

автордың кітабын онлайн тегін оқу Базы данных
И. Карпова
Базы данных. Учебное пособие
Курс лекций и материалы для практических занятий
Заведующий редакцией А. Кривцов
Руководитель проекта А. Кривцов
Ведущий редактор Ю. Сергиенко
Научный редактор А. Пасечник
Литературный редактор Е. Пасечник
Художник М. Кольцов
Корректор В. Листова
Верстка Е. Волошина
И. Карпова
Базы данных. Учебное пособие. — СПб.: Питер, 2014.
ISBN 978-5-496-00546-3
© ООО Издательство "Питер", 2014
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Список используемых сокращений
DCL (data control language)— язык контроля данных
DDL (data definition language)— язык определения данных
DML (data manipulation language)— язык модификации данных
RBS (rollback segment)— сегмент отката
АИС— автоматизированная информационная система
БД— база данных
ИМД— иерархическая модель данных
ИПС— информационно-поисковая система
КБД— ключ базы данных
ОП— оперативная память
ОС— операционная система
ПрО— предметная область
ППО— прикладное программное обеспечение
РК— резервная копия
РМД— реляционная модель данных
РСУБД— реляционная система управления базами данных
СМД— сетевая модель данных
СОД— системы обработки данных
СПО— системное программное обеспечение
СУБД— система управления базами данных
Введение
Технология баз данных появилась почти полвека назад и с тех пор не только оказала огромное влияние на развитие информационных технологий, но икардинально изменила методы работы многих организаций и предприятий. В наше время сложно найти такую компанию, в которой не использовались бы базы данных, точнее, информационные системы, основанные на базах данных. Широкое распространение этих систем, дружелюбность интерфейса и кажущаяся простота использования привели к тому, что за создание иэксплуатацию баз данных часто берутся люди, не имеющие достаточных специальных знаний в этой области, что влечет появление большого числа неэффективных, сложных в поддержке и сопровождении систем.
С другой стороны, существует большое количество учебных изданий, посвященных как отдельным вопросам теории и практики использования баз данных, так и претендующих на охват технологии БД в целом (или, по крайней мере, большей части основных аспектов этой технологии), отличающиеся большим объёмом и подробным изложением теории — это литература, рассчитанная на профессионалов. Кроме того, есть целый ряд книг, которые условно можно отнести к серии «база данных за два дня». Такие издания не способствуют увеличению количества специалистов в области баз данных. При этом практически отсутствуют учебники, дающие достаточно полное введение в технологию баз данных, не опирающиеся на какую-то конкретную СУБД и сохраняющие компактность изложения. Данное учебное пособие призвано восполнить этот пробел.
Учебное пособие основано на материалах лекций и практических занятий, которые в течение многих лет проводятся автором на факультете информационных технологий и вычислительной техники Московского института электроники и математики и на факультете нано-, био-, информационных икогнитивных технологий Московского физико-технического института.
Предлагаемое вашему вниманию учебное пособие имеет ряд отличий от существующих изданий аналогичной тематики:
1. Содержание пособия соответствует Федеральному государственному образовательному стандарту по направлению подготовки 230100 «Информатика и вычислительная техника» (квалификация «бакалавр»).
2. Все определения, используемые в пособии, взяты из ГОСТа и международных стандартов (ANSI/ISO).
3. Теория баз данных излагается только в том объёме, который необходим как основа, база для понимания особенностей технологии БД. Изложение теоретических вопросов сопровождается большим количеством примеров, что облегчает восприятие материала.
4. Все аспекты технологии БД рассматриваются с точки зрения их применения на практике.
5. Отсутствует ориентация на какую-либо конкретную систему управления базами данных (СУБД), при этом даётся представление о возможностях СУБД в целом. Это позволит студенту (специалисту) в будущем оценивать различные системы с точки зрения их соответствия требованиям, предъявляемым к СУБД, и выбирать в каждой конкретной ситуации ту систему, которая в наибольшей степени соответствует условиям решаемой задачи.
6. Подробно излагается оптимизация реляционных запросов, в том числе приёмы написания оптимальных запросов. Под оптимальными в данном случае понимаются такие запросы, по которым СУБД сможет построить более эффективный план выполнения запроса. Рациональность этих приёмов подтверждается, в том числе, и личным опытом автора, полученным во время работы с реальными базами данных большого объёма.
7. Пособие ориентировано на учебный курс, предполагающий выполнение лабораторных работ и курсового проекта, и содержит примеры заданий. Это позволяет рекомендовать его преподавателям не только как основу лекционного курса, но и для использования на практических занятиях ивходе курсового проектирования.
