

автордың кітабын онлайн тегін оқу Google BigQuery. Все о хранилищах данных, аналитике и машинном обучении
Переводчик А. Киселев
Литературный редактор А. Попова
Художник В. Мостипан
Корректоры С. Беляева, Н. Викторова
Валиаппа Лакшманан, Джордан Тайджани
Google BigQuery. Всё о хранилищах данных, аналитике и машинном обучении. — СПб.: Питер, 2020.
ISBN 978-5-4461-1707-9
© ООО Издательство "Питер", 2020
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Отзывы о книге «Google BigQuery. Всё о хранилищах данных, аналитике и машинном обучении»
Эта книга будет полезна организациям, которые переходят от применения устаревших технологий хранения корпоративных данных к использованию Google Cloud. Лак и Джордан подробно описывают BigQuery, чтобы вы могли не только использовать эту технологию для хранения корпоративных данных и бизнес-аналитики, но и выполнять SQL-запросы для получения потоков данных в масштабе реального времени, обращаться к BigQuery из кластеров Hadoop и Spark и использовать машинное обучение для автоматической классификации и получения прогнозов на основе данных.
Томас Курьян, генеральный директор Google Cloud
Иногда в мире технологий появляется какое-то программное обеспечение или сервис, которые все в корне меняет. Технология BigQuery кардинально изменила способ представления корпоративных данных. Будучи изначально предназначенной для работы с гигантскими наборами данных, BigQuery стала одной из лучших платформ для анализа и изучения данных. «Стандартный SQL», который был анонсирован в июне 2016 года, является одной из самых понятных, полных и функциональных реализаций SQL за все время. К числу наиболее функциональных особенностей, кроме всего прочего, относятся: поддержка глубоко вложенных данных, пользовательские функции на JavaScript и SQL, геопространственные данные, интегрированное машинное обучение и доступ к данным по URL-адресам. Едва ли вы найдете источник информации о BigQuery лучше, чем книга Джордана и Лака — людей, которые знают о BigQuery гораздо больше многих других.
Ллойд Табб, сооснователь и технический директор Looker
Даже при том, что я пользуюсь BigQuery уже больше семи лет, из этой книги я узнал много нового! Она содержит бесценную информацию о лучших приемах и методах, а сложные идеи объясняются простым языком. Примеры кода помогают увидеть применение теории на практике, благодаря чему книга получилась интересной и увлекательной. Вне всяких сомнений, она станет одним из лучших справочников для пользователей BigQuery.
Грэм Полли, управляющий консультант Servian
Благодаря BigQuery вы сможете обрабатывать большие объемы данных быстрее и дешевле. Эта платформа поможет вам собрать все данные в одном месте и быстро ознакомиться с ними. В книге подробно описываются ключевые компоненты BigQuery. Два выдающихся сотрудника Google — Лак Лакшманан и Джордан Тайджани — познакомят вас с основами BigQuery, а также с другими весьма сложными темами, такими как машинное обучение. Я давний поклонник BigQuery, и как пользователь этого инструмента могу сказать, что он сделает вашу жизнь с большими данными проще. Я испытал истинное наслаждение, читая эту книгу, а теперь это увлекательное путешествие в BigQuery начинается для вас!
Михаил Берлянт, первый вице-президент по технологиям Viant Inc.
Предисловие
Успех предприятий все больше зависит от данных, а ключевым компонентом информационной стратегии любого предприятия является хранилище данных — центральное хранилище интегрированных данных, стекающихся из всех подразделений компании. Обычно аналитики использовали хранилище данных для формирования аналитических отчетов. Но теперь оно все чаще используется для отображения информации в панелях мониторинга (дашбордах) в режиме реального времени, выполнения специализированных запросов и формирования рекомендаций по принятию решений с помощью прогнозной аналитики. Растущие бизнес-требования к углубленной аналитике, оптимизации затрат, гибкости и самообслуживанию доступа к данным заставляют многие организации переходить на использование облачных хранилищ данных, таких как Google BigQuery.
В этой книге мы отправимся в глубины BigQuery — бессерверное, легкомасштабируемое и недорогое корпоративное хранилище данных, доступное в Google Cloud. Отсутствие инфраструктуры дает предприятиям возможность сосредоточиться на анализе данных и находить ценные идеи, используя хорошо знакомый язык SQL.
Работая над BigQuery, мы стремились создать платформу, которая предлагает передовые возможности, использует преимущества многих замечательных технологий, доступных в современных облачных окружениях, и поддерживает проверенные временем технологии, актуальные и сейчас. Например, главное преимущество Google BigQuery — это бессерверная вычислительная архитектура, которая отделяет вычисления от хранилища. Такой подход позволяет разным уровням архитектуры функционировать и масштабироваться независимо друг от друга, а также дает разработчикам баз данных гибкость при разработке и развертывании. Уникальной чертой BigQuery является встроенная поддержка машинного обучения и геопространственного анализа. В сочетании с Pub/Sub, Cloud Dataflow, Cloud Bigtable, Cloud AI Platform и многими сторонними компонентами платформа BigQuery способна взаимодействовать и с традиционными, и с современными системами в широком диапазоне требований к пропускной способности и задержкам. Наконец, BigQuery поддерживает ANSI-стандарт SQL, колоночную оптимизацию и федеративные запросы — ключевые элементы самостоятельного исследования данных, востребованные многими пользователями.
Для кого написана эта книга?
Эта книга адресована аналитикам, инженерам, а также специалистам по обработке и анализу данных, желающим использовать BigQuery для извлечения информации из больших наборов данных. Дата-аналитики могут взаимодействовать с BigQuery, используя SQL и инструменты мониторинга, такие как Looker, Data Studio и Tableau. Дата-инженеры могут интегрировать BigQuery в конвейеры, написанные на Python или Java, и использовать такие фреймворки, как Apache Spark и Apache Beam. Специалисты по обработке и анализу данных могут создавать модели машинного обучения в BigQuery, запускать модели TensorFlow для обучения на данных в BigQuery и делегировать выполнение распределенных массивных вычислений платформе BigQuery из блокнота Jupyter.
Условные обозначения
В данной книге используются следующие типографские обозначения:
Курсив
Используется для обозначения новых терминов, адресов URL и электронной почты, имен файлов и расширений имен файлов.
Моноширинныйшрифт
Применяется для оформления листингов программ и программных элементов внутри обычного текста, таких как имена переменных и функций, баз данных, типов данных, переменных среды, операторов и ключевых слов.
Моноширинныйжирный
Обозначает команды или другой текст, который должен вводиться пользователем.
Моноширинный курсив
Обозначает текст, который должен замещаться фактическими значениями, вводимыми пользователем или определяемыми из контекста.



Использование примеров программного кода
Вспомогательные материалы (примеры кода, упражнения и т.д.) доступны для загрузки по адресу https://github.com/GoogleCloudPlatform/bigquery-oreilly-book.
Если у вас возникнут вопросы технического характера по использованию примеров кода, направляйте их по электронной почте bookquestions@oreilly.com.
Эта книга написана для того, чтобы помочь вам решать необходимые задачи. В целом вы можете использовать все примеры кода из этой книги в своих программах и в документации. Вам не нужно обращаться в издательство за разрешением, если вы не собираетесь воспроизводить существенные части программного кода. Например, если вы разрабатываете программу и используете в ней несколько отрывков программного кода из книги, разрешение не требуется. Однако в случае продажи или распространения примеров из этой книги вам необходимо получить разрешение от издательства O’Reilly. Если вы отвечаете на вопросы, цитируя данную книгу или примеры из нее, получение разрешения не требуется. Но при включении существенных объемов программного кода примеров из этой книги в вашу документацию вам необходимо будет получить разрешение издательства.
Благодарности
Нам (Лаку и Джордану) очень повезло с рецензентами — Эллиот Броссард (Elliott Brossard), Эван Джонс (Evan Jones), Грэм Полли (Graham Polley), Ребекка Уорд (Rebecca Ward) и Тиган Тигани (Tegan Tigani) внимательно прочитали каждую главу этой книги и внесли многочисленные предложения. Эллиот помогал нам писать более простые и понятные запросы SQL. Опыт Эвана пригодился, когда мы работали над описанием особенностей использования BigQuery в Google Finance. Грэм помог нам взглянуть на многие аспекты, касающиеся стоимости и регионализации, с точки зрения клиента. Ребекка снабжала нас фактами, а Тиган позаботилась о том, чтобы книга была написана простым и понятным языком. Нам также помогали многие сотрудники Google, каждый в своей сфере компетенций: Чед Дженнингс (Chad Jennings), Харис Хан (Haris Khan), Миша Брукман (Misha Brukman), Даниэль Гундрум (Daniel Gundrum), Моша Пашумански (Mosha Pashumansky), Амир Хормати (Amir Hormati) и Мингге Денг (Mingge Deng). Любые ошибки, оставшиеся неисправленными, — это только наша вина.
Спасибо нашим семьям, товарищам по команде и руководителям — Рочану Голани (Rochana Golani) и Судхиру Хасбе (Sudhir Hasbe) за поддержку. Мы получили большое удовольствие от работы с нашими редакторами в издательстве O’Reilly: Николь Таше (Nicole Taché) и Кристен Браун (Kristen Brown). Благодаря усилиям Боба Рассела (Bob Russell), нашего литературного редактора, текст получился намного лучше. Идея написать эту книгу принадлежит Саптарши Мукерджи (Saptarshi Mukherjee) — именно он подтолкнул нас к совместной работе над новой книгой о BigQuery. Наконец, мы хотели бы поблагодарить пользователей BigQuery (и конкурентов!) за то, что помогли нам сделать BigQuery лучше, а также команду разработчиков BigQuery, воплотивших это волшебство в жизнь.
Весь гонорар за эту книгу мы перечислим местной организации United Way of King County (https://www.uwkc.org). Мы советуем и вам принять участие в работе местной благотворительной организации, которая будет оказывать безвозмездную помощь в решении самых сложных локальных проблем.
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
На веб-сайте издательства www.piter.com вы найдете подробную информацию о наших книгах.
Глава 1. Что такое Google BigQuery?
Архитектуры обработки данных
Google BigQuery — это бессерверное масштабируемое хранилище данных со встроенным механизмом запросов. Механизм запросов способен выполнять запросы SQL на терабайтах данных за считаные секунды, а на петабайтах — за считаные минуты. Чтобы получить такую производительность, вам не придется организовывать и поддерживать какую-либо инфраструктуру и создавать или перестраивать индексы.
