

автордың кітабын онлайн тегін оқу Рецепты Python. Коллекция лучших техник программирования
Переводчик Е. Матвеев
Юн Цуй
Рецепты Python. Коллекция лучших техник программирования. — СПб.: Питер, 2024.
ISBN 978-5-4461-2156-4
© ООО Издательство "Питер", 2024
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Посвящаю своей жене Тинтин Гу, которая сидела рядом со мной поздними вечерами, пока я писал эту книгу.
Предисловие
Пожалуй, мы — самое везучее поколение в истории человечества. Мы живем не в период неолита и не в индустриальный век, мы вошли в информационную эпоху. Современные информационные технологии, особенно компьютеры и сети, полностью изменили жизнь человека. Мы можем перелететь из своего родного города в другое место, находящееся за тысячи километров, менее чем за полдня. В случае необходимости мы можем записаться на прием к врачу по смартфону и побеседовать с ним по видеосвязи. У нас есть возможность заказать почти любой товар в интернет-магазине и получить его в считаные дни и даже часы.
Изменения в нашей жизни сопровождались накоплением громадных объемов данных, особенно в последние двадцать лет. Работа по обработке и анализу данных привела к появлению новой межотраслевой дисциплины — data science. Будучи ученым-бихевиористом, я проводил много времени за работой с данными: можно сказать, что я применял теорию data science к исследованиям в области поведенческой психологии. Однако для обработки таких объемов данных не обойтись ручкой и листом бумаги. Вместо этого я писал на замечательном языке программирования Python код для анализа данных и применения статистических моделей.
Как программист-самоучка я знаю, что изучить Python или любой другой язык программирования достаточно сложно, и не только из-за того, что освоение всех средств (и умение правильно выбирать их в той или иной ситуации) занимает массу времени. Сейчас доступно слишком много учебных ресурсов — онлайн-курсов, учебных видеороликов, статей в блогах и, разумеется, книг. Как выбрать те, которые лучше всего подходят для вас?
Я столкнулся с этим вопросом в начале своего изучения Python. За прошедшие годы я пробовал пользоваться разными ресурсами и обнаружил, что лучшими источниками информации являются книги, потому что они содержат четко структурированный материал, а это позволяет овладеть языком на более глубоком уровне. В процессе обучения вы сами выбираете наиболее подходящий для вас темп проработки материала — при необходимости можно замедлить чтение, чтобы усвоить более сложные темы. Да и к стоящей на полке книге всегда легко обратиться при возникновении каких-либо вопросов.
Многие книги о Python, представленные на рынке, написаны либо для начинающих (с подробным описанием базовых возможностей языка), либо для опытных пользователей (с рассказом о специализированных методах, которые не столь универсальны). Бесспорно, некоторые из этих книг превосходны. Но приняв во внимание график роста мастерства с накоплением опыта, я счел, что среди этих книг не хватает предназначенной для тех, кто в своем освоении Python переходит с начального уровня на средний. Именно на этой решающей стадии у изучающих формируются правильные навыки работы с кодом и понимание того, какие средства Python лучше использовать в конкретном контексте. Что же касается материала, я решил, что в этой будущей книге должны рассматриваться общие проблемы программирования, которые большинство читателей смогут связать со своей работой независимо от того, применяют ли они Python для веб-программирования или в data science. Иначе говоря, такая книга пригодится многим читателям, потому что она предоставляет информацию, не привязанную к конкретной предметной области.
Я написал эту книгу, чтобы заполнить пробел между руководствами для начинающих и изданиями для опытных программистов. Надеюсь, вы узнаете из нее что-то новое для себя.
Благодарности
Хочу поблагодарить своих наставников, доктора Пола Чинчирипини (Dr. Paul Cinciripini) и доктора Джейсона Робинсона (Dr. Jason Robinson) из Андерсоновского онкологического центра Университета Техаса; они поддерживали меня, пока я учился использовать Python как язык для нашей аналитической работы, которая в конечном итоге и привела к появлению этой книги.
Также хочу поблагодарить команду издательства Manning: издателя Маржана Бейса (Marjan Bace) за руководство редакционной коллегией и технологической группой; соиздателя Майкла Стивенса (Michael Stephens), предложившего мне написать эту книгу; старшего ведущего редактора Марину Майклз (Marina Michaels) за координацию и редактирование; Рене ван ден Берг (René van den Berg) за научное редактирование; Уолтера Александера (Walter Alexander) и Игнасио Торреса (Ignacio Torres) за рецензирование кода; Александара Драгосавлевича (Aleksandar Dragosavljević) за организацию коллегиального рецензирования; весь персонал — за усердную работу по форматированию книги.
С благодарностью перечисляю рецензентов, предоставивших полезные отзывы: Алексей Знаменский (Alexei Znamensky), Алексей Выскубов (Alexey Vyskubov), Ариэль Андрес (Ariel Andres), Брент Бойлан (Brent Boylan), Крис Колосивски (Chris Kolosiwsky), Кристофер Карделл (Christopher Kardell), Кристофер Виллануэва (Christopher Villanueva), Клаудиу Шиллер (Claudiu Schiller), Клиффор Турбер (Clifford Thurber), Дирк Гомес (Dirk Gomez), Ганеш Сваминатан (Ganesh Swaminathan), Георгиос Думас (Georgios Doumas), Джеральд Мэк (Gerald Mack), Грегори Граймс (Gregory Grimes), Игорь Дудченко (Igor Dudchenko), Иябо Синдику (Iyabo Sindiku), Джеймс Мэтлок (James Matlock), Джеффри М. Смит (Jeffrey M. Smith), Джош Макадамс (Josh McAdams), Кирти Шетти (Keerthi Shetty), Ларри Кай (Larry Cai), Луис Алойа (Louis Aloia), Маркус Гезелл (Marcus Geselle), Мэри Энн Тигезен (Mary Anne Thygesen), Майк Баран (Mike Baran), Нинослав Черкез (Ninoslav Cerkez), Оливер Кортен (Oliver Korten), Пьерджиорджио Фаралья (Piergiorgio Faraglia), Радхакришна М.В. (Radhakrishna M.V.), Раджиндер Ядав (Rajinder Yadav), Рэймонд Чун (Raymond Cheung), Роберт Веннер (Robert Wenner), Шанкар Свами (Shankar Swamy), Шрирам Мачарла (Sriram Macharla), Гири С. Сваминатан (Giri S. Swaminathan), Стивен Эррера (Steven Herrera) и Витош К. Дойнов (Vitosh K. Doynov). Их предложения помогли улучшить эту книгу.
О книге
В этой книге я сосредоточился на основных приемах работы с Python, не привязывая их к какой-либо конкретной специализации. Хотя существует множество пакетов Python для разных специализированных областей (например, для data science или для веб-программирования), все эти пакеты строятся на основе базовых средств Python. Какие бы специализированные пакеты Python вы ни использовали в работе, также необходимо хорошо владеть основными навыками — скажем, правильно выбирать модели данных и писать структурированные функции и классы. С этими навыками вы сможете легко пользоваться любыми специализированными пакетами.
Для кого эта книга
Если какое-то время вы изучали Python самостоятельно, но ваши знания языка представляются вам недостаточно упорядоченными, то вы, вероятно, находитесь в процессе перехода с начального уровня на промежуточный. Эта книга написана специально для вас, потому что вам нужно подкрепить свои знания Python и обобщить их в структурированной форме. В каждой главе этой книги я выделяю несколько тем для решения общих проблем, с которыми вы можете столкнуться в процессе работы. Впрочем, изложение этих тем не ограничивается решением конкретной проблемы — материал помещается в более широкий контекст, чтобы показать, почему и насколько эта тема важна при работе над любым проектом. Таким образом, вы не ограничиваетесь конкретными приемами решения отдельных задач, а работаете над своим проектом, параллельно осваивая применение этих приемов.
Структура книги
Книга состоит из шести частей, названия которых представлены на следующей схеме («Дорожной карте»). В части 1 (главы 2–5) изучаются встроенные модели данных, включая строки, списки и словари. Эти модели данных являются структурными элементами любого проекта.

В части 2 (главы 6 и 7) рассказано о том, как определяются функции. Функции считаются неотъемлемой частью любого проекта, потому что они обеспечивают обработку данных для получения нужного вывода. В части 3 (главы 8 и 9) вы научитесь правильно определять пользовательские классы. Вместо применения встроенных классов мы определяем пользовательские классы для более эффективного моделирования данных в проекте. В части 4 (главы 10 и 11) представлены основы использования объектов и управления файлами. Часть 5 (главы 12 и 13) посвящена различным средствам повышения надежности программ, включая ведение журнала, обработку исключений и тестирование. В части 6 (глава 14) все полученные знания синтезируются для построения веб-приложения — проекта, который служит учебной основой для материала всех остальных глав.
