

автордың кітабын онлайн тегін оқу Глоссариум по искусственному интеллекту: 2500 терминов. Том 1
Александр Юрьевич Чесалов
Александр Николаевич Власкин
Матвей Олегович Баканач
Глоссариум по искусственному интеллекту: 2500 терминов
Том 1
Шрифты предоставлены компанией «ПараТайп»
Редактор Хаджимурад Ахмедович Магомедов
Дизайнер обложки Александр Юрьевич Чесалов
Иллюстратор Александр Юрьевич Чесалов
Корректор Александр Хафизович Юлдашев
© Александр Юрьевич Чесалов, 2024
© Александр Николаевич Власкин, 2024
© Матвей Олегович Баканач, 2024
© Александр Юрьевич Чесалов, дизайн обложки, 2024
© Александр Юрьевич Чесалов, иллюстрации, 2024
Дорогой читатель!
Вашему вниманию предлагается уникальная книга!
Современный глоссарий из более чем 2500 популярных терминов и определений по машинному обучению и искусственному интеллекту.
Эта книга написана экспертами-практиками, которые вместе работали над Программой Центра искусственного интеллекта, а также программами «Искусственный интеллект» и «Глубокая аналитика» проекта «Приоритет 2030» в МГТУ им. Н. Э. Баумана в 2021—2022 годах.
ISBN 978-5-0056-8677-0
Создано в интеллектуальной издательской системе Ridero
Оглавление
От Авторов-составителей
Александр Юрьевич Чесалов,
Власкин Александр Николаевич,
Баканач Матвей Олегович
Эксперты по информационным технологиям и искусственному интеллекту, разработчики программы Центра искусственного интеллекта МГТУ им. Н. Э. Баумана, программы «Искусственный интеллект» и «Глубокая аналитика» проекта «Приоритет 2030» МГТУ им. Н. Э. Баумана в 2021—2022 годах.
Дорогие Друзья и Коллеги!
Авторы составители этой книги посвятили подготовке и созданию данного глоссария (краткого словаря специализированных терминов) два года.
«Пилотная» версия книги была подготовлена всего за восемь месяцев и представлена на на 35-ой Московской международной книжной ярмарке в 2022 году.
В какой-то момент времени книга выросла до восьми ста шестидесяти страниц и нам пришлось подготовить двухтомное издание.
Сейчас мы рады представить Вам первый том книги, который содержит более тысячи двух сот пятидесяти терминов и определений по искусственному интеллекту на русском языке.
Изображение обложки к книге нарисовано в системе генеративного искусственного интеллекта Easy Diffusion.

Почему книга называется «Глоссариум»?
«Glossarium» на латинском языке означает словарь узкоспециализированных терминов.
Идея составления «глоссариев» принадлежит одному из соавторов книги — Александру Чесалову. Первый его опыт в этой области был в составлении глоссария по искусственному интеллекту и информационным технологиям, который он опубликовал в декабре 2021 года.[1] В нем первоначально было всего 400 терминов. Затем, уже в 2022 году, Александр его существенно расширил до более чем 1000 актуальных терминов и определений. Впоследствии он опубликовал целую серию книг, раскрывающих темы четвертой промышленной революции, цифровой экономики, цифрового здравоохранения и многих других.
Идея создания большого глоссария по искусственному интеллекту родилась в начале 2022 года. Авторы пришли к единодушному решению объединить свои усилия и свой опыт последних лет в области искусственного интеллекта, который был подкреплен несколькими знаменательными и судьбоносными событиями.
Несомненно, самое существенное событие, которое произошло несколько ранее в 2021 году — это участие авторов (как экспертов) в Конкурсе, проводимом Аналитическим Центром при Правительстве России по отбору получателей поддержки исследовательских центров в сфере искусственного интеллекта, в том числе в области «сильного» искусственного интеллекта, систем доверенного искусственного интеллекта и этических аспектов применения искусственного интеллекта. Перед нами стояла неординарная и еще на тот момент времени никем не решенная задача создания Центра разработки и внедрения сильного и прикладного искусственного интеллекта МГТУ им. Н. Э. Баумана. Все авторы этой книги приняли самое непосредственное участие в разработке и написании программы и плана мероприятий нового Центра. Подробнее об этой истории можно узнать из книги Александра Чесалова «Как создать центр искусственного интеллекта за 100 дней».
Далее мы приняли участие в Первом международном форуме «Этика искусственного интеллекта: начало доверия», который состоялся 26 октября 2021 года и в рамках которого была организована церемония торжественного подписания Национального кодекса этики искусственного интеллекта, устанавливающего общие этические принципы и стандарты поведения, которыми следует руководствоваться участникам отношений в сфере искусственного интеллекта в своей деятельности. По сути, форум стал первой в России специализированной площадкой, где собралось около полутора тысяч разработчиков и пользователей технологий искусственного интеллекта.
В дополнение ко всему мы не прошли мимо и Международной конференции по искусственному интеллекту и анализу данных AI Journey, в рамках которой 10 ноября 2021 года к подписанию Национального Кодекса этики искусственного интеллекта присоединились лидеры ИТ-рынка. Число спикеров конференции поражало воображение — их было более двухсот, а число онлайн-посещений сайта более сорока миллионов.
Уже в 2022 году мы приняли самое активное участие в Международном военно-техническом форуме «Армия-2022» с докладом «Разработка программно-аппаратных комплексов для решения широкого круга прикладных задач с использованием технологий машинного обучения и доверенного искусственного интеллекта в Оборонно-промышленном комплексе РФ».
Резюмируя всю нашу активную работу за последние пару лет и тот опыт, который был уже накоплен, мы пришли к необходимости систематизировать накопленные знания и изложить их в новой книге, которую вы держите в своих руках.
Мы часто с вами слышим «искусственный интеллект».
Но понимаем ли мы что это такое?
Например, в этой книге мы зафиксировали, что Искусственный интеллект — это компьютерная система, основанная на комплексе научных и инженерных знаний, а также технологий создания интеллектуальных машин, программ, сервисов и приложений, имитирующая мыслительные процессы человека или живых существ, способная с определенной степенью автономности воспринимать информацию, обучаться и принимать решения на основе анализа больших массивов данных, целью создания которой является помощь людям в решении их повседневных рутинных задач.
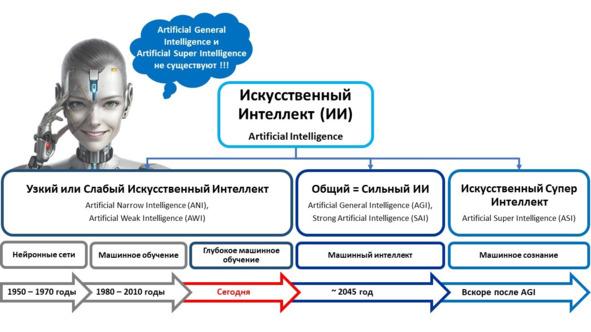
Или, еще один пример.
Что такое «доверенный искусственный интеллект»?
