

автордың кітабын онлайн тегін оқу Python: Искусственный интеллект, большие данные и облачные вычисления
Переводчики А. Логунов, Е. Матвеев
Технические редакторы Д. Абрамова, А. Шляго (Шантурова)
Литературные редакторы М. Петруненко, М. Рогожин
Художники Л. Егорова, В. Мостипан, А. Шляго (Шантурова)
Корректоры Н. Викторова, М. Молчанова (Котова)
Верстка Л. Егорова
Пол Дейтел, Харви Дейтел
Python: Искусственный интеллект, большие данные и облачные вычисления. — СПб.: Питер, 2021.
ISBN 978-5-4461-1432-0
© ООО Издательство "Питер", 2021
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
В память о Марвине Мински, отце-основателе искусственного интеллекта.
Мне выпала честь учиться у вас на двух учебных курсах по искусственному интеллекту в Массачусетском технологическом институте.
Вы вдохновляли ваших студентов мыслить, выходя за рамки традиционных представлений.
Харви Дейтел
Предисловие
«Там золото в этих холмах!»1
Перед вами книга «Python: Искусственный интеллект, большие данные и облачные вычисления». В ней вы займетесь практическим освоением самых интересных, самых революционных вычислительных технологий, а также программированием на Python — одном из самых популярных языков программирования в мире, лидирующем по темпам развития.
Python обычно сразу приходится по нраву разработчикам. Они ценят Python за выразительность, удобочитаемость, компактность и интерактивную природу. Разработчикам нравится мир разработки с открытым кодом, который порождает стремительно растущую базу программного обеспечения для невероятно широкого спектра прикладных областей.
Уже много десятилетий в мире действуют определенные тенденции. Компьютерное оборудование становится быстрее, дешевле и компактнее. Скорость доступа к интернету растет и дешевеет. Качественное программное обеспечение становится более массовым и практически бесплатным (или почти бесплатным) благодаря движению «открытого кода». Вскоре «интернет вещей» объединит десятки миллиардов устройств любых видов, которые только можно представить. Они порождают колоссальные количества данных на быстро растущих скоростях и объемах.
В современных вычислениях большинство последних новшеств связано с данными — data science, аналитика данных, большие данные, реляционные базы данных (SQL), базы данных NoSQL и NewSQL… Все эти темы будут рассматриваться в книге в сочетании с инновационным подходом к программированию на Python.
Спрос на квалификацию в области data science
В 2011 году Глобальный институт McKinsey опубликовал отчет «Большие данные: новый рубеж для инноваций, конкуренции и производительности». В отчете было сказано: «Только Соединенные Штаты сталкиваются с нехваткой от 140 тысяч до 190 тысяч специалистов, обладающих глубокими аналитическими познаниями, а также 1,5 миллиона менеджеров и аналитиков, которые бы анализировали большие данные и принимали решения на основании полученных результатов»2. Такое положение дел сохраняется. В отчете за август 2018 года «LinkedIn Workforce Report» сказано, что в Соединенных Штатах существует нехватка более 150 тысяч специалистов в области data science3. В отчете IBM, Burning Glass Technologies и Business-Higher Education Forum за 2017 года говорится, что к 2020 году в Соединенных Штатах будут существовать сотни тысяч вакансий, требующих квалификации в области data science4.
Модульная структура
Модульная структура книги обеспечивает потребности разных профессиональных аудиторий.
Главы 1–10 посвящены программированию на языке Python. Каждая из этих глав содержит краткий раздел «Введение в data science»; в этих разделах будут представлены такие темы, как искусственный интеллект, основные характеристики описательной статистики, метрики, характеризующие положение центра распределения и разброс, моделирование, статические и динамические визуализации, работа с файлами CSV, применение Pandas для исследования и первичной обработки данных, временные ряды и простая линейная регрессия. Эти разделы подготовят вас к изучению data science, искусственного интеллекта, больших данных и облачных технологий в главах 11–16, в которых вам представится возможность применить реальные наборы данных в полноценных практических примерах.
После описания Python в главах 1–5 и некоторых ключевых частей глав 6–7 вашей подготовки будет достаточно для основных частей практических примеров в главах 11–16. Раздел «Зависимость между главами» данного предисловия поможет преподавателям спланировать свои профессиональные курсы в контексте уникальной архитектуры книги.
Главы 11–16 переполнены занимательными, современными примерами. В них представлены практические реализации по таким темам, как обработка естественного языка, глубокий анализ данных Twitter, когнитивные вычисления на базе IBM Watson, машинное обучение с учителем для решения задач классификации и регрессии, машинное обучение без учителя для решения задач кластеризации, глубокое обучение на базе сверточных нейронных сетей, глубокое обучение на базе рекуррентных нейронных сетей, большие данные с Hadoop, Spark и баз данных NoSQL, «интернет вещей» и многое другое. Попутно вы освоите широкий спектр терминов и концепций data science, от кратких определений до применения концепций в малых, средних и больших программах. Подробное оглавление книги даст вам представление о широте изложения.
Ключевые особенности
• Простота: в каждом аспекте книги мы ставили на первое место простоту и ясность. Например, для обработки естественного языка мы используем простую и интуитивную библиотеку TextBlob вместо более сложной библиотеки NLTK. При описании глубокого обучения мы отдали предпочтение Keras перед TensorFlow. Как правило, если для решения какой-либо задачи можно было воспользоваться несколькими разными библиотеками, мы выбирали самый простой вариант.
• Компактность: большинство из 538 примеров этой книги невелики — они состоят всего из нескольких строк кода с немедленным интерактивным откликом от IPython. Также в книгу включены 40 больших сценариев и подробных практических примеров.
• Актуальность: мы прочитали множество книг о программировании Python и data science; просмотрели или прочитали около 15 000 статей, исследовательских работ, информационных документов, видеороликов, публикаций в блогах, сообщений на форумах и документов. Это позволило нам «держать руку на пульсе» сообществ Python, компьютерных технологий, data science, AI, больших данных и облачных технологий.
Быстрый отклик: исследования и эксперименты с IPython
• Если вы хотите учиться по этой книге, лучше всего читать текст и параллельно выполнять примеры кода. В этой книге используется интерпретатор IPython, который предоставляет удобный интерактивный режим с немедленным откликом для быстрых исследований и экспериментов с Python и обширным набором библиотек.
• Большая часть кода представлена в виде небольших интерактивных сеансов IPython. IPython немедленно читает каждый фрагмент кода, написанный вами, обрабатывает его и выводит результаты. Мгновенная обратная связь помогает сосредоточиться, повышает эффективность обучения, способствует быстрой прототипизации и ускоряет процесс разработки.
• В наших книгах на первый план всегда выходит живой код и ориентация на полноценные работоспособные программы с реальным вводом и выводом. «Волшебство» IPython как раз и заключается в том, что он превращает фрагменты в код, который «оживает» с каждой введенной строкой. Такой результат повышает эффективность обучения и поощряет эксперименты.
Основы программирования на Python
• Прежде всего в книге достаточно глубоко и подробно излагаются основы Python.
• В ней рассматриваются модели программирования на языке Python — процедурное программирование, программирование в функциональном стиле и объектно-ориентированное программирование.
• Мы стараемся наглядно выделять текущие идиомы.
• Программирование в функциональном стиле используется везде, где это уместно. На диаграмме в главе 4 перечислены ключевые средства программирования в функциональном стиле языка Python с указанием глав, в которых они впервые рассматриваются.
538 примеров кода
• Увлекательное, хотя и непростое введение в Python подкрепляется 538 реальными примерами — от небольших фрагментов до основательных практических примеров из области компьютерной теории, data science, искусственного интеллекта и больших данных.
• Мы займемся нетривиальными задачами из области искусственного интеллекта, больших данных и облачных технологий, такими как обработка естественного языка, глубокий анализ данных Twitter, машинное обучение, глубокое обучение, Hadoop, MapReduce, Spark, IBM Watson, ключевые библиотеки data science (NumPy, pandas, SciPy, NLTK, TextBlob, spaCy, Textatistic, Tweepy, Scikit-learn, Keras), ключевые библиотеки визуализации (Matplotlib, Seaborn, Folium) и т.д.
Объяснения вместо математических выкладок
• Мы стараемся сформулировать концептуальную сущность математических вычислений и использовать ее в своих примерах. Для этого применяются такие библиотеки, как statistics, NumPy, SciPy, pandas и многие другие, скрывающие математические сложности от пользователя. Таким образом, вы сможете пользоваться такими математическими методами, как линейная регрессия, даже не владея математической теорией, на которой они базируются. В примерах машинного обучения мы стараемся создавать объекты, которые выполнят все вычисления за вас.
Визуализации
• 67 статических, динамических, анимированных и интерактивных визуализаций (диаграмм, графиков, иллюстраций, анимаций и т.д.) помогут вам лучше понять концепции.
• Вместо того чтобы подолгу объяснять низкоуровневое графическое программирование, мы сосредоточимся на высокоуровневых визуализациях, построенных средствами Matplotlib, Seaborn, pandas и Folium (для интерактивных карт).
• Визуализации используются как учебный инструмент. Например, закон больших чисел наглядно демонстрируется динамической моделью бросков кубиков и построением гистограммы. С увеличением количества бросков процент выпадений каждой грани постепенно приближается к 16,667% (1/6), а размеры столбцов, представляющих эти проценты, постепенно выравниваются.
• Визуализации чрезвычайно важны при работе с большими данными: они упрощают исследование данных и получение воспроизводимых результатов исследований, когда количество элементов данных может достигать миллионов, миллиардов и более. Часто говорят, что одна картинка стоит тысячи слов5 — в мире больших данных визуализация может стоить миллиардов, триллионов и даже более записей в базе данных. Визуализации позволяют взглянуть на данные «с высоты птичьего полета», увидеть их «в перспективе» и составить о них представление. Описательные статистики полезны, но иногда могут увести в ошибочном направлении. Например, квартет Энскомба6 демонстрирует посредством визуализаций, что серьезно различающиеся наборы данных могут иметь почти одинаковые показатели описательной статистики.
• Мы приводим код визуализаций и анимаций, чтобы вы могли реализовать собственные решения. Также анимации предоставляются в виде файлов с исходным кодом и документов Jupyter Notebook, чтобы вам было удобно настраивать код и параметры анимаций, заново выполнить анимации и понаблюдать за эффектом изменений.
Опыт работы с данными
• В разделах «Введение в data science» и практических примерах из глав 11–16 вы получите полезный опыт работы с данными.
• Мы будем работать со многими реальными базами данных и источниками данных. В интернете существует огромное количество бесплатных открытых наборов данных, с которыми вы можете экспериментировать. На некоторых сайтах, упомянутых нами, приводятся ссылки на сотни и тысячи наборов данных.
• Многие библиотеки, которыми вы будете пользоваться, включают популярные наборы данных для экспериментов.
• В книге мы рассмотрим действия, необходимые для получения данных и подготовки их к анализу, анализ этих данных различными средствами, настройки моделей и эффективных средств передачи результатов, особенно посредством визуализации.
GitHub
• GitHub — превосходный ресурс для поиска открытого кода, который вы сможете интегрировать в свои проекты (а также поделиться своим кодом с сообществом). Также GitHub является важнейшим элементом арсенала разработчика с функциональностью контроля версий, которая помогает командам разработчиков управлять проектами с открытым (и закрытым) кодом.
• Мы будем использовать множество разнообразных библиотек Python и data science, распространяемых с открытым кодом, а также программных продуктов и облачных сервисов — бесплатных, имеющих пробный период и условно-бесплатных. Многие библиотеки размещаются на GitHub.
Практические облачные вычисления
• Большая часть аналитики больших данных выполняется в облачных средах, позволяющих легко динамически масштабировать объем аппаратных и программных ресурсов, необходимых вашему приложению. Мы будем работать с различными облачными сервисами (напрямую или опосредованно), включая Twitter, Google Translate, IBM Watson, Microsoft Azure, OpenMapQuest, geopy, Dweet.io и PubNub.
• Мы рекомендуем пользоваться бесплатными, имеющими пробный период или условно-бесплатными сервисами. Предпочтение отдается тем сервисам, которые не требуют ввода данных кредитной карты, чтобы избежать получения больших счетов. Если же вы решили использовать сервис, требующий ввода данных кредитной карты, убедитесь в том, что с выбранного вами бесплатного уровня не происходит автоматический переход на платный уровень.
Базы данных, большие данные и инфраструктура больших данных
• По данным IBM (ноябрь 2016 года), 90% мировых данных было создано за последние два года7. Факты показывают, что скорость создания данных стремительно растет.
• По данным статьи AnalyticsWeek за март 2016 года, в течение 5 лет к интернету будет подключено более 50 миллиардов устройств, а к 2020 году в мире будет ежесекундно производиться 1,7 мегабайт новых данных на каждого человека8!
• В книге рассматриваются основы работы с реляционными базами данных и использования SQL с SQLite.
• Базы данных — критический элемент инфраструктуры больших данных для хранения и обработки больших объемов информации. Реляционные базы данных предназначены для обработки структурированных данных — они не приспособлены для неструктурированных и полуструктурированных данных в приложениях больших данных. По этой причине с развитием больших данных были созданы базы данных NoSQL и NewSQL для эффективной работы с такими данными. Мы приводим обзор NoSQL и NewSQL, а также практический пример работы с документной базой данных MongoDB в формате JSON. MongoDB — самая популярная база данных NoSQL.
• Оборудование и программная инфраструктура больших данных рассматриваются в главе 16.
Практические примеры из области искусственного интеллекта
• В практических примерах глав 11–15 представлены темы искусственного интеллекта, включая обработку естественного языка, глубокий анализ данных Twitter для анализа эмоциональной окраски, когнитивные вычисления на базе IBM Watson, машинное обучение с учителем, машинное обучение без учителя и глубокое обучение. В главе 16 представлено оборудование больших данных и программная инфраструктура, которые позволяют специалистам по компьютерным технологиям и теоретикам data science реализовать ультрасовременные решения на базе искусственного интеллекта.
Встроенные коллекции: списки, кортежи, множества, словари
• Как правило, в наши дни самостоятельная реализация структур данных не имеет особого смысла. В книге приведено подробное, состоящее из двух глав описание встроенных структур данных Python — списков, кортежей, словарей и множеств, успешно решающих большинство задач структурирования данных.
Программирование с использованием массивов NumPy и коллекций pandas Series/DataFrame
• Мы также уделили особое внимание трем ключевым структурам данных из библиотек с открытым кодом: массивам NumPy, коллекциям pandas Series и pandas DataFrame. Эти коллекции находят широкое применение в data science, компьютерной теории, искусственном интеллекте и больших данных. NumPy обеспечивает эффективность на два порядка выше, чем у встроенных списков Python.
• В главу 7 включено подробное описание массивов NumPy. Многие библиотеки, например pandas, построены на базе NumPy. В разделах «Введение в data science» в главах 7–9 представлены коллекции pandas Series и DataFrame, которые хорошо работают в сочетании с массивами NumPy, а также используются в оставшихся главах.
Работа с файлами и сериализация
• В главе 9 рассказывается об обработке текстовых файлов, а затем показано, как сериализовать объекты в популярном формате JSON (JavaScript Object Notation). JSON часто используется в части, посвященной data science.
• Многие библиотеки data science предоставляют встроенные средства для работы с файлами и загрузки наборов данных в программы Python. Кроме простых текстовых файлов, мы также займемся обработкой файлов в популярном формате CSV (значения, разделенные запятыми) с использованием модуля csv стандартной библиотеки Python и средств библиотеки data science pandas.
Объектно-базированное программирование
• Мы стараемся использовать многочисленные классы, упакованные сообществом разработки с открытым кодом Python в библиотеки классов. Прежде всего мы разберемся в том, какие библиотеки существуют, как выбрать библиотеки, подходящие для ваших приложений, как создать объекты существующих классов (обычно в одной-двух строках кода) и пустить их в дело. Объектно-базированный стиль программирования позволяет быстро и компактно строить впечатляющие приложения, что является одной из важных причин популярности Python.
• Этот подход позволит вам применять машинное обучение, глубокое обучение и другие технологии искусственного интеллекта для быстрого решения широкого спектра интересных задач, включая такие задачи когнитивных вычислений, как распознавание речи и «компьютерное зрение».
Объектно-ориентированное программирование
• Разработка собственных классов — важнейшая составляющая объектно-ориентированного программирования наряду с наследованием, полиморфизмом и утиной типизацией. Эти составляющие рассматриваются в главе 10.
• В главе 10 рассматривается модульное тестирование с использованием doctest и интересного моделирования процесса тасования и раздачи карт.
• Для целей глав 11–16 хватает нескольких простых определений пользовательских классов. Вероятно, в коде Python вы будете применять объектно-базированное программирование чаще, чем полноценное объектно-ориентированное программирование.