Я рекомендую во время работы над книгой сразу воспроизводить все приведенные примеры на компьютере. Это позволит вам быстрее освоить синтаксис Python и основные приемы программирования. Я загрузил весь исходный код на GitHub, и мой общедоступный репозиторий доступен по адресу https://github.com/ycui1/python_how_to. Однако приводя в книге какой-либо код, я также привожу все необходимые пояснения и результаты, так что ничего страшного, если при чтении книги у вас под рукой не будет компьютера.
Если вы намерены воспроизводить примеры на компьютере, не имеет значения, какая на нем установлена операционная система. Windows, macOS и Linux — подойдет любая, потому что Python является кросс-платформенным языком программирования. Так как в книге я сосредоточусь на важнейших приемах и методах, которые устоялись в последних выпусках Python, не так важно, работаете ли вы на Python 3.8 или более ранней версии. Тем не менее, чтобы извлечь максимум пользы из книги, я рекомендую установить Python версии 3.10 и выше.
О коде в книге
Книга содержит множество примеров исходного кода, размещенного как в нумерованных листингах, так и в тексте. В обоих случаях исходный код форматируется моноширинным шрифтом, в отличие от обычного текста. Иногда для кода также применяется полужирный шрифт, чтобы выделить фрагменты, изменившиеся по сравнению с предыдущими шагами, например, при добавлении новой функциональности в существующую строку кода.
Во многих случаях оригинальная версия исходного кода переформатирована; я добавил разрывы строк и изменил отступы, чтобы код помещался на странице. Иногда в листинги включаются маркеры продолжения строк (➥). Также из исходного кода удалены комментарии, если код описывается в тексте. Многие листинги сопровождаются аннотациями, поясняющими важные понятия.
Исполняемые фрагменты кода можно загрузить из электронной версии книги на liveBook: https://livebook.manning.com/book/python-how-to. Полный код примеров книги доступен для загрузки на сайтах издательства Manning (https://www.manning.com/books/python-how-to) и GitHub (https://github.com/ycuil/python_how_to).
Форум LiveBook
Приобретая книгу «Рецепты Python», вы получаете бесплатный доступ к веб-форуму издательства Manning (на английском языке), на котором можно оставлять комментарии о книге, задавать технические вопросы и получать помощь от автора и других пользователей. Чтобы получить доступ к форуму, откройте страницу https://livebook.manning.com/book/python-how-to/discussion. Информация о форумах Manning и правилах поведения на них размещена на https://livebook.manning.com/#!/discussion.
В рамках своих обязательств перед читателями издательство Manning предоставляет ресурс для содержательного общения читателей и авторов. Эти обязательства не подразумевают конкретную степень участия автора, которое остается добровольным (и неоплачиваемым). Задавайте автору хорошие вопросы, чтобы он не терял интереса к происходящему! Форум и архивы обсуждений доступны на веб-сайте издательства, пока книга продолжает издаваться.
Другие источники информации
Официальную документацию, включая учебники и справочники, можно найти по адресу https://docs.python.org/3. Автор книги, доктор Юн Цуй, регулярно ведет блоги о Python и сопутствующих темах data science на платформе Medium (https://medium.com/@yongcui01).
Об авторе
Доктор Юн Цуй — ученый, проработавший в области биомедицины более пятнадцати лет. Его исследовательская работа была посвящена разработке мобильных приложений медицинского назначения для поведенческой психотерапии на языках Swift и Kotlin. Его любимый язык Python стал основным средством для анализа данных, машинного обучения и разработки исследовательского инструментария. В свободное время он публикует в блогах посты по различным техническим темам, включая мобильную разработку, программирование на языке Python и искусственный интеллект.
Иллюстрация на обложке
Иллюстрация, помещенная на обложку второго издания книги и озаглавленная «Paysanne des environs de Soleure», или «Крестьянка из окрестностей Золотурна», взята из вышедшего в 1788 году каталога национальных костюмов, составленного Жаком Грассе де Сен-Совером (Jacques Grasset de Saint-Sauveur). Каждая иллюстрация этого каталога тщательно прорисована и раскрашена от руки.
В прежние времена по одежде человека можно было легко определить, где он живет и какова его профессия или положение в обществе. Издательство Manning приветствует изобретательность и инициативность — качества, присущие индустрии IT, — и в знак этого размещает на обложках изображения, которые демонстрируют богатое разнообразие региональных культур, запечатленное на старинных иллюстрациях.
От издательства
На протяжении всей книги автор рассматривает сквозной пример: приложение для управления задачами (таск-менеджер). Названия задач в этом примере (такие, как Laundry — стирка, Homework — домашнее задание, Pay bills — оплатить счета и т.д.) мы не переводили, так как они являются составной частью исходного кода. На понимание излагаемого материала это не влияет!
Ваши замечания, предложения, вопросы отправляйте по адресу comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
На веб-сайте издательства www.piter.com вы найдете подробную информацию о наших книгах.
1. Разработка стратегии прагматичного обучения
В этой главе
• Что такое «прагматичный»
• На что способен Python
• Когда стоит подумать об использовании альтернативных языков
• Чему может научить эта книга
Python — замечательный язык программирования. Распространение с открытым кодом, универсальность, независимость от платформы способствовали формированию огромного сообщества разработчиков и невероятной экосистемы, включающей десятки тысяч находящихся в свободном доступе библиотек для веб-разработки, машинного обучения (МО), data science и многих других областей. Надеюсь, вы согласитесь с тем, что умение писать код на Python важно, но умение создавать по-настоящему эффективные, безопасные и простые в сопровождении приложения дает вам поистине огромное преимущество. Эта книга поможет вам перейти с уровня начинающего программиста Python на уровень уверенного владения языком.
При практической работе в экосистеме Python мы применяем инструменты, предназначенные для конкретной предметной области, например веб-фреймворки или библиотеки для машинного обучения. Эффективное применение этих инструментов — нетривиальное дело, для которого потребуется хорошее владение базовыми навыками программирования на Python: обработкой текста, работой со структурированными данными, созданием потоков управления и операций с файлами. Python-разработчики могут создавать разные решения для одних и тех же задач. Среди нескольких решений, как правило, можно найти наилучшее: наиболее компактное, или удобочитаемое, или эффективное. Все эти свойства часто объединяются под словосочетанием «питонический код»: имеется в виду идиоматический стиль программирования, овладеть которым стремятся все Python-разработчики. В этой книге рассказывается о том, как писать питонический код для решения различных задач программирования.
Python предоставляет разработчику столько возможностей, что было бы нереально или неразумно пытаться изучить их все по одной книге. Поэтому при выборе материала для своей книги я остановился на прагматичном подходе, а именно на обучении читателя тем основным навыкам, которые наиболее вероятно пригодятся в реальных проектах. Не менее важным я считаю регулярно обращаться к тому, как писать код, учитывая его удобочитаемость и простоту сопровождения. Это поможет вам выработать хороший стиль кодинга, который, я уверен, будет высоко оценен и вами, и вашими коллегам по команде.
Примечание В книге часто встречаются такие врезки. Многие из них содержат полезные советы относительно удобочитаемости и простоты сопровождения кода. Не пропускайте их!
1.1. О пользе прагматичного подхода
Мы программируем с определенной целью — для построения веб-сайта, обучения моделей МО или анализа данных. Какой бы ни была наша цель, нам нужно действовать прагматично, поскольку мы пишем код для решения реальных задач. Поэтому следует четко сформулировать свои цели, прежде чем изучать программирование с нуля или работать над повышением своей квалификации где-то в середине карьеры. Но даже если вы пока не уверены в том, чего именно хотите добиться при помощи Python, базовые средства Python универсально полезны. Освоив эти базовые средства, вы сможете применять их c любыми предметно-ориентированными инструментами Python.
Цель «стать прагматичным программистом» означает, что вам следует сосредоточиться на наиболее полезных приемах. Впрочем, освоение этих навыков — лишь первая веха на долгом пути, а вашей долгосрочной целью должно быть написание удобочитаемого кода, который не только работает, но и прост в сопровождении.
