

автордың кітабын онлайн тегін оқу System Design. Машинное обучение. Подготовка к сложному интервью
Переводчики Е. Матвеев
Алекс Сюй, Али Аминиан
System Design. Машинное обучение. Подготовка к сложному интервью. — СПб.: Питер, 2024.
ISBN 978-5-4461-2130-4
© ООО Издательство "Питер", 2024
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Посвящается Нилуфар, которая была и остается моим лучшим другом.
Али Аминиан
Посвящается Джулии.
Алекс Сюй
Предисловие
Мы рады, что вы читаете эту книгу, чтобы лучше подготовиться к собеседованию по проектированию систем машинного обучения (МО). Проектирование систем (system design) — одна из самых сложных тем на любом собеседовании из области МО, так что без хорошей подготовки не обойтись.
Что такое собеседование по проектированию систем МО (ML System Design interview)
Собеседование по проектированию систем МО, как правило, обязательно для претендентов на вакансии, связанные с проектированием и реализацией систем МО: инженер данных, дата-сайентист, инженер машинного обучения и т.д.
На таком собеседовании оценивается умение кандидата проектировать комплексные системы МО — визуальный поиск, рекомендации видео, предсказание кликов по рекламе и т.д. Вопросы на собеседовании бывают непростыми, потому что у них обычно нет четкой структуры. Часто однозначных ответов не существует, потому что темы вопросов оказываются широкими и затрагивают разные области, что открывает возможность для различных интерпретаций и решений.
Чтобы успешно пройти собеседование по проектированию систем МО, надо хорошо понимать фундаментальные концепции и методы МО, а также уметь их применять, чтобы решать практические задачи. На собеседовании обычно необходимо продемонстрировать, что вы разбираетесь в пайплайнах данных и конструировании признаков, а также умеете проектировать эффективные системы МО. Возможно, вам еще придется проявить умение выбирать подходящие модели для конкретных задач, настраивать их параметры и оценивать производительность. В принципе, цель собеседования состоит в том, чтобы оценить, насколько хорошо соискатель применяет теоретические знания МО, чтобы проектировать и реализовывать эффективные системы.
Почему это важно
Большинство соискателей, которые проходят собеседования по МО, владеют теоретическими основами, но затрудняются в области проектирования систем МО, где нет единых руководящих принципов. Тем не менее умение проектировать такие системы — это важнейший навык для инженеров, особенно в контексте карьерного роста. Неправильно выбранная архитектура системы МО может привести к значительным потерям времени и других ресурсов.
Очевидно, собеседование по проектированию систем МО — это важнейшая часть процедуры приема на работу. Чем лучше вы себя покажете, тем вернее можете рассчитывать на более привлекательную позицию и более высокий заработок.
Для кого эта книга
Книга будет ценным источником информации для всех, кто интересуется проектированием систем МО, будь то новички или опытные инженеры. А если вам нужно подготовиться к собеседованию по МО, то эта книга написана специально для вас.
Чего нет в книге
Эта книга — не пособие по основам машинного обучения. Она написана для дата-сайентистов, инженеров данных и инженеров МО, которым нужна помощь, чтобы подготовиться к собеседованию по проектированию систем МО. Книга предназначена в первую очередь для инженеров МО в бизнесе и в меньшей степени для ученых в области МО в образовательных учреждениях или НИИ.
