

автордың кітабын онлайн тегін оқу Производительность систем
Переводчик А. Киселев
Брендан Грегг
Производительность систем. — СПб.: Питер, 2023.
ISBN 978-5-4461-1818-2
© ООО Издательство "Питер", 2023
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Посвящается Дейрдре Страуган, удивительному специалисту и удивительному человеку, — мы сделали это!
Предисловие
Есть известные известные — вещи, о которых мы знаем, что знаем их. Есть также известные неизвестные — вещи, о которых мы знаем, что не знаем. Но еще есть неизвестные неизвестные — это вещи, о которых мы не знаем, что не знаем их.
Министр обороны США Дональд Рамсфельд, 12 февраля 2002 г.
Это заявление на пресс-брифинге встретили с усмешками. Однако оно определяет принцип, одинаково важный и для сложных технических систем, и для геополитики: проблемы с эффективностью могут возникать где угодно, включая те области системы, о которых вы ничего не знаете и поэтому не проверяете (неизвестные неизвестные). Эта книга поможет раскрыть многие из таких областей, а также предоставит методики и инструменты для их анализа.
Об этом издании
Первое издание я написал восемь лет назад и рассчитывал, что оно будет актуально достаточно долго. Главы структурированы так, чтобы сначала охватить то, что постоянно (модели, архитектуры и методологии), а затем то, что быстро меняется (инструменты и настройки). Инструменты и приемы настройки устаревают, но знание базовых вещей поможет всегда оставаться в курсе последних изменений.
За последние восемь лет в Linux появилось большое дополнение: Extended BPF — технология ядра, которая поддерживает новое поколение инструментов анализа производительности и используется в Netflix и Facebook. В это новое издание я включил главу о BPF и инструментах BPF, а также опубликовал подробный справочник по BPF [Gregg 19]. Инструменты perf и Ftrace в ОС Linux также претерпели множество изменений, и я добавил для них отдельные главы. Ядро Linux получило множество новых технологий и параметров оценки производительности, которые тоже рассматриваются в этом издании книги. Гипервизоры, управляющие облачными виртуальными машинами, и контейнерные технологии тоже существенно изменились, и главы, посвященные им, были обновлены и дополнены.
Первое издание в равной степени охватывало Linux и Solaris. Однако доля рынка Solaris за эти годы сильно сократилась [ITJobsWatch 20], поэтому я почти полностью убрал из этого издания все, что касалось Solaris, освободив место для дополнительной информации о Linux. Но как мне кажется, возможность сравнения с альтернативами укрепит общее понимание операционной системы или ядра. По этой причине я включил в это издание некоторые упоминания о Solaris и других ОС.
Последние шесть лет я работал старшим перформанс-инженером в Netflix, используя свои знания для оценки производительности микросервисов в Netflix и устранения проблем. Я занимался вопросами производительности гипервизоров, контейнеров, библиотек, ядер, баз данных и приложений. По мере необходимости я разрабатывал новые методологии и инструменты и обменивался опытом с экспертами в области производительности облачных систем и разработки ядра Linux. Все это в немалой степени улучшило второе издание книги.
Об этой книге
Итак, добро пожаловать во второе издание «Производительности систем»! Книга посвящена производительности (performance) ОС и приложений в контексте операционной системы и охватывает корпоративные серверы и облачные среды. Большая часть информации из книги может пригодиться также для анализа производительности клиентских устройств и ОС настольных компьютеров. Моя цель — помочь вам получить максимальную отдачу от ваших систем, какими бы они ни были.
При работе с прикладным программным обеспечением, находящимся в постоянном развитии, может возникнуть соблазн думать об эффективности ОС, ядро которой разрабатывалось и настраивалось десятилетиями, как о решенной проблеме. Но это не так! Операционная система — это сложный комплекс ПО, управляющего множеством постоянно меняющихся физических устройств и различными прикладными рабочими нагрузками. Ядра тоже находятся в постоянном развитии, в них добавляются новые возможности увеличения производительности определенных рабочих нагрузок, а вновь возникающие узкие места устраняются по мере масштабирования системы. Изменения в ядре, например, устраняющие уязвимость Meltdown и представленные в 2018 году, тоже могут отрицательно сказываться на производительности. Анализ и работа над улучшением производительности ОС — это непрерывный процесс. Производительность приложений тоже можно проанализировать в контексте операционной системы, чтобы отыскать подсказки, которые можно упустить при использовании только инструментов для приложений; об этом я тоже расскажу.
Рассматриваемые операционные системы
Эта книга изучает производительность систем. В роли основного представителя выступают ОС на базе Linux для процессоров Intel. Но книга организована так, чтобы вы могли изучить и другие ядра для других аппаратных архитектур.
Для представленных примеров конкретный дистрибутив Linux не важен, если явно не указано иное. Основная масса примеров была получена в дистрибутиве Ubuntu, и там, где это важно, в текст включены примечания, объясняющие отличия от других дистрибутивов. В книге приводятся примеры, полученные в системах различных типов: без операционной системы (на «голом железе») и в виртуальных средах, на производственных и тестовых машинах, на серверах и клиентских устройствах.
В своей работе я сталкивался со множеством разных операционных систем и ядер, что углубило мое понимание их дизайна. Чтобы вы могли во всем разобраться, в книгу включены некоторые упоминания о Unix, BSD, Solaris и Windows.
Другие материалы
Примеры скриншотов инструментов анализа производительности включены не только чтобы показать данные, но и для иллюстрации видов доступных данных. Инструменты часто представляют данные простым и понятным способом, многие из них реализованы в стиле, знакомом по более ранним инструментам для Unix. Учитывая это, скриншоты могут быть мощным средством показать назначение этих инструментов почти без дополнительного описания. (Если инструмент требует подробного объяснения, это может быть признаком неудачного дизайна.)
Там, где это уместно, я затрагиваю историю появления определенных технологий. Также полезно узнать немного о ключевых людях в этой отрасли: вы наверняка сталкивались с ними или их работой в сфере эффективности и в других контекстах. Их имена вы найдете в приложении E.
Некоторые темы, рассматриваемые в этом издании, также были освещены в моей предыдущей книге, «BPF Performance Tools»1 [Gregg 19]: в частности, BPF, BCC, bpftrace, tracepoints, kprobes, uprobes и множество других инструментов на основе BPF. В этой книге вы найдете дополнительную информацию. Краткое изложение этих тем здесь часто основано на той, более ранней книге. Иногда я использую тот же текст и примеры.
О чем здесь не рассказывается
Эта книга посвящена производительности. Для выполнения всех приведенных примеров потребуются некоторые действия по администрированию системы, включая установку или компиляцию программного обеспечения (которые здесь не рассматриваются).
Также здесь кратко описывается внутреннее устройство операционной системы, которое более подробно рассматривается в специализированных изданиях. Вопросы, касающиеся углубленного анализа производительности, здесь рассмотрены в общих чертах — лишь для того, чтобы вы знали об их существовании и могли заняться их изучением по другим источникам. См. раздел «Дополнительные источники, ссылки и библиография» в конце предисловия.
Структура
Глава 1 «Введение» — это введение в анализ производительности системы. Глава обобщает ключевые идеи и приводит примеры действий, направленных на улучшение производительности.
Глава 2 «Методологии» формирует основу для анализа и настройки производительности и описывает терминологию, основные понятия, модели, методологии для наблюдения и экспериментов, планирование емкости, анализ и статистику.
Глава 3 «Операционные системы» описывает внутреннее устройство ядра с точки зрения анализа производительности. Глава закладывает основы, необходимые для интерпретации и понимания действий операционной системы.
Глава 4 «Инструменты наблюдения» знакомит с доступными средствами наблюдения за системой, а также интерфейсами и фреймворками, на которых они построены.
Глава 5 «Приложения» обсуждает вопросы производительности приложений и наблюдение за ними из операционной системы.
Глава 6 «Процессоры» рассматривает процессоры, ядра, аппаратные потоки выполнения, кэш-память процессора, взаимосвязи между процессорами, взаимосвязи между устройствами и механизмы планирования в ядре.
Глава 7 «Память» посвящена виртуальной памяти, страничной организации, механизму подкачки, архитектурам памяти, шинам, адресным пространствам и механизмам распределения памяти.
Глава 8 «Файловые системы» посвящена производительности операций ввода/вывода с файловой системой, включая различные механизмы кэширования.
Глава 9 «Диски» описывает устройства хранения, рабочие нагрузки дискового ввода/вывода, контроллеры хранилищ, дисковые массивы RAID и подсистему ввода/вывода ядра.
Глава 10 «Сеть» посвящена сетевым протоколам, сокетам, интерфейсам и физическим соединениям.
Глава 11 «Облачные вычисления» знакомит с методами виртуализации операционных систем и оборудования, которые обычно используются для организации облачных вычислений, а также с их характеристиками производительности, изоляции и наблюдаемости. В этой главе также рассматриваются гипервизоры и контейнеры.
Глава 12 «Бенчмаркинг» показывает, как правильно проводить сравнительный анализ и как интерпретировать результаты бенчмаркинга. Это на удивление сложная тема, и в этой главе я покажу, как избежать типичных ошибок, и попробую объяснить их смысл.
Глава 13 «perf» кратко описывает стандартный профилировщик Linux, perf(1), и его многочисленные возможности. Ссылки на этот справочник по perf(1) вы будете встречать по всей книге.
Глава 14 «Ftrace» кратко описывает стандартное средство трассировки Linux, Ftrace, которое особенно подходит для исследования особенностей работы ядра.
Глава 15 «BPF» кратко описывает стандартные внешние интерфейсы BPF: BCC и bpftrace.
Глава 16 «Пример из практики» содержит пример исследования производительности системы, проводившегося в Netflix. Он показывает, как проводился анализ производительности.
Главы 1–4 содержат важную базовую информацию. Прочитав их, вы будете готовы перейти к любой из остальных глав в книге, в частности к главам 5–12, в которых рассматриваются конкретные цели для анализа.
Главы 13–15 посвящены продвинутому профилированию и трассировке и являются факультативным чтением для тех, кто хочет подробнее изучить один или несколько трассировщиков.
В главе 16 я привожу истории, которые позволят сформировать более широкое представление о работе перформанс-инженера. Если вы только начинаете заниматься анализом производительности, то можете прочитать сначала эту главу. Она покажет пример анализа производительности с использованием множества различных инструментов. Вы можете вернуться к ней после прочтения других глав.
Применимость в будущем
Я писал эту книгу так, чтобы ее полезность сохранялась на долгие годы. Основное внимание в ней уделяется опыту и методологиям анализа производительности систем.
Для этого многие главы были разделены на две части. Первая часть включает определения, описание понятий и методологий (часто соответствующие разделы именно так и называются), которые должны оставаться актуальными на протяжении многих лет. Во второй части приводятся примеры реализации: архитектура, инструменты анализа и настраиваемые параметры. Они могут устареть, но все же останутся полезными в качестве примеров.
Примеры трассировки
Часто требуется глубоко изучить операционную систему, чтобы знать, что можно сделать с помощью инструментов трассировки.
Уже после выхода первого издания была разработана и внедрена в ядро Linux расширенная технология BPF, в результате чего появилось новое поколение инструментов трассировки, использующих внешние интерфейсы BCC и bpftrace. Эта книга посвящена BCC и bpftrace, а также встроенному в ядро Linux трассировщику Ftrace. BPF, BCC и bpftrace более подробно описаны в моей предыдущей книге [Gregg 19].
В книге рассматривается еще один инструмент трассировки Linux — perf. Но perf здесь в основном используется для получения и анализа счетчиков контроля производительности (performance monitoring counter, PMC), а не для трассировки.
Возможно, вы захотите использовать другие инструменты трассировки, и это нормально. Представленные в этой книге инструменты показывают, какие вопросы можно задать системе. Часто именно эти вопросы и методологии, которые их ставят, труднее всего понять.
Для кого эта книга
В первую очередь книга адресована системным администраторам и операторам корпоративных и облачных вычислительных сред. Она послужит справочником для разработчиков, администраторов баз данных и администраторов веб-серверов, которые должны понимать, из чего складывается производительность операционных систем и приложений.
Как перформанс-инженеру в компании с гигантской вычислительной инфраструктурой (Netflix), мне часто приходится работать с SRE-инженерами и разработчиками, которым просто физически не хватает времени для решения сразу нескольких проблем с производительностью. Мне тоже доводилось работать дежурным инженером в Netflix CORE SRE, и я знаком с этой нехваткой времени на собственном опыте. Для многих людей обеспечение производительности не является их основной работой, и им достаточно знать ровно столько, чтобы решать текущие проблемы. Я понимаю, что у вас может быть мало времени, и я постарался сделать эту книгу как можно короче и проще по структуре.
Другая целевая аудитория — студенты. Книга поможет при изучении курса производительности систем. Я вел подобные курсы раньше и знаю, что лучше всего помогает студентам решать проблемы с успеваемостью. Этими знаниями я руководствовался при работе над книгой.
Кем бы вы ни были, упражнения в главах позволят проверить себя и надежнее усвоить материал. Среди них вы найдете особенно сложные упражнения, которые необязательно решать. (Они могут представлять проблемы, не имеющие решения, главная их цель — заставить задуматься.)
Наконец, с точки зрения размера компании эта книга содержит достаточно подробностей, чтобы удовлетворить потребности компаний от мала до велика. Для многих небольших компаний эта книга послужит справочником, в котором лишь некоторые части используются ежедневно.
Условные обозначения
В этой книге используются следующие условные обозначения:
| Пример |
Описание |
| netif_receive_skb() |
Имя функции |
| iostat(1) |
Команда со ссылкой на раздел в справочном руководстве man с ее описанием |
| read(2) |
Системный вызов со ссылкой на раздел в справочном руководстве man с его описанием |
| malloc(3) |
Имя функции из библиотеки языка C со ссылкой на раздел в справочном руководстве man с ее описанием |
| vmstat(8) |
Команда администрирования со ссылкой на раздел в справочном руководстве man с ее описанием |
| Documentation/... |
Каталог с документацией в дереве исходных текстов ядра Linux |
| kernel/... |
Каталог в дереве исходных текстов ядра Linux |
| fs/... |
Каталог с реализацией файловой системы в дереве исходных текстов ядра Linux |
| CONFIG_... |
Параметры настройки ядра Linux (Kconfig) |
| r_await |
Команда в командной строке и ее вывод |
| mpstat 1 |
Команда или ключевая деталь, на которую следует обратить особое внимание |
| # |
Приглашение к вводу в командной оболочке суперпользователя (root) |
| $ |
Приглашение к вводу в командной оболочке обычного пользователя (не root) |
| ^C |
Прерывание выполнения команды (комбинацией клавиш Ctrl-C) |
| [...] |
Усечение |
Дополнительные источники, ссылки и библиография
Список литературы приводится в конце каждой главы, а не в конце всей книги. Вы сразу можете смотреть источники, относящиеся к теме каждой главы. В списке ниже перечислены книги, из которых можно почерпнуть информацию об ОС и анализе производительности:
[Jain 91] Jain, R., «The Art of Computer Systems Performance Analysis: Techniques for Experimental Design, Measurement, Simulation, and Modeling», Wiley, 1991.
[Vahalia 96] Vahalia, U., «UNIX Internals: The New Frontiers», Prentice Hall, 1996.2
[Cockcroft 98] Cockcroft, A., and Pettit, R., «Sun Performance and Tuning: Java and the Internet, Prentice Hall», 1998.
[Musumeci 02] Musumeci, G.D., and Loukides, M., «System Performance Tuning, 2nd Edition», O’Reilly, 2002.3
[Bovet 05] Bovet, D., and Cesati, M., «Understanding the Linux Kernel, 3rd Edition», O’Reilly, 2005.4
[McDougall 06a] McDougall, R., Mauro, J., and Gregg, B., «Solaris Performance and Tools: DTrace and MDB Techniques for Solaris 10 and OpenSolaris», Prentice Hall, 2006.
[Gove 07] Gove, D., «Solaris Application Programming», Prentice Hall, 2007.
[Love 10] Love, R., «Linux Kernel Development, 3rd Edition», Addison-Wesley, 2010.5
[Gregg 11a] Gregg, B., and Mauro, J., «DTrace: Dynamic Tracing in Oracle Solaris, Mac OS X and FreeBSD», Prentice Hall, 2011.
[Gregg 13a] Gregg, B., «Systems Performance: Enterprise and the Cloud», Prentice Hall, 2013 (first edition).
[Gregg 19] Gregg, B., «BPF Performance Tools: Linux System and Application Observability»6, Addison-Wesley, 2019.
[ITJobsWatch 20] ITJobsWatch, «Solaris Jobs», https://www.itjobswatch.co.uk/jobs/uk/solaris.do#demand_trend, ссылка была действительна в феврале 2021.
1 Грегг Б. «BPF: Профессиональная оценка производительности». Выходит в издательстве «Питер» в 2023 году.
2 Вахалия Ю. «UNIX изнутри». СПб.: Издательство «Питер».
3 Мусумеси Дж.-П. Д. Лукидес М. «Настройка производительности UNIX-систем».
4 Бовет Д., Чезати М. «Ядро Linux».
5 Лав Р. «Ядро Linux. Описание процесса разработки».
6 Грегг Б. «BPF: Профессиональная оценка производительности». Выходит в издательстве «Питер» в 2023 году.
Некоторые темы, рассматриваемые в этом издании, также были освещены в моей предыдущей книге, «BPF Performance Tools»1 [Gregg 19]: в частности, BPF, BCC, bpftrace, tracepoints, kprobes, uprobes и множество других инструментов на основе BPF. В этой книге вы найдете дополнительную информацию. Краткое изложение этих тем здесь часто основано на той, более ранней книге. Иногда я использую тот же текст и примеры.
[Love 10] Love, R., «Linux Kernel Development, 3rd Edition», Addison-Wesley, 2010.5
[Gregg 19] Gregg, B., «BPF Performance Tools: Linux System and Application Observability»6, Addison-Wesley, 2019.
[Musumeci 02] Musumeci, G.D., and Loukides, M., «System Performance Tuning, 2nd Edition», O’Reilly, 2002.3
[Vahalia 96] Vahalia, U., «UNIX Internals: The New Frontiers», Prentice Hall, 1996.2
[Bovet 05] Bovet, D., and Cesati, M., «Understanding the Linux Kernel, 3rd Edition», O’Reilly, 2005.4
Лав Р. «Ядро Linux. Описание процесса разработки».
Бовет Д., Чезати М. «Ядро Linux».
Грегг Б. «BPF: Профессиональная оценка производительности». Выходит в издательстве «Питер» в 2023 году.
Грегг Б. «BPF: Профессиональная оценка производительности». Выходит в издательстве «Питер» в 2023 году.
Мусумеси Дж.-П. Д. Лукидес М. «Настройка производительности UNIX-систем».
Вахалия Ю. «UNIX изнутри». СПб.: Издательство «Питер».
Благодарности
Спасибо всем купившим первое издание, и особенно тем, кто рекомендовал прочитать его своим коллегам. Поддержка первой книги способствовала созданию второй. Спасибо вам.
Это моя последняя книга, посвященная производительности систем, но не первая. Я хотел бы поблагодарить авторов других книг по этой же тематике, на которые я опирался и на которые неоднократно ссылаюсь здесь. В частности, хотел бы поблагодарить Адриана Кокрофта (Adrian Cockcroft), Джима Мауро (Jim Mauro), Ричарда Макдугалла (Richard McDougall), Майка Лукидеса (Mike Loukides) и Раджа Джейна (Raj Jain). Все вы здорово помогли мне, и я надеюсь, что смогу помочь вам.