1.1.1. Написание удобочитаемого кода Python
Я разработчик, который фанатично стремится к удобочитаемости кода. Написание кода можно сравнить с разговором на обычном человеческом языке. Когда вы говорите на каком-нибудь языке, вы хотите, чтобы другие вас понимали? Если вы согласны, то, вероятно, согласитесь и с тем, что наш код должен быть понятным для других. Вопрос о том, обладают ли читатели нашего кода достаточной технической квалификацией для его понимания, находится вне зоны нашей ответственности. От нас зависит лишь то, как мы пишем код, — насколько удобочитаемым он получается. Попробуйте ответить на несколько простых вопросов:
• Указывают ли имена ваших переменных на их назначение? Никто не похвалит код, в котором полно переменных с именами вида var0, temp_var или x.
• Указывают ли сигнатуры ваших функций на то, что делают эти функции? Люди приходят в замешательство при виде функций с именами вида do_data(data) или run_step1().
• Насколько последовательно вы распределяете свой код по файлам? Люди ожидают, что разные файлы одного типа используют сходную структуру. Например, размещаете ли вы инструкции import в начале файлов?
• Хранятся ли конкретные файлы в правильных папках в структуре вашего проекта? С увеличением масштаба проекта следует создавать отдельные папки для взаимосвязанных файлов.
Все эти вопросы относятся к области удобочитаемости. Не следует вспоминать о ней лишь время от времени, мы должны помнить про удобочитаемость кода постоянно, на протяжении всего проекта. Причина проста: к совершенству ведет правильная практика. Будучи нейробиологом по образованию, я точно знаю, как работает мозг, когда дело доходит до поведенческого обучения. Мы тренируем нейронную сеть нашего мозга, практикуясь в улучшении читабельности и постоянно задавая себе вопросы для самоконтроля. В конце концов вы обучите мозг распознавать хорошую практику программирования и начнете писать удобочитаемый, простой в сопровождении код, даже не задумываясь об этом.
1.1.2. Думайте о опровождаемости еще до написания кода
В отдельных случаях мы создаем код, предназначенный для одноразового использования. Когда мы пишем скрипт, нам почти всегда удается убедить себя в том, что он не предназначается для повторного применения, а значит, не нужно беспокоиться о создании понятных имен переменных, о правильном структурировании кода или рефакторинге функций и моделей данных (не говоря уже том, что мы не пишем комментарии или оставляем устаревшие). Но сколько раз выяснялось, что тот же скрипт приходится использовать на следующей неделе и даже на следующий день? Вероятно, такое случалось с каждым из нас.
В предыдущем абзаце описана проблема простоты сопровождения (сопровождаемости) в малом масштабе. В данном случае она влияет только на вашу собственную производительность на коротком отрезке времени. Но если вы работаете в командной среде, сложности, создаваемые отдельными участниками, накапливаются и превращаются в крупномасштабные проблемы с сопровождаемостью. Участники команды не следуют одинаковым правилам выбора имен переменных, функций и файлов. В коде сплошь и рядом встречаются закомментированные фрагменты. Повсюду оставлены неактуальные комментарии.
Чтобы разрешить проблемы с сопровождаемостью на более поздних стадиях проектов, следует сформировать правильные установки еще во время обучения программированию. Ниже приводятся некоторые вопросы, которые стоит учитывать для выработки правильного отношения к простоте сопровождения в долгосрочной перспективе.
• Свободен ли ваш код от устаревших комментариев и закомментированных участков? Если ответ будет отрицательным, обновите или удалите их! Такие комментарии хуже их полного отсутствия, потому что они могут содержать противоречивую информацию.
• Значительное ли место в коде занимает дублирование? Если ответ будет положительным, вероятно, код требует рефакторинга. В программировании нередко упоминается практическое правило DRY (Don’t Repeat Yourself, то есть «не повторяйтесь»). Удалив дубликаты из кода, вы получите один совместно используемый блок, что снизит риск ошибок по сравнению с внесением изменений во все повторяющиеся фрагменты.
• Используете ли вы такие системы контроля версий, как Git? Если ответ будет отрицательным, изучите расширения или плагины для вашей интегрированной среды разработки (IDE). Для Python часто используются IDE PyCharm и Visual Studio Code. Во многих IDE имеются интегрированные средства контроля версий, которые заметно упрощают управление версиями.
Каждый прагматичный программист Python должен взять на вооружение эти приемы, упрощающие сопровождение. Ведь почти все инструменты Python распространяются с открытым кодом и быстро развиваются. Следовательно, учет будущей сопровождаемости должен занимать центральное место в любом реальном проекте. В этой книге мы постараемся затронуть вопросы реализации практик сопровождения при повседневном программировании на Python. Помните, что удобочитаемость кода является ключевым фактором долгосрочной простоты сопровождения. Если вы сосредоточитесь на написании удобочитаемого кода, это будет способствовать улучшению сопровождаемости вашей кодовой базы.
1.2. Что Python делает хорошо — или не хуже, чем другие языки
Растущая популярность Python обусловлена характеристиками самого языка. Хотя ни одна из этих характеристик не уникальна для Python, именно их гармоничное сочетание объясняет повсеместное его распространение. Ниже приведена краткая сводка важнейших характеристик Python.
• Кросс-платформенность — Python работает на всех основных платформах, включая Windows, Linux и MacOS. Любой код Python, который вы напишете на своей платформе, будет работать на других компьютерах без ограничений, связанных с различиями между платформами.
• Выразительность и удобочитаемость — синтаксис Python проще синтаксиса многих других языков. Выразительный, понятный стиль программирования широко распространен среди питонистов. Вы увидите, что хорошо написанный код Python легко читается, как хорошо написанный текст.
• Быстрота построения прототипов — благодаря простоте синтаксиса код Python обычно получается более компактным, чем код, написанный на других языках. Следовательно, для построения работоспособного прототипа на Python требуется меньше работы, чем при использовании других языков.
• Автономность — после того, как вы установите Python на своем компьютере, он будет готов к использованию сразу же после «распаковки». Базовый установочный пакет Python содержит все основные библиотеки, необходимые для выполнения любых задач повседневного программирования.
• Открытый код, бесплатное распространение и расширяемость — хотя Python работает автономно, это не мешает вам создавать и использовать собственные пакеты. Если другой разработчик опубликовал какой-либо нужный вам пакет, вы сможете установить его однострочной командой, не беспокоясь о лицензии или оплате подписки.
Эти ключевые характеристики привлекли многих программистов, в результате чего сформировалось огромное сообщество разработчиков. Модель открытого кода Python позволяет заинтересованным пользователям вносить свой вклад в язык и экосистему в целом. В табл. 1.1 суммируются сведения о некоторых важных предметных областях и средствах, предоставляемых для них Python. Приведенный список далеко не полон, и вам предстоит самостоятельно исследовать, какие средства предлагает Python для деятельности в интересующей вас области.
Таблица 1.1. Обзор предметно-ориентированных инструментов Python
| Предметная область |
Инструмент |
Краткая характеристика |
| Веб-разработка |
Flask |
Микрофреймворк для веб-разработки; хорошо подходит для построения облегченных веб-приложений; гибкий механизм расширения для сторонней функциональности |
| Django |
Полнофункциональный веб-фреймворк; хорошо подходит для построения веб-приложений, управляемых базами данных; обладает высокой масштабируемостью для корпоративных решений |
|
| FastAPI |
Веб-фреймворк для построения прикладных интерфейсов (API); проверка и преобразование данных; автоматическое генерирование веб-интерфейсов API |
|
| Streamlit |
Веб-фреймворк для простого построения приложений, ориентированных на данные; популярен среди специалистов data science и МО-инженеров |
|
| Data science |
NumPy |
Специализируется на обработке больших многомерных массивов; высокая вычислительная эффективность; интегрирован во многие библиотеки |
| pandas |
Гибкий пакет для обработки двумерных данных, сходных с электронными таблицами; широкий набор средств для работы с данными |
|
| statsmodels |
Популярный пакет статистических вычислений: линейная регрессия, корреляция, байесовские модели, анализ выживаемости |
|
| Matplotlib |
Объектно-ориентированная парадигма для построения гистограмм, точечных диаграмм, круговых диаграмм и других стандартных диаграмм с широкими возможностями настройки |
|
| Seaborn |
Простая в использовании библиотека визуализации для создания привлекательной графики; высокоуровневый API на базе Matplotlib |
|
| Машинное обучение |
Scikit-learn |
Широкий диапазон средств предварительной обработки для построения МО-моделей; реализация распространенных алгоритмов МО |
| TensorFlow |
Фреймворк с высокоуровневым и низкоуровневым API; система визуализации Tensor board; хорошо подходит для построения сложных нейронных сетей |
|
| Keras |
Высокоуровневые API для построения нейронных сетей; простота использования; хорошо подходит для построения низкопроизводительных моделей |
|
| PyTorch |
Фреймворк для построения нейронных сетей; более интуитивный стиль программирования, чем у TensorFlow; хорошо подходит для построения сложных нейронных сетей |
|
| FastAI |
Высокоуровневые API для построения нейронных сетей на базе PyTorch; простота использования |
Фреймворки, библиотеки, пакеты и модули
При обсуждении инструментария используются тесно связанные термины — фреймворки, библиотеки, пакеты и модули. В разных языках могут использоваться термины с несколько различающимися значениями. Стоит разобраться в том, какой смысл вкладывает в эти термины большинство программистов Python.