Дополнительные ресурсы
В конце каждой главы приводится длинный список ссылок на дополнительные материалы. Все активные ссылки доступны в репозитории GitHub:
https://bit.ly/ml-bytebytego
Благодарности
Как бы нам ни хотелось похвастаться, что все примеры проектирования в этой книге полностью оригинальны, все же придется признаться, что большинство идей, которые здесь рассматриваются, можно найти и в других местах: технических блогах, исследовательских статьях, коде, презентациях на YouTube и прочих источниках. Мы собрали эти блестящие идеи, исследовали их и дополнили собственными наблюдениями и опытом, чтобы представить в простой и понятной форме. Авторы хотели бы сказать огромное спасибо многим техническим специалистам и руководителям, которые внесли вклад в работу над этой книгой и рецензировали ее:
• Винит Ахлувалия (Vineet Ahluwalia) (Стэнфордский университет)
• Топоджой Бисвас (Topojoy Biswas) (Walmart)
• Да Чэн (Da Cheng) (Tiktok)
• Рохит Джайн (Rohit Jain) (Twitter)
• Кальян Дипак (Kalyan Deepak) (Flipkart)
• Димитрис Котсакос (Dimitris Kotsakos) (Elastic)
• Субхам Кумар (Subham Kumar) (Amazon)
• Джастин Ли (Justin Li) (Discord)
• Ли Сюй (Li Xu) (TikTok)
• Рави Мандлия (Ravi Mandliya) (Discord)
• Саранг Меткар (Sarang Metkar) (Meta)
• Шабаз Патель (Shabaz Patel) (One Concern)
• Каустубх Пхаднис (Kaustubh Phadnis) (Walmart)
• Рави Рамчандран (Ravi Ramchandran) (Walmart Labs)
• Дэван Султания (Dewang Sultania) (Adobe)
• Сяо Чжу (Xiao Zhu) (Databricks)
• Цзяин Ши (Jiaying Shi) (Amazon)
• Цзяньцян Ван (Jianqiang Wang) (Snapchat)
• Чжэхуэй Ван (Zhehui Wang) (Amazon)
• Шо Сян (Shuo Xiang) (Parafin)
• Бонту Шридеви (Bonthu Sridevi) (Технологический институт Вишну)
• Диала Эззеддин (Diala Ezzeddine) (Tao Media)
• Юаньцзюнь Ян (Yuanjun Yang) (Twitter)
Наконец, мы хотим особо поблагодарить Элвиса Жэня (Elvis Ren), Хуа Ли (Hua Li) и Сана Лама (Sahn Lam) за неоценимый вклад в работу над книгой.
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
На веб-сайте издательства www.piter.com вы найдете подробную информацию о наших книгах.
1. Введение и общие сведения
Мы написали эту книгу, чтобы помочь инженерам по машинному обучению и дата-сайентистам успешно пройти собеседование по проектированию систем МО. Книга также может пригодиться всем, кто хочет получить общее представление о том, как МО применяется в реальном мире.
Многие технические специалисты полагают, что системы МО исчерпываются такими алгоритмами МО, как логистическая регрессия или нейронные сети. Тем не менее реальные системы МО далеко не ограничиваются разработкой моделей. Эти системы обычно весьма сложны; они состоят из множества компонентов, включая стеки данных, служебную инфраструктуру (благодаря которой система становится доступной миллионам пользователей), пайплайн для оценки ее эффективности, а также средства мониторинга, которые следят за тем, чтобы качество модели не ухудшалось со временем.
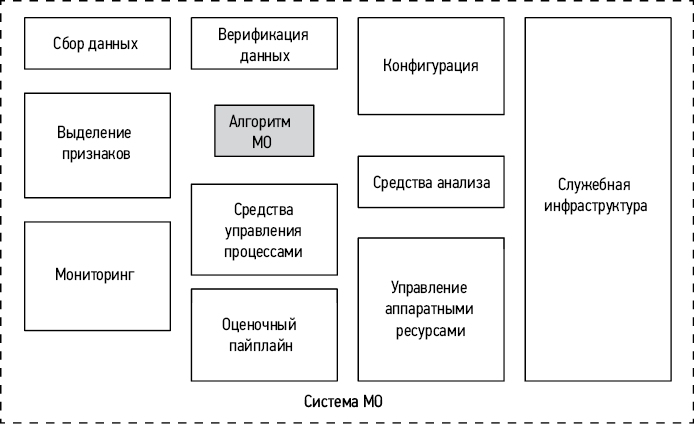
Рис. 1.1. Компоненты системы МО, готовой к эксплуатации
Скорее всего, на собеседовании по проектированию систем МО вам предстоит отвечать на вопросы открытого типа. Например, вам могут предложить спроектировать систему для рекомендаций фильмов или службу поиска видео. У таких задач нет единственно правильного решения. Эксперт, проводящий собеседование, хочет посмотреть, как вы размышляете, глубоко ли понимаете различные темы из области МО, умеете ли проектировать комплексные системы и находить компромиссы между конфликтующими факторами, которые влияют на проектирование.
