внести путаницу в работу инструмента mypy. Однако нет простого способа включить подсказки в определение класса Point. Можно включить подсказки в операторы присваивания, например: p1.x:float=5. Но на самом деле существует гораздо лучший способ работы с подсказками типов и атрибутами, который мы рассмотрим в разделе «Инициализация объекта». А пока сделаем первоочередное — добавим желаемое поведение в определение полученного класса.
Как заставить код работать
Хорошо, конечно, иметь объекты с атрибутами, но ООП связано с объектами и взаимодействием между ними. Разработчики заинтересованы в действиях, которые, в свою очередь, влияют на поведение атрибутов. У нас есть данные, и мы определим поведение в нашем классе.
Определим действия в классе Point. Начнем с метода reset, который перемещает точку в начало координат (начало координат — это место, где x и y равны нулю). Это подходящее поведение, так как оно не требует никаких параметров:
class Point:
def reset(self):
self.x = 0
self.y = 0
p = Point()
p.reset()
print(p.x, p.y)
В данном случае результат вывода — два нуля:
0 0
В Python синтаксис создания метода идентичен синтаксису создания функции. Метод начинается с ключевого слова def, за которым следует пробел и имя метода. Далее ставятся круглые скобки, внутри которых приводится список параметров (позже обсудим параметр self, который иногда называют переменной экземпляра), и строка завершается двоеточием. Следующая строка начинается с отступа, чтобы выделить определенный блок кода. Операторы этого блока могут быть любым кодом Python, работающим с самим объектом или любыми переданными параметрами.
В методе reset() мы опустили подсказки типа, так как в данном случае их можно не использовать. Применение подсказок рассмотрим в разделе «Инициализация объекта». А пока более подробно изучим переменные экземпляра и то, как работает переменная self.
Аргумент self
Единственное синтаксическое различие между методами классов и функциями вне классов состоит в том, что методы содержат один обязательный аргумент. Этот аргумент условно называется self. Мы никогда не видели, чтобы программист Python использовал какое-либо другое имя для такой переменной (общепринятые нормы для условных обозначений — очень мощная вещь). Конечно, технически ничто не мешает присвоить переменной, например, имя Martha. Однако рекомендуется придерживаться всеми признанных правил Python.
Аргумент self — это ссылка на объект, для которого вызывается метод. Объект является экземпляром класса, и его иногда называют переменной экземпляра.
Через эту переменную можно получить доступ к атрибутам и методам данного объекта, что мы и делаем внутри метода reset, когда устанавливаем атрибуты x и y объекта self.
Обратите внимание на проявившиеся здесь различия между классом и объектом. Можно предполагать, что метод — это функция, добавленная к классу. Параметр self относится к конкретному экземпляру класса. Когда вы вызываете метод для двух разных объектов, вы вызываете один и тот же метод дважды, но в качестве параметра self передаете два разных объекта.
Обратите внимание, что при вызове метода p.reset() аргумент self не передается в него явным образом. Python автоматически сделает это за нас. Python знает, что мы вызываем метод объекта p, поэтому он автоматически передает данный объект p методу класса Point.
Также можно представить, что метод — это функция, которая является частью класса. Вместо того чтобы вызывать метод для объекта, мы могли бы вызвать функцию, определенную в классе, явно передав наш объект в качестве аргумента self:
>>> p = Point()
>>> Point.reset(p)
>>> print(p.x, p.y)
Вывод будет такой же, как и в предыдущем примере. На самом деле это не очень хорошая практика программирования, но она поможет закрепить у вас понимание аргумента self.
Что произойдет, если мы забудем добавить аргумент self в определение класса? Программа выдаст следующее сообщение об ошибке:
>>> class Point:
... def reset():
... pass
...
>>> p = Point()
>>> p.reset()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: reset() takes 0 positional arguments but 1 was given
Что и говорить, сообщение об ошибке Hey, silly, you forgot to define the method with a self parameter («Эй, глупец, ты забыл определить метод с параметром self») не очень понятно и могло бы быть более информативным. Просто всегда помните, что, когда вы видите сообщение об ошибке, указывающее на отсутствующие аргументы, первое, что нужно проверить, — не забыли ли вы в определении метода указать параметр self.
Передача нескольких аргументов
Как передать несколько аргументов в метод? Попробуем добавить новый метод, позволяющий перемещать точку в произвольное положение в системе координат, а не только в ее начало. А также можно включить метод, который в качестве входных данных принимает другой объект Point и возвращает значение расстояния между ними:
import math
class Point:
def move(self, x: float, y: float) -> None:
self.x = x
self.y = y
def reset(self) -> None:
self.move(0, 0)
def calculate_distance(self, other: "Point") -> float:
return math.hypot(self.x - other.x, self.y - other.y)
Здесь определен класс с двумя атрибутами, x и y, и тремя отдельными методами: move(), reset() и calculate_distance().
