автордың кітабын онлайн тегін оқу Генеративный искусственный интеллект. Как ИИ меняет нашу жизнь и работу
Нума Дхамани, Мэгги Энглер
Генеративный искусственный интеллект
Как ИИ меняет нашу жизнь и работу
Нума посвящает эту книгу своим родителям Назарали и Надье, а также своему брату Нихалю
Мэгги посвящает эту книгу своему мужу Джо
Numa Dhamani, Maggie Engler
INTRODUCTION TO GENERATIVE AI
© Eksmo Publishing House 2025. Authorized translation of the English edition
© 2024 Manning Publications. This translation is published and sold by permission of Manning Publications, the owner of all rights to publish and sell the same.
© Жевлакова Е. В., перевод на руский язык, 2025
© Оформление. ООО «Издательство «Эксмо», 2026
Предисловие
Вы замечали, что все вокруг твердят, насколько хорош теперь ИИ? Люди бросаются модными терминами вроде «генеративный искусственный интеллект», «большая языковая модель» (LLM), «диалоговый агент» и тому подобное. Почему так происходит? Откуда это все взялось? Из-за чего так много определений? Разве они все не обозначают одно и то же? О чем-таки же все говорят? Что ж, у меня есть книга, которая нужна вам сейчас.
Как Нума, так и Мэгги имеют опыт работы в области моральных принципов. Они входят в состав «Института этики», аналитической группы и профессионального объединения специалистов, которые занимаются тем, что стараются понять, как и почему в интернете случаются нехорошие вещи, а также разрабатывают средства смягчения их последствий и ищут способы создать более здоровую среду онлайн. На протяжении своих карьер Нума и Мэгги разбирались во взаимодействиях в сети (сначала между людьми, а теперь между людьми и роботами) и фундаментальных законах того, что творится внутри этих невообразимо сложных систем, набитых личностями, пытающимися их сломать. Как оказалось, манера мышления авторов весьма хорошо подходит и для изучения того, как человечество будет использовать технологию генеративного ИИ, а также злоупотреблять ею. Через посредство «Института этики» Нума и Мэгги помогали нам просвещать и народные массы, и власть имущих о том, как функционирует интернет. Они входят в состав растущего движения технарей, которые разъясняют обществу, что же на самом деле происходит в мире, где все социальное общение ведется онлайн. Важность их занятия возрастает по мере того, как люди проводят все больше времени в сети.
Появление данной книги меня воодушевляет. Я верю, что она станет частью новой волны произведений и исследований (предварительно назовем все это «наукой об этичности»), авторы которых работали в соцсетях, стремясь разобраться в информационных экосистемах, образуемых нашим поведением и отношениями между нами в интернете. Подобный метод мышления применим не только к социальным медиа и приложениям для знакомств или игр: с его помощью можно самыми разными способами уяснять суть и людей, и сведений. Чтобы читать эту книгу, вам не нужно ни быть фанатом статистики, ни выдавать себя за него, ни становиться им. Точно так же вам не придется смотреть на ИИ как на ящик, в котором сидит непостижимый волшебный робот. Нума и Мэгги устраивают для нас экскурсию по системам генеративного искусственного интеллекта, обеспечивая возможность рассуждать о них и принимать взвешенные решения, касающиеся их. Отталкиваясь от такой стартовой колодки, авторы ведут нас в дальнее странствие, где, опираясь на понимание этого новомодного ИИ и свои знания, доставшиеся тяжким трудом в окопах борьбы за этичность, распутывают вопрос о том, как генеративный ИИ повлияет на общество. Мы узнаем, как изменятся экономика и сами наши разговоры, а также факторы, побуждающие нас к плохому поведению и распространению дезинформации.
Книга Нумы и Мэгги вышла в самый подходящий момент. Нам не обойтись без подобного руководства, в котором сложные концепции объясняются доступным языком. И хотя я уверен, что не все предсказания авторов сбудутся с точностью до буквы, вы, несомненно, не только погрузитесь в источник по-настоящему ценной информации о том, как в наше время действует генеративный ИИ, но и ознакомитесь с образом мыслей, отточенным за годы упорной работы на поприще сетевой этики. Прочтите эту книгу.
Шахар Массачи,
один из основателей и генеральный директор «Института этики»
Вступление
По иронии судьбы, нас двоих свели безумные теории заговоров из интернета: мы встретились, когда проектировали системы обработки естественного языка, призванные оценивать и анализировать наполнение экстремистских ресурсов в сети. Когда в общественное сознание по всему миру вошли такие концепции, как LLM и другие модели генеративного ИИ, мы осознали, что наша область деятельности необратимо преобразится. Еще никогда люди не могли так дешево создавать и распространять информационные материалы, и в то же время еще никогда не возникало столь острой необходимости в классификации этих материалов в огромных масштабах.
В ходе работы над книгой мы получили весьма запоминающийся отзыв такого содержания: «Авторам следует прояснить свою позицию в отношении генеративного ИИ. Они за него или против?» Читатель, мы, к сожалению, не в силах втиснуть наши соображения по данному поводу в одно слово. Вместо этого мы постарались отразить на следующих страницах все тонкости возможных последствий развития и применения генеративного ИИ. Чтобы решить эту задачу, мы сначала постепенно разъясняем вам, каким способом и на каких данных обучаются LLM, а также рассматриваем алгоритмы, вносящие вклад в их конечный продукт – текст, практически неотличимый от тех, что пишут люди.
Выдаваемые ими материалы (а равно те, что создаются генеративными моделями иных типов) имеют целый ряд применений, как благотворных, так и вредоносных. Ни одна из предыдущих систем не обладала подобными возможностями, однако за великолепными результатами генеративного ИИ на бенчмарках вроде прохождения типовых тестов порой скрываются их вопиющие недостатки, в том числе предвзятость, галлюцинации и формирование небезопасного контента. Помимо того, из-за их продукции встают серьезные вопросы о законных правах на контент, моральных принципах взаимодействия людей с ИИ, экономических параметрах работы при поддержке ИИ и очень многом другом.
Хотя мы попытались очертить наши позиции в данной книге, ссылаясь на научные статьи и примеры практического использования, у нас нет ни малейших иллюзий по поводу решения упомянутых проблем. Остается еще немало вопросов, и для ответа на них нужно запустить цикличный процесс, в который будут вовлечены все слои общества. Соответственно, мы надеемся, что эта книга побудит новичков, увлеченных персон и опытных профессионалов принять участие в публичном обсуждении темы генеративного ИИ. На этом поприще до сих пор звучит слишком мало голосов, что оборачивается дискуссиями в узком кругу, на которых не принимают в расчет точки зрения обособленных групп (маргиналов), наемных рабочих, творческих личностей и деятелей культуры, а также бессчетного множества других социальных категорий, на которые влияет искусственный интеллект. Просвещенный народ – наше главное орудие для постройки желаемого будущего в аспекте генеративного ИИ. Мы рассчитываем, что вы присоединитесь к нашим усилиям по созданию мира, где ИИ помогает людям, а не заменяет их, и ключевой ценностью остаются человеческие ощущения и переживания.
Благодарности
Мы хотели бы выразить сердечную признательность Шахару Массачи, чье обстоятельное предисловие заставляет задуматься и задает тон всей книге. Нас вдохновляют ваша увлеченность и приверженность работе в области этики, а этот проект стал еще более содержательным благодаря вашему вкладу.
Кроме того, данная книга не увидела бы свет, если бы не помощь и поддержка множества наших отзывчивых друзей и коллег. Не расставляя их в каком-то определенном порядке, мы благодарим Дэвида Салливана, Эрин Маколиф, Наталью Битюкову, доктора Дэниела Роджерса, Эдгара Маркевичюса, Сэма Планка, Дерека Слейтера, доктора Стива Крамера, Райана Уильямса, Брайана Джонса, доктора Фаиза Дживани, Рида Кока, Уитни Нельсон, Рахима Макани, Элис Хансбергер, Карана Лалу, Ребекку Руппель, Майкла Уортона, доктора Атиша Агарвалу, Рона Грина, доктора Кеннета Р. Флейшмана и Стивена Штрауса. Все эти люди предоставили нам ценные отзывы и разнообразные точки зрения, которые существенно повлияли на идеи, изложенные в тексте.
