

автордың кітабын онлайн тегін оқу Машинное обучение на R: экспертные техники для прогностического анализа
Научный редактор Н. Искра
Переводчик Е. Сандицкая (Полонская)
Технический редактор Н. Гринчик
Литературный редактор А. Дубейко
Художники Н. Гринчик, В. Мостипан, Г. Синякина (Маклакова)
Корректоры Н. Искра, Е. Павлович, Е. Рафалюк-Бузовская
Верстка Г. Блинов
Бретт Ланц
Машинное обучение на R: экспертные техники для прогностического анализа. — СПб.: Питер, 2021.
ISBN 978-5-4461-1512-9
© ООО Издательство "Питер", 2021
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Об авторе
Бретт Ланц (Brett Lantz, @DataSpelunking) более десяти лет использует инновационные методы обработки данных для изучения поведения человека. Будучи по образованию социологом, Бретт впервые увлекся машинным обучением во время исследования большой базы профилей подростков в социальных сетях. Бретт — преподаватель DataCamp и часто выступает с докладами на конференциях и семинарах по машинному обучению по всему миру. Он известный энтузиаст в сфере практического применения науки о данных в области спорта, беспилотных транспортных средств, изучения иностранных языков и моды, а также во многих других отраслях. Бретт надеется в один прекрасный день написать обо всем этом на сайте dataspelunking.com, посвященном обмену знаниями о поиске закономерностей в данных.
Я не смог бы написать эту книгу без поддержки моей семьи. В частности, моя жена Джессика заслуживает огромной благодарности за ее бесконечное терпение и поддержку. Мои сыновья Уилл и Кэл родились в тот период, когда создавались первое и второе издания соответственно, и я бы не смог написать третье, если бы они меня отвлекали. Я посвящаю им эту книгу в надежде, что однажды она вдохновит их на решение больших задач. Желаю им следовать своему любопытству, куда бы оно их ни привело.
Я также признателен многим другим людям, которые косвенно поддержали эту книгу. Общение с педагогами, коллегами и сотрудниками Мичиганского университета, Университета Нотр-Дам и Университета Центральной Флориды способствовало рождению многих идей, которые я попытался выразить в тексте; что же касается отсутствия ясности в их выражении, то это сугубо мое упущение. Кроме того, эта книга могла бы вообще не появиться без более широкого сообщества исследователей, которые поделились своим опытом в виде статей, лекций и исходного кода. Наконец, я ценю усилия команд R и RStudio, а также всех тех, кто внес вклад в создание R-пакетов. Благодаря проделанной работе мы смогли донести идеи машинного обучения до широкой публики. Я искренне надеюсь, что мой труд также станет важной частью этой мозаики.
О научном редакторе
Рагхав Бали (Raghav Bali) — старший научный сотрудник одной из крупнейших в мире организаций здравоохранения. Занимается исследованиями и разработкой корпоративных решений, основанных на машинном обучении, глубоком обучении и обработке естественного языка для использования в области здравоохранения и страхования. На своей предыдущей должности в Intel он участвовал в реализации проактивных инициатив в области информационных технологий, основанных на больших данных, с использованием обработки естественного языка, глубокого обучения и традиционных статистических методов. В American Express работал в области цифрового взаимодействия и удержания клиентов.
Рагхав является автором нескольких книг, выпущенных ведущими издательствами. Его последняя книга посвящена новейшим достижениям в области исследования трансферного обучения.
Рагхав окончил Международный институт информационных технологий в Бангалоре, имеет степень магистра (диплом с отличием). В те редкие моменты, когда он не занят решением научных проблем, Рагхав любит читать и фотографировать все подряд.
Предисловие
В основе машинного обучения (англ. Machine Learning, ML) лежат алгоритмы, которые преобразуют информацию в практически ценные данные. Именно поэтому машинное обучение так популярно в современную эру больших данных. Без него было бы почти невозможно отслеживать огромный поток информации.
Учитывая растущую популярность R — кросс-платформенной статистической свободно распространяемой среды программирования, — еще никогда не было более подходящего времени, чтобы начать использовать машинное обучение. R предоставляет мощный, но простой в освоении набор инструментов, которые помогут вам постигнуть суть ваших данных.
Сочетая практические примеры с базовой теорией, которая требуется для понимания того, как все работает внутри, эта книга даст вам возможность получить все необходимые знания, чтобы можно было начать работу с машинным обучением.
Для кого предназначена книга
Книга предназначена для тех, кто рассчитывает использовать данные в конкретной области. Возможно, вы уже немного знакомы с машинным обучением, но никогда не работали с языком R; или, наоборот, немного знаете об R, но почти не знаете о машинном обучении. В любом случае эта книга поможет вам быстро начать работу. Было бы полезно немного освежить в памяти основные понятия математики и программирования, но никакого предварительного опыта не потребуется. Вам нужно лишь желание учиться.
О чем вы прочтете в издании
Глава 1 «Введение в машинное обучение» содержит терминологию и понятия, которые определяют и выделяют теорию машинного обучения среди других областей, а также включает информацию о том, как выбрать алгоритм, подходящий для решения конкретной задачи.
Глава 2 «Управление данными и их интерпретация» даст вам возможность полностью погрузиться в работу с данными в среде R. Здесь речь пойдет об основных структурах данных и процедурах, используемых для загрузки, исследования и интерпретации данных.
Глава 3 «Ленивое обучение: классификация с использованием метода ближайших соседей» научит вас понимать и применять простой, но мощный алгоритм машинного обучения для решения вашей первой практической задачи: выявления особо опасных видов рака.
Глава 4 «Вероятностное обучение: классификация с использованием наивного байесовского классификатора» раскрывает основные понятия теории вероятностей, которые используются в современных системах фильтрации спама. Создавая собственный фильтр спама, вы изучите основы интеллектуального анализа текста.
Глава 5 «Разделяй и властвуй: классификация с использованием деревьев решений и правил» посвящена нескольким обучающим алгоритмам, прогнозы которых не только точны, но и легко интерпретируемы. Мы применим эти методы к задачам, в которых важна прозрачность.
Глава 6 «Прогнозирование числовых данных: регрессионные методы» познакомит с алгоритмами машинного обучения, используемыми для числовых прогнозов. Поскольку эти методы тесно связаны с областью статистики, вы также изучите базовые понятия, необходимые для понимания числовых отношений.
Глава 7 «Методы “черного ящика”: нейронные сети и метод опорных векторов» описывает два сложных, но мощных алгоритма машинного обучения. Их математика на первый взгляд может вас испугать, однако мы разберем примеры, иллюстрирующие их внутреннюю работу.
Глава 8 «Обнаружение закономерностей: анализ потребительской корзины с помощью ассоциативных правил» объясняет алгоритм, используемый в рекомендательных системах, применяемых во многих компаниях розничной торговли. Если вы когда-нибудь задумывались о том, почему системы розничных продаж знают ваши покупательские привычки лучше, чем вы сами, то эта глава раскроет их секреты.
Глава 9 «Поиск групп данных: кластеризация методом k-средних» посвящена процедуре поиска кластеров связанных элементов. Мы воспользуемся этим алгоритмом для идентификации профилей в онлайн-сообществе.
Глава 10 «Оценка эффективности модели» предоставит информацию о том, как измерить успешность проекта машинного обучения и получить надежный прогноз использования конкретного метода в будущем на других данных.
Глава 11 «Повышение эффективности модели» раскрывает методы, используемые теми, кто возглавляет список лидеров в области машинного обучения. Если в вас живет дух соревновательности или вы просто хотите получить максимальную отдачу от своих данных, то вам необходимо добавить эти методы в свой арсенал.
Глава 12 «Специальные разделы машинного обучения» исследует границы машинного обучения: от обработки больших данных до ускорения работы R. Прочитав ее, вы откроете для себя новые горизонты и узнаете, что еще можно делать с помощью R.
Что вам нужно для чтения книги
Примеры в этой книге написаны и протестированы для версии R 3.5.2, установленной в Microsoft Windows и Mac OS X, хотя они, вероятно, будут работать с любой текущей версией R.
