

автордың кітабын онлайн тегін оқу Настоящий SRE: инжиниринг надежности для специалистов и организаций
Переводчик С. Черников
Дэвид Н. Бланк-Эдельман
Настоящий SRE: инжиниринг надежности для специалистов и организаций. — Астана: "Спринт Бук", 2025.
ISBN 978-601-09-9695-3
© ТОО "Спринт Бук", 2025
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Отзывы о книге
Область SRE постоянно развивается, поэтому ее наработки интересно и изучать, и внедрять. Однако из-за ее изменчивости бывает трудно понять, с чего начать. Книга «Настоящий SRE: инжиниринг надежности для специалистов и организаций» — это подробное руководство, которое поможет начать путешествие и будет сопровождать вас на всем его протяжении.
Алекс Идальго, главный защитник надежности в компании Nobl9 и автор книги Implem enting Service Level Objectives
Незаменимое пособие о том, как развить у себя лично и в своей компании в целом менталитет SRE и добиться желаемых изменений в системах. Книга, безусловно, расширяет список основных руководств по обеспечению надежности систем с трех до четырех.
Лиз Фонг-Джонс, главный технический директор компании Honeycomb и соавтор книги Observability Engineering
Приготовьтесь к веселому приключению с неожиданными поворотами сюжета! В книге «Настоящий SRE: инжиниринг надежности для специалистов и организаций» история обеспечения надежности систем изложена в новом и вдохновляющем ракурсе. В каждой главе содержится жемчужина мудрости, раскрывающая важнейшие особенности менталитета, культуры и методов, составляющих суть деятельности SR-инженера. Вы столкнетесь с драконами: сложными системами, уровнями обслуживания, тяжелой работой, неудачами — и узнаете, почему SR-инженеры одержимы ими. Если вы только начинаете карьеру SR-инженера, уже работаете в этой области или приступаете к внедрению SRE в компании, эта книга станет для вас сокровищем, полным наставлений, историй из жизни и здорового юмора.
Джейсон А. Кокс, директор по глобальным технологиям SRE компании Disney
Если взять многолетний опыт в области SRE, накопленный Дэвидом и другими героями книги, и максимально его ужать, как раз получится эта книга. В «Настоящем SRE» трудная работа по обеспечению надежности систем описана так, что будет понятна читателям с разным уровнем подготовки.
Эми Тобей, старший главный инженер компании Equinix
В книге «Настоящий SRE: инжиниринг надежности для специалистов и организаций» рассказывается о том, почему SRE играет важную роль для сервисов в промышленной эксплуатации и как разработать правильные методы обеспечения надежности сайтов и систем для вашего бизнеса.
Салим Вирджи
Предисловие
Нам не говорили, что жизнь нужно изучать,
исследовать, как естественную историю
или музыку, и начинать нужно
с простых упражнений
и постепенно осваивать
трудные, пока сила
и точность не сравнятся со смелостью
прыгнуть в трансцендентность и рискнуть
нарушить дикие арпеджио
или целостность звучания фуги.
— По сути, так невозможно жить: мы хватаемся
за все сразу, даже не начав
читать или отмечать время, мы вынуждены начинать
в разгар напряженного движения,
которое уже шло в момент нашего рождения.
Отрывок из стихотворения «Трансцендентальный этюд» Адриенны Рич, The Fact of a Doorframe: Poems Selected and New 1950–1984 (Norton, 1984)
Где вы сейчас?
Здравствуйте, дорогие читатели. Я начал с этого отрывка из стихотворения Адриенны Рич потому, что она гораздо лучше меня осознает, что вы обратились к обеспечению надежности информационных систем (site reliability engineering, SRE) и взялись за эту книгу, уже находясь в определенном контексте. Возможно, у вас разразился кризис надежности на работе, вам предложили возглавить команду, вы сменили профессию или начинаете карьеру в новой области. Подозреваю, что движение вперед дается вам непросто, и обещаю помнить об этом, когда мы начнем вместе разбираться в SRE.
Сейчас вы читаете книгу, предназначенную прежде всего для тех, кто только начинает осваивать область SRE в том или ином качестве. Возможно, у вас есть большой опыт в смежных областях эксплуатации, разработки программного обеспечения или просто в ИТ, и это замечательно: нам все пригодится. Однако я не буду активно строить догадки о ваших фоновых знаниях в области SRE1.
За последние пять с хвостиком лет мне посчастливилось общаться со многими людьми, находившимися на самом краю трамплина и нервно глядевшими вниз, готовясь погрузиться в глубины SRE. Иногда мне удавалось поговорить с теми, кто уже решился и теперь, будучи на полпути, хотел обсудить, что делать, когда нырнет. Одни мертвой хваткой держались за лестницу, пытаясь решить, стоит ли забираться еще выше. Другим нужно было помочь объяснить остальным сотрудникам компании, в чем ценность процесса совершенствования, заключающегося в том, чтобы нырнуть, подняться на уровень выше, снова нырнуть и снова подняться. Кто-то хочет знать, как определить, что погружение прошло успешно. Кому-то хочется выяснить, можно ли перепрофилировать аквалангистов в команду дайверов (ведь их профессия тоже связана с «нырянием»). Метафора становится все более громоздкой, но вы поняли, о чем речь.
Я невероятно благодарен за то, что мне удалось пообщаться с каждым из этих людей, поделившихся своими историями о SRE. Так я смог сам увидеть, что даже при активно растущем количестве материалов на тему SRE по-прежнему очень востребована информация о том, как начать работать в этой области. Меня удивляет и даже восхищает, что большой процент людей, с которыми я разговаривал о SRE, читали книгу «Site Reliability Engineering. Надежность и безотказность как в Google»2. Многие также читали «The Site Reliability Workbook: практическое применение»3. И, черт возьми, кое-кто даже прочел мою книгу Seeking SRE: Conversations About Running Production Systems at Scale4 еще до того, как мы начали общаться. И все равно они хотели обсудить, с чего начинать.
Бо́льшая часть материала в перечисленных книгах предполагает наличие у вас знаний или более глубокого понимания современных методов эксплуатации. Моя книга не такая. Вот почему прежде всего необходимо прочитать важнейшую часть I, «Введение в SRE».
Структура книги
Книга построена таким образом, чтобы дать ответы на два отдельных, но одинаково актуальных вопроса: с чего начать лично мне? С чего начать моей организации?
Она состоит из трех частей.
• Часть I. Введение в SRE (обязательная для изучения следующих частей).
• Часть II. Как стать SR-инженером.
• Часть III. Как развить SRE в организации.
По моему опыту, начало деятельности отдельного человека и организации в области SRE характеризуется важными общими моментами. С этого мы и начнем: с информации, необходимой для того, чтобы приступить к работе как самостоятельно, так и в коллективе. Например, в обеих ситуациях вы не продвинетесь далеко, если участвующие в работе люди не будут иметь четкого представления о менталитете, характерном для SRE-специалистов, поэтому данной теме5 в книге посвящена целая глава (см. главу 2).
После рассмотрения этого вопроса вам предстоит выбрать приключение: хотите вы сначала прочитать о том, как приступить к работе самостоятельно или как начать работать в составе организации?
