

автордың кітабын онлайн тегін оқу Software Dynamics: оптимизация производительности программного обеспечения
Переводчик Д. Брайт
Научный редактор С. Долин
Ричард Л. Сайтс
Software Dynamics: оптимизация производительности программного обеспечения. — СПб.: Питер, 2024.
ISBN 978-5-4461-2264-6
© ООО Издательство "Питер", 2024
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Посвящается памяти Чака Таккера, истинного друга Electron, который мог в уме проанализировать производительность эффективнее, чем большинство смертных.
Предисловие
Дик Сайтс подходит к решению задач исключительно редким для современности способом: он очень не любит строить догадки и настаивает на том, что изначально явление нужно понять и уже потом исправлять. Сталкиваясь со сложностью современных компьютерных систем, в том числе в их аппаратной и программной частях, большинство программистов подходят к отладке производительности, вооружившись лишь предположением о том, что произошло, и пробуют то одно, то другое в надежде найти короткий путь к решению. Люди, использующие этот метод, упускают возможность полноценно понять сложные взаимодействия, которые могут вести к падению быстродействия программы. Идея, что нечто связанное с компьютером может находиться за гранью понимания, к Дику определенно не относится. Зачастую бывает так, что простые инструменты, которые могли бы предоставлять телеметрию поведения программы, отсутствуют. В таких ситуациях Дик делает очевидную (для себя) вещь: создает их, а также фреймворк визуализации, который сводит всю важную информацию о выполнении программы в понятные графики, проясняющие динамику ее работы.
Если проанализировать выдающуюся карьеру Дика, то станет ясно, почему он уверен в своей способности понимать сложные компьютерные системы. Он стал программистом в 1959 году, в возрасте десяти лет. А его любопытство в сфере информатики привело к карьерному пути, на котором он учился и работал в тесном взаимодействии с такими титанами индустрии, как Фрэн Аллен (Fran Allen), Фред Брукс (Fred Brooks), Джон Кок (John Cocke), Дон Кнут (Don Knuth), Чак Сейтц (Chuck Seitz) и не только. Достижения Дика в этой области невероятно обширны: начиная с участия в проектировании архитектуры DEC Alpha, продолжая работой над Adobe Photoshop и заканчивая ускорением веб-сервисов Google, таких как Gmail.
Когда я познакомился с Диком (присоединившись к проекту DEC в 1995 году), он уже был легендой в нашей сфере, и я имел уникальную возможность проводить с ним время в период его работы в Google, воочию наблюдая используемый им подход к решению задач. Читатели этой книги оценят ясность подачи материала Диком и то, как задачи по отладке производительности описаны в виде загадок, решить которые можно с помощью знаний об аппаратных/программных взаимодействиях и последовательностей подсказок, обнаруженных при наблюдении подробных трейсов выполнения программ. Эта книга окажется невероятно полезной для программистов и компьютерных дизайнеров в немалой степени потому, что нет другой подобной книги. Она уникальна, как и ее автор.
Луис Андре Баррозо (Luiz André Barroso), Google Fellow
Вступление
Разобраться в производительности сложного ПО непросто. Эта задача становится еще труднее, когда рассматриваемое ПО имеет ограничения по времени и загадочным образом периодически нарушает их. Профессионалы имеют представление о динамике выполнения их программ. Они понимают, как различные элементы работают и взаимодействуют во времени, а также приблизительно оценивают, как долго выполняется каждый элемент. (Иногда они даже документируют эти образы.) Но когда временны́е ограничения не выполняются, мы имеем не так много инструментов для выяснения почему — для поиска основных причин задержки и прочих аномалий быстродействия. Вы держите в руках учебник для разработчиков ПО.
