

автордың кітабын онлайн тегін оқу Основы компиляции: инкрементный подход
Переводчики Е. Матвеев
Джереми Сик
Основы компиляции: инкрементный подход. — СПб.: Питер, 2024.
ISBN 978-5-4461-2116-8
© ООО Издательство "Питер", 2024
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Посвящаю эту книгу Кэти, моему партнеру во всем; моим детям, выросшим за время работы над книгой; студентам, изучающим языки программирования в Университете штата Индиана, чьи острые вопросы сделали эту книгу лучше.
Предисловие
Всем разработчикам знаком тот магический момент, когда при нажатии кнопки run программа начинает выполняться. Программа, написанная на языке высокого уровня, каким-то образом выполняется на компьютере, способном работать только с битами. В этой книге раскрываются секреты волшебства, благодаря которым подобное становится возможным. Начиная с новаторской работы Бэкуса (Backus) и его коллег в 1950-х годах, компьютерные теоретики разработали методы построения компиляторов — программ, автоматически преобразующих код, написанный на языках высокого уровня, в машинный код.
В этой книге мы займемся построением собственного компилятора для небольшого, но мощного языка. Попутно мы разберем важнейшие концепции, алгоритмы и структуры данных, лежащие в основе компиляторов. Вы сможете лучше понять, какая связь существует между программами и аппаратной частью компьютера. Это необходимо, чтобы рассуждать о том, что происходит на стыке аппаратного и программного обеспечения: о времени выполнения, программных ошибках и уязвимостях в области безопасности. Читателям, которые намерены связать с построением компиляторов свою карьеру, книга облегчит переход к таким нетривиальным темам, как JIT-компиляция, анализ программ и оптимизация кода. Читателям, интересующимся проектированием и реализацией языков программирования, мы продемонстрируем связь между решениями, принимаемыми при создании языка, и их влиянием на компилятор и сгенерированный код.
Обычно работа компилятора состоит из серии этапов, которые последовательно преобразуют программу в машинный код, работающий на физическом оборудовании. Мы пойдем дальше и разделим компилятор на множество микропроходов, каждый из которых выполняет отдельную задачу. Это позволит провести изолированное тестирование каждого прохода и сосредоточить внимание на отдельном блоке, благодаря чему логика компилятора станет намного более понятной.
Самый очевидный способ описать работу компилятора — посвятить каждую главу отдельному проходу. К сожалению, при таком подходе остается нераскрытым вопрос, как языковые средства влияют на решения, принимаемые в ходе проектирования компилятора. Поэтому в книге выбран инкрементный подход: в каждой главе строится полный компилятор, начиная с маленького входного языка, поддерживающего только арифметические операции и переменные. По мере продвижения по главам мы будем добавлять новые возможности и расширять компилятор по мере необходимости.
Наш выбор языковых средств продиктован стремлением продемонстрировать фундаментальные концепции и алгоритмы, используемые в компиляторах.
• Мы начнем с целочисленной арифметики и локальных переменных в главах 1 и 2, где будут представлены фундаментальные средства построения компиляторов: абстрактные синтаксические деревья и рекурсивные функции.
• В главе 3 метод раскраски графа применяется для распределения переменных между машинными регистрами.
• В главе 4 добавляются условные выражения, для преобразования которых в условные команды goto будет применен элегантный рекурсивный алгоритм.
• В главе 5 добавляются циклы и изменяемые переменные, а также демонстрируется необходимость анализа потоков данных в распределителе регистров.
• В главе 6 добавляется поддержка кортежей, память для которых выделяется в куче. Новая возможность обусловливает потребность в механизме сборки мусора.
• В главе 7 добавляются функции как первоклассные значения без лексической области видимости, по аналогии с функциями языка программирования C (Kernighan and Ritchie, 1988)1. Читатель познакомится со стеком вызовов процедур и соглашениями о вызовах и их влиянием на выделение регистров и сборку мусора. Вы также узнаете, как генерировать эффективные хвостовые вызовы.
• В главе 8 добавляются анонимные функции с лексической областью видимости, то есть лямбда-выражения. Читатель узнает о преобразовании замыканий, при котором лямбда-выражения преобразуются в комбинацию функций и кортежей.
• В главе 9 добавляется динамическая типизация. До ее появления в языках использовалась статическая типизация. Мы расширим язык со статической типизацией типом Any, который становится признаком применения динамической типизации при компиляции.
• В главе 10 тип Any, представленный в главе 9, используется для реализации языка с постепенной типизацией, в котором в разных частях программы может использоваться статическая или динамическая типизация. Читатель реализует поддержку времени выполнения для заместителей, позволяющих безопасно перемещать значения между разными областями.
• В главе 11 добавляются обобщения с автоматической упаковкой, использующие тип Any и преобразования типов, реализованные в главах 9 и 10.