Воспроизводимость результатов
• В науке вообще и в data science в частности существует потребность в воспроизведении результатов экспериментов и исследований, а также эффективном распространении этих результатов. Для этого обычно рекомендуется применять документы Jupyter Notebook.
• Воспроизводимость результатов рассматривается в книге в контексте методов программирования и программных средств, таких как документы Jupyter Notebook и Docker.
Эффективность
• В нескольких примерах используется средство профилирования %timeit для сравнения эффективности разных подходов к решению одной задачи. Также рассматриваются такие средства, относящиеся к эффективности, как выражения-генераторы, сравнение массивов NumPy со списками Python, эффективность моделей машинного обучения и глубокого обучения, эффективность распределенных вычислений Hadoop и Spark.
Большие данные и параллелизм
В этой книге вместо написания собственного кода параллелизации мы поручим таким библиотекам, как Keras на базе TensorFlow, и таким инструментам больших данных, как Hadoop и Spark, провести параллелизацию за вас. В эру больших данных/искусственного интеллекта колоссальные требования к вычислительным мощностям приложений, работающих с большими массивами данных, заставляют нас задействовать полноценный параллелизм, обеспечиваемый многоядерными процессорами, графическими процессорами (GPU), тензорными процессорами (TPU) и гигантскими компьютерными кластерами в облаке. Некоторые задачи больших данных могли требовать параллельной работы тысяч процессоров для быстрого анализа огромных объемов данных.
Зависимость между главами
Допустим, вы — преподаватель, составляющий план лекций для профессиональных учебных курсов, или разработчик, решающий, какие главы следует читать в первую очередь. Тогда этот раздел поможет вам принять оптимальные решения. Главы лучше всего читать (или использовать для обучения) по порядку. Тем не менее для большей части материала разделов «Введение в data science» в конце глав 1–10 и практических примеров в главах 11–16 необходимы только главы 1–5 и небольшие части глав 6–10.
Часть 1: Основы Python
Мы рекомендуем читать все главы по порядку:
• В главе 1 «Компьютеры и Python» представлены концепции, которые закладывают фундамент для программирования на языке Python в главах 2–10 и практических примеров больших данных, искусственного интеллекта и облачных сервисов в главах 11–16. В главе также приведены результаты пробных запусков интерпретатора IPython и документов Jupyter Notebook.
• В главе 2 «Введение в программирование Python» изложены основы программирования Python с примерами кода, демонстрирующими ключевые возможности языка.
• В главе 3 «Управляющие команды» представлены управляющие команды Python и простейшие возможности обработки списков.
• В главе 4 «Функции» представлены пользовательские функции, методы моделирования с генерированием случайных чисел и основы работы с кортежами.
• В главе 5 «Последовательности: списки и кортежи» встроенные списки и кортежи Python описаны более подробно. Также в ней начинается изложение азов программирования в функциональном стиле.
Часть 2: Структуры данных Python, строки и файлы
Ниже приведена сводка зависимостей между главами для глав 6–9; предполагается, что вы уже прочитали главы 1–5.
• Глава 6 «Словари и множества» — раздел «6.4. Введение в data science» этой главы не зависит от материала главы.
• Глава 7 «NumPy и программирование, ориентированное на массивы» — для раздела «7.14. Введение в data science» необходимо знание словарей (глава 6) и массивов (глава 7).
• Глава 8 «Подробнее о строках» — для раздела «8.13. Введение в data science» необходимо знание необработанных строк и регулярных выражений (разделы 8.11–8.12), а также коллекций pandas Series и DataFrame из раздела 7.14.
• Глава 9 «Файлы и исключения» — для изучения сериализации JSON полезно знать основы работы со словарями (раздел 6.2). Кроме того, раздел «9.12. Введение в data science» требует знания встроенной функции open и команды with (раздел 9.3), а также коллекций pandas Series и DataFrame из раздела 7.14.
Часть 3: Нетривиальные аспекты Python
Ниже приведена сводка зависимостей между главами для глав 10; предполагается, что вы уже прочитали главы 1–5.
• Глава 10 «Объектно-ориентированное программирование» — раздел «Введение в data science» требует знания возможностей DataFrame из раздела 7.14. Преподаватели, которые намерены ограничиваться рассмотрением только классов и объектов, могут изложить материал разделов 10.1–10.6. Для преподавателей, которые собираются изложить более сложные темы (наследование, полиморфизм, утиная типизация), могут представлять интерес разделы 10.7–10.9. В разделах 10.10–10.15 изложены дополнительные перспективы.
Часть 4: Искусственный интеллект, облачные технологии и практические примеры больших данных
Ниже приведена сводка зависимостей между главами для глав 11–16; предполагается, что вы уже прочитали главы 1–5. Большинство глав 11–16 также требует знания словарей из раздела 6.2.
• В главе 11 «Обработка естественного языка» используются возможности pandas DataFrame из раздела 7.14.
• В главе 12 «Глубокий анализ данных Twitter» используются возможности pandas DataFrame из раздела 7.14, метод строк join (раздел 8.9), основы работы с JSON (раздел 9.5), TextBlob (раздел 11.2) и словарные облака (раздел 11.3). Некоторые примеры требуют определения классов с наследованием (глава 10).
• В главе 13 «IBM Watson и когнитивные вычисления» используется встроенная функция open и команда with (раздел 9.3).
• В главе 14 «Машинное обучение: классификация, регрессия и кластеризация» используются основные средства работы с массивами NumPy и метод unique (глава 7), возможности pandas DataFrame из раздела 7.14, а также функция subplots библиотеки Matplotlib (раздел 10.6).
• В главе 15 «Глубокое обучение» используются основные средства работы с массивами NumPy (глава 7), метод строк join (раздел 8.9), общие концепции машинного обучения из главы 14 и функциональность из практического примера главы 14 «Классификация методом k ближайших соседей и набор данных Digits».
• В главе 16 «Большие данные: Hadoop, Spark, NoSQL и IoT» используется метод строк split (раздел 6.2.7), объект Matplotlib FuncAnimation из раздела 6.4, коллекции pandas Series и DataFrame из раздела 7.14, метод строк join (раздел 8.9), модуль json (раздел 9.5), игнорируемые слова NLTK (раздел 11.2.13), аутентификация Twitter из главы 12, класс Tweepy StreamListener для потоковой передачи твитов, а также библиотеки geopy и folium. Некоторые примеры требуют определения классов с применением наследования (глава 10), но вы можете просто повторить наши определения классов без чтения главы 10.
Документы Jupyter Notebook
Для вашего удобства мы предоставили примеры кода книги в файлах с исходным кодом Python (.py) для использования с интерпретатором командной строки IPython, а также файлы Jupyter Notebook (.ipynb), которые можно загрузить в браузере и выполнить.
Jupyter Notebook — бесплатный проект с открытым кодом, который позволяет объединять текст, графику, аудио, видео и функциональность интерактивного программирования для быстрого и удобного ввода, редактирования, выполнения, отладки и изменения кода в браузере. Фрагмент статьи «Что такое Jupyter?»:
«Jupyter стал фактическим стандартом для научных исследований и анализа данных. Вычисления упаковываются вместе с аргументами, позволяя вам строить “вычислительные нарративы”; …это упрощает проблему распространения работоспособного кода между коллегами и участниками сообщества»9.
Наш опыт показывает, что эта среда прекрасно подходит для обучения и быстрой прототипизации. По этой причине мы используем документы Jupyter Notebook вместо традиционных интегрированных сред (IDE), таких как Eclipse, Visual Studio, PyCharm или Spyder. Ученые и специалисты уже широко применяют Jupyter для распространения результатов своих исследований. Поддержка Jupyter Notebook предоставляется через традиционные механизмы сообщества с открытым кодом10 (см. раздел «Поддержка Jupyter» в этом предисловии). За подробным описанием установки обращайтесь к разделу «Приступая к работе» после предисловия, а информация о запуске примеров книги приведена в разделе 1.5.
Совместная работа и обмен результатами
Работа в команде и распространение результатов исследований играют важную роль для разработчиков, которые занимают или собираются занять должность, связанную с аналитикой данных, в коммерческих, правительственных или образовательных организациях:
• Созданные вами документы Notebook удобно распространять среди участников команды простым копированием файлов или через GitHub.
• Результаты исследований, включая код и аналитику, могут публиковаться в виде статических веб-страниц при помощи таких инструментов, как nbviewer (https://nbviewer.jupyter.org) и GitHub, — оба ресурса автоматически визуализируют документы Notebook в виде веб-страниц.
Воспроизводимость результатов: веский аргумент в пользу Jupyter Notebook
В области data science и научных дисциплин вообще эксперименты и исследования должны быть воспроизводимыми. Об этом неоднократно упоминалось в литературе:
• Публикация Дональда Кнута «Грамотное программирование» в 1992 году11.
• Статья «Языково-независимый воспроизводимый анализ данных с применением грамотного программирования»12, в которой сказано: «Lir-вычисления (грамотные воспроизводимые вычисления) базируются на концепции грамотного программирования, предложенной Дональдом Кнутом».
По сути, воспроизводимость отражает полное состояние среды, использованной для получения результатов: оборудование, программное обеспечение, коммуникации, алгоритмы (особенно код), данные и родословная данных (источник и линия происхождения).
Docker
В главе 16 используется Docker — инструмент для упаковки программного кода в контейнеры, содержащие все необходимое для удобного, воспроизводимого и портируемого выполнения этого кода между платформами. Некоторые программные пакеты, используемые в главе 16, требуют сложной подготовки и настройки. Для многих из них можно бесплатно загрузить готовые контейнеры Docker. Это позволяет избежать сложных проблем установки и запускать программные продукты локально на настольном или портативном компьютере. Docker предоставляет идеальную возможность быстро и удобно приступить к использованию новых технологий.
Docker также помогает обеспечить воспроизводимость. Вы можете создавать специализированные контейнеры Docker с нужными версиями всех программных продуктов и всех библиотек, использованных в исследовании. Это позволит другим разработчикам воссоздать использованную вами среду, а затем повторить вашу работу и получить ваши результаты. В главе 16 мы используем Docker для загрузки и выполнения контейнера, заранее настроенного для программирования и запуска Spark-приложений больших данных на базе Jupyter Notebook.
IBM Watson и когнитивные вычисления
На ранней стадии исследований, проводимых для этой книги, мы распознали быстро растущий интерес к IBM Watson. Мы проанализировали предложения конкурентов и обнаружили, что политика Watson «без ввода данных кредитной карты» для бесплатных уровней является одной из самых удобных для наших читателей.
IBM Watson — платформа когнитивных вычислений, применяемая в широком спектре реальных сценариев. Системы когнитивных вычислений моделируют функции человеческого мозга по выявлению закономерностей и принятию решений для «обучения» с поглощением большего объема данных13,14,15. В книге Watson уделяется значительное внимание. Мы используем бесплатный пакет Watson Developer Cloud: Python SDK, который предоставляет различные API для взаимодействия с сервисами Watson на программном уровне. С Watson интересно работать, и эта платформа помогает раскрыть ваш творческий потенциал.
Сервисы Watson уровня Lite и практический пример Watson
Чтобы способствовать обучению и экспериментам, IBM предоставляет бесплатные lite-уровни для многих своих API16. В главе 13 будут опробованы демонстрационные приложения для многих сервисов Watson17. Затем мы используем lite-уровни сервисов Watson Text to Speech, Speech to Text и Translate для реализации приложения-переводчика. Пользователь произносит вопрос на английском языке, приложение преобразует речь в английский текст, переводит текст на испанский язык и зачитывает испанский текст. Собеседник произносит ответ на испанском языке (если вы не говорите на испанском, мы предоставили аудиофайл, который вы можете использовать). Приложение быстро преобразует речь в испанский текст, переводит текст на английский и зачитывает ответ на английском. Круто!
Подход к обучению
«Python: Искусственный интеллект, большие данные и облачные вычисления» содержит обширную подборку примеров, позаимствованных из многих областей. Мы рассмотрим некоторые интересные примеры с реальными наборами данных. В книге основное внимание уделяется принципам качественного проектирования программных продуктов, а на передний план выходит ясность кода.
538 примеров кода
538 примеров, приведенных в книге, содержат приблизительно 4000 строк кода. Это относительно небольшой объем для книги такого размера, что отчасти объясняется выразительностью языка Python. Кроме того, наш стиль программирования подразумевает, что мы по возможности используем полнофункциональные библиотеки классов; эти библиотеки берут на себя большую часть работы.
160 таблиц/иллюстраций/визуализаций
В книгу включено множество таблиц, графиков, а также статических, динамических и интерактивных визуализаций.
Житейская мудрость программирования
В материал книги интегрируется житейская мудрость программирования, основанная на девяти десятилетиях (в сумме) авторского опыта программирования и преподавания.
• Хороший стиль программирования и общепринятые идиомы Python помогают создавать более понятные, более четкие и простые в сопровождении программы.
• Описание распространенных ошибок программирования снижает вероятность того, что эти ошибки будут допущены читателями.
• Советы по предотвращению ошибок с рекомендациями по выявлению дефектов и исключению их из программ. Во многих советах описываются приемы, которые препятствуют изначальному проникновению ошибок в ваши программы.
• Советы по быстродействию, в которых выделяются возможности для ускорения работы ваших программ или сокращения объема занимаемой памяти.
• Наблюдения из области программирования, в которых выделяются архитектурные и проектировочные аспекты правильного построения программных продуктов (особенно для больших систем).
Программные продукты, используемые в книге
Программные продукты, используемые в книге, доступны для Windows, macOS и Linux, и их можно бесплатно загрузить из интернета. Для написания примеров используется бесплатный дистрибутив Anaconda Python. Он включает большую часть Python, библиотек визуализации и data science, которые вам понадобятся, а также интерпретатор IPython, Jupyter Notebook и Spyder — одну из самых лучших интегрированных сред Python для data science. Для разработки программ, приведенных в книге, используется только IPython и Jupyter Notebook. В разделе «Приступая к работе» после предисловия обсуждается установка Anaconda и других продуктов, необходимых для работы с нашими примерами.
Документация Python
Следующая документация особенно пригодится вам во время работы с книгой:
• Справочник по языку Python:
https://docs.python.org/3/reference/index.html
• Стандартная библиотека Python:
https://docs.python.org/3/library/index.html
• Список документации Python:
Ответы на вопросы
Несколько популярных форумов, посвященных Python и программированию вообще:
• python-forum.io
• https://www.dreamincode.net/forums/forum/29-python/
• StackOverflow.com
Кроме того, многие разработчики открывают форумы по своим инструментариям и библиотекам. Управление и сопровождение многих библиотек, используемых в книге, осуществляется через github.com. Для некоторых библиотек поддержка предоставляется через вкладку Issues на странице GinHub этих библиотек. Если вы не найдете ответ на свои вопросы, посетите веб-страницу этой книги на сайте
Поддержка Jupyter
Поддержка Jupyter Notebook предоставляется на следующих ресурсах:
• Project Jupyter Google Group:
https://groups.google.com/forum/#!forum/jupyter
• Jupyter-чат в реальном времени:
https://gitter.im/jupyter/jupyter
• GitHub
https://github.com/jupyter/help
• StackOverflow:
https://stackoverflow.com/questions/tagged/jupyter
• Jupyter for Education Google Group (для преподавателей, использующих Jupyter в ходе обучения):
https://groups.google.com/forum/#!forum/jupyter-education
Приложения
Чтобы извлечь максимум пользы из материала, выполняйте каждый пример кода параллельно с соответствующим описанием в книге. На веб-странице книги на сайте
предоставляются:
• исходный код Python (файлы .py), подготовленный к загрузке, и документы Jupyter Notebook (файлы .ipynb) для примеров кода;
• видеоролики, поясняющие использование примеров кода с IPython и документами Jupyter Notebook. Эти инструменты также описаны в разделе 1.5;
• сообщения в блогах и обновления книги.
За инструкциями по загрузке обращайтесь к разделу «Приступая к работе» после предисловия.
Как связаться с авторами книги
Мы ждем ваши комментарии, критические замечания, исправления и предложения по улучшению книги. С вопросами, найденными опечатками и предложениями обращайтесь по адресу: deitel@deitel.com.
Или ищите нас в соцсетях:
• Facebook® (http://www.deitel.com/deitelfan)
• Twitter® (@deitel)
• LinkedIn® (http://linkedin.com/company/deitel-&-associates)
• YouTube® (http://youtube.com/DeitelTV)
Благодарности
Спасибо Барбаре Дейтел (Barbara Deitel) за долгие часы, проведенные в интернете за поиском информации по проекту. Нам повезло работать с группой профессионалов из издательства Pearson. Мы высоко ценим все усилия и 25-летнее наставничество нашего друга и профессионала Марка Л. Тауба (Mark L. Taub), вице-президента издательской группы Pearson IT Professional Group. Марк со своей группой работает над всеми нашими профессиональными книгами, видеоуроками и учебными руководствами из сервиса Safari (https://learning.oreilly.com/). Они также являются спонсорами наших обучающих семинаров в Safari. Джули Наил (Julie Nahil) руководила выпуском книги. Мы выбрали иллюстрацию для обложки, а дизайн обложки был разработан Чати Презертсит (Chuti Prasertshith).
