

автордың кітабын онлайн тегін оқу Kubernetes: Лучшие практики
Научный редактор А. Сидоров
Переводчик С. Черников
Литературный редактор Н. Хлебина
Художник В. Мостипан
Корректоры Е. Павлович, Е. Рафалюк-Бузовская
Брендан Бернс, Эдди Вильяльба, Дейв Штребель, Лахлан Эвенсон
Kubernetes: Лучшие практики. — СПб.: Питер, 2021.
ISBN 978-5-4461-1688-1
© ООО Издательство "Питер", 2021
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Введение
Кому стоит прочесть эту книгу
Kubernetes — фактический стандарт для облачно-ориентированной разработки. Это эффективный инструмент, который может упростить создание ваших приложений, ускорить развертывание и сделать его более надежным. Но для раскрытия всего потенциала этой платформы нужно научиться ее корректно использовать. Книга предназначена для всех, кто развертывает реальные приложения в Kubernetes и заинтересован в изучении паттернов проектирования и методик, применимых к этим приложениям.
Важно понимать: это не введение в Kubernetes. Мы исходим из того, что вы уже имеете общее представление об API и инструментарии данной платформы и знаете, как создавать и администрировать кластеры на ее основе. Познакомиться с Kubernetes можно, в частности, прочитав книгу Kubernetes: Up and Running (O’Reilly) (https://oreil.ly/ziNRK).
Эта книга предназначена для читателей, желающих подробно изучить процесс развертывания конкретных приложений в Kubernetes. Она будет полезной как тем, кто собирается развернуть в Kubernetes свое первое приложение, так и специалистам с многолетним опытом использования данной платформы.
Почему мы написали эту книгу
Мы, четыре автора этой книги, многократно помогали развертывать приложения в Kubernetes. Мы видели, какие трудности возникали у разных пользователей, и помогали решать их. Приступая к написанию книги, мы хотели поделиться своим опытом, чтобы еще больше людей могло извлечь пользу из усвоенных нами уроков. Надеемся, таким образом нам удастся сделать наши знания общедоступными и благодаря этому вы сможете самостоятельно развертывать и администрировать свои приложения в Kubernetes.
Структура книги
Эту книгу можно читать последовательно, от первой до последней страницы, однако на самом деле мы задумывали ее как набор независимых глав. В каждой главе дается полноценный обзор определенной задачи, выполнимой с помощью Kubernetes. Мы ожидаем, что вы углубитесь в материал, чтобы узнать о конкретной проблеме или интересующем вас вопросе, а затем будете периодически обращаться к книге при возникновении новых запросов.
Несмотря на столь четкое разделение, некоторые темы будут встречаться вам на протяжении всей книги. Разработке приложений в Kubernetes посвящено сразу несколько глав. Глава 2 описывает рабочий процесс. В главе 5 обсуждаются непрерывная интеграция и тестирование. В главе 15 речь идет о построении на основе Kubernetes высокоуровневых платформ, а в главе 16 рассматривается управление stateless- и stateful-приложениями. Управлению сервисами в Kubernetes также отводится несколько глав. Глава 1 посвящена подготовке простого сервиса, а глава 3 — мониторингу и метрикам. В главе 4 вы научитесь управлять конфигурацией, а в главе 6 — версиями и релизами. В главе 7 описывается процесс глобального развертывания приложения.
Другая обширная тема — работа с кластерами. Сюда относятся управление ресурсами (глава 8), сетевые возможности (глава 9), безопасность pod (глава 10), политики и управляемость (глава 11), управление несколькими кластерами (глава 12), а также контроль доступа и авторизацию (глава 17). Кроме того, есть полностью самостоятельные главы, посвященные машинному обучению (глава 14) и интеграции с внешними сервисами (глава 13).
Прежде чем браться за выполнение реальной задачи, не помешает прочесть соответствующие главы, хотя мы надеемся, что вы будете использовать эту книгу как справочник.
Условные обозначения
В этой книге используются следующие условные обозначения:
Курсив
Курсивом выделены новые термины и важные слова.
Моноширинный шрифт
Используется для листингов программ, а также внутри абзацев для обозначения таких элементов, как переменные и функции, базы данных, типы данных, переменные среды, операторы и ключевые слова, имена файлов и их расширения.
