

автордың кітабын онлайн тегін оқу System Design. Подготовка к сложному интервью
Перевел с английского А. Павлов
Литературный редактор Ю. Зорина
Корректоры С. Беляева, Г. Шкатова
Алекс Сюй
System Design. Подготовка к сложному интервью. — СПб.: Питер, 2024.
ISBN 978-5-4461-1816-8
© ООО Издательство "Питер", 2024
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Об авторе
Алекс Сюй — опытный разработчик программного обеспечения и предприниматель. Ранее он работал в таких компаниях, как Twitter, Apple, Zynga и Oracle. Алекс получил степень магистра наук в Университете Карнеги-Меллона. Его страсть — проектирование и реализация сложных систем.
Введение
Мы весьма рады, что вы решили изучить особенности интервью по проектированию ИТ-систем вместе с нами. Из всех технических интервью именно на этом задают самые сложные вопросы. Претенденту предлагается спроектировать архитектуру программной системы: новостной ленты, поиска Google, системы мгновенных сообщений и т.д. Задачи такого рода наводят ужас, ведь у них нет единственно верных решений. Они обычно отличаются масштабностью и расплывчатостью. Допускаются свободные и неясные формулировки без стандартного или правильного ответа.
Интервью по проектированию ИТ-систем широко практикуются в компаниях, так как навыки общения и решения задач, которые можно проверить на этом этапе, необходимы в повседневной работе программиста. Ответы претендента оцениваются с учетом того, как он анализирует расплывчатую задачу и какие шаги он предпринимает для ее решения. При этом во внимание принимается то, как он объясняет свои идеи, обсуждает их с другими, оценивает и оптимизирует систему.
Здесь нет единственно правильных ответов. Как и в реальной жизни, на интервью обсуждают самые разные системы, каждую со своими нюансами. Претендент должен предложить архитектуру для достижения поставленных целей. Ход обсуждения может быть разным в зависимости от того, кто проводит интервью. Кто-то может выбрать общую архитектуру, чтобы пройтись по всем компонентам, а кто-то предпочитает сосредоточиться на одной или нескольких областях. Обычно ход мыслей всех участников интервью определяется тем, насколько хорошо они понимают системные требования, ограничения и узкие места.
Цель этой книги — предоставить надежную стратегию для решения задач по проектированию систем. Правильная стратегия и знания являются ключевыми факторами успешного прохождения интервью.
В этой книге шаг за шагом описывается систематический подход к поиску ответов на вопросы о проектировании систем. Здесь вы найдете множество наглядных примеров с подробными инструкциями. Постоянно практикуясь, вы сможете хорошо подготовиться к такого рода интервью.
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
На веб-сайте издательства www.piter.com вы найдете подробную информацию о наших книгах.
1. Масштабирование от нуля до миллионов пользователей
Проектирование системы с поддержкой миллионов пользователей — непростая задача. Это процесс, требующий непрерывного совершенствования и бесконечного улучшения. В этой главе мы создадим систему, которая работает в однопользовательском режиме, и постепенно расширим ее для обслуживания миллионов пользователей. Прочитав эту главу, вы освоите несколько методик, которые помогут вам справиться с вопросами на интервью по проектированию ИТ-систем.
Конфигурация из одного сервера
Путь в тысячу ли начинается с первого шага. То же самое относится и к созданию сложной системы. Начнем с чего-то простого и разместим все на одном сервере. На рис. 1.1 показана конфигурация одного сервера, на котором запускаются все компоненты: веб-приложение, база данных, кэш и т.д.
Исследование потока запросов и источника трафика поможет разобраться в этой конфигурации. Давайте сначала взглянем на поток запросов (рис. 1.2).
1. Пользователи обращаются к веб-сайтам по их доменным именам, таким как api.mysite.com. Обычно система доменных имен (Domain Name System, DNS) представляет собой сторонний платный сервис, размещенный за пределами наших серверов.
2. Адрес интернет-протокола (Internet Protocol, IP) возвращается браузеру или мобильному приложению. В этом примере он имеет вид 15.125.23.214.
3. После получения IP-адреса вашему веб-браузеру напрямую отправляются запросы протокола передачи гипертекста (Hypertext Transfer Protocol, HTTP) [1].