Термин «фреймворк» является самым широким. Фреймворки предоставляют полный набор функциональных средств, специально спроектированных для выполнения определенной работы на высоком уровне (например, веб-разработки).
Библиотеки являются структурными элементами фреймворков и состоят из пакетов. Предоставляемая библиотеками функциональность разрешает пользователям не разбираться в подробностях работы с используемыми пакетами.
Пакеты предоставляют конкретную функциональность. Точнее говоря, пакеты состоят из модулей, и каждый модуль представляет собой набор тесно связанных структур данных и функций в одном файле (например, файле .py).
1.3. Чего Python не делает или что делает недостаточно хорошо
Все имеет свои ограничения, есть они и у возможностей Python. Существует много всего, чего Python делать не может или, по крайней мере, не может делать так же хорошо, как альтернативные ему средства. Хотя некоторые люди пытаются «протолкнуть» Python как якобы используемый для всех целей язык, признаем, что на данный момент возможности Python в двух важных областях ограниченны:
• Мобильные приложения — в мобильную эпоху у всех есть смартфоны, а приложения используются практически во всех аспектах жизни: для банковских операций, покупок в интернете, заботы о здоровье, общения и, конечно, для игр. К сожалению, на сегодня хороших фреймворков Python для разработки приложений для смартфонов пока нет, несмотря на существование Kivy и BeeWare. Если вы работаете в сфере мобильной разработки, в качестве альтернативы стоит рассмотреть более развитые средства, такие как Swift для приложений iOS или Kotlin для приложений Android. Прагматичный программист выбирает язык, который позволяет создавать продукты, нравящиеся пользователю.
• Низкоуровневая разработка — при разработке программных продуктов, взаимодействующих напрямую с оборудованием, Python оказывается не лучшим вариантом. Из-за интерпретируемой природы Python общая скорость выполнения недостаточно высока для разработки низкоуровневых продуктов (скажем, драйверов устройств), требующих моментальной реакции. Если вас интересует низкоуровневая разработка, вам стоит обратить внимание на альтернативные языки, которые успешнее взаимодействуют с аппаратным уровнем. Например, C и C++ хорошо подходят для разработки драйверов устройств.
1.4. О чем вы узнаете из книги
Мы немного поговорили о том, что значит быть прагматичным программистом. Теперь обсудим, как прийти к этой цели. В ходе написания программ вы неизбежно столкнетесь с новыми проблемами из области программирования. В книге определены методы программирования, нужные для решения задач, с которыми вы с большой вероятностью встретитесь на практике.
1.4.1. Ориентация на предметно-независимые знания
Все вещи прямо или косвенно связаны друг с другом, это относится и к знанию Python. В контексте Python эта связь проиллюстрирована на рис. 1.1. На концептуальном уровне функциональность Python и его практическое применение можно представить как три взаимосвязанные сущности.
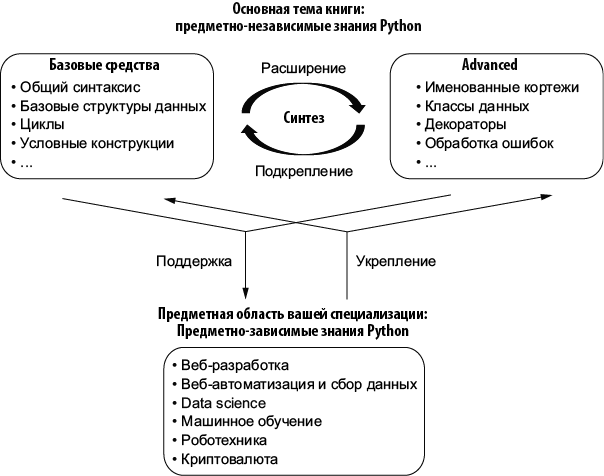
Рис. 1.1. Отношения между предметно-независимыми и предметно-зависимыми областями знаний Python. К предметно-независимым знаниям относятся базовые и расширенные средства Python, тесно связанные друг с другом. Совместно они формируют основу для предметно-зависимых знаний в разных предметных областях
Большинство людей изучают Python, чтобы применять язык для решения задач предметной области, в которой они работают. Для этого необходимы предметно-зависимые знания Python, например навыки веб-разработки и анализа данных. Необходимым условием успешного выполнения работы являются базовые навыки Python, а именно предметно-независимые знания. Даже если ваши должностные обязанности меняются или развиваются со временем, вы всегда можете применить базовые навыки Python в новой роли.
В этой книге мы сосредоточимся на предметно-независимых знаниях Python. Чтобы упростить процесс обучения, разделим предметно-независимые знания Python условно на два компонента: базовые и расширенные.
Что касается первого компонента, необходимо знать базовые структуры данных и операции с ними. Также нужно уметь вычислять результаты условий для построения инструкций if...else.... Для выполнения многократно повторяющихся операций можно воспользоваться циклами for и while, а для повторного использования блоков кода переработать их в функции и классы. Овладения этими основами будет достаточно для написания полезного кода Python, который решает ваши рабочие задачи. Когда вы освоите большую часть базовых навыков, можно переходить к расширенным.
Расширенные навыки позволяют писать еще лучший код, более эффективный и использующий универсальные возможности Python. Чтобы оценить его универсальность, рассмотрим простой пример. При переборе объекта list в цикле for часто требуется вывести не только сам элемент, но и его позицию:
prime_numbers = [2, 3, 5]
# Желательный вывод:
Prime Number #1: 2
Prime Number #2: 3
Prime Number #3: 5
Ограничиваясь только базовыми возможностями, мы придем к приведенному ниже решению. В этом решении создается объект range, который позволяет извлечь индекс (с начинающейся с 0 нумерацией) для получения позиционной информации. Для вывода применяется конкатенация строк:
for num_i in range(len(prime_numbers)):
num_pos = num_i + 1
num = prime_numbers[num_i]
print("Prime Number #" + str(num_pos) + ": " + str(num))
Но после прочтения этой книги вы станете более опытным пользователем Python и получите следующее решение, более элегантное и питоническое:
for num_pos, num in enumerate(prime_numbers, start=1):
print(f"Prime Number #{num_pos}: {num}")
В этом решении используются три приема: распаковка кортежа для получения num_pos и num (раздел 4.4), создание объекта enumerate (раздел 5.3) и форматирование вывода с использованием f-строк (раздел 2.1). Я не стану подробно описывать эти приемы здесь, потому что они будут рассмотрены в соответствующих разделах. Однако этот пример показывает, чему посвящена данная книга, — применению различных навыков для создания питонических решений.
Кроме этих приемов, вы научитесь применять расширенные концепции функций (например, декораторы и замыкания). При определении классов вам будет ясно, как организовать их совместную работу для минимизации объема кода и сокращения риска ошибок. А когда программа будет завершена, вы уже будете знать, как протестировать ваш код, чтобы он был готов к эксплуатации.
Вся эта книга — о синтезе предметно-независимых знаний Python. Вы освоите не только практически полезные расширенные возможности, но и базовые средства Python и фундаментальные концепции программирования (в случаях, где они применимы). Ключевую роль в этом играет термин «синтез», что и показано в разделе 1.4.2.
1.4.2. Решение задач посредством синтеза
Начинающие программисты нередко оказываются в сложной ситуации: вроде бы они знают множество разнообразных методов, но не представляют, когда и как использовать их для решения задач. Для каждого рассматриваемого в книге приема я покажу, как он работает автономно, а также продемонстрирую его применение совместно с другими методами. Надеюсь, вскоре вы начнете понимать, как из этих разнородных компонентов строится бесконечное множество новых программ.
Необходимо сделать принципиальное замечание по поводу изучения и синтеза различных приемов: будьте готовы к тому, что путь постижения программирования нелинеен. Ведь и технические возможности Python тесно связаны друг с другом: хотя мы и сосредоточимся на изучении промежуточных и расширенных средств Python, их невозможно полностью изолировать от базовых тем. Вы заметите, что я часто отмечаю базовые средства или намеренно возвращаюсь к уже рассмотренным темам.