Далее нам хотелось бы выразить признательность сотрудникам Manning, трудившимся над книгой. Мы особенно благодарны редактору-консультанту по аудитории Ребекке Джонсон, которая направляла нас от начала до конца, высказывала замечания и пожелания, а также координировала все движущиеся части издательского механизма, и редактору по контрактам Энди Уолдрону – за то, что он изначально поверил в наш проект. Кроме того, мы отмечаем усилия научного редактора Мариса Секара и всех рецензентов, читавших черновой текст на разных стадиях и дававших подробные отзывы: Алена Куньо, Альберта Лардисабаля, Амита Башнака, Арслана Габдулхакова, Бенедикта Стеммлера, Бруно Сонниньо, Чау Гиана, Дэна Шейха, Эли Хини, Ганеша Сваминатана, Джеффа Рекиту, Джереми Чена, Джона Маккормака, Джона Уильямса, Кита Кима, Лоренса Джильо, Мартина Цыгана, Мэри-Энн Тайгесен, Максима Волгина, Наджиба Арифа, Ондржея Крайчека, Павла Силистеану, Равшана Джа, Ричарда Мейнсена, Ритобрата Гхош, Руи Лью, Сивы Ди, Шрирама Махарле, Штефана Туральски, Сумита Пала, Тони Холдройда, Видье Виная, Уолтера Александра Мате Лопеса, Вэй Ло и Юрия Клеймана. После ваших дополнений книга стала настолько полезной для читателей, насколько вообще возможно.
Наконец, мы хотим поблагодарить вас, наш читатель. Спасибо, что взяли нашу книгу с полки или приобрели ее в сети. Спасибо, что решили почитать о разнообразных последствиях внедрения технологии генеративного ИИ и поразмыслить, как соразмерять инновации с ответственностью. Спасибо, что участвуете в публичном обсуждении генеративного ИИ и побуждаете других поступать так же. Спасибо, что доносите до своих коллег и друзей идеи или уроки, извлеченные из нашего текста и иных источников. Спасибо, что помогаете нам построить общество, которое знает о генеративном искусственном интеллекте и осмотрительно относится к нему.
Об этой книге
Когда ChatGPT стал доступным 30 ноября 2022 года, он не только поразил воображение миллионов пользователей, но и побудил многоопытных экспертов по технологиям указать на недостатки этого диалогового агента и призвать к осторожности. В данной книге мы рассматриваем генеративный искусственный интеллект высокого уровня, уделяя особое внимание большим языковым моделям (LLM). Мы обсуждаем прорыв в области генеративных моделей, то, как они работают, а также риски, связанные с этой технологией. Кроме того, мы углубленно изучаем более обширные последствия данной инновации в этическом, социальном и легальном аспектах. Наконец, мы рекомендуем наилучшие методики добросовестного обучения и применения LLM, основанные на нашем совместном опыте создания надежных технологий, средств защиты данных и частной жизни. На страницах книги мы ищем тонкий многофакторный баланс между использованием колоссального потенциала генеративного ИИ и необходимостью в наличии ответственных систем искусственного интеллекта [1].
Кому следует прочесть эту книгу
Наш текст предназначен для всех, кто интересуется технологией генеративного ИИ и желает выяснить, как стать добросовестным участником процесса нововведений в данной области. Хотя наличие базовых знаний о машинном обучении и обработке естественного языка поможет вам, для чтения оно не требуется. В книге нет ни кода, ни математики – она задумывалась как доступный источник сведений для тех, кто хочет разобраться в рисках и возможностях, связанных с LLM, а также в особенностях социальной, экономической и легальной сфер, в рамках которых действуют такие модели. Мы не углубляемся в вопросы разработки и применения LLM, тем более что в издательстве Manning вышло несколько более «технических» работ на данную тему, и вы можете обратиться к ним.
Мы надеемся, что из нашей книги будут черпать сведения не только профессионалы в области машинного обучения, но и рядовые читатели. Каждый из нас способен сыграть ту или иную роль в деле снижения рисков, исходящих от генеративных моделей, одновременно наслаждаясь плодами технологического прогресса и получая от него выгоду.
Как структурирована эта книга (общая схема)
На последующих страницах мы часто приводим термины «диалоговый агент», «чат-бот», «виртуальный собеседник» или «диалоговая система» как взаимозаменяемые понятия, которыми обозначается некая система ИИ, основанная на той или иной большой языковой модели (если не указано иного) и обученная вести беседы с пользователями.
Вот краткое описание того, что ждет вас в каждой из глав:
В главе 1 даются вводные сведения о больших языковых моделях. Мы приводим общую информацию о том, как LLM заняли столь преобладающее положение среди моделей обработки естественного языка, об их применении и пределах их возможностей. Также в ней кратко рассматриваются примечательные диалоговые LLM, выпущенные в конце 2022 – начале 2023 годов.
В главе 2 мы углубленно разбираем способы обучения LLM. Здесь обсуждается, каким образом факторы, неразрывно связанные с тренировкой больших языковых моделей, наделяют их как уникальными способностями, так и потенциальными уязвимостями.
Глава 3 посвящена средствам борьбы с изъянами систем, которые возникают из-за обучающих данных. Здесь приводятся стратегии противодействия генерации небезопасного контента, а также затрагиваются соображения о конфиденциальности данных и соответствующие нормативные требования.
В главе 4 разбираются методы создания синтетических медиа и проистекающие отсюда риски и возможности. Кроме того, здесь дополнительно обрисовываются правовые нормы, относящиеся к интеллектуальной собственности и нарушениям авторских прав.
Из главы 5 вы узнаете о нескольких типах ненадлежащего применения LLM, как злонамеренного, так и неумышленного. Также здесь даются рекомендации о том, как препятствовать подобным действиям, сочетая технические системы и обучение пользователей.
В главе 6 освещается применение LLM в личных, профессиональных и образовательных целях. Помимо того, здесь рассматриваются методы выявления машинно-сгенерированных материалов и осмысляется, какие перемены данная технология может привнести в экономику и педагогику.
В главе 7 вы найдете примеры того, как LLM задействуют в качестве социальных чат-ботов, чья основная задача состоит в налаживании дружеских связей с пользователями. Здесь обсуждаются возможные риски для межчеловеческих взаимоотношений и предоставляются советы для людей, общающихся с виртуальными собеседниками.
Глава 8 посвящена разбору описанных ранее опасностей и возможностей, которые несут в себе большие языковые модели. Также здесь перебрасываются мостики между различными концепциями, определяются области дальнейшего развития LLM, анализируются нормы законов, касающихся ИИ, и предлагаются маршруты в лучшее, более равноправное будущее.
Глава 9 служит чем-то вроде приложения – в ней основной текст дополняется ценными материалами на смежные темы. Здесь затрагиваются общий искусственный интеллект (artificial general intelligence, AGI), потенциальная способность ИИ чувствовать, сообщество разработчиков открытого ПО и влияние LLM на окружающую среду.
Данную книгу надлежит читать по порядку, так как последующие главы опираются на идеи, рассмотренные в предыдущих. Тематически она завершается в главе 8, тогда как в главе 9 обсуждаются вопросы, которые прилегают к концепциям, ранее изложенным в тексте.
Дискуссионный форум liveBook
Приобретая это издание, вы получаете бесплатный доступ на liveBook, платформу издательства Manning для онлайн-чтения. Эксклюзивные возможности этого дискуссионного форума позволяют вам добавлять комментарии как к книге в целом, так и к конкретным разделам или параграфам. Так вы сумеете с легкостью делать заметки для себя, задавать технические вопросы или отвечать на них, а также получать помощь от автора и других пользователей. Чтобы войти на форум, перейдите по ссылке https://livebook.manning.com/book/introduction-to-generative-ai/. Больше сведений о площадках Manning и правилах поведения на них ищите по адресу https://livebook.manning.com/discussion.
Мы в Manning обязуемся предоставлять нашим клиентам платформу, на которой читатели смогут плодотворно общаться как между собой, так и с авторами. При этом авторы не обязаны уделять таким беседам какое-то определенное время, то есть их участие в деятельности форума полностью добровольно (и не оплачивается). Чтобы они не утратили интерес, попробуйте удерживать их какими-нибудь хитроумными вопросами! Доступ к форуму и архивам предыдущих дискуссий будет поддерживаться на сайте издательства до тех пор, пока книга имеется в продаже.
Онлайн-ресурсы
На случай, если вы заинтересованы в том, чтобы более подробно узнать о каких-либо конкретных идеях или концепциях, представленных в данной книге, мы упоминаем в тексте ряд научных исследований, произведений и статей. Надеемся, что эти дополнительные материалы окажутся для вас ценными.
Ответственный искусственный интеллект (ответственный ИИ) – это подход, предполагающий разработку, оценку и развертывание систем ИИ с соблюдением принципов безопасности, надежности и этики (источник: https://learn.microsoft.com/ru-ru/azure/machine-learning/concept-responsible-ai? view=azureml-api‐2). – Прим. ред.
Об авторах

Инженер и исследователь Нума Дхамани трудится там, где пересекаются общество и технологии. Будучи экспертом в обработке естественного языка, она также владеет всесторонними знаниями об операциях влияния, безопасности и конфиденциальности. Нума разрабатывала системы машинного обучения как для компаний из списка Fortune 500 [2] и социальных сетей, так и для стартапов и некоммерческих организаций. Она консультировала различные фирмы и структуры, занимала должность научного руководителя в экспериментальных программах Министерства обороны США и сотрудничала со множеством международных журналов, публикующих рецензируемые статьи. Кроме того, она участвует в выработке политики в отношении технологий, поддерживая аналитические центры и некоммерческие организации своими данными и усилиями по контролю ИИ. О ее работе по противодействию дезинформации сообщалось в нескольких СМИ, включая New York Times и Washington Post. Нума увлеченно вносит свой вклад в построение более здоровой онлайн-экосистемы и продвижение ответственного ИИ, а также призывает к прозрачности и подотчетности в технологической сфере. Она владеет учеными степенями в областях физики и химии, полученными в Техасском университете в Остине.

