

автордың кітабын онлайн тегін оқу Создание микросервисов
Переводчик С. Черников
Сэм Ньюмен
Создание микросервисов. 2-е издание. — СПб.: Питер, 2023.
ISBN 978-5-4461-1145-9
© ООО Издательство "Питер", 2023
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Предисловие
Архитектурный стиль микросервисов — это подход к распределенным системам, при котором используются небольшие сервисы, каждый из которых можно изменять, развертывать и выпускать независимо друг от друга. Для организаций, переходящих к менее связанным между собой системам, с автономными командами, предоставляющими функциональность, ориентированную на пользователя, микросервисы значительно повышают эффективность. Помимо этого, они обеспечивают огромное количество вариантов построения систем, дают впечатляющую гибкость, позволяя системе изменяться в соответствии с потребностями пользователей.
Однако микросервисы обладают и существенными недостатками: будучи распределенной системой, они создают множество сложностей, которые могут поставить в тупик даже опытных разработчиков.
В этой книге собраны идеи с конкретными примерами из реальной жизни, которые помогут понять, подходят ли вам микросервисы.
Кому стоит прочитать эту книгу
Область применения данной книги широка, как и возможности микросервисных архитектур. Таким образом, это издание должно понравиться людям, интересующимся аспектами проектирования, разработки, развертывания, тестирования и обслуживания систем. Те из вас, кто уже вступил на путь создания мелкомодульных архитектур для использования в новых проектах или в рамках декомпозиции существующей монолитной системы, найдут здесь множество практических рекомендаций. Это руководство также поможет тем, кто хочет тщательнее разобраться в микросервисах и наконец определиться в необходимости их применения.
Почему я написал эту книгу
С одной стороны, я написал эту книгу, потому что хотел убедиться, что информация в первом издании остается актуальной, точной и полезной. Первое издание появилось, потому что на тот момент были действительно интересные идеи, которыми я мечтал поделиться. С самого начала я писал о микросервисах с достаточно объективной точки зрения, потому что не работал на крупного поставщика технологий. Я не продавал людям решения и надеялся, что не продавал и микросервисы, — мне просто нравилось разбираться в них и находить способы их более широкого использования.
Откровенно говоря, второе издание я написал по двум причинам. Во-первых, появилось ощущение, что на этот раз смогу сделать работу лучше: я больше узнал и, надеюсь, стал немного лучше как писатель. Во-вторых, я чувствую свою ответственность за популяризацию описанных в книге идей и поэтому хотел попробовать изложить их подробнее. Микросервисы стали для многих архитектурным выбором по умолчанию, который, на мой взгляд, трудно обосновать, поэтому я бы хотел поделиться своим видением причин.
В книге я не настаиваю на повсеместном использовании микросервисов, но и не отговариваю вас от их применения. Для меня важно донести до вас все изученные мной плюсы и минусы данного подхода.
Что изменилось с момента выхода первого издания
Первое издание я писал примерно год, на протяжении 2014 года, а выпущено оно было уже в феврале 2015-го. Это было в самом начале истории микросервисов, по крайней мере с точки зрения понимания этого термина широкими кругами в отрасли. С тех пор микросервисы стали популярны настолько, что я и предположить не мог. Чем популярнее становилась данная отрасль, тем больше появлялось возможностей и технологий для ее реализации.
По мере того как я работал с большим количеством команд после выхода первого издания, я совершенствовал свои знания о микросервисах. Иногда это означало, что идеи, существовавшие только на периферии моего сознания (например, скрытие информации), становились более ясными как основополагающие концепции, требующие более широкого освещения. Иногда новые технологии предоставляют не только новые решения, но и дополнительные сложности. Видя, как много людей стекаются в Kubernetes в надежде, что эта платформа поможет решить все их проблемы с микросервисными архитектурами, я, безусловно, задумался.
Кроме того, я написал первое издание книги «Создание микросервисов», чтобы не только рассказать о микросервисах, но и продемонстрировать, как этот архитектурный подход меняет суть разработки программного обеспечения (ПО). Поэтому, более глубоко изучив вопросы, связанные с безопасностью и отказоустойчивостью, я обнаружил, что хочу подробнее остановиться на тех темах, которые становятся все более важными для современной разработки программного обеспечения.
Таким образом, в этом, втором издании я потратил больше времени на подготовку наглядных примеров. Каждая глава была пересмотрена, и каждое предложение проанализировано. От первого издания осталось не так уж много с точки зрения непосредственно текста, но все идеи сохранились. Я старался излагать свои мысли более ясно, в то же время признавая существование нескольких способов решения проблемы. Это привело к более широкому описанию межпроцессной коммуникации, которое теперь занимает три главы. Я также потратил больше времени на изучение влияния применения таких технологий, как контейнеры, Kubernetes и бессерверные вычисления. В результате теперь есть отдельные главы о сборке и развертывании.
Я надеялся написать книгу примерно того же объема, что и первое издание, и при этом найти способ привести больше деталей. Как видно, мне не удалось достичь своей цели — это издание стало больше! Но я думаю, что смог более четко сформулировать свои идеи.
Навигация по книге
Книгу лучше читать целиком от начала и до конца, но, конечно, можно перейти к конкретным темам, которые вас больше всего интересуют. Если вы все-таки решите углубиться в конкретную главу, возможно, глоссарий в конце книги объяснит вам новые или незнакомые термины. Что касается терминологии, я использую слова «микросервис» и «сервис» взаимозаменяемо на протяжении всего повествования. Считайте, что эти два термина относятся к одному и тому же понятию, если явно не указано иное. Я также резюмирую основные концепции в послесловии, однако учтите, что вы упустите много важных деталей, если просто перейдете в конец книги!
Книга разбита на три отдельные части: «Основы», «Реализация» и «Люди». Давайте рассмотрим, какие вопросы охватывает каждая из них.
Часть I. Основы
В этой части я подробно описываю некоторые ключевые идеи, лежащие в основе микросервисов.
Глава 1 «Что такое микросервисы». Это общее введение в микросервисы, в нем я привожу ряд тем, которые будут подробно описаны позже в книге.
Глава 2 «Как моделировать микросервисы». В этой главе рассматривается важность таких понятий, как скрытие информации, связность и связанность, а также использование предметно-ориентированного проектирования для определения правильных границ ваших микросервисов.
Глава 3 «Разделение монолита на части». Здесь приведены некоторые рекомендации о том, как взять существующее монолитное приложение и разбить его на микросервисы.
Глава 4 «Стили взаимодействия микросервисов». В последней главе этой части мы обсудим различные типы связи микросервисов, включая асинхронные и синхронные вызовы, а также стили взаимодействия «запрос — ответ» и событийную архитектуру.
Часть II. Реализация
Переходя от концепций более высокого уровня к деталям реализации, в этой части мы рассмотрим методы и технологии, которые могут помочь получить максимальную отдачу от микросервисов.
Глава 5 «Реализация коммуникации микросервисов». В этой главе мы подробно рассмотрим конкретные технологии, используемые для реализации взаимодействия между микросервисами.
Глава 6 «Рабочий поток». В ней предлагается сравнение саг и распределенных транзакций и обсуждается их полезность при моделировании бизнес-процессов с использованием нескольких микросервисов.
Глава 7 «Сборка». В этой главе микросервис сопоставляется с репозиториями и сборками.
Глава 8 «Развертывание». В этой главе мы обсудим множество вариантов развертывания микросервиса, в том числе использование контейнеров, Kubernetes и FaaS.
Глава 9 «Тестирование». Здесь обсуждаются проблемы тестирования микросервисов, в том числе проблемы, вызванные сквозными тестами, и то, как могут помочь контракты, ориентированные на потребителя, и продакшен-тестирование.
Глава 10 «От мониторинга к наблюдаемости». В этой главе мы переходим от изучения деятельности по статическому мониторингу к более широкому взгляду на улучшение наблюдаемости микросервисных архитектур. Здесь приводятся некоторые рекомендации относительно инструментария.
Глава 11 «Безопасность». Микросервисные архитектуры создают большую площадь для внешних атак, но также дают нам больше возможностей для глубокой обороны. В этой главе мы рассмотрим правильный баланс между уязвимостью и защитой.
Глава 12 «Отказоустойчивость». В ней предлагается более широкий взгляд на то, что такое отказоустойчивость, и на ту роль, которую микросервисы могут сыграть в повышении отказоустойчивости ваших приложений.
Глава 13 «Масштабирование». В этой главе я описываю четыре оси масштабирования и показываю, как их можно использовать совместно для масштабирования микросервисной архитектуры.
Часть III. Люди
Идеи и технологии ничего не значат без людей и организаций, которые их используют.
Глава 14 «Пользовательские интерфейсы». В этой главе рассматриваются принципы совместной работы микросервисов и пользовательских интерфейсов, начиная с перехода от выделенных команд разработки пользовательского интерфейса (фронтенд-разработки) к использованию BFF и GraphQL.
Глава 15 «Организационные структуры». В предпоследней главе основное внимание уделяется тому, как потоковые команды и команды поддержки могут работать в контексте микросервисных архитектур.
Глава 16 «Эволюционный архитектор». Микросервисные архитектуры не статичны, поэтому вам, возможно, потребуется пересмотреть ваше отношение к системной архитектуре — тема, подробно рассматриваемая в этой главе.
Условные обозначения
В этой книге используются следующие типографические обозначения.
Курсив
Обозначает новые термины и важные понятия.
Моноширинный шрифт
Используется в листингах кода, а также в тексте, обозначая такие программные элементы, как имена переменных и функций, базы данных, типы данных, значения и ключевые слова.
Рубленый шрифт
Применяется для выделения URL, адресов электронной почты.

Обозначает совет или предложение.

Обозначает примечание общего характера.

Обозначает предупреждение или предостережение.
Благодарности
Я постоянно удивляюсь той поддержке, которую получаю от своей семьи, особенно от моей жены Линди Стивенс. Откровенно говоря, без нее этой книги бы не было. Спасибо ей. Я также благодарю своего отца, Джека, Джози, Кейна и весь клан Джилманко Стейнс.
Большая часть этой книги была написана во время глобальной пандемии, которая все еще продолжается, пока я пишу эти строки. Возможно, это мало что значит, но я хочу выразить свою благодарность Национальной службе здравоохранения Великобритании и всем людям в мире, которые обеспечивают нашу безопасность, работая над вакцинами, излечивая больных, доставляя нам еду и помогая тысячью различных способов, которые мне не так очевидны. Эта благодарность также предназначается всем вам.
Второго издания не было бы без первого, поэтому я хотел бы еще раз сказать спасибо всем, кто помогал мне в сложном процессе написания моей первой книги, включая технических рецензентов Бена Кристенсена, Мартина Фаулера, Венката Субраманьяма, Джеймса Льюиса за наши многочисленные поучительные беседы, команду O’Reilly в лице Брайана Макдональда, Рэйчел Монаган, Кристен Браун и Бетси Валишевски, и за отличные отзывы читателей Ананда Кришнасвами, Кента Макнила, Чарльза Хейнса, Криса Форда, Эйди Льюиса, Уилла Темза, Джона Ивса, Рольфа Рассела, Бадринатха Янакирамана, Дэниела Брайанта, Иэна Робинсона, Джима Уэббера, Стюарта Глидоу, Эвана Боттчера, Эрика Суорда и Оливию Леонард. И спасибо Майку Лукидесу, я думаю, за то, что он втянул меня в эту неразбериху в первую очередь!
Для второго издания Мартин Фаулер снова вернулся в качестве научного редактора, и к нему присоединились Дэниел Брайант и Сара Уэллс, которые не пожалели своего времени на отзывы. Я также хотел бы поблагодарить Ники Райтсон и Александра фон Цитцервитца за помощь в доведении технического обзора до конца. Что касается O’Reilly, то весь процесс контролировался моим потрясающим редактором Николь Таше, без которой я бы точно сошел с ума, Мелиссой Даффилд, которая, похоже, справляется с моей рабочей нагрузкой лучше, чем я. Благодарю также Деба Бейкера, Артура Джонсона и остальную производственную команду (мне жаль, что я не знаю всех ваших имен, но спасибо вам!), а также Мэри Трезелер за то, что в трудные времена брала штурвал в свои руки.
Кроме того, огромное спасибо за неоценимую помощь ряду людей, в том числе (в произвольном порядке) Дэйву Кумбсу и команде Tyro, Дэйву Хэлси и команде Money Supermarket, Тому Керхову, Эрике Доерненбург, Грэму Тэкли, Кенту Бек, Кевлин Хенни, Лоре Белл, Адриане Муат, Саре Тарапоревалла, Уве Фридрихсу, Лиз Фонг-Джонс, Кейну Стивенсу, Гилманко Стейнсу, Адаму Торнхиллу, Венкату Субраманьяму, Сюзанне Кайзер, Яне Шауманн, Грейди Бучу, Пини Резник, Николь Форсгрен, Джезу Хамблу, Джин Ким, Мануэлю Паис, Мэтью Скелтону и команде «Саут Сидней Рэббитоуз». Наконец, я хотел бы поблагодарить восхищенных читателей ранней версии книги, предоставивших бесценные отзывы. Среди них Фелипе де Мораис, Марк Гарднер, Дэвид Лозон, Ассам Зафар, Майкл Блетерман, Никола Мусатти, Элеонора Лестер, Фелипе де Мораис, Натан Димауро, Даниэль Лемке, Сонер Экер, Риппл Шах, Джоэл Лим и Химаншу Пант. И наконец, привет Джейсону Айзексу.
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
На веб-сайте издательства www.piter.com вы найдете подробную информацию о наших книгах.
Часть I Основы
Глава 1. Что такое микросервисы
С тех пор как я написал первое издание этой книги, прошло более пяти лет, и все это время микросервисы становились все более и более популярным архитектурным решением. Последовавший бум популярности этой технологии не моя заслуга, но взрывной рост микросервисных архитектур связан с тем, что пока новые идеи проверялись на практике, устаревшие методы становились все менее удобными. Итак, пришло время еще раз раскрыть суть архитектуры микросервисов, выделив при этом основные концепции, заставляющие микросервисы работать.
Основная цель книги — показать, как микросервисы влияют на различные аспекты поставки программного обеспечения. Для начала мы рассмотрим ключевые идеи, лежащие в основе микросервисов, предшествующий уровень развития техники и причины, по которым эти архитектуры так широко используются.
Первый взгляд на микросервисы
Микросервисы — это независимо выпускаемые сервисы, которые моделируются вокруг предметной области бизнеса. Сервис инкапсулирует функциональность и делает ее доступной для других сервисов через сети — вы создаете более сложную, комплексную систему из этих строительных блоков. Один микросервис может представлять складские запасы, другой — управление заказами и еще один — доставку, но вместе они могут составлять целую систему онлайн-продаж. Микросервисы — это пример архитектуры, где есть возможность выбирать из множества вариантов решения проблем, с которыми вы сталкиваетесь.
Они представляют собой тип сервис-ориентированной архитектуры (хотя и с особым пониманием того, как следует проводить границы сервисов), в которой ключевым фактором выступает возможность независимого развертывания. Они не зависят от технологий, что является одним из преимуществ.