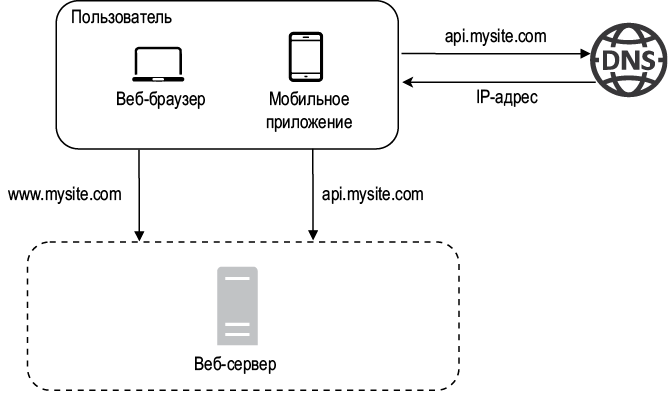
Рис. 1.1

Рис. 1.2
4. Веб-сервер возвращает HTML-страницы или JSON-ответы для рендеринга.
Теперь давайте исследуем источник трафика. Трафик, который получает ваш веб-сервер, приходит из двух мест: из веб- и мобильного приложения.
• Веб-приложение использует сочетание серверных и клиентских языков. Первые (Java, Python и т.д.) предназначены для реализации бизнес-логики, системы хранения и т.п., а вторые (HTML и JavaScript) — для предоставления информации.
• Мобильное приложение использует протокол HTTP для взаимодействия с веб-сервером. Для передачи данных зачастую применяется формат API-ответов JSON (JavaScript Object Notation — «представление объектов JavaScript»), отличающийся своей простотой. Пример API-ответа в формате JSON показан ниже:
GET /users/12 – Retrieve user object for id = 12
{
"id": 12,
"firstName": "John",
"lastName": "Smith",
"address":{
"streetAddress": "21 2nd Street",
"city": "New York",
"state": "NY",
"postalCode": 10021
}
"phoneNumbers": [
"212 555-1234",
"646 555-4567"
]
}
База данных
С увеличением количества пользователей одного сервера рано или поздно перестанет хватать, и нам понадобится несколько серверов: один для веб-/мобильного трафика, а другой — для базы данных (рис. 1.3). Разделение системы на веб-уровень и уровень данных позволяет масштабировать эти компоненты независимо друг от друга.
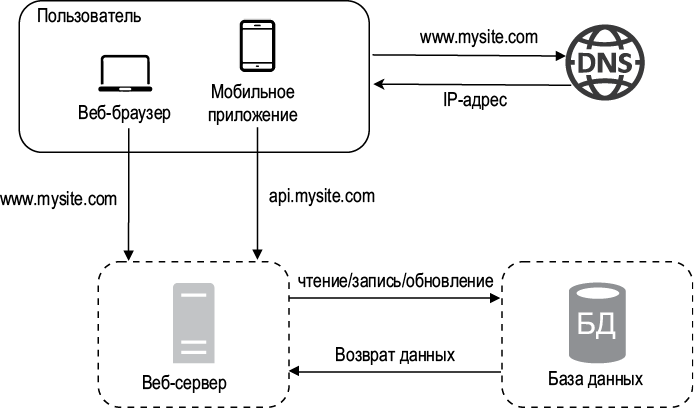
Рис. 1.3
Какую базу данных выбрать?
Базы данных (БД) бывают как реляционными (что является традиционным решением), так и нереляционными. Давайте посмотрим, чем они отличаются.
Реляционные БД также называют системами управления реляционными базами данных (СУРБД). К самым популярным относятся MySQL, Oracle, PostgreSQL и т.д. Реляционные БД предоставляют и хранят данные в таблицах и строках. С помощью SQL можно выполнять операции объединения между различными таблицами базы данных.
Нереляционные БД также называют NoSQL. Популярностью пользуются CouchDB, Neo4j, Cassandra, HBase, Amazon DynamoDB и т.д. [2]. Эти базы данных делятся на четыре категории: хранилища «ключ–значение», графовые, столбцовые и документные. Нереляционные БД обычно не поддерживают операции соединения.
Большинство разработчиков предпочитает реляционные базы данных, поскольку они применяются уже на протяжении более 40 лет и хорошо себя зарекомендовали. Но если они не подходят для ваших конкретных задач, стоит непременно обратить внимание на другие варианты. Нереляционные БД могут быть подходящим решением, если:
• ваше приложение нуждается в крайне низкой латентности;
• ваши данные не структурированы или не имеют никаких реляционных связей;
• вам нужно лишь сериализовать и десериализовать свои данные (JSON, XML, YAML и т.д.);
• вам нужно хранить огромные объемы данных.
Вертикальное и горизонтальное масштабирование
Вертикальное масштабирование, известное как наращивание, — это процесс повышения мощности ваших серверов (процессоров, памяти и т.д.). Горизонтальное масштабирование, которое еще называют расширением, заключается в добавлении новых серверов в пул ресурсов.
Вертикальное масштабирование отлично подходит для задач с небольшим трафиком. Его главным преимуществом является простота. К сожалению, у него есть ряд серьезных ограничений.
• Вертикальное масштабирование имеет жесткий лимит. Ресурсы отдельно взятого сервера нельзя увеличивать бесконечно.