Материал книги разбит на главы, каждая из которых соответствует одной теме. Каждая глава представляет собой более или менее законченный фрагмент, который можно изучать отдельно от других глав.
В главе 1 приводятся определения основных терминов, а также общие сведения о базах данных, уровнях представления данных и автоматизированных информационных системах, которые основаны на данных.
Глава 2 посвящена описанию моделей данных. Основное внимание уделяется реляционной модели, но также приводятся сведения и о других моделях: о сетевой, иерархической, объектно-реляционной и объектно-ориентированной. Проанализированы достоинства и недостатки этих моделей.
Главу 3 занимает введение в язык SQL— структурированный язык запросов к базам данных. Синтаксис команд и примеры использования соответствует стандарту SQL-92, который поддерживается большинством реляционных СУБД. В этой главе рассматриваются команды языка определения данных (Data Definition Language, DDL) и языка манипулирования данными (Data Manipulation Language, DML). Большая часть главы посвящена возможностям команды SELECT: использованию операторов, предикатов, функций агрегирования, запросам на нескольких таблицах, подзапросам, самосоединению таблиц и работе с представлениями.
Глава 4 касается общих вопросов организации систем управления базами данных (СУБД). Приводится классификация СУБД, требования к реляционным СУБД (по Кодду), описание основных функций реляционной СУБД и задач по администрированию баз данных.
Глава 5 посвящена физической организации баз данных, без знания которой невозможно организовать эффективно работающую БД. Рассматриваются механизмы среды хранения, структура хранимых данных и методы управления пространством памяти и размещением данных. Основное внимание уделяется изучению способов размещения данных и доступа к данным вреляционной БД, а именно: индексированию, хешированию и кластеризации. Для каждого из этих способов приводится не только назначение и описание принципов организации, но и правила использования.
В главе 6 представлены сведения об организации многопользовательского доступа к данным. Описывается механизм транзакций (ACID-транзакции), уровни изоляции транзакций (по стандарту ANSI/ISO), реализация механизма транзакций с помощью блокировок и временных отметок. Приводятся команды управления транзакциями и блокировками, входящие в состав языка SQL.
Глава 7 посвящена вопросам защиты данных в базах данных. В части обеспечения логической целостности данных приводится перечень ограничений целостности, которые входят в состав стандарта языка SQL. В части обеспечения безопасности данных рассматривается защита данных от сбоев (журналы транзакций, сегменты отката, резервное копирование, восстановление базы данных). В части защиты от несанкционированного доступа описываются системные и объектные привилегии (права доступа), команды языка SQL для управления доступом и правила назначения прав доступа.
Глава 8 касается практических аспектов оптимизации реляционных запросов. Описываются основные методы оптимизации (по синтаксису и по стоимости), а также другие возможности управления оптимизацией. Материал включает описание правил настройки приложений, приёмов написания эффективных запросов и примеры использования этих приёмов.
В главе 9 излагается методология проектирования баз данных, в первую очередь реляционных. Приводится описание последовательности этапов проектирования автоматизированных информационных систем, основанных на базах данных: предпроектная подготовка; собственно проектирование БД; реализация (создание БД и ППО). Основное внимание уделяется этапам инфологического, логического и физического проектирования баз данных. Описывается применение метода сущность—связь (entity—relation method, ER-метод)— это самый распространённый метод проектирования реляционных баз данных. Рассматриваются правила проектирования реляционных БД, в том числе правила преобразования ER-диаграммы в схему БД, определение первичных ключей и типов данных атрибутов, нормализация отношений (до 4-й нормальной формы) и денормализация. Описание сопровождается примером, иллюстрирующим полный цикл проектирования реляционной базы данных от описания предметной области до разработки стратегии резервного копирования.
В главе 10 рассматриваются те перспективные направления развития технологии баз данных, которые остались за рамками данного учебного пособия, но могут быть интересны читателю для дальнейшего изучения.
К главам 1–3, 8 и 9 прилагаются примеры заданий для практических занятий. В приложениях приведены примеры заданий для лабораторных работ и примеры заданий для курсового проекта.
Таким образом, материал данной книги охватывает наиболее важные вопросы проектирования и эксплуатации баз данных и ориентирован на практическое использование данной технологии.
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу электронной почты comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
На веб-сайте издательства http://www.piter.com вы найдете подробную информацию о наших книгах.
1. Основные сведения
Цивилизация развивается за счёт расширения числа важных операций, которые можно выполнять, не думая оних.
Альфред Норт Уайтхед, британский математик, логик, философ
Развитие средств вычислительной техники и информационных технологий обеспечило возможности для создания и широкого применения автоматизированных информационных систем (АИС) разнообразного назначения. Разрабатываются и внедряются информационные системы управления хозяйственными и техническими объектами, модельные комплексы для научных исследований, системы автоматизации проектирования и производства, всевозможные тренажеры и обучающие системы.
