

автордың кітабын онлайн тегін оқу Работа с BigData в облаках. Обработка и хранение данных с примерами из Microsoft Azure
Технический редактор Н. Хлебина
Литературный редактор Н. Хлебина
Художники Н. Гринчик, С. Заматевская
Корректоры О. Андриевич, Е. Павлович
Верстка Г. Блинов
Александр Сенько
Работа с BigData в облаках. Обработка и хранение данных с примерами из Microsoft Azure. — СПб.: Питер, 2021.
ISBN 978-5-4461-0578-6
© ООО Издательство "Питер", 2021
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Благодарности
Я хотел бы посвятить эту книгу моей семье: обожаемой жене Серафиме и любимому сыну Демьяну. Выражаю огромную признательность и благодарность своей неповторимой, замечательной и горячо любимой супруге. Ты очень поддерживала, помогала и вдохновляла меня. Спасибо тебе, Любимая!
Также выражаю благодарность всем тем, кто поддерживал меня и помогал мне: замечательной теще Инессе Витальевне, маме, папе, моему начальнику Мартину Ларссону и всем коллегам по работе. Выражаю отдельную благодарность специалисту проектной группы Олегу Сивченко и ведущему редактору Надежде Гринчик за терпение и неоценимую помощь.
Введение
...Мы просто расхаживаем по библиотеке, заполненной книгами на непонятном языке, и глазеем на цветные корешки... Вот и все!
Станислав Лем. Солярис
Человек, что бы он ни делал, почти никогда не знает, что именно он делает, во всяком случае, не знает до конца.
Станислав Лем. Сумма технологии
Книги, популяризующие нынешнее состояние знаний — скажем, знаний в области физики, — причем популяризующие хорошо, представляют дело так, будто существуют две четко отделенные друг от друга области: область того, что наукой уже раз и навсегда установлено, и того, что еще до конца не выяснено. Это похоже на посещение прекрасного, снизу доверху великолепно обставленного здания, его отдельных покоев, где то тут, то там лежат на столах нерешенные головоломки. Мы покидаем сей храм с уверенностью, что эти загадки рано или поздно будут решены, в чем убеждает нас великолепие всей постройки. У нас даже не мелькнет и мысли, что решение этих головоломок может привести к разрушению половины здания.
Станислав Лем. Сумма технологии
Любое время хорошо для пополнения знаний...
Жюль Верн. Дети капитана Гранта
Здравствуй, дорогой читатель!
В твоих руках книга о двух очень интересных направлениях современных Computer Science: облачных технологиях и больших данных. В последнее время оба этих направления получили широчайшее распространение благодаря новым интересным возможностям, которые предоставляются вместе с традиционными информационными системами, а также выгодам, получаемым конечным пользователем. Такое положение дел достигается за счет того, что технологии больших данных позволяют работать с огромными массивами неструктурированных и слабоструктурированных данных или с потоками данных, анализируя их и находя в них скрытые закономерности.
В качестве источников больших данных часто выступают события, совершаемые массово и фиксируемые в базе данных (БД) или в файлах. Например, это могут быть файлы логов высоконагруженного веб-сервера, игровые действия пользователя в массовой игре, хранящиеся в нереляционной базе, или данные, относящиеся к бизнес-процессам, хранящиеся в реляционном хранилище данных.
Прежде чем попасть в базу данных, все эти события на пути от источников к приемнику образуют поток сообщений. Если источников событий много и количество сообщений, отправляемых одиночным источником в единицу времени, велико, то возникает задача концентрации этих сообщений, то есть предоставления им общей входной точки («воронки» или «хаба») для последующего сохранения в той или иной базе данных. Согласование сообщений источников и хранилища, помимо их концентрации, может потребовать предварительной фильтрации (когда сохраняются только те сообщения, которые отвечают определенным критериям), маршрутизации (перенаправление сообщений различного типа в разные источники) и трансформации (например, выборка определенных полей сообщения, агрегация, арифметические преобразования и пр.). Выполнение всех этих действий относится к потоковому анализу больших данных. Помимо пассивного сохранения сообщений, очень часто может требоваться выполнение каких-либо действий в ответ на появление определенного сообщения или тренда в потоке. Пример такой задачи — обработка потока транзакций от банкомата в банковский процессинговый центр для установления факта мошеннических действий. Концептуально похожий пример — анализ потока сообщений в системе логирования в целях выявления хакерских атак (например, веб-приложений) или мошеннических действий (в онлайн-играх).
После того как в системе накопилось много данных за определенный промежуток времени, может потребоваться их анализ специалистом по анализу данных. Например, данные системы мониторинга потребления электроэнергии представляют интерес с точки зрения выявления как общей структуры энергопотребления, так и частных аномалий в виде поиска наиболее расточительных потребителей, узких мест. Подобный анализ должен производиться при непосредственном взаимодействии с исследователем данных (data scientist) и потому называется интерактивным.
Когда закономерности в данных нельзя обнаружить с помощью традиционных методов анализа, то есть путем выполнения стандартных действий (фильтрация, агрегирование, объединение, пересечение, сортировка), используются алгоритмы глубокого изучения данных, часто называемые машинным обучением. Суть его состоит в том, что для представления закономерностей, скрытых в данных, задействуют различные математические модели, и собственно «обучение» состоит в подборе изменяемых параметров этих моделей так, чтобы обеспечить наибольшее согласование между реальными результатами и результатами, полученными моделью.
Как только характер закономерностей в больших данных установлен на этапе интерактивного анализа, может возникнуть задача построения системы, выполняющей периодический анализ накопившихся данных — пакетный анализ. Самый простой пример — система мониторинга электроэнергии, в которой ежедневно формируются отчеты о суммарном потреблении каждым потребителем, распределяется потребление электроэнергии по часам, для каждого потребителя в отдельности, по потребителям и др. Результаты, полученные на этапе интерактивного анализа, могут быть использованы для выявления паттернов нерационального потребления электроэнергии и выдачи рекомендаций.
Помимо собственно данных, выдаваемых техническими устройствами того или иного вида, к большим данным можно отнести данные, генерируемые сложными социальными и техническими системами. В качестве примера можно привести систему общественного транспорта с регистрацией как прямых событий (включая данные мониторинга транспортных средств, оплаты пассажирами проезда), так и связанных с ними (например, событий, связанных с поломками подвижного состава и инфраструктурных элементов). Накопление и централизация данных в этом случае позволяет глобально оптимизировать транспортные потоки. Подобного результата можно достичь, например анализируя корреляции в загрузке транспорта и оперативно перераспределяя его между участками с неодновременными пиками.
Кроме того, анализ потоков поломок и установление корреляции его с внешними событиями (загруженность маршрута, износ транспортного средства, погодные условия, дорожная обстановка, стиль вождения и пр.) позволяет применить так называемое упреждающее обслуживание (predictive maintenance). Суть его заключается в том, чтобы на основе анализа исторических данных, касающихся отказов устройств и систем, выявить паттерны наступления отказов (допустим, перегрузка электросети при планируемом резком похолодании вечером в пятницу) и предотвратить их, заблаговременно приняв соответствующие меры. То есть в данном случае прогнозируется наступление отказа на основе анализа большого объема исторических данных и текущего состояния системы. Очевидно, что при правильном прогнозе своевременная диагностика и обслуживание позволят транспортным компаниям снизить математическое ожидание потерь, не прибегая при этом к существенному повышению стоимости обслуживания, поскольку его периодичность, по сути, не меняется, за исключением внепланового обслуживания, требующегося по результатам предсказания. И здесь снова возникает проблема сбора, хранения и анализа большого количества событий (в данном случае это отказ, информация о местоположении транспортного средства в настоящий момент и т.п.).
В настоящей книге будет уделяться пристальное внимание облачным сервисам потоковой, интерактивной и пакетной обработки, а также сервисам хранения и копирования этих данных между различными источниками. Машинное обучение (возможно, несправедливо) исключено из материала книги ввиду его специфичности и необходимости дополнительного описания теории. Эта интереснейшая тема заслуживает отдельной книги.
При построении систем, оперирующих большими данными, возникает много технических проблем, связанных с хранением данных и их обработкой, которые сводятся к построению больших кластеров серверов, объединенных высокоскоростными и высокопроизводительными сетями передачи данных. С ростом масштаба больших данных (объемы хранения, ежесекундный поток данных и др.) требуются все более мощные вычислительные ресурсы. Как следствие, каждой организации, отвечающей за подобные системы, становится необходимо иметь свой центр обработки данных (ЦОД, датацентр), что влечет определенные трудности: нужно помещение ЦОД с системой поддержания микроклимата, системой электроснабжения, вентиляции, кондиционирования и т.д. Кроме того, требуется штат как высококвалифицированных системных администраторов разного профиля для обслуживания центра, так и энергетиков, специалистов по кондиционированию, вентиляции и пр.
