

автордың кітабын онлайн тегін оқу BPF: профессиональная оценка производительности
Переводчик А. Киселев
Брендан Грегг
BPF: профессиональная оценка производительности. — СПб.: Питер, 2024.
ISBN 978-5-4461-1689-8
© ООО Издательство "Питер", 2023
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Предисловие
Иногда программисты говорят, что они «стряпают патч» («cook a patch»), а не «реализуют» (implement). Я начал увлекаться программированием еще в школе. Чтобы получить хороший код, программист должен выбрать лучшие «ингредиенты». Разные языки программирования предлагают множество разных строительных блоков — «ингредиентов», но когда дело доходит до программирования ядра Linux, то кроме самого ядра у вас ничего нет.
В 2012 году я занимался добавлением новых возможностей в ядро, но нужных мне «ингредиентов» тогда не оказалось. Я мог бы начать писать строительные блоки внутри ядра, и они были бы готовы к использованию годы спустя. Но я решил создать «универсальный ингредиент», который в руках опытного программиста мог бы стать сетевым мостом уровня 2 или сетевым маршрутизатором уровня 3 внутри ядра.
У меня было несколько важных требований: «универсальный ингредиент» должен быть безопасным в использовании независимо от уровня подготовки программиста, использующего его. Он не должен давать возможности злонамеренному или неопытному разработчику приготовить из него вирус — «универсальный ингредиент» не должен допускать этого.
В ядре Linux уже был похожий механизм, известный как BPF (Berkeley Packet Filter — пакетный фильтр Беркли), поддерживавший минимальный набор команд, которые можно использовать для фильтрации пакетов перед передачей их приложениям, таким как tcpdump. Я заимствовал это имя и назвал свой «ингредиент» eBPF, где «e» означает «extended» — расширенный.
Через несколько лет различия между eBPF и классическим BPF стерлись. Мой «универсальный ингредиент» повсеместно стали называть BPF. Известные корпорации создали на его основе большие системы для обслуживания миллиардов людей, в том числе меня и вас. Заложенный в него принцип «быть безопасным при любых условиях» позволил многим «поварам» стать всемирно известными «шефами».
Первым шеф-поваром BPF был Брендан Грегг. Он увидел, что BPF можно использовать не только для обеспечения работы сети и ее безопасности, но также для анализа производительности, самодиагностики и наблюдения. Однако для создания таких инструментов и интерпретации их результатов измерений нужны большой опыт и знания.
Надеюсь, что эта книга станет вашей настольной «кулинарной книгой», в которой известный шеф-повар учит, как использовать BPF на Linux-кухне.
Алексей Старовойтов (Alexei Starovoitov) Сиэтл, штат Вашингтон. Август, 2019
Вступление
...Расширенные сценарии использования BPF: ...безумные...
Алексей Старовойтов, создатель нового BPF, февраль 20151
В июле 2014 года Алексей Старовойтов посетил офисы Netflix в калифорнийском Лос-Гатосе, чтобы обсудить новую захватывающую технологию, которую разрабатывал: расширенный пакетный фильтр Беркли (сокращенно eBPF, или просто BPF). В то время BPF был малопонятной технологией, ускоряющей фильтрацию пакетов, и у Алексея была идея, как расширить область ее применения за рамки сетевых пакетов. Алексей работал в паре с другим сетевым инженером, Дэниелом Боркманом (Daniel Borkmann), поставив себе цель превратить BPF в универсальную виртуальную машину, способную выполнять продвинутые сетевые и другие программы. Это была невероятная идея. Но меня особенно заинтересовала возможность использования BPF в качестве инструмента анализа производительности, и я увидел, как BPF может дать мне необходимые программные возможности. Мы договорились с Алексеем, что если он сумеет реализовать свою идею, то я разработаю инструменты анализа производительности, использующие BPF.
Сейчас BPF может подключаться к самым разным источникам событий. Он превратился в новую популярную технологию системной инженерии, разработкой которой занимается множество активных специалистов. Я разработал и опубликовал уже более 70 инструментов анализа производительности на основе BPF, которые используются во всем мире, в том числе на серверах Netflix, Facebook и других компаний. Специально для этой книги я написал еще несколько разработок, а также включил в нее инструменты, созданные другими авторами. И теперь рад поделиться плодами своего труда в книге «BPF: профессиональная оценка производительности», чтобы вы могли воспользоваться ими на практике для анализа производительности, устранения неполадок и многого другого.
Как перформанс-инженер, я одержим использованием инструментов производительности в стремлении достичь совершенства. Слепыми пятнами в системах называют узкие места в производительности и ошибки в программном обеспечении. В своей предыдущей работе я использовал технологию DTrace и посвятил ей книгу «DTrace: Dynamic Tracing in Oracle Solaris, Mac OS X, and FreeBSD», изданную Prentice Hall в 2011 году. В ней я поделился инструментами, использующими DTrace и разработанными для этих операционных систем. Теперь мне выпала интересная возможность поделиться похожими инструментами для Linux — инструментами, способными видеть и делать намного больше.
Где могут пригодиться инструменты оценки производительности BPF?
Инструменты оценки производительности на основе BPF помогут вам максимально эффективно использовать свои системы и приложения, повысить их производительность, сократить оверхеды и устранить проблемы, имеющиеся в ПО. Они позволят вам проанализировать намного более широкий круг аспектов, чем традиционные инструменты, и найти ответы на самые разные вопросы непосредственно в среде эксплуатации.
Об этой книге
Эта книга рассказывает об инструментах на основе BPF, которые применяются в основном для анализа и оценки производительности, но их можно использовать и в других областях: для поиска и устранения неполадок в ПО, для анализа безопасности и многого другого. Самое сложное в изучении BPF — не как писать код: любой интерфейс вы можете изучить примерно за день. Намного сложнее понять, что именно делать: какие из многих тысяч событий анализировать? Эта книга поможет найти ответ на этот вопрос, предоставив всю необходимую информацию об анализе производительности на множестве примеров анализа различных программных и аппаратных целей с помощью инструментов оценки производительности BPF на промышленных серверах Netflix.
Технология BPF обладает уникальными особенностями, но только потому, что расширяет круг доступных возможностей, а не дублирует их. Для эффективного использования BPF важно понимать, в каких случаях лучше применять традиционные инструменты анализа производительности, включая iostat(1) и perf(1), а в каких — инструменты BPF. Традиционные инструменты (они также описаны здесь) могут напрямую решать проблемы с производительностью, а если нет, позволяют получить полезный контекст и подсказки для дальнейшего анализа с помощью BPF.
Во многих главах этой книги указаны цели обучения, чтобы вы могли выбрать наиболее важные для себя разделы. Представленный здесь материал используется в учебных курсах по анализу BPF внутри Netflix, а некоторые главы включают дополнительные упражнения2.
Многие описанные в книге инструменты на основе BPF взяты из репозиториев BCC и bpftrace, являющихся частью проекта Linux Foundation IO Visor. У них открытый исходный код, они доступны бесплатно не только на сайтах репозитория, но и в различных дистрибутивах Linux. Я также написал много новых инструментов bpftrace для этой книги и включил в нее их исходный код.
Эти инструменты были созданы не ради демонстрации различных возможностей BPF, а для решения практических задач. Они нужны мне для производственных задач, которые невозможно решить с помощью текущего набора инструментов анализа.
Исходный код инструментов, реализованных на bpftrace, я также включил в книгу. Если вы хотите модифицировать или разработать новые инструменты bpftrace, то можете изучить язык bpftrace из главы 5, а также учиться на примерах из многочисленных листингов кода, приведенных ниже. Этот код помогает понять, что делает каждый инструмент и какие события он использует: это все равно что включить в книгу псевдокод, который можно запустить.
Программные интерфейсы BCC и bpftrace достигли зрелости, но может случиться и так, что изменения в них в будущем нарушат работоспособность каких-то инструментов, код которых включен в книгу, и их потребуется обновить. Если это произойдет с инструментом, использующим BCC или bpftrace, загляните в их репозитории и проверьте наличие обновленных версий. Если инструмент написан для этой книги, зайдите на сайт книги: http://www.brendangregg.com/bpf-performance-tools-book.html. Но самое важное не работоспособность инструмента, а ваше знание того, как он устроен, и желание, чтобы он работал. Самое сложное в практике использования BPF — знать и понимать, что с ним делать. Даже неработающие инструменты могут служить источником полезных идей.
Новые инструменты
Для этой книги я разработал более 80 новых инструментов анализа, чтобы предоставить вам исчерпывающий набор инструментов. Одновременно они служат как примеры кода. Многие из них показаны на рис. В.1. Названия уже существовавших ранее инструментов показаны черным, а новые, созданные для этой книги, — серым шрифтом. В книге будут рассмотрены и существующие, и новые инструменты, но на многих последующих диаграммах черно-серая дифференциация не используется.
О графическом пользовательском интерфейсе
Некоторые из инструментов BCC уже применяются как источники информации для графических интерфейсов — предоставляют временные ряды данных для отображения линейных графиков, трассировку стека для построения флейм-графиков или посекундные гистограммы для тепловых карт. Я предполагаю, что все больше людей будет использовать инструменты BPF не напрямую, а через графические интерфейсы. Но независимо от способа использования, они могут предложить огромный объем информации. Я расскажу об этих данных — как их интерпретировать и как создавать новые инструменты самостоятельно.

Рис. В.1. Инструменты анализа производительности на основе BPF: ранее существовавшие и новые инструменты, написанные для этой книги
О версиях Linux
В этой книге представлено много технологий Linux, часто с номером версии ядра и годом появления. Кое-где я также называю разработчиков, чтобы вы могли найти вспомогательные материалы, написанные авторами этих технологий.
Расширенный BPF добавлялся в Linux по частям. Первая часть была добавлена в ядро 3.18 в 2014 году, и следующие продолжали добавляться в ядра 4.x и 5.x. Для опробования инструментов BPF, представленных здесь, рекомендуется использовать Linux 4.9 или выше. Примеры для книги взяты из ядер с версиями от 4.9 до 5.3.
Начата работа по внедрению расширенного BPF в другие ядра, и в будущем издании этой книги вполне может рассматриваться не только Linux.
О чем здесь не рассказывается
BPF — обширная тема, и кроме создания инструментов оценки производительности этот механизм можно использовать в самых разных ситуациях, многие из которых не рассмотрены здесь, в том числе для создания программно-конфигурируемых сетей и брандмауэров, защиты контейнеров и разработки драйверов устройств.
Эта книга посвящена использованию инструментов bpftrace и BCC, а также разработке новых инструментов bpftrace, но в ней не затронуты вопросы разработки новых инструментов для BCC. Листинги кода инструментов BCC, как правило, слишком длинные, чтобы включить их в книгу, но я все же представлю некоторые примеры в приложении C. В приложении D вы найдете примеры разработки инструментов на языке C, а в приложении E — список инструкций BPF с описаниями, который поможет желающим глубже понять, как работают инструменты BPF.
Эта книга не специализируется на использовании одного языка или приложения, как многие другие, в которых описаны средства анализа и отладки. Скорее всего, вы будете использовать некоторые из этих инструментов наряду с инструментами BPF для решения проблем и обнаружите, что разные наборы инструментов могут дополнять друг друга и дают различные подсказки. Здесь приведены основные инструменты анализа, которые есть в Linux. Владение ими поможет найти простые решения, прежде чем перейти к инструментам BPF и заглянуть еще дальше и глубже.
Эта книга содержит краткое описание основ и стратегии для каждого вида анализа. Более подробную информацию ищите в моей предыдущей книге «Systems Performance: Enterprise and the Cloud»3 [Gregg 13b].
Структура
Книга делится на три части. Первая часть, главы с 1-й по 5-ю, охватывает основы, знание которых необходимо для использования BPF: анализ производительности, технологии трассировки ядра и два основных интерфейса трассировки BPF: BCC и bpftrace.
Вторая часть включает главы с 6-й по 16-ю и описывает цели трассировки с использованием BPF: процессоры, память, файловые системы, дисковый ввод/вывод, сетевые операции, безопасность, языки, приложения, ядро, контейнеры и гипервизоры. Можно читать по порядку, а можно произвольно переходить к любой главе, представляющей для вас интерес. Все эти главы написаны по общему шаблону: предварительное обсуждение, предложения по стратегии анализа, а затем описание конкретных инструментов BPF. В текст также включены функциональные схемы, помогающие освоить сложные темы и получить более полное представление об используемых инструментах.
Последняя часть, включающая главы 17 и 18, охватывает некоторые дополнительные темы: другие инструменты BPF, а также советы, приемы и типичные проблемы.
В приложениях приводятся однострочные примеры использования bpftrace и краткие инструкции по его применению, введение в разработку инструментов для BCC, а также инструментов на C для BPF, в том числе с использованием perf(1) (инструмент Linux), и, наконец, список инструкций BPF с краткими описаниями.
В книге вы встретите много терминов и сокращений. Где это возможно, они объясняются. Полное описание приводится в глоссарии.
В конце вступления есть раздел «Дополнительные материалы и ссылки», где перечислены дополнительные источники информации. В конце книги вы найдете список использованной литературы.
Для кого эта книга
Книга адресована широкому кругу читателей. Для применения инструментов BPF, о которых я рассказываю, вам не потребуется писать программы: вы можете использовать книгу как сборник рецептов с уже готовыми инструментами. Если вы решите создавать свои инструменты, то приведенные примеры исходного кода и глава 5 помогут быстро научиться этому.
Наличие опыта в сфере анализа производительности также не требуется; каждая глава кратко излагает все необходимое.
В частности, книга адресована:
• Системным администраторам, SRE-инженерам, администраторам баз данных, перформанс-инженерам и сотрудникам служб поддержки, отвечающим за эксплуатацию систем. Они могут использовать ее как справочник по диагностике проблем производительности, анализу использования ресурсов и устранению неполадок.
• Разработчикам приложений, которые могут использовать описанные здесь инструменты для анализа собственного кода и его исследования в комплексе с системными событиями. Например, события дискового ввода/вывода можно исследовать в совокупности с кодом приложения, вызвавшим их. Это позволит получить более полное представление о поведении, чем это делается с помощью типичных прикладных инструментов, не имеющих прямого доступа к событиям ядра.
• Инженерам по безопасности, которые могут узнать, как отслеживать все события, обнаруживать подозрительное поведение и создавать белые списки типичной активности (см. главу 11).
• Разработчикам средств мониторинга производительности, которые могут почерпнуть идеи по добавлению новых возможностей в свои продукты.
• Разработчикам ядра, которые могут научиться писать однострочные инструменты для bpftrace с целью отладки собственного кода.
• Студентам, изучающим операционные системы и приложения, которые могут использовать инструменты BPF для исследования действующих систем новыми и нестандартными способами. Вместо изучения абстрактных технологий ядра на бумаге студенты могут воочию увидеть, как они работают.
Проще говоря, эта книга фокусируется на использовании инструментов BPF и предполагает минимальный уровень знаний, включая знание сетей (например, что такое адрес IPv4) и владение командной строкой.
Авторские права на исходный код
Здесь содержится исходный код многих инструментов BPF. В код каждого инструмента включен комментарий с описанием источника: взят из BCC, bpftrace или написан специально для этой книги. Полный текст примечания об авторских правах для любого инструмента из BCC или bpftrace ищите в соответствующем репозитории.
Ниже приводится примечание об авторских правах на новые инструменты, разработанные мной для этой книги. Этот комментарий включен во все листинги инструментов, хранящиеся в репозитории книги, вы должны оставить его при передаче исходного кода другим лицам или адаптации под свои условия:
/*
* Copyright 2019 Brendan Gregg.
* Licensed under the Apache License, Version 2.0 (the "License").
* This was originally created for the BPF Performance Tools book
* published by Addison Wesley. ISBN-13: 9780136554820
* When copying or porting, include this comment.
*/
Допускаю, что какие-то из этих инструментов будут включены в коммерческие продукты для целей мониторинга, как это было с моими более ранними разработками. Если вы возьмете на вооружение инструмент, созданный для этой книги, добавьте в документацию ссылку на эту книгу, технологию BPF и на меня.
Авторские права на рисунки:
Рисунки с 17.2 по 17.9: скриншоты инструмента Vector, © 2016 Netflix, Inc.
Рисунок 17.10: скриншот grafana-pcp-live, Copyright 2019 © Grafana Labs
Рисунки с 17.11 по 17.14: скриншоты Grafana, Copyright 2019 © Grafana Labs
Дополнительные материалы и ссылки
Сайт этой книги:
http://www.brendangregg.com/bpf-performance-tools-book.html
Здесь можно найти исходный код всех инструментов, содержащихся в книге, а также список опечаток и отзывы читателей.