Различают АИС, основанные на знаниях, и АИС, основанные на данных. К первым можно отнести, например, экспертные системы (ЭС), интеллектуальные системы поддержки принятия решений (СППР) ит.п. Ко вторым— всевозможные прикладные системы, которые сейчас активно используются как на предприятиях, так и в учреждениях. Такие прикладные системы применяются очень широко, и в рамках данного курса наше внимание будет сосредоточено именно на системах, которые основаны на данных.
Существует две основные предпосылки создания таких систем:
1. Разработка методов конструирования и эксплуатации систем, предназначенных для коллективного использования.
2. Возможность собирать, хранить и обрабатывать большое количество данных о реальных объектах и явлениях, то есть оснащение этих систем «памятью».
Массив данных общего пользования в системах, основанных на данных, называется базой данных. База данных является моделью предметной области информационной системы.
На заре развития вычислительной техники обрабатываемые данные являлись частью программ: они располагались сразу за кодом программы втак называемом сегменте данных (рис.1.1, а). Следующим шагом стало хранение данных в отдельных файлах (рис.1.1, б). Недостатком этих подходов являлась зависимость программ от данных: сведения о структуре данных включались в код программы. При изменении структуры данных необходимо было вносить изменения в программу.
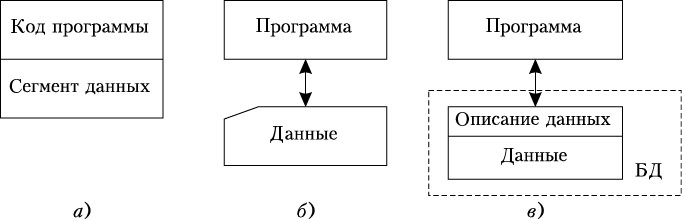
Рис. 1.1. Развитие принципов обработки данных
Логичным продолжением этой эволюции является перенос описания данных в массив данных (рис.1.1, в). Это позволило обеспечить независимость данных от программ.
Основным принципом организации баз данных является совместное хранение данных и их описание.
Описание данных называют метаданными. Метаданные хранятся в части базы данных, которая называется каталогом или словарём-справочником данных (ССД). Зная формат метаданных, можно запрашивать и изменять данные без написания дополнительных программ.
Одна и та же база данных может быть использована для решения многих прикладных задач. Наличие метаданных и возможность информационной поддержки решения нескольких задач— это принципиальные отличия базы данных от любой другой совокупности данных, находящихся во внешней памяти ЭВМ.
1.1.Информация, данные, знания. Терминология
Информация— любые сведения о каком-либо событии, сущности, процессе ит.п., являющиеся объектом некоторых операций: восприятия, передачи, преобразования, хранения или использования.
Данные— это информация, зафиксированная в форме, пригодной для последующей обработки, передачи и хранения, например находящаяся впамяти ЭВМ или подготовленная для ввода в ЭВМ.
Подготовка информации состоит в её формализации, сборе и переносе на машинные носители.
Обработка данных— это совокупность задач, осуществляющих преобразование массивов данных. Обработка данных включает: ввод данных в ЭВМ, отбор данных по заданным критериям, преобразование структуры данных, перемещение данных на внешней памяти ЭВМ, вывод данных, являющихся результатом решения задач, в табличном или ином, удобном для пользователя виде.
Система обработки данных(СОД)— это набор аппаратных и программных средств, осуществляющих выполнение задач по управлению данными.
Управление данными— совокупность функций обеспечения требуемого представления данных, их накопления и хранения, обновления, удаления, поиска по заданному критерию и выдачи данных [5].
Предметная область (ПрО)— часть реального мира, подлежащая изучению с целью организации управления и, в конечном итоге, автоматизации.
База данных (БД)— совокупность данных, организованных по определённым правилам, предусматривающим общие принципы описания, хранения иманипулирования данными, независимая от прикладных программ [5]. Эти данные относятся к определённой предметной области и организованы так, что могут быть использованы для решения многих задач многими пользователями.
Ведение базы данных — деятельность по обновлению, восстановлению и изменению структуры базы данных с целью обеспечения её целостности, сохранности и эффективности использования [5].
Система управления базами данных (СУБД) — это совокупность программ и языковых средств, предназначенных для управления данными вбазе данных, ведения базы данных и обеспечения взаимодействия её с прикладными программами [5].