Моноширинный жирный шрифт
Показывает команды или другой текст, который пользователь должен ввести самостоятельно.
Моноширинный зеленый шрифт
Показывает текст, который должен быть заменен значениями, введенными пользователем, или значениями, определяемыми контекстом.
Шрифт без засечек
Используется для обозначения URL, адресов электронной почты, названий кнопок, каталогов.

Этот рисунок указывает на совет или предложение.

Такой рисунок указывает на общее замечание.

Этот рисунок указывает на предупреждение.
Использование примеров кода
Дополнительный материал (примеры кода, упражнения и т.д.) доступен для скачивания по адресу oreil.ly/KBPsample.
Если при использовании примеров кода у вас возникнут технические вопросы или проблемы, то, пожалуйста, обращайтесь к нам по адресу bookquestions@oreilly.com.
Назначение книги — помочь решить ваши задачи. В ваших программах и документации разрешается использовать предложенный пример кода. Не нужно связываться с нами, если вы не воспроизводите его существенную часть: например, когда включаете в свою программу несколько фрагментов кода, приведенного здесь. Однако продажа или распространение компакт-дисков с примерами из книг издательства O’Reilly требует отдельного разрешения. Вы можете свободно цитировать эту книгу с примерами кода, отвечая на вопрос, но если хотите включить существенную часть приведенного здесь кода в документацию своего продукта, то вам следует связаться с нами.
Мы приветствуем, но не требуем отсылки на оригинал. Отсылка обычно состоит из названия, имени автора, издательства, ISBN и копирайта. Например, «Kubernetes: лучшие практики», Брендан Бернс, Эдди Вильяльба, Дейв Штребель, Лахлан Эвенсон (Питер). Copyright 2020 Brendan Burns, Eddie Villalba, Dave Strebel and Lachlan Evenson. 978-5-4461-1688-1.
Если вам кажется, что ваше обращение с примерами кода выходит за рамки добросовестного использования или условий, перечисленных выше, то можете обратиться к нам по адресу permissions@oreilly.com.
Благодарности
Брендан хотел бы поблагодарить свою чудесную семью: Робин, Джулию и Итана — за любовь и поддержку всех его действий; сообщество Kubernetes, благодаря которому все это стало возможным; своих потрясающих соавторов — без них книга не появилась бы на свет.
Дейв благодарит за поддержку свою прекрасную жену Джен и трех детей: Макса, Мэдди и Мэйсона. Он также хотел бы поблагодарить сообщество Kubernetes за все советы и помощь, полученные на протяжении многих лет. И наконец, он хотел бы выразить признательность своим соавторам, которые помогли воплотить этот проект в жизнь.
Лахлан хотел бы поблагодарить свою жену и троих детей за их любовь и поддержку. Он также хотел бы сказать спасибо всем участникам сообщества Kubernetes, в том числе замечательным людям, на протяжении этих лет находившим время, чтобы поделиться с ним знаниями. Он хотел бы выразить особую признательность Джозефу Сандовалу за наставничество. И наконец, Лахлан не может не поблагодарить своих фантастических соавторов, благодаря которым появилась эта книга.
Эдди хотел бы поблагодарить свою жену Сандру за моральную поддержку и возможность заниматься этим изданием часами напролет, в то время как она сама была в последнем триместре первой беременности. Он также хотел бы сказать спасибо своей дочери Джованне за дополнительную мотивацию. В завершение Эдди хотел бы выразить признательность сообществу Kubernetes и своим соавторам, на которых он всегда равнялся при работе с облачно-ориентированными технологиями.
Мы хотели бы поблагодарить Вирджинию Уилсон за ее помощь в работе над рукописью и объединении всех наших идей, а также Бриджет Кромхаут, Билгина Ибряма, Роланда Хуса и Джастина Домингуса за их внимание к деталям.
От издательства
Ваши замечания, предложения, вопросы отправляйте по электронному адресу comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
На веб-сайте издательства www.piter.com вы найдете подробную информацию о наших книгах.