В зависимости от того, что именно вас интересует в данный момент, можно начать с части II или III. Однако я бы посоветовал потом вернуться (или пролистать вперед) и прочитать другую часть, просто потому что люди объединяются в компании, а компании используют возможности отдельных личностей, чтобы выйти на новый уровень. «Другая» часть, в зависимости от того, какая из них станет таковой, расширит ваше понимание первой части. Подводя итог и приветствуя вас в сообществе SR-инженеров, поделюсь мудростью людей, уже давно работающих в этой области.
Нам понадобится лодка побольше
Как уже говорилось, сегодня существует множество действительно хороших книг и иных ресурсов, посвященных SRE. Я не буду пытаться переписать их, чтобы превратить книгу во всеобъемлющий сборник сведений о SRE. Даже если бы издатель позволил мне написать талмуд, во много раз превышающий оговоренный объем в страницах, для вас не было бы пользы в том, что я пересказал (менее удачно) информацию вместо того, чтобы просто направить вас к оригиналу. Единственное, что я могу сделать, — указать, как компас, на самые полезные ссылки, позволяющие узнать больше или углубиться в обсуждаемую тему, и именно так я и поступлю.
Итак, предупреждаю сразу: в тексте будет немало ссылок на другие книги и ресурсы.
Вам нравятся сноски и врезки?
...потому что мне они определенно нравятся. Еще в детстве, читая книги вроде The Annotated Alice под редакцией Мартина Гарднера, я наслаждался произведениями, в которых содержалась дополнительная информация, приводились ссылки на другие источники, цветные комментарии и сопутствующие замечания в сносках и на полях. Мне нравится, когда автор будто бы отводит меня в сторонку, чтобы шепнуть на ухо что-нибудь интересное или занимательное, пока я читаю книгу. Именно этот опыт я пытался передать здесь.
Если вы не такой большой поклонник, то сначала можете прочесть весь основной текст, а потом вернуться, чтобы прочитать сноски и врезки (обязательно вернитесь, там можно найти много интересной информации). Пожалуйста, читайте так, как вам удобно.
Я не Лоракс
Пока я в настроении предупреждать и предостерегать, позвольте добавить еще одно важное замечание: я не Лоракс6. Я не защищаю SR-инженеров. Ну, определенно, не всех.
В этой книге я постарался представить область SRE такой, какой мне ее описали умные люди. Здесь приводятся мнения, сформировавшиеся у меня в результате самостоятельного осмысления информации. Вы можете не соглашаться с этими мнениями или другими материалами книги.
Ничто не сделает меня счастливее, чем ваше признание в том, что вы серьезно увлеклись книгой и вам захотелось обсудить со мной или с кем-то еще прочитанное или вопросы, с которыми вы не согласны. Не все реализации и интерпретации в области SRE одинаковы. Нет единственно верного способа восприятия или обсуждения SRE; написание этой книги — всего лишь моя лучшая попытка. С нетерпением жду ваших.
Книга полна голосов
Пока на слуху слово «беседа», у меня есть еще одно, последнее пояснение, которое, возможно, будет полезно вам при чтении.
При чтении вы заметите, что я называю множество имен, цитирую и ссылаюсь на них. В процессе исследования, во время написания и рецензирования книги я беседовал со многими людьми. Когда они говорили что-то умное, я записывал это в книгу и постарался отдать им должное, указав имя. Если вас интересовал вопрос «Кто все эти люди?», то теперь вы знаете.
Готовы?
Надеюсь, я не отпугнул вас, ведь у нас та-а-ак много отличных тем для разговора. Присаживайтесь рядом и приступим.
Условные обозначения
В книге используются следующие типографские условные обозначения.
Курсив
Отмечает новые термины.
Рубленый шрифт
Им обозначены URL-адреса, адреса электронной почты и элементы интерфейса.
Благодарности
Слово «благодарность» кажется мне недостаточно выразительным. Я не просто благодарю, но еще и очень ценю и уважаю упомянутых в этом разделе людей и отношусь с большим почтением к ним и их вкладу в книгу. Для меня большая честь и радость работать с ними и учиться у них.
Книга не появилась бы или не была бы даже наполовину так хороша без:
• людей, делившихся своими идеями, надеждами и мечтами о SRE в беседах во время моего исследования: Бена Лача, Бена Пургасона, Дейва Ренсина, Джона Риза, Джозефа Биронаса, Нараяна Десаи, Нейла Мёрфи, Тани Рейли, Тома Лимончелли и многих других специалистов в области SRE, влиявших на мое мировоззрение на протяжении многих лет;
• команды технических обозревателей: Эми Тоби, Селесты Стингер, Джесс Малес, Курта Андерсена, Нейла Мёрфи, Патрика Кейбла и Ричарда Клоусона;
• моих редакторов (в порядке их взаимодействия с книгой): Джона Девинса, Вирджинии Уилсон7, Клэр Лейлок и Кэрол Келлер;
• иллюстраторов и волшебников графического дизайна, сотворивших обложку книги и рисунки в ней: Кейт Даллеа и Карен Монтгомери;
• моей семьи, которая каким-то образом научилась одновременно терпеть и поддерживать меня, пока я блуждаю в пустыне очередного книжного проекта. Люблю вас;
• вас, читатели. Без вас авторы — ничто.
Борьба со стрессом
Оглядываясь назад, вспоминая свои предыдущие книги, я понимаю, что всегда добавлял в них небольшое примечание о том, что позволило мне справиться с ситуацией (мбира, йога и т.д.) в то время/в том проекте, и о людях, помогавших мне. Полагаю, самое время воздать должное методам борьбы со стрессом. В этот раз писать книгу было легко, но мир оказался жесток. Действительно жесток. Для всех. Но я не обязан вам рассказывать. Тогда мне помогла и продолжает помогать сейчас (как бы банально это ни звучало) выпечка хлеба (как дома, так и профессионально в пекарне). Кто бы мог подумать, что смесь муки, воды, соли и закваски может быть настолько целительной? За эту книгу я должен поблагодарить Эрнеста и Джуниора, двух пекарей, которые пускали меня в пекарню в 04:30 утра и терпеливо помогали мне претворять в жизнь свои фантазии из теста.
1 Если же в действительности вы опытный SRE-специалист, тс-с-с, никому не говорите, но в этой книге найдется много интересного и для вас, в том числе советы по созданию команды или культуры вокруг себя. Но давайте оставим этот маленький секрет между нами, хорошо?
2 Бейер Б., Джоунс К., Петофф Дж., Мёрфи Р. Site Reliability Engineering. Надежность и безотказность как в Google. — СПб.: Питер, 2019.
3 Бейер Б., Рензин Д., Кавахара К., Торн С. The Site Reliability Workbook: практическое применение. — СПб.: Питер, 2021.
4 Blank-Edelman David N. Seeking SRE: Conversations About Running Production Systems at Scale. — O’Reilly Media, 2018.
5 Если по каким-то причинам вы вынуждены ограничиться чтением только одной главы книги, полагаю, стоит выбрать главу 2.
