

автордың кітабын онлайн тегін оқу MySQL по максимуму
Переводчик В. Дмитрущенков
Сильвия Ботрос, Джереми Тинли
MySQL по максимуму. 4-е издание. — СПб.: Питер, 2023.
ISBN 978-5-4461-2261-5
© ООО Издательство "Питер", 2023
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Отзывы о книге
Мне нравится, что в новом издании книги акценты смещаются на современное прагматическое мышление командных игроков, создающих ценность для бизнеса. Материал о том, как работают базы данных, по-прежнему подробно освещается, но теперь со свежим гуманистическим подходом, который очень необходим.
Барон Шварц, ведущий автор «MySQL по максимуму», 2-е и 3-е издания
«MySQL по максимуму» была одной из основных книг в мире MySQL с момента выхода первого издания 17 лет назад. MySQL постоянно движется вперед, и Сильвия и Джереми проделали отличную работу, приведя эту важную книгу в соответствие с сегодняшним состоянием MySQL.
Джереми Коул
Это последнее издание, обновленное с учетом современных практик, содержит полезные советы для администраторов и разработчиков MySQL.
Шломи Ноах, инженер баз данных, PlanetScale
«MySQL по максимуму» получило новый фокус. Речь больше не идет о том, чтобы выжимать из MySQL каждую унцию мощности. Теперь у нас есть большая экосистема инструментов и поставщиков.
Сильвия и Джереми прекрасно рассказывают, как MySQL вписывается в новую картину. Прочитать эту книгу обязательно, если вы запускаете MySQL на любой платформе.
Сугу Сугумаране, технический директор PlanetScale, один из создателей Vitess
Сильвия и Джереми проделали фантастическую работу, сохранив первоначальный дух книги и обновив ее, чтобы охватить быстро меняющийся мир MySQL.
Петр Зайцев, основатель и генеральный директор Percona и соавтор «MySQL по максимуму», 3-е издание
Предисловие
Новенький экземпляр «MySQL по максимуму» был первой книгой, которая ложилась на стол каждого вновь нанятого администратора баз данных, системного инженера или разработчика баз данных с тех пор, как она вышла почти два десятилетия назад.
Когда Джереми Заводны и Дерек Баллинг решили написать книгу о работе с MySQL на уровне, позволяющем внести ясность и структурировать многолетние загадки, ей суждено было стать классикой в мире MySQL. За прошедшие годы и несколько редакций книги часть содержимого оригинала и последующих обновлений сохранилась, а часть — не очень.
Сама MySQL развилась, сообщество MySQL сильно изменилось, и способы, которыми мы используем MySQL, поменялись. Теперь, в четвертом издании, Сильвия и Джереми берутся за колоссальную неблагодарную работу по обновлению этого классического труда для современной эпохи — и они идеально подходят для этой задачи.
Все время моего знакомства с MySQL (уже более 20 лет!) в сообществе MySQL единственной неизменной вещью была, ну, несогласованность. Все используют MySQL (и базы данных в целом) немного по-разному, и у всех разные ожидания от нее. Каждый принимает несколько хороших решений, несколько исполненных благих намерений, но сомнительных решений и всегда значительную долю плохих. Иногда добиться прогресса легко, но иногда требуется новый взгляд на проблему и мудрый совет, полученный непосредственно от эксперта.
Сильвия и Джереми как раз такие эксперты. Все области, в том числе архитектура MySQL, оптимизация, репликация, резервное копирование и многое другое, выиграют от того, что они поделятся своим обширным опытом работы с MySQL. В этом новом, четвертом издании многие темы получили новую трактовку, было удалено много устаревшего материала, исправлены ошибки, и в материал привнесен новый и свежий стиль.
Как и оригинальное (теперь устаревшее и просто маленькое) первое издание, четвертое обещает помочь новейшему поколению разработчиков, администраторов баз данных и их боссов войти в новый мир MySQL — иногда с волнением, но, возможно, иногда с пинками и криками.
Спасибо, Сильвия и Джереми, за вашу усердную работу по воспитанию следующего поколения фанатов MySQL, которые будут обеспечивать безопасность мировых данных, благодаря вам лучшие в мире веб-сайты и другие системы, управляемые данными, станут работать на пике своих возможностей.
Поздравляю с тем, что удалось это сделать с помощью COVID и всего остального. А все мы обязательно обеспечим экземпляром этой книги всех новых администраторов баз данных.
Джереми Коул, окрестности Рино, Невада, октябрь 2021 года
Введение
Официальная документация от Oracle дает вам знания, необходимые для установки и настройки MySQL и взаимодействия с ней. Наша книга служит дополнением к этой документации, помогая вам понять, как наилучшим образом использовать MySQL в качестве мощной платформы данных для вашего сценария применения.
В этом издании также раскрывается растущая роль соответствия требованиям и безопасности как части работы с базой данных. Новые реалии, такие как законы о конфиденциальности и суверенитете данных, изменили то, как компании создают свои продукты, и это, естественно, вносит новые сложности в развитие технической архитектуры.
Для кого эта книга
Эта книга в первую очередь предназначена для инженеров, желающих улучшить свой опыт работы с MySQL. Ее авторы предполагают, что аудитория знакома с основными принципами использования системы управления реляционными базами данных (RDBMS). Мы также предполагаем наличие некоторого опыта общего системного администрирования, работы с сетями и операционными системами.
Мы предложим вам проверенные стратегии масштабируемой эксплуатации MySQL с применением современной архитектуры и новейших инструментов и практик.
В конечном счете мы надеемся, что знания о внутреннем устройстве MySQL и стратегиях масштабирования, которые вы получите из этой книги, помогут вам в масштабировании уровня хранения данных в вашей организации. И еще надеемся, что новообретенное понимание поможет вам изучить и применить на практике методический подход к проектированию, поддержке и устранению неполадок в архитектуре, построенной на базе MySQL.
Новое в этом издании
«MySQL по максимуму» была непременным атрибутом сообщества инженеров баз данных в течение многих лет — предыдущие издания были выпущены в 2004, 2008 и 2012 годах. Их цель всегда заключалась в том, чтобы научить разработчиков и администраторов оптимизировать MySQL для любого случая потери производительности, сосредоточившись на глубоком анализе внутреннего устройства, объяснив, что означают различные параметры настройки, и вооружив пользователя знаниями, позволяющими эффективно изменять эти параметры. Это издание преследует ту же цель, но с несколько иной направленностью.
Начиная с третьего издания, экосистема MySQL претерпела множество изменений — были выпущены три новые основные версии. Ландшафт инструментальных средств значительно расширился за пределы сценариев Perl и Bash, и они превратились в полноценные инструментальные решения. Были созданы совершенно новые проекты с открытым исходным кодом, позволяющие организациям радикально изменить управление масштабированием MySQL.
Даже традиционная роль администратора базы данных (DBA) изменилась. В ИТ-отрасли есть старая шутка, гласящая, что DBA означает Don’t Bother Asking («Не трудись спрашивать»). У администраторов баз данных была репутация «спящих полицейских» в жизненном цикле разработки программного обеспечения (SDLC), не из-за отрицательного отношения к ним, а просто потому, что базы данных развивались не так быстро, как остальная часть SDLC вокруг них.
Благодаря таким книгам, как Database Reliability Engineering: Designing and Operating Resilient Database Systems1 Лейна Кэмпбелла и Черити Мейджорс (O’Reilly), новой реальностью стало то, что технические организации рассматривают инженеров баз данных больше как средство обеспечения роста бизнеса, а не просто как операторов всех баз данных. Когда-то основными задачами администратора баз данных было проектирование схемы и оптимизация запросов, теперь он отвечает за обучение этим навыкам разработчиков и управление системами, которые позволяют разработчикам быстро и безопасно развертывать собственные изменения схемы.
Из-за этих изменений основное внимание больше не стоит уделять оптимизации MySQL для ускорения на несколько процентов. Мы думаем, что теперь книга «MySQL по максимуму» предназначена для предоставления людям информации, необходимой для принятия обоснованных решений о том, как лучше всего использовать MySQL. Все начинается с объяснения того, как устроена MySQL, так что можно понять, что такое MySQL, а что — нет2. Современные релизы MySQL предлагают разумные значения по умолчанию, и вам нужно настраивать очень немногое, если только вы не сталкиваетесь с конкретной проблемой масштабирования. Современные команды теперь чаще имеют дело с изменениями схемы и проблемами соответствия нормативам и сегментирования. Мы хотим, чтобы «MySQL по максимуму» стала исчерпывающим руководством по тому, как современные компании могут задействовать MySQL при масштабируемой эксплуатации.
Используемые в книге соглашения
В данной книге применяются следующие шрифтовые соглашения.
Курсив
Отмечает новые термины.
Рубленый шрифт
Выделяет URL и адреса электронной почты.
Моноширинный шрифт
Показывает использованные внутри абзацев имена и расширения файлов, элементы программ, такие как переменные или имена функций, базы данных, переменные окружения, операторы и ключевые слова. Также применяется для листингов программ.

Эта пиктограмма означает совет или указание.

Эта пиктограмма означает общее примечание.

Эта пиктограмма указывает на предупреждение или предостережение.
Благодарности к четвертому изданию
От Сильвии
Прежде всего я хотела бы поблагодарить свою семью. Родителей, которые пожертвовали стабильной работой и жизнью в Египте, чтобы привезти меня и моего брата в Соединенные Штаты. Мужа Армеа — за то, что поддерживал меня в этот и все прошлые годы построения карьеры, когда я принимала один вызов за другим, достигнув кульминации в своих достижениях.
Я начала заниматься технологиями, будучи иммигранткой, которая прервала обучение на Ближнем Востоке, чтобы осуществить свою мечту — переехать в Соединенные Штаты. Получив степень в государственном университете в Калифорнии, я устроилась на работу в Нью-Йорке. Второе издание этой книги было самой первой технической книгой, которую я купила на свои деньги и которая не была учебником для колледжа. Я в долгу перед авторами предыдущих изданий, преподавших мне множество фундаментальных уроков, которые подготовили меня к управлению базами данных на протяжении всей моей карьеры. Я благодарна за поддержку очень многим людям, с которыми работала прежде. Их поддержка побудила меня написать новую редакцию этой книги, которая многому меня научила в начале карьеры. Я хотела бы поблагодарить Тима Дженкинса, бывшего технического директора SendGrid, за то, что нанял меня на работу всей моей жизни, хотя я сказала ему в своем интервью, что он неправильно использует репликацию MySQL, и за то, что он доверил мне то, что стало ракетным кораблем.