Мы хотим выразить свою благодарность своим редакторам. Патрисия Байрон-Кимболл (Patricia Byron-Kimball) и Меган Джейкоби (Meghan Jacoby) подбирали научных рецензентов и руководили процессом рецензирования. Держась в рамках жесткого графика, редакторы рецензировали нашу работу, делились многочисленными замечаниями для повышения точности, полноты и актуальности материала.
Научные редакторы
Книга
Дэниел Чен (Daniel Chen), специалист по data science, Lander Analytics
Гаррет Дансик (Garrett Dancik), доцент кафедры компьютерных наук/биоинформатики, Университет Восточного Коннектикута
Праншу Гупта (Pranshu Gupta), доцент кафедры компьютерных наук, Университет Десалс
Дэвид Куп (David Koop), доцент кафедры data science, содиректор по учебным программам, Университет Массачусетса в Дартмуте
Рамон Мата-Толедо (Ramon Mata-Toledo), профессор кафедры компьютерных наук, Университет Джеймса Мэдисона
Шьямал Митра (Shyamal Mitra), старший преподаватель кафедры компьютерных наук, Техасский университет в Остине
Элисон Санчес (Alison Sanchez), доцент кафедры экономики, Университет Сан-Диего
Хосе Антонио Гонсалес Секо (José Antonio González Seco), IT-консультант
Джейми Уайтакер (Jamie Whitacre), независимый консультант в области data science
Элизабет Уикс (Elizabeth Wickes), преподаватель, школа информатики, Университет штата Иллинойс
Черновик
Ирен Бруно (Dr. Irene Bruno), доцент кафедры информатики и информационных технологий, Университет Джорджа Мэйсона
Ланс Брайант (Lance Bryant), доцент кафедры математики, Шиппенсбургский университет
Дэниел Чен (Daniel Chen), специалист по data science, Lander Analytics
Гаррет Дансик (Garrett Dancik), доцент кафедры компьютерных наук/биоинформатики, Университет Восточного Коннектикута
Марша Дэвис (Dr. Marsha Davis), декан математического факультета, Университет Восточного Коннектикута
Роланд ДеПратти (Roland DePratti), доцент кафедры компьютерных наук, Университет Восточного Коннектикута
Шьямал Митра (Shyamal Mitra), старший преподаватель, Техасский университет в Остине
Марк Поли (Dr. Mark Pauley), старший научный сотрудник на кафедре биоинформатики, школа междисциплинарной информатики, Университет штата Небраска в Омахе
Шон Рейли (Sean Raleigh), доцент кафедры математики, заведующий кафедрой data science, Вестминстерский колледж
Элисон Санчес (Alison Sanchez), доцент кафедры экономики, Университет Сан-Диего
Харви Сай (Dr. Harvey Siy), доцент кафедры компьютерных наук, информатики и информационных технологий, Университет штата Небраска в Омахе
Джейми Уайтакр (Jamie Whitacre), независимый консультант в области data science
Мы будем благодарны за ваши комментарии, критику, исправления и предложения по улучшению. Если у вас возникают какие-либо вопросы, обращайтесь по адресу deitel@deitel.com.
Добро пожаловать в увлекательный мир разработки Python с открытым кодом. Надеемся, вам понравится эта книга, посвященная разработке современных приложений Python с использованием IPython и Jupyter Notebook и затрагивающая вопросы data science, искусственного интеллекта, больших данных и облачных технологий. Желаем успеха!
Пол и Харви Дейтелы
Об авторах
Пол Дж. Дейтел (Paul J. Deitel), генеральный и технический директор компании Deitel & Associates, Inc., окончил Массачусетский технологический институт (MIT), более 38 лет занимается компьютерами. Пол — один из самых опытных преподавателей языков программирования, он ведет учебные курсы для разработчиков с 1992 года. Он провел сотни занятий по всему миру для корпоративных клиентов, включая Cisco, IBM, Siemens, Sun Microsystems (сейчас Oracle), Dell, Fidelity, NASA (Космический центр имени Кеннеди), Национальный центр прогнозирования сильных штормов, ракетный полигон Уайт-Сэндз, Rogue Wave Software, Boeing, Nortel Networks, Puma, iRobot и многих других. Пол и его соавтор, д-р Харви М. Дейтел, являются авторами всемирно известных бестселлеров — учебников по языкам программирования, предназначенных для начинающих и для профессионалов, а также видеокурсов.
Харви М. Дейтел (Dr. Harvey M. Deitel), председатель и главный стратег компании Deitel & Associates, Inc., имеет 58-летний опыт работы в области информационных технологий. Он получил степени бакалавра и магистра Массачусетского технологического института и степень доктора философии Бостонского университета — он изучал компьютерные технологии во всех этих программах до того, как в них появились отдельные программы компьютерных наук. Харви имеет огромный опыт преподавания в колледже и занимал должность председателя отделения информационных технологий Бостонского колледжа. В 1991 году вместе с сыном — Полом Дж. Дейтелом — он основал компанию Deitel & Associates, Inc. Харви с Полом написали несколько десятков книг и выпустили десятки видеокурсов LiveLessons. Написанные ими книги получили международное признание и были изданы на японском, немецком, русском, испанском, французском, польском, итальянском, упрощенном китайском, традиционном китайском, корейском, португальском, греческом, турецком языках и на языке урду. Дейтел провел сотни семинаров по программированию в крупных корпорациях, академических институтах, правительственных и военных организациях.
О компании Deitel® & Associates, Inc.
Компания Deitel & Associates, Inc., основанная Полом Дейтелом и Харви Дейтелом, получила международное признание в области авторских разработок и корпоративного обучения. Компания специализируется на языках программирования, объектных технологиях, интернете и веб-программировании. В число клиентов компании входят многие ведущие корпорации, правительственные агентства, военные и образовательные учреждения. Компания предоставляет учебные курсы, проводимые на территории клиента по всему миру для многих языков программирования и платформ.
Благодаря своему 44-летнему партнерскому сотрудничеству с Pearson/Prentice Hall, компания Deitel & Associates, Inc., публикует передовые учебники по программированию и профессиональные книги в печатном и электронном виде, видеокурсы LiveLessons (доступны для покупки на https://www.informit.com), Learning Paths и интерактивные обучающие семинары в режиме реального времени в службе Safari (https://learning.oreilly.com) и интерактивные мультимедийные курсы Revel™.
Чтобы связаться с компанией Deitel & Associates, Inc. и авторами или запросить план-проспект или предложение по обучению, напишите: deitel@deitel.com
Чтобы узнать больше о корпоративном обучении Дейтелов, посетите
http://www.deitel.com/training.
Желающие приобрести книги Дейтелов, могут сделать это на
Крупные заказы корпораций, правительства, военных и академических учреждений следует размещать непосредственно на сайте Pearson. Для получения дополнительной информации посетите
https://www.informit.com/store/sales.aspx.
1 Источник неизвестен, часто ошибочно приписывается Марку Твену.
2https://www.mckinsey.com/~/media/McKinsey/Business%20Functions/McKinsey%20Digital/Our%20Insights/Big%20data%20The%20next%20frontier%20for%20innovation/MGI_big_data_full_report.ashx (с. 3).
7https://public.dhe.ibm.com/common/ssi/ecm/wr/en/wrl12345usen/watson-customer-engagement-watson-marketing-wr-other-papers-and-reports-wrl12345usen-20170719.pdf.
15https://www.forbes.com/sites/bernardmarr/2016/03/23/what-everyone-should-know-about-cognitive-computing.
16 Всегда проверяйте последние условия предоставления сервиса на сайте IBM, так как условия и сервисы могут меняться со временем.
18 Наш сайт сейчас проходит серьезную переработку. Если вы не найдете нужную информацию, обращайтесь к нам по адресу deitel@deitel.com.
Источник неизвестен, часто ошибочно приписывается Марку Твену.
Наш сайт сейчас проходит серьезную переработку. Если вы не найдете нужную информацию, обращайтесь к нам по адресу deitel@deitel.com.
Всегда проверяйте последние условия предоставления сервиса на сайте IBM, так как условия и сервисы могут меняться со временем.
«Там золото в этих холмах!»1
В 2011 году Глобальный институт McKinsey опубликовал отчет «Большие данные: новый рубеж для инноваций, конкуренции и производительности». В отчете было сказано: «Только Соединенные Штаты сталкиваются с нехваткой от 140 тысяч до 190 тысяч специалистов, обладающих глубокими аналитическими познаниями, а также 1,5 миллиона менеджеров и аналитиков, которые бы анализировали большие данные и принимали решения на основании полученных результатов»2. Такое положение дел сохраняется. В отчете за август 2018 года «LinkedIn Workforce Report» сказано, что в Соединенных Штатах существует нехватка более 150 тысяч специалистов в области data science3. В отчете IBM, Burning Glass Technologies и Business-Higher Education Forum за 2017 года говорится, что к 2020 году в Соединенных Штатах будут существовать сотни тысяч вакансий, требующих квалификации в области data science4.
• По данным статьи AnalyticsWeek за март 2016 года, в течение 5 лет к интернету будет подключено более 50 миллиардов устройств, а к 2020 году в мире будет ежесекундно производиться 1,7 мегабайт новых данных на каждого человека8!
В 2011 году Глобальный институт McKinsey опубликовал отчет «Большие данные: новый рубеж для инноваций, конкуренции и производительности». В отчете было сказано: «Только Соединенные Штаты сталкиваются с нехваткой от 140 тысяч до 190 тысяч специалистов, обладающих глубокими аналитическими познаниями, а также 1,5 миллиона менеджеров и аналитиков, которые бы анализировали большие данные и принимали решения на основании полученных результатов»2. Такое положение дел сохраняется. В отчете за август 2018 года «LinkedIn Workforce Report» сказано, что в Соединенных Штатах существует нехватка более 150 тысяч специалистов в области data science3. В отчете IBM, Burning Glass Technologies и Business-Higher Education Forum за 2017 года говорится, что к 2020 году в Соединенных Штатах будут существовать сотни тысяч вакансий, требующих квалификации в области data science4.
• По данным IBM (ноябрь 2016 года), 90% мировых данных было создано за последние два года7. Факты показывают, что скорость создания данных стремительно растет.
• Визуализации чрезвычайно важны при работе с большими данными: они упрощают исследование данных и получение воспроизводимых результатов исследований, когда количество элементов данных может достигать миллионов, миллиардов и более. Часто говорят, что одна картинка стоит тысячи слов5 — в мире больших данных визуализация может стоить миллиардов, триллионов и даже более записей в базе данных. Визуализации позволяют взглянуть на данные «с высоты птичьего полета», увидеть их «в перспективе» и составить о них представление. Описательные статистики полезны, но иногда могут увести в ошибочном направлении. Например, квартет Энскомба6 демонстрирует посредством визуализаций, что серьезно различающиеся наборы данных могут иметь почти одинаковые показатели описательной статистики.
«Jupyter стал фактическим стандартом для научных исследований и анализа данных. Вычисления упаковываются вместе с аргументами, позволяя вам строить “вычислительные нарративы”; …это упрощает проблему распространения работоспособного кода между коллегами и участниками сообщества»9.
В 2011 году Глобальный институт McKinsey опубликовал отчет «Большие данные: новый рубеж для инноваций, конкуренции и производительности». В отчете было сказано: «Только Соединенные Штаты сталкиваются с нехваткой от 140 тысяч до 190 тысяч специалистов, обладающих глубокими аналитическими познаниями, а также 1,5 миллиона менеджеров и аналитиков, которые бы анализировали большие данные и принимали решения на основании полученных результатов»2. Такое положение дел сохраняется. В отчете за август 2018 года «LinkedIn Workforce Report» сказано, что в Соединенных Штатах существует нехватка более 150 тысяч специалистов в области data science3. В отчете IBM, Burning Glass Technologies и Business-Higher Education Forum за 2017 года говорится, что к 2020 году в Соединенных Штатах будут существовать сотни тысяч вакансий, требующих квалификации в области data science4.
• Визуализации чрезвычайно важны при работе с большими данными: они упрощают исследование данных и получение воспроизводимых результатов исследований, когда количество элементов данных может достигать миллионов, миллиардов и более. Часто говорят, что одна картинка стоит тысячи слов5 — в мире больших данных визуализация может стоить миллиардов, триллионов и даже более записей в базе данных. Визуализации позволяют взглянуть на данные «с высоты птичьего полета», увидеть их «в перспективе» и составить о них представление. Описательные статистики полезны, но иногда могут увести в ошибочном направлении. Например, квартет Энскомба6 демонстрирует посредством визуализаций, что серьезно различающиеся наборы данных могут иметь почти одинаковые показатели описательной статистики.
Приступая к работе
От издательства
Некоторые иллюстрации для лучшего восприятия нужно смотреть в цветном варианте. Мы снабдили их QR-кодами, перейдя по которым, вы можете ознакомиться с цветной версией рисунка.
Ваши замечания, предложения, вопросы отправляйте по адресу comp@piter.com (издательство «Питер», компьютерная редакция). Мы будем рады узнать ваше мнение!
На веб-сайте издательства www.piter.com вы найдете подробную информацию о наших книгах.
В этом разделе собрана информация, которую следует просмотреть перед чтением книги. Обновления будут публиковаться на сайте http://www.deitel.com.
Загрузка примеров кода
Файл examples.zip с кодом примеров книги можно загрузить на нашей веб-странице книги на сайте:
Щелкните на ссылке Download Examples, чтобы сохранить файл на вашем компьютере. Многие браузеры помещают загруженный файл в папку Downloads вашей учетной записи. Когда загрузка завершится, найдите файл в своей системе и распакуйте папку examples в папку Documents вашей учетной записи:
• Windows: C:\Users\YourAccount\Documents\examples
• macOS или Linux: ~/Documents/examples
В большинстве операционных систем имеется встроенная программа распаковки архивов. Также можно воспользоваться внешней программой-архиватором — например, 7-Zip (www.7-zip.org) или WinZip (www.winzip.com).
Структура папки examples
В этой книге приводятся примеры трех типов:
• отдельные фрагменты кода для интерактивной среды IPython;
• законченные приложения, называемые сценариями;
• документы Jupyter Notebook — удобной интерактивной среды для браузера, в которой можно писать и выполнять код, а также чередовать код с текстом, графикой и видео.
Все варианты продемонстрированы в примерах из раздела 1.5.
Каталог examples содержит одну вложенную папку для каждой главы. Этим папкам присвоены имена вида ch##, где ## — двузначный номер главы от 01 до 16 — например, ch01. Кроме глав 13, 15 и 16, папка каждой главы содержит следующие элементы:
• snippets_ipynb — папка с файлами Jupyter Notebook этой главы;
• snippets_py — папка с файлами с исходным кодом Python, в которых хранятся все представленные фрагменты кода, разделенные пустой строкой. Вы можете скопировать эти фрагменты в IPython или в созданные вами новые документы Jupyter Notebook;
• файлы сценариев и используемые ими файлы.
Глава 13 содержит одно приложение. Главы 15 и 16 объясняют, где найти нужные файлы в папках ch15 и ch16 соответственно.
Установка Anaconda
В книге используется дистрибутив Anaconda Python, отличающийся простотой установки. В него входит практически все необходимое для работы с примерами, в том числе:
• интерпретатор IPython;
• большинство библиотек Python и data science, используемых в книге;
• локальный сервер Jupyter Notebook для загрузки и выполнения документов;
• другие программные пакеты, такие как Spyder IDE (Integrated Development Environment), — в книге используются только среды IPython и Jupyter Notebook.
Программу установки Python 3.x Anaconda для Windows, macOS и Linux можно загрузить по адресу:
https://www.anaconda.com/download/
Когда загрузка завершится, запустите программу установки и выполните инструкции на экране. Чтобы установленная копия Anaconda работала правильно, не перемещайте ее файлы после установки.
Обновление Anaconda
Затем проверьте актуальность установки Anaconda. Откройте окно командной строки в своей системе:
• В macOS откройте приложение Terminal из подкаталога Utilities в каталоге Applications.
• В Windows откройте командную строку Anaconda Prompt из меню Пуск. Когда вы делаете это для обновления Anaconda (как в данном случае) или для установки новых пакетов (см. ниже), выполните Anaconda Prompt с правами администратора: щелкните правой кнопкой мыши и выберите команду Запуск от имени администратора. (Если вы не можете найти команду Anaconda Prompt в меню Пуск, найдите ее при помощи поля поиска в нижней части экрана.)
• В Linux откройте терминал или командную оболочку своей системы (зависит от дистрибутива Linux).
