

Иван Андреевич Трещев
Екатерина Сергеевна Кудряшова
Базы данных. Учебное пособие
Для студентов
Шрифты предоставлены компанией «ПараТайп»
Тестирование баз данных Анастасия Сергеевна Ватолина
© Иван Андреевич Трещев, 2019
© Екатерина Сергеевна Кудряшова, 2019
В книге кратко рассмотрены теоретические вопросы проектирования баз данных. Приведены примеры лабораторных работ и рассчетно-графического задания, опробированные в учебном процессе ВУЗа. Книга будет полезна как преподавателям, так и студентам, а также всем заинтересованным в проектировании, реализации и тестировании информационных систем.
12+
ISBN 978-5-4496-4542-5
Создано в интеллектуальной издательской системе Ridero
Оглавление
- Базы данных. Учебное пособие
- Введение
- Лекции
- Лекция 1—3
- Лекция 4
- Лекция 5
- Лекция 6
- Лекция 7
- Лекция 8
- Методические указания к выполнению лабораторных работ по дисциплине Безопасность систем баз данных
- Лабораторная работа 1. Проектирование баз данных методом декомпозиции, методом сущность-связь
- Лабораторная работа 2. Проектирование реляционной базы данных в среде ERWIN
- Лабораторная работа 3. Создание баз данных в Microsoft SQL Server
- Лабораторная работа 4. Создание баз данных в MySQL с использованием phpMyAdmin
- Методические указания к выполнению расчетно-графического задания по дисциплине «Безопасность систем баз данных»
- Заключение
- Список использованных источников
«Сложная система, спроектированная наспех, никогда не работает, и исправить её, чтобы заставить работать, невозможно». Закон Мерфи
Введение
Любая информационная система сегодня в обязательном порядке включает в себя базу данных. Это может быть и база данных персонала и база данных контрагентов, товаров, услуг. Хотя большинство предприятий используют электронные таблицы, а не системы управления базами данных, но в ближайшем будущем все однозначно изменится. Использование электронных таблиц имеет свои неоспоримые преимущества в случае, если необходимо организовать небольшой массив данных и работать с ним приходится не часто. В случае же если «чистый» размер данных превосходит 100 Мб, то обработка таких массивов даже на современных ЭВМ с использованием электронных таблиц будет через мерно долгой.
СУБД эволюционируют вместе с данными. Сегодня OLAP кубы уже не являются ноу хау, а скорее превратились в обыденность, хотя еще 5 лет назад можно было по пальцам сосчитать предприятия использующие Oracle.
Отметим и все возрастающую роль распределенной обработки данных, поскольку когда возникают проблемы связанные с big data, даже хранение массивов в несколько десятков террабайт не представляется возможным на одной ЭВМ (исключая конечно специализированные системы хранения данных).
В данном пособии автор заостряет внимание на использовании СУБД Microsoft SQL Server и MySQL, поскольку первая используется во многих компаниях как стандарт дефакто, а вторая является свободно распространяемой и входит в комплект практически любого дистрибутива Unix-подобных операционных систем, дополнительно прекрасно интегрируется с PHP позволяя создавать платформы и приложения не только desktop но и web.
Все товарные знаки указанные в книге являются собственностью их правообладателей, а совпадения имен, названий, наименований и прочего — чистой случайностью.
Лекции
Лекция 1—3
База данных — это совокупность взаимосвязанных данных, находящихся под управлением системы управления базой данных (СУБД).
Система управления базой данных — совокупность языковых и программных средств, облегчающих для пользователей выполнение всех операций, связанных с организацией хранения данных, их корректировки и доступа к ним.
Этапы проектирования реляционной БД декомпозиционным методом
1) Разрабатывается универсальное отношение для БД (в универсальное отношение включаются все атрибуты, представляющие интерес для данного проектирования).
2) Определяются все функциональные зависимости между атрибутами данного отношения.
3) Определяется, находится ли отношение в нормальной форме Бойса — Кодда. Если да, то проектирование завершается, если нет, то осуществляется декомпозиция, т.е. разбиение отношения.
4) Шаги 2) и 3) повторяются для каждого нового отношения, полученного в результате декомпозиции. Проектирование завершается, когда все отношения будут находиться в НФБК.
Ключ — поле (атрибут), по которому можно однозначно определить каждую запись в таблице.
Функциональная зависимость — (А-> В) атрибут В функционально зависит от атрибута А если в любой момент времени каждому значению атрибута А соответствует одно значение атрибута В.
Атрибут В функционально полно зависит от атрибута А если В не зависит ни от какого подмножества А.
Нормализация — процесс построения оптимальной структуры таблиц и связи между ними.
Теория нормализации основана на том, что определенный набор таблиц обладает лучшими свойствами при включении, модификации и удалении данных, чем все остальные наборы таблиц, с помощью которых могут быть представлены те же данные.
Нормализованным отношением называют отношение, каждое поле которого содержит только атомарные значения. (пример про ФИО)
Определение первой нормальной формы (1НФ): отношение r находится в 1НФ, если каждый его элемент имеет и всегда будет иметь атомарное значение. (Это определение просто устанавливает тот факт, что любое нормализованное отношение находится в 1НФ.)
Определение второй нормальной формы (2НФ): отношение r находится во 2НФ, если оно находится в 1НФ и если каждый его атрибут, не являющийся основным атрибутом, функционально полно зависит от первичного ключа этого отношения.
Определение третьей нормальной формы (3НФ): отношение r находится в 3НФ, если оно является отношением во 2НФ и каждый его атрибут, не являющийся основным, не транзитивно зависит от первичного ключа этого отношения.
Транзитивная зависимость определяется следующим образом: если X -> Y и Y -> Z, то X -> Z (Z транзитивно зависит от X).
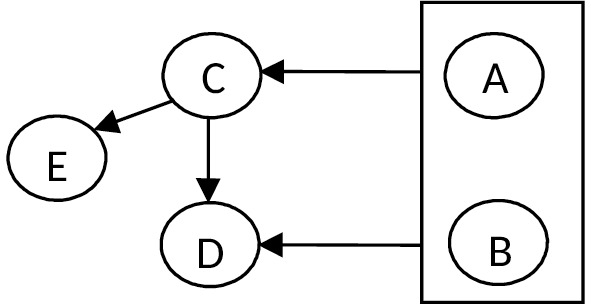
A, B -> C
A, B -> D
C -> D
C -> E
Первичный ключ: AB.
Отношение находится в 1НФ, поскольку все атрибуты имеют атомарные значения.
Отношение находится во 2НФ, т.к. все атрибуты функционально полно зависят от первичного ключа отношения.
Так как A, B -> C; C -> E, т. е. E транзитивно зависит от первичного ключа, значит отношение не находится в 3НФ.
Отношение находится в НФБК если каждый детерминант отношения является его возможным ключом.
Детерминант — это атрибут, от которого зависит другой атрибут.
Отношение r находится в 4НФ тогда и только тогда, когда при существовании многозначной зависимости в r атрибута Y от атрибута X, все остальные атрибуты r функционально зависят от Х.
Атрибут Х многозначно определяет атрибут Y, если с каждым значением x может использоваться значение y из фиксированного подмножества значений Y. Обозначается: X ↠ Y.
Избыточной функциональной зависимостью называют зависимость, заключающую в себе такую информацию, которая может быть получена на основе других зависимостей из числа использованных при проектировании БД.
Пусть r — отношение со схемой R,
w, x, y, z — подмножества R.
1-я аксиома вывода. Рефлексивность.
В r всегда имеет место Х -> Х
2-я аксиома вывода. Пополнение.
Если r удовлетворяет Х -> Y, то r удовлетворяет F-зависимости XZ -> Y
3-я аксиома вывода. Аддитивность (так же известна под названием — объединение).
Если отношение r удовлетворяет X -> Y и X -> Z, то r удовлетворяет F-зависимости Х -> YZ. (можно объединить правые части)
4-я аксиома вывода. Проективность.
Если отношение r удовлетворяет X -> YZ, то r удовлетворяет X -> Y и X -> Z.
(разбиваем совокупность)
5-я аксиома вывода. Транзитивность.
Х -> Y и Y -> Z влечет за собой X -> Z. (избыточная транзитивная зависимость может быть удалена)
6-я аксиома вывода. Псевдотранзитивность.
Если r удовлетворяет зависимостям X -> Y и YZ -> W, то r удовлетворяет XZ -> W.
Исходная диаграмма функциональных зависимостей:
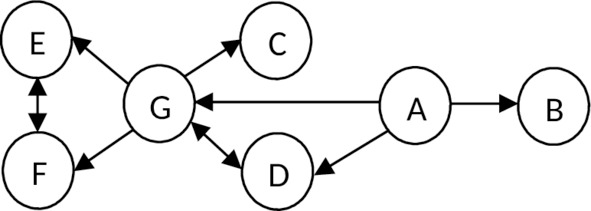
A -> B; A -> D; A -> G,
D -> G,
G -> D; G -> C; G -> F; G -> E,
E -> F,
F -> E
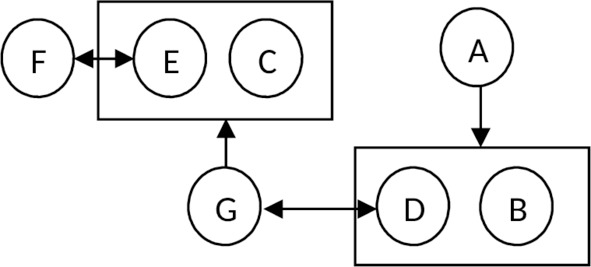
Удалим из исходного набора функциональных зависимостей все избыточные:
— т. к. A -> D, D -> G, то A -> G — исключим по аксиоме транзитивности
— т. к. G -> E, E -> F, то G -> F исключим по аксиоме транзитивности
— т. к. G -> E, G -> C, то по аксиоме аддитивности G -> E, C
— т. к. A -> B; A -> D, то по аксиоме аддитивности A -> D, B
Окончательная диаграмма функциональных зависимостей:
Пример проектирования методом декомпозиции БД интернет-магазин.
Уточнив вопрос о том какую информацию следует хранить в базе данных, определим все атрибуты, представляющие интерес для проектируемой базы данных. Это: для каждого товара его код, название, цена, процентная скидка; ФИО, адрес, телефон каждого клиента; для каждого заказа его код, сумма, дата выполнения и количество товара для каждого заказанного названия.
Применим для всех атрибутов краткие обозначения:
Название товара — НТ
Цена товара — ЦТ
Процентная скидка на товар — ПСТ
Код клиента — КК
ФИО клиента — ФИО
Адрес клиента — АК
Телефон клиента — ТК
Код заказа — КЗ
Сумма заказа — СЗ
Дата выполнения заказа — ДВЗ
Количество товара для каждого заказанного названия — КТЗ.
Универсальное отношение будет иметь вид: r (НТ, ЦТ, ПСТ, КК, ФИО, АК, ТК, КЗ, СЗ, ДВЗ, КТЗ).
Определив все функциональные зависимости, имеющиеся между атрибутами универсального отношения, построим диаграмму функциональных зависимостей (см. рис. 1.1).
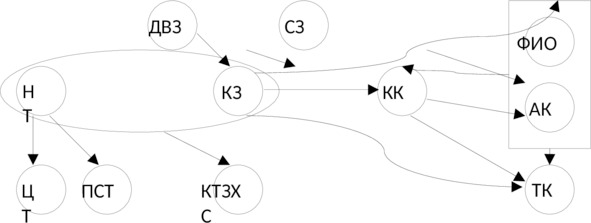
Удалим из исходного набора функциональных зависимостей все избыточные:
— КЗ → КК и КК → ТК, т. е. КЗ → ТК также можно удалить по аксиоме транзитивности.
— КК → ФИО и КК → АК по аксиоме аддитивности заменим на КК → ФИО, АК.
— ФИО, АК → КК и КК → ТК, т. е. ФИО, АК → ТК является избыточной зависимостью по аксиоме транзитивности и ее можно удалить.
— КЗ → КК и КК → ФИО, АК, т. е. КЗ → ФИО, АК также можно удалить по аксиоме транзитивности.
— НТ → ЦТ, НТ → ПСТ, НТ → НС по аксиоме аддитивности заменим на НТ → ЦТ, ПСТ.
— КЗ → СЗ, КЗ → ДВЗ, КЗ → КК по аксиоме аддитивности заменим на КЗ → СЗ, ДВЗ, КК.
— КК → ФИО, АК и КК → ТК по аксиоме аддитивности заменим на КК → ФИО, АК, ТК.
Окончательно диаграмма функциональных зависимостей примет вид, показанный на рис. 1.2.
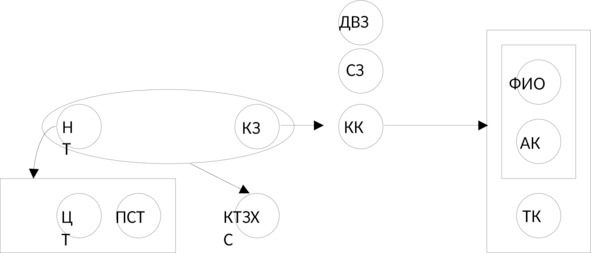
Выполним преобразование исходного отношения в набор НФБК — отношений:
1)
r1 (НТ, ЦТ, ПСТ, КК, ФИО, АК, ТК, КЗ, СЗ, ДВЗ, КТЗ).
Отношение r1 не находится в НФБК (есть зависимости от частей ключа (НТ → ЦТ, ПСТ); детерминанты НТ, КЗ, КК, (ФИО, АК) не являются возможными ключами) и поэтому разбивается далее.
2) Для проведения проекции по правилу цепочки выберем F-зависимость НТ → ЦТ, ПСТ. Получим следующие отношения:
r2 (НТ, ЦТ, ПСТ);
r3 (НТ, КК, ФИО, АК, ТК, КЗ, СЗ, ДВЗ, КТЗ).
Отношение r2 находится в НФБК (его детерминант (НТ) является возможным ключом) и не нуждается больше в декомпозиции. Отношение r3 не находится в НФБК (есть зависимости от частей ключа (КЗ → СЗ, ДВЗ, КК); детерминанты КЗ, КК, (ФИО, АК) не являются возможными ключами) и поэтому разбивается далее.
3) Для проведения второй проекции также по правилу цепочки выберем F-зависимость КК → ФИО, АК, ТК. Получим следующие отношения:
r4 (КК, ФИО, АК, ТК);
r5 (НТ, КК, КЗ, СЗ, ДВЗ, КТЗ).
Отношение r4 находится в НФБК (его детерминанты (КК, (ФИО, АК)) являются возможными ключами) и не нуждается больше в декомпозиции. Отношение r5 не находится в НФБК (есть зависимости от частей ключа (КЗ → СЗ, ДВЗ, КК); детерминант КЗ не является возможным ключом) и поэтому разбивается далее.
4) Для проведения третьей проекции по правилу цепочки выберем F-зависимость КЗ → СЗ, ДВЗ, КК.
r6 (КЗ, СЗ, ДВЗ, КК).