Я благодарен всем, кто давал мне обратную связь:
Дейрдра Страуган (Deirdré Straughan) всячески поддерживала меня и использовала свой богатый опыт редактирования технических книг, чтобы каждая страница этой книги стала лучше. Слова, которые вы читаете, принадлежат нам обоим. Нам нравится не только вместе проводить время (сейчас мы женаты), но и работать. Спасибо.
Филиппу Мареку (Philipp Marek) — эксперту в информационных технологиях, ИТ-архитектору и перформанс-инженеру в Австрийском федеральном вычислительном центре. Он одним из первых делился мнением по каждой теме этой книги (настоящий подвиг) и даже обнаружил проблемы в тексте первого издания. Филипп начал программировать в 1983 году, еще для микропроцессора 6502, и практически сразу стал искать способы экономии тактов процессора. Спасибо, Филипп, за твой опыт и неустанную работу!
Дейл Хэмел (Dale Hamel, Shopify) тоже внимательно прочитал каждую главу, предоставил важные сведения о различных облачных технологиях и помог взглянуть на книгу другими глазами. Спасибо тебе, Дейл, что взял на себя этот труд! Это случилось сразу после того, как ты помог мне с книгой о BPF.
Даниэль Боркманн (Daniel Borkmann, Isovalent) тщательно прорецензировал некоторые главы, в частности главы о сетях. Это помогло мне лучше понять имеющиеся сложности и сопутствующие технологии. Даниэль уже много лет занимается сопровождением ядра Linux и обладает огромным опытом работы над сетевым стеком ядра и расширенным BPF. Спасибо тебе, Даниэль, за профессионализм и строгость оценок.
Я особенно благодарен мейнтейнеру инструмента perf Арнальдо Карвалью де Мело (Arnaldo Carvalho de Melo; Red Hat) за помощь с главой 13 «perf» и Стивену Ростедту (Steven Rostedt; VMware), создателю Ftrace, за помощь с главой 14 «Ftrace» — двумя темами, которые я недостаточно полно рассмотрел в первом издании. Я высоко ценю их не только за помощь в написании этой книги, но также за их работу над этими инструментами повышения производительности, которые я использовал для решения бесчисленных проблем в Netflix.
Было очень приятно, что Доминик Кэй (Dominic Kay) пролистал несколько глав и оставил множество советов по улучшению читаемости и повышению технической точности. Доминик также помогал мне с первым изданием (а еще раньше мы вместе работали в Sun Microsystems, где занимались вопросами производительности). Спасибо, Доминик.
Мой нынешний коллега по Netflix, Амер Атер (Amer Ather), оставил очень ценные отзывы к нескольким главам. Амер — инженер, разбирающийся в сложных технологиях. Захарий Джонс (Zachary Jones, Verizon) тоже дал обратную связь по особенно сложным вопросам и поделился опытом в области производительности, чем очень помог улучшить книгу. Спасибо вам, Амер и Захарий.
Несколько рецензентов, взяв несколько глав, участвовали в обсуждении конкретных тем: Алехандро Проаньо (Alejandro Proaño, Amazon), Бикаш Шарма (Bikash Sharma, Facebook), Кори Луенингонер (Cory Lueninghoener, Национальная лаборатория в Лос-Аламосе), Грег Данн (Greg Dunn, Amazon), Джон Аррасджид (John Arrasjid, Ottometric), Джастин Гаррисон (Justin Garrison, Amazon), Майкл Хаузенблас (Michael Hausenblas, Amazon) и Патрик Кейбл (Patrick Cable, Threat Stack). Спасибо всем за вашу помощь и энтузиазм.
Также спасибо Адитье Сарваде (Aditya Sarwade, Facebook), Эндрю Галлатину (Andrew Gallatin, Netflix), Басу Смиту (Bas Smit), Джорджу Невиллу-Нилу (George Neville-Neil, JUUL Labs), Йенсу Аксбоу (Jens Axboe, Facebook), Джоэлю Фернандесу (Joel Fernandes, Google), Рэндаллу Стюарту (Randall Stewart, Netflix), Стефану Эраниану (Stephane Eranian, Google) и Токе Хойланд-Йоргенсену (Toke Høiland-Jørgensen, Red Hat) за ответы на вопросы и своевременную техническую помощь.
Те, кто участвовал в создании моей предыдущей книги — «BPF Performance Tools», тоже косвенно помогли мне, потому что некоторые материалы этого издания основаны на предыдущем. Улучшению той книги в немалой степени способствовали Аластер Робертсон (Alastair Robertson, Yellowbrick Data), Алексей Старовойтов (Alexei Starovoitov, Facebook), Дэниел Боркманн (Daniel Borkmann), Джейсон Кох (Jason Koch, Netflix), Мэри Марчини (Mary Marchini, Netflix), Масами Хирамацу (Masami Hiramatsu, Linaro), Мэтью Дезнойерс (Mathieu Desnoyers, EfficiOS), Йонгхонг Сонг (Yonghong Song, Facebook) и многие другие. Полный список вы найдете в разделе «Благодарности» предыдущего издания.
Многие, помогавшие мне в работе над первым изданием, помогли в работе и над этим. В частности, я получил техническую поддержку по нескольким главам от Адама Левенталя (Adam Leventhal), Карлоса Карденаса (Carlos Cardenas), Дэррила Гоува (Darryl Gove), Доминика Кэя (Dominic Kay), Джерри Елинека (Jerry Jelinek), Джима Мауро (Jim Mauro), Макса Брунинга (Max Bruning), Ричарда Лоу (Richard Lowe) и Роберта Мустаччи (Robert Mustacchi). Я также получил отзывы и поддержку от Адриана Кокрофта (Adrian Cockcroft), Брайана Кантрилла (Bryan Cantrill), Дэна Макдональда (Dan McDonald), Дэвида Пачеко (David Pacheco), Кита Весоловски (Keith Wesolowski), Марселля Кукульевича-Пирса (Marsell Kukuljevic-Pearce) и Пола Эгглтона (Paul Eggleton). Рох Бурбоннис (Roch Bourbonnais) и Ричард Макдугалл (Richard McDougall) многому научили меня на моей предыдущей работе, где мы занимались проблемами производительности, и тем самым оказали косвенную помощь в работе над этой книгой, как и Джейсон Хоффман (Jason Hoffman), косвенно помогавший в работе над первым изданием.
Ядро Linux — сложный и постоянно меняющийся программный продукт, и я ценю труд Джонатана Корбета (Jonathan Corbet) и Джейка Эджа (Jake Edge) из lwn.net по обобщению большого числа сложнейших тем. Многие из их статей упоминаются в этой книге.
Отдельное спасибо Грегу Доенчу (Greg Doench) — выпускающему редактору издательства Pearson за гибкость и поддержку, благодаря которым процесс двигался особенно эффективно. Спасибо продюсеру информационного наполнения Джулии Нахил (Julie Nahil; Pearson) и менеджеру проекта Рэйчел Пол (Rachel Paul) за внимание к деталям и помощь в создании качественного продукта. Спасибо редактору Киму Уимпсетту (Kim Wimpsett) за работу над еще одной из моих длинных и глубоко технических книг, за множество предложений по улучшению текста.
И спасибо тебе, Митчелл, за терпение и понимание.
Начиная с первого издания, я продолжал работать перформанс-инженером, устраняя проблемы по всему программно-аппаратному стеку. Теперь у меня еще больше опыта в работе с гипервизорами, в настройке производительности, в анализе среды выполнения (включая JVM), в применении трассировщиков, включая Ftrace и BPF, а также в реагировании на быстро меняющиеся микросервисы Netflix и ядро Linux. Многое из этого недостаточно хорошо задокументировано, и порой было очень сложно определить, что отразить в книге. Но я люблю сложности.
Об авторе
Брендан Грегг — эксперт в области производительности и облачных вычислений. Работает старшим перформанс-инженером в Netflix, где занимается проектированием, оценкой, анализом и настройкой производительности. Автор нескольких книг, в том числе «BPF Performance Tools7». Обладатель награды USENIX LISA за выдающиеся достижения в системном администрировании. Работал инженером по поддержке ядра, руководил командой обеспечения производительности и профессионально занимался преподаванием технических дисциплин, был сопредседателем конференции USENIX LISA 2018. Создал множество инструментов оценки производительности для разных операционных систем, а также разработал средства и методы визуализации для анализа производительности, включая флейм-графики.
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
На веб-сайте издательства www.piter.com вы найдете подробную информацию о наших книгах.
7 Грегг Б. «BPF: Профессиональная оценка производительности». Выходит в издательстве «Питер» в 2023 году.
Грегг Б. «BPF: Профессиональная оценка производительности». Выходит в издательстве «Питер» в 2023 году.
Брендан Грегг — эксперт в области производительности и облачных вычислений. Работает старшим перформанс-инженером в Netflix, где занимается проектированием, оценкой, анализом и настройкой производительности. Автор нескольких книг, в том числе «BPF Performance Tools7». Обладатель награды USENIX LISA за выдающиеся достижения в системном администрировании. Работал инженером по поддержке ядра, руководил командой обеспечения производительности и профессионально занимался преподаванием технических дисциплин, был сопредседателем конференции USENIX LISA 2018. Создал множество инструментов оценки производительности для разных операционных систем, а также разработал средства и методы визуализации для анализа производительности, включая флейм-графики.
Глава 1. Введение
Производительность компьютеров — увлекательная, многообразная и сложная дисциплина. В этой главе вы познакомитесь с понятием эффективности и производительности систем.
Цели главы:
• познакомить с понятием производительности системы, кто и как ее обеспечивает и какие сложности встречаются на этом пути;
• показать разницу между инструментами наблюдения и инструментами проведения экспериментов;
• дать общее представление о способах и средствах оценки производительности, таких как параметры, профилирование, флейм-графики, трассировка, статические и динамические инструменты;
• представить роль методологий и короткий чек-лист для исследования производительности Linux.
Здесь будут даны ссылки на последующие главы, поэтому данную главу можно считать введением и в дисциплину производительности систем, и в книгу в целом. Глава заканчивается реальными примерами, показывающими, насколько важно уделять внимание производительности систем.
1.1. Производительность системы
Под оценкой производительности системы понимается изучение производительности всей компьютерной системы, включая основные программные и аппаратные компоненты, — все, что находится на пути к данным, от устройств хранения до прикладного программного обеспечения, — потому что все они могут влиять на производительность. В случае с распределенными системами в этот список также входят все серверы и приложения. Если у вас нет схемы вашего окружения, отражающей путь к данным, найдите ее или нарисуйте сами; она поможет увидеть взаимосвязи между компонентами и не упустить из виду целые области.
Типичная цель оценки производительности системы — улучшить взаимодействие с конечным пользователем за счет уменьшения задержек и снижения затрат на вычисления. Снижения затрат можно достигнуть за счет устранения неэффективности, повышения пропускной способности и общей настройки системы.
На рис. 1.1 показан обобщенный стек системного ПО на одном сервере, включая ядро операционной системы (ОС), базу данных и приложение. Иногда термин фуллстек используется для описания только прикладного окружения, включающего базы данных, приложения и веб-серверы. Но говоря о производительности системы, под словом фуллстек мы подразумеваем весь программный стек — от приложений до железа (оборудования), включая системные библиотеки, ядро и само оборудование. При оценке производительности системы рассматривается фуллстек.
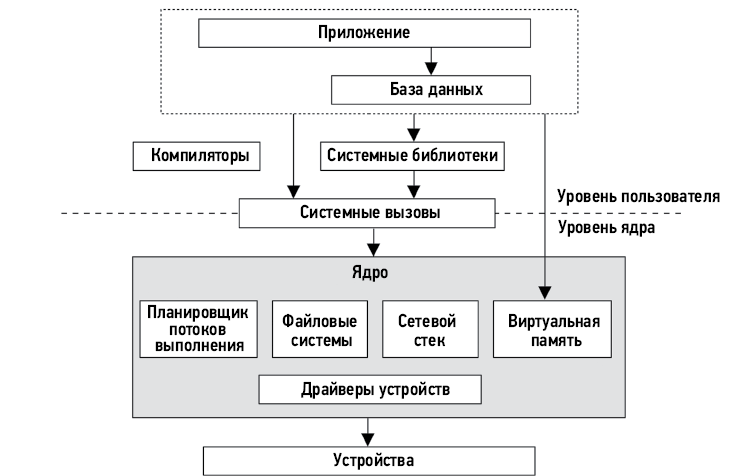
Рис. 1.1. Обобщенный стек системного программного обеспечения
Компиляторы включены в обобщенный стек на рис. 1.1, потому что играют важную роль в производительности системы. Этот стек мы обсудим в главе 3 «Операционные системы» и подробно рассмотрим в последующих главах. В следующих разделах будут более подробно описаны особенности оценки производительности системы.
1.2. Роли
Производительность системы обеспечивается различными специалистами, в том числе системными администраторами, SRE-инженерами, разработчиками приложений, сетевыми инженерами, администраторами баз данных, веб-администраторами и др. Для многих из этих специалистов обеспечение производительности является лишь частью их работы, поэтому при оценке производительности они фокусируются только на своей сфере ответственности: группа сетевых администраторов проверяет производительность сетевого стека, группа администраторов баз данных проверяет базу данных, и т.д. Однако иногда для выяснения причин низкой производительности или факторов, способствующих этому, требуются совместные усилия нескольких команд.
В некоторых компаниях работают перформанс-инженеры, для которых обеспечение высокой производительности — основная деятельность. Они могут взаимодействовать с несколькими командами для проведения комплексного исследования среды, что нередко очень важно для решения сложных проблем с производительностью. Они также могут выступать в качестве центрального звена, осуществляющего поиск и разработку инструментов для анализа производительности и планирования ресурсов во всей среде.
Например, в Netflix есть команда по производительности облачных вычислений, в которую вхожу и я. Мы помогаем командам микросервисов и обеспечения надежности анализировать производительность и создаем инструменты оценки производительности для всех остальных.
Компании, нанимающие несколько перформанс-инженеров, могут позволить им специализироваться в одной или нескольких областях и обеспечивать более глубокую поддержку. Например, большая группа перформанс-инженеров может включать специалистов по производительности ядра, клиентских приложений, языка (например, Java), среды выполнения (например, JVM), по разработке инструментов для оценки производительности и т.д.
1.3. Действия
Анализ и увеличение производительности системы предполагают выполнение множества действий. Ниже приводится список таких действий, которые одновременно представляют этапы идеального жизненного цикла программного проекта — от идеи до разработки и развертывания в продакшене. В этой книге описаны методологии и инструменты, помогающие выполнять эти действия.
1. Определение целей и моделирование производительности будущего продукта.
2. Определение характеристик производительности прототипа программного и аппаратного обеспечения.
3. Анализ производительности разрабатываемых продуктов в тестовой среде.
4. Регрессионное тестирование новых версий продукта.
5. Бенчмаркинг производительности разных версий продуктов.
6. Проверка концепции в целевой промышленной среде.
7. Оптимизация производительности в промышленной среде.
8. Мониторинг ПО, действующего в промышленной среде.
9. Анализ производительности промышленных задач.
10. Ревью инцидентов, возникающих в промышленной среде.
11. Разработка инструментов для повышения эффективности анализа производительности в промышленной среде.
Шаги с 1-го по 5-й охватывают традиционный процесс разработки продукта, будь то продукт, продаваемый клиентам или используемый внутри компании. После разработки продукт вводится в эксплуатацию, иногда сначала проверяется пригодность использования продукта в целевой среде (клиента или внутри компании), а иногда сразу же производится развертывание и настройка. Если в целевой среде обнаружится проблема (шаги с 6-го по 9-й), это говорит только о том, что она не была обнаружена или исправлена на этапах разработки.
В идеале проектирование производительности должно начинаться до выбора какого-либо оборудования или создания программного обеспечения: первым шагом должны быть постановка целей и создание модели производительности. Однако часто продукты разрабатываются, минуя этот шаг, из-за чего работы по проектированию производительности откладываются на более позднее время, когда проблемы уже возникнут. С каждым следующим этапом процесса разработки становится все труднее устранять проблемы с производительностью, обусловленные ранее принятыми архитектурными решениями.
Облачные вычисления предлагают новые методы проверки концепции (шаг 6), которые побуждают пропускать более ранние шаги (с 1-го по 5-й). Один из таких методов — тестирование нового ПО на единственном экземпляре с небольшой рабочей нагрузкой: это называется канареечным тестированием. Другой метод превращает его в обычный шаг при развертывании: трафик постепенно перемещается в новый пул экземпляров, при этом старый пул остается в горячем резерве; этот метод известен как сине-зеленое развертывание8. Применение таких приемов защиты от сбоев в новом ПО позволяет проводить тестирование в продакшене без всякого предварительного анализа производительности и при необходимости быстро возвращаться к исходному состоянию. Но я рекомендую всегда, когда это возможно, выполнить также первые этапы, чтобы достичь максимальной производительности (даже при том, что иногда могут быть веские причины миновать их, например, быстрый выход на рынок).
Некоторые из перечисленных этапов охватываются термином планирование мощности (capacity planning). На этапе проектирования он подразумевает изучение объема ресурсов, необходимых разрабатываемому ПО, чтобы увидеть, насколько полно его архитектура может удовлетворить целевые потребности. После развертывания он подразумевает мониторинг использования ресурсов для прогнозирования проблем до их возникновения.
В анализ производительности в промышленной среде (шаг 9) могут также вовлекаться SRE-инженеры. Далее следует шаг по ревью инцидентов в промышленной среде (шаг 10), когда производится анализ произошедшего, обмен опытом отладки и поиск способов избежать аналогичных инцидентов в будущем. Эти ревью похожи на ретроспективы разработчиков (см. [Corry 20], где рассказывается, что такое ретроспективы и их антипаттерны).
Среды и мероприятия различаются для разных компаний и продуктов, и во многих случаях выполняются не все десять шагов. Ваша работа также может быть сосредоточена только на некоторых или только на одном из этих мероприятий.
1.4. Перспективы
Помимо выполнения различных мероприятий, привлечение различных специалистов можно рассматривать как использование разных точек зрения — перспектив. На рис. 1.2 обозначены две точки зрения на анализ производительности: анализ рабочей нагрузки и анализ ресурсов — двух подходов к оценке программного стека.

Рис. 1.2. Анализ с двух перспектив
Перспектива анализа ресурсов обычно используется системными администраторами, отвечающими за системные ресурсы. Разработчики приложений, отвечающие за производительность под рабочей нагрузкой, обычно сосредоточиваются на перспективе анализа рабочей нагрузки. Каждая перспектива имеет свои сильные стороны, которые подробно обсуждаются в главе 2 «Методологии». При решении сложных вопросов полезно попытаться проанализировать ситуацию с обеих сторон.
1.5. Сложности оценки производительности
Проектирование производительности системы — сложная область по многим причинам, в том числе из-за субъективности, природной сложности, отсутствия какой-то единственной основной причины и наличия множества связанных проблем.
1.5.1. Субъективность
Технические дисциплины тяготеют к объективности, причем настолько, что занимающиеся ими люди видят мир в черно-белом цвете. Это может быть верно в отношении неполадок в софте, когда ошибка либо есть, либо ее нет и либо она исправлена, либо не исправлена. Такие ошибки часто проявляются в виде сообщений, которые легко интерпретировать и идентифицировать как сообщения об ошибках.
Производительность, напротив, часто бывает субъективной. В отношении проблем с производительностью часто неочевидно, имела ли место проблема изначально, и если да, то когда она была устранена. Один пользователь может считать производительность «плохой» и рассматривать ее как проблему, а другой может считать ее «хорошей».