Снаружи отдельный микросервис рассматривается как черный ящик. Он размещает бизнес-функции в одной или нескольких конечных точках сети (например, в очереди или REST API, как показано на рис. 1.1) по любым наиболее подходящим протоколам. Потребители, будь то другие микросервисы или иные виды программ, получают доступ к этой функциональности через такие точки. Внутренние детали реализации (например, технология, по которой был создан сервис, или способ хранения данных) полностью скрыты от внешнего мира. Это означает, что в микросервисных архитектурах в большинстве случаев не используются общие базы данных. Вместо этого каждый микросервис инкапсулирует свою собственную БД там, где это необходимо.
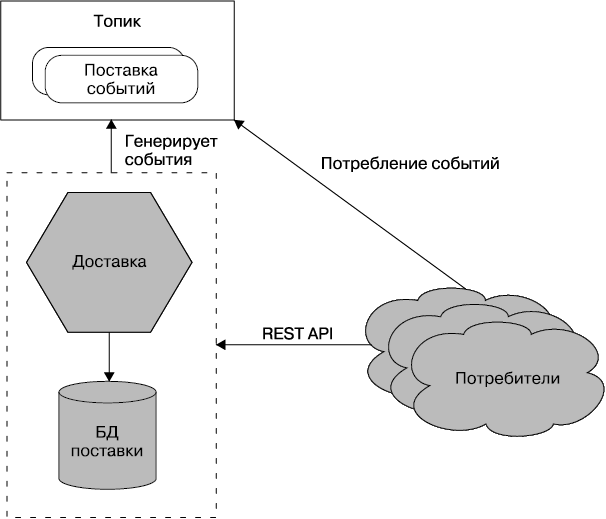
Рис. 1.1. Микросервис, предоставляющий свои функциональные возможности через REST API и топик
Микросервисы используют концепцию скрытия информации1. Это означает скрытие как можно большего количества информации внутри компонента и как можно меньшее ее раскрытие через внешние интерфейсы. Так можно провести четкую границу между легко и сложно изменяемыми данными. Реализацию, скрытую от сторонних участников процесса, можно свободно преобразовывать, пока у сетевых интерфейсов, предоставляемых микросервисом, сохраняется обратная совместимость. Изменения внутри границ микросервиса (как показано на рис. 1.1) не должны влиять на вышестоящего потребителя, обеспечивая возможность независимого выпуска функциональных возможностей. Это необходимо для того, чтобы микросервисы могли работать изолированно и выпускаться по требованию. Наличие четких, стабильных границ сервисов, не изменяющихся при преобразовании внутренней реализации, приводит к тому, что системы получают более слабую связанность (coupling) и более сильную связность (cohesion).
Пока мы говорим о скрытии деталей внутренней реализации, с моей стороны было бы упущением не упомянуть шаблон гексагональной архитектуры, впервые подробно описанный Алистером Кокберном2. Этот шаблон определяет важность сохранения внутренней реализации отдельно от ее внешних интерфейсов, поскольку вы, возможно, захотите взаимодействовать с одной и той же функциональностью через разные типы интерфейсов. Я изображаю свои микросервисы в виде шестиугольников (гексагонов) отчасти для того, чтобы отличить их от «обычных» сервисов, но также по причине моей любви к этим фигурам.
| Сервис-ориентированная архитектура и микросервисы — разные вещи? Сервис-ориентированная архитектура (SOA, service-oriented architecture) — это подход к проектированию, при котором несколько сервисов взаимодействуют для обеспечения определенного конечного набора возможностей (сервис здесь обычно означает полностью отдельный процесс операционной системы). Связь между этими сервисами осуществляется посредством сетевых вызовов, а не с помощью вызовов методов внутри границ процесса. SOA возникла как подход к решению проблем, связанных с большими монолитными приложениями. Данный подход направлен на поощрение повторного использования ПО. Например, два приложения или более могут использовать одни и те же сервисы. SOA стремится упростить обслуживание или переписывание ПО, поскольку теоретически мы можем заменить один сервис другим без чьего-либо ведома, если семантика сервиса не изменится слишком сильно. По своей сути SOA — разумная идея. Однако, несмотря на многочисленные усилия, отсутствует единый стандарт правильной реализации SOA. На мой взгляд, нет целостного взгляда на проблему, поэтому не получилось прийти к единому мнению, с которым были бы согласны все представители отрасли. Многие из проблем, лежащих в основе SOA, на самом деле относятся к проблемам с протоколами связи (например, SOAP), промежуточным ПО поставщика, отсутствием рекомендаций по детализации сервиса или неправильным руководством по выбору мест для разделения вашей системы. Циник мог бы предположить, что поставщики навязывали (а в некоторых случаях и стимулировали) внедрение SOA как способ продать больше продуктов, и эти самые продукты в конечном счете подорвали цель SOA. Я видел множество примеров SOA, в которых команды стремились сделать сервисы меньше, но эти сервисы все еще были связаны с базой данных, и приходилось развертывать все вместе. Сервис-ориентировано? Да. Но это не микросервисы. Микросервисный подход появился благодаря накопленному практическому опыту успешных реализаций SOA и лучшему пониманию систем и архитектуры. Вы должны воспринимать микросервисы как специфический подход к SOA. Это то же самое, что и экстремальное программирование (XP, Extreme Programming) или Scrum — особый подход к гибкой разработке ПО. |
Ключевые понятия микросервисов
При изучении микросервисов необходимо усвоить несколько ключевых идей. Учитывая, что некоторые детали часто упускаются из виду, важно продолжить изучение этих концепций, чтобы убедиться, что вы понимаете, что именно заставляет микросервисы работать.
Независимое развертывание
Возможность независимого развертывания — это идея о том, что мы можем внести изменения в микросервис, развернуть его и предоставить это изменение нашим пользователям без необходимости развертывания каких-либо других микросервисов. Важно не только то, что мы можем это сделать, но и то, что именно так вы управляете развертываниями в своей системе. Подходите к идее независимого развертывания как к чему-то обязательному. Это простая для понимания, но довольно сложная в реализации концепция.
Основная мысль, которую я хочу донести, звучит так: убедитесь, что вы придерживаетесь концепции независимого развертывания ваших микросервисов. Заведите привычку развертывать и выпускать изменения в одном микросервисе в готовом ПО без необходимости развертывания чего-либо еще. Это будет полезно.
Чтобы иметь возможность независимого развертывания, нам нужно убедиться, что наши микросервисы слабо связаны, то есть обеспечена возможность изменять один сервис без необходимости изменять что-либо еще. Это означает, что нужны явные, четко определенные и стабильные контракты между сервисами. Некоторые варианты реализации (например, совместное использование баз данных) затрудняют эту задачу.
Возможность независимого развертывания сама по себе, безусловно, невероятно ценна, но, чтобы добиться ее, вам предстоит решить множество других задач, которые, в свою очередь, имеют свои уникальные преимущества. Таким образом, можно рассматривать возможность независимого развертывания как принудительную функцию. Сосредоточив внимание на ней как на результате, вы получите ряд дополнительных преимуществ.
Стремление к слабо связанным сервисам со стабильными интерфейсами заставляет задуматься об определении границ микросервисов.
Моделирование вокруг предметной области бизнеса
Такие методы, как предметно-ориентированное проектирование, могут позволить структурировать код, чтобы лучше представлять реальную область, в которой работает программное обеспечение3. В микросервисных архитектурах мы используем ту же идею для определения границ сервисов. Моделируя сервисы вокруг предметных областей бизнеса, можно упростить внедрение новых функций и процесс комбинирования микросервисов для предоставления новых функциональных возможностей нашим пользователям.
Развертывание функции, требующей внесения изменений более чем в один микросервис, обходится дорого. Вам придется координировать работу каждого сервиса (и, возможно, отдельных команд) и тщательно отслеживать порядок развертывания новых версий этих сервисов. Это потребует гораздо большего объема работ, чем внесение таких же преобразований внутри одного сервиса (или внутри монолита). Следовательно, нужно найти способы сделать межсервисные изменения как можно более редкими.
Я часто вижу многоуровневые архитектуры, типичный пример которых представлен на рис. 1.2. Здесь каждый уровень определяет отдельную границу обслуживания, причем каждая из них относится к соответствующей технической функциональности. Если бы в этом примере я вносил изменения только в уровень представления, это было бы довольно эффективно. Однако опыт показывает, что изменения в функциональности обычно охватывают несколько уровней, что требует изменений в представлении, приложениях и уровне данных. Эта проблема усугубляется, если архитектура еще более многоуровневая, чем в простом примере на рис. 1.2. Часто каждый уровень разбит на дополнительные слои.
Наши сервисы выполнены в виде сквозных срезов бизнес-функциональности. Такая архитектура гарантирует, что вносимые изменения будут максимально эффективными. Можно утверждать, что в случае с микросервисами мы отдаем приоритет сильной связности бизнес-функциональности, а не технической функциональности.
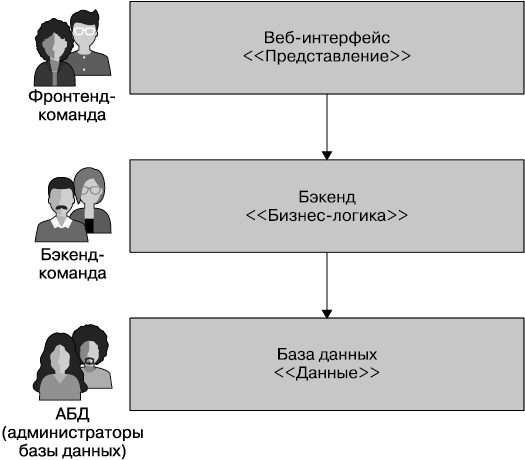
Рис. 1.2. Традиционная трехуровневая архитектура
Позже в этой главе мы еще вернемся к предметно-ориентированному проектированию и к тому, как оно взаимодействует с организационным проектированием.
Контроль над ситуацией
Одна из самых непривычных рекомендаций при использовании микросервисной архитектуры состоит в том, что необходимо избегать использования общих баз данных. Если микросервис хочет получить доступ к данным, хранящимся в другом микросервисе, он должен напрямую запросить их у него. Благодаря такому подходу микросервисы могут определять, что является общим, а что — скрытым. Это позволяет нам четко отделять свободно изменяемую (наша внутренняя реализация) функциональность от функциональности, которую не требуется часто преобразовывать (внешний контракт, используемый потребителями информации).
Если мы хотим реализовать независимое развертывание, нужно убедиться, что есть ограничения на обратно несовместимые изменения в микросервисах. Если нарушить совместимость с вышестоящими потребителями, это неизбежно повлечет за собой необходимость внесения изменений и в них тоже. Четкое разграничение между внутренними деталями реализации и внешним контрактом для микросервиса может помочь уменьшить потребность в обратно несовместимых преобразованиях.
Скрытие внутреннего состояния в микросервисе аналогично практике инкапсуляции в объектно-ориентированном (OO) программировании. Инкапсуляция данных в ОО-системах представляет собой пример скрытия информации в действии.
Не используйте базы данных совместно без крайней нужды. И даже при необходимости старайтесь избегать этого. На мой взгляд, совместное использование баз данных — одна из худших идей, которые вы можете реализовать при попытке добиться независимого развертывания.
Как обсуждалось в предыдущем разделе, необходимо рассматривать наши сервисы как сквозные срезы бизнес-функциональности, которые, где это уместно, инкапсулируют пользовательский интерфейс (user interface, UI), бизнес-логику и данные. Это связано с желанием прикладывать как можно меньше усилий, необходимых для изменения бизнес-функциональности. Инкапсуляция данных и подобное поведение обеспечивают сильную связность бизнес-функций. Скрывая поддерживающую сервис БД, мы также обеспечиваем ослабление связанности. Мы вернемся к связанности и связности в главе 2.
Размер
«Насколько большим должен быть микросервис?» — один из самых распространенных вопросов, которые я слышу. Учитывая, что часть «микро» присутствует прямо в названии, ответ однозначный. Однако, когда вы поймете, что из себя представляет микросервис как архитектура, размер перестанет быть одной из наиболее интересующих характеристик.
Как узнать размер? Сосчитав строки кода? Для меня это не имеет особого смысла. Задача, требующая 25 строк кода на Java, может быть написана в десяти строках Clojure. Это не значит, что Clojure лучше или хуже Java. Некоторые языки просто более выразительны, чем другие.
Джеймс Льюис, технический директор Thoughtworks, известен своим высказыванием: «Микросервис должен быть размером с мою голову». На первый взгляд, это выражение кажется бессмысленным. В конце концов, насколько велика голова Джеймса на самом деле? Однако суть этого утверждения в том, что микросервис должен быть такого размера, при котором его можно легко понять. Проблема, конечно, заключается в том, что разные люди могут неодинаково понимать какую-либо информацию, поэтому на вопрос, какой размер подходит именно вам, можете ответить только вы. Более опытная команда лучше справится с управлением крупной кодовой базы, чем любая другая. Так что, возможно, было бы правильнее интерпретировать цитату Джеймса как «микросервис должен быть размером с вашу голову».
Крис Ричардсон, автор книги «Микросервисы. Паттерны разработки и рефакторинга»4, говорит, что цель микросервисов — получить «как можно меньший интерфейс». Это снова согласуется с концепцией скрытия информации, но представляет собой попытку найти смысл в термине «микросервисы», которого изначально не было. Когда этот термин впервые использовался для определения архитектур, основное внимание, по крайней мере на начальном этапе, уделялось не размеру интерфейсов.
В конечном счете понятие размера в значительной степени зависит от контекста. Поговорите с человеком, который работал над системой в течение 15 лет, и он скажет, что по его ощущениям система со 100 000 строк кода действительно проста для понимания, в то время как недавно привлеченному к проекту сотруднику покажется, что она слишком масштабна. Аналогично и в компаниях, только что приступивших к переходу на микросервисы и создавших, возможно, десять или меньше элементов логики, по сравнению с компанией, для которой микросервисы были нормой в течение многих лет, и сейчас их в ней сотни.
Я призываю людей не беспокоиться о размере. В самом начале работы гораздо важнее сосредоточиться на двух ключевых моментах. Во-первых, сколько микросервисов вы можете обработать? По мере увеличения количества сервисов сложность вашей системы будет возрастать, и вам потребуется осваивать новые навыки (и, возможно, внедрять новые технологии), чтобы справиться с этим. Переход на микросервисы приведет к появлению дополнительных источников сложности со всеми вытекающими из этого проблемами. Именно по этой причине я являюсь убежденным сторонником постепенного перехода на микросервисную архитектуру. Во-вторых, как максимально эффективно определить границы микросервисов, не создавая при этом хаос в системе? Именно на этих темах гораздо важнее сосредоточиться, когда вы в начале пути.
Гибкость
Еще одна цитата Джеймса Льюиса гласит: «Приобретая микросервисы, вы покупаете себе новые возможности». Льюис преднамеренно употребил словосочетание «покупаете возможности». У микросервисов есть своя цена, и вы должны самостоятельно решить, стоит ли игра свеч. Результирующая гибкость по целому ряду направлений — организационному, техническому, масштабированию, надежности — может быть невероятно привлекательной.