Многие из представленных здесь инструментов доступны и в репозиториях проектов, где они поддерживаются и совершенствуются. Там можно найти самые последние версии этих инструментов:
https://github.com/iovisor/bcc
https://github.com/iovisor/bpftrace
В репозиториях есть и подробные справочные и учебные руководства, которые написал я, а сообщество BPF продолжает поддерживать и обновлять.
Условные обозначения
В книге рассматриваются различные виды технологий, а способ подачи материала дает дополнительный контекст.
В листингах, показывающих вывод инструментов, жирный шрифт указывает на выполняемую команду или на что-то интересное. Приглашение к вводу в виде хеша (#) означает, что команда или инструмент запущены от имени суперпользователя root (администратора). Например:
# id
uid=0(root) gid=0(root) groups=0(root)
Приглашение к вводу в виде доллара ($) означает, что команда или инструмент запущены от имени обычного, непривилегированного пользователя:
$ id
uid=1000(bgregg) gid=1000(bgregg) groups=1000(bgregg),4(adm),27(sudo)
Некоторые приглашения к вводу включают префикс с именем каталога, чтобы показать рабочий каталог:
bpftrace/tools$ ./biolatency.bt
Для выделения новых терминов и иногда для отображения текста, который требуется заменить, используется курсив.
Большинству инструментов, представленных здесь, для запуска необходимы привилегии суперпользователя root, о чем говорит приглашение к вводу в виде хеша. Чтобы инструмент мог запустить не суперпользователь, в начало строки нужно добавить команду sudo(8) (расшифровывается как super-user do — выполнить с привилегиями суперпользователя).
Для некоторых команд требуются одиночные кавычки, чтобы командная оболочка случайно не выполнила ненужную (хотя и маловероятную) операцию подстановки. Это хорошая привычка, рекомендую взять ее на вооружение. Например:
# funccount 'vfs_*'
За именами команд и системных вызовов Linux следует номер раздела справочного руководства man, заключенный в круглые скобки, например команда ls(1), системный вызов read(2) и команда системного администрирования funccount(8). Пустые скобки обозначают вызовы функций на языке программирования, например функция ядра vfs_read(). При включении команды с аргументами в текст абзацев они выделяются моноширинным шрифтом.
Длинный вывод команды, не умещающийся по ширине страницы, усекается и в конец добавляется многоточие в квадратных скобках ([...]). Строки, содержащие только пару символов ^C, указывают, что была нажата комбинация Ctrl-C для завершения программы.
Библиографические ссылки оформляются в виде чисел в квадратных скобках, например [123].
Благодарности
Над созданием компонентов, нужных для инструментов BPF, работали многие люди. Их вклад может быть малозаметным: решение непонятных проблем в инфраструктуре трассировки ядра, инструментах компиляции, верификаторе инструкций или в других сложных компонентах. Такая работа часто недооценивается и остается незамеченной. Тем не менее именно благодаря их усилиям вы можете использовать инструменты BPF. Многие из этих инструментов были написаны мной. Может сложиться ложное представление, будто я написал их в одиночку, — на самом деле я опирался на множество различных технологий и плоды труда других людей. Я хотел бы поблагодарить за работу их, а также всех тех, кто участвовал в создании этой книги.
Технологии, затронутые в книге, и их авторы:
• eBPF: спасибо Алексею Старовойтову (Facebook; ранее PLUMgrid) и Дэниелу Боркману (Isovalent; ранее Cisco, Red Hat) за создание технологии, управление разработкой, поддержку кода BPF в ядре и реализацию их идеи eBPF. Спасибо всем другим участникам eBPF и особенно Дэвиду С. Миллеру (David S. Miller, Red Hat) за поддержку и совершенствование технологии. На момент написания этой книги в BPF-сообществе насчитывалось 249 человек, внесших свой вклад в код BPF, а общее число коммитов, отправленных с 2014 года, составило 3224. Основными разработчиками BPF после Дэниеля и Алексея, если судить по числу коммитов, являются: Якуб Кичински (Jakub Kicinski, Netronome), Йонгхонг Сонг (Yonghong Song, Facebook), Мартин Ка Фай Лау (Martin KaFai Lau, Facebook), Джон Фастабенд (John Fastabend, Isovalent; ранее Intel), Квентин Моне (Quentin Monnet, Netronome), Джеспер Дангаард Брауэр (Jesper Dangaard Brouer, Red Hat), Андрей Игнатов (Andrey Ignatov, Facebook) и Станислав Фомичев (Stanislav Fomichev, Google).
• BCC: спасибо Брэндану Бланко (Brenden Blanco, VMware; ранее PLUMgrid) за создание и развитие BCC. К числу основных участников этого проекта относятся: Саша Гольдштейн (Sasha Goldshtein, Google; ранее SELA), Йонгхонг Сонг (Yonghong Song, Facebook; ранее PLUMgrid), Тен Цинь (Teng Qin, Facebook), Поль Шиньон (Paul Chaignon, Orange), Висент Марти (Vicent Martí, github), Марк Дрейтон (Mark Drayton, Facebook), Алан Макаливи (Allan McAleavy, Sky) и Гари Чинг-Пан Лин (Gary Ching-Pang Lin, SUSE).
• bpftrace: спасибо Аластеру Робертсону (Alastair Robertson, Yellowbrick Data; ранее G-Research, Cisco) за создание bpftrace и за высокие требования к качеству кода и наличию всеобъемлющих тестов. Спасибо всем остальным авторам bpftrace, особенно Матеусу Марчини (Matheus Marchini, Netflix; ранее Shtima), Виллиану Гасперу (Willian Gasper, Shtima), Дейлу Хэмелю (Dale Hamel, Shopify), Аугусто Меккингу Каринги (Augusto Mecking Caringi, Red Hat) и Дэну Сюю (Dan Xu, Facebook).
• ply: спасибо Тобиасу Вальдекранцу (Tobias Waldekranz) за разработку первого высокоуровневого инструмента трассировки на основе BPF.
• LLVM: спасибо Алексею Старовойтову, Чандлеру Карруту (Chandler Carruth, Google), Йонгхонг Сонгу и другим за поддержку BPF для LLVM, на которой основаны BCC и bpftrace.
• kprobes: спасибо всем, кто проектировал, разрабатывал и работал над поддержкой динамического анализа ядра Linux, которая широко используется в этой книге. Среди них Ричард Мур (Richard Moore, IBM), Супарна Бхаттачарья (Suparna Bhattacharya, IBM), Вамси Кришна Сангаварапу (Vamsi Krishna Sangavarapu, IBM), Прасанна С. Панчамухи (Prasanna S. Panchamukhi, IBM), Анант Н. Мавинакаянахалли (Ananth N. Mavinakayanahalli, IBM), Джеймс Кенистон (James Keniston, IBM), Навин Н Рао (Naveen N Rao, IBM), Хьен Нгуен (Hien Nguyen, IBM), Масами Хирамацу (Masami Hiramatsu, Linaro; ранее Hitachi), Расти Линч (Rusty Lynch, Intel), Анил Кешавамурти (Anil Keshavamurthy, Intel), Расти Рассел (Rusty Russell), Уилл Коэн (Will Cohen, Red Hat) и Дэвид С. Миллер (David S. Miller, Red Hat).
• uprobes: спасибо Шрикару Дронамражу (Srikar Dronamraju, IBM), Джиму Кенистону (Jim Keniston) и Олегу Нестерову (Oleg Nesterov, Red Hat) за разработку инструментов уровня пользователя для динамического анализа ядра Linux и Петеру Зийльстре (Peter Zijlstra) за рецензирование этой книги.
• точки трассировки: спасибо Матье Деснойерсу (Mathieu Desnoyers, EfficiOS) за его вклад в технологию трассировки для Linux. В частности, Матье разработал и предложил статические точки трассировки для включения в ядро, что позволило создавать стабильные инструменты трассировки и приложения.
• perf: спасибо Арнальдо Карвальо де Мело (Arnaldo Carvalho de Melo, Red Hat) за его работу над утилитой perf(1), добавившей в ядро новые возможности, которые используются инструментами BPF.
• Ftrace: спасибо Стивену Ростедту (Steven Rostedt, VMware; ранее Red Hat) за трассировщик Ftrace и вообще за его вклад в технологию трассировки. Ftrace помог в разработке инструментов трассировки на основе BPF, так как я по возможности перепроверял вывод своих инструментов, сопоставляя его с выводом эквивалентных инструментов в Ftrace. Спасибо также Тому Занусси (Tom Zanussi, Intel), недавно внесшему свой вклад в историю Ftrace.
• (Классический) BPF: спасибо Ван Якобсону (Van Jacobson) и Стиву Маккану (Steve McCanne).
• Динамическая инструментация: спасибо профессору Бартону Миллеру (Barton Miller, Университет штата Висконсин в городе Мэдисон) и его студенту Джеффри Холлингсворту (Jeffrey Hollingsworth) за создание области динамической инструментации в 1992 году [Hollingsworth 94], которая во многом обусловила появление DTrace, SystemTap, BCC, bpftrace и других динамических трассировщиков. Большинство инструментов в этой книге основаны на динамической инструментации (точнее, те из них, что используют kprobes и uprobes).
• LTT: спасибо Кариму Ягмуру (Karim Yaghmour) и Мишелю Р. Дагенаису (Michel R. Dagenais) за разработку LTT — первого трассировщика для Linux — в 1999 году. Также спасибо Кариму за его неустанные усилия по продвижению технологий трассировки в сообществе Linux, а также за создание и поддержку более поздних трассировщиков.
• Dprobes: Спасибо Ричарду Дж. Муру (Richard J. Moore) и его команде в IBM за разработку DProbes в 2000 году — первой технологии динамической инструментации для Linux, которая привела к появлению современной технологии kprobes.
• SystemTap: несмотря на то что SystemTap не используется в этой книге, работа Фрэнка Ч. Иглера (Frank Ch. Eigler, Red Hat) и других пользователей SystemTap очень способствовала совершенствованию технологий трассировки в Linux. Часто они первыми внедряли трассировку в новые области и обнаруживали ошибки в технологиях трассировки ядра.
• ktap: спасибо Джови Чжанвэю (Jovi Zhangwei) за ktap — высокоуровневый трассировщик, который помог в создании поддержки трассировщиков для Linux на основе виртуальных машин.
• Также спасибо инженерам Sun Microsystems Брайану Кантриллу (Bryan Cantrill), Майку Шапиро (Mike Shapiro) и Адаму Левенталю (Adam Leventhal) за их выдающуюся работу по разработке DTrace — первой технологии динамической инструментации, появившейся в 2005 году и получившей широкое распространение. Спасибо специалистам по маркетингу и продажам в Sun, популяризаторам и многим другим, как внутри, так и за пределами Sun, что помогли сделать DTrace широко известной в мире и увеличить спрос на трассировщики в Linux.
Спасибо всем остальным, не перечисленным здесь, кто также вносил свой вклад в эти технологии на протяжении многих лет.
Кроме создания перечисленных технологий, многие из этих людей помогли в работе над моей книгой: Дэниел Боркман сделал весьма ценные технические замечания и предложения для нескольких глав. Алексей Старовойтов дал критические отзывы и советы к тексту с описанием ядра eBPF (а также написал предисловие для книги). Аластер Робертсон поделился информацией для главы о bpftrace, а Йонгхонг Сонг давал консультации по BTF во время разработки BTF.
Многие, кто сыграл активную роль в разработке технологий BPF, помогали в работе над этой книгой, предоставляя материалы и оставляя замечания.
Спасибо Матеусу Марчини (Matheus Marchini, Netflix), Полу Шеньону (Paul Chaignon, Orange), Дейлу Хэмелу (Dale Hamel, Shopify), Амеру Азеру (Amer Ather, Netflix), Мартину Спайеру (Martin Spier, Netflix), Брайану В. Кернигану (Brian W. Kernighan, Google), Джоэлу Фернандесу (Joel Fernandes, Google), Джесперу Брауэру (Jesper Brouer, Red Hat), Грегу Данну (Greg Dunn, AWS), Джулии Эванс (Julia Evans, Stripe), Токе Хойланд-Йоргенсену (Toke Høiland-Jørgensen, Red Hat), Станиславу Козине (Stanislav Kozina, Red Hat), Иржи Ольсу (Jiri Olsa, Red Hat), Дженсу Аксбо (Jens Axboe, Facebook), Джону Хасламу (Jon Haslam, Facebook), Андрию Накрийко (Andrii Nakryiko, Facebook), Саргуну Диллону (Sargun Dhillon, Netflix), Алексу Маэстретти (Alex Maestretti, Netflix), Джозефу Линчу (Joseph Lynch, Netflix), Ричарду Эллингу (Richard Elling, Viking Enterprise Solutions), Брюсу Кертису (Bruce Curtis, Netflix) и Хавьеру Гондувилле Кото (Javier Honduvilla Coto, Facebook). Благодаря им многие разделы были переписаны, дополнены и улучшены. C некоторыми разделами мне помогли Матье Деснойер (Mathieu Desnoyers, EfficiOS) и Масами Хирамацу (Masami Hiramatsu, Linaro). Клэр Блэк (Claire Black) выполнила окончательную проверку глав и дала свои замечания.
Мой коллега Джейсон Кох (Jason Koch) написал бо́льшую часть главы «Другие инструменты» и прокомментировал почти все главы (он писал замечания вручную в печатной копии толщиной около двух дюймов).
Ядро Linux — сложный и постоянно меняющийся программный продукт, и я высоко ценю труд Джонатана Корбета (Jonathan Corbet) и Джейка Эджа (Jake Edge) из lwn.net по обобщению большого числа сложнейших тем. Многие из их статей упоминаются в библиографии в конце книги.
Для завершения этой книги также потребовалось добавить множество новых возможностей в интерфейсы BCC и bpftrace и устранить ряд проблемы. Я и мои коллеги написали тысячи строк кода, чтобы обеспечить возможность создания инструментов, представленных в этой книге. В связи с этим я хочу выразить особую благодарность Матеусу Марчини (Matheus Marchini), Виллиану Гасперу (Willian Gasper), Дейлу Хэмелу (Dale Hamel), Дэну Сюю (Dan Xu) и Аугусто Каринги (Augusto Caringi) за своевременные исправления.
Спасибо моим нынешнему и бывшему руководителям в Netflix Эду Хантеру (Ed Hunter) и Кобурну Уотсону (Coburn Watson) за поддержку моей работы над BPF. Также спасибо моим коллегам Скотту Эммонсу (Scott Emmons), Брайану Майлзу (Brian Moyles) и Габриелю Муносу (Gabrielle Munoz) за помощь в установке BCC и bpftrace на производственных серверах в Netflix, благодаря которым мне удалось получить множество примеров скриншотов.
Спасибо моей жене Дейрдре Страуган (Deirdré Straughan, AWS) за ее научную редактуру и предложения, а также за поддержку еще одной книги. Мои навыки писателя заметно усовершенствовались благодаря ее многолетней помощи. И спасибо моему сыну Митчеллу за поддержку и терпение, пока я был занят написанием.
Написать эту книгу меня вдохновила книга о DTrace, написанная мной и Джимом Мауро (Jim Mauro). Упорный труд Джима, направленный на достижение максимального успеха книги о DTrace, и наши бесконечные дискуссии о структуре и описаниях инструментов во многом помогли повысить качество этой книги. Джим, спасибо за все.
Отдельное спасибо старшему редактору издательства Pearson Грегу Доенчу (Greg Doench) за помощь и энтузиазм, проявленный при работе над этим проектом.
Эта работа дала мне шанс показать возможности BPF. Из 156 инструментов, представленных здесь, 135 написаны мной, в том числе 89 новых инструментов, созданных специально для этой книги (вообще их больше ста, если считать все разновидности, хотя я не рассчитывал достигнуть этого рубежа). Для создания новых инструментов потребовалось заняться дополнительными исследованиями, выполнить настройки сред серверных и клиентских приложений, провести эксперименты и произвести тестирование. Порой это было очень утомительно, но в итоге я испытал приятное чувство глубокого удовлетворения, зная, что эти инструменты для многих будут иметь немалую ценность.
Брендан Грегг (Brendan Gregg), Сан-Хосе, Калифорния (а перед этим Сидней, Австралия), ноябрь 2019
Об авторе
Брендан Грегг — старший перформанс-инженер в Netflix, основной контрибьютор проекта BPF (eBPF), помогавший разрабатывать и поддерживать оба интерфейса BPF. Впервые применил BPF для анализа производительности и создал десятки инструментов на основе BPF. Автор бестселлера «Systems Performance: Enterprise and the Cloud»4.
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
На веб-сайте издательства www.piter.com вы найдете подробную информацию о наших книгах.