У BigQuery масса поклонников. Пол Ламер (Paul Lamere), инженер из компании Spotify, был рад наконец-то рассказать о том, как его команда использует BigQuery для анализа больших наборов данных: «Google BigQuery — это *просто бомба*», — написал он в Твиттере в феврале 2016 года (https://twitter.com/plamere/status/702168809445134336). «Из 2,2 миллиарда записей я смог вычленить 20 тысяч меньше чем за минуту». Масштаб и скорость — это лишь две из примечательных особенностей BigQuery. Не менее важно отсутствие необходимости поддерживать инфраструктуру, поскольку простота бессерверных вычислений способна открыть новые способы работы.
Компании все активнее принимают решения, основанные на анализе данных, и поощряют открытую культуру, когда доступность данных не ограничивается подразделениями. Предлагая средства для реализации гибкости и открытости, BigQuery играет важную роль в ускорении внедрения инноваций. Например, недавно представитель Twitter сообщил (https://blog.twitter.com/engineering/en_us/topics/infrastructure/2019/democratizing-data-analysis-with-google-bigquery.html), что с помощью BigQuery им удалось сделать анализ данных доступнее, предоставив некоторые часто используемые таблицы сотрудникам Twitter из разных подразделений (в частности, отделы проектирования, управления финансами и маркетинга).
Для Alpega Group, компании-разработчика программного обеспечения для логистики, инновационный потенциал и гибкость BigQuery стали залогом успеха. Компания преодолела барьер, мешавший быстрому получению результатов анализа информации, и сумела обеспечить своих клиентов аналитикой практически в реальном времени. Поскольку в Alpega Group избавились от необходимости содержать кластеры и необходимую для этого инфраструктуру, ее небольшая техническая команда теперь может свободно заниматься разработкой программного обеспечения и средствами обработки данных. «Это стало для нас потрясающей новостью», — сказал ведущий архитектор компании Аарт Вербеке (Aart Verbeke, https://cloud.google.com/customers/alpega). «При традиционном подходе нам пришлось бы устанавливать, настраивать, разворачивать и размещать каждый отдельный компонент. Здесь же мы просто подключаемся к сервису и используем его по мере необходимости».
Представьте, что вы руководите сетью пунктов проката оборудования. Цена зависит от срока аренды, поэтому, чтобы правильно подсчитать сумму, которую должен заплатить клиент, вам нужна следующая информация:
1. Где было арендовано оборудование.
2. Когда оно было арендовано.
3. Куда его вернули.
4. Когда его вернули.
Возможно, вы вносите эту информацию в базу данных каждый раз, когда клиент возвращает оборудование.1
На основании этого набора данных вы можете определить количество ежемесячных арендных платежей за последние 10 лет. Или, может быть, вы хотите ввести доплату за возврат оборудования в другой пункт проката, и вам нужно выяснить, на какую долю аренды повлияет это нововведение. Желание знать ответ на подобные вопросы возникает весьма часто, но важно, чтобы вы сами умели найти ответ, если вы хотите принимать решения, основанные на данных.
Какую архитектуру вы могли бы использовать? Рассмотрим некоторые возможные варианты.
Система управления реляционными базами данных
Информацию о сделках можно записывать в реляционную базу данных с оперативной обработкой транзакций (OnLine Transaction Processing, OLTP), например MySQL или PostgreSQL. Одним из ключевых преимуществ таких баз данных является поддержка запросов на языке структурированных запросов (Structured Query Language, SQL) — вашим сотрудникам не придется использовать высокоуровневые языки программирования, такие как Java или Python, чтобы получать ответы на возникающие вопросы. Они могут просто писать запросы, которые можно отправить серверу базы данных:
SELECT
EXTRACT(YEAR FROM starttime) AS year,
EXTRACT(MONTH FROM starttime) AS month,
COUNT(starttime) AS number_one_way
FROM
mydb.return_transactions
WHERE
start_station_name != end_station_name
GROUP BY year, month
ORDER BY year ASC, month ASC
Не обращайте пока внимания на синтаксис, подробнее мы поговорим о SQL-запросах позже, а сейчас давайте сосредоточимся на преимуществах и недостатках баз данных OLTP.
Во-первых, обратите внимание, что язык SQL позволяет не просто получать исходные данные, хранящиеся в столбцах таблиц, — предыдущий запрос анализирует отметку времени и извлекает из нее год и месяц. Он также выполняет агрегирование (подсчитывает число строк), фильтрацию (выбирает сделки, в которых пункт, где было взято оборудование, не совпадает с пунктом его возвращения), группировку (по году и месяцу) и сортировку. Важным преимуществом SQL является возможность конкретизировать, что именно мы хотим получить, и позволить программному обеспечению базы данных определить оптимальный способ выполнения запроса.
К сожалению, базы данных OLTP довольно неэффективно выполняют подобные запросы. Основной упор в них делается на согласованность данных; дело в том, что базы данных позволяют считывать данные, даже когда в них одновременно производится запись. Это достигается за счет блокировок, обеспечивающих сохранение целостности данных. Чтобы фильтрация по полю station_name выполнялась эффективно, необходимо создать индекс для поля с названием пункта проката. Только если название пункта проката индексируется, база данных будет выполнять специальные операции с хранилищем для оптимизации поиска, правда, при этом увеличение скорости чтения достигается за счет уменьшения скорости записи. Если название пункта проката не индексируется, фильтрация по этому полю будет работать довольно медленно. И даже если для названия пункта проката создать индекс, этот конкретный запрос все равно будет выполняться медленно из-за операций агрегирования, группировки и сортировки. Базы данных OLTP не созданы для таких ситуативных2 запросов, требующих выполнить обход всего набора данных.
Фреймворк MapReduce
Поскольку базы данных OLTP плохо подходят для ситуативных запросов и запросов, требующих обхода всего набора данных, специализированные виды анализа, требующие такого обхода, можно запрограммировать на языках высокого уровня, таких как Java или Python. В 2003 году Джефф Дин (Jeff Dean) и Санджай Гемават (Sanjay Ghemawat) заметили, что они и их коллеги из Google реализуют сотни таких специализированных вычислений для обработки больших объемов исходных данных. Для решения этой проблемы они разработали абстракцию, позволяющую выражать вычисления в виде двух шагов: функции map (отображения), которая обрабатывает пару ключ/значение и генерирует набор промежуточных пар ключ/значение, и функции reduce (свертки), которая объединяет все промежуточные значения, связанные с тем же промежуточным ключом.3 Эта парадигма, известная как MapReduce, оказала существенное влияние на фреймворки и привела к разработке Apache Hadoop.
Экосистема Hadoop начиналась как библиотека, написанная на Java, но теперь пользовательский анализ в кластерах Hadoop обычно выполняется с использованием Apache Spark (http://spark.apache.org/). Spark поддерживает программы, написанные на Python или Scala, а также позволяет выполнять специальные SQL-запросы к распределенным наборам данных.
То есть чтобы узнать количество платежей за аренду, можно организовать следующий конвейер данных:
1. Периодически экспортировать записи в текстовые файлы в формате CSV (Comma-Separated Values — значения, разделенные запятыми) в распределенной файловой системе Hadoop (Hadoop Distributed File System, HDFS).
2. Для выполнения ситуативного анализа написать программу Spark, которая:
a) выгружает данные из текстовых файлов в «DataFrame»;
б) выполняет SQL-запрос, подобный запросу, представленному в предыдущем разделе, за исключением того, что имя таблицы заменяется именем кадра данных DataFrame;
в) экспортирует результаты обратно в текстовый файл.
3. Выполнить программу Spark в кластере Hadoop.
На первый взгляд архитектура может показаться простой, тем не менее, в ней есть ряд скрытых недостатков. Для сохранения данных в HDFS необходим достаточно большой кластер. Еще одна немаловажная особенность архитектуры MapReduce, которой часто пренебрегают, заключается в том, что обычно вычислительным узлам требуется доступ к локальным для них данным. Соответственно, файловая система HDFS должна быть разбита на сегменты между вычислительными узлами кластера. Поскольку объемы данных и потребности в анализе быстро растут независимо друг от друга, часто происходит так, что кластеры испытывают нехватку или переизбыток вычислительных мощностей.4 То есть чтобы выполнять программы Spark в кластере Hadoop, сотрудникам вашей организации придется стать экспертами в управлении, мониторинге и настройке кластеров Hadoop. Это может не входить в ваши планы.
BigQuery: бессерверный распределенный движок SQL
А теперь представьте, что у вас есть возможность выполнять SQL-запросы как в системе управления реляционными базами данных (Relational Database Management System, RDBMS), эффективно выполнять обход распределенных наборов данных как в MapReduce и не обременять себя поддержкой инфраструктуры. Это третий вариант, и именно эти особенности делают BigQuery таким привлекательным. BigQuery — это бессерверная служба, позволяющая выполнять запросы, не требуя поддерживать свою инфраструктуру. Она дает возможность анализировать большие наборы данных и агрегировать их в считаные секунды или минуты.
Мы не призываем вас верить нам на слово. Попробуйте сами. Перейдите по ссылке https://console.cloud.google.com/bigquery (зарегистрируйтесь в Google Cloud Platform и, если потребуется, выберите свой проект), скопируйте и вставьте следующий запрос в окно,5 а затем щелкните на «Run query» («Выполнить»):
SELECT
EXTRACT(YEAR FROM starttime) AS year,
EXTRACT(MONTH FROM starttime) AS month,
COUNT(starttime) AS number_one_way
FROM
`bigquery-public-data.new_york_citibike.citibike_trips`
WHERE
start_station_name != end_station_name
GROUP BY year, month
ORDER BY year ASC, month ASC
Когда мы запустили его, пользовательский интерфейс BigQuery сообщил, что запрос обработал 2.51 Гбайт данных и на это потребовалось примерно 2.7 секунды, как показано на рис. 1.1.