6 «Лоракс» (англ. The Lorax) — детская книга, написанная Доктором Сьюзом и впервые опубликованная в 1971 году. Она ведет рассказ о плачевном состоянии окружающей среды, а Лоракс — главный персонаж, который «говорит за деревья». — Примеч. пер.
7 Я искренне надеюсь, что она не отредактирует эти слова, ведь она невероятно скромная, но Вирджиния, мой редактор — консультант по аудитории — самая лучшая. Это человек, с которым я наиболее тесно сотрудничал при работе над текстом; она действительно замечательный редактор и... просто лучшая.
Я невероятно благодарен за то, что мне удалось пообщаться с каждым из этих людей, поделившихся своими историями о SRE. Так я смог сам увидеть, что даже при активно растущем количестве материалов на тему SRE по-прежнему очень востребована информация о том, как начать работать в этой области. Меня удивляет и даже восхищает, что большой процент людей, с которыми я разговаривал о SRE, читали книгу «Site Reliability Engineering. Надежность и безотказность как в Google»2. Многие также читали «The Site Reliability Workbook: практическое применение»3. И, черт возьми, кое-кто даже прочел мою книгу Seeking SRE: Conversations About Running Production Systems at Scale4 еще до того, как мы начали общаться. И все равно они хотели обсудить, с чего начинать.
Я невероятно благодарен за то, что мне удалось пообщаться с каждым из этих людей, поделившихся своими историями о SRE. Так я смог сам увидеть, что даже при активно растущем количестве материалов на тему SRE по-прежнему очень востребована информация о том, как начать работать в этой области. Меня удивляет и даже восхищает, что большой процент людей, с которыми я разговаривал о SRE, читали книгу «Site Reliability Engineering. Надежность и безотказность как в Google»2. Многие также читали «The Site Reliability Workbook: практическое применение»3. И, черт возьми, кое-кто даже прочел мою книгу Seeking SRE: Conversations About Running Production Systems at Scale4 еще до того, как мы начали общаться. И все равно они хотели обсудить, с чего начинать.
Я невероятно благодарен за то, что мне удалось пообщаться с каждым из этих людей, поделившихся своими историями о SRE. Так я смог сам увидеть, что даже при активно растущем количестве материалов на тему SRE по-прежнему очень востребована информация о том, как начать работать в этой области. Меня удивляет и даже восхищает, что большой процент людей, с которыми я разговаривал о SRE, читали книгу «Site Reliability Engineering. Надежность и безотказность как в Google»2. Многие также читали «The Site Reliability Workbook: практическое применение»3. И, черт возьми, кое-кто даже прочел мою книгу Seeking SRE: Conversations About Running Production Systems at Scale4 еще до того, как мы начали общаться. И все равно они хотели обсудить, с чего начинать.
По моему опыту, начало деятельности отдельного человека и организации в области SRE характеризуется важными общими моментами. С этого мы и начнем: с информации, необходимой для того, чтобы приступить к работе как самостоятельно, так и в коллективе. Например, в обеих ситуациях вы не продвинетесь далеко, если участвующие в работе люди не будут иметь четкого представления о менталитете, характерном для SRE-специалистов, поэтому данной теме5 в книге посвящена целая глава (см. главу 2).
Пока я в настроении предупреждать и предостерегать, позвольте добавить еще одно важное замечание: я не Лоракс6. Я не защищаю SR-инженеров. Ну, определенно, не всех.
Сейчас вы читаете книгу, предназначенную прежде всего для тех, кто только начинает осваивать область SRE в том или ином качестве. Возможно, у вас есть большой опыт в смежных областях эксплуатации, разработки программного обеспечения или просто в ИТ, и это замечательно: нам все пригодится. Однако я не буду активно строить догадки о ваших фоновых знаниях в области SRE1.
• моих редакторов (в порядке их взаимодействия с книгой): Джона Девинса, Вирджинии Уилсон7, Клэр Лейлок и Кэрол Келлер;
Если же в действительности вы опытный SRE-специалист, тс-с-с, никому не говорите, но в этой книге найдется много интересного и для вас, в том числе советы по созданию команды или культуры вокруг себя. Но давайте оставим этот маленький секрет между нами, хорошо?
Бейер Б., Джоунс К., Петофф Дж., Мёрфи Р. Site Reliability Engineering. Надежность и безотказность как в Google. — СПб.: Питер, 2019.
Бейер Б., Рензин Д., Кавахара К., Торн С. The Site Reliability Workbook: практическое применение. — СПб.: Питер, 2021.
Blank-Edelman David N. Seeking SRE: Conversations About Running Production Systems at Scale. — O’Reilly Media, 2018.
Если по каким-то причинам вы вынуждены ограничиться чтением только одной главы книги, полагаю, стоит выбрать главу 2.
«Лоракс» (англ. The Lorax) — детская книга, написанная Доктором Сьюзом и впервые опубликованная в 1971 году. Она ведет рассказ о плачевном состоянии окружающей среды, а Лоракс — главный персонаж, который «говорит за деревья». — Примеч. пер.
Я искренне надеюсь, что она не отредактирует эти слова, ведь она невероятно скромная, но Вирджиния, мой редактор — консультант по аудитории — самая лучшая. Это человек, с которым я наиболее тесно сотрудничал при работе над текстом; она действительно замечательный редактор и... просто лучшая.
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу comp@sprintbook.kz (издательство SprintBook, компьютерная редакция).
Мы будем рады узнать ваше мнение!
Часть I. Введение в SRE
Глава 1. Сначала главное
Добро пожаловать! Давайте разберемся, что такое обеспечение надежности информационных систем (site reliability engineering, SRE) и как оно появилось.
Что такое SRE
Вам может встретиться несколько определений понятия «обеспечение надежности информационных систем». Вот лучшее из тех, что мне удалось сформулировать за многие годы:
Обеспечение надежности информационных систем — это инженерная дисциплина, призванная помочь организации стабильно достигать соответствующего уровня надежности своих систем, сервисов и продуктов.
Озвучивая это определение аудитории, я обычно говорю, что в нем есть как минимум три слова, наличие которых, если их правильно понять, даст достаточно полное представление о SRE. Если появляется возможность, я спрашиваю у слушателей: «Какие три слова, по вашему мнению, самые важные в этом определении?» Пожалуйста, не стесняйтесь, остановитесь, перечитайте определение выше и ответьте для себя на этот вопрос, прежде чем продолжить.
Я задаю его не только потому, что мне нравится общение с аудиторией, но и потому, что он позволяет протестировать слушателей и сделать выводы. В главе 4 я подробнее остановлюсь на том, что можно узнать с помощью такой диагностики. А пока посмотрим, какие три слова я бы выбрал в первую очередь, если бы спросили меня.
Надежность
Весьма очевидное первое предположение, правда? Надежность занимает центральное место во всем, что мы делаем в SRE (да, это прямо в названии указано). Один из способов подчеркнуть важность надежности — отметить, что компания может потратить миллионы в местной валюте на создание самого лучшего программного обеспечения с самыми новомодными характеристиками, нанять отличных специалистов по продажам, которые будут его продавать, собрать отличную команду специалистов из службы техподдержки, чтобы поддерживать его работу, и т.д., но, если программное обеспечение не будет работать, когда клиент попытается им воспользоваться, все деньги и усилия окажутся выброшены на ветер (или смыты в унитаз, в зависимости от того, какая метафора вам больше нравится).