Книга не охватывает все языковые средства. В своем выборе мы старались выдержать баланс между сложностью, присущей языковому средству, и фундаментальностью концепций, которые оно демонстрирует. Например, мы включили в книгу кортежи вместо записей; хотя и те и другие позволяют изучить механизмы выделения памяти из кучи и сборки мусора, записям присуща более высокая сложность.
С 2009 года черновики этой книги используются в 16-недельном курсе построения компиляторов для студентов старших курсов в Университете Колорадо и Университете штата Индиана. Слушатели этого курса уже владеют основами программирования, структур данных, алгоритмов и дискретной математики. В начале обучения студенты разбиваются на группы от 2 до 4 человек. Группы изучают главы, соответствующие их интересам, начиная с главы 2, по одной примерно за две недели, соблюдая при этом зависимости между главами, показанные на илл. 0.1. Глава 7 (функции) зависит от главы 6 (кортежи) только в реализации эффективных хвостовых вызовов. Последние две недели курса отводятся под курсовой проект, в котором студенты проектируют и реализуют расширение компилятора по своему выбору. Для поддержки таких проектов могут использоваться заключительные главы книги. Во многие главы включены задания повышенной сложности.

Илл. 0.1. Диаграмма зависимостей между главами
Для университетских учебных курсов, строящихся по триместровой системе (около 10 недель), мы рекомендуем завершить курс на главе 6 или 7 и предоставлять студентам часть вспомогательного кода для каждого прохода компилятора. Курс можно адаптировать так, чтобы уделить особое внимание функциональным языкам; для этого целесообразно пропустить главу 5 (циклы) и включить главу 8 (лямбда-выражения). Чтобы адаптировать курс для языков с динамической типизацией, включите в него главу 9.
Книга используется на курсах построения компиляторов в Политехническом университете штата Калифорния, Университете Портленда, Технологическом институте Роуз-Хульман, Университете Фрайбурга, Массачусетском университете Лоуэлла и Вермонтском университете.
Мы используем язык Racket как для реализации компилятора, так и для входного языка, так что от читателя потребуется хорошее знание Racket или Scheme. Существует много отличных ресурсов для изучения Scheme и Racket (Dybvig, 1987a; Abelson and Sussman, 1996; Friedman and Felleisen, 1996; Felleisen et al., 2001; Felleisen et al., 2013; Flatt, Findler, and PLT, 2014). Вспомогательный код книги доступен в репозитории GitHub по следующему адресу:
https://github.com/IUCompilerCourse/
Компилятор генерирует код на языке ассемблера x86 (Intel, 2015), поэтому полезно, но не обязательно изучить работу вычислительных систем (Bryant and O’Hallaron, 2010). В книге представлены части языка ассемблера x86-64, необходимые для компилятора. Мы используем соглашения о вызовах System V (Bryant and O’Hallaron, 2005; Matz et al., 2013), так что генерируемый код на языке ассемблера будет работать с системой исполнения (написанной на C), если он откомпилирован компилятором GNU C (gcc) в ОС Linux и MacOS на оборудовании Intel. В ОС Windows gcc использует соглашения о вызовах Microsoft x64 (Microsoft, 2018, 2020), поэтому сгенерированный код на языке ассемблера не будет работать с системой исполнения в Windows. Одно из возможных решений — использовать виртуальную машину с Linux в качестве гостевой ОС.
Благодарности
Практика разработки компиляторов в Университете штата Индиана восходит к исследованиям и курсам Дэниела Фридмана (Daniel Friedman) по языкам программирования в 1970-х и 1980-х годах. Один из его студентов, Кент Дибвиг (Kent Dybvig), реализовал Chez Scheme (Dybvig, 2006) — эффективный компилятор Scheme коммерческого уровня. В 1990-е и 2000-е годы Дибвиг вел курс проектирования компиляторов и продолжал разработку Chez Scheme. Учебный курс постепенно развивался, в него включались новые обучающие приемы, а также элементы реально существующих компиляторов. Одно из предложений Фридмана заключалось в том, чтобы разбить компилятор на множество мелких проходов. Другое предложение, названное «игра», — тестировать код, сгенерированный при каждом проходе, с применением интерпретаторов.
Дибвиг с помощью своих студентов Дипанвиты Саркар (Dipanwita Sarkar) и Эндрю Кипа (Andrew Keep) разработал инфраструктуру для поддержки этого метода и доработал курс так, чтобы использовать микропроходы (Sarkar, Waddell, and Dybvig, 2004; Keep, 2012). Многие решения в области проектирования компиляторов, представленные в книге, были вдохновлены описаниями Дибвига и Кипа (2010). В середине 2000-х годов студент Дибвига Абдулазиз Гулум (Abdulaziz Ghuloum) заметил, что при строго направленной структуре курса студентам было труднее понять обоснование выбора тех или иных проектировочных решений. Гулум предложил инкрементный подход (Ghuloum, 2006), который был взят за основу в этой книге.