Отношение r6 находится в НФБК (его детерминант (КЗ) является возможным ключом) и не нуждается больше в декомпозиции.
r7 (НТ, КЗ, КТЗ).
Отношение r7 находится в НФБК (его детерминант (НТ, КЗ) является возможным ключом) и не нуждается больше в декомпозиции.
Преобразование исходного отношения в набор НФБК — отношений завершено.
Таким образом, получили следующий набор отношений:
r2 (НТ, ЦТ, ПСТ);
r4 (КК, ФИО, АК, ТК);
r6 (КЗ, СЗ, ДВЗ, КК);
r7 (НТ, КЗ, КТЗ).
Выполним проверку полученного набора отношений:
1) Проверим отношения на наличие дублирующихся функциональных зависимостей. Для этого составим списки F-зависимостей для каждого отношения.
F-зависимости в отношении r2:
НТ → ЦТ, ПСТ.
F-зависимости в отношении r4:
КК → ФИО, АК, ТК;
ФИО, АК → КК;
ФИО, АК → ТК.
F-зависимости в отношении r6:
КЗ → СЗ, ДВЗ, КК.
F-зависимости в отношении r7:
НТ, КЗ → КТЗ.
Таким образом, в полученном наборе отношений нет F-зависимости, которая появлялась бы более чем в одном отношении. Полученный набор F-зависимостей не совпадает с набором минимального покрытия и может быть получен из него с помощью аксиомы аддитивности (в отношении r4 объединим F-зависимости ФИО, АК → КК и ФИО, АК → ТК).
2) Осуществим проверку набора отношений на наличие избыточных. В полученном наборе отношений нет отношения, все атрибуты которого находились бы в одном другом отношении набора или могли быть найдены в отношении, получаемом с помощью операции соединения любых других отношений проектного набора.
3) Рассмотрим отношения с практической точки зрения. Все полученные отношения разумны с практической точки зрения: в отношении r2 регистрируются данные о товарах, в отношении r4 хранятся данные о клиентах, отношение r6 отвечает за учет полученных товаров, в отношение r7 записывается информация о количестве каждого товара в заказе.
Проектирование базы данных методом «сущность-связь»
При проектировании базы данных методом «сущность — связь» необходимо выполнить следующие действия:
— Уточнить, какая именно информация о предметной области будет храниться в проектируемой базе данных. Выделить в предметной области объекты и их свойства. Зафиксировать связи между объектами и их свойствами и связи между объектами разных классов. Построить ER — модель.
— Осуществить переход от инфологической модели предметной области к даталогической модели базы данных.
— Выявить, в какой нормальной форме находятся полученные отношения (отобразить функциональные зависимости между атрибутами каждого отношения).
Выделяют три этапа проектирования БД:
— инфологическое моделирование
— даталогическое моделирование
— физическая реализация
1) На первом этапе создается инфологическая модель предметной области.
Предметная область — это часть реального мира, представляющего интерес для данного проектирования.
Инфологической моделью предметной области называют описание предметной области, выполненное с использованием специальных языковых средств, и независящее от используемых в дальнейшем программных и технических средств.
2) На основе инфологической модели строится даталогическая модель.
Даталогическая модель является моделью логического уровня и представляет собой отображение логических связей между элементами данных безотносительно к их содержанию и среде хранения. Описание логической структуры БД на языке СУБД называется схемой.
3) Третий этап проектирования состоит в привязке ДЛМ к среде хранения с помощью модели данных физического уровня (физической модели). Описание физической структуры БД называется схемой хранения.
Компоненты ИЛМ:
— описание объектов и связей между ними (ER — модель);
— описание информационных потребностей пользователей;
— алгоритмические связи показателей;
— лингвистические отношения;
— ограничения целостности.
В предметной области в результате ее анализа выделяют классы объектов. Классом объектов называют совокупность объектов, обладающих одинаковым набором свойств. Каждый объект в информационной системе представляется своим идентификатором, а каждый класс объектов представляется именем класса. Каждый объект обладает определенным набором свойств.
Связь между объектом и характеризующим его свойством изображается в виде линии. Связь может быть единичной или множественной.
Если объект обладает только одним значением какого-то свойства, то такое свойство называют единичными. Если для свойства возможно существование одновременно нескольких значений у одного объекта, то такие свойства называют множественными.
Свойства, значения которых не могут изменяться с течением времени (например, Дата рождения), называются статическими и обозначаются буквой S. Свойства, значения которых могут изменяться со временем (например, Фамилия, Адрес, Телефон), называются динамическими и обозначаются буквой D.
Свойство, которое может отсутствовать у некоторых объектов одного класса (например, свойство Ученая степень, не все объекты класса Сотрудники могут обладать указанным свойством), называют условными и изображают пунктирной линией.
Существует понятие составного свойства (примеры таких свойств: Адрес, состоящий из «улицы», «дома», «квартиры»; Дата рождения, состоящая из «числа», «месяца», «года»). Для его обозначения используют квадрат.
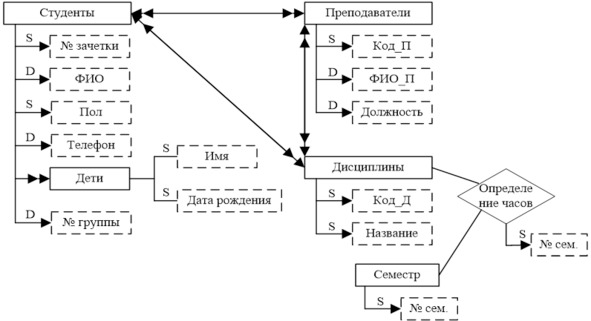
В инфологической модели фиксируются не только связи между объектом и его свойствами, но и связи между объектами разных классов.
Различают связи типа:
— один к одному (1:1);
— один ко многим (1:М);
— многие к одному (М:1);
— многие ко многим (М:М).
Объект называют простым, если он рассматривается как неделимый. Сложный объект представляет собой объединение других объектов, простых или сложных, также отображаемых в информационной системе. Понятия простой и сложный являются относительными. Сложные объекты подразделяют на составные, обобщенные и агрегированные.
Составной объект соответствует отображению связи «целое — часть». Примеры таких объектов: класс — ученики, группа — студенты и т. п. (связь между составным и составляющими его объектами отображается отношением 1:М)
Обобщенный объект отражает наличие связи «род — вид» между объектами предметной области. Например, объекты Студент, Школьник, Аспирант образуют обобщенный объект Учащиеся. Объекты, составляющие обобщенный объект, называются его категориями. Как «родовой» объект, так и «видовые» объекты могут обладать определенным набором свойств. Причем «видовые» объекты обладают всеми теми свойствами, которыми обладает «родовой» объект, плюс свойствами, присущими только объектам этого вида.
Определение родо-видовых связей означает классификацию объектов предметной области по тем или иным признакам. Подклассы могут выделяться в ИЛМ в явном виде (см. рис. 3.5).
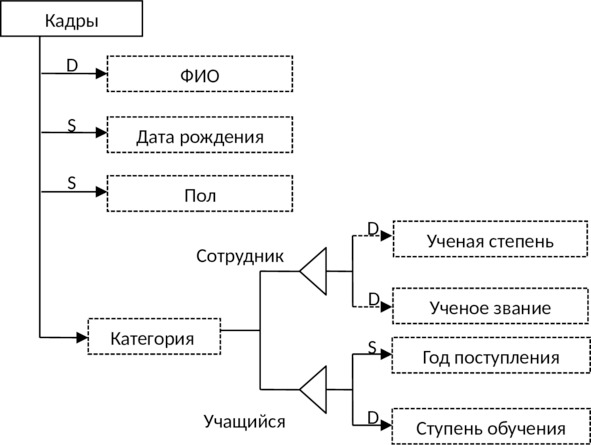
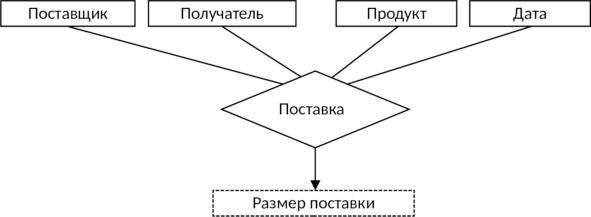
Агрегированный объект соответствует обычно какому-либо процессу, в который оказываются «вовлеченными» другие объекты. Например, агрегированный объект Поставка (см. рис. 3.6) объединяет в себе объекты Поставщик, Получатель, Продукт и Дата. Для отображения агрегированного объекта в схеме использован ромб. Агрегированный объект может, так же как и простой объект, иметь характеризующие его свойства.
Правила, по которым строится даталогическая модель:
1) Для каждого простого объекта и его единичных свойств строится таблица, атрибутами которой являются идентификатор объекта и реквизиты, соответствующие каждому из единичных свойств:

2) Если у объекта имеются множественные свойства, то каждому из них ставится в соответствие отдельная таблица:
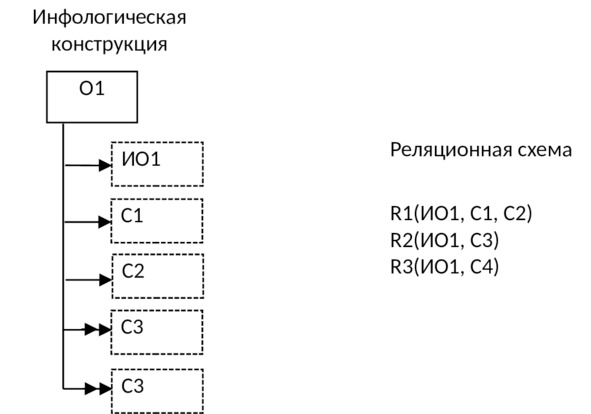
3) Если между объектом и его свойством имеется условная связь, то при отображении в реляционную модель возможны следующие варианты:
— если многие из объектов обладают рассматриваемым свойством, то его можно хранить в БД так же, как и обычное свойство;
— если только незначительное число объектов обладает указанным свойством, то при использовании предыдущего решения для многих записей в таблице значение соответствующего поля будет пустым. Для устранения этого недостатка выделяют отдельную таблицу, которая будет включать в себя идентификатор объекта и атрибут, соответствующий рассматриваемому свойству.
4) Если у объекта имеется составное свойство:
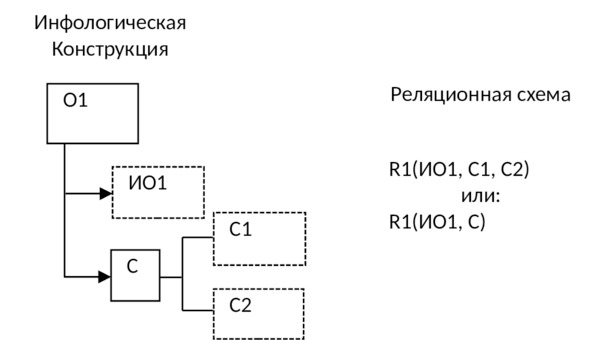
5) Если связь между объектами 1:1 и классы принадлежности обоих объектов являются обязательными, то для отображения данных объектов и связи между ними:
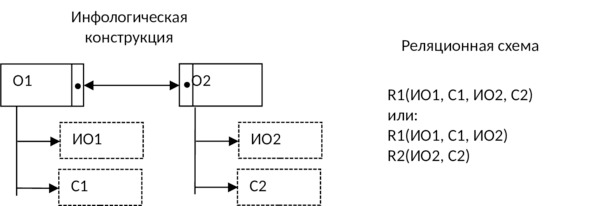
6) Если связь между объектами 1:1 и класс принадлежности одного объекта является обязательным, а другого — необязательным, то для каждого из этих объектов используют отдельные таблицы, а идентификатор объекта, для которого класс принадлежности является необязательным, добавляется в таблицу, соответствующую тому объекту, для которого класс принадлежности обязательный:
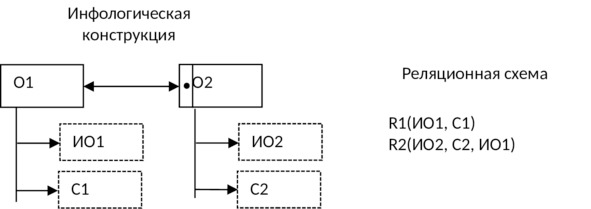
7) Если связь между объектами 1:1 и класс принадлежности каждого объекта является необязательным, то следует использовать три таблицы: по одной для каждого объекта и одно для отображения связи между ними:
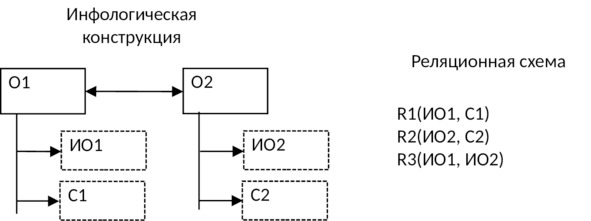
8) Если между объектами предметной области имеется связь 1:М и класс принадлежности n — связного объекта является обязательным, то используют две таблицы: по одной для каждого объекта, и в таблицу, соответствующую n — связному объекту, добавляется идентификатор 1 — связного объекта:
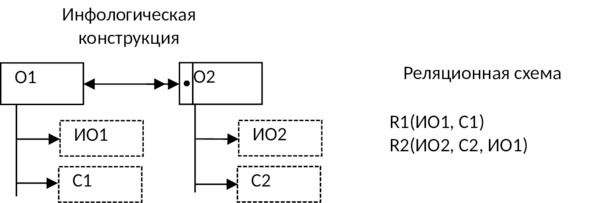
9) Если между объектами предметной области имеется связь 1:М и класс принадлежности n — связного объекта является необязательным, то создают три таблицы: по одной для каждого объекта и одну для отображения связи между ними:
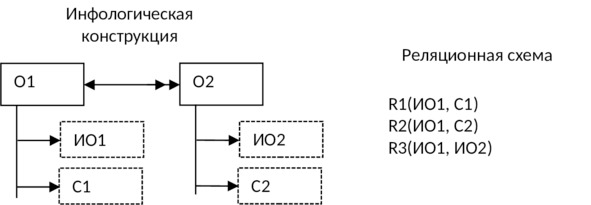
10) Если между объектами предметной области имеется связь М:М, то для хранения такой информации потребуется три таблицы: по одной для каждого объекта и одна для отображения связи между ними (классы принадлежности могут быть: оба — обязательными, оба — необязательными, один — обязательный, другой — необязательный):
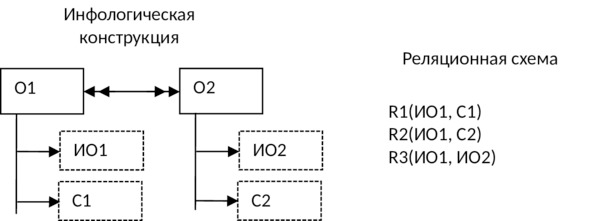
11) Агрегированному объекту, имеющему место в предметной области, в ДЛМ ставится в соответствие одна таблица, атрибутами которой являются идентификаторы всех объектов, «задействованных» в данном агрегированном объекте, а также реквизиты, соответствующие свойствам этого объекта:
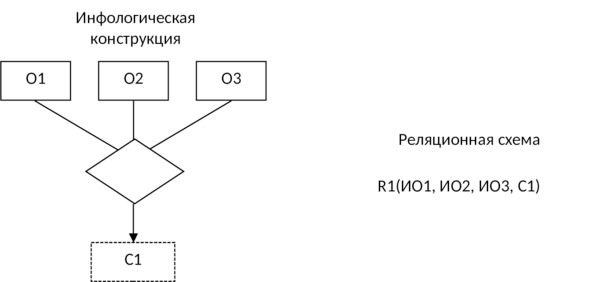
Модели представления данных
Иерархическая модель
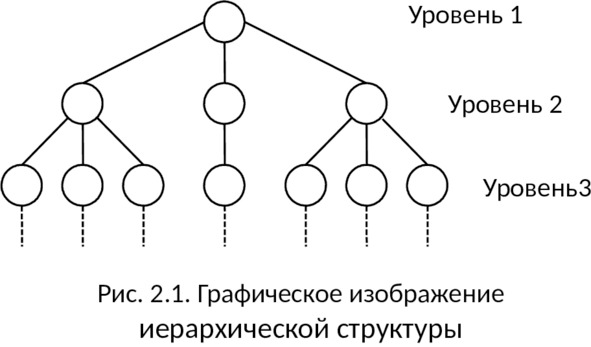
Иерархическая структура представляет совокупность элементов, связанных между собой по определенным правилам. Графическим способом представления иерархической структуры является дерево (см. рис. 2.1).