Я хотела бы поблагодарить всех замечательных женщин, работающих в сфере технологий, которые были моей группой поддержки и болельщиками. Особая благодарность Камилле Фурнье и доктору Николь Форсгрен за написание двух книг, которые повлияли на последние несколько лет моей карьеры и изменили мой взгляд на повседневную работу.
Спасибо моей команде в Twilio. Шону Килгору — за то, что под его влиянием я стала гораздо лучшим инженером, который заботится не только о базах данных. Джону Мартину — это самый оптимистичный человек, с которым я когда-либо работала. Спасибо Лайне Кэмпбелл и ее команде PalominoDB (позже приобретенной Pythian), которые помогали мне и многому научили в самые трудные годы, а также Барону Шварцу — за то, что он вдохновил меня написать о своем опыте.
Наконец, спасибо Вирджинии Уилсон — за то, что она была превосходным редактором и помогла превратить мой поток идей в предложения, которые имеют смысл, и делала это очень доброжелательно.
От Джереми
Когда Сильвия обратилась ко мне с просьбой помочь с этой книгой, это было в разгар необычайно напряженного периода жизни большинства людей — глобальной пандемии, которая началась в 2020 году. Я не был уверен, что хочу добавить в свою жизнь еще больше стресса. Моя жена Селена сказала, что я пожалею, если не соглашусь, а я знаю, что с ней лучше не спорить. Она всегда поддерживала меня и поощряла быть наилучшим человеком из возможных. Я всегда буду любить ее за все, что она для меня делает.
Моей семье, коллегам и друзьям по сообществу: без вас я бы никогда не добился этого. Вы все научили меня быть тем, кто я есть сегодня. Моя карьера — это сумма опыта общения со всеми вами. Вы научили меня, как принимать критику, как подавать пример, как терпеть неудачи и восстанавливаться и, самое главное, тому, что сумма лучше, чем индивидуальность.
Наконец, хочу поблагодарить Сильвию, которая доверила мне привнести в эту книгу общее понимание, но другую точку зрения. Надеюсь, я оправдал ваши ожидания.
Спасибо рецензентам
Авторы также хотят отметить рецензентов, которые помогли сделать эту книгу именно такой — это Аиша Имран, Эндрю Регнер, Барон Шварц, Дэниел Нихтер, Хейли Андерсон, Иван Мора Перес, Джем Леони, Джарид Ремиллард, Дженнифер Дэвис, Джереми Коул, Кейт Уэллс, Крис Хамуд, Ник Визас, Шубхекша Джалан, Том Крупер и Уилл Ганти. Спасибо всем за ваши время и усилия.
1 Кэмпбелл Л., Мейджорс Ч. Базы данных. Инжиниринг надежности. — Питер, 2020.
2 Известны примеры того, как некоторые люди использовали MySQL в качестве очереди, а затем на собственном горьком опыте поняли, почему это плохо. Наиболее часто упоминаемыми причинами были накладные расходы на выборку новых элементов очереди, управление блокировкой записей при их обработке и громоздкие таблицы очереди, получающиеся по мере роста объема данных с течением времени.
Кэмпбелл Л., Мейджорс Ч. Базы данных. Инжиниринг надежности. — Питер, 2020.
Известны примеры того, как некоторые люди использовали MySQL в качестве очереди, а затем на собственном горьком опыте поняли, почему это плохо. Наиболее часто упоминаемыми причинами были накладные расходы на выборку новых элементов очереди, управление блокировкой записей при их обработке и громоздкие таблицы очереди, получающиеся по мере роста объема данных с течением времени.
Благодаря таким книгам, как Database Reliability Engineering: Designing and Operating Resilient Database Systems1 Лейна Кэмпбелла и Черити Мейджорс (O’Reilly), новой реальностью стало то, что технические организации рассматривают инженеров баз данных больше как средство обеспечения роста бизнеса, а не просто как операторов всех баз данных. Когда-то основными задачами администратора баз данных было проектирование схемы и оптимизация запросов, теперь он отвечает за обучение этим навыкам разработчиков и управление системами, которые позволяют разработчикам быстро и безопасно развертывать собственные изменения схемы.
Из-за этих изменений основное внимание больше не стоит уделять оптимизации MySQL для ускорения на несколько процентов. Мы думаем, что теперь книга «MySQL по максимуму» предназначена для предоставления людям информации, необходимой для принятия обоснованных решений о том, как лучше всего использовать MySQL. Все начинается с объяснения того, как устроена MySQL, так что можно понять, что такое MySQL, а что — нет2. Современные релизы MySQL предлагают разумные значения по умолчанию, и вам нужно настраивать очень немногое, если только вы не сталкиваетесь с конкретной проблемой масштабирования. Современные команды теперь чаще имеют дело с изменениями схемы и проблемами соответствия нормативам и сегментирования. Мы хотим, чтобы «MySQL по максимуму» стала исчерпывающим руководством по тому, как современные компании могут задействовать MySQL при масштабируемой эксплуатации.
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
На веб-сайте издательства www.piter.com вы найдете подробную информацию о наших книгах.
Глава 1. Архитектура MySQL
Архитектурные характеристики MySQL делают эту СУБД полезной для широкого круга целей. Хотя она и неидеальна, она достаточно гибка для того, чтобы хорошо работать как в малых, так и в больших средах. Они варьируются от личного веб-сайта до крупномасштабных корпоративных приложений. Чтобы получить максимальную отдачу от MySQL, вам нужно понять ее структуру, чтобы вы могли работать с ней, а не против нее.
В этой главе представлен общий обзор архитектуры сервера MySQL, основных различий между подсистемами хранения и того, почему эти различия важны. Мы попытались объяснить MySQL, упростив детали и показав примеры. Это обсуждение будет полезно тем, кто плохо знаком с серверами баз данных, а также читателям, которые являются экспертами в других серверах баз данных.
Логическая архитектура MySQL
Хорошее понимание того, как компоненты MySQL работают вместе, поможет вам понять сервер. На рис. 1.1 представлен логический вид архитектуры MySQL.
На самом верхнем уровне — уровне клиентов — располагаются службы, не являющиеся уникальными для MySQL. Это службы, в которых нуждается большинство сетевых клиент-серверных инструментов или серверов: обработка соединений, аутентификация, безопасность и т.д.
На втором уровне все намного интереснее. Здесь находится б![]()
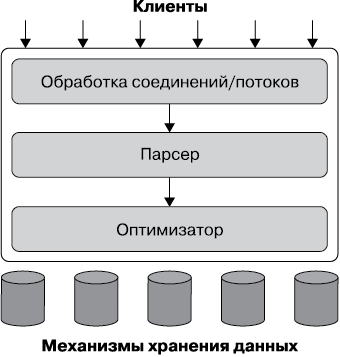
Рис. 1.1. Логический взгляд на архитектуру сервера MySQL
Третий уровень содержит подсистемы хранения данных. Они отвечают за хранение в MySQL всех данных и их извлечение. Подобно различным файловым системам, доступным для GNU/Linux, каждая подсистема хранения имеет свои преимущества и недостатки. Сервер взаимодействует с ними через API подсистемы хранения. Этот API скрывает различия между подсистемами хранения и делает их в значительной степени прозрачными на уровне запросов. Он также содержит пару десятков низкоуровневых функций, которые выполняют такие операции, как «начать транзакцию» или «извлечь строку, содержащую данный первичный ключ». Подсистемы хранения не анализируют SQL3 и не взаимодействуют друг с другом — они просто отвечают на запросы от сервера.
Управление соединениями и их безопасность
По умолчанию каждое клиентское соединение получает собственный поток внутри серверного процесса. Запросы соединения выполняются в этом единственном потоке, который, в свою очередь, находится на одном ядре или ЦП. Сервер поддерживает кэш готовых к использованию потоков, поэтому их не нужно создавать и уничтожать для каждого нового подключения4.
Когда клиенты (приложения) подключаются к серверу MySQL, сервер должен их аутентифицировать. Аутентификация основана на имени пользователя, адресе хоста, с которого происходит соединение, и пароле. Сертификаты X.509 можно задействовать также через соединение Transport Layer Security (TLS). После подключения клиента сервер проверяет, есть ли у того привилегии для каждого запроса, который он выдает, например, разрешено ли клиенту выполнять оператор SELECT, который обращается к таблице Country в базе данных world.
Оптимизация и исполнение
MySQL анализирует запросы для создания внутренней структуры (дерева разбора), а затем применяет множество оптимизаций. Сюда может входить переписывание запроса, определение порядка чтения таблиц, выбор используемых индексов и т.д. Через специальные ключевые слова в запросе можно передавать оптимизатору подсказки, влияющие на процесс принятия им решения. Вы также можете обратиться к серверу за объяснением различных аспектов оптимизации. Это позволит узнать, какие решения принимает сервер, и даст вам ориентир для изменения запросов, схем и настроек таким образом, чтобы все работало максимально эффективно. Подробнее об этом читайте в главе 8.
Оптимизатору на самом деле неважно, какую подсистему хранения использует конкретная таблица, но подсистема хранения влияет на то, как сервер оптимизирует запрос. Оптимизатор запрашивает у подсистемы хранения некоторые его возможности и стоимость определенных операций, а также статистику по данным таблицы. Например, некоторые подсистемы хранения поддерживают типы индексов, которые могут быть полезны для определенных запросов. Вы сможете больше узнать об оптимизации схемы и индексации в главах 6 и 7.
В более старых версиях MySQL использовала внутренний кэш запросов, чтобы увидеть, сможет ли она обработать оттуда результаты. Однако по мере роста параллелизма кэш запросов стал печально известным узким местом. Начиная с MySQL 5.7.20 кэш запросов официально объявлен устаревшим как функция MySQL, а в версии 8.0 он полностью удален. Несмотря на то что кэш запросов больше не является основной частью сервера MySQL, кэширование часто обслуживаемых наборов результатов является хорошей практикой. Популярным шаблоном проектирования является кэширование данных с помощью memcached или Redis, но это выходит за рамки книги.