А как быть с переменной нагрузкой на все имеющиеся серверы, например очень большой в одних ситуациях (возможно, 10 % времени), и совсем маленькой в других (остальные 90 %)? Масштабирование системы в подобных случаях сопряжено с необходимостью закупки серверов, расширения площадей хранения, расширения полосы пропускания сети, подвода новых мощностей от электросетей и т.д. И это решение совершенно негибкое, то есть слабо нагруженные серверы все равно будут включены и задействованы с минимальной нагрузкой или просто будут занимать место в стойках ЦОДа. Приведу другой пример: допустим, данные нужно обработать разово, но быстро, что требует использования больших вычислительных ресурсов. Например, необходимо проанализировать логи веб-сервера, чтобы определить посещаемость за большой промежуток времени. Если лог-файл огромен, а анализ надо произвести разово, то как быть с вычислительными мощностями? Закупить, а потом продать?
В подобных ситуациях на помощь приходят облака. По сути, это сети дата-центров, по требованию предоставляющие их пользователям вычислительные ресурсы в аренду. Масштабы ресурсов могут значительно разниться: от «маленьких» виртуальных машин с оперативной памятью 0,25 Гбайт и одним низкопроизводительным ядром до кластеров из многих сотен виртуальных машин. Кроме того, при использовании облака легко решается проблема масштабирования ресурсов — у облачных провайдеров выделение и освобождение ресурсов происходит динамически и занимает минуты, так что можно создать автоматически масштабируемые архитектуры. Однако виртуальные машины, пусть и размещенные в облаках, все равно требуют штата системных администраторов, ведь необходимо обслуживать их операционные системы, собирать метрики, обеспечивать безопасность, надежность, доступность…
Чтобы помочь справиться со всеми этими задачами, облачные провайдеры предоставляют целый арсенал сервисов, упрощающих хранение, анализ и визуализацию больших данных. Итак, обе технологии — большие данные и облачные среды — дополняют и обогащают друг друга, создавая симбиотическую среду для анализа и обработки огромных массивов информации.
Из приведенного описания может сложиться впечатление, что большие данные, да еще и в виде размещенной в облаках системы, имеют отношение только к «большим» проектам, но это далеко не так. Задачи, подобные анализу файлов логов веб-сервера, онлайн-обработке событий из мобильных приложений или сети технических устройств, тоже можно решить с помощью систем больших данных. Однако на сей раз решающий фактор — высокая скорость обработки относительно небольших объемов данных, быстрота и простота построения системы анализа. Это возможно благодаря тому, что облачные среды предоставляют сервисы, значительно упрощающие работу с большими данными.
Настоящая книга описывает существующие облачные сервисы и облачные архитектуры, предназначенные для обработки данных, на примере Microsoft Azure и Amazon Web Services (AWS). Другие популярные и интересные облачные платформы (IBM, Google Cloud и др.) не рассмотрены ввиду ограниченности объема книги и конечности сроков ее написания. Кроме того, не затрагиваются вопросы машинного обучения и визуализации данных.
Вы можете недоуменно спросить, что же есть в этой книге? Отвечаю: описание облачных сервисов хранения данных разных типов, сервисов онлайн- и пакетного анализа данных, концентраторов сообщений и коннекторов для доставки данных в облако. Помимо того, представлены Hadoop as a Service (aaS), средства копирования и трансформации данных, архитектуры систем, описано применение подхода Event Driven Design. Примером практического использования этого подхода в книге служит построение сервиса онлайн-покера. Обе технологии, описываемые в книге (облака и большие данные) развиваются очень быстро, и потому крайне тяжело написать о них книгу, которая будет актуальной через год, два, три… Как следствие, я постарался сделать упор на универсальные принципы, идеи и концепции, которые не скоро утратят актуальность. Но книга отнюдь не теоретическая, в ней достаточно кода, примеров из моей практики и рекомендаций по применению той или иной технологии. Особенностью книги является то, что основной упор в ней сделан на архитектуре и возможностях систем, построенных на основе современных сервисов, представленных в облачных средах. Очень широко и всесторонне рассматриваются сервисы и концепции, относящиеся к концепции Event Driven Design. Собственно наука анализа данных затронута лишь в том объеме, который необходим для понимания того, как работает тот или иной сервис, поскольку это тема отдельной книги. Кроме того, разнообразные алгоритмы из арсенала науки анализа данных мало влияют на вид облачной архитектуры конечной системы.
Я надеюсь, что после прочтения книги вы будете ясно понимать принципы работы общих архитектур и существующих облачных сервисов, получите четкое представление о том, как создавать свое приложение на их основе. Знакомство с разнообразием сервисов и технологий доставило мне огромное удовольствие, и я выражаю надежду на то, что вы испытаете это чувство хотя бы частично. Кроме того, еще раз обращаю внимание: как большие данные, так и облачные среды сейчас являются бурно развивающимися областями, и новые сервисы появляются очень быстро. Например, пока я писал книгу, и у Azure, и у AWS появилось порядка полудюжины новых сервисов хранения и анализа данных, а у части существующих поменялся пользовательский интерфейс. (Возьмем сервис Azure Data Factory. Когда я только обсуждал концепцию книги с издательством, интерфейс был убран. А за пару недель до крайнего срока сдачи книги он опять появился! Это повлекло срочный пересмотр и переписывание соответствующей главы, что потребовало от меня много усилий и нервов.) Однако не стоит думать, что книга неактуальна или скоро перестанет быть таковой. Все описанные в ней сервисы будут существовать еще долго, а концепции и архитектуры помогут вам выполнить самостоятельный анализ и принять решение о создании систем в других облачных средах или на собственном физическом оборудовании.
Часть I. Общие вопросы и понятия
1. Что такое облако
Хотите —
буду от мяса бешеный
— и, как небо, меняя тона —
хотите —
буду безукоризненно нежный,
не мужчина, а — облако в штанах!
Владимир Маяковский. Облако в штанах
1.1. Общие сведения
Облачные технологии появились совсем недавно: в 2006 году один из крупнейших американских интернет-магазинов Amazon предоставил свои неиспользуемые вычислительные ресурсы (а к тому времени их объем стал огромным) совершенно новым образом. Традиционно для аренды ресурсов в дата-центрах необходимо было составить договор и внести плату за определенный срок. Линейка типоразмеров серверов (объем оперативной памяти, количество ядер, размер дискового пространства и др.) достаточно обширна и выбирается заранее, до подписания договора. Можно арендовать много серверов, связать их высокопроизводительной сетью, подключить балансировщик нагрузки и получить систему, обрабатывающую большую нагрузку. У подобной модели использования ресурсов есть существенные неудобства. При создании приложений зачастую неизвестно, какая потребуется нагрузка, на какой срок арендовать серверы приложения. Или такой пример: создается стартап, арендуются серверы и до завершения срока аренды этот стартап «умирает». Что делать со ставшими ненужными арендованными серверами? Еще сложнее дело обстоит с покупкой физических серверов. Ведь их, помимо администрирования операционной системы и установленных приложений, необходимо обслуживать физически. Сюда входит подбор помещения, электропитания, системы охлаждения, вентиляции… Все эти проблемы можно решить с помощью эластичных вычислительных ресурсов, предоставляемых облачными провайдерами. (Платформа Amazon Web Services называет эти ресурсы EC2 — Elastic Cloud Computers.) Ключевые преимущества облачной модели таковы:
• ресурсы предоставляются по требованию и таким же образом освобождаются;
• плата начисляется за фактическое время использования ресурсов;
• предоставление и освобождение ресурсов производится самим потребителем ресурсов через веб-портал, без всякой бумажной волокиты с договорами.
Помимо виртуальных машин, в облачных средах предоставляются различные сервисы, позволяющие строить различные архитектуры: сервисы виртуальных сетей, подсетей, балансировщики нагрузки, списки контроля доступа (Access Control Lists, ACL)), выделенные IP-адреса и др. Эти сервисы составляют основу инфраструктуры как сервиса (Infrastructure as a Service, IaaS). Конечно, прямая стоимость годовой аренды физического сервера может быть меньше, чем стоимость аренды облачного сервера с почасовой оплатой с такими же характеристиками, но многие облачные провайдеры (например, AWS) предоставляют возможность долгосрочной аренды виртуальных машин по ценам существенно меньшим, чем при почасовой оплате. Если же серверы требуются на небольшое время и заранее не известно, какого размера должна быть виртуальная машина, то эластичные виртуальные машины могут стать единственным приемлемым выбором. В случае же прямой покупки физических серверов задача выбора, приобретения, настройки и обслуживания, а также их продажи после применения становится весьма непростой. Чтобы обеспечить возможность выделения пользователям ресурсов, облачные провайдеры имеют крупные, географически разнесенные дата-центры, веб-порталы для получения доступа к их ресурсам, а также API для программного доступа. Это позволяет сделать то, что нельзя выполнить с помощью любой другой традиционной технологии: код программы может сам себе выделять столько ресурсов, сколько ему нужно. Или же программы могут создавать инфраструктуру, на которой они будут выполняться.