Дерево представляет собой иерархию элементов, называемых узлами. Под элементами понимается совокупность атрибутов, описывающих объекты. В модели имеется корневой узел (корень дерева), который находится на самом верхнем уровне и не имеет узлов, стоящих выше него. У одного дерева может быть только один корень. Остальные узлы, называемые порожденными, связаны между собой следующим образом: каждый узел имеет только один исходный, находящийся на более высоком уровне, и любое число (один, два или более, либо ни одного) подчиненных узлов на следующем уровне.
Примером простого иерархического представления может служить административная структура высшего учебного заведения: институт — отделение — факультет — студенческая группа (см. рис. 2.2).
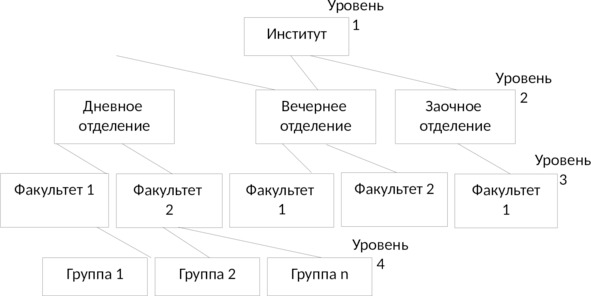
К достоинствам иерархической модели данных относятся эффективное использование памяти ЭВМ и неплохие показатели времени выполнения операций над данными.
Недостатком иерархической модели является ее громоздкость для обработки информации с достаточно сложными логическими связями.
На иерархической модели данных основано сравнительно ограниченное количество СУБД, в числе которых можно назвать зарубежные системы IMS, PC/Focus, Team-Up и Data Edge, а также отечественные системы Ока, ИНЭС и МИРИС.
Сетевая модель данных
Отличие сетевой структуры от иерархической заключается в том, что каждый элемент в сетевой структуре может быть связан с любым другим элементом (см. рис. 2.3). Пример простой сетевой структуры показан на рис. 2.4.

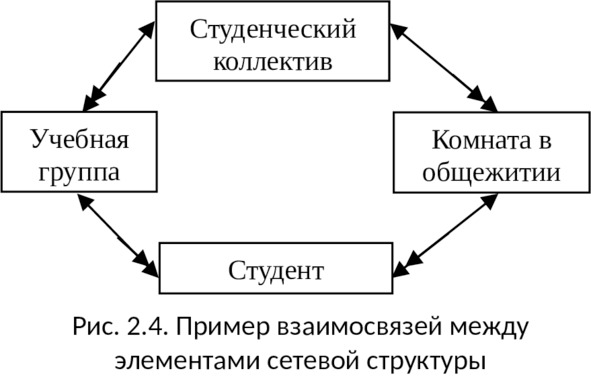
Достоинством сетевой модели данных является возможность эффективной реализации по показателям затрат памяти и оперативности.
Недостатком сетевой модели данных являются высокая сложность и жесткость схемы БД, построенной на ее основе.
Наиболее известными сетевыми СУБД являются IDMS, db_VistaIII, СЕТЬ, СЕТОР и КОМПАС.
Реляционная модель данных
Реляционная модель данных была предложена Е. Ф. Коддом.
Реляционная база данных представляет собой хранилище данных, организованных в виде двумерных таблиц (см. рис. 2.5). Любая таблица реляционной базы данных состоит из строк (называемых также записями) и столбцов (называемых также полями).
Строки таблицы содержат сведения о представленных в ней фактах (или документах, или людях, одним словом, — об однотипных объектах). На пересечении столбца и строки находятся конкретные значения содержащихся в таблице данных.
Данные в таблицах удовлетворяют следующим принципам:
1. Каждое значение, содержащееся на пересечении строки и столбца, должно быть атомарным.
2. Значения данных в одном и том же столбце должны принадлежать к одному и тому же типу, доступному для использования в данной СУБД.
3. Каждая запись в таблице уникальна, то есть в таблице не существует двух записей с полностью совпадающим набором значений ее полей.
4. Каждое поле имеет уникальное имя.
5. Последовательность полей в таблице несущественна.
6. Последовательность записей в таблице несущественна.
Поле или комбинацию полей, значения которых однозначно идентифицируют каждую запись таблицы, называют возможным ключом (или просто ключом).
Если таблица имеет более одного возможного ключа, тогда один ключ выделяют в качестве первичного. Первичный ключ любой таблицы обязан содержать уникальные непустые значения для каждой строки.
Поле, указывающее на запись в другой таблице, связанную с данной записью, называется внешним ключом.
Подобное взаимоотношение между таблицами называется связью. Связь между двумя таблицами устанавливается путем присвоения значений внешнего ключа одной таблицы значениям первичного ключа другой.
Группа связанных таблиц называется схемой базы данных. Информация о таблицах, их полях, первичных и внешних ключах, а также иных объектах базы данных, называется метаданными.
Достоинство реляционной модели данных заключается в простоте, понятности и удобстве физической реализации на ЭВМ. Именно простота и понятность для пользователя явились основной причиной ее широкого использования.
К основным недостаткам реляционной модели относятся отсутствие стандартных средств идентификации отдельных записей и сложность описания иерархических и сетевых связей.
Примерами зарубежных реляционных СУБД для ПЭВМ являются: DB2, Paradox, FoxPro, Access, Clarion, Ingres, Oracle.
К отечественным СУБД реляционного типа относятся системы ПАЛЬМА и HyTech.
Постреляционная модель
Классическая реляционная модель предполагает неделимость данных, хранящихся в полях записей таблиц. Постреляционная модель представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных. Модель допускает многозначные поля — поля, значения которых состоят из подзначений. Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу.
На рис. 2.6 на примере информации о накладных и товарах для сравнения приведено представление одних и тех же данных с помощью реляционной (а) и постреляционной (б) моделей. Из рисунка видно, что по сравнению с реляционной моделью в постреляционной модели данные хранятся более эффективно, а при обработке не потребуется выполнять операцию соединения данных из двух таблиц.
а) Накладные Накладные-товары

б) Накладные

Поскольку постреляционная модель допускает хранение в таблицах ненормализованных данных, возникает проблема обеспечения целостности и непротиворечивости данных. Эта проблема решается включением в СУБД соответствующих механизмов.
Достоинством постреляционной модели является возможность представления совокупности связанных реляционных таблиц одной постреляционной таблицей. Это обеспечивает высокую наглядность представления информации и повышение эффективности ее обработки.
Недостатком постреляционной модели является сложность решения проблемы обеспечения целостности и непротиворечивости хранимых данных.
Рассмотренная постреляционная модель данных поддерживается СУБД uniVers. К числу других СУБД, основанных на постреляционной модели данных, относятся также системы Bubba и Dasdb.
Многомерная модель
Многомерный подход к представлению данных появился практически одновременно с реляционным, но интерес к многомерным СУБД стал приобретать массовый характер с середины 90-х годов. Толчком послужила в 1993 году статья Э. Кодда. В ней были сформулированы 12 основных требований к системам класса OLAP (OnLine Analytical Processing — оперативная аналитическая обработка), важнейшие из которых связаны с возможностями концептуального представления и обработки многомерных данных.
В развитии концепций информационных систем можно выделить следующие два направления:
— системы оперативной (транзакционной) обработки;
— системы аналитической обработки (системы поддержки принятия решений).
Реляционные СУБД предназначались для информационных систем оперативной обработки информации и в этой области весьма эффективны. В системах аналитической обработки они показали себя несколько неповоротливыми и недостаточно гибкими. Более эффективными здесь оказываются многомерные СУБД.
Многомерные СУБД являются узкоспециализированными СУБД, предназначенными для интерактивной аналитической обработки информации. Основные понятия, используемые в этих СУБД: агрегируемость, историчность и прогнозируемость.
Агрегируемость данных означает рассмотрение информации на различных уровнях ее обобщения. В информационных системах степень детальности представления информации для пользователя зависит от его уровня: аналитик, пользователь, управляющий, руководитель.
Историчность данных предполагает обеспечение высокого уровня статичности собственно данных и их взаимосвязей, а также обязательность привязки данных ко времени.
Прогнозируемость данных подразумевает задание функций прогнозирования и применение их к различным временным интервалам.
Многомерность модели данных означает не многомерность визуализации цифровых данных, а многомерное логическое представление структуры информации при описании и в операциях манипулирования данными.
По сравнению с реляционной моделью многомерная организация данных обладает более высокой наглядностью и информативностью. Для иллюстрации на рис. 2.7 приведены реляционное (а) и многомерное (б) представления одних и тех же данных об объемах продаж автомобилей.
Основные понятия многомерных моделей данных: измерение и ячейка.
Измерение — это множество однотипных данных, образующих одну из граней гиперкуба. В многомерной модели измерения играют роль индексов, служащих для идентификации конкретных значений в ячейках гиперкуба.
Ячейка — это поле, значение которого однозначно определяется фиксированным набором измерений. Тип поля чаще всего определен как цифровой. В зависимости от того, как формируются значения некоторой ячейки, она может быть переменной (значения изменяются и могут быть загружены из внешнего источника данных или сформированы программно) либо формулой (значения, подобно формульным ячейкам электронных таблиц, вычисляются по заранее заданным формулам).

В примере на рис. 2.7 б каждое значение ячейки Объем продаж однозначно определяется комбинацией временного измерения.
В существующих многомерных СУБД используются две основных схемы организации данных: гиперкубическая и поликубическая.
В поликубической схеме предполагается, что в БД может быть определено несколько гиперкубов с различной размерностью и с различными измерениями в качестве граней. Примером системы, поддерживающей поликубический вариант БД, является сервер Oracle Express Server.
В случае гиперкубической схемы предполагается, что все ячейки определяются одним и тем же набором измерений. Это означает, что при наличии нескольких гиперкубов в БД, все они имеют одинаковую размерность и совпадающие измерения.
Основным достоинством многомерной модели данных является удобство и эффективность аналитической обработки больших объемов данных, связанных со временем.
Недостатком многомерной модели данных является ее громоздкость для простейших задач обычной оперативной обработки информации.
Примерами систем, поддерживающими многомерные модели данных, является Essbase, Media Multi-matrix, Oracle Express Server, Cache. Существуют программные продукты, например Media/MR, позволяющие одновременно работать с многомерными и с реляционными БД.
Объектно-ориентированная модель
В объектно-ориентированной модели при представлении данных имеется возможность идентифицировать отдельные записи базы данных. Между записями и функциями их обработки устанавливаются взаимосвязи с помощью механизмов, подобных соответствующим средствам в объектно-ориентированных языках программирования.
Стандартизированная объектно-ориентированная модель описана в рекомендациях стандарта ODMG-93 (Object Database Management Group — группа управления объектно-ориентированными базами данных).
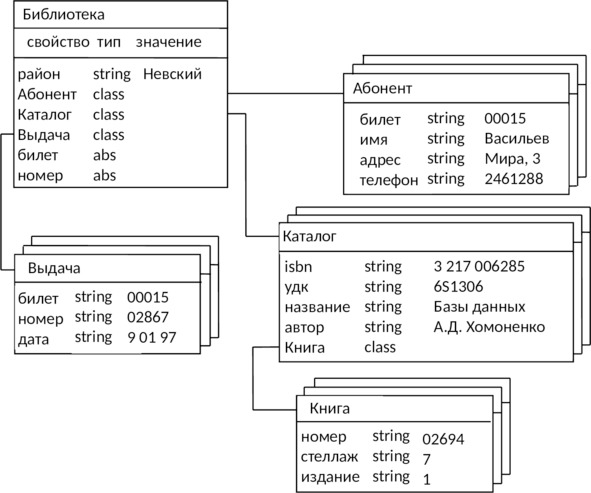
Рассмотрим упрощенную модель объектно-ориентированной БД. Структура объектно-ориентированной БД графически представима в виде дерева, узлами которого являются объекты. Свойства объектов описываются некоторым стандартным типом или типом, конструируемым пользователем (определяется как class). Значение свойства типа class есть объект, являющийся экземпляром соответствующего класса. Каждый объект-экземпляр класса считается потомком объекта, в котором он определен как свойство. Объект-экземпляр класса принадлежит своему классу и имеет одного родителя. Родовые отношения в БД образуют связную иерархию объектов. Пример логической структуры объектно-ориентированной БД библиотечного дела приведен на рис. 2.9. Здесь объект типа Библиотека является родительским для объектов-экземпляров классов Абонент, Каталог и Выдача. Различные объекты типа Книга могут иметь одного или разных родителей. Объекты типа Книга, имеющие одного и того же родителя, должны различаться, по крайней мере, инвентарным номером (уникален для каждого экземпляра книги), но имеют одинаковые значения свойств isbn, удк, название и автор.
Логическая структура объектно-ориентированной БД внешне похожа на структуру иерархической БД. Основное различие между ними состоит в методах манипулирования данными.
Для выполнения действий над данными в рассматриваемой модели БД применяются логические операции, усиленные объектно-ориентированными механизмами инкапсуляции, наследования и полиморфизма.
Инкапсуляция ограничивает область видимости имени свойства пределами того объекта, в котором оно определено. Так, если в объект типа Каталог добавить свойство, задающее телефон автора книги и имеющее название телефон, то мы получим одноименные свойства у объектов Абонент и Каталог. Смысл такого свойства будет определяться тем объектом, в который оно инкапсулировано.