Автоматизированнаяинформационнаясистема (АИС) представляет собой совокупность данных, экономико-математических методов и моделей, технических, программных средств и обслуживающих систему специалистов, предназначенную для обработки информации и принятия управленческих решений.
Банкданных (БнД)— это автоматизированная информационная система, включающая комплекс специальных методов и средств (математических, информационных, программных, языковых, организационных и технических) для поддержания динамической информационной модели предметной области с целью обеспечения информационных запросов пользователей. Взадачи банка данных входит:
1. обеспечение информационных потребностей внешних пользователей;
2. обеспечение возможности хранения и модификации больших объёмов многоаспектных данных;
3. обеспечение заданного уровеня достоверности хранимых данных и их непротиворечивости;
4. ограничение доступа к данным только кругом пользователей с соответствующими полномочиями;
5. обеспечение поиска данных по произвольной группе признаков;
6. удовлетворение заданных требований по производительности при обработке запросов;
7. обеспечение выдачи пользователям данных в различной форме;
8. обеспечение простоты и удобства обращения внешних пользователей кданным.
Помимо этого банк данных должен допускать возможность реорганизации при изменении границ ПрО.
1.2.Автоматизированная информационная система
Под автоматизированной информационной системой (АИС) понимается совокупность программно-аппаратных средств, предназначенных для автоматизации деятельности, связанной с хранением, передачей и обработкой информации.
АИС, основанная на базе данных, служит для сбора, накопления, хранения информации, а также её эффективного использования для различных целей. Информация представляется в виде данных, хранимых в памяти ЭВМ. При проектировании АИС, с одной стороны, решается вопрос о том, какие сведения и для каких целей будут содержаться в системе, с другой— как соответствующие данные будут организованы в памяти ЭВМ и как они будут обрабатываться при эксплуатации АИС.
По сферам применения и правилам организации различают два основных класса АИС, основанных на базе данных: информационно-поисковые (ИПС) и системы обработки данных (СОД). ИПС ориентированы, как правило, на извлечение подмножества хранимых данных, удовлетворяющих некоторому поисковому критерию. Пользователя ИПС интересуют в основном сами извлекаемые из базы данных сведения, а не результаты их обработки. Примером ИПС является любая справочная служба: к ней обращаются сзапросом иполучают в результате те данные, которые удовлетворяют этому запросу.
Обращения пользователя к СОД чаще всего приводят к обновлению данных. Вывод данных может вовсе отсутствовать или представлять собой результат программной обработки хранимых сведений. Пример СОД— банковские системы, осуществляющие открытие/закрытие счетов, пересчёт вкладов в зависимости от процентов, приём/снятие сумм ит.п.
В зависимости от характера информационных ресурсов, с которыми имеют дело АИС, их подразделяют на документальные и фактографические системы. На практике используются также системы комбинированного типа.
Фактографические АИС хранят сведения об объектах предметной области, их свойствах и взаимосвязях. Сведения о каждом объекте могут поступать всистему из множества различных источников. Кроме поиска и модификации данных, фактографические системы поддерживают статистические функции (нахождение суммы, минимума, максимума ит.п.). Фактографические АИС обычно принадлежат к классу систем обработки данных.
В документальной системе объект хранения— документ, который содержит информацию, относящуюся к определённой предметной области. Это могут быть графические изображения (например, географические карты); информация на естественном языке (монографии, тексты законодательных актов, научные отчёты ит.п.); звуковая информация (например, мелодии— для системы, хранящей фонотеку) ит.д. Для обработки данных не важно, какие сведения хранятся в документах. Обычно (но не всегда) документальные АИС реализуются в виде информационно-поисковых систем (ИПС).
Основные компоненты документальной ИПС:
• программные средства;
• поисковый массив документов;
• средства поддержки информационного языка системы.
Программные средства ИПС служат для организации управления данными (ввода, хранения, защиты, поиска и выдачи). Поисковый массив документов в ИПС обычно называется базой данных. Он представляет собой набор ссылок на документы (или их описаний), хранящий основную информацию о документах и организованный так, чтобы обеспечить быстрый поиск документов. Описание документа зависит от предметной области и состоит из значений атрибутов, характеризующих содержание документа. Например, для БД географических карт это могут быть координаты и масштаб, а для БД законодательных актов— тип документа (закон, постановление и др.), дата принятия, область действия ит.п.
Информационный язык ИПС предназначен для того, чтобы пользователь мог запросить данные у системы. Системными средствами пользовательский запрос преобразуется в формальный запрос, понятный системе. Информационный язык ИПС может быть основан на подмножестве естественного языка, которое относится к обслуживаемой ПрО. Но чаще поиск документа осуществляется с помощью шаблонов— экранных форм, включающих поля описания документа. В эти поля вносятся конкретные значения, которые и определяют условия поиска документов. На рис.1.2 приведён пример поиска через экранную форму в справочнике библиотек. В форме указаны два условия— округ и фрагмент названия библиотеки, и в результате поиска система выдала три записи, удовлетворяющие этим условиям.
