

автордың кітабын онлайн тегін оқу Elasticsearch для разработчиков: индексирование, анализ, поиск и агрегирование данных. 2-е изд.
Анураг Шривастава
Elasticsearch для разработчиков: индексирование, анализ, поиск и агрегирование данных. 2-е изд.. — СПб.: Питер, 2025.
ISBN 978-5-4461-4211-8
© ООО Издательство "Питер", 2025
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Посвящается моим любимым родителям:
Вирендре Натху Шриваставе Киран Шриваставе
&
моей жене Чанчал
и
детям Анвиту и Адитри
Об авторе
Анураг Шривастава работает в сфере ИТ уже более 16 лет и имеет успешный опыт ведения различных государственных и частных проектов. Он занимал ключевые должности в области разработки и технического управления, позволявшие ему демонстрировать свою адаптивность и умение достигать успеха.
В сфере профессиональных интересов Анурага лежит и литература: он автор нескольких высоко оцененных книг. Его публикации широко известны благодаря представленному в них комплексному и практическому подходу к Kibana и Elasticsearch.
Помимо написания книг, Анураг проводит корпоративные тренинги по эффективному использованию Elasticsearch, Kibana, ELK и Cumulocity IoT.
Обладая разнообразным набором навыков, сильными лидерскими качествами и страстью к инновациям, Анураг Шривастава делает большой вклад в ИТ-инициативы. Он стремится добиваться исключительных результатов и быть в курсе тенденций и достижений в отрасли. Анураг — проверенный эксперт, помогающий совершенствовать сферу технологий.
О научном редакторе
Джива — сооснователь компании Epsil Technologies Private Limited, которая специализируется на предоставлении высококачественной поддержки и решений для Elasticsearch и ее экосистемы. Под эгидой Epsil он собрал сплоченную группу высококвалифицированных сертифицированных инженеров Elasticsearch.
Он помогает другим компаниям использовать возможности Elastic в различных сценариях, включая корпоративные поисковые системы, решения для мониторинга, оптимизацию кластеров и обновление версий.
Джива обладает обширным опытом проектирования, создания и устранения неисправностей кластеров Elasticsearch в различных средах, включая локальные, облачные системы и системы Elastic Cloud Enterprise (ECE).
Благодаря своему богатому опыту он не только хорошо разбирается в Elastic (и стеке ELK), но и с большим удовольствием делится информацией о последних версиях и возможностях стека Elastic.
Он также получил бронзовую награду Elastic Contributor — 2022 в знак признания своего вклада в развитие продукта и продуктового сообщества.
В центре вселенной Дживы — любимая жена Сандхия и двое их необыкновенных детей, Дхияра и Аадхира, и он дорожит каждым моментом, который они проводят вместе.
Благодарности
Я глубоко благодарен своей семье и друзьям за их неизменную поддержку и за то, что вдохновили меня на написание этой книги. Особенно я благодарен своим родителям, своей жене Чанчал и своим детям, Анвиту и Адитри, за их терпение и понимание во время этой работы.
Я также благодарен издательству BPB Publications за руководство и опыт в подготовке книги к изданию. Это был долгий путь, пройденный при участии рецензентов, технических экспертов и редакторов, оказавших мне неоценимую поддержку.
Я также хотел бы отметить ценный вклад своих коллег и сослуживцев, которые на протяжении многих лет работы в технологической отрасли многому меня научили и давали полезную обратную связь.
Наконец, я благодарен всем читателям, которые проявили интерес к моей книге и способствовали ее появлению на свет. Ваша поддержка бесценна.
Предисловие
Эта книга предназначена для широкого круга специалистов, включая разработчиков, архитекторов, администраторов баз данных, инженеров DevOps и других читателей, заинтересованных в эффективном изучении Elasticsearch и применении его1 в своих приложениях — как новых, так и уже существующих. Особенно она полезна для тех, кто хочет работать с данными с помощью Elasticsearch.
Для чтения книги желательно иметь базовые знания computer science, а также быть знакомыми с JSON и REST. В книге рассматривается Elasticsearch, а также введение в другие инструменты стека Elastic.
Никаких знаний Elasticsearch не требуется, поскольку структура книги предполагает изучение основ и постепенный переход к продвинутым темам в понятной форме и с примерами практического применения. Благодаря такому подходу любой читатель сможет освоить представленные в ней концепции.
К концу книги вы будете хорошо разбираться в системе Elasticsearch и сможете использовать ее для управления и анализа огромных объемов данных. Книга представляет собой исчерпывающее руководство по управлению данными с помощью Elasticsearch, что делает ее незаменимой для разработчиков, аналитиков данных и всех тех, кто работает с данными. Я надеюсь, что она окажется информативной и полезной для вас.
Глава 1 «Начало работы с Elasticsearch» содержит обзор системы Elasticsearch и ее возможностей. В этой главе вы узнаете, что такое поиск и аналитика и почему они важны в современном мире, основанном на данных. Далее будет рассказано о том, как работает Elasticsearch, рассмотрены различные сценарии ее использования и ее преимущества. В заключение будет приведена краткая история Elasticsearch и ее эволюции с течением времени. К концу главы читатели будут хорошо понимать, что такое система Elasticsearch, ее назначение и то, как она вписывается в широкий контекст аналитики данных.