Помимо «голой» инфраструктуры, облачные провайдеры предоставляют наиболее типовые приложения в виде веб-сервисов. В качестве примера можно привести облачное хранилище данных (cloud storage), сервис предоставления учетных записей (identity provider), сервис хостинга веб-приложений, базу данных как сервис, брокер сообщений, концентратор сообщений и др. Все эти сервисы, кажущиеся на первый взгляд разрозненным набором, предоставляются как общая платформа. Доступ к ним унифицируется в виде единообразных API, SDK, возможны их «соединение» между собой, общий мониторинг логов и событий и пр. Это иной уровень применения ресурсов облака: платформа как сервис (Platform as a Service). PaaS позволяет пользователям создавать не просто программные продукты в рамках одной операционной системы, веб-платформы и др., но целые информационные системы, компонентами которых будут экземпляры облачных сервисов. Подобно IaaS, сервисы PaaS обычно допускают масштабирование (как ручное, путем выбора соответствующего их размера, так и автоматическое, с помощью различных метрик и событий). Как правило, сервисы PaaS предоставляют гораздо меньшие права для доступа к вычислительным ресурсам инфраструктуры, лежащей в их основе. Например, сервисы хостинга веб-приложений не позволяют установить специфические программы, COM-компоненты, поменять библиотеку DLL в GAC, изменить запись в реестре и др., поскольку отсутствует root-доступ. Но взамен они предоставляют удобные порталы администрирования, интеграцию с другими сервисами, встроенные средства логирования и мониторинга, доступность 99,99 % времени и др.
В настоящее время крупнейшими облачными провайдерами являются Amazon Web Services (AWS), Microsoft Azure, Google Cloud, IBM Bluemix, Oracle. В книге приведены описания сервисов двух облачных провайдеров: AWS и Microsoft Azure. AWS — первый в истории облачный провайдер, а Microsoft Azure — облачный провайдер от корпорации Microsoft, обеспечивающий интеграцию практически со всеми сервисами Microsoft.
1.2. Способы создания ресурсов в облаке
В каюте первого класса Остап, лежа с башмаками на кожаном диване и задумчиво глядя на пробочный пояс, обтянутый зеленой парусиной, допрашивал Ипполита Матвеевича:
— Вы умеете рисовать? Очень жалко. Я, к сожалению, тоже не умею.
Он подумал и продолжал:
— А буквы вы умеете рисовать? Тоже не умеете? Совсем нехорошо! Ведь мы-то попали сюда как художники. Ну, дня два можно будет мотать, а потом выкинут.
Ильф и Петров. Двенадцать стульев
Прежде чем начать описывать способы создания ресурсов, поясню, что это такое. Как отмечалось выше, облачные провайдеры имеют в основе своих сервисов огромные дата-центры, чьи вычислительные ресурсы с помощью системы виртуализации разделяются на небольшие части: голые виртуальные машины различных размеров с установленной операционной системой (IaaS) и группы виртуальных машин с установленным софтом, предоставляющим доступ только к своим возможностям (PaaS). Так вот, создать облачный ресурс — значит отправить запрос контроллеру ресурсов, размещенному в облачном ЦОДе, на выделение требуемых вычислительных ресурсов из пула доступных. То есть, по сути, ресурс не создается из ничего, а только выделяется по требованию. И тут возможна ситуация (редко, но бывает), когда пользователь запросил ресурсы у контроллера, а они не появились. Это случается из-за того, что физические ресурсы, на которых размещаются виртуальные, уже задействованы другими пользователями. Задачу оптимального распределения доступных ресурсов между пользователями целиком решает контроллер. И если пользователь при создании ресурсов столкнулся с проблемой, он должен повторить попытку, прибегнув к различным вариациям (повторить через некоторое время, сменить регион и повторить, сменить аккаунт и повторить и пр.).
С точки зрения пользователя, выделение ресурсов выглядит как создание ресурсов: он выполнил ряд действий на веб-портале, и в последнем появились ресурсы. На самом деле, конечно же, они были выделены, и об этом не стоит забывать. Однако для простоты и наглядности я буду применять термин «создание».
Существует четыре способа управления облачной инфраструктурой (рис. 1.1). Первый, самый простой и очевидный — задействовать веб-портал. При этом пользователь должен иметь соответствующие права на создание ресурсов. Ручной способ очень прост: у всех облачных провайдеров есть удобные порталы, обширная документация, видеоинструкции и др. Не нужны никакие дополнительные сервисы, SDK и пр.
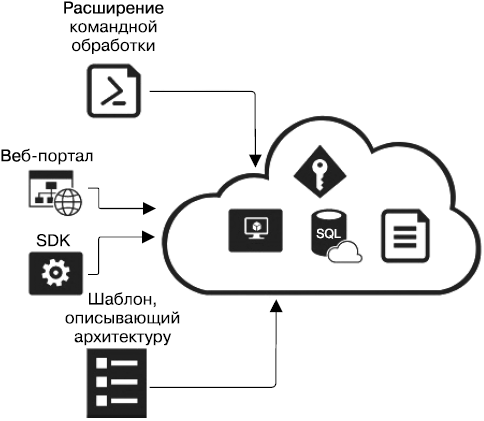
Рис. 1.1. Способы управления облачной инфраструктурой
Однако у данного способа есть недостатки:
• длительное время создания инфраструктуры;
• недостаточная надежность (в случае проблем с ресурсами их придется пересоздавать вручную, со всеми ручными настройками, конфигурированием и пр.);
• трудность переноса инфраструктуры в новый регион или аккаунт — ее понадобится вручную клонировать или копировать (данный недостаток частично сглаживается тем, что облачные провайдеры позволяют копировать или клонировать ресурсы, но эта процедура все равно требует ручного инициирования);
• процесс создания ресурсов в этом случае невозможно автоматизировать.
Второй способ — применить программные библиотеки (Software Development Kit, SDK), обеспечивающие доступ к ресурсам облака из кода пользовательских программ. Как правило, SDK представляет собой набор классов и методов, облегчающих программные операции с ресурсами облака. Чтобы обеспечить доступ к таким ресурсам, программа с облачным SDK должна содержать ключи учетной записи, которая будет иметь доступ к облаку. В облаке эти ключи зарегистрированы в виде пользователя в активном каталоге облачного аккаунта, обладающего правами выполнять программное манипулирование ресурсами облака (такой пользователь называется принципалом — service principal). И управление этими учетными записями происходит таким же образом, как и учетными записями пользователей облачного веб-портала. В числе достоинства такого подхода — возможность создания программ, которые сами себе создают облачные ресурсы, а также автоматизированного управления облачным аккаунтом.
К третьему способу создания облачных ресурсов относят специализированные расширения для языков командной строки — shell, CMD и др. (например Azure PowerShell, AWS CLI и пр.), работающие в ней напрямую. Для подключения этих расширений к облачным ресурсам необходимо импортировать ключи или выполнить вход в аккаунт через форму ввода логина/пароля. Как и в случае SDK для сценарных языков программирования, SDK для командной оболочки позволяет описывать облачную инфраструктуру в виде набора команд, каждая из которых создает или конфигурирует соответствующий облачный сервис.
И SDK, и команды оболочки оперируют в конечном итоге с API облачного провайдера (как правило, REST API), доступ к которым также позволит манипулировать ресурсами облака.
Четвертый способ создания облачных ресурсов — применить шаблоны. В этом случае все требуемые ресурсы и связи между ними описываются с помощью текстового файла в формате YAML или JSON. Такой шаблон может быть загружен в соответствующий облачный сервис напрямую через веб-портал или через CLI-команды.
Описание инфраструктуры через шаблон — очень мощный механизм, широко применяемый для конфигурирования различных инфраструктур (например, в системах Ansible, Chef, Puppet и др.). Как уже указывалось, шаблоны представляют собой текстовые файлы, которые могут храниться в репозитории шаблонов или чаще всего в репозитории GitHub. Для облака AWS сервис создания ресурсов с помощью шаблонов называется CloudFormation (поддерживает YAML и JSON), у Azure это ARM Template (в настоящее время поддерживает только JSON). На веб-портале AWS имеется специальный редактор, упрощающий создание и конфигурирование шаблона. Последний может быть загружен в файловое хранилище S3, репозиторий CodeCommit или любое другое место, доступное для сервиса CloudFormation. Этот сервис создает стек — набор ресурсов, управляемых совместно (создание, удаление и обновление).
Сервис CloudFormation очень удобен в применении со сторонними сервисами конфигурирования — например, Ansible. Это широко используемое приложение, задействующее YAML для создания конфигурационных шаблонов, которые служат для администрирования группы серверов (преимущественно Linux, но есть расширения и для Windows), не требуя инсталляции на этих серверах «агентов». Для работы Ansible необходимы только ключи доступа к ресурсам (SSH-ключи для Linux-хостов, сертификат для PowerShell-доступа к Windows-хостам или ключи доступа к AWS). Шаблон CloudFormation для Ansible представлен в виде JINJA, допускающего передачу параметров через переменные Ansible.
1.3. Безопасность облачных ресурсов
В мире существует нежелательный парадокс: чем больше власти, тем меньше ответственности.
Валентин Пикуль. Битва железных канцлеров
Воруют так, что печку раскаленную нельзя без присмотра оставить.