Я благодарен многим студентам, ассистентам кафедры на курсе проектирования компиляторов в Университете штата Индиана, в том числе Карлу Факторе (Carl Factora), Райану Скотту (Ryan Scott), Кэмерону Сордсу (Cameron Swords) и Крису Уэйлзу (Chris Wailes). Спасибо Андре Кюленшмидту (Andre Kuhlenschmidt) за работу над сборщиком мусора и интерпретатором x86, Майклу Воллмеру (Michael Vollmer) за работу над эффективными хвостовыми вызовами и Майклу Витусеку (Michael Vitousek) за помощь с внедрением инкрементного курса проектирования компиляторов в Университете штата Индиана.
Спасибо профессорам Бор-Ю Чану (Bor-Yuh Chang), Джону Клементсу (John Clements), Джею Маккарти (Jay McCarthy), Джозефу Ниру (Joseph Near), Райану Ньютону (Ryan Newton), Нейту Нистрому (Nate Nystrom), Питеру Тиманну (Peter Thiemann), Эндрю Толмачу (Andrew Tolmach) и Майклу Волловски (Michael Wollowski) за учебные курсы, в основу которых были положены черновики этой книги, и за обратную связь. Спасибо Национальному научному фонду за гранты, обеспечившие поддержку этой работы: номера грантов 1518844, 1763922 и 1814460.
Я благодарен Рональду Гарсиа (Ronald Garcia) за то, что он помог мне выжить на курсе Дибвига по проектированию компиляторов в начале 2000-х — и особенно за то, что он нашел ошибку, из-за которой у нашего сборщика мусора сносило крышу!
Джереми Дж. Сик. Блумингтон, штат Индиана
1 Керниган Б., Ритчи Д. «Язык программирования С».
Керниган Б., Ритчи Д. «Язык программирования С».
• В главе 7 добавляются функции как первоклассные значения без лексической области видимости, по аналогии с функциями языка программирования C (Kernighan and Ritchie, 1988)1. Читатель познакомится со стеком вызовов процедур и соглашениями о вызовах и их влиянием на выделение регистров и сборку мусора. Вы также узнаете, как генерировать эффективные хвостовые вызовы.
Глава 1. Введение
В этой главе будут рассмотрены основные средства, необходимые для реализации компилятора. Программы обычно вводятся в компьютер в виде текста, то есть последовательности символов. Представление программы в виде текста называется конкретным синтаксисом (concrete syntax). Конкретный синтаксис используется для записи и анализа программ. Внутри компилятора используются абстрактные синтаксические деревья (AST, abstract syntax tree), которые формируют представления программ, позволяющие компилятору выполнять необходимые операции. Процесс преобразования конкретного синтаксиса в абстрактный называется парсингом, а программный код, в котором он реализуется, — парсером. Теория и реализация парсинга программ в книге не рассматривается. Читателям, интересующимся данной процедурой на достаточно серьезном уровне, стоит обратиться к книге (Aho et al., 2006)2. Парсер включается в исходный код для преобразования конкретного синтаксиса в абстрактный.
В зависимости от языка программирования, на котором написан компилятор, существует много разных способов представления абстрактных синтаксических деревьев внутри компилятора. Для представления AST в книге будет использоваться конструкция struct языка Racket (раздел 1.1). Грамматики будут использоваться для определения абстрактного синтаксиса языков программирования (раздел 1.2), а поиск по шаблону — для поиска отдельных узлов AST (раздел 1.3). Рекурсивные функции будут использоваться для построения и разложения AST (раздел 1.4). В этой главе приводится краткое вводное описание этих компонентов.
1.1. Абстрактные синтаксические деревья
Компиляторы используют абстрактные синтаксические деревья для представления программ, поскольку, обрабатывая фрагмент программы, они должны знать в том числе, какой языковой конструкции он соответствует, какие элементы содержит. Рассмотрим программу в левой части схемы и диаграмму AST справа (1.1). Программа выполняет операцию сложения, состоящую из двух элементов: операции чтения и операции изменения знака. Операция изменения знака включает еще один элемент – целочисленную константу 8. Используя дерево для представления программы, можно легко переходить от фрагмента программы к его составным элементам.

Для описания AST будет использоваться стандартная терминология: каждый прямоугольник на схеме выше называется узлом (node). Линии со стрелками соединяют узлы с их потомками, которые также являются узлами (дочерними). Узел верхнего уровня называется корневым. У каждого узла, кроме корневого, имеется родитель (то есть узел, по отношению к которому этот узел является дочерним). Если у узла нет дочерних узлов, такой узел называется листовым; в противном случае он называется внутренним узлом.
Для каждой разновидности узлов мы определим структуру (struct) Racket. Для этой главы достаточно всего двух разновидностей узлов: для целочисленных констант (литералов) и для примитивных операций. Ниже приведено определение struct для целочисленных констант3.
(struct Int (value))
Целочисленный узел содержит только целое значение. Мы будем использовать соглашение, в соответствии с которым имена структур (такие, как Int) записываются с прописной буквы. Чтобы создать узел AST для целого числа 8, используется запись (Int 8).