Глава 2 «Установка Elasticsearch» содержит исчерпывающее руководство по установке и настройке Elasticsearch на различных операционных системах. Рассматриваются предварительные требования, необходимые для установки Elasticsearch, методы установки, а также способы настройки Elasticsearch для достижения оптимальной производительности. Кроме того, глава содержит инструкции по проверке установки и настройки. В результате у читателя окажется система Elasticsearch, готовая к работе на выбранной платформе.
Глава 3 «Elastic Stack: экосистема Elasticsearch» представляет обзор стека Elastic Stack, включающий инструменты Kibana, Logstash и Beats. В главе объясняется, как эти компоненты работают вместе, составляя полное решение для анализа данных. Читатели узнают о роли каждого компонента и о том, как их можно использовать для создания мощных дашбордов, визуализации данных и получения данных из различных источников.
Глава 4 «Подготовка данных к индексированию» рассматривает этапы подготовки данных к индексированию. В их число входит изучение типов анализаторов, нормализаторов, токенизаторов, фильтров токенов и фильтров символов, которые могут быть использованы в Elasticsearch для предварительной обработки данных. Мы рассмотрим практические примеры применения этих методов к различным источникам данных, таким как текстовые файлы, веб-логи и структурированные данные из баз данных. Вы получите четкое представление об оптимизации данных для эффективного и результативного индексирования в Elasticsearch.
Глава 5 «Импорт данных в Elasticsearch» расскажет, как импортировать в Elasticsearch данные из разных источников, таких как реляционные базы данных, CSV-файлы и т.д. Вы также узнаете, как преобразовывать и предварительно обрабатывать данные с помощью Logstash и Beats, двух важных компонентов стека Elastic. Кроме того, вы узнаете, как обрабатывать ошибки и контролировать процесс ввода данных для их эффективной обработки.
Глава 6 «Управление индексами: создание, обновление и удаление индексов Elasticsearch» раскрывает фундаментальные вопросы управления индексами Elasticsearch, включая их создание, обновление и удаление. В главе описываются особенности разных типов данных и маппинга, а также способы определения и управления элементами. Кроме того, рассматриваются методы обслуживания индексов, включая настройку распределения шардов и реализацию политик управления жизненным циклом индексов.
Глава 7 «Возможности поиска: освоение Query DSL и техник поиска» повествует о возможностях поиска в Elasticsearch. Вы поймете, что такое Query DSL и различные техники поиска, которые предлагает Elasticsearch. Вы научитесь писать сложные запросы для получения конкретной информации из проиндексированных данных. Кроме того, вы узнаете о таких методах оптимизации поиска, как разбивка на страницы, сортировка и выделение.
Глава 8 «Работа с геоданными в Elasticsearch» посвящена использованию Elasticsearch для геопространственного поиска и анализа. В ней рассматриваются типы геопространственных данных, геозапросы, фильтрация по местоположению, геопространственные агрегации и геопространственный маппинг.
Глава 9 «Анализ данных с помощью агрегаций Elasticsearch» учит использовать агрегации Elasticsearch для анализа и обобщения данных. Агрегации позволяют выполнять сложные вычисления и получать информацию из данных, например находить среднее, максимальное, минимальное или наиболее часто встречающееся значение для определенного поля. Мы рассмотрим различные виды агрегации, такие как агрегации метрик, бакетов и пайплайнов, а также способы их комбинирования для еще более эффективного анализа.
Глава 10 «Настройка производительности» рассказывает об оптимизации производительности Elasticsearch для работы с большими объемами данных. Мы рассмотрим аппаратные и сетевые параметры, управление памятью, распределение шардов и производительность индексирования. Вы также узнаете об инструментах и методах мониторинга и диагностики проблем производительности и о том, как настроить Elasticsearch для горизонтального масштабирования.
Глава 11 «Администрирование: управление кластерами Elasticsearch» посвящена администрированию кластеров Elasticsearch, включая управление и масштабирование. Будут рассмотрены такие темы, как управление кластером, управление узлами, распределение шардов и масштабирование кластеров Elasticsearch. Вы также узнаете о стратегиях резервного копирования и восстановления, функциях безопасности и мониторинге кластеров Elasticsearch.
1 Обычно Elasticsearch воспринимается и используется как «он» (поисковый движок, инструмент), если перед ним нет явного указания «система» или «экосистема», — в этом случае — «она». — Примеч. науч. ред.
Эта книга предназначена для широкого круга специалистов, включая разработчиков, архитекторов, администраторов баз данных, инженеров DevOps и других читателей, заинтересованных в эффективном изучении Elasticsearch и применении его1 в своих приложениях — как новых, так и уже существующих. Особенно она полезна для тех, кто хочет работать с данными с помощью Elasticsearch.
Обычно Elasticsearch воспринимается и используется как «он» (поисковый движок, инструмент), если перед ним нет явного указания «система» или «экосистема», — в этом случае — «она». — Примеч. науч. ред.