В окне командной строки своей системы выполните следующие команды, чтобы обновить установленные пакеты Anaconda до последних версий:
conda update conda
conda update --all
Менеджеры пакетов
Приведенная выше команда conda запускает менеджер пакетов conda — один из двух основных менеджеров пакетов Python, используемых в книге (другой — pip). Пакеты содержат файлы, необходимые для установки отдельных библиотек или инструментов Python. В книге conda будет использоваться для установки дополнительных пакетов, если только не окажется, что эти пакеты недоступны в conda; в этом случае будет использоваться pip. Некоторые разработчики предпочитают пользоваться исключительно pip, потому что эта программа в настоящее время поддерживает больше пакетов. Если у вас возникнут проблемы с установкой пакетов из conda, попробуйте использовать pip.
Установка программы статического анализа кода Prospector
Для анализа кода Python можно воспользоваться аналитической программой Prospector, которая проверяет ваш код на наличие типичных ошибок и помогает улучшить его. Чтобы установить программу Prospector и используемые ею библиотеки Python, выполните следующую команду в окне командной строки:
pip install prospector
Установка jupyter-matplotlib
В книге для построения некоторых анимаций используется библиотека визуализации Matplotlib. Чтобы использовать анимации в документах Jupyter Notebook, необходимо установить программу ipympl. В терминале в командной строке Anaconda или в оболочке, открытой ранее, последовательно выполните следующие команды19:
conda install -c conda-forge ipympl
conda install nodejs
jupyter labextension install @jupyter-widgets/jupyterlab-manager
jupyter labextension install jupyter-matplotlib
Установка других пакетов
Дистрибутив Anaconda включает приблизительно 300 популярных пакетов Python и data science, включая NumPy, Matplotlib, pandas, Regex, BeautifulSoup, requests, Bokeh, SciPy, SciKit-Learn, Seaborn, Spacy, sqlite, statsmodels и многие другие. Количество дополнительных пакетов, которые вам придется устанавливать в книге, будет небольшим, и мы будем приводить инструкции по установке в таких местах. В документации новых пакетов объясняется, как их следует устанавливать.
Получение учетной записи разработчика Twitter
Если вы намереваетесь использовать главу «Глубокий анализ данных Twitter» и все примеры на базе Twitter в последующих главах, подайте заявку на получение учетной записи разработчика Twitter. Сейчас Twitter требует регистрации для получения доступа к их API. Чтобы подать заявку на создание учетной записи разработчика, заполните и отправьте форму по адресу:
https://developer.twitter.com/en/apply-for-access
Twitter проверяет каждую заявку. На момент написания книги заявки на создание личных учетных записей разработчиков утверждались практически немедленно, а на утверждение заявок от компаний требовалось от нескольких дней до нескольких недель. Успешное утверждение не гарантировано.
Необходимость подключения к интернету в некоторых главах
При использовании этой книги вам может понадобиться подключение к интернету для установки дополнительных библиотек. В некоторых главах вы будете регистрироваться для создания учетных записей в облачных сервисах (в основном для использования их бесплатных уровней). Некоторые сервисы требуют кредитных карт для подтверждения личности. В отдельных случаях будут использоваться платные сервисы. Тогда мы воспользуемся кредитом, который предоставляется фирмой-поставщиком, так что вы сможете опробовать сервис без каких-либо затрат. Предупреждение: некоторые облачные сервисы начинают выставлять счета после их настройки. Когда вы закончите анализ примеров с использованием таких сервисов, без промедления удалите выделенные ресурсы.
Различия в выводе программ
При выполнении наших примеров вы можете заметить некоторые различия между приведенными и вашими результатами:
• Из-за различий в выполнении вычислений в формате с плавающей точкой (например, –123.45, 7.5 или 0.0236937) в разных операционных системах вы можете заметить незначительные различия в выводе, особенно в младших разрядах дробной части.
• Когда мы приводим выходные данные, отображаемые в разных окнах, мы обрезаем границы окон для экономии места.
Получение ответов на вопросы
На форумах в интернете вы сможете общаться с другими программистами Python и получать ответы на свои вопросы. Некоторые популярные форумы по тематике Python и программирования в целом:
• python-forum.io
• StackOverflow.com
• https://www.dreamincode.net/forums/forum/29-python/
Кроме того, многие фирмы-разработчики предоставляют форумы, посвященные их инструментам и библиотекам. Управление большинством упоминаемых в книге библиотек и их сопровождение осуществляется на github.com. Некоторые разработчики, занимающиеся сопровождением библиотек, предоставляют поддержку на вкладке Issues страницы GitHub библиотеки. Если вам не удастся найти ответ на свой вопрос в интернете, обращайтесь к веб-странице книги на сайте20
Теперь все готово к чтению книги. Надеемся, она вам понравится!
20 В настоящее время наш сайт проходит глобальную реконструкцию. Если вы не найдете какую-то необходимую информацию, напишите нам по адресу deitel@deitel.com.
В настоящее время наш сайт проходит глобальную реконструкцию. Если вы не найдете какую-то необходимую информацию, напишите нам по адресу deitel@deitel.com.
Глава 1. Компьютеры и Python
В этой главе…
• Наиболее интересные тенденции в области современных вычислительных технологий.
• Краткий обзор основ объектно-ориентированного программирования.
• Сильные стороны Python.
• Знакомство с важнейшими библиотеками Python и data science, используемыми в этой книге.
• Интерактивный режим интерпретатора IPython и выполнение кода Python.
• Выполнение сценария Python для анимации гистограммы.
• Создание и тестирование веб-оболочки Jupyter Notebook для выполнения кода Python.
• Большие данные: с каждым днем еще больше.
• Анализ больших данных на примере популярного мобильного навигационного приложения.
• Искусственный интеллект: пересечение компьютерной теории и data science.
1.1. Введение
Знакомьтесь: Python — один из наиболее широко используемых языков программирования, а согласно индексу PYPL (Popularity of Programming Languages) — самый популярный в мире21.
В этом разделе представлены терминология и концепции, закладывающие основу для программирования на языке Python, которому будут посвящены главы 2–10, и для практических примеров из области больших данных, искусственного интеллекта и облачных технологий, описываемых в главах 11–16.
Читатели узнают, почему язык Python стал таким популярным, познакомятся со стандартной библиотекой Python и различными библиотеками data science, благодаря которым не придется заново «изобретать велосипед». Эти библиотеки используются для создания объектов. С их помощью можно решать серьезные задачи при умеренном объеме программного кода.
Затем будут рассмотрены три примера, демонстрирующие различные способы выполнения кода Python:
• В первом примере вы будете выполнять команды Python в оболочке IPython в интерактивном режиме и сразу же видеть результаты.
• Во втором примере мы выполним серьезное приложение Python, отображающее анимированную гистограмму результатов бросков шестигранного кубика. Это позволит увидеть «закон больших чисел» в действии. Забегая чуть вперед, отметим, что в главе 6 это же приложение будет построено с использованием библиотеки визуализации Matplotlib.
• В последнем примере будет продемонстрирована работа с документами Jupyter Notebook с использованием JupyterLab — интерактивной оболочки на базе веб-браузера, обеспечивающей удобство в процессе формирования и выполнения инструкции Python. К слову, в документы Jupyter Notebook можно включать текст, изображения, звуковые данные, видеоролики, анимации и программный код.
В прошлом большинство компьютерных приложений выполнялось на автономных (то есть не объединенных в сеть) компьютерах. Современные приложения могут создаваться с расчетом на взаимодействие с миллиардами компьютеров по всему мире через интернет. Мы расскажем об облачных технологиях и концепции IoT (Internet of Things), закладывающих основу для современных приложений (подробнее об этом в главах 11–16).
Вы, кроме того, узнаете, насколько велики большие данные и как они стремительно становятся еще больше. Затем будет представлен вариант анализа больших данных на примере мобильного навигационного приложения Waze. Это приложение многие современные технологии использует для построения динамических инструкций, помогающих быстро и безопасно добраться до конечной точки маршрута. При описании этих технологий будет указано, где многие из них используются в этой книге. Глава завершается разделом «Введение в data science», посвященным важнейшей области пересечения компьютерной теории и дисциплины data science — искусственному интеллекту.
1.2. Основы объектных технологий
Потребность в новых, более мощных программах стремительно растет, поэтому очень важно, чтобы программные продукты строились по возможности быстро, корректно и эффективно. Объекты (точнее, классы, на основе которых строятся объекты), по сути, представляют собой программные компоненты, пригодные для повторного использования. Объектом может быть что угодно: дата, время, аудио, видео, автомобиль, человек и т.д. Практически каждое существительное может быть адекватным образом представлено программным объектом, обладающим атрибутами (например, имя, цвет и размер) и способностями к выполнению определенных действий (например, вычисление, перемещение и обмен данными). Разработчики программ используют модульную структуру и объектно-ориентированную методологию проектирования с большей эффективностью, чем некогда популярные методологии вроде «структурного программирования». Объектно-ориентированные программы зачастую более понятны, их проще исправлять и модифицировать.
Автомобиль как объект
Чтобы лучше понять суть объектов и их внутреннее устройство, воспользуемся простой аналогией. Представьте, что вы ведете автомобиль и нажимаете педаль газа, чтобы набрать скорость. Но что должно произойти до того, как вы получите возможность водить автомобиль? Прежде всего автомобиль нужно изготовить. Изготовление любого автомобиля начинается с инженерных чертежей (калек), подробно описывающих устройство автомобиля. На этих чертежах даже показано устройство педали акселератора. За этой педалью скрываются сложные механизмы, которые при приведении в действие ускоряют автомобиль. Аналогично и педаль тормоза «скрывает» механизмы, тормозящие автомобиль, руль «скрывает» механизмы, поворачивающие автомобиль, и т.д. Благодаря этому люди, не имеющие понятия о внутреннем устройстве автомобиля, могут легко им управлять.
Невозможно готовить пищу на кухне, существующей лишь на листе бумаги; точно так же нельзя водить автомобиль, существующий лишь в чертежах. Прежде чем вы сядете за руль машины, ее нужно воплотить в металл на основе чертежей. Воплощенный в металле автомобиль имеет реальную педаль газа, с помощью которой он может ускоряться, но (к счастью!) не может делать это самостоятельно — нажимает на педаль газа водитель.
Методы и классы
Воспользуемся примером с автомобилем для иллюстрации некоторых ключевых концепций объектно-ориентированного программирования. Для выполнения задачи в программе требуется метод, «скрывающий» инструкции программы, которые фактически выполняют задание. Метод скрывает эти инструкции от пользователя подобно тому, как педаль газа автомобиля скрывает от водителя механизмы, вызывающие ускорение автомобиля. В Python программная единица, именуемая классом, включает методы, выполняющие задачи класса. Например, класс, представляющий банковский счет, может включать три метода, один из которых выполняет пополнение счета, второй — вывод средств со счета, а третий — запрос текущего баланса. Класс напоминает концепцию автомобиля, представленного чертежами, включая чертежи педали газа, рулевого колеса и других механизмов.
Создание экземпляра класса
Итак, чтобы управлять автомобилем, его сначала необходимо изготовить по чертежам; точно так же перед выполнением задач, определяемых методами этого класса, сначала необходимо создать объект класса. Этот процесс называется созданием экземпляра. Полученный при этом объект называется экземпляром класса.
Повторное использование
Подобно тому как один и тот же чертеж можно повторно использовать для создания многих автомобилей, один класс можно повторно использовать для создания многих объектов. Повторное использование существующих классов при построении новых классов и программ экономит время и силы разработчика, облегчает создание более надежных и эффективных систем, поскольку ранее созданные классы и компоненты прошли тщательное тестирование, отладку и оптимизацию производительности. Подобно тому как концепция взаимозаменяемых частей легла в основу индустриальной революции, повторно используемые классы — двигатель прогресса в области создания программ, который был вызван внедрением объектной технологии.
В Python для создания программ обычно применяется принцип компоновки из готовых блоков. Дабы заново не «изобретать велосипед», используйте качественные готовые компоненты там, где это возможно. Повторное использование программного кода — важнейшее преимущество объектно-ориентированного программирования.
Сообщения и вызовы методов
Нажимая педаль газа, вы тем самым отсылаете автомобилю сообщение с запросом на выполнение определенной задачи (ускорение движения). Подобным же образом отсылаются и сообщения объекту. Каждое сообщение реализуется вызовом метода, который «сообщает» методу объекта о необходимости выполнения определенной задачи. Например, программа может вызвать метод deposit объекта банковского счета для его пополнения.
Атрибуты и переменные экземпляра класса
Любой автомобиль не только способен выполнять определенные задачи, но и обладает и характерными атрибутами: цвет, количество дверей, запас топлива в баке, текущая скорость и пройденное расстояние. Атрибуты автомобиля, как и его возможности по выполнению определенных действий, представлены на инженерных диаграммах как часть проекта (например, им могут соответствовать одометр и указатель уровня бензина). При вождении автомобиля его атрибуты существуют вместе с ним. Каждому автомобилю присущ собственный набор атрибутов. Например, каждый автомобиль «знает» о том, сколько бензина осталось в его баке, но ему ничего не известно о запасах горючего в баках других автомобилей.
Объект, как и автомобиль, имеет собственный набор атрибутов, которые он «переносит» с собой при использовании этого объекта в программах. Эти атрибуты определены в качестве части объекта класса. Например, объект банковского счета bank-account имеет атрибутбаланса, представляющий количество средств на банковском счете. Каждый объект bank-account «знает» о количестве средств на собственном счете, но ничего не «знает» о размерах других банковских счетов. Атрибуты определяются с помощью других переменных экземпляра класса. Между атрибутами и методами класса (и его объектов) существует тесная связь, поэтому классы хранят вместе свои атрибуты и методы.
Наследование
С помощью наследования можно быстро и просто создать новый класс объектов. При этом новый класс (называемый подклассом) наследует характеристики существующего класса (называемого суперклассом) — возможно, частично изменяя их или добавляя новые характеристики, уникальные для этого класса. Если вспомнить аналогию с автомобилем, то «трансформер» является объектом более обобщенного класса «автомобиль» с конкретной особенностью: у него может подниматься или опускаться крыша.
Объектно-ориентированный анализ и проектирование
Вскоре вы начнете писать программы на Python. Как же вы будете формировать код своих программ? Скорее всего, как и большинство других программистов, вы включите компьютер и начнете вводить с клавиатуры исходный код программы. Подобный подход годится при создании маленьких программ (вроде тех, что представлены в начальных главах книги), но что делать при создании крупного программного комплекса, который, например, управляет тысячами банкоматов крупного банка? А если вы руководите командой из 1000 программистов, занятых разработкой системы управления воздушным движением следующего поколения? В таких крупных и сложных проектах нельзя просто сесть за компьютер и строка за строкой вводить код.
Чтобы выработать наилучшее решение, следует провести процесс детального анализатребований к программному проекту (то есть определить, что должна делать система) и разработать проектное решение, которое будет соответствовать этим требованиям (то есть определить, как система будет выполнять поставленные задачи). В идеале вы должны тщательно проанализировать проект (либо поручить выполнение этой задачи коллегам-профессионалам) еще до написания какого-либо кода. Если этот процесс подразумевает применение объектно-ориентированного подхода, то, значит, мы имеем дело с процессомOOAD (object-oriented analysis and design, объектно-ориентированный анализ и проектирование). Языки программирования, подобные Python, тоже называются объектно-ориентированными. Программирование на таком языке — объектно-ориентированное программирование (ООП) — позволяет реализовать результат объектно-ориентированного проектирования в форме работоспособной системы.
1.3. Python
Python — объектно-ориентированный сценарный язык, официально опубликованный в 1991 году. Он был разработан Гвидо ван Россумом (Guido van Rossum) из Национального исследовательского института математики и компьютерных наук в Амстердаме.
Python быстро стал одним из самых популярных языков программирования в мире. Он пользуется особой популярностью в среде образования и научных вычислений22, а в последнее время превзошел язык программирования R в качестве самого популярного языка обработки данных23,24,25. Назовем основные причины популярности Python, пояснив, почему каждому стоит задуматься об изучении этого языка26,27,28:
• Python — бесплатный общедоступный проект с открытым кодом, имеющий огромное сообщество пользователей.
• Он проще в изучении, чем такие языки, как C, C++, C# и Java, что позволяет быстро включиться в работу как новичкам, так и профессиональным разработчикам.
• Код Python проще читается, чем большинство других популярных языков программирования.
• Он широко применяется в образовательной области29.
• Он повышает эффективность труда разработчика за счет обширной подборки стандартных и сторонних библиотек с открытым кодом, так что программисты могут быстрее писать код и решать сложные задачи с минимумом кода (подробнее см. раздел 1.4).
• Существует множество бесплатных приложений Python с открытым кодом.
• Python — популярный язык веб-разработки (Django, Flask и т.д.).