Отвернись только — и печку голыми руками вынесут…
Валентин Пикуль. На задворках великой империи
Наряду с неоспоримыми преимуществами, хранение и обработка данных в облачных средах потенциально может доставить ряд проблем, которых нет (или, вернее, они проявляются не так отчетливо) в случае размещения и обработки данных в собственных дата-центрах. Это обусловлено рядом причин. Во-первых, облачные среды сами по себе публично доступны и все сервисы, если явно не сконфигурировано иное, доступны для всех в Интернете. Во-вторых, защита данных и инфраструктуры от непреднамеренных действий пользователей лежит вне компетенции облачного провайдера. Кроме того, облачные инфраструктуры, работающие с большими данными, часто содержат в своем составе большие кластеры виртуальных машин, что требует применения специальных мер для обеспечения надежной работы всей системы. Помимо этого, информация физически будет передаваться по незащищенным каналам и существует угроза ее перехвата. Рассмотрим подробнее все перечисленные и некоторые другие аспекты безопасности облачных сред.
Наиболее распространенный способ защиты конечных точек облачных сервисов — ограничение доступа к ним с помощью механизмов аутентификации и создания списков разрешенных IP-адресов, с которых можно получить доступ к точкам. Рассмотрим прежде всего различные способы обеспечения доступа из заданного адресного пространства.
Сервисы, относящиеся к IaaS, а также в ряде случаев к PaaS, требуют для своего создания сконфигурированной облачной виртуальной частной сети (VNet, VPC), разбитой на подсети. Доступ к конечным точкам сервисов, расположенным в этих подсетях, можно регулировать с помощью конфигурирования сетевых групп безопасности (Network Security Group, NSG) (рис. 1.2), которые представляют собой списки контроля доступа, ACL.
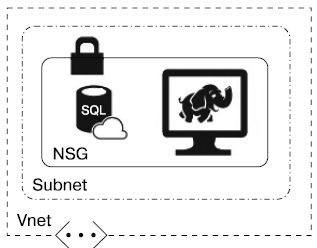
Рис. 1.2. Ограничение доступа к конечным точкам облачных сервисов с помощью сетевых групп безопасности
Итак, виртуальная часть сети — один из базовых сервисов IaaS. Он представляет собой облачный аналог локальной сети и служит для предоставления диапазона IP-адресов для размещения в них ресурсов. Виртуальную частную сеть можно разделить на подсети (subnet), а между ними — установить правила маршрутизации IP-пакетов. Кроме того, на подсети можно установить списки контроля доступа, которые именуются сетевыми группами безопасности. Это позволяет логически разделять архитектуры информационных систем на различные уровни (например, уровень данных, бизнес-логики, фронтенд) путем размещения каждого уровня в своей подсети и установления правил маршрутизации.
NSG представляет собой список доступа, содержащий набор записей. Каждая запись состоит из таких элементов, как:
• название;
• число, определяющее приоритет просмотра списка записей;
• диапазон IP-адресов (для одного конкретного адреса это /32);
• номер порта;
• действие — ALLOW или DENY («Позволить» или «Отклонить») по отношению к запросу, поступившему с данного адреса.
Кроме того, указывается протокол, к которому применимо действие ALLOW или DENY (TCP, UDP, ICMP и пр.). Безопасность конечных точек в данном случае обеспечивается ограничением к ним доступа извне. Помимо NSG, ряд облачных сервисов, не требующих виртуальной частной сети (например, Azure SQL), имеют фаерволы — списки «разрешенных» и «запрещенных» диапазонов. Хорошей практикой является повсеместное использование NSG и фаерволов. При этом необходимо, чтобы все порты, относящиеся к удаленному доступу/управлению (например, 22 для SSH, 3388 для RDP) или непосредственно к сервису (скажем, 1433 для MS SQL), были недоступны из Интернета вне диапазона адресов виртуальной частной сети. Для получения же доступа к сервисам из «разрешенной» локальной сети или с разрешенного компьютера следует установить VPN-шлюз из локальной сети или с компьютера в виртуальную частную сеть или непосредственно к экземпляру сервиса. Помимо шлюза, при соединении локальной сети с виртуальной частной сетью необходимо применить промежуточный хост, прокси-хост (рис. 1.3), который будет транслировать запросы и разрешать частные адреса облачных ресурсов из локальной сети. Прокси-хост в различных реализациях можно разместить как в облачной сети, так и в локальной. В последней может располагаться контроллер домена, сервер БД с данными, которые не могут быть размещены в облаке, а также прочие серверы, которые могут быть размещены только в локальной сети.
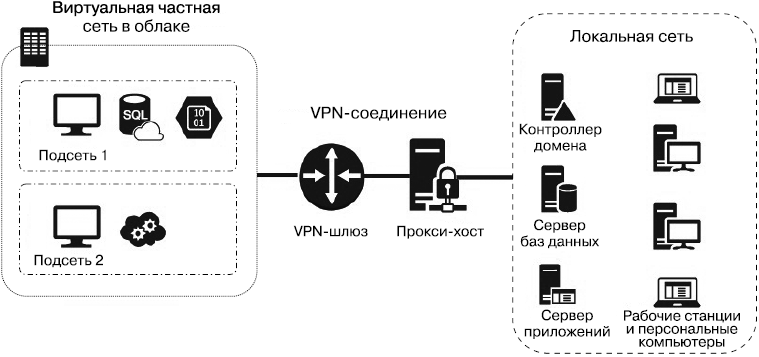
Рис. 1.3. Обеспечение защищенного доступа к облачным ресурсам
Некоторые конечные точки (скажем, API управления самого облачного аккаунта) не оборудованы ни фаерволом, ни NSG. Для их защиты используется как шифрование трафика (HTTPS), так и специальные ключи доступа к ресурсам. Ключи могут генерироваться непосредственно защищаемым сервисом и применяться в заголовках REST-запросов. Например, сервис хранилища Azure Storage задействует аутентификацию на основе HMAC — Hash-based Message Authentication Code, который должен содержать подписанный алгоритмом SHA-256 токен как заголовок аутентификации. Следующий стандартный механизм аутентификации запросов — применение протокола OAuth 2.0, при котором пользовательские учетные данные хранятся в сервисе хранения учетных данных (в случае Azure это Azure Active Directory, а AWS — Cognito). В общем случае облачный сервис хранения учетных данных включает в себя пользователей, роли и API-ресурсы, защищаемые этим протоколом. Любой запрос к REST API ресурсов, зарегистрированным в этом сервисе (а это, по сути, все REST API конечных точек управления облачными ресурсами), должен в своем заголовке содержать токен, который можно получить, если выполнить процедуру ввода учетных данных в каталог.
Еще один «эшелон» защиты данных в облачных ресурсах — это их шифрование. Распространенный подход в данном случае — так называемое прозрачное шифрование данных (transparent data encryption, TDE). Суть его состоит в том, что все шифрование и дешифрование данных происходит «за кулисами», без участия пользователя, с помощью ключей шифрования, которые генерируются и хранятся самим облачным аккаунтом. В случае Azure эти ключи хранятся в Azure KeyVault, а в случае AWS — в AWS KMS.
Следующее звено защиты — сервисы, отвечающие за мониторинг запросов, поступающих к ресурсам и осуществляющие аудит пользовательской активности. Например, Azure Security Center, который может выполнять мониторинг очень многих ресурсов, выдает рекомендации по их защите и следит за входящим трафиком. На практике в реальной рабочей системе подобный сервис позволил обнаружить и успешно отразить несколько крупных хакерских атак на систему, за которую я отвечал, в том числе с использованием распределенной сети зараженных серверов (ботнет). Поэтому я настоятельно рекомендую применять подобные сервисы для обязательной защиты облачных ресурсов.
И последняя линия защиты данных, встроенная в облачные ресурсы, включает в себя сервисы анализа пользовательской активности, например Audit & Threat Detection для Azure SQL. Этот сервис обеспечивает внутренний аудит всех запросов в базе данных Azure SQL и анализ их на предмет подозрительных действий. У данного вида защиты есть один недостаток: в результате использования в реальной системе при включении максимального уровня аудита и защиты существенно снижается отзывчивость и общая производительность.
1.4. Резюме
В данной главе мы рассмотрели пути создания облачных ресурсов и уровни обеспечения безопасности. Эти ресурсы можно создавать с помощью веб-портала, через SDK (или напрямую с использованием REST API), расширения для интерфейса командной строки и, наконец, применив специальный шаблон, описывающий требуемое состояние облачных ресурсов. Шаблоны автоматизации наиболее удобны при построении больших и сложных систем, поскольку обеспечивают полный контроль над ресурсами и не допускают неконтролируемого разрастания неиспользованных ресурсов и, соответственно, увеличения месячного счета за использованные ресурсы.
Вопросы безопасности информации в облаках являются комплексными. Пользователь облачных ресурсов сам отвечает за защиту своих ресурсов от несанкционированного доступа и должен самостоятельно выбирать для этого стратегию.
2. Что такое BigData
Поэзия —
та же добыча радия,
в грамм добыча,
в годы труды.