1.4.3. Изучение навыков в контексте
Как упоминалось ранее, в книге основное внимание уделяется изучению навыков, основанных на предметно-независимых знаниях Python. Определение «предметно-независимый» означает, что навыки, рассмотренные в книге, применимы к любой области, в которой вы хотите использовать Python. Впрочем, без примеров вряд ли можно что-либо изучить. Многие средства, описанные в книге, будут продемонстрированы на примере текущего проекта, который послужит единым контекстом для обсуждения конкретных навыков. Если какие-то навыки вами уже освоены, можете переходить к подразделу «Обсуждение», в котором разбираются некоторые ключевые аспекты рассмотренной темы.
Забегая вперед, сообщу, что общим проектом станет веб-приложение для управления задачами (таск-менеджер). В этом приложении пользователь должен выполнять различные операции, включая добавление, редактирование и удаление задач. В нем задействовано все, что может быть реализовано на «чистом» Python: модели данных, функции, классы и вообще все, что обычно встречается в подобных приложениях. Сразу скажу, что целью вовсе не является построение идеально работающего совершенного приложения. В процессе работы над веб-приложением вы будете изучать важнейшие средства Python, чтобы потом применить предметно-независимые знания к вашим рабочим проектам.
Итоги
• Очень важно сформировать стратегию прагматичного обучения. Сосредоточившись на предметно-независимых аспектах Python, вы сможете подготовиться к любой профессиональной роли, связанной с программированием на Python.
• Python — язык программирования общего назначения, распространяемый с открытым кодом. Вокруг него сформировалось огромное сообщество разработчиков, которые создают и распространяют пакеты Python.
• Python конкурентоспособен во многих областях, включая веб-разработку, data science и машинное обучение. В каждой области существуют свои фреймворки и пакеты Python, которыми вы сможете пользоваться.
• Возможности Python не безграничны. Если вы планируете разрабатывать мобильные приложения или низкоуровневые драйверы устройств, используйте Swift, Kotlin, Java, C, C++, Rust или любой другой подходящий для этого язык.
• В книге проводится различие между предметно-независимыми и предметно-зависимыми знаниями Python. При этом на первое место ставится изучение предметно-независимых знаний Python.
• Путь изучения программирования не линеен. Хотя в книге будут рассматриваться расширенные средства, я также буду часто упоминать о базовых. Кроме того, вы столкнетесь с некоторыми сложными темами, изучение которых требует движения по восходящей спирали.
• Важнейшим рецептом для изучения Python (или любого другого языка программирования) является синтез отдельных технических навыков для формирования их разностороннего набора. В процессе синтеза вы будете изучать язык с прагматичной точки зрения, зная, какие методы подойдут для решаемой вами проблемы.
Часть 1. Использование встроенных моделей данных
Мы создаем приложения для решения неких повседневных задач. Интернет-магазины предназначены для того, чтобы люди покупали одежду и книги, не выходя из дому. Программы управления кадрами — чтобы компании могли управлять своими сотрудниками. Программы для работы с текстом дают возможность редактировать документы. С точки зрения разработки, какие бы задачи ни решало приложение, необходимо извлечь и обработать информацию об этих задачах. В программировании для моделирования разных видов информации в приложениях (например, описаний продуктов и сотрудников) должны использоваться соответствующие структуры данных. Они обеспечивают нас стандартизированными способами представления реальных сущностей в приложениях, позволяя применять конкретные правила, структуры и реализации для решения бизнес-задач.
В этой части мы сосредоточимся на использовании встроенных моделей данных, включая строки, списки, кортежи, словари и множества. Кроме того, вы освоите приемы, общие для разных типов структур, в том числе для данных, сходных с последовательностями, и итерируемых объектов.
2. Обработка и форматирование строк
В этой главе
• Использование f-строк для интерполяции выражений и применения форматирования
• Преобразование строк в другие типы данных
• Объединение и разбиение строк
• Применение регулярных выражений для расширенной обработки строк
Текстовая информация — самая важная форма данных практически в любом приложении. Текстовые данные, как и числовые, можно сохранять в текстовых файлах, а чтение из таких файлов требует обработки строк. На веб-сайте интернет-магазина, например, текст используется для вывода описания товаров. Машинное обучение сейчас в моде, и вы, возможно, уже слышали об одной из его специализаций — обработке естественных языков, направленной на извлечение информации из текстов. Из-за повсеместного использования строк обработка текстов становится неизбежным шагом подготовки данных в таких сценариях. В контексте нашего таск-менеджера атрибуты задачи нужно преобразовать в текстовые данные, чтобы они могли отображаться интерфейсной частью веб-приложения. При получении данных от интерфейсной части приложения необходимо преобразовать эти строки к правильному типу (например, к целому) для дальнейшей обработки. Необходимость правильной обработки и форматирования строк возникает во множестве реальных ситуаций. В этой главе будут рассмотрены некоторые распространенные задачи, встречающиеся при обработке текста.
2.1. Как использовать f-строки для интерполяции и форматирования
В языке Python предусмотрены разные способы форматирования текстовых строк. Один из популярных способов основан на использовании f-строк, позволяющих встраивать выражения в строковый литерал. Можно использовать и другие методы форматирования, но решения с f-строками лучше читаются, следовательно, f-строки становятся предпочтительным вариантом при подготовке строк для вывода.
ОБРАТИТЕ ВНИМАНИЕ F-строки впервые появились в Python 3.6. Префиксом f-строки может быть как символ f, так и символ F (от слова formatted — отформатированный). Строковый литерал представляет собой последовательность символов, заключенную в одинарные или двойные кавычки.
При использовании строк для вывода часто приходится иметь дело с не-строковыми данными, например целыми числами и числами с плавающей точкой. Допустим, таск-менеджер требует создания строкового вывода с использованием существующих переменных:
# Существующие переменные
name = "Homework"
urgency = 5
# Желательный вывод:
Name: Homework; Urgency Level: 5
В этом разделе вы научитесь использовать f-строки для интерполяции не-строковых данных и представления строк в нужном формате. Вы увидите, что при форматировании строк с использованием существующих строк и других разновидностей переменных f-строки являются лучшим решением с точки зрения удобочитаемости.
2.1.1. Форматирование строк до появления f-строк
Класс str работает с текстовыми данными через свои экземпляры, которые мы будем называть строковыми переменными. Помимо строковых переменных, в текстовую информацию также часто включаются такие типы данных, как целые числа и числа с плавающей точкой. Теоретически мы могли бы преобразовать нестроковые данные в строки и соединить их для получения нужного текстового вывода, как показано в листинге 2.1.
Листинг 2.1. Создание строкового вывода с применением конкатенации строк
task = "Name: " + name + "; Urgency Level: " + str(urgency)
print(task)
# Вывод: Name: Homework; Urgency Level: 5
В коде создания переменной task скрываются две потенциальные проблемы. Во-первых, он выглядит громоздко и не особенно хорошо читается, так как мы имеем дело с несколькими разными строками, каждая из которых заключена в кавычки. Во-вторых, urgency необходимо преобразовать из int в str, прежде чем значение может быть объединено с другими строками, что дополнительно усложняет операцию конкатенации.
Старые методы форматирования строк
До появления f-строк были доступны два решения. Первое решение записывается в классической форме языка C со знаком %, а во втором используется метод format.
Следующий фрагмент демонстрирует эти два решения:

Решение в стиле C использует символ % в строковом литерале для обозначения форматируемой переменной, за которой следует знак % и кортеж соответствующих переменных. Решение с методом format используется примерно так же. Вместо знаков % в литерале в нем применяются фигурные скобки как маркеры строковой интерполяции, а соответствующие переменные перечисляются в методе format.
Следует заметить, что оба способа все еще поддерживаются в Python, но они считаются устаревшими и вам практически не придется пользоваться ими. По этой причине я не стану подробно на них останавливаться. Важно знать, что все, что они позволяют сделать, можно сделать с помощью f-строк — более наглядного механизма строковой интерполяции и форматирования, — как будет показано в разделе 2.1.2.
основные понятия Методами обычно называются функции, определяемые в классах. В данном случае функция format определяется в классе str, поэтому этот метод вызывается для экземпляров str.