• Он поддерживает популярные парадигмы программирования — процедурную, функциональную и объектно-ориентированную30. Обратите внимание: мы начнем описывать средства функционального программирования в главе 4, а потом будем использовать их в последующих главах.
• Он упрощает параллельное программирование — с asyncio и async/await вы можете писать однопоточный параллельный код31, что существенно упрощает сложные по своей природе процессы написания, отладки и сопровождения кода32.
• Существует множество возможностей для повышения быстродействия программ на языке Python.
• Python используется для построения любых программ от простых сценариев до сложных приложений со множеством пользователей, таких как Dropbox, YouTube, Reddit, Instagram или Quora33.
• Python — популярный язык для задач искусственного интеллекта, а эта область в последнее время стремительно развивается (отчасти благодаря ее особой связи с областью data science).
• Он широко используется в финансовом сообществе34.
• Для программистов Python существует обширный рынок труда во многих областях, особенно в должностях, связанных с data science, причем вакансии Python входят в число самых высокооплачиваемых вакансий для программистов35,36. Ближайший конкурент Python — R, популярный язык программирования с открытым кодом для разработки статистических приложений и визуализации. Сейчас Python и R — два наиболее широко применяемых языка data science.
Anaconda
Мы будем использовать дистрибутив Python Anaconda — он легко устанавливается в Windows, macOS и Linux, поддерживая последние версии Python, интерпретатора IPython (раздел 1.5.1) и Jupyter Notebooks (раздел 1.5.3). Anaconda также включает другие программные пакеты и библиотеки, часто используемые в программировании Python и data science, что позволяет разработчикам сосредоточиться на коде Python и аспектах data science, не отвлекаясь на возню с проблемами установки. Интерпретатор IPython37 обладает интересными возможностями, позволяющими проводить исследования и эксперименты с Python, стандартной библиотекой Python и обширным набором сторонних библиотек.
Дзен Python
Мы придерживаемся принципов из статьи Тима Петерса (Tim Peters) «The Zen of Python», в которой приведена квинтэссенция идеологии проектирования от создателя Python Гвидо ван Россума. Этот список также можно просмотреть в IPython, воспользовавшись командой import this. Принципы «дзена Python» определяются в предложении об улучшении языка Python (PEP, Python Enhancement Proposal) 20, согласно которому «PEP — проектный документ с информацией для сообщества Python или с описанием новой возможности Python, его процессов или окружения»38.
1.4. Библиотеки
В этой книге мы будем по возможности пользоваться существующими библиотеками (включая стандартные библиотеки Python, библиотеки data science и некоторые сторонние библиотеки) — их применение способствует повышению эффективности разработки программных продуктов. Так, вместо того чтобы писать большой объем исходного кода (дорогостоящий и длительный процесс), можно просто создать объект уже существующего библиотечного класса посредством всего одной команды Python. Библиотеки позволяют решать серьезные задачи с минимальным объемом кода.
1.4.1. Стандартная библиотека Python
Стандартная библиотека Python предоставляет богатую функциональность обработки текстовых/двоичных данных, математических вычислений, программирования в функциональном стиле, работы с файлами/каталогами, хранения данных, сжатия/архивирования данных, криптографии, сервисных функций операционной системы, параллельного программирования, межпро цессных взаимодействий, сетевых протоколов, работы с JSON/XML/другими форматами данных в интернете, мультимедиа, интернационализации, построения графического интерфейса, отладки, профилирования и т.д. В таблице выше перечислены некоторые модули стандартной библиотеки Python, которые будут использоваться в примерах.
| Некоторые модули стандартной библиотеки Python, используемые в книге |
| collections — дополнительные структуры данных помимо списков, кортежей, словарей и множеств. csv — обработка файлов с данными, разделенными запятыми. datetime, time — операции с датой и временем. decimal — вычисления с фиксированной и плавающей точкой, включая финансовые вычисления. doctest — простое модульное тестирование с использованием проверочных тестов и ожидаемых результатов, закодированных в doc-строках. json — обработка формата JSON (JavaScript Object Notation) для использования с веб-сервисами и базами данных документов NoSQL. math — распространенные математические константы и операции. os — взаимодействие с операционной системой. queue — структура данных, работающая по принципу «первым зашел, первым вышел» (FIFO). random — псевдослучайные числа. re — регулярные выражения для поиска по шаблону. sqlite3 — работа с реляционной базой данных SQLite. statistics — функции математической статистики (среднее, медиана, дисперсия, мода и т.д.). string — обработка строк. sys — обработка аргументов командной строки; потоки стандартного ввода, стандартного вывода; стандартный поток ошибок. timeit — анализ быстродействия. |
1.4.2. Библиотеки data science
У Python сформировалось огромное и стремительно развивающееся сообщество разработчиков с открытым кодом во многих областях. Одним из самых серьезных факторов популярности Python стала замечательная подборка библиотек, разработанных сообществом с открытым кодом. Среди прочего мы стремились создавать примеры и практические примеры, которые бы послужили увлекательным и интересным введением в программирование Python, но при этом одновременно познакомили читателей с практическими аспектами data science, ключевыми библиотеками data science и т.д. Вы не поверите, какие серьезные задачи можно решать всего в нескольких строках кода. В следующей таблице перечислены некоторые популярные библиотеки data science. Многие из них будут использоваться нами в примерах. Для визуализации будут использоваться Matplotlib, Seaborn и Folium, но существует и немало других (хорошая сводка библиотек визуализации Python доступна по адресу http://pyviz.org/).
| Популярные библиотеки Python, используемые в data science |
| Научные вычисления и статистика NumPy (Numerical Python) — в Python нет встроенной структуры данных массива. В нем используются списки — удобные, но относительно медленные. NumPy предоставляет высокопроизводительную структуру данных ndarray для представления списков и матриц, а также функции для обработки таких структур данных. SciPy (Scientific Python) — библиотека SciPy, встроенная в NumPy, добавляет функции для научных вычислений: интегралы, дифференциальные уравнения, расширенная обработка матриц и т.д. Сайт scipy.org обеспечивает поддержку SciPy и NumPy. StatsModels — библиотека, предоставляющая функциональность оценки статистических моделей, статистических критериев и статистического анализа данных. |
| Анализ и управление данными pandas — чрезвычайно популярная библиотека для управления данными. В pandas широко используется структура ndarray из NumPy. Ее две ключевые структуры данных — Series (одномерная) и DataFrames (двумерная). |
| Визуализация Matplotlib — библиотека визуализации и построения диаграмм с широкими возможностями настройки. Среди прочего в ней поддерживаются обычные графики, точечные диаграммы, гистограммы, контурные и секторные диаграммы, графики поля направлений, полярные системы координат, трехмерные диаграммы и текст. Seaborn — высокоуровневая библиотека визуализации, построенная на базе Matplotlib. Seaborn добавляет более качественное оформление и дополнительные средства визуализации, а также позволяет строить визуализации с меньшим объемом кода. |
| Машинное обучение, глубокое обучение и обучение с подкреплением scikit-learn — ведущая библиотека машинного обучения. Машинное обучение является подмножеством области искусственного интеллекта, а глубокое обучение — подмножеством машинного обучения, ориентированным на нейронные сети. Keras — одна из самых простых библиотек глубокого обучения. Keras работает на базе TensorFlow (Google), CNTK (когнитивный инструментарий Microsoft для глубокого обучения) или Theano (Монреальский университет). TensorFlow — самая популярная библиотека глубокого обучения от Google. TensorFlow использует графические процессоры или тензорные процессоры Google для повышения быстродействия. TensorFlow играет важную роль в областях искусственного интеллекта и аналитики больших данных с их огромными требованиями к вычислительным мощностям. Мы будем использовать версию Keras, встроенную в TensorFlow. OpenAI Gym — библиотека и среда для разработки, тестирования и сравнения алгоритмов обучения с подкреплением. |
| Обработка естественного языка (NLP, Natural Language Processing) NLTK (Natural Language Toolkit) — используется для задач обработки естественного языка (NLP). TextBlob — объектно-ориентированная NLP-библиотека обработки текста, построенная на базе библиотек NLTK и NLP с паттернами. TextBlob упрощает многие задачи NLP. Gensim — похожа на NLTK. Обычно используется для построения индекса для коллекции документов и последующего определения его схожести с остальными документами в индексе. |
1.5. Первые эксперименты: использование IPython и Jupyter Notebook
В этом разделе мы опробуем интерпретатор IPython39 в двух режимах:
• В интерактивном режиме будем вводить небольшие фрагменты кода Python и немедленно просматривать результаты их выполнения.
• В режиме сценариев будет выполняться код, загруженный из файла с расширением .py (сокращение от Python). Такие файлы, называемые сценариями или программами, обычно имеют большую длину, чем фрагменты кода, используемые в интерактивном режиме.
Затем вы научитесь использовать браузерную среду Jupyter Notebook для написания и выполнения кода Python40.
1.5.1. Использование интерактивного режима IPython как калькулятора
Попробуем использовать интерактивный режим IPython для вычисления простых арифметических выражений.
Запуск IPython в интерактивном режиме
Сначала откройте окно командной строки в своей системе:
• В macOS откройте Терминал из папки Utilities в папке Applications.
• В Windows запустите командную строку Anaconda из меню Пуск.
• В Linux откройте Терминал или командный интерпретатор своей системы (зависит от дистрибутива Linux).
В окне командной строки введите команду ipython и нажмите Enter (или Return). На экране появится сообщение вроде (зависит от платформы и версии IPython):
Python 3.7.0 | packaged by conda-forge | (default, Jan 20 2019, 17:24:52)
Type 'copyright', 'credits' or 'license' for more information
IPython 6.5.0 -- An enhanced Interactive Python. Type '?' for help.
In [1]:
Текст "In [1]:" — приглашение, означающее, что IPython ожидает вашего ввода. Вы можете ввести ? для получения справки или перейти непосредственно к вводу фрагментов, чем мы сейчас и займемся.
Вычисление выражений
В интерактивном режиме можно вычислять выражения:
In [1]: 45 + 72
Out[1]: 117
In [2]:
После того как вы введете 45 + 72 и нажмете Enter, IPython читает фрагмент, вычисляет его и выводит результат в Out[1]41. Затем IPython выводит приглашение In [2], означающее, что среда ожидает от вас ввода второго фрагмента. Для каждого нового фрагмента IPython добавляет 1 к числу в квадратных скобках. Каждое приглашение In [1] в книге указывает на то, что мы начали новый интерактивный сеанс. Обычно мы будем делать это для каждого нового раздела главы.
Создадим более сложное выражение:
In [2]: 5 * (12.7 - 4) / 2
Out[2]: 21.75
В Python звездочка (*) обозначает операцию умножения, а косая черта (/) — операцию деления. Как и в математике, круглые скобки определяют порядок вычисления, так что сначала будет вычислено выражение в круглых скобках (12.7 - 4) и получен результат 8.7. Затем вычисляется результат 5 * 8.7, который равен 43.5. После этого вычисляется выражение 43.5 / 2, а полученный результат 21.75 выводится средой IPython в Out[2]. Числа, такие как 5, 4 и 2, называются целыми числами. Числа с дробной частью, такие как 12.7, 43.5 и 21.75, называются числами с плавающей точкой.
Выход из интерактивного режима
Чтобы выйти из интерактивного режима, можно воспользоваться одним из нескольких способов:
• Ввести команду exit в приглашении In [] и нажать Enter для немедленного выхода.
• Нажать клавиши <Ctrl>+d (или <control>+d). На экране появляется предложение подтвердить выход "Do you really want to exit ([y]/n)?". Квадратные скобки вокруг y означают, что этот ответ выбирается по умолчанию — нажатие клавиши Enter отправляет ответ по умолчанию и завершает интерактивный режим.
• Нажать <Ctrl>+d (или <control>+d) дважды (только в macOS и Linux).
1.5.2. Выполнение программы Python с использованием интерпретатора IPython
В этом разделе выполним сценарий с именем RollDieDynamic.py, который будет написан в главе 6. Расширение.py указывает на то, что файл содержит исходный код Python. Сценарий RollDieDynamic.py моделирует бросок шестигранного кубика. Он отображает цветную диаграмму с анимацией, которая в динамическом режиме отображает частоты выпадения всех граней.
Переход в папку с примерами этой главы
Сценарий находится в папке ch01 исходного кода книги. В разделе «Приступая к работе» папка examples была распакована в папку Documents вашей учетной записи пользователя. У каждой главы существует папка с исходным кодом этой главы. Этой папке присвоено имя ch##, где ## — номер главы от 01 до 16. Откройте окно командной строки вашей системы и введите команду cd («change directory»), чтобы перейти в папку ch01:
• В macOS/Linux введите команду cd ~/Documents/examples/ch01 и нажмите Enter.
• В Windows введите команду cd
C:\Users\YourAccount\Documents\examples\ch01
и нажмите Enter.
Выполнение сценария
Чтобы выполнить сценарий, введите следующую команду в командной строке и нажмите Enter:
ipython RollDieDynamic.py 6000 1
Сценарий открывает окно, в котором отображается его визуализация. Числа 6000 и 1 сообщают сценарию, сколько бросков должно быть сделано и сколько кубиков нужно бросать каждый раз. В данном случае диаграмма будет обновляться 6000 раз по одному кубику за раз.

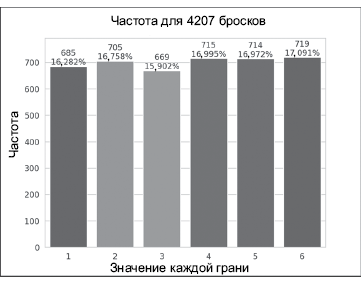
Для шестигранного кубика значения от 1 до 6 выпадают с равной вероятностью — вероятность каждого результата равна 1/6, или около 16,667%. Если бросить кубик 6000 раз, каждая грань выпадет около 1000 раз. Бросок кубиков, как и бросок монетки, является случайным процессом, поэтому некоторые грани могут выпасть менее 1000 раз, а другие — более 1000 раз. Мы сделали несколько снимков экрана во время выполнения сценария. Сценарий использует случайно сгенерированные значения, поэтому ваши результаты будут другими. Поэкспериментируйте со сценарием; попробуйте заменить значение 1 на 100, 1000 и 10 000. Обратите внимание: с увеличением количества бросков частоты сходятся к величине 16,667%. В этом проявляется действие «закона больших чисел».
Создание сценария
Обычно исходный код Python создается в редакторе для ввода текста. Вы вводите программу в редакторе, вносите все необходимые исправления и сохраняете ее на своем компьютере. Интегрированные среды разработки (IDE, Integrated Development Environments) предоставляют средства, обеспечивающие поддержку всего процесса разработки программного обеспечения: редакторы, отладчики для поиска логических ошибок, нарушающих работу программы, и т.д. Среди популярных интегрированных сред Python можно выделить Spyder (входящий в комплект Anaconda), PyCharm и Visual Studio Code.
Проблемы, которые могут возникнуть во время выполнения программы
Далеко не все программы работают с первой попытки. Например, программа может попытаться выполнить деление на 0 (недопустимая операция в Python). В этом случае программа выдаст сообщение об ошибке. Если это произойдет в сценарии, то вы снова возвращаетесь к редактору, вносите необходимые изменения и повторно выполняете сценарий, чтобы определить, решило ли исправление проблему(-ы).
Такие ошибки, как деление на 0, происходят во время выполнения программы, поэтому они называются ошибками времени выполнения. Фатальныеошибки времени выполнения приводят к немедленному завершению программы. При возникновении нефатальнойошибки программа может продолжить выполнение, часто — с получением ошибочных результатов.
1.5.3. Написание и выполнение кода в Jupyter Notebook
Дистрибутив Anaconda, установленный вами в разделе «Приступая к работе», включает Jupyter Notebook — интерактивную браузерную среду, в которой можно писать и выполнять код, а также комбинировать его с текстом, изображениями и видео. Документы Jupyter Notebook широко применяются в сообществе data science в частности и в более широком научном сообществе в целом. Они рассматриваются как предпочтительный механизм проведения аналитических исследований данных и распространения воспроизводимых результатов. Среда Jupyter Notebook поддерживает все больше языков программирования.
Для вашего удобства весь исходный код книги также предоставляется в формате документов Jupyter Notebook, которые вы можете просто загружать и выполнять. В этом разделе используется интерфейс JupyterLab, который позволяет управлять файлами документов Notebook и другими файлами, используемыми в них (например, графическими изображениями и видеороликами). Как вы убедитесь, JupyterLab также позволяет легко писать код, выполнять его, просматривать результаты, вносить изменения и снова выполнять его.
Вы увидите, что программирование в Jupyter Notebook имеет много общего с работой в IPython, более того, документы Jupyter Notebooks используют IPython по умолчанию. В этом разделе вы создадите документ Notebook, добавите в него код из раздела 1.5.1 и выполните этот код.