(define eight (Int 8))
Значение, созданное обозначением (Int 8), называется экземпляром структуры Int.
Определение структуры для примитивных операций выглядит так:
(struct Prim (op args))
Узел примитивной операции включает обозначение оператора op и список дочерних аргументов args. Например, при создании AST для изменения знака числа 8 используется следующая конструкция:
(define neg-eight (Prim '- (list eight)))
У примитивных операций может быть нуль и более дочерних узлов. У оператора read их нуль:
(define rd (Prim 'read '()))
Оператор сложения имеет два дочерних узла:
(define ast1_1 (Prim '+ (list rd neg-eight)))
В отношении структуры Prim было принято проектировочное решение. Вместо того чтобы использовать одну структуру для нескольких разных операций (read, + и -), можно было определить отдельную структуру для каждой операции:
(struct Read ())
(struct Add (left right))
(struct Neg (value))
Почему же мы используем только одну структуру? Потому что разные части компилятора могут использовать один и тот же код для разных примитивных операций, и этот код с таким же успехом можно написать с использованием одной структуры.
Чтобы откомпилировать такую программу, как (1.1), необходимо знать, что с корневым узлом связана операция сложения, и иметь возможность обратиться к двум его дочерним узлам. Для подобных запросов в Racket существует механизм поиска по шаблону, который более подробно рассматривается в разделе 1.3.
Конкретный синтаксис программы часто приводится даже в том случае, когда на самом деле имеется в виду AST, потому что конкретный синтаксис более компактный. Мы рекомендуем всегда рассматривать программы как абстрактные синтаксические деревья.
1.2. Грамматики
Язык программирования можно рассматривать как множество программ. Это множество бесконечно (то есть всегда можно создать программу большего размера), так что язык невозможно описать простым перечислением всех его программ. Вместо этого записывается набор правил построения программ — контекстно-свободная грамматика. Грамматики часто используются для определения конкретного синтаксиса языка, но они также могут использоваться для описания абстрактного синтаксиса. Правила записываются как разновидность формы Бэкуса — Наура (BNF) (Backus et al., 1960; Knuth, 1964). Для примера можно описать маленький язык LInt, состоящий из целых чисел и арифметических операций.
Первое правило грамматики для абстрактного синтаксиса LInt гласит, что экземпляр структуры Int является выражением:
exp ::= (Int int) (1.2)
У каждого правила есть левая и правая сторона. Если имеется узел AST, соответствующий правой стороне, это означает, что его можно классифицировать в соответствии с левой стороной. Символы, записанные моноширинным шрифтом (например, Int), называются терминальными; они должны буквально входить в программу, чтобы правило было применимо. В наших грамматиках не упоминаются пропуски (то есть такие символы-ограничители, как пробелы, табуляции и новые строки.) Пропуски могут вставляться между символами для устранения неоднозначности и улучшения удобочитаемости. Имя, определяемое правилами грамматики (такое, как exp), является нетерминальным. Имя int тоже является нетерминальным, но вместо того чтобы определять его правилом грамматики, мы определяем его следующим описанием. int представляет собой последовательность десятичных цифр (от 0 до 9), которая может начинаться с необязательного знака «–» (минус, для отрицательных чисел) и позволяет представлять целые числа в диапазоне от –262 до 262 – 1. Такое определение открывает возможность представления целых чисел в 63-разрядном виде, что немного упрощает вычисления. Таким образом, эти числа соответствуют типу данных Racket fixnum на 64-разрядных машинах.
Второе правило грамматики — операция read, которая получает целое число от пользователя программы.
exp ::= (Prim ’read ()) (1.3)
Третье правило классифицирует изменение знака узла exp как exp.
exp ::= (Prim ’- (exp)) (1.4)
Эти правила можно применить для классификации AST, принадлежащих языку LInt. Например, по правилу (1.2) (Int 8) является exp (выражением), и тогда по правилу (1.4) следующее AST тоже является exp.
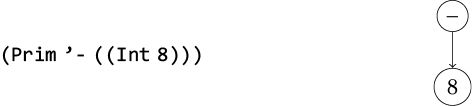
Следующие два правила грамматики предназначены для сложения и вычитания выражений:
exp ::= (Prim ’+ (exp exp)) (1.6)
exp ::= (Prim ’- (exp exp)) (1.7)
Теперь можно проверить, что AST (1.1) является exp в LInt. Мы знаем, что (Prim 'read ()) является exp согласно правилу (1.3), и мы уже классифицировали (Prim '- ((Int 8))) как exp, поэтому применение правила (1.6) доказывает, что
(Prim ’+ ((Prim ’read ()) (Prim ’- ((Int 8)))))
также является exp в языке LInt.
Если имеется AST, к которому эти правила неприменимы, то AST не принадлежит LInt. Например, программа (* (read) 8) не принадлежит LInt, потому что правила для оператора * не существует. Когда мы определяем язык грамматикой, язык включает только те программы, которые соответствуют правилам грамматики.