Загрузите файлы примеров кода
Пакет с примерами кода для этой книги размещен в GitHub по адресу https://github.com/PacktPublishing/Machine-Learning-with-R-Third-Edition и по адресу https://github.com/dataspelunking/MLwR/.
Для того чтобы скачать файлы кода, нужно выполнить следующие действия.
1. Перейдите по указанной ссылке на сайт github.com.
2. Нажмите кнопку Clone or Download.
3. Щелкните кнопкой мыши на ссылке Download ZIP.
4. Скачайте архив с файлами примеров.
После загрузки файла распакуйте папку, используя последнюю версию одного из следующих архиваторов:
• WinRAR/7-Zip для Windows;
• Zipeg/iZip/UnRarX для Mac;
• 7-Zip/PeaZip для Linux.
Цветные иллюстрации
Мы также предоставляем PDF-файл с цветными скриншотами и схемами, приведенными в книге. Вы можете скачать его по адресу https://www.packtpub.com/sites/default/files/downloads/9781788295864_ColorImages.pdf.
Условные обозначения
В издании вы увидите несколько стилей текста, с помощью которых выделяются разные виды информации. Вот несколько примеров этих стилей и объяснение их значения.
Код в тексте, имена функций, имена файлов, расширения файлов, пользовательский ввод и названия R-пакетов отображаются следующим образом: «Функция knn() в пакете class предоставляет стандартную классическую реализацию алгоритма k-NN».
Пользовательский ввод и вывод в среде R записывается следующим образом:
> table(mushrooms$type)
edible poisonous
4208 3916
Новые термины выделены курсивом, а важные слова — жирным шрифтом. Слова, которые вы видите на экране, например в меню или диалоговых окнах, выделены в тексте следующим образом: «Ссылка Task Views в левой части страницы CRAN указывает на список рекомендованных пакетов».

Важные примечания выглядят так.

Советы и подсказки описаны в таких врезках.
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
На веб-сайте издательства www.piter.com вы найдете подробную информацию о наших книгах.
1. Введение в машинное обучение
Если верить фантастике, то изобретение искусственного интеллекта неизбежно ведет к апокалиптическим войнам между машинами и их создателями. Эти истории начинаются с сегодняшней реальности: сначала мы обучаем компьютеры играть в простые игры, такие как крестики-нолики, и автоматизировать рутинные задачи. Затем, как пишут в этих книжках, машинам передают контроль над светофорами и коммуникациями, потом следуют военные беспилотники и ракеты. Эволюция машин принимает зловещий оборот, когда компьютеры становятся разумными и начинают обучать сами себя. Больше не нуждаясь в людях-программистах, они «удаляют» человечество.
К счастью, на момент написания этой книги машины все еще требовали ввода данных от пользователя.
Возможно, ваши впечатления от машинного обучения все еще до некоторой степени определяются картинками из средств массовой информации. Однако современные алгоритмы не являются универсальными и позволяют решать лишь конкретные задачи, чтобы представлять какую-либо опасность превратиться в самосознание. Цель современного машинного обучения — не создать искусственный мозг, а помочь нам разобраться в огромных запасах генерируемых человечеством данных.
К концу этой главы вы оставите в стороне популярные заблуждения и начнете лучше понимать суть машинного обучения. Вы также познакомитесь с основными понятиями, которые определяют и позволяют различать популярные подходы машинного обучения. Мы рассмотрим:
• происхождение, приложения и подводные камни машинного обучения;
• способы, которыми компьютеры превращают данные в знания и действия;
• этапы сопоставления алгоритмов машинного обучения с данными.
Технология машинного обучения предоставляет набор алгоритмов, преобразующих данные в руководство к действию. Продолжив читать книгу, вы увидите, как легко использовать R, чтобы начать применять машинное обучение для решения реальных задач.
Происхождение машинного обучения
Начиная с рождения, мы завалены данными. На датчики нашего тела — глаза, уши, нос, язык — постоянно воздействуют потоки необработанных данных, которые наш мозг преобразует в зрительные образы, звуки, запахи, вкусы. Используя речь, мы можем поделиться этим опытом с другими.
С появлением письменности человек начал записывать свои наблюдения. Охотники следили за движением стад животных; первые астрономы фиксировали расположение планет и звезд; в городах регистрировались налоговые поступления и т.д. Сегодня такие и многие другие наблюдения становятся все более автоматизированными и систематически регистрируются в постоянно растущих компьютеризированных базах данных.
Изобретение электронных датчиков способствовало новому взрывному росту объемов и разнообразия регистрируемых данных. Специальные датчики, такие как камеры, микрофоны, химические «носы», электронные «языки» и датчики давления, имитируют способность человека видеть, слышать, обонять, ощущать вкус и осязать. Эти датчики обрабатывают данные совсем не так, как это делает человек. В отличие от человека, отличающегося ограниченным и субъективным восприятием, электронный датчик никогда не делает перерывы и не выражает эмоций, способных исказить его «ощущения».

Датчики видят объективную информацию, однако далеко не всегда предоставляют однозначное изображение реальности. Одни датчики имеют погрешность измерения вследствие аппаратных ограничений. У других ограничена область применения. Черно-белая фотография дает одно описание предмета, цветной снимок — другое. Микроскоп и телескоп позволяют увеличить изображение, но используются для объектов, расположенных на разных расстояниях.
В базах данных фиксируются многие показатели нашей жизни. Правительства, предприятия и частные лица регистрируют и используют всевозможную информацию — от глобально важной до бытовой. Датчики погоды записывают данные о температуре и давлении; камеры наблюдения следят за тротуарами и тоннелями метро; отслеживаются всевозможные детали цифрового следа: транзакции, переписка, связи в социальных сетях и многие другие.
Этот поток данных породил заявления о том, что мы вступили в эру больших данных, но это не совсем так. Люди всегда были окружены большими объемами данных. Уникальность нынешней эпохи в том, что теперь у нас есть огромное количество зарегистрированных данных, значительная часть которых напрямую доступна с компьютеров. Все больше интересных данных становятся доступными почти моментально, стоит только поискать в Интернете. Это огромное количество информации может побудить к обоснованным действиям, если систематически извлекать из нее осмысленные данные.
Область исследования, занимающаяся созданием компьютерных алгоритмов для преобразования данных в обоснованные действия, называется машинным обучением. Эта область возникла в среде, где доступные данные, статистические методы и вычислительные мощности развивались быстро и одновременно. Рост объемов данных потребовал дополнительных вычислительных мощностей, что, в свою очередь, стимулировало разработку статистических методов анализа больших наборов данных. Это породило цикл развития (схематично представлен на рис. 1.1), позволивший собирать все больше интересных данных и сформировавший современную среду, в которой практически по любой теме доступны бесконечные потоки данных.
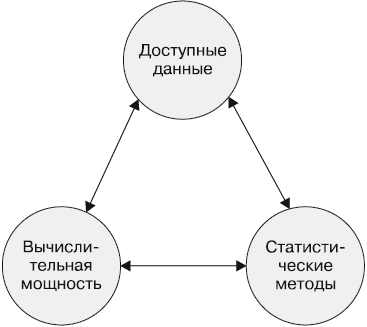
Рис. 1.1. Цикл развития, который сделал возможным машинное обучение
С машинным обучением тесно связан его родной брат — интеллектуальный анализ данных (data mining), который занимается генерированием новых идей из баз данных большого объема. Как следует из названия, интеллектуальный анализ данных включает в себя систематическую охоту на зачатки настоящего интеллекта. Несмотря на некоторые разногласия по поводу того, насколько сильно пересекаются машинное обучение и интеллектуальный анализ данных, потенциальное различие между ними заключается в том, что машинное обучение фокусируется на обучении компьютеров тому, как применять данные для решения задач, а интеллектуальный анализ данных направлен на обучение компьютеров выявлять закономерности, по которым люди обычно решают свои задачи.
Интеллектуальный анализ данных практически всегда подразумевает использование машинного обучения, но не любое машинное обучение требует интеллектуального анализа данных. Например, можно применить машинное обучение для сбора данных об автомобильном трафике для построения моделей, связанных с частотой аварий. С другой стороны, если компьютер учится водить автомобиль, то это чисто машинное обучение без интеллектуального анализа данных.