1 https://events.static.linuxfound.org/sites/events/files/slides/bpf_collabsummit_2015feb20.pdf
2 В число упражнений включены также некоторые сложные и «нерешенные» проблемы, для которых мне еще только предстоит найти рабочее решение. Возможно, что некоторые из этих проблем нельзя решить без изменения ядра или приложения.
3 Грегг Б. «Производительность систем». Санкт-Петербург, издательство «Питер».
4 Грегг Б. «Производительность систем». Санкт-Петербург, издательство «Питер».
Эта книга содержит краткое описание основ и стратегии для каждого вида анализа. Более подробную информацию ищите в моей предыдущей книге «Systems Performance: Enterprise and the Cloud»3 [Gregg 13b].
Алексей Старовойтов, создатель нового BPF, февраль 20151
Грегг Б. «Производительность систем». Санкт-Петербург, издательство «Питер».
В число упражнений включены также некоторые сложные и «нерешенные» проблемы, для которых мне еще только предстоит найти рабочее решение. Возможно, что некоторые из этих проблем нельзя решить без изменения ядра или приложения.
https://events.static.linuxfound.org/sites/events/files/slides/bpf_collabsummit_2015feb20.pdf
Грегг Б. «Производительность систем». Санкт-Петербург, издательство «Питер».
Брендан Грегг — старший перформанс-инженер в Netflix, основной контрибьютор проекта BPF (eBPF), помогавший разрабатывать и поддерживать оба интерфейса BPF. Впервые применил BPF для анализа производительности и создал десятки инструментов на основе BPF. Автор бестселлера «Systems Performance: Enterprise and the Cloud»4.
Во многих главах этой книги указаны цели обучения, чтобы вы могли выбрать наиболее важные для себя разделы. Представленный здесь материал используется в учебных курсах по анализу BPF внутри Netflix, а некоторые главы включают дополнительные упражнения2.
Глава 1. Введение
Эта глава знакомит с основными терминами и технологиями и показывает применение некоторых инструментов анализа производительности на основе BPF. Представленные здесь технологии будут подробно описаны в последующих главах.
1.1. Что такое BPF и eBPF?
BPF расшифровывается как Berkeley Packet Filter (пакетный фильтр Беркли). Эта малоизвестная когда-то технология, разработанная в 1992 году, создавалась для увеличения производительности инструментов захвата пакетов [McCanne 92]. В 2013 году Алексей Старовойтов предложил существенно переделанную версию BPF5, развитие которой продолжил с Дэниелем Боркманом. В 2014 она была включена в ядро Linux6. Это превратило BPF в механизм выполнения общего назначения, который можно использовать для самых разных целей, включая создание продвинутых инструментов анализа производительности.
Из-за широкой области применения BPF трудно описать. Она позволяет запускать мини-программы для обработки самых разных событий, происходящих в ядре и приложениях. Те, кто знаком с JavaScript, наверняка заметят некоторые сходства: с помощью JavaScript можно запускать на сайте мини-программы для обработки событий в браузере, например щелчков мыши, что дает возможность создавать веб-приложения для самых разных целей. Механизм BPF позволяет ядру запускать мини-программы в ответ на события в системе и в приложениях, таких как дисковый ввод/вывод, что открывает дорогу для новых системных технологий. Он делает ядро полностью программируемым и дает пользователям (включая прикладных программистов) возможность настраивать и контролировать свои системы для решения насущных проблем.
BPF — это гибкая и эффективная технология, состоящая из набора инструкций, хранимых объектов и вспомогательных функций. Она определяет набор виртуальных инструкций, поэтому ее можно считать виртуальной машиной. Эти инструкции исполняются средой выполнения BPF в ядре Linux, которая включает интерпретатор и JIT-компилятор, преобразующие инструкции BPF в машинные инструкции. Инструкции BPF сначала попадают в верификатор, который проверяет их безопасность и гарантирует, что программа BPF не приведет к сбою или повреждению ядра (что не мешает конечному пользователю писать нелогичные программы, которые могут выполняться, но не иметь смысла). Компоненты BPF подробно описаны в главе 2.
До сих пор технология BPF в основном использовалась для организации сетевых взаимодействий, наблюдаемости и обеспечения безопасности. В этой книге основное внимание уделяется наблюдаемости (трассировке).
Расширенную версию BPF часто обозначают аббревиатурой eBPF (extended BPR — расширенная BPF), но официальной считается прежнее обозначение — BPF, без «e», поэтому в этой книге я буду использовать аббревиатуру «BPF». Ядро содержит только один механизм выполнения BPF (расширенный BPF), который выполняет инструкции как расширенной технологии BPF, так и «классической» BPF7.
1.2. Что такое трассировка, прослушивание, выборка, профилирование и наблюдаемость?
Эти термины используются для классификации методов и инструментов анализа.
Трассировка (tracing) — технология фиксации (записи) происходящих событий, основанная на использовании соответствующих инструментов BPF. Возможно, вам уже приходилось иметь дело с некоторыми специализированными инструментами трассировки. Инструмент strace(1), например, фиксирует и выводит события обращения к системным вызовам. Есть и инструменты, которые не трассируют, а измеряют события, используя фиксированные статистические счетчики, а затем выводят их, как, например, top(1). Отличительная черта трассировщика — это способность фиксировать исходные события и их метаданные. Такая информация может иметь очень большой объем, требующий последующей обработки и обобщения. Программные трассировщики, использующие BPF, могут запускать небольшие программы для обработки событий и формировать статистические метрики «на лету» или выполнять другие действия, чтобы избежать последующей дорогостоящей обработки.
Не у всех трассировщиков в названии есть слово «trace», как strace(1). Например, tcpdump(8) — это еще один специализированный инструмент трассировки сетевых пакетов. (Возможно, его следовало назвать tcptrace?) В ОС Solaris была своя версия tcpdump с именем snoop(1M)8, названная так потому, что использовалась для прослушивания (snooping) сетевых пакетов. Я был первым, кто разработал и опубликовал множество инструментов трассировки для Solaris, в названиях которых (может и неправильно) использовал «snoop». Поэтому у нас теперь есть execsnoop(8), opensnoop(8), biosnoop(8) и т.д. Прослушивание, вывод событий и трассировка обычно обозначают одно и то же. Эти инструменты будут описаны в следующих главах.
Термин «трассировка» (tracing) встречается не только в названиях инструментов, но также в описании механизма BPF, когда тот используется для наблюдаемости.
Инструменты выборки (sampling) выполняют некоторые измерения, чтобы составить общую картину цели. Их также называют инструментами создания профиля, или профилирования. Есть BPF-инструмент под названием profile(8), который берет выполняемый код по таймеру. Например, он может производить выборку каждые 10 миллисекунд, или, иначе говоря, 100 раз в секунду (на каждом процессоре). Преимущество инструментов выборки состоит в том, что у них обычно более низкий уровень оверхеда, чем у трассировщиков, потому что они оценивают только одно из большого числа событий. С другой стороны, выборка дает только приблизительную картину и может пропускать некоторые важные события.
Под наблюдаемостью (observability) понимается исследование системы через наблюдение с использованием специальных инструментов. К инструментам наблюдаемости относятся инструменты трассировки и выборки, а также инструменты, основанные на фиксированных счетчиках. К ним не относятся инструменты бенчмаркинга, которые изменяют состояние системы, экспериментируя с рабочей нагрузкой. Инструменты BPF, представленные в этой книге, все относятся к категории инструментов наблюдаемости и используют BPF для трассировки программ.
1.3. Что такое BCC, bpftrace и IO Visor?
Программировать, используя непосредственно инструкции BPF, довольно сложно, поэтому для языков высокого уровня были разработаны интерфейсы. Для трассировки в основном используются интерфейсы BCC и bpftrace.
Первой инфраструктурой трассировки на основе BPF стала BCC (BPF Compiler Collection — коллекция компиляторов для BPF). Она предоставляет среду программирования на C для использования BPF и интерфейсы для других языков: Python, Lua и C ++. Она также дала начало библиотекам libbcc и текущей версии libbpf9 с функциями для обработки событий с помощью программ BPF. Репозиторий BCC содержит более 70 инструментов на основе BPF для анализа производительности и устранения неполадок. Вы можете установить BCC в своей системе и использовать готовые инструменты, не написав ни строчки кода для BCC. В этой книге вы познакомитесь со многими такими инструментами.
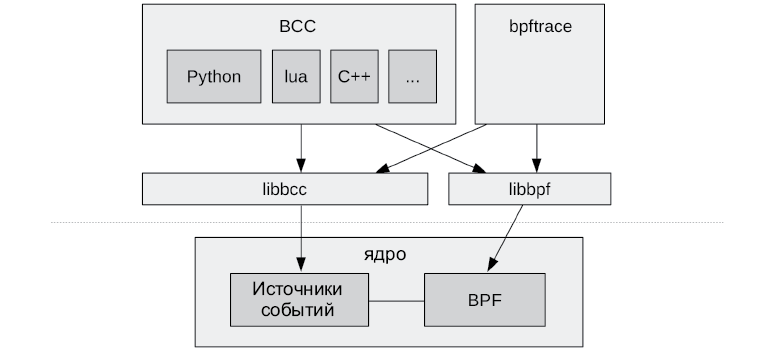
Рис. 1.1. BCC, bpftrace и BPF
bpftrace — более новый интерфейс, предоставляющий специализированный язык высокого уровня для разработки инструментов BPF. Язык bpftrace настолько лаконичен, что мне удалось вставить в эту книгу исходный код инструментов, чтобы показать, какие механизмы они используют и как именно. bpftrace построен на основе библиотек libbcc и libbpf.
Связь между BCC и bpftrace можно видеть на рис. 1.1. Они прекрасно дополняют друг друга: bpftrace идеально подходит для создания однострочных и нестандартных коротких сценариев, а BCC лучше подходит для сложных сценариев и демонов и позволяет использовать другие библиотеки. Например, многие BCC-инструменты на Python используют библиотеку argparse для сложного и точного управления аргументами командной строки.
Сейчас разрабатывается еще один интерфейс BPF — ply10. Предполагается, что он должен получиться максимально легковесным и с минимумом зависимостей, чтобы его можно было использовать во встраиваемых системах Linux. Если для вашей среды ply подходит лучше, чем bpftrace, эта книга все равно будет вам полезна в качестве руководства по анализу с использованием BPF. Десятки инструментов на bpftrace, представленные здесь, с таким же успехом могут выполняться с ply, если их переписать с помощью синтаксиса ply. (В будущих версиях ply может появиться прямая поддержка синтаксиса bpftrace.) Основное внимание в этой книге уделяется интерфейсу bpftrace как более развитому и обладающему всеми возможностями, необходимыми для анализа всех целей.
BCC и bpftrace не входят в код ядра и размещены в проекте Linux Foundation на Github c названием IO Visor:
https://github.com/iovisor/bcc
https://github.com/iovisor/bpftrace
В этой книге под словами трассировка с использованием BPF я буду подразумевать инструменты, использующие любой из интерфейсов — BCC и bpftrace.
1.4. Первый взгляд на BCC: быстрый анализ
Посмотрим на некоторые результаты, возвращаемые разными инструментами. Следующий инструмент следит за новыми процессами и выводит сводную информацию о каждом сразу после его запуска. Этот BCC-инструмент execsnoop(8) трассирует системный вызов execve(2), который является вариантом exec(2) (отсюда и имя). Установка инструментов BCC описана в главе 4, и в следующих главах эти инструменты будут представлены подробнее.
# execsnoop
PCOMM PID PPID RET ARGS
run 12983 4469 0 ./run
bash 12983 4469 0 /bin/bash
svstat 12985 12984 0 /command/svstat /service/httpd
perl 12986 12984 0 /usr/bin/perl -e $l=<>;$l=~/(\d+) sec/;print $1||0
ps 12988 12987 0 /bin/ps --ppid 1 -o pid,cmd,args
grep 12989 12987 0 /bin/grep org.apache.catalina
sed 12990 12987 0 /bin/sed s/^ *//;
cut 12991 12987 0 /usr/bin/cut -d -f 1
xargs 12992 12987 0 /usr/bin/xargs
echo 12993 12992 0 /bin/echo
mkdir 12994 12983 0 /bin/mkdir -v -p /data/tomcat
mkdir 12995 12983 0 /bin/mkdir -v -p /apps/tomcat/webapps
^C
#
В полученном выводе видно, какие процессы запускались, пока происходила трассировка: в основном это настолько кратковременные процессы, что они невидимы для других инструментов. Здесь можно видеть строки, соответствующие запуску стандартных утилит Unix: ps(1), grep(1), sed(1), cut(1) и т.д. Но рассматривая этот вывод на книжной странице, нельзя сказать, насколько быстро выводились показанные строки. Чтобы исправить этот недостаток, добавим параметр командной строки -t, который заставит execsnoop(8) выводить время, прошедшее с начала трассировки:
# execsnoop -t
TIME(s) PCOMM PID PPID RET ARGS
0.437 run 15524 4469 0 ./run
0.438 bash 15524 4469 0 /bin/bash
0.440 svstat 15526 15525 0 /command/svstat /service/httpd
0.440 perl 15527 15525 0 /usr/bin/perl -e $l=<>;$l=~/(\d+) sec/;prin...
0.442 ps 15529 15528 0 /bin/ps --ppid 1 -o pid,cmd,args
[...]
0.487 catalina.sh 15524 4469 0 /apps/tomcat/bin/catalina.sh start
0.488 dirname 15549 15524 0 /usr/bin/dirname /apps/tomcat/bin/
catalina.sh
1.459 run 15550 4469 0 ./run
1.459 bash 15550 4469 0 /bin/bash
1.462 svstat 15552 15551 0 /command/svstat /service/nflx-httpd
1.462 perl 15553 15551 0 /usr/bin/perl -e $l=<>;$l=~/(\d+) sec/;prin...
[...]
Я сократил вывод (о чем свидетельствует [...]), но новый столбец с отметкой времени помогает заметить закономерность: новые процессы запускаются с интервалом в 1 секунду. Просматривая вывод, я могу сказать, что каждую секунду запускается 30 новых процессов, после чего следует пауза в 1 секунду.
В этом выводе показана реальная проблема, которая была в Netflix и которую я анализировал с помощью execsnoop(8). Это происходило на сервере для микробенчмаркинга, но результаты бенчмарков слишком сильно отличались, чтобы им доверять. Я запустил execsnoop(8), когда система должна была простаивать, и обнаружил проблему! Каждую секунду эти процессы запускались и нарушали работу бенмчмарков. Причина крылась в неправильно настроенном сервисе, который пытался запуститься каждую секунду, терпел неудачу и запускался снова. После того как сервис был деактивирован, эти процессы перестали появляться (что было подтверждено с помощью execsnoop(8)) и бенчмарки стали стабильными.
Вывод execsnoop(8) помогает в анализе производительности с использованием методологии под названием характеристика рабочей нагрузки, которая поддерживается многими другими инструментами BPF, описанными здесь. Эта методология решает простую задачу: определить величину рабочей нагрузки. Понимания, как распределяется рабочая нагрузка, часто достаточно для решения проблем, без нужды углубляться в исследование задержек или в детальный анализ. Здесь к системе была применена процедура определения рабочей нагрузки. Более подробно с этой и другими методологиями вы познакомитесь в главе 3.
Попробуйте запустить инструмент execsnoop(8) в своих системах и оставьте его поработать в течение часа. Что необычного вы заметили?
execsnoop(8) выводит информацию о каждом событии, однако другие инструменты используют BPF для получения сводной информации. Еще один инструмент, который можно использовать для быстрого анализа, — biolatency(8), который обобщает сведения об операциях ввода/вывода для блочного устройства (дисковый ввод/вывод) в виде гистограммы задержки.
Ниже показан вывод инструмента biolatency(8) на промышленной базе данных, которая чувствительна к высокой задержке, так как имеет соглашение об уровне обслуживания по доставке запросов в течение определенного количества миллисекунд.
# biolatency -m
Tracing block device I/O... Hit Ctrl-C to end.
^C
msecs : count distribution
0 -> 1 : 16335 |****************************************|
2 -> 3 : 2272 |***** |
4 -> 7 : 3603 |******** |
8 -> 15 : 4328 |********** |
16 -> 31 : 3379 |******** |
32 -> 63 : 5815 |************** |
64 -> 127 : 0 | |
128 -> 255 : 0 | |
256 -> 511 : 0 | |
512 -> 1023 : 11 | |
После запуска инструмент biolatency(8) включает регистрацию событий блочного ввода/вывода, а их задержки вычисляются и обобщаются механизмом BPF. Когда инструмент завершается (пользователь нажимает Ctrl-C), выводится сводная информация. Я добавил параметр -m, чтобы обеспечить вывод информации в миллисекундах.