Последнее правило грамматики LInt утверждает, что существует узел Program для пометки верхнего уровня всей программы:
LInt ::= (Program ’() exp)
Структура Program определяется следующим образом:
(struct Program (info body)),
где body — выражение. В следующих главах часть info будет использоваться для хранения дополнительной информации, а пока это просто пустой список.
На практике часто существует множество правил грамматики с одинаковой левой стороной, но разными правыми сторонами, как в правилах exp в грамматике LInt. Сокращенная форма записи позволяет объединить несколько правых сторон в одно правило, разделив их символом | (вертикальная черта).
Конкретный синтаксис LInt представлен на илл. 1.1, а абстрактный синтаксис LInt — на илл. 1.2. Функция read-program, содержащаяся в файле utilities.rkt из прилагаемого кода, читает программу из файла (последовательность символов в конкретном синтаксисе Racket) и преобразует ее в абстрактное синтаксическое дерево. Чтобы узнать больше, перейдите к описанию read-program в приложении А.2.

Илл. 1.1. Конкретный синтаксис LInt

Илл. 1.2. Абстрактный синтаксис LInt
1.3. Поиск по шаблону
Как упоминалось в разделе 1.1, компиляторам часто требуется доступ к частям узла AST. Для обращения к частям значений Racket предоставляет функциональность поиска по шаблону. Рассмотрим следующий пример:
(match ast1_1
[(Prim op (list child1 child2))
(print op)])
В этом примере форма match проверяет, является ли AST (1.1) бинарным оператором, и связывает его части с тремя переменными шаблона op, child1 и child2. В общем случае условие match состоит из шаблона и тела. Шаблоны рекурсивно определяются как переменная шаблона, имя структуры, за которой следует шаблон для каждого из аргументов структуры, или S-выражение (символ, список и т.д.) (полное описание match см. в разделе 12 документа Racket Guide4 и главе 9 Racket Reference5.) Тело условия match может содержать произвольный код Racket. Переменные шаблона могут использоваться в области видимости тела, как op в (print op).
Форма match может иметь несколько условий, как в следующей функции leaf, проверяющей, что узел LInt является листовым в AST. match обрабатывает условия по порядку, проверяя, существует ли совпадение шаблона во входном AST. После этого выполняется тело первого условия, для которого найдено совпадение. Вывод leaf для нескольких AST приведен в правой части:

При построении выражений match мы используем грамматическое определение, чтобы установить, в каких нетерминальных элементах должно быть совпадение, после чего проверяем, что (1) имеется одно условие для каждой альтернативы этого нетерминального элемента и (2) шаблон в каждом условии соответствует аналогичной правой части правила грамматики. Для match в функции leaf мы обращаемся к грамматике LInt, показанной на илл. 1.2. Нетерминальное имя exp имеет четыре альтернативы, поэтому match содержит четыре условия. Шаблон в каждом условии соответствует правой части правила грамматики. Например, шаблон (Prim ’+ (list e1 e2)) соответствует правой части (Prim ’+ (exp exp)). При переходе от грамматики к шаблонам замените нетерминальные имена (такие, как exp) переменными шаблонов по своему выбору (например, e1 и e2).
1.4. Рекурсивные функции
Программы рекурсивны по своей природе. Например, выражение часто состоит из нескольких меньших подвыражений. Таким образом, можно рассматривать рекурсивную функцию как естественный метод обработки всей программы. В качестве первого примера такой рекурсивной функции определим функцию is_exp, как показано на илл. 1.3; она получает произвольное значение и определяет, является ли оно выражением в LInt. Говорят, что функция определяется структурной рекурсией, если для ее определения используется последовательность условий match, соответствующих грамматике, а тело каждого условия содержит рекурсивный вызов к каждому дочернему узлу6. Иллюстрация 1.3 также содержит определение функции is_Lint, устанавливающей, является ли AST программой в языке LInt. В общем случае можно написать одну рекурсивную функцию для обработки каждого нетерминального элемента в грамматике. Из двух примеров в нижней части листинга первый принадлежит LInt, а второй нет.

Илл. 1.3. Пример рекурсивных функций для LInt. Эти функции проверяют, принадлежит ли AST языку LInt
1.5. Интерпретаторы
Поведение программы определяется спецификацией языка программирования. Например, язык Scheme определяется в докладе Спербера и др. (Sperber et al.) (2009). Язык Racket определяется в его справочном руководстве (Flatt and PLT, 2014). В этой книге для определения каждого рассматриваемого языка будут использоваться интерпретаторы. Интерпретатор, спроектированный как определение языка, называется определительным интерпретатором (definitional interpreter) (Reynolds, 1972). Начнем с создания определительного интерпретатора для языка LInt. Этот интерпретатор служит вторым примером структурной рекурсии. Определение функции interp_Lint приведено на илл. 1.4. Тело функции содержит вызов match для входной программы, за которым следует вызов вспомогательной функции interp_exp. В свою очередь, эта функция содержит отдельное условие match для каждого правила грамматики для выражений LInt.