От издательства
Мы выражаем огромную благодарность компании КРОК за помощь в работе над русскоязычным изданием книги и вклад в повышение качества переводной литературы.
Ваши замечания, предложения, вопросы отправляйте по адресу comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
На веб-сайте издательства www.piter.com вы найдете подробную информацию о наших книгах.
О научном редакторе русского издания
Анна Белых — старший инженер-разработчик в компании КРОК. Занимается проектированием и разработкой высоконагруженных информационных систем разных масштабов. Специализируется на вопросах производительности и оптимизации серверной (backend) части.
Глава 1. Начало работы с Elasticsearch
Введение
В этой главе мы поближе познакомимся с Elasticsearch. Начнем с обсуждения преимуществ Elasticsearch и того, как эта система может помочь компаниям достичь целей в области управления данными. Затем рассмотрим, что представляет собой Elasticsearch и как она использует мощный поисковый движок Lucene для быстрого и масштабируемого поиска. Чтобы как следует разобраться в основах Elasticsearch, мы рассмотрим некоторые базовые понятия, такие как узлы, кластеры, документы, индексы и шарды. Это необходимо для понимания того, как Elasticsearch хранит и организует данные в целях эффективного поиска и извлечения информации.
Затем мы рассмотрим некоторые основные сценарии использования Elasticsearch, включая поиск данных, ведение логов и анализ, мониторинг производительности приложений и систем, а также визуализацию данных. Эти примеры подчеркивают универсальность Elasticsearch и демонстрируют его аналитический потенциал в широком спектре отраслей и приложений. Кроме того, мы обсудим клиенты Elasticsearch, доступные для разработчиков, такие как Java, PHP, Perl, Python, .NET и JavaScript. Эти клиенты позволяют разработчикам применять поисковые возможности Elasticsearch в языке программирования, который они используют, и его экосистеме.
Наконец, мы обсудим, как использовать Elasticsearch в качестве первичного источника данных, вторичного источника данных или отдельной системы. Мы дадим рекомендации по принятию обоснованных решений о включении Elasticsearch в архитектуру данных на основе конкретных бизнес-потребностей и технических требований.
Структура главы
В этой главе:
• Введение в поиск данных
• Что такое Elasticsearch и почему он важен для поиска и аналитики
• Обзор архитектуры и компонентов Elasticsearch
• Области применения и сценарии использования Elasticsearch
• Клиенты Elasticsearch и сценарии их использования
Цели
В этой главе представлен обзор движка Elasticsearch и его возможностей. В начале главы вводятся понятия поиска и аналитики и объясняется, почему они важны в современном мире, основанном на данных. Далее рассказывается о том, как эффективно использовать клиенты Elasticsearch.
Введение в поиск данных
В современном мире экспоненциальный рост объема оцифрованных данных из различных источников, таких как смарт-устройства, датчики IoT и онлайн-транзакции, представляет собой серьезную проблему. Один из основных вызовов, стоящих перед отраслью, — преобразование неструктурированных данных в структурированную форму для оптимизации процесса хранения данных. Однако настоящая проблема кроется в поиске нужной информации в хранящихся данных. Традиционные системы хранения данных, такие как РСУБД, не подходят для текстового поиска из-за сложности написания SQL-запросов и неэффективности поиска даже после применения всех необходимых индексов. В отличие от них Elasticsearch, поисковая система на базе Lucene, предлагает сложный механизм поиска с выдачей релевантных результатов, агрегацией данных и многими другими преимуществами, недоступными РСУБД. Поэтому понимание важности поиска и того, как Elasticsearch способна помочь оптимизировать хранение и поиск данных, крайне важно для любой организации, работающей с большими объемами данных.
Поиск — важнейший компонент современных приложений, поскольку именно благодаря ему пользователи могут быстро и точно находить нужную информацию. Для всех приложений, работающих с большими объемами данных, будь то блог, интернет-магазин или любое другое приложение, механизм поиска необходим, чтобы предоставлять пользователям релевантные результаты. Важность быстрых и точных результатов поиска трудно переоценить, поскольку пользователи, скорее всего, откажутся от приложения, которое не соответствует их требованиям к поиску. Поэтому оптимизация работы поиска чрезвычайно важна для эффективного взаимодействия с пользователями и сохранения их вовлеченности.
Помимо предоставления быстрых результатов, необходимо учитывать и другие важные параметры, такие как релевантность, агрегация и анализ данных. Это требование успешно обеспечивает Elasticsearch — мощная и масштабируемая поисковая система, способная работать с разными типами и источниками данных. Используя возможности Elasticsearch, приложения предоставляют пользователям быстрые, точные и релевантные результаты; это делает ее важнейшим компонентом современных приложений, ориентированных на поиск.
Важность функциональности поиска трудно переоценить. Помимо обеспечения быстрого отклика на запрос и получения релевантных результатов, существуют и другие критерии.
• Предложение поиска. Эффективная система поиска должна предлагать потенциальные поисковые запросы, как только пользователь начинает вводить текст.