Чтобы успешно проектировать сложные системы МО, очень важно придерживаться определенной логики. Без структуры сложно разобраться в проектировочных решениях. Здесь мы предлагаем схему, на которую в этой книге будут опираться примеры проектирования систем МО. Схема состоит из семи основных шагов.
1. Прояснение требований
2. Формулировка проблемы как задачи МО
3. Подготовка данных
4. Разработка модели
5. Оценка
6. Развертывание и эксплуатация
7. Мониторинг и инфраструктура

Рис. 1.2. Основные шаги проектирования систем МО
Каждое собеседование по проектированию систем МО отличается от других, потому что вопросы носят открытый характер и не существует универсальных удачных решений. Эта схема помогает упорядочить мысли, но строго следовать ей необязательно. Сохраняйте гибкость. Если эксперта, проводящего собеседование, в первую очередь интересует разработка модели, почти всегда стоит подстраиваться под его запросы.
Давайте подробнее рассмотрим каждый шаг этой схемы.
Прояснение требований
Вопросы на собеседовании по проектированию систем МО обычно намеренно ставятся нечетко, с минимумом информации. Например, вопрос может звучать так: «Спроектируйте систему для рекомендации событий». Прежде всего стоит задать уточняющие вопросы. Но какие именно? Нужны такие вопросы, которые помогут понять конкретные требования. Этот систематизированный список вопросов можно взять за основу.
• Бизнес-цель. Если система должна рекомендовать отпускное жилье для бронирования, то цели могут заключаться в том, чтобы увеличить количество бронирований и выручку.
• Функции, которые должна поддерживать система. Какие из требуемых функциональных возможностей могут повлиять на проектирование системы МО? Допустим, вам предложено спроектировать систему для рекомендации видео. Вероятно, стоит уточнить, могут ли пользователи ставить рекомендуемому контенту лайки или дизлайки, потому что этими оценками можно размечать обучающие данные.
• Данные. Откуда поступают данные? Каков размер датасета? Размечены ли данные?
• Ограничения. Какая вычислительная мощность доступна? Будет ли система работать в облаке или на локальном устройстве? Планируется ли, что со временем модель будет автоматически совершенствоваться?
• Масштаб системы. Сколько пользователей будет у системы? С каким количеством объектов (например, видеороликов) придется иметь дело? С какой скоростью растут эти показатели?
• Производительность. Насколько быстрыми должны быть предсказания? Должна ли система работать в реальном времени? Что важнее — точность или низкая задержка?
Это не исчерпывающий список, но его можно принять за отправную точку. Не забывайте, что могут быть и другие важные аспекты — например, конфиденциальность и этика.
Предполагается, что к концу этого этапа вы согласуете с экспертом рамки системы и требования к ней. Обычно имеет смысл составить список требований и ограничений: это поможет убедиться, что все одинаково представляют себе задачу.
Формулировка проблемы в виде задачи МО
При решении задач МО крайне важно правильно сформулировать проблему. Допустим, эксперт предлагает вам увеличить степень вовлеченности пользователей на платформе видеостриминга. Безусловно, недостаточная вовлеченность — это проблема, но это не задача МО. Таким образом, чтобы решить проблему, ее следует переформулировать в виде задачи МО.
В реальности сначала надо выяснить, действительно ли для решения проблемы нужно МО. Однако на собеседовании по проектированию систем МО логично допустить, что от МО все-таки будет польза. Таким образом, чтобы сформулировать проблему как задачу МО, можно поступить так:
• Определить цель МО.
• Определить входные и выходные данные системы.
• Выбрать подходящую категорию МО.
Определение цели МО
Бизнес-цель может состоять в том, чтобы повысить продажи на 20 % или увеличить степень удержания пользователей. Однако цели не всегда определяются четко, а модель невозможно обучить, просто приказав ей увеличить продажи на 20 %. Чтобы система МО решила задачу, нужно преобразовать бизнес-цель в точно определенную цель МО. Хорошей целью МО будет такая, которую можно решить с помощью моделей МО. Некоторые примеры перечислены в табл. 1.1, а в дальнейших главах встретятся и другие примеры.