Выражение «интеллектуальный анализ данных» также иногда используется в уничижительном смысле для описания практики обманного сбора данных в поддержку некоей теории.
Область применения машинного обучения и злоупотребление им
Большинство людей слышали о Deep Blue — шахматном компьютере, который в 1997 году впервые выиграл у чемпиона мира. Другой известный компьютер, Watson, победил двух оппонентов в телевикторине Jeopardy (у нас известна как «Своя игра») в 2011 году. Основываясь на этих потрясающих достижениях, эксперты предположили, что компьютерный интеллект заменит людей в сфере информационных технологий точно так же, как сейчас машины заменили рабочих на полях и сборочных линиях.
Правда заключается в том, что, даже когда машины достигают таких впечатляющих результатов, их способности полностью понять проблему заметно ограниченны. Компьютер может лучше, чем человек, находить неявные закономерности в больших данных, но все равно требуется участие человека, чтобы проанализировать данные и превратить результат в осмысленное действие.
Мы не будем углубляться в обсуждение достижений Deep Blue и Watson, однако важно отметить, что ни один из этих компьютеров не умнее обычного пятилетнего ребенка. Подробнее о том, почему «меряться умами — дело скользкое», читайте в статье Уилла Грюнвальда (Will Grunewald) FYI: Which Computer Is Smarter, Watson Or Deep Blue?, опубликованной в журнале Popular Science в 2012 году (https://www.popsci.com/science/article/2012-12/fyi-which-computer-smarter-watson-or-deep-blue).
Машины не умеют задавать вопросы и даже не знают, какие вопросы следует задавать. Если вопрос сформулирован понятно для машины, то компьютер ответит на него гораздо лучше, чем человек. Современные алгоритмы машинного обучения сотрудничают с людьми так же, как гончие собаки — с охотниками: обоняние собаки во много раз сильнее, чем у ее хозяина, но без верного направления гончая может в итоге гоняться только за своим хвостом (рис. 1.2).
Рис. 1.2. Алгоритмы машинного обучения — мощные инструменты, которые требуют тщательного руководства
Чтобы лучше понять, где можно использовать машинное обучение, мы рассмотрим несколько примеров его успешного применения, случаи, где еще есть куда расти, и ряд ситуаций, в которых оно может принести больше вреда, чем пользы.
Успехи машинного обучения
Машинное обучение наиболее успешно там, где оно дополняет, а не заменяет специализированные знания эксперта в определенной области. Врачи применяют ML в борьбе с раком; оно помогает инженерам и программистам строить более умные дома и автомобили, а социологам — накапливать знания о том, как функционирует общество. С этой целью машинное обучение используется на многих предприятиях, в научных лабораториях, больницах и правительственных организациях. Везде, где производятся или накапливаются данные, скорее всего, используется хотя бы один алгоритм ML.
Невозможно перечислить все варианты использования машинного обучения, однако, рассмотрев недавние истории успеха, можно выделить несколько ярких примеров:
• выявление спама в электронной почте;
• разделение клиентов по поведению для создания таргетированной рекламы;
• прогнозы изменений погоды и долгосрочных изменений климата;
• борьба с мошенническими операциями по кредитным картам;
• страховые оценки финансового ущерба от штормов и стихийных бедствий;
• прогнозирование результатов всеобщих голосований;
• разработка алгоритмов автопилота для беспилотных летательных аппаратов и автомобилей;
• оптимизация расходования энергии в жилых и офисных зданиях;
• прогнозирование районов, где наиболее вероятна преступная деятельность;
• обнаружение цепочек генов, связанных с болезнями.
К концу книги вы познакомитесь с основными алгоритмами ML, которые используются для обучения компьютеров выполнению этих задач. Пока достаточно сказать, что, независимо от контекста, процесс машинного обучения одинаков. При любой задаче алгоритм берет данные и выявляет закономерности, которые позволяют принимать обоснованные решения.
Пределы возможностей машинного обучения
Несмотря на широкое применение и огромный потенциал машинного обучения, важно понимать его границы. В настоящее время машинное обучение имитирует относительно ограниченный набор возможностей человеческого мозга. Его гибкость для экстраполяции за пределами строгих параметров невелика, и ему не знаком здравый смысл. Имея это в виду, следует проявлять предельную осторожность и точно определять, чему научился алгоритм, прежде чем применять его в реальном мире.
Не имея жизненного опыта, компьютеры также ограничены в способности делать простые выводы о следующих логических шагах. Возьмем, к примеру, рекламные баннеры, встречающиеся на многих сайтах. Они отображаются в соответствии с закономерностями, определенными с помощью интеллектуального анализа истории миллионов пользователей. Основываясь на этих данных, алгоритм делает вывод, что тот, кто просматривает сайты, продающие обувь, заинтересован в ее покупке и поэтому должен увидеть рекламу обуви. Проблема заключается в том, что это превращается в бесконечный цикл, в котором даже после покупки обуви пользователю предлагается дополнительная реклама обуви, а не шнурков для ботинок и крема для ухода за обувью.
Многие сталкивались с неполноценностью машинного обучения в понимании или переводе языка, а также распознаванию речи и рукописного текста. Возможно, самый первый пример подобного рода неудач — эпизод из телесериала «Симпсоны» (1994), в котором демонстрировалась пародия на планшет Apple Newton (рис. 1.3). В свое время Newton был известен передовой на то время системой распознавания рукописного текста. К сожалению для Apple, иногда эта система оказывалась неэффективной. В эпизоде телесериала это было обыграно так: Newton расшифровал хулиганскую записку «Избить Мартина» как «Съесть Марту».
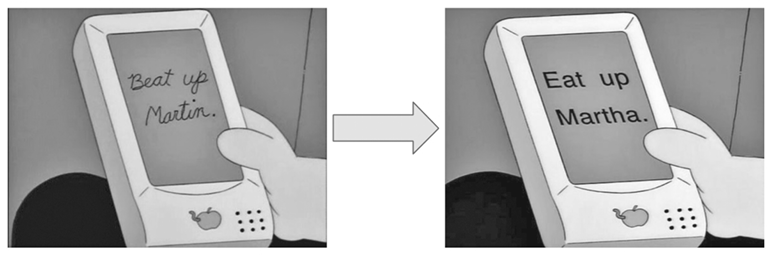
Рис. 1.3. Кадры из эпизода «Лиза на льду» из сериала «Симпсоны», 20th Century Fox (1994)
С тех пор машинная обработка естественного языка в Apple Newton значительно улучшилась, и теперь Google, Apple и Microsoft уверенно предлагают голосовые сервисы виртуального помощника, такие как Google Assistant, Siri и Cortana. Но и эти сервисы часто затрудняются ответить на относительно простые вопросы.
Кроме того, сервисы онлайн-перевода иногда неверно истолковывают предложения, которые даже ребенок легко понимает, а функция прогнозирования ввода текста на многих устройствах привела к появлению многочисленных юмористических сайтов с примерами «сбоя при автозамене», которые иллюстрируют, что компьютеры способны понимать базовый язык, но совершенно не понимают контекст.
Некоторые из этих ошибок, безусловно, ожидаемы. Язык сложен, имеет смысловую многослойность и подтекст, и даже люди иногда неправильно понимают контекст. Несмотря на то что машинное обучение быстро совершенствуется в области обработки естественного языка, постоянно проявляющиеся недостатки демонстрируют тот важный факт, что оно хорошо ровно настолько, насколько хороши обработанные им данные. Если контекст во входных данных явно не представлен, то компьютеру, как и человеку, приходится делать лучшую догадку на основе своего ограниченного прошлого опыта.
Этика машинного обучения
По своей сути машинное обучение — просто инструмент, который помогает нам разобраться в сложных мировых данных. Как и любой инструмент, его можно использовать во благо или во зло. Хуже всего, когда машинное обучение применяется настолько широко или так жестко, что к людям относятся как к лабораторным крысам, автоматам или бездушным потребителям. На первый взгляд безвредный процесс, автоматизированный при помощи безэмоционального компьютера, может привести к непредвиденным последствиям. Именно поэтому было бы упущением, обсуждая использование машинного обучения и интеллектуальный анализ данных, хотя бы кратко не рассмотреть возможные этические последствия.