Изводишь
единого слова ради
Тысячи тонн
словесной руды.
Владимир Маяковский
Следует избегать бесполезных знаний.
Станислав Лем. Магелланово облако
Современное состояние Computer Science характеризуется тем, что, помимо естественных данных — результатов научных наблюдений, метеорологических данных, социологических и др., — появляется огромное количество данных, связанных с работой информационных систем. Эти новые данные существенно отличаются от тех, что анализировались на заре компьютерной эры. Те старые данные (их можно условно назвать естественно-научными) в основном требовали математической обработки.
В отличие от них данные современных информационных систем (большие данные) не могут быть представлены простыми математическими моделями, чьи параметры следует определить. Кроме того, эти данные отличаются существенной неоднородностью, разнообразной и непредсказуемой структурой, и зачастую непонятно, как их обрабатывать и нужно ли это вообще? Можно ли в них найти что-либо полезное? Этих данных настолько много, что их анализ за разумное время требует вычислительных ресурсов, существенно превышающих вычислительные ресурсы самой информационной системы. Это значит, что данные часто лежат мертвым грузом, несмотря на скрытые в них закономерности, составляющие полезную информацию, которую требуется найти. Поиск таких закономерностей называется Data Mining — добывание данных из груды пустых данных (по аналогии с пустой породой). Что значит «обрабатывать» данные, и как их добывать? Для ответа на все приведенные вопросы необходимо сначала выяснить, откуда берутся эти большие данные. Их источниками могут быть:
• социальные сети — посты, комментарии, сообщения между пользователями и пр.;
• события, связанные с действиями пользователей в веб- или мобильных приложениях;
• логи приложений;
• телеметрия сети устройств из мира «Интернета вещей» (Internet of Things, IoT);
• потоки событий крупных веб-приложений;
• потоки транзакций банковских платежей с метаданными (время, место платежа и т.д.).
Все эти данные должны быть обработаны в режиме реального времени или же постфактум. В обоих случаях они могут размещаться в различных хранилищах (как общего назначения, так и специализированных) и в разных форматах: CVS, XML, JSON, таблицы в реляционных БД, базах данных NoSQL и пр.
Для пакетной обработки исторических данных различных форматов, расположенных в разных хранилищах, необходим единый подход, обеспечивающий выполнение запросов к данным, хранящимся в указанных выше форматах. В настоящее время распространены следующие подходы.
1. Преобразование данных из различных форматов в общий, допускающий выполнение запросов к единообразным данным. Это можно сделать с помощью облачных сервисов трансформации и копирования, таких как Azure Data Factory и AWS Glue, которые консолидируют данные из разных источников в один. Такое хранилище традиционно называется Data Warehouse (DWH, «склад данных»), а преобразование данных — ETL (Extract Transform Load — «извлечение, преобразование, загрузка»). Данный подход достаточно распространен в традиционных системах, в которых DWH строится на основе кластера SQL-серверов. Подход позволяет использовать все элементы синтаксиса SQL.
2. Складирование данных в единое хранилище без изменения формата. При этом форматы данных остаются прежними (JSON, XML, CSV и т. д). Такое хранилище, в котором данные размещаются в виде несвязанного набора данных, называется Data Lake («озеро данных»). Файловая система, лежащая в основе подобных хранилищ, совместима с HDFS — распределенной файловой системой, которая, в свою очередь, совместима с Hadoop (Azure Data Lake, AWS EMRFS). Такое хранилище позволяет задействовать сервисы из экосистемы Hadoop (например, Hive, Apache Spark и др.) и применять иной подход к операциям с данными: ELT (Extract Load Transform — «извлечение, загрузка, преобразование»), когда данные можно трансформировать после загрузки. При этом используется сервер аналитики или кластер серверов, содержащий процессор специализированного языка запросов, в котором все разнородные источники данных представляются как внешние источники данных, к которым применим SQL-подобный синтаксис. Для подобного хранилища также может использоваться подход MapReduce (будет более подробно описан далее) и обработка данных в оперативной памяти (in memory processing).
3. Кроме того, для обработки потоковых данных существуют специализированные сервисы, допускающие обработку потока сообщений с помощью SQL-подобного синтаксиса (например, сервисы Azure Stream Analytics, AWS Kinesis Analytics) или программных структур (Apache Spark Streaming), а также сервисы для приема и концентрации этих сообщений (например, Azure Event Hub, Kafka, Azure Spark и пр.).
Итак, что же такое большие данные? Прежде всего, это огромные массивы данных или потоки, которые содержат подлежащую извлечению информацию, или же умеренно большие объемы данных, требующие быстрой интерактивной обработки с целью исследования, проверки гипотез, тренировки алгоритмов машинного обучения. Для выполнения этой обработки необходим высокий уровень параллелизма, большой объем оперативной памяти (для in memory processing), что достигается применением кластеров виртуальных машин. Вот тут-то и проявляются все преимущества облачных сред: модель IaaS позволяет создавать кластеры и удалять их по требованию с минимальными затратами. Виртуальные серверы создаются и задействуются только в течение того промежутка времени, когда они нужны, и, соответственно, плата за них взимается только во время прямого использования. Но просто создание кластера для обработки больших данных с последующей установкой требуемых программ и их настройкой — весьма трудоемкое занятие. Кроме того, облачные провайдеры предоставляют отдельные сервисы PaaS больших данных.
2.1. Обработка больших данных
А что значит «обработать большие данные»? Поясню на трех возможных видах анализа: пакетном, интерактивном и потоковом.
Большие данные могут быть обработаны в пакетном режиме, когда они уже присутствуют в хранилище. Чаще всего это необходимо для агрегирования данных и построения аналитических отчетов на их основе.
Рассмотрим в качестве примера систему мониторинга электроэнергии сети зданий. В этой системе замеры потребляемой мощности передаются с малой периодичностью как сообщения от каждого измерительного модуля. Чтобы получить величину дневного потребления электроэнергии, необходимо сложить все замеры с измерительного модуля каждого пользователя в отдельности. Если итоговый результат нужно, к примеру, формировать в виде ежедневного (еженедельного, ежемесячного и пр.) отчета, то наиболее просто реализовать такую систему следующим образом (рис. 2.1).
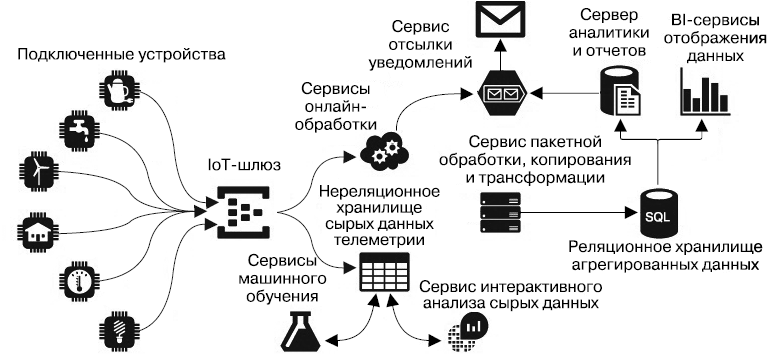
Рис. 2.1. Архитектура системы учета электроэнергии, построенная на основе разделения хранилищ сырых и агрегированных данных — так называемая лямбда-архитектура
Все сообщения от измерительных устройств можно хранить в нереляционном хранилище табличного типа (этот вопрос подробнее рассматривается в части II), например HBase или Cassandra. Каждая строка таблицы будет содержать временну'ю метку (то есть время поступления или отправления сообщения), идентификатор устройства, его отправившего, и собственно величину замера.
Для построения периодического отчета с помощью системы бизнес-аналитики (business intelligence, BI) (например, PowerBI или Microsoft SSRS) или отображения этой величины в браузере необходимо, чтобы данные в агрегированном виде были размещены в БД SQL. А почему нельзя сразу размещать их непосредственно в этой базе? Посчитаем. Предположим, что измерительное устройство отсылает сообщения каждые пять минут. Это значит — 12 отсчетов в час, или около 105 тыс. в год. Теперь предположим, что система мониторинга собирает данные энергопотребления с каждого устройства заказчика, которых могут быть десятки, а самих заказчиков — тысячи. В итоге таблица, хранящая события в реляционной БД, будет содержать многие миллионы строк: допустим, при наличии 100 заказчиков со средним числом подключенных приборов 20 за год такая таблица пополнится 200 миллионами строк. Вот они, большие данные!
Простое применение запроса на выборку данных к подобной таблице может занять очень много время. А если добавить еще необходимость постоянных запросов на обновление таблицы поступающими от устройств сообщениями, а также постоянные запросы от веб-портала или от пользователей на получение отчетов, то станут очевидны будущие проблемы такой архитектуры с одной базой данных. Пакетная же обработка с группировкой и суммированием результатов может быть выполнена, например, с использованием Hadoop MapReduce или Apache Spark. Сами алгоритмы группировки в данном случае можно реализовать с помощью программ на Java (для MapReduce, Spark) или Python (Spark) и запустить в кластере. В итоге размеры таблицы с агрегированными данными в базе данных SQL будут существенно меньше, чем в таблице с сырыми данными. Так, если хранится часовое агрегирование, то в SQL-таблице в 12 раз меньше строк, чем в NoSQL, а если суточное — то в 288 раз. При этом для клиентов запрос на получение данных будет очень простой и высокопроизводительный: выбрать из таблицы агрегатов строки, отфильтрованные по идентификатору заказчика и по требуемому временно'му интервалу без каких бы то ни было группировок в самом запросе.