В этом выводе есть интересная деталь — бимодальный характер распределения задержек, а также наличие выбросов. Наиболее типичный режим (как видно на ASCII-гистограмме) приходится на диапазон от 0 до 1 миллисекунды, которому соответствует 16 355 операций ввода/вывода, зарегистрированных во время трассировки. Скорее всего, к этим операциям относятся попадания в дисковый кэш, а также операции с устройством флеш-памяти. Второй наиболее типичный режим охватывает диапазон от 32 до 63 миллисекунд и включает намного более медленные операции, чем ожидалось, и вероятно, это замедление обусловлено постановкой запросов в очередь. Для более подробного исследования этого режима можно использовать другие инструменты BPF. Наконец, 11 операций ввода/вывода попали в диапазон от 512 до 1023 миллисекунд. Эти очень медленные операции называют выбросами. Теперь, когда мы знаем, что они есть, их можно более детально изучить с помощью других инструментов BPF. Для команды базы данных это приоритетная задача: если БД будет блокироваться на этих операциях ввода/вывода, произойдет превышение целевого уровня задержки.
1.5. Область видимости механизма трассировки BPF
Механизму трассировки BPF доступен для наблюдения весь программный стек, что позволяет создавать новые инструменты и производить инструментацию по мере необходимости. Механизм трассировки BPF можно использовать на промышленном сервере без всякой подготовки, то есть без перезагрузки системы или перезапуска приложений в каком-то специальном режиме. Его можно сравнить с рентгеновским зрением: если нужно исследовать какой-то компонент ядра, устройство или прикладную библиотеку, вы сможете увидеть все это в таком свете, в каком никто и никогда не видел их — вживую на продакшене.
Для иллюстрации на рис. 1.2 показан обобщенный программный стек системы, который я аннотировал названиями инструментов трассировки на основе BPF, предназначенными для наблюдения за различными компонентами. Все эти инструменты созданы в проектах BCC и bpftrace, а также специально для этой книги. Многие из них будут описаны в следующих главах.
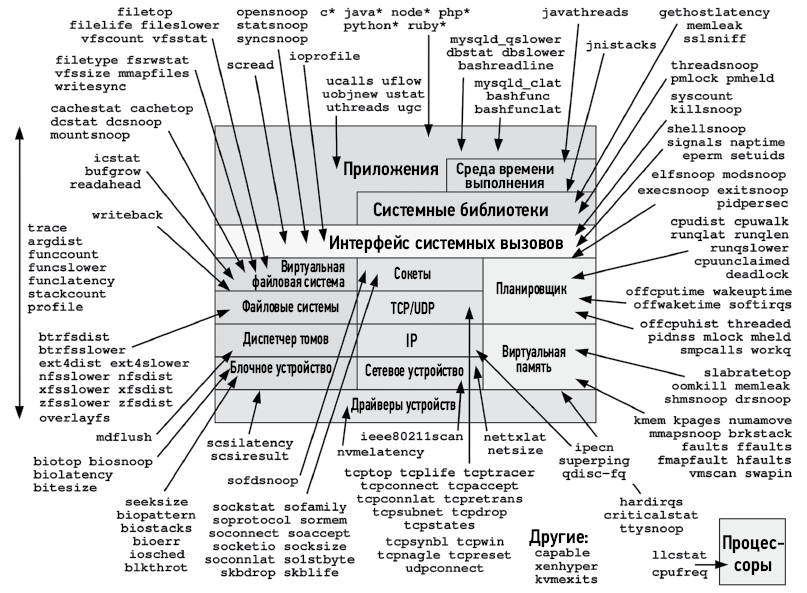
Рис. 1.2. Инструменты оценки производительности на основе BPF и их области видимости
Посмотрите на различные инструменты, которые можно использовать для исследования таких компонентов, как планировщик процессов в ядре, виртуальная память, файловые системы и т.д. Из диаграммы на рис. 1.2 можно заметить, что у механизма BPF нет слепых зон.
В табл. 1.1 перечислены инструменты, традиционно используемые для исследования этих компонентов, а также указана способность механизма BPF наблюдать за этими компонентами.
Таблица 1.1. Традиционные инструменты анализа 11
| Компоненты |
Традиционные инструменты анализа |
Механизм трассировки BPF |
| Приложения со средами выполнения своих языков: Java, Node.js, Ruby, PHP |
Отладчики среды времени выполнения |
Да, с поддержкой среды времени выполнения |
| Приложения на компилируемых языках: C, C++, Golang |
Системные отладчики |
Да |
| Системные библиотеки: /lib/* |
ltrace(1) |
Да |
| Интерфейс системных вызовов |
strace(1), perf(1) |
Да |
| Ядро: планировщик, файловые системы, сетевые протоколы (TCP, IP и др.) |
Ftrace, perf(1) для выборки |
Да, и более подробно |
| Аппаратное обеспечение: процессоры, устройства |
perf, sar, счетчики в /proc |
Да, прямо или косвенно1 |
Традиционные инструменты могут дать полезную начальную информацию о компоненте, исследование которого можно продолжить на более детальном уровне с помощью инструментов трассировки BPF. В главе 3 кратко описывается базовый анализ производительности с помощью системных инструментов, помогающий получить начальную информацию.
1.6. Динамическая инструментация: kprobes и uprobes
Механизм трассировки BPF поддерживает несколько источников событий для обеспечения видимости всего программного стека. Особого упоминания заслуживает поддержка динамической инструментации (иногда ее называют динамической трассировкой) — возможность вставлять контрольные точки в действующее ПО в процессе его выполнения. Динамическая инструментация не порождает оверхед, когда не используется, так как в этом случае ПО выполняется в своем первоначальном виде. Она часто применяется инструментами BPF для определения начала и конца выполнения функций в ядре и в приложении (для любой из десятков тысяч функций, которые обычно имеются в программном стеке). Такое глубокое и всеобъемлющее ви́дение напоминает суперсилу!
Впервые идея динамической инструментации была предложена в 1990-х годах [Hollingsworth 94]. Она основывалась на технологии, используемой отладчиками для вставки точек останова по произвольным адресам команд. Встретив такую точку, динамически инструментированное ПО записывает нужную информацию и автоматически продолжает выполнение, не передавая управление интерактивному отладчику. Тогда же были разработаны первые инструменты динамической трассировки (например, kerninst [Tamches 99]), включавшие языки трассировки, но эти инструменты оставались малоизвестными и редко используемыми. Отчасти это было связано с тем, что их применение сопряжено с большим риском: динамическая трассировка требует изменения инструкций в адресном пространстве, и любая ошибка может привести к немедленному повреждению кода и аварийному завершению процесса или ядра.
Первая поддержка динамической инструментации в Linux была реализована в 2000 году в IBM, она получила название DProbes, но набор исправлений был отклонен12. Динамическая инструментация для функций ядра (kprobes), добавленная в Linux в 2004 году и корнями уходящая в DProbes, все еще оставалась малоизвестной и сложной в использовании.
Все изменилось в 2005 году, когда Sun Microsystems выпустила свою версию динамической трассировки DTrace с простым в использовании языком D и включила ее в ОС Solaris 10. В ту пору Solaris была известной операционной системой, славившейся стабильностью работы, поэтому включение в нее пакета DTrace помогло доказать, что динамическая трассировка может быть безопасной для применения в промышленных системах. Это стало поворотным моментом для технологии. Я опубликовал много статей, где показаны реальные случаи использования DTrace, а также разработал и опубликовал множество инструментов DTrace. Кроме того, отдел маркетинга в Sun продвигал не только продажи, но и технологии Sun. Считалось, что это дает дополнительные конкурентные преимущества. Sun Educational Services включили DTrace в стандартные курсы изучения Solaris и разработали специальные курсы по DTrace. Все это способствовало превращению динамической инструментации из малопонятной технологии в широко известную и востребованную.
В 2012 году в Linux была добавлена поддержка динамической инструментации для функций пользовательского уровня в виде uprobes. Механизм трассировки BPF использует и kprobes, и uprobes для динамической инструментации всего программного стека.
Чтобы показать, как можно применять динамическую трассировку, в табл. 1.2 приведены примеры зондов bpftrace, которые используют kprobes и uprobes (bpftrace подробно рассматривается в главе 5).
Таблица 1.2. Примеры использования kprobe и uprobe в bpftrace 13
| Зонд |
Описание |
| kprobe:vfs_read |
Инструментирует начало выполнения функции ядра vfs_read() |
| kretprobe:vfs_read |
Инструментирует возврат1 из функции ядра vfs_read() |
| uprobe:/bin/bash:readline |
Инструментирует начало выполнения функции readline() в /bin/bash |
| uretprobe:/bin/bash:readline |
Инструментирует возврат из функции readline() в /bin/bash |
1.7. Статическая инструментация: точки трассировки и USDT
Динамическая инструментация имеет и обратную сторону: инструменты могут переименовываться или удаляться в новой версии ПО. Это называется проблемой стабильности интерфейса. После обновления ядра или прикладного ПО иногда оказывается, что инструмент BPF работает не так, как должен. Он может вызывать ошибку, сообщая о невозможности найти функцию для инструментации, или вообще ничего не выводить. Другая проблема в том, что компиляторы могут преобразовывать функции во встраиваемые фрагменты кода с целью оптимизации, делая их недоступными для инструментации через kprobes или uprobes14.
Одно из решений проблем стабильности интерфейса и встраивания функций — это статическая инструментация, когда стабильные имена событий внедряются в ПО и поддерживаются разработчиками. Механизм трассировки BPF поддерживает точки трассировки для статической инструментации ядра и статически определяемые точки трассировки на уровне пользователя (User-level Statically Defined Tracing, USDT) для статической инструментации на уровне пользователя. Недостаток статической инструментации в том, что поддержка таких точек инструментации становится бременем для разработчиков, поэтому если они существуют, их количество обычно ограниченно.
Эти детали важны, только если вы собираетесь разрабатывать свои инструменты BPF. В таком случае рекомендуется сначала попытаться использовать статическую трассировку (с использованием точек трассировки и USDT), а к динамической трассировке (с помощью kprobes и uprobes) переходить только тогда, когда статическая недоступна.
В табл. 1.3 приводятся примеры зондов bpftrace для статической инструментации с использованием точек трассировки и USDT. Об упомянутой в этой таблице точке трассировки open(2) рассказано в разделе 1.8.
Таблица 1.3. Примеры точек трассировки и USDTв bpftrace
| Зонд |
Описание |
| tracepoint:syscalls:sys_enter_open |
Инструментирует системный вызов open(2) |
| usdt:/usr/sbin/mysqld:mysql:query__start |
Инструментирует вызов query__start из /usr/sbin/mysqld |
1.8. Первый взгляд на bpftrace: трассировка open()
Начнем знакомство с bpftrace с попытки выполнить трассировку системного вызова open(2). Для этого есть статическая точка трассировки (syscalls:sys_enter_open15). Я покажу дальше короткую программу на bpftrace в командной строке: однострочный сценарий.
От вас пока не требуется понимать код этого однострочного сценария; язык bpftrace и инструкции по установке описаны ниже, в главе 5. Но вы наверняка догадаетесь, что делает эта программа, даже не зная языка, потому что он достаточно прост и понятен (понятность языка — признак хорошего дизайна). А пока просто обратите внимание на вывод инструмента.
# bpftrace -e 'tracepoint:syscalls:sys_enter_open { printf("%s %s\n", comm,
str(args->filename)); }'
Attaching 1 probe...
slack /run/user/1000/gdm/Xauthority
slack /run/user/1000/gdm/Xauthority
slack /run/user/1000/gdm/Xauthority
slack /run/user/1000/gdm/Xauthority
^C
#
Вывод показывает имя процесса и имя файла, переданное системному вызову open(2): bpftrace трассирует всю систему, поэтому в выводе будет видно любое приложение, вызывающее open(2). Каждая строка вывода соответствует одному системному вызову, и этот сценарий является примером инструмента, который выводит информацию о каждом событии. Механизм трассировки BPF можно использовать не только для анализа промышленных серверов. Например, я запускал его на своем ноутбуке, когда писал эту книгу, и он показывал файлы, которые открывало приложение чата Slack.
Программа для BPF определена в одинарных кавычках. Она была скомпилирована и запущена сразу, как только я нажал Enter для запуска команды bpftrace. bpftrace также активировала точку трассировки open(2). Когда я нажал Ctrl-C, чтобы остановить команду, точка трассировки open(2) была деактивирована и моя маленькая программа для BPF была остановлена и удалена. Вот как работает инструментация в механизме трассировки BPF: активация точки трассировки и выполнение производятся, только пока выполняется команда, и могут длиться всего несколько секунд.
Этот сценарий генерировал вывод медленнее, чем я ожидал: думаю, что я пропустил какие-то события системного вызова open(2). Ядро поддерживает несколько вариантов open, а я трассировал только один из них. С помощью bpftrace можно вывести список всех точек трассировки open, использовав параметр -l и подстановочный знак:
# bpftrace -l 'tracepoint:syscalls:sys_enter_open*'
tracepoint:syscalls:sys_enter_open_by_handle_at
tracepoint:syscalls:sys_enter_open
tracepoint:syscalls:sys_enter_openat
Как мне кажется, вариант openat(2) используется чаще. Мое предположение подтвердил другой однострочный сценарий для bpftrace:
# bpftrace -e 'tracepoint:syscalls:sys_enter_open* { @[probe] = count(); }'
Attaching 3 probes...
^C
@[tracepoint:syscalls:sys_enter_open]: 5
@[tracepoint:syscalls:sys_enter_openat]: 308
Повторюсь: детали кода этого однострочного сценария я объясню в главе 5. А пока вам важно понимать только вывод. Теперь сценарий выводит количество задействованных точек трассировки, а не события. Результат подтверждает, что системный вызов openat(2) вызывается чаще — в данном случае 308 раз против пяти вызовов open(2). Эта информация вычисляется в ядре программой BPF.
Я могу добавить вторую точку трассировки в свой сценарий и трассировать сразу два системных вызова, open(2) и openat(2). Но этот новый сценарий получится слишком громоздким для командной строки, поэтому лучше сохранить его в выполняемом файле, чтобы его было легче править с помощью текстового редактора. Это уже было сделано: bpftrace поставляется со сценарием opensnoop.bt, который трассирует начало и конец каждого системного вызова и выводит данные в виде столбцов:
# opensnoop.bt
Attaching 3 probes...
Tracing open syscalls... Hit Ctrl-C to end.
PID COMM FD ERR PATH
2440 snmp-pass 4 0 /proc/cpuinfo
2440 snmp-pass 4 0 /proc/stat
25706 ls 3 0 /etc/ld.so.cache
25706 ls 3 0 /lib/x86_64-linux-gnu/libselinux.so.1
25706 ls 3 0 /lib/x86_64-linux-gnu/libc.so.6
25706 ls 3 0 /lib/x86_64-linux-gnu/libpcre.so.3
25706 ls 3 0 /lib/x86_64-linux-gnu/libdl.so.2
25706 ls 3 0 /lib/x86_64-linux-gnu/libpthread.so.0
25706 ls 3 0 /proc/filesystems
25706 ls 3 0 /usr/lib/locale/locale-archive
25706 ls 3 0 .
1744 snmpd 8 0 /proc/net/dev
1744 snmpd -1 2 /sys/class/net/lo/device/vendor
2440 snmp-pass 4 0 /proc/cpuinfo
^C
#
В столбцах выводится следующая информация: идентификатор процесса (PID), имя команды процесса (COMM), дескриптор файла (FD), код ошибки (ERR) и путь к файлу, который системный вызов пытался открыть (PATH). Инструмент opensnoop.bt можно использовать для устранения неполадок в ПО, которое будет пытаться открыть файлы, используя неправильный путь, а также для определения местоположения конфигурационных файлов и журналов по событиям обращения к ним. Он также может выявить некоторые проблемы с производительностью, например слишком быстрое открытие файлов или слишком частую проверку неправильных местоположений. У этого инструмента множество применений.
bpftrace поставляется с более чем 20 подобными готовыми инструментами, а BCC — с более чем 70. Помимо помощи в непосредственном решении проблем, эти инструменты показывают код, изучив который можно понять, как трассировать разные цели. Иногда могут наблюдаться некоторые странности, как мы видели на примере трассировки системного вызова open(2), и код инструментов способен подсказать их причины.