Из-за относительной молодости ML как дисциплины и той скорости, с которой оно развивается, сопутствующие правовые вопросы и социальные нормы часто бывают весьма неопределенны и постоянно меняются. Получая или анализируя данные, следует соблюдать осторожность, чтобы не нарушить закон, соблюсти условия обслуживания и соглашения об использовании данных, не злоупотребить доверием, не нарушить конфиденциальность клиентов или общественности.
Неофициальный корпоративный девиз Google — организации, которая собирает, возможно, больше данных о людях, чем кто-либо другой в мире, некогда звучал так: «Не причини зла» (англ. don't be evil). Все кажется вполне понятным, однако этого может оказаться недостаточно. Лучшим подходом может стать следование клятве Гиппократа, медицинскому принципу, который гласит: «Прежде всего — не навреди».
Компании розничной торговли обычно используют ML для создания таргетированной рекламы, складского учета и размещения товаров на полках магазинов. Многие из них снабжают свои кассы устройствами, которые печатают купоны рекламных акций на основе истории покупок клиента. В обмен на небольшое количество личных данных клиент получает скидки на определенные продукты, которые он, вероятно, захочет купить. На первый взгляд это кажется относительно безвредным, однако посмотрим, что произойдет, если такая практика будет развиваться дальше.
Одна из историй, возможно выдуманных, касается крупной американской сети розничной торговли, в которой с помощью машинного обучения выявляли будущих мам, чтобы рассылать им купоны. Торговая сеть рассчитывала, что если будущим матерям предоставить значительные скидки, то они станут лояльными покупателями, которые впоследствии будут приобретать выгодные товары, такие как подгузники, детские смеси и игрушки.
Вооружившись методами машинного обучения, торговая сеть выделила в истории покупок товары, по которым можно с высокой степенью вероятности спрогнозировать не только то, является ли женщина беременной, но и приблизительные сроки родов.
После того как торговая сеть использовала эти данные для рекламных рассылок, некий человек связался с представителями сети и потребовал объяснить, почему его дочь получила купоны на товары для беременных. Он был в ярости от того, что продавец, похоже, поощрял беременность в подростковом возрасте! Как гласит история, когда из торговой сети позвонили, чтобы принести извинения, в итоге именно отец извинился после того, как поговорил с дочерью и узнал, что она действительно беременна!
Независимо от того, правда это или нет, урок, извлеченный из этой истории, заключается в том, что необходимо подключать здравый смысл, прежде чем слепо применять результаты анализа, полученного методами машинного обучения. Это особенно верно в тех случаях, когда речь идет о конфиденциальной информации, такой как данные о состоянии здоровья. Будь эта торговая сеть немного осторожнее, можно было предвидеть такой сценарий и быть осмотрительнее, выбирая способ применения данных, полученных по результатам анализа в процессе машинного обучения.
Подробнее о том, как розничные торговые сети используют машинное обучение для выявления беременностей, читайте в статье Чарльза Духигга (Charles Duhigg) How Companies Learn Your Secrets в журнале New York Times Magazine в 2012 году: https://www.nytimes.com/2012/02/19/magazine/shopping-habits.html.
Поскольку алгоритмы машинного обучения применяются все активнее, мы постоянно обнаруживаем, что компьютеры могут изучать некоторые неудачные варианты поведения человека. К сожалению, это может проявляться в расовой и гендерной дискриминации и в появлении негативных стереотипов. Например, исследователи обнаружили, что сервис онлайн-рекламы Google показывает объявления о высокооплачиваемой работе чаще мужчинам, чем женщинам, а объявления о проверке криминального прошлого — чаще темнокожим, чем белым людям.
Эти типы ошибок распространились не только в Кремниевой долине. Разработанный Microsoft чат-бот Twitter быстро отключили после того, как он начал пропагандировать нацизм и антифеминизм. Часто алгоритмы, которые на первый взгляд кажутся «нейтральными по содержанию», спустя время начинают отражать убеждения большинства или доминирующие идеологии. Алгоритм, созданный Beauty.AI для отражения объективности человеческой красоты, вызвал споры, когда в числе победителей оказались почти только белые люди. Представьте себе, какие последствия имел бы этот алгоритм, если бы он был применен для распознавания лиц, подозреваемых в преступной деятельности!

Подробнее о реальных последствиях машинного обучения и дискриминации читайте в статье Клер Чейн Миллер (Claire Cain Miller) When Algorithms Discriminate, вышедшей в журнале New York Times в 2015 году: https://www.nytimes.com/2015/07/10/upshot/when-algorithms-discriminate.html.
Для того чтобы избежать дискриминации при применении алгоритмов ML, в некоторых юридических областях введены законы, запрещающие использование расовых, этнических, религиозных или других личных данных в коммерческих целях. Однако простого исключения таких данных из проекта может быть недостаточно, поскольку алгоритмы машинного обучения все равно могут непреднамеренно их различать. Если какая-то группа людей стремится жить в конкретном регионе, покупает определенные продукты или ведет себя таким образом, что можно однозначно идентифицировать их как группу, алгоритмы машинного обучения могут сделать вывод о личной информации на основании других факторов. В таких случаях может потребоваться полностью деидентифицировать этих людей, исключив любые потенциально идентифицирующие их данные в дополнение к уже закрытым статусам.
Помимо юридических последствий, ненадлежащее использование данных может помешать в достижении цели. Клиенты могут почувствовать себя некомфортно или испугаться, если какие-то стороны их жизни, которые они считают личными, станут достоянием общественности. В последние годы несколько известных веб-приложений пережили массовый отток пользователей, которым показалось, что их эксплуатируют. Это произошло после того, как в приложениях изменились условия соглашений об обслуживании или выяснилось, что данные применялись в целях, на которые пользователи первоначально не рассчитывали. Поскольку состав конфиденциальной информации зависит от контекста, возрастной категории и места жительства, сложно установить границы надлежащего использования личных данных. Прежде чем начать проект, целесообразно рассмотреть возможные последствия, характерные для той или иной культуры, а также изучить актуальные законы, например недавно внедренные в Европейском союзе Общие правила защиты данных (General Data Protection Regulation, GDPR) и неизбежные изменения в политике конфиденциальности, которые за ними последуют.
Тот факт, что данные можно использовать с определенной целью, еще не означает, что это следует делать.
Наконец, важно отметить, что, по мере того как алгоритмы машинного обучения становятся все более важными в нашей повседневной жизни, у недобросовестных людей появляется соблазн воспользоваться ими в корыстных целях. Иногда злоумышленники хотят лишь сломать алгоритмы ради забавы или дурной славы, организовав что-то вроде «бомбардировки Google» — обмана системы ранжирования страниц Google методом толоки (англ. crowdsourced method). В других случаях результат может быть более драматичным. Актуальный пример — недавняя волна так называемых ложных новостей и вмешательство в выборы путем манипулирования алгоритмами, которые показывали рекламу и давали рекомендации в соответствии с личностными характеристиками пользователя. Чтобы избежать предоставления таких возможностей посторонним лицам, при создании систем машинного обучения важно учитывать, как на эти алгоритмы может повлиять определенный человек или группа людей1.
Исследователь соцсетей danah boyd (именно так, строчными буквами) выступила с речью на конференции Strata Data Conference 2017 в Нью-Йорке, где обсуждалась важность усиления защиты алгоритмов машинного обучения от злоумышленников. Краткий вариант ее выступления вы найдете по адресу https://points.datasociety.net/your-data-is-being-manipulated-a7e31a83577b.