Наследование, наоборот, распространяет область видимости свойства на всех потомков объекта. Так, всем объектам типа Книга, являющимся потомками объекта типа Каталог, можно приписать свойства объекта-родителя: isbn, удк, название и автор. Если необходимо расширить действие механизма наследования на объекты, не являющиеся непосредственными родственниками (например, между двумя потомками одного родителя), то в их общем предке определяется абстрактное свойство типа abs. Так, определение абстрактных свойств билет и номер в объекте Библиотека приводит к наследованию этих свойств всеми дочерними объектами Абонент, Книга и Выдача. Не случайно, поэтому значения свойства билет классов Абонент и Выдача, показанных на рис. 2.9, являются одинаковыми — 00015.
Полиморфизм в объектно-ориентированных языках программирования означает способность одного и того же программного кода работать с разнотипными данными. Другими словами, он означает допустимость в объектах разных типов иметь методы (процедуры или функции) с одинаковыми именами. Во время выполнения объектной программы одни и те же методы оперируют с разными объектами в зависимости от типа аргумента. Применительно к рассматриваемому примеру полиморфизм означает, что объекты класса Книга, имеющие разных родителей из класса Каталог, могут иметь разный набор свойств. Следовательно, программы работы с объектами класса Книга могут содержать полиморфный код.
Поиск в объектно-ориентированной БД состоит в выяснении сходства между объектом, задаваемым пользователем, и объектами, хранящимися в БД.
Основным достоинством объектно-ориентированной модели данных в сравнении с реляционной является возможность отображения информации о сложных взаимосвязях объектов. Объектно-ориентированная модель данных позволяет идентифицировать отдельную запись базы данных и определять функции их обработки.
Недостатками объектно-ориентированной модели являются высокая понятийная сложность, неудобство обработки данных и низкая скорость выполнения запросов.
К объектно-ориентированным СУБД относятся POET, Jasmine, Versant, O2, ODB-Jupiter, Iris, Orion, Postgres.
Лекция 4
БЕЗОПАСНОСТЬ БАЗ ДАННЫХ
В контексте обсуждения баз данных часто совместно используются термины безопасность и целостность, хотя на самом деле, это совершенно разные понятия. Термин безопасность относится к защите данных от несанкционированного доступа, изменения или разрушения данных, целостность — к точности или истинности данных. По-другому их можно описать следующим образом:
— Под безопасностью подразумевается, что пользователям разрешается выполнять некоторые действия.
— Под целостностью подразумевается, что эти действия выполняются корректно.
В современных СУБД поддерживается один из двух широко распространенных подходов к вопросу обеспечения безопасности данных, а именно избирательный подход или обязательный подход, либо оба подхода. В обоих подходах единицей данных или объектом данных, для которых должна быть создана система безопасности, может быть как вся база данных целиком или какой-либо набор отношений, так и некоторое значение данных для заданного атрибута внутри некоторого кортежа в определенном отношении. Эти подходы отличаются следующими свойствами:
— В случае избирательного управления некий пользователь обладает различными правами (привилегиями или полномочиями) при работе с объектами. Более того, разные пользователи обычно обладают и разными правами доступа к одному и тому же объекту. Поэтому избирательные схемы характеризуются значительной гибкостью.
— В случае обязательного управления, наоборот, каждому объекту данных присваивается некоторый классификационный уровень, а каждый пользователь обладает некоторым уровнем допуска. Таким образом, при таком подходе доступом к определенному объекту данных обладают только пользователи с соответствующим уровнем допуска. Поэтому обязательные схемы достаточно жестки и статичны.
Обязательное управление доступом
Требования к обязательному управлению доступом изложены в двух важных публикациях министерства обороны США (Стандарт Правительства США «Trusted Computer System Evaluation Criteria, DOD standard 5200.28 — STD, December, 1985», описывающий защищенные архитектуры информационных систем и определяющий уровни защиты от A1 (наивысшего) до D (минимального)), которые неформально называются «оранжевой книгой» и «розовой книгой». В «оранжевой книге» перечислен набор требований к безопасности для некой «надежной вычислительной базы», а в «розовой книге» дается интерпретация этих требований для систем управления базами данных.
В этих документах определяется четыре класса безопасности — D, C, B и A. Говорят, что класс D обеспечивает минимальную защиту (данный класс предназначен для систем, признанных неудовлетворительными), класс С — избирательную защиту, класс В — обязательную, а класс А — проверенную защиту.
Избирательная защита. Класс С делится на два подкласса — С1 и С2 (где подкласс С1 менее безопасен, чем подкласс С2), которые поддерживают избирательное управление доступом в том смысле, что управление доступом осуществляется по усмотрению владельца данных.
Согласно требованиям класса С1 необходимо разделение данных и пользователя, т.е. наряду с поддержкой концепции взаимного доступа к данным здесь возможно также организовать раздельное использование данных пользователями.
Согласно требованиям класса С2 необходимо дополнительно организовать учет на основе процедур входа в систему, аудита и изоляции ресурсов.
Обязательная защита. Класс В содержит требования к методам обязательного управления доступом и делится на три подкласса — В1, В2 и В3 (где В1 является наименее, а В3 — наиболее безопасным подклассом).
Согласно требованиям класса В1 необходимо обеспечить «отмеченную защиту» (это значит, что каждый объект данных должен содержать отметку о его уровне классификации, например: секретно, для служебного пользования и т.д.), а также неформальное сообщение о действующей стратегии безопасности.
Согласно требованиям класса В2 необходимо дополнительно обеспечить формальное утверждение о действующей стратегии безопасности, а также обнаружить и исключить плохо защищенные каналы передачи информации.
Согласно требованиям класса В3 необходимо дополнительно обеспечить поддержку аудита и восстановления данных, а также назначение администратора режима безопасности.
Проверенная защита. Класс А является наиболее безопасным и согласно его требованиям необходимо математическое доказательство того, что данный метод обеспечения безопасности совместим и адекватен заданной стратегии безопасности.
Коммерческие СУБД обычно обеспечивают избирательное управление на уровне класса С2. СУБД, в которых поддерживаются методы обязательной защиты, называют системами с многоуровневой защитой.
Согласно статистике, защите периметра сети уделяется втрое больше внимания, чем защите от внутренних возможных нарушений.
Кроме того, если вернуться к случаям взлома БД и провести простой расчет, то он покажет несостоятельность попыток свалить всю вину за происшедшее на хакеров. Разделив объем украденных данных на типовую скорость канала доступа в Интернет, мы получим, что даже при максимальной загруженности канала на передачу данных должно было бы уйти до нескольких месяцев. Логично предположить, что такой канал утечки данных был бы обнаружен даже самой невнимательной службой безопасности.
И если перед нами стоит задача обеспечить безопасность корпоративной СУБД, давайте озадачимся простым вопросом: кто в компании вообще пользуется базой данных и имеет к ней доступ?
Существует три большие группы пользователей СУБД, которых условно можно назвать операторами; аналитиками; администраторами.
Под операторами в предложенной классификации мы понимаем в основном тех, кто либо заполняет базу данных (вводят туда вручную информацию о клиентах, товарах и т. п.), либо выполняют задачи, связанные с обработкой информации: кладовщики, отмечающие перемещение товара, продавцы, выписывающие счета и т. п.
Под аналитиками мы понимаем тех, ради кого, собственно, создается эта база данных: логистики, маркетологи, финансовые аналитики и прочие. Эти люди по роду своей работы получают обширнейшие отчеты по собранной информации.
Термин «администратор» говорит сам за себя. Эта категория людей может только в общих чертах представлять, что хранится и обрабатывается в хранилище данных. Но они решают ряд важнейших задач, связанных с жизнеобеспечением системы, ее отказоустойчивости.
Но различные роли по отношению к обрабатываемой информации — не единственный критерий. Указанные группы различаются еще и по способу взаимодействия с СУБД.
Операторы чаще всего работают с информацией через различные приложения. Безопасность и разграничение доступа к информации тут реализованы очень хорошо, проработаны и реализованы методы защиты. Производители СУБД, говоря о возможностях своих систем, акцентируют внимание именно на такие способы защиты. Доступ к терминалам/компьютерам, с которых ведется работа, разграничение полномочий внутри приложения, разграничение полномочий в самой СУБД — все это выполнено на высоком техническом уровне. Честно внедрив все эти механизмы защиты, специалисты по безопасности чувствуют успокоение и удовлетворение.
Но беда в том, что основные проблемы с безопасностью приходятся на две оставшиеся категории пользователей.
Проблема с аналитиками заключается в том, что они работают с СУБД на уровне ядра. Они должны иметь возможность задавать и получать всевозможные выборки информации из всех хранящихся там таблиц. Включая и запросы общего типа «select * *».
С администраторами дело обстоит не намного лучше. Начиная с того, что в крупных информационных системах их число сопоставимо с числом аналитиков. И хотя абсолютно полными правами на СУБД наделены лишь два-три человека, администраторы, решающие узкие проблемы (например, резервное копирование данных), все равно имеют доступ ко всей информации, хранящейся в СУБД.
Между аналитиками и администраторами на первый взгляд нет никакой разницы: и те и другие имеют доступ ко всей обрабатываемой информации. Но все же отличие между этими группами есть, и состоит оно в том, что аналитики работают с данными, используя некие стандартные механизмы и интерфейсы СУБД, а администраторы могут получить непосредственный доступ к информации, например на физическом уровне, выполнив лишний раз ту же операцию по резервному копированию данных.
Какие еще защитные механизмы можно задействовать, чтобы решить проблему безопасности данных?
В принципе, в любой СУБД есть встроенные возможности по разграничению и ограничению доступа на уровне привилегий пользователей. Но возможность эта существует только чисто теоретически. Кто хоть раз имел дело с администрированием большой СУБД в большой организации, хорошо знает, что на уровне групп пользователей что-либо разграничить слишком сложно, ибо даже, помимо многообразия организационных ролей и профилей доступа, в дело вмешиваются проблемы обеспечения индивидуального доступа, который вписать в рамки ролей практически невозможно.
Но и это еще не все. Очень часто обработка данных ведется не самим пользователем, а созданным и запущенным в СУБД скриптом. Так, например, поступают для формирования типовых или периодических отчетов. В этом случае скрипт запускается не от имени пользователя, а от имени системной учетной записи, что серьезно затрудняет понимание того, что же на самом деле происходит в базе данных. Притом сам скрипт может содержать практически любые команды, включая пресловутое «select * *». В ходе работы скрипт может сформировать новый массив данных, в том числе и дублирующий все основные таблицы. В итоге пользователь получит возможность работать с этим набором данных и таким образом обходить установленные нами средства аудита.
Попытка использовать для разграничения доступа криптографию также обречена на провал: это долго, ресурсоемко и опасно с точки зрения повреждения данных и их последующего восстановления. К тому же возникают проблемы с обработкой информации, ибо индексироваться по зашифрованным полям бесполезно. А самое главное, что некоторым администраторам все равно придется дать «ключи от всех замков».
В результате, если перед компанией стоит задача по сохранению своих корпоративных СУБД, то ее нельзя разрешить простым ограничением и разграничением доступа к информации. Как мы разобрались, где это хоть как-то возможно, это уже сделано. Во всех остальных случаях можно лишь по факту понимать, что происходило с данными.
Задачу необходимо формулировать так: мы должны знать, кто, когда получает доступ к данным и к каким.
Попытка решить поставленную задачу средствами СУБД столкнется с вычислительными ресурсами серверов, поскольку помимо обработки данных им придется вести полное протоколирование своих действий. Но самое неприятное будет заключаться в том, что если за кражу информации возьмется один из администраторов, то его полномочий, скорее всего, хватит и на затирание следов своей деятельности в журналах регистрации.
Именно поэтому необходимо использовать внешние средства аудита.
Производители средств защиты готовы нам помочь средствами, которые способны контролировать и все входящие запросы и выборки данных на запуск скриптов для обработки информации, и обращения к отдельным таблицам. Подобные средства представляют собой некоторый сервис, работающий на сервере с установленной СУБД и контролирующий все обращения к базе.
Однако крупные хранилища данных работают под управлением специализированных ОС. Цены на решения для таких СУБД «кусаются». Ко всему прочему, администраторы начинают сильно переживать, что лишний установленный сервис если и не затормозит работу, то по крайней мере станет дополнительным «очагом нестабильности» системы в целом.
Когда нет возможности сломать этот стереотип, на помощь могут прийти средства сетевого контроля. По сути они представляют собой специализированные снифферы (сниффер-анализатор трафика), которые контролируют и детально разбирают протоколы взаимодействия с базами данных. Ставятся либо непосредственно перед сервером баз данных, либо на входе в сегмент сети, где располагаются сразу несколько серверов с СУБД. При этом из сетевого может быть извлечена как информация о сделанных запросах, так и непосредственно та информация, которая была направлена пользователю.
Таким образом, мы сможем контролировать аналитиков, но не администраторов, и в этом заключается наибольшая трудность при использовании описываемых средств. Ведь администраторы имеют доступ к серверам баз данных не только через стандартные интерфейсы, но и, например, через средства удаленного администрирования. Тут способны помочь лишь жесткие административные ограничения: все манипуляции с сервером и СУБД — только локально. При проведении такой жесткой политики администраторы, скорее всего, будут сопротивляться и кивать на оперативность разрешения проблем, но чаще всего эти доводы бывают слишком притянуты за уши. Если проблема небольшая, то 3 минуты, затрачиваемые на проход по коридору, ничего не решат. Если же проблема действительно большая, то им так или иначе придется работать непосредственно с севером в течение достаточно продолжительного времени. Тут очевидно противостояние: что важнее, удобство работы администратора или безопасность данных, а то и репутация компании? Полагаю, при такой постановке вопроса пробежка по коридору не должна восприниматься как весомый аргумент.
Защититься от физического доступа к базам данных также возможно только путем введения жестких регламентов съема и хранения информации и слежения за отступлениями от этих регламентов. К примеру, изготовление лишней резервной копии. Если процессы происходят по сети, с несанкционированными всплесками сетевого трафика по силам справиться средствам обнаружения и предотвращения атак. Стоит ли говорить, что отдельно надо побеспокоиться о безопасном хранении самих резервных копий. В идеале физический доступ к ним должен быть строго ограничен, а администратор, отвечающий за процесс, должен либо настроить расписание, либо иметь возможность только запустить этот процесс и контролировать его прохождение без доступа к резервным носителям информации.
Подводя итог, скажем: безопасность — процесс комплексный. И еще раз хочется предостеречь пользователей от стереотипа, что опасность корпоративным ресурсам, в том числе и базам данных, угрожает только из внешнего окружения компании или организации.
Дискреционная защита
В современных СУБД достаточно развиты средства дискреционной защиты.
Дискреционное управление доступам (discretionary access control) — разграничение доступа между поименованными субъектами и поименованными объектами. Субъект с определенным правом доступа может передать это право любому другому субъекту.
Дискреционная защита является многоуровневой логической защитой.