Открытие JupyterLab в браузере
Чтобы открыть JupyterLab, перейдите в папку примеров ch01 архива примеров в терминале, окне командной строки или приглашении Anaconda (раздел 1.5.2), введите следующую команду и нажмите Enter (или Return):
jupyter lab
Команда запускает на вашем компьютере сервер Jupyter Notebook и открывает JupyterLab в браузере по умолчанию; содержимое папки ch01 отображается на вкладке File Browser

Сервер Jupyter Notebook позволяет загружать и выполнять документы Jupyter Notebook в браузере. На вкладке JupyterLab Files вы можете сделать двойной щелчок на файле, чтобы открыть его в правой части окна, где в настоящее время отображается вкладка Launcher. Каждый файл, который вы открываете, отображается на отдельной вкладке в этой части окна. Если вы случайно закроете браузер, то сможете повторно открыть JupyterLab — для этого достаточно ввести в браузере следующий адрес:
Создание нового документа Notebook Jupyter
На вкладке Launcher в Notebook щелкните на кнопке Python 3, чтобы создать новый документ Jupyter Notebook с именем Untitled.ipynb. В этом документе можно вводить и выполнять код Python 3. Расширение файла .ipynb является сокращением от «IPython Notebook» — исходное название Jupyter Notebook.
Переименование документа Notebook
Переименуйте Untitled.ipynb в TestDrive.ipynb:
1. Щелкните правой кнопкой мыши на вкладку Untitled.ipynb и выберите Rename Notebook.
2. Измените имя на TestDrive.ipynb и нажмите RENAME.
Верхняя часть JupyterLab должна выглядеть так:

Вычисление выражений
Рабочей единицей в документе Notebook является ячейка, в которой вводятся фрагменты кода. По умолчанию новый документ Notebook состоит из одной ячейки (прямоугольник в документе TestDrive.ipynb), но вы можете добавить в нее и другие ячейки. Обозначение []: слева от ячейки показывает, где Jupyter Notebook будет выводить номер фрагмента ячейки после ее выполнения. Щелкните в ячейке и введите следующее выражение:
45 + 72
Чтобы выполнить код текущей ячейки, нажмите Ctrl + Enter (или control + Enter). JupyterLab выполняет код в IPython, после чего выводит результаты под ячейкой:

Добавление и выполнение дополнительной ячейки
Попробуем вычислить более сложное выражение. Сначала щелкните на кнопке + на панели инструментов над первой ячейкой документа — она добавляет новую ячейку под текущей:

Щелкните в новой ячейке и введите выражение
5 * (12.7 - 4) / 2
и выполните код ячейки комбинацией клавиш Ctrl + Enter (или control + Enter):

Сохранение документа Notebook
Если ваш документ Notebook содержит несохраненные изменения, то знак X на вкладке заменяется на
Документы Notebook с примерами каждой главы
Для удобства примеры каждой главы также предоставляются в форме готовых к исполнению документов Notebook без вывода. Вы сможете проработать их фрагмент за фрагментом и увидеть результат при выполнении каждого фрагмента.
Чтобы показать, как загрузить существующий документ Notebook и выполнить его ячейки, выполним сброс блокнота TestDrive.ipynb, чтобы удалить выходные данные и номера фрагментов. Документ вернется в исходное состояние, аналогичное состоянию примеров последующих глав. В меню Kernel выберите команду Restart Kernel and Clear All Outputs…, затем щелкните на кнопке RESTART. Эта команда также полезна в тех случаях, когда вы захотите повторно выполнить фрагменты документа Notebook. Документ должен выглядеть примерно так:

В меню File выберите команду Save Notebook. Щелкните на кнопке X на вкладке TestDrive.ipynb, чтобы закрыть документ.
Открытие и выполнение существующего документа Notebook
Запустив JupyterLab из папки примеров конкретной главы, вы сможете открывать документы Notebook из любой папки или любой из его вложенных папок. Обнаружив нужный документ, откройте его двойным щелчком. Снова откройте файл TestDrive.ipynb. После того как документ Notebook будет открыт, вы сможете выполнить каждую его ячейку по отдельности, как это делалось ранее в этом разделе, или же выполнить всю книгу сразу. Для этого откройте меню Run и выберите команду Run All Cells. Все ячейки выполняются по порядку, а выходные данные каждой ячейки выводятся под этой ячейкой.
Закрытие JupyterLab
Завершив работу с JupyterLab, закройте вкладку в браузере, а затем в терминале, командном интерпретаторе или приглашении Anaconda, из которого была запущена оболочка JupyterLab, дважды нажмите Ctrl + c (или control + c).
Советы по работе с JupyterLab
Возможно, следующие советы пригодятся вам при работе с JupyterLab:
• Если требуется вводить и выполнять много фрагментов, то можно выполнить текущую ячейку и добавить новую комбинацией клавиш Shift + Enter вместо Ctrl + Enter (или control + Enter).
• В более поздних главах отдельные фрагменты, которые вы вводите в документах Jupyter Notebook, будут состоять из многих строк кода. Чтобы в каждой ячейке выводились номера строк, откройте в JupyterLab меню View и выберите команду Show line numbers.
О работе с JupyterLab
JupyterLab содержит много возможностей, которые будут полезны в вашей работе. Мы рекомендуем ознакомиться с вводным курсом JupyterLab от создателей Jupyter по адресу:
https://jupyterlab.readthedocs.io/en/stable/index.html
Краткий обзор открывается по ссылке Overview в разделе GETTING STARTED. В разделе USER GUIDE приведены вводные уроки по работе с интерфейсом JupyterLab, работе с файлами, текстовым редактором, документами Notebook и др.
1.6. Облачные вычисления и «интернет вещей»
1.6.1. Облачные вычисления
В наши дни все больше вычислений осуществляется «в облаке», то есть выполняется в распределенном виде в интернете по всему миру. Многие приложения, используемые в повседневной работе, зависят от облачных сервисов, использующих масштабные кластеры вычислительных ресурсов (компьютеры, процессоры, память, дисковое пространство и т.д.) и баз данных, взаимодействующих по интернету друг с другом и с приложениями, которыми вы пользуетесь. Сервис, доступ к которому предоставляется по интернету, называется веб-сервисом. Как вы увидите, использование облачных сервисов в Python часто сводится к простому созданию программных объектов и взаимодействию с ними. Созданные объекты используют веб-сервисы, которые связываются с облаком за вас.
В примерах глав 11–16 вы будете работать со многими сервисами на базе облака:
• В главах 12 и 16 веб-сервисы Twitter будут использоваться (через библиотеку Python Tweepy) для получения информации о конкретных пользователях Twitter, поиска твитов за последние семь дней и получения потока твитов в процессе их появления (то есть в реальном времени).
• В главах 11 и 12 библиотека Python TextBlob применяется для перевода текста с одного языка на другой. Во внутренней реализации TextBlob использует веб-сервис Google Translate для выполнения перевода.
• В главе 13 будут использоваться сервисы IBM Watson: Text to Speech, Speech to Text и Translate. Мы реализуем приложение-переводчик, позволяющее зачитать вопрос на английском языке, преобразовать речь в текст, переводить текст на испанский и зачитывать испанский текст. Затем пользователь произносит ответ на испанском (если вы не говорите на испанском, используйте предоставленный аудиофайл), приложение преобразует речь в текст, переводит текст на английский и зачитывает ответ на английском. Благодаря демонстрационным приложениям IBM Watson мы также поэкспериментируем в главе 13 с некоторыми другими облачными сервисами Watson.
• В главе 16 мы поработаем с сервисом Microsoft Azure HDInsight и другими веб-сервисами Azure в ходе реализации приложений больших данных на базе технологий Apache Hadoop и Spark. Azure — группа облачных сервисов от компании Microsoft.
• В главе 16 веб-сервис Dweet.io будет использоваться для моделирования подключенного к интернету термостата, который публикует показания температуры. Также при помощи сервиса на базе веб-технологий мы создадим панель, отображающую динамически изменяемый график температуры и предупреждающую пользователя о том, что температура стала слишком высокой или слишком низкой.
• В главе 16 веб-панель будет использована для наглядного представления моделируемого потока оперативных данных с датчиков веб-сервиса PubNub. Также будет построено приложение Python для визуального представления моделируемого потока изменений биржевых котировок PubNub.
В большинстве случаев мы будем создавать объекты Python, которые взаимодействуют с веб-сервисами за вас, скрывая технические подробности обращений к этим сервисам по интернету.
Гибриды
Методология разработки гибридных приложений позволяет быстро разрабатывать мощные продукты за счет объединения веб-сервисов (часто бесплатных) и других форм информационных поставок — как мы поступим при разработке приложения-переводчика на базе IBM Watson.
Одно из первых гибридных приложений объединяло списки продаваемых объектов недвижимости, предоставляемые сайтом http://www.craigslist.org, с картографическими средствами Google Maps; таким образом строились карты с местоположением домов, продаваемых или сдаваемых в аренду в заданной области.
На сайте ProgrammableWeb (http://www.programmableweb.com/) представлен каталог более 20 750 веб-сервисов и почти 8000 гибридных приложений. Также здесь имеются учебные руководства и примеры кода работы с веб-сервисами и создания собственных гибридных приложений. По данным сайта, к числу наиболее часто используемых веб-сервисов принадлежат Facebook, Google Maps, Twitter и YouTube.
1.6.2. «Интернет вещей»
Интернет уже нельзя рассматривать как сеть, объединяющую компьютеры, — сегодня уже говорят об «интернете вещей», или IoT (Internet of Things). Вещью считается любой объект, обладающий IP-адресом и способностью отправлять, а в некоторых случаях и автоматически получать данные по интернету. Вот несколько примеров:
• автомобиль с транспондером для оплаты дорожных сборов;
• мониторы доступности места для парковки в гараже;
• кардиомониторы в человеческом организме;
• мониторы качества воды;
• интеллектуальный датчик, сообщающий о расходе энергии;
• датчики излучения;
• устройства отслеживания товаров на складе;
• мобильные приложения, способные отслеживать ваше местонахождение и перемещения;
• умные термостаты, регулирующие температуру в комнате на основании прогнозов погоды и текущей активности в доме;
• устройства для умных домов.
По данным statista.com, в наши дни уже используются свыше 23 миллиардов IoT-устройств, а к 2025 году их число может превысить 75 миллиардов42.
1.7. Насколько велики большие данные?
Для специалистов по компьютерной теории и data science данные играют не менее важную роль, чем написание программ. По данным IBM, в мире ежедневно создаются приблизительно 2,5 квинтиллиона байт (2,5 экзабайта) данных43, а 90% мировых данных были созданы за последние два года44. По материалам IDC, к 2025 году ежегодный объем глобального генерирования данных достигнет уровня 175 зеттабайт (175 триллионов гигабайт, или 175 миллиардов терабайт)45. Рассмотрим наиболее популярные единицы объема данных.
Мегабайт (Мбайт)
Один мегабайт составляет приблизительно 1 миллион (а на самом деле 220) байт. Многие файлы, используемыми нами в повседневной работе, занимают один или несколько мегабайтов. Примеры:
• Аудиофайлы в формате MP3 — минута качественного звука в формате MP3 занимает от 1 до 2,4 Мбайт46.
• Фотографии — фотография в формате JPEG, сделанная на цифровую камеру, может занимать от 8 до 10 Мбайт.
• Видеоданные — на камеру смартфона можно записывать видео с разным разрешением. Каждая минута видео может занимать много мегабайтов. Например, на одном из наших iPhone приложение настроек камеры сообщало, что видео в разрешении 1080p при 30 кадрах в секунду (FPS) занимает 130 Мбайт/мин, а видео в разрешении 4K при 30 FPS занимает 350 Мбайт/мин.
Гигабайт (Гбайт)
Один гигабайт составляет приблизительно 1000 мегабайт (а точнее, 230 байт). Двуслойный диск DVD способен вмещать до 8,5 Гбайт47, что соответствует:
• до 141 часа аудио в формате MP3;
• приблизительно 1000 фотографий на 16-мегапиксельную камеру;
• приблизительно 7,7 минуты видео 1080p при 30 FPS, или
• приблизительно 2,85 минуты видео 4K при 30 FPS.
Современные диски наивысшей емкости Ultra HD Blu-ray вмещают до 100 Гбайт видеоданных48. Потоковая передача фильма в разрешении 4K может происходить со скоростью от 7 до 10 Гбайт (с высокой степенью сжатия).
Терабайт (Тбайт)
Один терабайт составляет около 1000 гигабайт (а точнее, 240 байт). Емкость современного диска для настольных компьютеров достигает 15 Тбайт49, что соответствует:
• приблизительно 28 годам аудио в формате MP3;
• приблизительно 1,68 миллиона фотографий на 16-мегапиксельную камеру;
• приблизительно 226 часов видео 1080p при 30 FPS;
• приблизительно 84 часов видео 4K при 30 FPS.
У Nimbus Data наибольший объем диска SSD составляет 100 Тбайт; он вмещает в 6,67 раза больше данных, чем приведенные выше примеры аудио-, фото- и видеоданных для 15-терабайтных дисков50.
Петабайт, экзабайт и зеттабайт
Почти 4 миллиарда людей в интернете ежедневно создают около 2,5 квинтиллиона байт данных51, то есть 2500 петабайт (1 петабайт составляет около 1000 терабайт) или 2,5 экзабайта (1 экзабайт составляет около 1000 петабайт). По материалам статьи из AnalyticsWeek за март 2016 года, через пять лет к интернету будет подключено свыше 50 миллиардов устройств (в основном через «интернет вещей», который рассматривается в разделах 1.6.2 и 16.8), а к 2020 году на каждого человека на планете ежесекундно будет производиться 1,7 мегабайта новых данных52. Для современного уровня населения (приблизительно 7,7 миллиарда людей53) это соответствует приблизительно:
• 13 петабайт новых данных в секунду;
• 780 петабайт в минуту;
• 46 800 петабайт (46,8 экзабайт) в час;
• 1123 экзабайта в день, то есть 1,123 зеттабайта (ЗБ) в день (1 зеттабайт составляет около 1000 экзабайт).
Это эквивалентно приблизительно 5,5 миллиона часов (более 600 лет) видео в разрешении 4K в день, или приблизительно 116 миллиардам фотографий в день!
Дополнительная статистика по большим данным
На сайте https://www.internetlive-stats.com доступна различная занимательная статистика, в том числе количество:
• поисков в Google;
• твитов;
• просмотров роликов на YouTube;
• загрузок фотографий на Instagram за сегодняшний день.
Вы можете получить доступ и к иной интересующей вас статистической информации. Например, по данным сайта видно, что за 2018 год создано более 250 миллиардов твитов.
Приведем еще несколько интересных фактов из области больших данных:
• Ежечасно пользователи YouTube загружают 24 000 часов видео, а за день на YouTube просматривается почти 1 миллиард часов видео54.
• Каждую секунду в интернете проходит объем трафика 51 773 Гбайт (или 51,773 Тбайт), отправляется 7894 твита, проводится 64 332 поиска в Google55.
• На Facebook ежедневно ставятся 800 миллионов лайков56, отправляются 60 миллионов эмодзи57 и проводятся свыше 2 миллиардов поисков в более чем 2,5 триллиона постов Facebook, накопившихся с момента появления сайта58.
• Компания Planet использует 142 спутника, которые раз в сутки фотографируют весь массив суши на планете. Таким образом, ежедневно к имеющимся данным добавляется 1 миллион изображений и 7 Тбайт новых данных. Компания вместе с партнерами применяет машинное обучение для повышения урожайности, контроля численности кораблей в портах и контроля за исчезновением лесов. В том, что касается потери леса в джунглях Амазонки, Уилл Маршалл (Will Marshall), исполнительный директор Planet, сказал: «Прежде мы могли обнаружить большую дыру на месте амазонских джунглей лишь спустя несколько лет после ее образования. Сегодня возможно каждый день подсчитывать число деревьев, растущих на планете»59.
У Domo, Inc. есть хорошая инфографика «Данные никогда не спят 6.0», которая наглядно показывает, сколько данных генерируется каждую минуту60:
• 473 400 твитов;
• 2 083 333 фотографии публикуются в Snapchat;
• 97 222 часа видео просматриваются в сервисе Netflix;
• отправляются 12 986 111 текстовых сообщений;
• 49 380 сообщений добавляется в Instagram;
• по Skype проходят 176 220 звонков;
• в Spotify прослушиваются 750 000 песен;
• в Google проводятся 3 877 140 поисков;
• в YouTube просматриваются 4 333 560 видеороликов.
