МАССИВ ДАННЫХ
Что такое массив
В этой главе речь пойдет об организации данных.
Как Вы уже знаете, для работы требуется структурированный в виде таблицы массив данных. Видов таблиц укрупнено есть два:
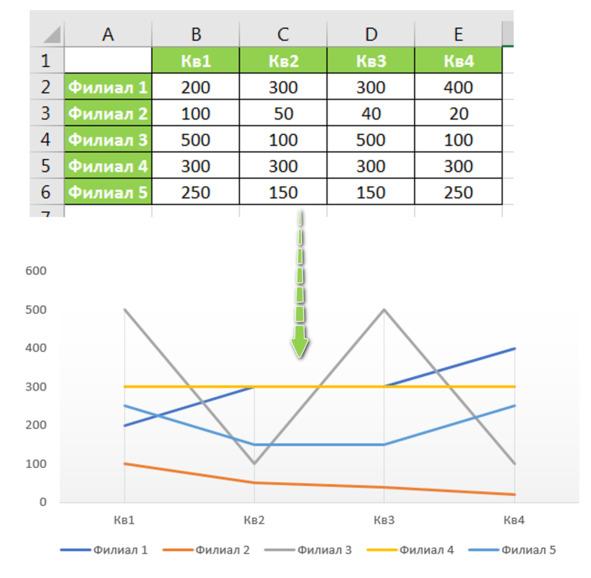
1) Сведенные таблицы. Этот вид используется для отчетности и построения визуализаций в программах MS Office. Пример такой таблицы с диаграммой-графиком на рис.1:
Рис.1. Сведенный отчет и его визуализация Графиком
Наглядно выглядит — но это худший вариант для обработки и анализа данных. Это, по сути, уже обработанные (сведенные, агрегированные в разных разрезах) данные. Тем не менее в бизнесе циркулируют такие данные — и Вам буде доводиться работать и с такими таблицам.
Особенно когда данные существуют только в печатном виде без исходного массива или Вам их в телефонном режиме «надиктовал» коллега\руководитель\партнер.
2) Второй вариант: массив данных. Массивом для нас является «плоская» двумерная таблица (не сведенный отчет). В такой таблице:
— по строкам идут случаи\объекты\наблюдения для нашего анализа (компания, отдел, дата замера, человек, клиент, товар и т.д.),
— по столбцам\колонкам — параметры\признаки (называются «переменные») со значениями для случаев, объектов или процессов (ФИО, название компании, ID клиента, скорость, деньги, город или страна, отдел, род войск, зарплата, пол, частота курения и т. д.).
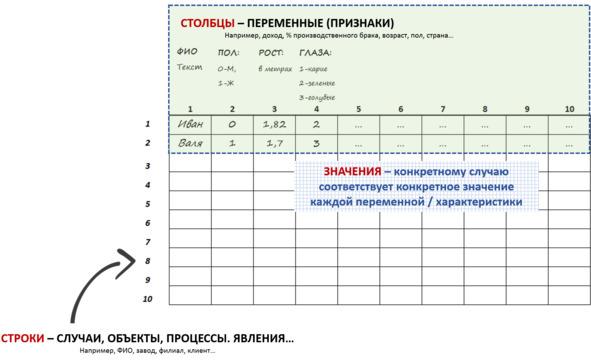
Если взять пример той же сведенной таблицы — то в виде массива она будет выглядеть так (рис.2):
Рис.2. Массив данных
Новичков в анализе данных (тех, кто просто до этого видел готовые отчеты) такой вид таблицы может «вогнать в ступор»: на предыдущем рисунке была нормальная понятная таблица, в которой можно было разобраться и что-то понять — а это что такое?
Но на самом деле это более удобное структурирование таблицы — из нее легко получать те самые сведенные отчеты в разных разрезах (как в виде сводных таблиц, так и диаграмм). И более того — такая таблица сможет ВЗАИМОДЕЙСТВОВАТЬ с другими таблицами путем установления с ними связей по общим переменным-идентификаторам (так называемым «ключам»).
Если на этом этапе Вы еще не смогли понять важность именно такого структурирования данных — то просто пока поверьте.
А из этой главы вынесите то, что данные должны быть внесены в упорядоченную таблицу — и Вам до начала ввода данных надо эту таблицу уже представить в собственной голове. И моя рекомендация: всегда старайтесь получить массив — где по строкам указаны случаи\объекты (сотрудники, клиенты, предприятия, товары и т.д.), а по столбцам — переменные (их признаки или характеристики). Причем Power Query имеет встроенный механизм преобразования сведенных отчетов в массивы — но об этом поговорим позже.