Метод move() принимает два аргумента, x и y, и устанавливает значения для объекта self. Метод reset() вызывает метод move(), поскольку reset — это просто перемещение в конкретное известное место.
Метод calculate_distance() вычисляет евклидово расстояние между двумя точками. Для того чтобы рассчитать расстояние, существует множество других способов. В главе 3 нам еще предстоит изучить некоторые из них. А пока понадеемся на ваши знания математики. Сейчас мы рассмотрим формулу
Перейдем к следующему примеру работы с данным определением класса. Ниже показано, как вызвать метод с аргументами: аргументы заключаются в круглые скобки, и для доступа к имени метода в экземпляре используется точечная нотация. Сейчас для проверки методов выбраны несколько случайных позиций. Код вызывает каждый метод и выводит результаты на консоль:
>>> point1 = Point()
>>> point2 = Point()
>>> point1.reset()
>>> point2.move(5, 0)
>>> print(point2.calculate_distance(point1))
5.0
>>> assert point2.calculate_distance(point1) ==
point1.calculate_distance(
... point2
... )
>>> point1.move(3, 4)
>>> print(point1.calculate_distance(point2))
4.47213595499958
>>> print(point1.calculate_distance(point1))
0.0
Оператор assert — отличный инструмент тестирования. Если выражение после оператора assert примет значение False (а также ноль, пустое или None), произойдет сбой программы. В этом случае мы используем assert для того, чтобы гарантировать, что вычисленное расстояние будет одинаковым независимо от того, в каком месте был вызван метод calculate_distance(). В главе 13 случаи использования оператора assert будут анализироваться более подробно.
Инициализация объекта
Если мы явно не определим положение x и y для объекта Point, используя move или доступ к координатам напрямую, получим невалидный объект Point, не имеющий реального положения. Что произойдет при попытке получить к нему доступ?
А мы просто попробуем и посмотрим. «Попробуйте и убедитесь» — это во множестве случаев очень полезный инструмент для изучения Python. Откройте интерактивный интерпретатор и введите текст. Интерактивная подсказка — один из инструментов, который мы использовали при написании этой книги.
Следующий фрагмент интерактивного сеанса демонстрирует, что произойдет при попытке получить доступ к отсутствующему атрибуту. Если вы сохранили предыдущий пример в виде файла или используете примеры из книги, то можете загрузить их в интерпретатор Python с помощью команды python -i more_arguments.py:
>>> point = Point()
>>> point.x = 5
>>> print(point.x)
5
>>> print(point.y)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'Point' object has no attribute 'y'
По крайней мере, код выдал полезное исключение. Более подробно исключения мы будем изучать в главе 4. Вы, скорее всего, видели их раньше (особенно популярное исключение SyntaxError, которое означает, что у вас синтаксическая ошибка!). В данный момент просто имейте в виду: появление исключения означает, что что-то пошло не так.
Вывод полезен для отладки. В интерактивном интерпретаторе он сообщает нам, что ошибка произошла в строке 1, что верно лишь отчасти (в интерактивном сеансе одновременно выполняется только один оператор). Если бы мы запускали скрипт в файле, вывод содержал бы точный номер строки, и это еще больше облегчало бы поиск проблемного кода. Кроме того, в выводе отображается ошибка AttributeError и приведено описание, что она означает.
Можно перехватить и исправить эту ошибку, но в данном случае кажется, что мы должны были указать значение по умолчанию. Возможно, каждый новый объект должен быть reset() по умолчанию, или, может быть, следует заставить пользователя указывать, какие должны быть значения при создании объекта.
Интересно, что mypy не может определить, является ли y атрибутом объекта Point. Атрибуты по определению являются динамическими, поэтому простого их списка, являющегося частью определения класса, не существует. Однако в Python имеются некоторые широко используемые соглашения, которые помогут нам назвать ожидаемые атрибуты.
Большинство объектно-ориентированных языков программирования имеют концепцию конструктора, специального метода, который создает и инициализирует объект при его создании. Python немного отличается. Python имеет конструктор и инициализатор. Метод конструктора __new__() используется очень редко. Итак, в первую очередь рассмотрим метод инициализации __init__().
Метод инициализации Python такой же, как и любой



