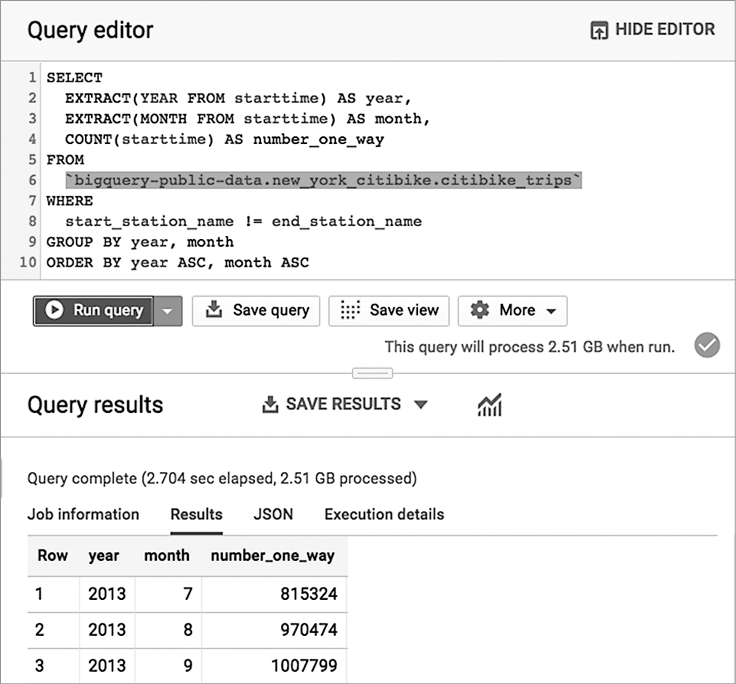
Рис. 1.1. Выполнение запроса для определения количества платежей за прокат в веб-интерфейсе BigQuery
Арендуемое оборудование — это велосипеды, таким образом, предыдущий запрос подводит помесячный итог проката велосипедов в Нью-Йорке по большому набору данных. Сам набор данных находится в открытом доступе (то есть любой желающий может запросить эти данные) и выпущен в Нью-Йорке в рамках инициативы «Открытый город». Результат этого запроса показывает, что в июле 2013 года в Нью-Йорке велосипеды арендовались 815 324 раза.
Обратите внимание на несколько моментов. Во-первых, вы смогли выполнить запрос к набору данных, который уже есть в BigQuery. Все, что должен сделать ответственный за проект, в котором размещены данные, — это предоставить вам6 доступ к этому набору данных для «просмотра». Вам не нужно запускать кластер или входить в него — вы просто отправляете запрос сервису и получаете результаты. Сам запрос написан на SQL:2011, который поддерживает синтаксис, хорошо знакомый аналитикам данных. Мы продемонстрировали пример обработки гигабайтов данных, но вообще сервис легко масштабируется и способен агрегировать терабайты и петабайты данных. Такая масштабируемость возможна, потому что сервис распределяет обработку запросов между тысячами рабочих узлов практически мгновенно.
Работа с BigQuery
BigQuery — это хранилище данных с определенной степенью централизации. Запрос, продемонстрированный в предыдущем разделе, был применен к единственному набору данных. Однако преимущества BigQuery становятся еще более очевидными при объединении наборов данных из совершенно разных источников или при обращении к данным, хранящимся вне BigQuery.
Анализ наборов данных
Данные о прокате велосипедов поступают из Нью-Йорка. А можно ли объединить их с данными о погоде Национального управления океанических и атмосферных исследований США, чтобы узнать, как дождливая погода влияла на прокат велосипедов?7
-- Дождливая погода влияла на прокат велосипедов?
WITH bicycle_rentals AS (
SELECT
COUNT(starttime) as num_trips,
EXTRACT(DATE from starttime) as trip_date
FROM `bigquery-public-data.new_york_citibike.citibike_trips`
GROUP BY trip_date
),
rainy_days AS
(
SELECT
date,
(MAX(prcp) > 5) AS rainy
FROM (
SELECT
wx.date AS date,
IF (wx.element = 'PRCP', wx.value/10, NULL) AS prcp
FROM
`bigquery-public-data.ghcn_d.ghcnd_2016` AS wx
WHERE
wx.id = 'USW00094728'
)
GROUP BY
date
)
SELECT
ROUND(AVG(bk.num_trips)) AS num_trips,
wx.rainy
FROM bicycle_rentals AS bk
JOIN rainy_days AS wx
ON wx.date = bk.trip_date
GROUP BY wx.rainy
Пока оставим в стороне синтаксис запроса. Обратите внимание только на строки, выделенные жирным шрифтом. Здесь мы соединяем набор данных о прокате велосипедов и набор данных о погоде, взятый из совершенно другого источника. Результаты запроса подтверждают предположение, что жители Нью-Йорка слабаки — в дождливые дни берут велосипеды в прокат на 20% реже:8
Row num_trips rainy
1 39107.0 false
2 32052.0 true
Что означает возможность совместного использования наборов данных и отправления запросов в контексте предприятия? Разные подразделения вашей компании могут хранить свои наборы данных в BigQuery и легко обмениваться ими с другими подразделениями компании и даже с партнерскими организациями. Бессерверные технологии BigQuery помогают устранить разрозненность подразделений и оптимизировать сотрудничество.
ETL, EL и ELT
Традиционный подход к работе с хранилищами данных включает три этапа: извлечение, преобразование и загрузку (Extract, Transform, Load; ETL), когда исходные данные извлекаются из источника, преобразуются и затем загружаются в хранилище данных. В действительности BigQuery поддерживает собственный высокоэффективный формат колоночного хранения,9 что делает методологию ETL особенно привлекательной. Конвейер обработки данных, обычно реализованный на основе Apache Beam или Apache Spark, извлекает необходимые исходные данные (потоковых данных или пакетных файлов), преобразует извлеченные данные, подготавливая их к очистке или агрегированию, а затем загружает их в BigQuery, как показано на рис. 1.2.
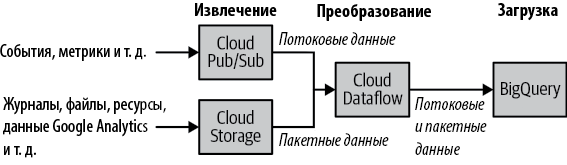
Рис. 1.2. Эталонная архитектура ETL в BigQuery использует конвейеры Apache Beam, выполняемые в Cloud Dataflow, и может обрабатывать как потоковые, так и пакетные данные с одним и тем же кодом
Хотя создание конвейера ETL в Apache Beam или Apache Spark весьма распространено, его можно создать исключительно в BigQuery. Так как BigQuery отделяет вычисления от хранилища, SQL-запросы BigQuery можно выполнять для файлов в формате CSV (а также JSON и Avro), которые хранятся в исходном виде в облачном хранилище Google Cloud Storage; эта возможность называется федеративным запросом. С помощью федеративных запросов можно извлекать данные, выполняя запросы SQL к Google Cloud Storage, преобразовывать данные внутри этих запросов SQL и сохранять результаты в собственных таблицах BigQuery.
Если преобразование не требуется, BigQuery может напрямую загружать стандартные форматы, такие как CSV, JSON или Avro, в свое хранилище — рабочий процесс EL (извлечение и загрузка). Такой подход, когда данные загружаются непосредственно в хранилище, используется потому, что хранение данных в собственном хранилище обеспечивает наибольшую эффективность запросов.
Мы настоятельно советуем реализовать процесс EL, если это возможно, и использовать процесс ETL, только если необходимы преобразования. По возможности выполните все необходимые преобразования в запросе SQL и сохраните весь конвейер ETL в BigQuery. Если преобразования трудно реализовать исключительно в SQL или если конвейер должен передавать данные в BigQuery по мере их поступления, создайте конвейер Apache Beam и выполняйте его бессерверным способом с использованием Cloud Dataflow. Другое преимущество реализации конвейеров ETL в Beam/Dataflow заключается в лучшем объединении таких конвейеров с системами непрерывной интеграции (CI) и модульного тестирования, потому что они содержат программный код.
Помимо процессов ETL и EL, BigQuery позволяет выполнять извлечение, загрузку и преобразование. Идея состоит в том, чтобы извлекать и загружать исходные данные «как есть» и использовать представления BigQuery для преобразования данных во время работы. Процесс ELT особенно удобен, если схема исходных данных постоянно меняется. Например, вы можете реализовать определение необходимости исправления конкретной временной метки с учетом местного часового пояса. Процесс ELT может пригодиться для создания прототипов и позволяет организации начать извлекать информацию из данных, не принимая потенциально необратимых решений на ранних этапах.
Весь этот винегрет может сбивать с толку, поэтому мы подготовили краткую сводку в табл. 1.1.
Таблица 1.1. Краткое описание процессов, примеры архитектур и сценарии, в которых они могут использоваться
| Процесс |
Архитектура |
Когда используется |
| EL |
Извлечение данных из файлов в Google Cloud Storage. Загрузка в собственное хранилище BigQuery. Можно вызывать из Cloud Composer, Cloud Functions или запланированных запросов |
Пакетная загрузка архивных данных. Периодическая загрузка файлов журналов по расписанию (например, один раз в день) |
| ETL |
Извлечение данных из Pub/Sub, Google Cloud Storage, Cloud Spanner, Cloud SQL и т.д. Преобразование данных с использованием Cloud Dataflow. Имеет конвейер Dataflow для записи данных в BigQuery |
Когда требуется проверить качество, выполнить преобразование или обогатить исходные данные перед загрузкой в BigQuery. Когда загрузка данных должна происходить непрерывно, то есть если сценарий требует потоковой передачи. Когда необходимы интеграция с системами непрерывной интеграции/непрерывной доставки (CI/CD) и модульное тестирование всех компонентов |
| ELT |
Извлечение данных из файлов в Google Cloud Storage. Хранение в BigQuery данных в формате, близком к исходному. Преобразование данных в процессе работы с использованием представлений BigQuery |
При использовании экспериментальных наборов данных, когда еще неясно, какие преобразования необходимо применить, чтобы сделать данные пригодными для использования. С любыми промышленными данными, когда преобразование можно выразить в SQL |
Процессы в табл. 1.1 перечислены в том порядке, в каком мы рекомендуем их применять.
Эффективная аналитика
Преимущества использования хранилища напрямую вытекают из видов анализа, которые можно выполнять с хранящимися в нем данными. Основной способ взаимодействия с BigQuery — выполнение запросов SQL, а поскольку BigQuery является движком SQL, вы можете использовать широкий спектр инструментов бизнес-аналитики (Business Intelligence, BI), таких как Tableau, Looker и Google Data Studio, для реализации разных видов анализа, визуальных диаграмм и отчетов на основе данных, хранящихся в BigQuery. Например, кликнув на «Explore in Data Studio» («Исследовать в Data Studio») в веб-интерфейсе BigQuery, можно быстро создать график помесячного изменения проката велосипедов, как показано на рис. 1.3.