Инженер и исследователь Мэгги Энглер в настоящее время занимается безопасностью LLM. Основное внимание она уделяет проблеме злоупотреблений в онлайн-экосистеме, изучая их с применением аналитики данных и машинного обучения. Мэгги владеет экспертными знаниями в областях защиты информации и обеспечения «безопасности и доверия» пользователей. Она создавала системы машинного обучения для обнаружения вредоносных программ и попыток мошенничества, модерирования платформ и оценки рисков. Кроме того, Мэгги консультировала стартапы и некоммерческие организации по вопросам конфиденциальности и информационной инфраструктуры, а также проводила предварительный технический анализ для венчурных компаний. Будучи идейным наставником и популяризатором науки, она трудится внештатным преподавателем в Школе информатики при Техасском университете в Остине. Мэгги глубоко вовлечена в выработку политики в отношении технологий и сотрудничает с группами гражданского общества, которые выступают за ответственный подход к ИИ и управлению данными. Она владеет степенями бакалавра и магистра электротехники, полученными в Стэнфордском университете.
Об иллюстрации на обложке
На обложке книги размещена картина «Няня» (La nourrice) из книги Луи Кюрмера, выпущенной в 1841 году. Каждая иллюстрация в ней тщательно прорисована и раскрашена от руки.
В те дни можно было с легкостью определить, где живет человек, какое у него ремесло или положение в жизни, просто взглянув на его одежду. Издательство Manning восхваляет изобретательность и инициативность компьютерного бизнеса, выбирая для своих книг обложки, основанные на богатом разнообразии региональных нравов многовековой давности, воскресающих на картинах из подобных коллекций.
1
Большие языковые модели: вся мощь ИИ
Темы этой главы
• Знакомство с большими языковыми моделями (LLM)
• Принцип работы трансформеров
• Области применения LLM, их ограничения и риски
• Обзор передовых диалоговых LLM
Компания OpenAI из Сан-Франциско 30 ноября 2022 года написала в X (Twitter): «Попробуйте пообщаться с ChatGPT – нашей новой системой искусственного интеллекта, оптимизированной для диалога. Ваши отзывы помогут нам улучшить ее»1. Чат-бот ChatGPT, с которым пользователи могут взаимодействовать через веб-интерфейс, компания представила как небольшое обновление уже существующих моделей OpenAI, доступных через API [3]. Однако именно благодаря запуску веб-приложения у любого желающего внезапно появилась возможность общаться с ChatGPT, просить его написать стих или код, посоветовать фильмы или планы тренировок, обобщить или объяснить фрагменты текста. Многие ответы выглядели как волшебство. ChatGPT взбудоражил мир технологий, и за считаные дни у него появился один миллион пользователей, а через два месяца после запуска – 100 миллионов. По некоторым показателям это самый быстрорастущий интернет-сервис за всю историю2.
С момента запуска ChatGPT смог поразить воображение миллионов пользователей и одновременно вызвать опасение у опытных специалистов по поводу недостатков диалоговых моделей. ChatGPT и аналогичные модели относятся к классу больших языковых моделей (LLM), которые навсегда изменили область обработки естественного языка (natural language processing, NLP) и позволили достичь новых результатов в таких задачах, как ответы на вопросы, обобщение текста и генерация текста. Уже существуют прогнозы, что LLM изменят то, как мы учим, творим, работаем и общаемся. Люди почти всех профессий будут как минимум использовать такие модели, а возможно даже, принимать участие в их развитии. Таким образом, люди, которые смогут освоить LLM для получения нужных результатов – при этом избегая распространенных ловушек, о которых мы еще поговорим, – смогут возглавить тренд развития генеративного ИИ.
Как практики в области ИИ мы считаем, что для получения представления о том, когда и как использовать эти модели, необходимо базовое понимание их работы. В этой главе мы поговорим о том, почему LLM совершили прорыв, как они работают и где их можно применять, какие у них есть поразительные возможности и потенциальные проблемы. Мы также объясним, что делает LLM такими важными и почему так много людей взбудоражены (и обеспокоены) ими, и почему мы посвятили им целую книгу. Билл Гейтс назвал этот тип искусственного интеллекта «столь же важным, как компьютер или интернет» и сказал, что ChatGPT изменит мир3. Тысячи людей, включая Илона Маска и Стива Возняка, поддержали и подписали открытое письмо организации Future of Life Institute, в котором содержится призыв приостановить исследования и разработку этих моделей, пока человечество не будет лучше подготовлено к возможным рискам (см. http://mng.bz/847B). Это напомнило ситуацию, когда компания OpenAI в 2019 году уже создала предшественника ChatGPT, но заявила, что не будет выпускать полноценную модель из-за опасений ее неправильного использования4. Из-за всей этой шумихи, обилия противоречащих друг другу мнений и преувеличенных заявлений непросто продраться к сути и понять, на что LLM способны, а на что – нет. Но вам поможет это сделать наша книга. Кроме того, мы надеемся, что она послужит полезной опорой для понимания основных идей «ответственных технологий», включая конфиденциальность данных и алгоритмическую прозрачность, а также связанных с ними проблем.
Поскольку вы читаете эту книгу, возможно, вы уже кое-что знаете о генеративном ИИ. Вероятно, вы переписывались с ChatGPT или другим чат-ботом; может быть, этот опыт привел вас в восторг или даже встревожил. Эти реакции вполне понятны. В этой книге мы рассмотрим LLM детально и прагматично, поскольку считаем, что, несмотря на несовершенства, LLM появились, чтобы остаться надолго, и нужно, чтобы как можно больше людей помогали им лучше работать на благо общества.
Несмотря на шумиху, ChatGPT – это не глобальный технический прорыв, а скорее, очередной шаг в постепенном усовершенствовании быстро развивающейся области обработки естественного языка – больших языковых моделях. В частности, ChatGPT – это LLM, предназначенная для ведения диалогов; другие модели могут быть адаптированы для других целей или для общего использования в задачах по обработке естественного языка. Подобная гибкость – один из аспектов больших языковых моделей, который делает их такими производительными по сравнению с предшественниками. В этой главе мы дадим определение большим языковым моделям и обсудим, как они достигли таких преимущества в области обработки естественного языка.
«Доступных через API» означает, что такие системы не имеют визуального пользовательского интерфейса и работать с ними можно, только используя какой-либо из языков программирования. – Прим. науч. ред.
Fortune 500 – список пятисот крупнейших компаний США по размеру выручки, ежегодно составляемый журналом Fortune.
1.1. Как развивалась обработка естественного языка
Обработка естественного языка – это техническая дисциплина, связанная с созданием машин, которые могут обрабатывать человеческий язык или данные, похожие на него, тем самым выполняя полезные для пользователя задачи. Эта дисциплина так же стара, как сами компьютеры: когда они были только изобретены, одной из потенциальных областей их применения предполагался перевод с одного человеческого языка на другой. Конечно, в то время само программирование выполнялось совсем иначе – программа задавалась последовательностью логических операций, записанных на перфокарте. Тем не менее, чтобы компьютеры могли полностью реализовать свой потенциал (и люди это осознавали), необходимо было научить их понимать естественный язык – преобладающую форму общения в мире. В 1950 году британский ученый в области компьютерных наук Алан Тьюринг опубликовал статью, в которой предложил способ оценки искусственного интеллекта, ныне известный как тест Тьюринга5. В популярной формулировке, машина считается «обладающей интеллектом», если в разговоре она способна давать ответы, неотличимые от человеческих. И хотя сам Тьюринг не использовал подобную терминологию, это каноническая задача для понимания и генерации естественного языка. В настоящее время тест Тьюринга как способ оценки интеллектуальной системы считается неполным, поскольку его легко проходят многие современные программы, способные имитировать человеческую речь, но при этом негибкие и не умеющие выстраивать логические выводы6. Тем не менее он служил критерием для оценки на протяжении десятилетий, да и сейчас остается популярным стандартом для современных моделей по обработке естественного языка.
Ранние программы по обработке естественного языка использовали тот же подход, что и первые системы искусственного интеллекта, следуя набору правил и эвристик. В 1966 году Джозеф Вейценбаум, профессор Массачусетского технологического института (MIT), выпустил чат-бота, которого назвал ELIZA в честь персонажа пьесы «Пигмалион». ELIZA разрабатывалась для терапевтических целей. Предполагалось, что чат-бот будет общаться с пациентом с помощью открытых вопросов, а на слова и фразы, которые не смог распознать, будет давать общие ответы, например «Продолжайте, пожалуйста». Хотя бот работал по простому алгоритму сопоставления с образцом, люди чувствовали себя с ним вполне комфортно и могли делиться интимными подробностями. Например, во время тестирования бота секретарша Вейценбаума попросила его выйти из комнаты7. Вейценбаум писал, что был ошеломлен, до какой степени люди, беседовавшие с ELIZA, приписывали модели настоящее сочувствие и понимание. Однако антропоморфизм, примененный к его инструменту, беспокоил Вейценбаума, и впоследствии он потратил немало времени, пытаясь убедить людей, что чат-бот ELIZA на самом деле не так хорош, как его восхваляли.