Управление конкурентным доступом
Каждый раз, когда несколько запросов должны одновременно изменить данные, возникает проблема управления конкурентным доступом. Для целей данной главы MySQL должна делать это на двух уровнях — сервера и подсистемы хранения. Мы представим упрощенный обзор того, как MySQL работает с параллельными операциями чтения и записи, чтобы вы получили общее представление об этой теме, позволяющее разобраться в материале остальной части главы.
Чтобы проиллюстрировать, как MySQL обрабатывает параллельную работу с одним и тем же набором данных, используем в качестве примера традиционный файл электронной таблицы. Эта таблица состоит из строк и столбцов, как и таблица базы данных. Предположим, что файл находится на вашем ноутбуке и доступ к нему есть только у вас. В таком случае нет потенциальных конфликтов, ведь только вы можете вносить изменения в файл. Теперь представьте, что вам нужно совместно с коллегой работать над этой электронной таблицей. Теперь она находится на общем сервере, к которому у вас обоих есть доступ. Что происходит, когда вам обоим нужно внести изменения в этот файл одновременно? А что, если есть целая команда людей, активно пытающихся редактировать эту электронную таблицу, добавляя и удаляя ячейки? Можно сказать, что они должны по очереди вносить изменения, но это неэффективно. Нам нужен подход для обеспечения одновременного доступа к электронной таблице большого объема.
Блокировки чтения/записи
Чтение из электронной таблицы не вызывает таких проблем. Нет ничего плохого в том, что несколько клиентов одновременно читают один и тот же файл: поскольку они не вносят изменений, это ничем не грозит. Но что произойдет, если кто-то попытается удалить ячейку с номером A25, пока другие читают электронную таблицу? Это зависит от обстоятельств, но читатель может получить искаженное или противоречивое представление данных. Таким образом, чтобы не возникла опасность, даже читать из электронной таблицы требуется с особой осторожностью.
Если вы думаете об электронной таблице как о таблице базы данных, легко увидеть, что в этом контексте проблема та же самая. Во многих отношениях электронная таблица — это просто обычная таблица базы данных. Изменение строк в таблице базы данных очень похоже на удаление или изменение содержимого ячеек в файле электронной таблицы.
Решение этой классической проблемы управления параллелизмом довольно простое. Системы, имеющие дело с одновременным доступом для чтения/записи, обычно реализуют систему блокировки, состоящую из двух типов блокировки. Эти блокировки обычно известны как разделяемые блокировки и монопольные блокировки, или блокировки чтения и записи.
Не вдаваясь в подробности технологии блокировки, можем описать концепцию следующим образом. Блокировки чтения ресурса являются общими или взаимно не блокирующими: множество клиентов могут читать из ресурса одновременно и не мешать друг другу. В то же время блокировки записи являются эксклюзивными, то есть они исключают возможность установки как блокировки чтения, так и других блокировок записи, потому что единственная безопасная политика — иметь одного клиента, записывающего в ресурс в заданное время, и предотвращать все операции чтения, когда это происходит.
В мире баз данных блокировка происходит постоянно: MySQL должна препятствовать тому, чтобы один клиент считывал часть данных, в то время как другой изменяет ее. Если сервер базы данных работает приемлемым образом, управление блокировками выполняется достаточно быстро, чтобы не быть заметным для клиентов. В главе 8 мы обсудим, как настроить ваши запросы, чтобы избежать проблем с производительностью, вызванных блокировкой.
Гранулярность блокировок
Один из способов улучшить конкурентность разделяемого ресурса — быть более избирательными в отношении того, что вы блокируете. Вместо блокировки всего ресурса заблокируйте только его часть, содержащую данные, которые необходимо изменить. А еще лучше заблокируйте только ту часть данных, которую вы планируете менять. Минимизация объема данных, которые вы блокируете в любой момент времени, позволяет одновременно выполнять несколько изменений одного и того же ресурса, если эти операции не конфликтуют друг с другом.
К сожалению, блокировки не бесплатны — они потребляют ресурсы. Каждая операция блокировки — получение блокировки, проверка на свободную блокировку, освобождение блокировки и т.д. — увеличивает накладные расходы. Если система тратит слишком много времени на управление блокировками вместо хранения и извлечения данных, производительность может пострадать.
Стратегия блокировки — это компромисс между накладными расходами на блокировку и безопасностью данных, он влияет на производительность. Большинство коммерческих серверов баз данных не предоставляют большого выбора: вы получаете то, что известно как блокировка на уровне строк в ваших таблицах, с множеством часто сложных способов, обеспечивающих хорошую производительность при множестве блокировок. Блокировки — это то, как базы данных реализуют гарантии согласованности данных. Опытному оператору базы данных придется дойти до чтения исходного кода, чтобы определить наиболее подходящий набор настраиваемых конфигураций для оптимизации компромисса между скоростью и безопасностью данных.
В то же время MySQL предлагает выбор. Ее подсистемы хранения могут реализовывать собственные политики блокировки и гранулярность блокировок. Управление блокировками — очень важное решение при проектировании подсистемы хранения: установка гранулярности блокировок на определенном уровне может повысить производительность для определенных целей, но сделать этот движок менее подходящим для других. Поскольку MySQL предлагает несколько подсистем хранения, здесь не требуется единого универсального решения. Рассмотрим две наиболее важные стратегии блокировки.
Табличные блокировки
Самая простая стратегия блокировки, доступная в MySQL и требующая наименьших затрат, — это блокировка таблицы. Она аналогична блокировкам электронных таблиц, описанным ранее: блокирует всю таблицу. Когда клиент хочет произвести запись в таблицу (вставить, удалить, обновить и т.д.), он получает блокировку записи. Это тормозит все другие операции чтения и записи. Когда никто не пишет, читатели могут получить блокировки чтения, которые не конфликтуют с другими блокировками чтения.
Табличные блокировки имеют варианты для повышения производительности в определенных ситуациях. Например, блокировка таблицы READ LOCAL разрешает некоторые типы параллельных операций записи. Очереди блокировки записи и чтения разделены, при этом очередь записи имеет более высокий приоритет, чем очередь чтения5.
Построчные блокировки
Стиль блокировки, обеспечивающий наилучший параллелизм и влекущий за собой наибольшие накладные расходы, — это использование построчных блокировок. Возвращаясь к аналогии с электронными таблицами, построчная блокировка будет такой же, как блокировка только строки в электронной таблице. Это позволяет серверу выполнять больше одновременных операций записи, но увеличивает затраты на отслеживание того, кто заблокировал каждую строку, как долго они были открыты и какие применялись блокировки строк, а также на снятие блокировок, когда они больше не нужны.
Построчные блокировки реализованы в подсистеме хранения, а не на сервере. Сервер обычно6 не знает о блокировках, реализованных в подсистемах хранения, и, как вы увидите далее в этой главе и на протяжении всей книги, все подсистемы хранения реализуют блокировки по-своему.
Транзакции
До тех пор пока не познакомитесь с транзакциями, вы не сможете изучать более сложные функции СУБД.
Транзакция представляет собой группу операторов SQL, которые обрабатываются атомарно, то есть как цельная единица работы. Если механизм базы данных может применить всю группу операторов к базе данных, он делает это, но если какой-либо из операторов не может быть выполнен из-за сбоя или по другой причине, ни один из них не применяется. Всё или ничего.
Немногое из этого раздела характерно именно для MySQL. Если вы уже знакомы с транзакциями ACID, смело переходите к подразделу «Транзакции в MySQL» далее в этом разделе.
Банковское приложение — классический пример, демонстрирующий, почему необходимы транзакции7. Представьте базу данных банка с двумя таблицами: checking (текущие счета) и savings (сберегательные счета). Чтобы перевести 200 долларов с расчетного счета Джейн на ее сберегательный счет, необходимо выполнить как минимум три шага.
1. Убедиться, что остаток на ее текущем счете превышает 200 долларов.
2. Вычесть 200 долларов из остатка текущего счета.
3. Добавить 200 долларов к остатку сберегательного счета.
Вся операция должна быть организована как транзакция, чтобы в случае сбоя любого из шагов можно было выполнить откат всех выполненных.
Вы начинаете транзакцию с помощью команды START TRANSACTION, а затем либо сохраняете изменения командой COMMIT, либо отменяете их с помощью команды ROLLBACK. Итак, SQL для примера транзакции может выглядеть следующим образом:
1 START TRANSACTION;
2 SELECT balance FROM checking WHERE customer_id = 10233276;
3 UPDATE checking SET balance = balance - 200.00 WHERE customer_id = 10233276;4
4 UPDATE savings SET balance = balance + 200.00 WHERE customer_id = 10233276;
5 COMMIT;
Но сами по себе транзакции — это еще не все. Что произойдет, если сервер базы данных выйдет из строя при выполнении строки 4? Кто знает? Клиент, вероятно, только что потерял 200 долларов. А что, если другой процесс вклинится между выполнением строк 3 и 4 и снимет весь остаток с текущего счета? Банк предоставил клиенту кредит в размере 200 долларов, даже не подозревая об этом.
И в этой последовательности операций существует гораздо больше возможностей для отказа. Вы могли видеть обрывы соединения, тайм-ауты или даже сбой сервера базы данных, выполняющего их в середине операций. Обычно именно поэтому существуют очень сложные и медленные системы с двухфазной фиксацией для смягчения последствий всевозможных сценариев сбоев. Транзакций недостаточно, пока система не проходит тест ACID. ACID расшифровывается как atomicity, consistency, isolation и durability (атомарность, согласованность, изолированность и долговечность). Это тесно связанные критерии, которым должна соответствовать система обработки транзакций с защитой данных.
• Атомарность. Транзакция должна функционировать как единая неделимая единица работы, чтобы вся она была либо выполнена, либо отменена. Не существует такого понятия, как частично завершенная атомарная транзакция: либо всё, либо ничего.