Таблица 1.1. Преобразование бизнес-целей в цели МО
| Приложение |
Бизнес-цель |
Цель МО |
| Приложение для продажи билетов на мероприятия |
Повысить продажи билетов |
Максимизировать количество регистраций на мероприятия |
| Видеостриминговое приложение |
Повысить степень вовлеченности пользователей |
Максимизировать время, которое пользователи проводят за просмотром видео |
| Система прогнозирования кликов по рекламе |
Увеличить количество кликов |
Максимизировать CTR (кликабельность) |
| Выявление вредоносного контента в социальной сети |
Сделать платформу безопаснее |
Точно предсказывать, является ли контент вредоносным |
| Система рекомендации друзей |
Увеличить темп расширения сети пользователя |
Максимизировать количество установленных связей |
Определение входных и выходных данных системы
Когда цель МО ясна, нужно определить входные и выходные данные системы. Например, для системы выявления вредоносного контента в социальной сети входными данными является пост, а выходными — решение о том, считать ли его вредоносным.
Иногда система может состоять более чем из одной модели МО. В таком случае требуется определить входные и выходные данные для каждой модели. Например, в примере с выявлением вредоносного контента одна модель может выявлять призыв к насилию, а другая — непристойные изображения. Система опирается на обе эти модели, чтобы решить, считать ли пост вредоносным.
Еще одно важное соображение состоит в том, что может существовать несколько способов определить входные и выходные данные модели — см. пример на рис. 1.4.
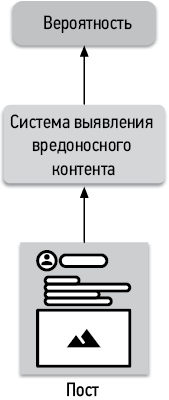
Рис. 1.3. Входные и выходные данные системы выявления вредоносного контента
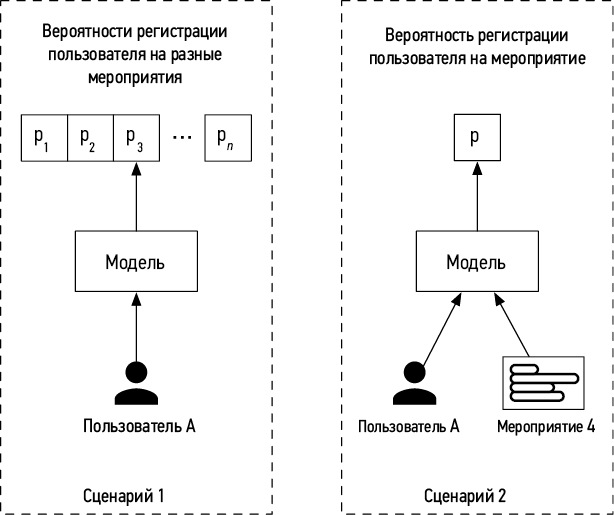
Рис. 1.4. Разные способы определения входных и выходных данных модели
Выбор подходящей категории МО
Существует много способов переформулировать проблему в виде задачи МО. Большинство проблем можно представить так, чтобы они относились к одной из категорий МО, изображенных на рис. 1.5. Поскольку эти категории, вероятно, уже знакомы большинству читателей, мы ограничимся краткой сводкой.
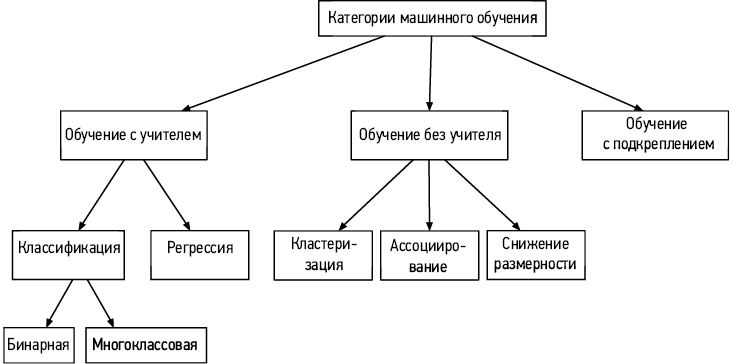
Рис. 1.5. Распространенные категории МО
Обучение с учителем. В этих моделях используется обучающий набор данных. На практике многие проблемы относятся к этой категории, потому что обучение на размеченном наборе данных обычно приводит к лучшим результатам.