Непрерывный рост вычислительной мощности
Данных становится все больше и больше, а вместе с ними растет вычислительная мощность, необходимая для их обработки. Производительность современных компьютеров часто измеряется в количестве операций с плавающей точкой в секунду (FLOPS). Вспомним, что в начале и середине 1990-х скорость самых быстрых суперкомпьютеров измерялась в гигафлопсах (109 FLOPS). К концу 1990-х компания Intel выпустила первые суперкомпьютеры с производительностью уровня терафлопс (1012 FLOPS). В начале и середине 2000-х скорости достигали сотен терафлопс, после чего в 2008 году компания IBM выпустила первый суперкомпьютер с производительностью уровня петафлопс (1015 FLOPS). В настоящее время самый быстрый суперкомпьютер IBM Summit, расположенный в Оукриджской национальной лаборатории Министерства энергетики США, обладает производительностью в 122,3 петафлопс61.
Распределенные вычисления могут связывать тысячи персональных компьютеров в интернете для достижения еще более высокой производительности. В конце 2016 года сеть Folding@home — распределенная сеть, участники которой выделяют ресурсы своих персональных компьютеров для изучения заболеваний и поиска новых лекарств62, — была способна достигать суммарной производительности свыше 100 петафлопс. Такие компании, как IBM, в настоящее время работают над созданием суперкомпьютеров, способных достигать производительности уровня экзафлопс (1018 FLOPS63).
Квантовые компьютеры, разрабатываемые в настоящее время, теоретически могут функционировать на скорости, в 18 000 000 000 000 000 000 раз превышающей скорость современных «традиционных» компьютеров64! Это число настолько огромно, что квантовый компьютер теоретически может выполнить за одну секунду неизмеримо больше вычислений, чем было выполнено всеми компьютерами мира с момента появления первого компьютера. Эта почти невообразимая вычислительная мощность ставит под угрозу технологию криптовалют на базе технологии блокчейна (например, Bitcoin). Инженеры уже работают над тем, как адаптировать блокчейн для столь значительного роста вычислительных мощностей65.
Мощь суперкомпьютеров постепенно проникает из исследовательских лабораторий, где для достижения такой производительности тратятся огромные суммы денег, в бюджетные коммерческие компьютерные системы и даже настольные компьютеры, ноутбуки, планшеты и смартфоны.
Стоимость вычислительной мощности продолжает снижаться, особенно с применением облачных вычислений. Прежде люди спрашивали: «Какой вычислительной мощностью должна обладать моя система, чтобы справиться с пиковой нагрузкой?». Сегодня этот подход заменился другим: «Смогу ли я быстро получить в облаке ресурсы, временно необходимые для выполнения моих наиболее насущных вычислительных задач?». Таким образом, все чаще вы платите только за то, что фактически используется вами для решения конкретной задачи.
Обработка данных требует значительных затрат электроэнергии
Объем данных от устройств, подключенных к интернету, стремительно растет, а обработка этих данных требует колоссальных объемов энергии. Так, энергозатраты на обработку данных в 2015 году росли на 20% в год и составляли приблизительно от 3 до 5% мирового производства энергии. Но к 2025 году общие затраты на обработку данных должны достичь 20%66.
Другим серьезным потребителем электроэнергии является криптовалюта Bitcoin на базе блокчейна. На обработку всего одной транзакции Bitcoin расходуется примерно столько же энергии, сколько расходуется средним американским домом за неделю! Расходы энергии обусловлены процессом, который используется «майнерами» Bitcoin для подтверждения достоверности данных транзакции67.
По некоторым оценкам, за год транзакции Bitcoin расходуют больше энергии, чем экономика многих стран68. Так, в совокупности Bitcoin и Ethereum (другая популярная криптовалюта и платформа на базе блокчейна) расходуют больше энергии, чем Израиль, и почти столько же, сколько расходует Греция69.
В 2018 году компания Morgan Stanley предсказывала, что «затраты электроэнергии на создание криптовалют в этом году могут превзойти прогнозируемые компанией глобальные затраты на электротранспорт в 2025 году»70. Такая ситуация становится небезопасной, особенно с учетом огромного интереса к блокчейновым технологиям даже за пределами стремительно развивающихся криптовалют. Сообщество блокчейна работает над решением проблемы71,72.
Потенциал больших данных
Вероятно, в ближайшие годы в области больших данных будет наблюдаться экспоненциальный рост. В перспективе количество вычислительных устройств достигнет 50 миллиардов, и трудно представить, сколько еще их появится за несколько ближайших десятилетий. Очень важно, чтобы всеми этими данными могли пользоваться не только бизнес, правительственные организации, военные, но и частные лица.
Интересно, что некоторых из лучших работ по поводу больших данных, data science, искусственного интеллекта и т.д. были написаны в авторитетных коммерческих организациях: J.P. Morgan, McKinsey и др. Привлекательность больших данных для большого бизнеса бесспорна, особенно если принять во внимание стремительно развивающиеся результаты. Многие компании осуществляют значительные инвестиции в области технологий, описанных в книге (большие данные, машинное обучение, глубокое обучение, обработка естественных языков, и т.д.), и добиваются ценных результатов. Это заставляет конкурентов также вкладывать средства, что стремительно повышает спрос на профессионалов с опытом работы в области больших данных и теории вычислений. По всей вероятности, эта тенденция сохранится в течение многих лет.
1.7.1. Анализ больших данных
Аналитическая обработка данных — зрелая, хорошо проработанная научная и профессиональная дисциплина. Сам термин «анализ данных» появился в 1962 году73, хотя люди применяли статистику для анализа данных в течение тысяч лет, еще со времен Древнего Египта74. Анализ больших данных следует считать более современным явлением — так, термин «большие данные» появился около 2000 года75. Назовем четыре основные характеристики больших данных, обычно называемые «четырьмя V»76,77:
1. Объем (Volume) — количество данных, производимых в мире, растет с экспоненциальной скоростью.
2. Скорость (Velocity) — темпы производства данных, их перемещения между организациями и изменения данных стремительно растут78,79,80.
3. Разнообразие (Variety) — некогда данные в основном были алфавитно-цифровыми (то есть состояли из символов алфавита, цифр, знаков препинания и некоторых специальных знаков). В наши дни они также включают графику, аудио, видео и данные от стремительно растущего числа датчиков «интернета вещей», установленных в жилищах, коммерческих организациях, транспортных средствах, городах и т.д.
4. Достоверность (Veracity) — характеристика, указывающая на то, являются ли данными полными и точными, и, как следствие, позволяющая ответить на вопросы вроде: «Можно ли на них полагаться при принятии критических решений?», «Насколько реальна информация?» и пр.
Большая часть данных сейчас создается в цифровой форме, относится к самым разным типам, достигает невероятных объемов и перемещается с потрясающей скоростью. Закон Мура и связанные с ним наблюдения позволяют нам организовать экономичное хранение данных, ускорить их обработку и перемещение — и все это на скоростях, экспоненциально растущих со временем. Хранилища цифровых данных обладают настолько огромной емкостью, низкой стоимостью и выдающейся компактностью, что мы сейчас можем удобно и экономично хранить все создаваемые цифровые данные81. Таковы наиболее существенные характеристики больших данных. Но давайте двинемся дальше.
Следующая цитата Ричарда Хемминга (Richard W. Hamming), пусть и относящаяся к 1962 году, задает тон для всей этой книги:
«Целью вычислений является понимание сути, а не числа»82.
Область data science производит новую, более глубокую, неочевидную и более ценную аналитическую информацию в потрясающем темпе. Инфраструктура больших данных рассматривается в главе 16 на практических примерах использования баз данных NoSQL, программирования Hadoop MapReduce, Spark, потокового программирования IoT и т.д. Чтобы получить некоторое представление о роли больших данных в промышленности, правительственных и научных организациях, взгляните на следующий график83:
1.7.2. Data Science и большие данные изменяют ситуацию: практические примеры
Область data science стремительно развивается, потому что она производит важные результаты, которые действительно влияют на ситуацию. Некоторые примеры практического применения data science и больших данных перечислены в таблице. Надеемся, эти примеры, а также некоторые другие примеры из книги вдохновят читателей на поиск новых сценариев использования данных в работе. Аналитика больших данных приводила к повышению прибыли, улучшению отношений с клиентами и даже к повышению процента побед у спортивных команд при сокращении затрат на игроков84,85,86.
| Некоторые примеры практического применения data science и больших данных |
|
| автоматизированное генерирование подписей к изображениям автоматизированное генерирование субтитров автоматизированные инвестиции автоматизированные суда автономные автомобили агенты по обслуживанию клиентов адаптированная диета анализ пространственных данных анализ социальных графов анализ тональности высказываний беспилотные летательные аппараты борьба с похищением личных данных борьба с фишингом ведение электронных историй болезни визуализация данных визуальный поиск продуктов выявление мошенничества выявление рыночных тенденций выявление спама выявление сходства генерирование музыки геномика и здравоохранение географические информационные системы (GIS) глубокий анализ данных голосовой поиск диагностика рака груди диагностика сердечных заболеваний диагностика/лечение рака диагностическая медицина |
динамическое построение маршрута динамическое ценообразование дистанционная медицина игры идентификация вызывающего абонента идентификация жертв стихийных бедствий иммунотерапия индивидуализированная медицина интеллектуальные системы управления движением «интернет вещей» (IoT) и мониторинг медицинских устройств «интернет вещей» (IoT) и прогнозы погоды картирование головного мозга картография качество обслуживания клиентов кибербезопасность классификация рукописного текста личные помощники маркетинг маркетинговая аналитика минимизация рисков наем и тренерская работа в спорте обнаружение аномалий обнаружение вредоносных программ обнаружение новых вирусов обнаружение эмоций обслуживание клиентов оценка заемщика оценка недвижимости оценка успеваемости студентов |
| перевод естественного языка перевод иностранных языков персонализация лекарственных средств персонализация покупок повышение урожайности поиск новых препаратов поиск попутчиков помощь инвалидам построение рекомендуемых маршрутов построение сводки текста предиктивный анализ предотвращение вспышек болезней предотвращение злоупотреблений опиатами предотвращение краж предотвращение оттока клиентов предотвращение террористических актов преступления: предиктивная полицейская деятельность преступления: предотвращение преступления: прогнозирование места преступления: прогнозирование рецидивизма прогнозирование биржевого рынка прогнозирование вспышек болезней прогнозирование выживания при раке прогнозирование погоды прогнозирование продаж, зависящих от погоды прогнозирование регистрации абитуриентов прогнозирование результатов лечения прогнозирование рисков автострахования |
программы лояльности профилактическая медицина распознавание выражения лица распознавание голоса распознавание изображений редактирование генома CRISPR рекомендательные системы роботизированные финансовые советники секвенирование человеческого генома системы GPS складской учет снижение частоты повторной госпитализации сокращение выбросов углерода сокращение загрязнения окружающей среды сокращение избыточного резервирования сокращение энергопотребления социальная аналитика удержание клиентов удовлетворение запросов потреби-телей улучшение безопасности улучшение результатов лечения умные города умные датчики умные дома умные помощники умные термостаты услуги на основе определения местоположения установление страховых тарифов фитнес-мониторинг чтение языка знаков экономика совместного потребления |
1.8. Практический пример: использование больших данных в мобильном приложении
Навигационное GPS-приложение Google Waze с его 90 миллионами активных пользователей в месяц87 стало одним из самых успешных приложений, использующих большие данные. Ранние устройства и приложения GPS-навигации использовали статические карты и координаты GPS для определения оптимального маршрута к конечной точке, но при этом не могли динамически адаптироваться к изменяющейся дорожной обстановке.
Waze обрабатывает огромные объемы краудсорсинговых данных, то есть данных, непрерывно поставляемых пользователями и их устройствами по всему миру. Поступающие данные анализируются для определения оптимального маршрута к месту назначения за минимальное время. Для решения этой задачи Waze использует подключение вашего смартфона к интернету. Приложение автоматически отправляет обновленную информацию о местоположении на свои серверы (при условии что вы разрешите это делать). Данные используются для динамического изменения маршрута на основании текущей дорожной обстановки и для настройки карт. Пользователи также сообщают другую информацию: о пробках, строительстве, препятствиях, транспорте на аварийных полосах, полицейских постах, ценах на бензин и др. Обо всем этом Waze затем оповещает других водителей.
Для предоставления своего сервиса Waze использует множество технологий. Ниже приведен список технологий, которые с большой вероятностью используются этим сервисом (подробнее о некоторых из них см. главы 11–16). Итак:
• Многие приложения, создаваемые в наши дни, используют и некоторые программные продукты с открытым кодом. В этой книге мы будем пользоваться многими библиотеками и служебными программами с открытым кодом.
• Waze передает информацию через интернет. В наши дни такие данные часто передаются в формате JSON (JavaScript Object Notation); мы представим этот формат в главе 9 и будем использовать его в последующих главах. Данные JSON обычно скрываются от вас используемыми библиотеками.
• Waze использует синтез речи, для того чтобы передавать пользователю рекомендации и сигналы, и распознавание речи для понимания речевых команд. Мы поговорим о функциональности синтеза и распознавания речи IBM Watson в главе 13.
• После того как приложение Waze преобразует речевую команду на естественном языке в текст, оно должно выбрать правильное действие, что требует обработки естественного языка (NLP). Мы представим технологию NLP в главе 11 и используем ее в нескольких последующих главах.
• Waze отображает динамические визуализации (в частности, оповещения и карты). Также Waze предоставляет возможность взаимодействия с картами: перемещения, увеличения/уменьшения и т.д. Мы рассмотрим динамические визуализации (с использованием Matplotlib и Seaborn) и отображением интерактивных карт (с использованием Folium) в главах 12 и 16.
• Waze использует ваш мобильный телефон / смартфон как устройство потоковой передачи IoT. Каждое подобное устройство представляет собой GPS-датчик, постоянно передающий данные Waze по интернету. В главе 16 мы представим IoT и будем работать с моделируемыми потоковыми датчиками IoT.
• Waze получает IoT-потоки от миллионов устройств мобильной связи одновременно. Приложение должно обрабатывать, сохранять и анализировать эти данные для обновления карт на ваших устройствах, для отображения и речевого воспроизведения оповещений и, возможно, для обновления указаний для водителя. Все это требует массово-параллельных возможностей обработки данных, реализованных на базе компьютерных кластеров в облаке. В главе 16 мы представим различные инфраструктурные технологии больших данных для получения потоковых данных, сохранения этих больших данных в соответствующих базах данных и их обработки с применением программ и оборудования, обладающего массово-параллельными вычислительными возможностями.
• Waze использует возможности искусственного интеллекта для решения задач анализа данных, позволяющих спрогнозировать лучший маршрут на основании полученной информации. В главах 14 и 15 машинное обучение и глубокое обучение соответственно используются для анализа огромных объемов данных и формирования прогнозов на основании этих данных.
• Вероятно, Waze хранит свою маршрутную информацию в графовой базе данных. Такие базы данных способны эффективно вычислять кратчайшие маршруты. Графовые базы данных, такие как Neo4J, будут представлены в главе 16.
• Многие машины в наше время оснащаются устройствами, позволяющими им «видеть» другие машины и препятствия. Например, они используются для реализации автоматизированных систем торможения и являются ключевым компонентом технологии автономных («необитаемых») автомобилей. Вместо того чтобы полагаться на пользователей, сообщающих о препятствиях и машинах, стоящих на обочине, навигационные приложения пользуются камерами и другими датчиками, применяют методы распознавания изображений с глубоким обучением для анализа изображений «на ходу» и автоматической передачи информации об обнаруженных объектах. Глубокое обучение в области распознавания изображений рассматривается в главе 15.
1.9. Введение в data science: искусственный интеллект — на пересечении компьютерной теории и data science
Когда ребенок впервые открывает глаза, «видит» ли он лица своих родителей? Имеет ли он представление о том, что такое лицо, — или хотя бы о том, что такое форма? Как бы то ни было, ребенок должен «познать» окружающий мир. Именно этим занимается искусственный интеллект (AI, Artificial Intelligence). Он обрабатывает колоссальные объемы данных и обучается по ним. Искусственный интеллект применяется для игр, для реализации широкого спектра приложений распознавания изображений, управления автономными машинами, обучения роботов, предназначенных для выполнения новых операций, диагностики медицинских состояний, перевода речи на другие языки практически в реальном времени, создания виртуальных собеседников, способных отвечать на произвольные вопросы на основании огромных баз знаний, и многих других целей. Кто бы мог представить всего несколько лет назад, что автономные машины с искусственным интеллектом появятся на дорогах, став вскоре обыденным явлением? А сегодня в этой области идет острая конкуренция! Конечной целью всех этих усилий является общий искусственный интеллект, то есть искусственный интеллект, способный действовать разумно на уровне человека. Многим эта мысль кажется пугающей.