Динамика ПО относится не только к быстродействию или времени выполнения одного потока программы, но и к взаимодействию между потоками, между несвязанными программами, а также между операционной системой и пользовательскими программами. Задержки в сложном ПО зачастую вызваны этими взаимодействиями: блокировка кода и ожидание его пробуждения другим кодом; код, ожидающий, что планировщик выделит CPU для его выполнения; код, выполняющийся медленно из-за частичной занятости общего оборудования другим кодом; код, не выполняющийся вовсе, поскольку процедура прерывания использует его CPU; код, незаметно проводящий много своего времени в службах операционной системы или за обработкой отказов страниц; код, ожидающий устройства ввода-вывода или сетевых сообщений от других компьютеров, и т.д.
Ограниченное по времени ПО обрабатывает повторяющиеся задачи, которые имеют периодические дедлайны, или задачи, которые имеют апериодическую частоту прибывания новых запросов, каждого со своим дедлайном. Эти задачи могут иметь жесткие дедлайны на отправку управляющих сигналов в подвижных механизмах (самолетах, автомобилях, промышленных роботах), мягкие дедлайны, например, при преобразовании речи в текст в реальном времени, или же амбициозные дедлайны, например время поиска по клиентской базе данных или время ответа механизма веб-поиска. Термин «ограниченный по времени» обширнее термина «реальное время», который обычно подразумевает жесткие ограничения.
В каждом случае задачи ПО имеют некий стимул, или запрос, и результат, или ответ. Время, прошедшее между стимулом и результатом, называемое задержкой или временем отклика, имеет некий дедлайн. Задачи, превышающие свои дедлайны, завершаются неудачно, что иногда просто вызывает досаду, а порой ведет к катастрофическим последствиям. Из данной книги вы узнаете, как находить первопричины этих сбоев.
Отдельные задачи в таком ПО в зависимости от контекста можно назвать транзакциями, запросами, реакциями на управление или игровыми реакциями. Здесь мы будем использовать термин «транзакции», подразумевая в нем все остальные. Зачастую одна комплексная задача состоит из нескольких подзадач, одни из которых выполняются параллельно, а другие зависят от завершения других. Подзадачи могут быть привязаны к процессору, к памяти, диску или сети. Они могут выполняться, но медленнее ожидаемого из-за вмешательства других программ в общие ресурсы оборудования или стратегий энергосбережения, реализуемых в современных микросхемах процессоров. Они могут находиться в ожидании (то есть не выполняться) программных блокировок, ответов от других задач, компьютеров или внешних устройств. При этом также могут наблюдаться неожиданные задержки или помехи со стороны операционной системы или ее драйверов устройств в режиме ядра, а не написанного программистом кода, работающего в режиме пользователя.
Во многих ситуациях рассматриваемое ПО состоит из десятка или более слоев, или подсистем, все из которых могут вносить свой вклад в неожиданные задержки и выполняться на отдельных компьютерах сети. К примеру, веб-поиск Google может распределять запрос на 2000 компьютеров, каждый из которых выполняет небольшую часть поиска, после чего результаты отправляются обратно и ранжируются в порядке приоритета. Прибытие сообщения электронной почты в облако может запускать подсистемы баз данных, сетевого хранилища, индексирования, блокировки, шифрования, репликации и межконтинентальной передачи. Компьютер, управляющий автомобилем, может выполнять 50 различных программ, часть из которых взаимодействует с каждым видеокадром, поступающим от множества камер, и с информацией радара, изменяя координаты GPS, корректируя силы 3D-ускорения машины, а также предоставляя информацию о дожде, видимости, проскальзывании шин и пр. Небольшая система базы данных может иметь в себе подсистемы оптимизации запросов и доступа к дискам, используя десятки дисков, распределенных по нескольким компьютерам сети. В игре могут быть подсистемы для локальных вычислений, графической обработки и сетевых взаимодействий с другими игроками.