Рис. 1.3. Статистика в Data Studio проката велосипедов в зависимости от месяца; почти 15% проката в Нью-Йорке приходится на сентябрь
BigQuery предлагает полноценную поддержку SQL:2011, включая массивы и сложные соединения. В частности, поддержка массивов позволяет хранить в BigQuery иерархические данные (такие, как записи JSON) без преобразования вложенных и повторяющихся полей в плоские структуры. Помимо поддержки SQL:2011, BigQuery имеет несколько расширений, которые позволяют использовать этот сервис не только в качестве хранилища данных. Одним из таких расширений является поддержка широкого спектра геопространственных функций, позволяющих проверять в запросах местоположение, а также соединять таблицы на основе критериев расстояния или совпадения.10 Поэтому BigQuery является полезным инструментом для проведения описательной аналитики.
Другое расширение BigQuery — поддержка в стандартном SQL создания моделей машинного обучения и выполнения пакетных прогнозов. Мы подробно рассмотрим возможности машинного обучения в BigQuery в главе 9, но суть в том, что они позволяют обучать модели BigQuery и делать прогнозы, не экспортируя данные из BigQuery. Преимущества безопасности и локальности данных в этом случае огромны. То есть BigQuery — это хранилище данных, которое поддерживает не только описательную, но и прогнозную аналитику.
Идеология хранилища подразумевает возможность хранения данных разных типов. И действительно, BigQuery может хранить самые разные данные: числовые и текстовые данные как само собой разумеющееся, а также геопространственные и иерархические данные. BigQuery дает возможность хранить данные в упорядоченном виде, но это вовсе не обязательно, схемы могут быть очень разнообразными и сложными. Сочетание запросов с учетом пространственного местоположения, иерархических данных и машинного обучения делает BigQuery эффективным решением, не ограниченным рамками обычного хранилища и бизнес-аналитики.
BigQuery может принимать не только пакетные, но и потоковые данные. Данные можно передавать в BigQuery напрямую через REST API. Часто пользователи, которым требуется преобразовать данные — например, проводя вычисления с временным окном, — используют конвейеры Apache Beam, выполняемые сервисом Cloud Dataflow. И даже при передаче потоковых данных в BigQuery вы можете запросить их. Наличие общей инфраструктуры запросов для архивных (пакетных) и текущих (потоковых) данных открывает широкие возможности и упрощает многие процессы.
Простота управления
При разработке BigQuery немало внимания уделялось тому, чтобы обратить внимание пользователей на результаты анализа, а не на инфраструктуру. При вводе данных в BigQuery вам не нужно думать о разных типах хранилищ или о поиске золотой середины между скоростью работы и стоимостью услуги; хранилище полностью управляемое. На момент написания этой книги стоимость хранения автоматически снижается, если таблица не обновлялась в течение 90 дней.11
Мы уже говорили, что в BigQuery не требуется настраивать индексы; ваши запросы SQL могут фильтровать результаты по любому столбцу, а BigQuery позаботится об их планировании и оптимизации. Более того, мы советуем писать запросы максимально понятно и разборчиво, а выбор стратегии оптимизации оставить для BigQuery. В этой книге мы будем говорить о настройке производительности, но в BigQuery она сводится в основном к логике и выбору соответствующих функций SQL. Вам не придется заниматься администрированием базы данных и решать такие задачи, как репликация, дефрагментация или восстановление после сбоев; обо всем этом позаботится BigQuery.
Запросы автоматически распределяются по тысячам машин и выполняются параллельно. Вам не нужно ничего предпринимать, чтобы запустить этот процесс. Машины уже подготовлены для обработки различных этапов заданий; вам не придется их настраивать.
Отсутствие необходимости поддерживать инфраструктуру уменьшает число проблем, связанных с безопасностью. Данные в BigQuery автоматически шифруются как при хранении, так и при передаче. BigQuery заботится о безопасности многопользовательских запросов и изоляции заданий. Вы сможете организовать общий доступ к своим наборам данных с помощью сервиса Google Cloud Identity and Access Management (IAM), а также применять к наборам данных (а также таблицам и представлениям в них) различные меры безопасности, в зависимости от того, нужна ли вам открытость, возможность аудита или конфиденциальность.
В других системах обеспечение надежности, гибкости, безопасности и производительности инфраструктуры часто отнимает много времени. Учитывая, что BigQuery практически избавляет от необходимости администрирования, организации, использующие BigQuery, считают, что это дает их аналитикам дополнительное время, чтобы сосредоточиться на получении информации из своих данных.
История появления BigQuery
В конце 2010 года директор подразделения Google в Сиэтле пригласил нескольких инженеров (один из которых является автором этой книги) и поставил перед ними задачу: создать коммерческую онлайн-платформу для хранения и анализа данных (data marketplace). Мы постарались найти лучший способ создания такой платформы. Основной проблемой были объемы данных, потому что мы не хотели предоставлять простую ссылку для скачивания. Платформа данных не сможет существовать, если людям придется загружать терабайты данных, чтобы начать с ней работу. Что бы вы сделали для того, чтобы не заставлять пользователей начинать работу с загрузки наборов данных?
Представляем вашему вниманию принцип Джима Грея (Jim Gray), первого исследователя в области баз данных (https://en.wikipedia.org/wiki/Jim_Gray_(computer_scientist)12): «При работе с “большими данными”, — сказал Грей, — нужно помещать вычисления в данные, а не данные в вычисления». И уточнил:
Другая ключевая проблема состоит в том, что по мере увеличения наборов данных становится все труднее получить их по FTP или выполнить поиск с помощью grep. Петабайт данных очень трудно передать по FTP! Поэтому рано или поздно вам понадобятся индексы и параллельный доступ к данным, и именно в этом вам помогут базы данных. Для анализа можно скачать данные, но точно так же можно направить запрос к данным. Вы можете переместить то или другое — запросы или данные. Но часто эффективнее перемещать запросы, а не данные.13
Наша платформа данных не требовала бы от пользователей загружать наборы данных на компьютеры, если бы мы позволили им перенести свои вычисления в данные. Нам не пришлось бы давать ссылку для скачивания, потому что пользователи смогли бы работать со своими данными, не перемещая их.14
Мы, сотрудники Google, которым было поручено создать платформу данных, решили отложить этот проект и сосредоточиться на создании вычислительного механизма и системы хранения в облаке. Дав пользователям возможность что-то делать с данными, мы вернулись и добавили функции, характерные для коммерческой онлайн-платформы.
Какой язык пользователи должны использовать, чтобы писать вычисления для передачи в данные, хранящиеся в облаке? Мы выбрали SQL как обладающий тремя ключевыми характеристиками. Во-первых, SQL — универсальный язык, позволяющий не только разработчикам, но и широкому кругу людей задавать вопросы и решать задачи с использованием своих данных. Такая простота чрезвычайно важна. Во-вторых, SQL является «реляционно полным» языком, то есть на нем можно выразить любые вычисления с участием данных. Язык SQL не только прост и доступен. Он еще и очень функциональный. И наконец, что очень важно для выбора языка облачных вычислений, SQL не является «полным по Тьюрингу» в одном важном аспекте: код на этом языке всегда завершается.15 Как следствие, вычисления на SQL можно размещать, не беспокоясь, что кто-то напишет бесконечный цикл и монополизирует все вычислительные ресурсы вычислительного центра.
Затем нам нужно было выбрать движок SQL. В Google было несколько движков для работы с данными, в том числе очень популярные. Самый продвинутый движок назывался Dremel; он широко использовался в Google и был способен обрабатывать терабайты журналов за считаные секунды. Движок Dremel часто выбирали люди, занимавшиеся созданием конвейеров MapReduce и желавшие получить возможность задавать вопросы о своих данных.
В 2006 году инженер Андрей Губарев, который устал ждать завершения работ над MapReduce, создал движок Dremel. В научной литературе росла популярность колоночных хранилищ, и он быстро придумал формат колоночного хранения (рис. 1.4), который мог бы обрабатывать формат сериализации Protocol Buffers (Protobufs), повсеместно распространенный в Google.
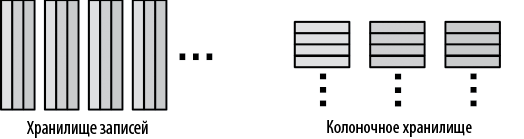
Рис. 1.4. Колоночные хранилища могут сократить объем данных, считываемых запросами, которые обрабатывают все строки, но не все столбцы
Колоночные хранилища в целом хорошо подходят для аналитики, но в Google они оказались особенно полезными для анализа журналов, потому что многие команды работают с типами Protobuf, насчитывающими сотни тысяч столбцов. Если бы Андрей использовал типичное хранилище записей, пользователям пришлось бы читать файлы построчно и принимать огромное количество данных в полях, которые они все равно собирались отбросить. Сохраняя данные столбец за столбцом, Андрей сделал так, что если пользователю требовалось всего несколько тысяч полей из журнала Protobufs, он мог прочитать только часть общего объема данных. Это было одной из причин, почему Dremel справлялся с обработкой терабайтов журналов за считаные секунды.
Другая причина, по которой Dremel мог обработать данные так быстро, заключалась в том, что его механизм запросов использовал распределенные вычисления. Движок был способен распределить вычисления между тысячами рабочих процессов, структурируя вычисления как дерево, с фильтрами в листьях и агрегированием ближе к корню.
К 2010 году Google каждый день сканировала с помощью Dremel уже петабайты данных, и многие сотрудники использовали их в той или иной форме. Это был идеальный инструмент для нашей команды, начинавшей разработку коммерческой платформы данных.
Когда команда доработала движок Dremel, добавила к нему систему хранения, реализовала автоматическую настройку и предложила сторонним пользователям, стало понятно, что разработка облачной версии Dremel, возможно, даже более интересная задача, чем та, которая была поставлена изначально. Команда переименовала себя в «BigQuery», по аналогии с «Bigtable» — базой данных NoSQL, также созданной в Google.
В Google движок Dremel используется для анализа файлов, которые хранятся в Google Colossus — хранилище файлов. Команда BigQuery добавила систему хранения с абстракцией таблицы. Эта система хранения играла ключевую роль, делая платформу BigQuery простой и быстрой в использовании, потому что позволяла использовать такие важные особенности, как свойства ACID (Atomicity, Consistency, Isolation, Durability — атомарность, согласованность, изолированность, долговечность) транзакций, а также автоматическую оптимизацию, благодаря чему пользователям не требовалось управлять файлами.