• Нечеткий поиск. Система должна предлагать релевантные результаты, даже если пользователь допустил орфографическую ошибку в поисковом термине или использовал синоним.
• Поиск по производным. Качественная поисковая система должна распознавать производные поисковых терминов, например слова во множественном или единственном числе, чтобы предоставлять наиболее полные результаты.
• Агрегация данных. Система должна поддерживать агрегацию данных, чтобы предлагать пользователю дополнительные опции и фильтры, например ценовой диапазон, рейтинги, бренды и другую соответствующую информацию.
• Релевантные результаты. Результаты поиска должны выводиться в порядке соответствия запросу, с учетом таких факторов, как частота поискового термина, периодичность и поведение пользователей.
• Расширенные фильтры. Пользователи должны иметь возможность применять расширенные фильтры к результатам поиска, например по разрешению экрана, объему оперативной памяти, цвету и другим важным критериям.
• Быстрое время отклика. Поисковая система должна предоставлять результаты поиска быстро, в течение нескольких секунд, чтобы избежать промедлений в работе пользователей и не вызывать у них негативных эмоций.
Учитывая эти критерии, разработчики могут создавать эффективные поисковые системы, выдающие быстрые и точные результаты, что в конечном итоге обеспечивает повышение вовлеченности и удовлетворенности пользователей.
Что такое Elasticsearch и почему он важен для поиска и аналитики
Поисковый движок Elasticsearch был создан Шаем Баноном (Shay Banon), основателем компании Elastic, которая занимается дальнейшей разработкой и поддержкой этого продукта. Elasticsearch — это ПО с открытым исходным кодом, которое может быть запущено на одном сервере или на сотнях серверов, чтобы обрабатывать петабайты данных. Elasticsearch — это мощная система, которая используется для поиска нужных данных в хранилищах большого объема.
В наш информационный век объем данных растет в геометрической прогрессии благодаря оцифровке и появлению новых источников данных, таких как смарт-устройства, датчики IoT (интернета вещей) и онлайн-транзакции. Эти данные могут быть структурированными или неструктурированными, относящимися к конкретному устройству или временным рядам и поступать из разных источников, что затрудняет их поиск вручную. Для решения этих проблем Elasticsearch предоставляет распределенную, масштабируемую и документоориентированную поисковую систему на базе библиотеки Lucene. Lucene — это высокопроизводительная библиотека, которая обеспечивает быстрые и эффективные результаты поиска. Однако для ее использования требуется сложный код Java, и ее нелегко распределить по нескольким узлам.
Elasticsearch инкапсулирует все сложности Lucene и предоставляет REST API, которые облегчают пользовательское взаимодействие с Elasticsearch. Он также обеспечивает поддержку нескольких языков программирования с помощью языковых клиентов, поэтому можно писать код на желаемом языке и при этом взаимодействовать с Elasticsearch. Кроме того, с Elasticsearch можно взаимодействовать с помощью инструмента командной строки cURL.
Итак, Elasticsearch — это мощный поисковый и аналитический движок, обеспечивающий быстрый и эффективный поиск в больших объемах данных, что делает его жизненно важным инструментом для организаций, стремящихся извлечь из своих данных максимальную ценность.
Обзор архитектуры и компонентов Elasticsearch
Elasticsearch имеет распределенную архитектуру, которая позволяет обрабатывать большие объемы данных на нескольких узлах. Она включает несколько компонентов, которые работают вместе и обеспечивают масштабируемую и высокодоступную платформу для поиска и аналитики.
Узел
В Elasticsearch под узлом (node) понимается отдельный рабочий экземпляр поисковой системы. Elasticsearch состоит из одного или нескольких узлов, которые являются экземплярами сервера Elasticsearch. Например, в кластере из десяти серверов, на которых работает Elasticsearch, каждый сервер будет считаться узлом. В некоторых случаях для нерабочих сред может быть достаточно кластера с одним узлом. Однако по мере увеличения объема данных возникает необходимость в дополнительных узлах для горизонтального масштабирования кластера, что также обеспечивает отказоустойчивость. Зная о других узлах кластера, узел может передавать запросы клиентов соответствующему узлу. Стоит отметить, что узлы могут играть разные роли: узлы данных хранят и выполняют запросы; главные узлы управляют операциями всего кластера; узлы-координаторы пересылают запросы на соответствующие узлы. Каждый узел работает независимо и взаимодействует с другими, образуя кластер. Узлы можно добавлять или удалять из кластера динамически, не влияя на работу всей системы. Узлы могут быть разных типов.
Узел, допустимый для выбора в качестве главного (master-eligible node)
В Elasticsearch 8 узел, допустимый для выбора в качестве главного узла, или мастера, отвечает за управление состоянием кластера, включая добавление или удаление узлов, распределение шардов между узлами и поддержание работоспособности кластера. Рекомендуется иметь в кластере не менее трех таких узлов-кандидатов, чтобы обеспечить высокую доступность и избежать ситуаций разделения мозга (split-brain) (cм. врезку ниже).