• Согласованность. База данных должна всегда переходить из одного согласованного состояния в другое. В нашем примере согласованность гарантирует, что сбой между строками 3 и 4 не приведет к исчезновению 200 долларов с текущего счета. Если транзакция никогда не фиксируется, ни одно из ее изменений никогда не отражается в базе данных.
• Изолированность. Результаты транзакции обычно невидимы для других транзакций до тех пор, пока она не будет завершена. В нашем примере это гарантирует, что, если программа суммирования остатков на банковских счетах будет запущена после строки 3, но перед строкой 4, она все равно увидит 200 долларов на текущем счете. Когда позже в этой главе будем обсуждать уровни изолированности, вы поймете, почему мы сказали «обычно невидимы».
• Долговечность. После подтверждения изменения транзакции становятся постоянными. Это означает, что изменения должны быть записаны, чтобы данные не были потеряны при сбое системы. Однако долговечность — это немного расплывчатое понятие, потому что на самом деле существует много уровней. Некоторые стратегии обеспечения надежности гарантируют безопасность более надежно, чем другие, но ничто не может быть на 100 % долговечным (если бы сама база данных была действительно надежной, то как резервные копии могли бы увеличить ее надежность?).
Транзакции ACID и гарантии, предоставляемые ими в подсистеме InnoDB, в частности, — это одна из самых сильных и наиболее зрелых функций MySQL. Несмотря на то что они связаны с определенными компромиссами в отношении пропускной способности, при правильном применении они могут избавить вас от реализации большого количества сложной логики на прикладном уровне.
Уровни изолированности
Изолированность — более сложное понятие, чем кажется на первый взгляд. Стандарт ANSI SQL8 определяет четыре уровня изолированности. Если вы новичок в мире баз данных, мы настоятельно рекомендуем ознакомиться с общим стандартом ANSI SQL, прежде чем возвращаться к чтению о конкретной реализации MySQL. Цель этого стандарта — определить правила, по которым изменения видны или не видны внутри и вне транзакции. Более низкие уровни изолированности обычно допускают б![]()

Каждая подсистема хранения реализует уровни изолированности немного по-разному, и они не обязательно соответствуют вашим ожиданиям, если вы привыкли к другой СУБД (поэтому в этом разделе мы не будем вдаваться в исчерпывающие подробности). Вам следует прочитать руководства для тех подсистем хранения, которые решите использовать.
Кратко рассмотрим четыре уровня изолированности.
• READ UNCOMMITTED. На уровне изолированности READ UNCOMMITTED транзакции могут просматривать результаты незавершенных транзакций. На этом уровне может возникнуть много проблем, если вы не знаете абсолютно точно, что делаете, и не имеете для этого веской причины. Этот уровень редко используется на практике, потому что его производительность лишь немного лучше, чем у других уровней, которые имеют много преимуществ. Чтение незафиксированных данных известно также как черновое или «грязное» чтение (dirty read).
• READ COMMITTED. Уровень изолированности по умолчанию в большинстве систем баз данных (но не в MySQL!) — READ COMMITTED. Он удовлетворяет простому определению изолированности, приведенному ранее: транзакция будет продолжать видеть изменения, которые к моменту ее начала подтверждены другими транзакциями, а произведенные ею изменения останутся невидимыми для других транзакций, пока текущая транзакция не будет подтверждена. Этот уровень по-прежнему допускает так называемое неповторяющееся чтение (nonrepeatable read). Это означает, что вы можете выполнить один и тот же оператор дважды и увидеть разные данные.
• REPEATABLE READ позволяет решить проблемы, которые возникают на уровне READ UNCOMMITTED. Он гарантирует, что любые строки, прочитанные транзакцией, будут выглядеть одинаково при последующем чтении в рамках одной и той же транзакции, но теоретически по-прежнему допускает другую сложную проблему, которая называется фантомным чтением (phantom reads). Если попросту, фантомное чтение может произойти в случае, когда вы выбираете какой-то диапазон строк, затем другая транзакция вставляет в него новую строку, после чего вы снова выбираете тот же диапазон. В результате вы увидите новую фантомную строку. InnoDB и XtraDB решают проблему фантомного чтения с помощью многоверсионного управления конкурентным доступом (multiversion concurrency control), которое мы объясним позже в этой главе.
Уровень изолированности REPEATABLE READ устанавливается в MySQL по умолчанию.
• SERIALIZABLE. Самый высокий уровень изолированности, SERIALIZABLE, решает проблему фантомного чтения, заставляя транзакции выполняться в таком порядке, который исключает возможность конфликта. В двух словах: SERIALIZABLE блокирует каждую читаемую строку. На этом уровне может возникнуть множество тайм-аутов и конфликтов из-за блокировки. Нам редко встречались люди, использующие этот уровень, но потребности вашего приложения могут заставить применять его, смирившись с меньшей степенью конкурентного доступа, но обеспечивая стабильность данных.
В табл. 1.1 приведена сводка различных уровней изолированности и указаны недостатки, свойственные каждому из них.
Таблица 1.1. Уровни изолированности ANSI SQL
| Уровень изолированности |
Возможность чернового чтения |
Возможность неповторяющегося чтения |
Возможность фантомного чтения |
Блокировка чтения |
| READ UNCOMMITTED |
Да |
Да |
Да |
Нет |
| READ COMMITTED |
Нет |
Да |
Да |
Нет |
| REPEATABLE READ |
Нет |
Нет |
Да |
Нет |
| SERIALIZABLE |
Нет |
Нет |
Нет |
Да |
Взаимоблокировки
Взаимоблокировки возникают тогда, когда две и более транзакции взаимно удерживают и запрашивают блокировки одних и тех же ресурсов, создавая циклическую зависимость. Взаимоблокировки появляются, когда транзакции пытаются заблокировать ресурсы в разном порядке. Они могут возникнуть всякий раз, когда несколько транзакций блокируют одни и те же ресурсы. Для примера рассмотрим две транзакции, обращающиеся к таблице StockPrice, которая имеет первичный ключ (stock_id, date).
Транзакция 1:
START TRANSACTION;
UPDATE StockPrice SET close = 45.50 WHERE stock_id = 4 and date = '2020-05-01';
UPDATE StockPrice SET close = 19.80 WHERE stock_id = 3 and date = '2020-05-02';
COMMIT;
Транзакция 2:
START TRANSACTION;
UPDATE StockPrice SET high = 20.12 WHERE stock_id = 3 and date = '2020-05-02';
UPDATE StockPrice SET high = 47.20 WHERE stock_id = 4 and date = '2020-05-01';
COMMIT;
Каждая транзакция будет выполнять свой первый запрос и обновлять строку данных, блокируя ее в индексе первичного ключа и любом дополнительном уникальном индексе, частью которого она является в процессе. Затем каждая транзакция попытается обновить свою вторую строку, но обнаружит, что та уже заблокирована. В итоге каждая транзакция будет до бесконечности ожидать окончания другой, пока не произойдет вмешательство извне, которое снимет взаимоблокировку. В главе 7 мы рассмотрим, как индексирование может повысить или снизить производительность ваших запросов по мере развития схемы.
Для борьбы с этой проблемой в системах баз данных реализованы различные формы обнаружения взаимоблокировок и тайм-аутов. Более сложные системы, такие как подсистема хранения InnoDB, заметят циклические зависимости и немедленно вернут ошибку. Это очень хорошо, иначе взаимоблокировки будут проявляться как очень медленные запросы. Другие системы откатывают транзакцию по истечении тайм-аута, что не всегда хорошо. Способ, которым InnoDB в настоящее время обрабатывает взаимоблокировки, заключается в откате транзакции, которая захватила наименьшее количество монопольных блокировок строк (приблизительный показатель, указывающий для какой транзакции будет проще всего выполнить откат).
Поведение и порядок блокировки зависят от подсистемы хранения, поэтому некоторые подсистемы могут заблокировать определенную последовательность операторов, а другие этого не сделают. Взаимоблокировки имеют двойную природу: некоторые из них неизбежны из-за реальных конфликтов данных, а некоторые вызваны схемой работы конкретной подсистемы хранения9.
Возникшие взаимоблокировки не получится преодолеть без частичного или полного отката одной из транзакций. Это суровая проза жизни в транзакционных системах, и ваши приложения должны быть рассчитаны на их обработку. Многие приложения могут просто попытаться повторить свои транзакции с самого начала, и если они не столкнутся еще с одним тупиком, то должны быть успешными.
Ведение журнала транзакций
Ведение журнала транзакций помогает сделать их более эффективными. Вместо обновления таблиц на диске каждый раз, когда происходит изменение, подсистема хранения может изменить свою копию данных в памяти. Это очень быстро. Затем подсистема хранения может сделать запись об изменении в журнал транзакций, который находится на диске и поэтому долговечен. Это довольно быстрая операция, поскольку добавление событий в журнал включает последовательный ввод/вывод в одной небольшой области диска, а не произвольный ввод/вывод во многих местах. Затем через какое-то время процесс может обновить таблицу на диске. Таким образом, большинство подсистем хранения, использующих этот метод, известный как упреждающая запись в журнал, в итоге дважды записывают изменения на диск.
Если сбой произошел после того, как обновление было записано в журнал транзакций, но до внесения изменений в сами данные, подсистема хранения все еще может восстановить изменения после перезапуска. Метод восстановления зависит от подсистемы хранения.
Транзакции в MySQL
Подсистемы хранения — это программное обеспечение, которое управляет тем, как данные будут храниться на диске и извлекаться с него. В то время как MySQL традиционно предлагает несколько подсистем хранения, поддерживающих транзакции, InnoDB является золотым стандартом и рекомендуемой для использования подсистемой хранения. Описанные здесь примитивы транзакций будут основаны на транзакциях в подсистеме InnoDB.
AUTOCOMMIT
По умолчанию одиночная инструкция INSERT, UPDATE или DELETE неявно включается в транзакцию и немедленно подтверждается. Она известна как режим AUTOCOMMIT. Отключив этот режим, вы можете выполнить серию операторов внутри транзакции и в конце — COMMIT или ROLLBACK.