Глава 1. Создание простого сервиса
В этой главе описываются приемы создания простого многоуровневого приложения в Kubernetes, представляющего собой веб-сервис и базу данных. Это далеко не самый сложный пример, однако он послужит хорошей отправной точкой, на которую следует ориентироваться при управлении приложениями в Kubernetes.
Обзор приложения
Приложение, которое мы будем использовать в данном примере, не отличается особой сложностью. Это простой журнальный сервис, хранящий свои данные в Redis. Он также содержит отдельный сервер статических файлов на основе NGINX и предоставляет единый URL с двумя веб-путями. Первый путь, https://my-host.io, предназначен для файлового сервера, а второй, https://my-host.io/api, — для программного интерфейса приложения (application programming interface, API) в формате REST. Мы будем использовать SSL-сертификаты от Let’s Encrypt (https://letsencrypt.org). На рис. 1.1 показана схема приложения. Для его построения мы воспользуемся сначала конфигурационными файлами YAML, а затем Heml-чартами.
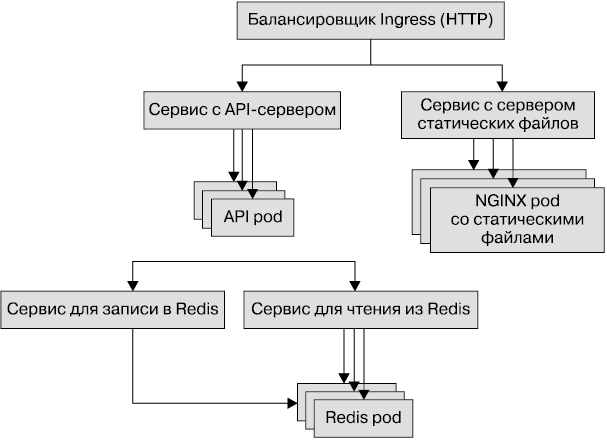
Рис. 1.1. Схема приложения
Управление конфигурационными файлами
Прежде чем погружаться в подробности развертывания данного приложения в Kubernetes, следует поговорить о том, как управлять конфигурацией. В Kubernetes все представлено в декларативном виде. Это значит, что для определения всех аспектов своего приложения вы сначала описываете, каким должно быть его состояние в кластере (обычно в формате YAML или JSON). Декларативный подход куда более предпочтителен по сравнению с императивным, в котором состояние кластера представляет собой совокупность внесенных в него изменений. В случае императивной конфигурации очень сложно понять и воспроизвести состояние, в котором находится кластер. Это существенно затрудняет диагностику и исправление проблем, возникающих в приложении.
Предпочтительный формат для объявления состояния приложения — YAML, хотя Kubernetes поддерживает и JSON. Дело в том, что YAML выглядит несколько более компактно и лучше подходит для редактирования вручную. Однако стоит отметить: этот формат чувствителен к отступам, из-за чего многие ошибки в конфигурационных файлах связаны с некорректными пробельными символами. Если что-то идет не так, то имеет смысл проверить отступы.
Поскольку декларативное состояние, хранящееся в этих YAML-файлах, служит источником истины, из которого ваше приложение черпает информацию, правильная работа с состоянием — залог успеха. В ходе его редактирования вы должны иметь возможность управлять изменениями, проверять их корректность, проводить аудит их авторов и откатывать изменения в случае неполадок. К счастью, в контексте разработки ПО для всего этого уже есть подходящие инструменты. В частности, практические рекомендации, относящиеся к управлению версиями и аудиту изменений кода, можно смело использовать в работе с декларативным состоянием приложения.
В наши дни большинство людей хранят конфигурацию для Kubernetes в Git. И хотя выбор той или иной системы контроля версий непринципиален, многие инструменты в экосистеме Kubernetes рассчитаны на хранение файлов в Git-репозитории. В сфере аудита изменения кода все не так однозначно: многие используют локальные инструменты и сервисы, хотя платформа GitHub, несомненно, довольно популярна. Независимо от того, как вы реализуете процесс аудита изменения кода для конфигурации своего приложения, относиться к нему следует с тем же вниманием, что и к системе контроля версий.
Для организации компонентов приложения обычно стоит использовать структуру папок файлов системы. Сервис приложения (какой бы смысл ни вкладывала ваша команда в это понятие) обычно хранится в отдельном каталоге, а его компоненты — в подкаталогах.