1.9. Назад к BCC: трассировка open()
Теперь рассмотрим BCC-версию opensnoop(8):
# opensnoop
PID COMM FD ERR PATH
2262 DNS Res~er #657 22 0 /etc/hosts
2262 DNS Res~er #654 178 0 /etc/hosts
29588 device poll 4 0 /dev/bus/usb
29588 device poll 6 0 /dev/bus/usb/004
29588 device poll 7 0 /dev/bus/usb/004/001
29588 device poll 6 0 /dev/bus/usb/003
^C
#
Вывод этого инструмента выглядит очень похожим на вывод более раннего однострочного сценария, по крайней мере он имеет те же столбцы. Но в выводе этого инструмента opensnoop(8) есть то, чего нет в bpftrace-версии: его можно вызвать с разными параметрами командной строки:
# opensnoop -h
порядок использования: opensnoop [-h] [-T] [-x] [-p PID] [-t TID]
[-d DURATION] [-n NAME]
[-e] [-f FLAG_FILTER]
Трассирует системные вызовы open()
необязательные аргументы:
-h, --help вывести эту справку и выйти
-T, --timestamp включить отметку времени в вывод
-x, --failed показать только неудачные вызовы open
-p PID, --pid PID трассировать только этот PID
-t TID, --tid TID трассировать только этот TID
-d DURATION, --duration DURATION
общая продолжительность трассировки в секундах
-n NAME, --name NAME выводить только имена процессов, содержащие это имя
-e, --extended_fields
показать дополнительные поля
-f FLAG_FILTER, --flag_filter FLAG_FILTER
фильтровать по аргументу с флагами (например, O_WRONLY)
примеры:
./opensnoop # трассировать все системные вызовы open()
./opensnoop -T # включить отметки времени
./opensnoop -x # показать только неудачные вызовы open
./opensnoop -p 181 # трассировать только PID 181
./opensnoop -t 123 # трассировать только TID 123
./opensnoop -d 10 # трассировать только 10 секунд
./opensnoop -n main # выводить только имена процессов, содержащие "main"
./opensnoop -e # показать дополнительные поля
./opensnoop -f O_WRONLY -f O_RDWR # выводить только вызовы для записи
Инструменты bpftrace, как правило, проще и выполняют одну конкретную задачу. Инструменты BCC, напротив, обычно сложнее и поддерживают несколько режимов работы. Конечно, можно изменить инструмент для bpftrace, чтобы он отображал только неудачные вызовы open, но уже есть BCC-версия, поддерживающая такую возможность с параметром -x:
# opensnoop -x
PID COMM FD ERR PATH
991 irqbalance -1 2 /proc/irq/133/smp_affinity
991 irqbalance -1 2 /proc/irq/141/smp_affinity
991 irqbalance -1 2 /proc/irq/131/smp_affinity
991 irqbalance -1 2 /proc/irq/138/smp_affinity
991 irqbalance -1 2 /proc/irq/18/smp_affinity
20543 systemd-resolve -1 2 /run/systemd/netif/links/5
20543 systemd-resolve -1 2 /run/systemd/netif/links/5
20543 systemd-resolve -1 2 /run/systemd/netif/links/5
[...]
Этот вывод показывает повторяющиеся сбои. Такие закономерности могут указывать на неэффективность или неправильную конфигурацию, которые можно исправить.
Инструменты BCC часто имеют несколько параметров для изменения поведения, что делает их более универсальными, чем инструменты bpftrace. Они могут послужить хорошей отправной точкой: с их помощью вы сумеете решить проблему, не написав ни строчки кода для BPF. Но если им не хватит глубины видимости, можно переключиться на bpftrace, имеющий более простой язык для разработки, и создать свои инструменты.
bpftrace впоследствии можно преобразовать в более сложный инструмент BCC, поддерживающий разнообразные параметры, подобно инструменту opensnoop(8), который был показан выше. Инструменты BCC также могут поддерживать различные события: использовать точки трассировки, если они доступны, а в противном случае переключаться на kprobes. Но имейте в виду, что программировать инструменты BCC намного сложнее, и эта тема выходит за рамки книги, где основное внимание уделяется программированию на bpftrace. В приложении C вы найдете ускоренный курс по разработке инструментов BCC.
1.10. Итоги
Инструменты трассировки BPF могут использоваться для анализа производительности и устранения неполадок, и есть два основных проекта, которые предоставляют их: BCC и bpftrace. В этой главе мы познакомились с расширенным механизмом BPF, BCC, bpftrace, а также с динамической и статической инструментацией.
Следующая глава более подробно расскажет об этих технологиях. Если вы спешите приступить к решению проблем, можете пропустить главу 2 и перейти к главе 3 или другой, затрагивающей интересующую вас тему. В этих последующих главах широко используются термины, многие из которых объясняются в главе 2, но их описание также можно найти в глоссарии.
5 https://lkml.org/lkml/2013/9/30/627
6 https://lore.kernel.org/netdev/1395404418-25376-1-git-send-email-dborkman@redhat.com/T/
7 Программы на основе классической версии BPF [McCanne 92] автоматически выполняются под управлением расширенного механизма BPF. Кроме того, развитие классической технологии BPF было прекращено.
8 Раздел 2 в справочном руководстве Solaris предназначен для команд администрирования и обслуживания (в Linux ему соответствует раздел 8).
9 Первая версия libbpf была разработана Ван Нанем (Wang Nan) для использования с perf (https://lore.kernel.org/lkml/1435328155-87115-1-git-send-email-wangnan0@huawei.com/T/). Сейчас libbpf — это часть исходного кода ядра.
10 https://github.com/iovisor/ply
11 BPF может не иметь возможности непосредственно инструментировать прошивку на устройстве, но он может косвенно определять поведение на основе отслеживания событий драйвера ядра или PMC.
12 Причины отказа принять DProbes в ядро Linux обсуждаются в первом примере в статье Энди Клина (Andi Kleen) «On submitting kernel patches», где дается ссылка на источник в Documentation/process/submitting-patches.rst (http://halobates.de/on-submitting-patches.pdf).
13 Функция имеет одну точку входа, но может иметь несколько точек выхода: она может вызывать return в нескольких местах. Зонд, настроенный на возврат из функции, реагирует на все точки выхода. (См. главу 2, где объясняется, как это возможно.)
14 Одно из возможных решений — трассировка по смещению в функции, но этот прием еще менее стабилен, чем трассировка входа в функцию.
15 Для доступа к этим точкам трассировки системных вызовов ядро Linux должно быть собрано с включенным параметром CONFIG_FTRACE_SYSCALLS.
BPF расшифровывается как Berkeley Packet Filter (пакетный фильтр Беркли). Эта малоизвестная когда-то технология, разработанная в 1992 году, создавалась для увеличения производительности инструментов захвата пакетов [McCanne 92]. В 2013 году Алексей Старовойтов предложил существенно переделанную версию BPF5, развитие которой продолжил с Дэниелем Боркманом. В 2014 она была включена в ядро Linux6. Это превратило BPF в механизм выполнения общего назначения, который можно использовать для самых разных целей, включая создание продвинутых инструментов анализа производительности.
BPF расшифровывается как Berkeley Packet Filter (пакетный фильтр Беркли). Эта малоизвестная когда-то технология, разработанная в 1992 году, создавалась для увеличения производительности инструментов захвата пакетов [McCanne 92]. В 2013 году Алексей Старовойтов предложил существенно переделанную версию BPF5, развитие которой продолжил с Дэниелем Боркманом. В 2014 она была включена в ядро Linux6. Это превратило BPF в механизм выполнения общего назначения, который можно использовать для самых разных целей, включая создание продвинутых инструментов анализа производительности.
Первой инфраструктурой трассировки на основе BPF стала BCC (BPF Compiler Collection — коллекция компиляторов для BPF). Она предоставляет среду программирования на C для использования BPF и интерфейсы для других языков: Python, Lua и C ++. Она также дала начало библиотекам libbcc и текущей версии libbpf9 с функциями для обработки событий с помощью программ BPF. Репозиторий BCC содержит более 70 инструментов на основе BPF для анализа производительности и устранения неполадок. Вы можете установить BCC в своей системе и использовать готовые инструменты, не написав ни строчки кода для BCC. В этой книге вы познакомитесь со многими такими инструментами.
https://lore.kernel.org/netdev/1395404418-25376-1-git-send-email-dborkman@redhat.com/T/
https://lkml.org/lkml/2013/9/30/627
Раздел 2 в справочном руководстве Solaris предназначен для команд администрирования и обслуживания (в Linux ему соответствует раздел 8).
Программы на основе классической версии BPF [McCanne 92] автоматически выполняются под управлением расширенного механизма BPF. Кроме того, развитие классической технологии BPF было прекращено.
Первая версия libbpf была разработана Ван Нанем (Wang Nan) для использования с perf (https://lore.kernel.org/lkml/1435328155-87115-1-git-send-email-wangnan0@huawei.com/T/). Сейчас libbpf — это часть исходного кода ядра.
BPF может не иметь возможности непосредственно инструментировать прошивку на устройстве, но он может косвенно определять поведение на основе отслеживания событий драйвера ядра или PMC.
https://github.com/iovisor/ply
Функция имеет одну точку входа, но может иметь несколько точек выхода: она может вызывать return в нескольких местах. Зонд, настроенный на возврат из функции, реагирует на все точки выхода. (См. главу 2, где объясняется, как это возможно.)
Причины отказа принять DProbes в ядро Linux обсуждаются в первом примере в статье Энди Клина (Andi Kleen) «On submitting kernel patches», где дается ссылка на источник в Documentation/process/submitting-patches.rst (http://halobates.de/on-submitting-patches.pdf).
Для доступа к этим точкам трассировки системных вызовов ядро Linux должно быть собрано с включенным параметром CONFIG_FTRACE_SYSCALLS.
Одно из возможных решений — трассировка по смещению в функции, но этот прием еще менее стабилен, чем трассировка входа в функцию.
Расширенную версию BPF часто обозначают аббревиатурой eBPF (extended BPR — расширенная BPF), но официальной считается прежнее обозначение — BPF, без «e», поэтому в этой книге я буду использовать аббревиатуру «BPF». Ядро содержит только один механизм выполнения BPF (расширенный BPF), который выполняет инструкции как расширенной технологии BPF, так и «классической» BPF7.
Не у всех трассировщиков в названии есть слово «trace», как strace(1). Например, tcpdump(8) — это еще один специализированный инструмент трассировки сетевых пакетов. (Возможно, его следовало назвать tcptrace?) В ОС Solaris была своя версия tcpdump с именем snoop(1M)8, названная так потому, что использовалась для прослушивания (snooping) сетевых пакетов. Я был первым, кто разработал и опубликовал множество инструментов трассировки для Solaris, в названиях которых (может и неправильно) использовал «snoop». Поэтому у нас теперь есть execsnoop(8), opensnoop(8), biosnoop(8) и т.д. Прослушивание, вывод событий и трассировка обычно обозначают одно и то же. Эти инструменты будут описаны в следующих главах.
Глава 2. Основы технологии
В главе 1 были представлены различные технологии, используемые инструментами BPF. В главе 2 они рассматриваются более подробно: история их развития, интерфейсы, внутреннее устройство и использование в комплексе с BPF.
Это самая техническая глава в книге, и для краткости изложения я предполагаю, что у вас есть некоторое представление о внутренних компонентах ядра и программировании на уровне инструкций16.
Цель не в том, чтобы запомнить каждую страницу в этой главе, а в том, чтобы:
• познакомиться с историей происхождения BPF и современной ролью расширенного BPF;
• узнать, как выполнять обход фреймов стека и другие приемы;
• узнать, как читать флейм-графики;
• узнать, как использовать kprobes и uprobes, и познакомиться с причинами их нестабильности;
• разобраться с назначением точек трассировки, зондов USDT и динамического USDT;
• познакомиться со счетчиками мониторинга производительности (PMC) и приемами их использования с инструментами трассировки BPF;
• познакомиться с перспективными разработками: BTF и другими средствами обхода стека BPF.
Эта информация поможет освоить последующие главы, но если хотите, можете просто бегло просмотреть главу 2 и вернуться к ней позднее, когда потребуется более глубокое понимание. Глава 3 даст возможность начать практическое применение инструментов BPF для поиска и устранения узких мест производительности.
2.1. BPF в иллюстрациях
На рис. 2.1 показаны многие из технологий этой главы и то, как они связаны.

Рис. 2.1. Технологии трассировки BPF
2.2. BPF
Первоначально механизм BPF был разработан для ОС BSD и описан в 1992 году в статье «The BSD Packet Filter: A New Architecture for User-level Packet Capture» [McCanne 92]. Она была представлена на зимней конференции USENIX 1993 года в Сан-Диего вместе со статьей «Measurement, Analysis, and Improvement of UDP/IP Throughput for the DECstation 5000»17. Рабочие станции DEC давно ушли в прошлое, но технология BPF сохранилась как стандартное решение для фильтрации пакетов.
В BPF используется интересный принцип работы: выражение фильтра определяется конечным пользователем с помощью набора инструкций для виртуальной машины BPF (иногда их называют байт-кодом BPF) и передается ядру для выполнения интерпретатором. Это позволяет выполнять фильтрацию на уровне ядра без дорогостоящего копирования каждого пакета на уровне пользовательского процесса, что обеспечивает высокую производительность фильтрации пакетов, как, например, в tcpdump(8). Это решение также обеспечивает дополнительную безопасность, так как фильтры из пространства пользователя можно проверить на безопасность перед выполнением. Учитывая, что фильтрация пакетов происходит в пространстве ядра, требования к безопасности были очень жесткими. На рис. 2.2 показано, как это работает.
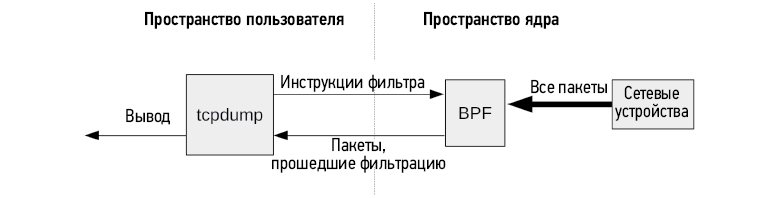
Рис. 2.2. tcpdump и BPF
При желании можно запустить команду tcpdump(8) с параметром -d, чтобы получить инструкции BPF, выражающие фильтр. Например:
# tcpdump -d host 127.0.0.1 and port 80
(000) ldh [12]
(001) jeq #0x800 jt 2 jf 18
(002) ld [26]
(003) jeq #0x7f000001 jt 6 jf 4
(004) ld [30]
(005) jeq #0x7f000001 jt 6 jf 18
(006) ldb [23]
(007) jeq #0x84 jt 10 jf 8
(008) jeq #0x6 jt 10 jf 9
(009) jeq #0x11 jt 10 jf 18
(010) ldh [20]
(011) jset #0x1fff jt 18 jf 12
(012) ldxb 4*([14]&0xf)
(013) ldh [x + 14]
(014) jeq #0x50 jt 17 jf 15
(015) ldh [x + 16]
(016) jeq #0x50 jt 17 jf 18
(017) ret #262144
(018) ret #0
Оригинальный механизм BPF, который сейчас называют «классическим BPF», представлял собой ограниченную виртуальную машину. Она имела два регистра, внутреннее хранилище с 16 ячейками памяти и счетчик программных инструкций. Все они работали с 32-битными регистрами18. В Linux классический BPF появился в 1997 году, в ядре 2.1.7519.
После включения BPF в ядро Linux были реализованы некоторые важные улучшения. Эрик Думазет (Eric Dumazet) добавил в ядро Linux 3.0, вышедшее в июле 2011 года20, динамический (JIT) компилятор BPF, имеющий более высокую производительность по сравнению с интерпретатором. В 2012 году Уилл Дрюри (Will Drewry) добавил фильтры BPF для политик безопасности системных вызовов seccomp21. Это было первое использование BPF за рамками сетевого стека, показавшее потенциал применения BPF в роли универсального механизма выполнения.
2.3. Расширенный BPF (eBPF)
Расширенная версия BPF был спроектирована Алексеем Старовойтовым, тогда работавшим в компании PLUMgrid и изучавшим новые способы создания программно-определяемых сетевых решений. Она могла бы стать первым серьезным усовершенствованием BPF за последние 20 лет и подняла бы BPF до уровня виртуальной машины общего назначения22. Когда расширенный BPF находился еще на стадии предложения, Дэниел Боркман, специалист по ядру из Red Hat, помог переработать его для включения в ядро в качестве замены имеющегося BPF23. Эта расширенная версия BPF была успешно включена в ядро, и с тех пор в ее развитии участвовали многие другие разработчики (см. раздел «Благодарности»).
В расширенный BPF было добавлено больше регистров, вместо 32-разрядных слов стали использоваться 64-разрядные, создано гибкое хранилище «карт» и разрешены вызовы некоторых ограниченных функций ядра24. Он также включает JIT-компиляцию с отображением «один к одному» в машинные инструкции и регистры, что позволяет повторно использовать методы оптимизации команд, реализованные ранее для BPF. Верификатор BPF тоже обновился и теперь поддерживает обработку этих расширений и отклоняет любой небезопасный код.
Основные различия между классическим и расширенным BPF перечислены в табл. 2.1.