Вы можете включить или отключить переменную AUTOCOMMIT для текущего соединения с помощью команды SET. Значения 1 и ON эквивалентны, как и 0 и OFF. Когда вы работаете с AUTOCOMMIT=0, то всегда находитесь в транзакции, пока не выполните COMMIT или ROLLBACK. После этого MySQL немедленно начинает новую транзакцию. Кроме того, при включенном AUTOCOMMIT вы можете начать транзакцию с несколькими инструкциями, используя ключевое слово BEGIN или START TRANSACTION. Изменение значения AUTOCOMMIT не влияет на нетранзакционные таблицы, которые не имеют представления о подтверждении или отмене изменений.
Некоторые команды, выдаваемые во время открытой транзакции, заставляют MySQL подтвердить транзакцию до их выполнения. Обычно это команды языка определения данных (Data Definition Language, DDL), которые вносят существенные изменения, такие как ALTER TABLE, но LOCK TABLES и некоторые другие операторы также обладают этим свойством. Проверьте документацию вашей версии для получения полного списка команд, которые автоматически фиксируют транзакцию.
MySQL позволяет вам установить уровень изолированности с помощью команды SET TRANSACTION ISOLATION LEVEL, которая вступает в силу при запуске следующей транзакции. Вы можете настроить уровень изолированности для всего сервера в файле конфигурации или только для вашей сессии:
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
Предпочтительно устанавливать уровень изолированности, который вы чаще всего используете, на уровне сервера и изменять ее только в явных случаях. MySQL распознает все четыре стандартных уровня изолированности ANSI, и InnoDB поддерживает их все.
Применение нескольких подсистем хранения данных в транзакциях
MySQL не управляет транзакциями на уровне сервера. Вместо этого базовые подсистемы хранения сами реализуют транзакции. Это означает, что вы не можете надежно сочетать разные подсистемы в одной транзакции.
Если вы используете транзакционные и нетранзакционные таблицы (например, таблицы InnoDB и MyISAM) в одной транзакции, она будет работать правильно, когда все в порядке. Однако, если потребуется выполнить откат, изменения в нетранзакционной таблице нельзя будет отменить. Это оставляет базу данных в несогласованном состоянии, из которого ее может быть трудно восстановить, и ставит под сомнение идею транзакций в целом. Вот почему очень важно выбрать правильную подсистему хранения для каждой таблицы и любой ценой избегать смешивания подсистем хранения в логике вашего приложения.
MySQL обычно не станет предупреждать вас или вызывать ошибки, если вы выполняете транзакционные операции над нетранзакционной таблицей. Иногда откат транзакции будет генерировать предупреждение «Не удалось откатить некоторые нетранзакционные измененные таблицы», но в большинстве случаев не будет никаких указаний на то, что вы работаете с нетранзакционными таблицами.

Лучше всего не смешивать подсистемы хранения в своем приложении. Неудачные транзакции могут привести к противоречивым результатам, поскольку некоторые части могут откатиться, а другие — нет.
Неявная и явная блокировка
InnoDB использует двухфазный протокол блокировки. Она может устанавливать блокировки в любой момент транзакции, но не снимает их до тех пор, пока не будет выполнена команда COMMIT или ROLLBACK. Все блокировки снимаются одновременно. Все механизмы блокировки, описанные ранее, являются неявными. InnoDB автоматически обрабатывает блокировки в соответствии с вашим уровнем изоляции.
Однако InnoDB также поддерживает явную блокировку, чего нет в стандарте SQL10, 11.
SELECT ... FOR SHARE
SELECT ... FOR UPDATE
MySQL также поддерживает команды LOCK TABLES и UNLOCK TABLES, которые реализованы на сервере, а не в подсистемах хранения. Если вам нужны транзакции, используйте транзакционную подсистему хранения. Команда LOCK TABLES не нужна, поскольку InnoDB поддерживает блокировку на уровне строк.

Взаимодействие между LOCK TABLES и транзакциями сложное, и в некоторых версиях сервера наблюдается непредвиденное поведение. Поэтому мы рекомендуем никогда не применять LOCK TABLES, если вы не находитесь в транзакции и AUTOCOMMIT не отключен, независимо от того, какой подсистемой хранения пользуетесь.
Управление конкурентным доступом с помощью многоверсионности
Большинство транзакционных подсистем хранения в MySQL не используют простой механизм построчной блокировки. Вместо этого они задействуют блокировку на уровне строк в сочетании с методом повышения уровня конкурентности, известным как управление конкурентным доступом с помощью многоверсионности (multiversion concurrency control, MVCC). MVCC не уникален для MySQL: Oracle, PostgreSQL и некоторые другие системы баз данных также используют его, хотя есть существенные различия, поскольку не существует стандарта работы MVCC.
Вы можете воспринимать MVCC как разновидность блокировки на уровне строк — во многих случаях вообще нет необходимости блокировки и можно существенно снизить накладные расходы. В зависимости от способа реализации MVCC может разрешать чтение без блокировки, блокируя только необходимые строки во время операций записи.
MVCC сохраняет моментальные снимки данных в том виде, в каком они существовали в какой-то момент времени. Это означает, что транзакции могут видеть согласованное представление данных независимо от того, как долго они выполняются. Это также означает, что разные транзакции могут одновременно видеть разные данные в одних и тех же таблицах! Если вы никогда не сталкивались с этим раньше, это может сбить вас с толку, но по мере знакомства с данной технологией все становится понятнее.
Каждая подсистема хранения реализует MVCC по-разному. Некоторые варианты включают оптимистическое и пессимистическое управление конкурентным доступом. Мы проиллюстрируем один из способов работы MVCC, объяснив поведение InnoDB12 в виде диаграммы последовательности на рис. 1.2.
InnoDB реализует MVCC, назначая идентификатор транзакции для каждой начавшейся транзакции. Он назначается при первом чтении транзакцией каких-либо данных. Когда запись изменяется в этой транзакции, запись отмены (undo record), которая объясняет, как отменить это изменение, вносится в журнал отмены (undo log), а указатель отката транзакции указывает на эту запись журнала отмены. Таким образом транзакция может найти способ отката, если это необходимо.
Когда другой сеанс считывает запись ключа кластерного индекса, InnoDB сравнивает идентификатор транзакции записи с представлением чтения этого сеанса. Если запись в ее текущем состоянии не должна быть видимой (транзакция, изменившая ее, еще не зафиксирована), записи журнала отмены считываются и применяются до тех пор, пока сеанс не достигнет идентификатора транзакции, который должен быть видимым. Этот процесс может зацикливаться до записи отмены, которая полностью удаляет эту строку, сигнализируя представлению чтения, что строки не существует. Записи в транзакции удаляются с помощью установки бита «удалено» в информационных флагах записи. Это действие также помечается в журнале отмены как «удалить метку удаления».
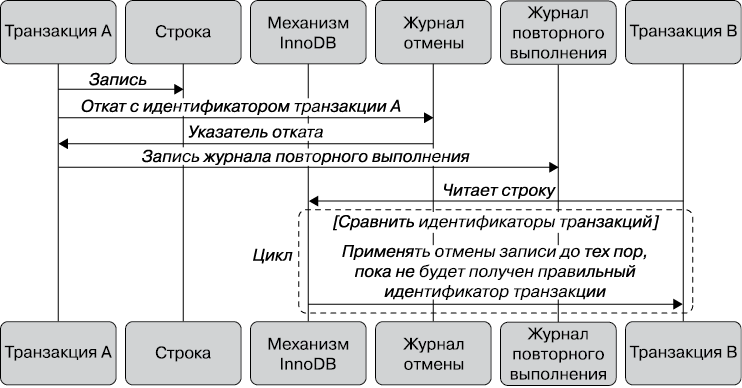
Рис. 1.2. Диаграмма последовательности обработки нескольких версий строки в разных транзакциях
Стоит отметить, что все записи, сделанные в журнале отмены, заносятся также в журнал повторов, потому что записи в журнале отмены — это часть процесса восстановления после сбоя сервера и они являются транзакционными13. Размер журналов повторов и отмены играет важную роль в том, как выполняются транзакции с высокой степенью конкурентности. Мы рассмотрим их конфигурацию более подробно в главе 5.
Результатом этого дополнительного учета является то, что большинство запросов на чтение никогда не получают блокировки. Они просто считывают данные так быстро, как только могут, выбирая лишь строки, соответствующие указанным критериям. Недостатки подхода заключаются в том, что подсистема хранения должна хранить больше данных с каждой строкой, выполнять больше работы при проверке строк и реализовывать дополнительные вспомогательные операции.
MVCC работает только с уровнями изоляции REPEATABLE READ и READ COMMITTED. READ UNCOMMITTED несовместим с MVCC14, поскольку запросы не считывают версию строки, подходящую для их версии транзакции, — они читают новейшую версию, несмотря ни на что. SERIALIZABLE несовместим с MVCC, потому что чтение блокирует каждую возвращаемую строку.
Репликация
MySQL разработана для приема записей на одном узле в любой момент времени. Это дает преимущества при управлении согласованностью данных, но требует компромиссов, когда вам нужны данные, записанные на нескольких серверах или в нескольких местах. MySQL предлагает собственный способ рассылки записей, которые один узел передает другим узлам. Этот способ называется репликацией. В MySQL узел — источник данных использует поток для каждой реплики, зарегистрированный как клиент репликации, который просыпается, когда происходит запись, отправляя новые данные. На рис. 1.3 показан простой пример этой системы, которую обычно называют деревом топологии нескольких серверов MySQL в структуре источника и реплик.
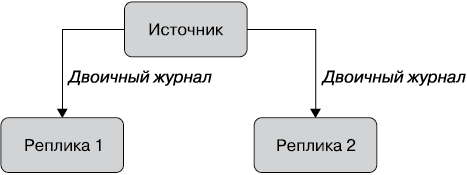
Рис. 1.3. Упрощенное представление топологии репликации сервера MySQL
Для любых данных, с которыми вы работаете в производственной среде, необходимо использовать репликацию и иметь как минимум еще три реплики, в идеале размещенные в разных местах (в облачных средах, известных как регионы) для планирования аварийного восстановления.
С годами репликация в MySQL стала более сложной. Глобальные идентификаторы транзакций, репликация с несколькими источниками, параллельная репликация на репликах и полусинхронная репликация — вот некоторые из основных обновлений. Мы подробно рассмотрим репликацию в главе 9.