Когда возникают проблемы с надежностью, компания может терять:
Деньги
Это особенно актуально, если вышедшая из строя система критически важна для получения прибыли.
Время
Вместо выполнения запланированной работы сотрудники решают проблемы, вызвавшие сбой.
Репутацию
Люди не захотят пользоваться услугами, которые им кажутся некачественными, и с радостью уйдут к конкуренту.
Здоровье
Если условия работы постоянно экстремальные, если дежурных регулярно будят, если сотрудникам постоянно приходится тратить время на работу, а не на друзей или семью, — это может серьезно испортить их здоровье.
Людей
Специалисты в этой отрасли общаются друг с другом. Если станет известно, что у вас на работе постоянный аврал, вам будет очень трудно нанимать новых сотрудников.
Соответствие
Полагаю, одна из ключевых идей, выделяемых или подчеркиваемых SR-инженерами в обсуждениях методов эксплуатации, — что стопроцентная надежность является желательной или хотя бы возможной целью лишь в редчайших случаях. Во многих ситуациях это невозможно, ведь в нашем взаимосвязанном мире очень высока вероятность того, что зависимости не будут на 100 % надежны. Добиться более высокого уровня надежности, чем существующий у зависимостей, порой (но не всегда) можно с помощью продуманных планирования и кода.
Вместо этого область SRE сосредотачивается на таких методах, как показатели уровня обслуживания/цели уровня обслуживания (service level indicators, SLIs/service level objectives, SLOs)8, чтобы помочь вам определить соответствующий уровень надежности системы, передать информацию об этом и работать над его достижением.
Стабильность
Это слово вошло в определение позже остальных, когда стало ясно, что для достижения успеха методы работы эксплуатации должны быть стабильными. Стабильность напоминает о проблеме «потери здоровья», связанной с надежностью. Надежные системы создаются людьми. Если люди в вашей компании выгорели, истощены, не имеют возможности общаться со своими близкими вне работы или позаботиться о самих себе, они не смогут создавать надежные системы. Многие узнают это на собственном опыте; пожалуйста, не становитесь одним из них, если можете этого избежать.
(Дополнительные слова)
В определении есть еще несколько слов, которые я пока просто перечислю, предвосхищая обсуждение в главе 4: инженерия, дисциплина, помощь и организация. До скорой встречи в четвертой главе!
История происхождения
Я считаю, что полезно знать о происхождении области SRE и о том, как она возникла, когда я работал в корпорации Google (примерно в 2003 году), однако не мне рассказывать эту историю. Бен Трейнор Слосс, создатель направления SRE, излагает официальную версию в книге Site Reliability Engineering (ее еще называют книгой по SRE).
Вместо этого я хочу рассказать о том, когда впервые начал по-настоящему понимать тему, потому что данная информация должна помочь и вам. Это связано с историей возникновения SRE, описанной Google, поскольку именно тогда Трейнор Слосс изложил свое понимание SRE на первом большом собрании, посвященном данной теме. Я искренне верю, что истории, которые мы сами рассказываем, очень важны для понимания нашей личности, так что это был весьма значимый момент.
Тридцать первого мая 2014 года в городе Санта-Клара, штат Калифорния, я слушал пленарный доклад Трейнора Слосса Keys to SRE на самой первой конференции SREcon (https://oreil.ly/cSXef)9. Рекомендую и вам посмотреть видеозапись выступления.
Во время того доклада он показал слайд, который подтолкнул меня к пониманию SRE. На рис. 1.1 показан снимок слайда.

Рис. 1.1. Слайд из пленарного доклада Бена Трейнора Слосса на конференции SREcon14 (в переводе)
На рис. 1.1 представлен список, с которого я начинал, и он по-прежнему отлично подходит для начала работы.
На момент написания книги10 прошло уже девять лет с того дня, как я впервые увидел данный слайд, и, глядя на него теперь, я поражаюсь тому, сколько пунктов не изменилось с течением времени, и некоторые, похоже, зависят от контекста работы корпорации Google, в которой они появились. Со времени доклада добавилось несколько нюансов (можно сказать, по меньшей мере три книги; см. ресурсы на тему SRE в приложении В), и, возможно, это тоже веская причина, по которой вы читаете мою книгу.
Связь SRE с разработкой и эксплуатацией
Всякий раз, общаясь с людьми, которые пытаются понять, что такое обеспечение надежности систем, я практически могу гарантировать, что в какой-то момент беседа затронет вопросы вроде: как соотносятся с SRE разработка и эксплуатация (development operations, DevOps)? Какова взаимосвязь между ними? Разумно ли иметь оба отдела в одной компании? Это непростые вопросы, и у меня ушли годы на поиск убедительных ответов на них. Именно поэтому главу 12 в книге Seeking SRE, посвященную этой теме, я решил сделать коллективной. На тот момент у меня не было исчерпывающего ответа, и я очень надеялся, что его даст кто-нибудь другой11.
С помощью ответов из той главы, а также в результате последующей переоценки ценностей и проведенного исследования я наконец нашел решение, которое мне понравилось. Осознав, что для ответа на эти вопросы потребуется применить несколько подходов, я сумел сформулировать многокомпонентное определение, которое меня устроило. Надеюсь, оно устроит и вас.
Позвольте изложить все три части с небольшими комментариями к каждой.
Часть 1. В области SRE задействованы высококлассные DevOps-специалисты
Идея заимствована из главы 1 книги Site Reliability Workbook и последующих сообщений корпорации Google. Если вы не программист, но читаете эту книгу, хочу пояснить, что SRE — одна из реализаций12 общей философии DevOps. Это не самое мое любимое сравнение по нескольким причинам.
• Не будучи специалистом в области программирования, невозможно понять формулировку и ее нюансы.
• Мне кажется, я не знаю другой реализации DevOps, кроме стандартной, которая развивалась в течение долгого времени и применялась на практике в реальной жизни, так что идея кажется немного сомнительной.
• В сравнении содержится намек на историческую связь, уходящую корнями в туманные времена, к истокам SRE (или, по крайней мере, к открытию двух направлений), но я не нашел доказательств в его поддержку.
• Я все еще не уверен, что согласен с этим сравнением.
Я не отказываюсь от данной идеи о SRE и DevOps, потому что (помимо того, что она исходит от людей умнее меня) она действительно отражает сходство или, по крайней мере, места пересечения, общие для двух современных методологий создания ПО.
Часть 2. Область SRE ассоциируется с надежностью, а DevOps — с доставкой
Не знаю, как у вас, а у меня периодически случается кризис веры в DevOps. В этот раз я понял, что не могу найти описание области DevOps или принятых в ней методов, которое помогло бы мне сразу выделить ее среди других подходов эксплуатации, существующих в мире. Мне нужны были слова, которые бы позволили сразу отличить DevOps от всего остального, чтобы можно было однозначно выбрать ее из списка («Пункт 3, это же DevOps! Я бы узнал их где угодно!»). Я просмотрел все свои ресурсы и лично составленный список аббревиатур из области DevOps, но безуспешно.