Системой доверенного искусственного интеллекта называют прикладную систему искусственного интеллекта, обеспечивающую выполнение возложенных на нее задач с учетом ряда дополнительных требований, учитывающих этические аспекты применения искусственного интеллекта, которая обеспечивает доверие к результатам ее работы, которые, в свою очередь, включают в себя: достоверность (надежность) и интерпретируемость выводов и предлагаемых решений, полученных с помощью системы и проверенных на верифицированных тестовых примерах; безопасность как с точки зрения невозможности причинения вреда пользователям системы на протяжении всего жизненного цикла системы, так и с точки зрения защиты от взлома, несанкционированного доступа и других негативных внешних воздействий, приватность и проверяемость данных, с которыми работают алгоритмы искусственного интеллекта, включая разграничение доступа и другие связанные с этим вопросы.
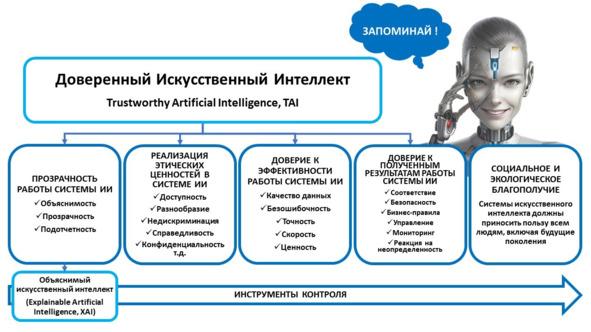
А что же тогда такое «машинное обучение»?
Машинное обучение — это одно из направлений (подмножеств) искусственного интеллекта, благодаря которому воплощается ключевое свойство интеллектуальных компьютерных систем — самообучение на основе анализа и обработки больших разнородных данных. Чем больше объем информации и ее разнообразие, тем проще искусственному интеллекту найти закономерности и тем точнее будет получаемый результат.
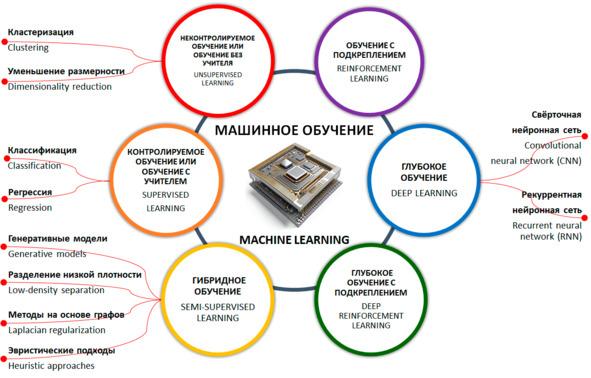
Чтобы заинтересовать уважаемого читателя, приведем еще несколько «забавных» примеров.
Слышали ли вы когда-нибудь о «Трансгуманистах»?
С одной стороны, как идея Трансгуманизм (Transhumanism) — это расширение возможностей человека с помощью науки. С другой стороны — это философская концепция и международное движение, приверженцы которого желают стать «постлюдьми» и преодолеть всевозможные физические ограничения, болезни, душевные страдания, старость и смерть благодаря использованию возможностей нано- и био- технологий, искусственного интеллекта и когнитивной науки.
На наш взгляд, идеи «трансгуманизма» очень тесно пересекаются с идеями и концепциями «цифрового человеческого бессмертия».

Несомненно, вы слышали и конечно знаете, кто такой «Data Scientist» — ученый и специалист по работе с данными.
А слышали ли вы когда-нибудь о «датасатанистах»? :-)
Датасатанисты — это определение, придуманное авторами, но отражающее современную действительность (наравне, например, с термином «инфоцыганщина»), которая сформировалась в период популяризации и повсеместной реализации идей искусственного интеллекта в современном информационном обществе. По своей сути датасатанисты — это мошенники и преступники, которые очень умело маскируются под ученых и специалистов в области ИИ и МО, но при этом пользуются чужими заслугами, знаниями и опытом, в своих корыстных целях и целях незаконного обогащения.
А, как вам такой термин — «библеоклазм»?
Библиоклазм — человек, в силу своего трансформированного мировоззрения и чрезмерно раздутого эго, из зависти или какой-либо другой корыстной цели, который стремится уничтожить книги других авторов. Вы не поверите, но таких людей, как «датасатанисты» или «библиоклазмы» сейчас достаточно.
А, как вам такие термины: «искусственная жизнь», «искусственный сверхинтеллект», «нейроморфный искусственный интеллект», «человеко-ориентированный искусственный интеллект», «синтетический интеллект», «распределенный искусственный интеллект», «дружественный искусственный интеллект», «дополненный искусственный интеллект», «композитный искусственный интеллект», «объяснимый искусственный интеллект», «причинно-следственный искусственный интеллект», «символический искусственный интеллект» и многие другие (все они есть в этой книге).
Таких примеров «удивительных» терминов мы можем привести еще не мало. Но в своей работе мы не стали тратить время на «суровую действительность» и сместили акцент на конструктивный и позитивный настрой. Одним словом, мы провели для Вас большую работу и собрали более 2500 терминов и определений по машинному обучению и искусственному интеллекту на основе своего опыта и данных из огромного числа различных источников.
2500 терминов и определений.
Много это или мало?
Наш опыт подсказывает, что для взаимопонимания двум собеседникам достаточно знать десяток или, максимум, два десятка определений. Но, когда дело касается профессиональной деятельности, то может получиться так, что мало знать, даже, несколько десятков терминов.
В этой книге приведены самые актуальные термины и определения, по-нашему мнению, наиболее часто употребляемые, как в повседневной работе, так и профессиональной деятельности специалистами самых разных профессий, интересующихся темой «искусственного интеллекта».
Мы очень старались сделать для вас нужный и полезный «инструмент» для вашей работы.
В заключение хочется добавить и проинформировать уважаемого читателя о том, что эта книга является абсолютно открытым и свободным к распространению документом. В случае, если Вы используете ее в своей практической работе, просим Вас делать ссылку на нее.
Многие из терминов и определений к ним, в этой книге, встречаются в сети Интернет. Они повторяются десятки или сотни раз на различных информационных ресурсах (в основном на зарубежных). Тем не менее, мы поставили перед собой цель — собрать и систематизировать самые актуальные из них в одном месте из самых разных источников, нужные из них перевести на русский язык и/или адаптировать, а какие-то и написать заново, исходя из собственного опыта.
Учитывая вышесказанное, мы не претендуем на авторство или уникальность представленных терминов и определений, но, несомненно, мы внесли свой собственный вклад в систематизацию и адаптацию многих из них.
Книга написана, прежде всего, для вашего удовольствия.
Мы продолжаем работу по улучшению качества и содержания текста этой книги, в том числе дополняем ее новыми знаниями по предметной области. Будем вам благодарны за любые отзывы, предложения и уточнения. Направляйте их, пожалуйста, на aleksander.chesalov@yandex.ru
Приятного Вам чтения и продуктивной работы!
Ваши, Александр Чесалов, Александр Власкин и Матвей Баканач.
16.08.2022. Издание первое.
09.03.2023. Издание второе. Исправленное и дополненное.
01.01.2024. Издание третье. Исправленное и дополненное.