Структура файлов данных
В версии 8.0 MySQL метаданные таблиц были преобразованы в словарь данных, содержащийся в таблицах, размещенных в табличном пространстве с именем mysql.ibd. Это позволяет информации о структуре таблицы поддерживать транзакции и изменения определения атомарных данных. Вместо того чтобы полагаться только на information_schema для извлечения определения таблицы и метаданных во время операций, нам предлагается кэш объектов словаря, который представляет собой структуру в памяти для сохранения последних использованных объектов (применяет стратегию LRU): определений разделов, таблиц, хранимых процедур и функций, кодовой страницы и информации о сопоставлении. Это серьезное изменение в том, как сервер обращается к метаданным о таблицах, сокращает количество операций ввода/вывода и повышает эффективность, особенно если подмножество таблиц является наиболее активным и, следовательно, чаще всего находится в кэше. Файлы .ibd и .frm заменены файлами .sdi с сериализованной словарной информацией для каждой таблицы.
Подсистема хранения InnoDB
InnoDB — это транзакционная подсистема хранения по умолчанию для MySQL, а также самая важная и в целом широко используемая подсистема хранения. Она была создана для обработки многих краткосрочных транзакций, которые успешно выполняются намного чаще, чем откатываются. Ее производительность и автоматическое восстановление после сбоев делают ее популярной и для нетранзакционных хранилищ. Если вы хотите изучить подсистемы хранения, стоит потратить время на углубленное рассмотрение InnoDB, чтобы узнать о ней как можно больше, а не изучать все подсистемы хранения в равной степени.

Лучше всего использовать InnoDB в качестве подсистемы хранения по умолчанию для любого приложения. MySQL упростила эту задачу, сделав InnoDB подсистемой хранения по умолчанию несколько основных версий назад.
InnoDB — это подсистема хранения общего назначения MySQL по умолчанию. Она сохраняет данные в одном или нескольких файлах данных, которые называются табличным пространством (tablespace). Табличное пространство — это, по сути, черный ящик, объектами которого управляет сама InnoDB.
InnoDB использует MVCC для достижения высокого уровня конкурентности и реализует все четыре стандартных уровня изолированности SQL. По умолчанию применяется уровень REPEATABLE READ, и у него есть стратегия блокировки следующего ключа, которая предотвращает возможность фантомного чтения на этом уровне безопасности: вдобавок к блокировке строк, затронутых в запросе, InnoDB блокирует также пропуски в структуре индекса, предотвращая вставку фантомных строк.
Таблицы InnoDB построены на кластеризованных индексах, которые мы подробно рассмотрим в главе 8, когда будем обсуждать дизайн схемы. Структуры индексов InnoDB сильно отличаются от структур индексов большинства других подсистем хранения MySQL. В результате они обеспечивают очень быстрый поиск по первичному ключу. Однако вторичные индексы (индексы, не являющиеся первичным ключом) содержат столбцы первичного ключа, поэтому, если ваш первичный ключ большой, другие индексы также будут большими. Вы должны стремиться к небольшому первичному ключу, если у вас будет много индексов в таблице.
InnoDB поддерживает множество внутренних оптимизаций. К ним относятся упреждающее чтение для предварительной выборки данных с диска, адаптивный хеш-индекс, который автоматически создает хеш-индексы в памяти для очень быстрого поиска, и буфер вставок для ускорения операций вставки. Мы рассмотрим эти вопросы в главе 4 этой книги.
Поведение InnoDB очень сложное, и мы настоятельно рекомендуем прочитать раздел «Модель блокировки и транзакций InnoDB» в руководстве по MySQL, если вы используете InnoDB. Из-за наличия архитектуры MVCC есть много тонкостей, о которых вы должны узнать, прежде чем создавать приложение с InnoDB. Работа с подсистемой хранения, поддерживающей согласованные представления данных для всех пользователей, даже когда некоторые из них изменяют данные, может быть сложной.
В качестве транзакционной подсистемы хранения InnoDB поддерживает по-настоящему горячее онлайновое резервное копирование с помощью различных механизмов, включая MySQL Enterprise Backup, запатентованную Oracle, и Percona XtraBackup с открытым исходным кодом. Мы подробно рассмотрим резервное копирование и восстановление в главе 10.
Начиная с MySQL 5.6, InnoDB предоставила онлайн-DDL, который сначала имел ограниченные сценарии использования, в дальнейшем расширенные в выпусках 5.7 и 8.0. Изменения схемы онлайн позволяют вносить определенные изменения в таблицу без полной ее блокировки и без применения внешних инструментов, что значительно улучшает работу таблиц MySQL InnoDB. В главе 6 мы рассмотрим варианты онлайн-изменения схемы с помощью как собственных, так и внешних инструментов.
Поддержка JSON-документов
Тип JSON, впервые представленный в InnoDB как часть версии 5.7, включал автоматическую проверку JSON-документов и оптимизированное хранилище, обеспечивающее быстрый доступ для чтения, что являлось значительным улучшением по сравнению со старым хранилищем больших бинарных объектов (BLOB), которое использовалось для хранения JSON-документов прежде. Наряду с поддержкой нового типа данных InnoDB предоставила также функции SQL для поддержки расширенных операций с JSON-документами. В дальнейшем в MySQL 8.0.7 была добавлена возможность определять многозначные индексы для JSON-массивов. Эта функция может обеспечить способ еще больше ускорить выполнение запросов для чтения JSON-типов с помощью сопоставления общих шаблонов доступа с функциями, которые отображают значения JSON-документа. Мы рассмотрим применение типа данных JSON и его влияние на производительность в подразделе «JSON-данные» в главе 6.
Изменения словаря данных
Еще одним важным изменением в MySQL 8.0 является удаление основанного на файлах хранилища метаданных таблиц и переход к словарю данных с использованием табличного пространства InnoDB. Это изменение обеспечивает все транзакционные преимущества InnoDB по восстановлению после сбоев в таких операциях, как изменение таблиц.
Это значительно улучшает управление определениями данных в MySQL, а также требует серьезных изменений в работе сервера MySQL. В частности, процессы резервного копирования, которые раньше полагались на файлы метаданных таблиц, теперь должны запрашивать новый словарь данных для извлечения определений таблиц.
Атомарный DDL
Наконец, в MySQL 8.0 представлены атомарные изменения определения данных. Это означает, что операторы определения данных теперь могут либо полностью завершиться успешно, либо полностью откатиться. Это становится возможным благодаря созданию специального журнала отмены (undo log) и повторного выполнения (redo log) для DDL, который InnoDB использует для отслеживания изменений, — еще одно место, где проверенный дизайн InnoDB был распространен на работу сервера MySQL.
Резюме
MySQL имеет многоуровневую архитектуру, на верхнем уровне которой находятся серверные службы и функции выполнения запросов, а под ними — подсистемы хранения. Существует множество различных подключаемых API, а наиболее важным является API подсистемы хранения. Если вы понимаете, что MySQL выполняет запросы, передавая строки туда и обратно через API подсистемы хранения, то вы усвоили основы архитектуры сервера.
В нескольких последних крупных выпусках MySQL InnoDB была выбрана в качестве основного направления разработки, на нее даже перенесли внутренний учет метаданных таблиц, аутентификацию и авторизацию после многих лет работы в MyISAM. Увеличение инвестиций Oracle в подсистему InnoDB привело к значительным улучшениям, таким как атомарные DDL, более надежные онлайновые DDL, повышенная устойчивость к сбоям и улучшенная работоспособность для развертываний, ориентированных на безопасность.
InnoDB — это подсистема хранения по умолчанию, которая должна охватывать почти все сценарии использования. Поэтому в следующих главах, когда речь идет о функциях, производительности и ограничениях, основное внимание уделяется подсистеме хранения InnoDB, и лишь изредка мы будем касаться какой-либо другой подсистемы хранения.
3 Единственным исключением является InnoDB, который анализирует определения внешнего ключа, потому что сервер MySQL еще не реализует их сам.
4 MySQL 5.5 и более поздние версии поддерживают API, который может принимать подключаемые модули объединения потоков, хотя и не часто используемые. Обычно объединение потоков выполняется на уровнях доступа, которые мы обсудим в главе 5.
5 Рекомендуем вам прочитать документацию об эксклюзивных и разделяемых блокировках, блокировках с намерением и блокировках записи (https://oreil.ly/EPfwc).
6 Существуют блокировки метаданных, которые используются при изменении имени таблицы или изменении схемы, а в версии 8.0 мы познакомились с «функциями блокировки на уровне приложения». При обычных изменениях данных внутренняя блокировка выполняется подсистемой InnoDB.
7 Хотя это обычное учебное упражнение, большинство банков на самом деле полагаются на ежедневную сверку, а не на строгие транзакционные операции в течение дня.
8 Для получения дополнительной информации прочитайте обзор ANSI SQL (https://oreil.ly/joikF) Адриана Койлера (Adrian Coyler) и объяснение моделей согласованности (http://jepsen.io/consistency) Кайла Кингсбери (Kyle Kingsbury).
9 Как вы увидите далее в главе, одни подсистемы хранения данных блокируют таблицы целиком, а другие реализуют более сложную блокировку на уровне строк. Вся эта логика по большей части находится на уровне подсистемы хранения данных.
10 Этими блокирующими подсказками часто злоупотребляют, и их обычно следует избегать.
11 SELECT ... FOR SHARE — это функция MySQL 8.0, которая заменяет SELECT…LOCK IN SHARE MODE предыдущих версий.
12 Рекомендуем прочитать эту запись в блоге Джереми Коула, чтобы получить более глубокое представление о структуре записей в InnoDB (https://oreil.ly/jbljq).
13 Для получения более подробной информации о том, как InnoDB обрабатывает несколько версий своих записей, прочтите этот пост в блоге Джереми Коула (Jeremy Cole): https://oreil.ly/exaaL.
14 Не существует формального стандарта, определяющего MVCC, поэтому разные механизмы и базы данных реализуют его очень по-разному и никто не может сказать, что какой-то из них неправильный.