В случае со SRE я могу сказать: «SRE — это надежность». Если меня спросят «Какие методы эксплуатации уделяют особое внимание надежности?», то простой ответ будет — SRE. Поэтому я решил спросить у светил в области DevOps: «Если SRE — это надежность, как одним словом охарактеризовать DevOps?»
Я обращался со своим вопросом к одному светилу, потом к другому (все они были очень милы), пока наконец не получил от Донована Брауна ответ, который меня порадовал. Для него суть DevOps — в доставке. Доставке ценности клиентам, доставке программного обеспечения и т.д. В итоге я нашел слово, которое искал.
Область SRE ассоциируется с надежностью, а DevOps — с доставкой.
Я могу с этим жить.
Часть 3. Все дело в направлении внимания
Этот последний фрагмент головоломки я получил от своего друга Тома Лимончелли, который был достаточно любезен и представил его в виде ответа на мою просьбу прислать материалы для коллективной главы книги Seeking SRE (я упоминал о ней ранее). Рисунок 1.2 — иллюстрация к этой главе (изменена по его просьбе).
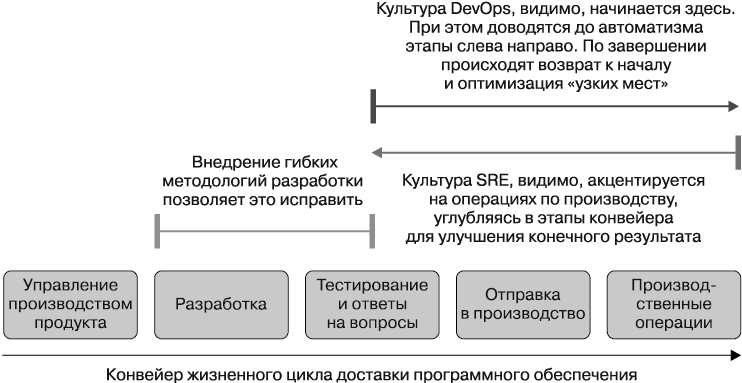
Рис. 1.2. Модель Лимончелли для стратегий SRE, DevOps и Agile. Изменена по сравнению с оригиналом, приведенным в книге Seeking SRE (в переводе)
Кое в чем эта модель нравится мне больше других, поскольку в ней поясняются возникающие на практике пересечения между областями DevOps и SRE, которые, на первый взгляд, не прослеживаются в их подходах или целях. Чуть позже я приведу примеры, а ниже представлено мое лучшее резюме теории Тома.
1. История DevOps начинается с того, что разработчик набирает код на ноутбуке. DevOps-инженер занимается (среди прочего) работой, которую необходимо выполнить для доставки кода в производство (production), чтобы клиенты могли пользоваться им с максимальной выгодой. Внимание направлено от ноутбука к производству13. Можно предположить, что это одна из причин того, почему системы непрерывной интеграции и непрерывной доставки (continuous integration and continuous delivery, CI/CD) занимают такое значимое место в арсенале инструментов DevOps-инженеров, их наборе навыков и указаны в объявлениях о вакансиях.
2. SRE начинается с другого. Оно начинается с производства (и действительно, работа SR-инженеров сосредоточена именно здесь). Что должен сделать SR-инженер, чтобы создать надежную среду производства? Для ответа на этот вопрос потребуется посмотреть назад на этапы, предшествующие производству, повторяя вопрос на каждом, пока не доберетесь до ноутбука разработчика.
3. Разное направление внимания. Могут применяться одни и те же инструменты (например, конвейер CI/CD), но с разными целями. В сферах DevOps и SRE можно активно заниматься созданием системы мониторинга, но делать это по разным причинам14.
И здесь мы подходим к ответу на поставленный выше вопрос: могут ли/должны ли SR- и DevOps-инженеры сосуществовать в одной организации? Для меня ответ — да15. Возможно, некоторые их инструменты, а иногда и навыки будут совпадать, но они акцентируются на разных вещах и обеспечивают организации разные преимущества.
Переходим к основам SRE
Теперь, если кто-то спросит: «Что же такое SRE?» — у вас есть базовые знания, чтобы объяснить им. Я расскажу об этом гораздо подробнее в главе 4. А сейчас, когда мы немного обсудили определения и историю SRE, перейдем действительно к основам SRE, которые станут ключевыми для понимания темы и остальных частей книги.
8 Настоятельно рекомендую ознакомиться с книгой Алекса Идальго на эту тему: Hidalgo A. Implementing Service Level Objectives: A Practical Guide to SLIs, SLOs and Error Budgets. — O’Reilly, 2020.
9 Должен признаться: я один из организаторов конференции SREcon.
10 Конец 2023 года.
11 Один из моих любимых ответов дал Майкл Доэрти, который сказал: «Обеспечение надежности систем: мы не знаем, что такое DevOps, но знаем, что занимаемся немного другими вещами». Этот ответ не входит в официальные, приведенные выше, но я не могу с ним спорить.
12 В частности, она носит директивный характер, поскольку сфера DevOps во многом старается избегать ограничений, накладываемых конкретной методологией или инструментами. Удалось ли этого добиться — еще одна интересная тема для беседы.
13 С остановками по пути для сохранения кода в репозитории и тестирования с целью убедиться, что его можно безопасно развернуть, чтобы клиенты могли начать пользоваться им.
14 Мне не встречались подобные исследования, но интуиция подсказывает, что в результате они будут отслеживать разные вещи. Было бы интересно изучить этот аспект.
15 При наличии подходящих условий, таких как размер организации (новому стартапу, возможно, не нужны оба специалиста), культура компании (если SR-инженер в нее вписывается, о чем мы поговорим далее) и потребности (нанимайте тех специалистов, которые нужны, а не коллекционируйте всех подряд).
Настоятельно рекомендую ознакомиться с книгой Алекса Идальго на эту тему: Hidalgo A. Implementing Service Level Objectives: A Practical Guide to SLIs, SLOs and Error Budgets. — O’Reilly, 2020.
Один из моих любимых ответов дал Майкл Доэрти, который сказал: «Обеспечение надежности систем: мы не знаем, что такое DevOps, но знаем, что занимаемся немного другими вещами». Этот ответ не входит в официальные, приведенные выше, но я не могу с ним спорить.
В частности, она носит директивный характер, поскольку сфера DevOps во многом старается избегать ограничений, накладываемых конкретной методологией или инструментами. Удалось ли этого добиться — еще одна интересная тема для беседы.
Должен признаться: я один из организаторов конференции SREcon.
Конец 2023 года.
Мне не встречались подобные исследования, но интуиция подсказывает, что в результате они будут отслеживать разные вещи. Было бы интересно изучить этот аспект.
При наличии подходящих условий, таких как размер организации (новому стартапу, возможно, не нужны оба специалиста), культура компании (если SR-инженер в нее вписывается, о чем мы поговорим далее) и потребности (нанимайте тех специалистов, которые нужны, а не коллекционируйте всех подряд).