Мы не знаем, что ждет нас в будущем, поэтому нужна архитектура, теоретически способная помочь решить любые возможные проблемы. Нахождение баланса между сохранением открытых возможностей и затратами на подобную архитектуру может быть настоящим искусством.
Внедрение микросервисов не происходит по щелчку пальцев. Это постепенный процесс, по мере реализации которого повышается гибкость. Но, скорее всего, так же увеличивается и количество слабых мест. Это еще одна причина, по которой я решительно выступаю за последовательное внедрение микросервисов, потому что только так вы сможете объективно оценить их воздействие и при необходимости остановиться.
Согласование архитектуры и структуры организации
MusicCorp — компания, торгующая компакт-дисками онлайн. В ее системе использована простая трехуровневая архитектура (как на рис. 1.2). Мы решили перенести сопротивляющуюся современным тенденциям MusicCorp в XXI век и в рамках этого перемещения оцениваем существующую системную архитектуру. У нас есть веб-интерфейс, уровень бизнес-логики в виде монолитного бэкенда и хранилище данных в виде традиционной БД. За эти слои, как обычно бывает, отвечают разные команды. Мы будем возвращаться к примеру MusicCorp на протяжении всей книги.
Хочется внести простое обновление в функциональность: мы решили позволить клиентам указывать свой любимый жанр музыки. Это обновление требует внесения изменений в пользовательский интерфейс (для выбора жанра), в бэкенд сервиса (чтобы разрешить отображение жанра в пользовательском интерфейсе и иметь возможность менять значение), а также в базу данных (чтобы принять это изменение). Каждая команда должна будет управлять этими изменениями и внедрять их в правильном порядке, как показано на рис. 1.3.
Теперь эта архитектура выглядит получше. Вся она в конечном итоге оптимизируется вокруг набора целей. Трехуровневая архитектура так распространена отчасти потому, что она универсальна — все о ней слышали. Таким образом, тенденция выбирать то, что на слуху, является одной из причин, по которым мы продолжаем повсеместно встречать этот шаблон. Однако я считаю, что основная проблема, из-за которой мы сталкиваемся с подобной архитектурой снова и снова, заключается в привычных для нас принципах формирования рабочих команд.
Ныне известный закон Конвея гласит следующее.
Организации, разрабатывающие системы... создают проекты, представляющие собой копии коммуникационных структур этих организаций.
Мелвин Конвей, Как комитеты изобретают? (Melvin Conway, How Do Committees Invent?, https://oreil.ly/NhE86)

Рис. 1.3. Внесение изменений на всех трех уровнях требует больших усилий
Трехуровневая архитектура представляет собой хороший пример этого закона в действии. В прошлом ИТ-организации в основном группировали работников по их ключевым компетенциям: администраторы баз данных были в команде с другими администраторами БД, разработчики Java — с другими разработчиками Java, а фронтенд-разработчики (которые сегодня знают такие экзотические вещи, как JavaScript, и занимаются разработкой собственных мобильных приложений) — в еще одной такой же команде. Мы объединяем сотрудников на основе их базовых компетенций, поэтому создаем ИТ-ресурсы, адаптированные к этим командам.
Это объясняет, почему рассматриваемая архитектура так популярна. Она не плохая, просто такой способ группировки людей сосредоточен вокруг принципа «мы всегда так делали». Но времена меняются, а вместе с ними и наши устремления в отношении разрабатываемого программного обеспечения. Теперь мы объединяем в команды людей с различной квалификацией, чтобы сократить количество передаваемых друг другу функций и число случаев разрозненности данных. Сейчас требуется поставлять ПО гораздо быстрее, чем когда-либо прежде. Это заставляет нас по-другому формировать наши команды с точки зрения разделения системы на части.
Большинство изменений, которые нас просят внести в систему, связаны с преобразованиями в бизнес-функциональности. Но на рис. 1.3 бизнес-функциональность фактически распределена по всем трем уровням, что увеличивает вероятность того, что изменения затронут всю систему. Эта архитектура с сильной связностью технологий, но слабой связностью бизнес-функциональности. Если мы хотим упростить процесс внесения изменений, нужно пересмотреть способ группировки кода, выбрав связность бизнес-функциональности, а не технологий. Каждый сервис может как содержать, так и не содержать эти три уровня, но это проблема его локальной реализации.
Сравним это с потенциальной альтернативной архитектурой, проиллюстрированной на рис. 1.4. Вместо горизонтальной многоуровневой архитектуры и организации — вертикальная. Здесь мы видим отдельную команду, которая несет полную сквозную ответственность за внесение изменений в профиль клиента. Это гарантирует, что объем преобразований в этом примере будет ограничен одной командой.
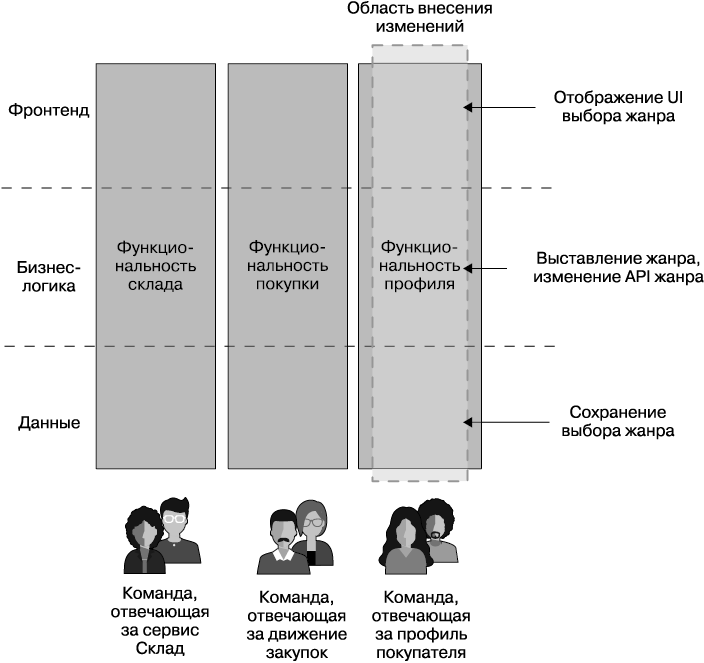
Рис. 1.4. Пользовательский интерфейс разделен на части и управляется командой, которая также управляет функциональностью, поддерживающей UI, но на стороне сервера
Поставленная задача может быть достигнута с помощью единого микросервиса, принадлежащего команде по работе с профилями и предоставляющего UI. Он позволит клиентам обновлять свою информацию, сохраняя при этом их данные. Выбор предпочтительного жанра связан с конкретным клиентом, поэтому такое изменение гораздо более локализовано. На рис. 1.5 также показан список доступных жанров, получаемых из микросервиса Каталог, который, вероятно, уже существует. Мы также видим новый микросервис Рекомендация, предоставляющий доступ к информации о наших любимых жанрах.
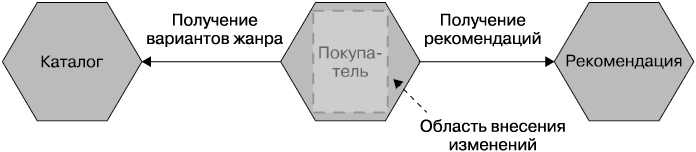
Рис. 1.5. Специализированный микросервис Покупатель может значительно упростить запись любимого музыкального жанра для покупателя
Наш микросервис Покупатель инкапсулирует тонкий срез каждого из трех уровней: в нем есть немного UI, немного логики приложения и немного хранилища данных. Наша предметная область бизнеса становится основной движущей силой системной архитектуры, что, как мы надеемся, облегчает внесение изменений и согласование между командами и бизнес-отделами внутри организации.
Часто UI не предоставляется непосредственно микросервисом, но даже если это так, мы ожидаем, что часть его, связанная с этой функциональностью, по-прежнему будет принадлежать команде, отвечающей за профиль клиента, как показано на рис. 1.4. Концепция создавать команды, владеющие сквозным набором функций, ориентированных на пользователя, набирает обороты. В книге «Топологии команд»5 представлена идея потоковой команды, которая воплощает эту концепцию.
Потоковая команда — это команда, ориентированная на отдельный, представляющий значение поток работы... Команда уполномочена создавать и предоставлять ценности для клиентов или пользователей максимально быстро, безопасно и независимо, не требуя передачи другим командам части работы для выполнения.
Команды, показанные на рис. 1.4, были бы потоковыми. Эту концепцию мы рассмотрим более подробно в главах 14 и 15, в том числе обсудим, как эти типы организационной структуры работают на практике, и поговорим о степени их соответствия микросервисам.
| Заметка о «выдуманных» компаниях На протяжении всей книги мы будем встречаться с MusicCorp, FinanceCo, FoodCo, AdvertCo и PaymentCo. FoodCo, AdvertCo и PaymentCo — это реальные компании, названия которых я изменил по соображениям конфиденциальности. Кроме того, делясь информацией об этих компаниях, я всегда стремился избавиться от посторонних, не несущих практической ценности деталей без ущерба для основного повествования, чтобы внести больше ясности. С другой стороны, MusicCorp — это собирательный образ многих организаций, с которыми я работал. Истории, рассказанные мной о MusicCorp, представляют собой отражение реальных событий, свидетелем которых я был, но не все они произошли с одной и той же компанией! |
Монолит
Поговорим о микросервисах как об архитектурном подходе, представляющем собой альтернативу монолитной архитектуре. Чтобы более четко понять микросервисную архитектуру и помочь вам разобраться, стоит ли в принципе рассматривать микросервисы, необходимо также пояснить, что именно я подразумеваю под монолитами.
Говоря о монолитах, я в первую очередь имею в виду единицы развертывания. Когда все функциональные возможности в системе должны развертываться вместе, я считаю ее монолитом. Возможно, под это определение подходит несколько архитектур, но я собираюсь обсудить те, которые встречаются чаще всего: однопроцессный, модульный и распределенный монолиты.
Однопроцессный монолит
Наиболее распространенный пример, который приходит на ум при обсуждении монолитов, — это система, в которой весь код развертывается как единый процесс (рис. 1.6). Может существовать несколько экземпляров этого процесса (из соображений надежности или масштабирования), но в реальности весь код упакован в один процесс. В действительности эти однопроцессные системы сами по себе могут быть простыми распределенными системами, поскольку они почти всегда завершаются считыванием данных из базы данных или их сохранением, или представлением информации мобильным или веб-приложениям.
Хотя большинство людей именно так и представляют классический монолит, основная масса встречающихся систем несколько сложнее. Может существовать два или более тесно связанных друг с другом монолита, возможно, с использованием программного обеспечения какого-либо производителя.
Классическое однопроцессное монолитное развертывание может иметь смысл для многих компаний. Дэвид Хайнемайер Ханссон, создатель фреймворка Ruby on Rails, доказал, что такая архитектура имеет смысл для небольших организаций6. Однако даже по мере роста компании монолит потенциально может расти вместе с ней, что подводит нас к модульному монолиту.
Модульный монолит
Модульный монолит, являясь подмножеством однопроцессного, представляет собой систему, в которой один процесс состоит из отдельных модулей. С каждым модулем можно работать независимо, но для развертывания их все равно необходимо объединить, как показано на рис. 1.7. Концепция разбиения ПО на модули не нова — модульное ПО появилось благодаря работе, проделанной в области структурного программирования в 1970-х годах и даже раньше. Тем не менее я все еще не вижу достаточного количества организаций, которые должным образом используют этот подход.
Для многих компаний модульный монолит может стать отличным выбором архитектуры. Если границы модулей четко определены, это может обеспечить высокую степень параллельной работы и отсутствие проблем, связанных с более распределенной микросервисной архитектурой, благодаря упрощенной топологии развертывания. Shopify — отличный пример организации, в которой этот метод успешно реализован в качестве альтернативы декомпозиции микросервисов7.
Одна из проблем модульного монолита заключается в том, что базе данных, как правило, не хватает декомпозиции, которую мы находим на уровне кода, что приводит к значительным проблемам, если потребуется разобрать монолит в будущем. Я видел, как некоторые команды пытались развить идею модульного монолита дальше, разделив БД по границам разбиения модулей, как показано на рис. 1.8.

Рис. 1.7. В модульном монолите код процесса разделен на модули

Рис. 1.8. Модульный монолит с разделенной базой данных
Распределенный монолит
Распределенная система — это система, в которой сбой компьютера, о существовании которого вы даже не подозревали, может привести к сбою в работе вашего собственного компьютера8.
Лесли Лэмпорт
Распределенный монолит — это состоящая из нескольких сервисов система, которая должна быть развернута единовременно. Распределенный монолит вполне подходит под определение SOA, однако он не всегда соответствует требованиям SOA.
По моему опыту, распределенный монолит обладает всеми недостатками распределенной системы и однопроцессного монолита, не имея при этом достаточного количества преимуществ ни того ни другого. Поработав с несколькими распределенными монолитами, я и заинтересовался микросервисной архитектурой.
Рассматриваемые системы обычно формируются в среде, в которой недостаточно внимания уделялось таким понятиям, как скрытие информации и связность бизнес-функций. Вместо этого сильно связанные архитектуры приводят к тому, что изменения распространяются через границы сервисов и, казалось бы, незначительные локальные преобразования нарушают другие части системы.
Монолиты и конфликт доставки
Когда над одним проектом работает слишком много людей, неизбежен конфликт интересов. Например, одни разработчики хотят изменить определенный фрагмент кода, а другие хотят запустить функциональность, за которую они отвечают (или отложить развертывание). На этом этапе становится непонятно, кто за что отвечает и кто принимает решения. В результате множества исследований были выявлены проблемы, связанные с границами владения9. Я называю их конфликтом доставки.
Использование монолита не означает, что вы обязательно столкнетесь с конфликтом доставки, равно как и наличие микросервисной архитектуры не гарантирует, что на вас никогда не свалится эта проблема. Но микросервисная архитектура действительно предлагает более конкретные границы, по которым можно определить «зоны влияния» в системе, что дает гораздо больше гибкости.
Преимущества монолитов
Некоторые монолиты, такие как модульные и однопроцессные, обладают целым рядом преимуществ. Их гораздо более простая топология развертывания позволяет избежать многих ошибок, связанных с распределенными системами. Это может привести к значительному упрощению рабочих процессов, мониторинга, устранения неполадок и сквозного тестирования.
Для разработчика монолиты также могут упростить повторное использование кода внутри самого монолита. Если необходимо вторично использовать код в распределенной системе, то потребуется решить, стоит ли копировать код, разбивать библиотеки или внедрять общие функции в сервис. С монолитом все намного проще: весь код уже есть и готов к использованию — и многим это нравится!
К сожалению, люди стали относиться к монолиту как к чему-то, чего следует избегать, — чему-то изначально проблематичному. Я встречал множество разработчиков, для которых термин «монолит» стал синонимом слова «устаревший» — и это проблема. Монолитная архитектура — это решение, и притом обоснованное. Более того, на мой взгляд, это стандартный и разумный выбор архитектурного стиля. Другими словами, назовите мне убедительную причину использовать микросервисы.