.Чесалов А. Ю. Глоссариум по искусственному интеллекту и информационным технологиям.-М.: Ridero. 2021.-304c. [Электронный ресурс] // Ridero.ru. URL: https://ridero.ru/books/glossarium_po_ informacionnym_tekhnologiyam_i_iskusstvennomu_intellektu/
.Чесалов А. Ю. Глоссариум по искусственному интеллекту и информационным технологиям.-М.: Ridero. 2021.-304c. [Электронный ресурс] // Ridero.ru. URL: https://ridero.ru/books/glossarium_po_ informacionnym_tekhnologiyam_i_iskusstvennomu_intellektu/
Глоссариум по искусственному интеллекту
«А»
А/B-тестирование, также известное как сплит-тестирование (A/B Testing) — это процесс экспериментирования, при котором две или более версии переменной (веб-страницы, элемента страницы и т.д.) одновременно демонстрируются разным сегментам посетителей веб-сайта, чтобы определить, какая версия оказывает максимальное влияние и повышает бизнес-показатели[1].
Абдуктивное логическое программирование (Abductive logic programming, ALP) — это высокоуровневая структура представления знаний, которая может использоваться для решения проблем декларативно — на основе абдуктивного рассуждения. Она расширяет нормальное логическое программирование, позволяя некоторым предикатам быть неполно определенными, объявленными как абдуктивные предикаты[2].
Абдукция (Abductive reasoning) — (от латинского ab — «c, от», ducere — «водить») — это форма логического вывода, которая начинается с наблюдения или набора наблюдений, а затем пытается найти самое простое и наиболее вероятное объяснение. Этот процесс, в отличие от дедуктивного рассуждения, дает правдоподобный вывод, но не подтверждает его основаниями для вывода[3].
Абстрактный тип данных (Abstract data type) — это математическая модель для типов данных, где тип данных определяется поведением (семантикой) с точки зрения пользователя, а именно в терминах возможных значений, возможных операций над данными этого типа и поведения этих операций. Формально АТД может быть определён как множество объектов, определяемое списком компонентов (операций, применимых к этим объектам, и их свойств)[4].
Абстракция (Abstraction) — это использование только тех характеристик объекта, которые с достаточной точностью представляют его в данной системе. Основная идея состоит в том, чтобы представить объект минимальным набором полей и методов и при этом с достаточной точностью для решаемой задачи[5].
Автоассоциативная память (Auto Associative Memory) — это однослойная нейронная сеть, в которой входной обучающий вектор и выходные целевые векторы совпадают. Веса определяются таким образом, чтобы сеть хранила набор шаблонов. Как показано на следующем рисунке, архитектура сети автоассоциативной памяти имеет «n» количество входных обучающих векторов и аналогичное «n» количество выходных целевых векторов[6].
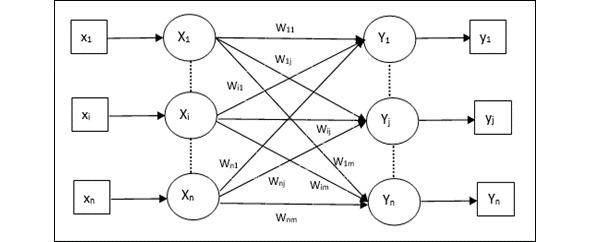
Автокодер (Автоэнкодер) (Autoencoder, AE) — это нейронная сеть, которая копирует входные данные на выход. По архитектуре похож на персептрон. Автоэнкодеры сжимают входные данные для представления их в latent-space (скрытое пространство), а затем восстанавливают из этого представления output (выходные данные). Цель — получить на выходном слое отклик, наиболее близкий к входному. Отличительная особенность автоэнкодеров — количество нейронов на входе и на выходе совпадает[7].
Автоматизация (Automation) — это технология, с помощью которой процесс или процедура выполняется с минимальным участием человека[8].
Автоматизированная обработка персональных данных (Automated processing of personal data) — это обработка персональных данных с помощью средств вычислительной техники[9].
Автоматизированная система (Automated system) — это организационно-техническая система, которая гарантирует выработку решений, основанных на автоматизации информационных процессов во всевозможных отраслях деятельности[10].
Автоматизированная система управления (Automated control system) — это комплекс программных и программно-аппаратных средств, предназначенных для контроля за технологическим и (или) производственным оборудованием (исполнительными устройствами) и производимыми ими процессами, а также для управления такими оборудованием и процессами[11].
Автоматизированное мышление (Automated reasoning) — это область информатики, которая занимается применением рассуждений в форме логики к вычислительным системам. Если задан набор предположений и цель, автоматизированная система рассуждений должна быть способна автоматически делать логические выводы для достижения этой цели[12].
Автономное транспортное средство (Autonomous vehicle) — это вид транспорта, основанный на автономной системе управления. Управление автономным транспортным средством полностью автоматизировано и осуществляется без водителя при помощи оптических датчиков, радиолокации и компьютерных алгоритмов[13].
Автономность (Autonomous) — это способность машины выполнять свою задачу без вмешательства и контроля человека[14].
Автономные вычисления (Autonomic computing) — это способность системы к адаптивному самоуправлению собственными ресурсами для высокоуровневых вычислительных функций без ввода данных пользователем[15].
Автономный автомобиль (Autonomous car) — это транспортное средство, способное воспринимать окружающую среду и работать без участия человека. Пассажир-человек не обязан брать на себя управление транспортным средством в любое время, и пассажиру-человеку вообще не требуется присутствовать в транспортном средстве. Автономный автомобиль может проехать везде, где ездит традиционный автомобиль, и делать все то же, что и опытный водитель-человек[16].
Автономный вывод (Offline inference) — это генерация группы прогнозов, сохранение этих прогнозов, а затем извлечение этих прогнозов по запросу[17].
Автономный искусственный интеллект (Autonomous artificial intelligence) — это биологически инспирированная система, которая пытается воспроизвести устройство мозга, принципы его действия со всеми вытекающими отсюда свойствами[18],[19].
Автономный робот (Autonomous robot) — это робот, который спроектирован и сконструирован так, чтобы самостоятельно взаимодействовать с окружающей средой и работать в течение длительных периодов времени без вмешательства человека. Автономные роботы часто обладают сложными функциями, которые могут помочь им воспринимать физическое окружение и автоматизировать действия и процессы, которые раньше выполнялись руками человека[20].
Авторегрессионная модель (Autoregressive Model) — это модель временного ряда, в которой наблюдения за предыдущими временными шагами используются в качестве входных данных для уравнения регрессии для прогнозирования значения на следующем временном шаге. В статистике и обработке сигналов авторегрессионная модель представляет собой тип случайного процесса. Он используется для описания некоторых изменяющихся во времени процессов в природе, экономике и т.д.[21].
Агент (Agent) в обучении с подкреплением — это испытуемая система, которая обучается и взаимодействует с некоторой средой. Агент воздействует на среду, а среда воздействует на агента[22].
Агрегат (Aggregate) — это сумма, созданная из более мелких единиц. Например, население области — это совокупность населения городов, сельских районов и т.д., входящих в состав области. Суммировать данные из меньших единиц в большую единицу[23].