• Вертикальное масштабирование не предусматривает отказоустойчивость и резервирование избыточных ресурсов. Если один из серверов выйдет из строя, веб-сайт/приложение станет полностью недоступным.
Из-за этих ограничений для крупномасштабных приложений лучше подходит горизонтальное масштабирование.
В предыдущей конфигурации пользователи подключались к веб-серверу напрямую. Если веб-сервер выйдет из строя, они потеряют доступ к веб-сайту. Если же к веб-серверу одновременно обратится большое количество пользователей и нагрузит его до предела, в результате, как правило, ответы будут приходить медленно либо к серверу вовсе станет невозможно подключиться. Для решения этих проблем больше всего подходит балансировщик нагрузки.
Балансировщик нагрузки
Балансировщик нагрузки равномерно распределяет входящий трафик между веб-серверами, которые указаны в его списке. На рис. 1.4 показано, как это работает.
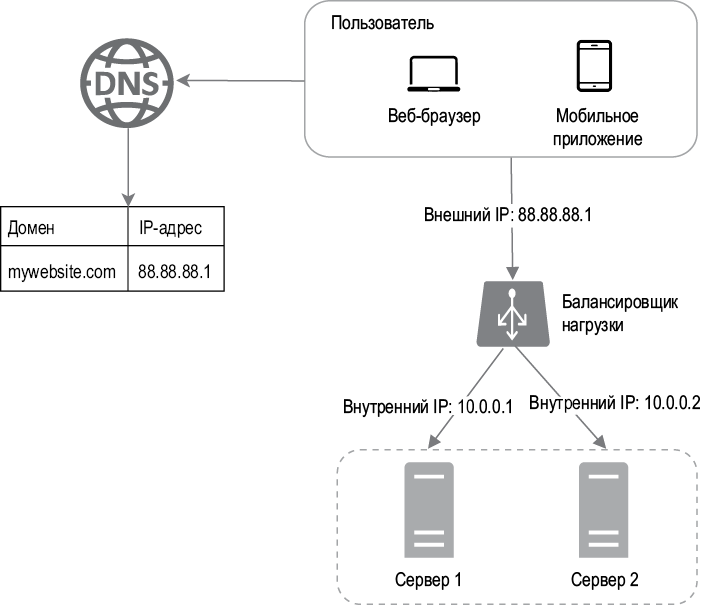
Рис. 1.4
Как видно на рис. 1.4, пользователи напрямую подключаются к внешнему IP-адресу балансировщика нагрузки. В этой конфигурации клиенты больше не имеют прямого доступа к веб-серверам. По соображениям безопасности для взаимодействия между серверами используются внутренние IP-адреса. Внутренний IP доступен только для серверов из той же сети, но не виден из интернета. Балансировщик нагрузки взаимодействует с веб-серверами с помощью внутренних IP-адресов.
На рис. 1.4 показано, как за счет добавления балансировщика нагрузки и второго сервера нам удалось решить проблему с отсутствием отказоустойчивости и улучшить доступность веб-уровня. Подробности объясняются ниже.
• Если сервер 1 выходит из строя, весь трафик перенаправляется к серверу 2. Благодаря этому веб-сайт остается доступным. Чтобы сбалансировать нагрузку, мы добавим в пул серверов новый исправный веб-сервер.
• Если посещаемость веб-сайта стремительно растет и для обслуживания трафика не хватает двух серверов, балансировщик нагрузки может изящно справиться с этой проблемой. Для этого достаточно расширить пул серверов, и балансировщик начнет автоматически передавать запросы новым веб-серверам.
Веб-уровень выглядит хорошо, но что насчет уровня данных? Текущая конфигурация предусматривает лишь одну БД, что исключает поддержку отказоустойчивости и резервирования. Для решения этих проблем обычно применяют репликацию. Давайте посмотрим, что это такое.
Репликация базы данных
Цитата из английской Википедии: «Репликация баз данных может использоваться во многих СУБД, обычно в режиме “ведущий–ведомый”, где роль ведущего сервера играет оригинал (master), а его копии являются ведомыми (slave)» [3].
Ведущая база данных обычно поддерживает только операции записи. Ведомые БД получают от ведущей копии ее содержимого и поддерживают только операции чтения. Все команды для модификации данных, такие как вставка, удаление или обновление, должны направляться ведущей базе данных. В большинстве приложений чтение происходит намного чаще, чем запись, поэтому ведомых БД обычно больше, чем ведущих. На рис. 1.5 показана ведущая база данных с несколькими ведомыми.
Преимущества репликации базы данных:
• Повышенная производительность. В модели «ведущий–ведомый» все операции записи и обновления происходят на ведущих узлах, а операции чтения распределяются между ведомыми. Это улучшает производительность, увеличивая количество запросов, которые можно обрабатывать параллельно.