Последствия атак злоумышленников на алгоритмы машинного обучения могут быть и смертельными. Исследователи показали, что, создавая «враждебную атаку», которая незаметно искажает дорожный знак с помощью тщательно подобранных граффити, злоумышленник может заставить беспилотный автомобиль неверно истолковать знак остановки, что, возможно, приведет к аварии со смертельным исходом. Несмотря на отсутствие злого умысла, ошибки, как в программном обеспечении, так и человеческие, уже привели к ряду несчастных случаев со смертельным исходом при внедрении технологии беспилотного управления транспортными средствами Uber и Tesla. С учетом этих примеров крайне важно, в том числе с этической точки зрения, чтобы специалисты по машинному обучению учитывали, как их алгоритмы могут быть использованы в реальном мире.
Как учатся машины
Формальное определение машинного обучения, приписываемое ученому, специалисту по информатике Тому М. Митчеллу (Tom M. Mitchell), гласит, что машина учится всякий раз, когда может использовать свой опыт, так что каждый следующий раз, когда ей приходится решать ту же задачу, она делает это эффективнее. Это определение интуитивно понятно, однако в нем полностью игнорируется процесс того, как именно опыт может быть преобразован в действия. И конечно, всегда легче сказать, чем действительно сделать!
Человеческий мозг способен учиться с рождения, а вот компьютеру следует четко указать условия. Несмотря на то что вовсе не обязательно знать теоретические основы обучения, все же это поможет нам понимать, различать и использовать на практике алгоритмы машинного обучения.
Сравнивая машинное обучение с обучением человека, вы, возможно, взглянете на собственный разум в ином свете.
Независимо от того, является ли обучаемый человеком или машиной, процесс обучения одинаков. Его можно разделить на четыре взаимосвязанные составляющие:
• хранение данных использует наблюдение, память и вспоминание, чтобы обеспечить основу в виде фактов для дальнейших рассуждений;
• абстрагирование подразумевает преобразование хранимых данных в более широкие представления и концепции;
• обобщение использует абстрактные данные для создания знаний и умозаключений, которые будут определять действия в новых контекстах;
• оценка обеспечивает механизм обратной связи для измерения полезности полученных знаний и информирования о потенциальных улучшениях.
На рис. 1.4 процесс обучения представлен в виде четырех отдельных составляющих, однако они организованы таким образом лишь в иллюстративных целях. На самом деле весь учебный процесс неразрывно связан. У людей обучение происходит на подсознательном уровне. Мы вспоминаем, обобщаем, делаем выводы и интуитивные прогнозы в пределах границ нашего разума, и поскольку этот процесс скрыт, то любые различия между людьми относятся к неопределенному понятию субъективности. Компьютеры, наоборот, выполняют эти процессы явно2, и, поскольку весь процесс прозрачен, полученные знания можно исследовать, передавать, использовать в последующих действиях и рассматривать как науку о данных.

Рис. 1.4. Процесс обучения
Модное выражение «наука о данных» предполагает связь между данными, машиной и людьми, которые руководят процессом обучения. Все более широкое употребление этого термина в описаниях вакансий и различных академических трудах отражает его практическое применение как области исследований, связанной с теорией статистики и вычислений, а также с технологической инфраструктурой, обеспечивающей машинное обучение и сферы его применения. От специалистов в этой области требуется быть убедительными рассказчиками, сочетающими смелость в использовании данных с ограничениями того, на что могут повлиять эти данные и что можно прогнозировать с их помощью. Чтобы стать профессионалом в обработке данных, необходимо хорошо понимать, как работают алгоритмы обучения.
Хранение данных
Все обучение начинается с данных. Люди и компьютеры используют хранение данных как основу для более сложных рассуждений. Мозг человека принимает электрохимические сигналы, передаваемые в сети биологических клеток для хранения и обработки наблюдений в кратковременной и долговременной памяти. У компьютеров есть аналогичные возможности кратковременного и долговременного воспроизведения данных благодаря использованию жестких дисков, флеш-памяти и оперативной памяти (Random-Access Memory, RAM) в сочетании с центральным процессором (Central Processing Unit, CPU).
Тем не менее одной способности хранить и извлекать данные для обучения недостаточно. Сохраненные данные — это лишь единицы и нули на диске. Это набор воспоминаний, которые без более широкого контекста являются бессмысленными. Без высокого уровня понимания знание — это всего лишь воспоминание, ограниченное тем, что было увидено ранее, и ничто иное.
Чтобы лучше понять суть этой идеи, вспомните, как вы в последний раз готовились к сложному тесту, например, перед выпускным экзаменом в университете, или к аттестации. Вы бы хотели иметь эйдетическую (фотографическую) память? Если это так, то вы, возможно, будете разочарованы, узнав, что идеальное воспроизведение вам вряд ли помогло бы. Даже если бы вы могли отлично запоминать материал, это бесполезно, если не знать точных вопросов и ответов, которые будут на экзамене. В противном случае пришлось бы запомнить ответы на каждый вопрос, который можно было бы задать по предмету, а вопросов — бесконечное количество. Очевидно, что это ненадежная стратегия.
Лучше потратить время на то, чтобы выборочно запомнить относительно небольшой набор репрезентативных идей, развивая при этом понимание того, как эти идеи взаимосвязаны и могут быть применены в случае непредвиденных обстоятельств. Таким образом определяются более широкие закономерности, и не требуется запоминать все детали, нюансы и потенциальные способы применения.
Абстрагирование
В процессе абстрагирования выполняется работа по выявлению более широкого значения хранимых данных, когда необработанные данные представляют более широкую, абстрактную концепцию или идею. Этот тип взаимосвязи, скажем, между объектом и его представлением, иллюстрируется знаменитой картиной Рене Магритта «Вероломство образов», представленной на рис. 1.5. На рисунке изображена курительная трубка с подписью Ceci n’est pas une pipe («Это не трубка»). Магритт продемонстрировал, что представление о трубке — это не сама трубка. Однако, несмотря на то что трубка ненастоящая, любой, кто смотрит на картину, видит именно трубку. Это говорит о том, что человек способен сопоставить изображение трубки с идеей трубки и с образом в памяти о настоящей трубке, которую можно держать в руке. Подобные абстрактные связи являются основой представления знаний, формирования логических структур, которые помогают превратить необработанную сенсорную информацию в осмысленное понимание.
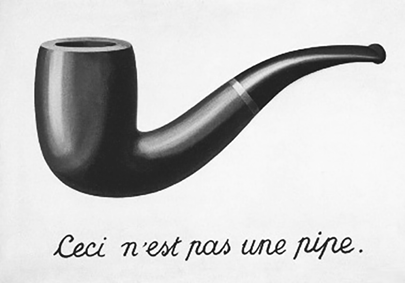
Рис. 1.5. «Это не трубка». Источник: http://collections.lacma.org/node/239578
В процессе машинного представления знаний компьютер суммирует сохраненные необработанные данные, используя модель — явное описание закономерностей, связанных с данными. Подобно трубке Магритта, представление модели продолжает жить за пределами необработанных данных. Оно представляет идею большую, чем сумма ее частей.
Существует много разных типов моделей. Возможно, вы уже знакомы с некоторыми из них, например:
• математические уравнения;
• деревья и графы;
• логическое правило «если-то-иначе»;
• группы данных, известные как кластеры.
Выбор модели, как правило, не оставлен на усмотрение машины. Выбор определяют задача и тип имеющихся данных. О методах выбора подходящего типа модели речь пойдет далее в этой главе.
Процесс подгонки модели к набору данных называется обучением. После того как модель обучена, данные преобразуются в абстрактную форму, которая делает выводы из исходной информации.
Возможно, вы спросите, почему этот шаг называется обучением, а не учебой. Во-первых, обратите внимание, что процесс учебы не заканчивается абстрагированием данных — учащийся еще должен обобщить и оценить то, что было получено в процессе обучения. Во-вторых, слово «обучение» лучше отражает тот факт, что учитель-человек обучает ученика-машину понимать данные определенным образом.
Важно отметить, что обученная модель сама по себе не предоставляет новых данных, но в то же время ведет к получению новых знаний. Как это может быть? Ответ заключается в том, что наложение структуры на известные данные дает представление о том, чего мы еще не знаем. Это предполагает новое правило, по которому могут быть связаны элементы данных.