Например, представьте, что вам поступила такая информация:
Среднее время отклика подсистемы дискового ввода/вывода составляет 1 мс.
Это «хорошо» или «плохо»? Время отклика, или задержка, является одним из лучших доступных показателей, но интерпретировать информацию о задержке сложно. Часто выбор между оценками «хорошая» или «плохая» зависит от ожиданий разработчиков приложений и конечных пользователей.
Субъективную оценку производительности можно сделать объективной, определив четкие цели, например целевое среднее время отклика или попадание определенного процента запросов в некоторый диапазон задержек. Другие способы борьбы с субъективностью будут представлены в главе 2 «Методологии», в том числе и анализ задержки.
1.5.2. Сложность
Помимо субъективности, сложность оценки производительности может быть связана со свойственной системам сложностью и отсутствием очевидной отправной точки для анализа. В облачных средах порой даже нет возможности узнать, на какой экземпляр обратить внимание в первую очередь. Иногда мы начинаем с выдвижения гипотезы, например, обвиняя сеть или базу данных, а аналитик производительности должен выяснить, является ли эта гипотеза верной.
Проблемы с производительностью также могут возникать из-за сложных взаимодействий между подсистемами, которые показывают хорошие характеристики при их анализе в изоляции друг от друга. Падение производительности может произойти из-за каскадного сбоя, когда один отказавший компонент вызывает проблемы с производительностью в других компонентах. Чтобы понять причину возникшей проблемы, необходимо распутать клубок взаимосвязей между компонентами и понять, какой вклад они вносят.
Сложность также может быть обусловлена наличием неожиданных взаимосвязей, когда устранение проблемы в одном месте может привести к появлению проблемы в другом месте системы, при этом общая производительность улучшится не так сильно, как ожидалось. Помимо сложности системы, проблемы с производительностью также могут быть вызваны сложным характером производственной нагрузки. Некоторые случаи могут просто не воспроизводиться в лабораторных условиях или возникать лишь периодически.
Решение сложных проблем производительности часто требует комплексного подхода. Возможно, потребуется исследовать всю систему — и ее внутренние элементы, и внешние взаимодействия. Для этого необходимо обладать широким спектром навыков, что может сделать проектирование производительности многообразным и интеллектуально сложным делом.
Для преодоления этих сложностей можно использовать разные методологии, как описано в главе 2. В главах 6–10 вы найдете описания конкретных методологий анализа конкретных системных ресурсов: процессоры, память, файловые системы, диски и сеть. (Комплексный анализ сложных систем, включая разливы нефти и крах финансовых систем, описан в [Dekker 18].)
В некоторых случаях проблема производительности может быть вызвана взаимодействием этих ресурсов.
1.5.3. Множественные причины
Некоторые проблемы с производительностью не имеют единственной первопричины и обусловлены множеством факторов. Представьте сценарий, когда одновременно происходят три вполне обычных события, которые в совокупности вызывают проблему с производительностью: каждое из этих событий — обычное и само по себе не является первопричиной.
Множественными могут быть не только причины, но и сами проблемы с производительностью.
1.5.4. Множественные проблемы с производительностью
В сложном программном обеспечении обычно бывает немало проблем с производительностью. Для примера попробуйте найти базу данных ошибок для вашей ОС или приложений и поищите по слову performance (производительность). Результаты могут удивить вас! Как правило, в таких базах данных даже для зрелого ПО, считающегося высокопроизводительным, есть множество известных, но пока не исправленных проблем с производительностью. Это создает еще одну трудность при анализе: настоящая задача не в том, чтобы найти проблему, а в том, чтобы определить, какая проблема или проблемы наиболее важны.
Для этого специалист по анализу производительности должен количественно оценить масштаб проблемы. Некоторые проблемы с производительностью могут быть не свойственны вашей рабочей нагрузке или проявляться в весьма незначительной степени. В идеале вы должны не только количественно оценить проблемы, но также оценить потенциальное ускорение, которое можно получить за счет устранения каждой из них. Эта информация может пригодиться, когда менеджеры будут искать оправдание расходам на инженерные или операционные ресурсы.
Один из показателей, хорошо подходящих для количественной оценки производительности, если он доступен, — это задержка.
1.6. Задержка
Задержка характеризует время, затраченное на ожидание, и является важной метрикой производительности. В широком смысле под задержкой понимается время до завершения любой операции, такой как обработка запроса приложением или базой данных, операция файловой системы и т.д. Например, задержка может выражать время полной загрузки веб-страницы от щелчка на ссылке до появления полного изображения страницы на экране. Это важный показатель как для клиента, так и для владельца сайта: большая задержка может вызвать разочарование и желание у клиентов разместить заказ в другом месте.
В роли метрики задержка позволяет оценить максимальное ускорение. Например, на рис. 1.3 изображена временна́я диаграмма обработки запроса к базе данных, на что уходит 100 мс (это время и является задержкой), из которых 80 мс тратится на ожидание завершения операции чтения с диска. В данном случае за счет исключения операций чтения с диска (например, путем кэширования) можно добиться уменьшения времени обработки со 100 мс до 20 мс (100–80), то есть добиться пятикратного (в 5 раз) улучшения производительности. Это оценочное ускорение, и вычисления также помогли количественно оценить масштаб проблемы производительности: чтение с диска в 5 раз замедляет обработку запросов.

Рис. 1.3. Пример задержки, вызванной дисковым вводом/выводом
Подобные вычисления невозможны при использовании других метрик. Например, количество операций ввода/вывода в секунду (IOPS) зависит от типа ввода/вывода и часто напрямую несопоставимо для разных ситуаций. Если какое-то изменение приведет к уменьшению IOPS на 80 %, то трудно предсказать, как это отразится на производительности. Операций в секунду может быть в 5 раз меньше, но что, если каждая из этих операций обрабатывает в 10 раз больше данных?
Значение задержки также может быть неоднозначным без уточняющих терминов. Например, задержка в сети может означать время, необходимое для установления соединения, но не время передачи данных; или общую продолжительность соединения, включая передачу данных (например, так обычно измеряется задержка DNS). По мере возможности в этой книге я буду использовать уточняющие термины: эти примеры лучше описать как задержку соединения и задержку обработки запроса. Терминология, связанная с задержкой, также приводится в начале каждой главы.
Задержка — полезная метрика, но она не всегда доступна. Некоторые системные области позволяют измерить только среднюю задержку; некоторые вообще не дают возможности измерения. С появлением новых инструментов наблюдения на основе BPF9 задержку теперь можно измерять практически в любых точках и получить данные, описывающие полное распределение задержки.
1.7. Наблюдаемость
Под наблюдаемостью подразумевается исследование системы через наблюдение и инструменты, предназначенные для этого. Сюда входят инструменты, использующие счетчики, профилирование и трассировку, но не входят инструменты тестирования производительности, которые изменяют состояние системы, выполняя эксперименты с рабочей нагрузкой. В промышленных средах желательно сначала попробовать применить инструменты наблюдения, где это возможно, потому что инструменты для экспериментов могут препятствовать обработке промышленных рабочих нагрузок из-за конкуренции за ресурсы. В тестовых средах, которые большую часть времени простаивают, можно сразу начать с инструментов тестирования производительности для определения быстродействия оборудования.
В этом разделе я расскажу о счетчиках, метриках, профилировании и трассировке. Более подробно о наблюдаемости речь пойдет в главе 4, где рассмотрены общесистемная и индивидуальная наблюдаемость, инструменты наблюдения Linux и их внутреннее устройство. Кроме того, в главах 5–11 есть разделы, посвященные наблюдаемости, например, раздел 6.6 описывает инструменты наблюдения за процессором.
1.7.1. Счетчики, статистики и метрики
Приложения и ядро обычно предоставляют данные c информацией о своем состоянии и активности: счетчики операций, счетчики байтов, измеренные задержки, использованный объем ресурсов и частоту ошибок. Обычно эти данные доступны в виде целочисленных переменных, называемых счетчиками; они жестко «вшиты» в программное обеспечение, часть из них являются кумулятивными и постоянно увеличиваются. Эти кумулятивные счетчики можно читать в разное время инструментами оценки производительности для вычисления таких статистик, как скорость изменения во времени, среднее значение, процентили и т.д.
Например, утилита vmstat(8) выводит общесистемную статистику по виртуальной памяти и другие данные на основе счетчиков ядра, доступных в файловой системе /proc. Вот пример вывода vmstat(8) на производственном сервере с 48 процессорами:
$ vmstat 1 5
procs ---------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
19 0 0 6531592 42656 1672040 0 0 1 7 21 33 51 4 46 0 0
26 0 0 6533412 42656 1672064 0 0 0 0 81262 188942 54 4 43 0 0
62 0 0 6533856 42656 1672088 0 0 0 8 80865 180514 53 4 43 0 0
34 0 0 6532972 42656 1672088 0 0 0 0 81250 180651 53 4 43 0 0
31 0 0 6534876 42656 1672088 0 0 0 0 74389 168210 46 3 51 0 0
Судя по этому примеру, доля занятости процессора в системе составляет около 57 % (столбцы cpu us + sy). Более подробно значение столбцов объясняется в главах 6 и 7.
Метрика — это статистика, выбранная для оценки или мониторинга цели. Большинство компаний используют агенты мониторинга для записи выбранных статистик (метрик) через регулярные промежутки времени и построения графиков их изменения в графическом интерфейсе, чтобы видеть, как они меняются с течением времени. Программное обеспечение для мониторинга также может поддерживать создание специальных предупреждений на основе этих метрик, например отправку электронных писем для уведомления персонала об обнаружении проблем.
Эта иерархия от счетчиков до предупреждений изображена на рис. 1.4, который поможет вам понять эти термины, но их использование в отрасли не является жестко фиксированным. Термины счетчики, статистики и метрики часто используются как синонимы. Кроме того, оповещения могут генерироваться на любом уровне, а не только специальной системой оповещения.
В качестве примера графического представления метрик на рис. 1.5 показан скриншот инструмента на основе Grafana, который наблюдает за тем же сервером, на котором был получен предыдущий вывод vmstat(8).
Эти линейные графики удобно использовать для планирования мощности — они помогают предсказать, когда наступит момент исчерпания ресурсов.
Ваша интерпретация статистик производительности улучшится, если вы поймете, как они вычисляются. Статистики, включая средние значения, распределения, моды и выбросы, более подробно описываются в главе 2 «Методологии», в разделе 2.8 «Статистики».
Иногда для решения проблемы с производительностью достаточно получить временны́е ряды с метриками. Время, когда проявилась проблема, может коррелировать с известным изменением в ПО или конфигурации, которое можно отменить. Иногда метрики лишь подсказывают направление, сообщая о проблеме с процессором или диском, но без объяснения причин. В таких случаях, чтобы копнуть глубже и отыскать причину, необходимо использовать инструменты профилирования.
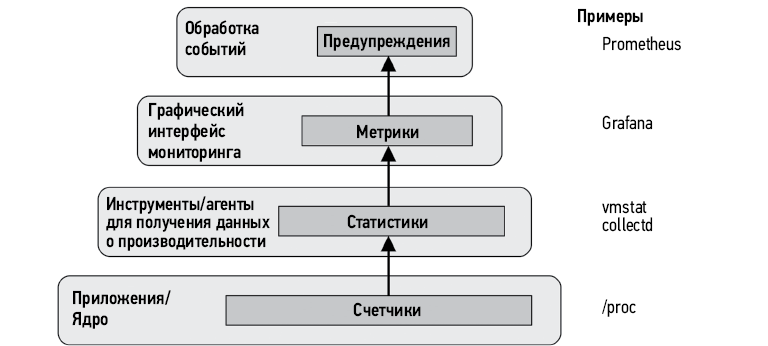
Рис. 1.4. Терминология, связанная с оценкой производительности
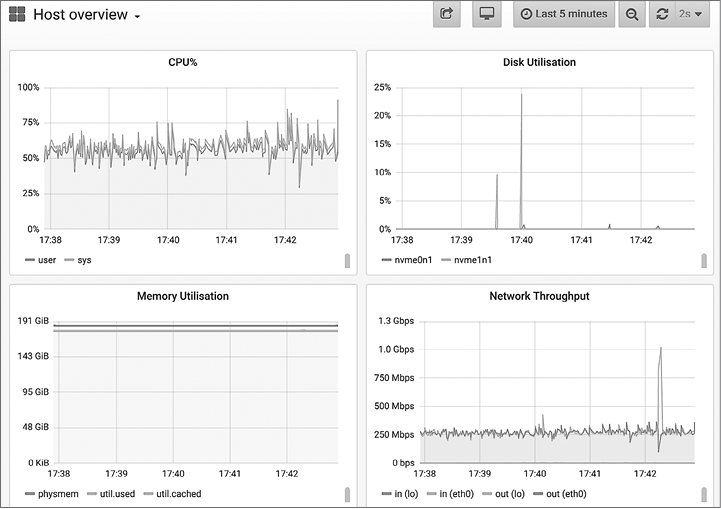
Рис. 1.5. Графический интерфейс с метриками (Grafana)
1.7.2. Профилирование
В контексте производительности систем термин профилирование обычно означает использование инструментов для выборки подмножества измерений и создания на их основе приблизительной картины, характеризующей цель. Часто целью профилирования является доля занятости процессора. Обычно для этого используется метод профилирования, основанный на выборке путей в коде, выполняющемся на процессоре, с заданным интервалом времени.
Один из эффективных способов визуализации результатов профилирования процессора — флейм-графики (или графики пламени — flame graphs). Флейм-графики помогают добиться большего выигрыша в производительности, чем любой другой инструмент, после метрик. Они позволяют выявить не только проблемы с занятостью процессора, но и другие типы проблем, обнаруживаемые по характерным особенностям использования процессора. Проблемы, связанные с конфликтом блокировок, например, можно обнаружить по большим затратам процессорного времени в циклах ожидания блокировок; проблемы с памятью легко обнаруживаются по чрезмерным затратам процессорного времени в функциях распределения памяти (malloc()) и в коде, вызывающем эти функции; проблемы, связанные с ошибками в настройках сети, можно обнаружить по затратам процессорного времени в медленных или устаревших путях в коде; и т.д.
На рис. 1.6 приведен пример флейм-графика, показывающего процессорное время, потраченное инструментом тестирования сети iperf(1).

Рис. 1.6. Флейм-график расходования процессорного времени
На этом флейм-графике видно, насколько больше процессорного времени тратится на копирование байтов (путь в коде, заканчивающийся функцией copy_user_enhanced_fast_string()) по сравнению с передачей TCP-пакетов (второй большой пик слева, включающий функцию tcp_write_xmit()). Ширина пиков (или пирамид, как их еще называют) пропорциональна потраченному процессорному времени, а вдоль вертикальной оси откладывается путь в коде.
Подробнее приемы профилирования обсуждаются в главах 4, 5 и 6, а об использовании флейм-графиков рассказывается в главе 6 «Процессор», в разделе 6.7.3 «Флейм-графики».
1.7.3. Трассировка
Трассировка — это запись событий, когда данные о событиях фиксируются и сохраняются для последующего анализа или используются на лету для обобщения и выполнения других действий. Есть специальные инструменты трассировки для системных вызовов (например, strace(1) в Linux) и сетевых пакетов (например, tcpdump(8) в Linux), а также инструменты трассировки общего назначения, способные анализировать все программные и аппаратные события (например, Ftrace, BCC и bpftrace в Linux). Эти всевидящие трассировщики используют различные источники событий, в частности точки статической и динамической инструментации, а также механизм BPF, поддерживающий возможность программного управления.
Точки статической инструментации
Под точками статической инструментации подразумеваются жестко закодированные точки в ПО. В ядре Linux сотни таких точек, позволяющих выполнять трассировку дискового ввода/вывода, событий планировщика, системных вызовов и многого другого. Технология статической инструментации ядра Linux называется tracepoints (точки трассировки). Есть технология статической инструментации ПО в пространстве пользователя, которая называется статически определяемой трассировкой на уровне пользователя (User-level Statically Defined Tracing, USDT). Точки USDT используются во многих библиотеках (например, libc) для инструментации библиотечных вызовов и в приложениях для инструментации функций обработки запросов.
Примером утилиты, использующей статическую инструментацию, может служить execsnoop(8), которая выводит информацию о процессах, запущенных во время трассировки, получаемую путем инструментации точки трассировки в системном вызове execve(2). Ниже показано, как execsnoop(8) трассирует вход по SSH:
# execsnoop
PCOMM PID PPID RET ARGS
ssh 30656 20063 0 /usr/bin/ssh 0
sshd 30657 1401 0 /usr/sbin/sshd -D -R
sh 30660 30657 0
env 30661 30660 0 /usr/bin/env -i PATH=/usr/local/sbin:/usr/local...
run-parts 30661 30660 0 /bin/run-parts --lsbsysinit /etc/update-motd.d
00-header 30662 30661 0 /etc/update-motd.d/00-header
uname 30663 30662 0 /bin/uname -o
uname 30664 30662 0 /bin/uname -r
uname 30665 30662 0 /bin/uname -m
10-help-text 30666 30661 0 /etc/update-motd.d/10-help-text
50-motd-news 30667 30661 0 /etc/update-motd.d/50-motd-news
cat 30668 30667 0 /bin/cat /var/cache/motd-news
cut 30671 30667 0 /usr/bin/cut -c -80
tr 30670 30667 0 /usr/bin/tr -d \000-\011\013\014\016-\037
head 30669 30667 0 /usr/bin/head -n 10
80-esm 30672 30661 0 /etc/update-motd.d/80-esm
lsb_release 30673 30672 0 /usr/bin/lsb_release -cs
[...]
Этот прием особенно удобен для трассировки короткоживущих процессов, которые могут остаться незамеченными другими инструментами наблюдения, такими как top(1). Эти короткоживущие процессы могут быть источником проблем с производительностью.
Дополнительную информацию о точках трассировки и зондах USDT вы найдете в главе 4.
Динамическая инструментация
Технология динамической инструментации создает точки трассировки уже после запуска ПО путем подмены инструкций в памяти процесса вызовами процедур трассировки. Примерно так отладчики вставляют точки останова в любые функции в запущенном ПО. Разница лишь в том, что когда при отладке поток выполнения достигает точки останова, управление передается интерактивному отладчику, а при динамической инструментации вызывается процедура трассировки, по окончании которой целевое ПО продолжает работу как ни в чем не бывало. Динамическая инструментация позволяет собирать необходимую статистику производительности из любого выполняющегося ПО. Проблемы, которые раньше было невозможно или очень сложно решить из-за недостаточной наблюдаемости, теперь можно исправить.
Динамическая инструментация настолько отличается от традиционного наблюдения и мониторинга, что поначалу трудно понять ее роль. Возьмем для примера ядро операционной системы: анализ внутреннего устройства ядра часто похож на блуждание в темной комнате со свечами (системными счетчиками), установленными там, где разработчики ядра посчитали необходимым. Динамическую инструментацию я бы сравнил с фонариком, луч которого можно направить куда угодно.
Первые методы динамической инструментации были разработаны в 1990-х годах [Hollingsworth 94] вместе с инструментами, которые их используют. Эти инструменты называют динамическими трассировщиками (например, kerninst [Tamches 99]). Поддержка динамической инструментации для ядра Linux была разработана в 2000 году [Kleen 08] и начала внедряться в 2004 году (kprobes). Но эти технологии были малоизвестны и сложны в использовании. Ситуация изменилась, когда в 2005 году Sun Microsystems выпустила свою версию DTrace — простую в использовании и безопасную для применения в производственной среде. Я разработал множество инструментов на основе DTrace, которые доказали свою важность для оценки производительности системы, получили широкое распространение и принесли широкую известность DTrace и динамической инструментации.