В этом примере мы структурируем файлы таким образом:
journal/
frontend/
redis/
fileserver/
Внутри каждого каталога находятся конкретные YAML-файлы, необходимые для определения сервиса. Как вы позже сами увидите, по мере развертывания нашего приложения в разных регионах или кластерах эта структура каталогов будет все более усложняться.
Создание реплицированного сервиса с помощью ресурса Deployment
Мы начнем описание нашего приложения с клиентской части и будем продвигаться вниз. В качестве этой части журнала будет выступать приложение для Node.js, написанное на языке TypeScript. Его код (https://oreil.ly/70kFT) слишком велик, чтобы приводить его здесь целиком. На порте 8080 работает HTTP-сервис, который обслуживает запросы к /api/* и использует сервер Redis для добавления, удаления и вывода актуальных записей журнала. Вы можете собрать это приложение в виде образа контейнера, используя включенный в его код файл Dockerfile, и загрузить его в собственный репозиторий образов. Затем вы сможете подставить его имя в YAML-файлы, приведенные ниже.
Практические рекомендации по управлению образами
В целом сборка и обслуживание образов контейнеров выходит за рамки этой книги, но все же будет уместно перечислить некоторые рекомендации. Процесс сборки образов как таковой уязвим к «атакам на поставщиков». В ходе подобных атак злоумышленник внедряет код или двоичные файлы в одну из зависимостей, которая хранится в доверенном источнике и участвует в сборке вашего приложения. Поскольку это создает слишком высокий риск, в сборке должны участвовать только хорошо известные и доверенные провайдеры образов. В качестве альтернативы все образы можно собирать с нуля; для некоторых языков (например, Go) это не составляет труда, поскольку они могут создавать статические исполняемые файлы, но в интерпретируемых языках, таких как Python, JavaScript и Ruby, это может быть большой проблемой.
Некоторые рекомендации касаются выбора имен для образов. Теоретически тег с версией образа контейнера в реестре можно изменить, но вы никогда не должны этого делать. Хороший пример системы именования — сочетание семантической версии и SHA-хеша фиксации кода, из которой собирается образ (например, v1.0.1-bfeda01f). Если версию не указать, то по умолчанию используется значение latest. Оно может быть удобно в процессе разработки, но в промышленных условиях данного значения лучше избегать, так как оно явно изменяется при создании каждого нового образа.
Создание реплицированного приложения
Наше клиентское приложение является stateless (не хранит свое состояние), делегируя данную функцию серверу Redis. Благодаря этому его можно реплицировать произвольным образом без воздействия на трафик. И хотя наш пример вряд ли будет испытывать серьезные нагрузки, все же неплохо использовать как минимум две реплики (копии): это позволяет справляться с неожиданными сбоями и выкатывать новые версии без простоя.
В Kubernetes есть объект ReplicaSet, отвечающий за репликацию контейнеризованных приложений, но его лучше не использовать напрямую. Для наших задач подойдет объект Deployment, который сочетает в себе возможности объекта ReplicaSet, систему управления версиями и поддержку поэтапного развертывания обновлений. Объект Deployment позволяет применять встроенные в Kubernetes механизмы для перехода от одной версии к другой.
Ресурс Deployment нашего приложения выглядит следующим образом:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
labels:
app: frontend
name: frontend
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: frontend
template:
metadata:
labels:
app: frontend
spec:
containers:
- image: my-repo/journal-server:v1-abcde
imagePullPolicy: IfNotPresent
name: frontend
resources:
requests:
cpu: "1.0"
memory: "1G"
limits:
cpu: "1.0"
memory: "1G"
В этом ресурсе следует обратить внимание на несколько деталей. Так, для идентификации экземпляров ReplicaSet, объекта Deployment и создаваемых им pod используются метки (labels). Мы добавили метку layer:frontend для всех этих объектов, благодаря чему они теперь находятся в общем слое (layer) и их можно просматривать вместе с помощью одного запроса. Как вы увидите позже, мы будем применять данный подход и при добавлении других ресурсов.
Помимо этого, мы добавили комментарии в разные участки YAML-файла. Как и комментарии в программном коде, они не попадут в итоговый ресурс, хранящийся на сервере; их задача — сделать конфигурацию более понятной для тех, кто не видел ее раньше.