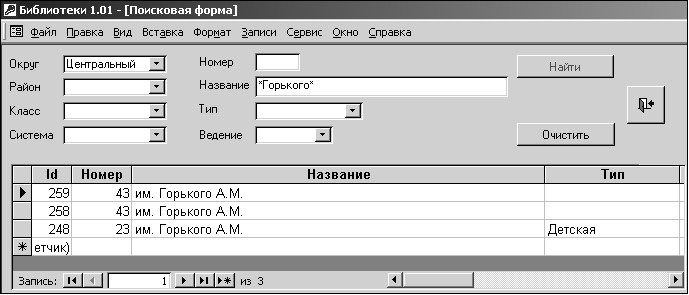
Рис. 1.2. Пример поиска данных через экранную форму
Мы будем основное внимание уделять фактографическим АИС, имея ввиду, что ИПС и документальные АИС создаются с помощью тех же программных средств и на тех же принципах, что и СОД, а специфические моменты обработки данных реализуются через приложения (программы, внешние по отношению к ядру СОД).
Разработка любой АИС начинается с определения предметной области.
1.3.Предметная область информационной системы
Предметная область (ПрО) информационной системы рассматривается как совокупность реальных процессов и объектов (сущностей), представляющих интерес для её пользователей [6]. Каждая из сущностей ПрО обладает определённым набором свойств (атрибутов).
Для упрощения процедуры описания ПрО в большинстве случаев прибегают к определению типов сущностей. Тип позволяет выделить из всего множества сущностей ПрО группу сущностей, однородных по структуре иповедению (относительно рамок рассматриваемой ПрО). Например, для ПрО «Институт» в качестве типов сущностей могут рассматриваться студенты, преподаватели, дисциплины ит.п.
Данные предметной области представляются экземплярами сущностей (студент Иванов, преподаватель Сидоров, дисциплина «Базы данных»). Экземпляры сущностей одного типа обладают одинаковыми наборами атрибутов, но должны отличаться значением хотя бы одного атрибута для того, чтобы быть узнаваемыми (например, студенты могут иметь одинаковые ФИО, но должны иметь разные номера зачётных книжек).
Среди атрибутов сущности можно выделить существенные и малозначительные. Признание какого-либо свойства существенным носит относительный характер. Например, атрибут Должность для сотрудника является существенным, а для читателя библиотеки— малозначительным.
Атрибуты можно условно классифицировать следующим образом:
1. Идентифицирующие и описательные атрибуты. Идентифицирующие атрибуты имеют уникальное значение для сущностей данного типа, описательные атрибуты заключают в себе интересующие свойства сущности.
2. Составные и простые атрибуты. Простой атрибут состоит из одного компонента, его значение неделимо; составной атрибут является комбинацией нескольких компонентов, возможно, принадлежащих разным типам данных.
3. Однозначные и многозначные атрибуты (могут иметь соответственно одно или много значений для каждого экземпляра сущности).
4. Основные и производные атрибуты. Значение основного атрибута не зависит от других атрибутов. Значение производного атрибута вычисляется на основе значений других атрибутов.
5. Обязательные и необязательные. Значение обязательного атрибута всегда устанавливается при помещении данных в БД; значение необязательного атрибута может быть пропущено.
Спецификация атрибута состоит из его названия, типа данных, размера иописания ограничений целостности— множества значений, которые может принимать данный атрибут.
Примечание
В данном учебном пособии наименования сущностей, атрибутов и связей выделяются курсивом и подчёркиванием. Кроме того:
1. Сущность записывается прописными буквами (ОТДЕЛ ).
2. Атрибут сущности начинается с прописной буквы (Название). Ключевой атрибут выделяется полужирным шрифтом (Табельный номер).
3. Связь между сущностями определяется глаголом (работает ).
Между сущностями ПрО могут существовать связи, имеющие различный содержательный смысл (семантику). Например, студент учится в группе, врач лечит пациента, клиент имеет вклад в банке. Связи могут быть факультативными или обязательными. Если вновь порождённая сущность одного из типов оказывается по необходимости связанной с сущностью другого типа, то между этими типами сущностей есть обязательная связь. Впротивном случае связь является факультативной. Примеры обязательной ифакультативной связей приведены на рис.1.3. Здесь связь замещает является обязательной (изображается двойной линией), потому что каждый сотрудник должен работать на определённой должности, а связь замещается является факультативной, поскольку должность может быть вакантна.