BPF
Механизм BPF, название которого первоначально произошло от Berkeley Packet Filter, поддерживает новейшие инструменты динамической трассировки для Linux. BPF создавался как миниатюрная виртуальная машина в ядре для ускорения выполнения выражений tcpdump(8). Но в 2013 году был расширен (поэтому иногда его называют eBPF10) и превратился в универсальную среду выполнения в ядре, обеспечивающую безопасный и быстрый доступ к ресурсам. Среди многочисленных новых применений обновленного механизма BPF — инструменты трассировки, для которых он обеспечивает поддержку программирования операций с применением коллекции компиляторов BPF (BPF Compiler Collection, BCC), и внешний интерфейс bpftrace. Например, инструмент execsnoop(8), показанный выше, является инструментом BCC11.
Подробнее о BPF рассказывается в главе 3, а глава 15 знакомит с интерфейсами трассировки BPF: BCC и bpftrace. В других главах, в разделах о наблюдаемости, будут представлены многие инструменты трассировки на основе BPF; например, инструменты трассировки процессора описываются в главе 6 «Процессор» в разделе 6.6 «Инструменты наблюдения». Также ранее я опубликовал книги по инструментам трассировки (для DTrace [Gregg 11a] и BPF [Gregg 19]).
Оба инструмента, perf(1) и Ftrace, тоже являются трассировщиками и обладают возможностями, аналогичными интерфейсам BPF. Подробнее о perf(1) и Ftrace рассказывается в главах 13 и 14.
1.8. Эксперименты
Помимо инструментов наблюдения, также есть инструменты для экспериментов, большинство из которых применяется для бенчмаркинга. Они позволяют ставить эксперименты, применяя искусственную рабочую нагрузку к системе и измеряя ее производительность. Такие эксперименты следует проводить с осторожностью, потому что они могут ухудшать производительность тестируемых систем.
Есть инструменты макробенчмарикинга, которые имитируют реальную рабочую нагрузку, например действия клиентов, посылающих запросы приложениям, а есть инструменты микробенчмаркинга, которые тестируют конкретный компонент системы, например процессоры, диски или сети. В качестве аналогии: определение времени, необходимого для преодоления круга на трассе Laguna Seca Raceway, можно считать макробенчмаркингом, а определение времени разгона от 0 до 100 км/ч можно считать микробенчмаркингом. Оба типа тестов важны, но микробенчмарки обычно проще в разработке, отладке, использовании и понимании, и они более стабильны.
Следующий пример показывает использование iperf(1) на простаивающем сервере для микробенчмаркинга пропускной способности канала TCP с удаленным неактивным сервером. Этот бенчмарк выполнялся в течение 10 с (-t 10) и выводит средние значения в секунду (-i 1):
# iperf -c 100.65.33.90 -i 1 -t 10
------------------------------------------------------------
Client connecting to 100.65.33.90, TCP port 5001
TCP window size: 12.0 MByte (default)
------------------------------------------------------------
[ 3] local 100.65.170.28 port 39570 connected with 100.65.33.90 port 5001
[ ID] Interval Transfer Bandwidth
[ 3] 0.0- 1.0 sec 582 MBytes 4.88 Gbits/sec
[ 3] 1.0- 2.0 sec 568 MBytes 4.77 Gbits/sec
[ 3] 2.0- 3.0 sec 574 MBytes 4.82 Gbits/sec
[ 3] 3.0- 4.0 sec 571 MBytes 4.79 Gbits/sec
[ 3] 4.0- 5.0 sec 571 MBytes 4.79 Gbits/sec
[ 3] 5.0- 6.0 sec 432 MBytes 3.63 Gbits/sec
[ 3] 6.0- 7.0 sec 383 MBytes 3.21 Gbits/sec
[ 3] 7.0- 8.0 sec 388 MBytes 3.26 Gbits/sec
[ 3] 8.0- 9.0 sec 390 MBytes 3.28 Gbits/sec
[ 3] 9.0-10.0 sec 383 MBytes 3.22 Gbits/sec
[ 3] 0.0-10.0 sec 4.73 GBytes 4.06 Gbits/sec
Как показывают результаты эксперимента, пропускная способность12 в первые 5 с находилась на уровне около 4,8 Гбит/с, а затем упала до примерно 3,2 Гбит/с. Этот интересный результат демонстрирует бимодальную пропускную способность. Чтобы увеличить производительность, можно сосредоточиться на моде 3,2 Гбит/с и поискать другие метрики, объясняющие ее.
Рассмотрим недостатки отладки подобной проблемы производительности на рабочем сервере с использованием только инструментов наблюдения. Пропускная способность сети может меняться с течением времени из-за естественной разницы в рабочей нагрузке клиента, и подобное бимодальное поведение сети может оставаться незамеченным. Используя инструмент iperf(1), генерирующий фиксированную рабочую нагрузку, можно избавиться от влияния изменчивости поведения клиентов и обнаружить отклонения, вызванные другими факторами (например, наличием ограничений во внешней сети, использованием буферов и т.д.).
Как я рекомендовал выше, в производственных системах следует сначала попробовать применить инструменты наблюдения. Но их так много, что с ними можно работать часами, тогда как инструмент для экспериментов позволит быстрее прийти к результатам. Много лет назад старший перформанс-инженер Рох Бурбоннис (Roch Bourbonnais) рассказал мне о такой аналогии: у вас есть две руки, наблюдение и эксперименты. Использование инструментов только одного типа похоже на попытку решить проблему одной рукой.
Главы 6–10 включают разделы об инструментах для экспериментирования. Например, инструменты для экспериментирования с процессором описаны в главе 6 «Процессор» в разделе 6.8 «Эксперименты».
1.9. Облачные вычисления
Облачные вычисления как способ развертывания вычислительных ресурсов по запросу позволяют быстро масштабировать приложения, развертывая их во все большем количестве небольших виртуальных систем, называемых экземплярами (instances). Этот подход избавляет от необходимости тщательно планировать емкость, потому что в кратчайшие сроки можно добавить дополнительные ресурсы из облака. В некоторых случаях это также увеличило потребность в анализе производительности, потому что использование меньшего количества ресурсов может означать меньшее количество систем. Поскольку за использование облачных ресурсов обычно взимается поминутная или часовая оплата, выигрыш в производительности, способствующий использованию меньшего количества систем, дает прямую экономию средств. Сравните этот сценарий с услугами корпоративного вычислительного центра, с которым вы можете быть связаны фиксированным договором на поддержку в течение многих лет без возможности экономии, пока срок действия договора не истечет.
Облачные вычисления и виртуализация принесли новые трудности, включая управление влиянием других подписчиков на производительность (иногда это называют изоляцией производительности) и возможность мониторинга физической системы со стороны каждого подписчика. Например, в отсутствие должного управления системой производительность дискового ввода/вывода может упасть из-за конфликта с соседом. В некоторых средах информация о фактической нагрузке на физические диски может быть недоступна подписчикам, что затрудняет выявление таких проблем.
Более подробно эти вопросы рассматриваются в главе 11 «Облачные вычисления».
1.10. Методологии
Методология — это способ задокументировать рекомендуемые шаги для решения различных задач по оценке производительности системы. Без методологии исследование производительности может превратиться в рыбалку, когда рыбак пробует разные наживки в надежде на удачу. Это неэффективный и потенциально долгий путь с риском упустить из виду важные области. В главе 2 «Методологии» я привожу перечень методологий для оценки производительности систем. В следующем подразделе я покажу первое, что использую для решения любой проблемы с производительностью: чек-лист инструментов.
1.10.1. Анализ производительности Linux за 60 секунд
Это чек-лист инструментов анализа производительности для Linux, который можно выполнить за 60 секунд в самом начале исследования проблемы производительности. Здесь перечислены традиционные инструменты, доступные в большинстве дистрибутивов Linux [Gregg 15a]. В табл. 1.1 показаны конкретные команды, которые следует выполнить, а также разделы в этой книге, где соответствующие команды рассматриваются более подробно.
Таблица 1.1. Чек-лист для анализа производительности Linux за 60 секунд
| № |
Инструмент |
Проверяет |
Раздел |
| 1 |
uptime |
Средние значения нагрузки, чтобы определить, увеличивается или уменьшается нагрузка (можно сравнить средние значения за 1, 5 и 15 минут) |
6.6.1 |
| 2 |
dmesg -T | tail |
Ошибки в ядре, включая события OOM (нехватки памяти) |
7.5.11 |
| 3 |
vmstat -SM 1 |
Общесистемные статистики: длина очереди на выполнение, подкачка (swapping), общая доля занятости процессора |
7.5.1 |
| 4 |
mpstat -P ALL 1 |
Баланс нагрузки по процессорам: увеличенная нагрузка на один из процессоров может указывать на плохое масштабирование потоков выполнения |
6.6.3 |
| 5 |
pidstat 1 |
Потребление процессора каждым процессом: позволяет выявить непредвиденных потребителей процессорного времени и определить, сколько процессорного времени потрачено каждым процессом в пространстве ядра и в пространстве пользователя |
6.6.7 |
| 6 |
iostat -sxz 1 |
Статистики дискового ввода/вывода: количество операций ввода/вывода в секунду (IOPS) и пропускная способность, среднее время ожидания, процент занятости |
9.6.1 |
| 7 |
free –m |
Потребление памяти, включая кэши файловой системы |
8.6.2 |
| 8 |
sar -n DEV 1 |
Статистики сетевого устройства ввода/вывода: количество пакетов и пропускная способность |
10.6.6 |
| 9 |
sar -n TCP,ETCP |
Статистики TCP: частота приема соединений, частота повторных передач |
10.6.6 |
| 10 |
top |
Общий обзор |
6.6.6 |
Этот чек-лист также можно использовать в графическом интерфейсе мониторинга, если в нем доступны те же метрики13.
Глава 2 «Методологии» и следующие за ней содержат описание множества методологий анализа производительности, включая метод USE, определение характеристик рабочей нагрузки, анализ задержки и многие другие.
1.11. Практические примеры
Если вы новичок в вопросах оценки производительности систем, то практические примеры, показывающие, когда и почему выполняются различные действия, помогут вам провести аналогию с вашим текущим окружением. В этом разделе представлены два гипотетических примера. Первый показывает проблему производительности, связанную с дисковым вводом/выводом, а второй — тестирование производительности после изменения ПО.
Примеры описывают действия, о которых подробно рассказывается в других главах этой книги. Основная цель этих примеров — показать не правильный или единственный способ, а скорее один из способов, которым можно выполнить эти действия.
1.11.1. Медленные диски
Сумит — системный администратор в компании среднего размера. Группа обслуживания базы данных добавила тикет с жалобой на «медленные диски» на одном из серверов баз данных.
Первая задача Сумита — узнать как можно больше о проблеме, собрать необходимую информацию и сформулировать проблему. В тикете утверждается, что диски работают медленно, но не объясняется, действительно ли это является причиной проблемы в базе данных. В ответ Сумит задает следующие вопросы:
• Наблюдаются ли проблемы с производительностью базы данных сейчас? Как она измеряется?
• Как давно существует эта проблема?
• Изменилось ли что-нибудь в базе данных за последнее время?
• Почему подозрение пало на диски?
В ответ команда базы данных пишет: «В нашем отделе ведется журнал, в котором фиксируются запросы, продолжительность обработки которых превышает 1000 мс. Обычно такие запросы встречаются редко, но за последнюю неделю их число выросло до нескольких десятков в час. Анализ с применением AcmeMon показал большую загруженность дисков».
Этот ответ подтверждает наличие проблемы с базой данных, но также показывает, что гипотеза о том, что причиной является низкая производительность диска, скорее всего, является предположением. Сумит решает проверить диски, а также другие ресурсы на тот случай, если гипотеза окажется неверной.
AcmeMon — это базовая система мониторинга серверов компании, предоставляющая исторические графики изменения стандартных метрик операционной системы, которые можно получить с помощью mpstat(1), iostat(1) и других системных утилит. Сумит входит в AcmeMon, чтобы выполнить задуманные проверки.
На первом шаге Сумит применяет методологию USE (описывается в главе 2 «Методологии» в разделе 2.5.9), чтобы быстро проверить наличие узких мест в ресурсах. Как сообщила группа обслуживания базы данных, доля загруженности дисков достигла высокого уровня, около 80 %, тогда как потребление других ресурсов (процессор, сеть) намного ниже. По историческим данным выяснилось, что загруженность дисков неуклонно росла в течение последней недели, в то время как потребление процессора оставалось постоянным. Система AcmeMon не предоставляет статистики, характеризующие насыщенность или частоту ошибок для дисков, поэтому для применения методологии USE Сумит должен выполнить некоторые команды на самом сервере.
Он проверил счетчики ошибок дискового ввода/вывода в /sys — они оказались равны нулю. Запустил iostat(1), задав интервал равным одной секунде, и понаблюдал за изменением метрик потребления и насыщенности с течением времени. Система AcmeMon сообщала об уровне загруженности 80 %, но проводила измерения с интервалом в одну минуту. Используя интервал измерений в одну секунду, Сумит увидел, что загруженность диска колеблется, часто достигая 100 % и вызывая увеличение уровня насыщенности и задержки дискового ввода/вывода.
Чтобы еще раз убедиться, что загруженность диска является причиной блокировки базы данных и возрастает синхронно с запросами к ней, он решил использовать инструмент трассировки BCC/BPF под названием offcputime(8) и с его помощью захватывать трассировки стека всякий раз, когда база приостанавливается ядром, а также определять продолжительность приостановки. Трассировки стека показали, что база данных часто блокируется на время чтения файловой системы в процессе обработки запроса. Для Сумита этого было достаточно.
Следующий вопрос — почему. Статистики производительности диска соответствуют высокой нагрузке. Сумит решил выяснить характеристики рабочей нагрузки, измерив с помощью iostat(1) частоту операций ввода/вывода, пропускную способность, среднюю задержку дискового ввода/вывода и соотношение операций чтения/записи. Для получения дополнительной информации Сумит мог бы использовать трассировку дискового ввода/вывода, однако ему достаточно информации, указывающей, что имеет место высокая нагрузка на диск, а не проблема с производительностью дисков.
Сумит добавляет дополнительные детали в тикет, указав, что было проверено, и включив скриншоты команд, использовавшихся для анализа работы дисков. На данный момент он пришел к выводу, что диски работают под высокой нагрузкой, из-за чего увеличивается задержка ввода/вывода и медленно обрабатываются запросы. Но судя по имеющимся данным, диски вполне справляются с нагрузкой, и он задает вопрос: есть ли простое объяснение случившемуся; увеличилась ли нагрузка на базу данных?
Команда обслуживания БД ответила, что простого объяснения нет и количество запросов (о которых не сообщает AcmeMon) остается постоянным. Похоже, это согласуется с более ранним выводом о неизменности нагрузки на процессор.
Сумит размышляет о том, какие еще причины могут вызвать увеличение нагрузки на дисковый ввод/вывод без заметного увеличения потребления процессора, и консультируется со своими коллегами. Один из них выдвигает предположение о сильной фрагментированности файловой системы, что вполне ожидаемо, когда заполненность файловой система приближается к 100 %. Но, как выяснил Сумит, файловая система заполнена всего на 30 %.
Сумит знает, как провести более детальный анализ14, чтобы выяснить точные причины, но на это требуется много времени. Основываясь на своем знании стека ввода/вывода в ядре, он пытается придумать другие простые объяснения, которые можно быстро проверить. Он помнит, что часто дисковые операции обусловлены промахами кэша файловой системы (кэша страниц).
Сумит проверяет коэффициент попаданий в кэш файловой системы с помощью cachestat(8)15 и обнаруживает, что в данный момент он составляет 91 %. Выглядит неплохо (и даже очень хорошо), но у него нет исторических данных для сравнения. Тогда он заходит на другие серверы баз данных, обслуживающие аналогичные рабочие нагрузки, и обнаруживает, что в них коэффициент попадания в кэш превышает 98 %. Он также обнаруживает, что размер кэша файловой системы на других серверах намного больше.
Обратив внимание на размер кэша файловой системы и потребление памяти сервера, он замечает, что было упущено из виду: в разрабатываемом проекте имеется прототип приложения, потребляющий все больше памяти, хотя пока работает вхолостую. В результате для кэша файловой системы остается меньше свободной памяти, из-за чего снижается частота попаданий в кэш и увеличивается количество дисковых операций чтения с диска.
Сумит связался с командой разработчиков приложения и попросил их остановить приложение и переместить его на другой сервер, сославшись на проблему с базой данных. После того как они выполнили его просьбу, Сумит увидел в AcmeMon, как по мере восстановления кэша файловой системы до исходного объема нагрузка на диск стала постепенно снижаться. Количество медленно обрабатываемых запросов упало до нуля, и он закрыл тикет как разрешенный.
1.11.2. Изменение в программном обеспечении
Памела — перформанс-инженер в небольшой компании, она занимается всем, что так или иначе связано с производительностью. Разработчики приложений реализовали новую возможность, но не уверены, что ее внедрение не ухудшит производительность. Памела решает провести регрессионное тестирование новой версии приложения перед внедрением в продакшен.
Для тестирования Памела выбирает простаивающий сервер, и теперь ей нужен имитатор рабочей нагрузки клиента. В недавнем прошлом группа разработчиков приложений написала такой имитатор, но у него есть различные ограничения и известные ошибки. Памела решает попробовать его, но прежде хочет убедиться, что он способен создавать рабочую нагрузку, адекватную текущей.
Она настраивает сервер в соответствии с текущей конфигурацией развертывания и запускает имитатор в другой системе для создания рабочей нагрузки на сервер. Нагрузку, имитирующую действия клиентов, можно оценить, изучив журнал доступа, и в компании уже есть подходящий для этого инструмент. Она запускает этот инструмент, передает ему журнал с рабочего сервера с данными за разные периоды в течение суток и сравнивает рабочие нагрузки. Как оказалось, имитатор создает среднюю рабочую нагрузку без всяких отклонений. Она отмечает это и продолжает анализ.
Памела знает несколько подходов, которые можно применить на этом этапе. Она выбирает самый простой: увеличивать нагрузку до достижения предела (иногда этот подход называют стресс-тестированием). Имитатор клиента можно настроить на отправку определенного количества клиентских запросов в секунду со значением по умолчанию 1000. Она решает начать со 100 запросов в секунду и постепенно увеличивать нагрузку с шагом 100, пока не будет достигнут предел, при этом на каждом уровне нагрузки тестирование продолжается в течение одной минуты. Она пишет сценарий на языке командной оболочки, который собирает результаты в файл для анализа другими инструментами.
При действующей нагрузке она проводит активный анализ производительности, чтобы выявить ограничивающие факторы. Ресурсы сервера кажутся свободными, а потоки выполнения по большей части бездействующими. Как показал имитатор, пропускная способность составила примерно 700 запросов в секунду.
После этого она запускает новую версию приложения и повторяет тесты. Достигается тот же уровень 700 запросов в секунду, и никаких ограничивающих факторов не выявляется.
Она наносит результаты на графики, отражающие зависимость количества обработанных запросов в секунду от нагрузки, чтобы визуально определить профиль масштабируемости, и отмечает присутствие на обоих графиках резкой верхней границы.
По всей видимости, обе версии ПО имеют схожие характеристики производительности, но Памела разочарована, потому что не смогла выявить ограничивающий фактор, определяющий потолок масштабируемости. Она знает, что проверяла только ресурсы сервера, а ограничение может скрываться в логике приложения, в работе сети, в имитаторе клиента или где-то еще.