Обратите внимание и на то, что для контейнеров в ресурсе Deployment установлены запросы ресурсов Request и Limit с одинаковыми значениями. Request гарантирует выделение определенного объема ресурсов на сервере, на котором запущено приложение. Limit — максимальное потребление ресурсов, разрешенное к использованию контейнером. На первых порах установка одинаковых значений для этих двух запросов обеспечивает наиболее предсказуемое поведение приложения. Но за это приходится платить неоптимальным использованием ресурсов. С одной стороны, когда Request и Limit равны, ваше приложение не тратит слишком много процессорного времени и не потребляет лишние ресурсы при бездействии. С другой — если не проявить крайнюю осторожность при подборе этих значений, то вы не можете в полной мере использовать ресурсы сервера. Начав лучше ориентироваться в модели управления ресурсами Kubernetes, вы сможете попробовать откорректировать параметры Request и Limit своего приложения по отдельности, но в целом большинство пользователей предпочитают пожертвовать эффективностью в угоду стабильности, получаемой в результате предсказуемости.
Итак, мы определили ресурс Deployment. Теперь сохраним его в системе контроля версий и развернем в Kubernetes:
git add frontend/deployment.yaml
git commit -m "Added deployment" frontend/deployment.yaml
kubectl apply -f frontend/deployment.yaml
Рекомендуется также следить за тем, чтобы содержимое вашего кластера в точности соответствовало содержимому репозитория. Для этого лучше всего использовать методику GitOps и брать код для промышленной среды только из определенной ветки системы контроля версий. Данный процесс можно автоматизировать с помощью непрерывной интеграции (Continuous Integration, CI) и непрерывной доставки (Continuous Delivery, CD). Это позволяет гарантировать соответствие между репозиторием и промышленной системой. Для простого приложения полноценный процесс CI/CD может показаться избыточным, но автоматизация как таковая, даже если не брать во внимание повышение надежности, которое она обеспечивает, обычно стоит затраченных усилий. Внедрение CI/CD в уже существующий проект с императивным развертыванием — чрезвычайно сложная задача.
В следующих разделах мы обсудим другие фрагменты этого YAML-файла (например, ConfigMap и секретные тома) и качество обслуживания (Quality of Service) pod-оболочки.
Настройка внешнего доступа для HTTP-трафика
Контейнеры нашего приложения уже развернуты, но к нему все еще нельзя обратиться. Ресурсы кластера по умолчанию недоступны снаружи. Чтобы с ними мог работать кто угодно, нам нужно создать объект Service и балансировщик нагрузки; это позволит присвоить контейнерам внешний IP-адрес и направить к ним трафик. Для этого мы воспользуемся двумя ресурсами. Первый — это Service, который распределяет (балансирует) трафик, поступающий по TCP или UDP. В нашем примере мы задействуем протокол TCP. Второй ресурс — объект Ingress, обеспечивающий балансировку нагрузки с гибкой маршрутизацией запросов в зависимости от доменных имен и HTTP-путей. Вам, наверное, интересно, зачем такому простому приложению, как наше, настолько сложный ресурс, коим является Ingress. Но в последующих главах вы увидите, что даже в этом незамысловатом примере обслуживаются HTTP-запросы из двух разных сервисов. Более того, наличие Ingress на границе кластера обеспечивает гибкость, необходимую для дальнейшего расширения нашего сервиса.
Прежде чем определять ресурс Ingress, следует создать Kubernetes Service, на который он будет указывать. А чтобы связать этот Service с pod, созданными в предыдущем разделе, мы воспользуемся метками. Определение Service выглядит намного проще, чем ресурс Deployment:
apiVersion: v1
kind: Service
metadata:
labels:
app: frontend
name: frontend
namespace: default
spec:
ports:
- port: 8080
protocol: TCP
targetPort: 8080
selector:
app: frontend
type: ClusterIP
Теперь можно определить ресурс Ingress. Он, в отличие от Service, требует наличия в кластере контейнера с подходящим контроллером. Контроллеры бывают разные: одни из них предоставляются облачными провайдерами, а другие основываются на серверах с открытым исходным кодом. Если вы выбрали открытую реализацию Ingress, то для ее установки и обслуживания лучше использовать диспетчер пакетов Helm (helm.sh). Популярностью пользуются такие реализации, как nginx и haproxy:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: frontend-ingress
spec:
rules:
- http:
paths:
- path: /api
backend:
serviceName: frontend
servicePort: 8080
Конфигурация приложения с помощью ConfigMap
Любое приложение должно быть в той или иной степени настраиваемым. Это может касаться количества отображаемых журнальных записей на странице, цвета фона, специального праздничного представления и многих других параметров. Обычно такую конфигурационную информацию лучше всего хранить отдельно от самого приложения.