По поводу подобной архитектуры следует сделать целый ряд замечаний.
1. Обеспечить высокую точность позволяет большое количество замеров, следующих с малым временны'м интервалом. Если интервал постоянный, то можно упустить включение/выключение прибора, произошедшее между замерами. Эта проблема решается путем передачи не периодических замеров, а замеров, приуроченных к событию: включению или изменению величины проходящей мощности более чем на заданную величину. Такое решение, во-первых, разгрузит сеть от слишком частых передач отсчетов (но не полностью — необходимо оставить периодические сообщения от измерителя о его работоспособности), и во-вторых, существенно уменьшит объем сырой таблицы.
2. В случае проблем с сетью и для обеспечения высокой точности вместе с требованием разгрузки сети необходимо физическое разделение отсчетов замера мощности на уровне АЦП измерительного прибора (они могут быть выполнены с высокой частотой дискретизации) и отсылка результатов суммирования измерений в виде сообщения в систему. Чтобы обеспечить это разделение, измерительное устройство должно быть достаточно «интеллектуальным»: обладать памятью и иметь возможность синхронизировать часы, чтобы установить временну'ю метку. Может показаться, что достаточно иметь момент времени приема сообщения, но это неверно. Для получения высокой точности и обеспечения надежности важно каждое сообщение. Они могут быть потеряны как из-за отказа измерительного устройства, так и из-за проблем с телекоммуникационной сетью. Чтобы устранить проблемы с сетью, устройство может запоминать сообщения и пересылать их, когда сеть восстановит работоспособность. И вот тут-то очень важно, чтобы каждому сообщению была присвоена метка времени: когда оно сгенерировано. Это позволит в итоге правильно подсчитать суммарное энергопотребление в заданный временной интервал.
Теперь рассмотрим еще один вопрос: а зачем вообще нужно промежуточное хранилище такого большого объема (рис. 2.2)?
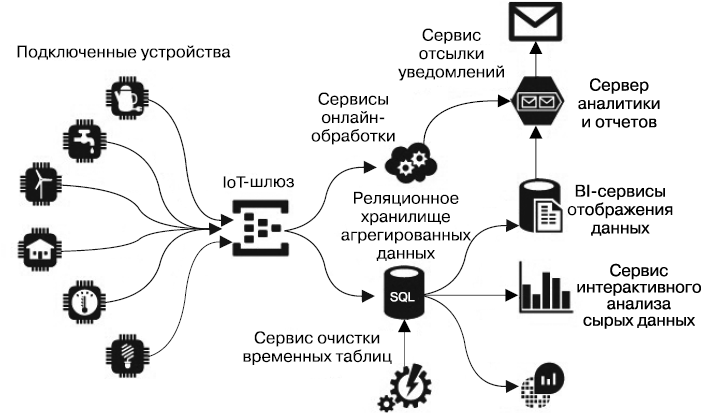
Рис. 2.2. Архитектура системы учета электроэнергии, построенная на основе единого реляционного хранилища данных
Ведь можно периодически очищать сырую таблицу в SQL-хранилище после заполнения данными агрегированной таблицы и хранить только результаты агрегирования. Действительно, при наличии данных энергопотребления в течение каждого дня недели/месяца/года можно легко подсчитать суммарное энергопотребление за бо'льшие периоды времени. Против такого подхода есть ряд возражений. Например, возможна ситуация, когда из-за проблем с сетью не все устройства отослали свои данные вовремя. И если сырая таблица очистится перед тем, как восстановится работоспособность сети и устройства сбросят свои данные, то последние останутся неучтенными и не будет никакого смысла дополнительно усложнять измерители в виде внутреннего буфера сообщений и синхронизируемых часов. В то же время реализация дополнительной логики, обеспечивающей пересчет агрегированных данных в пакетном режиме при приеме недостающих сообщений, позволит произвести правильный и надежный подсчет потребления даже при ненадежной сети передачи данных.
Тут мы сталкиваемся еще с одним аспектом анализа больших данных: потоковой обработкой. В данном случае необходимо из всего потока сообщений обнаруживать те, чья временна'я метка меньше, чем текущее время минус самая большая временная задержка, и при их обнаружении запускать внепланово или планировать дополнительно запустить в определенное время (если построение агрегированных таблиц происходит в конкретное время, скажем по ночам) задачу по повторному пересчету. Для этой цели может служить, например, Apache Storm, Apache Spark Streaming или же Apache Pig.
Следующая причина, побуждающая оставить-таки сырую таблицу без удаления данных, — возможность провести интерактивный анализ хранящихся в ней данных. То есть применить к ним запросы на специальном языке, позволяющем комбинировать, фильтровать, группировать, проводить арифметические операции в режиме реального времени. Это позволяет находить скрытые закономерности в данных, например определять пики энергопотребления, устанавливать корреляцию их с внешними событиями (скажем, с погодой), определять профили пользователей, характеризующиеся оптимальным энергопотреблением. Или для одного пользователя строить типовой профиль применения энергоресурсов и обнаруживать отклонения от него (допустим, утечку электроэнергии, несвоевременное выключение освещения и пр.). Подобные задачи могут решаться с помощью системы интерактивного анализа данных, таких как Spark SQL или Apache Hive, а расширенный интеллектуальный анализ — благодаря применению библиотеки машинного обучения Spark MLib.
Архитектура, содержащая в своем составе хранилища как сырых данных, так и агрегированных, является очень гибкой и позволит создать не просто очередную систему учета электроэнергии, но и интеллектуальную, которая может «подсказать», как уменьшить потребление энергии, где есть узкие места, а это уже принципиально новый уровень по сравнению с простой телеметрией. Такое развитие возможно благодаря тому, что данные в ней хранятся в том виде, в котором они наиболее удобны для выполнения анализа различными сервисами: для обычного сервиса построения отчетов об энергопотреблении — в агрегированном виде, а для целей Data Mining — в сыром.
Ключевой момент всех технологий, работающих с большими данными, — возможность распараллеливания выполняемых задач, областей хранения, памяти и т.д. между группой компьютеров (кластер). Кроме того, эти технологии должны:
• обладать возможностью линейного масштабирования и наращивания производительности путем добавления новых серверов в кластер. Линейность масштабирования означает пропорциональность производительности/объема хранения количеству компьютеров в кластере;
• иметь специальную файловую систему для надежного хранения и доступа к данным, позволяющую оперировать очень большими объемами данных и допускать их репликацию в целях повышения надежности и производительности;
• позволять выполнять запросы к файлам с помощью специального языка запросов или программного интерфейса;
• иметь планировщик, позволяющий распределять эти запросы среди узлов кластера для обеспечения их параллельной работы.
Всеми этими свойствами обладает наиболее популярный фреймворк Apache Hadoop и компоненты его экосистемы — MapReduce, Hive, Pig, Spark, Storm, Kafka, HBase и др. Они более подробно будут описаны ниже.
2.2. Резюме
В главе 2 мы начали знакомиться с большими данными. На примере системы мониторинга электроэнергии я показал, как в системе, оперирующей достаточно малым количеством источников, могут возникнуть большие данные. Отмечалось, что чаще всего сырые данные малопригодны для построения информационных систем и требуется их предварительная обработка, чаще всего агрегация. Однако при этом неизбежно теряется часть информации, которую потенциально можно использовать для глубокого анализа (именуемого еще интеллектуальным, Data Mining). Чтобы разрешить данное противоречие, следует разделять хранение сырых и агрегированных данных. Последнее обеспечивается тем, что источники данных посылают их непосредственно (или через специальные сервисы-концентраторы) в хранилище сырых данных. Далее с помощью сервисов трансформации и копирования информация поступает в хранилище агрегированных данных и становится доступна для построения отчетов.
Мы рассмотрели применение трех видов анализа данных: пакетного, потокового и интерактивного — в контексте этой системы мониторинга. В последующих главах каждый составной элемент подобной системы будет подробно описан.
3. Архитектура облачных систем, оперирующих BigData
Пожалуй, самым трудным и вместе с тем обязательным в архитектуре является простота. Простота форм обязывает придавать им прекрасные пропорции и соотношения, которые сообщали бы необходимую гармонию.
Алексей Викторович Щусев
3.1. Общие сведения
Итак, в предыдущих главах мы рассмотрели облачные среды и небольшой пример архитектуры системы, оперирующей с большими данными. Теперь обобщим все эти сведения и кратко рассмотрим сервисы, предоставляемые облачными провайдерами (рис. 3.1).