Илл. 1.4. Интерпретатор для языка LInt
Рассмотрим результат интерпретации нескольких программ LInt. Следующая программа складывает два целых числа:
(+ 10 32)
Результат равен 42 – ответ на главный вопрос жизни, Вселенной и всего остального: 42!7 Мы записали эту программу в конкретном синтаксисе, тогда как разобранный абстрактный синтаксис имеет вид:
(Program '() (Prim '+ (list (Int 10) (Int 32))))
Следующая программа демонстрирует, что выражения могут быть вложенными — в примере ниже используются вложенные операции сложения и изменения знака.
(+ 10 (- (+ 12 20)))
Как выглядит результат выполнения этой программы?
Как уже говорилось, язык LInt не поддерживает произвольные большие числа, а работает только с 63-разрядными целыми числами, поэтому арифметические операции LInt интерпретируются с использованием арифметики fixnum в Racket. Допустим, имеется число
n = 999999999999999999,
которое действительно помещается в 63 бита. Что произойдет при выполнении следующей программы в интерпретаторе?
(+ (+ (+ n n) (+ n n)) (+ (+ n n) (+ n n)))))
Программа выдает ошибку:
fx+: result is not a fixnum
Будем считать, что если при запуске определительного интерпретатора для программы выдается ошибка, то поведение этой программы не определено (кроме ошибок trapped-error). Компилятор для языка не имеет никаких обязательств в отношении программ с неопределенным поведением; он не обязан создавать исполняемый файл, а если такой файл все же создается, то он может делать все что угодно. С другой стороны, для ошибок trapped-error компилятор должен построить исполняемый файл и сообщать о возникновении ошибки. Сигналом об ошибке является завершение работы с кодом возврата 255. Интерпретаторы в главах 9 и 10, а также в разделе 6.10 используют trapped-error.
Последняя функция языка LInt — операция read — запрашивает у пользователя программы целое число. Вспомните, что программа (1.1) запрашивает целое число и вычитает из него 8. Таким образом, при выполнении
(interp_Lint (Program '() ast1_1))
для ввода 50 результат будет равен 42.
Мы включили в LInt операцию read, чтобы какой-нибудь хитрый студент не мог реализовать компилятор LInt, который просто запускает интерпретатор во время компиляции для получения вывода, а затем генерирует тривиальный код для создания такого вывода8.
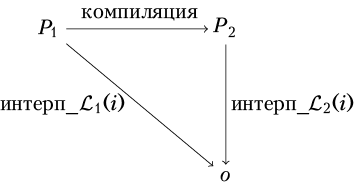
Задача компилятора – преобразовать программу на одном языке в программу на другом языке, чтобы выходная программа обладала таким же поведением, как исходная. Этот принцип представлен на следующей диаграмме. Допустим, имеются два языка, L1 и L2, и определительный интерпретатор для каждого языка. Если имеется компилятор, преобразующий программу из языка L1 в L2, и некоторая программа P1 на L1, компилятор должен преобразовать ее в программу P2 такую, что интерпретация P1 и P2 соответствующими интерпретаторами с одинаковыми входными данными приведет к одинаковым результатам o.
В следующем разделе рассматривается первый пример компилятора.
1.6. Пример компилятора: частичный вычислитель
В этом разделе рассматривается компилятор, который преобразует программы LInt в более эффективные программы LInt. Компилятор немедленно вычисляет части программы, которые не зависят от ввода, – этот процесс называется частичным вычислением (Jones, Gomard, and Sestoft, 1993). Например, следующую программу:
(+ (read) (- (+ 5 3)))
компилятор преобразует в такую программу:
(+ (read) -8)
На илл. 1.5 приведен код простого частичного вычислителя для языка LInt. Выводом частичного вычислителя является программа на LInt. На илл. 1.5 структурная рекурсия по exp отражена в функции pe_exp, тогда как код частичного вычисления операций изменения знака и сложения распределяется по трем вспомогательным функциям: pe_neg, pe_add и pe_sub. Вводом для этих функций является вывод частичного вычисления дочерних узлов. Функции pe_neg, pe_add и pe_sub проверяют, являются ли их аргументы целыми числами, и если да, выполняют соответствующие арифметические вычисления. В противном случае они создают узел AST для арифметической операции.

Илл. 1.5. Частичный вычислитель для LInt
Чтобы убедиться, что частичный вычислитель работает правильно, можно проверить, генерируют ли программы на его выходе тот же результат, что и программы на входе. Иначе говоря, можно проверить, удовлетворяют ли они схеме на диаграмме (1.8). Следующий код запускает частичный вычислитель для нескольких примеров и тестирует выходную программу. Функции parse-program и assert определены в приложении A.2.