Хотя основанный на правилах синтаксический анализ текста оставался распространенным в течение последующих нескольких десятилетий, такого рода подходы оказались нестабильными, требовали сложной логики «если – то» и значительных лингвистических знаний. Однако к 1990‐м годам некоторые из лучших результатов в задачах типа машинного перевода были достигнуты с помощью статистических методов, чему способствовали возросшая доступность как данных, так и вычислительных мощностей. Переход от методов, основанных на правилах, к статистическим методам представлял собой серьезную смену парадигмы в обработке естественного языка: людям уже не надо было обучать свои модели грамматике, тщательно определяя и выстраивая такие языковые понятия, как части речи и времена. Новые статистические модели добивались большего успеха, самостоятельно изучая закономерности при обработке тысяч переведенных документов.
Этот тип машинного обучения называется обучением с учителем, поскольку модель получает то, что мы обычно называем размеченными данными, – данные, для которых известны правильные ответы, в данном случае – переведенные документы. В других системах могут использовать обучение без учителя, то есть по неразмеченным данным, или обучение с подкреплением – метод на основе проб и ошибок, где модель постоянно обучается находить наилучший результат, получая обратную связь в виде вознаграждений и штрафов. Сравнение между этими тремя типами приведено в таблице 1.1.
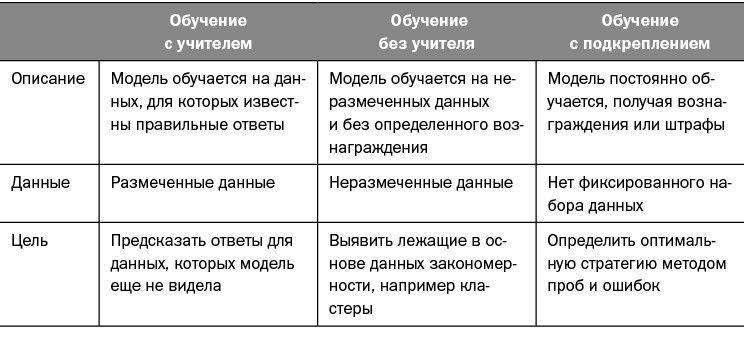
Таблица 1.1. Типы машинного обучения
При обучении с подкреплением (рис. 1.1) вознаграждения и штрафы – это числовые значения, которые направляют прогресс модели в выполнении конкретной задачи. Когда поведение вознаграждается, эта положительная обратная связь создает цикл подкрепления, при котором модель с большей вероятностью будет снова повторять это действие, тогда как наказуемое поведение становится менее вероятным. Как мы увидим дальше, большие языковые модели обычно используют комбинацию этих стратегий.
Обучение с подкреплением – это метод обучения на основе проб и ошибок, при котором модель постоянно обучается находить наилучший результат, получая за свои ответы либо вознаграждение, либо штрафы от алгоритма.
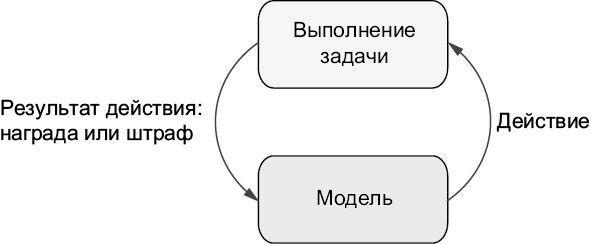
Рис. 1.1. Цикл обучения с подкреплением
Кроме особенностей обучения, есть еще несколько ключевых компонентов, которые характерны для модели NLP (обработка естественного языка). Первый – это данные, которые для задач на естественном языке представлены в виде текста. Второй – это целевая функция, которая, по сути, является математической формулировкой цели модели. Цель может заключаться в том, чтобы свести к минимуму количество ошибок, допущенных в конкретной задаче, или минимизировать различие между прогнозом модели для какой-то величины и ее истинным значением. Третий – существуют различные типы моделей и архитектуры, но фактически все продвинутые модели NLP за последние несколько десятилетий относились к единственной категории – нейронным сетям.
Нейронные сети были представлены в 1944 году как алгоритмическое представление человеческого мозга8. В каждой нейронной сети есть входной и выходной слой, а между ними – какое-либо количество «скрытых» слоев; каждый слой, в свою очередь, имеет несколько нейронов, или узлов, которые могут соединяться разными способами. Каждый нейрон присваивает передаваемым ему входным данным весовые коэффициенты (веса) [4], суммирует их и «активируется», то есть передает сигнал на следующий слой, если сумма входных данных превышает некоторое пороговое значение. Сутью обучения таких нейронных сетей является подбор оптимальных значений для весовых коэффициентов и пороговых значений. Обрабатывая обучающие данные, алгоритм будет итеративно обновлять весовые коэффициенты и пороговые значения до тех пор, пока не найдет те, которые лучше всего соответствуют целевой функции модели. Мы не будем сейчас обсуждать точную математику, лежащую в основе этого процесса, но важно отметить, что большие нейронные сети могут аппроксимировать любую функцию, какой бы сложной она ни была, что делает их полезными при обработке огромных объемов данных, например во многих задачах по обработке естественного языка. Количество параметров относится к количеству весовых коэффициентов, встроенных в модель, и является условным обозначением уровня сложности, с которым она способна справиться, что, в свою очередь, определяет ее возможности. Самые эффективные на сегодняшний день LLM учитывают сотни миллиардов параметров.
За последние несколько десятилетий доступность больших объемов данных и вычислительных мощностей способствовала укреплению доминирования нейронных сетей и привела к бесчисленным экспериментам с различными сетевыми архитектурами. Глубокое обучение возникло как подраздел, где «глубокое» означает просто глубину задействованных нейронных сетей, то есть количество скрытых слоев между входом и выходом. Было обнаружено, что по мере увеличения масштаба и глубины нейронных сетей – при наличии достаточного количества данных – производительность моделей улучшалась.
Весовой коэффициент – это показатель силы связи между нейронами. – Прим. авт.
1.2. Рождение LLM: все, что вам нужно, – это внимание
Когда люди начали обучать модели генерации текста, классификации и другим задачам по обработке естественного языка, они стремились понять, чему именно обучаются модели. Это не чисто научное любопытство: изучение того, как модели делают прогнозы, является важным шагом к тому, чтобы доверять полученным результатам в достаточной степени для использования. Давайте возьмем в качестве примера машинный перевод с английского на испанский.
Когда мы подаем на вход модели текстовую последовательность, например The cat wore red socks («Кот носил красные носки»), то вначале ее необходимо закодировать в математическое представление. Последовательность разбивается на токены – обычно это либо слова, либо их части. Нейронная сеть преобразует эти токены в свое математическое представление и применяет к ним обученный алгоритм. В конце для получения удобочитаемого результата выходные данные преобразуются обратно в токены, то есть декодируются. В данном случае выходная последовательность – это перевод предложения (El gato usó calcetines rojos). Модели, которые получают на вход последовательность и возвращают также последовательность, мы называем sequence-to-sequence. Когда модель выдает правильный перевод, мы приходим к выводу, что модель удовлетворительно «выучила» функцию перевода, по крайней мере, для слов и грамматических структур, представленных в этих входных данных.
Традиционно для таких задач использовали последовательные алгоритмы: токены обрабатывались по очереди, в том порядке, в котором они представлены в последовательности [5]. В 2014 году исследователи машинного обучения, вновь вдохновленные некоторыми особенностями человеческого мышления9, предложили альтернативу традиционному подходу передачи последовательностей по частям через модель энкодер-декодер [6]. В новом подходе декодер «видел» всю входную последовательность целиком и, более того, пытался найти в ней кусочки, наиболее релевантные для очередного генерируемого токена. Такой подход называется механизмом внимания. Давайте вернемся к примеру с машинным переводом. Если вас попросят выделить ключевые слова из предложения That cat chased a mouse, but it didn’t catch it («Эта кошка гонялась за мышкой, но не поймала ее»), вы, вероятно, выберете cat (кошка) и mouse (мышка), поскольку местоимения that и артикль a не так важны в переводе. Как показано на рис. 1.2, вы сосредоточили свое «внимание» на важных словах. Механизм внимания имитирует это, добавляя весовые коэффициенты внимания, чтобы усилить важные части последовательности.
МЕХАНИЗМ ВНИМАНИЯ вычисляет индивидуальный контекст для каждого слова в последовательности.