• Надежность. Если один из ваших серверов с базой данных сломается из-за стихийного бедствия, такого как тайфун или землетрясение, данные не будут утеряны. Вам не нужно беспокоиться о потере данных, так как они реплицируются по разным местам.
• Высокая доступность. За счет репликации данных по разным местам ваш веб-сайт будет продолжать работать, даже если одна из БД выйдет из строя, поскольку у вас по-прежнему будет доступ к данным, размещенным на другом сервере.
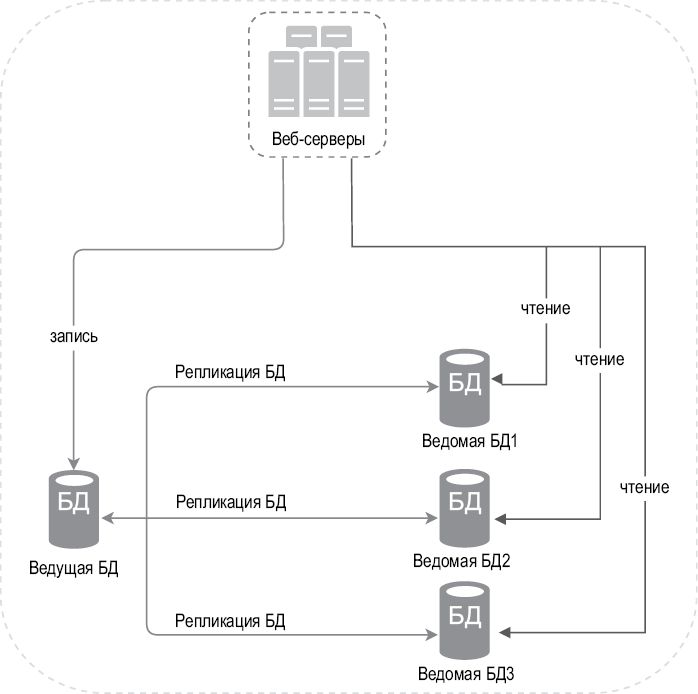
Рис. 1.5
В предыдущем разделе мы обсудили то, как балансировщик нагрузки улучшает доступность системы. Зададим здесь тот же вопрос: что, если одна из БД перестанет работать? Архитектурная конфигурация, представленная на рис. 1.5, может справиться с этой ситуацией:
• Если имеется лишь одна ведомая база данных и она выходит из строя, операции чтения будут временно перенаправлены к ведущей БД. Сразу после выявления проблемы новая ведомая БД заменит старую. Если ведомых БД несколько, операции чтения перенаправляются к другим исправным экземплярам. Новый сервер базы данных заменит старый.
• Если ведущая база данных выйдет из строя, ее место займет одна из ведомых. Все операции будут временно выполняться на сервере новой ведущей БД. Новая ведомая БД, предназначенная для репликации данных, немедленно заменит старую. В промышленных системах переквалификация ведомой БД в ведущую требует дополнительных усилий, так как ее содержимое может быть неактуальным. Недостающие данные придется обновить с помощью скриптов восстановления. В качестве решения можно использовать и другие методы, включая конфигурации с несколькими ведущими узлами и циклическую репликацию, но они более сложные, поэтому мы не станем рассматривать их в этой книге. Если вам интересна эта тема, обратитесь к справочным материалам [4] [5].
На рис. 1.6 показана архитектура системы после добавления балансировщика нагрузки и репликации базы данных.
Рассмотрим эту конфигурацию.
• Пользователь получает из DNS IP-адрес балансировщика нагрузки.
• Пользователь подключается к балансировщику нагрузки с помощью этого IP-адреса.
• HTTP-запрос направляется либо к серверу 1, либо к серверу 2.
• Веб-сервер считывает пользовательские данные из ведомой БД.
• Веб-сервер направляет любые операции по изменению данных ведущей БД, включая чтение, обновление и удаление.
Итак, мы как следует разобрались в веб-уровне и уровне данных. Теперь пришло время улучшить время загрузки/ответа. Для этого можно добавить слой кэша и разместить статические ресурсы (JavaScript/CSS/изображения/видеофайлы) в сети доставки содержимого (content delivery network, CDN).