Рассмотрим, к примеру, открытие гравитации. Подбирая уравнения к данным наблюдений, Исаак Ньютон вывел концепцию гравитации, но сила, которую мы теперь называем гравитационной, существовала всегда. Ее просто не замечали, пока Ньютон не описал гравитацию как абстрактную концепцию, связывающую одни данные с другими, — а именно, введя константу g в модель, которая объясняет наблюдения за падающими объектами (рис. 1.6).

Рис. 1.6. Модели — это абстракции, которые объясняют наблюдаемые данные
Большинство моделей не приводит к развитию теорий, которые бы пошатнули научную мысль, сложившуюся на протяжении веков. Тем не менее в процессе абстрагирования можно выявить важные, но ранее не замечаемые закономерности и связи между данными. Модель, обученная на данных о геноме, может найти несколько генов, сочетание которых ответственно за возникновение диабета; банки могут обнаружить, казалось бы, безобидный тип транзакций, которые систематически появляются перед началом мошеннической деятельности; психологи могут определить комбинацию личностных характеристик, указывающих на какое-то расстройство. Эти закономерности были всегда, но, поскольку они представляют информацию в другом формате, из них можно сформулировать новую идею.
Обобщение
Следующим шагом в процессе обучения является использование абстрактных знаний для планирования действий. Однако среди бесчисленных базовых паттернов, которые могут быть идентифицированы в процессе абстрагирования, и бесконечных способов моделирования этих паттернов одни из них будут более полезными, чем другие. Если не ограничить создание абстракций неким полезным множеством, то обучаемый застрянет на том же месте, откуда начал, имея большой объем информации, но не зная, как дать ей практическую оценку.
Формально понятие «обобщение» означает процесс превращения абстрагированных знаний в форму, которую можно использовать для решения задач, подобных, но не идентичных тем, с которыми обучаемый уже сталкивался. Обобщение действует как поиск по всему набору моделей (теорий или выводов), которые могут быть созданы на основе данных в процессе обучения.
Если бы мы могли представить себе множество, содержащее все возможные способы абстрагирования данных, то обобщение означало бы сокращение этого множества до меньшего, более управляемого множества важных выводов.
При обобщении перед обучаемым стоит задача ограничить обнаруживаемые им паттерны только теми, которые будут наиболее релевантными для решения последующих задач. Как правило, невозможно уменьшить количество паттернов, рассматривая их один за другим и ранжируя по степени полезности в будущем. Алгоритмы ML обычно используют ускоренные методы, которые быстрее сокращают пространство поиска. Для этого в алгоритмах применяются эвристики, которые представляют собой обоснованные предположения о том, где могут находиться наиболее полезные выводы.
В эвристиках используются аппроксимация и другие эмпирические правила. Это означает, что эвристики не гарантируют, что будет найдена наилучшая модель данных. Однако без таких ускоренных методов найти полезную информацию в большом наборе данных было бы невозможно.
Люди часто используют эвристики для быстрого обобщения опыта, чтобы задействовать его в новых обстоятельствах. Если вы когда-либо при необходимости быстро принять решение прислушивались к своему внутреннему голосу, прежде чем полностью оценить ситуацию, то вы интуитивно использовали ментальные эвристики.
Невероятная способность человека быстро принимать решения часто зависит не от логики, подобной компьютерной, а от эвристик, управляемых эмоциями. Иногда это может привести к нелогичным выводам. Например, людей, которые боятся летать самолетами, больше, чем тех, кто боится ездить на автомобилях, несмотря на то что, по статистике, автомобили более опасны. Это можно объяснить эвристикой доступности — тенденцией людей оценивать вероятность события по тому, насколько легко они могут вспомнить примеры. Аварии, связанные с авиаперелетами, широко освещаются. Поскольку это травмирующие события, о них, вероятно, будут помнить очень долго, тогда как автомобильные аварии едва заслуживают упоминания в новостях.
Безрассудство неверного применения эвристик характерно не только для людей. Эвристики, используемае алгоритмами машинного обучения, также иногда приводят к ошибочным выводам. Говорят, что алгоритм характеризуется смещением (bias, можно перевести и как «предвзятость»), если его выводы систематически оказываются ошибочными. Это предполагает, что выводы являются ошибочными последовательно или предсказуемо.
Предположим, что алгоритм машинного обучения научился распознавать лица, выделяя два темных круга, обозначающих глаза, которые расположены над прямой линией — ртом. В этом случае алгоритму сложно будет распознать лицо или же он может систематически ошибаться в отношении лиц, которые не соответствуют его модели. Алгоритм может не распознавать лица в очках, а также лица, повернутые под углом, смотрящие вбок или лица с определенными оттенками кожи, формой или особенностями, которые не соответствуют его восприятию. Схематично этот процесс изображен на рис. 1.7.
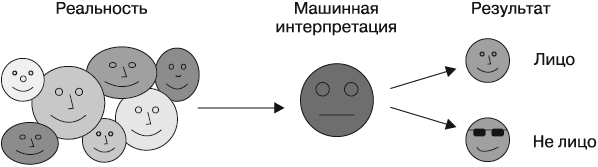
Рис. 1.7. В процессе обобщения опыта появляется смещение (систематическая ошибка)
В современном понимании «предвзятость» имеет весьма негативные коннотации. СМИ постоянно заявляют, что они свободны от предвзятости, и утверждают, что подают факты объективно, без эмоций. Тем не менее представьте себе, что незначительная предвзятость может быть полезной. Без некой доли своеволия бывает трудно выбрать один из нескольких конкурирующих вариантов, у каждого из которых есть свои плюсы и минусы, не так ли? Действительно, исследования в области психологии показали, что люди, рожденные с повреждениями участков головного мозга, ответственных за эмоции, могут испытывать сложности при принятии решений. Они способны часами обсуждать простые решения — например, какого цвета рубашку надеть или куда пойти на обед. Как это ни парадоксально, именно предвзятость ограждает нас от части лишней информации, а также позволяет использовать другую информацию для действий. Именно так алгоритмы машинного обучения выбирают способ понимания данных из бесчисленного множества, предлагаемого им для изучения.
Оценка
Предвзятость — неизбежное зло, связанное с процессами абстракции и обобщения, характерными для любого обучения. Для того чтобы выбрать действие в условиях безграничных возможностей, необходима предвзятость на протяжении всего обучения. Следовательно, у каждой стратегии обучения есть свои недостатки; не существует единого алгоритма обучения. Таким образом, последний этап учебного процесса — оценка его успешности и определение степени успеваемости ученика, несмотря на предвзятость. Информацию, полученную на этапе оценки, затем можно использовать для принятия решения о необходимости дополнительного обучения.
После того как вы успешно освоите какую-нибудь из техник машинного обучения, у вас может возникнуть желание применять ее ко всем задачам. Главное — не поддаться этому искушению, поскольку ни один подход ML не является универсальным для всех возможных ситуаций. Это обстоятельство описывается «теоремой об отсутствии бесплатных завтраков» (No Free Lunch), сформулированной Дэвидом Вольпертом (David Wolpert) в 1996 году. Подробнее об этом читайте на сайте http://www.no-free-lunch.org.
Как правило, оценка выполняется после окончания обучения модели на начальном тренировочном наборе данных (training dataset). Затем модель оценивается по отдельному тестовому набору данных (test dataset), чтобы определить, насколько хорошо характеристика тренировочных данных позволяет делать обобщения для новых данных, не входящих в тренировочный набор (unseen cases). Следует отметить, что модель крайне редко позволяет делать обобщения для данных, не входящих в тренировочный набор, — ошибки почти всегда неизбежны.
В частности, модели не позволяют делать идеальные обобщения из-за шума (noise) — термин описывает необъясненные или необъяснимые изменения данных. Зашумление данных может быть вызвано внешне случайными событиями, такими как:
• ошибка измерения из-за неточности датчиков, которые иногда прибавляют к показаниям небольшие значения (или вычитают их);
• проблемы, связанные с поведением человека, например, когда респонденты дают случайные ответы на вопросы, чтобы быстрее закончить опрос;
• проблемы качества данных, в том числе отсутствующие, неполные, неправильно закодированные или искаженные значения;
• процессы настолько сложные или малопонятные, что влияют на данные способами, которые кажутся случайными.