С остановками по пути для сохранения кода в репозитории и тестирования с целью убедиться, что его можно безопасно развернуть, чтобы клиенты могли начать пользоваться им.
Вместо этого область SRE сосредотачивается на таких методах, как показатели уровня обслуживания/цели уровня обслуживания (service level indicators, SLIs/service level objectives, SLOs)8, чтобы помочь вам определить соответствующий уровень надежности системы, передать информацию об этом и работать над его достижением.
Тридцать первого мая 2014 года в городе Санта-Клара, штат Калифорния, я слушал пленарный доклад Трейнора Слосса Keys to SRE на самой первой конференции SREcon (https://oreil.ly/cSXef)9. Рекомендую и вам посмотреть видеозапись выступления.
Глава 2. Менталитет SR-инженера
Все начинается с любопытства.
Как работает система? Из-за чего в ней происходит сбой?
В сфере SRE главный вопрос не «Как это должно работать?», а скорее «Как это на самом деле работает? Как это на самом деле работает в производстве?».
Вот краткий примерный сценарий: ваша клиентская часть приложения обращается к базе данных. Но что случится, когда она не сможет обратиться? Что произойдет, когда несколько экземпляров, которые не должны были запускаться, обратятся к базе данных одновременно? Что, если база данных даст ответ на 20... 34... 60 % медленнее, чем при тестировании работы кода (предполагается, что код тестировали)? Откуда код знает, что обращается к нужной базе данных? Каковы неявные зависимости? Я могу написать целую главу, состоящую только из таких вопросов, ведь выяснение того, как в действительности работает система, — занятие для очень любопытных.
В этой главе я рассмотрю фундаментальный вопрос, вокруг которого строится основной материал книги: что такое менталитет SR-инженера? Какие качества его определяют, чем он отличается от других менталитетов, как начать мыслить в этом направлении и т.д.?
Этот вопрос легко задать, но на него трудно ответить, поэтому я обратился к большой группе самых умных SR-инженеров из всех, кого я знаю, чтобы выяснить их мнение по этому вопросу (а также о культуре SRE, которую мы обсудим в главе 3). Я объединил их ответы со своим, но указывал авторство, когда это было уместно, так что в данной главе цитаты других людей будут встречаться чаще, чем обычно (чтобы заслуженно отдать им должное).
Менталитет SR-инженера важно понять перед чтением остальной части книги, и здесь встретится довольно много отсылок к следующим главам.
Понимание системы как таковой (вопрос)
В беседе на эту тему Дейв Ренсин предложил следующий сценарий.
Представьте, что Пэт заходит в центр обработки данных и спотыкается о силовой кабель. (Оскар оставил кабель на полу во время установки и тестирования нового сервера.) Кабель отсоединяется, и сервер оказывается обесточен.
Если сервер обесточен, экземпляр сервера базы данных (созданный для работы на этом сервере с помощью функций автоматизации/оркестрации, которые настроила Сьюзан) выходит из строя. На этом сервере базы данных хранился важный фрагмент данных для приложения; фрагментацию конфигурировала Ясмин.
Резервное копирование приложения (написанное Нираджем) начинает медленно блокироваться, поскольку потоки зависают в ожидании, пытаясь получить данные, необходимые им для продолжения обработки. Время отклика клиентской части приложения, которую создала Сара, все растет и растет по мере того, как соединения с серверной частью зависают, а затем завершаются из-за превышения времени ожидания отклика программы. Система мониторинга (ее настраивала Лиз) замечает, что на этом этапе возникла проблема, и рассылает оповещение всем членам команды, но некоторым из них оно приходит с задержкой. Наконец, балансировщик нагрузки (настроенный Сэмом) просто начинает раздавать сообщения «Ошибка 500» направо и налево.
Клиент, пытавшийся купить виджет на сайте, разозлившись, прекращает попытки и покупает его у конкурента.
Вопрос. Кто несет ответственность за этот сбой (и потерю продаж)?
Так кто же ответственен за убытки в бизнесе? Подумайте над этим вопросом и обсудите его между собой. Ответ Дейва приведен во врезке «Понимание системы как таковой (ответ)» на с. 34.
Уменьшение масштаба для сохранения целостного взгляда на систему
Список вопросов о подключении к базе данных, приведенный в начале этой главы, может ввести в заблуждение потому, что я начал с очень частного аспекта. Акцентирование внимания на мельчайших деталях соединения с базой данных может быть оправданно, но, спрашивая «Как работает система?», я также имею в виду:
• приложение в целом с процессами его разработки и развертывания;
• сервис целиком, в том числе код приложения и вспомогательные автоматизированные или второстепенные процессы (например, сборщики журналов или сценарии очистки);
• сервис и инфраструктуру, на которой он работает;
• физическое покрытие для инфраструктуры (в скольких регионах земного шара она работает?) и связи между фрагментами покрытия;
• социотехнический контекст, в котором функционируют сервис и инфраструктура;
• организационный контекст, в котором находится данный социотехнический контекст.
Все это и многое другое принимается во внимание, когда я говорю, что для SR-инженера характерен системный подход.
SR-инженер учитывает как большую, так и маленькую картину. Пытаясь понять, как работает система, мы часто увеличиваем масштаб до микроуровня и уменьшаем до макроуровня. Мы готовы рассматривать проблему на любом необходимом уровне детализации.
Создание и развитие циклов обратной связи
В следующих главах (например, в главах 10 и 15) я рассмотрю эту идею гораздо подробнее, но данная тема заслуживает отдельного упоминания. В основе менталитета SR-инженера лежит представление о том, что надежность повышается благодаря циклу обратной связи. Наша задача как SR-инженеров — создавать и развивать цикл обратной связи всякий раз, когда это возможно. Специалист с менталитетом SRE всегда ищет места, обладающие потенциалом для создания или поддержки этого итеративного движения к надежности.
Сосредоточьтесь на клиенте
Как работает система? Из-за чего в ней происходит сбой?
Важно ответить на эти вопросы с позиции, учитывающей множество различных аспектов, составляющих «систему», однако существует еще один центральный аспект, который необходимо обсудить, чтобы правильно описать менталитет SR-инженера: как работает система... с точки зрения клиента? Из-за чего в ней происходит сбой... с точки зрения клиента?
Мы будем обсуждать это на протяжении всей книги, но давайте отвлечемся на минутку и очень-очень четко сформулируем данный аспект.
И хотя я не встречал SR-инженеров, которые не интересовались бы тем, как работают системы и технологии или почему в них происходят сбои в абстрактном смысле, я обнаружил, что максимального влияния добились те, кто больше всех проявлял любопытство в отношении воздействия на клиента16. Они постоянно выясняют, что и как будет воспринимать клиент и насколько система соответствует его ожиданиям.