У такого разделения есть несколько причин. Прежде всего, у вас может быть несколько одинаковых исполняемых файлов с разными настройками, зависящими от определенных условий. Например, вы можете предусмотреть две отдельные страницы, где будут поздравления с Пасхой в Европе и китайским Новым годом в Китае. Помимо региональной специфики, разделение вызвано еще одной причиной — гибкостью. Двоичные релизы, как правило, содержат некоторый новый функционал; если включать их непосредственно в коде, то это потребует выпуска нового двоичного файла, что может быть затратным и медленным процессом.
Конфигурация позволяет быстро (и даже динамически) активизировать и деактивизировать возможности в зависимости от потребностей пользователей или программных сбоев. Вы можете выкатывать и откатывать каждую отдельную функцию. Такая гибкость позволяет непрерывно развивать приложение, даже если некоторые из его возможностей приходится выключать из-за плохой производительности или некорректного поведения.
В Kubernetes такого рода конфигурация представлена ресурсом под названием ConfigMap. Данный ресурс содержит пары типа «ключ — значение», описывающие конфигурационную информацию или файл. Эта информация предоставляется pod с помощью файлов или переменных среды. Представьте, что вам нужно сделать настраиваемым количество журнальных записей, отображаемых на каждой странице. Для этого можно создать ресурс ConfigMap:
kubectl create configmap frontend-config --from-literal=journalEntries=10
Затем вы должны предоставить конфигурационную информацию в виде переменной среды в самом приложении. Для этого в раздел containers ресурса Deployment, который вы определили ранее, можно добавить следующий код:
...
# Массив контейнеров в PodTemplate внутри Deployment.
containers:
- name: frontend
...
env:
- name: JOURNAL_ENTRIES
valueFrom:
configMapKeyRef:
name: frontend-config
key: journalEntries
...
Это один из примеров использования ConfigMap для конфигурации приложения, но в реальных условиях изменения в данный ресурс можно вносить на регулярной основе: еженедельно или еще чаще. У вас может возникнуть соблазн делать это напрямую, редактируя сам файл ConfigMap, но это не самый удачный подход. Тому есть несколько причин: прежде всего, изменение конфигурации само по себе не инициирует обновление существующих pod. Чтобы применить настройки, pod нужно перезапустить. В связи с этим развертывание не зависит от работоспособности приложения и может происходить по мере необходимости или произвольным образом.
Вместо этого номер версии лучше указывать и в имени самого ресурса ConfigMap. Например, frontend-config-v1, а не frontend-config. Если вам нужно внести изменение, то не обновляйте существующую конфигурацию, а создайте новый экземпляр ConfigMap с версией v2 и затем отредактируйте Deployment так, чтобы он его использовал. Благодаря этому развертывание происходит автоматически, с использованием соответствующих проверок работоспособности и пауз между изменениями. Более того, если вам нужно откатить обновление, то конфигурация v1 по-прежнему находится в кластере и, чтобы переключиться на нее, достаточно еще раз отредактировать Deployment.
Управление аутентификацией с помощью объектов Secret
До сих пор мы обходили вниманием сервис Redis, к которому подключена клиентская часть нашего приложения. Но в любом реальном проекте соединение между сервисами должно быть защищенным. Это отчасти делается в целях повышения безопасности пользователей и их данных, но в то же время необходимо для предотвращения ошибок, таких как подключение клиентской части к промышленной базе данных.