2.1.2. Использование f-строк для интерполяции переменных
Форматирование строк часто подразумевает объединение строковых литералов и переменных разных типов (например, целых чисел и строк). При интеграции переменных в f-строку можно интерполировать эти переменные, чтобы они автоматически преобразовывались в строки нужного вида. В этом разделе описаны разные варианты интерполяции распространенных типов данных с использованием f-строк. Для начала рассмотрим, как использовать f-строки при создании вывода, представленного в листинге 2.1.
task_f = f"Name: {name}; Urgency Level: {urgency}"
assert task == task_f == "Name: Homework; Urgency Level: 5"
В этом примере переменная task_f создается с применением f-строк. Главное, на что следует обратить внимание, — фигурные скобки, в которые заключаются интерполируемые переменные. Так как f-строки интегрируют механизм строковой интерполяции, они также называются интерполируемыми строковыми литералами.
основные понятия Термин «строковая интерполяция» (string interpolation) не относится к специфике Python, этот механизм присутствует в большинстве основных современных языков (таких, как JavaScript, Swift и C#). В общем случае он предоставляет более компактный и удобочитаемый синтаксис для создания отформатированных строк, чем конкатенация строк и альтернативные способы их форматирования.
Инструкция assert
Ключевое слово Python assert используется для проверок (ассертов), которые вычисляют заданное условие. Если результат равен True, программа продолжает выполняться. Если же результат равен False, выполнение прерывается, а программа выдает ошибку AssertionError.
В этой книге я буду использовать инструкцию assert для демонстрации эквивалентности переменных, задействованных в сравнении. В особом случае, когда проверяемая переменная относится к логическому типу, с технической точки зрения лучше использовать assert true_var и assert not false_var. Но чтобы более наглядно отразить логическое значение переменной, я предпочел использовать assert true_var == True и assert false_var == False.
Вы уже видели, как f-строки интерполируют строки и целочисленные переменные. Как насчет других типов, например, списков list и кортежей tuple? Эти типы также поддерживаются f-строками, как показывает следующий фрагмент:

Забегая вперед F-строки также поддерживают экземпляры пользовательских классов. Когда в главе 8 мы займемся созданием пользовательских классов, мы еще вернемся к тому, как строковая интерполяция работает с пользовательскими экземплярами (раздел 8.4).
2.1.3. Использование f-строк для интерполяции выражений
Мы рассмотрели, как в f-строках интерполируются переменные. На более общем уровне f-строки также могут интерполировать выражения, что избавляет вас от необходимости создания промежуточных переменных. Например, при создании строкового вывода можно обратиться к элементу объекта dict или использовать результат вызова функции. В таких распространенных ситуациях можно включить эти выражения в f-строки, как показывает следующий фрагмент кода:

Эти выражения заключаются в фигурные скобки, чтобы f-строки напрямую вычислили их для получения нужного строкового вывода: {tasks[0]} -> "homework"; {task_name.title()} -> "Grocery Shopping"; {number*number} -> 25.
В тексте часто встречается термин «выражение» (expression), относящийся к числу ключевых понятий программирования. Начинающие программисты могут путать его со связанным понятием — инструкцией (statement). Выражение обычно представляет собой одну строку кода (хотя может занимать несколько строк при заключении в тройные кавычки), результатом вычисления которой является значение объекта, например строки или экземпляра нестандартного класса. Из этого определения легко выводится, что переменные являются разновидностями выражений.
С другой стороны, инструкции не создают никакого значения или объекта. Цель инструкции заключается в выполнении некоторого действия. Например, ключевое слово assert создает проверочную инструкцию (или команду), которая проверяет выполнение некоторого условия, прежде чем процесс продолжится. Мы не пытаемся получить логическое значение True или False, а проверяем условие. Рисунок 2.1 показывает, чем выражения отличаются от инструкций.
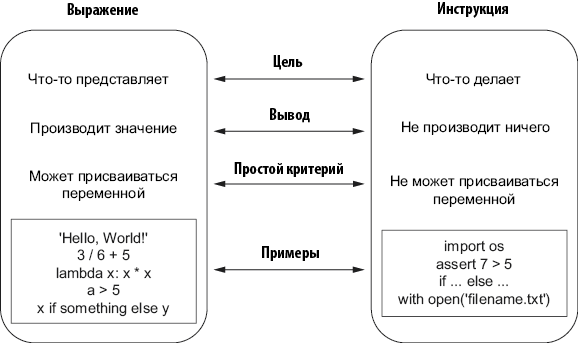
Рис. 2.1. Различия между выражениями и инструкциями. Выражения представляют некие вычисления, в результате которых получается значение или объект, тогда как инструкция выполняет конкретные действия и не может вычисляться для получения значения
Хотя f-строки поддерживают интерполяцию выражений, эту возможность следует использовать с осторожностью, потому что любые сложные выражения в f-строках ухудшают читаемость вашего кода. Следующий пример демонстрирует злоупотребление f-строками, использующими сложные выражения:
summary_text = f"Your Average Score: {sum([95, 98, 97, 96, 97, 93]) /
➥ len([95, 98, 97, 96, 97, 93])}."
Существует хороший практический критерий оценки удобочитаемости вашего кода — определите, сколько времени потребуется читателю, чтобы разобраться в нем. Чтобы понять, что происходит в приведенном выше фрагменте, читателю понадобятся десятки секунд. Сравните со следующей переработанной версией:
scores = [95, 98, 97, 96, 97, 93]
total_score = sum(scores)
subject_count = len(scores)
average_score = total_score / subject_count
summary_text = f"Your Average Score: {average_score}."
В этой версии заслуживает внимания ряд обстоятельств. Во-первых, оценки сохраняются в объекте list, что позволяет избавиться от дублирования данных. Во-вторых, вычисления разбиты на несколько шагов, при этом каждый шаг представляет собой более простое вычисление. В-третьих, ключевым фактором для улучшения удобочитаемости становится использование на каждом шаге содержательного имени, обозначающего результат вычислений. Такой код хорошо читается без единого комментария, все понятно само по себе.
Удобочитаемость Создайте необходимые промежуточные переменные с содержательными именами, чтобы наглядно обозначить каждый шаг ваших операций. Для простых операций вам даже не придется писать комментарии, потому что содержательные имена описывают смысл каждой операции.
2.1.4. Применение спецификаторов для форматирования f-строк
Правильное форматирование текстовых данных (например, выравнивание) играет ключевую роль в передаче информации. Так как f-строки проектировались для форматирования строк, они предоставляют возможность задать спецификатор формата (начинающийся с двоеточия) для применения дополнительных правил форматирования к выражению в фигурных скобках (рис. 2.2). В этом разделе вы узнаете, как применять спецификаторы для форматирования f-строк.
При интерполяции можно воспользоваться спецификатором формата — необязательным компонентом, который определяет, как должна форматироваться интерполированная строка выражения. F-строка может получать разные виды спецификаторов формата. Рассмотрим самые полезные их разновидности, начиная с выравнивания текста.
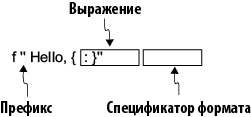
Рис. 2.2. Компоненты f-строки. Выражение — первая и обязательная часть. Сначала вычисляется выражение, затем создается соответствующая строка. Вторая часть — спецификатор формата — не является обязательной
Выравнивание строк для формирования визуальной структуры
Одним из способов повышения эффективности передачи информации является ее структурированная организация; это в полной мере относится к представлению текстовых данных. Как показано на рис. 2.3, сценарий B благодаря применению более организованной структуры с выравниванием столбцов предоставляет информацию нагляднее, чем сценарий А.

Рис. 2.3. Наглядность представления при организованной структуре текста (сценарий B) по сравнению с выравниванием по левому краю, используемым по умолчанию (сценарий А)
Для выравнивания текста в f-строках используются три символа: <, > и ^, включающие выравнивание текста по левому краю, по правому краю и по центру соответственно. Если вы начнете путаться в том, какой символ что делает, посмотрите, в каком направлении указывает стрелка: например, если она направлена влево, то текст выравнивается по левому краю.
Для определения режима выравнивания текста в спецификаторе формата используется синтаксис f"{expr:x<n}", где expr — интерполированное выражение, x — символ-заполнитель для выравнивания (если не указан, по умолчанию используется пробел), < — признак выравнивания по левому краю и n — целочисленный интервал, до которого расширяется вывод. Следующий листинг показывает, как создать две записи с выровненными полями для получения более наглядного вывода.