Агрегатор (Aggregator) — это тип программного обеспечения, которое объединяет различные типы веб-контента и предоставляет его в виде легкодоступного списка. Агрегаторы каналов собирают такие данные, как онлайн-статьи из газет или цифровых изданий, публикации в блогах, видео, подкасты и т. д. Агрегатор каналов также известен как агрегатор новостей, программа для чтения каналов, агрегатор контента или программа для чтения RSS[24].
Агломеративная кластеризация (Agglomerative clustering) — это один из алгоритмов кластеризации, в котором процесс группировки похожих экземпляров начинается с создания нескольких групп, где каждая группа содержит один объект на начальном этапе, затем он находит две наиболее похожие группы, объединяет их, повторяет процесс до тех пор, пока не получит единую группу наиболее похожих экземпляров[25].
Адаптивная система (Adaptive system) — это система, которая автоматически изменяет данные алгоритма своего функционирования и (иногда) свою структуру для поддержания или достижения оптимального состояния при изменении внешних условий[26].
Адаптивная система нейро-нечеткого вывода (Adaptive neuro fuzzy inference system) (ANFIS) (также адаптивная система нечеткого вывода на основе сети) — это разновидность искусственной нейронной сети, основанная на системе нечеткого вывода Такаги-Сугено. Методика была разработана в начале 1990-х годов. Поскольку она объединяет как нейронные сети, так и принципы нечеткой логики, то может использовать одновременно все имеющиеся преимущества в одной структуре. Его система вывода соответствует набору нечетких правил ЕСЛИ-ТО, которые имеют возможность обучения для аппроксимации нелинейных функций. Следовательно, ANFIS считается универсальной оценочной функцией. Для более эффективного и оптимального использования ANFIS можно использовать наилучшие параметры, полученные с помощью генетического алгоритма[27].
Адаптивный алгоритм (Adaptive algorithm) — это алгоритм, который пытается выдать лучшие результаты путём постоянной подстройки под входные данные. Такие алгоритмы применяются при сжатии без потерь. Классическим вариантом можно считать Алгоритм Хаффмана[28],[29].
Адаптивный градиентный алгоритм (Adaptive Gradient Algorithm) (AdaGrad) — это cложный алгоритм градиентного спуска, который перемасштабирует градиент отдельно на каждом параметре, эффективно присваивая каждому параметру независимый коэффициент обучения[30].
Аддитивные технологии (Additive technologies) — это технологии послойного создания трехмерных объектов на основе их цифровых моделей («двойников»), позволяющие изготавливать изделия сложных геометрических форм и профилей[31].
Айзек Азимов (Isaac Asimov) (1920—1992) — автор научной фантастики, сформулировал три закона робототехники, которые продолжают оказывать влияние на исследователей в области робототехники и искусственного интеллекта (ИИ)[32].
Три закона робототехники Айзека Азимова (Three Laws of Robotics by Isaac Asimov) — Робот не может причинить вред человеку или своим бездействием допустить, чтобы человеку был причинен вред. Робот должен подчиняться приказам, отданным ему людьми, за исключением случаев, когда такие приказы противоречат Первому закону. Робот должен защищать свое существование до тех пор, пока такая защита не противоречит Первому или Второму закону[33].
Активное обучение/Стратегия активного обучения (Active Learning/ Active Learning Strategy) — это особый способ полууправляемого машинного обучения, в котором обучающий агент может в интерактивном режиме запрашивать оракула (обычно человека-аннотатора) для получения меток в новых точках данных. Подход к такому обучению основывается на самостоятельном выборе алгоритма некоторых данных из массы тех, на которых он учится. Активное обучение особенно ценно, когда помеченных примеров мало или их получение слишком затратно. Вместо слепого поиска разнообразных помеченных примеров алгоритм активного обучения выборочно ищет конкретный набор примеров, необходимых для обучения[34],[35],[36].
Алгоритм (Algorithm) — это точное предписание о выполнении в определенном порядке системы операций для решения любой задачи из некоторого данного класса (множества) задач. Термин «алгоритм» происходит от имени узбекского математика Мусы аль-Хорезми, который еще в 9 веке (ок. 820 г. н.э.) предложил простейшие арифметические алгоритмы. В математике и кибернетике класс задач определенного типа считается решенным, когда для ее решения установлен алгоритм. Нахождение алгоритмов является естественной целью человека при решении им разнообразных классов задач. Также, алгоритм — это набор правил или инструкций, данных ИИ, нейронной сети или другим машинам, чтобы помочь им учиться самостоятельно; классификация, кластеризация, рекомендация и регрессия — четыре самых популярных типа[37].
Алгоритм BLEU (BLEU) — это алгоритм оценки качества текста, который был автоматически переведен с одного естественного языка на другой. Качество считается соответствием между переводом машины и человека: «чем ближе машинный перевод к профессиональному человеческому переводу, тем лучше» — это основная идея BLEU[38].
Алгоритм Q-обучения (Q-learning) — это алгоритм обучения, основанный на ценностях. Алгоритмы на основе значений обновляют функцию значений на основе уравнения (в частности, уравнения Беллмана). В то время как другой тип, основанный на политике, оценивает функцию ценности с помощью жадной политики, полученной из последнего улучшения политики. Табличное Q-обучение (при обучении с подкреплением) представляет собой реализацию Q-обучения с использованием таблицы для хранения Q-функций для каждой комбинации состояния и действия. «Q» в Q-learning означает качество. Качество здесь показывает, насколько полезно данное действие для получения вознаграждения в будущем[39].
Алгоритм дерева соединений (также алгоритм Хьюгина) (Junction tree algorithm) — это метод, используемый в машинном обучении для извлечения маргинализации в общих графах. Граф называется деревом, потому что он разветвляется на разные разделы данных; узлы переменных являются ветвями[40],[41].
Алгоритм любого времени (Anytime algorithm) — это алгоритм, который может дать частичный ответ, качество которого зависит от объема вычислений, которые он смог выполнить. Ответ, генерируемый алгоритмами anytime, является приближенным к правильному. Большинство алгоритмов выполняются до конца: они дают единственный ответ после выполнения некоторого фиксированного объема вычислений. Однако в некоторых случаях пользователь может захотеть завершить алгоритм до его завершения. Эта особенность алгоритмов anytime моделируется такой теоретической конструкцией, как предельная машина Тьюринга (Бургин, 1992; 2005)[42].
Алгоритм обучения (Learning Algorithm) — это фрагменты кода, которые помогают исследовать, анализировать и находить смысл в сложных наборах данных. Каждый алгоритм представляет собой конечный набор однозначных пошаговых инструкций, которым машина может следовать для достижения определенной цели. В модели машинного обучения цель состоит в том, чтобы установить или обнаружить шаблоны, которые люди могут использовать для прогнозирования или классификации информации. Они используют параметры, основанные на обучающих данных — подмножестве данных, которое представляет больший набор. По мере расширения обучающих данных для более реалистичного представления мира, алгоритм вычисляет более точные результаты[43].
Алгоритм оптимизации Адам (Adam optimization algorithm) — это расширение стохастического градиентного спуска, который в последнее время получил широкое распространение для приложений глубокого обучения в области компьютерного зрения и обработки естественного языка[44].