Обучение без учителя. Чтобы делать предсказания, такие модели обрабатывают данные, которые не содержат правильных ответов. Цель обучения — выявить осмысленные закономерности в данных. Популярные алгоритмы обучения без учителя — кластеризация, ассоциирование и снижение размерности.
Обучение с подкреплением. Система учится решать задачу, многократно взаимодействуя со средой методом проб и ошибок. Например, таким способом можно научить робота ходить по комнате или натренировать такую программу, как AlphaGo, чтобы она успешно соревновалась с человеком в игре го.
По сравнению с обучением с учителем, обучение без учителя и обучение с подкреплением менее популярны в реальных системах, потому что модели МО обычно лучше обучаются, если есть обучающие данные. Поэтому для большинства проблем, которые рассматриваются в этой книге, применяется обучение с учителем. Давайте поближе познакомимся с разными его видами.
Регрессионная модель. Регрессия предсказывает непрерывное числовое значение — например, ожидаемую стоимость дома.
Классификационная модель. Классификация предсказывает дискретную метку класса — например, следует ли отнести входное изображение к классу «собака», «кошка» или «кролик». Классификационные модели можно разделить на две группы.
• Бинарная классификация предсказывает бинарный результат — например, есть на изображении собака или нет.
• Многоклассовая классификация разбивает входные данные на несколько классов: например, можно классифицировать объект на изображении как собаку, кошку или кролика.
Предполагается, что на этом шаге вы выберете правильную категорию МО. В следующих главах приводятся примеры того, как выбрать подходящую категорию во время собеседования.
Темы для обсуждения
Вот некоторые из тем, которые могут обсуждаться во время собеседования.
• Что такое хорошая цель МО? Как сравнить между собой разные цели МО? Какие у них плюсы и минусы?
• Какие входные и выходные данные будут у системы для конкретной цели МО?
• Если в системе МО задействованы несколько моделей, каковы входные и выходные данные у каждой из них?
• Как должно проводиться обучение — с учителем или без?
• Какая модель лучше поможет решить проблему — регрессия или классификация? Если используется классификация, то должна ли она быть бинарной или многоклассовой? А если регрессия, то каким должен быть диапазон выходных значений?
Подготовка данных
Модели МО обучаются непосредственно на данных, а это значит, что для обучения чрезвычайно важны данные с высокой предсказательной способностью. Этот раздел посвящен тому, как готовить качественные входные данные для моделей МО с помощью двух основных процессов — инженерии данных (data engineering) и конструирования признаков (feature engineering). Мы рассмотрим важные аспекты того и другого.

Рис. 1.6. Процесс подготовки данных
Инженерия данных
Инженерия данных заключается в том, чтобы проектировать и строить пайплайны для сбора, хранения, извлечения и обработки данных. Кратко рассмотрим основные принципы инженерии данных, чтобы понять, какие основные компоненты для нее могут понадобиться.
Источники данных
Система МО может работать с данными из многих источников. Полезно разбираться в источниках данных, чтобы отвечать на различные контекстные вопросы, например: кто собирал данные? Насколько они чисты? Можно ли доверять источнику? Данные созданы пользователями или сгенерированы машиной?
Хранилище данных
Хранилище данных (или база данных, БД) — это репозиторий, который позволяет долгосрочно хранить коллекции данных и управлять ими. Для разных сценариев использования применяются разные БД, поэтому важно понимать на высоком уровне, как работают те или иные базы данных. Для собеседования по проектированию систем МО обычно не требуется разбираться во внутреннем устройстве баз данных.