Листинг 2.2. Применение спецификаторов формата в f-строках
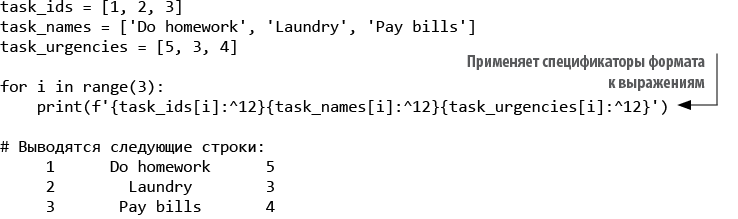
В этом листинге стоит обратить внимание на то, что применение одного спецификатора формата ко всем выражениям приводит к повторению. Если в вашем коде встречаются повторения, скорее всего, вы нарушаете принцип DRY (Don’t Repeat Yourself, то есть «не повторяйтесь»), а это указывает на необходимость рефакторинга.
Принцип DRY и рефакторинг
В программировании разработчики руководствуются рядом принципов. К их числу относится знаменитый принцип DRY. Если в вашей программе встречается повторяющийся код, скорее всего, следует провести рефакторинг для устранения таких повторений. Некоторые IDE, в частности PyCharm, включают средства автоматического выявления повторений. Пользуйтесь ими для улучшения своих программ.
Говоря о рефакторинге, я имею в виду меры по обновлению существующего кода для улучшения его структуры и, как следствие, повышения удобства сопровождения. Рефакторинг не добавляет новые возможности в вашу программу; вместо этого он изменяет структуру существующего кода без добавления каких-либо изменений в его поведение. Примеры рефакторинга будут приводиться в книге там, где его применение уместно.
Если появятся новые требования к выравниванию текста, в листинге 2.2 код придется обновлять в трех местах; это неудобно и повышает риск ошибок. В результате рефакторинга мы хотим получить механизм использования переменной в качестве спецификатора формата. В листинге 2.3 приведено возможное решение, в котором выделяется повторяющаяся часть — спецификатор формата. Если же пойти немного дальше по пути рефакторинга, можно определить функцию, которая будет получать спецификатор формата в параметре; это позволит экспериментировать с разными спецификаторами формата. Чтобы улучшить удобочитаемость кода, мы создадим отдельные переменные для данных задачи.
Листинг 2.3. Функция, получающая произвольный спецификатор формата
def create_formatted_records(fmt):
for i in range(3):
task_id = task_ids[i]
name = task_names[i]
urgency = task_urgencies[i]
print(f'{task_id:{fmt}}{name:{fmt}}{urgency:{fmt}}')
В листинге 2.3 стоит обратить внимание на то, что спецификатор формата fmt заключен в фигурные скобки внутри внешних фигурных скобок. Python знает, как заменить {fmt} правильным спецификатором формата. Опробуем эту функцию с разными спецификаторами формата:
>>> create_formatted_records('^15')
1 Do homework 5
2 Laundry 3
3 Pay bills 4
>>> create_formatted_records('^18')
1 Do homework 5
2 Laundry 3
3 Pay bills 4
Как видите, полученный в результате рефакторинга код позволяет назначить произвольный спецификатор формата, и эта гибкость подчеркивает преимущества рефакторинга. Когда спецификаторы формата используются для выравнивания, текст образует четко различимые столбцы. Тем самым создаются визуальные границы для разделения разных информационных полей.
СОПРОВОЖДАЕМОСТЬ Мы постоянно ищем возможности для рефакторинга своего кода, обычно на «локальном» уровне. Локальная оптимизация может показаться чем-то незначительным, но эти мелкие усовершенствования накапливаются и определяют общее удобство сопровождения проекта.
Для заполнения в приведенном примере используются пробелы, но можно использовать и другие символы. Выбор символов зависит от того, способствуют ли они наглядному выделению информации. В табл. 2.1 приведены примеры использования разных заполнителей и режимов выравнивания.
Таблица 2.1. Спецификаторы формата f-строк для выравнивания текста
| F-строка |
Вывод |
Описание |
| f"{task:*>10}"a |
"**homework" |
Выравнивание по правому краю, заполнитель * |
| f"{task:*<10}" |
"homework**" |
Выравнивание по левому краю, заполнитель * |
| f"{task:*^10}" |
"*homework*" |
Выравнивание по центру, заполнитель * |
| f"{task:^10}" |
" homework " |
Выравнивание по центру, заполнитель — пробел |
a Задача task определяется как строковая переменная: task = "homework"
Форматирование чисел
Числа — неотъемлемые источники информации, которые часто включаются в текстовый материал. Существуют различные формы числовых значений: большие целые числа, числа с плавающей точкой, проценты и т.д. В этом разделе вы узнаете, как f-строки представляют числовые значения со спецификаторами формата, упрощающими восприятие информации.
Множество простых чисел бесконечно. Обычный поиск в Google показывает, что наименьшее простое число, превышающее 1 миллиард, равно 1 000 000 007. При выводе такого большого числа желательно разделять группы цифр, и чаще всего после каждых трех цифр вставляется запятая. Для назначения разделителей групп разрядов в целых числах в f-строке используется спецификатор формата xd, где x — разделитель, а d — спецификатор формата для целых чисел:
large_prime_number = 1000000007
print(f"Use commas: {large_prime_number:,d}")
# Вывод: Use commas: 1,000,000,007
Числа с плавающей точкой, как и дробные числа вообще, встречаются почти в каждом научном или инженерном отчете. Как и следовало ожидать, у f-строк существуют спецификаторы формата, которые позволяют форматировать дробные числа в удобочитаемом виде. Рассмотрим следующие примеры:
decimal_number = 1.23456
print(f"Two digits: {decimal_number:.2f}")
# Вывод: Two digits: 1.23
print(f"Four digits: {decimal_number:.4f}")
# Вывод: Four digits: 1.2346
Если для целых чисел использовался спецификатор формата d, то для дробных значений используется спецификатор f. Хотя спецификатор f может использоваться автономно, чаще указывается, сколько цифр должно выводиться в дробной части: .2 для вывода двух цифр, .4 — для четырех цифр, и т.д.
По аналогии с использованием f для дробных чисел, можно воспользоваться спецификатором формата e для экспоненциальной (научной) записи. Пример использования этой возможности:
sci_number = 0.00000000412733
print(f"Sci notation: {sci_number:e}")
# Вывод: Sci notation: 4.1227330e-09
print(f"Sci notation: {sci_number:.2e}")
# Вывод: Sci notation: 4.13e-09
Другая распространенная форма числовых значений — проценты. При выводе процентов используется спецификатор формата %. Как и в случае со спецификаторами e и f, мы можем использовать спецификатор % сам по себе или с указанием точности (например, .2 для вывода двух знаков в дробной части):
pct_number = 0.179323
print(f"Percentage: {pct_number:%}")
# Вывод: Percentage: 17.932300%
print(f"Percentage two digits: {pct_number:.2%}")
# Вывод: Percentage two digits: 17.93%
Помимо этих спецификаторов, f-строки поддерживают и другие. В табл. 2.2 приведены популярные спецификаторы, применяемые к f-строкам при работе с числами.
Таблица 2.2. Популярные спецификаторы при форматировании чисел с использованием f-строк
| Числовой тип |
F-строка |
Вывод |
Описание |
| int |
f"{number:b}" |
"1111" |
Двоичный формат (запись по основанию 2) |
| f"{number:c}" |
"\x0f" |
Представление целого числа в Юникоде |
|
| f"{number:d}" |
"15" |
Десятичный формат (запись по основанию 10) |
|
| f"{number:o}" |
"17" |
Восьмеричный формат (запись по основанию 8) |
|
| f"{number:x}" |
"f" |
Шестнадцатеричный формат (запись по основанию 16) |
|
| float |
f"{point:.2e}" |
"1.23e+00" |
Научная запись |
| f"{point:.2f}" |
"1.23" |
Запись с фиксированной точкой и двумя цифрами в дробной части |
|
| f"{point:.2g}" |
"1.23" |
Общий формат с автоматическим применением e или f |
|
| f"{point:.2%}" |
"123.45%" |
Проценты с точностью 2 знакаa |
a Мы определяем number как целочисленную переменную (number = 15), а point — как переменную с плавающей точкой (point = 1.2345). Обратите внимание: часть .2 в спецификаторе формата для float не является обязательной. При использовании записи .3 будет использоваться точность с тремя цифрами в дробной части.
2.1.5. Обсуждение
Хотя с прямой интерполяцией выражений f-строками код становится более чистым, избегайте использования сложных выражений в f-строках — они могут запутать читателей вашего кода. Если выражения слишком сложные, создайте промежуточные переменные с содержательными именами.