Первоначально служба BigQuery сохраняла свою связь с Dremel и была ориентирована на сканирование журналов. Однако по мере увеличения числа клиентов, желавших создавать хранилища данных и выполнять все более сложные запросы, в BigQuery была добавлена улучшенная поддержка соединений и расширенные возможности SQL, включая аналитические функции. В 2016 году Google добавила поддержку стандартного SQL в BigQuery, что позволило пользователям выполнять запросы, используя стандартный язык SQL вместо неудобного диалекта «DremelSQL», использовавшегося вначале.
На начальном этапе BigQuery не была хранилищем данных, но со временем стала именно им. В этой трансформации есть свои преимущества и недостатки. Преимуществом является то, что BigQuery разрабатывалась для решения задач с данными, даже при том, что эта сторона платформы плохо вписывается в модели хранилищ данных. То есть BigQuery — это больше чем простое хранилище данных. С другой стороны, до недавнего времени в BigQuery отсутствовали некоторые особенности, свойственные хранилищам данных, такие как язык определения данных (Data Definition Language, DDL; например, оператор CREATE) и язык манипулирования данными (Data Manipulation Language, DML; например, оператор INSERT). Тем не менее BigQuery фокусируется на развитии в двух направлениях: добавление отличительных особенностей, которые может предложить Google, и превращение в отличное облачное хранилище данных.
Что позволило создать BigQuery?
С точки зрения архитектуры BigQuery принципиально отличается от хранилищ данных, таких как Teradata или Vertica, а также от облачных хранилищ данных, таких как Redshift и Microsoft Azure Data Warehouse. BigQuery — первое хранилище данных с поддержкой горизонтального масштабирования, поэтому единственным ограничением скорости и масштабирования является количество оборудования в дата-центре.
В этом разделе описываются некоторые компоненты, делающие BigQuery успешным и уникальным проектом.
Отделение вычислений от хранилища
Во многих хранилищах данных вычисления и хранение осуществляются на одном и том же физическом оборудовании. Это значит, что для увеличения объема хранилища может потребоваться увеличить вычислительную мощность. Или для увеличения вычислительной мощности вам также понадобится увеличить емкость хранилища.
Не было бы никаких проблем, будь у всех одинаковые потребности в данных; можно было бы найти золотую середину между вычислительной мощностью и объемом хранилища. Но на практике то один, то другой фактор оказывается ограничивающим. Некоторые хранилища имеют ограниченную вычислительную мощность и могут работать медленно в часы пиковых нагрузок. Другие хранилища имеют ограниченную емкость, из-за чего администраторы вынуждены решать, какие данные выбрасывать.
Отделив вычисления от хранилища, как это сделано в BigQuery, вам никогда не придется отбрасывать ненужные данные. Вы, может, и не придаете этому особого значения, тем не менее, доступ к данным с максимальной точностью невероятно эффективен. Вы можете решить выполнить вычисления как-то иначе, а значит, вам придется вернуться к исходным данным и запросить их. Но у вас не получится сделать это, если вы удалите исходные данные из-за нехватки места. Возможно, вы захотите разобраться, почему некоторые агрегированные значения странно себя ведут. Но вы не сможете это узнать, если удалили данные, которые участвовали в агрегировании.
Неменьший эффект дает масштабирование вычислений. Ресурсы BigQuery измеряются в слотах. Один слот соответствует примерно половине ядра процессора (мы подробно рассмотрим слоты в главе 6). BigQuery использует слоты как абстракцию количества доступных физических вычислительных ресурсов. Запросы выполняются слишком медленно? Просто добавьте слоты. Больше людей хотят создавать отчеты? Добавьте больше слотов. Хотите сократить свои расходы? Уменьшите число слотов.
Поскольку BigQuery — это многопользовательская система, управляющая большими пулами аппаратных ресурсов, она позволяет распределять слоты и на уровне запросов, и на уровне пользователей. Вы можете зарезервировать оборудование для своего проекта или организации или выполнять запросы в общем пуле. Благодаря такому механизму совместного использования ресурсов, BigQuery может выделять очень большие вычислительные мощности для обработки ваших запросов. Если вам потребуется больше вычислительной мощности, чем доступно в общем пуле, вы сможете приобрести дополнительные ресурсы с помощью интерфейса бронирования BigQuery Reservation API.
Некоторые клиенты BigQuery резервируют десятки тысяч слотов, то есть когда они выполняют запросы по одному, эти запросы могут обрабатываться десятками тысяч процессорных ядер одновременно. С некоторыми допущениями о количестве тактов процессора, необходимых для обработки одной записи, довольно легко подсчитать, что, имея подобные мощности, можно обрабатывать миллиарды или даже триллионы записей в секунду.
Некоторые клиенты BigQuery имеют петабайты данных, но ежедневно используют лишь относительно небольшую их часть. Другие хранят всего несколько гигабайтов данных, но выполняют сложные запросы, используя тысячи процессоров. Не существует универсального решения. К счастью, разделение вычислений и хранилищ позволяет BigQuery удовлетворить широкий спектр потребностей клиентов.
Хранилище и сетевая инфраструктура
В отличие от других облачных хранилищ данных, запросы в BigQuery обрабатывают данные, находящиеся в основном на вращающихся дисках в распределенной файловой системе. Большинство конкурирующих систем вынуждено кешировать данные на вычислительных узлах, чтобы получить хорошую производительность. BigQuery, напротив, использует две уникальные системы, разработанные в Google: файловую систему Colossus (https://cloud.google.com/files/storage_architecture_and_challenges.pdf) и сеть Jupiter (https://cloudplatform.googleblog.com/2015/06/A-Look-Inside-Googles-Data-Center-Networks.html), обеспечивающие быстрый доступ к данным, независимо от их физического местоположения в вычислительном кластере.
Структура сети Google Jupiter основана на конфигурации, в которой менее производительные (и, следовательно, более дешевые) коммутаторы размещены так, чтобы обеспечить пропускную способность, для которой в противном случае потребовался бы гораздо более производительный коммутатор. Эта топология коммутаторов, наряду с централизованным программным стеком и настраиваемым аппаратным и программным обеспечением, обеспечивает пропускную способность в один петабит в пределах вычислительного центра. Это эквивалентно 100 000 серверов, обменивающихся данными со скоростью 10 Гбит/с, и это означает, что BigQuery может работать без необходимости объединять вычисления и хранилище. Если машины, на которых размещены диски, находятся в другом конце вычислительного центра, в отдалении от машин, на которых выполняются вычисления, они будут работать так же быстро, как если бы они размещались в одной стойке.
Быстрая сетевая структура дает два преимущества: она позволяет быстро считывать с диска и перемещать их между этапами обработки. Как уже было упомянуто, разделение вычислений и хранилищ в BigQuery позволяет любой машине в вычислительном центре получать данные с любого диска хранилища. Однако для этого требуется передавать входные данные, необходимые для выполнения запросов, с очень высокой скоростью. Подробнее это описано в главе 6, а пока достаточно отметить, что для выполнения сложных распределенных запросов обычно требуется перемещать большие объемы данных между компьютерами на промежуточных этапах. Без быстрой сети, соединяющей вычислительные узлы, перемещение данных станет узким местом и может значительно замедлить обработку запросов.
Сетевая инфраструктура обеспечивает не только высокую скорость, но и высокую производительность. Вычислительные центры Google связаны магистральной сетью под названием B4 (https://www.usenix.org/conference/atc15/technical-session/presentation/mandal), которая управляется программным обеспечением, распределяющим пропускную способность между пользователями и обеспечивающим высокое качество обслуживания приоритетных операций. Это очень важно для высокопроизводительной параллельной обработки запросов.
Однако быстрой сети недостаточно, если дисковая подсистема работает медленно или недостаточно хорошо масштабируется. Для поддержки интерактивных запросов считывание данных с дисков должно быть достаточно быстрым, чтобы ими можно было наполнить доступную пропускную способность сети. В Google используется распределенная файловая система Colossus, способная координировать сотни тысяч дисков, постоянно выполнять перебалансировку старых, «холодных» данных и равномерно распределять новые данные по дискам.16 Это означает, что эффективная пропускная способность составляет десятки терабайт в секунду. Сочетая эту эффективную пропускную способность с эффективными форматами данных и хранилищем, BigQuery имеет возможность запрашивать таблицы с петабайтами данных за считаные минуты.
Управляемое хранилище
Система хранения в BigQuery основана на идее использования абстракции таблицы вместо абстракции файла при работе со структурированным хранилищем. Некоторые облачные системы обработки данных с открытым исходным кодом предлагают пользователям формат файла, что позволяет управлять размерами файлов и обеспечивать согласованность схемы. Хранилища позволяют создавать файлы соответствующего размера для хранения статических данных, но, как известно, поддерживать оптимальный размер файлов для данных, которые со временем меняются, очень сложно. Точно так же трудно поддерживать согласованность схемы при наличии большого количества файлов со схемами, предусматривающими самоописание (например, Avro или Parquet), — обычно каждое обновление программного обеспечения в системах, производящего эти файлы, приводит к изменениям схемы. BigQuery гарантирует согласованность схем для всех данных, хранящихся в таблицах, и обеспечивает надежный переход архивных данных. Абстрагируя форматы данных и размеры файлов, BigQuery может обеспечить непрерывную работу и быструю обработку запросов.
Еще одно преимущество BigQuery в управлении собственным хранилищем: возможность увеличения скорости работы без усилий со стороны конечного пользователя. Например, улучшения в форматах хранения могут автоматически применяться к пользовательским данным. Аналогично, улучшения в инфраструктуре хранения немедленно отражаются на работе системы. Поскольку хранилищем управляет только BigQuery, пользователям не нужно беспокоиться о резервном копировании или репликации. Все, от обновлений и репликации до резервного копирования и восстановления, выполняется системой управления хранилищем автоматически.
Одним из ключевых преимуществ работы со структурированным хранилищем на уровне абстракции таблицы (а не файла) и простого управления хранением этих таблиц является возможность для BigQuery поддерживать соответствующие функции, например DML. Вы можете отправить запрос, обновляющий или удаляющий строки в таблице, и положиться на BigQuery в выборе наиболее подходящего способа изменения хранилища для представления этой информации. Операции в BigQuery поддерживают свойства ACID; то есть изменения, произведенные в ходе выполнения запросов, либо подтверждаются полностью, либо отменяются. Будьте уверены, что ваши запросы никогда не будут пересекаться с промежуточным состоянием другого запроса, а запросы, запущенные после завершения другого запроса, никогда не пересекутся со старыми данными. У вас есть возможность точно настроить хранилище с помощью директив, управляющих хранением данных, но они работают на уровне абстракции таблиц, а не файлов. Например, вы можете управлять сегментированием и кластеризацией таблиц (мы подробно рассмотрим эти возможности в главе 7) и тем самым улучшить производительность и/или уменьшить стоимость запросов к этим таблицам.