Попытка смоделировать шум лежит в основе проблемы, называемой переобучением, или перетренировкой (overfitting). Поскольку большинство зашумленных данных необъяснимы по определению, попытки объяснить шум приводят к появлению моделей, которые не будут хорошо обобщаться для новых случаев, а также более сложных моделей, не соответствующих реальному паттерну, который обучаемый пытается выявить (рис. 1.8).
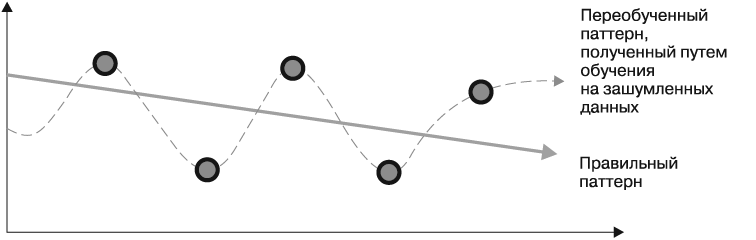
Рис. 1.8. Моделирование шума обычно приводит к появлению более сложных моделей, в которых упускаются основные паттерны
Считается, что модель, которая сравнительно хорошо работает на этапе обучения, но сравнительно плохо — на этапе оценки, является переобученной для тренировочного набора данных, потому что плохо поддается обобщению для тестового набора данных. С практической точки зрения это означает, что модель выявила закономерность в данных, бесполезную для предстоящих действий; процесс обобщения не удался. Для каждого конкретного подхода машинного обучения применяются свои решения проблемы перетренированности. Пока нам нужно лишь знать об этой проблеме. Важным показателем качества методов обучения является то, насколько хорошо они способны обрабатывать зашумленные данные и избегать перетренированности.
Машинное обучение на практике
До сих пор речь шла о том, как машинное обучение работает в теории. Чтобы применить процесс обучения к реальным задачам, мы будем использовать пятиэтапный процесс. Независимо от задачи, любой алгоритм ML можно разбить на следующие этапы.
1. Сбор данных. Этап включает в себя сбор материалов для обучения, которые алгоритм будет использовать для получения практических знаний. В большинстве случаев данные необходимо собрать в единый источник, такой как текстовый файл, электронная таблица или база данных.
2. Исследование и подготовка данных. Качество любого проекта по машинному обучению во многом определяется качеством входных данных. Таким образом, на этом этапе важно как можно больше узнать о данных и их особенностях. Необходимо выполнить дополнительную работу по подготовке данных к процессу обучения. Сюда входит исправление или очистка так называемых грязных данных, удаление ненужных данных и их перекодирование в соответствии с тем, какие входные данные ожидает получить обучаемый.
3. Обучение модели. К тому времени, как данные будут готовы для анализа, у вас, вероятно, уже будет представление о том, что можно извлечь из них. Выбор алгоритма определяется конкретной задачей машинного обучения, а сам алгоритм предоставляет данные в форме модели.
4. Оценка модели. Каждая модель машинного обучения приводит к предвзятому решению задачи обучения. Это означает, что важно оценить, насколько хорошо алгоритм извлек уроки из своего опыта. В зависимости от типа используемой модели можно оценить ее точность с помощью тестового набора данных или же может потребоваться подобрать показатели производительности, специфичные для предполагаемой области применения.
5. Улучшение модели. Если нужна более высокая производительность, необходимо использовать улучшенные стратегии. Иногда может потребоваться вообще перейти на другой тип модели. Возможно, вам придется дополнить данные или выполнить подготовительную работу, как на втором этапе этого процесса.
После того как эти шаги выполнены, модель, если она, как вам кажется, работает хорошо, можно применить для решения поставленной задачи. В зависимости от обстоятельств можно использовать ее для предоставления расчетных данных прогнозов (возможно, в режиме реального времени); прогнозирования финансовых данных; проведения аналитического обзора для маркетинга; автоматизации некоторых задач. Успехи и неудачи используемой модели могут также предоставить дополнительные данные для последующего обучения.
Типы входных данных
Практика машинного обучения включает в себя сопоставление характеристик входных данных с предвзятостью имеющихся обучающих алгоритмов. Таким образом, прежде, чем применить ML для решения реальных задач, важно понимать терминологию, которая различает разные входные наборы данных.
Выражение «единица наблюдения» используется для описания наименьшего объекта с измеренными свойствами, представляющего интерес для исследований. Обычно единицей наблюдения выступают люди, объекты, транзакции, моменты времени, географические регионы или измерения. Иногда единицы наблюдения объединяются в сложные единицы, например человеко-года (когда наблюдение ведется за одним и тем же человеком в течение нескольких лет; каждый человеко-год включает в себя данные о человеке за один год).
Единица наблюдения связана с единицей анализа, но не идентична ей. Единица анализа — наименьшая единица, на основании которой делается вывод. Единицы наблюдения и анализа часто совпадают, но не всегда. Например, данные, полученные от людей (единица наблюдения), можно использовать для анализа тенденций в разных странах (единица анализа).
Наборы данных, в которых хранятся единицы наблюдения и их свойства, можно объединить в коллекции:
• примеров — экземпляров единиц наблюдения, для которых были зарегистрированы свойства;
• признаков — зарегистрированных свойств или атрибутов примеров, которые могут пригодиться для обучения.
Понять, что такое признаки и примеры, проще всего на реальных сценариях. Так, для создания обучающего алгоритма, распознающего спам, единицами наблюдения могут выступать сообщения электронной почты, примерами — конкретные сообщения, а признаками могут выступать слова, используемые в сообщениях.
Для алгоритма диагностики рака единицей наблюдения могут быть пациенты, примеры могут включать в себя случайную выборку онкологических пациентов, а признаками могут быть геномные маркеры из клеток, полученных после биопсии, а также характеристики пациента, такие как вес, рост или артериальное давление.
Люди и машины различаются по типам сложности входных данных, которые они способны обработать. Людям удобно принимать неструктурированные данные, такие как произвольный текст, изображения или звук. Люди также гибко относятся к таким случаям обработки, в которых у одних наблюдений множество признаков, а у других — совсем мало. Компьютеры, напротив, обычно требуют структурированных данных: каждый пример явления имеет одинаковые признаки, которые представлены в форме, понятной компьютеру. Для использования машинного прямого перебора для больших неструктурированных наборов данных обычно требуется преобразовать входные данные в структурированную форму.
На рис. 1.9 данные представлены в матричном формате, где каждая строка таблицы является примером, а каждый столбец — признаком. В данном случае строки — это примеры продаваемых автомобилей, а в столбцах отражены характеристики каждого автомобиля, такие как цена, пробег, цвет и тип трансмиссии. Данные в матричном формате сегодня являются наиболее распространенной формой представления, используемой в машинном обучении. Как будет видно в следующих главах, где рассматриваются форматы данных в специализированных приложениях, перед началом машинного обучения эти форматы в итоге преобразуются в матрицу.
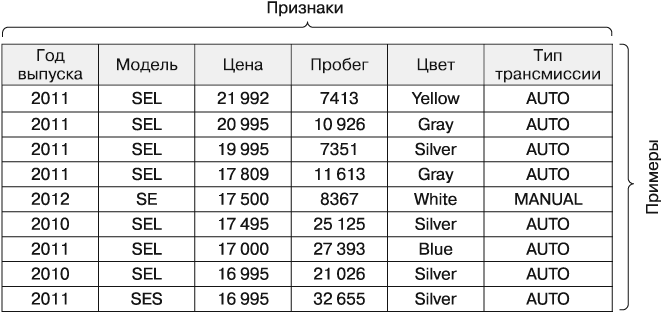
Рис. 1.9. Простой набор данных, представленных в матричном формате: описание автомобилей, выставленных на продажу
Признаки набора данных могут быть представлены в различной форме. Если признак обозначает характеристику, измеряемую в числах, логично, что он именуется числовым. И напротив, если признак — набор категорий, то он называется категориальным или номинальным. Особая разновидность категориальной переменной называется порядковой, что означает номинальную переменную, категории которой образуют упорядоченный список. В качестве примеров порядковых переменных можно привести размеры одежды: маленький, средний и большой; определение степени удовлетворенности клиентов по шкале от «совершенно недоволен» до «не очень доволен» и «очень доволен». Какова бы ни была задача обучения, рассуждения о том, что представляют собой признаки ее набора данных, их типы и единицы измерения, помогут выбрать подходящий алгоритм машинного обучения.