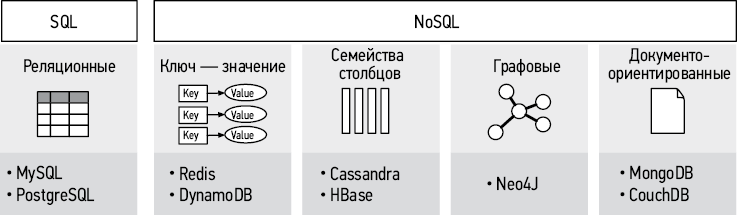
Рис. 1.7. Разные виды баз данных
Извлечение, преобразование и загрузка (ETL)
Процедура ETL (Extract, Transform, Load — «извлечение, преобразование, загрузка») состоит из трех фаз:
• извлечение: данные извлекаются из разных источников;
• преобразование: в этой фазе данные обычно очищаются, приводятся в порядок и преобразуются в тот формат, который нужен для выполняемых задач;
• загрузка: преобразованные данные загружаются в приемник — файл, базу данных или хранилище данных [1].
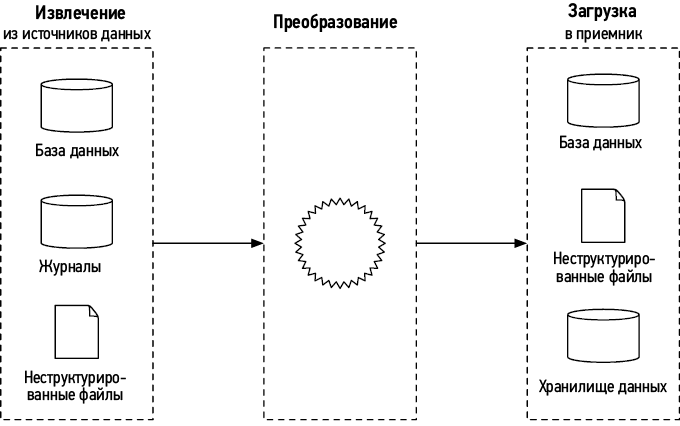
Рис. 1.8. Обзор процесса ETL
Типы данных
Типы данных в машинном обучении отличаются от типов в языках программирования (int, float, string и т.д.). На высоком уровне типы данных можно разделить на две категории: структурированные и неструктурированные (рис. 1.9).
Структурированные данные подчиняются заранее определенной схеме. Например, структурированными данными можно считать даты, имена, адреса, номера кредитных карт и вообще все, что можно представить в табличном формате со строками и столбцами. Неструктурированные данные не соответствуют какой-то конкретной схеме; к этой категории относятся текст, изображения, аудио- и видеозаписи. В табл. 1.2 перечислены основные различия между структурированными и неструктурированными данными.
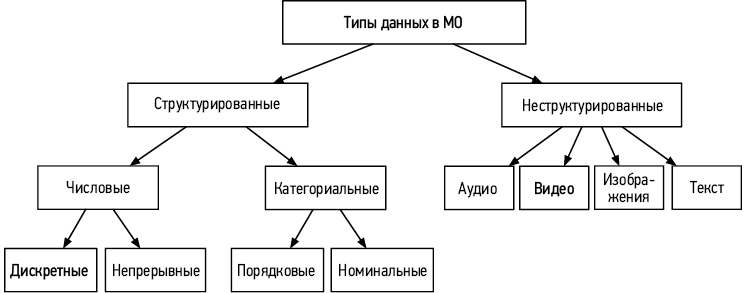
Рис. 1.9. Типы данных в МО
Таблица 1.2. Структурированные и неструктурированные данные
| Структурированные данные |
Неструктурированные данные |
|
| Характеристики |
Заранее определенная схема. Просто выполнять поиск |
Нет определенной схемы. Трудно выполнять поиск |
| Место хранения |
Реляционные базы данных. Во многих базах данных NoSQL могут храниться структурированные данные. Хранилища данных |
Базы данных NoSQL. Озера данных |
| Примеры |
Даты. Телефонные номера. Номера кредитных карт. Адреса. Имена |
Текстовые файлы. Аудиофайлы. Изображения. Видео |
Как показано на рис. 1.10, для разных типов данных подходят разные модели МО. Важно понимать, структурированы данные или нет, чтобы выбрать подходящую модель МО на шаге разработки модели.
Числовые данные
К числовым данным относятся любые значения, представленные числами. Как показано на рис. 1.9, числовые данные делятся на непрерывные и дискретные. Например, цены на недвижимость можно считать непрерывными, потому что цена может принимать любое значение из соответствующего диапазона. С другой стороны, количество домов, проданных за последний год, можно считать примером дискретных числовых данных, так как оно принимает только целые значения.