Выделенный узел, допустимый для выбора в качестве главного (dedicated master-eligible node)
Выделенный узел, который является кандидатом в мастер-узел, — это узел в кластере Elasticsearch, который сконфигурирован как главный и не имеет никаких других обязанностей, таких как хранение данных или обработка поисковых запросов. Задача выделенного узла — повысить стабильность и надежность кластера, в котором задачи главного узла выполняет выделенный узел.
Чтобы сконфигурировать узел как главный (мастер-узел) в Elasticsearch 8, необходимо задать следующие параметры в файле конфигурации elasticsearch.yml:
node.roles: [ master ]
Параметр node.roles должен иметь значение master, указывая, что этот узел может быть использован в качестве главного.
Ситуация разделения мозга (split-brain)
В Elasticsearch ситуация разделения мозга возникает, когда кластер разделяется на несколько подкластеров, каждый из которых считает, что только он контролирует ситуацию. Это может произойти из-за нарушения связи между узлами в кластере вследствие сетевых проблем или других сбоев. В таких случаях каждый подкластер продолжает работать независимо, самостоятельно обновляя одни и те же данные, что может привести к несогласованности данных.
Ситуации split-brain можно предотвратить, создав систему на основе кворума, когда большинство узлов должно согласиться с принятым решением. В Elasticsearch это достигается путем наделения определенных узлов правами главных и требованием, чтобы для нормального функционирования кластера было доступно большинство таких узлов. Когда узел с правами главного обнаруживает, что больше не имеет связи с большинством этих узлов, он отключается и инициирует процесс выбора нового главного узла.
Важно правильно настроить Elasticsearch для обработки ситуаций разделения мозга, чтобы обеспечить согласованность данных и избежать их потери. Рекомендуется использовать выделенный главный узел и следить, чтобы в кластере всегда было нечетное количество узлов-кандидатов в главный узел (для гарантии большинства). Правильная настройка сетевых параметров и мониторинг потенциальных проблем также помогут предотвратить возникновение ситуаций split-brain.
Примечание Важно отметить, что главный узел не должен быть перегружен другими задачами, поскольку ему требуется достаточно ресурсов для управления состоянием кластера. Если один главный узел выходит из строя или становится недоступным, оставшиеся узлы-кандидаты выбирают новый главный узел для управления состоянием кластера.
Голосующий узел (voting-only master-eligible node)
В Elasticsearch голосующий узел — это узел, который только участвует в процессе выбора главного узла, но сам не может им стать. Когда главный узел выходит из строя или становится недоступным, оставшиеся узлы должны выбрать новый главный узел для поддержания стабильности кластера. В это время узлы-кандидаты участвуют в выборе нового главного узла. Чтобы настроить в Elasticsearch 8 голосующий узел, необходимо задать следующие параметры в файле конфигурации elasticsearch.yml:
node.roles: [ data, master, voting_only ]
В примере выше мы задаем голосующий узел данных. Также можно задать выделенный голосующий узел, используя опцию в файле конфигурации elasticsearch.yml:
node.roles: [ master, voting_only ]
В примере выше мы устанавливаем голосующий узел, не имеющий обязанностей узла данных.
Узел данных (data node)
Узлы данных отвечают за хранение и управление данными, а также за выполнение CRUD-операций, поиска и агрегации данных. Можно настроить узел как узел данных, установив для параметра node.data значение true в файле конфигурации Elasticsearch. Если необходим отдельный узел данных, можно установить для других типов значение false, как показано в следующем фрагменте кода:
node.roles: [ data ]
В примере выше мы устанавливаем для параметра "node.role" значение data, а для всех остальных параметров — false, что делает узел выделенным узлом данных. Добавив в кластер больше узлов данных, можно горизонтально масштабировать кластер и обрабатывать большие объемы данных. Узлы данных также могут выполнять распределение и ребалансировку шардов, что помогает равномерно распределять данные по кластеру для повышения производительности и отказоустойчивости.
Узел поглощения данных (ingest node)
Узел поглощения данных — это специализированный тип узла в Elasticsearch, который позволяет выполнять предварительную обработку документов перед их индексацией. Он отвечает за обработку данных по мере их прохождения через пайплайн Elasticsearch, например, добавление в документы дополнительных данных, обработку значений полей и выполнение преобразований данных.
Узлы поглощения имеют собственный специальный пайплайн, который можно настраивать для извлечения и преобразования данных с помощью различных процессоров, таких как grok, dissect и geoip. Это особенно полезно в случаях, когда необходимо извлечь релевантную информацию из неструктурированных данных, таких как файлы логов или потоки социальных сетей.
Чтобы сконфигурировать узел поглощения данных, установим для параметра node.roles в файле конфигурации Elasticsearch значение ingest. Вот пример:
node.roles: [ ingest ]
Узел поглощения позволяет выполнять предварительную обработку данных без необходимости писать собственный код или использовать внешние инструменты. Это упрощает пайплайн обработки данных и делает его более эффективным, особенно когда требуется обрабатывать большие объемы данных в реальном времени.
Узел машинного обучения (machine learning node)
Узел машинного обучения — это узел, способный выполнять задания машинного обучения на данных, хранящихся в кластере Elasticsearch. Узлы машинного обучения имеют специализированные аппаратные конфигурации и оптимизированы для обработки больших объемов данных в реальном времени.