Управляемое хранилище строго типизировано, то есть данные проверяются на входе в систему. Поскольку управление хранилищем осуществляет платформа BigQuery и пользователи могут взаимодействовать с этим хранилищем только через ее API, она предусматривает, что базовые данные не изменятся за ее пределами. То есть BigQuery может гарантировать, что при чтении любых данных, находящихся в управляемом хранилище, не возникнет никаких ошибок проверки. Эта гарантия также подразумевает надежность схемы, которая может пригодиться для выяснения, как правильно запрашивать таблицы. Помимо улучшенной производительности запросов, наличие надежной схемы помогает понять, какие данные у вас есть, потому что схема в BigQuery содержит не только информацию о типе, но также аннотации и описания таблиц о том, как можно использовать поля.
Одним из недостатков управляемого хранилища является сложность получения прямого доступа к данным и их обработки с использованием других платформ. Например, если бы данные были доступны на уровне абстракции файлов, вы могли бы запустить задание Hadoop на наборе данных из BigQuery. BigQuery решает эту проблему, предоставляя структурированный параллельный API для чтения данных. Этот API позволяет читать на полной скорости из заданий Spark или Hadoop, а также предлагает дополнительные возможности, такие как создание проекций, фильтрация и динамическая перебалансировка.
Интеграция с платформой Google Cloud
Платформа Google Cloud следует принципу «разделения ответственности», согласно которому небольшое количество высококачественных и узкоспециализированных продуктов тесно интегрируются друг с другом. Поэтому, сравнивая BigQuery с другими продуктами баз данных, важно учитывать всю облачную платформу Google (Google Cloud Platform, GCP).
Существует множество разных продуктов GCP, которые пополняют список достоинств BigQuery или помогают понять, как пользоваться BigQuery. Мы подробно поговорим о многих из этих продуктов позже, но не забывайте об общем принципе разделения ответственности:
• StackDriver, инструмент мониторинга и аудита журналов, помогает понять, как лучше использовать BigQuery в вашей организации.
• Cloud Dataproc обеспечивает возможность чтения, обработки и записи в таблицы BigQuery с помощью программ Apache Spark.
• Федеративные запросы позволяют BigQuery извлекать данные, хранящиеся в Google Cloud Storage, Cloud SQL (реляционная база данных), Bigtable (база данных NoSQL), Spanner (распределенная база данных) или Google Drive (электронные таблицы).
• Google Cloud Data Loss Prevention API (https://cloud.google.com/dlp) помогает управлять конфиденциальными данными и дает возможность редактировать или маскировать личную информацию (Personally Identifiable Information, PII) в таблицах.
• Другие API машинного обучения добавляют новые возможности в анализ данных, хранящихся в BigQuery; например, API Cloud Natural Language может идентифицировать людей, места, эмоциональную окраску и многое другое в произвольном тексте (например, в отзывах клиентов), размещенном в каком-либо столбце таблицы.
• AutoML Tables и AutoML Text могут создавать высокоэффективные модели машинного обучения на основе данных, хранящихся в таблицах BigQuery.
• Cloud Catalog позволяет обнаруживать данные, хранящиеся в вашей организации.
• Cloud Pub/Sub можно использовать для передачи потоковых данных, а Cloud Dataflow — для преобразования и загрузки их в BigQuery. Также Cloud Dataflow можно использовать для выполнения потоковых запросов. И конечно же, потоковые данные внутри самой платформы BigQuery можно запрашивать интерактивно.17
• Data Studio предоставляет диаграммы и информационные панели (дашборды), отображающие данные из BigQuery. Сторонние инструменты, такие как Tableau и Looker, тоже поддерживают возможность получения данных из BigQuery.
• Cloud AI Platform дает возможность обучать сложные программы машинного обучения на данных, хранящихся в BigQuery.
• Cloud Scheduler и Cloud Functions позволяют планировать или запускать запросы BigQuery как часть более крупных рабочих процессов.
• Cloud Composer позволяет координировать задания BigQuery с задачами, которые необходимо выполнить в Cloud Dataflow или в других фреймворках обработки данных, в Google Cloud или локальных гибридных облаках.
В совокупности BigQuery и экосистема GCP обладают возможностями, охватывающими некоторые другие продукты баз данных от сторонних поставщиков облачных решений; их можно использовать как хранилище аналитики, а также как систему ELT, озеро данных (запросы к файлам) или источник BI. Далее мы более подробно расскажем, как можно использовать все аспекты платформы BigQuery.
Безопасность и соответствие требованиям
Интеграция с GCP не ограничивается простыми взаимодействиями с другими продуктами. Сквозные функции, предлагаемые платформой, обеспечивают постоянную безопасность и соответствие требованиям.
Самое быстрое оборудование и самое современное программное обеспечение бесполезны, если вы не сможете доверить им свои данные. Модель безопасности BigQuery тесно интегрирована с остальной частью GCP, что позволяет получить целостное представление о безопасности ваших данных. Для назначения конкретных разрешений отдельным пользователям или их группам BigQuery использует систему контроля доступа Google IAM. Также BigQuery тесно связана с управлением виртуальным частным облаком Google (Virtual Private Cloud, VPC), способным защитить вас от внешних попыток доступа к данным вашей организации или их передачи третьей стороне. Элементы управления IAM и VPC проектировались для работы со всеми продуктами Google Cloud, поэтому вам не придется беспокоиться о том, что какие-то продукты могут создать слабое звено в системе безопасности.
BigQuery доступна во всех регионах, где есть Google Cloud, благодаря чему вы можете обрабатывать данные в любом выбранном месте. На момент написания этой книги в Google Cloud имелось более двух десятков вычислительных центров по всему миру, и компания продолжает открывать новые. Если у вас есть свои причины хранить данные в Австралии или Германии, вы легко сможете это сделать. Просто создайте свой набор данных с кодом региона Австралии или Германии, и все ваши запросы к данным будут выполняться в этом регионе.
Некоторые организации предъявляют еще более строгие требования к размещению данных, не ограничиваясь требованием к выбору региона, где должны храниться и обрабатываться данные. В частности, многие хотят иметь гарантии, что их данные не будут скопированы или иным образом не покинут определенную географическую область. GCP имеет элементы управления географической областью, которые применяются ко всем продуктам; вы можете создать систему «управление службами VPC» (VPC service controls), которая запрещает перемещение данных за пределы выбранной области. Если у вас настроены подобные системы, пользователи не смогут копировать или экспортировать данные в другие сегменты Google Cloud Storage, находящиеся в других регионах.
Выводы
BigQuery — это масштабируемое хранилище данных, обеспечивающее быстрые бессерверные вычисления больших наборов данных с помощью SQL-запросов. Пользователи ценят масштаб и скорость BigQuery, но руководители компаний часто более высоко оценивают возможность перехода на более качественный уровень, который дает возможность выполнять специальные запросы с помощью бессерверных вычислений и позволяет принимать решения на основе данных во всех подразделениях компании.
Для загрузки данных в BigQuery можно использовать конвейер EL (часто применяется для периодической загрузки файлов журналов), конвейер ETL (когда необходимо обогащение данных или контроль качества) или конвейер ELT (для исследовательской работы).
Платформа BigQuery предназначена для аналитической обработки данных в реальном времени (OnLine Analytical Processing, OLAP) и предоставляет полноценную поддержку SQL:2011. Высокая скорость BigQuery достигается за счет инновационных инженерных решений, таких как использование колоночного хранилища, поддержка вложенных и повторяющихся полей, а также отделение вычислений от хранения, о котором Google продолжает публиковать статьи. BigQuery является частью экосистемы GCP инструментов анализа больших данных и тесно интегрируется как с элементами инфраструктуры (обеспечивающими, например, безопасность, мониторинг и ведение журналов), так и с элементами обработки данных и машинного обучения (такими, как потоковая передача, Cloud DLP и AutoML).
1 На самом деле запись должна создаваться в момент получения оборудования в аренду, чтобы можно было узнать, не сбежал ли клиент с ним. Однако на данном этапе об этом пока рано волноваться!
2 В этой книге под «ситуативными» мы будем понимать запросы, написанные без какой-либо предварительной подготовки базы данных с применением таких возможностей, как индексы.
3 Jeffrey Dean and Sanjay Ghemawat, «MapReduce: Simplified Data Processing on Large Clusters», OSDI ’04: Sixth Symposium on Operating Systems Design and Implementation, San Francisco, CA (2004), pp. 137–150. Доступна по ссылке https://research.google.com/archive/mapreduce-osdi04.pdf.
4 Облачная платформа Google Cloud Dataproc (управляемое предложение Hadoop) решает эту проблему по-другому. Благодаря высокой пропускной способности в центрах обработки данных Google, кластеры Cloud Dataproc могут быть привязаны к конкретной работе — данные хранятся в облачном хранилище Google Cloud Storage и передаются по сети по запросу. Такое возможно только при достаточно высокой пропускной способности, сопоставимой с пропускной способностью дисков. Не пытайтесь повторить.
5 Для удобства копирования и вставки все фрагменты кода и запросов, которые приведены в этой книге, включая запрос в этом примере (https://github.com/GoogleCloudPlatform/bigquery-oreilly-book/blob/master/01_intro/queries.txt), доступны в репозитории GitHub (https://github.com/GoogleCloudPlatform/bigquery-oreilly-book).
6 Не конкретно вам. Это общедоступный набор данных, и владелец набора данных дал это разрешение всем аутентифицированным пользователям. Вы можете быть менее щедрыми в отношении своих данных и предоставлять к ним доступ только тем, кто находится в вашем домене или в вашей команде.
7 Этот код можно загрузить из репозитория GitHub с примерами для книги.
8 Имейте в виду, что оба автора живут в Сиэтле, где дождь идет 150 дней в году.
9 Более подробно колоночный формат хранения описывается в разделе «История появления BigQuery» ниже.
10 Например, для оценки расстояния, которое должен преодолеть клиент, чтобы купить продукт.
11 Все цены актуальны на момент написания этой книги, но вы обязательно должны сами свериться с соответствующими правилами и ценами (https://cloud.google.com/bigquery/pricing), так как они могут измениться.