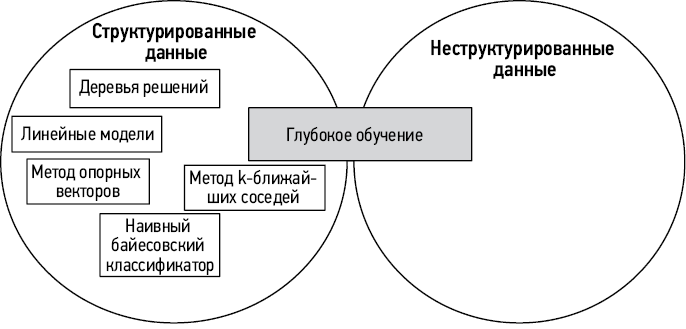
Рис. 1.10. Модели для структурированных и неструктурированных данных (см. [2])
Категориальные данные
Категориальные данные — это данные, которые можно хранить и идентифицировать с помощью присвоенных им имен или меток. Например, пол относится к категориальным данным, потому что его значение берется из ограниченного набора нечисловых значений. Категориальные данные можно разделить на две группы: номинальные и порядковые.
Под номинальными данными понимаются данные, между категориями которых нет числовой связи. Например, сюда относится пол, потому что между значениями «мужской» и «женский» нет числовых отношений. Порядковые данные состоят из значений, между которыми есть заранее определенный или последовательный порядок, — например, сюда относятся оценки с тремя уникальными значениями: «недоволен», «нейтрально» и «доволен».
Конструирование признаков
К конструированию признаков относятся два процесса:
• использование знаний о предметной области, чтобы выбирать и извлекать предсказательные признаки из необработанных данных;
• преобразование предсказательных признаков в формат, пригодный для модели.
Выбрать подходящие признаки — одна из главных задач при разработке и обучении моделей МО. Важно выбрать признаки, которые приносят наибольшую практическую пользу. На этом этапе нужно хорошо знать предметную область, причем процесс также сильно зависит от конкретной задачи. Чтобы помочь вам его освоить, в книге мы приводим многочисленные примеры.
После того как предсказательные признаки выбраны, их нужно преобразовать в подходящие форматы с помощью операций конструирования признаков, которые рассматриваются ниже.
Операции конструирования признаков
Нередко выясняется, что некоторые из выбранных признаков представлены не в том формате, который может использовать модель. Операции конструирования признаков преобразуют их в подходящий формат. Среди таких операций — обработка отсутствующих значений, масштабирование значений со смещенным распределением, а также кодирование категориальных признаков. Хотя приведенный ниже список не исчерпывающий, в него включены самые распространенные операции со структурированными данными.
Обработка отсутствующих значений
В реальных данных часто встречаются отсутствующие значения. Эту проблему обычно решают одним из двух способов: удалением или импутацией.
Удаление. В этом случае удаляются все записи, где отсутствуют значения каких-либо признаков. Удалять можно столбцы или строки. В первом случае удаляется весь столбец, соответствующий признаку, если в нем слишком много пропущенных значений. Во втором случае удаляется строка, представляющая один объект предметной области, у которого не хватает слишком большого количества значений.

Рис. 1.11. Удаление столбцов
Недостаток удаления заключается в том, что сокращается объем данных, которые модель потенциально может использовать для обучения, — притом, что модели МО обычно работают лучше, когда располагают бо́льшим объемом данных.
Импутация (восполнение). Также можно попытаться восполнить отсутствующие данные, подставив на пустые места те или иные значения. Некоторые распространенные приемы:
• отсутствующие значения заменяются значениями по умолчанию;
• отсутствующие значения заменяются средним, медианой или модой (наиболее часто встречающимся значением).
Недостаток импутации в том, что она может повышать уровень шума в данных. Имейте в виду, что не существует идеального способа обработки отсутствующих значений: у каждого варианта есть свои достоинства и недостатки.
Масштабирование признаков
Масштабирование признаков заключается в том, что они приводятся к стандартному диапазону и распределению. Для начала разберемся, почему это вообще может понадобиться.