Алгоритм оптимизации роя светлячков (Glowworm swarm optimization algorithm) — это метаэвристический алгоритм без производных, имитирующий поведение свечения светлячков, который может эффективно фиксировать все максимальные мультимодальные функции[45].
Алгоритм Персептрона (Perceptron algorithm) — это линейный алгоритм машинного обучения для задач бинарной классификации. Его можно считать одним из первых и одним из самых простых типов искусственных нейронных сетей. Это определенно не «глубокое» обучение, но это важный строительный блок. Как и логистическая регрессия, он может быстро изучить линейное разделение в пространстве признаков для задач классификации двух классов, хотя, в отличие от логистической регрессии, он обучается с использованием алгоритма оптимизации стохастического градиентного спуска и не предсказывает калиброванные вероятности[46].
Алгоритм поиска (Search algorithm) — это любой алгоритм, который решает задачу поиска, а именно извлекает информацию, хранящуюся в некоторой структуре данных или вычисленную в пространстве поиска проблемной области, либо с дискретными, либо с непрерывными значениями[47].
Алгоритм пчелиной колонии (алгоритм оптимизации подражанием пчелиной колонии, artificial bee colony optimization, ABC) (Bees algorithm) — это один из полиномиальных эвристических алгоритмов для решения оптимизационных задач в области информатики и исследования операций. Относится к категории стохастических биоинспирированных алгоритмов, базируется на имитации поведения колонии медоносных пчел при сборе нектара в природе[48].
Алгоритмическая оценка (Algorithmic Assessment) — это техническая оценка, которая помогает выявлять и устранять потенциальные риски и непредвиденные последствия использования систем искусственного интеллекта, чтобы вызвать доверие и создать поддерживающие системы вокруг принятия решений ИИ[49].
Алгоритмическая предвзятость (Biased algorithm) — это систематические и повторяющиеся ошибки в компьютерной системе, которые приводят к несправедливым результатам, например, привилегия одной произвольной группы пользователей над другими[50],[51].
Алгоритмы машинного обучения (Machine learning algorithms) — это фрагменты кода, которые помогают пользователям исследовать и анализировать сложные наборы данных и находить в них смысл или закономерность. Каждый алгоритм — это конечный набор однозначных пошаговых инструкций, которые компьютер может выполнять для достижения определенной цели. В модели машинного обучения цель заключается в том, чтобы установить или обнаружить закономерности, с помощью которых пользователи могут создавать прогнозы либо классифицировать информацию. В алгоритмах машинного обучения используются параметры, основанные на учебных данных (подмножество данных, представляющее более широкий набор). При расширении учебных данных для более реалистичного представления мира с помощью алгоритма вычисляются более точные результаты. В различных алгоритмах применяются разные способы анализа данных. Они часто группируются по методам машинного обучения, в рамках которых используются: контролируемое обучение, неконтролируемое обучение и обучение с подкреплением. В наиболее популярных алгоритмах для прогнозирования целевых категорий, поиска необычных точек данных, прогнозирования значений и обнаружения сходства используются регрессия и классификация[52].
Анализ алгоритмов (Analysis of algorithms) — это область на границе компьютерных наук и математики. Цель его состоит в том, чтобы получить точное представление об асимптотических характеристиках алгоритмов и структур данных в усредненном виде. Объединяющей темой является использование вероятностных, комбинаторных и аналитических методов. Объектами изучения являются случайные ветвящиеся процессы, графы, перестановки, деревья и строки[53].
Анализ временных рядов (Time series analysis) — это раздел машинного обучения и статистики, который анализирует временные данные. Многие типы задач машинного обучения требуют анализа временных рядов, включая классификацию, кластеризацию, прогнозирование и обнаружение аномалий. Например, вы можете использовать анализ временных рядов, чтобы спрогнозировать будущие продажи зимних пальто по месяцам на основе исторических данных о продажах[54],[55].
Анализ данных (Data analysis) — это область математики и информатики, занимающаяся построением и исследованием наиболее общих математических методов и вычислительных алгоритмов извлечения знаний из экспериментальных (в широком смысле) данных; процесс исследования, фильтрации, преобразования и моделирования данных с целью извлечения полезной информации и принятия решений. Анализ данных имеет множество аспектов и подходов, охватывает разные методы в различных областях науки и деятельности[56].
Анализ настроений (Sentiment analysis) — это использование статистических алгоритмов или алгоритмов машинного обучения для определения общего отношения группы — положительного или отрицательного — к услуге, продукту, организации или теме. Например, используя понимание естественного языка, алгоритм может выполнять анализ настроений по текстовой обратной связи по университетскому курсу, чтобы определить степень, в которой студентам в целом понравился или не понравился учебный курс[57].
Анализ основных компонентов (PCA) (Principal component analysis (PCA)) — это построение новых функций, которые являются основными компонентами набора данных. Главные компоненты представляют собой случайные величины максимальной дисперсии, построенные из линейных комбинаций входных признаков. Эквивалентно, они являются проекциями на оси главных компонентов, которые представляют собой линии, минимизирующие среднеквадратичное расстояние до каждой точки в наборе данных. Чтобы обеспечить уникальность, все оси главных компонентов должны быть ортогональны. PCA — это метод максимального правдоподобия для линейной регрессии при наличии гауссовского шума как на входе, так и на выходе. В некоторых случаях PCA соответствует преобразованию Фурье, например DCT, используемому при сжатии изображений JPEG[58].
Аналитика принятия решений (Decision intelligence) — это практическая дисциплина, используемая для улучшения процесса принятия решений путем четкого понимания и программной разработки того, как принимаются решения, и как итоговые результаты оцениваются, управляются и улучшаются с помощью обратной связи[59].
Аналитика данных (Data analytics) — это наука об анализе необработанных данных, чтобы делать выводы об этой информации. Многие методы и процессы анализа данных были автоматизированы в механические процессы и алгоритмы, которые работают с необработанными данными для потребления человеком[60].
Аннотация (Annotation) — это специальный модификатор, используемый в объявлении класса, метода, параметра, переменной, конструктора и пакета, а также инструмент, выбранный стандартом JSR-175 для описания метаданных[61].
Аннотация объекта (Entity annotation) — это процесс маркировки неструктурированных предложений такой информацией, чтобы машина могла их прочитать. Это может включать, например, маркировку всех людей, организаций и местоположений в документе[62].
Анонимизация (Anonymization) — это процесс удаления данных (из документов, баз данных и т.д.) с целью сокрытия источника информации, действующего лица и т. д. Например: анонимизация выписки из стационара процесс удаления данных с целью предотвращения идентификации личности пациента[63].
Ансамбль (Ensemble) — это слияние прогнозов нескольких моделей. Можно создать ансамбль с помощью одного или нескольких из следующих способов: различные инициализации; различные гиперпараметры; другая общая структура. Глубокие и широкие модели представляют собой своеобразный ансамбль[64].
Антивирусное программное обеспечение (Antivirus software) — это программа или набор программ, предназначенных для предотвращения, поиска, обнаружения и удаления программных вирусов и других вредоносных программ, таких как черви, трояны, рекламное ПО и т.д.[65].
АПИ-как-услуга (API-AS-a-service) — это подход, который сочетает в себе экономию API и аренду программного обеспечения и предоставляет интерфейсы прикладного программирования как услугу[66].