12 Статья в Википедии на русском языке: https://ru.wikipedia.org/wiki/Грей,_Джим. — Примеч. пер.
13 Статья Jim Gray on eScience:A Transformed Scientific Method из сборника The Fourth Paradigm: Data-Intensive ScientificDiscovery, под редакцией Тони Хея (Tony Hey), Стюарта Тенсли (Stewart Tansley) и Кристин Толле (Kristin Tolle), Microsoft, 2009, xiv. Доступна по ссылке https://oreil.ly/M6zMN.
14 В настоящее время BigQuery позволяет экспортировать таблицы и результаты в Google Cloud Storage, поэтому мы все-таки создали ссылку для скачивания! Но BigQuery не просто ссылка — в большинстве случаев BigQuery предполагают обработку данных на месте.
15 В SQL есть ключевое слово RECURSIVE, но, как и многие движки SQL, BigQuery не поддерживает его и предлагает более эффективные способы работы с иерархическими данными, поддерживая массивы и вложение.
16 Узнать больше о Colossus можно по ссылкам http://www.pdsw.org/pdsw-discs17/slides/PDSW-DISCS-Google-Keynote.pdf и https://www.wired.com/2012/07/google-colossus/.
17 Разделение ответственности заключается в том, что Cloud Dataflow лучше подходит для непрерывной рутинной обработки, а BigQuery — для специальной интерактивной обработки. Cloud Dataflow и BigQuery способны обрабатывать как пакетные, так и потоковые данные, и Cloud Dataflow позволяет выполнять запросы SQL.
Пока оставим в стороне синтаксис запроса. Обратите внимание только на строки, выделенные жирным шрифтом. Здесь мы соединяем набор данных о прокате велосипедов и набор данных о погоде, взятый из совершенно другого источника. Результаты запроса подтверждают предположение, что жители Нью-Йорка слабаки — в дождливые дни берут велосипеды в прокат на 20% реже:8
Мы не призываем вас верить нам на слово. Попробуйте сами. Перейдите по ссылке https://console.cloud.google.com/bigquery (зарегистрируйтесь в Google Cloud Platform и, если потребуется, выберите свой проект), скопируйте и вставьте следующий запрос в окно,5 а затем щелкните на «Run query» («Выполнить»):
Традиционный подход к работе с хранилищами данных включает три этапа: извлечение, преобразование и загрузку (Extract, Transform, Load; ETL), когда исходные данные извлекаются из источника, преобразуются и затем загружаются в хранилище данных. В действительности BigQuery поддерживает собственный высокоэффективный формат колоночного хранения,9 что делает методологию ETL особенно привлекательной. Конвейер обработки данных, обычно реализованный на основе Apache Beam или Apache Spark, извлекает необходимые исходные данные (потоковых данных или пакетных файлов), преобразует извлеченные данные, подготавливая их к очистке или агрегированию, а затем загружает их в BigQuery, как показано на рис. 1.2.
На первый взгляд архитектура может показаться простой, тем не менее, в ней есть ряд скрытых недостатков. Для сохранения данных в HDFS необходим достаточно большой кластер. Еще одна немаловажная особенность архитектуры MapReduce, которой часто пренебрегают, заключается в том, что обычно вычислительным узлам требуется доступ к локальным для них данным. Соответственно, файловая система HDFS должна быть разбита на сегменты между вычислительными узлами кластера. Поскольку объемы данных и потребности в анализе быстро растут независимо друг от друга, часто происходит так, что кластеры испытывают нехватку или переизбыток вычислительных мощностей.4 То есть чтобы выполнять программы Spark в кластере Hadoop, сотрудникам вашей организации придется стать экспертами в управлении, мониторинге и настройке кластеров Hadoop. Это может не входить в ваши планы.
Возможно, вы вносите эту информацию в базу данных каждый раз, когда клиент возвращает оборудование.1
Данные о прокате велосипедов поступают из Нью-Йорка. А можно ли объединить их с данными о погоде Национального управления океанических и атмосферных исследований США, чтобы узнать, как дождливая погода влияла на прокат велосипедов?7
К сожалению, базы данных OLTP довольно неэффективно выполняют подобные запросы. Основной упор в них делается на согласованность данных; дело в том, что базы данных позволяют считывать данные, даже когда в них одновременно производится запись. Это достигается за счет блокировок, обеспечивающих сохранение целостности данных. Чтобы фильтрация по полю station_name выполнялась эффективно, необходимо создать индекс для поля с названием пункта проката. Только если название пункта проката индексируется, база данных будет выполнять специальные операции с хранилищем для оптимизации поиска, правда, при этом увеличение скорости чтения достигается за счет уменьшения скорости записи. Если название пункта проката не индексируется, фильтрация по этому полю будет работать довольно медленно. И даже если для названия пункта проката создать индекс, этот конкретный запрос все равно будет выполняться медленно из-за операций агрегирования, группировки и сортировки. Базы данных OLTP не созданы для таких ситуативных2 запросов, требующих выполнить обход всего набора данных.
Не конкретно вам. Это общедоступный набор данных, и владелец набора данных дал это разрешение всем аутентифицированным пользователям. Вы можете быть менее щедрыми в отношении своих данных и предоставлять к ним доступ только тем, кто находится в вашем домене или в вашей команде.
Этот код можно загрузить из репозитория GitHub с примерами для книги.
На самом деле запись должна создаваться в момент получения оборудования в аренду, чтобы можно было узнать, не сбежал ли клиент с ним. Однако на данном этапе об этом пока рано волноваться!
В этой книге под «ситуативными» мы будем понимать запросы, написанные без какой-либо предварительной подготовки базы данных с применением таких возможностей, как индексы.
Jeffrey Dean and Sanjay Ghemawat, «MapReduce: Simplified Data Processing on Large Clusters», OSDI ’04: Sixth Symposium on Operating Systems Design and Implementation, San Francisco, CA (2004), pp. 137–150. Доступна по ссылке https://research.google.com/archive/mapreduce-osdi04.pdf.
Облачная платформа Google Cloud Dataproc (управляемое предложение Hadoop) решает эту проблему по-другому. Благодаря высокой пропускной способности в центрах обработки данных Google, кластеры Cloud Dataproc могут быть привязаны к конкретной работе — данные хранятся в облачном хранилище Google Cloud Storage и передаются по сети по запросу. Такое возможно только при достаточно высокой пропускной способности, сопоставимой с пропускной способностью дисков. Не пытайтесь повторить.
Обратите внимание на несколько моментов. Во-первых, вы смогли выполнить запрос к набору данных, который уже есть в BigQuery. Все, что должен сделать ответственный за проект, в котором размещены данные, — это предоставить вам6 доступ к этому набору данных для «просмотра». Вам не нужно запускать кластер или входить в него — вы просто отправляете запрос сервису и получаете результаты. Сам запрос написан на SQL:2011, который поддерживает синтаксис, хорошо знакомый аналитикам данных. Мы продемонстрировали пример обработки гигабайтов данных, но вообще сервис легко масштабируется и способен агрегировать терабайты и петабайты данных. Такая масштабируемость возможна, потому что сервис распределяет обработку запросов между тысячами рабочих узлов практически мгновенно.
Для удобства копирования и вставки все фрагменты кода и запросов, которые приведены в этой книге, включая запрос в этом примере (https://github.com/GoogleCloudPlatform/bigquery-oreilly-book/blob/master/01_intro/queries.txt), доступны в репозитории GitHub (https://github.com/GoogleCloudPlatform/bigquery-oreilly-book).
Разделение ответственности заключается в том, что Cloud Dataflow лучше подходит для непрерывной рутинной обработки, а BigQuery — для специальной интерактивной обработки. Cloud Dataflow и BigQuery способны обрабатывать как пакетные, так и потоковые данные, и Cloud Dataflow позволяет выполнять запросы SQL.
Более подробно колоночный формат хранения описывается в разделе «История появления BigQuery» ниже.
Например, для оценки расстояния, которое должен преодолеть клиент, чтобы купить продукт.
Все цены актуальны на момент написания этой книги, но вы обязательно должны сами свериться с соответствующими правилами и ценами (https://cloud.google.com/bigquery/pricing), так как они могут измениться.
Статья в Википедии на русском языке: https://ru.wikipedia.org/wiki/Грей,_Джим. — Примеч. пер.
Статья Jim Gray on eScience:A Transformed Scientific Method из сборника The Fourth Paradigm: Data-Intensive ScientificDiscovery, под редакцией Тони Хея (Tony Hey), Стюарта Тенсли (Stewart Tansley) и Кристин Толле (Kristin Tolle), Microsoft, 2009, xiv. Доступна по ссылке https://oreil.ly/M6zMN.
В настоящее время BigQuery позволяет экспортировать таблицы и результаты в Google Cloud Storage, поэтому мы все-таки создали ссылку для скачивания! Но BigQuery не просто ссылка — в большинстве случаев BigQuery предполагают обработку данных на месте.
В SQL есть ключевое слово RECURSIVE, но, как и многие движки SQL, BigQuery не поддерживает его и предлагает более эффективные способы работы с иерархическими данными, поддерживая массивы и вложение.
Узнать больше о Colossus можно по ссылкам http://www.pdsw.org/pdsw-discs17/slides/PDSW-DISCS-Google-Keynote.pdf и https://www.wired.com/2012/07/google-colossus/.
Имейте в виду, что оба автора живут в Сиэтле, где дождь идет 150 дней в году.
Поскольку базы данных OLTP плохо подходят для ситуативных запросов и запросов, требующих обхода всего набора данных, специализированные виды анализа, требующие такого обхода, можно запрограммировать на языках высокого уровня, таких как Java или Python. В 2003 году Джефф Дин (Jeff Dean) и Санджай Гемават (Sanjay Ghemawat) заметили, что они и их коллеги из Google реализуют сотни таких специализированных вычислений для обработки больших объемов исходных данных. Для решения этой проблемы они разработали абстракцию, позволяющую выражать вычисления в виде двух шагов: функции map (отображения), которая обрабатывает пару ключ/значение и генерирует набор промежуточных пар ключ/значение, и функции reduce (свертки), которая объединяет все промежуточные значения, связанные с тем же промежуточным ключом.3 Эта парадигма, известная как MapReduce, оказала существенное влияние на фреймворки и привела к разработке Apache Hadoop.