Многие модели МО плохо обучаются, когда признаки датасета лежат в разных диапазонах. Например, таким признакам, как возраст и доход, соответствуют разные числовые диапазоны. Кроме того, некоторые модели плохо обучаются, если признаки имеют смещенное распределение. Рассмотрим несколько методов масштабирования признаков, которые применяются на практике.
Нормализация (min-max масштабирование). Признаки масштабируются так, чтобы все значения принадлежали отрезку [0, 1], по следующей формуле:
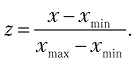
Обратите внимание, что распределение признака при нормализации не меняется. Чтобы изменить распределение и привести его к стандартному виду, применяется стандартизация.
Стандартизация (нормализация z-оценки). Распределение признака изменяется так, чтобы его среднее значение было равно 0, а стандартное отклонение было равно 1. Для стандартизации используется следующая формула:
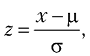
где µ — среднее значение признака, а σ — стандартное отклонение.
Логарифмическое масштабирование. Этот распространенный прием позволяет компенсировать асимметричное распределение признака, преобразовав его по следующей формуле:
z = log(x).
В результате логарифмического масштабирования распределение данных может стать более симметричным, и тогда алгоритм оптимизации будет сходиться быстрее.
Дискретизация (bucketing)
Дискретизация — это преобразование непрерывного признака в категориальный. Например, вместо того чтобы представлять рост как непрерывный признак, можно разделить шкалу роста на интервалы, или бакеты (buckets), и сопоставить с каждым ростом интервал, к которому он относится. Это позволяет обучать модель на нескольких категориях вместо того, чтобы заставлять ее учитывать бесконечное количество возможных вариантов.
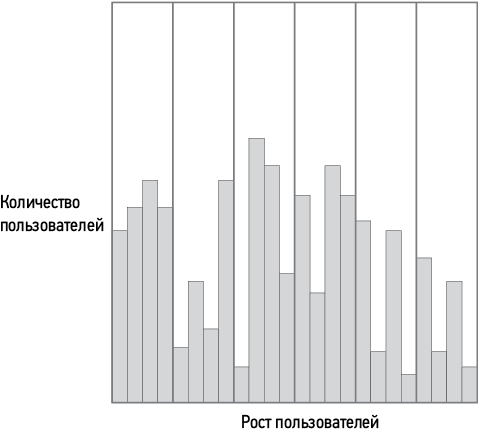
Рис. 1.12. Дискретизация роста пользователей по 6 интервалам (бакетам)
Дискретизацию можно применять и к дискретным признакам. Например, возраст пользователя — дискретный признак, но дискретизация позволяет сократить количество категорий, как показано в табл. 1.3.
Таблица 1.3. Дискретизация возраста
| Номер интервала |
Диапазон возрастов |
| 1 |
0–9 |
| 2 |
10–19 |
| 3 |
20–39 |
| 4 |
40–59 |
| 5 |
60+ |
Кодирование категориальных признаков
В большинстве моделей МО все входные и выходные данные должны быть числовыми. Это значит, что категориальные признаки нужно закодировать в числовой форме, прежде чем передавать их модели. Существует три распространенных метода преобразования категориальных признаков в числовые представления: целочисленное кодирование, унитарное кодирование (one-hot coding) и обучение с эмбеддингами.
Целочисленное кодирование. Каждому уникальному категориальному значению ставится в соответствие целое число. Например, «Отлично» — 1, «Хорошо» — 2, «Плохо» — 3. Этот способ особенно полезен, если порядок целых значений соответствует естественному порядку категорий.

Рис. 1.13. Целочисленное кодирование
Однако если между значениями категориального признака нет порядка, то целочисленное кодирование — не лучший вариант. Проблему решает унитарное кодирование.
Унитарное (one-hot) кодирование. Для каждого уникального значения создается новый бинарный признак. Как показано на рис. 1.14, исходный признак (цвет) заменяется тремя новыми бинарными признаками (красный, зеленый и синий). Например, если точке данных соответствует красный цвет, он заменяется тройкой «1, 0, 0».



