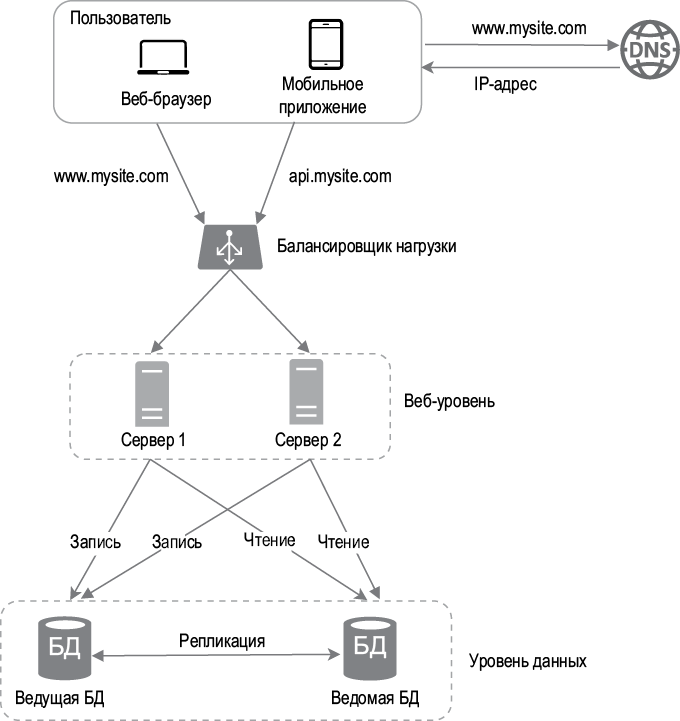
Рис. 1.6
Кэш
Кэш — это участок памяти, в который временно записываются результаты ресурсоемких ответов или данных, к которым часто обращаются. Это позволяет ускорить обслуживание последующих запросов. Как проиллюстрировано на рис. 1.6, при каждой загрузке новой веб-страницы выполняется один или несколько запросов к БД для извлечения данных. Многократное обращение к базе данных существенно влияет на производительность. Кэш может смягчить эту проблему.
Уровень кэша
Уровень кэша — это слой временного хранилища данных, который по своей скорости работы намного опережает БД. К преимуществам отдельного уровня кэша можно отнести улучшение производительности системы, возможность снизить нагрузку на базу данных и масштабировать этот уровень независимо от других. На рис. 1.7 показан пример конфигурации сервера кэширования.

Рис. 1.7
Получив запрос, веб-сервер сначала проверяет наличие ответа в кэше. Если ответ есть, данные возвращаются клиенту. Если нет, то веб-сервер обращается к базе данных, сохраняет ответ в кэше и пересылает его обратно клиенту. Эта стратегия называется кэшем сквозного чтения. В зависимости от типа и размера данных, а также от того, как к ним обычно обращаются, можно использовать и другие подходы. В предыдущем исследовании объясняется принцип работы разных стратегий кэширования [6].
Взаимодействовать с серверами кэширования просто, так как большинство из них предоставляют API-интерфейсы для распространенных языков программирования. В следующем фрагменте кода показан типичный пример использования API-интерфейса Memcached:
SECONDS=1
cache.set('myKey', 'hi there', 3600 * SECONDS)
cache.get('myKey')
Некоторые аспекты использования кэша
Вот несколько соображений касательно использования систем кеширования.
• Определитесь с тем, когда будет использоваться кэш. Это лучше делать в ситуациях, когда чтение данных происходит часто, а изменение — редко. Поскольку кэшированные данные хранятся в энергозависимой памяти, сервер кеширования не подходит для постоянного хранения. Например, если он перезапустится, все данные, хранившиеся в памяти, будут утрачены. В связи с этим данные необходимо записывать в постоянные хранилища.
• Выбор срока действия. Рекомендуется реализовать механизм, ограничивающий срок действия кэша. Просроченные данные немедленно удаляются. Если такого механизма нет, данные будут храниться в памяти постоянно. Срок действия лучше не делать слишком коротким, иначе система будет слишком часто обновлять данные, загружая их из БД. С другой стороны, из-за слишком длинного срока действия данные могут оказаться неактуальными.
• Согласованность. Это подразумевает синхронизацию данных в хранилище и кэше. Несогласованность может возникнуть из-за того, что операции изменения данных в хранилище и кэше выполняются не за одну транзакцию. При масштабировании системы в пределах нескольких регионов может быть непросто поддерживать согласованность. Подробнее об этом можно почитать в документе Scaling Memcache at Facebook, опубликованном Facebook [7].
• Предотвращение сбоев. Наличие лишь одного сервера кэширования может оказаться потенциальной единой точкой отказа (single point of failure, SPOF), которая, согласно английской Википедии, имеет следующее определение: «Единая точка отказа — это компонент, выход из строя которого приводит к прекращению работы всей системы» [8]. В связи с этим, чтобы избежать SPOF, рекомендуется использовать несколько серверов кэширования, размещенных в разных центрах обработки данных (ЦОД). А еще можно выделить какой-нибудь дополнительный объем памяти: это создаст буфер на случай, если память начнет использоваться более активно.