АПИ набора данных (Dataset API) — это высокоуровневый API TensorFlow для чтения данных и преобразования их в форму, требуемую алгоритмом машинного обучения. Объект tf. data. Dataset представляет собой последовательность элементов, в которой каждый элемент содержит один или несколько тензоров. Объект tf.data.Iterator обеспечивает доступ к элементам набора данных[67].
Аппаратное обеспечение (Hardware) — это система взаимосвязанных технических устройств, предназначенных для ввода (вывода), обработки и хранения данных[68].
Аппаратное обеспечение ИИ (AI hardware, AI-enabled hardware, AI hardware platform) — это аппаратное обеспечение ИИ, аппаратные средства ИИ, аппаратная часть инфраструктуры или системы искусственного интеллекта, ИИ-инфраструктуры.
Аппаратное ускорение (Hardware acceleration) — это применение аппаратного обеспечения для выполнения некоторых функций быстрее по сравнению с выполнением программ процессором общего назначения[69].
Аппаратно-программный комплекс (Hardware-software complex) — это набор технических и программных средств, работающих совместно для выполнения одной или нескольких сходных задач[70].
Аппаратный акселератор (Hardware accelerator) — это устройство, выполняющее некоторый ограниченный набор функций для повышения производительности всей системы или отдельной её подсистемы. Например, purpose-built hardware accelerator — специализированный аппаратный ускоритель[71].
Аппаратный Сервер (аппаратное обеспечение) (Hardware Server) — это выделенный или специализированный компьютер для выполнения сервисного программного обеспечения (в том числе серверов тех или иных задач) без непосредственного участия человека. Одновременное использование как высокопроизводительных процессоров, так и FPGA позволяет обрабатывать сложные гибридные приложения[72].
Априорное (Prior) — это распределение вероятностей, которое будет представлять ранее существовавшие убеждения о конкретной величине до того, как будут рассмотрены новые данные[73].
Артефакт (Artifact) — это один из многих видов материальных побочных продуктов, производимых в процессе разработки программного обеспечения. Некоторые артефакты (например, варианты использования, диаграммы классов и другие модели унифицированного языка моделирования (UML), требования и проектные документы) помогают описать функции, архитектуру и дизайн программного обеспечения. Другие артефакты связаны с самим процессом разработки, например, планы проектов, бизнес-кейсы и оценки рисков[74].
Архивное хранилище (Archival Storage) — это источник данных, которые не нужны для повседневных операций организации, но к которым может потребоваться доступ время от времени. Используя архивное хранилище, организации могут использовать вторичные источники, сохраняя при этом защиту данных. Использование источников архивного хранения снижает необходимые затраты на первичное хранение и позволяет организации поддерживать данные, которые могут потребоваться для соблюдения нормативных или других требований[75].
Архивный пакет информации (AIC) (Archival Information Collection (AIC)) — это информация, содержание которой представляет собой агрегацию других пакетов архивной информации. Функция цифрового сохранения сохраняет способность регенерировать провалы (пакеты информации) по мере необходимости с течением времени[76].
Архитектура агента (Agent architecture) — это план программных агентов и интеллектуальных систем управления, изображающий расположение компонентов. Архитектуры, реализованные интеллектуальными агентами, называются когнитивными архитектурами[77].
Архитектура вычислительной машины (Architecture of a computer) — это концептуальная структура вычислительной машины, определяющая проведение обработки информации и включающая методы преобразования информации в данные и принципы взаимодействия технических средств и программного обеспечения[78].
Архитектура вычислительной системы (Architecture of a computing system) — это конфигурация, состав и принципы взаимодействия (включая обмен данными) элементов вычислительной системы[79].
Архитектура механизма обработки матриц (MPE) (Matrix Processing Engine Architecture) — это многомерный массив обработки физических матриц цифровых устройств с умножением (MAC), который вычисляет серию матричных операций сверточной нейронной сети[80],[81].
Архитектура системы (Architecture of a system) — это принципиальная организация системы, воплощенная в её элементах, их взаимоотношениях друг с другом и со средой, а также принципы, направляющие её проектирование и эволюцию[82].
Архитектура фон Неймана (Von Neumann architecture) — это широко известный принцип совместного хранения команд и данных в памяти компьютера. Вычислительные машины такого рода часто обозначают термином «машина фон Неймана», однако соответствие этих понятий не всегда однозначно. В общем случае, когда говорят об архитектуре фон Неймана, подразумевают принцип хранения данных и инструкций в одной памяти[83].
Архитектурная группа описаний (Architectural description group, Architectural view) — это представление системы в целом с точки зрения связанного набора интересов[84],[85].
Архитектурный фреймворк (Architectural frameworks) — это высокоуровневые описания организации как системы; они охватывают структуру его основных компонентов на разных уровнях, взаимосвязи между этими компонентами и принципы, определяющие их эволюцию[86].
Асимптотическая вычислительная сложность (Asymptotic computational complexity) — это использование асимптотического анализа для оценки вычислительной сложности алгоритмов и вычислительных задач, обычно связанных с использованием большой нотации O. Асимптотическая сложность является ключом к сравнению алгоритмов. Асимптотическая сложность раскрывает более глубокие математические истины об алгоритмах, которые не зависят от аппаратного обеспечения[87].
Асинхронные межкристальные протоколы (Asynchronous inter-chip protocols) — это протоколы для обмена данных в низкоскоростных устройствах; для управления обменом данными используются не кадры, а отдельные символы[88].
Ассоциация (Association) — это еще один тип метода обучения без учителя, который использует разные правила для поиска взаимосвязей между переменными в заданном наборе данных. Эти методы часто используются для анализа потребительской корзины и механизмов рекомендаций, подобно рекомендациям «Клиенты, которые купили этот товар, также купили»[89].
Ассоциация по развитию искусственного интеллекта (Association for the Advancement of Artificial Intelligence) — это международное научное сообщество, занимающееся продвижением исследований и ответственным использованием искусственного интеллекта. AAAI также стремится повысить общественное понимание искусственного интеллекта (ИИ), улучшить обучение и подготовку специалистов, занимающихся ИИ, и предоставить рекомендации для планировщиков исследований и спонсоров относительно важности и потенциала текущих разработок ИИ и будущих направлений[90][91].
Атрибутивное исчисление (Attributional calculus) — это типизированная логическая система, сочетающая элементы логики высказываний, исчисления предикатов и многозначной логики с целью естественной индукции. Под естественной индукцией понимается форма индуктивного обучения, которая генерирует гипотезы в формах, ориентированных на человека, то есть в формах, которые кажутся людям естественными, их легко понять и соотнести с человеческим знанием. Для достижения этой цели AИ включает нетрадиционные логические операции и формы, которые могут сделать логические выражения более простыми и более тесно связанными с эквивалентными описаниями на естественном языке[92].
Аффективные вычисления (также искусственный эмоциональный интеллект или эмоциональный ИИ) (Affective computing) — это вычисления, в которых системы и устройства могут распознавать, интерпретировать, обрабатывать и имитировать человеческие аффекты. Это междисциплинарная область, охватывающая информатику, психологию и когнитивную науку[93].