Попадая в ловушку систематического отрицания монолита как работающего варианта доставки ПО, мы рискуем поступить неправильно по отношению к себе или к пользователям нашего программного продукта.
Технологии, обеспечивающие развитие
Как я уже говорил, поначалу вам не стоит внедрять много новых технологий — это может быть контрпродуктивно. По мере расширения микросервисной архитектуры лучше сосредоточиться на поиске проблем, вызванных распределением системы, а уже затем на технологиях для их решения.
Тем не менее технологии сыграли большую роль в принятии микросервисов как концепции. Понимание доступных инструментов позволит вам получить максимальную отдачу от этой архитектуры и станет ключевым фактором успеха любой реализации микросервисов. В целом я бы сказал, что микросервисы требуют четкого понимания различий между логической и физической архитектурой.
Мы подробно поговорим об этом в последующих главах, но для начала давайте кратко представим некоторые вспомогательные технологии, способные помочь при использовании микросервисов.
Агрегирование логов и распределенная трассировка
С увеличением числа процессов, которыми вы управляете, становится сложнее понять, как система поведет себя в эксплуатации, что значительно затруднит устранение неполадок. Более детально об этом поговорим в главе 10, но как минимум я настоятельно рекомендую внедрить систему агрегирования логов (журналов) в качестве предварительного условия для реализации микросервисной архитектуры.
Будьте осторожны, не используйте слишком много новых технологий в начале работы с микросервисами. Тем не менее инструмент агрегации логов настолько важен, что стоит рассматривать его как обязательное условие для внедрения микросервисов.
Такие системы позволяют собирать и объединять логи из всех ваших сервисов, предоставляя возможности для анализа и включения журналов в активный механизм оповещения. Мне очень нравится сервис ведения логов Humio (https://www.humio.com), однако на первое время вам хватит чего-то попроще из того, что предоставляют основные поставщики публичных облачных сервисов.
Можно сделать эти инструменты агрегирования еще более полезными, внедрив идентификаторы корреляции, где один идентификатор используется для связанного набора вызовов сервисов, например цепочки вызовов, возникающей из-за взаимодействия с пользователем. Если регистрировать этот идентификатор как часть каждой записи журнала, становится намного проще изолировать логи, связанные с данным потоком вызовов, что, в свою очередь, значительно упрощает устранение неполадок.
По мере усложнения системы важно подобрать инструменты, позволяющие лучше изучить, что делает ваша система. Они предоставляют возможность анализировать трассировки между несколькими сервисами, находить узкие места и задавать о вашей системе вопросы, о которых вы даже не подозревали. Инструменты с открытым исходным кодом могут предоставить некоторые из этих функций. Одним из примеров может служить Jaeger (https://www.jaegertracing.io), фокусирующийся на стороне распределенной трассировки уравнения.
Но такие программные продукты, как Lightstep (https://lightstep.com) и Honeycomb (https://honeycomb.io) (показан на рис. 1.9), дают больше возможностей. Они представляют собой новое поколение инструментов, выходящих за рамки традиционных подходов к мониторингу, значительно упрощая изучение состояния работающей системы. Возможно, вы уже пользуетесь чем-то более привычным, но тем не менее я советую обратить внимание на возможности, предоставляемые этими продуктами. Они были созданы с нуля для решения тех проблем, с которыми приходится сталкиваться операторам микросервисных архитектур.
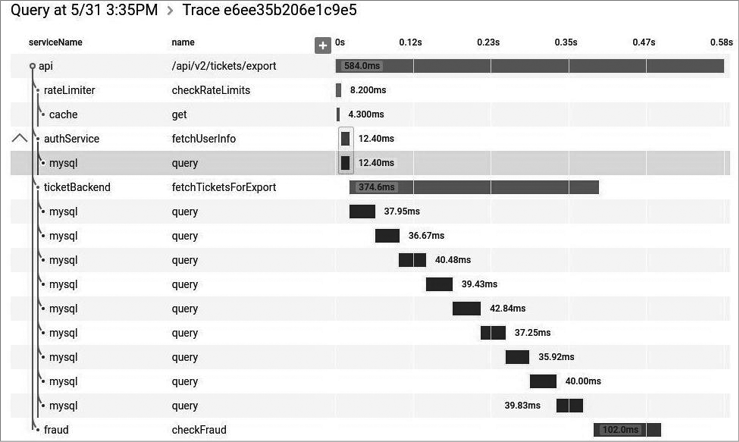
Рис. 1.9. Распределенная трассировка, показанная в Honeycomb, позволяет определить, где тратится время на операции, которые могут затрагивать несколько микросервисов
Контейнеры и Kubernetes
В идеале хотелось бы запускать каждый экземпляр микросервиса изолированно. Это бы гарантировало, что проблема одного микросервиса не будет влиять на работу другого, например, путем поглощения всех ресурсов процессора. Виртуализация — это один из способов создания изолированных сред выполнения на имеющемся оборудовании. Обычные методы виртуализации могут быть довольно затратными, если учесть размер микросервисов. А вот контейнеры, напротив, обеспечивают гораздо более легкий способ максимально быстро развернуть новые экземпляры контейнеров, а также повысить рентабельность многих архитектур.
Поэкспериментировав с контейнерами, вы придете к мысли, что для администрирования ими на множестве машин вам потребуется дополнительный инструментарий. Платформы оркестрации контейнеров, такие как Kubernetes, дают возможность распределять экземпляры контейнеров, обеспечивая надежность и пропускную способность, которые необходимы вашему сервису, при этом позволяя эффективно использовать базовые машины. В главе 8 описана концепция операционной изоляции, контейнеров и Kubernetes.
Однако не стоит спешить с внедрением Kubernetes или даже контейнеров. Они, безусловно, предлагают значительные преимущества по сравнению с более традиционными технологиями развертывания, но в них нет особого смысла, если у вас всего несколько микросервисов. После того как накладные расходы на управление развертыванием перерастут в серьезную головную боль, начните рассматривать возможность контейнеризации своего сервиса и использования Kubernetes. И если вы решитесь на этот шаг, сделайте все возможное, чтобы кто-то другой управлял кластером Kubernetes вместо вас, пусть даже и с использованием управляемого сервиса от облачного провайдера. Запуск собственного кластера Kubernetes может потребовать значительного объема работы!
Потоковая передача данных
Микросервисы позволяют отойти от использования монолитных баз данных, однако потребуется найти иные способы обмена данными. Такая необходимость возникает, когда организации хотят отказаться от пакетной отчетности и перейти к более оперативной обратной связи. Поэтому среди людей, применяющих микросервисную архитектуру, стали популярными продукты, дающие возможность легко передавать и обрабатывать внушительные объемы данных.
Для многих людей Apache Kafka (https://kafka.apache.org) — стандартный выбор для потоковой передачи информации в среде микросервисов, и на то есть веские причины. Такие возможности, как постоянство сообщений, сжатие и способность масштабирования для обработки больших объемов сообщений, могут быть невероятно полезными. С появлением Kafka возникла возможность потоковой обработки в виде базы данных KSQLDB, которую также можно использовать с выделенными решениями для потоковой обработки, такими как Apache Flink (https://flink.apache.org).
Debezium (https://debezium.io) — это инструмент с открытым исходным кодом, разработанный для потоковой передачи из существующих источников данных через Kafka. Такой способ передачи гарантирует, что традиционные источники данных могут стать частью потоковой архитектуры. В главе 4 мы рассмотрим, какую роль технология потоковой передачи может сыграть в интеграции микросервисов.
Публичное облако и бессерверный подход
Поставщики (провайдеры) публичных (общедоступных) облачных сервисов, или, точнее, три основных поставщика — Google Cloud, Microsoft Azure и Amazon Web Services (AWS), — предлагают огромный набор управляемых сервисов и вариантов развертывания для управления вашим приложением. По мере роста микросервисной архитектуры работа все больше и больше будет переноситься в эксплуатационное пространство. Провайдеры облаков предоставляют множество услуг: от управляемых экземпляров баз данных или кластеров Kubernetes до брокеров сообщений или распределенных файловых систем. Используя эти управляемые сервисы, вы перекладываете большой объем работы на третью сторону, которая, возможно, лучше справится с такими задачами.
Особый интерес среди облачных предложений представляют программные продукты, которые позиционируются как бессерверные. Они скрывают базовые машины, позволяя вам работать на более высоком уровне абстракции. Примерами программных продуктов с бессерверной стратегией могут служить брокеры сообщений, решения для хранения данных и БД. Платформы «функция как услуга» (FaaS, function as a service) представляют особый интерес, поскольку обеспечивают хорошую абстракцию вокруг развертывания кода. Не беспокоясь о том, сколько серверов требуется для запуска вашего сервиса, вы просто развертываете код и позволяете базовой платформе запускать его экземпляры по требованию. Мы рассмотрим бессерверный подход более подробно в главе 8.
Преимущества микросервисов
У микросервисов множество разнообразных преимуществ (некоторые из них могут быть заложены в основу любой распределенной системы), которые достигаются прежде всего благодаря независимой позиции в отношении определения границ сервисов. Сочетая концепции скрытия информации и предметно-ориентированного проектирования с возможностями распределенных систем, микросервисы по своим возможностям могут уйти далеко вперед по сравнению с другими формами распределенных архитектур.
Технологическая неоднородность
В системе, состоящей из нескольких взаимодействующих микросервисов, могут быть использованы разные технологии для каждого отдельного микросервиса. Так можно выбирать правильный инструмент для конкретной задачи вместо того, чтобы искать более стандартизированный, универсальный подход, который часто приводит к наименьшей отдаче.
Для повышения производительности одной части системы можно использовать другой технологический стек, более подходящий для достижения требуемого уровня эффективности. Может также измениться способ хранения данных в разных частях нашей системы. Например, для социальной сети оптимально хранить взаимодействия пользователей в графовой БД, чтобы отразить сильно взаимосвязанный характер социального графа. А сообщения, которые оставляют пользователи, хранить в документо-ориентированном хранилище данных, используя гетерогенную архитектуру (рис. 1.10).
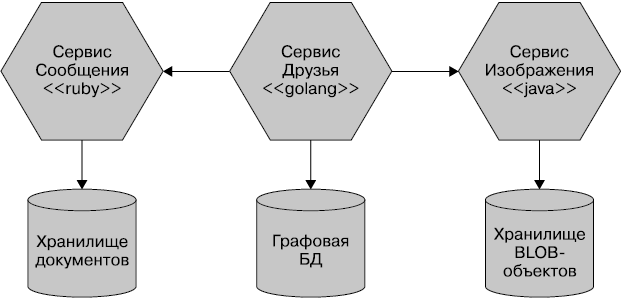
Рис. 1.10. Микросервисы могут упростить использование различных технологий
Микросервисы не только помогут быстрее интегрировать технологии, но и позволят оценить их пользу. Одно из самых больших препятствий на пути внедрения новой технологии — связанные с ее использованием риски. В монолитном приложении, если возникнет желание попробовать новый язык программирования, базу данных или фреймворк, любое изменение повлияет на большую часть системы. В системе, состоящей из сервисов, существует несколько мест, где можно опробовать новую технологию. Появляется возможность выбрать микросервис с наименьшим, по вашему мнению, риском и реализовать технологию там, зная, что любое потенциальное негативное воздействие может быть ограничено. Быстрое внедрение новых идей — реальное преимущество, по мнению многих организаций.
Конечно, использование различных технологий не обходится без накладных расходов. Некоторые компании предпочитают устанавливать определенные ограничения на выбор языка. Например, Netflix и Twitter в основном в качестве платформы используют виртуальную машину Java (JVM, Java Virtual Machine) из-за ее надежности и производительности. Они также разрабатывают библиотеки и инструменты для JVM, которые действительно очень полезны. Но зависимость от них усложняет работу сервисов или клиентов, не базирующихся на Java. Однако ни Twitter, ни Netflix не используют только один технологический стек для всех задач.
Тот факт, что внутренняя реализация технологий скрыта от потребителей, также может облегчить их модернизацию. Например, если вся ваша микросервисная архитектура основана на Spring Boot, то вы можете изменить версию JVM или фреймворка только для одного микросервиса, что упрощает управление рисками обновлений.
Надежность
Основной концепцией повышения надежности вашего приложения является переборка (bulkhead). Вовремя обнаруженный вышедший из строя компонент системы можно изолировать, при этом остальная часть системы сохранит работоспособность. Границы сервисов становятся потенциальными переборками. В монолитной системе, если сервис выходит из строя, перестает функционировать все. В ней мы можем работать на нескольких машинах, чтобы снизить вероятность сбоя, а с микросервисами появляется возможность создавать системы, способные справляться с полным отказом некоторых сервисов и соответствующим образом понижать производительность.
Однако следует быть осторожными. Чтобы гарантировать такую надежность, нужно проанализировать новые источники сбоев, с которыми приходится сталкиваться распределенным системам. Сети могут и будут выходить из строя, как и машины. Необходимо знать, как справляться с такими сбоями и какое влияние (если таковое имеется) они окажут на конечных пользователей. В свое время я работал с командами, которые из-за недостаточно серьезного подхода к такого рода проблемам после перехода на микросервисы получили менее стабильную систему.
Масштабирование
С массивным монолитным сервисом масштабировать придется все целиком. Допустим, одна небольшая часть общей системы ограничена в производительности, и если это поведение заложено в основе гигантского монолитного приложения, нам потребуется масштабировать всю систему как единое целое. С помощью сервисов поменьше можно масштабировать только ту часть программы, для которой это необходимо. Это позволяет запускать другие части системы на меньшем и менее мощном оборудовании, как показано на рис. 1.11.
Интернет-магазин модной одежды Gilt внедрил микросервисы именно по этой причине. В 2007 году компания начала с монолитного приложения Rails, но к 2009 году система Gilt не смогла справиться с нагрузкой. Разделив основные части своей системы, компания сумела решить проблему со скачками трафика, и сегодня в этой системе более 450 микросервисов, каждый из которых работает на нескольких отдельных машинах.
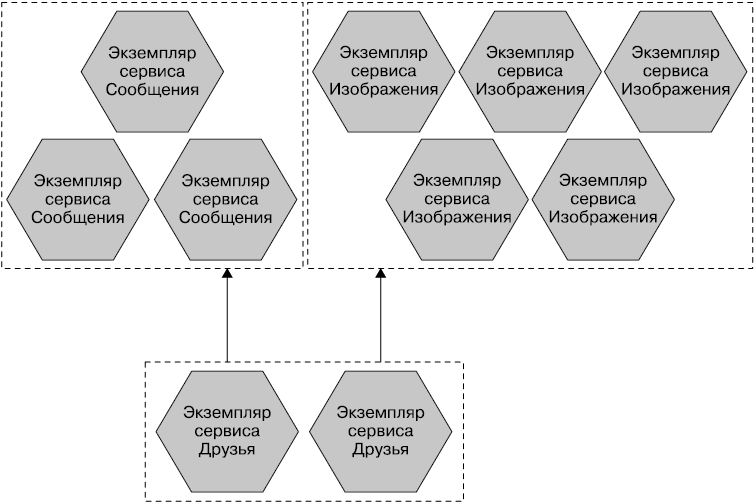
Рис. 1.11. Можно сделать целью масштабирования только те микросервисы, которые в нем нуждаются
В системах обеспечения по требованию, похожих на те, что предоставляет AWS, мы можем использовать масштабирование по требованию только для тех элементов, которые в нем нуждаются. Это позволяет более эффективно контролировать расходы. Нечасто архитектурный подход бывает тесно связан с экономией средств.