(define (test_pe p)
(assert "testing pe_Lint"
(equal? (interp_Lint p) (interp_Lint (pe_Lint p)))))
(test_pe (parse-program `(program () (+ 10 (- (+ 5 3))))))
(test_pe (parse-program `(program () (+ 1 (+ 3 1)))))
(test_pe (parse-program `(program () (- (+ 3 (- 5))))))
Упражнение 1.1. Создайте три программы на языке LInt и проверьте, будет ли результат, полученный при их частичном вычислении функцией pe_Lint и последующей интерпретации функцией interp_Lint, совпадать с результатом их прямой интерпретации функцией interp_Lint.
2 Ахо А. и др. «Компиляторы: принципы, технологии и инструменты».
3 Все структуры AST определены в файле utilities.rkt в прилагаемом коде.
4 См. https://docs.racket-lang.org/guide/match.html.
5 См. https://docs.racket-lang.org/reference/match.html.
6 Этот принцип структурирования кода в соответствии с определением данных был предложен в книге How to Design Programs Фелляйзена и др. (Felleisen et al.) («Как проектировать программы. Введение в программирование и компьютерное вычисление»).
7 Адамс Д. «Автостопом по Галактике».
8 Да, один сообразительный студент в первой версии курса именно так и поступил!
Мы включили в LInt операцию read, чтобы какой-нибудь хитрый студент не мог реализовать компилятор LInt, который просто запускает интерпретатор во время компиляции для получения вывода, а затем генерирует тривиальный код для создания такого вывода8.
В этой главе будут рассмотрены основные средства, необходимые для реализации компилятора. Программы обычно вводятся в компьютер в виде текста, то есть последовательности символов. Представление программы в виде текста называется конкретным синтаксисом (concrete syntax). Конкретный синтаксис используется для записи и анализа программ. Внутри компилятора используются абстрактные синтаксические деревья (AST, abstract syntax tree), которые формируют представления программ, позволяющие компилятору выполнять необходимые операции. Процесс преобразования конкретного синтаксиса в абстрактный называется парсингом, а программный код, в котором он реализуется, — парсером. Теория и реализация парсинга программ в книге не рассматривается. Читателям, интересующимся данной процедурой на достаточно серьезном уровне, стоит обратиться к книге (Aho et al., 2006)2. Парсер включается в исходный код для преобразования конкретного синтаксиса в абстрактный.
В этом примере форма match проверяет, является ли AST (1.1) бинарным оператором, и связывает его части с тремя переменными шаблона op, child1 и child2. В общем случае условие match состоит из шаблона и тела. Шаблоны рекурсивно определяются как переменная шаблона, имя структуры, за которой следует шаблон для каждого из аргументов структуры, или S-выражение (символ, список и т.д.) (полное описание match см. в разделе 12 документа Racket Guide4 и главе 9 Racket Reference5.) Тело условия match может содержать произвольный код Racket. Переменные шаблона могут использоваться в области видимости тела, как op в (print op).
Адамс Д. «Автостопом по Галактике».
Этот принцип структурирования кода в соответствии с определением данных был предложен в книге How to Design Programs Фелляйзена и др. (Felleisen et al.) («Как проектировать программы. Введение в программирование и компьютерное вычисление»).
Да, один сообразительный студент в первой версии курса именно так и поступил!
Все структуры AST определены в файле utilities.rkt в прилагаемом коде.
Ахо А. и др. «Компиляторы: принципы, технологии и инструменты».
См. https://docs.racket-lang.org/reference/match.html.
См. https://docs.racket-lang.org/guide/match.html.
В этом примере форма match проверяет, является ли AST (1.1) бинарным оператором, и связывает его части с тремя переменными шаблона op, child1 и child2. В общем случае условие match состоит из шаблона и тела. Шаблоны рекурсивно определяются как переменная шаблона, имя структуры, за которой следует шаблон для каждого из аргументов структуры, или S-выражение (символ, список и т.д.) (полное описание match см. в разделе 12 документа Racket Guide4 и главе 9 Racket Reference5.) Тело условия match может содержать произвольный код Racket. Переменные шаблона могут использоваться в области видимости тела, как op в (print op).
Результат равен 42 – ответ на главный вопрос жизни, Вселенной и всего остального: 42!7 Мы записали эту программу в конкретном синтаксисе, тогда как разобранный абстрактный синтаксис имеет вид:
Программы рекурсивны по своей природе. Например, выражение часто состоит из нескольких меньших подвыражений. Таким образом, можно рассматривать рекурсивную функцию как естественный метод обработки всей программы. В качестве первого примера такой рекурсивной функции определим функцию is_exp, как показано на илл. 1.3; она получает произвольное значение и определяет, является ли оно выражением в LInt. Говорят, что функция определяется структурной рекурсией, если для ее определения используется последовательность условий match, соответствующих грамматике, а тело каждого условия содержит рекурсивный вызов к каждому дочернему узлу6. Иллюстрация 1.3 также содержит определение функции is_Lint, устанавливающей, является ли AST программой в языке LInt. В общем случае можно написать одну рекурсивную функцию для обработки каждого нетерминального элемента в грамматике. Из двух примеров в нижней части листинга первый принадлежит LInt, а второй нет.