Табличные блокировки имеют варианты для повышения производительности в определенных ситуациях. Например, блокировка таблицы READ LOCAL разрешает некоторые типы параллельных операций записи. Очереди блокировки записи и чтения разделены, при этом очередь записи имеет более высокий приоритет, чем очередь чтения5.
Построчные блокировки реализованы в подсистеме хранения, а не на сервере. Сервер обычно6 не знает о блокировках, реализованных в подсистемах хранения, и, как вы увидите далее в этой главе и на протяжении всей книги, все подсистемы хранения реализуют блокировки по-своему.
Третий уровень содержит подсистемы хранения данных. Они отвечают за хранение в MySQL всех данных и их извлечение. Подобно различным файловым системам, доступным для GNU/Linux, каждая подсистема хранения имеет свои преимущества и недостатки. Сервер взаимодействует с ними через API подсистемы хранения. Этот API скрывает различия между подсистемами хранения и делает их в значительной степени прозрачными на уровне запросов. Он также содержит пару десятков низкоуровневых функций, которые выполняют такие операции, как «начать транзакцию» или «извлечь строку, содержащую данный первичный ключ». Подсистемы хранения не анализируют SQL3 и не взаимодействуют друг с другом — они просто отвечают на запросы от сервера.
Изолированность — более сложное понятие, чем кажется на первый взгляд. Стандарт ANSI SQL8 определяет четыре уровня изолированности. Если вы новичок в мире баз данных, мы настоятельно рекомендуем ознакомиться с общим стандартом ANSI SQL, прежде чем возвращаться к чтению о конкретной реализации MySQL. Цель этого стандарта — определить правила, по которым изменения видны или не видны внутри и вне транзакции. Более низкие уровни изолированности обычно допускают б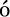 льшую степень конкурентного доступа и влекут за собой меньшие накладные расходы.
льшую степень конкурентного доступа и влекут за собой меньшие накладные расходы.
Существуют блокировки метаданных, которые используются при изменении имени таблицы или изменении схемы, а в версии 8.0 мы познакомились с «функциями блокировки на уровне приложения». При обычных изменениях данных внутренняя блокировка выполняется подсистемой InnoDB.
Хотя это обычное учебное упражнение, большинство банков на самом деле полагаются на ежедневную сверку, а не на строгие транзакционные операции в течение дня.
Для получения дополнительной информации прочитайте обзор ANSI SQL (https://oreil.ly/joikF) Адриана Койлера (Adrian Coyler) и объяснение моделей согласованности (http://jepsen.io/consistency) Кайла Кингсбери (Kyle Kingsbury).
Как вы увидите далее в главе, одни подсистемы хранения данных блокируют таблицы целиком, а другие реализуют более сложную блокировку на уровне строк. Вся эта логика по большей части находится на уровне подсистемы хранения данных.
Банковское приложение — классический пример, демонстрирующий, почему необходимы транзакции7. Представьте базу данных банка с двумя таблицами: checking (текущие счета) и savings (сберегательные счета). Чтобы перевести 200 долларов с расчетного счета Джейн на ее сберегательный счет, необходимо выполнить как минимум три шага.
Единственным исключением является InnoDB, который анализирует определения внешнего ключа, потому что сервер MySQL еще не реализует их сам.
MySQL 5.5 и более поздние версии поддерживают API, который может принимать подключаемые модули объединения потоков, хотя и не часто используемые. Обычно объединение потоков выполняется на уровнях доступа, которые мы обсудим в главе 5.
Рекомендуем вам прочитать документацию об эксклюзивных и разделяемых блокировках, блокировках с намерением и блокировках записи (https://oreil.ly/EPfwc).
Рекомендуем прочитать эту запись в блоге Джереми Коула, чтобы получить более глубокое представление о структуре записей в InnoDB (https://oreil.ly/jbljq).
SELECT ... FOR SHARE — это функция MySQL 8.0, которая заменяет SELECT…LOCK IN SHARE MODE предыдущих версий.
Этими блокирующими подсказками часто злоупотребляют, и их обычно следует избегать.
Не существует формального стандарта, определяющего MVCC, поэтому разные механизмы и базы данных реализуют его очень по-разному и никто не может сказать, что какой-то из них неправильный.
Для получения более подробной информации о том, как InnoDB обрабатывает несколько версий своих записей, прочтите этот пост в блоге Джереми Коула (Jeremy Cole): https://oreil.ly/exaaL.
По умолчанию каждое клиентское соединение получает собственный поток внутри серверного процесса. Запросы соединения выполняются в этом единственном потоке, который, в свою очередь, находится на одном ядре или ЦП. Сервер поддерживает кэш готовых к использованию потоков, поэтому их не нужно создавать и уничтожать для каждого нового подключения4.
Поведение и порядок блокировки зависят от подсистемы хранения, поэтому некоторые подсистемы могут заблокировать определенную последовательность операторов, а другие этого не сделают. Взаимоблокировки имеют двойную природу: некоторые из них неизбежны из-за реальных конфликтов данных, а некоторые вызваны схемой работы конкретной подсистемы хранения9.
Глава 2. Мониторинг в мире проектирования надежности
Системы мониторинга — это обширная тема, которая за последние несколько лет получила широкое распространение благодаря основополагающей работе Site Reliability Engineering: How Google Runs Production Systems15 (O’Reilly) и ее продолжению The Site Reliability Workbook: Practical Ways to Implement SRE16 (O’Reilly). С момента выхода этих двух книг проектирование надежности и безотказности сайтов (SRE) стало популярной тенденцией в открытых списках вакансий. Некоторые компании зашли так далеко, что переименовали существующие должности в некие разновидности «инженера по надежности».
Проектирование надежности сайтов изменило то, что команды думают о работе по эксплуатации систем. Это привело к формулированию набора принципов, которые позволяют нам легко ответить на следующие вопросы.
• Обеспечиваем ли мы приемлемое качество обслуживания клиентов?
• Должны ли мы сосредоточиться на работе по обеспечению надежности и устойчивости?
• Как мы уравновешиваем новые функции с высокой нагрузкой?
В этой главе предполагается, что читатель понимает, что представляют собой эти принципы. Если вы не читали ни одну из упомянутых книг, мы рекомендуем следующие главы из The Site Reliability Workbook в качестве ускоренного курса.
• Глава 1 предлагает углубленное рассмотрение философии перехода к управлению производительностью на основе соглашений об уровне обслуживания (SLA) в производственной среде.
• В главе 2 рассказывается о том, как реализовать цели уровня обслуживания (SLO).
• Глава 5 посвящена оповещению о SLO.
Некоторые могут возразить, что реализация SRE, строго говоря, не является частью архитектуры высокопроизводительной MySQL, но мы с этим не согласны. В своей книге Accelerate17 доктор Николь Форсгрен говорит: «Наша оценка должна быть сосредоточена на результатах, а не на выводах». Ключевым аспектом эффективного управления MySQL является хороший мониторинг работоспособности ваших баз данных. Традиционный мониторинг — это довольно хорошо проторенный путь. Поскольку SRE — это новая область, не очень понятно, как реализовать принципы SRE в отношении MySQL. По мере того как принципы SRE продолжают получать признание, традиционная роль администратора баз данных будет изменяться и включать требование, что администраторы баз данных не должны забывать о мониторинге своих систем.
Влияние проектирования надежности на DBA группы
В течение многих лет мониторинг производительности базы данных основывался на глубоком анализе производительности отдельного сервера. Это по-прежнему имеет большое значение, но, как правило, больше связано с измерениями, реагирующими на конкретную проблему, такими как профилирование сервера, который работает плохо. Это была стандартная рабочая процедура во времена групп администраторов баз данных, когда никто другой не имел права знать, как работает база данных.
Прочтите введение Google в область проектирования надежности. Роль администратора базы данных стала более сложной, и он превратился в инженера по надежности сайта (SRE) или инженера по надежности базы данных (DBRE). Команды должны были оптимизировать свое время. Уровни обслуживания помогают вам определить, когда клиенты недовольны, и позволяют лучше распределить свое время между решением таких вопросов, как проблемы с производительностью и масштабированием, и работой над внутренними инструментами. Обсудим различные способы мониторинга MySQL, необходимые для обеспечения успешного обслуживания клиентов.
Определение целей уровня обслуживания
Прежде чем перейти к вопросу о том, как измерить, довольны ли клиенты производительностью ваших кластеров баз данных, вы должны сначала узнать, каковы ваши цели, и определить общий язык для их описания. Вот несколько вопросов, которые в вашей организации могут послужить началом разговора для определения указанных целей.
• Какие показатели подходят для измерения успеха?
• Какие значения этих показателей приемлемы для клиентов и потребностей нашего бизнеса?
• Какой момент мы будем считать деградировавшим состоянием?
• Когда мы полностью несостоятельны и нуждаемся в максимально быстром восстановлении?
Существуют сценарии с очевидными ответами на эти вопросы, например: исходная база данных не работает, мы не делаем никаких записей, поэтому бизнес останавливается. Некоторые из них менее очевидны, например: периодическая задача иногда перегружает весь дисковый ввод/вывод базы данных, и внезапно все остальные операции замедляются. Наличие в организации общего понимания того, что мы измеряем и почему, может помочь при обсуждении приоритетов. Достижение общего понимания в ходе непрерывных обсуждений в рамках всей организации помогает понять, можете ли вы тратить инженерные усилия на новые функции, или нужно больше инвестировать в повышение производительности или стабильности. В практике SRE эти обсуждения удовлетворенности клиентов помогают команде понять, что полезно для бизнеса с точки зрения индикаторов уровня обслуживания (SLI), целевых показателей качества обслуживания (SLO) и соглашений об уровне обслуживания (SLA). Начнем с определения значения этих терминов.
• Показатели уровня качества обслуживания (service level indicators, SLI). Если просто, то SLI отвечают на вопрос «Как мне измерить, довольны ли мои клиенты?». Ответ подтверждает, что система находится в рабочем состоянии, с точки зрения пользователей. SLI могут быть индикаторами бизнес-уровня, такими как «время отклика для клиентского API» или более фундаментальное «обслуживание доступно». Вы можете понять, что вам нужны разные индикаторы или показатели, в зависимости от контекста данных и их отношения к продукту.