Итак, облачные провайдеры позволяют подключать различные устройства, программные продукты, сервисы (игровые устройства, стационарные устройства IoT, подключенные автомобили, мобильные приложения, веб-серверы и серверы приложений, медиасервисы и пр.) через специальные сервисы концентраторов сообщений и шлюзы устройств «Интернета вещей» (IoT Gateway). Концентраторы (AWS Kinesis Stream, Azure Event Hub) обеспечивают однонаправленный прием сообщений извне в облако, а IoT-шлюз (Azure IoT Hub) — двунаправленную коммуникацию с устройствами, то есть возможность обратной отсылки команд устройствам из облака.
Этот поток может быть обработан сервисами потоковой обработки и анализа. Я разделил оба вида терминологически и на рис. 3.1. К сервисам потокового анализа относятся сервисы, которые допускают интерактивный анализ потока данных и позволяют создавать аналитические запросы на специальном языке (чаще всего с SQL-подобным синтаксисом), интерактивно их применять и отображать результаты (например, Azure Stream Analytics). К сервисам потоковой обработки относятся те, которые задействуют модули, написанные на компилируемых языках для построения потоковых задач анализа (таких как Apache Storm в HDInsight или AWS EMR) и не допускающие интерактивного использования.
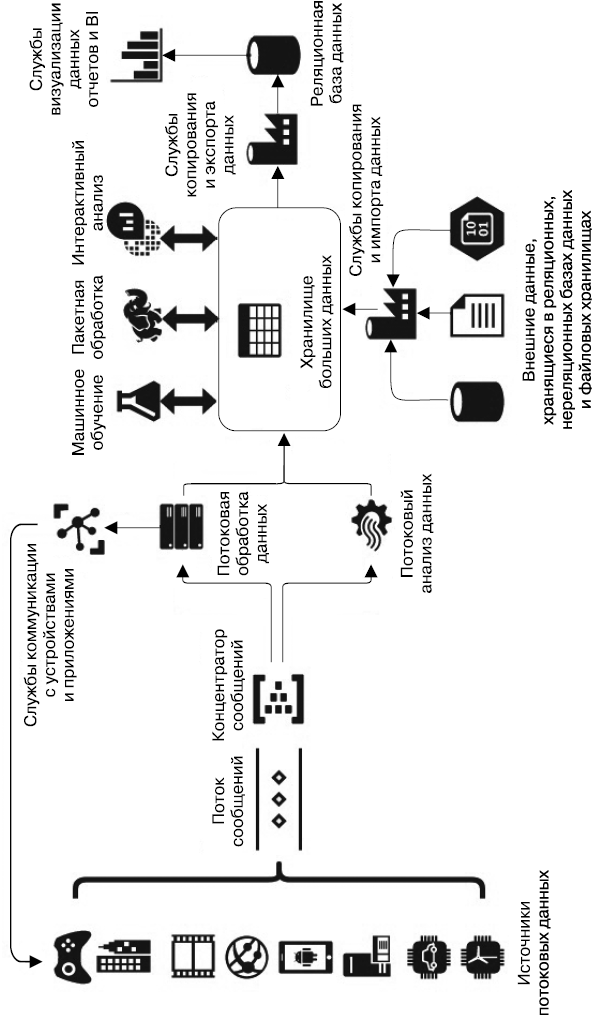
Рис. 3.1. Облачные сервисы, относящиеся к большим данным
Сообщения, полученные от концентраторов или IoT-шлюзов, могут быть направлены по своим назначениям, в зависимости от внутренних признаков (такая возможность обеспечивается системой маршрутизации сообщений: Azure Event Grid или аналогичной системой в IoT-шлюзе), или целиком направлены в облачное хранилище. Это может быть либо хранилище общего назначения (типа Azure BLOB Storage или AWS S3), либо HDFS-совместимое (Azure Data Lake).
Кроме того, данные в такое хранилище могут доставляться сервисами копирования и трансформации данных (AWS Glue или Azure DataFactoy) или специализированными сторонними программами через предоставляемые этими сервисами API. Источниками данных могут быть внешние реляционные и нереляционные базы данных и файлы.
После размещения в облачном хранилище информацию можно обработать в пакетном режиме (например, с помощью Hadoop MapRerduce в Azure HDInsight или AWS EMR), интерактивном режиме (Azure Data Lake Analytics, AWS Athena) или с применением машинного обучения. Результаты обработки могут быть размещены в реляционном хранилище данных и доступны для средств BI (Microsoft PowerBI или AWS QuickSight).
Опишу подробнее облачные сервисы. Любой облачный провайдер предоставляет сервисы IaaS, позволяющие создать ряд виртуальных машин, которые можно объединить в кластер. В этом случае пользователю придется самому создавать и конфигурировать нужный BigData-фреймворк. Ситуация в какой-то мере облегчается тем, что имеются готовые образы виртуальных машин с предустановленными утилитами и компонентами. Но реализация IaaS-решения требует достаточно высокой квалификации у пользователей облачных сред. Ведь, помимо навыков инсталляции и конфигурирования образцов виртуальных машин, необходимо оперировать сервисами IaaS, чтобы построить нужную инфраструктуру, что требует больших затрат времени и обширных знаний, не относящихся к области BigData. Частично задачу упрощает тот факт, что облачные сервисы можно создавать с помощью шаблонов: AWS CloudFormation или Azure ARM Template. Но остаются сложности интеграции IaaS-решения с другими сервисами, сервисами логирования и мониторинга.
В то же время для каждого описанного компонента общей архитектуры, приведенной на рис. 3.1, у облачных провайдеров Microsoft Azure и AWS существует свой PaaS-сервис. Но у обоих провайдеров для ряда компонентов имеются два вида сервисов.
К первому виду относятся сервисы, которые целиком применяют существующие фреймворки больших данных из экосистемы Hadoop. Задействуются стандартные средства взаимодействия с пользователем (например, Jupiter Notebook для написания запросов и отображения результатов). При этом создание, конфигурирование и масштабирование кластера полностью автоматизировано. К таким сервисам относятся Azure HDInsight и AWS EMR. Они позволяют разворачивать кластеры Hadoop, Spark, Storm, HBase, Kafka и R-Server (только Azure). Кроме того, компоненты облачных сервисов могут быть размещены на кластерах AWS ECS / EKS или Azure Kontainer Services в Docker-контейнерах.
Ко второму виду относятся облачные сервисы, целиком и полностью (нативно) предоставляемые облачными провайдерами. Такие сервисы конфигурируются и управляются только из облачного портала или через его REST API и не используют сторонние средства и сервисы.
3.2. Архитектуры традиционных информационных систем
Традиции всех мертвых поколений тяготеют, как кошмар, над умами живых.
Карл Маркс
Для получения представления о том, что такое большие данные, как они возникают и обрабатываются, следует подробнее разобраться с тем, что собой представляют современные информационные системы. Системы обработки больших данных подразумевают возможность, позволяющую реализовать не только систему обработки данных, но и приложение, которое решает конкретную бизнес-задачу. Эта идея — асинхронная передача сообщений (событий) между компонентами системы и применение отдельных сервисов, обеспечивающих надежную передачу сообщений. Казалось бы, практически любая информационная система имеет дело с обменом сообщений, представленном в том или ином виде, так что тут нового? Разберемся по порядку.
Многие годы информационные системы строились в виде одного крупного монолита с единообразной кодовой базой, которая разворачивается на сервере как единое целое: вместе со всеми подключаемыми модулями, библиотеками и т.д. Такой монолит (рис. 3.2) отвечал за все (или почти): за взаимодействие с базами данных, обеспечение системы контроля учетных данных, работу периодических сервисов синхронизации, логирования и пр.
Ниже представлены проблемы, свойственные такой архитектуре.
• Любое изменение в любом компоненте монолита, даже самое незначительное, требует компилирования и разворачивания всей системы, что при большом размере монолита задача весьма небыстрая.
• Монолит очень плохо масштабируется и подвержен существенным проблемам с использованием ресурсов. Действительно, как правило, подобные архитектуры разворачиваются на одном сервере или в виде полных копий на группе серверов. Поэтому любой компонент (или компоненты), который задействует ресурсы сервера (скажем, оперативную память, процессор и т.д.), в значительной степени может затруднить работу всего монолита и потребует увеличения производительности всего сервера, на котором расположена данная архитектура. Компоненты монолита невозможно масштабировать независимо.
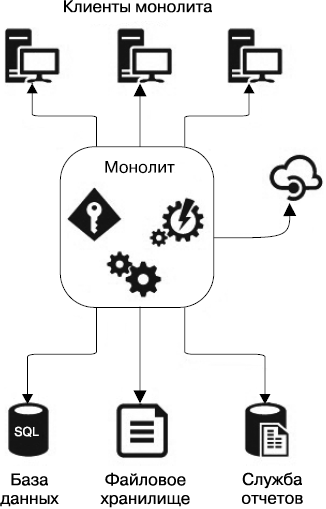
Рис. 3.2. Монолитная архитектура
• Монолит жестко диктует стек технологий программирования, и обновить его, а также обновить саму архитектуру — значит, по сути, переписать весь код заново. Сюда же можно отнести проблемы с быстрым «старением» монолита, склонностью к обрастанию спагетти-кодом, а также «тупиковой внутренней архитектурой» — это когда невозможно исправить баг или улучшить что-либо, не вызвав появления нового бага или ухудшения системы.