Чтобы настроить узел машинного обучения, необходимо активировать функцию машинного обучения в файле конфигурации Elasticsearch и назначить узлу роль узла машинного обучения. Это можно сделать, добавив следующую строку в файл конфигурации elasticsearch.yml:
xpack.ml.enabled: true
Параметр xpack.ml.enabled включает функцию машинного обучения, а параметр node.ml назначает узлу роль узла машинного обучения.
После того как узел настроен, можно создавать задания машинного обучения с помощью API машинного обучения Elasticsearch. Эти задания могут анализировать данные в реальном времени и выявлять паттерны, аномалии и тенденции.
Чтобы создать выделенный узел машинного обучения, отредактируйте файл конфигурации Elasticsearch (elasticsearch.yml) и добавьте следующую строку:
node.roles: [ ml, remote_cluster_client]
Эта строка указывает Elasticsearch настроить узел в качестве узла машинного обучения и узла удаленного клиента кластера. Настройка удаленного клиента кластера необходима, поскольку она позволяет узлу машинного обучения получать доступ к данным из других кластеров, что может понадобиться для анализа. Узел машинного обучения — платная функция Elasticsearch, которая позволяет запускать модели машинного обучения на данных Elasticsearch.
Предположим, что у вас есть узел машинного обучения в одном кластере Elasticsearch, но данные, которые вы хотите использовать для машинного обучения, хранятся в другом кластере. Настроив узел машинного обучения как узел удаленного клиента кластера, вы можете получить доступ к данным, хранящимся в другом кластере, не перенося их в кластер узла машинного обучения. Это позволяет сэкономить время и ресурсы, а также избежать ненужного дублирования данных.
Узел горячих данных (hot data node)
Узлы горячих данных — это особый тип узлов данных в Elasticsearch, которые оптимизированы для работы с высокопроизводительными рабочими нагрузками и высоким трафиком. Они предназначены для хранения наиболее часто используемых и запрашиваемых данных, также известных как горячие данные, и обычно развертываются на высокопроизводительном оборудовании для обеспечения быстрого времени отклика.
Узлы горячих данных характеризуются способностью обрабатывать большой объем запросов на чтение и запись в реальном времени. Они оптимизированы для эффективного индексирования и поиска данных, что делает их идеальными для таких сценариев использования, в которых требуется быстрый и частый доступ к данным, например для интернет-магазинов, социальных сетей и приложений финансовых услуг.
Чтобы настроить узел горячих данных, укажите следующие параметры в файле конфигурации Elasticsearch:
node.roles: [ data-hot ]
Используя настройки выше, можно определить узел горячих данных в Elasticsearch.
Узел теплых данных (warm data node)
Узел теплых данных в Elasticsearch — это тип узла, оптимизированный для хранения и поиска больших объемов данных, к которым обращаются реже. К ним могут относиться старые или реже используемые логи, исторические данные или резервные копии. Теплый узел обычно имеет меньшую производительность хранения и меньшие требования к памяти по сравнению с горячими узлами, но он может хранить большой объем данных при меньших затратах.
Теплые узлы также предназначены для работы с нагрузками, связанными с чтением, и могут быть не так отзывчивы на запросы записи, как горячие узлы. Чтобы настроить узел теплых данных в Elasticsearch 8, задайте следующие параметры в файле конфигурации elasticsearch.yml:
node.roles: [ data-warm ]
Таким образом узел будет настроен для обработки теплых данных и оптимизирован для хранения нечасто используемых данных и доступа к ним.
Узел холодных данных (cold data node)
Узел холодных данных — это тип узла данных в Elasticsearch, специально предназначенный для хранения редко используемых или архивных данных. Холодные узлы обычно создаются более медленными и имеющими меньшие вычислительные ресурсы, что делает выгодным их использование для хранения больших объемов данных с редким доступом.
Чтобы настроить узел холодных данных в Elasticsearch 8, измените параметр node.roles в файле конфигурации elasticsearch.yml следующим образом:
node.roles: [ data-cold ]
Таким образом узел будет настроен для обработки холодных данных и оптимизирован для хранения редко используемых данных и управления ими, в то время как другие узлы в кластере будут обрабатывать более активные и часто используемые данные.
Узлы холодных данных полезны для долгосрочного хранения данных, а также соблюдения нормативных и регуляторных требований. Отделение холодных данных от горячих или теплых позволит оптимизировать распределение ресурсов и производительность кластера Elasticsearch. Узлы холодных данных обычно используются для данных, которые не требуют частых запросов или анализа в реальном времени, но при этом должны храниться и быть доступными для соблюдения нормативных требований или для исторических целей.