В конечном счете можно масштабировать свои приложения множеством способов, и микросервисы — эффективная часть этого процесса. Мы рассмотрим масштабирование микросервисов более подробно в главе 13.
Простота развертывания
Изменение одной строки в монолитном приложении на миллион строк требует развертывания всего приложения для реализации новой сборки. Подобные события происходят нечасто из-за высоких рисков и страха серьезных последствий. К сожалению, это означает, что изменения накапливаются до момента выхода новой версии приложения. И чем больше разница между релизами, тем выше риск того, что что-то пойдет не так!
Микросервисы же позволяют внести изменения в один сервис и развернуть его независимо от остальной части системы. Если проблема все же возникает, ее можно за короткое время изолировать и откатиться к предыдущему состоянию. Такие возможности помогают быстрее внедрить новые функции в действующее приложение. Именно поэтому такие организации, как Amazon и Netflix, используют аналогичные архитектуры.
Согласованность рабочих процессов в организации
Многие из нас сталкивались с трудностями, которые возникают из-за слишком больших рабочих команд и раздутого кода. Эти проблемы могут усугубиться при рассредоточении команды. Известно, что маленькие коллективы, работающие над небольшими кодовыми базами, как правило, более продуктивны.
Микросервисы помогают оптимизировать количество людей, работающих над какой-либо одной кодовой базой, чтобы достичь оптимального соотношения размера команды и эффективности разработки, и дают возможность переопределять ответственность за сервисы по мере изменения организации. Это позволяет поддерживать согласованность между архитектурой и организацией в будущем.
Компонуемость
Одной из ключевых особенностей распределенных систем и сервис-ориентированных архитектур является возможность повторного применения функциональности. Микросервисы позволяют использовать функциональные возможности по-разному для разных целей. Это может быть особенно важно, когда мы думаем о том, как потребители эксплуатируют наше ПО.
Прошли те времена, когда для взаимодействия с пользователем достаточно было только веб-сайта для ПК или мобильного приложения. Теперь требуется мультиплатформенность. По мере того как организации переходят от мышления в терминах узких каналов коммуникации с пользователями к более целостным концепциям привлечения клиентов, появляется необходимость в архитектурах, способных идти в ногу со временем.
Представьте, что с микросервисами мы стираем границы между нашей системой и внешней стороной. По мере изменения обстоятельств мы можем собирать приложения различными способами. В монолите же обычно есть один крупный канал, с которым можно взаимодействовать со стороны. И если я захочу разделить его на части, чтобы получить что-то более полезное, мне понадобится кувалда!
Слабые места микросервисов
Как вы уже поняли, микросервисные архитектуры дают множество преимуществ. Но их использование влечет за собой и определенные сложности. Если вы рассматриваете возможность внедрения такой архитектуры, важно, чтобы у вас было полное представление о ней. Большинство проблем, связанных с микросервисами, можно отнести к распределенным системам, поэтому они с такой же вероятностью проявятся как в распределенном монолите, так и в микросервисной архитектуре.
Более подробно об этом мы поговорим в других главах. На самом деле я бы сказал, что большая часть книги посвящена преодолению всех возможных трудностей, связанных с применением микросервисной архитектуры.
Опыт разработчика
По мере того как у вас появляется все больше и больше сервисов, отношение разработчиков к ним может начать ухудшаться. Более ресурсоемкие среды выполнения (например, JVM) способны ограничить количество микросервисов, допущенных к запуску на одной машине. Вероятно, я мог бы запустить четыре или пять микросервисов на основе JVM как отдельные процессы на своем ноутбуке, но могу ли я запустить 10 или 20? Скорее всего, нет. Даже при меньшем времени выполнения будет ограничение на количество процессов, доступных для локального запуска. Это неизбежно приведет к невозможности запустить всю систему на одной машине. Ситуация осложнится еще больше при использовании облачных сервисов, которые нельзя запустить локально.
Экстремальные решения могут включать разработку в облаке, когда у программистов больше нет возможности заниматься разработкой локально. Я не поклонник такого решения, потому что циклы обратной связи могут сильно пострадать. Я думаю, что более простой подход — ограничить объем фрагментов, над которыми будет трудиться специалист. Однако это может быть проблематично, если появится желание использовать модель «коллективного владения». Она подразумевает, что любой разработчик может работать над любой частью системы.
Технологическая перегрузка
Огромное количество новых технологий, появившихся для внедрения микросервисных архитектур, ошеломляет. Откровенно говоря, многие из них были просто переименованы в «совместимые с микросервисами», но некоторые достижения действительно помогли справиться со сложностью такого рода архитектур. Однако существует опасность, что это изобилие новых игрушек может привести к определенной форме технологического фетишизма. Я видел очень много компаний, внедряющих архитектуру микросервисов, которые решили, что это еще и самое удачное время для введения огромного количества новых и непонятных технологий.
Архитектура микросервисов вполне может предоставить возможность написать каждый микросервис на отдельном языке программирования, выполнять его в своей среде или использовать отдельную базу данных, но это возможности, а не требования. Необходимо найти баланс масштабности и сложности используемой вами технологии с издержками, которые она может повлечь.
В самом начале внедрения микросервисов неизбежны некоторые фундаментальные проблемы: затраты времени на понимание проблем, связанных с согласованностью данных, задержкой, моделированием сервисов и т.п. Если вы возьметесь все это изучать во время освоения огромного количества новых технологий, вам придется нелегко. Также стоит отметить, что, пытаясь понять все эти новые технологии, вы отнимете у себя время, доступное для фактической реализации проекта.
Старайтесь внедрять новые сервисы в свою микросервисную архитектуру по мере необходимости. Нет нужды в кластере Kubernetes, когда у вас в системе всего три сервиса! Вы не только не будете перегружены сложностью этих инструментов, но и получите больше вариантов решения задач, которые, несомненно, появятся со временем.
Стоимость
Весьма вероятно, что в краткосрочной перспективе вы увидите увеличение затрат из-за ряда факторов. Во-первых, вам, скорее всего, потребуется запускать больше процессов, больше компьютеров, сетей, хранилищ и вспомогательного программного обеспечения (а это дополнительные лицензионные сборы).
Во-вторых, любые изменения, вносимые в команду или организацию, замедлят процесс работы. Чтобы изучить новые идеи и понять, как их эффективно использовать, потребуется время. Пока вы будете заняты этим, иные задачи никуда не денутся. Это приведет либо к прямому замедлению рабочего процесса, либо к необходимости добавить больше сотрудников, чтобы компенсировать эти затраты.
По моему опыту, микросервисы — плохой выбор для организации, в первую очередь озабоченной снижением издержек, поскольку тактика сокращения затрат, когда сфера ИТ рассматривается как центр расходов, а не доходов, постоянно будет мешать получить максимальную отдачу от этой архитектуры. С другой стороны, микросервисы могут принести больше прибыли, если вы сможете использовать их для привлечения новых клиентов или для параллельной разработки дополнительных функциональных возможностей. Итак, помогут ли микросервисы разбогатеть? Возможно. Способны ли микросервисы снизить затраты? Не уверен.
Отчетность
В монолитной системе обычно присутствует и монолитная БД. Это означает, что при анализе всех данных единовременно, часто с использованием крупных операций объединения данных, стейкхолдеры применяют готовую схему для создания отчетов. Они могут просто запускать инструменты формирования отчетности непосредственно в монолитной базе данных, возможно в копии для считывания, как показано на рис. 1.12.
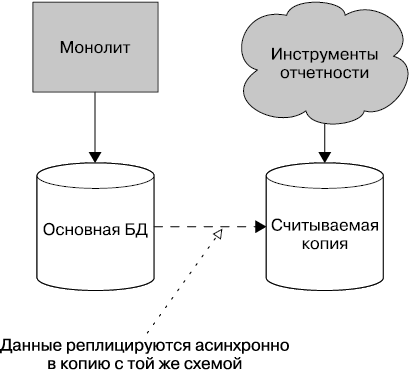
Рис. 1.12. Отчетность ведется непосредственно по базе данных монолита
С помощью архитектуры микросервисов мы разрушили эту монолитную схему. Это не означает, что необходимость в отчетности по всем данным отпала. Она просто значительно усложнится, потому что теперь данные разбросаны по нескольким логически изолированным схемам.
Более современные подходы к отчетности, такие как потоковая передача данных в режиме реального времени, отлично взаимодействуют с микросервисной архитектурой, однако требуют внедрения новых идей и связанных с ними технологий. В качестве альтернативы можно просто публиковать данные из ваших микросервисов в централизованных базах данных отчетов (или, возможно, в менее структурированных озерах данных).
Мониторинг и устранение неполадок
В стандартном монолитном приложении допускается использовать довольно упрощенный подход к мониторингу. У нас есть небольшое количество машин, о которых необходимо позаботиться, а режим сбоя приложения в некотором роде бинарный — приложение обычно либо работает, либо нет. Понимаем ли мы последствия для архитектуры микросервисов, если выйдет из строя хотя бы один экземпляр сервиса?
В монолите, если центральный процессор (ЦП) долгое время зависает при 100%-ной нагрузке, становится ясно: в системе большая проблема. Можно ли сказать то же самое о микросервисной архитектуре с десятками или сотнями процессов? Стоит ли будить кого-то в 3 часа ночи, когда один процесс застрял на 100%-ной нагрузке ЦП?
К счастью, в этом случае есть огромное пространство для маневров. Если вы хотите изучить эту концепцию более подробно, то в качестве отправной точки рекомендую книгу Distributed Systems Observability за авторством Cindy Sridharan (O’Reilly), хотя мы тоже еще рассмотрим мониторинг и наблюдаемость в главе 10.
Безопасность
В однопроцессной монолитной системе большая часть информации протекала в рамках этого же процесса. Теперь больше информации передается по сетям между нашими сервисами. Это может повлечь утечку данных при передаче, а также позволит манипулировать ими в рамках кибератак типа «человек посередине». Это означает, что вам, возможно, потребуется уделять больше внимания защите передаваемых данных, чтобы только авторизованные лица имели к ним доступ. Глава 11 полностью посвящена рассмотрению проблем в этой области.
Тестирование
При любом типе автоматизированного функционального тестирования нужно соблюдать тонкий баланс. Чем больше функций покрывает тест, то есть чем шире его охват, тем больше уверенности в стабильности работы приложения. С другой стороны, увеличение объема теста влечет за собой сложности в настройке тестовых данных и вспомогательных приспособлений, затраты времени для его выполнения вырастут, а определить, что нарушено при возникновении сбоя, станет затруднительно. В главе 9 я поделюсь рядом методов, позволяющих эффективнее проводить тестирование.
Сквозные тесты для любого типа систем находятся на крайнем конце шкалы с точки зрения функциональности, которую они охватывают. Их сложнее писать и поддерживать, чем модульные тесты с меньшим объемом. Однако цель оправдывает средства: процесс сквозного тестирования максимально приближен к пользовательскому опыту.
С микросервисной архитектурой объем таких тестов становится очень внушительным. Теперь потребуется запускать тесты в нескольких процессах, и все они должны быть развернуты и соответствующим образом настроены для тестовых сценариев. Также необходимо быть готовыми к ложным срабатываниям, возникающим, когда проблемы с окружающей средой, такие как отказ экземпляров сервисов или сетевые тайм-ауты неудачных развертываний, приводят к сбою тестов.
Эти факторы означают, что по мере роста архитектуры микросервисов вы получите меньшую отдачу от инвестиций, когда дело дойдет до сквозного тестирования. Оно будет стоить дороже, но не сможет дать ту же степень уверенности, что и раньше. Это подтолкнет вас к новым формам тестирования, таким как контрактное тестирование или тестирование в эксплуатации, а также к изучению поэтапных методов доставки, таких как параллельное выполнение или канареечные релизы, которые мы рассмотрим в главе 8.
Время ожидания
Благодаря микросервисной архитектуре обработку, которую ранее можно было выполнять только локально на одном процессоре, теперь можно разделить на несколько отдельных микросервисов. Информацию, ранее передаваемую только в рамках одного процесса, теперь необходимо сериализовать, передавать и десериализовать по сетям, которые вы, возможно, используете больше прежнего. Все это может привести к увеличению времени ожидания в вашей системе.
На этапе проектирования или кодирования может быть трудно измерить точное влияние операций на задержку, однако это еще пункт в пользу поэтапного перехода к микросервисам. Внесите небольшое изменение, а затем оцените его воздействие. Это предполагает, что у вас есть какой-то способ измерения сквозного времени ожидания для интересующих операций (здесь могут помочь распределенные инструменты трассировки, такие как Jaeger). Но также необходимо иметь представление о том, какая задержка приемлема. Иногда замедление вполне допустимо, если операция все еще достаточно быстрая!
Согласованность данных
Переход от монолита, где данные хранятся и управляются в единой базе данных, к распределенной системе, в которой несколько процессов управляют состоянием в разных БД, создает потенциальные проблемы в отношении согласованности данных. В прошлом вы, возможно, полагались на транзакции базы данных для управления изменениями состояния, но, работая с микросервисной архитектурой, необходимо понимать, что подобную безопасность нелегко обеспечить. Использование распределенных транзакций в большинстве случаев оказывается весьма проблематичным при координации изменений состояния.
Вместо этого, возможно, придется использовать такие концепции, как саги (о чем я подробно расскажу в главе 6) и согласованность в конечном счете, чтобы управлять состоянием вашей системы и анализировать его. Эти идеи могут потребовать основательных изменений вашего отношения к данным в своих системах, что может оказаться довольно сложной задачей при переносе существующих систем. Опять же это еще одна веская причина быть осторожными в скорости декомпозиции своего приложения. Принятие поэтапного подхода к декомпозиции, чтобы получить возможность оценить влияние изменений на архитектуру, действительно важно.
Стоит ли вам использовать микросервисы?
Несмотря на стремление определенных групп сделать микросервисные архитектуры подходом по умолчанию, я считаю, что их внедрение все еще требует тщательного обдумывания из-за многочисленных сложностей, описанных выше. Необходимо оценить предметную область, навыки разработчиков и технологический арсенал и понять, каких целей вы пытаетесь достичь, прежде чем принимать решение, подходят ли вам микросервисы. Они представляют собой общий архитектурный подход, а не какой-то конкретный метод. Контекст вашей организации должен сыграть решающую роль в принятии решения, идти ли по этому пути.
Тем не менее я хочу обрисовать несколько ситуаций, которые обычно склоняют меня к выбору микросервисов и наоборот.