• Целевые показатели уровня качества обслуживания (service level objectives, SLO). SLO отвечают на вопрос «Какой минимум допустим для SLI, чтобы мои клиенты были довольны?». SLO устанавливают целевой диапазон, в котором должны находиться SLI, соответствующие работоспособному сервису. Если вы считаете, что время безотказной работы — это SLI, то количество девяток доступности, которое хотите получить для сервиса, работающего нормально в течение заданного промежутка времени, — это SLO. SLO должны быть определены как значение за некий период времени, чтобы гарантировать, что все согласны с тем, что означают SLO. SLI вместе с SLO формулируют базовое уравнение для определения того, довольны ли ваши клиенты.
• Соглашения об уровне качества обслуживания (service level agreements, SLA). SLA дают ответ на вопрос «На какие SLO, имеющие значение, я готов согласиться?». SLA — это SLO, которые были включены в соглашение с одним или несколькими клиентами компании (плательщиками, а не внутренними заинтересованными сторонами), предусматривающее финансовые или иные санкции в случае несоблюдения этих SLA. Важно отметить, какие соглашения об уровне обслуживания необязательны.
Мы не будем подробно рассматривать SLA в этой главе, так как они, как правило, требуют скорее делового обсуждения, чем инженерного. Решение такого рода в основном зависит от того, какие продажи ожидает получить компания, если она пообещает SLA в контрактах, и стоит ли это риска для доходов в случае нарушения SLA. Будем надеяться: решение будет основано на том, что мы здесь рассказываем о выборе как SLI, так и соответствующих SLO.
Определение SLI, SLO и SLA влияет не только на состояние бизнеса, но и на планирование внутри инженерных групп. Если команда не выполняет свои согласованные SLO, она не должна приступать к работе над новой функциональностью. То же самое верно и для команд разработки баз данных. Если один из потенциальных SLO, которые мы обсуждаем в этой главе, не выполняется, это должно стимулировать обсуждение того, почему так происходит. Когда вы вооружитесь данными, которые позволят объяснить, почему качество обслуживания клиентов неоптимально, то сможете более содержательно говорить о приоритетах команды.
Что нужно, чтобы клиенты были довольны
После выбора набора показателей в качестве SLI может возникнуть соблазн достичь абсолютно всех целей. Однако вы должны бороться с этим желанием. Помните, что выбор показателей и целей обеспечит возможность в любое время оценить с помощью объективных данных, может ли ваша команда внедрять инновации с помощью новых функций, или существует риск падения стабильности ниже приемлемого уровня для клиентов и, следовательно, требуется больше внимания и ресурсов. Цель состоит в том, чтобы определить, что является абсолютным минимумом, которого вам нужно добиться, чтобы клиенты были довольны. Если клиент доволен загрузкой страниц за 2 с, нет необходимости устанавливать цель загрузки страниц за 750 мс. Это может привести к необоснованной нагрузке на инженерные группы.
Взяв, например, время безотказной работы в качестве показателя уровня качества обслуживания и целевых значений для него, мы можем заявить, что у нас не будет простоев. Но что это означает для реализации и отслеживания достижения целей? Получение трех девяток показателя доступности — немалый подвиг. Три девятки за целый год составляют немногим более 8 ч, то есть всего 10 мин в неделю. Чем больше девяток вы обещаете, тем сложнее этого добиться и тем больше времени придется потратить инженерной команде, чтобы выполнить обещание. В табл. 2.1 представлены полезные данные от Amazon Web Services, иллюстрирующие проблему с помощью простых чисел.
Таблица 2.1. Время доступности в девятках
| Доступность, % |
Время простоя в год |
Время простоя в месяц |
Время простоя в неделю |
Время простоя в день |
| 99,999 |
5 мин 15,36 с |
26,28 с |
6,06 с |
0,14 с |
| 99,995 |
26 мин 16,8 с |
2 мин 11,4 с |
30,30 с |
4,32 с |
| 99,990 |
52 мин 33,6 с |
4 мин 22,8 с |
1 мин 0,66 с |
8,64 с |
| 99,950 |
4 ч 22 мин 48 с |
31 мин 54 с |
5 мин 3 с |
43,00 с |
| 99,900 |
8 ч 45 мин 36 с |
43 мин 53 с |
10 мин 6 с |
1 мин 26 с |
| 99,500 |
43 ч 48 мин 36 с |
3 ч 39 мин |
32 мин 17 с |
7 мин 12 с |
| 99,250 |
65 ч 42 мин |
5 ч 34 мин 30 с |
1 ч 15 мин 48 с |
10 мин 48 с |
| 99,000 |
3 дня 15 ч 54 мин |
7 ч 18 мин |
1 ч 41 мин, 5 с |
14 мин 24 с |
Поскольку время разработки — ограниченный ресурс, вы должны быть внимательны и не стремиться к совершенству при выборе SLO. Не все функции вашего продукта требуют всех этих девяток, чтобы удовлетворить клиентов. Поэтому вы обнаружите, что по мере роста набора функций продукта у вас будут разные SLI и SLO в зависимости от влияния конкретной функции или дохода, который она обеспечивает. Это вполне ожидаемо и является признаком обдуманного процесса. При этом у вас есть критическая задача: определить, когда набор данных становится узким местом для разных профилей запросов разными заинтересованными сторонами, ставящим под угрозу производительность системы. Это также показывает необходимость поиска способа разделения различных потребностей заинтересованных сторон, позволяющего предоставить им разумные SLI и SLO.
Определение показателей и целей уровня качества обслуживания является эффективным способом поиска общего языка между командой развития продукта и разработчиками, что позволит находить компромисс между задачами «тратить время на разработку новых функций» и «тратить время на отказоустойчивость и устранение проблем». Они также помогают, основываясь на опыте клиентов, выбрать наиболее важные из списка задач, которые необходимо выполнить. Вы можете использовать SLI и SLO как ориентиры, чтобы говорить о приоритетах работ, которые в противном случае бывает трудно согласовать.
Что измерять
Представим себе компанию, продуктом которой является интернет-магазин. В результате увеличения количества онлайн-покупок компания получает значительно больше трафика, поэтому группе инфраструктуры ставится задача гарантировать, что база данных может справиться с возросшей нагрузкой. В этом разделе мы поговорим о том, что необходимо измерять нашей вымышленной инфраструктурной команде.
Определение SLI и SLO
Определение хороших SLI и соответствующих SLO требует краткого объяснения того, как обеспечить замечательный пользовательский опыт вашим клиентам. Мы не будем тратить массу времени на абстрактное объяснение того, как создавать осмысленные SLI и SLO18.
В контексте MySQL это должно быть утверждение, определяющее три основных параметра: доступность, задержку и отсутствие критических ошибок.
Для примера с интернет-магазином это означает, что страницы загружаются быстро, менее чем за несколько сотен миллисекунд, по крайней мере для 99,5 % случаев в течение месяца. Это также означает надежный процесс оформления заказа, в котором непредвиденные сбои допускаются только в 1 % случаев в течение данного календарного месяца. Обратите внимание на то, как определяются эти показатели и цели. Мы не устанавливаем 100 % как требование, потому что работаем в мире, где отказы неизбежны. Мы используем временной интервал, позволяющий команде тщательно распределить время работы между созданием новых функций и обеспечением надежности системы.
«Я рассчитываю на то, что 99,5 % моих запросов к базе данных будут обслуживаться менее чем за 2 мс без ошибок» — это одновременно и достаточные SLI с четкими SLO, и не тривиальные. Вы не можете определить все это одним показателем. Здесь одним предложением сформулировано ваше представление о том, как слой базы данных будет вести себя, чтобы обеспечить приемлемое качество обслуживания клиентов.
Итак, что может быть хорошими примерами показателей нашего интернет-магазина, на которых может основываться картина клиентского опыта? Начните с общих тестов, таких как загрузка страниц в производственной среде, с примерами скорости загрузки. Они полезны в качестве ясного сигнала о том, что «все в порядке». Но это только начало. Обсудим различные аспекты сигналов, которые нужно отслеживать для построения общей картины. По мере рассмотрения различных примеров мы свяжем их с нашим интернет-магазином, чтобы помочь вам понять, как различные показатели создают картину хорошего обслуживания клиентов. Вначале поговорим об отслеживании времени ответа на запрос.
Решения для мониторинга
Анализ запросов и отслеживание их задержки в контексте SLI и SLO должны фокусироваться на клиентском опыте. Это означает что вам необходимы инструменты, которые могут максимально быстро предупредить, когда время ответа на запрос становится больше, чем согласованный порог. Обсудим несколько способов, которыми вы можете воспользоваться для достижения такого уровня мониторинга.
Коммерческие инструменты
Рассмотрим пример, когда плата поставщику, чьим конкурентным преимуществом является конкретная задача профилирования производительности MySQL, может принести вашей организации ощутимую пользу. Такие инструменты, как программное обеспечение для управления производительностью базы данных компании SolarWinds, могут здорово помочь автоматизировать профилирование производительности запросов и обеспечить его доступность для большого числа ваших инженеров.
Варианты инструментов с открытым исходным кодом
Хорошо зарекомендовавший себя вариант инструмента с открытым исходным кодом — Percona Monitoring and Management (PMM). Он работает в архитектуре «клиент/сервер». Вы устанавливаете на свои экземпляры базы данных клиент, который собирает данные и отправляет на серверную часть. На стороне сервера имеется набор панелей мониторинга, которые позволяют просматривать графики, относящиеся к производительности. Одним из основных преимуществ PMM является то, что организация информационных панелей основана на многолетнем опыте сообщества Percona в области мониторинга производительности MySQL. Это делает его отличным инструментом для отслеживания производительности MySQL инженерами, плохо знакомыми с MySQL.
Еще один способ проверки производительности, который вы можете выбрать, — отправить журнал медленных запросов вашей базы данных и выходные данные MySQL Performance Schema в централизованное место, где можете использовать известные инструменты, такие как pt-query-digest (часть пакета Percona Toolkit), для анализа журналов и получения дополнительной информации о том, на что экземпляры вашей базы данных тратят свое время. Хотя этот процесс эффективен, он может быть медленным и способен отрицательно сказаться на



