Вехи развития искусственного интеллекта
Несколько ключевых точек в развитии искусственного интеллекта особенно сильно повлияли на внимание и воображение людей. Из-за них общественность начала думать о том, что искусственный интеллект становится реальностью, а бизнес стал искать возможности коммерческого применения AI:
• В 1997 году в ходе шахматного поединка между компьютерной системой IBM DeepBlue и гроссмейстером Гарри Каспаровым DeepBlue стал первым компьютером, победившим действующего чемпиона мира в условиях турнира88. Компания IBM загрузила в DeepBlue сотни тысяч записей партий гроссмейстеров89. Вычислительная мощь DeepBlue позволяла оценивать до 200 миллионов ходов в секунду90! Это классический пример использования больших данных. К слову, по окончании состязания компания IBM получила премию Фредкина, учрежденную Университетом Карнеги — Меллона, который в 1980 году предложил 100 000 долларов создателю первого компьютера, который победит действующего чемпиона мира по шахматам91.
• В 2011 году суперкомпьютер IBM Watson победил двух сильнейших игроков в телевизионной викторине Jeopardy! в матче с призовым фондом в 1 000 000 долларов. Watson одновременно использовал сотни методов анализа языка для поиска правильных ответов в 200 миллионах страницах контента (включая всю «Википедию»), для хранения которых требовалось 4 терабайта9293. Для тренировки Watson использовались методы машинного обучения и глубокого обучения94. В главе 13 обсуждается IBM Watson, а в главе 14 — машинное обучение.
• Го — настольная игра, созданная в Китае тысячи лет назад95, — обычно считалась одной из самых сложных из когда-либо изобретенных игр с 10170 потенциально возможными позициями на доске96. Чтобы представить, насколько огромно это число, поясним, что, по некоторым оценкам, известная часть Вселенной содержит (всего лишь) от 1078 до 1087 атомов97,98! Программа AlphaGo, созданная группой DeepMind (принадлежит Google), использовала методы глубокого обучения с двумя нейронными сетями и одержала победу над чемпионом Европы Фан Хуэем. Заметим, го считается намного более сложной игрой, чем шахматы. Нейронные сети и глубокое обучение рассматриваются в главе 15.
• Позднее компания Google обобщила искусственный интеллект AlphaGo для создания AlphaZero — игрового искусственного интеллекта, который самостоятельно обучается играть в другие игры. В декабре 2017 года программа AlphaZero узнала правила и научилась играть в шахматы менее чем за 4 часа, используя методы обучения с подкреплением. Затем программа победила шахматную программу Stockfish 8, которая являлась чемпионом мира, в матче из 100 партий, причем все партии завершились ее победой или ничьей. После обучения го в течение всего 8 часов AlphaZero смогла играть со своим предшественником AlphaGo и победила в 60 партиях из 10099.
Личные воспоминания
Один из авторов этой книги, Харви Дейтел, будучи студентом бакалавриата Массачусетского технологического университета в середине 1960-х проходил магистерский курс у Марвина Мински (Marvin Minsky), одного из основателей дисциплины искусственного интеллекта (AI). Вот что вспоминает об этом Харви:
Профессор Мински раздавал курсовые проекты. Он предложил нам поразмышлять над тем, что такое интеллект и как заставить компьютер сделать что-то разумное. Наша оценка по этому курсу будет почти полностью зависеть от этого проекта. Полная свобода выбора!
Я исследовал стандартизированные IQ-тесты, проводимые в учебных заведениях для оценки интеллектуальных способностей учеников. Будучи математиком по своей природе, я решил взяться за часто встречающуюся в IQ-тестах задачу по предсказанию следующего числа в серии чисел произвольной длины и сложности. Я использовал интерактивный Lisp, работающий на одной из ранних моделей DEC PDP-1, и моя программа предсказания чисел справлялась с довольно сложными задачами, выходившими далеко за рамки тех, что встречались в IQ-тестах. Возможности Lisp по рекурсивной обработке списков произвольной длины были именно тем, что было нужно для выполнения требований проекта. Замечу, Python также поддерживает рекурсию и обобщенную работку со списками (глава 5).
Я опробовал программу на многих сокурсниках из MIT. Они выдумывали числовые серии и вводили их в моей программе. PDP-1 некоторое время «думала» (иногда довольно долго) и почти всегда выдавала правильный ответ. Но потом возникли трудности. Один из моих сокурсников ввел последовательность 14, 23, 34 и 42. Программа взялась за работу. PDP-1 долгое время размышляла, но так и не смогла предсказать следующее число. Я тоже не мог этого сделать. Сокурсник предложил мне немного подумать и пообещал открыть ответ на следующий день; он утверждал, что это простая последовательность. Все мои усилия были напрасными.
На следующий день сокурсник сообщил, что следующее число — 57, но я не понял почему. Он снова предложил подумать до завтра, а на следующий день заявил, что следующее число — 125. Это нисколько не помогло, я был в замешательстве. Видя это, сокурсник пояснил, что последовательность состояла... из номеров сквозных улиц с двусторонним движением на Манхэттене. Я закричал: «Нечестно!», но он парировал — задача соответствует заданному критерию. Я смотрел на мир с точки зрения математика — его взгляд был шире. За прошедшие годы я опробовал эту последовательность на друзьях, родственниках и коллегах. Несколько жителей Манхэттена дали правильный ответ. Для таких задач моей программе было нужно нечто большее, чем математические знания, — ей требовались (потенциально огромные) знания о мире.
Watson и Big Data открывают новые возможности
Харви продолжает:
Когда мы с Полом начали работать над этой книгой о Python, нас сразу же привлекла история о том, как суперкомпьютер IBM Watson использовал большие данные и методы искусственного интеллекта (в частности, обработку естественного языка (NLP) и машинное обучение), чтобы одержать победу над двумя сильнейшими игроками в Jeopardy! Мы поняли, что Watson, вероятно, сможет решать такие задачи, потому что в его память были загружены планы городов мира и много других подобных данных. Все это усилило наш интерес к глубокому изучению больших данных и современным методам искусственного интеллекта и помогло сформировать структуру глав 11–16 этой книги.
Следует заметить, что все практические примеры реализации data science в главах 11–16 либо уходят корнями к технологиям искусственного интеллекта либо описывают программы и оборудование больших данных, позволяющие специалистам по компьютерной теории и data science эффективно реализовать революционные решения на базе AI.
AI: область, в которой есть задачи, но нет решений
В течение многих десятилетий искусственный интеллект рассматривался как область, в которой есть задачи, но нет решений. Дело в том, что после того, как конкретная задача была решена, люди начинают говорить: «Что ж, это не интеллект, а просто компьютерная программа, которая указывает компьютеру, что нужно делать». Однако благодаря методам машинного обучения (глава 14) и глубокого обучения (глава 15) мы уже не программируем компьютер для решения конкретных задач. Вместо этого мы предлагаем компьютерам решать задачи, обучаясь по данным, и обычно по очень большим объемам данных.
Для решения многих самых интересных и сложных задач применялись методы глубокого обучения. Компания Google (одна из многих подобных себе) ведет тысячи проектов глубокого обучения, причем их число быстро растет100,101. По мере изложения материала книги мы расскажем вам о многих ультрасовременных технологиях искусственного интеллекта, больших данных и облачных технологиях.
1.10. Итоги
В этой главе представлена терминология и концепции, закладывающие фундамент для программирования на языке Python, которому будут посвящены главы 2–10, а также практические примеры применения больших данных, искусственного интеллекта и облачных технологий (подробнее об этом в главах 11–16). Мы обсудили концепции объектно-ориентированного программирования и выяснили, почему язык Python стал настолько популярным. Также в этой главе рассмотрена стандартная библиотека Python и различные библиотеки data science, избавляющие программистов от необходимости «изобретать велосипед». В дальнейшем эти библиотеки будут использоваться для создания программных объектов, с которыми вы будете взаимодействовать для решения серьезных задач при умеренном объеме кода. В главе рассмотрены и три примера, показывающие, как выполнять код Python с помощью интерпретатора IPython и Jupyter Notebook. Мы представили облачные технологии и концепцию «интернета вещей» (IoT), закладывающие основу для современных приложений, которые будут разрабатываться в главах 11–16.
Также мы обсудили, насколько велики «большие данные» и с какой скоростью они становятся еще больше; рассмотрели пример использования больших данных в мобильном навигационном приложении Waze, в котором многие современные технологии задействованы для генерирования динамических указаний по выбору маршрута, по возможности быстро и безопасно приводящих вас к конечной точке маршрута. Мы пояснили, в каких главах книги используются многие из этих технологий. Глава завершается разделом «Введение в data science», в котором рассматривается ключевая область на стыке компьютерной теории и data science — искусственный интеллект.
21https://pypl.github.io/PYPL.html (на январь 2019 г.).
24https://www.r-bloggers.com/data-science-job-report-2017-r-passes-sas-but-python-leaves-them-both-behind/.
29Tollervey N. Python in Education: Teach, Learn, Program (O’Reilly Media, Inc., 2015).
33https://www.hartmannsoftware.com/Blog/Articles_from_Software_Fans/Most-Famous-Software-Programs-Written-in-Python.
34Kolanovic M., Krishnamachari R. Big Data and AI Strategies: Machine Learning and Alternative Data Approach to Investing (J. P. Morgan, 2017).
35https://www.infoworld.com/article/3170838/developer/get-paid-10-programming-languages-to-learn-in-2017.html.
36https://medium.com/@ChallengeRocket/top-10-of-programming-languages-with-the-highest-salaries-in-2017-4390f468256e.
39 Прежде чем читать этот раздел, выполните инструкции из раздела «Приступая к работе» и установите дистрибутив Python Anaconda, содержащий интерпретатор IPython.
40 Jupyter поддерживает многие языки программирования, для чего следует установить соответствующее «ядро». За дополнительной информацией обращайтесь по адресу https://github.com/jupyter/jupyter/wi.
41 В следующей главе вы увидите, что в некоторых ситуациях приглашение Out[] не выводится.
44https://public.dhe.ibm.com/common/ssi/ecm/wr/en/wrl12345usen/watson-customer-engagement-watson-marketing-wr-other-papers-and-reports-wrl12345usen-20170719.pdf.
45https://www.networkworld.com/article/3325397/storage/idc-expect-175-zettabytes-of-data-worldwide-by-2025.html.
51https://public.dhe.ibm.com/common/ssi/ecm/wr/en/wrl12345usen/watson-customer-engagement-watson-marketing-wr-other-papers-and-reports-wrl12345usen-20170719.pdf.
59https://www.bloomberg.com/news/videos/2017-06-30/learning-from-planet-s-shoe-boxed-sized-satellites-video, 30 июня 2017 г.
64https://medium.com/@n.biedrzycki/only-god-can-count-that-fast-the-world-of-quantum-computing-406a0a91fcf4.
65https://singularityhub.com/2017/11/05/is-quantum-computing-an-existential-threat-to-blockchain-technology/.
66https://www.theguardian.com/environment/2017/dec/11/tsunami-of-data-could-consume-fifth-global-electricity-by-2025.
67https://motherboard.vice.com/en_us/article/ywbbpm/bitcoin-mining-electricity-consumption-ethereum-energy-climate-change.
71https://www.technologyreview.com/s/609480/bitcoin-uses-massive-amounts-of-energy-but-theres-a-plan-to-fix-it/.
75https://bits.blogs.nytimes.com/2013/02/01/the-origins-of-big-data-an-etymological-detective-story/.
77 Во многих статьях и публикациях в этот список добавляется много других «слов на букву V».
78https://www.zdnet.com/article/volume-velocity-and-variety-understanding-the-three-vs-of-big-data/.
80https://www.forbes.com/sites/brentdykes/2017/06/28/big-data-forget-volume-and-variety-focus-on-velocity.
81http://www.lesk.com/mlesk/ksg97/ksg.html. [К статье Майкла Леска (Michael Lesk) нас привела статья: https://www.forbes.com/sites/gilpress/2013/05/28/a-very-short-history-of-data-science/.]
82 Hamming, R.W., Numerical Methods for Scientists and Engineers (New York, NY., McGraw Hill, 1962). [К книге Хемминга и его цитате нас привела следующая статья: https://www.forbes.com/sites/gilpress/2013/05/28/a-very-short-history-of-data-science/.]
83 Turck, M., and J. Hao, «Great Power, Great Responsibility: The 2018 Big Data & AI Landscape», http://mattturck.com/bigdata2018/.
84 Sawchik, T., Big Data Baseball: Math, Miracles, and the End of a 20-Year Losing Streak (New York, Flat Iron Books, 2015).
85 Ayres, I., Super Crunchers (Bantam Books, 2007), с. 7–10.
86 Lewis, M., Moneyball: The Art of Winning an Unfair Game (W. W. Norton & Company, 2004).
90 Ibid.
92https://www.techrepublic.com/article/ibm-watson-the-inside-story-of-how-the-jeopardy-winning-supercomputer-was-born-and-what-it-wants-to-do-next/.
94https://www.aaai.org/Magazine/Watson/watson.php, AI Magazine, осень 2010 г.
96https://www.pbs.org/newshour/science/google-artificial-intelligence-beats-champion-at-worlds-most-complicated-board-game.
99https://www.theguardian.com/technology/2017/dec/07/alphazero-google-deepmind-ai-beats-champion-program-teaching-itself-to-play-four-hours.
Tollervey N. Python in Education: Teach, Learn, Program (O’Reilly Media, Inc., 2015).
Kolanovic M., Krishnamachari R. Big Data and AI Strategies: Machine Learning and Alternative Data Approach to Investing (J. P. Morgan, 2017).
В следующей главе вы увидите, что в некоторых ситуациях приглашение Out[] не выводится.
Jupyter поддерживает многие языки программирования, для чего следует установить соответствующее «ядро». За дополнительной информацией обращайтесь по адресу https://github.com/jupyter/jupyter/wi.
Прежде чем читать этот раздел, выполните инструкции из раздела «Приступая к работе» и установите дистрибутив Python Anaconda, содержащий интерпретатор IPython.
https://pypl.github.io/PYPL.html (на январь 2019 г.).
https://www.aaai.org/Magazine/Watson/watson.php, AI Magazine, осень 2010 г.
Во многих статьях и публикациях в этот список добавляется много других «слов на букву V».
http://www.lesk.com/mlesk/ksg97/ksg.html. [К статье Майкла Леска (Michael Lesk) нас привела статья: https://www.forbes.com/sites/gilpress/2013/05/28/a-very-short-history-of-data-science/.]
Ayres, I., Super Crunchers (Bantam Books, 2007), с. 7–10.
Sawchik, T., Big Data Baseball: Math, Miracles, and the End of a 20-Year Losing Streak (New York, Flat Iron Books, 2015).
Turck, M., and J. Hao, «Great Power, Great Responsibility: The 2018 Big Data & AI Landscape», http://mattturck.com/bigdata2018/.
Hamming, R.W., Numerical Methods for Scientists and Engineers (New York, NY., McGraw Hill, 1962). [К книге Хемминга и его цитате нас привела следующая статья: https://www.forbes.com/sites/gilpress/2013/05/28/a-very-short-history-of-data-science/.]
Lewis, M., Moneyball: The Art of Winning an Unfair Game (W. W. Norton & Company, 2004).
Ibid.
Глава 2. Введение в программирование Python
В этой главе…
• Ввод фрагментов кода и немедленный просмотр результатов в интерактивном режиме IPython.
• Написание простых команд и сценариев Python.
• Создание переменных для хранения данных.
• Знакомство со встроенными типами данных.
• Арифметические операторы и операторы сравнения, их приоритеты.
• Строки в одинарных, двойных и тройных кавычках.
• Использование встроенной функции print для вывода текста.
• Использование встроенной функции input для запроса данных с клавиатуры и получения этих данных для использования в программе.
• Преобразование текста в целочисленные значения встроенной функцией int.
• Использование операторов сравнения и команды if для принятия решений о выполнении команды или группы команд.
• Объекты и динамическая типизация в Python.
• Получение типа объекта встроенной функцией type.
2.1. Введение
В этой главе представлены основы программирования на Python, а также приведены примеры, демонстрирующие ключевые возможности языка. Предполагается, что вы прочитали раздел с описанием экспериментов с IPython в главе 1, где представлен интерпретатор IPython и продемонстрированы его возможности для вычисления простых арифметических выражений.
2.2. Переменные и команды присваивания
Напомним, мы использовали интерактивный режим IPython как калькулятор для выражений:
In [1]: 45 + 72
Out[1]: 117
Теперь создадим переменную x для хранения целого числа 7:
In [2]: x = 7
Фрагмент [2] является командой (statement). Каждая команда определяет выполняемую операцию. Предыдущая команда создает x и использует знак равенства (=), для того чтобы назначить x значение. Большинство команд завершается в конце строки, хотя команда также может охватывать сразу несколько строк. Следующая команда создает переменную y и присваивает ей значение 3:
In [3]: y = 3
Теперь значения x и y могут использоваться в выражениях:
In [4]: x + y
Out[4]: 10
Вычисления в командах присваивания
Следующая команда складывает значения переменных x и y,




















{kind=link}