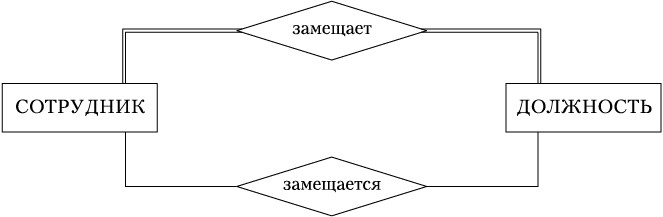
Рис. 1.3. Примеры обязательной и факультативной связей
Для удобства каждую связь между сущностями можно изображать одним ромбом (рис.1.4). Выделяют также показатель кардинальности связи: «один к одному» (1:1), «один ко многим» (1:n) и «многие ко многим» (m:n) (рис.1.4).
Связи, приведённые на рис.1.4, с учётом семантики означают следующее:
• пациент—койка (1:1)— каждый пациент занимает одну койку, каждая койка в каждый момент времени может быть занята только одним пациентом;
• палата—пациент (1:n) — каждый пациент находится в одной палате, вкаждой палате могут находиться несколько пациентов;
• пациент—врач (n:m) — каждый пациент может лечиться у нескольких врачей, каждый врач может лечить несколько пациентов.
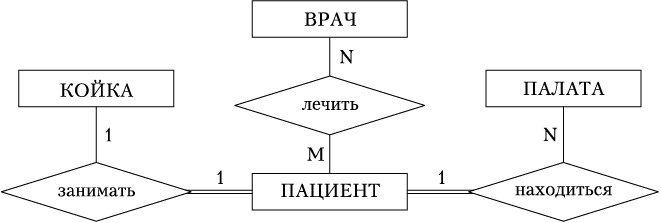
Рис. 1.4. Примеры различной кардинальности связей
Обратите внимание: необязательная связь имеет модификатор «может», а у обязательной связи его нет.
Степень связи— это количество типов сущностей, которые входят в связь. Различают унарные (рис.1.5, а), бинарные (рис.1.5, б) и тернарные (рис.1.5, в) связи. (На практике связи с большей степенью редко используются). Унарная связь означает, что одни экземпляры сущности связаны с другими экземплярами этой же сущности (например, одни сотрудники руководят другими, адеталь может являться частью механизма).
Различают тип связи и экземпляр связи. Тип связи определяется её именем, обязательностью, степенью и кардинальностью, например бинарная связь учится между сущностями ГРУППА и СТУДЕНТ, обязательная для студента, кардинальностью 1:n. А экземпляр связи— это конкретная связь между студентом Сидоровым и группой Н-11, в которой он учится.
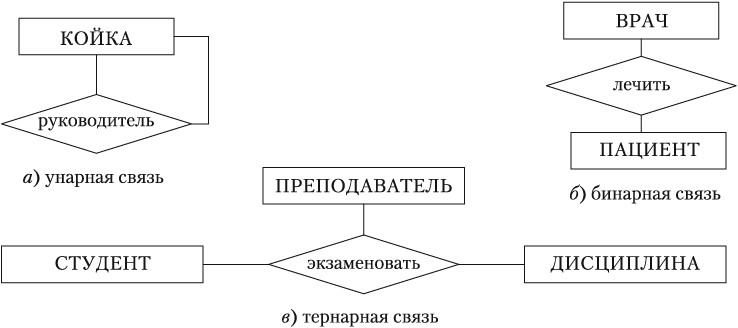
Рис. 1.5. Примеры связей различной степени
Совокупность типов сущностей и типов связей между сущностями характеризует структуру предметной области. Собственно данные представлены экземплярами сущностей и связей между ними. Данные экземпляров сущностей и связей хранятся в базе данных информационной системы, а описание типов сущностей и связей является метаданными.
Множества экземпляров сущностей, значения атрибутов сущностей иэкземпляры связей между ними могут изменяться во времени. Поэтому каждому моменту времени можно сопоставить некоторое состояние предметной области. Состояния ПрО должны подчиняться совокупности правил, которые характеризуют семантику предметной области. В базе данных эти правила могут быть заданы с помощью так называемых ограничений целостности, которые накладываются на атрибуты сущностей, типы сущностей, типы связей и/или их экземпляры. Фактически ограничения целостности— это правила, которым должны удовлетворять значения данных в БД. Например, для библиотеки можно привести такие ограничения целостности: количество экземпляров книги не может быть отрицательным; номер паспорта читателя должен быть уникальным; каждая книга относится к определённому разделу рубрикатора ББК— библиотечно-библиографической классификации ит.д.