Для аутентификации в сервере Redis используется обычный пароль, который было бы удобно хранить в исходном коде приложения или в одном из файлов вашего образа. Однако оба варианта являются плохими по целому ряду причин. Для начала это раскрывает ваши секретные данные (пароль) в среде, в которой может не быть никакой системы контроля доступа. Если пароль находится в исходном коде, то доступ к вашему репозиторию эквивалентен доступу ко всем секретным данным. Это, скорее всего, плохое решение. Обычно доступ к исходному коду имеет более широкий круг пользователей, чем к серверу Redis. Точно так же не всех пользователей, имеющих доступ к образу контейнера, следует допускать к промышленной базе данных.
Помимо проблем с контролем доступа, есть еще одна причина, почему не стоит привязывать секретные данные к исходному коду и/или образам: параметризация. Вы должны иметь возможность использовать одни и те же образы и код в разных средах (отладочной, канареечной или промышленной). Если секретные данные привязаны к исходному коду или образу, то вам придется собирать новый образ (или код) для каждой отдельной среды.
В прошлом разделе вы познакомились с ресурсом ConfigMap и, наверное, думаете, что пароль можно было бы хранить в качестве конфигурации и затем передавать его приложению. Действительно, конфигурация и секретные данные отделяются от приложения по тому же принципу. Но дело в том, что последние сами по себе являются важной концепцией. Вам вряд ли захочется управлять контролем доступа, администрированием и обновлением секретных данных так, как вы это делаете с конфигурацией. Что еще важнее, ваши разработчики должны по-разному воспринимать доступ к конфигурации и секретным данным. В связи с этим Kubernetes располагает встроенным ресурсом Secret, предназначенным специально для этих целей.
Вы можете создать секретный пароль для своей базы данных Redis следующим образом:
kubectl create secret generic redis-passwd --from-literal=passwd=${RANDOM}
Очевидно, что в качестве пароля лучше не использовать просто случайные числа. К тому же вам, вероятно, захочется подключить сервис для управления секретными данными или ключами; это может быть решение вашего облачного провайдера, такое как Microsoft Azure Key Vault, или открытый проект наподобие HashiCorp Vault. Обычно сервисы по управлению ключами имеют более тесную интеграцию с ресурсами Secret в Kubernetes.

По умолчанию секретные данные в Kubernetes хранятся в незашифрованном виде. Если вам нужно шифрование, то можете воспользоваться интеграцией с провайдером ключей; вы получите ключ, с помощью которого будут шифроваться все секретные данные в кластере. Это защищает от непосредственных атак на базу данных etcd, но вам все равно необходимо позаботиться о безопасном доступе через API-сервер Kubernetes.
Сохранив пароль к Redis в виде объекта Secret, вы должны привязать его к приложению, которое развертывается в Kubernetes. Для этого можно использовать ресурс Volume (том). Том — это, в сущности, файл или каталог с возможностью подключения к запущенному контейнеру по заданному пользователем пути. В случае с секретными данными том создается в виде файловой системы tmpfs, размещенной в оперативной памяти, и затем подключается к контейнеру. Благодаря этому, даже если злоумышленник имеет физический доступ к серверу (что маловероятно в облаке, но может случиться в вычислительном центре), ему будет намного сложнее заполучить секретные данные.
Чтобы добавить секретный том в объект Deployment, вам нужно указать в YAML-файле последнего два дополнительных раздела. Первый раздел, volumes, добавляет том в pod:
...
volumes:
- name: passwd-volume
secret:
secretName: redis-passwd
Затем том нужно подключить к определенному контейнеру. Для этого в описании контейнера следует указать поле volumeMounts:
...
volumeMounts:
- name: passwd-volume
readOnly: true
mountPath: "/etc/redis-passwd"
...
Благодаря этому том становится доступным для клиентского кода в каталоге redis-passwd. Итоговый объект Deployment будет выглядеть следующим образом:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
labels:
app: frontend
name: frontend
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: frontend
template:
metadata:
labels:
app: frontend
spec:
containers:
- image: my-repo/journal-server:v1-abcde
imagePullPolicy: IfNotPresent
name: frontend
volumeMounts:
- name: passwd-volume
readOnly: true
mountPath: "/etc/redis-passwd"
resources:
requests:
cpu: "1.0"
memory: "1G"
limits:
cpu: "1.0"
m



