Узел замороженных данных (frozen data node)
В Elasticsearch 8 узел замороженных данных — это специализированный тип узла, оптимизированный для хранения данных, к которым обращаются редко или которые доступны только для чтения. Узлы замороженных данных предназначены для эффективного и малозатратного хранения больших объемов данных, которые не запрашиваются и не обновляются. Такие узлы особенно хорошо подходят для долгосрочного архивирования и обеспечения соответствия нормативным требованиям, когда данные должны храниться в течение определенного времени, но доступ к ним осуществляется редко. Отделение замороженных данных от других типов, таких как горячие или теплые данные, позволяет оптимизировать использование ресурсов и повысить общую производительность кластера. Узлы замороженных данных позволяют хранить большие объемы данных и управлять ими с малыми затратами, обеспечивая при этом доступность данных и соответствие нормативным требованиям.
Чтобы настроить узел замороженных данных в Elasticsearch, измените параметр node.roles в файле конфигурации elasticsearch.yml следующим образом:
node.roles: [ data-frozen ]
Таким образом узел будет настроен для обработки замороженных данных и оптимизирован для их хранения и управления ими.
Примечание Важно отметить, что узлы замороженных данных предназначены только для чтения, то есть данные в них можно записывать лишь на этапе начального индексирования. После того как данные будут проиндексированы и сохранены, их нельзя будет изменить или обновить. Однако они останутся доступными для поиска и извлечения, что делает узлы замороженных данных полезным средством для хранения и архивирования крупных данных в Elasticsearch.
Кластер
В Elasticsearch кластер — это набор узлов, которые взаимодействуют между собой, создавая целостную и распределенную среду для хранения и обработки данных. Каждый кластер идентифицируется уникальным именем, что позволяет узлам соединяться и взаимодействовать с конкретным кластером, к которому они принадлежат. Узлы внутри кластера работают вместе, обеспечивая единое и согласованное представление данных. Они взаимодействуют друг с другом для равномерного распределения и репликации данных на нескольких узлах; это позволяет повысить доступность данных, отказоустойчивость и общую производительность системы.
Распределяя данные по узлам, кластер обеспечивает горизонтальную масштабируемость. По мере увеличения объема данных или роста рабочей нагрузки в кластер могут быть добавлены дополнительные узлы, чтобы он мог справиться с возросшими требованиями к хранению и обработке данных. Такая масштабируемая архитектура позволяет Elasticsearch обрабатывать большие массивы данных и эффективно справляться с большими объемами запросов.
Кластеры также играют важную роль в обеспечении надежности и отказоустойчивости данных. Благодаря репликации данных на нескольких узлах кластер может выдерживать сбои и предотвращать потерю данных. Если один из узлов становится недоступным или выходит из строя, кластер автоматически перераспределяет хранящиеся на нем данные на другие доступные узлы, поддерживая необходимую избыточность данных и гарантируя их доступность даже при сбое узлов.
Помимо распределения данных и обеспечения отказоустойчивости, кластеры предоставляют централизованную точку управления для мониторинга и администрирования. Такие операции, как мониторинг состояния кластера, управление индексами и ребалансировка данных, могут выполняться на уровне кластера; таким образом осуществляется единый и систематизированный подход к управлению всем развертыванием Elasticsearch.
Индекс
В Elasticsearch индекс представляет собой логическое пространство имен, или контейнер, в котором хранится коллекция документов. Индекс можно рассматривать как традиционную базу данных, где данные организованы и хранятся в структурированном виде. Задача индекса — сгруппировать документы, которые имеют схожие характеристики или принадлежат к одной категории. Например, в приложении онлайн-магазина можно задать отдельные индексы для товаров, клиентов и заказов. Это позволит выполнять эффективный поиск и извлекать необходимую информацию по определенным предметным областям (доменам).
Elasticsearch использует структуру инвертированного индекса для быстрого полнотекстового поиска. Инвертированный индекс состоит из списка уникальных терминов, встречающихся во всех документах в индексе, а также идентификаторов документов, указывающих на вхождения каждого термина. Подобная техника индексирования значительно ускоряет операции поиска за счет предварительного вычисления связей между терминами и документами.
Для обработки больших объемов данных и распределения рабочей нагрузки индекс делится на один или несколько шардов. Каждый шард — это независимое подмножество данных индекса, которое может храниться на отдельном узле в кластере Elasticsearch. Разбивая индекс на шарды, Elasticsearch может распараллелить операции поиска и индексирования, повышая производительность и масштабируемость.
Шарды
В Elasticsearch индекс состоит из одного или нескольких шардов, и каждый шард является самостоятельной единицей индекса. Разбивая индекс на более мелкие шарды, Elasticsearch распределяет данные и операции между несколькими узлами, что повышает производительность и масштабируемость системы. Шарды позволяют Elasticsearch распараллеливать операции поиска и индексирования. Выдаваемый запрос на поиск параллельно передается во все шарды, а результаты поиска объединяются и возвращаются пользователю. Такое распараллеливание позволяет Elasticsearch обрабатывать большие объемы данных и сложные поисковые запросы.
При создании индекса можно указать количество шардов, и Elasticsearch автоматически распределит их между доступными узлами кластера. Необходимое количество шардов индекса зависит от разных факторов, таких как размер индекса, количество документов и ожидаемая производительность поиска и индексирования. Elasticsearch также поддерживает возможность создания реплик шардов, которые представляют собой копии основных шардов. Шарды-реплики обеспечивают избыточность и высокую доступность, позволяя системе продолжать функционировать, даже если некоторые узлы выйдут из строя. При создании индекса можно также указать количество реплик. Реплики распределяются по доступным узлам кластера, отдельно от первичных шардов.