«Б»
База данных (Database) — это упорядоченный набор структурированной информации или данных, которые обычно хранятся в электронном виде в компьютерной системе. База данных обычно управляется системой управления базами данных (СУБД). Данные вместе с СУБД, а также приложения, которые с ними связаны, называются системой баз данных, или, для краткости, просто базой данных[94].
База Данных ImageNet (ImageNet) — это большая визуальная база данных, предназначенная для использования в исследованиях программного обеспечения для распознавания визуальных объектов. Более 14 миллионов изображений были вручную аннотированы в рамках проекта, чтобы указать, какие объекты изображены, и, по крайней мере, в одном миллионе изображений также предусмотрены ограничивающие рамки. ImageNet содержит более 20 000 категорий, среди которых типичная категория, такая как «воздушный шар» или «клубника», состоит из нескольких сотен изображений. База данных аннотаций URL-адресов сторонних изображений находится в свободном доступе непосредственно из ImageNet, хотя фактические изображения не принадлежат ImageNet. С 2010 года в рамках проекта ImageNet проводится ежегодный конкурс программного обеспечения ImageNet Large Scale Visual Recognition Challenge (ILSVRC), в котором программы соревнуются за правильную классификацию и обнаружение объектов и сцен. В задаче используется «усеченный» список из тысячи неперекрывающихся классов[95].
База данных MNIST (MNIST) — это база данных образцов рукописного написания цифр от 0 до 9, содержит 60 000 образцов наборов данных для обучения и тестовый набор из 10 000 образцов. Цифры были нормализованы по размеру и расположены в центре изображения фиксированного размера. Каждое изображение хранится в виде массива целых чисел 28x28, где каждое целое число представляет собой значение в оттенках серого от 0 до 255 включительно. MNIST — это канонический набор данных для машинного обучения, часто используемый для тестирования новых подходов к машинному обучению. Это часть большой базы данных рукописных форм и символов, опубликованной Национальным институтом стандартов и технологий США (NIST)[96].
Базовый уровень (Baseline) — это модель, используемая в качестве контрольной точки для сравнения того, насколько хорошо работает другая модель (как правило, более сложная). Например, модель логистической регрессии может служить базовым уровнем для глубокой модели. Для конкретной проблемы базовый уровень помогает разработчикам моделей количественно определить минимальную ожидаемую производительность, которую новая модель должна обеспечить, чтобы быть полезной[97].
Байесовская оптимизация (Bayesian optimization) — это метод вероятностной регрессионной модели для оптимизации ресурсоемких целевых функций путем оптимизации суррогата с помощью байесовского метода обучения. Поскольку байесовская оптимизация сама по себе очень дорогая, ее обычно используют для оптимизации дорогостоящих задач с небольшим количеством параметров, таких как выбор гиперпараметров[98].
Байесовская сеть (или Байесова сеть, Байесовская сеть доверия) (Bayesian Network) — это графическая вероятностная модель, представляющая собой множество переменных и их вероятностных зависимостей. Например, байесовская сеть может быть использована для вычисления вероятности того, чем болен пациент по наличию или отсутствию ряда симптомов, основываясь на данных о зависимости между симптомами и болезнями[99].
Байесовский классификатор в машинном обучении (Bayesian classifier in machine learning) — это семейство простых вероятностных классификаторов, основанных на использовании теоремы Байеса и «наивном» предположении о независимости признаков классифицируемых объектов. Анализ на основе байесовской классификации активно изучался и использовался начиная с 1950-х годов в области классификации документов, где в качестве признаков использовались частоты слов. Алгоритм является масштабируемым по числу признаков, а по точности сопоставим с другими популярными методами, такими как машины опорных векторов. Как и любой классификатор, байесовский присваивает метки классов наблюдениям, представленным векторами признаков. При этом предполагается, что каждый признак независимо влияет на вероятность принадлежности наблюдения к классу. Например, объект можно считать яблоком, если он имеет округлую форму, красный цвет и диаметр около 10 см. Наивный байесовский классификатор «считает», что каждый из этих признаков независимо влияет на вероятность того, что этот объект является яблоком, независимо от любых возможных корреляций между характеристиками цвета, формы и размера. Простой байесовский классификатор строится на основе обучения с учителем. Несмотря на мало реалистичное предположение о независимости признаков, простые байесовские классификаторы хорошо зарекомендовали себя при решении многих практических задач. Дополнительным преимуществом метода является небольшое число примеров, необходимых для обучения[100].
Байесовское программирование (Bayesian programming) — это формальная система и методология определения вероятностных моделей и решения задач, когда не вся необходимая информация является доступной[101],[102].
Башня (Tower) — это компонент глубокой нейронной сети, которая сама по себе является глубокой нейронной сетью без выходного слоя. Как правило, каждая башня считывает данные из независимого источника. Башни независимы до тех пор, пока их выходные данные не будут объединены в последнем слое[103].
Байт (Byte) — это восемь битов. Байт — это просто кусок из 8 единиц и нулей. Например: 01000001 — это байт. Компьютер часто работает с группами битов, а не с отдельными битами, и наименьшая группа битов, с которой обычно работает компьютер, — это байт. Байт равен одному столбцу в файле, записанном в символьном формате[104].
Безопасность критической информационной инфраструктуры (Security of a critical information infrastructure) — это состояние защищенности критической информационной инфраструктуры, обеспечивающее ее устойчивое функционирование при проведении в отношении ее компьютерных атак[105].
Безопасность приложений (Application security) — это процесс повышения безопасности приложений путем поиска, исправления и повышения безопасности приложений. Многое из этого происходит на этапе разработки, но включает инструменты и методы для защиты приложений после их развертывания. Это становится все более важным, поскольку хакеры все чаще атакуют приложения[106].
Бенчмарк (Benchmark) (также benchmark program, benchmarking program, benchmark test) — это тестовая программа или пакет для оценки (измерения и/или сравнения) различных аспектов производительности процессора, отдельных устройств, компьютера, системы или конкретного приложения, программного обеспечения; эталон, который позволяет сравнивать продукты разных производителей друг с другом или с некоторым стандартом. Например, онлайн-бенчмарк — онлайн-бенчмарк; стандартный бенчмарк — стандартный бенчмарк; сравнение времени бенчмарка — сравнение времени выполнения бенчмарка[107].
Бенчмаркинг (Benchmarking) — это набор методик, которые позволяют изучить опыт конкурентов и внедрить лучшие практики в своей компании[108].
Беспроводная сеть (Wireless network) — это компьютерная сеть, в которой используются беспроводные соединения для передачи данных между сетевыми узлами. Беспроводная сеть — это метод, с помощью которого дома, телекоммуникационные сети и бизнес-установки избегают дорогостоящего процесса ввода кабелей в здание или в качестве соединения между различными местоположениями оборудования. Административные телекоммуникационные сети обычно реализуются и администрируются с использованием радиосвязи. Эта реализация происходит на физическом уровне (слое) сетевой структуры модели OSI[109].
Беспроводная широкополосная связь (WiBB Wireless broadband) — это телекоммуникационная технология, которая обеспечивает высокоскоростной беспроводной доступ в Интернет или доступ к компьютерным сетям на большой территории. Этот термин включает как фиксированную, так и мобильную широкополосную связь[110].