Сопровождение монолита может причинить множество неудобств программистам, системным администраторам, тестировщикам…
Решить указанные проблемы была призвана многослойная архитектура (рис. 3.3). В ней за специфическую задачу отвечает отдельный слой: пользовательского интерфейса (user interface layer, UI layer), бизнес-логики (business logic layer, BL layer) и доступа к данным (data access layer, DAL).
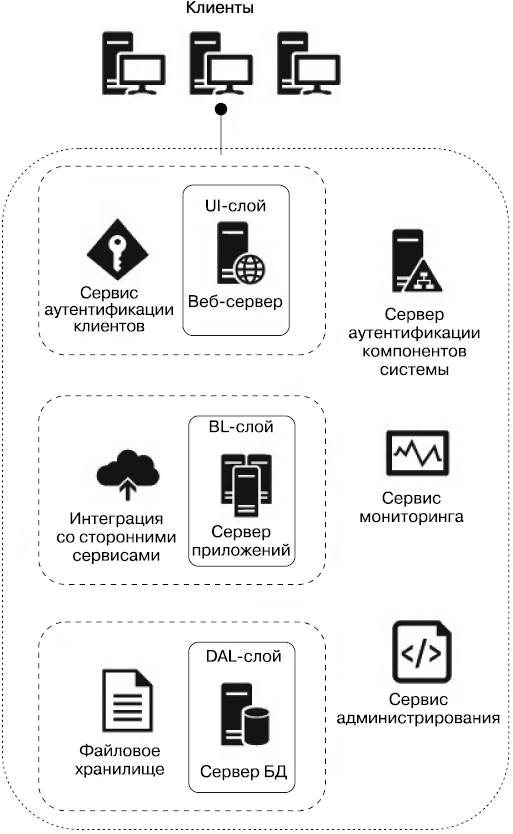
Рис. 3.3. Многослойная архитектура
Рассмотрим эту архитектуру подробнее. Каждый слой отвечает только за определенную группу задач. UI-слой содержит только веб-серверы, являющиеся источником веб-страниц, или размещает сервисы (REST, SOAP или др.) для взаимодействия с клиентскими приложениями. Кроме того, данный слой принимает запросы от клиентов и транслирует их слою бизнес-логики. Поскольку с клиентом напрямую взаимодействует только UI-слой, то на одном уровне с ним в тесной интеграции находится сервис аутентификации клиентов. Слой BL содержит серверы приложений и отвечает, собственно, за бизнес-логику и интеграцию со сторонними сервисами. Слой DAL обеспечивает программный доступ слоя BL к базе данных и файловому хранилищу.
Подобная архитектура по сравнению с монолитной имеет следующие преимущества.
• Разделение на слои позволяет реализовать в каждом слое наиболее подходящий для него стек технологий. Можно независимо обновлять фреймворки на каждом слое.
• Логическое разделение на слои существенно упрощает процесс разработки и сопровождение всей системы. Распределение команд программистов по слоям и специализация разработчиков (фронтенд, бэкенд), уменьшение объема кода на каждом слое, а также независимый деплой (развертывание) значительно улучшают качество всей системы, делая ее более гибкой и пригодной для сопровождения.
• Возможно независимое масштабирование каждого слоя.
Наиболее часто подобная архитектура реализуется в виде серверов, расположенных в локальной сети, разбитой на подсети с настроенными фаерволами. Адреса серверов (IP или URL) разных слоев и учетные данные для доступа к ним прописаны в конфигурационных файлах других серверов. В этой архитектуре уже необходимо централизованно хранить учетные данные, иметь серверы DNS, сервис хранения логов и мониторинга, а также сервер для администрирования. В монолитной архитектуре все это могло быть расположено на одном большом общем сервере. Логирование также было весьма простым, поскольку вся система строилась в рамках одного стека технологий. В многослойной архитектуре каждый слой может генерировать логи, существенно отличающиеся от логов другого слоя. Кроме того, увеличение количества серверов тоже ведет к увеличению количества и видов логов.
Многослойная архитектура информационных систем в настоящее время чрезвычайно распространена, она более гибкая и удобная по сравнению с монолитной, однако не может решить ряд проблем. В частности, при разрастании проекта до такого масштаба, что слой BL становится сопоставимым с монолитом, появляются аналогичные проблемы с масштабированием, производительностью, сопровождением и т.д.
Следующая разновидность многослойной архитектуры — SOA: сервис-ориентированная архитектура. Ее квинтэссенцией является архитектура микросервисов (рис. 3.4), суть которой заключается в том, что каждое приложение разбивается на наименьшие самостоятельные модули, и каждый из них отвечает только за один аспект: отсылку писем, загрузку и выгрузку файлов и пр. Каждый такой сервис можно совершенно независимо развернуть и обновить в любой момент, не затрагивая остальные сервисы. Код подобного сервиса может быть совсем небольшим, и для его сопровождения нужна маленькая команда. Более того, все микросервисы можно писать на разных языках, лучше всего подходящих для решения текущей задачи. И наконец, каждый микросервис может быть развернут на своем сервере или в кластере серверов, которые могут быть совершенно независимо масштабируемы. Каждый сервис доступен по URL конечной точки и из них, как из элементов конструктора, можно собрать новые системы, а каждый сервис использовать в различных системах.
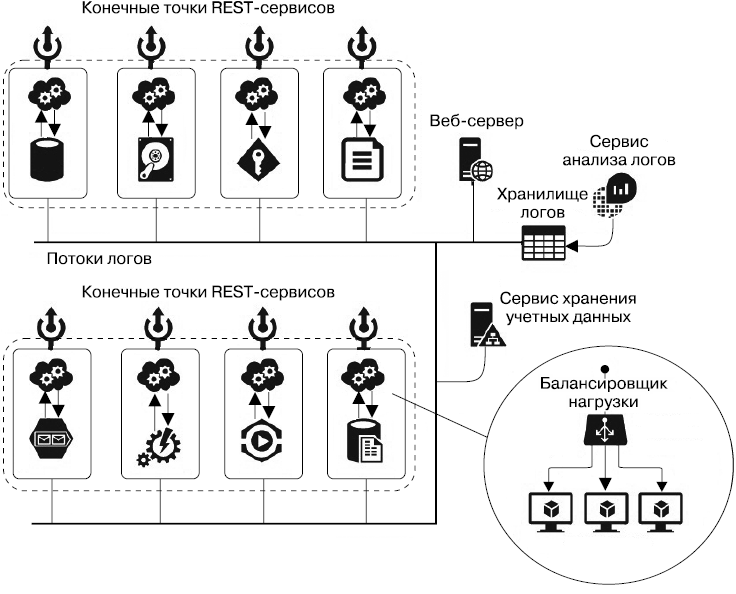
Рис. 3.4. Архитектура микросервисов
Однако работа с микросервисной архитектурой предполагает ряд трудностей.
• Большое количество сервисов, размещенных на многих серверах, означает большое количество разнообразных логов. По сути, вот они, большие данные! Анализ этих данных, определение метрик производительности, узких мест, поиск логов и отображение результатов в виде графиков в режиме, близкому к режиму реального времени, требует не просто сервиса, но целой подсистемы, сопоставимой с основной системой. В качестве примера такой подсистемы можно привести ELK-стек — Elasticsearch (хранение логов и поиск), Logstash (агенты, обеспечивающие доставку логов с серверов в кластер Elasticsearch) и Kibana (интерактивные диаграммы, графики и др.), Splunk.
• Взаимодействие между сервисами происходит преимущественно с помощью REST. А потому каждый сервис должен знать URL всех сервисов, с которыми он может потенциально взаимодействовать.
• Если по какой-то причине запрос не был обработан (например, сервис был недоступен), то для его повторения необходимо организовать логику повтора в рамках самого кода.
Синхронизировать работу микросервисов позволит отдельный сервис, обеспечивающий надежную доставку сообщений, а также предоставляющий малое количество конечных точек. И вот тут мы постепенно подходим к Event Driven Design — архитектуре, основанной на обмене сообщениями. Базовые элементы сервисов обмена сообщениями, лежащие в основе этой архитектуры, будут рассмотрены в части III данной книги.
Архитектуры, построенные на базе микросервисов, каждый из которых можно разместить в кластере серверов, дополненные сервисами обмена сообщениями (брокерами сообщений — message brokers), могут быть чрезвычайно масштабируемыми. Для этого нужно, чтобы сами сервисы обмена сообщениями были масштабируемыми. Брокеры, как правило, имеют архитектуру с одним или несколькими головными узлами, отвечающими за управление кластером, и исполнительными узлами, на которых выполняются необходимые вычисления и хранятся данные (сообщения) (рис. 3.5). Чтобы обеспечить надежность кластера, данные могут быть реплицированы между исполнительными узлами.



