Для каждой разновидности узлов мы определим структуру (struct) Racket. Для этой главы достаточно всего двух разновидностей узлов: для целочисленных констант (литералов) и для примитивных операций. Ниже приведено определение struct для целочисленных констант3.
Глава 2. Целые числа и переменные
В этой главе рассматривается компиляция подмножества Racket в код ассемблера x86-64 (Intel, 2015). Это подмножество, называемое LVar, включает целочисленную арифметику и локальные переменные. Для простоты вместо x86-64 мы будем использовать короткое x86. Глава сначала описывает язык LVar (раздел 2.1), после чего представляет язык ассемблера x86 (раздел 2.2). Так как язык ассемблера x86 весьма обширен, мы обсудим только инструкции, необходимые для компиляции LVar. Другие инструкции x86 будут представлены в следующих главах. После знакомства с LVar и x86 мы поговорим о том, чем они отличаются, и построим план преобразования с LVar на x86 за несколько шагов (раздел 2.3). В оставшейся части главы подробно разбирается каждый шаг. Мы постараемся предоставить достаточно информации, чтобы хорошо подготовленный читатель в компании нескольких друзей мог быстро реализовать компилятор с LVar на x86. Чтобы дать представление о масштабе первого компилятора, отметим, что учебный образец решения для компилятора LVar содержит приблизительно 500 строк кода.
2.1. Язык LVar
Язык LVar расширяет язык LInt, добавляя в него переменные. Конкретный синтаксис языка LVar определяется грамматикой, представленной на илл. 2.1, и абстрактным синтаксисом, представленным на илл. 2.2. Нетерминальный элемент var может быть любым идентификатором Racket. Как и в случае с LInt, оператор read является нулевым, оператор «-» — унарным, а «+» — бинарным. По аналогии с LInt абстрактный синтаксис LVar включает структуру Program для обозначения начала программы. Несмотря на простоту языка LVar, его возможностей достаточно для демонстрации некоторых методов компиляции.
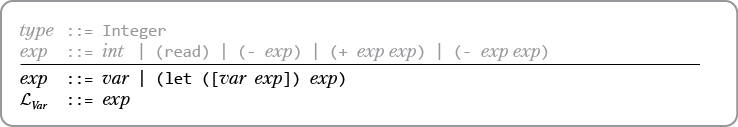
Илл. 2.1. Конкретный синтаксис LVar

Илл. 2.2. Абстрактный синтаксис LVar
Познакомимся ближе с синтаксисом и семантикой языка LVar. Конструкция let определяет переменную для использования в теле программы и инициализирует переменную значением выражения. Абстрактный синтаксис let представлен на илл. 2.2. Конкретный синтаксис let выглядит так:
(let ([var exp]) exp)
Например, следующая программа инициализирует x значением 32, а затем вычисляет тело (+ 10 x), что дает результат 42.
(let ([x (+ 12 20)]) (+ 10 x))
Если для одной переменной существуют несколько let, используется ближайший экземпляр let. Иначе говоря, определения переменных замещают предшествующие определения. Перед вами программа с двумя let, определяющими две переменные с именем x. Сможете ли вы предсказать результат?
(let ([x 32]) (+ (let ([x 10]) x) x))
Чтобы вы лучше понимали, какое вхождение переменной соответствует тому или иному определению, в следующем фрагменте вхождения x помечаются круглыми скобками. Убедитесь, что ваш ответ к предыдущему примеру совпадает с ответом из следующей аннотированной версии:
(let ([x1 32]) (+ (let ([x2 10]) x2) x1))
Инициализирующее выражение всегда вычисляется до тела let, так что в следующем примере оператор read для x будет выполнен раньше оператора read для y. Если передать следующей программе 52, а затем 10, она выдаст результат 42 (а не –42).
(let ([x (read)]) (let ([y (read)]) (+ x (- y))))
2.1.1. Расширение интерпретаторов через переопределение методов
Чтобы подготовиться к рассмотрению интерпретатора LVar, сначала объясним, почему мы реализуем его в объектно-ориентированном стиле. В этой книге мы определяем множество интерпретаторов, по одному для каждого изучаемого языка. Так как каждый язык строится на базе предыдущего, у этих интерпретаторов много общего. Конечно, общий код хотелось бы написать только один раз, чтобы обойтись без лишних повторений. Простейший интерпретатор LVar мог бы обрабатывать условия для переменных и let, передавая управление интерпретатору LInt в остальных случаях. Эта идея продемонстрирована в следующем коде (смысл параметра env объясняется в разделе 2.1.2):
(define ((interp_Lvar env) e)
(match e
(define ((interp_Lint env) e) [(Var x)
(match e (dict-ref env x)]
[(Prim '- (list e1)) [(Let x e body)



