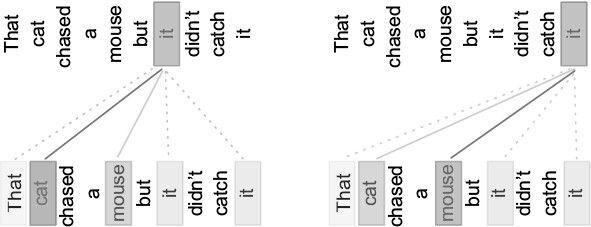
Рис. 1.2. Распределение внимания к слову it в различных контекстах
Несколько лет спустя в статье Google Brain с удачным заголовком «Все, что вам нужно, – это внимание» авторы показали, что механизм внимания позволяет отказаться от последовательной обработки входных последовательностей, и предложили архитектуру, позволяющую распараллелить больший объем вычислений и таким образом существенно ускорить работу модели. Они назвали эти модели трансформерами. Трансформеры обрабатывают каждое слово в предложении, многократно применяя механизм внимания. Результатом обработки является новое численное представление слова [7], которое отражает его связь с другими словами в предложении, что позволяет модели более точно «понять» его смысл. И все эти вычисления могут проводиться параллельно для разных слов в предложении. В статье «Все, что вам нужно, – это внимание» авторы показали, что эти модели достигли высочайшей производительности при выполнении задач по переводу с английского на немецкий и на французский10. Это был крупнейший прорыв в NLP за это десятилетие, заложивший основу для последующих работ.
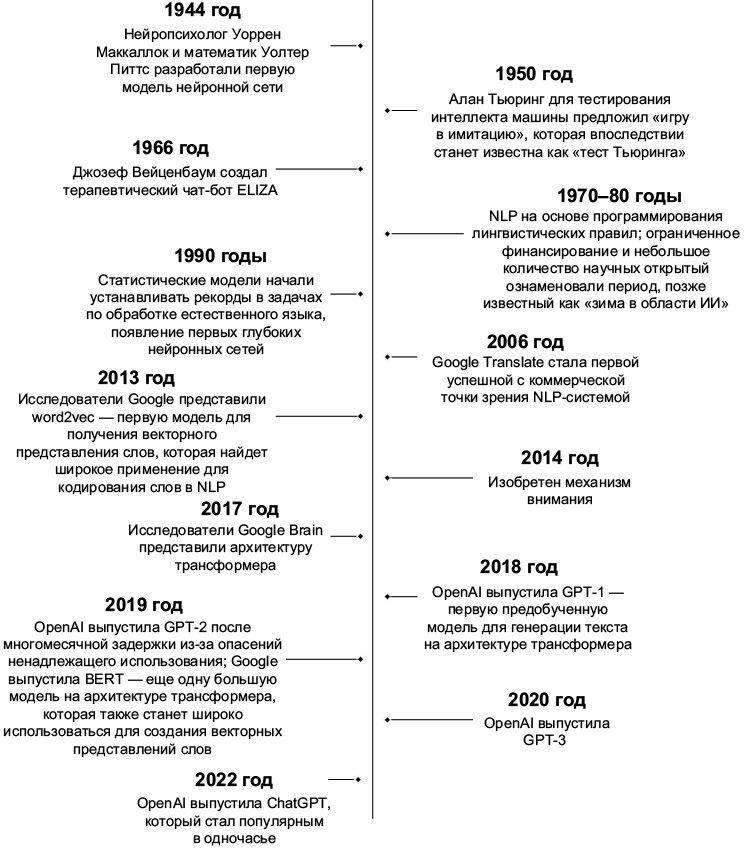
Рис. 1.3. Хронология наиболее значимых событий в области обработки естественного языка
Благодаря экономии времени и ресурсов с трансформерами стало возможным обучать модели на гораздо больших объемах данных. Это привело к рождению большой языковой модели. Компания OpenAI в 2018 году представила основанную на трансформере большую языковую модель Generative Pre-training (GPT), которая была предобучена на огромных объемах неразмеченных данных из интернета и допускала тонкую настройку [8] для выполнения конкретных задач, таких как анализ сентимента [9] текста, машинный перевод, классификация текста и так далее11. До этого большинство моделей NLP обучались для решения конкретной задачи, и это было их главным узким местом, поскольку им требовалось огромное количество размеченных данных, создание которых является трудоемким и дорогостоящим. Для решения этой проблемы и были разработаны универсальные большие языковые модели, которые способны создавать информативные внутренние представления слов и понятий самостоятельно, используя неразмеченные данные. А пока специалисты спорили, какой размер модели стоит считать «большим», Google разработал еще одну из первых больших языковых моделей, работающую на архитектуре трансформера, – BERT (Bidirectional Encoder Representations from Transformers), которая была обучена на миллиарде слов и имела более 100 миллионов параметров или выученных весов12. На рис. 1.3 приведена хронология основных событий в NLP.
1.3. Бурное развитие больших языковых моделей
В предыдущем разделе мы обсудили, как языковые модели могут научиться решать конкретные задачи, изучая закономерности в данных. Например, для перевода можно использовать набор данных с документами, продублированными на нескольких языках; для задач обобщения – набор данных в виде документов с краткими выводами, подготовленными человеком и так далее. Однако, в отличие от таких ранних систем, большие языковые модели не ограничены решением конкретных задач. Наоборот, они обучены решать задачу, которая состоит в том, чтобы для последовательности с пропущенным токеном (например, пропущенное слово в предложении) предсказать, какой токен лучше всего подходит на место пропущенного, учитывая весь контекст последовательности. Прелесть этой задачи в том, что она является обучением без учителя: модель самостоятельно обучается предсказывать недостающую часть входных данных по имеющейся, поэтому разметка не требуется. Это также называют предиктивным обучением или pretext learning.
Поскольку LLM применяются в различных областях, они становятся неотъемлемой частью нашей повседневной жизни. Обработка естественного языка используется такими виртуальными собеседниками, как Apple Siri, Amazon Alexa и Google Home, которые прослушивают запросы пользователей, преобразуют звук в текст, а затем выполняют поставленные им задачи или находят ответы. Мы встречаем чат-ботов для обслуживания клиентов в розничной торговле, а в следующем разделе обсудим более сложные диалоговые агенты, такие как ChatGPT. Технология NLP используется в медицине для обработки электронных медицинских карт, а также для решения повседневных задач в юриспруденции, таких как поиск соответствующих прецедентов в судебной практике или определенной информации в документах. Обработка естественного языка также используется на платформах социальных сетей, таких как Facebook [10], X (Twitter) и Reddit, в том числе для того, чтобы сделать онлайн-общение более позитивным путем выявления разжигающих ненависть высказываний или оскорбительных комментариев.
Позже мы поговорим о том, как проводится тонкая настройка LLM, после которой они могут хорошо выполнять определенный тип задач; однако структура первого этапа обучения означает, что большие языковые модели могут свободно генерировать текст в самых разных контекстах. Это свойство делает их не только идеальными кандидатами в диалоговые агенты, но и дает им некоторые неожиданные способности в выполнении задач, для которых они не были специально обучены.
Принадлежит организации Meta, которая признана экстремистской и запрещена на территории РФ.
Энкодер кодирует входную последовательность (например, слова) в вектор (т. е. набор чисел), декодер – декодирует ее в виде новой последовательности. – Прим. ред.
Например, рекуррентные нейронные сети RNN. Отметим недостаток последовательных алгоритмов – невозможность распараллелить вычисления и ускорить их за счет использования нескольких процессоров. – Прим. науч. ред.
Для тонкой настройки модель, обученную на большом наборе данных, дополнительно обучают на данных с более специфической тематикой. Таким образом можно использовать уже имеющиеся базовые знания модели без необходимости обучать ее с нуля. – Прим. авт.
О численном или векторном представлении слов см. подробнее раздел 1.5.1. – Прим. ред.
Сентимент (текста) – эмоциональная окрашенность, эмоциональная тональность текста. – Прим. ред.
1.4. Где примененяются LLM?
Благодаря своей универсальности и многофункциональности большие языковые модели имеют широкий спектр применения и могут использоваться в разных областях. Они способны решать самые разные задачи на естественном языке, включая общение с пользователями, ответы на вопросы, классификацию или обобщение текста. В этом разделе мы обсудим несколько распространенных случаев применения LLM, поставленные перед ними проблемы, а также перспективы в решении ими новых задач, например помощь в программировании и логическом рассуждении, где языковые модели ранее не применялись.
1.4.1. Моделирование языка
Моделирование языка – это наиболее естественное применение языковых моделей. Одним из таких применений является продолжение текста – это задача прогнозирования следующего слова или символа в документе. Модель изучает особенности и характеристики естественного языка и генерирует следующее наиболее вероятное слово или символ. Эту технологию можно применять также для обучения больших языковых моделей, которые затем используются для широкого спектра задач на естественном языке, и некоторые из них мы обсудим в последующих разделах.