Памела решает использовать другой подход, например, запустить имитацию клиента с фиксированной частотой следования запросов и оценить потребление ресурсов (процессора, дискового ввода/вывода, сетевого ввода/вывода), чтобы потом выразить затраты ресурсов на обработку одного клиентского запроса. Она запускает имитатор с частотой 700 запросов в секунду и измеряет потребление ресурсов при использовании текущего и нового программного обеспечения. С текущим ПО в системе с 32 процессорами загрузка процессоров составила 20 %, а с новым программным обеспечением при той же нагрузке она увеличилась до 30 %. Похоже, что в новом ПО действительно имеется регресс производительности из-за увеличенного потребления вычислительных ресурсов.
Но было бы интересно понять причину предела в 700 запросов в секунду. Памела настраивает имитатор на более высокую нагрузку и исследует все компоненты на пути к данным, включая сеть, клиентскую систему и генератор клиентской рабочей нагрузки. Она также выполняет детальный анализ серверного и клиентского ПО, документируя проверенные метрики и скриншоты для справки.
Для исследования клиентского ПО она проанализировала состояния потоков выполнения и обнаружила, что оно однопоточное! Этот единственный поток потребляет все 100 % процессорного времени, что, по всей видимости, и является причиной столь резкой границы в 700 запросов в секунду, обнаруженной во время тестирования.
Чтобы подтвердить догадку, она запускает имитатор сразу на нескольких клиентских системах и доводит потребление процессора на сервере до 100 % как с текущим, так и с новым программным обеспечением. По результатам этого тестирования производительность текущей версии достигла 3500 запросов в секунду, а новой версии — 2300 запросов в секунду, что согласуется с более ранними данными о потреблении ресурсов.
Памела сообщает разработчикам, что в новой версии ПО наблюдается регресс, и приступает к профилированию потребления процессора с помощью флейм-графика, чтобы понять, какие пути в коде вносят наибольший вклад. Она отмечает, что тестирование выполнялось с нагрузкой, сопоставимой со средней на производственном сервере, и другие нагрузки не проверялись. Она также сообщает об ошибке в имитаторе клиентской рабочей нагрузки — что он однопоточный и может стать узким местом.
1.11.3. Дополнительное чтение
Подробный практический пример представлен в главе 16 «Пример из практики», где описывается решение конкретной проблемы с производительностью в облачной среде. В следующей главе будут представлены методологии, используемые для анализа производительности, а в последующих главах дается вся необходимая информация.
1.12. Ссылки
[Hollingsworth 94] Hollingsworth, J., Miller, B., and Cargille, J., «Dynamic Program Instrumentation for Scalable Performance Tools», Scalable High-Performance Computing Conference (SHPCC), May 1994.
[Tamches 99] Tamches, A., and Miller, B., «Fine-Grained Dynamic Instrumentation of Commodity Operating System Kernels», Proceedings of the 3rd Symposium on Operating Systems Design and Implementation, February 1999.
[Kleen 08] Kleen, A., «On Submitting Kernel Patches», Intel Open Source Technology Center, http://halobates.de/on-submitting-patches.pdf, 2008.
[Gregg 11a] Gregg, B., and Mauro, J., «DTrace: Dynamic Tracing in Oracle Solaris, Mac OS X and FreeBSD», Prentice Hall, 2011.
[Gregg 15a] Gregg, B., «Linux Performance Analysis in 60,000 Milliseconds», Netflix Technology Blog, http://techblog.netflix.com/2015/11/linux-performance-analysis-in-60s.html, 2015.
[Dekker 18] Dekker, S., «Drift into Failure: From Hunting Broken Components to Understanding Complex Systems», CRC Press, 2018.
[Gregg 19] Gregg, B., «BPF Performance Tools: Linux System and Application Observability»16, Addison-Wesley, 2019.
[Corry 20] Corry, A., «Retrospectives Antipatterns», Addison-Wesley, 2020.
8 В Netflix используется термин красно-черное развертывание.
9 В настоящее время BPF является названием, а не аббревиатурой от Berkeley Packet Filter, как было первоначально.
10 Первое время для описания расширенного BPF (extended BPF) использовалось название eBPF; однако в настоящее время эта технология называется просто BPF.
11 Сначала я разработал версию для DTrace, а потом и для других трассировщиков, включая BCC и bpftrace.
12 В этом выводе можно видеть термин «Bandwidth» (полоса пропускания), который часто используется не по назначению. Под полосой пропускания подразумевается максимально возможная пропускная способность, которую iperf(1) не измеряет. iperf(1) измеряет текущую скорость передачи данных по сети: ее пропускную способность.
13 Можно даже создать свой дашборд для такого чек-листа, но имейте в виду, что этот чек-лист составлен с целью максимально использовать доступные инструменты командной строки, тогда как средства мониторинга могут иметь множество других (и более информативных) метрик. Я более склонен создавать дашборды для методологии USE и др.
14 Об этом рассказывается в главе 2 «Методологии» в разделе 2.5.12 «Анализ с увеличением детализации».
15 Инструмент трассировки BCC, описывается в главе 8 «Файловые системы» в разделе 8.6.12 «cachestat».
16 Грегг Б. «BPF: Профессиональная оценка производительности». Выходит в издательстве «Питер» в 2023 году.
Задержка — полезная метрика, но она не всегда доступна. Некоторые системные области позволяют измерить только среднюю задержку; некоторые вообще не дают возможности измерения. С появлением новых инструментов наблюдения на основе BPF9 задержку теперь можно измерять практически в любых точках и получить данные, описывающие полное распределение задержки.
Облачные вычисления предлагают новые методы проверки концепции (шаг 6), которые побуждают пропускать более ранние шаги (с 1-го по 5-й). Один из таких методов — тестирование нового ПО на единственном экземпляре с небольшой рабочей нагрузкой: это называется канареечным тестированием. Другой метод превращает его в обычный шаг при развертывании: трафик постепенно перемещается в новый пул экземпляров, при этом старый пул остается в горячем резерве; этот метод известен как сине-зеленое развертывание8. Применение таких приемов защиты от сбоев в новом ПО позволяет проводить тестирование в продакшене без всякого предварительного анализа производительности и при необходимости быстро возвращаться к исходному состоянию. Но я рекомендую всегда, когда это возможно, выполнить также первые этапы, чтобы достичь максимальной производительности (даже при том, что иногда могут быть веские причины миновать их, например, быстрый выход на рынок).
В настоящее время BPF является названием, а не аббревиатурой от Berkeley Packet Filter, как было первоначально.
В Netflix используется термин красно-черное развертывание.
В этом выводе можно видеть термин «Bandwidth» (полоса пропускания), который часто используется не по назначению. Под полосой пропускания подразумевается максимально возможная пропускная способность, которую iperf(1) не измеряет. iperf(1) измеряет текущую скорость передачи данных по сети: ее пропускную способность.
Можно даже создать свой дашборд для такого чек-листа, но имейте в виду, что этот чек-лист составлен с целью максимально использовать доступные инструменты командной строки, тогда как средства мониторинга могут иметь множество других (и более информативных) метрик. Я более склонен создавать дашборды для методологии USE и др.
Первое время для описания расширенного BPF (extended BPF) использовалось название eBPF; однако в настоящее время эта технология называется просто BPF.
Сначала я разработал версию для DTrace, а потом и для других трассировщиков, включая BCC и bpftrace.
Грегг Б. «BPF: Профессиональная оценка производительности». Выходит в издательстве «Питер» в 2023 году.
Об этом рассказывается в главе 2 «Методологии» в разделе 2.5.12 «Анализ с увеличением детализации».
Инструмент трассировки BCC, описывается в главе 8 «Файловые системы» в разделе 8.6.12 «cachestat».
Глава 2. Методологии
Дай человеку рыбу, и он будет сыт один день.
Научи его ловить рыбу, и он будет сыт до конца жизни.
Китайская пословица
Свою карьеру я начинал младшим системным администратором и думал тогда, что смогу освоить оценку производительности, изучая только метрики и инструменты командной строки. Как же я ошибался! Я прочитал страницы справочного руководства от корки до корки и изучил, как определять сбои страниц (page faults), переключения контекста и множество других системных показателей, но я не знал, что с ними делать: как перейти от сигналов к решениям.
Я заметил, что всякий раз, когда возникала проблема с производительностью, старшие системные администраторы применяли свои методики использования инструментов и метрик, чтобы как можно быстрее добраться до первопричины. Они понимали, какие метрики наиболее информативны, когда они указывают на проблему, и как их использовать для сужения исследуемой области. Именно этого ноу-хау не хватало на страницах справочного руководства, и мы, молодежь, перенимали этот опыт, заглядывая через плечо старшего администратора или инженера.
С тех пор я собрал, разработал, задокументировал и опубликовал собственные методологии оценки эффективности и включил их в эту главу вместе с другой важной информацией о производительности системы: понятиями, терминологией, статистиками и приемами визуализации. Здесь та теория, которая пригодится в последующих главах, где мы перейдем к практическому применению этих методологий.
Цели главы:
• Познакомить с ключевыми метриками производительности: задержкой, коэффициентом использования (потреблением) и насыщенностью.
• Развить интуицию в выборе масштаба измеряемого времени вплоть до наносекунд.
• Научить правильно выстраивать компромиссы, определять цели и момент прекращения анализа.
• Показать, как выявлять проблемы рабочей нагрузки в зависимости от архитектуры.
• Научить анализировать ресурсы и рабочие нагрузки.
• Представить различные методологии оценки производительности, в том числе метод USE, определение характеристик рабочей нагрузки, анализ задержки, статическую настройку производительности и мантры производительности.
• Познакомить с основами статистики и теории массового обслуживания.
Из всех глав моей книги эта меньше всего изменилась по сравнению с первым изданием. Программное и аппаратное обеспечение, инструменты оценки и настройки производительности — все это не раз менялось в течение моей карьеры, но теория и методология, о которых идет речь в этой главе, оставались неизменными.
Глава делится на три части:
• Основы: знакомит с терминологией, базовыми моделями, ключевыми понятиями и перспективами. Практически вся оставшаяся часть книги предполагает знание этих основ.
• Методологии: рассматривает методологии анализа производительности, основанные как на наблюдениях, так и на экспериментах, моделирование, а также планирование мощности.
• Метрики: представляет статистики производительности, приемы мониторинга и визуализации.
Многие из представленных здесь методологий мы рассмотрим подробнее в последующих главах, в том числе в разделах, посвященных методологиям, в главах 5–10.
2.1. Терминология
Ниже перечислены ключевые термины, используемые в сфере анализа производительности систем. В последующих главах будут представлены дополнительные термины с описаниями в различных контекстах.
• IOPS (input/output operations per second): количество операций ввода/вывода в секунду; является мерой частоты следования операций передачи данных. Для дискового ввода/вывода под количеством операций ввода/вывода (IOPS) подразумевается сумма операций чтения и записи в секунду.
• Пропускная способность (throughput): скорость выполненной работы. В частности, в области связи этот термин используется для обозначения скорости передачи данных (байтов или битов в секунду). В некоторых контекстах (например, в базах данных) под пропускной способностью может подразумеваться скорость работы (количество операций или транзакций в секунду).
• Время отклика (response time): время от начала до завершения операции. Включает в себя время на ожидание, на обслуживание (время обслуживания — service time) и на передачу результата.
• Задержка (latency): время, в течение которого операция ожидает обслуживания. В некоторых контекстах под задержкой подразумевается все время выполнения операции, то есть время отклика. См. примеры в разделе 2.3 «Основные понятия».
• Потребление (utilization): для ресурсов, необходимых для обслуживания, потребление определяет меру занятости ресурса, исходя из продолжительности в данном интервале времени, когда этот ресурс активно выполнял работу. Для ресурсов, которые обеспечивают хранение, под коэффициентом использования (потреблением) может подразумеваться потребленный объем (например, потребленный объем памяти).
• Насыщенность (saturation): степень заполнения очереди заданий, которые ресурс не может обслужить немедленно.
• Узкое место (bottleneck). В сфере анализа производительности систем под узким местом подразумевается ресурс, ограничивающий производительность системы. Основная работа по повышению производительности системы как раз заключается в выявлении и устранении узких мест.
• Рабочая нагрузка (workload): рабочей нагрузкой называются входные данные для системы или приложенная к ней нагрузка. Для базы данных рабочей нагрузкой является поток запросов и команд, отправляемых клиентами.
• Кэш (cache): область быстродействующего хранилища, в которой могут храниться копии или буферы ограниченного объема данных. Кэш используется, чтобы предотвратить операции с более медленными хранилищами и тем самым повысить производительность. По экономическим причинам кэш часто меньше основного и более медленного хранилища.
В глоссарии можно найти описания дополнительных терминов.
2.2. Модели
Следующие простые модели показывают некоторые основные принципы оценки производительности системы.
2.2.1. Тестируемая система
На рис. 2.1 показаны характеристики тестируемой системы (System Under Test, SUT).
Важно помнить, что на результат могут влиять посторонние возмущения (помехи), в том числе вызванные запланированной активностью системы, пользователями системы и другими рабочими нагрузками. Происхождение возмущений не всегда очевидно, и для их определения может потребоваться тщательное изучение характеристик системы. Это особенно сложно в некоторых облачных средах, где другие действия (со стороны подписчиков) в физической системе хоста могут быть недоступны для наблюдения из гостевой SUT.
Рис. 2.1. Схема тестируемой системы
Другая сложность современных окружений заключается в том, что они могут включать несколько сетевых компонентов, обслуживающих входную рабочую нагрузку, в том числе балансировщики нагрузки, прокси-серверы, веб-серверы, серверы кэширования, серверы приложений, серверы баз данных и системы хранения. Простое картографирование окружения может помочь выявить ранее упущенные из виду источники возмущений. Для аналитических исследований окружение также можно представить как сеть систем массового обслуживания (queueing systems).
2.2.2. Система массового обслуживания
Некоторые компоненты и ресурсы можно смоделировать как систему массового обслуживания и получить возможность предсказывать их производительность в различных ситуациях. Диски, например, часто моделируют как систему массового обслуживания, которая может предсказать, насколько ухудшится время отклика под нагрузкой. На рис. 2.2 показана простая система массового обслуживания.
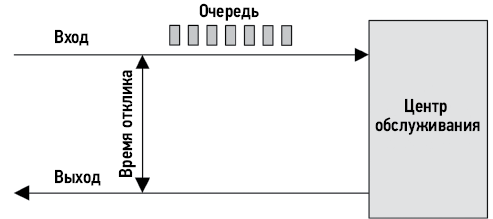
Рис. 2.2. Простая модель системы массового обслуживания
Теория массового обслуживания, представленная в разделе 2.6 «Моделирование», изучает системы массового обслуживания и сети систем массового обслуживания.
2.3. Основные понятия
Далее приводится описание важных концепций в сфере оценки производительности систем, понимание которых понадобится в оставшейся части этой главы и всей книги. Здесь приводится лишь общее описание понятий, а более подробные разъяснения, связанные с реализацией, будут даны в последующих главах — в разделах, посвященных архитектуре.
2.3.1. Задержка
В некоторых средах задержка — единственный фактор, позволяющий хоть как-то оценить производительность. В других средах это одна из двух основных метрик наряду с пропускной способностью.
В качестве примера на рис. 2.3 показана передача данных по сети, в данном случае запрос HTTP GET, с разделением времени на задержку и передачу данных.

Рис. 2.3. Задержка при передаче данных по сети
Задержка — это время ожидания до завершения операции. В этом примере операцией является запрос к сетевой службе на передачу данных. Прежде чем эта операция завершится, система должна дождаться, пока будет установлено сетевое соединение, что является задержкой для этой операции. Время отклика включает в себя эту задержку и время выполнения самой операции.
Поскольку задержку можно измерить в разных местах, ее часто выражают с использованием цели измерений. Например, время загрузки страницы веб-сайта может включать в себя три разных значения времени, измеренных в разных местах: задержка DNS, задержка соединения TCP и время передачи данных TCP. Задержка DNS охватывает всю операцию разрешения имен в DNS. Задержка соединения TCP охватывает только инициализацию соединения («рукопожатие» TCP).
На более высоком уровне все эти времена, включая время передачи данных TCP, можно рассматривать как задержку чего-то еще. Например, время с момента щелчка на ссылке до полной загрузки веб-страницы можно назвать задержкой, включающей время получения браузером страницы из сети и ее отображение на экране. Поскольку само слово «задержка» может быть неоднозначным, его лучше сопровождать уточняющими терминами, объясняющими, что именно измеряет эта задержка: задержка запроса, задержка соединения TCP и т.д.
Поскольку задержка является метрикой времени, ее можно использовать в различных вычислениях. Проблемы производительности можно количественно оценить с помощью задержки и затем ранжировать, потому что они выражаются в одних и тех же единицах (времени). Также, опираясь на задержки, можно рассчитать прогнозируемое ускорение, определив степень уменьшения задержки. Подобные вычисления и прогнозы невозможны с использованием, например, только метрики IOPS.
В табл. 2.1 приводятся краткие обозначения единиц измерения времени и их масштаб.
Таблица 2.1. Единицы измерения времени
| Единица |
Краткое обозначение |
Величина в секундах |
| Минута |
мин |
60 |
| Секунда |
с |
1 |
| Миллисекунда |
мс |
0,001, или 1/1000, или 1×10–3 |
| Микросекунда |
мкс |
0,000001, или 1/1000000, или 1×10–6 |
| Наносекунда |
нс |
0,000000001, или 1/1000000000, или 1×10–9 |
| Пикосекунда |
пс |
0,000000000001, или 1/1000000000000, или 1×10–12 |
Преобразование других типов метрик в задержку или время, если это возможно, позволяет сравнивать их. Если вам нужно было бы выбирать между 100 сетевыми и 50 дисковыми операциями ввода/вывода, как бы вы узнали, что лучше? Это сложный вопрос, требующий учета множества факторов: количества сетевых переходов, частоты сброса сетевых пакетов и повторных передач, объема ввода/вывода, характера ввода/вывода — произвольный или последовательный, типов дисков и т.д. Но если сравнивать 100 мс сетевого ввода/вывода и 50 мс дискового ввода/вывода, разница очевидна.
2.3.2. Шкалы времени
Время можно сравнивать численно, но у нас также есть интуитивное понимание времени, и мы можем выдвигать разумные предположения относительно задержек из разных источников. Компоненты системы работают в совершенно разных временных масштабах (отличающихся порой на порядки), разных до такой степени, что порой трудно понять, насколько велики эти различия. В табл. 2.2 представлены примеры задержек, начиная с доступа к регистру процессора с тактовой частотой 3,5 ГГц. Чтобы наглядно показать разницу во временных масштабах, с которыми приходится работать, в таблице показано также среднее время выполнения каждой операции в масштабе воображаемой системы, в которой один такт процессора длительностью в 0,3 нс (примерно одна треть от одной миллиардной доли секунды) занимает целую секунду.
Как видите, один такт процессора длится очень короткое время. Чтобы преодолеть расстояние 0,5 м — примерно столько же, сколько от ваших глаз до этой страницы, — свету требуется около 1,7 нс. За это время современный процессор может выполнить пять тактов и обработать несколько инструкций.