• Политика вытеснения. Когда кэш полностью заполнен, любой запрос на добавление новых элементов может привести к удалению существующих. Это называют вытеснением кэша. Самой популярной политикой считается вытеснение давно неиспользуемых данных (least-recently-used, LRU). Для разных ситуаций могут также подойти вытеснение наименее часто используемых данных (least-frequently-used, LFU) или метод «первым пришел, первым ушел» (FIFO, first-in-first-out).
Рис. 1.8
Сеть доставки содержимого (CDN)
CDN — это сеть географически распределенных серверов, которая используется для доставки статического содержимого. Серверы CDN кэшируют такие статические файлы, как изображения, видео, CSS, JavaScript и т.д.
Кэширование динамического содержимого — идея относительно новая. Здесь мы не будем углубляться в детали. Ограничимся лишь следующим: такой способ позволяет записывать в кэш HTML-страницы в зависимости от пути, параметров, cookie-файлов и заголовков запроса. Подробнее об этом можно почитать в статье из списка дополнительной литературы [9]. В этой книге мы сосредоточимся на использовании CDN для кэширования статического содержимого.
Вот общий принцип работы CDN: когда пользователь посещает веб-сайт, ближайший к нему сервер CDN доставляет статическое содержимое. Очевидно, что чем дальше от серверов CDN находятся пользователи, тем медленнее загружается веб-сайт. Например, если серверы CDN расположены в Сан-Франциско, пользователь из Лос-Анджелеса получит содержимое быстрее, чем пользователь из Европы. На рис. 1.9 проиллюстрировано, как CDN может уменьшать время загрузки.
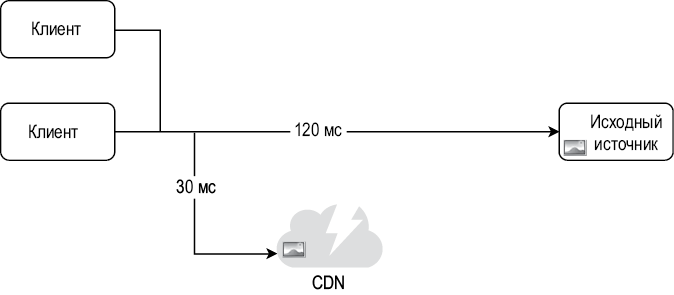
Рис. 1.9
Принцип работы CDN продемонстрирован на рис. 1.10.
1. Пользователь A пытается получить image.png с помощью URL-адреса изображения. Домен этого URL-адреса предоставляется провайдером CDN. Ниже показано, как могут выглядеть URL-адреса изображений, на примере CDN от Amazon и Akami:
• https://mysite.cloudfront.net/logo.jpg
• https://mysite.akamai.com/image-manager/img/logo.jpg
2. Если в кэше сервера CDN нет image.png, он запрашивает этот файл из оригинального источника, например веб-сервера или онлайн-хранилища вроде Amazon S3.
3. Источник возвращает серверу CDN файл image.png вместе с дополнительным HTTP-заголовком TTL (Time-to-Live — «время жизни»), который определяет, как долго изображение будет находиться в кэше.
4. CDN кэширует изображение и возвращает его пользователю A. Оно остается в кэше CDN, пока не истечет срок TTL.
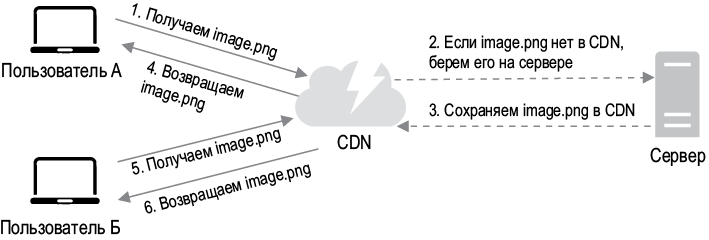
Рис. 1.10
5. Пользователь Б отправляет запрос на получение того же файла.
6. Если срок TTL еще не истек, изображение возвращается из кэша.
Нюансы использования CDN
• Стоимость. Серверы CDN предоставляются сторонними компаниями, а перемещение данных в CDN и из CDN стоит денег. Кэширование нечасто используемых ресурсов не даст существенных преимуществ, поэтому из CDN их лучше убрать.
• Подбор подходящего срока годности кэша. Для содержимого, которое зависит от времени, необходимо предусмотреть срок годности кэша. Он должен быть не слишком длинным, но и не слишком коротким. В первом случае содержимое может потерять свою актуальность, а во втором — привести к повторной перезагрузке содержимого с исходных серверов в CDN.
• Возможность сбоев. Вы должны подумать о том, как ваши веб-сайты/приложения будут справляться с недоступностью CDN. Если CDN временно выходит из строя, у клиента должна быть возможность обнаружить эту проблему и запросить ресурсы из исходного источника.