Кому микросервисы не подойдут
Учитывая важность определения стабильных границ сервисов, я считаю, что микросервисные архитектуры часто не подходят для совершенно новых продуктов или стартапов. В любом случае предметная область, с которой вы работаете, обычно претерпевает значительные изменения по мере создания проекта. Этот сдвиг, в свою очередь, приведет к большему количеству преобразований, вносимых в границы сервисов, а их координация представляется дорогостоящим мероприятием. В целом я считаю, что более целесообразно подождать, пока модель предметной области не стабилизируется, прежде чем пытаться определить границы сервиса.
Действительно существует соблазн для стартапов начать работать на микросервисах, мотивируя это тем, что «если мы действительно добьемся успеха, нам нужно будет масштабироваться!». Проблема в том, что заранее не известно, захочет ли кто-нибудь вообще использовать ваш продукт. И даже если вы добьетесь такого успеха, что потребуется масштабируемая архитектура, то финальный вариант может сильно отличаться от того, что вы начали создавать в принципе. Изначально компания Uber ориентировалась на лимузины, а хостинг Flickr сформировался из попыток создать многопользовательскую онлайн-игру. Процесс поиска соответствия продукта рынку означает, что в конечном счете вы рискуете получить продукт, совершенно отличный от того, что вы задумывали.
Стартапы, как правило, располагают меньшим количеством людей, что создает больше проблем в отношении микросервисов. Микросервисы приносят с собой источники новых задач и усложнение системы, а это может ограничить ценную пропускную способность. Чем меньше команда, тем более заметными будут эти затраты. Поэтому при работе с небольшими коллективами, состоящими всего из нескольких разработчиков, я настоятельно не рекомендую микросервисы.
Камнем преткновения в вопросе микросервисов для стартапов является весьма ограниченное количество человеческих ресурсов. Для небольшой команды может быть трудно обосновать использование рассматриваемой архитектуры из-за проблем с развертыванием и управлением самими микросервисами. Некоторые называют это «налогом на микросервисы». Когда эти инвестиции приносят пользу большему количеству людей, их легче оправдать. Но если в команде из пяти человек один тратит свое время на решение этих проблем, это означает, что создание вашего продукта замедляется. Гораздо проще перейти к микросервисам позже, когда вы поймете, где находятся ограничения в архитектуре и каковы слабые места системы, — тогда вы сможете сосредоточить свою энергию на внедрении микросервисов.
Наконец, испытывать трудности с микросервисами могут и организации, создающие ПО, которое будет развертываться и управляться их клиентами. Как я уже говорил, архитектуры микросервисов могут значительно усложнить процесс развертывания и эксплуатации. Если вы используете программное обеспечение самостоятельно, можете компенсировать это, внедрив новые технологии, развив определенные навыки и изменив методы работы. Но не стоит ожидать подобного от своих клиентов, которые привыкли получать ваше ПО в качестве установочного пакета для Windows. Для них будет шоком, если вы отправите следующую версию своего приложения и скажете: «Просто поместите эти 20 подов в свой кластер Kubernetes!» Скорее всего, они даже не представляют, что такое под, Kubernetes или кластер.
Где микросервисы хорошо работают
По моему опыту, главной причиной, по которой организации внедряют микросервисы, является возможность большему количеству программистов работать над одной и той же системой, при этом не мешая друг другу. Правильно определив свою архитектуру и организационные границы, вы позволите многим людям работать независимо друг от друга, снижая вероятность возникновения разногласий. Если пять человек организовали стартап, они, скорее всего, сочтут микросервисную архитектуру обузой. В то время как быстро растущая компания, состоящая из сотен сотрудников, скорее всего, придет к выводу, что ее рост гораздо легче приспособить к рассматриваемой нами архитектуре.
Приложения типа «программное обеспечение как услуга» (software as a service, SaaS) также хорошо подходят для архитектуры микросервисов. Обычно такие продукты работают 24/7, что создает проблемы, когда дело доходит до внедрения изменений. Возможность независимого выпуска микросервисных архитектур предоставляет огромное преимущество. Кроме того, микросервисы по мере необходимости можно увеличить или уменьшить. Это означает, что по мере того, как вы устанавливаете базовый уровень нагрузки вашей системы, вы наиболее экономичным способом получаете больше контроля над обеспечением возможности масштабирования.
Благодаря технологически независимой природе микросервисов вы сможете получить максимальную отдачу от облачных платформ. Провайдеры публичных облачных сервисов предоставляют широкий спектр услуг и механизмов развертывания для вашего кода. Вам гораздо проще сопоставить требования конкретных служб с облачными сервисами, которые наилучшим образом помогут вам реализовать ваши задачи. Например, вы можете решить развернуть один сервис как набор функций, другой — как управляемую виртуальную машину (VM), а третий — на управляемой платформе «платформа как услуга» (platform as a service, PaaS).
Хотя стоит отметить, что внедрение различных технологий развертывания часто может представлять собой проблему. Возможность легко опробовать какую-либо технологию — хороший способ быстро определить новые подходы. Одним из таких примеров является набирающая популярность платформа FaaS. Для соответствующих рабочих нагрузок она может значительно сократить объем операционных накладных расходов, но в настоящее время это не универсальный механизм развертывания.
Микросервисы также дают очевидные преимущества для организаций, стремящихся предоставлять услуги своим клиентам по множеству различных каналов. Многие компании ведут работы по цифровому преобразованию, по-видимому, связанные с попытками раскрыть функциональность, скрытую в существующих системах. Они хотят дать пользователям новые впечатления и уникальный опыт взаимодействия с приложением, чтобы удовлетворить их потребности.
Прежде всего, микросервисная архитектура может предоставить вам большую гибкость по мере дальнейшего развития системы. Конечно, такая гибкость имеет свою цену. Но если вы не хотите отказываться от возможностей для будущих изменений — эту цену стоит заплатить.
Резюме
Микросервисные архитектуры могут предоставить огромную степень гибкости в выборе технологий, обеспечении надежности и масштабировании, организации команд и многом другом. Эта гибкость отчасти объясняет, почему многие люди используют микросервисные архитектуры. Но микросервисы влекут за собой значительные издержки, и вам необходимо убедиться, что они оправданны. Для многих микросервисы стали системной архитектурой по умолчанию, которую можно использовать практически во всех ситуациях. Тем не менее я по-прежнему считаю, что этот архитектурный выбор должен быть оправдан поставленными целями. Часто наименее сложные подходы могут обеспечить более легкое достижение результата.
Вместе с тем многие организации, особенно крупные, показали, насколько эффективными могут быть микросервисы. Когда основные концепции правильно поняты и реализованы, микросервисы могут стать чем-то большим, чем просто суммой частей системы.
Я надеюсь, что эта глава послужила хорошим введением. Далее мы рассмотрим, как лучше определять границы микросервиса, попутно исследуя темы структурированного программирования и предметно-ориентированного проектирования.
1 Parnas D. Information Distribution Aspects of Design Methodology (https://oreil.ly/rDPWA) // Information Processing: Proceedings of the IFIP Congress 1971. — Amsterdam: North-Holland, 1972. — Р. 339–344.
2 Cockburn A. Hexagonal Architecture, 4 января 2005 года. https://oreil.ly/NfvTP.
3 Более подробно о предметно-ориентированном проектировании рассказано в книге Эрика Эванса «Предметно-ориентированное проектирование», а более кратко — в книге «Дистиллированное предметно-ориентированное проектирование» Вона Вернона.
4 Ричардсон К. Микросервисы. Паттерны разработки и рефакторинга. — Питер, 2019.
5 Skelton M., Pais M. Team Topologies. — Portland, OR: IT Revolution, 2019.
6 Hansson D.H. The Majestic Monolith // Signal v. Noise, 29 февраля 2016 года. https://oreil.ly/WwG1C.
7 Для получения полезной информации о том, как Shopify использует модульный монолит, а не микросервисы, см.: Westeinde K. Deconstructing the Monolith.
8 Лесли Лэмпорт, сообщение по электронной почте (https://oreil.ly/2nHF1) на доску объявлений DEC SRC в 12:23:29 PDT, 28 мая 1987 года.
9 Microsoft Research провела исследования в этой области, и я рекомендую узнать о них подробнее, но в качестве отправной точки предлагаю статью Don’t Touch My Code! Examining the Effects of Ownership on Software Quality за авторством Christian Bird (https://oreil.ly/0ahXX).
Микросервисы используют концепцию скрытия информации1. Это означает скрытие как можно большего количества информации внутри компонента и как можно меньшее ее раскрытие через внешние интерфейсы. Так можно провести четкую границу между легко и сложно изменяемыми данными. Реализацию, скрытую от сторонних участников процесса, можно свободно преобразовывать, пока у сетевых интерфейсов, предоставляемых микросервисом, сохраняется обратная совместимость. Изменения внутри границ микросервиса (как показано на рис. 1.1) не должны влиять на вышестоящего потребителя, обеспечивая возможность независимого выпуска функциональных возможностей. Это необходимо для того, чтобы микросервисы могли работать изолированно и выпускаться по требованию. Наличие четких, стабильных границ сервисов, не изменяющихся при преобразовании внутренней реализации, приводит к тому, что системы получают более слабую связанность (coupling) и более сильную связность (cohesion).
Распределенная система — это система, в которой сбой компьютера, о существовании которого вы даже не подозревали, может привести к сбою в работе вашего собственного компьютера8.
Более подробно о предметно-ориентированном проектировании рассказано в книге Эрика Эванса «Предметно-ориентированное проектирование», а более кратко — в книге «Дистиллированное предметно-ориентированное проектирование» Вона Вернона.
Ричардсон К. Микросервисы. Паттерны разработки и рефакторинга. — Питер, 2019.
Parnas D. Information Distribution Aspects of Design Methodology (https://oreil.ly/rDPWA) // Information Processing: Proceedings of the IFIP Congress 1971. — Amsterdam: North-Holland, 1972. — Р. 339–344.
Cockburn A. Hexagonal Architecture, 4 января 2005 года. https://oreil.ly/NfvTP.
Microsoft Research провела исследования в этой области, и я рекомендую узнать о них подробнее, но в качестве отправной точки предлагаю статью Don’t Touch My Code! Examining the Effects of Ownership on Software Quality за авторством Christian Bird (https://oreil.ly/0ahXX).
Для получения полезной информации о том, как Shopify использует модульный монолит, а не микросервисы, см.: Westeinde K. Deconstructing the Monolith.
Лесли Лэмпорт, сообщение по электронной почте (https://oreil.ly/2nHF1) на доску объявлений DEC SRC в 12:23:29 PDT, 28 мая 1987 года.
Skelton M., Pais M. Team Topologies. — Portland, OR: IT Revolution, 2019.
Hansson D.H. The Majestic Monolith // Signal v. Noise, 29 февраля 2016 года. https://oreil.ly/WwG1C.
Классическое однопроцессное монолитное развертывание может иметь смысл для многих компаний. Дэвид Хайнемайер Ханссон, создатель фреймворка Ruby on Rails, доказал, что такая архитектура имеет смысл для небольших организаций6. Однако даже по мере роста компании монолит потенциально может расти вместе с ней, что подводит нас к модульному монолиту.
Когда над одним проектом работает слишком много людей, неизбежен конфликт интересов. Например, одни разработчики хотят изменить определенный фрагмент кода, а другие хотят запустить функциональность, за которую они отвечают (или отложить развертывание). На этом этапе становится непонятно, кто за что отвечает и кто принимает решения. В результате множества исследований были выявлены проблемы, связанные с границами владения9. Я называю их конфликтом доставки.
Пока мы говорим о скрытии деталей внутренней реализации, с моей стороны было бы упущением не упомянуть шаблон гексагональной архитектуры, впервые подробно описанный Алистером Кокберном2. Этот шаблон определяет важность сохранения внутренней реализации отдельно от ее внешних интерфейсов, поскольку вы, возможно, захотите взаимодействовать с одной и той же функциональностью через разные типы интерфейсов. Я изображаю свои микросервисы в виде шестиугольников (гексагонов) отчасти для того, чтобы отличить их от «обычных» сервисов, но также по причине моей любви к этим фигурам.
Часто UI не предоставляется непосредственно микросервисом, но даже если это так, мы ожидаем, что часть его, связанная с этой функциональностью, по-прежнему будет принадлежать команде, отвечающей за профиль клиента, как показано на рис. 1.4. Концепция создавать команды, владеющие сквозным набором функций, ориентированных на пользователя, набирает обороты. В книге «Топологии команд»5 представлена идея потоковой команды, которая воплощает эту концепцию.
Для многих компаний модульный монолит может стать отличным выбором архитектуры. Если границы модулей четко определены, это может обеспечить высокую степень параллельной работы и отсутствие проблем, связанных с более распределенной микросервисной архитектурой, благодаря упрощенной топологии развертывания. Shopify — отличный пример организации, в которой этот метод успешно реализован в качестве альтернативы декомпозиции микросервисов7.
Крис Ричардсон, автор книги «Микросервисы. Паттерны разработки и рефакторинга»4, говорит, что цель микросервисов — получить «как можно меньший интерфейс». Это снова согласуется с концепцией скрытия информации, но представляет собой попытку найти смысл в термине «микросервисы», которого изначально не было. Когда этот термин впервые использовался для определения архитектур, основное внимание, по крайней мере на начальном этапе, уделялось не размеру интерфейсов.
Такие методы, как предметно-ориентированное проектирование, могут позволить структурировать код, чтобы лучше представлять реальную область, в которой работает программное обеспечение3. В микросервисных архитектурах мы используем ту же идею для определения границ сервисов. Моделируя сервисы вокруг предметных областей бизнеса, можно упростить внедрение новых функций и процесс комбинирования микросервисов для предоставления новых функциональных возможностей нашим пользователям.
Глава 2. Как моделировать микросервисы
Мой оппонент в своих рассуждениях напоминает мне язычника, который, когда его спросили, на чем стоит мир, ответил: «На черепахе». — «Но на чем стоит черепаха?» — «На другой черепахе».
Преподобный Джозеф Фредерик Берг (1854)
Итак, вы знаете, что такое микросервисы, и, я надеюсь, имеете представление об их ключевых преимуществах. Вам, наверное, не терпится прямо сейчас пойти и создать их, правда? Но с чего начать? В этой главе мы поговорим о некоторых основополагающих концепциях, таких как скрытие информации, связанность (coupling) и связность (cohesion), и поймем, как они могут изменить представление о проведении границ микросервисов. Затем рассмотрим различные формы декомпозиции, а также более подробно обсудим методы предметно-ориентированного проектирования. Узнаем, как продумать границы ваших микросервисов, чтобы максимально использовать преимущества этого подхода и избежать возможного появления некоторых потенциальных проблем. Но сначала нам нужно определиться, с чем мы будем работать.
Представляем MusicCorp
Любые книги лучше усваиваются, если в них есть примеры. Там, где это возможно, я буду делиться реальными историями из жизни, а иногда описывать вымышленный сценарий, чтобы вы понимали, как концепция микросервисов работает в реальном мире.