Таблица 2.1. Основные различия между классическим и расширенным BPF
| Фактор |
Классический BPF |
Расширенный BPF |
| Количество регистров |
2: A, X |
10: R0–R9 и R10, как указатель на список фреймов стека, доступный только для чтения |
| Разрядность регистров |
32 бита |
64 бита |
| Хранилище |
16 ячеек памяти: M[0–15] |
512 байт в пространстве стека плюс неограниченное хранилище «карт» |
| Ограниченные вызовы ядра |
Очень ограниченный круг, определяемый JIT-компилятором |
Да, через инструкцию bpf_call |
| Целевые события |
Пакеты, seccomp-BPF |
Пакеты, функции в пространстве ядра, функции в пространстве пользователя, точки трассировки, пользовательские маркеры, счетчики производительности (PMC) |
Первоначальное предложение Алексея, отправленное в сентябре 2013 года, было набором патчей «extended BPF»25. А в декабре 2013 года Алексей уже предложил использовать его для трассировки фильтров26. После обсуждения и разработки совместно с Дэниелем в марте 2014 года27,28 патчи начали включаться в ядро Linux29. Компоненты JIT-компилятора были включены в Linux 3.15 в июне 2014 года, а системный вызов bpf(2) для управления механизмом BPF был добавлен в Linux 3.18 в декабре 2014 года30. Позднее в ветку Linux 4.x была добавлена поддержка BPF для kprobes, uprobes, точек трассировки и perf_events.
В самых ранних наборах патчей эта технология сокращенно обозначалась как eBPF, но позже Алексей перешел к использованию более простого названия BPF31. Все сообщество разработчиков BPF теперь называют ее в списке рассылки net-dev32 просто BPF.
На рис. 2.3 показана архитектура среды выполнения BPF в Linux, где видно, как инструкции BPF проходят проверку в верификаторе BPF перед выполнением виртуальной машиной BPF. Реализация виртуальной машины BPF включает как интерпретатор, так и JIT-компилятор: JIT-компилятор генерирует машинные инструкции для выполнения непосредственно на процессоре. Верификатор отклоняет небезопасные операции, включая неограниченные циклы: программы BPF должны завершаться в ограниченное время.
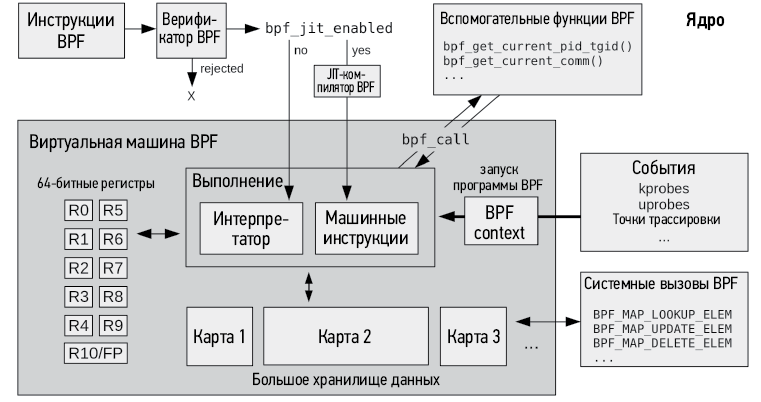
Рис. 2.3. Архитектура среды выполнения BPF
BPF может использовать вспомогательные функции для определения состояния ядра и карт BPF для хранения. Программа BPF запускается по событиям, включая события kprobes, uprobes и точки трассировки.
В разделах ниже обсуждается, зачем инструментам оценки производительности нужен механизм BPF и как писать программы для расширенного BPF, а также дается обзор инструкций BPF, BPF API, ограничений BPF и BTF. Эти разделы закладывают основы понимания особенностей работы BPF при использовании bpftrace и BCC. В приложении D рассказано о программировании BPF на языке C, а в приложении E описаны инструкции BPF.
2.3.1. Зачем инструментам оценки производительности нужен BPF
Инструменты оценки производительности используют возможность программирования расширенного BPF. Программы для BPF могут вычислять задержки и статистические характеристики. Эти возможности сами по себе интересны, хотя есть множество других инструментов трассировки с такими же возможностями. Отличительная черта BPF — это эффективность и безопасность для промышленного использования, а также его включение в ядро Linux. С помощью BPF эти инструменты можно запускать в промышленной среде без добавления любых новых компонентов ядра.
Рассмотрим некоторые результаты и диаграмму, чтобы понять, как инструменты оценки производительности используют BPF. Пример ниже получен с помощью одного из ранних инструментов BPF, который я опубликовал под названием bitehist. Он сообщает объем дискового ввода/вывода в виде гистограммы33:
# bitehist
Tracing block device I/O... Interval 5 secs. Ctrl-C to end.
kbytes : count distribution
0 -> 1 : 3 | |
2 -> 3 : 0 | |
4 -> 7 : 3395 |************************************* |
8 -> 15 : 1 | |
16 -> 31 : 2 | |
32 -> 63 : 738 |******* |
64 -> 127 : 3 | |
128 -> 255 : 1 | |
На рис. 2.4 показано, как BPF улучшает эффективность этого инструмента.
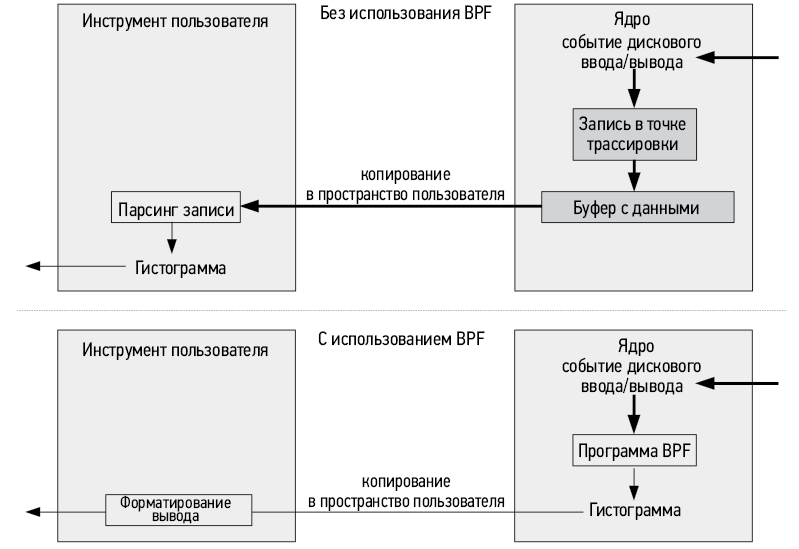
Рис. 2.4. Создание гистограммы до и после появления BPF
Главное отличие — при использовании BPF гистограмма генерируется в контексте ядра, что значительно уменьшает объем данных, копируемых в пространство пользователя. Этот выигрыш в эффективности настолько значителен, что инструменты можно использовать в промышленной среде (обычно это дорогостоящее мероприятие). Рассмотрим это более подробно.
Без использования BPF для получения гистограммы требуется34:
1. В ядре: включить перехват событий дискового ввода/вывода.
2. В ядре для каждого события: сохранить в буфере данных запись с информацией о событии. Если используются точки трассировки (что желательно), запись содержит несколько полей метаданных о дисковом вводе/выводе.
3. В пространстве пользователя: периодически копировать буфер со всеми событиями в пространство пользователя.
4. В пространстве пользователя: выполнить обход всех событий в буфере, извлечь из метаданных события значение поля с числом байтов. Остальные поля игнорировать.
5. В пространстве пользователя: сгенерировать гистограмму, опираясь на значения в поле с числом байтов.
Шаги со 2-го по 4-й имеют высокий оверхед в системах с большим объемом ввода/вывода. Представьте, что каждую секунду в пространство пользователя передаются для анализа и обобщения 10 000 записей с данными трассировки дискового ввода/вывода.
С использованием BPF программа bitesize должна:
1. В ядре: включить перехват событий дискового ввода/вывода и установить программу для BPF, определяемую программой bitesize.
2. В ядре для каждого события: запустить программу для BPF, которая извлекает только поле с числом байтов и сохраняет его в карте BPF для гистограммы.
3. В пространстве пользователя: прочитать карту BPF для гистограммы один раз и вывести ее.
Этот метод избавляет от оверхедов на копирование событий в пространство пользователя и их повторную обработку. Он также позволяет избежать копирования неиспользуемых полей метаданных. Единственные данные из вывода инструмента, которые копируются в пространство пользователя, — это столбец «count», являющийся массивом чисел.
2.3.2. BPF и модули ядра
Другой способ оценить преимущества механизма BPF — сравнить его с модулями ядра. Точки трассировки и kprobes существуют уже довольно давно, и их можно использовать непосредственно из загружаемых модулей ядра. Вот какие преимущества дает использование BPF перед модулями ядра:
• Программы для BPF проверяются с помощью верификатора: модули ядра могут содержать ошибки (способные вызвать крах ядра) или уязвимости безопасности.
• BPF поддерживает богатый набор структур посредством карт.
• Программы для BPF можно скомпилировать один раз и выполнять где угодно, потому что набор команд BPF, карты, вспомогательные функции и инфраструктура имеют стабильный ABI. (Но это не относится к отдельным программам трассировки для BPF, которые используют нестабильные компоненты, например kprobes, для инструментации структур ядра. Решение для этого случая приводится в разделе 2.3.10.)
• Программы для BPF не требуют компиляции модулей ядра.
• Программирование для BPF осваивается легче, чем программирование модулей ядра, что делает его доступным для большего числа людей.
Обратите внимание, что использование BPF для оценки работы сетевых сервисов дает дополнительные преимущества, в том числе возможность атомарной замены программ для BPF. Модуль ядра сначала нужно полностью выгрузить, а затем загрузить новую версию, что может вызвать сбои в работе сервиса.
Преимущество модулей ядра в том, что они могут задействовать другие функции и возможности ядра, не ограничиваясь узким кругом вспомогательных функций BPF. Однако это создает дополнительный риск появления ошибок при неправильном использовании функций ядра.
2.3.3. Разработка программ для BPF
BPF предлагает множество интерфейсов, доступных для программирования. Вот основные языки для трассировки, от самого низкого до самого высокого уровня:
• LLVM
• BCC
• bpftrace
Компилятор LLVM поддерживает BPF как одну из целей компиляции. Программы для BPF можно писать на языках высокого уровня, поддерживаемых компилятором LLVM, например на C (через Clang) или LLVM Intermediate Presentation (IR), а затем компилировать в инструкции BPF. LLVM включает оптимизатор, улучшающий эффективность и размер генерируемых инструкций BPF.
Разработка для BPF на LLVM IR — несомненное улучшение, но переход на BCC или bpftrace — еще лучше. BCC позволяет писать программы для BPF на языке C, а bpftrace предлагает свой язык высокого уровня. Внутренне они используют LLVM IR и библиотеку LLVM для компиляции в инструкции BPF.
Инструменты оценки производительности, представленные в этой книге, запрограммированы на BCC и bpftrace. Программирование непосредственно в инструкциях BPF или LLVM IR больше подходит для разработчиков, занимающихся созданием внутренних компонентов BCC и bpftrace, и обсуждение этой темы выходит за рамки книги. Это умение не требуется тем из нас, кто использует и разрабатывает инструменты оценки производительности для BPF35. Если вы хотите освоить программирование инструкций BPF или просто удовлетворить свое любопытство, вот несколько ресурсов для дополнительного чтения:
• В приложении E приводится краткое описание инструкций и макросов BPF.
• Описание инструкций BPF можно найти в дереве исходного кода ядра Linux, в файле Documentation/networking/filter.txt36.
• Описание LLVM IR есть в онлайн-документации LLVM. Начните с описания класса llvm::IRBuilderBase37.
• Справочное руководство по BPF и XDP в документации к подсистеме Cilium38.
Большинство из нас никогда не будет программировать с помощью инструкций BPF, но многие будут время от времени их встречать, например, столкнувшись с проблемами в инструментах. В следующих двух разделах я приведу примеры использования bpftool(8) и bpftrace.
2.3.4. Обзор инструкций BPF: bpftool
Интерфейс bpftool(8) был добавлен в Linux 4.15 для просмотра и управления объектами BPF, включая программы и карты. Его реализация находится в исходном коде Linux в tools/bpf/bpftool. В этом разделе я расскажу, как использовать bpftool(8) для поиска загруженных BPF-программ и вывода их содержимого.
bpftool
По умолчанию bpftool(8) выводит типы объектов, с которыми работает. Для Linux 5.2:
# bpftool
Usage: bpftool [OPTIONS] OBJECT { COMMAND | help }
bpftool batch file FILE
bpftool version
OBJECT := { prog | map | cgroup | perf | net | feature | btf }
OPTIONS := { {-j|--json} [{-p|--pretty}] | {-f|--bpffs} |
{-m|--mapcompat} | {-n|--nomount} }
Для каждого объекта есть своя справочная страница. Например, для программ:
# bpftool prog help
Usage: bpftool prog { show | list } [PROG]
bpftool prog dump xlated PROG [{ file FILE | opcodes | visual | linum }]
bpftool prog dump jited PROG [{ file FILE | opcodes | linum }]
bpftool prog pin PROG FILE
bpftool prog { load | loadall } OBJ PATH \
[type TYPE] [dev NAME] \
[map { idx IDX | name NAME } MAP]\
[pinmaps MAP_DIR]
bpftool prog attach PROG ATTACH_TYPE [MAP]
bpftool prog detach PROG ATTACH_TYPE [MAP]
bpftool prog tracelog
bpftool prog help
MAP := { id MAP_ID | pinned FILE }
PROG := { id PROG_ID | pinned FILE | tag PROG_TAG }
TYPE := { socket | kprobe | kretprobe | classifier | action |q
[...]
Подкоманды perf и prog можно использовать для поиска и вывода программ трассировки. К возможностям bpftool(8), которые здесь не рассматриваются, относятся: добавление программ, чтение и запись карт, работа с cgroups и получение списка возможностей BPF.
bpftool perf
Подкоманда perf выводит список программ BPF, подключенных через perf_event_open(), и это обычное дело для программ BCC и bpftrace в версиях Linux 4.17 и выше. Например:
# bpftool perf
pid 1765 fd 6: prog_id 26 kprobe func blk_account_io_start offset 0
pid 1765 fd 8: prog_id 27 kprobe func blk_account_io_done offset 0
pid 1765 fd 11: prog_id 28 kprobe func sched_fork offset 0
pid 1765 fd 15: prog_id 29 kprobe func ttwu_do_wakeup offset 0
pid 1765 fd 17: prog_id 30 kprobe func wake_up_new_task offset 0
pid 1765 fd 19: prog_id 31 kprobe func finish_task_switch offset 0
pid 1765 fd 26: prog_id 33 tracepoint inet_sock_set_state
pid 21993 fd 6: prog_id 232 uprobe filename /proc/self/exe offset 1781927
pid 21993 fd 8: prog_id 233 uprobe filename /proc/self/exe offset 1781920
pid 21993 fd 15: prog_id 234 kprobe func blk_account_io_done offset 0
pid 21993 fd 17: prog_id 235 kprobe func blk_account_io_start offset 0
pid 25440 fd 8: prog_id 262 kprobe func blk_mq_start_request offset 0
pid 25440 fd 10: prog_id 263 kprobe func blk_account_io_done offset 0
В этом списке видно три разных PID с разными программами BPF:
• PID 1765 — идентификатор агента Vector BPF PMDA для анализа экземпляра (подробности см. в главе 17).
• PID 21993 — версия biolatency(8), реализованная на основе bpftrace. Она выполняет две проверки uprobes: начало и конец программы bpftrace, а также две проверки kprobes: начала и конца блочного ввода/вывода (исходный код этой программы приводится в главе 9).
• PID 25440 — версия biolatency(8), реализованная на основе BCC(8), которая сейчас использует другую проверку начала блочного ввода/вывода.
Поле offset показывает смещение точки инструментации от начала объекта. В bpftrace смещение 1781920 соответствует функции BEGIN_trigger в двоичном файле bpftrace, а смещение 1781927 соответствует функции END_trigger (в чем можно убедиться, выполнив команду readelf -s bpftrace).
В поле prog_id выводятся числовые идентификаторы программ BPF, которые можно вывести с помощью следующих подкоманд.
bpftool prog show
Подкоманда prog show выводит список всех программ (не только тех, что основаны на perf_event_open()):
# bpftool prog show
[...]