Из этой книги вы узнаете, как обеспечить для подобного ПО наблюдаемость, логирование и временны́е метки, как измерять поведение процессора/памяти/диска/сети, как проектировать нетребовательные инструменты наблюдения и как оценивать полученные данные о производительности. Получив представление о фактическом времени выполнения задач и подзадач нормальных и медленных транзакций, вы сможете понять, как реальность отличается от картины в вашей голове. В этот момент значительное улучшение медленных транзакций может потребовать всего 20 минут редактирования ПО. Однако, не имея качественной картинки реальности, программисты вынуждены гадать и пробовать различные подходы с целью сократить задержки и повысить быстродействие. Эта же книга посвящена не построению догадок, а получению фундаментального понимания.
Все приведенные здесь примеры, упражнения по программированию и предоставленное ПО написаны на С или С++ и основаны на ОС Linux, выполняющейся на 64-битных процессорах AMD, AEM или Intel. Предполагается, что читатель знаком с разработкой ПО в данной среде. Я также предполагаю, что у читателя есть некое ПО с ограничениями по времени, у которого наблюдаются проблемы, требующие решения. Это ПО уже должно быть функциональным, отлаженным и иметь приемлемый средний уровень быстродействия — проблема должна состоять лишь в необъяснимых отклонениях его быстродействия. Читатель также должен иметь в сознании картину того, как выполняется его ПО, и быть готовым по запросу набросать схему предполагаемого взаимодействия его элементов в типичной транзакции. Наконец, предполагается, что читатель имеет некие знания о процессорах, виртуальной памяти, дисковом и сетевом вводе-выводе, программных блокировках, выполнении на нескольких ядрах и параллельной обработке. С этой отправной точки дальше мы уже будем действовать вместе.
Всего мы разберем три главные темы: измерения, наблюдение и анализ.
• Измерения. Любое исследование быстродействия начинается с измерения происходящих процессов. Численные измерения — количество транзакций в секунду, время отклика 99-го перцентиля или просадка в количестве кадров — расскажут лишь, что происходит, но не почему.
• Наблюдение. Чтобы понять, почему некоторые измерения оказались неожиданно медленными или плохими по иным причинам, притом что повторное измерение той же работы показывает быстрый результат, необходимо внимательно пронаблюдать, куда уходит все время или какая именно обработка выполняется в быстром и медленном сценариях. В сложном случае, когда неожиданно плохое поведение проявляется лишь при тяжелой нагрузке, необходимо произвести наблюдение в течение значительного интервала времени, чтобы повысить вероятность выявления нескольких медленных случаев. Причем делать это нужно в ситуации с минимальными отклонениями, полноценно нагружая программу.
• Анализ (и исправление). Собрав результаты наблюдений, нужно поразмышлять над ними: чем медленные случаи отличаются от нормальных, как взаимодействия ПО и оборудования создают медленные случаи и как можно улучшить ситуацию? В последней части книги мы разберем практические примеры подобного анализа и некоторые примеры исправлений.
Материал книги разделен на четыре части, одна из которых посвящена созданию нетребовательного к ресурсам инструмента наблюдения KUTrace.
• В части I (главы 1–7) описано, как проводить тщательные измерения четырех фундаментальных компьютерных ресурсов: процессора, памяти, диска/SSD и сети.
• В части II (главы 8–13) представлены типичные инструменты наблюдения: логирование, информационные панели, подсчет/профилирование/выборка и трассировка.
• В части III (главы 14–19) описаны проектирование и построение нетребовательного инструмента Linux для трассировки, записывающего действия каждого ядра процессора каждую наносекунду, а также программ постобработки для создания динамических HTML-страниц, отображающих полученные временны́е линии и взаимодействия.
• В части IV (главы 20–30) содержатся практические примеры анализа помех, лежащих в основе необычных задержек при слишком длительном выполнении, медленном выполнении инструкций, ожидании процессора, памяти, диска, сети, программных блокировок, очередей и таймеров.