• Аннулирование файлов. Файлы можно удалять из CDN до истечения их срока годности одним из следующих способов:
• аннулировать объект CDN с помощью API-интерфейсов, предоставляемых поставщиками CDN;
• использовать версионирование, чтобы возвращать разные версии объектов. Для этого к URL-адресу можно добавить параметр с номером версии. Например, версия 2 может быть представлена строкой запроса: image.png?v=2.
На рис. 1.11 показана конфигурация после добавления CDN и кэша.
1. Статические ресурсы (JS, CSS, изображения и т.д.) больше не раздаются веб-серверами. Для повышения производительности они извлекаются из CDN.
2. Нагрузка на базу данных снижается за счет кэширования.
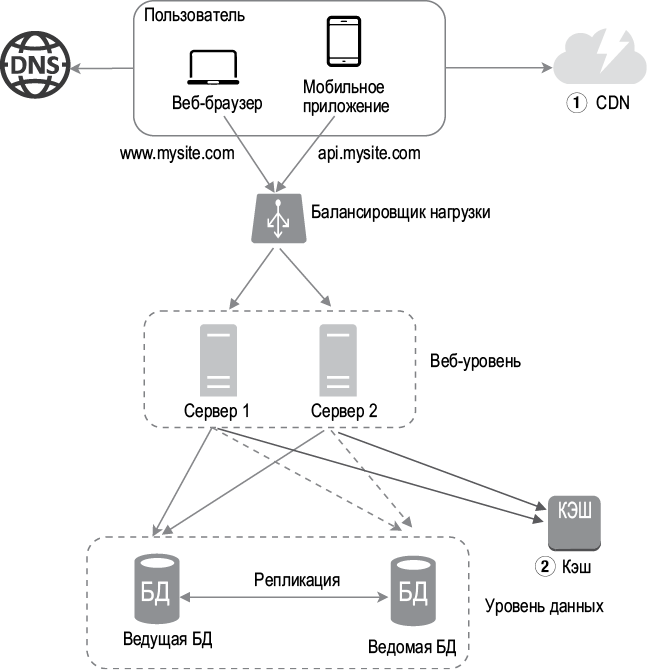
Рис. 1.11
Веб-уровень без сохранения состояния
Пришло время поговорить о горизонтальном масштабировании веб-уровня. Для этого нужно вынести из него состояние (например, информацию о пользовательских сеансах). Данные сеансов рекомендуется записывать в постоянные хранилища, такие как реляционные БД или NoSQL. Каждый веб-сервер в кластере может запросить состояние из базы данных. Таким образом получается веб-уровень без сохранения состояния.
Архитектура с сохранением состояния
От того, хранит сервер состояние или нет, зависит, будет ли он «помнить» данные клиента (состояние) между разными запросами.
На рис. 1.12 показан пример архитектуры с сохранением состояния.
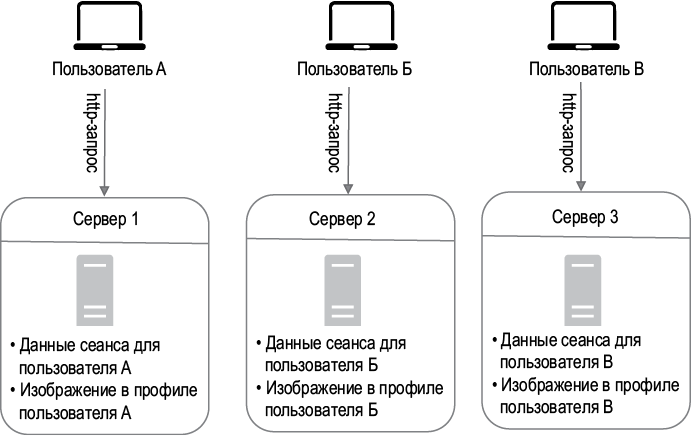
Рис. 1.12
На рис. 1.12 данные сеанса и изображение в профиле пользователя A хранятся на сервере 1. Чтобы аутентифицировать пользователя A, HTTP-запрос должен быть направлен к этому серверу. Если отправить этот запрос, к примеру, серверу 2, аутентификация не пройдет, так как на втором сервере нет данных соответствующего сеанса. Точно так же все HTTP-запросы пользователя Б должны направляться к серверу 2, а запросы пользователя В — к серверу 3.
Проблема в том, что каждый запрос с отдельно взятого клиента необходимо оправлять на соответствующий сервер. В большинстве балансировщиков нагрузки для этого предусмотрены липкие сеансы [10], но такой подход увеличивает накладные расходы. Из-за него добавление и удаление серверов дается с трудом. Также возникают проблемы, если сервер выходит из строя.