232: kprobe name END tag b7cc714c79700b37 gpl
loaded_at 2019-06-18T21:29:26+0000 uid 0
xlated 168B jited 138B memlock 4096B map_ids 130
233: kprobe name BEGIN tag 7de8b38ee40a4762 gpl
loaded_at 2019-06-18T21:29:26+0000 uid 0
xlated 120B jited 112B memlock 4096B map_ids 130
234: kprobe name blk_account_io_ tag d89dcf82fc3e48d8 gpl
loaded_at 2019-06-18T21:29:26+0000 uid 0
xlated 848B jited 540B memlock 4096B map_ids 128,129
235: kprobe name blk_account_io_ tag 499ff93d9cff0eb2 gpl
loaded_at 2019-06-18T21:29:26+0000 uid 0
xlated 176B jited 139B memlock 4096B map_ids 128
[...]
258: cgroup_skb tag 7be49e3934a125ba gpl
loaded_at 2019-06-18T21:31:27+0000 uid 0
xlated 296B jited 229B memlock 4096B map_ids 153,154
259: cgroup_skb tag 2a142ef67aaad174 gpl
loaded_at 2019-06-18T21:31:27+0000 uid 0
xlated 296B jited 229B memlock 4096B map_ids 153,154
262: kprobe name trace_req_start tag 1dfc28ba8b3dd597 gpl
loaded_at 2019-06-18T21:37:51+0000 uid 0
xlated 112B jited 109B memlock 4096B map_ids 158
btf_id 5
263: kprobe name trace_req_done tag d9bc05b87ea5498c gpl
loaded_at 2019-06-18T21:37:51+0000 uid 0
xlated 912B jited 567B memlock 4096B map_ids 158,157
btf_id 5
В этом списке есть числовые идентификаторы программ bpftrace (с 232 по 235) и программ BCC (262 и 263), а также другие загруженные программы BPF. Обратите внимание, что для программ BCC kprobe выводится информация о формате BPF (BPF Type Format, BTF) в поле btf_id в этих выходных данных. Более подробно о BTF рассказывается в разделе 2.3.9, а пока просто имейте в виду, что BTF — это аналог отладочной информации для BPF.
bpftool prog dump xlated
По числовому идентификатору можно получить исходный код любой программы BPF. В режиме xlate выводятся ассемблерные инструкции BPF. Вот код программы с идентификатором 234, это программа bpftrace, отслеживающая завершение блочного ввода/вывода39:
# bpftool prog dump xlated id 234
0: (bf) r6 = r1
1: (07) r6 += 112
2: (bf) r1 = r10
3: (07) r1 += -8
4: (b7) r2 = 8
5: (bf) r3 = r6
6: (85) call bpf_probe_read#-51584
7: (79) r1 = *(u64 *)(r10 -8)
8: (7b) *(u64 *)(r10 -16) = r1
9: (18) r1 = map[id:128]
11: (bf) r2 = r10
12: (07) r2 += -16
13: (85) call __htab_map_lookup_elem#93808
14: (15) if r0 == 0x0 goto pc+1
15: (07) r0 += 56
16: (55) if r0 != 0x0 goto pc+2
[...]
Вывод показывает вызов одной из ограниченных вспомогательных функций ядра, доступных в BPF: bpf_probe_read(). (Другие вспомогательные функции перечислены в табл. 2.2.)
Теперь сравните этот код с кодом программы BCC с идентификатором 263, отслеживающей завершение блочного ввода/вывода, которая была скомпилирована с BTF40:
# bpftool prog dump xlated id 263
int trace_req_done(struct pt_regs * ctx):
; struct request *req = ctx->di;
0: (79) r1 = *(u64 *)(r1 +112)
; struct request *req = ctx->di;
1: (7b) *(u64 *)(r10 -8) = r1
; tsp = bpf_map_lookup_elem((void *)bpf_pseudo_fd(1, -1), &req);
2: (18) r1 = map[id:158]
4: (bf) r2 = r10
;
5: (07) r2 += -8
; tsp = bpf_map_lookup_elem((void *)bpf_pseudo_fd(1, -1), &req);
6: (85) call __htab_map_lookup_elem#93808
7: (15) if r0 == 0x0 goto pc+1
8: (07) r0 += 56
9: (bf) r6 = r0
; if (tsp == 0) {
10: (15) if r6 == 0x0 goto pc+101
; delta = bpf_ktime_get_ns() - *tsp;
11: (85) call bpf_ktime_get_ns#88176
; delta = bpf_ktime_get_ns() - *tsp;
12: (79) r1 = *(u64 *)(r6 +0)
[...]
Этот вывод включает информацию об исходном коде (выделена жирным) из BTF. Обратите внимание, что это другая программа (содержит другие инструкции и вызовы).
Модификатор linum добавляет информацию об исходном файле и номера строк, в том числе из BTF, если она доступна (выделена жирным):
# bpftool prog dump xlated id 263 linum
int trace_req_done(struct pt_regs * ctx):
; struct request *req = ctx->di; [file:/virtual/main.c line_num:42 line_col:29]
0: (79) r1 = *(u64 *)(r1 +112)
; struct request *req = ctx->di; [file:/virtual/main.c line_num:42 line_col:18]
1: (7b) *(u64 *)(r10 -8) = r1
; tsp = bpf_map_lookup_elem((void *)bpf_pseudo_fd(1, -1), &req);
[file:/virtual/main.c line_num:46 line_col:39]
2: (18) r1 = map[id:158]
4: (bf) r2 = r10
[...]
Здесь информация о номерах строк относится к виртуальным файлам, которые BCC создает при запуске программ.
Модификатор opcodes добавляет коды инструкций BPF (выделены жирным):
# bpftool prog dump xlated id 263 opcodes
int trace_req_done(struct pt_regs * ctx):
; struct request *req = ctx->di;
0: (79) r1 = *(u64 *)(r1 +112)
79 11 70 00 00 00 00 00
; struct request *req = ctx->di;
1: (7b) *(u64 *)(r10 -8) = r1
7b 1a f8 ff 00 00 00 00
; tsp = bpf_map_lookup_elem((void *)bpf_pseudo_fd(1, -1), &req);
2: (18) r1 = map[id:158]
18 11 00 00 9e 00 00 00 00 00 00 00 00 00 00 00
4: (bf) r2 = r10
bf a2 00 00 00 00 00 00
[...]
Коды инструкций BPF описаны в приложении E.
Есть и модификатор visual, который выводит граф потока управления в формате DOT для отображения с помощью внешнего ПО, например GraphViz и его инструмента отображения ориентированных графов dot(1)41:
# bpftool prog dump xlated id 263 visual > biolatency_done.dot
$ dot -Tpng -Elen=2.5 biolatency_done.dot -o biolatency_done.png
После этого можно заглянуть в файл PNG, чтобы посмотреть порядок выполнения инструкций. GraphViz предоставляет различные инструменты: для отображения данных в формате DOT я обычно использую dot(1), neato(1), fdp(1) и sfdp(1). Эти инструменты поддерживают различные настройки (например, параметр -Elen, определяющий длину ребра). На рис. 2.5 показан результат использования osage(1) из GraphViz для визуализации потока выполнения этой программы BPF.

Рис. 2.5. Диаграмма потока выполнения инструкций BPF, полученная с помощью GraphViz osage(1)
Как видите, программа довольно сложная. Другие инструменты GraphViz размещают блоки кода так, чтобы не допустить объединения стрелок в пучки, но создают файлы гораздо большего размера. Если вам понадобится исследовать инструкции подобной программы BPF, поэкспериментируйте с разными инструментами и подберите тот, который подойдет лучше всего.
bpftool prog dump jited
Подкоманда prog dump jited выводит машинный код, выполняемый процессором. В этом разделе показан код для архитектуры x86_64, но в BPF есть JIT-компиляторы для всех основных архитектур, поддерживаемых ядром Linux. Для программы BCC, отслеживающей завершение блочного ввода/вывода:
# bpftool prog dump jited id 263
int trace_req_done(struct pt_regs * ctx):
0xffffffffc082dc6f:
; struct request *req = ctx->di;
0: push %rbp
1: mov %rsp,%rbp
4: sub $0x38,%rsp
b: sub $0x28,%rbp
f: mov %rbx,0x0(%rbp)
13: mov %r13,0x8(%rbp)
17: mov %r14,0x10(%rbp)
1b: mov %r15,0x18(%rbp)
1f: xor %eax,%eax
21: mov %rax,0x20(%rbp)
25: mov 0x70(%rdi),%rdi
; struct request *req = ctx->di;
29: mov %rdi,-0x8(%rbp)
; tsp = bpf_map_lookup_elem((void *)bpf_pseudo_fd(1, -1), &req);
2d: movabs $0xffff96e680ab0000,%rdi
37: mov %rbp,%rsi
3a: add $0xfffffffffffffff8,%rsi
; tsp = bpf_map_lookup_elem((void *)bpf_pseudo_fd(1, -1), &req);
3e: callq 0xffffffffc39a49c1
[...]
Как отмечалось выше, наличие BTF для этой программы позволяет команде bpftool(8) включить строки исходного кода — иначе бы их не было.
bpftool btf
bpftool(8) также может выводить числовые идентификаторы BTF. Например, вот BTF ID 5 для программы BCC, отслеживающей завершение блочного ввода/вывода:
# bpftool btf dump id 5
[1] PTR '(anon)' type_id=0
[2] TYPEDEF 'u64' type_id=3
[3] TYPEDEF '__u64' type_id=4
[4] INT 'long long unsigned int' size=8 bits_offset=0 nr_bits=64 encoding=(none)
[5] FUNC_PROTO '(anon)' ret_type_id=2 vlen=4
'pkt' type_id=1
'off' type_id=2
'bofs' type_id=2
'bsz' type_id=2
[6] FUNC 'bpf_dext_pkt' type_id=5
[7] FUNC_PROTO '(anon)' ret_type_id=0 vlen=5
'pkt' type_id=1
'off' type_id=2
'bofs' type_id=2
'bsz' type_id=2
'val' type_id=2
[8] FUNC 'bpf_dins_pkt' type_id=7
[9] TYPEDEF 'uintptr_t' type_id=10
[10] INT 'long unsigned int' size=8 bits_offset=0 nr_bits=64 encoding=(none)
[...]
[347] STRUCT 'task_struct' size=9152 vlen=204
'thread_info' type_id=348 bits_offset=0
'state' type_id=349 bits_offset=128
'stack' type_id=1 bits_offset=192
'usage' type_id=350 bits_offset=256
'flags' type_id=28 bits_offset=288
[...]
Этот пример показывает, что BTF включает информацию о типах и структурах.
2.3.5. Обзор инструкций BPF: bpftrace
В отличие от команды tcpdump(8), которая выводит инструкции BPF при вызове с ключом -d, bpftrace выводит инструкции, если вызывается с ключом -v42:
# bpftrace -v biolatency.bt
Attaching 4 probes...
Program ID: 677
Bytecode:
0: (bf) r6 = r1
1: (b7) r1 = 29810
2: (6b) *(u16 *)(r10 -4) = r1
3: (b7) r1 = 1635021632
4: (63) *(u32 *)(r10 -8) = r1
5: (b7) r1 = 20002
6: (7b) *(u64 *)(r10 -16) = r1
7: (b7) r1 = 0
8: (73) *(u8 *)(r10 -2) = r1
9: (18) r7 = 0xffff96e697298800
11: (85) call bpf_get_smp_processor_id#8
12: (bf) r4 = r10
13: (07) r4 += -16
14: (bf) r1 = r6
15: (bf) r2 = r7
16: (bf) r3 = r0
17: (b7) r5 = 15
18: (85) call bpf_perf_event_output#25
19: (b7) r0 = 0
20: (95) exit
[...]
Такой вывод можно получить, даже если программа столкнется с ошибкой внутри bpftrace. Занимаясь разработкой внутренних компонентов bpftrace, легко столкнуться с ситуацией, когда программа отвергается верификатором BPF и не запускается. В таком случае можно распечатать инструкции и изучить их, чтобы определить и устранить проблему.
Большинство людей никогда не столкнется с внутренними ошибками bpftrace или BCC и не будет изучать инструкции BPF. Если у вас возникла такая проблема, отправьте тикет в проект bpftrace или BCC или, если сумеете, исправьте ее самостоятельно.
2.3.6. BPF API
Для лучшего понимания возможностей BPF в следующих разделах описаны отдельные части расширенного BPF API из файла include/uapi/linux/bpf.h в Linux 4.20.
Вспомогательные функции BPF
Программы BPF не могут вызывать произвольные функции ядра. Для решения определенных задач предусмотрен ограниченный круг «вспомогательных» функций, которые BPF может вызвать. Некоторые из этих функций перечислены в табл. 2.2.
Таблица 2.2. Некоторые вспомогательные функции BPF
| Вспомогательная функция BPF |
Описание |
| bpf_map_lookup_elem(map, key) |
Выполняет поиск ключа key в карте map и возвращает его значение (указатель) |
| bpf_map_update_elem(map, key, value, flags) |
Записывает значение value в элемент с ключом key |
| bpf_map_delete_elem(map, key) |
Удаляет элемент с ключом key из карты map |
| bpf_probe_read(dst, size, src) |
Безопасно читает size байт из адреса src и копирует их в dst |
| bpf_ktime_get_ns() |
Возвращает время в наносекундах, прошедших с момента загрузки |
| bpf_trace_printk(fmt, fmt_size, ...) |
Вспомогательная функция для отладки. Выводит в TraceFS trace{_pipe} |
| bpf_get_current_pid_tgid() |
Возвращает значение — 64-битное целое без знака, содержащее текущий TGID (в пространстве пользователя называется PID) в старшем 32-битном слове и PID (в пространстве пользователя называется идентификатором потока ядра) в младшем слове |
| bpf_get_current_comm(buf, buf_size) |
Копирует имя задачи в буфер buf |
| bpf_perf_event_output(ctx, map, data, size) |
Записывает данные data в кольцевой буфер perf_event; используется для регистрации отдельных событий |
| bpf_get_stackid(ctx, map, flags) |
Извлекает трассировку стека в пространстве пользователя или ядра и возвращает идентификатор |
| bpf_get_current_task() |
Возвращает структуру текущей задачи, которая содержит множество подробностей о запущенном процессе и ссылки на другие структуры, описывающие состояние системы. Обратите внимание, что эта функция относится к нестабильному API |
| bpf_probe_read_str(dst, size, ptr) |
Копирует строку, завершающуюся символом NULL, из небезопасного указателя ptr в буфер с адресом dst, но не более size байт (включая байт NULL) |
| bpf_perf_event_read_value(map, flags, buf, size) |
Читает счетчик perf_event и сохраняет его в буфере buf. С помощью этой функции программы BPF читают счетчики мониторинга производительности (PMC) |
| bpf_get_current_cgroup_id() |
Возвращает числовой идентификатор текущей группы cgroup |
| bpf_spin_lock(lock), bpf_spin_unlock(lock) |
Механизм управления конкурентностью (сoncurrency) в сетевых программах |
Некоторые из этих вспомогательных функций показаны в выводах, полученных выше с помощью bpftool(8) xlated и bpftrace -v.
Понятие текущий (current), встречающееся в описаниях функций, относится к текущему потоку, который в данный момент выполняется процессором.
Обратите внимание, что файл include/uapi/linux/bpf.h содержит подробное описание многих из этих вспомогательных функций. Вот выдержка из описания функции bpf_get_stackid()43:
* int bpf_get_stackid(struct pt_reg *ctx, struct bpf_map *map, u64 flags)
* Описание
* Отыскивает стек в пространстве пользователя или ядра и возвращает
* его идентификатор. Для этого функции следует передать *ctx*,
* указатель на контекст, в котором выполняется трассируемая
* программа, и указатель на *map* типа **BPF_MAP_TYPE_STACK_TRACE**.
*
* В последнем аргументе *flags* передается число пропускаемых
* фреймов стека (от 0 до 255) с маской **BPF_F_SKIP_FIELD_MASK**.
* Это число можно комбинировать со следующими флагами:
*
* **BPF_F_USER_STACK**
* Выбрать стек из пространства пользователя,
а не из пространства ядра.
* **BPF_F_FAST_STACK_CMP**
* Сравнивать стеки только по значению хеша.
* **BPF_F_REUSE_STACKID**
* Если два разных стека хешируются в один и тот же *stackid*,
* отбросить более старый.
*
* Возвращает 32-битный дескриптор стека, который в дальнейшем можно
* комбинировать с другими данными (включая идентификаторы других
* стеков) и использовать как ключи в картах. Это может пригодиться
* для создания разных графиков (флейм-графики или графики
* ожидания вызова (off-cpu)).
[...]
Эти файлы можно просматривать онлайн на любом сайте, где размещены исходные тексты ядра Linux, например: https://github.com/torvalds/linux/blob/master/include/uapi/linux/bpf.h.