Рассказывая слушателям об SLI и SLO, я всегда начинаю с утверждения, что «надежность измеряется на стороне клиента, а не на стороне компонента». Чтобы донести это до аудитории, я предлагаю выполнить следующий мысленный эксперимент:
Представьте, что вы выделили 100 веб-серверов, которые будут работать как внешний пул для запущенного сервиса. Через некоторое время, когда сервис окажется запущен в производство, возникнет проблема в центре обработки данных. Возможно, это будет проблема с питанием или автоматически установится неправильная прошивка, из-за чего 14 серверов сгорят (метафорически) и перестанут работать. Теперь у вас есть 86 работающих серверов и 14 мертвых.
А теперь тест. Учитывая, что 86 серверов работают, а 14 находятся в аварийном состоянии, эта ситуация:
1) не является проблемой, можно разобраться в ней на досуге;
2) требует вашего немедленного внимания, следует бросить все дела и разобраться в ней;
3) экзистенциальный кризис; даже если сейчас два часа ночи, необходимо собрать всех, включая руководителей высшего звена, и не отпускать, пока проблема не будет решена.
Подумайте об этом, прежде чем продолжить чтение. Я проводил такой тест с бесчисленным множеством людей на протяжении многих лет, поэтому у меня есть вполне обоснованные предположения о том, какой ответ вы выберете вероятнее всего. Если вы уже проходили этот тест, проверьте коллегу. Если вы окажетесь в аудитории, где я буду задавать этот вопрос, не раскрывайте ответ — посидите тихонько и понаблюдайте за тем, как другие размышляют над вопросом и отвечают17.
Ответ? Зависит от ситуации. Если система спроектирована таким образом, что никто из клиентов не заметит проблему, вполне можно выбрать вариант 1. Если снижение работоспособности сервиса заметно клиентам, весьма вероятно, что подойдет вариант 2. Если система была построена так, что сервис прекратил работу и в ключевой момент перестает поступать прибыль, готов поспорить, вы и генерального директора дома разбудите.
Мне хотелось бы, чтобы вы, подавив остатки раздражения от того, что вам задали вопрос с подвохом, обратили внимание, что информация, которую я вам предоставил, фактически верна (86 серверов работают, 14 вышли из строя). Почти наверняка именно такие данные вы получили бы в первую очередь от системы мониторинга. Имея менталитет SR-инженера, делающего упор на то, как работает система для клиента, вы придете к правильному ответу — «зависит от ситуации»18. Когда мы с Джоном Ризом обсуждали данный сценарий, чтобы добавить его в главу, он отметил, что SR-инженеры всегда пытаются выяснить: «В чем замысел системы с точки зрения клиента?»
Понимание системы как таковой (ответ)
Во врезке «Понимание системы как таковой (вопрос)» на с. 31 я привел сценарий Дейва Ренсина, в котором был задан вопрос: кто несет ответственность за этот сбой (и снижение продаж)?
Ответ: система.
Именно так, назначение виновным конкретного человека не поможет вам лучше понять проблему или решить, с чего следует начать исправление. Сценарий наглядно показывает, почему важнейшим компонентом менталитета SR-инженера является системное мышление.
Знаю, некоторые читатели возразят, что данный пример нереалистичный или надуманный. Не бывает так, чтобы виноваты были одновременно все и никто. Отчасти вы правы, пример надуманный.
Но ради интереса предлагаю отложить книгу и проанализировать имеющиеся в открытом доступе данные о сбое в работе корпорации Microsoft в южно-центральной части США в 2018 году (одном из самых серьезных). Официальное сообщение об этом удалено с их страницы состояния, но в новостном репортаже (https://oreil.ly/ceV4) и в сообщении в официальном блоге разработчика (https://oreil.ly/h3kPD) приведено большинство значимых подробностей.
Как сообщалось в публичных заявлениях корпорации Microsoft, погодные условия в этом районе привели к возникновению перебоев с электропитанием, а те вызвали сбои в системе охлаждения центров обработки данных. Эти сбои стали причиной неполадок оборудования, которые спровоцировали выход из строя серверов, а затем и сервисов, и это привело к возникновению неожиданного каскадного эффекта, сказавшегося на работе основных сервисов за пределами региона. Пострадали множество сервисов и клиентов (например, сбой в работе привел к ошибкам в логике повторного выполнения операции клиентами в сервисе Outlook, и это не улучшило ситуацию).
Просто читая опубликованный тогда же отчет корпорации, вы будете вздрагивать вновь и вновь. Многие отдельные компоненты в этой ситуации работали именно так, как должны были, однако системы целиком рушились.
Следующий естественный шаг — обдумывание причинно-следственной (-ых) цепочки (-чек) этого сбоя и того, какие меры следует принять корпорации Microsoft по его устранению. Была ли проблема в плохой погоде в Сан-Антонио, из-за которой вышло из строя множество сервисов по всему миру? Действительно ли проблема с системой охлаждения центра обработки данных стала причиной того, что сервисы Outlook устроили DDoS-атаку на серверы обмена сообщениями? Патологически узкий взгляд может привести к выводу, что причиной всему стали неполадки с отоплением, вентиляцией и кондиционированием воздуха, и корпорация Microsoft должна была провести остаток 2018 года, работая над улучшением этих систем, чтобы подобное не повторилось. Однако это звучит нелепо, не правда ли?
В определенный момент вы, скорее всего, придете к такому же выводу об ответственности, как и я в примере из врезок: это система.
Отношение (к людям и вещам)
Я только что высказал идею о том, что менталитет SR-инженеров описывается определенными взаимоотношениями с клиентами. Во многом нас можно охарактеризовать по связям, которые мы поддерживаем в жизни. В связи с этим хотелось бы отметить еще несколько видов отношений, ключевых для SR-инженеров.
Отношения SR-инженеров с (другими) людьми
Первое, что можно относительно легко и быстро заявить, — SR-инженеры неустанно сотрудничают. Мы знаем, что проявлением надежности в реальном мире является совместная работа. Мы не сможем делать свою работу, если не будем трудиться плечом к плечу с самыми разными коллегами, работающими над системами, которые нам важны. Для тех, у кого проявляется менталитет SRE, сотрудничество — это стандарт.
Более развитая вариация этой идеи, над которой я рекомендую вам поразмыслить: мы также сотрудничаем с клиентами в том, что касается надежности19.
И еще одно замечание по поводу сотрудничества, тесно связанное с повторяющейся в этой главе темой: помимо веских этических и ценностных оснований для стремления к сотрудничеству с самыми разными людьми, имеющими разнообразные индивидуальные особенности, SR-инженер также признает, что подобное сотрудничество дает наилучшие данные и результаты. SR-инженеры постоянно ищут качественные данные, способные помочь им обеспечить надежность.
Добро пожаловать к нейроотличным коллегам!
Тема многообразия и инклюзивности применительно к области SRE очень широка (она неоднократно затрагивалась в книге Seeking SRE, но мне бы хотелось увидеть более существенное ее изучение). Один из аспектов, оказавшийся для меня неожиданным во время работы над этой главой, связан с когнитивным разнообразием.
Без каких-либо подсказок и не договариваясь заранее, три разных человека сказали мне о совместимости нейроразнообразия (особенно синдрома дефицита внимания и гиперактивности (СДВГ)) и SRE. Было высказано предположение, что эта работа хорошо подходит для людей с СДВГ и что люди с СДВГ — одни из лучших специалистов в данной профессии.