Таблица 2.2. Масштабы задержек в системе
| Событие |
Задержка |
В масштабе |
| 1 такт процессора |
0,3 нс |
1 с |
| Доступ к кэшу 1-го уровня |
0,9 нс |
3 с |
| Доступ к кэшу 2-го уровня |
3 нс |
10 с |
| Доступ к кэшу 3-го уровня |
10 нс |
33 с |
| Доступ к оперативной памяти (DRAM из процессора) |
100 нс |
6 мин |
| Продолжительность ввода/вывода для твердотельного накопителя (флеш-память) |
10–100 мкс |
9–90 часов |
| Продолжительность ввода/вывода для вращающегося жесткого диска |
1–10 мс |
1–12 месяцев |
| Интернет: время передачи сигнала от Сан-Франциско до Нью-Йорка |
40 мс |
4 года |
| Интернет: время передачи сигнала от Сан-Франциско до Великобритании |
81 мс |
8 лет |
| Облегченная загрузка с аппаратной виртуализацией |
100 мс |
11 лет |
| Интернет: время передачи сигнала от Сан-Франциско до Австралии |
183 мс |
19 лет |
| Загрузка системы с виртуализацией на уровне ОС |
< 1 с |
105 лет |
| Задержка перед повторной передачей TCP |
1–3 с |
105–317 лет |
| Тайм-аут команды SCSI |
30 с |
3 тысячелетия |
| Загрузка системы с аппаратной виртуализацией |
40 с |
4 тысячелетия |
| Перезагрузка физической системы |
5 мин |
32 тысячелетия |
Дополнительные сведения о тактах процессора и задержках вы найдете в главе 6 «Процессоры», а о задержках дискового ввода/вывода — в главе 9 «Диски». Задержки в интернете взяты из главы 10 «Сеть», где вы найдете еще множество примеров.
2.3.3. Компромиссы
Вы должны знать о некоторых типичных компромиссах, связанных с производительностью. Компромисс «выбора двух из трех» — качественно/быстро/дешево — показан на рис. 2.4 вместе с терминологией, скорректированной для ИТ-проектов.
Многие ИТ-проекты выбирают своевременность и экономичность, оставляя высокую эффективность на потом. Этот выбор может превратиться в проблему, когда принятые решения впоследствии будут препятствовать повышению производительности, как, например, выбор и реализация неоптимальной архитектуры хранилища, использование неэффективного языка программирования или операционной системы или выбор компонента, в котором нет инструментов комплексного анализа производительности.

Рис. 2.4. Компромиссы: выбор двух из трех
Типичный компромисс при настройке производительности — это компромисс между процессором и памятью, потому что память можно использовать для кэширования результатов и тем самым снизить нагрузку на процессор. В современных системах с большим количеством процессоров выбор может измениться, например, в сторону использования процессора для сжатия данных, чтобы уменьшить потребление памяти.
Настраиваемые параметры часто требуют компромиссов. Вот пара примеров:
• Размер записи в файловой системе (или размер блока): записи небольшого размера, близкие к размеру блоков ввода/вывода в приложении, лучше подходят для рабочих нагрузок с произвольным вводом/выводом и позволяют эффективнее использовать кэш файловой системы во время работы приложения. Записи большого размера лучше подходят для рабочих нагрузок с потоковой передачей данных, включая резервное копирование файловой системы.
• Размер сетевого буфера: буферы небольшого размера уменьшают оверхед памяти на одно соединение, облегчая масштабирование системы. Буферы большого размера улучшают пропускную способность сети.
Учитывайте подобные компромиссы при внесении изменений в систему.
2.3.4. Настройка производительности
Настройка производительности наиболее эффективна, когда выполняется в непосредственной близости от места выполнения работы. Для рабочих нагрузок, управляемых приложениями, это означает настройку в самом приложении. В табл. 2.3 приведен пример программного стека с возможностями настройки.
Выполняя настройки на уровне приложения, можно исключить или уменьшить количество запросов к базе данных и значительно повысить производительность (например, в 20 раз). Спустившись на уровень устройства хранения, можно улучшить производительность операций ввода/вывода с хранилищем, но в этом случае оверхед на выполнение кода стека ОС никуда не исчезает, поэтому такая настройка может улучшить итоговую производительность приложения только на проценты (например, на 20 %).
Таблица 2.3. Примеры целей для настройки
| Уровень |
Примеры цели |
| Приложение |
Логика приложения, размеры очередей запросов, выполнение запросов к базе данных |
| База данных |
Структура таблиц, индексы, буферизация |
| Системные вызовы |
Отображение в память или чтение/запись, флаги синхронного или асинхронного ввода/вывода |
| Файловая система |
Размер записи, размер кэша, параметры файловой системы, журналирование |
| Устройства хранения |
Уровень RAID, количество и типы дисков, параметры устройств хранения |
Есть еще одна причина для поиска выигрышей в производительности на уровне приложений. Многие современные среды нацелены на быстрое развертывание, что способствует внедрению изменений в ПО еженедельно или даже ежедневно17. Поэтому процессы разработки и тестирования приложений, как правило, сосредоточены на корректности, и в них почти не остается времени для оценки производительности или оптимизации перед развертыванием в производственной среде. Оценка и оптимизация делаются позже, когда производительность становится проблемой.
Уровень приложения может быть самым эффективным для настройки производительности, но это не обязательно самый эффективный уровень для наблюдения за производительностью. Неэффективность обработки запросов легче выявить по времени выполнения на процессоре или по операциям ввода/вывода с файловой системой и дисками, то есть по информации, которую легко получить с помощью инструментов ОС.
Во многих средах (особенно в облачных) уровень приложений постоянно развивается, и изменения внедряются в продакшен еженедельно и ежедневно. Кроме того, самый значительный выигрыш в производительности, включая исправление регрессий, достигается при изменении кода приложения. В этих средах легко упустить из виду настройки на уровне операционной системы и возможность наблюдения со стороны операционной системы. Помните, что анализ производительности ОС может выявить проблемы не только на уровне ОС, но и на уровне приложений, и в некоторых случаях такой анализ выполнить легче, чем анализ самого приложения.
2.3.5. Целесообразность
В разных организациях и средах предъявляются разные требования к производительности. Может так сложиться, что в компании, куда вы устроитесь, принято проводить гораздо более глубокий анализ, чем вы привыкли делать, и вы даже не думали, что это возможно. Или, наоборот, на новом месте работы анализ, который вы считали базовым, может считаться углубленным и никогда раньше не проводился (легкая работа!).
Это не обязательно означает, что одни компании поступают правильно, а другие — нет. Многое зависит от окупаемости затрат и наличия опыта. Организации с большими вычислительными центрами или большими облачными средами могут позволить себе нанять команду перформанс-инженеров, которые анализируют все, включая внутренние механизмы ядра и счетчики производительности процессора, и часто используют различные инструменты трассировки. Они также могут формально моделировать производительность и разрабатывать точные прогнозы будущего роста. Для сред, тратящих миллионы в год на вычисления, легко оправдать затраты на такие группы специалистов, потому что выигрыши, которые они получают, — это рентабельность инвестиций. Небольшие стартапы со скромными затратами на вычисления могут выполнять только поверхностные проверки, доверяя мониторинг производительности сторонним решениям.
Но как было сказано в главе 1, производительность системы — это не только стоимость, но и удобство конечного пользователя. Стартап может посчитать необходимым инвестировать в оптимизацию производительности, чтобы уменьшить время отклика сайта или приложения. Рентабельность инвестиций в данном случае не обязательно означает снижение затрат, но уж точно будет означать наличие довольных, а не потерянных клиентов.
К наиболее экстремальным средам с точки зрения производительности относятся фондовые биржи и торговые площадки, где производительность и задержка имеют решающее значение, и увеличение эффективности может оправдать значительные усилия и затраты. В качестве примера можно привести прокладку трансатлантического кабеля, соединяющего биржи Нью-Йорка и Лондона, стоимостью 300 миллионов долларов, который позволил уменьшить задержку передачи на 6 мс [Williams 11].
Целесообразность также играет важную роль при принятии решения о том, когда прекратить анализ производительности.
2.3.6. Когда лучше остановить анализ
При анализе производительности всегда сложно правильно оценить, когда нужно остановиться, ведь инструментов и факторов, которые нужно исследовать, так много.
Когда я провожу уроки по анализу производительности (в последнее время я снова начал это делать), то часто даю студентам проблему для исследования, имеющую три причины. Выясняется, что некоторые останавливаются, найдя одну причину, другие — найдя две, третьи — все три, а некоторые продолжают исследования, пытаясь найти еще больше причин. Кто из них поступает правильно? Может показаться, что правильнее остановиться после того, как будут найдены все три причины, но в реальной жизни количество причин неизвестно.
Вот три сценария, когда анализ можно остановить, с некоторыми личными примерами:
• Когда вы объяснили основной вклад в проблему производительности. Приложение на Java начало потреблять в 3 раза больше процессорного времени, чем раньше. Первой я обнаружил проблему со стеком исключений, потребляющих процессорное время. Затем я подсчитал затраты времени в этих стеках и обнаружил, что на них приходится только 12 % от общего объема процессорного времени. Если бы эта цифра была близка к 66 %, я бы прекратил анализ, потому что это объясняло бы трехкратное замедление. Но получив цифру в 12 %, я решил продолжить поиски.
• Когда потенциальная выгода меньше стоимости анализа. Некоторые проблемы с производительностью, над которыми я работаю, могут приносить выигрыш, измеряемый десятками миллионов долларов в год. Такой выигрыш позволяет оправдать месяцы моего времени (инженерные затраты), потраченные на анализ. Другие выигрыши, например, за счет увеличения производительности крошечных микросервисов, могут измеряться сотнями долларов. Для их анализа может не хватить часа инженерного времени, разве что мне будет нечем заняться (чего в реальности никогда не бывает) или если я подозреваю, что эта проблема может быть предвестницей более серьезной проблемы и поэтому ее стоит решить до того, как она разрастется.
• Когда окупаемость затрат на решение других проблем выше. Если текущая ситуация не подпадает под предыдущие два сценария, исследование других проблем может принести больший выигрыш, и тогда имеет смысл перенести свое внимание на них.
Если вы работаете перформанс-инженером на полную ставку, определение приоритетности различных проблем на основе их потенциальной окупаемости, вероятно, станет для вас повседневной задачей.
2.3.7. Рекомендации действительны на данный момент времени
Характеристики производительности окружения со временем меняются из-за расширения круга пользователей, обновления оборудования и ПО или прошивки. Например, после увеличения пропускной способности сети с 10 до 100 Гбит/с диски или процессор могут превратиться в узкое место.
Рекомендации по производительности, в частности значения настраиваемых параметров, являются действительными только в определенный момент времени. Хороший на данный момент совет специалиста по производительности может стать недействительным после обновления программного или аппаратного обеспечения либо после появления новых пользователей.
Значения настраиваемых параметров, найденные в интернете, иногда могут дать быстрый выигрыш. Но могут также снизить производительность, если не подходят для вашей системы или рабочей нагрузки. Возможно, когда-то они были подходящими, но не сейчас, или подходят только как временное решение для обхода ошибки в ПО, которая будет в одном из ближайших его релизов. Это как если бы вы начали искать в чужой аптечке лекарство, но нашли бы там только просроченное или то, что вам не годится.
Искать такие рекомендации полезно, чтобы узнать, какие настраиваемые параметры существуют и как они настраивались в прошлом. Следующая задача после знакомства с параметрами — определить, нужно ли их настраивать для вашей системы и рабочей нагрузки и как. При этом все равно есть риск пропустить важный параметр, если другим не приходилось его настраивать или они настраивали его, но не поделились своим опытом.
При изменении настраиваемых параметров полезно сохранить их в системе контроля версий с подробной историей. (Возможно, вы уже так и поступаете, используя инструменты управления конфигурациями — Puppet, Salt, Chef и т.д.) Благодаря этому можно изучать изменения настраиваемых параметров и причины позже.
2.3.8. Нагрузка и архитектура
Приложение может работать неэффективно из-за проблем с конфигурацией ПО и оборудования, на котором оно выполняется, то есть из-за проблем с архитектурой и реализацией среды. Но приложение также может работать неэффективно просто из-за слишком большой нагрузки, вызывающей появление больших очередей и длительных задержек. Нагрузка и архитектура показаны на рис. 2.5.
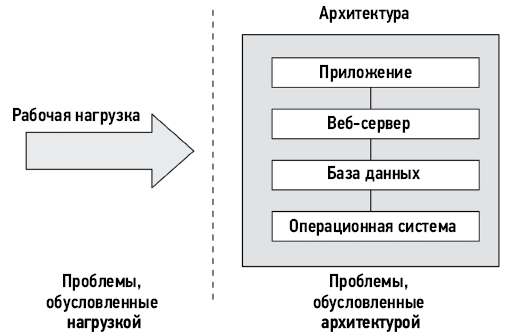
Рис. 2.5. Нагрузка и архитектура
Если анализ архитектуры показывает рост очередей с заданиями, но обрабатываются они достаточно эффективно, то проблема может быть в слишком большой приложенной нагрузке. В облачных средах в такие моменты можно организовать увеличение количества экземпляров для обслуживания дополнительной нагрузки.
Проблема с архитектурой может заключаться в однопоточном характере приложения, которое полностью нагружает один процессор, тогда как другие процессоры простаивают. В этом случае производительность ограничена однопоточной архитектурой приложения. Еще одна проблема с архитектурой — конкуренция за единственную блокировку в многопоточной программе, из-за чего только один поток может двигаться вперед, а остальные вынуждены ждать.
Многопоточные приложения тоже могут страдать от проблемы слишком высокой нагрузки, когда все доступные процессоры уже задействованы, а запросы продолжают прибывать в очереди. В этом случае производительность ограничена вычислительной мощностью процессора или, иначе говоря, система испытывает нагрузку большую, чем могут обрабатывать ее процессоры.
2.3.9. Масштабируемость
Изменение производительности системы при возрастающей нагрузке определяется ее масштабируемостью. На рис. 2.6 показан типичный график изменения пропускной способности с увеличением нагрузки на систему.
Рис. 2.6. Изменение пропускной способности с увеличением нагрузки
Какое-то время наблюдается линейный рост пропускной способности. Затем достигается уровень нагрузки, отмеченный вертикальной пунктирной линией, на котором конкуренция за ресурсы начинает снижать пропускную способность. Эту точку можно описать как точку перегиба, которая является границей между двумя функциями. Правее этой точки график отклоняется от линейного из-за возрастания конкуренции за ресурсы. В итоге оверхеды на конкуренцию и когерентность приводят к уменьшению объема выполняемой работы и снижению пропускной способности.
Эта точка может возникнуть, когда доля использования (потребление) компонента достигает 100 %: точки насыщения. Также это может произойти, когда доля использования компонента приближается к 100 % и операции с очередями выполняются все чаще и отнимают все больше времени.
Примером системы с подобным профилем может служить приложение, выполняющее тяжелые вычисления и обслуживающее дополнительную нагрузку, запуская дополнительные потоки выполнения. По мере того как нагрузка на процессор приближается к 100 %, время отклика начинает деградировать с увеличением задержки планировщика. После достижения пиковой производительности при 100 %-ном использовании процессоров пропускная способность начинает снижаться с добавлением новых потоков выполнения, потому что увеличивается количество переключений контекста, которые потребляют ресурсы процессора, и для выполнения фактической работы остается меньше процессорного времени.
Эту же кривую можно получить, если заменить «нагрузку» на оси X таким ресурсом, как ядра процессора. Дополнительную информацию по этой теме можно найти в разделе 2.6 «Моделирование».
На рис. 2.7 показано, как деградирует производительность в случае нелинейной масштабируемости с точки зрения среднего времени отклика или задержки [Cockcroft 95].
Рис. 2.7. Деградация производительности
Большое время отклика — это, конечно, плохо. Профиль «быстрой» деградации особенно характерен для случаев исчерпания оперативной памяти, когда система начинает перемещать страницы памяти на диск, чтобы освободить оперативную память. Профиль «медленной» деградации более характерен для случаев высокой нагрузки на процессор.
Еще одним примером ситуации с профилем «быстрой» деградации производительности может служить увеличение операций дискового ввода/вывода. По мере увеличения нагрузки (и, соответственно, операций с диском) операции ввода/вывода с большей вероятностью будут оказываться в очереди за другими операциями ввода/вывода. Неактивный вращающийся (не твердотельный) диск может обслуживать ввод/вывод с временем отклика около 1 мс, но при увеличении нагрузки это время может увеличиться до 10 мс. Эта ситуация смоделирована в разделе 2.6.5 «Теория массового обслуживания» в виде системы M/D/1 с 60 % нагрузкой, а производительность дисков рассматривается в главе 9 «Диски».
Линейный профиль времени отклика может возникнуть, если при недоступности ресурсов приложение начнет возвращать ошибки вместо добавления заданий в очередь. Например, веб-сервер может возвращать ошибку 503 «Служба недоступна» («service unavailable») вместо добавления запросов в очередь, чтобы запросы, которые приняты к обслуживанию, были обработаны за установленное время.
2.3.10. Метрики
Метрики производительности — это статистические данные, генерируемые системой, приложениями или дополнительными инструментами, которые измеряют интересующую активность. Метрики изучаются при анализе и мониторинге производительности либо в числовом виде в командной строке, либо графически с использованием средств визуализации.
К общим метрикам производительности системы можно отнести:
• пропускную способность: количество выполняемых операций или объем обрабатываемых данных в секунду;
• IOPS: количество операций ввода/вывода в секунду;
• доля использования (потребление): уровень потребления ресурса в процентах;
• задержка: время выполнения операции в виде среднего значения или процентилей.
Значение пропускной способности зависит от контекста. Под пропускной способностью базы данных обычно понимается количество запросов (операций) в секунду. Пропускная способность сети — это количество битов или байтов (объем), передаваемых в секунду.
IOPS — это мера пропускной способности для операций ввода/вывода (чтения и записи). И снова смысл этой метрики может меняться в зависимости от контекста.
Оверхед
Метрики производительности имеют определенную стоимость, потому что за их сбор и хранение приходится платить тактами процессорного времени. Такой оверхед может отрицательно влиять на производительность объекта измерения. Это называется эффектом наблюдателя. (Его часто путают с принципом неопределенности Гейзенберга, который описывает предел точности, с которой можно измерить пары физических свойств, например положение и импульс.)
Проблемы
Вы можете полагать, что поставщик ПО предоставил хорошо подобранные и безошибочные метрики, обеспечивающие полную наглядность. Но на самом деле метрики могут быть запутанными, сложными, ненадежными, неточными и совсем неверными (из-за ошибок). Иногда метрика может быть точной и верной в одной версии ПО и оказаться ошибочной в другой версии, потому что не отражает вновь появившиеся пути в коде.
Дополнительную информацию о проблемах с метриками ищите в главе 4 «Инструменты наблюдения» в разделе 4.6 «Наблюдение за наблюдаемостью».
2.3.11. Потребление
Термин потребление (utilization) часто применяется для описания уровня использования устройств, например процессоров и дисковых устройств. Потребление может зависеть от времени или мощности.
По времени
Потребление по времени в теории массового обслуживания формально определяется как (например, [Gunther 97])
среднее количество времени, в течение которого сервер или ресурс были заняты
и задается соотношением
U = B/T,
где U = потребление (utilization), B = суммарное время, когда ресурс был занят (busy) в течение времени наблюдения T.
Влияние на потребление является также одним из наиболее доступных средств повышения производительности операционной системы. Инструмент мониторинга дисков iostat(1) называет эту метрику %b (от percent busy — процент занятости); это название точно соответствует базовой метрике B/T.
Метрика потребления показывает уровень использования компонента: когда компонент используется на все 100 %, производительность может серьезно ухудшиться из-за возникающей конкуренции за ресурс. Чтобы убедиться, что компонент стал узким местом в системе, необходимо проверить также другие метрики.
Некоторые компоненты могут выполнять сразу несколько операций, и их производительность может не сильно пострадать при уровне использования 100 %, потому что они способны выполнять больше работы. Для примера рассмотрим строительный лифт. Он может считаться используемым, когда перемещается между этажами, и неиспользуемым, когда простаивает. Но лифт может перевозить большее количество пассажиров и грузов, даже когда занят все 100 % времени.