На самом деле вспомогательных функций гораздо больше, но большинство из них предназначено для реализации программно-определяемых сетей. Текущая версия Linux (5.2) включает 98 вспомогательных функций.
bpf_probe_read()
bpf_probe_read() — одна из особенно важных вспомогательных функций. Доступ к памяти в BPF ограничен регистрами BPF и стеком (а также картами BPF через вспомогательные функции). Функция bpf_probe_read() позволяет читать данные из произвольной памяти (например, из другой памяти ядра вне BPF), попутно выполняя проверки безопасности и отключая ошибки доступа к страницам, чтобы гарантировать, что попытка чтения не вызовет сбой в контексте проверки (что, в свою очередь, может вызвать проблемы с ядром).
Помимо чтения памяти ядра эта функция также часто используется для копирования данных из пространства пользователя в пространство ядра. Порядок работы зависит от архитектуры: в архитектуре x86_64 адресные пространства пользователя и ядра не перекрываются, поэтому режим можно определить по адресу. Это не относится к другим архитектурам, таким как SPARC44, для поддержки которых в BPF используются дополнительные вспомогательные функции: bpf_probe_read_kernel() и bpf_probe_read_user()45.
Команды системного вызова bpf
В табл. 2.3 перечислены некоторые операции BPF, которые можно выполнять из пространства пользователя.
Таблица 2.3. Некоторые команды системного вызова bpf
| bpf_cmd |
Описание |
| BPF_MAP_CREATE |
Создает карту BPF: гибкое хранилище объектов, которое можно использовать как хеш-таблицу (ассоциативный массив), хранящую пары ключ — значение |
| BPF_MAP_LOOKUP_ELEM |
Ищет элемент с заданным ключом |
| BPF_MAP_UPDATE_ELEM |
Изменяет элемент с заданным ключом |
| BPF_MAP_DELETE_ELEM |
Удаляет элемент с заданным ключом |
| BPF_MAP_GET_NEXT_KEY |
Выполняет итерации по всем ключам в карте |
| BPF_PROG_LOAD |
Проверяет и загружает программу BPF |
| BPF_PROG_ATTACH |
Подключает программу к событию |
| BPF_PROG_DETACH |
Отключает программу от события |
| BPF_OBJ_PIN |
Создает экземпляр объекта BPF в /sys/fs/bpf |
Эти команды передаются в первом аргументе системному вызову bpf(2). Увидеть их в действии можно с помощью strace(1). Например, исследуем системные вызовы bpf(2), выполняемые при запуске инструмента BCC execsnoop(8):
# strace -ebpf execsnoop
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_PERF_EVENT_ARRAY, key_size=4,
value_size=4, max_entries=8, map_flags=0, inner_map_fd=0, ...}, 72) = 3
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_KPROBE, insn_cnt=513,
insns=0x7f31c0a89000, license="GPL", log_level=0, log_size=0, log_buf=0,
kern_version=266002, prog_flags=0, ...}, 72) = 4
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_KPROBE, insn_cnt=60,
insns=0x7f31c0a8b7d0, license="GPL", log_level=0, log_size=0, log_buf=0,
kern_version=266002, prog_flags=0, ...}, 72) = 6
PCOMM PID PPID RET ARGS
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=3, key=0x7f31ba81e880, value=0x7f31ba81e910,
flags=BPF_ANY}, 72) = 0
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=3, key=0x7f31ba81e910, value=0x7f31ba81e880,
flags=BPF_ANY}, 72) = 0
[...]
Команды в этом выводе выделены жирным. Обычно я стараюсь избегать использования strace(1), поскольку его текущая реализация ptrace() может значительно замедлить целевой процесс — более чем в 100 раз46. Здесь я использовал эту команду, потому что она уже поддерживает системный вызов bpf(2) и преобразует числа в читаемые строки (например, «BPF_PROG_LOAD»).
Типы программ BPF
Тип программы BPF определяет тип событий, к которым ее можно подключать, и аргументы для событий. Основные типы программ трассировки на основе BPF перечислены в табл. 2.4.
Таблица 2.4. Типы программ трассировки на основе BPF
| bpf_prog_type |
Описание |
| BPF_PROG_TYPE_KPROBE |
Для kprobes и uprobes |
| BPF_PROG_TYPE_TRACEPOINT |
Для точек трассировки |
| BPF_PROG_TYPE_PERF_EVENT |
Для perf_events, включая счетчики мониторинга производительности (PMC) |
| BPF_PROG_TYPE_RAW_TRACEPOINT |
Для точек трассировки, без обработки аргументов |
Предыдущий вывод команды strace(1) включал два вызова BPF_PROG_LOAD с типом BPF_PROG_TYPE_KPROBE, так как эта версия execsnoop(8) использует kprobe и kretprobe для инструментации начала и окончания выполнения execve().
В bpf.h есть дополнительные типы программ для анализа сетевых взаимодействий и для других целей, включая те, что перечислены в табл. 2.5.
Таблица 2.5. Некоторые другие типы программ BPF
| bpf_prog_type |
Описание |
| BPF_PROG_TYPE_SOCKET_FILTER |
Для подключения к сокетам — традиционная сфера использования BPF |
| BPF_PROG_TYPE_SCHED_CLS |
Для классификации управляющего трафика |
| BPF_PROG_TYPE_XDP |
Для программ eXpress Data Path |
| BPF_PROG_TYPE_CGROUP_SKB |
Для фильтров пакетов в cgroup (skb) |
Типы карт BPF
Типы карт BPF, включая те, что перечислены в табл. 2.6, определяют разные типы карт.
Таблица 2.6. Некоторые типы карт BPF
| bpf_map_type |
Описание |
| BPF_MAP_TYPE_HASH |
Хеш-таблица: хранилище пар ключ — значение |
| BPF_MAP_TYPE_ARRAY |
Массив элементов |
| BPF_MAP_TYPE_PERF_EVENT_ARRAY |
Интерфейс циклических буферов perf_event для отправки записей трассировки в пространство пользователя |
| BPF_MAP_TYPE_PERCPU_HASH |
Быстрая хеш-таблица, поддерживаемая для каждого процессора |
| BPF_MAP_TYPE_PERCPU_ARRAY |
Быстрый массив, поддерживаемый для каждого процессора |
| BPF_MAP_TYPE_STACK_TRACE |
Хранилище для трассировок стека, индексируемое идентификаторами стеков |
| BPF_MAP_TYPE_STACK |
Хранилище для трассировок стека |
Предыдущий вывод команды strace(1) включает команду BPF_MAP_CREATE создания карты с типом BPF_MAP_TYPE_PERF_EVENT_ARRAY, которая используется в execsnoop(8) для передачи событий в пространство пользователя для печати.
В bpf.h определено еще много типов карт для специальных целей.
2.3.7. Управление конкурентностью в BPF
Первоначально в BPF отсутствовали средства управления конкурентностью, и только в Linux 5.1 были добавлены вспомогательные циклические блокировки (spin lock). (Но пока они недоступны для использования в программах трассировки.) В ходе трассировки параллельно выполняющиеся потоки могут одновременно искать и изменять поля карты BPF, что может приводить к повреждениям, когда один поток затирает данные, записанные другим потоком. Эта проблема известна как проблема «потерянных изменений», когда конкурентные операции чтения и записи перекрываются, что приводит к потере изменений. Интерфейсы трассировки, BCC и bpftrace, по возможности, используют хеш-таблицы и массивы, отдельные для каждого процессора, чтобы избежать таких повреждений. Они создают экземпляры для каждого логического процессора, чтобы параллельные потоки не изменяли общие данные. Например, карту, ведущую счет событиям, можно изменять для каждого процессора в отдельности, а затем объединять отдельные значения, когда потребуется получить суммарное количество.
В качестве примера ниже приводится однострочная программа bpftrace, использующая отдельный хеш для каждого процессора с целью подсчета:
# strace -febpf bpftrace -e 'k:vfs_read { @ = count(); }'
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_PERCPU_HASH, key_size=8, value_size=8,
max_entries=128, map_flags=0, inner_map_fd=0}, 72) = 3
[...]
А вот однострочная программа bpftrace, использующая обычный хеш:
# strace -febpf bpftrace -e 'k:vfs_read { @++; }'
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_HASH, key_size=8, value_size=8,
max_entries=128, map_flags=0, inner_map_fd=0}, 72) = 3
[...]
При одновременном их использовании в восьмипроцессорной системе для трассировки часто вызываемой функции, которая может работать параллельно, получаются следующие результаты:
# bpftrace -e 'k:vfs_read { @cpuhash = count(); @hash++; }'
Attaching 1 probe...
^C
@cpuhash: 1061370
@hash: 1061269
Сравнение счетчиков показывает, что количество событий в нормальном хеше занижено на 0.01%.
Помимо карт, поддерживаемых для каждого процессора в отдельности, есть и другие механизмы управления конкурентностью, в том числе инструкция исключающего сложения (BPF_XADD), карта в карте, которая может обновлять целые карты атомарно, и циклические блокировки BPF. Изменение обычного хеша и карты LRU с помощью bpf_map_update_elem() выполняется атомарно и не подвержено состоянию гонки при одновременном выполнении нескольких операций записи. Циклические блокировки, которые были добавлены в Linux 5.1, управляются с помощью вспомогательных функций bpf_spin_lock() и bpf_spin_unlock()47.
2.3.8. Интерфейс sysfs для BPF
В Linux 4.4 появились команды для организации доступа к программам и картам BPF через виртуальную файловую систему, обычно монтируемую в /sys/fs/bpf. Эта возможность, получившая название «закрепление» (pinning), имеет множество применений. Она позволяет создавать программы BPF, действующие постоянно (подобно демонам) и продолжающие работать после завершения процесса, который их загрузил. Это предоставляет программам пользовательского уровня еще один способ взаимодействия с работающей программой BPF: они могут читать и писать данные в карты BPF.
Механизм закрепления не используется инструментами трассировки на основе BPF, представленными в этой книге, которые запускаются и останавливаются подобно стандартным утилитам Unix. Тем не менее любой из этих инструментов можно превратить в закрепленный, если потребуется. Обычно этот прием используется в сетевых программах (например, в Cilium48).
В качестве примера можно привести ОС Android, где механизм закрепления используется для автоматической загрузки и закрепления BPF-программ, находящихся в /system/etc/bpf49. Для взаимодействия с этими закрепленными программами в библиотеке Android предусмотрены специальные функции.
2.3.9. BPF Type Format (BTF)
Одна из повторяющихся проблем, описанная в этой книге, — это отсутствие информации об инструментируемом коде, что затрудняет разработку инструментов BPF. И идеальным решением этих проблем будет представленный здесь формат BTF.
BTF (BPF Type Format) — это формат метаданных, которые определяют отладочную информацию для описания программ BPF, карт BPF и многого другого. Название «BTF» выбрано потому, что первоначально этот формат использовался для описания типов данных, однако позднее был расширен для включения информации об определенных подпрограммах, об именах файлов с исходным кодом и номерах строк в этих файлах, а также о глобальных переменных.
Отладочная информация BTF может встраиваться в двоичный файл vmlinux или генерироваться вместе с программами BPF компилятором Clang или LLVM JIT, что упрощает проверку программ BPF с помощью загрузчиков (например, libbpf) и инструментов (например, bpftool(8)). Инструменты проверки и трассировки, включая bpftool(8) и perf(1), могут извлекать эту информацию и, опираясь на нее, выводить аннотированные исходники программ BPF или пары ключ — значение, хранящиеся в картах с учетом их структуры на языке C вместо «сырого» шестнадцатеричного дампа. Это показывают примеры использования bpftool(8) для вывода кода программ BCC, скомпилированных с использованием LLVM-9.
Помимо описания программ BPF, формат BTF можно использовать как универсальный формат описания всех структур данных в ядре. В некотором смысле его можно считать легковесной альтернативой отладочной информации в ядре для использования BPF и более полной и надежной альтернативой заголовкам ядра.
Инструменты трассировки BPF часто требуют установки заголовков ядра (обычно распространяются в виде пакета linux-headers), чтобы можно было перемещаться по различным структурам на языке C. Но эти заголовки содержат определения не всех структур, имеющихся в ядре, что затрудняет разработку некоторых инструментов BPF: решить эту проблему можно, определив отсутствующие структуры в исходном коде инструментов BPF. Есть и проблемы со сложными заголовками, которые обрабатываются неправильно. В таких случаях bpftrace предпочитает прервать выполнение вместо использования потенциально неправильных смещений полей внутри структур. BTF позволяет решить и эту проблему, предоставляя надежные определения для всех структур. (Результат выполнения bpftool btf показывает, как можно включить task_struct.) В будущем двоичный файл ядра Linux vmlinux, содержащий BTF, будет самоописательным.
На момент написания этой книги формат BTF все еще находился в разработке. Чтобы поддержать инициативу «скомпилировать один раз, выполнять везде» (compile-once-run-everywhere), нужно добавить в BTF больше информации. Новую информацию о BTF ищите в Documentation/bpf/btf.rst в исходных текстах ядра50.
2.3.10. BPF CO-RE
Цель проекта BPF Compile Once — Run Everywhere (CO-RE) — один раз скомпилировать программы BPF в байт-код BPF, сохранить, а затем распространять и выполнять их в других системах. Это позволит не устанавливать компиляторы BPF (LLVM и Clang) везде и всюду, что может быть непросто во встраиваемых системах Linux, имеющих ограниченный объем памяти, а также избежать затрат вычислительных ресурсов и памяти на запуск компилятора при каждом запуске инструмента BPF.
В проекте CO-RE (программист Андрий Накрийко (Andrii Nakryiko)) ведется работа над такими проблемами, как разные смещения в структурах ядра в разных системах, что требует переопределять смещения полей в байт-коде BPF при необходимости. Другая проблема — отсутствие членов структур, из-за этого приходится применять условный доступ к полям в зависимости от версии ядра, его конфигурации и/или предоставленных пользователем флагов времени выполнения. Проект CO-RE будет использовать информацию BTF, и на момент написания этой книги он все еще находился в стадии разработки.
2.3.11. Ограничения BPF
Программы BPF не могут вызывать произвольные функции ядра, им доступны только вспомогательные функции BPF, перечисленные в определении API. Но их список может быть расширен в будущих версиях ядра. Программы BPF также накладывают ограничения на использование циклов: было бы небезопасно разрешать программам BPF использовать бесконечные циклы в произвольных потоках kprobes, потому что они могут содержать критические блокировки, блокирующие работу остальной части системы. К обходным решениям этой проблемы можно отнести развертывание циклов и добавление вспомогательных функций, позволяющих решать задачи, которые требуют применения циклов. В Linux 5.3 появилась поддержка ограниченных циклов в BPF, для которых определяется проверяемый верхний предел времени выполнения51.
Размер стека BPF ограничен значением MAX_BPF_STACK, равным 512. Этот предел иногда превращается в серьезное ограничение в инструментах трассировки BPF, особенно при сохранении в стеке нескольких строковых буферов: один буфер, объявленный как char[256], занимает половину этого стека. Планов по увеличению этого ограничения нет. Для решения проблемы нехватки стека предлагается использовать хранилище карт BPF, которое фактически бесконечно. Началась работа по переносу строк bpftrace в хранилище карт вместо стека.
Первоначально число инструкций в программе BPF было ограничено 4096. Иногда длинные программы BPF сталкивались с этим пределом (и сталкивались бы с ним гораздо чаще без оптимизаций компилятора LLVM, которые сокращают количество команд). В Linux 5.2 этот предел существенно увеличен и не должен вызывать проблем52. Цель верификатора BPF — принять любую безопасную программу, и ограничения не должны мешать этому.
2.3.12. Дополнительные источники о BPF
Вот список дополнительных источников о расширенном BPF:
• Documentation/networking/filter.txt в исходных текстах ядра53;
• Documentation/bpf/bpf_design_QA.txt в исходных текстах ядра54;
• страница справочного руководства bpf(2)55;
• страница справочного руководства bpf-helpers(7)56;
• статья Джонатана Корбета (Jonathan Corbet) «BPF: the universal in-kernel virtual machine»57;
• статья Сучакры Шармы (Suchakra Sharma) «BPF Internals — II»58;
• справочное руководство по BPF и XDP в документации к Cilium59.
Дополнительные примеры программ BPF приводятся в главе 4 и в приложениях C, D и E.
2.4. Обход трассировки стека
Трассировка стека — бесценный инструмент для понимания пути кода, который привел к событию, а также профилирования кода ядра и уровня пользователя для наблюдения за тем, на что тратится время выполнения. Для записи трассировок стека BPF предоставляет специальные типы карт и может извлекать их, выполняя обход стека с использованием указателей на список фреймов или ORC. В будущем в BPF могут также появиться другие методы обхода стека.
2.4.1. Стеки на основе указателя на список фреймов
Метод с использованием указателя на список фреймов (frame pointer) основан на соглашении, в соответствии с которым заголовок связанного списка фреймов стека всегда находится в регистре проц



