Архитектура без сохранения состояния
На рис. 1.13 показана архитектура без сохранения состояния.
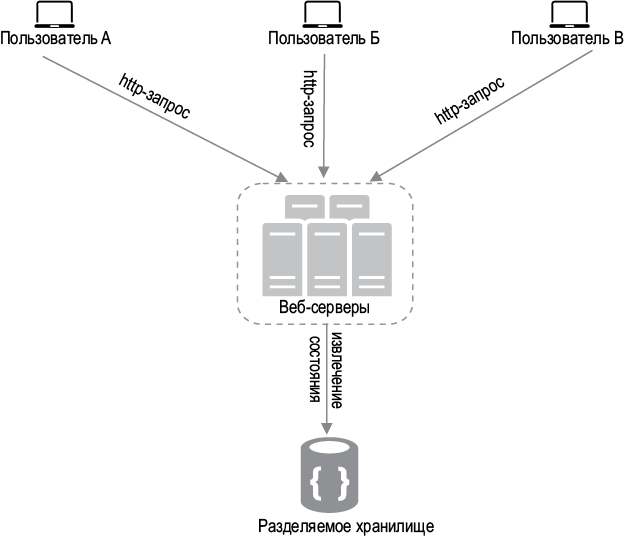
Рис. 1.13
В этой не хранящей состояние архитектуре пользовательские HTTP-запросы могут быть направлены любым веб-серверам, которые извлекают данные о состоянии из общего хранилища. Хранилище отделено от веб-серверов. Отсутствие состояния делает систему более простой, надежной и масштабируемой.
На рис. 1.14 показана обновленная конфигурация с веб-уровнем, не хранящим состояние.

Рис. 1.14
На рис. 1.14 данные сеанса вынесены из веб-уровня и теперь находятся в постоянном хранилище, роль которого могут играть реляционные базы данных: Memcached/Redis, NoSQL и т.д. Здесь хранилище NoSQL выбрано в связи с простотой его масштабирования. Автомасштабирование означает, что добавление и удаление веб-серверов происходит автоматически в зависимости от объемов трафика. После того как данные о состоянии вынесены в отдельное хранилище, автомасштабирование веб-уровня легко достигается за счет добавления и удаления серверов с учетом нагрузки.
Ваш веб-сайт стремительно развивается, привлекая множество пользователей со всего мира. Для улучшения доступности и UX в различных регионах крайне необходима поддержка нескольких центров обработки данных.
Центры обработки данных
На рис. 1.15 показана демонстрационная конфигурация с двумя центрами обработки данных (ЦОД). В нормальных условиях пользователи, скажем,
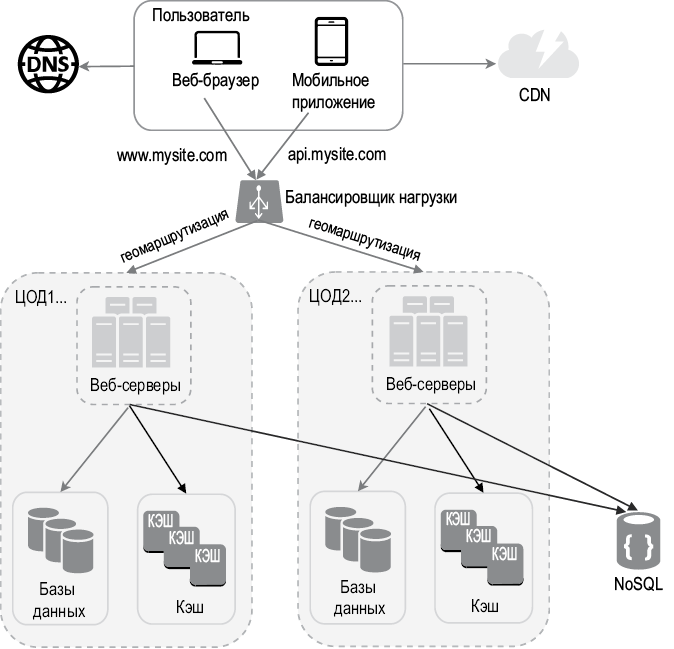
Рис. 1.15
из США с помощью geoDNS направляются к ближайшему центру обработки данных с разделением трафика между регионами US-East и US-West в пропорции x % к (100 – x) %. Это называется географической маршрутизацией. geoDNS — это сервис, который сопоставляет доменные имена с IP-адресами в зависимости от местонахождения пользователя.
В случае любого серьезного нарушения работы одного из центров обработки данных мы перенаправляем весь трафик к исправному ЦОД. На рис. 1.16 ЦОД2 (US-West) недоступен, поэтому 100 % трафика направляется к ЦОД1 (US-East).



