Для того чтобы обеспечить соответствие базы данных текущему состоянию предметной области, база данных динамически обновляется (периодически или в режиме реального времени). Это обновление называется актуализацией данных. Актуализация может проводиться:
• вручную, если изменения в данные вносит пользователь (например, запись сведений о выдаче абоненту книги в библиотеке);
• автоматизировано, если изменения инициируются пользователем, но выполняются программно (например, обновление списка должников вбиблиотеке— читателей, которые просрочили дату возврата книг);
• автоматически, если данные поступают в электронном виде и обрабатываются программой без участия человека (это касается, например, автоматизированных систем управления производством).
Правильность обновлений может контролироваться программно, но правильнее контролировать их автоматически с помощью ограничений целостности БД.
База данных является информационной моделью внешнего мира, некоторой предметной области. Во внешнем мире сущности ПрО взаимосвязаны, поэтому в БД эти связи должны быть отражены. Если связи между данными в БД отсутствуют, то имеет смысл говорить о нескольких независимых БД и хранить их раздельно.
1.4.Назначение и основные компоненты системы баз данных
Система БД включает два основных компонента: собственно базу данных исистему управления базами данных— СУБД (рис.1.6). Большинство СОД содержат также программы обработки данных (прикладное программное обеспечение, ППО), которые обращаются к данным через СУБД.
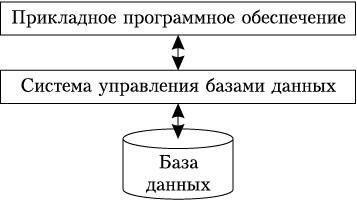
Рис. 1.6. Компоненты системы баз данных
В соответствии с рис.1.6 СУБД обеспечивает выполнение двух групп функций:
• предоставление доступа к базе данных прикладному программному обеспечению (или квалифицированным пользователям);
• управление хранением и обработкой данных в БД.
Таким образом, обращение к базе данных возможно только через СУБД.
База данных предназначена для хранения данных информационной системы. Пользователи обращаются к БД обычно не напрямую через средства СУБД, а с помощью внешнего интерфейса— приложения, входящего всостав АИС. Если пользователей можно разделить на группы по характеру решаемых задач, то приложений может быть несколько (по количеству задач или групп пользователей). Например, для библиотеки можно выделить три группы пользователей: читатели, которым нужно осуществлять поиск книг по различным признакам; сотрудники, выдающие и принимающие у читателей книги (библиотекари); сотрудники отдела комплектации, осуществляющие приём новых книг и списание старых.
1.5. Уровни представления данных
Современная технология баз данных основана на концепции многоуровневой архитектуры СУБД. Эти идеи впервые были сформулированы в отчёте рабочей группы по базам данных Комитета по планированию стандартов Американского национального института стандартов (ANSI/X3/SPARC). Этот отчёт был опубликован в 1975г. В нём предлагалась обобщенная трёхуровневая модель архитектуры СУБД, включающая концептуальный, внешний и внутренний уровни (рис.1.7).
Концептуальный уровень архитектуры ANSI/SPARC служит для поддержки единого взгляда на базу данных, общего для всех её приложений и независимого от них и от среды хранения [5]. Концептуальный уровень представляет собой формализованную информационно-логическую модель ПрО. Описание этого представления называется концептуальной схемой или схемой БД.
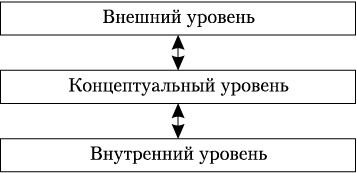
Рис. 1.7. Уровни представления данных
Схема базы данных— это описание базы данных в терминах конкретной модели данных.
Внутренний уровень архитектуры поддерживает представление данных всреде хранения и пути доступа к ним [5]. На этом архитектурном уровне БД представлена в полностью «материализованном» виде, тогда как на других уровнях идёт работа на уровне отдельных экземпляров или множества экземпляров данных. Описание БД на внутреннем уровне называется внутренней схемой или схемой хранения.
Внешний уровень архитектуры БД предназначен для групп пользователей. Описание представления данных для группы пользователей называется внешней схемой. Наличие внешнего уровня позволяет поддерживать разное представление одних и тех же данных для различных групп пользователей или задач [5].
Каждый из этих уровней может считаться управляемым, если он обладает внешним интерфейсом, обеспечивающим возможности определения данных. В этом случае становятся возможными формирование и системная поддержка независимого взгляда на БД для какой-либо группы персонала или пользователей, взаимодействующих с БД через интерфейс данного уровня.