БЕТА версия (BETA) — это термин, который относится к этапу разработки онлайн-сервиса, на котором сервис объединяется с точки зрения функциональности, но требуется подлинный пользовательский опыт, прежде чем сервис можно будет завершить ориентированным на пользователя способом. При разработке онлайн-сервиса цель бета-фазы состоит в том, чтобы распознать как проблемы программирования, так и процедуры, повышающие удобство использования. Бета-фаза особенно часто используется в связи с онлайн-сервисами и, может быть, либо бесплатной (открытая бета-версия), либо ограниченной для определенной целевой группы (закрытая бета-версия)[111].
Библиотека Keras (The Keras Library) — это библиотека Python, используемая для глубокого обучения и создания искусственных нейронных сетей. Выпущенный в 2015 году, Keras предназначен для быстрого экспериментирования с глубокими нейронными сетями. Keras предлагает несколько инструментов, которые упрощают работу с изображениями и текстовыми данными. Помимо стандартных нейронных сетей, Keras также поддерживает сверточные и рекуррентные нейронные сети. В качестве бэкэнда Keras обычно использует TensorFlow, Microsoft Cognitive toolkit или Theano. Он удобен для пользователя и требует минимального кода для выполнения функций и команд. Keras имеет модульную структуру и имеет несколько методов предварительной обработки данных. Keras также предлагает методы. evaluate () и predict_classes () для тестирования и оценки моделей. Github и Slack организуют форумы сообщества для Keras[112].
Библиотека Matplotlib (Matplotlib) — это комплексная, популярная библиотека Python с открытым исходным кодом для создания визуализаций «качества публикации». Визуализации могут быть статическими, анимированными или интерактивными. Он был эмулирован из MATLAB и, таким образом, содержит глобальные стили, очень похожие на MATLAB, включая иерархию объектов[113].
Библиотека Numpy (Numpy) — это библиотека Python, представленная в 2006 году для поддержки многомерных массивов и матриц. Библиотека также позволяет программистам выполнять высокоуровневые математические вычисления с массивами и матрицами. Можно сказать, что это объединение своих предшественников — The Numeric и Numarray. NumPy является неотъемлемой частью Python и по существу предоставляет программе математические функции типа MATLAB. По сравнению с обычными списками Python, он занимает меньше памяти, удобен в использовании и имеет более быструю обработку. При интеграции с другими библиотеками, такими как SciPy и / или Matplotlib, его можно эффективно использовать для целей анализа данных и анализа данных[114].
Библиотека PyTorch & Torch (PyTorch (Torch Library) — это библиотека машинного обучения, которая в основном используется для приложений обработки естественного языка и компьютерного зрения. Разработанная исследовательской лабораторией искусственного интеллекта и выпущенная в сентябре 2016 года, это библиотека с открытым исходным кодом, основанная на библиотеке Torch для научных вычислений и машинного обучения. PyTorch предоставляет операции с объектом n-мерного массива, аналогичные NumPy, однако, кроме того, он предлагает более быстрые вычисления за счет интеграции с графическим процессором. PyTorch автоматически различает построение и обучение нейронных сетей. PyTorch — это внесла свой вклад в разработку нескольких программ глубокого обучения — Tesla Autopilot, Uber’s Pyro, PyTorch Lighten и т.д.[115].
Библиотека Scikit-learn (Scikit-learn Library) — это простая в освоении библиотека Python с открытым исходным кодом для машинного обучения, построенная на NumPy, SciPy и matplotlib. Его можно использовать для классификации данных, регрессии, кластеризации, уменьшения размерности, выбора модели и предварительной обработки[116].
Библиотека SciPy (SciPy Library) — это библиотека Python с открытым исходным кодом для выполнения научных и технических вычислений на Python. Она была разработана открытым сообществом разработчиков, которое также поддерживает его поддержку и спонсирует разработки. SciPy предлагает несколько пакетов алгоритмов и функций, которые поддерживают научные вычисления: константы, кластер, fft, fftpack, интегрировать и т. д. SciPy по сути является частью стека NumPy и использует многомерные массивы в качестве структур данных, предоставляемых модулем NumPy. Первоначально выпущенный в 2001 году, она распространялась по лицензии BSD с репозиторием на GitHub[117].
Библиотека Seaborn (Seaborn) — это библиотека визуализации данных Python для построения «привлекательных и информативных» статистических графиков. Seaborn основан на Matplotlib. Он включает в себя множество визуализаций на выбор, включая временные ряды и совместные графики.
Библиотека Theano (Theano) — это библиотека Python, используемая для компиляции, определения, оптимизации и оценки математических выражений, содержащих многомерные массивы. Она была разработана Монреальским институтом алгоритмов обучения (MILA) при Монреальском университете и выпущена в 2007 году. Это библиотека с открытым исходным кодом под лицензией BSD. Библиотека построена поверх NumPy и имеет аналогичный интерфейс. Наряду с процессором он позволяет использовать графический процессор для ускорения вычислений. Theano вносит значительный вклад в крупномасштабные научные вычисления и связанные с ними исследования и поддерживается специальной группой из 13 разработчиков[118].
Биграмм (Bigram) — N-грамм, в которой N=2[119].
Бинарное дерево (Binary tree) — это иерархическая структура данных, в которой каждый узел имеет значение (оно же является в данном случае и ключом) и ссылки на левого и правого потомка. Как правило, первый называется родительским узлом, а дети называются левым и правым наследниками. Двоичное дерево не является упорядоченным ориентированным деревом[120].
Биннинг (машинное зрение) (Binning) — это процесс объединения заряда от соседних пикселей в CCD матрице во время считывания. Этот процесс выполняется до оцифровки в микросхеме ПЗС (Прибор с обратной Зарядной Связью — CCD матрица) с помощью специализированного управления последовательным и параллельным регистрами. Двумя основными преимуществами биннинга являются улучшенное отношение сигнал/ шум (SNR) и возможность увеличивать частоту кадров, хотя и за счет уменьшения пиксельного разрешения.
Биоконсерватизм (Bioconservatism) — это позиция нерешительности и скептицизма в отношении радикальных технологических достижений, особенно тех, которые направлены на изменение или улучшение условий жизни человека. Биоконсерватизм характеризуется верой в то, что технологические тенденции в современном обществе рискуют поставить под угрозу человеческое достоинство, а также противодействием движениям и технологиям, включая трансгуманизм, генетическую модификацию человека, «сильный» искусственный интеллект и технологическую сингулярность. Многие биоконсерваторы также выступают против использования таких технологий, как продление жизни и преимплантационный генетический скрининг[121],[122].
Биометрия (Biometrics) — это система распознавания людей по одному или более физическим или поведенческим чертам[123],[124].
Блок IFU (Instruction Fetch Unit, IFU) — это блок предвыборки команд, который выстраивает в единую очередь команды, считываемые из внутренней или внешней памяти системы по шине EIB в соответствии с адресом, выставляемым по шине IAB[125].
Блок обработки изображений (Vision Process



