Итак, представьте себе современный интернет-магазин MusicCorp. Компания MusicCorp до недавнего времени была традиционным розничным магазином, но после выхода из бизнеса по продаже виниловых пластинок она все больше и больше сосредотачивала свои усилия в Интернете. У фирмы есть веб-сайт, но ее руководство считает, что сейчас самое время удвоить усилия в онлайн-мире. В конце концов, эти смартфоны для прослушивания музыки — всего лишь мимолетное увлечение (очевидно, что портативный плеер Zune намного лучше), и меломаны с нетерпением ждут, когда им доставят их любимые пластинки. Качество важнее удобства, верно? И хотя, возможно, только недавно стало известно, что Spotify на самом деле является цифровым музыкальным сервисом, а не каким-то средством для ухода за кожей для подростков, компания MusicCorp вполне довольна своей собственной направленностью и уверена, что весь этот стриминговый бизнес скоро прогорит.
Несмотря на то что MusicCorp немного отстает от жизни, у нее большие планы. К счастью, в компании решили, что отличный шанс захватить рынок — убедиться, что есть возможность вносить изменения самым простым способом. Микросервисы для победы!
Что делает границу микросервиса качественной
Прежде чем команда MusicCorp встанет на путь создания сервиса за сервисом в попытке доставить восьмидорожечные кассеты всем и каждому, давайте немного поговорим о самой важной основополагающей идее, которую не стоит забывать. Мы хотим, чтобы микросервисы можно было изменять и развертывать, а их функциональность предоставлялась нашим пользователям независимым образом. Возможность изменять один микросервис изолированно от другого имеет жизненно важное значение. Итак, о чем нужно помнить, когда мы хотим провести границы вокруг сервисов?
По сути, микросервисы — это просто еще одна форма модульной декомпозиции, хотя и с сетевым взаимодействием между моделями и всеми вытекающими проблемами. К счастью, это означает, что мы можем полагаться на высокий уровень развития техники в области модульного ПО и использовать структурированное программирование для определения границ. Имея это в виду, давайте более подробно рассмотрим три ключевые концепции, которые определяют качество границ микросервиса и которые мы кратко затронули в главе 1, — скрытие информации, связанность и связность.
Скрытие информации
Скрытие информации — это концепция, разработанная Дэвидом Парнасом для поиска наиболее эффективного способа определения границ модулей10. Скрытие информации подразумевает скрытие как можно большего количества деталей за границей модуля (или в нашем случае микросервиса). Парнас рассмотрел преимущества, которые теоретически должны дать нам модули.
Ускоренное время разработки
Разрабатывая модули независимо, мы можем выполнять больше параллельной работы и уменьшить влияние от добавления большего количества разработчиков в проект.
Понятность
Каждый модуль можно рассматривать и понимать изолированно. Это, в свою очередь, дает представление о том, что делает система в целом.
Гибкость
Модули можно изменять независимо друг от друга, что позволяет вносить изменения в функциональность системы, не требуя преобразований других модулей. Кроме того, их можно комбинировать различными способами для обеспечения новых возможностей.
Этот список желаемых характеристик прекрасно дополняет то, чего мы пытаемся достичь с помощью микросервисных архитектур — и действительно, теперь я рассматриваю микросервисы просто как еще одну форму модульной архитектуры. Адриан Колер просмотрел ряд работ Дэвида Парнаса и, изучив их с точки зрения микросервисов, составил свое резюме11.
Реальность такова, что наличие модулей не приводит к фактическому достижению необходимых результатов. Многое зависит от того, как формируются границы модуля. Согласно исследованиям Парнаса, скрытие информации стало ключевым методом, помогающим получить максимальную отдачу от модульных архитектур, и с современной точки зрения то же самое относится к микросервисам.
В другой статье Парнаса12 мы нашли такую цитату: «Связи между модулями — это предположения, которые модули делают друг о друге».
Уменьшая количество предположений, которые один модуль (или микросервис) делает относительно другого, мы напрямую влияем на связи между ними. Сохраняя число предположений небольшим, легче гарантировать, что мы сможем изменить одну часть, не затрагивая другие. Если разработчик, модифицирующий блок, имеет четкое представление о том, как модуль используется другими элементами системы, ему будет проще безопасно вносить преобразования, чтобы вышестоящим абонентам не приходилось делать то же самое.
Это относится и к микросервисам, за исключением уже имеющейся у нас возможности развернуть измененный сервис без необходимости развертывания чего-либо еще, тем самым усиливая описанные Парнасом преимущества: ускорение времени разработки, понятность и гибкость.
Последствия скрытия информации проявляются во многих отношениях, и я буду поднимать эту тему на протяжении всей книги.
Связность
Самое краткое объяснение, которое я слышал для описания связности13, звучит так: «Код, в который вносят изменения как в единое целое, остается единым целым». Для наших целей это довольно хорошее определение. Как обсуждалось ранее, мы оптимизируем нашу микросервисную архитектуру с учетом простоты преобразований бизнес-функциональности. Поэтому нам требуется функциональность, сгруппированная таким образом, чтобы иметь возможность вносить изменения в как можно меньшем количестве мест.
Хотелось бы, чтобы связанное поведение находилось в одном месте, а несвязанное — где-то в другом. Почему? Да потому, что, если требуется пересмотреть поведение, хотелось бы иметь возможность изменить его в одном месте и опубликовать как можно скорее. Если же придется изменять его во многих разных местах, то понадобится выпустить множество различных сервисов (возможно, одновременно). Такой процесс происходит медленнее, а одновременное развертывание большого количества сервисов сопряжено с риском, поэтому хотелось бы избежать и того и другого. Следовательно, нужно найти в нашей предметной области границы, которые помогут обеспечить нахождение связанного поведения в одном месте; требуется также, чтобы эти границы имели как можно более слабую связь с другими границами. Если соответствующая функциональность распределена по всей системе, мы говорим, что связность слабая, тогда как для наших микросервисных архитектур мы стремимся к сильной связности.
Связанность
Когда между сервисами наблюдается слабая связанность14, изменения, вносимые в один сервис, не требуют изменений в другом. Для микросервиса самое главное — возможность внесения изменений в один сервис и его развертывания без необходимости вносить изменения в любую другую часть системы. И это действительно очень важно.
Что вызывает необходимость сильной связанности? Классической ошибкой является выбор такого стиля интеграции, который тесно привязывает один сервис к другому, что при изменении внутри сервиса требует изменений в его потребителях.
Слабо связанный сервис имеет необходимый минимум сведений о сервисах, с которыми ему приходится сотрудничать. Это также означает, что нам следует ограничить количество различных типов вызовов от одного сервиса к другому, потому что помимо потенциальной проблемы с производительностью интенсивное общение может привести к сильной связанности.
Взаимодействие связанности и связности
Как упоминалось ранее, понятия связанности и связности, очевидно, смежные. Логично предположить, что, если связанная функциональность распределена по всей системе, изменения в этой функциональности будут распространяться через проложенные границы, что подразумевает более сильную связанность. Закон Константина, названный в честь пионера структурированного проектирования Ларри Константина, четко резюмирует это.
Структура стабильна, если связность сильная, а связанность слабая15.
Здесь для нас важна концепция стабильности. Чтобы границы обеспечивали возможность независимого развертывания и позволяли работать над микросервисами параллельно, снижая уровень координации между командами, работающими над этими сервисами, необходима определенная степень стабильности самих границ. Если контракт, предоставляемый микросервисом, постоянно меняется обратно несовместимым образом, то это приведет к постоянному изменению вышестоящих потребителей.
Связанность и связность тесно переплетены, то есть совпадают в том смысле, что оба понятия описывают взаимосвязь между вещами. Связность применима к отношениям между вещами внутри границы (микросервис в нашем контексте), а связанность представляет отношения между объектами через границу. Нет наилучшего способа организовать код. Связанность и связность — всего лишь характеристики, позволяющие сформулировать различные компромиссы, на которые мы идем в отношении кода. Все, к чему мы можем стремиться, — найти правильный баланс между этими двумя идеями, наиболее подходящий для вашего конкретного контекста и проблем.
Помните, что мир не статичен — вполне возможно, что по мере изменения системных требований найдутся причины пересмотреть принятые решения. Иногда части системы могут претерпевать столь значительные преобразования, что стабильность может стать невозможной. Мы рассмотрим такой пример в главе 3, когда я поделюсь опытом разработчиков, стоящих за системой Snap CI.
Типы связанности
Из вышеприведенной информации можно сделать вывод, что любая связанность — плохо. Однако это не совсем так. В конечном счете определенная связаность в нашей системе будет неизбежно. Все, что мы хотим сделать, — уменьшить ее.
Была проделана огромная работа по изучению различных форм связанности в контексте парадигмы структурированного программирования, позволявшей рассматривать по большей части модульное (нераспределенное, монолитное) ПО. Многие из моделей оценки связанности пересекаются или противоречат друг другу. Но в первую очередь они говорят о процессах на уровне кода, а не о рассмотрении сервис-ориентированных взаимодействий. Поскольку микросервисы представляют собой стиль модульной архитектуры (хотя и с дополнительной сложностью распределенных систем), можно использовать многие из этих оригинальных концепций и применять их в отношении наших систем на основе микросервисов.
| Уровень техники в области структурированного программирования Большая часть нашей текущей работы в области вычислительной техники опирается на предыдущую. Невозможно учесть все, что было ранее, но в этом издании я стремился охватить как можно больше вопросов. Отчасти для того, чтобы отдать должное там, где это необходимо, отчасти, чтобы оставить несколько хлебных крошек для читателей, желающих изучить определенные темы более подробно. А также чтобы показать, что многие из этих идей опробованы и проверены. Если говорить о создании новых фрагментов систем на основе предыдущих работ, в этой книге есть несколько предметных областей, у которых такой же предшествующий уровень техники, как у структурированного программирования. Книга Ларри Константина, написанная в соавторстве с Эдвардом Йордоном, считается одной из самых важных в этой области. Также советую книгу Мейлира Пейджа-Джонса «Практическое руководство по проектированию структурированных систем». К сожалению, обе книги сложно достать, поскольку тиражи уже давно распроданы, а электронные варианты не выпускались. |
Не все идеи четко соответствуют друг другу, поэтому я сделал все возможное, чтобы синтезировать рабочую модель для различных типов связанности микросервисов. Там, где эти идеи сопоставляются с предыдущими определениями, я придерживаюсь уже описанных терминов. В других местах мне приходилось придумывать новые понятия или смешивать идеи из иных источников. Поэтому, пожалуйста, считайте весь материал построенным на основе множества предыдущих работ в этой области. Я просто пытаюсь придать этому больше смысла в контексте микросервисов.
На рис. 2.1 представлен краткий обзор различных типов связанности, организованных от слабых (желательно) до сильных (нежелательно).

Рис. 2.1. Различные типы связанностей, от слабых (низких) до сильных (высоких)
Далее мы изучим каждую форму по очереди и рассмотрим примеры, показывающие, как эти формы могут проявляться в нашей микросервисной архитектуре.
Предметная связанность
Предметная (доменная) связь описывает ситуацию, в которой одному микросервису необходимо взаимодействовать с другим, поскольку первому требуется использовать функциональность, предоставляемую вторым микросервисом16.
На рис. 2.2 показана часть того, как заказы на компакт-диски управляются внутри MusicCorp. В этом примере Обработчик заказа вызывает микросервис Склад для резервирования на складе, а микросервис Оплата принимает оплату. Следовательно, Обработчик заказа в этой операции зависит от микросервисов Склад и Оплата и связан с ними. Между сервисами Склад и Оплата нет такой связи, поскольку они не взаимодействуют.
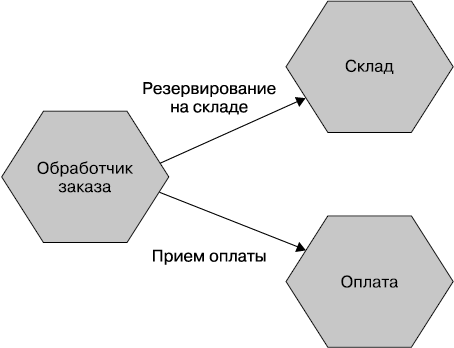
Рис. 2.2. Пример доменной связи, где сервису Обработчик заказов необходимо использовать функциональность, предоставляемую другими микросервисами
В микросервисной архитектуре данный тип взаимодействия практически неизбежен. Система, основанная на микросервисах, для выполнения своей работы полагается на взаимодействие нескольких микросервисов. Однако нам по-прежнему требуется свести это к минимуму. Ситуация, когда один микросервис зависит от нескольких нижестоящих микросервисов, означает, что он выполняет слишком много задач.
Как правило, доменная связанность считается слабой формой связи, хотя даже здесь вполне реально столкнуться с проблемами. Микросервис, которому необходимо взаимодействовать с большим количеством нижестоящих микросервисов, может указывать на то, что слишком много логики было централизовано. Предметная связанность также может стать проблематичной, поскольку между сервисами передаются все более усложняющиеся наборы данных. Обычно это говорит о менее благоприятных формах связи, которые мы рассмотрим в дальнейшем.
Помните о важности скрытия информации. Делитесь только тем, что необходимо, и отправляйте только минимальный требуемый объем данных.
| Примечание о временной связанности Другая достаточно известная форма связанности — временная. С точки зрения связи, ориентированной на код, временная связанность относится к ситуации, в которой понятия объединяются вместе только потому, что они происходят одновременно. Временная связь в контексте распределенной системы имеет немного другое значение: одному микросервису требуется, чтобы другой микросервис выполнял что-то в то же время. Для завершения операции оба микросервиса должны быть запущены и доступны для одновременной связи друг с другом. Итак, на рис. 2.3, где Обработчик заказов MusicCorp выполняет синхронный HTTP-вызов сервиса Склад, сервис Склад должен быть запущен и доступен одновременно с вызовом. 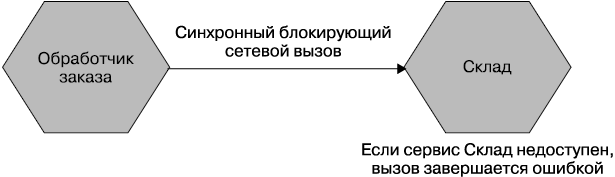
Рис. 2.3. Пример временной связи, при которой Обработчик заказов выполняет синхронный HTTP-вызов микросервиса Склад Если по какой-либо причине Обработчик заказов не может связаться со складом, операция завершается ошибкой, так как не получается зарезервировать компакт-диски для отправки. Сервису Обработчик заказов также придется выполнять блокировку и ждать ответа от сервиса Склад, что может вызвать проблемы с точки зрения конкуренции за ресурсы. Это не значит, что временная связь плоха. Просто об этом следует знать. По мере роста количества микросервисов с более сложными взаимодействиями проблемы временной связанности могут возрасти до такой степени, что становится все труднее масштабировать систему и поддерживать ее работоспособность. Один из способов избежать временной связанности — использовать некоторую форму асинхронной связи, такую как брокер сообщений. |
Сквозная связанность
Сквозная связанность17 описывает ситуацию, в которой один микросервис передает данные другому микросервису исключительно потому, что данные нужны какому-то третьему микросервису, находящемуся дальше по потоку. Во многих отношениях это одна из самых проблемных форм связи, поскольку она подразумевает, что вызывающий сервис должен знать, что вызываемый им сервис вызывает еще один. А также вызывающему микросервису необходимо знать, как работает удаленный от него микросервис.