Диск, который занят на 100 %, тоже может выполнять больше работы, например, за счет буферизации записываемых данных в кэш-памяти диска и записи их позже. Массивы хранения часто работают со 100 %-ной загрузкой, потому что некоторые диски заняты 100 % времени, но при этом в массиве много бездействующих дисков, и поэтому он может выполнять больший объем работы.
По мощности
Другое определение потребления используется в информатике в контексте планирования мощности [Wong 97]:
Система или компонент (например, дисковый накопитель) могут обеспечить определенную пропускную способность. На любом уровне производительности система или компонент работают с определенной долей своей мощности. Эта доля называется потреблением.
В этом случае потребление определяется с точки зрения мощности, а не времени. Это означает, что диск, используемый на 100 %, не может выполнять больше работы. По определению, основанному на времени, под 100 %-ным потреблением подразумевается всего лишь, что он занят 100 % времени.
100 %-ная занятость не означает потребление 100 % мощности.
В примере с лифтом потребление 100 % мощности может означать, что лифт работает с максимальной полезной нагрузкой и не может перевозить больше пассажиров.
В идеальном мире мы могли бы измерить обе метрики потребления и узнать, например, когда диск занят на 100 % и производительность снижается из-за конкуренции, а когда он используется на 100 % мощности и не способен выполнять больше работы. К сожалению, обычно это невозможно. В случае с диском для этого нужно знать, что делает встроенный контроллер диска, и прогнозировать его мощность. В настоящее время диски не предоставляют эту информацию.
В этой книге термин потребление (или использование) обычно относится к версии определения на основе времени, которую также можно назвать временем работы без простоев. Версия определения на основе мощности применяется для описания занятости ресурсов на основе объема, например памяти.
2.3.12. Насыщенность
Степень превышения потребности в ресурсе над его возможностями называется насыщенностью. Насыщение наступает при пересечении отметки, равной 100 % потребления (по мощности), когда дополнительные задания не могут быть обработаны немедленно и ставятся в очередь. Эта ситуация показана на рис. 2.8.
На рисунке видно, что с увеличением нагрузки насыщенность продолжает расти линейно и после пересечения отметки 100 % доли потребления по мощности. Любая степень насыщенности — это проблема производительности, потому что при насыщении часть времени тратится на ожидание (задержку). При использовании метрики занятости на основе времени (процента занятости) насыщение и, следовательно, создание очередей, может не наступать на отметке 100 % потребления в зависимости от способности ресурса обслуживать задания параллельно.
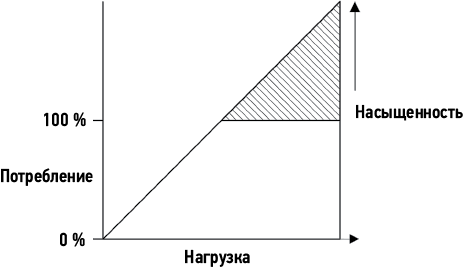
Рис. 2.8. Потребление и насыщенность
2.3.13. Профилирование
Профилирование создает картину цели, которую можно изучить. Профилирование с целью оценки производительности вычислений обычно выполняется путем выборки, или семплинга (sampling), состояния системы через определенные интервалы времени и последующего изучения набора выборок.
В отличие от рассмотренных ранее показателей, включая количество операций ввода/вывода в секунду и пропускную способность, выборки помогают получить приблизительное представление об активности цели. Степень приблизительности зависит от частоты дискретизации.
Например, с помощью профилирования путем частой выборки указателя инструкций процессора или трассировок стека можно достаточно полно понять, какие пути в коде потребляют больше всего процессорного времени. Более подробно об этом рассказывается в главе 6 «Процессоры».
2.3.14. Кэширование
Кэширование часто используется для повышения производительности. В кэше хранятся результаты, полученные из более медленного хранилища. Примером может служить кэширование дисковых блоков в оперативной памяти (ОЗУ).
Кэши могут быть многоуровневыми. Например, в процессорах используется несколько аппаратных кэшей (1-го, 2-го и 3-го уровней). На уровне 1 находится самый быстрый и небольшой кэш, и с каждым следующим уровнем размер кэша и время доступа к нему увеличиваются. Это экономический компромисс между объемом и задержкой. Размеры для разных уровней выбраны с учетом компромисса между производительностью и доступным пространством на кристалле. Подробнее об этих кэшах рассказывается в главе 6 «Процессоры».
В системе есть множество других кэшей, большинство из которых реализованы в ПО с использованием оперативной памяти. Список уровней кэширования вы найдете в главе 3 «Операционные системы» в разделе 3.2.11 «Кэширование».
Одной из метрик производительности кэша является коэффициент попаданий в кэш (hit ratio) — сколько раз необходимые данные были обнаружены в кэше (попадания) по отношению к общему числу обращений к кэшу (попадания + промахи):
Коэффициент попаданий = попадания / (попадания + промахи).
Чем больше значение этой метрики, тем лучше, ведь чем больше этот коэффициент, тем чаще данные получают из быстродействующего хранилища. На рис. 2.9 показано ожидаемое улучшение производительности с увеличением коэффициента попадания в кэш.
Рис. 2.9. Коэффициент попадания в кэш и производительность
Разница между производительностями, соответствующими коэффициентам попадания в кэш 98 % и 99 %, намного больше, чем между коэффициентами 10 % и 11 %. Эта нелинейность обусловлена разницей в скорости между попаданиями и промахами кэша — двумя уровнями хранения. Чем больше разница, тем круче кривая.
Еще одна метрика производительности кэша — частота промахов в кэше — выражает количество промахов в секунду. Она пропорциональна (линейно) потере производительности с каждым промахом, и ее проще интерпретировать.
Например, рабочие нагрузки A и B решают одну и ту же задачу с применением разных алгоритмов и используют кэш в оперативной памяти, чтобы избежать чтения с диска. Рабочая нагрузка A имеет коэффициент попадания в кэш 90 %, а рабочая нагрузка B имеет коэффициент попадания в кэш 80 %. Казалось бы, эта информация говорит о том, что рабочая нагрузка A действует эффективнее. Но что, если рабочая нагрузка A имеет частоту промахов 200 в секунду, а рабочая нагрузка B — 20 в секунду? Согласно этой информации, рабочая нагрузка B выполняет в 10 раз меньше операций чтения с диска, благодаря чему может справиться с задачей намного раньше, чем рабочая нагрузка A. Для большей уверенности можно рассчитать общее время выполнения каждой рабочей нагрузки как
время выполнения = (коэффициент попаданий × задержка попадания) + (частота промахов × задержка промаха).
В этой формуле используются средние значения задержек попаданий и промахов и предполагается, что все операции выполняются последовательно.
Алгоритмы
Алгоритмы и стратегии управления кэшем определяют, какие элементы будут продолжать храниться в ограниченном пространстве кэша.
Последний использовавшийся (most recently used, MRU) — это стратегия хранения в кэше, согласно которой там сохраняются объекты, которые использовались недавно. Дольше всех не использовавшийся (least recently used, LRU) — это похожая стратегия, но она описывает стратегию вытеснения из кэша: какие объекты удалять, когда требуется освободить место в кэше для новых объектов. Также есть стратегии наиболее часто используемые (most frequently used, MFU) и наименее часто используемые (least frequently used, LFU).
Иногда можно столкнуться со стратегией нечасто используемые (not frequently used, NFU), которая является менее дорогостоящей и менее полной версией LRU.
Горячие, холодные и теплые кэши
Эти характеристики широко используются для описания состояния кэша:
• Холодный: холодный кэш — это пустой кэш или заполненный посторонними данными. Коэффициент попаданий для холодного кэша равен нулю (и начинает увеличиваться по мере разогрева кэша).
• Теплый: теплый кэш — это кэш, наполненный полезными данными, но коэффициент попаданий в который пока недостаточно высок, чтобы можно было считать его горячим.
• Горячий: горячий кэш — это кэш, наполненный полезными данными и имеющий высокий коэффициент попаданий, например более 99 %.
• Теплота: теплота кэша описывает, насколько он горяч или холоден. Действие, увеличивающее «температуру» кэша, увеличивает коэффициент попаданий в него.
После инициализации кэш сначала холодный, а затем постепенно разогревается. Когда кэш очень большой или хранилище следующего уровня работает очень медленно (или и то и другое), на разогрев кэша может потребоваться много времени.
Например, мне довелось работать с устройством хранения, имевшим 128 Гбайт DRAM для кэширования файловой системы, 600 Гбайт флеш-памяти в качестве кэша второго уровня и вращающиеся диски для фактического хранения данных. При рабочей нагрузке с произвольным доступом диски производили около 2000 операций чтения в секунду. При размере блока ввода/вывода 8 Кбайт это означало, что кэш-память разогревалась со скоростью всего 16 Мбайт/с (2000 × 8 Кбайт). Сразу после включения, когда оба кэша еще холодные, требовалось более 2 часов для разогрева кэша в DRAM и более 10 часов для разогрева во флеш-памяти.
2.3.15. Известные неизвестные
Представленные в предисловии понятия известные известные (известные и изученные вещи), известные неизвестные (известные и неизученные вещи) и неизвестные неизвестные (неизвестные и неизученные вещи) очень важны в анализе производительности. Ниже для каждого из них приводятся примеры из анализа производительности систем:
• Известные известные: это то, что вы знаете. Вы знаете, какую метрику производительности следует проверить, и знаете ее текущее значение. Например, вы знаете, что должны проверить потребление процессора, и известно также, что эта метрика имеет среднее значение 10 %.
• Известные неизвестные: это то, о существовании чего вы знаете, но конкретные характеристики этого чего-то не знаете. Вы знаете, что можете проверить некоторую метрику или наличие подсистемы, но пока не сделали этого. Например, вы знаете, что можете выполнить профилирование, чтобы проверить, чем заняты процессоры, но еще не сделали этого.
• Неизвестные неизвестные: это то, о существовании чего вы и не подозреваете. Например, вы можете не подозревать о том, что прерывания от устройства могут оказывать существенную нагрузку на процессор, и, соответственно, не проверяете их.
Производительность — это область, в которой «чем больше знаешь, тем больше не знаешь». Чем больше вы узнаёте о системах, тем больше неизвестных неизвестных выявляете; далее они становятся известными неизвестными и у вас появляется возможность проверить их.
2.4. Точки зрения
Есть две общие точки зрения в анализе производительности со своими последователями, метриками и подходами: анализ рабочей нагрузки и анализ ресурсов. Их можно рассматривать как нисходящий и восходящий виды анализа программного стека операционной системы, как показано на рис. 2.10.
Конкретные стратегии для каждой из них будут представлены в разделе 2.5 «Методология», а здесь поговорим о самих точках зрения.
2.4.1. Анализ ресурсов
Анализ ресурсов начинается с анализа системных ресурсов: процессоров, памяти, дисков, сетевых интерфейсов, шин и соединений. Обычно это делают системные администраторы — те, кто отвечает за физические ресурсы. В число выполняемых мероприятий входят:
• исследование проблем с производительностью: чтобы определить меру ответственности конкретного ресурса за проблемы;
• планирование мощности: для получения информации, которая поможет определить размер и мощность новых систем и когда имеющиеся системные ресурсы будут исчерпаны.
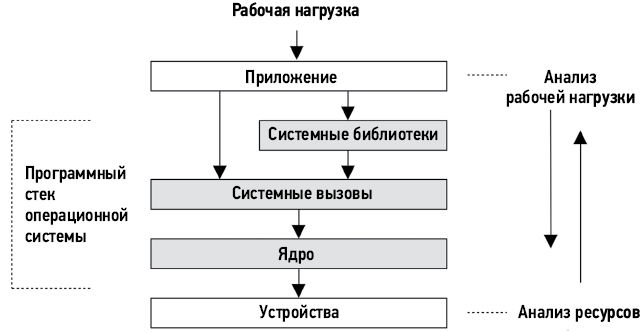
Рис. 2.10. Разные точки зрения на анализ
Эта точка зрения фокусируется на потреблении ресурсов, чтобы определить, когда произошло или произойдет исчерпание имеющихся ресурсов. Метрики потребления одних ресурсов, таких как процессоры, легкодоступны. Метрики потребления других ресурсов можно оценить на основе доступных метрик, например, оценить уровень потребления сетевого интерфейса, сравнив объем передаваемых и принимаемых данных в единицу времени (пропускной способности) с известной или ожидаемой максимальной пропускной способностью.
К числу метрик, которые лучше всего подходят для анализа ресурсов, относятся:
• IOPS;
• пропускная способность;
• потребление;
• насыщенность.
Они оценивают уровень потребления и насыщения ресурса для данной нагрузки. Другие метрики, такие как задержка, тоже могут пригодиться, помогая увидеть, насколько хорошо ресурс соответствует данной рабочей нагрузке.
Анализ ресурсов — это распространенный подход к анализу производительности, отчасти благодаря широкодоступной документации по этой теме. В этой документации основное внимание уделяется инструментам «stat» операционной системы: vmstat(8), iostat(1), mpstat(1). При чтении такой документации важно понимать, что это одна из точек зрения, но не единственная.
2.4.2. Анализ рабочей нагрузки
Анализ рабочей нагрузки (рис. 2.11) исследует производительность приложений: прикладываемую рабочую нагрузку и реакцию приложения. Этот вид анализа чаще используют разработчики приложений и команда поддержки — те, кто отвечает за сопровождение ПО и настройку приложения.
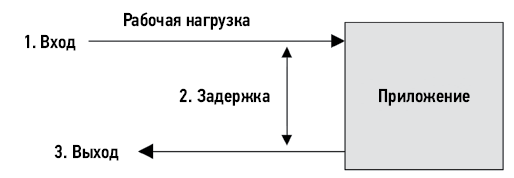
Рис. 2.11. Анализ рабочей нагрузки
Цели анализа рабочей нагрузки:
• вход: прикладываемая рабочая нагрузка;
• задержка: время отклика приложения;
• выход: выявление ошибок.
Изучение прикладываемой рабочей нагрузки обычно включает проверку и обобщение атрибутов запросов: это процесс определения характеристик рабочей нагрузки (более подробно описывается в разделе 2.5 «Методология»). Для баз данных в число этих атрибутов могут входить клиентский хост, имя базы данных, используемые таблицы и строка запроса. Эти данные могут помочь определить ненужную или несбалансированную работу. Даже когда система хорошо справляется с текущей рабочей нагрузкой (показывает низкую задержку), изучение этих атрибутов поможет найти способы уменьшения объема выполняемой работы. Помните, что самый быстрый запрос — это запрос, который не требуется выполнять.
Задержка (время отклика) — самый важный показатель, выражающий производительность приложения. Для базы данных MySQL — это задержка обработки запроса, для веб-сервера Apache — это задержка обработки HTTP-запроса, и т.д. В этих случаях термин задержка используется для обозначения времени ответа (см. раздел 2.3.1 «Задержка», чтобы узнать больше о контексте).
Задачи анализа рабочей нагрузки включают выявление и подтверждение проблем, например, поиск задержек, превышающих допустимый порог, а затем поиск источника задержки и подтверждение, что задержка уменьшилась после внесения исправлений. Обратите внимание, что отправной точкой в этом анализе является приложение. Исследование задержки обычно включает более глубокое изучение приложения, библиотек и операционной системы (ядра).
При изучении особенностей обработки запроса могут быть выявлены системные проблемы, включая состояние ошибки. Обработка запроса может завершиться быстро, но с признаком ошибки, что вызовет повторную попытку отправки запроса, увеличивая задержку.
Для анализа рабочей нагрузки лучше всего подходят следующие метрики:
• пропускная способность (транзакций в секунду);
• задержка.
Они оценивают скорость обработки запросов и итоговую производительность.
2.5. Методология
Если вы столкнулись с неэффективным и сложным системным окружением, первая проблема, которую нужно решить, — определить, с чего начать анализ и как действовать дальше. Как отмечалось в главе 1, проблемы с производительностью могут возникать где угодно — в софте, в оборудовании и вообще в любом компоненте на пути к данным. Методологии могут помочь приступить к анализу таких сложных систем, показывая, с чего начать анализ, и предлагая эффективную последовательность шагов.
В этом разделе описывается множество методологий и процедур анализа и настройки производительности, часть из которых разработаны мной. Эти методики помогут новичкам приступить к работе и послужат напоминанием для экспертов. Также в этом разделе упоминаются некоторые антиметодологии.
Я разделил методологии на типы — анализ наблюдений и анализ результатов экспериментов (табл. 2.4).
Таблица 2.4. Методологии анализа производительности
| Раздел |
Методология |
Тип |
| 2.5.1 |
Антиметодология «Уличный фонарь» |
Анализ наблюдений |
| 2.5.2 |
Антиметодология «Случайное изменение» |
Анализ результатов экспериментов |
| 2.5.3 |
Антиметодология «Виноват кто-то другой» |
Гипотетический анализ |
| 2.5.4 |
Специальный чек-лист |
Анализ наблюдений и результатов экспериментов |
| 2.5.5 |
Формулировка проблемы |
Сбор информации |
| 2.5.6 |
Научный метод |
Анализ наблюдений |
| 2.5.7 |
Цикл диагностики |
Анализ жизненного цикла |
| 2.5.8 |
Метод инструментов |
Анализ наблюдений |
| 2.5.9 |
Метод USE |
Анализ наблюдений |
| 2.5.10 |
Метод RED |
Анализ наблюдений |
| 2.5.11 |
Определение характеристик рабочей нагрузки |
Анализ наблюдений, планирование мощности |
| 2.5.12 |
Анализ с увеличением детализации |
Анализ наблюдений |
| 2.5.13 |
Анализ задержек |
Анализ наблюдений |
| 2.5.14 |
Метод R |
Анализ наблюдений |
| 2.5.15 |
Трассировка событий |
Анализ наблюдений |
| 2.5.16 |
Базовые статистики |
Анализ наблюдений |
| 2.5.17 |
Статическая настройка производительности |
Анализ наблюдений, планирование мощности |
| 2.5.18 |
Настройка кэширования |
Анализ наблюдений, настройка |
| 2.5.19 |
Микробенчмаркинг производительности |
Анализ результатов экспериментов |
| 2.5.20 |
Мантры производительности |
Настройка |
| 2.6.5 |
Теория массового обслуживания |
Статистический анализ, планирование мощности |
| 2.7 |
Планирование мощности |
Планирование мощности, настройка |
| 2.8.1 |
Количественная оценка прироста производительности |
Статистический анализ |
| 2.9 |
Мониторинг производительности |
Анализ наблюдений, планирование мощности |
Мониторинг производительности, теория массового обслуживания и планирование мощности рассматриваются далее в этой главе. Некоторые из упомянутых методологий подробнее обсуждаются в других главах в различных контекстах, где также представлены дополнительные методологии для конкретных целей анализа производительности. Эти дополнительные методологии перечислены в табл. 2.5.