Логическая защита в СУБД представляет собой набор привилегий или ролей по отношению к защищаемому объекту. К логической защите можно отнести и владение таблицей (представлением). Владелец таблицы может изменять (расширять, отнимать, ограничивать доступ) набор привилегий (логическую защиту). Данные о логической защите находятся в системных таблицах базы данных и отделены от защищаемых объектов (от таблиц или представлений).
Информация о зарегистрированных пользователях базы данных хранится в ее системном каталоге. Современные СУБД не имеют общего синтаксиса SQL-предложения соединения с базой данных, так как их собственный синтаксис сложился раньше, чем стандарт ISO. Тем не менее часто таким ключевым предложением является CONNECT. Ниже приведен синтаксис данного предложения для Oracle и IBM DB2 соответственно:
CONNECT [[logon] [AS {SYSOPER|SYSDBA}]] пользователь/пароль [@база_данных]
CONNECT TO база_данных USER пользователь USING пароль
В данных предложениях отражен необходимый набор атрибутов, а также показано различие синтаксиса. Формат атрибута база_данных, как правило, определяется производителем СУБД, так же как и имя пользователя, имеющего по умолчанию системные привилегии (SYSDBA/SYSOPER в случае Oracle).
Соединение с системой не идентифицированных пользователей и пользователей, подлинность идентификации которых при аутентификации не подтвердилась, исключается. В процессе сеанса работы пользователя (от удачного прохождения идентификации и аутентификации до отсоединения от системы) все его действия непосредственно связываются с результатом идентификации. Отсоединение пользователя может быть как нормальным (операция DISCONNECT), так и насильственным (исходящим от пользователя-администратора, например в случае удаления пользователя или при аварийном обрыве канала связи клиента и сервера). Во втором случае пользователь будет проинформирован об этом, и все его действия аннулируются до последней фиксации изменений, произведенных им в таблицах базы данных. В любом случае на время сеанса работы идентифицированный пользователь будет субъектом доступа для средств защиты информации от несанкционированного доступа (далее — СЗИ НСД) СУБД.
Следуя технологии открытых систем, субъект доступа может обращаться посредством СУБД к базе данных только из программ, поставляемых в дистрибутиве или подготовленных им самим, и только с помощью штатных средств системы.
Все субъекты контроля системы хранятся в таблице полномочий системы
Набор привилегий можно определить для конкретного зарегистрированного пользователя или для группы пользователей (это могут быть собственно группы пользователей, роли и т.п.). Объектом защиты может являться таблица, представление, хранимая процедура и т. д. (подробный список объектов защиты имеется в документации к используемой СУБД). Субъектом защиты может быть пользователь, группа пользователей или роль, а также хранимая процедура, если такое предусматривается используемой реализацией. Если из используемой реализации следует, что хранимая процедура имеет «двойной статус» (она и объект защиты, и субъект защиты), то нужно очень внимательно рассмотреть возможные модели нарушителей разграничения прав доступа и предотвратить эти нарушения, построив, по возможности, соответствующую систему защиты.
Привилегии конкретному пользователю могут быть назначены администратором явно и неявно, например через роль. Роль — это еще один возможный именованный носитель привилегий. С ролью не ассоциируют перечень допустимых пользователей — вместо этого роли защищают паролями, если, конечно, такая возможность поддерживается производителем СУБД. Роли удобно использовать, когда тот или иной набор привилегий необходимо выдать (или отобрать) группе пользователей. С одной стороны, это облегчает администратору управление привилегиями, с другой — вносит определенный порядок в случае необходимости изменить набор привилегий для группы пользователей сразу. Нужно особо отметить, что при выполнении хранимых процедур и интерактивных запросов может существовать зависимость набора привилегий пользователя от того, как они были получены: явно или через роль. Имеют место и реализации, например в Oracle, где в хранимых процедурах используются привилегии, полученные пользователем явно. Если используемая вами реализация обладает подобным свойством, то изменение привилегий у группы пользователей следует реализовать как набор команд или как административную процедуру (в зависимости от предпочтений администратора).
Однако дискреционная защита является довольно слабой, так как доступ ограничивается только к именованным объектам, а не собственно к хранящимся данным. В случае реализации информационной системы с использованием реляционной СУБД объектом будет, например, именованное отношение (то есть таблица), а субъектом — зарегистрированный пользователь. В этом случае нельзя в полном объеме ограничить доступ только к части информации, хранящейся в таблице. Частично проблему ограничения доступа к информации решают представления и использование хранимых процедур, которые реализуют тот или иной набор бизнес-действий.
Метки безопасности и принудительный контроль доступа
Выше были описаны средства произвольного управления доступом, характерные для уровня безопасности C. Как уже указывалось, они в принципе достаточны для подавляющего большинства коммерческих приложений. Тем не менее, они не решают одной весьма важной задачи — задачи слежения за передачей информации. Средства произвольного управления доступом не могут помешать авторизованному пользователю законным образом получить секретную информацию и затем сделать ее доступной для других, неавторизованных пользователей. Нетрудно понять, почему это так. При произвольном управлении доступом привилегии существуют отдельно от данных (в случае реляционных СУБД — отдельно от строк реляционных таблиц). В результате данные оказываются «обезличенными», и ничто не мешает передать их кому угодно даже средствами самой СУБД.
В «Критериях оценки надежных компьютерных систем», применительно к системам уровня безопасности B, описан механизм меток безопасности, реализованный в версии INGRES/Enhanced Security (INGRES с повышенной безопасностью). Применять эту версию на практике имеет смысл только в сочетании с операционной системой и другими программными компонентами того же уровня безопасности. Тем не менее, рассмотрение реализации меточной безопасности в СУБД INGRES интересно с познавательной точки зрения, а сам подход, основанный на разделении данных по уровням секретности и категориям доступа, может оказаться полезным при проектировании системы привилегий многочисленных пользователей по отношению к большим массивам данных.
В СУБД INGRES/Enhanced Security к каждой реляционной таблице неявно добавляется столбец, содержащий метки безопасности строк таблицы. Метка безопасности состоит из трех компонентов:
— Уровень секретности. Смысл этого компонента зависит от приложения. В частности, возможен традиционный спектр уровней от «совершенно секретно» до «несекретно».
— Категории. Понятие категории позволяет разделить данные на «отсеки» и тем самым повысить надежность системы безопасности. В коммерческих приложениях категориями могут служить «финансы», «кадры», «материальные ценности» и т. п. Ниже назначение категорий разъясняется более подробно.
— Области. Является дополнительным средством деления информации на отсеки. На практике компонент «область» может действительно иметь географический смысл, обозначая, например, страну, к которой относятся данные.
Каждый пользователь СУБД INGRES/Enhanced Security характеризуется степенью благонадежности, которая также определяется меткой безопасности, присвоенной данному пользователю. Пользователь может получить доступ к данным, если степень его благонадежности удовлетворяет требованиям соответствующей метки безопасности. Более точно:
— уровень секретности пользователя должен быть не ниже уровня секретности данных;
— набор категорий, заданных в метке безопасности данных, должен целиком содержаться в метке безопасности пользователя;
— набор областей, заданных в метке безопасности пользователя, должен целиком содержаться в метке безопасности данных.
Рассмотрим пример. Пусть данные имеют уровень секретности «конфиденциально», принадлежат категории «финансы» и относятся к областям «Россия» и «СНГ». Далее, пусть степень благонадежности пользователя характеризуется меткой безопасности с уровнем секретности «совершенно секретно», категориями «финансы» и «кадры», а также областью «Россия». Такой пользователь получит доступ к данным. Если бы, однако, в метке пользователя была указана только категории «кадры», в доступе к данным ему было бы отказано, несмотря на его «совершенно секретный» уровень.
Когда пользователь производит выборку данных из таблицы, он получает только те строки, меткам безопасности которых удовлетворяет степень его благонадежности. Для совместимости с обычными версиями СУБД, столбец с метками безопасности не включается в результирующую информацию.
Отметим, что механизм меток безопасности не отменяет, а дополняет произвольное управление доступом. Пользователи по-прежнему могут оперировать с таблицами только в рамках своих привилегий, но даже при наличии привилегии SELECT им доступна, вообще говоря, только часть данных.
При добавлении или изменении строк они, как правило, наследуют метки безопасности пользователя, инициировавшего операцию. Таким образом, даже если авторизованный пользователь перепишет секретную информацию в общедоступную таблицу, менее благонадежные пользователи не смогут ее прочитать.
Специальная привилегия, DOWNGRADE, позволяет изменять метки безопасности, ассоциированные с данными. Подобная возможность необходима, например, для коррекции меток, по тем или иным причинам оказавшихся неправильными.
Представляется естественным, что СУБД INGRES/Enhanced Security допускает не только скрытое, но и явное включение меток безопасности в реляционные таблицы. Появился новый тип данных, security label, поддерживающий соответствующие операции сравнения.
INGRES/Enhanced Security — первая СУБД, получившая сертификат, эквивалентный аттестации на класс безопасности B1. Вероятно, метки безопасности постепенно войдут в стандартный репертуар систем управления базами данных.
ОБЕСПЕЧЕНИЕ ЦЕЛОСТНОСТИ БАЗЫ ДАННЫХ
Целостность данных обеспечивается набором специальных предложений, называемых ограничениями целостности.
Ограничения целостности представляют собой утверждения о допустимых значениях отдельных информационных единиц и связях между ними.
В большинстве случаев ограничения целостности определяются особенностями предметной области (хотя могут отражать и чисто информационные характеристики).
Ограничения целостности могут относиться к разным информационным объектам: атрибутам, кортежам, отношениям, связям между ними и тому подобное.
Для полей (атрибутов) используются следующие виды ограничений:
— Тип и формат поля (автоматически допускают ввод только данных определенного типа).
— Задание диапазона значений. Данное ограничение используется обычно для числовых полей. Различают открытые и закрытые диапазоны: первые фиксируют значение только одной из границ, вторые — обеих границ.
— Недопустимость пустого поля. Ограничение позволяет избежать появления в БД «ничейных» записей, в которых пропущены какие-либо обязательные данные, например: поле «ФИО» должно обязательно иметь значение, а у поля «ученая степень» значение может отсутствовать.
— Задание домена. Ограничение позволяет избежать излишнего разнообразия данных, если его можно ограничить, например, значением поля «должность» для преподавателей может быть одно из следующих значений: ассистент, старший преподаватель, доцент, профессор.
— Проверка на уникальность значения какого-либо поля. Ограничение позволяет избежать записей-дубликатов. Данное ограничение возникает при отображении в базе данных каких-либо объектов, когда уникальное поле является идентификатором объекта; поэтому данное ограничение часто называют ограничением целостности объекта.
Приведенная классификация видов ограничений является довольно условной, так задание диапазона также можно считать способом задания домена.
Перечисленные выше ограничения определяют проверку значения поля вне зависимости от того, вводится ли это ограничение впервые или корректируется имеющееся в БД значение. Ограничения, используемые только при проверке допустимости корректировки, называют ограничениями перехода. Например, если в БД имеется поле «возраст сотрудника», то при корректировке значение этого поля может только увеличиваться; если в БД имеется поле «год рождения», то на корректировку этого поля должен быть наложен запрет. В случае попытки произвести некорректное исправление должно выдаваться диагностирующее сообщение.
Ограничения целостности, относящиеся к кортежам: здесь имеется в виду либо ограничение на значение всей строки, рассматриваемой как единое целое (естественным ограничением является требование уникальности каждой строки таблицы), либо ограничения на соотношения значений отдельных полей в пределах одной строки (например, значение поля «стаж» не должно превышать «возраст»).
Ограничения, проверяющие соотношения между записями одной таблицы, например, «год рождения матери» должен быть меньше, чем «год рождения ребенка»; нельзя быть родителем и ребенком одного и того же человека.
В качестве примера ограничений, относящихся ко всей таблице можно привести следующий. Предположим, что фонд заработной платы формируется исходя из величины средней заработной платы одного сотрудника, которая составляет 10 000 р. Тогда в качестве ограничения целостности таблицы может быть задано выражение, указывающее, что среднее значение поля «оклад» должно быть не больше 10 000.
Если СУБД не позволяет контролировать какие-либо ограничения целостности, то следует создавать процедуры (программы), позволяющие это делать.
Все ограничения, которые были рассмотрены выше, затрагивают информационные единицы в пределах одной таблицы. Кроме такого рода ограничений имеются ограничения, относящиеся к нескольким взаимосвязанным таблицам, например, ограничение целостности связи, которое выражается в том, что значение атрибута, отражающего связь между объектами и являющегося внешним ключом отношения, обязательно должно совпадать с одним из значений атрибута, являющегося ключом отношения, описывающего соответствующий объект. Например, в БД имеются три таблицы: «Преподаватели», «Дисциплины» и таблица, отражающая связь между преподавателями и дисциплинами: код преподавателя в последней из трех таблиц должен соответствовать одному их кодов в таблице «Преподаватели», а код дисциплины — значению соответствующего поля в таблице «Дисциплины».
Своеобразным видом ограничения является запрет на обновление. Он может относиться и к отдельному полю, и ко всей записи, и к целой таблице. Например, не могут меняться значения таких полей, как «Дата рождения», «Место рождения»; или пусть имеется таблица «Поощрения» с полями: «Табельный номер сотрудника», «Вид поощрения», «Дата», — в такую таблицу записи могут только добавляться, а изменяться не могут.
В рассматриваемом примере наблюдается также ограничение по существованию между таблицей «Поощрения» и таблицей «Сотрудники»: табельный номер в таблице «Поощрения» должен обязательно присутствовать в таблице «Сотрудники»; при удалении записи в таблице «Сотрудники» все связанные с ней записи в таблице «Поощрения» также должны быть удалены.
Ограничения целостности разделяют по моменту контроля за соблюдением ограничения — на одномоментные и отложенные. Отложенные ограничения целостности могут не соблюдаться в процессе выполнения какой-либо группы операций, но обязаны быть соблюдены по завершению выполнения этой группы операций. С понятием отложенного ограничения тесно связано понятие транзакции. В системе Microsoft Access транзакция определяется как набор операций, результат которых подтверждается (сохраняется) в том и только том случае, если все операции набора прошли успешно. Если какая-либо из операций транзакции не выполнена, то все выполненные ранее операции отменяются, и данные возвращаются к тому состоянию, которое они имели до начала выполнения транзакции. Примером может служить перевод денег с одного банковского счета на другой, состоящий из двух операций: удаление денег с одного счета и добавление такой же суммы денег на другой счет.
Ограничения целостности разделяют по способу задания — на явные и неявные. Неявные ограничения определяются спецификой модели данных и проверяются СУБД автоматически. Неявные ограничения обычно относятся к классу синтаксических ограничений в отличие от семантических ограничений целостности, обусловленных спецификой предметной области.
Рассмотренные примеры ограничений целостности относятся к данным пользователя. Понятие же целостности может относиться и к служебной информации.
Наряду с понятием целостности БД может быть введено понятие информационной целостности БнД, заключающееся в обеспечении правильности взаимосвязи всех его информационных компонентов.