Оперируя этими идеями, вы сможете превратить эту картинку, на которой показана неожиданная задержка:
в следующее подробное изображение, показывающее, какие подзадачи и когда выполнялись, что происходило параллельно, что зависело от завершения другого этапа, а следовательно, почему на все ушло три часа:

Используя те же идеи, можно превратить пример задержки программы в следующую картинку, на которой удаленный демон авторизации ssh пробуждает gedit на CPU 1:
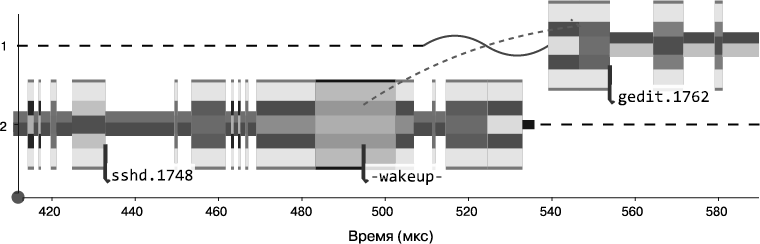
(В части III вы узнаете, как создать эту картинку для вашего ПО.)
Эта книга в первую очередь предназначена для заинтересованных читателей, которые будут выполнять приведенные в ней задачи по программированию и реализовывать части описанных инструментов мониторинга ПО.
Содержание книги перемежается с комментариями о современных сложных процессорах и их механизмах повышения быстродействия. Случайное повреждение этих механизмов может вызвать удивительные задержки. Внимательные читатели, наряду со всем прочим, обретут более глубокое понимание компьютерной архитектуры и микроархитектуры.
Эта книга — учебник для профессионалов в сфере разработки ПО и студентов. Однако в ней также представлен материал, который будет интересен архитекторам аппаратного обеспечения, разработчикам ОС, специалистам в сфере архитектуры систем, дизайнерам систем реального времени и разработчикам игр. Основное внимание в книге уделяется пониманию наблюдаемой пользователем задержки, что позволит выработать навыки, которые помогут в карьере любого программиста.
Исходный код
В книге используется несколько компьютерных программ: mystery1, mystery2 и т.д. Их исходный код доступен для скачивания на сайте издательства Addison-Wesley по ссылке informit.com/title/9780137589739.
Полноцветные иллюстрации
Поскольку эта книга напечатана в черно-белом исполнении, мы подготовили PDF-файл с полноцветными и полноразмерными изображениями, который вы найдете по адресу https://storage.piter.com/support_insale/files_list.php?code=978544612264&partner=3401.
Благодарности
Эта книга появилась благодаря многим людям. Амер Диван, В. Брюс-Хант, Ричард Кауфман и Хэл Мурри (Amer Diwan, V. Bruce Hunt, Richard Kaufmann, Hal Murry) активно вычитывали текст, давая обратную связь. Коннор Сайтс-Боуэн, Дж. Крейг Мадж, Джим Морер и Рик Фэрроу (Connor Sites-Bowen, J. Craig Mudge, Jim Maurer, Rik Farrow) предоставили содержательные рецензии и поддержку для первых версий и сопутствующих статей. Брайан Керниган (Brian Kernighan) тщательно вычитал рукопись и внес предложения по значительному улучшению итоговой версии.
Большая часть приведенного в книге материала была разработана на основе курсов для выпускников, которые я вел после увольнения из Google в 2016 году. Я признателен за предоставление такой возможности и получение обратной связи от студентов, организованной Майклом Брауном (Michael Brown) в Национальном университете Сингапура; Джимом Ларусом и Вилли Звэнполем (Jim Larus и Willy Zwaenepoel) в Федеральной политехнической школе Лозанны; Кристосом Козиракисом (Christos Kozyrakis) в Стэнфордском университете; а также Кевином Джеффеем и Фредом Бруксом (Kevin Jeffay and Fred Brooks) в Университете Северной Каролины.
Джошуа Бакита, Дрю Галлатин и Хэл Мюррей (Joshua Bakita, Drew Gallatin, Hal Murray) выполнили порты KUTrace для различных дистрибутивов Unix. Джим Келлер и Пит Бэннон (Jim Keller, Pete Bannon) предоставили мне возможность сделать порт в Tesla Motors. Сандхья Дваркадас (Sandhya Dwarkadas) задал ключевой вопрос об обнаружении помех в кэше, благодаря чему я добавил в KUTrace подсчет количества инструкций за такт.