Таблица 2.5. Дополнительные методологии анализа производительности
| Раздел |
Методология |
Тип |
| 1.10.1 |
Анализ производительности Linux за 60 секунд |
Анализ наблюдений |
| 5.4.1 |
Профилирование процессора |
Анализ наблюдений |
| 5.4.2 |
Анализ простоев |
Анализ наблюдений |
| 6.5.5 |
Анализ тактов |
Анализ наблюдений |
| 6.5.8 |
Настройка приоритетов |
Настройка |
| 6.5.9 |
Управление ресурсами |
Настройка |
| 6.5.10 |
Привязка к процессору |
Настройка |
| 7.4.6 |
Определение утечек |
Анализ наблюдений |
| 7.4.10 |
Уменьшение потребления памяти |
Анализ результатов экспериментов |
| 8.5.1 |
Анализ дисков |
Анализ наблюдений |
| 8.5.7 |
Разделение рабочей нагрузки |
Настройка |
| 9.5.10 |
Масштабирование |
Планирование мощности, настройка |
| 10.5.6 |
Перехват пакетов |
Анализ наблюдений |
| 10.5.7 |
Анализ TCP |
Анализ наблюдений |
| 12.3.1 |
Пассивное тестирование производительности |
Анализ результатов экспериментов |
| 12.3.2 |
Активное тестирование производительности |
Анализ наблюдений |
| 12.3.6 |
Нестандартное тестирование производительности |
Разработка программного обеспечения |
| 12.3.7 |
Пиковая нагрузка |
Анализ результатов экспериментов |
| 12.3.8 |
Проверка правильности |
Анализ наблюдений |
Мы начнем с исследования часто используемых, но наиболее слабых методологий, включая антиметодологии. Приступая к анализу проблем с производительностью, в первую очередь нужно применить методологию постановки задачи и только потом переходить к другим.
2.5.1. Антиметодология «Уличный фонарь»
В действительности это методология отсутствия продуманной методологии. Исследователь анализирует производительность, выбирая знакомые инструменты наблюдения, найденные в интернете или просто наугад, и пытается обнаружить что-нибудь очевидное. Этот подход может увенчаться или не увенчаться успехом и сопряжен с риском упустить из виду многие типы проблем.
Аналогично можно попытаться настроить производительность, используя метод проб и ошибок, изменяя известные и знакомые настраиваемые параметры и наблюдая, дает ли такое изменение положительный результат. Даже если с помощью этого метода удается обнаружить проблему, путь к ней может быть долгим, потому что перед этим случается опробовать инструменты или настройки, не связанные с проблемой, только потому, что они знакомы. По этой причине эта методология названа в честь эффекта, получившего название «эффект уличного фонаря», который отлично иллюстрирует притча:
Однажды ночью полицейский увидел, как пьяный что-то ищет под фонарем. Полицейский подошел поближе и спросил, что тот ищет. Пьяный отвечает, что потерял ключи. Полицейский начинает помогать ему и после долгих безуспешных поисков спрашивает: «Вы уверены, что потеряли их здесь, под фонарем?» Пьяный отвечает: «Нет, но здесь светлее».
Характеристики производительности можно пытаться искать в top(1), но не потому, что это имеет смысл, а потому, что исследователь не умеет пользоваться другими инструментами.
Проблема, которую обнаруживает эта методология, может оказаться не основной, а побочной проблемой. Другие методологии позволяют количественно оценить результаты, позволяя исключить ложные срабатывания и уделить основное внимание более серьезным проблемам.
2.5.2. Антиметодология «Случайное изменение»
Эта антиметодология опирается на анализ результатов экспериментов. Исследователь пытается угадать причину проблемы, а затем меняет настройки, пока проблема не исчезнет. Чтобы определить, улучшилась ли производительность, после каждого изменения изучается метрика, например время выполнения приложения, время выполнения операции, задержка, скорость работы (операций в секунду) или пропускная способность (байтов в секунду). При этом используется следующий подход:
1. Выбирается случайная настройка для изменения (например, некоторый параметр).
2. Изменяется в одном направлении.
3. Измеряется производительность.
4. Затем эта настройка изменяется в другом направлении.
5. Снова измеряется производительность.
6. Результаты, полученные на шаге 3 или 5, сравниваются с исходными показателями. Если производительность улучшилась, изменения сохраняются и процесс повторяется с шага 1.
Этот процесс может в итоге помочь обнаружить настройку, которая подходит для тестируемой рабочей нагрузки, но он занимает очень много времени и может привести к настройкам, не имеющим смысла в долгосрочной перспективе. Например, изменение приложения для обхода ошибки в базе данных или в ОС может улучшить производительность, но позже эта ошибка может быть исправлена, а приложение все еще будет использовать настройку, которая потеряла смысл и суть которой никто не понял.
Также есть риск, что изменение, которое неправильно понято, вызовет более серьезную проблему при пиковой нагрузке, и тогда потребуется откатить его.
2.5.3. Антиметодология «Виноват кто-то другой»
Эта антиметодология включает следующие шаги:
1. Найти компонент системы или среды, за который вы не несете ответственности.
2. Выдвинуть предположение, что проблема в этом компоненте.
3. Направить задачу команде, ответственной за этот компонент.
4. Если окажется, что вы ошиблись, повторить процесс с шага 1.
«Может быть, все дело в сети? Уточните у сетевых администраторов, возможно, какие-то маршрутизаторы сбрасывают пакеты или типа того».
Вместо исследования проблемы с производительностью использующий эту методологию делает ее чужой проблемой, что может привести к напрасному расходованию ресурсов других команд, если окажется, что это не их проблема. Эту антиметодологию можно определить по отсутствию данных, обосновывающих гипотезу.
Чтобы не стать жертвой голословного обвинения, попросите обвинителя предоставить скриншоты, показывающие, какие инструменты были запущены и как интерпретировался вывод. Эти скриншоты и результаты интерпретации можно передать кому-нибудь, чтобы получить подкрепляющее мнение.
2.5.4. Специальный чек-лист
Методология пошагового выполнения чек-листа широко распространена среди специалистов служб поддержки и используется ими для проверки и настройки системы. Типичным сценарием может служить развертывание нового сервера или приложения в промышленной среде с последующей проверкой распространенных проблем под реальной нагрузкой. Такие чек-листы обычно являются специализированными — основанными на недавнем опыте и проблемах, характерных для систем этого типа.
Вот пример одного элемента такого чек-листа:
Запустить iostat –x 1 и проверить столбец r_await. Если под нагрузкой его значение неизменно превышает 10 (мс), то либо операции чтения с диска выполняются медленно, либо диск перегружен.
Чек-лист может состоять из десятка подобных пунктов.
Чек-листы нередко оказываются очень ценными в условиях ограниченного времени, отпущенного на диагностику, но часто они действительны лишь на определенный период времени (см. раздел 2.3 «Основные понятия») и их следует обновлять как можно чаще, чтобы сохранить их актуальность. Кроме того, они имеют тенденцию сосредоточивать внимание на проблемах, для которых есть известные и легко выполнимые исправления, например установка настраиваемых параметров, но не на проблемах, решаемых нестандартными способами, требующими изменения исходного кода или окружения.
Если вы руководите службой поддержки, то специальный чек-лист может быть для вас эффективным способом убедиться, что сотрудники знают, как проверить наличие типичных проблем. Чек-лист может быть ясным и четким, показывающим, как идентифицировать каждую проблему и как ее решить. Но учтите, что этот список нужно постоянно обновлять.
2.5.5. Формулировка проблемы
Реагируя на появившуюся проблему, команда поддержки первым делом должна сформулировать проблему. Для этого клиенту задают следующие вопросы:
1. Почему вы думаете, что проблема именно с производительностью?
2. Хорошо ли работала система до этого?
3. Что изменилось за последнее время? Программное обеспечение? Аппаратное обеспечение? Нагрузка?
4. Можно ли обозначить проблему в терминах задержки или времени выполнения?
5. Влияет ли проблема на других людей либо приложения или только на вас?
6. Какое программное и аппаратное обеспечение используется? Версии? Конфигурация?
Простые вопросы и ответы на них часто помогают выявить непосредственную причину и решение. По этой причине формулировка проблемы включена как отдельная методология и должна использоваться при решении новых проблем.
Мне доводилось решать проблемы с производительностью по телефону, используя только метод формулировки проблемы, без входа на какой-либо сервер или просмотра каких-либо метрик.
2.5.6. Научный метод
Научный метод предназначен для изучения неизвестного и основывается на выдвижении гипотез и их проверке. Его можно кратко описать следующими шагами:
1. Вопрос.
2. Гипотеза.
3. Прогноз.
4. Проверка.
5. Анализ.
Вопрос — это формулировка проблемы. Сформулировав проблему, можно выдвинуть предположение о причине плохой работы. Затем создается тест, который может быть тестом наблюдения или экспериментальным, для проверки прогноза, основанного на гипотезе. И в заключение проводится анализ результатов, полученных в ходе тестирования.
Например, вы обнаруживаете, что производительность приложения снизилась после переноса в систему с меньшим объемом оперативной памяти, и предполагаете, что причиной снижения производительности является меньший размер кэша файловой системы. Вы можете использовать тест наблюдения, чтобы измерить частоту промахов кэша в обеих системах, предсказав, что в системе с меньшим кэшем частота промахов будет выше. Экспериментальный тест будет заключаться в увеличении размера кэша (добавлении ОЗУ) и предсказания, что производительность улучшится. Другой, более простой экспериментальный тест — искусственное уменьшение размера кэша (с использованием настраиваемых параметров) и предсказание, что производительность после этого ухудшится.
Ниже приводятся еще несколько примеров.
Пример (наблюдение)
1. Вопрос: в чем причина медленной обработки запросов в базе данных?
2. Гипотеза: влияние действий других подписчиков (других клиентов облачного окружения), вызывающих дисковый ввод/вывод, из-за чего возникает конкуренция за дисковый ввод/вывод (через файловую систему).
3. Прогноз: если измерить задержку ввода/вывода в файловой системе во время выполнения запроса, то выяснится, что причина кроется в файловой системе.
4. Проверка: трассировка задержек в файловой системе относительно задержек в обработке запросов показала, что на ожидание файловой системы тратится менее 5 % времени.
5. Анализ: причина медленной обработки запросов не в файловой системе.
Проблема еще не решена, но некоторые крупные компоненты среды уже можно исключить из рассмотрения. Человек, проводящий исследование, может вернуться к шагу 2 и выдвинуть новую гипотезу.
Пример (эксперимент)
1. Вопрос: почему HTTP-запросы, посылаемые хостом A, обрабатываются хостом C дольше, чем запросы, посылаемые хостом B?
2. Гипотеза: хосты A и B находятся в разных вычислительных центрах.
3. Прогноз: если хост A перенести в вычислительный центр, где находится хост B, то это решит проблему.
4. Проверка: перенос хоста A и измерение производительности.
5. Анализ: производительность изменилась в соответствии с гипотезой, проблема решена.
Если проблема не была решена, то перед выдвижением новой гипотезы отмените экспериментальное изменение (в данном случае верните хост А назад) — одновременное изменение нескольких факторов затрудняет определение, какой из них оказал наибольшее влияние!
Пример (эксперимент)
1. Вопрос: почему производительность файловой системы снижается при увеличении размера кэша?
2. Гипотеза: в большом кэше хранится больше записей, и для управления большим кэшем требуется больше вычислительных ресурсов.
3. Прогноз: если постепенно уменьшать размер записи, то в кэш того же объема поместится больше записей, что, соответственно, повлечет ухудшение производительности.
4. Проверка: протестировать ту же рабочую нагрузку, постепенно уменьшая размер записей.
5. Анализ: результаты представлены в виде графиков и согласуются с прогнозом. Далее необходимо выполнить анализ процедур управления кэшем.
Это пример отрицательного теста — намеренного снижения производительности, чтобы узнать больше о целевой системе.
2.5.7. Цикл диагностики
Цикл диагностики похож на научный метод:
гипотеза → инструментальная проверка → результаты → гипотеза.
Как и научный метод, этот метод проверяет гипотезу путем сбора данных. Слово «цикл» в названии подчеркивает, что результаты измерений могут привести к новой гипотезе, ее проверке и уточнению и т.д. Примерно так врач проводит серию тестов для диагностики заболевания, уточняя диагноз по результатам каждого теста.
Оба подхода имеют хороший баланс теории и фактических данных. Старайтесь быстрее переходить от гипотез к данным, чтобы как можно раньше отбраковать ошибочные гипотезы и уделить больше внимания верным.
2.5.8. Метод инструментов
Инструментально-ориентированный подход заключается в следующем:
1. Составить список доступных инструментов анализа производительности (при желании можно установить или приобрести дополнительные инструменты).
2. Перечислить полезные метрики, измеряемые каждым инструментом.
3. Перечислить возможные способы интерпретации каждой метрики.
В результате должен получиться чек-лист, описывающий, какие метрики и с помощью каких инструментов можно получить и как эти метрики интерпретировать. Этот метод может быть очень эффективным, но полагается исключительно на доступные (или известные) инструменты, из-за чего может сложиться неполное представление о системе как в антиметодологии «Уличный фонарь». Хуже того, исследователь даже не подозревает об этой неполноте. Проблемы, требующие применения специальных инструментов (например, динамической трассировки), могут остаться невыявленными и нерешенными.
На практике метод инструментов действительно выявляет определенные узкие места, ошибки и проблемы других видов, но страдает некоторой неэффективностью.
При наличии большого количества инструментов и метрик их перебор может занять много времени. Ситуация усугубляется, когда имеется несколько инструментов с одинаковыми или почти одинаковыми функциональными возможностями, и исследователь тратит дополнительное время, пытаясь понять плюсы и минусы каждого из них. В некоторых случаях, например в микробенчмаркинге файловой системы, может быть более десятка инструментов на выбор, тогда как достаточно одного из них18.
2.5.9. Метод USE
Метод USE (Utilization, Saturation, and Errors — потребление, насыщение и ошибки) следует использовать на ранних этапах исследования производительности для выявления узких мест [Gregg 13b]. Эта методология предназначена для анализа с точки зрения ресурсов, и в общем виде ее можно представить так:
Для каждого ресурса проверьте его потребление, насыщение и наличие ошибок.
Термины в этом определении интерпретируются так:
• Ресурсы: все функциональные компоненты физического сервера (процессоры, шины, ...). Также исследованию могут быть подвергнуты некоторые программные ресурсы, при условии, что метрики имеют смысл.
• Потребление: процент времени для заданного временного интервала, в течение которого ресурс обслуживал рабочую нагрузку. Часто, когда ресурс занят, он все еще может выполнять дополнительную работу; невозможность этого определяется уровнем насыщения.
• Насыщение: такое состояние ресурса, когда для него есть дополнительная работа, но он не может приступить к ее выполнению немедленно, из-за чего задания часто вынуждены ждать в очереди. Иногда это называют давлением.
• Ошибки: количество ошибок.
Для некоторых типов ресурсов, включая оперативную память, под потреблением подразумевается использованный объем. Это отличие от определения, основанного на времени, объяснялось выше в разделе 2.3.11 «Потребление». Когда потребление ресурса достигает 100 %, он оказывается не в состоянии принять дополнительные задания и либо ставит их в очередь (увеличивает насыщение), либо возвращает ошибки, которые также выявляются с помощью метода USE.
Ошибки важно изучать, потому что они могут снижать производительность, оставаясь незамеченными, особенно когда ресурс работает в режиме автоматического восстановления после отказов. Сюда можно отнести операции, выполняющие повторные попытки после завершения с ошибкой, и устройства, перемещающиеся в резервный пул после неудачи.
В отличие от метода инструментов, метод USE предполагает перебор системных ресурсов, а не инструментов. Этот метод поможет вам составить полный список вопросов, после чего вы сможете приступить к выбору инструментов для поиска ответов на них. Даже когда не удается найти инструменты для ответа на некоторые вопросы, знание самих этих вопросов может быть чрезвычайно полезно для аналитика, потому что это «известные неизвестные».
Метод USE также фокусируется на анализе ограниченного числа ключевых метрик, поэтому все системные ресурсы проверяются очень быстро. После этого, если проблемы не обнаружились, можно использовать другие методики.
Процедура
На рис. 2.12 изображена схема метода USE. Проверка ошибок стоит первой, потому что обычно они легко интерпретируются (чаще всего ошибки — это объективная, а не субъективная метрика), и исключение ошибок перед исследованием других метрик позволяет эффективно экономить время. Затем проверяется насыщенность, потому что это состояние интерпретируется быстрее, чем потребление: проблемой может быть любой уровень насыщения.
Этот метод выявляет проблемы, которые могут быть узкими местами в системе. К сожалению, у системы может быть несколько проблем с производительностью, поэтому есть риск первой обнаружить незначительную проблему. Каждый выявленный недостаток можно исследовать с помощью дополнительных методологий перед возвратом к методу USE, если потребуется изучить другие ресурсы.
Выражение метрик
Метрики в методе USE обычно выражаются так:
• Потребление: в процентах за интервал времени (например, «один процессор загружен работой на 90 %»).
• Насыщенность: как длина очереди ожидания (например, «средняя длина очереди задач, готовых к выполнению на процессоре, равна четырем»).
• Ошибки: как количество зарегистрированных ошибок (например, «на этом диске было зафиксировано 50 ошибок»).
Рис. 2.12. Схема метода USE
Это может показаться нелогичным, но кратковременное увеличение потребления может вызвать проблемы с насыщенностью и производительностью, даже если общее потребление оставалось низким в течение длительного периода времени. Некоторые инструменты мониторинга сообщают среднюю величину потребления за последние 5 минут. Например, нагрузка на процессор может сильно меняться с каждой секундой, поэтому пятиминутное среднее значение может скрывать короткие периоды 100 %-ной нагрузки и, следовательно, насыщения.
Рассмотрим оплату проезда на платном шоссе. Коэффициент использования можно определить как количество пунктов оплаты, занятых обслуживанием автомобилей. Стопроцентная занятость означает, что вы не сможете найти пустую будку и должны встать в очередь (возникло состояние насыщения). Если бы я сказал, что средняя загрузка пункта оплаты в течение дня составляет 40 %, означает ли это, что в течение дня ни один автомобиль не стоял в очереди? Вполне возможны часы пиковой нагрузки, когда занятость пункта оплаты достигает 100 %, но средняя занятость за день намного ниже.
Список ресурсов
Первый шаг в методе USE — создание списка ресурсов. Список должен быть как можно более полным. Вот типичный список аппаратных ресурсов сервера с конкретными примерами:
• Процессоры: тип сокета, количество ядер, аппаратные потоки (виртуальные процессоры).
• Оперативная память: DRAM.
• Сетевые интерфейсы: используемые порты Ethernet, высокоскоростная коммутируемая сеть.
• Устройства хранения: диски, адаптеры хранения.
• Ускорители: графические процессоры, TPU, FPGA и т.д., если используются.
• Контроллеры: хранилище, сеть.
• Шины: процессора, памяти, ввода/вывода.
Обычно каждый компонент интерпретируется как отдельный тип ресурса. Например, оперативная память — это ресурс емкости, а сетевые интерфейсы — это ресурс ввода/вывода (который может оцениваться такими метриками, как IOPS или пропускная способность). Некоторые компоненты могут иметь черты ресурсов нескольких типов, например, устройство хранения является одновременно ресурсом ввода/вывода и ресурсом емкости. Учитывать необходимо все типы, которые могут привести к снижению производительности. Также обратите внимание, что ресурсы ввода/вывода можно дополнительно исследовать как системы массового обслуживания, которые ставят запросы в очередь, а затем обслуживают их.
Некоторые физические компоненты, такие как аппаратные кэши (например, кэши процессора), можно не включать в чек-лист. Метод USE наиболее эффективен для ресурсов, производительность которых снижается при высоком потреблении или насыщении, тогда как высокий коэффициент использования кэша улучшает производительность. Эти компоненты можно проверить с помощью других методик. Если вы не уверены, следует ли включать ресурс в список, то включите его, а затем оцените, насколько это было оправданно.
Функциональная блок-схема
Другой способ составить список ресурсов — найти или нарисовать функциональную блок-схему системы, как, например, на рис. 2.13. Такая блок-схема также пока



