Например, если необходимо проиндексировать 100 Гбайт данных и настроены четыре шарда, то 100 Гбайт данных будут разделены на шарды по 25 Гбайт. Если узел один, все четыре шарда останутся на этом узле. Если добавить в кластер еще один узел, шарды будут равномерно распределены на обоих узлах. Так, два шарда останутся на узле 1, а два переместятся на второй узел кластера.
Шарды могут быть двух типов: первичные и реплики. Первичные шарды содержат первичные данные, а реплики — копии первичных шардов. Мы используем реплики, чтобы защититься от любых аппаратных сбоев и повысить производительность поиска в кластере.
На следующем рисунке (рис. 1.1) показан кластер Elasticsearch с тремя узлами. Конфигурация шардов на нем следующая:
• количество первичных шардов: 2;
• количество реплик шардов: 1.
Теперь, если узлов в кластере два — один первичный и одна реплика, — два шарда переместятся на один узел, а первичный второй шард и первая реплика шарда — на другой.
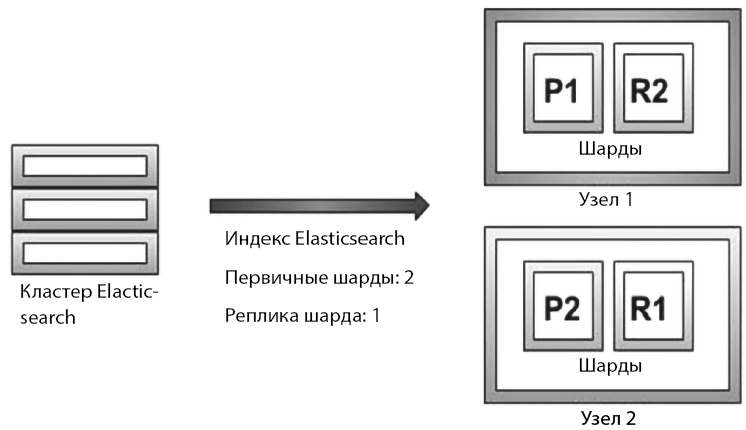
Рис. 1.1. Шарды Elasticsearch
На рисунке выше показан кластер с узлом 1 и узлом 2. На узле 1 находятся шарды P1 и R2, а на узле 2 — шарды P2 и R1. P обозначает первичные шарды, а R — шарды-реплики.
Документы
В Elasticsearch документ — это основная единица информации, которую можно индексировать и искать. Он представляет собой один объект данных, обычно в формате JSON, и содержит фактические данные, которые хранятся и извлекаются в Elasticsearch. Документы в Elasticsearch организованы в индексе и однозначно идентифицируются по идентификатору. Каждый документ состоит из полей, которые представляют собой пары «ключ — значение», отражающие атрибуты или свойства данных. Типы данных полей могут быть различными, включая строки, числа, булевы выражения, даты и др.
Документы в Elasticsearch являются гибкими, то есть не требуют предопределенной схемы. Такая гибкость позволяет осуществлять динамическое индексирование, когда в документ можно добавлять новые поля, не изменяя структуру индекса. Она также позволяет работать с разными типами и структурами данных в рамках одного индекса.
Когда документ индексируется в Elasticsearch, он сохраняется и становится доступным для поиска в указанном индексе. Документ автоматически назначается одному или нескольким шардам в зависимости от конфигурации индекса. Процесс индексирования включает в себя анализ текста и извлечение релевантных терминов для построения инвертированного индекса, обеспечивающего эффективный полнотекстовый поиск.
Области применения и варианты использования Elasticsearch
Мы уже обсуждали некоторые возможности Elasticsearch, например аналитику, которая позволяет формировать срезы данных, чтобы извлечь максимально полную информацию. Аналитика позволяет искать неточные совпадения или, благодаря нечеткому поиску, выдавать результаты, даже если пользователь неверно ввел слово. Таким образом, функции Elasticsearch оказываются полезными в разных ситуациях. Перечислить все потенциальные сценарии использования Elasticsearch невозможно, назовем лишь основные.
Поиск данных
Основная задача Elasticsearch — поиск данных, особенно при работе с большими массивами данных. В прошлом для хранения и поиска данных обычно использовались реляционные БД. Однако в современных условиях реляционные базы данных часто не в состоянии обеспечить оптимальную производительность поиска, поскольку они не предназначены для работы в качестве поисковых систем.
А Elasticsearch является высокомасштабируемой поисковой системой, которая обеспечивает быстрый поиск. Ее возможности выходят за рамки базовых и включают такие функции, как агрегация, анализ и нечеткий поиск. Эти функции делают Elasticsearch идеальным инструментом для разнообразных задач поиска данных.
Онлайн-магазины, сайты продажи пу



