Итак, надеюсь Вы уловили разницу между массивом данных и сведенным отчетом. И запомнили, что на выходе из Power Query должен получиться вычищенный и готовый к анализу массив данных, в котором по строкам идут объекты\наблюдения, а по столбцам — переменных\характеристики со своими значениями для каждого объекта.
Объекты (строки) в массиве
Итак, в массиве у нас по строкам идут объекты нашего анализа (еще их называют случаи или наблюдения). Это то, что мы анализируем и по чему собираем информацию. Это могут быть:
· люди
· клиенты
· посетители
· товары
· предприятия
· подразделения
· магазины
· дата замера \ получения показателя
· и т. д.
Например, если мы собираем информацию по продажам в городах — то объектами будут города.
Если по магазинам — то объектами будут магазины.
Если нас интересуют продажи по конкретным отделам в магазине — то это будут отделы.
А если интерес представляют продажи по конкретным продавцам-консультантам — то это будут ФИО конкретных продавцов-консультантов. Причем в массиве у каждого из них может присутствовать признак отдела и магазина, а также города, в котором магазин находится — и мы сможем при необходимости агрегировать\обобщить информацию о продажах и в разрезе магазина, и в разрезе отдела, и в разрезе городов.
Т.е., если Вас интересуют показатели магазинов (магазины — это объекты Вашего анализа), но Вы можете получить данные на более детализированном уровне (на уровне объектов в виде продавцов-консультантов) — то используйте максимально возможный детализированный уровень сбора информации, но содержащий нужные Вам признаки (в данном случае магазин, в котором продавец-консультант осуществлял продажу).
Это все сказано к тому, что наиболее желательно заполучить массив на максимально детализированном уровне объектов с необходимым набором признаков (переменных) для его укрупнения (обобщения, агрегации) в случае необходимости. Но об уровне детализации массива мы поговорим еще в отдельной главе.
Переменные (столбцы\колонки) в массиве
В отличии от Excel, работающего с каждой конкретной ячейкой, Power-надстройки и Power BI работают со столбцами целиком — т.е. с переменными.
Если у Вас случаи\объекты анализа — конкретные люди. То, например, цвет глаз у каждого человека будет свой. И цвет глаз — это переменная. А карие, голубые, зеленые и т. д. — это значения этой переменной у конкретного объекта.
Т.о., каждый случай\объект имеет своих характеристики, т.е., может принимать свое значение той или иной переменной.
Например, рост Вали = 1,7 метра, а Ивана 1,82. У Вали глаза голубые, у Ивана — зеленые. Валя — женщина, а Иван — мужчина. Валя живет в Омске, Иван — в Москве. Месячный доход Вали — 80.000 руб, а Ивана — 200.000 руб. Вадя ездит на отдых за границу редко — раз в несколько лет, Иван часто — несколько раз в год.
Валя и Ваня — это наши объекты/случаи/наблюдения.
Рост, цвет глаз, доход, место проживания, частота путешествий — характеристики\признаки или переменные.
См. рис. 3:
Рис.3. Объекты анализа и их признаки\переменные
Вместо Вали и Ивана могут быть предприятия, товары. А в качестве переменных — доходы, объем производства и численность персонала для предприятий, или цена и количество проданных единиц товара.
В общем, по столбцам в массиве идут переменные, которые характеризуют наши объекты — и именно с переменными ведется работа в Power-надстройках и Power BI.
И каждая переменная принимает свое значение для конкретного объекта\наблюдения (рис.4), которые могут быть разными не только с т.з. самого значения переменной (например, голубой или зеленый цвет глаз), а и с т.з. шкал измерения переменных.
Рис.4. Массив: строки (объекты), столбцы (переменные) и ячейки (значения)
А какие бывают типы шкал для записи переменных — разберем в следующей главе.
Шкалы для измерения переменных
Обратим внимание на то, что каждая переменная (колонка\столбец) имеет свое значение для того или иного случая\объекта.
И значения переменных варьируются и отличаются от случая к случаю, от объекта к объекту. К примеру, цвет глаз может быть синим или зеленым; рост 1,7 и 1,82; пол — мужской или женский; доход 80.000 или 200.000 и т. д.
Т.е., каждое значение по конкретной взятой переменной соответствует его замеру у конкретного объекта.
Но также Вы наверняка заметили, что переменные могут быть измерены в разных шкалах.