В качестве примера сквозной связи более внимательно рассмотрим фрагмент системы обработки заказов MusicCorp. На рис. 2.4 показан Обработчик заказов, посылающий запрос к сервису Склад для подготовки заказа к отправке. В качестве полезной нагрузки запроса мы отправляем Путевой лист. Этот Путевой лист содержит не только адрес клиента, но и тип доставки. Сервис Склад просто передает эту информацию нижестоящему микросервису Доставка.
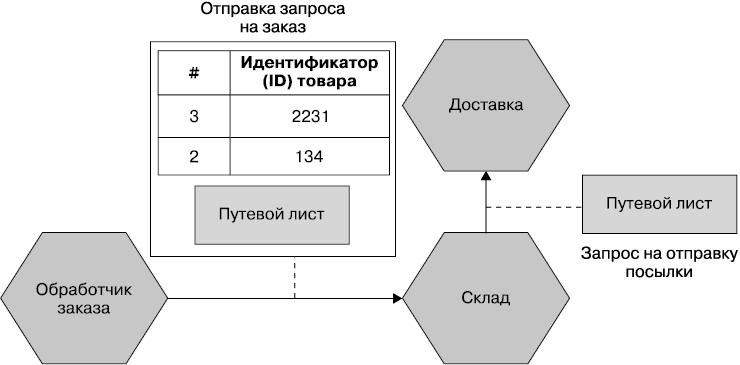
Рис. 2.4. Сквозная связанность, при которой данные передаются микросервису исключительно потому, что они нужны другому нижестоящему сервису
Основная проблема сквозной связи заключается в том, что изменение требуемых данных ниже по потоку может привести к более значительному изменению выше по потоку. В нашем примере если сервису Доставка в настоящее время требуется изменение формата или содержания данных, то сервисам Склад и Обработчик заказов, скорее всего, тоже потребуется что-то изменить.
Есть несколько способов, с помощью которых это можно исправить. Первый — рассмотреть, имеет ли смысл для вызывающего микросервиса просто обходить посредника. В нашем примере это означает, что Обработчик заказов напрямую обращается к сервису Доставка, как показано на рис. 2.5. Однако это влечет за собой иные проблемы. Наш Обработчик заказов усиливает свою доменную связанность, поскольку Доставка станет еще одним микросервисом, с которым придется взаимодействовать. Если бы это была единственная проблема, такое решение все еще было бы допустимым, поскольку предметная связь представляет собой более слабую форму связи. Однако здесь это решение только усугубляет ситуацию, поскольку резервирование на складе должно происходить при помощи сервиса Склад, прежде чем посылка будет отправлена с помощью сервиса Доставка, и после завершения доставки необходимо соответствующим образом обновить перечень товаров на складе. Это добавляет больше сложности и логики в Обработчик заказов, которая ранее была скрыта внутри Склада.
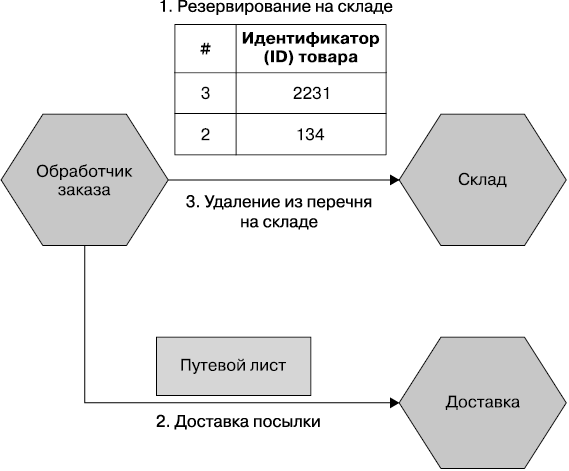
Рис. 2.5. Один из способов обойти сквозную связь заключается в непосредственном взаимодействии с нижестоящим сервисом
Для этого конкретного примера я мог бы рассмотреть более простое (хотя и более тонкое) изменение, а именно — полностью скрыть запрос документа Путевой лист от сервиса Обработчик заказов. Идея делегировать работу по управлению запасами и по организации отправки посылки сервису Склад имеет смысл, но не очень хорошо, что мы допустили утечку некоторых реализаций более низкого уровня, а именно тот факт, что микросервису Доставка требуется Путевой лист. Один из способов скрыть эту деталь — сделать так, чтобы Склад получал необходимую информацию в рамках своего контракта, и тогда он создаст Путевой лист локально, как показано на рис. 2.6. Теперь, если сервис Доставка меняет свой сервисный контракт, такое изменение будет невидимым для сервиса Обработчик заказов, пока Склад собирает необходимые данные.
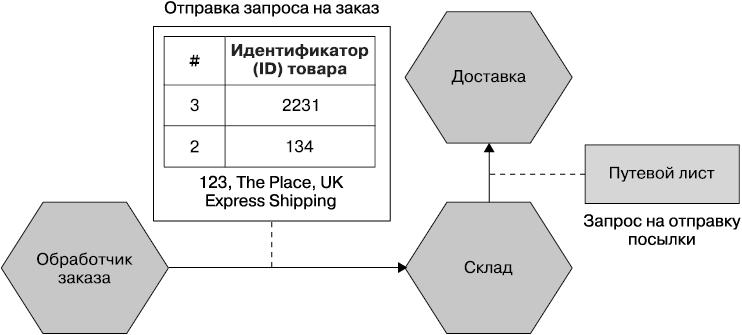
Рис. 2.6. Скрытие необходимости в Путевом листе от Обработчика заказов
Пример на рис. 2.7, условно говоря, довольно безобидный. Это связано с тем, что по самой своей природе справочные данные нечасто меняются, а также потому, что они доступны только для чтения. Поэтому я спокойно отношусь к совместному использованию справочных данных таким образом. Однако общая связанность становится более проблематичной, если структура данных меняется чаще или если несколько микросервисов читают и записывают одни и те же данные.
Хотя описанные действия помогут защитить микросервис Склад от некоторых изменений в сервисе Доставка, есть вещи, которые все равно потребуют преобразований от всех участников. Допустим, мы хотим осуществлять международные поставки. Сервису Доставка потребуется включить документ Таможенная декларация в перечень документов запроса Путевой лист. Если это необязательный параметр, то мы могли бы без проблем развернуть новую версию микросервиса Доставка. Однако если он обязательный, то сервису Склад необходимо будет создать его. Данный сервис может сделать это с помощью имеющейся у него информации или потребовать ее от Обработчика заказов.
В этом случае необходимость модификации всех трех микросервисов не исчезла, но нам было предоставлено гораздо больше возможностей в отношении того, когда и как эти изменения можно вносить. Если бы у нас была сильная (сквозная) связь из начального примера, добавление нового документа Таможенная декларация могло бы потребовать поэтапного развертывания всех трех микросервисов. По крайней мере, скрыв эту деталь, мы могли бы гораздо легче пошагово осуществить развертывание.
Рис. 2.7. Несколько сервисов, получающих доступ к общим статическим справочным данным
Один из последних подходов, который мог бы помочь уменьшить сквозную связь, состоит в том, чтобы указать сервису Обработчик заказов продолжать отправлять Путевой лист в микросервис Доставка через Склад. Но Складу не нужно знать структуру самого Путевого листа. Обработчик заказов отправляет лист как часть запроса на заказ, но Склад не пытается просмотреть или обработать поле — он просто относится к нему как к неструктурированному объекту данных и не заботится о содержимом. Вместо этого он просто отправляет документ дальше. При изменении формата в Путевом листе все же придется внести изменения в микросервисы Обработчик заказов и Доставка, но, так как Склад не интересуется фактическим содержимым листа, его менять не надо.
Общая связанность
Общая связанность возникает, когда два или более микросервиса используют общий набор данных. Простым и распространенным примером такой формы связанности могут служить множественные микросервисы, использующие одну и ту же БД, но это также может проявляться в использовании общей памяти или файловой системы.
Основная проблема систем с общей связанностью заключается в том, что изменения в структуре данных могут повлиять на несколько микросервисов одновременно. Рассмотрим пример некоторых сервисов MusicCorp на рис. 2.7. Как мы условились ранее, MusicCorp работает по всему миру, поэтому компании требуется различная информация о странах, в которых она зарегистрирована. Здесь все множество сервисов считывает статические справочные данные из общей БД. Если схема этой базы изменится обратно несовместимым образом, это потребует преобразований для каждого потребителя БД. На практике подобные общие данные, как правило, очень трудно изменить.
На рис. 2.8 показана ситуация, в которой сервисы Обработчик заказов и Склад считывают и записывают данные из общей таблицы Заказ, чтобы помочь управлять процессом отправки компакт-дисков клиентам MusicCorp. Оба микросервиса обновляют столбец Статус. Обработчик заказов может задать статусы РАЗМЕЩЕН, ОПЛАЧЕН и ЗАВЕРШЕН, в то время как Склад задает статусы СОБИРАЕТСЯ или ОТПРАВЛЕН.
Рис. 2.8. Пример общей связанности, при которой сервисы Обработчик заказов и Склад обновляют одну и ту же запись заказа
Хотя вы можете счесть рис. 2.8 несколько надуманным, этот простой пример помогает проиллюстрировать основную проблему общей связанности. Концептуально у нас есть микросервисы Обработчик заказов и Склад, управляющие различными аспектами жизненного цикла заказа. Можно ли быть уверенными, что при внесении изменений в Обработчик заказов не возникнет конфликта интересов с сервисом Склад?
Гарантией того, что состояние чего-либо изменяется правильным образом, было бы создание конечного автомата. Конечный автомат может использоваться для управления переходом некоторого объекта из одного состояния в другое, запрещая недопустимые переходы состояний. На рис. 2.9 можно увидеть разрешенные переходы состояний для заказа в MusicCorp. Заказ может перейти непосредственно из статуса РАЗМЕЩЕН в статус ОПЛАЧЕН, но не напрямую из статуса РАЗМЕЩЕН к СОБИРАЕТСЯ (этого конечного автомата, скорее всего, будет недостаточно для реальных бизнес-процессов, выполняемых при покупке и доставке товаров, но смысл этого простого примера — проиллюстрировать идею).
Рис. 2.9. Обзор допустимых переходов статусов для заказа в MusicCorp
Проблема этого конкретного примера в том, что и Склад, и Обработчик заказов разделяют ответственность за управление этим конечным автоматом. Как мы можем быть уверены, что они согласуют допустимые переходы? Существуют способы управления подобными процессами через границы микросервиса; мы вернемся к этой теме, когда будем обсуждать саги в главе 6.
Потенциальным решением здесь было бы обеспечить состояние, при котором один микросервис управлял бы заказом. На рис. 2.10 отправлять запросы на обновление статуса заказа в сервисе Заказ могут микросервисы Склад или Обработчик заказов. Здесь сервис Заказ будет источником истины для любого размещенного заказа. В этой ситуации действительно важно, чтобы мы рассматривали запросы от сервисов Склад и Обработчик заказов именно как запросы. Задачей сервиса Заказ станет управление допустимыми переходами статусов, целиком связанными с заказом. Таким образом, если сервис Заказ получит запрос от Обработчика заказов на изменение статуса с РАЗМЕЩЕН непосредственно на ЗАВЕРШЕН, сервис заказа вправе отклонить заявку, если такое изменение недопустимо.
Убедитесь, что у нижестоящего микросервиса есть возможность отклонить недействительный запрос, отправленный в микросервис.
Альтернативным подходом в данном случае будет реализация сервиса Заказ в виде чего-то большего, чем просто оболочка для операций CRUD с базой данных, где запросы сопоставляются непосредственно с обновлениями БД. Это похоже на объект, содержащий приватные поля, в котором публичные геттеры и сеттеры просочились из микросервиса к вышестоящим потребителям (снижение связности), и мы вернулись в мир управления приемлемыми переходами состояний между несколькими различными сервисами.
Рис. 2.10. Сервисы Обработчик заказов и Склад могут выполнить запрос на изменения в заказе, но решение о том, какие запросы допустимы, принимает микросервис Заказ
Если вы видите микросервис, который выглядит просто как тонкая оболочка для CRUD-операций с базой данных, — это признак слабой связности и более сильной связанности, поскольку логика, которая должна быть в этом сервисе для управления данными, распределена по другим местам вашей системы.
Источники общей связанности также являются потенциальными виновниками конкуренции за ресурсы. Множество микросервисов, использующих одну и ту же файловую систему или базу данных, могут перегружать этот ресурс, вызывая серьезные последствия при его замедлении или недоступности. Общая БД особенно подвержена такой проблеме из-за возможной подачи к ней произвольных запросов различной сложности. Я видел не одну базу данных, поставленную на колени ресурсоемким SQL-запросом, — возможно, я даже был виновником такой ситуации один или два раза18.
Так что общая связанность иногда допустима, но чаще всего — нет. Даже если это неопасно, мы все равно ограничены в тех изменениях, которые можно внести в общие данные, что говорит об отсутствии связности в нашем коде. Это также может вызвать разногласия между сервисами. Именно по этим причинам мы считаем общую связанность одной из наименее желательных форм связи, но бывает и хуже.
Связанность по содержимому
Связанность по содержимому проявляется, когда вышестоящий сервис проникает во внутренние компоненты нижестоящего и изменяет его состояние. Наиболее распространенный вариант этого типа связанности представлен обращением внешнего сервиса к базе данных другого микросервиса и изменением ее напрямую. Различия между связанностью по содержимому и общей связанностью практически не заметны. В обоих случаях два или более микросервиса выполняют чтение и запись одного и того же набора данных. При общей связанности используется общая внешняя зависимость, которую вы не контролируете. При связанности по содержимому границы становятся менее четкими, а разработчикам все сложнее изменять систему.
Вернемся к нашему предыдущему примеру MusicCorp. На рис. 2.11 показан сервис Заказ, который управляет допустимыми изменениями статусов заказов в нашей системе. Обработчик заказов отправляет запросы сервису Заказ, делегируя не только право на изменение статуса, но и ответственность за принятие решения о том, какие переходы статусов допустимы. С другой стороны, Склад напрямую обновляет таблицу, в которой хранятся данные заказа, минуя любые функции сервиса Заказ, способные проверять допустимые преобразования. Мы должны надеяться, что сервис Склад содержит согласованный набор логики, гарантирующий внесение только разрешенных изменений. В лучшем случае логика продублируется. В худшем — мы можем получить заказы в очень необычных местах.
В этой ситуации у нас также возникает проблема, связанная с тем, что внутренняя структура данных нашей таблицы заказов общедоступна. Теперь при преобразовании сервиса Заказ стоит предельно осторожно вносить изменения в эту конкретную таблицу — даже когда для нас очевидно, что к ней напрямую обращаются сторонние пользователи. Исправить ситуацию с минимумом усилий поможет разрешение сервису



