Я говорю об этом по одной причине: если вы нейроотличны и задумываетесь о том, чтобы заняться проектированием надежности систем, добро пожаловать!
Отношение SR-инженеров к неудачам и ошибкам
Одна из концепций, помогающих отличить менталитет SR-инженера от прочих, — наше отношение к неудачам и ошибкам в целом. Обсудим каждый аспект отдельно.
В этой книге косвенно проявляется отношение к неудачам, которое я хотел бы выразить явно. Нет, мы не жаждем неудач до такой степени, чтобы радоваться сбоям и стремиться вызвать их самостоятельно20, но помните вопрос: как работает система? Из-за чего в ней происходит сбой?
Менталитет SR-инженера отличается от большинства прочих тем, что неудача рассматривается как шанс научиться. Обучение на ошибках — основной компонент менталитета SR-инженера, и потому ему посвящена целая глава (см. главу 10).
Я нигде не встречал такого отношения к ошибкам (особенно к ошибкам из-за случайных обстоятельств), как в сфере SRE. В большинстве других контекстов, особенно в контекстах предыдущих операций, ошибки необходимо искоренять, избавляться от них полностью на каждом шагу. Большинство людей хотят, чтобы в системах не было ошибок, и открыто озвучивают эту цель (даже если никогда ее не достигнут). В сфере SRE к ошибкам относятся как к сигналу, а мы любим четкие сигналы. Реальные данные могут помочь нам сфокусировать внимание.
Расскажу вам одну историю, чтобы проиллюстрировать этот тезис. Много лун назад на конференции SREcon я сидел в солнечном дворике и завтракал с Джоном Луни перед началом секции. К нашему столику подсел человек, которого я раньше не встречал, и мы познакомились. Мы разговорились о задачах, над которыми работали. Новый знакомый, чье имя и место работы затерялись в тумане времени, описывал новую платформу непрерывной интеграции и развертывания программного обеспечения (CI/CD), которую они с коллегами создавали и уже находились на завершающей стадии работ. Звучало сногсшибательно. Насколько помню, он особенно гордился функциями, которые они добавили, чтобы помочь уменьшить и в идеале полностью устранить ошибки, и которые будут развернуты в производственной среде.
Вскоре после этого ему пришлось уйти пораньше, чтобы успеть на секцию, а мы с Джоном Луни остались греться на солнышке, потягивая горячие напитки. Насколько помню, Джон сказал что-то вроде: «Хм, если бы я создавал такую платформу, то специально допустил бы несколько ошибок. Мне бы хотелось знать, в чем слабости моего сервиса или что может в нем разладиться». Комментарий не давал мне покоя, и время от времени я думал о нем. Лишь спустя несколько лет я наконец понял, что он имел в виду и насколько сильно отличалось его отношение к ошибкам от тех, с которыми мне приходилось сталкиваться.
Сам не заметив21, Джон продемонстрировал, что для SR-инженеров ошибки вовсе не обязательно являются врагами. Он не говорил: «Ошибки — это здорово, давайте совершать их почаще!» Он признавал, что ошибки уже есть в системе и всегда там будут. В контексте менталитета SR-инженера ошибки могут служить более важной цели — помогать нам понять систему22. Для этого необходимо «выявлять» ошибки, а не только предпринимать шаги по их устранению. Опять же: как работает система? Из-за чего в ней происходит сбой?
Более глубоко в этой истории прослеживаются еще несколько аспектов менталитета SRE. Один из ключевых аспектов — принадлежность. Отличительной чертой менталитета является сильно выраженное собственническое отношение к сервисам, которыми управляют SR-инженеры. Они изучат каждый уголок системы или любое другое место, куда их занесет в поисках проблемы или всего лишь чтобы разобраться23. Это не значит, что у других нет собственнических чувств, просто SR-инженеры будут автоматически расширять масштаб ответственности настолько, насколько им необходимо, чтобы заботиться о системах. От этих людей редко можно услышать фразу «Код не мой, и проблема не моя». Если с сервисом возникла проблема — это их проблема, их головоломка, которую нужно решить, и они последуют за ней, куда бы она ни привела.
Один из побочных эффектов этой особенности менталитета SRE заключается в том, что SR-инженеры, как правило, универсалы по натуре (Нараян Десаи называет это защитой от специализации). Это не значит, что SR-инженеры не изучают углубленно конкретную область или не специализируются на какой-то теме, как, допустим, специалисты по проектированию надежности систем хранения данных.
Для поиска ответа на вопрос «как работает система» часто требуется универсал. Надежность — это эмерджентное свойство системы. Работа с эмерджентными свойствами (безопасность — тоже одно из них) предполагает решение проблем, где бы и когда бы они ни возникли.
Добро пожаловать в барбершоп (бритье яков)
Полагаю, я обязан упоминать и о недостатках менталитета SR-инженеров. У них может иметься склонность «брить яков». Если вы не слышали этот термин раньше, с радостью вас с ним познакомлю.
«Бритьем яков» называют ситуации, которые выглядят примерно так: у вас есть задача, для выполнения которой требуется установить некое программное обеспечение (ПО). Неважно, какое именно, это может быть любое ПО, необходимое для выполнения конкретной задачи.
Чтобы установить программное обеспечение, необходимо обновить общую библиотеку на компьютере.
Вы обнаруживаете, что для этого требуется обновить операционную систему (ОС).
Для новой версии ОС требуется больше места на системном диске, поэтому сначала нужно очистить дисковое пространство в хранилище, где содержатся образы дисков.
В процессе обновления ОС вы обнаружили, что есть обязательное обновление ПО для управления предоставлением ресурсов, поэтому сначала устанавливаете его.
К сожалению, новая версия плохо совместима с вашими текущими настройками виртуальной сети, так что необходимо решить эту проблему, прежде чем обновленный компьютер загрузится.
Но для этого нужно...
И так далее, и так далее, пока в какой-то момент, посмотрев на свою руку, вы не заметите, что держите в руках электрический триммер. А подняв глаза, не увидите, что стоите перед яком.
Вы собираетесь брить яка, и хотя вы знаете, что для этого у вас была веская причина, вы едва ли сможете вспомнить, как до такого дошли. Вот что такое «бритье яков».
Моя короткая история о бритье яка24 весьма локальная, но я гарантирую, что подобное можно легко рассказать об облачных ресурсах или масштабных системах. Менталитет SR-инженеров, в основе которого — собственническое отношение и стремление обнаружить проблему независимо от того, где она находится, также означает, что иногда мы склонны тратить время на качественный уход за яком. Со временем вы научитесь лучше определять, когда брить яка важно, а когда — нет.
Менталитет в развитии
Глава о менталитете SR-инженеров была бы неполной без обсуждения того, как меняются основные вопросы по мере углубления в область SRE. Вот несколько вариантов наших основных вопросов на будущее.
Как работает система? → Как будет работать система, если мы ее масштабируем?
Помощь в масштабировании сервисов — одно из основных преимуществ SR-инженеров, но она необязательно начинается с большого масштаба



