Резюме. Задание ограничений целостности и их проверка являются важной частью проектирования и функционирования БнД. При проектировании БнД необходимо изучить, какие возможности по контролю целостности предоставляет используемая СУБД. Если СУБД автоматически не поддерживает нужное ограничение, то обеспечение его соблюдения становится заботой проектировщика.
Лекция 5
База данных создается в несколько этапов, на каждом из которых необходимо согласовывать структуру данных с заказчиком и, что самое важное, подвергать созданную структуру данных экспертизе внутри команды, которая создает систему. Поэтому представление данных должно быть простым и понятным всем заинтересованным лицам. Именно по этой причине, наибольшее распространение получило представление базы данных под названием «сущность-связь» (entity-relationship), которое также известно как ER-диаграмма. Модели, представленные в виде ER-диаграмм, крайне просты и удобны для понимания.
ER-диаграммы были приняты в качестве основы для создания стандарта IDEF1X. Предварительный вариант этого стандарта был разработан в военно-воздушных силах США и предназначался для увеличения производительности при разработке компьютерных систем.
В 1981 году этот стандарт был формализован и опубликован организацией ICAM (Integrated Computed Aided Manufacturing), и с тех пор является наиболее распространенным стандартом для создания моделей баз данных по всему миру.
Повышение продуктивности производства в рамках программы ICAM потребовало совершенствования методов анализа и передачи информации. В результате был разработан ряд технологий, известных как IDEF-методологии (ICAM DEFinition). IDEF состоит из трех методологий моделирования, основанных на графическом представлении производственных систем:
— IDEFO используется для создания функциональной модели, которая является структурированным изображением функций производственной системы или среды, а также информации и объектов, связывающих эти функции;
— IDEF1 применяется для построения информационной модели, которая представляет структуру информации, необходимой для поддержки функций производственной системы или среды;
— IDEF2 позволяет построить динамическую модель меняющегося во времени поведения функций, информации и ресурсов производственной системы или среды.
Методология IDEF1X — расширенная версия IDEF1. Она определяет стандарты терминологии, используемой при информационном моделировании, и графического изображения типовых элементов на диаграммах.
Компонентами IDEF1X-модели являются:
1. Сущности — Независимые от идентификаторов сущности — Зависимые от идентификаторов сущности
2. Отношения
— Отношения, идентифицирующие связи
— Отношения, не идентифицирующие связи
— Отношения категоризации
— Неспецифические отношения
3. Атрибуты/ключи
— Атрибуты
— Первичные ключи
— Альтернативные ключи
— Внешние ключи
Семантика сущностей
«Сущность» представляет множество реальных или абстрактных предметов (людей, объектов, мест, событий, состояний, идей, пар предметов и т.д.), обладающих общими атрибутами или характеристиками. Отдельный элемент этого множества называется экземпляром сущности.
Сущность является независимой от идентификаторов или просто независимой, если каждый экземпляр сущности может быть однозначно идентифицирован без определения его отношений с другими сущностями. Сущность называется зависимой от идентификаторов или просто зависимой, если однозначная идентификация экземпляра сущности зависит от его отношения к другой сущности.
Синтаксис сущностей
Сущность изображается блоком (прямоугольником). Если сущность зависима от идентификаторов, то углы блока закругляются.
Семантика отношений связи
Специфическое отношение связи, или просто отношение связи, называемое также отношение родитель-потомок или отношение зависимости существования, — это ассоциация или связь между сущностями, при которой каждый экземпляр одной сущности, называемой родительской сущностью, ассоциирован с произвольным (в том числе нулевым) количеством экземпляров второй сущности, называемой сущностью-потомком, а каждый экземпляр сущности-потомка ассоциирован в точности с одним экземпляром сущности-родителя. Таким образом, экземпляр сущности-потомка может существовать только при существовании сущности-родителя.
Отношение связи может дополнительно определяться с помощью указания мощности отношения. А именно определяется, какое количество экземпляров сущности-потомка может существовать для каждого экземпляра сущности-родителя. В IDEF1X могут быть выражены следующие мощности отношений:
— Каждый экземпляр сущности-родителя может иметь ноль, один или более связанных с ним экземпляров сущности-потомка.
— Каждый экземпляр сущности-родителя должен иметь не менее одного связанного с ним экземпляра сущности-потомка.
— Каждый экземпляр сущности-родителя может иметь не более одного связанного с ним экземпляра сущности-потомка.
— Каждый экземпляр сущности-родителя связан с некоторым фиксированным числом экземпляров сущности-потомка.
Если экземпляр сущности-потомка однозначно определяется своей связью с сущностью-родителем, то отношение называется идентифицирующим отношением. В противном случае отношение называется неидентифицирующим. Например, если с каждым проектом связано одно или более заданий и задания однозначно идентифицируются только в пределах, своего проекта, то между сущностями ПРОЕКТ и ЗАДАНИЕ будет существовать идентифицирующее отношение. То есть для того, чтобы однозначно идентифицировать одно задание среди других заданий, должен быть известен проект, с которым связано это задание (см. также раздел 3.7 «Внешние ключи»).
Если каждый экземпляр сущности-потомка может быть однозначно идентифицирован без знания связанного с ним экземпляра сущности-родителя, то отношение называется неидентифицирующим отношением. Например, хотя между сущностями ПОКУПАТЕЛЬ и ЗАКАЗ_НА ПОКУПКУ может существовать отношение зависимого существования, заказы на покупку могут однозначно идентифицироваться номером заказа на покупку без идентификации ассоциированного покупателя.
Синтаксис отношения связи
Специфическое отношение связи изображается линией, проводимой между сущностью-родителем и сущностью-потомком с точкой на конце линии у сущности-потомка.
Неспецифическое отношение, называемое также отношением многого_ко_многому, — это связь между двумя сущностями, при которой каждый экземпляр первой сущности связан с произвольным (в том числе нулевым) количеством экземпляров второй сущности, а каждый экземпляр второй сущности связан с произвольным (в том числе нулевым) количеством экземпляров первой сущности.
Неспецифическое отношение изображается линией, соединяющей две связанные сущности и имеющей точки на обоих концах.
Семантика атрибутов
Атрибут представляет тип характеристик или свойств, ассоциированных со множеством реальных или абстрактных объектов (людей, объектов, мест, событий, состояний, идей, пар предметов и т.д.). Экземпляр атрибута — это определенная характеристика отдельного элемента множества. Экземпляр атрибута определяется типом характеристики и ее значением, называемым значением атрибута. В IDEF1X-модели атрибуты ассоциируются со специфическими сущностями. Таким образом, экземпляр сущности должен обладать единственным определенным значением для ассоциированного атрибута. Например, ассоциированными с сущностью СЛУЖАЩИЙ могут быть атрибуты ФАМИЛИЯ_СЛУЖАЩЕГО и ДАТА_РОЖДЕНИЯ. Экземпляр сущности СЛУЖАЩИЙ может иметь в качестве значений атрибутов «Дженни Линн» и «27 февраля, 1973».
Сущность должна обладать, атрибутом или комбинацией атрибутов, чьи значения однозначно определяют каждый экземпляр сущности. Эти атрибуты образуют первичный ключ сущности.
Синтаксис атрибутов
Каждый атрибут идентифицируется уникальным именем, выражаемым грамматическим оборотом существительного (существительным и, возможно, присутствующими прилагательными и предлогами), описывающим представляемую атрибутом характеристику. Существительное в грамматическом обороте должно стоять в единственном, а не во множественном числе.
Атрибуты изображаются в виде списка их имен внутри блока ассоциированной сущности, причем каждый атрибут занимает отдельную строку. Атрибуты, определяющие первичный ключ, размещаются наверху списка и отделяются от других атрибутов горизонтальной чертой.
Процесс построения информационной модели состоит из следующих шагов:
— определение сущностей;
— определение зависимостей между сущностями;
— задание первичных и альтернативных ключей;
— определение атрибутов сущностей;
— приведение модели к требуемому уровню нормальной формы;
— переход к физическому описанию модели: назначение соответствий имя сущности — имя таблицы, атрибут сущности — атрибут таблицы; задание триггеров, процедур и ограничений;
— генерация базы данных.
С развитием компьютерных технологий и появлением CASE-моделирования (Computer Aided Software Engineering) возникла потребность в инструментах, которые бы поддерживали стандарты моделирования. Современный инструмент моделирования баз данных должен удовлетворять ряду требований.
— Позволять разработчику сконцентрироваться на самом моделировании, а не на проблемах с графическим отображением диаграммы. Инструмент должен автоматически размещать сущности на диаграмме, иметь развитые и простые в управлении средства визуализации и создания представлений модели.
— Инструмент должен проверять диаграмму на согласованность, автоматически определяя и разрешая несоответствия. Однако инструмент должен быть настраиваемым и при желании предоставлять разработчику некоторую свободу в действиях и право самому разрешать несоответствия или отступления от методологии.
— Инструмент моделирования должен поддерживать как логическое, так и физическое моделирование.
— Современный инструмент должен автоматически генерировать базу данных на СУБД назначения.
Возможны две точки зрения на информационную модель и, соответственно, два уровня модели. Первый — логический (точка зрения пользователя) — описывает данные, задействованные в бизнесе предприятия. Второй — физический — определяет представление информации в БД. ERwin объединяет их в единую диаграмму, имеющую несколько уровней представления.
На нынешний момент ERwin является наиболее мощным средством для разработки структуры данных как на логическом, так и на физическом уровне.
Разработка в среде ERwin
Обычно разработка модели базы данных состоит из двух этапов: составление логической модели и создание на ее основе физической модели. ERwin полностью поддерживает такой процесс, он имеет два представления модели: логическое (logical) и физическое (physical). Таким образом, разработчик может строить логическую модель базы данных, не задумываясь над деталями физической реализации, т.е. уделяя основное внимание требованиям к информации и бизнес-процессам, которые будет поддерживать будущая база данных. ERwin имеет очень удобный пользовательский интерфейс, позволяющий представить базу данных в самых различных аспектах. Например, ERwin имеет такие средства визуализации как «хранимое представление» (stored display) и «предметная область» (subject area). Хранимые представления позволяют иметь несколько вариантов представления модели, в каждом из которых могут быть подчеркнуты определенные детали, которые вызвали бы перенасыщение модели, если бы они были помещены на одном представлении. Предметные области помогают вычленить из сложной и трудной для восприятия модели отдельные фрагменты, которые относятся лишь к определенной области, из числа тех, что охватывает информационная модель.
Возможности редактирования и визуализации в среде ERwin весьма широки, так, например, создание отношений возможно при помощи перетаскивания атрибута из одной сущности в другую. Такое редактирование модели позволяет вносить изменения и проводить нормализацию быстрее и эффективнее, чем с использованием других инструментов. Для того чтобы добавить новый элемент на диаграмму, его просто нужно выбрать на панели инструментов (Toolbox) и перенести в нужное место диаграммы. Добавив новую сущность на диаграмму, в нее можно добавить атрибуты, не открывая никаких редакторов, а просто ввести их названия прямо на диаграмме. Таким образом, ERwin позволяет значительно снизить время на создание самой диаграммы и сконцентрироваться на самих задачах, стоящих перед разработчиком.
ERwin имеет мощные средства визуализации модели, такие, как использование различных шрифтов, цветов и отображение модели на различных уровнях, например, на уровне описания сущности, на уровне первичных ключей сущности и т. д. Эти средства ERwin значительно помогают при презентации модели в кругу разработчиков системы или сторонним лицам.
ERwin является не только инструментом для дизайна баз данных, он также поддерживает автоматическую генерацию спроектированной и определенной на физическом уровне структуры данных. ERwin поддерживает широчайший спектр серверных и настольных СУБД. В этот список входят такие продукты, как Microsoft SQL Server, Oracle, Sybase, DB2, INFORMIX, Red Brick, Teradata, PROGRESS, Microsoft Access, FoxPro, Clipper и многие другие. Для каждой из перечисленных СУБД в ERwin предусмотрено присоединение по «родному» для этой СУБД протоколу и поддержка всех средств управления данными, присущих этой СУБД. Инструмент имеет богатый и гибкий макроязык, позволяющий создавать сценарии (pre- и postscripts), которые будут выполняться до и после генерации определенного объекта на СУБД назначения. С помощью этого макроязыка можно также сгенерировать на СУБД назначения тысячи строк шаблонов, хранимых процедур и триггеров. ERwin не поддерживает моделирования механизмов защиты базы данных, однако при помощи макроязыка можно автоматически выдать права на объект, пользуясь языком определения прав, который используется в конкретной СУБД.
ERwin имеет средство, выполняющее задачу, обратную генерации, что называется «обратная разработка» (reverse engineering). Т. е. ERwin может присоединиться к СУБД, получить всю информацию о структуре базы данных и отобразить ее в графическом интерфейсе, сохранив все сущности, связи, атрибуты и прочие свойства. Таким образом, можно переносить существующую структуру данных с одной платформы на другую, а также исследовать структуру существующих баз данных.
Компоненты диаграммы ERwin и основные виды представлений диаграммы
Диаграмма ERwin строится из трех основных блоков — сущностей, атрибутов и связей. Если рассматривать диаграмму как графическое представление правил предметной области, то сущности являются существительными, а связи — глаголами.
Выбор между логическим и физическим уровнем отображения осуществляется через линейку инструментов или меню. Внутри каждого из этих уровней есть следующие режимы отображения:
— Режим «сущности» — внутри прямоугольников отображается имя сущности (для логической модели) или имя таблицы (для физического представления модели); служит для удобства обзора большой диаграммы или размещения прямоугольников сущностей на диаграмме.
— Режим «определение сущности» служит для презентации диаграммы другим людям.
— Режим «атрибуты». При переходе от предметной области к модели требуется вводить информацию о том, что составляет сущность. Эта информация вводится путем задания атрибутов (на физическом уровне — колонок таблиц). В этом режиме прямоугольник-сущность делится линией на две части — в верхней части отображаются атрибуты (колонки), составляющие первичный ключ, а в нижней — остальные атрибуты. Этот режим является основным при проектировании на логическом и физическом уровнях.
— Режим «первичные ключи» — внутри прямоугольников — сущностей показываются только атрибуты/колонки, составляющие первичный ключ.
— Режим «пиктограммы». Для презентационных целей каждой таблице может быть поставлена в соответствие пиктограмма (bitmap).
Лекция 6
Службы SQL Server
Как и многие серверные продукты, работающие под управлением операционной
системы Windows, Microsoft SQL Server реализован в виде набора служб операционной системы, каждая из которых запускается самостоятельно и отвечает за определенный круг задач.
Приведем список служб SQL Server:
• MSSQLServer;
• SQLServerAgent;
• Microsoft Search (MSSearch);
• Microsoft Distributed Transaction Coordinator (MSDTC).