В архитектурной модели ANSI/SPARC предполагается наличие в СУБД механизмов, обеспечивающих междууровневое отображение данных «внешний—концептуальный» и «концептуальный—внутренний». Функциональные возможности этих механизмов определяют степень независимости данных на всех уровнях. На переходе «внешний—концептуальный» обеспечивается логическая независимость данных, на переходе «концептуальный—внутренний» — физическая независимость. Под логической независимостью подразумевается возможность вносить изменения в концептуальный уровень, не меняя представление БД для пользователей, или изменять представление данных для пользователей без изменения концептуальной схемы. Физическая независимость данных подразумевает возможность вносить изменения в схему хранения, не меняя концептуальную схему БД.
Основной характеристикой баз данных является совместное использование данных многими пользователями АИС. Должно существовать какое-то общее понимание информации, представленной данными. Общее понимание должно относиться к чему-либо внешнему по отношению к пользователям, и оно должно быть зафиксировано. Для этого необходима некоторая предварительно определённая грамматика, которую принято называть моделью данных.
Задания для практических занятий
Тема: предметная область информационной системы
1. Выделить базовые и зависимые сущности для различных ПрО («Отдел кадров», «Магазин», «Институт», «Проектная организация»).
2. Определить набор атрибутов для различных сущностей («Студент», «Сотрудник», «Проект»).
3. Определить связи между сущностями в различных ПрО («Отдел кадров», «Магазин», «Институт», «Проектная организация»).
2. Основные модели данных
Мозг, хорошо устроенный, стоит больше, чем мозг, хорошо наполненный.
М. Монтень, французский философ и писатель
Модель данных является инструментом моделирования произвольной предметной области.
2.1. Понятие модели данных
Модель данных— это совокупность правил порождения структур данных вбазе данных, операций над ними, а также ограничений целостности, определяющих допустимые связи и значения данных, последовательность их изменения [5]. Итак, модель данных состоит из трёх частей:
1. Набор типов структур данных.
Здесь можно провести аналогию с языками программирования, в которых тоже есть предопределённые типы структур данных, такие как скалярные данные, векторы, массивы, структуры (например, тип struct в языке С) ит.д.
2. Набор операторов или правил вывода, которые могут быть применены к любым правильным примерам типов данных, перечисленных в наборе типов структур данных, чтобы находить, выводить или преобразовывать информацию, содержащуюся в любых частях этих структур в любых комбинациях.
Такими операциями являются: создание и модификация структур данных, внесение новых данных, удаление и модификация существующих данных, поиск данных по различным условиям.
3. Набор общих правил целостности, которые прямо или косвенно определяют множество непротиворечивых состояний базы данных и/или множество изменений её состояния.
Правила целостности определяются типом данных и предметной областью. Например, значение атрибута Счётчик является целым числом, то есть может состоять только из цифр. А ограничения предметной области таковы, что это число не может быть меньше нуля.
Рассмотрим подробнее наборы, составляющие модель данных.
2.1.1. Типы структур данных
Структуризация данных базируется на использовании концепций «агрегации» и «обобщения». Один из первых вариантов структуризации данных был предложен Ассоциацией по языкам обработки данных (Conference on Data Systems Languages, CODASYL) (рис.2.1).

Рис. 2.1. Композиция структур данных по версии CODASYL
Элемент данных— наименьшая поименованная единица данных, к которой СУБД может обращаться непосредственно и с помощью которой выполняется построение всех остальных структур. Для каждого элемента данных должен быть определён его тип.
Агрегат данных— поименованная совокупность элементов данных внутри записи, которую можно рассматривать как единое целое. Агрегат может быть простым (включающим только элементы данных, рис.2.2, а) исоставным (включающим наряду с элементами данных и другие агрегаты, рис.2.2, б).
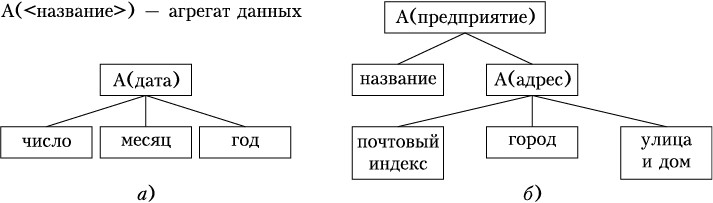
Рис. 2.2. Примеры агрегатов: а— простой и б— составной агрегат
Запись— поименованная совокупность элементов данных или элементов данных и агрегатов. Запись— это агрегат, не входящий в состав никакого другого агрегата; она может иметь сложную иерархическую структуру, поскольку допускается многократное применение агрегации. Различают тип записи (её структуру) и экземпляр записи, то есть запись с ко
...


