В Python все еще поддерживаются традиционные способы в стиле C и с использованием format, но реальной необходимости в их изучении нет (впрочем, они могут встретиться вам в старом коде). Каждый раз, когда вам потребуется создать строковый вывод, используйте f-строки. И не забывайте о выравнивании текста и форматировании числовых значений — это сделает текстовый вывод более понятным.
2.1.6. Задача
Джеймс работает в IT-отделе компании оптовой торговли и готовит шаблон для ценников. Допустим, данные товара сохраняются в объекте dict: {"name": "Vacuum", "price": 130.675}. Как Джеймсу записать f-строку, если нужно, чтобы в ценнике выводилась строка Vacuum: {130.68}? Обратите внимание: цена должна выводиться с точностью до двух знаков, а вывод включает фигурные скобки — символы, используемые для строковой интерполяции в f-строках.
Подсказка Фигурные скобки являются специальными символами в f-строках. Если строковый литерал включает специальные символы, необходимо экранировать их, чтобы они не рассматривались как специальные символы. Для экранирования фигурных скобок включите дополнительную фигурную скобку: {{ означает {, а }} означает }.
2.2. Как преобразовать строки для получения представляемых данных
Хотя внешне строки являются текстовыми данными, фактически они могут представлять целые числа, словари и другие типы данных. Например, встроенная функция input предоставляет простейший способ получения пользовательского ввода с консоли Python:

Как показывает приведенный фрагмент кода, ввод пользователя представляет собой строку. Допустим, вы хотите проверить, что пользователю исполнилось не менее 18 лет. Казалось бы, достаточно выполнить следующий фрагмент:
>>> age > 18
# ERROR: TypeError: '>' not supported between instances of 'str' and 'int'
К сожалению, сравнение не работает, потому что age является строкой, а строку нельзя сравнивать с целым числом. В более широком смысле многие ситуации требуют преобразования строк в списки, словари и другие применимые типы данных. Такое преобразование крайне важно для последующей обработки данных. В этом разделе вы узнаете, как проверить типы данных, представляемые строками, и как правильно преобразовывать строки к нужному типу данных.
2.2.1. Проверка строк на представление алфавитно-цифровых значений
В языке Python строки могут содержать любую последовательность символов, которые вводятся с клавиатуры. Одна из типичных задач при работе с ними — проверка того, содержит ли строка только алфавитно-цифровые символы. В этом разделе рассматриваются различные способы проверки символов строки.
Допустим, таск-менеджер требует, чтобы пользователи вводили свое имя, которое должно состоять из алфавитно-цифровых символов. Для реализации этой функциональности можно воспользоваться методом isalnum, проверяющим, что строка состоит только из символов a-z, A-Z и 0-9. Несколько примеров:
bad_username0 = "123!@#"
assert bad_username0.isalnum() == False
bad_username1 = "abc..."
assert bad_username1.isalnum() == False
good_username = "1a2b3c"
assert good_username.isalnum() == True
Предположим, название создаваемой задачи должно состоять только из букв. Для проверки этого можно воспользоваться методом isalpha, который возвращает True или False. Как вы, вероятно, уже заметили, все is-методы возвращают логические значения:
assert "Homework".isalpha() == True
assert "Homework123".isalpha() == False
Аналогичным образом при помощи метода isnumeric можно проверить, являются ли все символы в строке цифровыми символами:
assert "123".isnumeric() == True
assert "a123".isnumeric() == False
Стоит обсудить несколько подводных камней, на которые можно натолкнуться при использовании метода isnumeric для проверки того, представляет ли строка числовое значение:
• Строки, представляющие числа с плавающей точкой, не проходят проверку isnumeric. Казалось бы, для строк, содержащих действительные числовые значения, вызов этого метода должен возвращать True. К сожалению, это не так:
assert "3.5".isnumeric() == False
• Строки, представляющие отрицательные числа, не проходят проверку isnumeric. Вероятно, это тоже противоречит нашим интуитивным представлениям, как в следующем примере:
assert "-2".isnumeric() == False
• Для пустых строк isnumeric возвращает False. Пожалуй, интерпретация пустых строк как нецифровых значений соответствует нашим ожиданиям. При преобразовании строк в целые числа следует понимать, что происходит.
Чтобы избежать всех этих проблем, запомните, что строка выдает значение True при проверке методом isnumeric только в том случае, если все символы непустой строки являются цифровыми. К категории цифровых символов не относятся точка или знак «минус». По этой причине метод isnumeric интерпретирует числа с плавающей точкой и отрицательные числа как False.
Чем различаются isnumeric, isdigit и isdecimal
Методы isdigit и isdecimal, родственные с isnumeric, часто используются для проверки того, содержат ли строки только цифры или символы десятичных чисел. Казалось бы, их имена означают одно и то же, и в большинстве случаев — например, для строки "123" — они возвращают одинаковые логические результаты. Однако существуют нюансы, из-за которых они возвращают разные значения для некоторых строк, особенно если числовые строки не содержат арабские цифры.
По определению эти три метода связаны следующими отношениями в контексте жесткости проверки: isdecimal < isdigit < isnumeric. Если вы боитесь запутаться в этих методах, лучше использовать наиболее общий метод isnumeric.
Напомним, что кроме описанных методов is… для проверки числового содержимого у строк Python имеются другие методы is… для выполнения других проверок, например islower и isupper. И хотя в этой книге другие методы is… не рассматриваются, вам стоит ознакомиться с ними.
ОБРАТИТЕ ВНИМАНИЕ В категории is… присутствует интересный метод isidentifier. Он проверяет, является ли строка допустимым идентификатором, который может использоваться в качестве имени переменной, функции или объекта.
2.2.2. Преобразование строк в числа
В предыдущем разделе вы узнали, как проверить, представляет ли строка положительное целое число. Однако вообще-то не существует простого способа определить, представляет ли строка числовое значение, особенно если это число с плавающей точкой или отрицательное число. Преобразования строк в числа важны, потому что со строками невозможно выполнять числовые вычисления — например, сравнить age с 18. Поэтому во многих случаях для последующей обработки требуется получить числовое значение, представляемое строкой. В этом разделе вы научитесь преобразовывать строки в числа — этот процесс также называется приведением типа (casting).
основные понятия В программировании приведением типа называется процесс преобразования типа данных к другому типу данных (например, преобразования строки в целое число).
Для работы с числовыми значениями обычно используются типы float и int. Для создания экземпляров этих типов на базе строк используется синтаксис float("string") и int("string"). Python вычисляет объекты строк, чтобы преобразовать их в правильный объект float или int, если это возможно.
Если вы предполагаете, что строка представляет число с плавающей точкой, передайте ее встроенному конструктору float. В следующих примерах все преобразованные числа относятся к типу float, хотя строка представляет целое число:

основные понятия Конструктором (constructor) называется особая разновидность функций, которые создают экземпляр (объект) класса. За дополнительной информацией по этой теме обращайтесь к главе 8. Здесь мы используем конструкторы float и int для создания объектов типов float и int соответственно.
Если вы ожидаете, что строка содержит целое число, используйте встроенный конструктор int:
>>> int("-5")
-5
>>> int("123")
123
Операции преобразования завершаются успешно, если эти строки содержат предполагаемые числовые значения. Но в противном случае попытка преобразования приводит к ошибке, а ваша программа аварийно завершается, как показано в следующем фрагменте:
>>> float("3.5a")
# ERROR: ValueError: could not convert string to float: '3.5a'
>>> int("one")
# ERROR: ValueError: invalid literal for int() with base 10: 'one'
Чтобы программа не завершалась из-за этой ошибки, используйте конструкцию try…except… для обработки исключения. Хотя я не буду подробно обсуждать эту тему здесь, следующий листинг продемонстрирует такое применение. Данная возможность рассматривается в главе 12 (раздел 12.3).
Листинг 2.4. Преобразование чисел в строки

2.2.3. Вычисление строк для получения представляемых данных
Кроме числовых значений, в приложениях также используются текстовые данные, представляющие данные других типов, например списки и кортежи. Так, в веб-приложении данные часто вводятся в текстовом формате — скажем, строка «[1, 2, 3]» представляет объект list. Так как в данном случае используется тип данных str, к текстовым данным не могут применяться никакие методы list; иначе говоря, методы list могут вызываться только для объектов list. В таком случае требуется преобразование данных. В этом разделе вы узнаете, как получить из строк другие виды данных помимо чисел.
В предыдущем разделе вы научились использовать конструкторы float и int для преобразования строк и получения числовых значений. Впрочем, решение, когда вызывается конструктор с объектом строки, работает не всегда. Возьме



