Служба MSSQLServer
Служба MSSQLServer является ядром SQL Server и выполняет все основные операции. В задачи службы MSSQLServer входит регистрация пользователей, контроль их прав доступа, установление соединения, обслуживание обращений пользователей к базам данных, выполнение хранимых процедур, работу с файлами баз данных и журнала транзакций и многое другое. В функции службы MSSQLServer также входит контроль за использованием SQL Server системных ресурсов. Служба MSSQLServer периодически опрашивает систему о количестве свободных ресурсов и при достаточном их наличии автоматически выделяет SQL Server дополнительную память или процессорное время. Полученные ресурсы наиболее эффективным образом распределяются между всеми подключенными пользователями, и тем самым достигается максимальная производительность обработки запросов. При использование многопроцессорной системы служба MSSQLServer выполняет распараллеливание «тяжелых» запросов пользователей между всеми доступными процессорами для повышения производительности. Все остальные службы можно рассматривать как расширения службы MSSQLServer, добавляющие гибкость и функциональность SQL Server. Служба MSSQLServer всегда запускается первой и уже после ее успешного старта другие службы, например SQLServerAgent, могут быть запушены и начать свою работу.
Служба SQLServerAgent
Служба SQLServerAgent, прежде всего, предназначена для автоматизации администрирования и использования SQL Server. В задачи этой службы входит автоматический запуск заданий и извещение операторов о сбоях в работе сервера. С помощью службы SQLServerAgent можно выполнять запуск различных задач в определенное время, что при грамотном использовании может избавить администратора от большей части рутинной работы. Например, администратор может спланировать автоматическое выполнение операций резервного копирования и проверки целостности информации в базе данных во время наименьшей активности пользователей. При этом администратору не нужно будет находиться рядом и контролировать ход выполнения операций.
Служба SQLServerAgent является зависимой по отношению к службе MSSQLServer. Последняя может успешно работать и без службы SQLServerAgent, в то время как для запуска службы SQLServeiAgent необходимо предварительно запустить службу MSSQLServer. Служба SQLServerAgent устанавливает соединение с ядром SQL Server наподобие обычного клиента, но имеет при этом широкие права. Большая часть операций, выполняемых службой SQLServerAgent, реализована в виде системных хранимых процедур, которые, выполняются службой MSSQLServer. Для успешного взаимодействия служб SQLServerAgent и MSSQLServer необходимо правильно настроить учетные записи, под которыми они будут запускаться. В работе службы SQLServerAgent применяются объекты трех типов:
— Jobs (задания);
— Operators (операторы);
— Alerts (события).
Информация обо всех этих объектах, включая расписание автоматического запуска задач, хранится в системной базе данных Msdb. При каждом старте SQLServerAgent анализирует содержание этой базы данных. Если к моменту запуска службы накопились «просроченные» задания или произошло сконфигурированное событие, то служба SQLServerAgent выполняет соответствующие действия.
Объекты Jobs
Объекты этого типа описывают задачи, которые должны быть выполнены автоматически. Для каждого задания указывается одно или более расписаний (schedule) его запуска. Кроме того, задание может быть выполнено по требованию (on demand), т. е. вручную. Каждое задание состоит из одного или более шагов (step). В качестве шага может выступать команда или запрос Transact-SQL, команды управления подсистемой репликации, запуск утилиты командной строки или приложения Windows, выполнение скрипта JavaScript и другие.
Объекты Operators
Объекты этого типа описывают операторов. Оператор — это служащий, отвечающий за поддержание сервера в рабочем состоянии. В небольших организациях роли оператора и администратора обычно совмещает один человек. На больших предприятиях и в корпорациях роли администратора и оператора чаще всего разделены между несколькими людьми. Администратор выполняет только ответственную работу, например планирование, создание и изменение баз данных. Оператор же чаще занимается рутинной работой, такой как выполнение резервного копирования базы данных, добавление пользователей, контроль за целостностью данных и. т. д. Если организация большая, то можно использовать специализированных операторов. Например, один из операторов будет ответственен за выполнение операций резервного копирования, другой станет следить за целостностью данных и т. д. Соответственно, каждый из операторов должен получать сообщения, относящиеся к его виду деятельности. Нежелательно, чтобы оператор резервного копирования начал разрешать проблемы мертвых блокировок. SQL Server отслеживает параметры своей работы и при обнаружении неполадок, например, при недостатке свободного пространства на диске, может известить оператора о неприятностях. Для этого используется служба SQLServerAgent.
Необходимо предварительно сконфигурировать операторов и указать события, при наступлении которых будет отправляться извещение операторам. Служба SQLServerAgent для извещения операторов может рассылать определенные сообщения по электронной почте или отправлять сообщение непосредственно на телефон оператора.
Объекты Alerts
Объекты типа Alerts описывают события, на которые должен реагировать SQL Server. При наступлении описанного события сервер с помощью службы SQLServerAgent отправляет одному или нескольким операторам извещение об обнаружении неполадок в работе сервера. События SQL Server охватывают почти все аспекты работы сервера, что позволяет эффективно контролировать работу SQL Server. Операторам не обязательно постоянно находиться рядом с сервером, чтобы знать о параметрах его работы. Оператор может даже не присутствовать в здании при обнаружении сбоя, но он может получить извещение на пейджер и предпринять необходимые действия, в том числе и удаленно.
Системные базы данных MS SQL Server
SQL Server в своей работе использует несколько системных баз данных. Эти базы данных создаются автоматически при установке SQL Server и не должны удаляться.
База данных Master
Эта системная база данных является главной базой данных SQL Server. Остальные системные базы данных имеют второстепенное значение и их можно считать вспомогательными. В базе данных Master хранится вся системная информация о параметрах конфигурации сервера, имеющихся на сервере пользовательских баз данных, пользователях, имеющих доступ к серверу и другая системная информация.
В табл. 2.1 приведены таблицы системной базы данных Master, используемые для хранения параметров конфигурации сервера.
По умолчанию база данных Master создается в каталоге Data установочного каталога SQL Server.
База данных Model
Эта системная база данных является шаблоном для создания новых баз данных. Технология создания новой базы данных в SQL Server построена следующим образом: сервер копирует базу данных Model в указанное место и изменяет ее имя соответствующим образом. Если при создании базы данных не указаны никакие параметры, кроме ее имени, то новая база данных будет являться полной копией базы данных Model. Если же размер и состав файлов создаваемой базы данных указан явно, то скопированная база данных изменяется соответствующим образом. Но в любом случае в качестве основы используется база данных Model. Независимо от того, создаете ли вы базу данных с помощью интерфейса Enterprise Manager, команд Transact-SQL или интерфейса SQL-DMO. Последовательность действий во всех случаях будет одинакова.
Изменяя параметры базы данных Model, можно управлять параметрами по умолчанию создаваемых баз данных. Кроме того, базу данных Model можно использовать в качестве корпоративного стандарта на содержимое и свойства базы данных. Администратор может создать в базе данных Model набор таблиц и хранимых процедур, которые должны быть в каждой базе данных, а не утруждать себя изменением очередной вновь созданной базы данных вручную.
Можно ускорить создание множества однотипных таблиц со специализированной конфигурацией, если соответствующим образом изменить базу данных Model. Если на предприятии имеются операторы, выполняющие специализированные задачи, или пользователи, которые всегда должны иметь возможность читать данные из базы данных, то, настроив соответствующим образом права доступа этих пользователей к базе данных Model, можно не бояться забыть это сделать после создания базы данных.
База данных Tempdb
Пользователям иногда необходимо создавать временные таблицы, представления, курсоры и другие объекты для сохранения промежуточных результатов. SQL Server позволяет создавать такие временные объекты. Для создания временной таблицы достаточно добавить перед ее именем символ # или ##. Сервер автоматически создаст временную таблицу. Временные объекты могут быть локальными или глобальными. Локальные объекты доступны только из того соединения, в котором они созданы. При этом можно создавать одноименные объекты в различных соединениях. Для организации локальной временной таблицы или представления в имя объекта добавляется символ #, а при создании локальной переменной предназначен символ @.
Глобальные объекты, созданные в одном соединении, доступны из всех остальных активных соединений. При этом допускается создание единственного глобального временного объекта с уникальным именем. Для создания глобальной временной таблицы или представления в имя объекта добавляется символы ##, а при создании переменной используются символы @@.
База данных Tempdb, полное название которой Temporary DataBase, служит в SQL Server для хранения всех временных объектов, создаваемых пользователями во время сеанса работы. Если постоянные объекты, такие как таблицы или представления, создаются в пользовательской базе данных, то временные объекты возникают в базе данных Tempdb. Доступ к базе данных Tempdb автоматически имеется у всех пользователей, и администратор не должен предпринимать никаких действий для предоставления им доступа к этой базе данных. Отличительной особенностью базы данных Tempdb является то, что она уничтожается каждый раз, когда происходит останов сервера. Естественно, все временные объекты, созданные пользователями, также уничтожаются. При следующем запуске SQL Server база данных Tempdb создается заново. Поведение этой базы данных мало чем отличается от поведения обычных баз данных.
При создании базы данных Tempdb, также как и для пользовательских база данных, в качестве основы применяется база данных Model. При этом наследуются все свойства последней. Администратор должен учитывать это, изменяя параметры базы данных Model. Неверное конфигурирование параметров этой базы данных может неблагоприятным образом повлиять на работу всех пользователей. Кроме того, при планировании параметров базы данных Tempdb следует учитывать требования к свободному пространству на диске.
База данных Msdb
Системная база данных Msdb предназначены для хранения всей информации, относящейся к автоматизации администрирования и управлений SQL Server, а также информации об операторах и событиях. Кроме того, в этой базе данных хранится информация о расписании автоматического запуска заданий. То есть в базе данных Msdb размещается вся системная информация, используемая службой SQLServerAgent.
В табл. 2.2 приведены сведения о составе и назначении таблиц базы данных Msdb.
+ типы данных SQL Server
Лекция 7
Создание представлений, триггеров и хранимых процедур в MS SQL Server
Представление (view) для конечных пользователей выглядит как таблица, но при этом не содержит данных, а лишь представляет данные, расположенные в таблице. Физически представления — это виртуальные таблицы, определяемые запросом. Подобно реальным таблицам представления содержат именованные столбцы и строки с данными, которые они динамически выбирают из таблиц и предлагают пользователю как самостоятельные данные.
Чтобы создать представление, вызываем контекстное меню для папки «View» и выбираем пункт «New View». В ответ сервер откроет окно, разделенное на четыре части: Diagram Pane (панель диаграммы), Grid Pane (панель таблицы), SQL Pane (панель SQL-кода) и Result Pane (панель результатов).
Далее выбираем таблицы, которые хотим включить в представление (они показаны в панели диаграммы), галочкой выбираем необходимые столбцы. В панели таблицы уже непосредственно формируем запрос, задав логическое условие, на основе которого будет осуществляться фильтрация. Для просмотра результата достаточно нажать кнопку «Run» — (см. рис. 7).
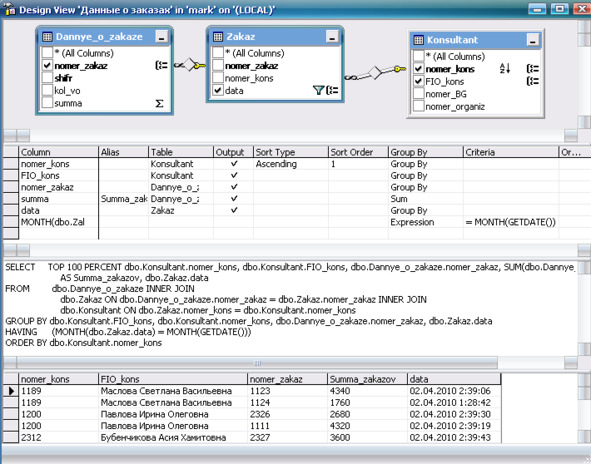
Триггер — это специальный тип хранимых процедур, запускаемых сервером автоматически при выполнении тех или иных действий с данными таблицы. Каждый триггер привязывается к конкретной таблице.
Для создания триггера нужно выбрать папку Таблицы, установить курсор на таблицу для которой будет создаваться триггер. В контекстном меню таблицы выбрать All tasks-> Manager Triggers, тогда появится окно задания триггера.
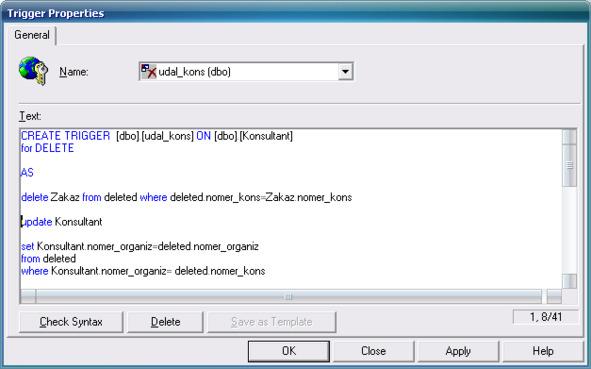
CREATE TRIGGER trigger_name
ON {table I view} [WITH ENCRYPTION]
{{FOR [{AFTER | INSTEAD OF}]
{[DELETE] [,] [INSERT] [,] [UPDATE]}
[NOT FOR REPLICATION]
«AS
[{IF UPDATE (column)
[{AND | OR) UPDATE (column)]
[…П] I IF (COLUMNS_UPDATED ()
{bitwise_operator) updated_bitmask)
(comparison_operator} column_bitmask […n]}]
sql statement [… n]}
}
trigger_name
Этот параметр подразумевает указание имени триггера.
{table I view}
Имя таблицы или представления текущей базы данных, к которой будет привязан триггер.
WITH ENCRYPTION
При указании этой опции сервер будет выполнять шифрование кода, используемого для создания триггера.
FOR
После этого ключевого слова указывается тип создаваемого триггера. Допустимы варианты:
• AFTER. Будет создан стандартный триггер. Если не указано ни AFTER, НИ INSTEAD OF, то по умолчанию используется AFTER.
• INSTEAD OF. Создаваемый триггер будет выполняться взамен команды, приведшей к запуску триггера.
• DELETE. Создаваемый триггер будет вызываться при попытке удаления данных из указанной таблицы.
• INSERT. Создаваемый триггер будет вызываться при попытке добавления в указанную таблицу новых строк с помощью команды.
• UPDATE. Создаваемый триггер будет вызываться при попытке изменения данных в указанной таблице.
• NOT FOR REPLICATION
При указании этой опции триггер не будет вызываться, если модификация данных (вставка, изменение или удаление) производится средствами подсистемы репликации. Это необходимо для триггеров репликации сведением, чтобы избежать повторного считывания данных. Однако эта возможность может быть использована и пользователями.
• AS
Ha этом ключевом слове заканчивается определение триггера, и описываются действия, которые он будет производить, а также некоторые дополнительные условия выполнения триггера.
• IF UPDATE (column)
С помощью этой конструкции можно разрешить выполнение триггера только при осуществлении изменений в определенном столбце таблицы. Имя нужного столбца указывается с помощью параметра’column. Однако использование этой возможности допускается только для триггеров типа UPDATE И INSERT.
IF (COLUMNS JJPDATEDО…)
Эта конструкция является вторым способом выполнения проверки изменений определенных столбцов.