Глава 2. Основы запросов
Платформа BigQuery — это прежде всего хранилище данных, то есть она обеспечивает постоянное хранение структурированных и полуструктурированных данных (например, объектов JSON). В этом постоянном хранилище поддерживаются четыре основные CRUD-операции:
Create (создание)
Добавляет новые записи. Осуществляется с помощью операций загрузки, SQL-оператора INSERT и интерфейса потоковой вставки. С помощью SQL-операторов, которые являются частью поддерживаемого в BigQuery языка определения данных (Data Definition Language, DDL), также можно создавать объекты баз данных, такие как таблицы, представления и модели машинного обучения. Ниже мы рассмотрим примеры каждой из перечисленных возможностей.
Read (чтение)
Извлекает записи. Осуществляется с помощью SQL-оператора SELECT и массового считывания API.
Update (изменение)
Изменяет существующие записи. Осуществляется с помощью SQL-операторов UPDATE и MERGE, которые являются частью поддерживаемого в BigQuery языка манипулирования данными (Data Manipulation Language, DML). Обратите внимание на то, что, как уже было отмечено в главе 1, платформа BigQuery является аналитическим инструментом и не предназначена для частых обновлений.
Delete (удаление)
Удаляет существующие записи. Осуществляется с помощью SQL-оператора DELETE, который также является частью поддерживаемого в BigQuery языка DML.
BigQuery — это инструмент анализа данных, и большинство запросов, которые вам предстоит написать, будут вышеупомянутыми операциями чтения. Чтение и анализ данных осуществляются с помощью оператора SELECT, о котором пойдет речь в этой главе. Операции создания, изменения и удаления данных мы рассмотрим в следующих главах.
что такое устаревший SQL?
Долгое время BigQuery поддерживала только ограниченное подмножество языка SQL с некоторыми расширениями Google. Все потому, что BigQuery была основана на движке SQL (под названием Dremel), использовавшемся внутри компании Google. Изначально этот движок создавался для обработки журналов, хранящихся в формате Protocol Buffers (Protobufs).18 Поскольку Dremel создавался не как универсальный движок SQL, он мог использовать диалект SQL (сейчас его называют устаревшим SQL), хорошо подходящий для работы с форматом Protobufs, использующимся для хранения иерархических структур. Например, устаревший SQL различает записи (иерархическая структура, включающая все сообщения в журнале) и строки (срез структуры).19 Соответственно инструкция COUNT(*) в Dremel подсчитывает количество значений, не равных NULL в большинстве повторяющихся полей. Несмотря на то что это значительно облегчало написание запросов определенных типов, к диалекту Dremel нужно было привыкнуть, потому что это был нестандартный SQL.
В этой книге мы сосредоточимся на стандартном SQL. Пользовательский интерфейс BigQuery в облачной консоли Google Cloud Platform (GCP) по умолчанию использует стандартный SQL, а новые возможности не переносятся в устаревший SQL. Тем не менее некоторые инструменты и пользовательские интерфейсы все еще используют устаревший SQL. Если вы столкнетесь с подобным инструментом, просто добавьте в запрос первую строку #standardsql, как показано в следующем примере:
#standardsql
SELECT DISTINCT gender
FROM `bigquery-public-data`.new_york_citibike.citibike_trips
Если BigQuery обнаружит в запросе первую строку #standardsql, механизм обработки запросов будет интерпретировать последующий код как стандартный SQL, даже если сам клиент ничего не знает о стандартном SQL.
Простые запросы
BigQuery поддерживает диалект SQL, совместимый с SQL:2011 (https://www.iso.org/standard/53681.html). Если спецификация неоднозначна или имеет пробелы, BigQuery следует требованиям, принятым в существующих движках SQL. Есть также области, для которых спецификации отсутствуют, например машинное обучение; в таких случаях BigQuery определяет свой собственный синтаксис и семантику.
Извлечение записей с помощью SELECT
Оператор SELECT позволяет извлекать из таблицы значения указанных столбцов. Например, рассмотрим набор данных по прокату велосипедов в Нью-Йорке (https://bigquery.cloud.google.com/table/bigquery-public-data:new_york.citibike_trips) — он содержит несколько столбцов, касающихся проката велосипедов, включая продолжительность поездки и пол человека, арендовавшего велосипед. Вот как с помощью оператора SELECT можно извлечь значения столбцов (строки, начинающиеся с двух дефисов или с #, являются комментариями):
-- простая выборка
SELECT
gender, tripduration
FROM
`bigquery-public-data`.new_york_citibike.citibike_trips
LIMIT 5
Результаты должны выглядеть примерно так:
| Row |
gender |
tripduration |
| 1 |
male |
371 |
| 2 |
male |
1330 |
| 3 |
male |
830 |
| 4 |
male |
555 |
| 5 |
male |
328 |
Полученный в итоге набор имеет два столбца (gender и tripduration), следующих в том же порядке, что и в операторе SELECT, и пять записей, потому что мы ограничили их количество в последней строке запроса. BigQuery распределяет задачу выборки записей между несколькими рабочими процессами, каждый из которых может читать свой сегмент (или часть) исходного набора данных, поэтому, выполнив предыдущий запрос еще раз, можно получить другой набор из пяти записей.
Обратите внимание, что оператор LIMIT ограничивает только объем отображаемых данных, а не объем данных, которые должен обработать движок запросов. Обычно клиенты BigQuery платят за объем данных, обработанных их запросами, и, как правило, это означает, что чем больше столбцов прочитает ваш запрос, тем больше вы заплатите. Количество обработанных записей обычно определяется общим размером таблицы, хотя есть способы оптимизировать и этот показатель (о чем мы поговорим в главе 7). Вопросы эффективности и ценообразования мы рассмотрим в следующих главах.
Значения извлекаются из следующего источника:
bigquery-public-data.new_york_citibike.citibike_trips
Здесь bigquery-public-data — это идентификатор проекта, new_york_citibike — набор данных, а citibike_trips — таблица. Идентификатор проекта определяет принадлежность постоянного хранилища, связанного с набором данных и его таблицами. Владелец bigquery-public-data оплачивает расходы на хранение набора данных new_york. Стоимость запроса оплачивается проектом, в рамках которого был запущен запрос. Выполнив предыдущий запрос, вы должны будете оплатить его стоимость. Наборы данных обеспечивают управление идентификацией и доступом (Identity and Access Management, IAM). Человек,20 создавший набор данных new_york_citibike в BigQuery, сделал его общедоступным, поэтому мы смогли перечислить таблицы (https://bigquery.cloud.google.com/dataset/bigquery-public-data:new_york) в наборе данных и выполнить запрос к одной из них. Таблица citibike_trips содержит все поездки на арендованных велосипедах. Идентификатор проекта, название набора данных и имя таблицы разделены точками. Обратные апострофы в данном случае используются в качестве экранирующего символа из-за присутствия дефиса (-) в идентификаторе проекта (bigquery-public-data) — без них дефисы интерпретировались бы как операторы вычитания. Большинство разработчиков просто заключают всю строку в обратные апострофы, например:
-- простая выборка
SELECT
gender, tripduration
FROM
`bigquery-public-data.new_york_citibike.citibike_trips`
LIMIT 5
Такой способ проще, но при этом теряется возможность использовать имя таблицы (citibike_trips) в качестве псевдонима. Поэтому лучше выработать привычку заключать в обратные апострофы только имя проекта и не использовать дефисы при определении имен наборов данных и таблиц.
Долгое время мы рекомендовали хранить таблицы в BigQuery в денормализованной форме (то есть помещать все необходимые данные в одну таблицу, чтобы избежать необходимости соединения нескольких таблиц). Однако, благодаря усовершенствованию сервиса, эта рекомендация потеряла свою актуальность. Теперь хорошей производительности можно добиться даже с использованием звездообразной схемы.
В табл. 2.1 перечислены три ключевых компонента имени `bigquery-publicdata`.new_york_citibike.citibike_trips.
Таблица 2.1. Основные объекты BigQuery и их описание21
| Объект BigQuery |
Имя |
Описание |
| Проект |
bigquery-public-data |
Владелец хранилища, связанного с набором данных и его таблицами. Проект также регулирует использование всех других продуктов GCP |
| Набор данных |
new_york_citibike |
Наборы данных — это контейнеры верхнего уровня, которые используются для организации и управления доступом к таблицам и представлениям. Пользователь может иметь несколько наборов данных |
| Таблица/представление |
citibike_trips |
Таблица или представление должны принадлежать набору данных, поэтому перед загрузкой данных в BigQuery необходимо создать хотя бы один набор данных1 |
Различие между этими тремя компонентами будет иметь решающее значение позже, когда речь пойдет о географическом местоположении, доступе к данным и их совместном использовании.
Создание псевдонимов столбцов с помощью AS
По умолчанию имена столбцов в наборе результатов совпадают с именами столбцов в таблице, откуда извлекаются данные. Однако с помощью AS именам столбцов можно присвоить свои псевдонимы:
-- Определение псевдонимов для имен столбцов
SELECT
gender, tripduration AS rental_duration
FROM
`bigquery-public-data`.new_york_citibike.citibike_trips
LIMIT 5
Этот запрос вернул следующие результаты (у вас конкретные значения могут отличаться):
| Row |
gender |
rental_duration |
| 1 |
male |
432 |
| 2 |
female |
1186 |
| 3 |
male |
799 |
| 4 |
female |
238 |
| 5 |
male |
668 |
Псевдонимы могут быть полезны при преобразовании данных. Например, без псевдонима следующий оператор:
SELECT
gender, tripduration/60
FROM
`bigquery-public-data`.new_york_citibike.citibike_trips
LIMIT 5
присвоит второму столбцу в наборе результатов имя автоматически:
| Row |
gender |
f0_ |
| 1 |
male |
6.183333333333334 |
| 2 |
male |
22.166666666666668 |
| 3 |
male |
13.833333333333334 |
| 4 |
male |
9.25 |
| 5 |
male |
5.466666666666667 |
Вы можете дать второму столбцу осмысленное имя, добавив псевдоним в запрос:
SELECT
gender, tripduration/60 AS duration_minutes
FROM
`bigquery-public-data`.new_york_citibike.citibike_trips
LIMIT 5
Этот запрос даст примерно такие результаты:
| Row |
gender |
duration_minutes |
| 1 |
male |
6.183333333333334 |
| 2 |
male |
22.166666666666668 |
| 3 |
male |
13.833333333333334 |
| 4 |
male |
9.25 |
| 5 |
male |
5.466666666666667 |



