Выполнение задач моделирования языка часто оценивается по различным наборам данных. Это могут быть, например, задачи по моделированию отдаленных зависимостей, когда модель просят предсказать следующее слово в предложении, учитывая контекст всего предшествующего абзаца. Давайте рассмотрим пример задачи с отдаленной зависимостью13. Модели дается такой контекст:
«Он покачал головой, сделал шаг назад, поднял руки вверх и попытался улыбнуться. „Ты сможешь“, – ободряюще сказала Джулия. – „Я уже навела фокус на своего друга. Тебе нужно просто нажать кнопку затвора, вот здесь, сверху“».
А предложение, в котором модель должна предсказать последнее слово, звучит так: «Он с опаской кивнул и взял __________». Правильный ответ – слово «фотоаппарат».
Еще одной задачей, по которой можно оценить эффективность модели, является выбор наилучшего завершения рассказа, набора инструкций14 или выбор правильной финальной фразы в истории длиной в пару предложений. Давайте рассмотрим еще один пример со следующим рассказом15: «В комнату Карен заселили соседку-первокурсницу. Соседка пригласила ее поехать на концерт в соседний город. Карен с радостью согласилась. Шоу было поистине захватывающим». Наиболее вероятной концовкой и правильным ответом, ожидаемым от модели, было предложение: «Карен подружилась со своей соседкой по комнате», а наименее вероятной – «Карен ненавидела свою соседку по комнате».
Поскольку эти модели обучены создавать текст, напоминающий написанный человеком, они используются для генерации текста или генерации естественного языка (natural language generation, NLG). Они особенно полезны для диалоговых чат-ботов и автозаполнения [11], а также их можно тонко настроить для написания текстов в разных стилях и форматах, включая сообщения в социальных сетях, новостные статьи и даже программный код. Генерация текста выполнялась с использованием BERT, GPT и других моделей.
1.4.2. Генерация ответов на вопросы
Популярным применением больших языковых моделей является генерация ответов на вопросы (Q&A), где им приходится отвечать на вопросы людей на естественном языке. В целом существует два типа задач в этой области: выбор наилучшего ответа и свободный ответ. Для первой из этих задач цель обучения модели заключается в поиске правильного ответа из набора возможных вариантов, в то время как в задаче со свободным ответом модель дает ответ на вопрос на естественном языке без каких-либо предварительно подготовленных вариантов.
В зависимости от входных и выходных данных существуют три основные разновидности Q&A-моделей. Первая – это извлекающая Q&A-модель; она ищет готовый ответ из контекста, который может быть представлен в виде текста или таблицы. Вторая разновидность – это модель с «открытой книгой» (open-book generative Q&A), которая использует предоставленный контекст для генерации ответа. Ее работа напоминает первый подход с той разницей, что модель здесь извлекает не дословный ответ из контекста, а использует контекст для генерации ответа своими словами. Последняя разновидность – это модель генерации ответов на вопросы с «закрытой книгой» (closed-book generative Q&A). Здесь вы не предоставляете никакого контекста в своих входных данных, кроме самого вопроса, а модель генерирует наиболее вероятный ответ в соответствии со своими «познаниями».
До недавних усовершенствований в технологии LLM задача «ответ на вопрос» обычно решалась методом «открытой книги» при наличии доступа к бесконечному множеству запросов и ответов. Более новые модели, такие как GPT‐3, оценивались в чрезвычайно строгих условиях «закрытой книги», где модели не предоставлялся никакой дополнительный контекст, а также ей не разрешалось ни в каком виде обучаться по наборам данных, используемых для оценки. В популярные датасеты [12] для оценки моделей Q&A входят простые вопросы (см. http://mng.bz/E9Rj) и поисковые запросы Google (см. http://mng.bz/NVy7). В качестве примера можно привести такие вопросы: «Какой политик получил Нобелевскую премию мира в 2009 году?», «Какую музыку сочинил Бетховен?».
Еще одно применение моделей, которое тесно связано с данной предметной областью, – понимание прочитанного. В этой задаче модели показывается несколько предложений или абзацев, а затем ее просят ответить на конкретный вопрос. Чтобы наилучшим образом имитировать человеческие качества, LLM часто тестировали по вопросам в разных форматах на понимание прочитанного, включая вопросы с множественным выбором, диалоги и абстрактные наборы данных. Давайте рассмотрим пример с набором входных данных, включающих диалог16. Задача состоит в том чтобы дать правильный ответ на вопрос, учитывая как контекст, так и происходящий диалог: «Джессика решила посидеть в своем кресле-качалке. Сегодня у нее был день рождения, ей исполнялось 80 лет. Во второй половине дня должна была приехать ее внучка Энни, и Джессика была очень рада ее увидеть. Ее дочь Мелани вместе со своим мужем Джошем тоже должны были приехать. У Джессики был…» Если первый вопрос диалога «У кого был день рождения?», правильный ответ будет «У Джессики». Затем модели задают следующий вопрос: «Сколько ей исполнялось лет?» – на который она должна ответить: «80».
Одним из наиболее ярких примеров модели, разработанной для генерации ответов на вопросы, была модель Watson от IBM Research. В 2011 году компьютер Watson соревновался в популярном игровом шоу Jeopardy! с двумя крупнейшими победителями за все время существования телешоу и победил17.
Наборы данных. – Прим. ред.
Автозаполнение предсказывает, какое слово будет следующим. Системы автозаполнения используются в различных приложениях, таких как Gmail, Google Search, iMessage, WhatsApp и других. – Прим. авт.
1.4.3. Программирование
В последнее время генерация программного кода стала одним из самых популярных применений LLM. Такие модели принимают входные данные на естественном языке и пишут фрагменты кода на заданном языке программирования. Несмотря на то, что в этой области все еще предстоит решить определенные проблемы, такие как безопасность, прозрачность и лицензирование, разработчики и инженеры с разным уровнем квалификации ежедневно используют инструменты с поддержкой LLM, чтобы повысить свою производительность.
Инструменты для генерации кода появились в середине 2022 года, когда был выпущена GitHub CoPilot. Программа CoPilot, которую называют «Ваш напарник-программист с искусственным интеллектом», была запущена в июне 2022 года и распространялась по системе подписки (см. https://github.com/features/copilot). Основанная на модели Codex, разработанной OpenAI, она быстро стала использоваться в роли виртуального помощника в «парном программировании» [13], чтобы повысить продуктивность разработчиков. Codex – это версия GPT‐3, для которой была проведена тонкая настройка для решения задач программирования на более чем десяти различных языках. GitHub CoPilot предлагает продолжение кода по мере ввода, автоматически заполняет повторяющийся код, показывает альтернативные варианты и преобразует комментарии в код. Разработчики находили для себя различные творческие и неожиданные способы использования «программиста с искусственным интеллектом», например: он помогал неносителям английского языка, готовил к собеседованиям по программированию, тестировал код и многое другое. В тот же месяц, в июне 2022 года, Amazon анонсировала выпуск аналогичного инструмента под названием CodeWhisperer, который описывается как помощник по программированию на основе искусственного интеллекта для повышения производительности разработчиков за счет генерации рекомендаций по коду и проверки безопасности (см. https://aws.amazon.com/codewhisperer/). Стоит отметить, что эти инструменты программирования продвигаются как «напарники-программисты» или «помощники по программированию», цель которых – дополнить человека, а не заменить его. Хотя CoPilot и CodeWhisperer, как правило, дают хорошие рекомендации, они не могут продумывать программы целиком так, как это делает человек, и иногда могут допускать глупые ошибки. В главе 6 мы подробно обсудим идею повышения производительности с помощью машин.
GPT‐4, итерация моделей класса GPT, выпущенная в марте 2023 года, была протестирована на различных задачах программирования18. Leetcode – это популярная платформа, где собраны задачи по программированию, например по структурам данных или алгоритмам, которые часто приходится решать при прохождении технических собеседований. Хотя GPT‐4 относительно хорошо справляется с простыми задачами на Leetcode, средние или сложные задачи даются ему с трудом, следовательно, многие работы по программированию по-прежнему нуждаются в участии человека.
1.4.4. Генерация контента
Чрезвычайно перспективным и широко используемым применением LLM является генерация контента. Способность генерировать для новостей текст, напоминающий написанный человеком, традиционно использовалась для оценки работы LLM. В задаче давались название и подзаголовок или первое предложение, учитывая которые необходимо было сгенерировать развернутую статью, а результат оценивался по критерию «насколько вероятно, что статья написана машиной»: чем лучше статья была сгенерирована, тем сложнее установить ее машинное «авторство». Существует вариант задачи – также имеющий отношение к потенциально неправильному использованию LLM, обсуждаемому в разделе 1.5.2, – когда качество новостной статьи определяется тем, способны ли люди отличить созданный машиной контент от созданного человеком. Этот вариант аналогичен тесту Тьюринга, но здесь проверяется способность создавать контент, а не вести диалог. GPT‐3 и другие разновидности LLM продолжают создавать новостные статьи, которые человеку трудно идентифицировать как написанные машиной.