В начале моей карьеры я был сосредоточен на производительности и трассировке процессоров, занимаясь этим под руководством Элейн Бонд, Пэт Голдберг, Рэя Хедберга, Фрэн Аллен и Джона Кока (Elaine Bond, Pat Goldberg, Ray Hedberg, Fran Allen, John Cocke) из IBM; Дона Кнута (Don Knuth) из Стэнфорда; а также Джоэл Эмер, Аниты Борг и Шэрон Перл (Joel Emer, Anita Borg, Sharon Perl) из Digital Equipment Corporation.
Моя жена, Люси Боуэн (Lucey Bowen), была особенно благосклонна и терпелива, пока я сосредоточенно завершал книгу, уделяя этому очень много времени.
Мой редактор, Грег Данч (Greg Doench), оказал особую помощь в доведении этого проекта до успешного завершения. В первые месяцы его реализации Грег озадачился пробным импортом текста и крупных чисел в поток публикации, что сэкономило нам время и нервы в конце всего процесса. Мой выпускающий редактор, Ким Вимпсетт (Kim Wimpsett), проделала фантастическую работу, внеся буквально тысячи мелких доработок.
Ричард Л. Сайтс (Richard L. Sites), сентябрь 2021 года
Об авторе
Ричард Л. Сайтс написал свою первую компьютерную программу в 1959 году и бо́льшую часть карьеры занимался аппаратным и программным обеспечением, проявляя особый интерес к производительности и взаимодействиям процессоров и ПО. В числе последних работ — создание микрокода VAX, участие в разработке архитектуры DEC Alpha и изобретение счетчиков производительности, которые сегодня встречаются практически во всех процессорах. Занимался написанием нетребовательного микрокода и трассировкой ПО в DEC, Adobe, Google и Tesla. Ричард Сайтс получил степень доктора философии в Стэнфорде в 1974 году. Имеет 66 патентов и является членом Национальной инженерной академии США.
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
На веб-сайте издательства www.piter.com вы найдете подробную информацию о наших книгах.
Часть I. Измерение
Понимание вариативности — ключ к успешному достижению качества и преуспеванию в бизнесе.
У. Эдвардс Деминг (W. Edwards Deming)
Измерение — это действие по установлению размера, количества или степени чего-либо. Тщательные измерения лежат в основе понимания быстродействия ПО.
В данной части описывается сложная аппаратная и программная среда, основная тема книги — задержки транзакций, понятие распределений задержки, а также последствия длительных задержек 99-го перцентиля.
Наша конечная цель — понять первопричины разброса в задержке транзакций: явно произвольное неожиданно длинное время отклика в сложном ПО.
Надмножество сред, которые вы могли настроить в процессе изучения быстродействия транзакций базы данных, задержек десктопного ПО, выделенных контроллеров или игр, представляет собой среду дата-центра. В этой части также описывается важная практика оценки того, сколько должно занимать выполнение элементов кода. Данная часть книги выступает в качестве основы для всего оставшегося материала, с помощью которой читатель проходит через подробный процесс измерения показателей процессора, памяти, диска и сетевых задержек. В этих главах используются готовые, но имеющие в себе ошибки программы, которые любой читатель может запустить, чтобы получить базовое представление и, внеся предписанные изменения для исправления недочетов, сформировать уже значительно более глубокое понимание. Итоговые измерения начнут показывать источники колебания показателей задержки в простых программах.
Задача части I — привести читателей с разным опытом к общей основе знаний об измерениях производительности, программных взаимодействиях в режиме ядра и режиме пользователя, кросс-потоковых и кросс-программных помехах, а также взаимодействиях между сложным ПО и аппаратным обеспечением. В конце этой части каждый читатель сможет давать обоснованную оценку того, сколько времени должно занимать выполнение интересующего его компонента кода.



