Рассмотрим параметры, применяемые для проверки изменения нужных столбцов:
• bitwiseoperator. Этот параметр подразумевает указание оператора побитовой обработки. Возвращаемое функцией COLUMNS JJPDATEDо двоичное значение подвергается дополнительной обработке для выделения из него флагов изменения отдельных столбцов. Для этого обычно используется оператор & (побитовое AND). НО также допускается использование и любых других побитовых операторов, хотя область их применения довольно узка.
• updated_bitmask. Этот параметр подразумевает указание константы, определяющей маску анализа изменяемости столбцов. Если используется побитовый оператор &, то в маске необходимо установить биты, соответствующие столбцам, при изменении которых должен выполняться триггер. Например, если таблица имеет 6 столбцов, но пользователь изменяет лишь 1, 3 и 4 столбцы, то функция COLUMNSJJPDATEDO возвратит десятичное значение 13 (двоичное 001101). Если триггер должен выполняться при изменении 1 и 4 столбцов, то маска должна быть равна 9 (двоичное 001001). В качестве же побитового оператора нужно использовать &. Тогда общий синтаксис будет выглядеть как (COLUMNS_UPDATEDO & 9).
• comparison_operator. После того, как возвращенное функцией COLUMNS_UPDATED () двоичное значение будет обработано побитово, полученный результат необходимо проверить — действительно ли выполняется изменение нужных столбцов. Параметр comparisonoperator подразумевает указание оператора сравнения. Обычно указывается оператор =, но также могут использоваться и другие операторы (<,>,! = и т. д.).
• column_bitmask. Этот параметр подразумевает указание битовой маски столбцов, с которой будет сравниваться значение, полученное после выполнения выражения (COLUMNSJJPDATEDO {bitwise_operator} updated^bitmask). Триггер будет вызван только в том случае, если выполняется указанное условие. Продолжим рассмотрение предыдущего примера. Если необходимо, чтобы триггер выполнился только при изменении как 1, так и 4 столбцов, то полное условие будет выглядеть как IF (COLUMNSJJPDATEDO & 9) = 9. Если же необходимо выполнить триггер, когда производится изменение либо 1, либо 4 столбца, то нужно использовать условие (COLUMNS_UPDATED () & 9)> 0.
• […п]. Этот параметр говорит о том, что можно использовать множество проверок на то, какие столбцы были изменены. О sql_statement […п] Этот параметр подразумевает указание команд Transact-SQL, которые будут выполняться при вызове триггера. Могут применяться команды цикла, выборки данных, изменения, вставки и удаления строк. Внутри триггера также можно создавать транзакции.
Хранимая процедура — это именованный набор команд Transact-SQL, хранящийся непосредственно на сервере и представляющий собой самостоятельный объект базы данных. Благодаря хранимым процедурам пользователю не приходится снова и снова вводить один и тот же набор команд для выполнения какого-либо действия.
Для создания хранимой процедуры выберем нашу базу данных, а в ней папку Stored Procedures. В контекстном меню данной папки выберем пункт New Stored Procedure (новая хранимая процедура). В результате откроется окно Stored Procedures Properties (см. рис. 11), куда и будет занесен код процедуры.
Создание хранимой процедуры производится с помощью команды CREATE PROCEDURE, имеющей следующий синтаксис:
CREATE PROCEDURE procedure_name [;number]
[{@parameter data_type) [VARYING] [= default] [OUTPUT]]
[,…n] [WITH {RECOMPILE | ENCRYPTION | RECOMPILE, ENCRYPTION}]
[FOR REPLICATION]
AS sql_statemen t […n]
Рассмотрим назначение и использование параметров команды:
procedure_name
С помощью этого параметра указывается имя, которое будет иметь хранимая процедура.
/number
Этот параметр предназначен для создания группы одноименных процедур.
@parameter
С помощью этого аргумента для хранимой процедуры указываются входные параметры. При вызове хранимой процедуры пользователь должен будет указать значения для этих параметров, если не определено значение по умолчанию. С помощью параметров хранимой процедуры пользователи могут управлять логикой ее выполнения. В принципе, хранимая процедура может не иметь ни одного параметра. Но даже если параметры указаны, то они могут никак не влиять на ход выполнения процедуры. Параметры представляют собой не что иное, как обычные локальные переменные, создаваемые во время выполнения процедуры. Однако этим переменным автоматически присваиваются значения, указанные пользователями при вызове хранимой процедуры.
data_type
Этот параметр определяет тип данных, который будет иметь соответствующий параметр хранимой процедуры.
VARYING
Это ключевое слово используется только для параметров хранимой процедуры, имеющих тип данных cursor. Использование VARYING необходимо, когда в хранимой процедуре происходит создание динамического курсора и полученные данные нужно возвратить из процедуры для дальнейшего использования.
default
С помощью этого аргумента указывается значение по умолчанию, которое будет автоматически присваиваться соответствующему параметру хранимой процедуры, если при ее вызове пользователь не задал явного значения параметра.
OUTPUT
Это ключевое слово приводится, когда необходимо возвратить измененное значение параметра хранимой процедуры.
3п
Эта конструкция подразумевает, что для хранимой процедуры может быть указано множество параметров, общее количество которых может достигать 1024.
WITH
После этого ключевого слова приводятся дополнительные опции хранимой процедуры. Рассмотрим их:
• RECOMPILE. Использование этого параметра предписывает не выполнять кэширование плана выполнения хранимой процедуры. То есть всякий раз при вызове процедуры будет происходить генерирование плана обработки запроса. В обычных ситуациях использование этого параметра не рекомендуется.
• ENCRYPTION. При указании данного параметра происходит шифрование кода процедуры в таблице syscomments, где хранится исходный текст процедуры. Если разработанный алгоритм является коммерческой тайной, то использование шифрования позволит сохранить в тайне код процедуры.
• FOR REPLICATION. Этот параметр применяется только при выполнении репликации хранимых процедур. Указанный тип репликации позволяет передавать от издателя к подписчикам не весь набор выполненных изменений, и лишь вызов хранимой процедуры со значениями всех входных параметров. Таким образом можно резко снизить объем сетевого трафика. Хранимая процедура, созданная на подписчике с использованием FOR REPLICATION, не может быть вызвана пользователем. Ее запуск разрешен только подсистеме репликации.
AS
После этого ключевого слова начинается тело хранимой процедуры, которое содержит набор команд Transact-SQL.
sql_statement […п]
Этот параметр подразумевает указание собственно команд Transact-SQL, из которых и формируется тело хранимой процедуры. В теле процедуры могут присутствовать вызовы других процедур, команды создания, фиксирования и отката транзакций, команды создания объектов базы данных, команды управления данными и т. д.
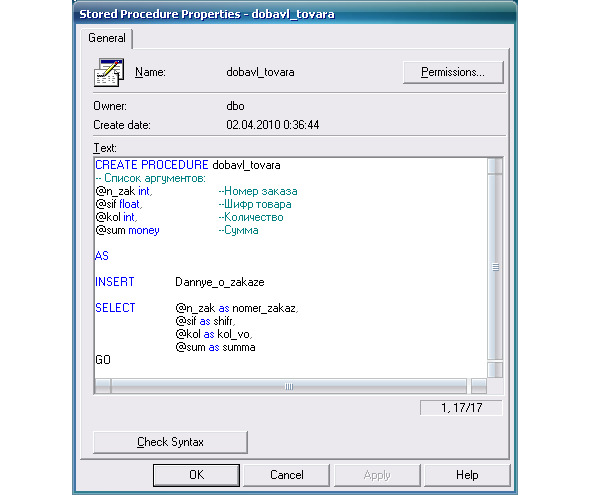
Чтобы запустить написанную процедуру, выполним команду главного меню «Tools -> SQL Query Analyzer». В открывшемся окне наберем текст вызова процедуры (см. рис. 12), после чего нажмем кнопку «Execute Query».
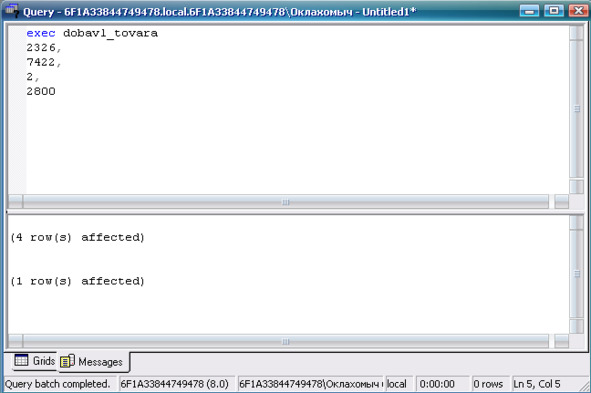
Задания и оповещения
Задания Задание (jobs) можно рассматривать как построенный пользователем логически законченный механизм, реализующий то или иное действие по администрированию SQL Server. Физически задание представляется набором шагов (steps), которые выполняются последовательно. При этом выполнение любого шага задания можно поставить в зависимость от результатов исполнения предыдущего шага.
Рассмотрим, какие типы шагов имеются в распоряжении пользователей при конфигурировании заданий службы SQLServerAgent:
• пакеты команд Transact-SQL, которые также могут включать вызовы хранимых процедур и функций;
• запуск утилит командной строки и приложений Win32;
• вызов агентов репликации;
• выполнение сценариев ActiveX, написанных на языке VBScript или Jscript.
Для создания задания и отдельных его шагов можно использовать следующие инструменты:
• специальные системные хранимые процедуры;
• средства Enterprise Manager;
• мастер Create Job Wizard.
С целью упрощения администрирования заданий в SQL Server введены категории заданий. Категории выступают в качестве групп, используемых для объединения заданий. При установке SQL Server создаются 14 стандартных категорий, которые вы можете дополнить собственными категориями:
• Database Maintenance;
• Full-Text;
• Jobs from MSX;
• REPL — Alert Response;
• REPL — Checkup;
• REPL — Distribution;
• REPL — Distribution Cleanup;
• REPL — History Cleanup;
• REPL — LogReader;
• REPL — Merge;
• REPL — QueueReader;
• REPL — Snapshot;
• REPL — Subscription Cleanup;
• Web Assistant;
• [Uncategorized (Local)].
Для хранения заданий, как и любой другой информации, предназначенной для автоматизации службой SQLServer Agent, используется системная база данных MSDB. Информация о заданиях сохраняется в таблице sysjobs. Информация же о конкретных шагах задания хранится в таблице sysjobsteps. Можно работать с заданиями не только средствами Enterpise Manager, но и напрямую обращаться к указанным системным таблицам. Например, в столбце command таблицы sysjobsteps хранится текст, представляющий совокупность команд конкретного шага.
Периодически служба SQLServerAgent проверяет системную таблицу sysjobs базы данных MSDB, чтобы определить, какие задания должны быть выполнены в ближайшее время.
Оповещения Оповещения (alerts) представляют собой проявления реакции системы на наступление определенных событий. Администратор сам задает реакцию системы на наступление тех или иных событий. В качестве подобных событий чаще всего выступают различного рода нежелательные ситуации, приводящие к возникновению ошибок. Информация о созданных на сервере оповещениях сохраняется в системной таблице sysalerts базы данных MSDB.
При конфигурировании оповещений можно указывать две категории событий, наступление которых будет приводить к инициализации оповещения.
1. Показания счетчиков производительности (performance counters). Наступлением события считается момент, когда показания одного из счетчиков SQL Server 2000 достигнет критической точки. При этом можно контролировать точное совпадение значения счетчика с эталонным значением, превышение его или уменьшение показателя счетчика ниже указанного значения.
2. Сообщения об ошибках SQL Server 2000. В этом случае моментом наступления события считается генерирование в SQL Server 2000 сообщения об ошибке. При этом также имеется возможность настроить реакцию на ошибки, определяемые пользователями. Сама по себе активизация оповещения не представляет особого интереса.
Необходимо определить реакцию службы SQLServerAgent на инициализацию оповещения.
• Выполнение задания. В случае возникновения оповещения будет выполнено одно из сконфигурированных на сервере заданий. Это позволяет автоматизировать решение несложных проблем. Например, при возникновении определенной ошибки SQL Server 2000 может быть выполнено удаление промежуточных файлов. Довольно часто этот тип реакции используется для решения проблем с нехваткой свободного пространства на диске для роста баз данных. Если счетчик, отображающий объем свободного пространства, снизился до критичной отметки, то служба SQLServerAgent запустит задание, которое выполнит архивирование журнала транзакций с последующим его усечением. Дополнительно можно выполнить и усечение пользовательских баз данных, которые имеют много свободного пространства.
• Извещение оператора. Этот тип реакции используется при наступлении событий, которые не могут быть разрешены в автоматическом режиме и требуют вмешательства администратора. Например, если количество «мертвых» блокировок в системе становится критичным, то система отправит администратору соответствующее сообщение. Уже непосредственно администратор должен найти причину образования большого количества «мертвых» блокировок и предпринять действия к их устранению. Автоматическое решение подобных проблем вряд ли возможно. Это в первую очередь связано с их природой. Возникновение тех же «мертвых» блокировок может быть вызвано неверной логикой работы хранимых процедур. Очевидно, что внести исправления в хранимые процедуры, которые бы исправили логику, с помощью заданий практически невозможно.
Для SQL Server Agent может быть сконфигурирован собственный почтовый профиль. Также возможно совместное использование почтового профиля с SQL Server.
• Перенаправление возникающих ошибок. При работе с этим типом реакции выполняется перенаправление сообщений об инициализации сообщений на один из серверов сети. Подобный подход используется, если в сети имеется множество серверов SQL Server 2000, но администрирование всех их выполняется одним и тем же администратором (или администраторами). Для упрощения наблюдения за работой всех серверов SQL Server 2000 можно переадресовывать информацию о критических ситуациях на один центральный сервер. В обычной ситуации каждый из серверов хранит информацию обо всех инициированных событиях в одной из таблиц системной базы данных MSDB. При перенаправлении ошибок вся эта информация дополнительно дублируется на указанном сервере. В случае выхода из строя одного из серверов сети часто бывает нужно проанализировать цепочку событий, которые привели к его выходу из строя. Однако получить доступ к информации, хранящейся на этом сервере, невозможно. В этом случае перенаправление информации на центральный сервер может оказаться весьма полезным.
Как видим, события предоставляют весьма неплохой механизм обнаружения различных нештатных ситуаций и определения реакции на них.
Профилирование
Лекция 8
Система безопасности СУБД SQL Server: пользователи, роли, логины, группы, разрешения
Компоненты структуры безопасности. Фундаментом системы безопасности SQL Server 2000 являются учетные записи (login), пользователи (user), роли (role) и группы (group).
Пользователь, подключающийся к SQL Server, должен идентифицировать себя, используя учетную запись. После того как клиент успешно прошел аутентификацию, он получает доступ к SQL Server. Для получен



















- Басты
- ⭐️Прикладная наука
- Иван Трещев
- Базы данных
- 📖Тегін фрагмент