Как упоминалось в предыдущем подразделе, использование возможности генерации контента вышло за пределы только написания новостных статей. Благодаря повышению доступности сложных диалоговых агентов люди используют LLM для создания контента в различных жанрах, стилях и форматах, включая создание планов маркетинговых кампаний, сообщений в блогах и электронных письмах, постов в социальных сетях и многое другое. В область создания генеративного контента также вошли несколько стартапов, в том числе Jasper AI, Anthropic AI, Cohere, Runway, Stability AI и Adept AI. В следующей главе мы подробно обсудим использование LLM для генерации контента, а также рассмотрим любые потенциальные риски.
1.4.5. Логические рассуждения
Новым и интересным применением LLM является использование их способности «рассуждать» – делать выводы или заключения на основе новой или существующей информации. Недавней, но уже распространенной логической задачей для LLM является арифметика. Задания часто представляют собой простые арифметические действия: сложение, вычитание или умножение с 2–5 числами. LLM выполняют такие задания с ошибками и не демонстрируют стабильные результаты, поэтому мы не можем сказать, что они «понимают» арифметику, однако результаты оценки GPT‐3 показывают, что выполнять очень простые арифметические задачи они способны. Примечательной в области математики является модель Facebook[14] AI Research Transformer, обученная решать дифференциальные уравнения и интегралы. Когда модели задавали задачи, которые она еще не видела (то есть уравнения, которые не были частью обучающих данных), она превосходила системы, основанные на применении алгебраических правил, такие как MATLAB и Mathematica19.
Еще одно применение, заслуживающее обсуждения, – это здравый смысл или логические рассуждения, когда модель пытается уловить смысл фактических или научных обоснований. Это отличается от понимания прочитанного или генерации ответов на общие тривиальные вопросы, поскольку требует от модели определенного понимания окружающего мира. Успехов добилась языковая модель Minerva от Google Research, которая способна отвечать на математические и научные вопросы с помощью пошаговых рассуждений20. GPT‐4 прошел проверку на различных академических и профессиональных экзаменах, включая Единый экзамен для юристов (Uniform Bar Examination), тест для поступления в юридический колледж (LSAT), тест оценки успеваемости (SAT) по чтению, письму, математике, вступительные экзамены для выпускников (GRE), экзамены по физике, статистике, математическому анализу и многое другое. На большинстве этих экзаменов модель показала результаты на уровне человека и, что примечательно, сдала Единый экзамен для юристов, набрав на 10 % больше баллов, чем биологические образцы18.
В последнее время в юридической практике все чаще используют LLM, например, в инструментах для обобщения документов, в юридической экспертизе, для повышения доступности услуг в этой области и для помощи в юридическом обосновании. В марте 2023 года юридическая ИИ-компания Casetext представила инструмент CoCounsel – первого юридического помощника с искусственным интеллектом, созданного в сотрудничестве с OpenAI на их самой продвинутой LLM21. CoCounsel может выполнять различные юридические задачи, такие как юридические исследования, обзор документов, подготовка свидетельских показаний, анализ контрактов и многое другое. Harvey AI – аналогичный инструмент, который помогает в решении таких задач, как анализ контрактов, юридическая экспертиза, судебные процессы и соблюдение нормативных требований. Компания Harvey AI сотрудничала с одной из крупнейших юридических фирм мира Allen&Overy, а также объявила о стратегическом партнерстве с PricewaterhouseCoopers (PwC)22.
Парное программирование – это метод разработки программного обеспечения, когда над написанием кода совместно работают два человека. – Прим. авт.
Принадлежит организации Meta, которая признана экстремистской и запрещена на территории РФ.
1.4.6. Другие задачи на естественном языке
Как и следовало ожидать, большие языковые модели также хорошо подходят для решения множества других лингвистических задач. LLM уже давно и широко используются для машинного перевода, автоматизируя перевод между языками. Как обсуждалось ранее, на самом деле машинный перевод был одной из первых задач, которую поставили перед компьютерами еще 70 лет назад. Начиная с 1950‐х годов, эту задачу решали путем переноса лингвистических правил в компьютерную программу, что было не только вычислительноемким и времязатратным процессом, но и требовало набора компьютерных инструкций с полным словарным запасом для каждого языка и множеством типов грамматик. К 1990‐м годам американская многонациональная технологическая корпорация International Business Machines, более известная как IBM, внедрила статистический машинный перевод, поскольку исследователи предположили, что если они просмотрят достаточное количество текстов, то смогут найти закономерности в переводах. Это стало огромным прорывом в области перевода и привело к запуску в 2006 году Google Translate, в котором использовался статистический машинный перевод. Google Translate стал первым коммерчески успешным применением NLP и, возможно, наиболее известным. Область машинного перевода изменилась навсегда в 2015 году, когда компания Google стала использовать большие языковые модели и получать гораздо более впечатляющие результаты. В 2020 году Facebook Inc [15]. анонсировал выпуск первой многоязычной модели машинного перевода, которая позволяет переводить между любыми ста парами языков напрямую, минуя английский, – еще одна важная веха в области машинного перевода, поскольку теперь уменьшилась вероятность потери смысла при итерациях23.
Еще одним практическим применением является реферирование текста, то есть создание его краткой версии, в которой выделяется наиболее важная информация. Существует два типа методов реферирования: извлекающий (экстракция) и генерирующий (абстракция). Извлекающее реферирование связано с выделением наиболее важных предложений из длинного текста, которые объединяются в кратком обзоре. А вот генерирующее реферирование перефразирует текст и формирует краткий обзор, что похоже на написание «аннотации», которая может содержать слова и предложения, отсутствующие в исходном тексте.
Существуют и другие разнообразные области применения, например приложения, которые могут исправлять грамматику английского языка, изучать и использовать новые слова, а также решать лингвистические головоломки. Вот пример того, как GPT‐3 может изучать и использовать новые слова: модели дается определение несуществующего слова, например «гигамуру», а затем ее просят использовать его в предложении. Такие компании, как Grammarly и Duolingo, быстро внедряют LLM в свои продукты. В марте 2023 году Grammarly, популярный инструмент для проверки грамматики и орфографии, представил новую версию GrammarlyGO, в которой для генерации текста применяется ChatGPT (см. http://mng.bz/D9oa). Также в марте 2023 года Duolingo представила версию Duolingo Max, в которой GPT‐4 используется для реализации таких функций обучающей платформы, как «объясните мой ответ» и «ролевая игра» (см. http://mng.bz/lVvB).
1.5. В чем недостатки LLM?
Несмотря на то, что большие языковые модели достигли беспрецедентного успеха в решении самых разнообразных задач, стратегии, которые привели LLM к их нынешнему взлету, в то же время сопряжены со значительными рисками и ограничениями. Обучающие данные для LLM несут в себе риски, и это связано, в частности, с тем, что они неизбежно содержат в себе множество взглядов и убеждений, которые модель, по мнению разработчиков LLM, не должна воспроизводить. Кроме того, здесь есть риски, связанные с непредсказуемостью выходных данных LLM. Наконец, нынешний ажиотаж в создании и использовании LLM в повседневных задачах заставляет задуматься о последствиях еще большего увеличения энергопотребления.
1.5.1. Обучающие данные и предвзятость
Большие языковые модели обучаются на огромных объемах текстовых данных. Таким образом, для создания модели, которая сможет качественно сгенерировать естественно написанные формулировки, крайне важно собрать огромное количество текстов, идеально написанных человеком на естественном языке. К счастью, в интернете уже существует и легко доступно достаточное количество текстового контента. Конечно, количество – только одна часть уравнения; качество – гораздо более крепкий орешек.
Компании и исследовательские лаборатории, которые обучают LLM, собирают наборы данных с сотнями миллиардов слов из Интернета. Самые распространенные текстовые корпусы для обучения LLM [16]– это Wikipedia и Reddit, а также Google News и Google Books. Wikipedia, вероятно, является наиболее известным источником данных для LLM, и у нее есть много преимуществ: тексты здесь написаны и отредактированы человеком; это, как правило, достоверный источник информации благодаря активному сообществу фактчекеров; она написана на сотнях языков. Другой пример – Google Books – представляет собой коллекцию цифровых копий тысяч опубликованных книг, которые стали общественным достоянием. Хотя некоторые из таких книг могут содержать фактические ошибки или устаревшую информацию, они, как правило, считаются высококачественными текстовыми материалами, хотя и более формальными, чем большинство разговорных текстов на естественном языке.
А теперь давайте рассмотрим датасет всего сайта социальной сети Reddit или большей его части. Преимущества существенны: он включает в себя миллионы бесед между людьми, в которых отражена динамика диалога. Контент Reddit, как и других источников, уточняет внутреннее представление различных токенов в модели. Чем чаще модель будет встречать слово или фразу в обучающем наборе, тем лучше она сможет определить, когда это слово или фразу нужно сгенерировать. Однако некоторые разделы Reddit содержат огромное количество неприемлемых высказываний, в том числе расовые оскорбления или пренебрежительные шутки, опасные теории заговоров или дезинформацию, экстремистские идеологии и ненормативную лексику. При сборе большого количества данных из интернета практически неизбежно будет попадаться подобный тип контента, из-за чего сама модель может быть склонна к порождению речи такого типа. Кроме того, серьезные последствия имеет использование данных, которые могут являться личной информацией или материалами, защищенными авторским правом.
Кроме того, существуют также трудно уловимые предвзятости, которые могут проявляться в LLM через обучающие данные. Термин «предвзятость» чрезвычайно широко используется в машинном обучении, причем в разнообразных контекстах: иногда люди обозначают им статистическую предвзятость, которая подразумевает, что средний прогноз их модели отличается от истинного значения; обучающий набор данных может называться предвзятым, если в нем наблюдаются иные статистические закономерности, нежели в тестовом датасете, который часто берется совершенно случайно. Чтобы избежать путаницы, мы будем использовать «предвзятость» исключительно для обозначения несопоставимых результатов, которые модель может выдавать в зависимости от таких признаков личной идентичности, как раса, пол, класс, возраст или религия. Предвзятость – это давняя проблема алгоритмов машинного обучения, и она может по-разному в них проявляться, но важно помнить, что, по сути, эти модели отражают закономерности в тексте, на котором они обучались. Если в наших книгах, средствах массовой информации и социальных сетях существует предвзятость, то она отразится в наших языковых моделях.
ПРЕДВЗЯТОСТЬ – это склонность модели генерировать несопоставимые результаты в зависимости от таких признаков личной идентичности, как раса, пол, класс, возраст или религия.
Некоторые самые ранние языковые модели общего назначения, обученные на больших объемах неразмеченных наборов данных, создавались для того, чтобы получить числовые или векторные представления слов [17]. Сегодня каждая LLM фактически создает свои собственные векторные представления слов, которые мы называем ее внутренними представлениями. Еще до появления LLM всем, кто занимался компьютерной обработкой естественного языка, необходимо было как-то реализовать этап обработки текста для его численного представления, чтобы компьютерный алгоритм мог с ним работать. Векторное представление позволяет преобразовывать текст в осмысленные представления слов в виде числовых точек в трехмерном пространстве. У слов, которые используются в похожем контексте, например «огурец» и «корнишон», векторные представления будут располагаться близко друг к другу, а у слов «огурец» и «философия» они будут находиться далеко друг от друга (см. рис. 1.4). Придумано множество более простых способов представить слова в виде чисел: простейший, по сути, заключается в том, чтобы каждому уникальному слову в обучающих данных просто назначить случайную точку в числовом пространстве. Однако векторные представления позволяют зафиксировать гораздо больше информации о семантическом значении слова и создать более совершенные модели.
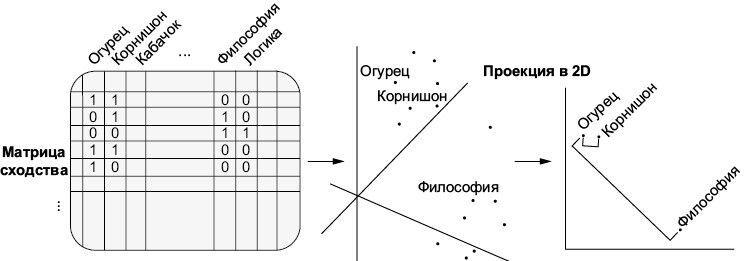
Рис. 1.4. Представление слов в векторной форме
В хорошо известной статье «Мужчина соотносится с программистом так же, как женщина с домохозяйкой? Избавляемся от предвзятости в векторных представлениях» (Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings) о векторном представлении слов, полученном на основе обучающих данных из Google News, ученые из Бостонского университета в сотрудничестве с Microsoft Research продемонстрировали, что векторы слов внутри самой модели показывали сильные гендерные стереотипы [18]как в отношении профессий, так и в отношении описаний24. Авторы разработали оценочное задание, в котором модель должна была генерировать аналогии «она – он» на основе своих векторных представлений. Некоторые результаты были безобидными, например: сестра – брат, королева – король. Однако модель создала и другие аналогии «она – он» с явно неравноценными ролями: медсестра – врач (или хирург), косметолог – фармацевт, дизайнер интерьеров – архитектор. Основная причина такой предвзятости объясняется просто тем, что в новостных статьях, которые входят в набор данных, в качестве архитекторов чаще всего упоминаются мужчины, а в качестве медсестер – женщины и так далее. Таким образом, модель отражает и фактически усиливает неравенство, существующее в обществе.
LLM, как и векторные представления слов, подвержены этой предвзятости. В статье 2021 года под заголовком «Об опасностях стохастических попугаев: могут ли языковые модели быть слишком большими?» (On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?) авторы показали, как большие языковые модели отражают и усиливают предвзятость, существующую в обучающих данных25. Несмотря на то, что есть методы устранения предвзятости в моделях и способы более аккуратного обучения, чрезвычайно сложно устранить ассоциации с полом, расой, сексуальной ориентацией и другими характеристиками, которые глубоко укоренились в повседневной жизни, или несопоставимость в данных, существовавшую веками. В итоге, если в контексте или промпте [19] присутствуют подобные характеристики, например пол или раса, LLM могут генерировать совершенно разные результаты.
Организация Meta (бывший Facebook Inc.) признана экстремистской и запрещена на территории РФ.
Корпус – совокупность текстов, используемых в качестве базы для исследования языка. – Прим. ред.
Англ. embeddings переводится на русский язык по-разному в разных контекстах, в том числе «вложения», «включения», «эмбеддинги», «семантические векторы». Здесь мы используем термин «векторное представление слова». – Прим. науч. ред.
Стереотипы – это специфическая преобладающая форма социальных предубеждений, в которых широко распространен образ или представление о конкретном человеке или понятии. Они, как правило, фиксированы и чрезмерно упрощены. – Прим. авт.
Промпт – запрос или подсказка, по которому LLM генерирует ответ. – Прим. ред.
1.5.2. Весьма правдоподобные, но неверные ответы
После того, как были выпущены ChatGPT от OpenAI и поисковая система Bing на базе ChatGPT в сотрудничестве с Microsoft, компания Google тоже выпустила своего собственного чат-бота Bard. Во время презентации в прямом эфире транслировалось видео, в котором чат-боту Bard задавали вопросы, а он отвечал на них. Один из вопросов звучал так: «О каких новых открытиях, сделанных космическим телескопом „Джеймс Уэбб“ (JWST), я могу рассказать своему девятилетнему ребенку?» В видео Bard рассказывает о JWST и в числе прочего упоминает, что этот телескоп впервые сделал фотографии экзопланет, то есть планет за пределами Солнечной системы. Одна (большая) ошибка: первые экзопланеты были сфотографированы более десяти лет назад несколькими старыми телескопами. Астрономы и астрофизики сразу же начали говорить об этом в X (Twitter) и сообщать по другим каналам; компания Google удалила ролик и запись видео на YouTube сразу после окончания трансляции. Но удар был нанесен, и в первые дни после запуска акции Google упали примерно на 9 %, при этом общая потеря рыночной капитализации составила около 100 миллиардов долларов26.
LLM очень трудно избежать такого типа ошибок, поскольку они не изучают текст и не могут понимать его суть так, как это делают люди. Они просто генерируют текст, предсказывая и аппроксимируя распространенные структуры предложений. Легкость, с которой LLM генерируют текст, сильно контрастирует с тем фактом, что они не понимают, о чем говорят, и могут выдавать ложную информацию или придумывать весьма правдоподобные, но неверные объяснения. Эти ошибки называются галлюцинациями. Чат-боты могут галлюцинировать сами по себе, или они бывают уязвимы перед противоречивыми входными данными от пользователей, когда собеседник убеждает их в чем-то, возможно, ложном.
ГАЛЛЮЦИНАЦИИ – это ложная информация или выдуманные, но весьма правдоподобные неверные объяснения, которые может выдавать LLM.
Генерация галлюцинаций общепризнанно считается одной из самых серьезных проблем, связанных в настоящее время с LLM. Галлюцинации могут появиться из-за проблем с обучающим набором (например, если кто-то в интернете ошибочно написал, что первые снимки экзопланет сделал JWST), но также они могут возникать в контекстах, которых нет ни в одном из ранее известных модели текстов, и она должна сама создавать свои знания. Янн Ле Кун, светило в области машинного обучения и главный специалист по искусственному интеллекту в Meta [20], утверждает, что LLM не могут обеспечить 100 % точности ни в каких пределах вероятности, поскольку, по мере того как ответы, генерируемые моделью, становятся длиннее, количество возможных вариантов ответа множится, становясь почти бесконечным, и лишь небольшая доля из них может быть верна по смыслу27. Конечно, польза от работы LLM во многом зависит от того, можно ли улучшить их точность. Позже в этой книге мы обсудим подходы, которые используют разработчики LLM, пытаясь уменьшить количество галлюцинаций и других нежелательных ответов.