Типы алгоритмов машинного обучения
Алгоритмы машинного обучения делятся на категории в соответствии с их назначением. Понимание категорий алгоритмов обучения является первым шагом к использованию данных для совершения желаемых действий. Модель прогнозирования применяется для задач, которые включают в себя, как следует из названия, прогноз одного значения с использованием других значений из набора данных. Обучающий алгоритм пытается обнаружить и смоделировать взаимосвязь между целевым признаком (прогнозируемым) и другими признаками.
В отличие от обычного трактования слова «прогноз» как предсказания модели прогнозирования не обязательно должны предвидеть предстоящие события. Например, модель прогнозирования можно использовать для предсказания прошлых событий, таких как дата зачатия ребенка на основании текущих уровней гормонов у матери. Модели прогнозирования также применяют для управления светофорами в час пик в режиме реального времени.
Поскольку модели прогнозирования получают четкие инструкции о том, что и как именно им нужно изучить, процесс обучения прогнозирующей модели называется обучением с учителем. Под учителем здесь подразумевается не участие человека, а скорее тот факт, что целевые значения дают обучаемому возможность определить, насколько хорошо он усвоил задачу. С более формальной точки зрения алгоритм обучения с учителем пытается оптимизировать функцию (модель), чтобы найти сочетание значений признаков, которые приводят к целевому результату для конкретного набора данных.
Часто встречается задача машинного обучения с учителем, состоящая в прогнозировании того, к какой категории относится пример. Такая задача называется классификацией. Представить себе потенциальное использование классификатора легко. Например, можно спрогнозировать следующие события:
• сообщение, полученное по электронной почте, является спамом;
• у этого пациента рак;
• футбольная команда выиграет;
• заявитель не выполнит своих обязательств по кредиту.
В задаче классификации целевой признак, который должен быть спрогнозирован, является категориальным признаком и называется классом. Класс делится на категории — уровни. Класс может иметь два уровня и более, а уровни могут быть упорядоченными или неупорядоченными. Классификация используется в машинном обучении так широко, что существует множество типов алгоритмов классификации. У каждого из них есть плюсы и минусы, каждый из них подходит для определенных типов входных данных. Примеры алгоритмов мы увидим и в этой главе, и в книге далее.
Алгоритмы, обучаемые с учителем, могут также использоваться для прогнозирования числовых данных, таких как доход, лабораторные показатели, результаты тестов или количество предметов. Для прогнозирования таких числовых значений предназначен популярный тип алгоритмов числового прогнозирования, соответствующих моделям линейной регрессии для входных данных. Хотя регрессия не единственный метод числового прогнозирования, она, безусловно, наиболее популярна. Методы регрессии широко используются для прогнозирования, поскольку они точно, количественно определяют взаимосвязь между исходными данными и целевым значением, включая как величину, так и степень неопределенности этой взаимосвязи.
Поскольку числа легко преобразовать в категории (например, возраст от 13 до 19 лет — подростки), а категории — в числа (например, 1 — мужчины, 0 — женщины), то граница между классификационными моделями и моделями числового прогнозирования не всегда является жесткой.
Описательная модель используется для задач, где можно извлечь выгоду из результатов обобщения данных, выполненного новыми, более интересными способами. В отличие от прогнозирующих моделей, которые предсказывают интересующий объект, в описательной модели все признаки одинаково важны. В сущности, поскольку цель обучения отсутствует, процесс обучения описательной модели называется обучением без учителя. Возможно, представить применение описательных моделей сложнее — в конце концов, что хорошего в том, что обучаемый ничего не изучает, — однако эти модели регулярно используются для интеллектуального анализа данных.
Например, задача описательного моделирования, называемая обнаружением закономерности, используется для выделения среди данных полезных ассоциаций. Обнаружение закономерностей — цель анализа потребительской корзины, который применяется к данным о транзакциях, касающимся розничных продаж. В этом случае розничные продавцы стремятся выделить сопутствующие товары, так что полученная информация может быть использована для совершенствования тактики маркетинга. Например, если продавец заметит, что плавки обычно покупают вместе с солнцезащитным кремом, то он может разместить эти предметы в магазине рядом или устроить акцию, чтобы продать их покупателям вместе.
Первоначально использовавшееся только в контексте розничной торговли, «обнаружение закономерностей» теперь стали задействовать весьма инновационным образом. Например, его можно применять для выявления моделей мошеннического поведения, генетических дефектов или «горячих точек» преступной деятельности.
Задача описательного моделирования по разделению набора данных на однородные группы называется кластеризацией. Она иногда применяется для сегментного анализа рынка, который позволяет идентифицировать группы людей с похожим поведением или по демографическим признакам, чтобы, основываясь на общих характеристиках, нацелить на них рекламные кампании. При таком подходе машина идентифицирует кластеры, но для их интерпретации требуется вмешательство человека. Например, если клиенты продуктового магазина разделились на пять кластеров, то отдел маркетинга должен будет понять различия между этими группами, чтобы составить рекламную кампанию, которая лучше всего будет подходить для каждой из групп. Несмотря на необходимые усилия человека, это все равно требует меньше трудозатрат, чем создание уникальной привлекательности магазина для каждого клиента.
Наконец, класс алгоритмов машинного обучения, называемых метаобучением, не привязан к конкретной задаче обучения, а скорее сосредоточен на обучении тому, как учиться более эффективно. Алгоритм метаобучения использует результаты прошлого обучения для дополнительного обучения.
В эту группу входят алгоритмы обучения, которые учатся работать совместно, в группах, именуемых ансамблями, а также алгоритмы, которые, похоже, со временем, превращаются в процесс, называемый обучением с подкреплением. Метаобучение может быть полезным для очень сложных задач или в тех случаях, когда результат алгоритма прогнозирования должен быть максимально точным.
Одно из самых захватывающих исследований, выполняемых сегодня в области машинного обучения, относится к области метаобучения. Например, состязательное обучение включает в себя изучение слабых сторон модели для повышения ее продуктивности или защиты от вредоносных атак. Значительные инвестиции также вкладываются в исследования и разработки, направленные на создание более крупных и быстрых ансамблей, способных моделировать огромные наборы данных с использованием высокопроизводительных компьютеров или облачных сред.
Подбор алгоритмов по входным данным
В табл. 1.1 перечислены основные типы алгоритмов машинного обучения, описанные в данной книге. Это лишь часть всего множества алгоритмов машинного обучения, однако изучения перечисленных методов будет достаточно для понимания любых других методов, с которыми вы можете столкнуться.
Таблица 1.1. Основные типы алгоритмов машинного обучения
| Модель |
Задача обучения |
Где прочитать |
| Алгоритмы обучения с учителем |
||
| Метод k-ближайших соседей |
Классификация |
Глава 3 |
| Наивный байесовский классификатор |
Классификация |
Глава 4 |
| Деревья решений |
Классификация |
Глава 5 |
| Правила классификации |
Классификация |
Глава 5 |
| Линейная регрессия |
Числовое прогнозирование |
Глава 6 |
| Регрессионные деревья |
Числовое прогнозирование |
Глава 6 |
| Деревья моделей |
Числовое прогнозирование |
Глава 6 |
| Нейронные сети |
Двойное назначение |
Глава 7 |
| Метод опорных векторов |
Двойное назначение |
Глава 7 |
| Алгоритмы обучения без учителя |
||
| Ассоциативные правила |
Обнаружение закономерностей |
Глава 8 |
| Кластеризация методом k-средних |
Кластеризация |
Глава 9 |
| Алгоритмы метаобучения |
||
| Бэггинг |
Двойное назначение |
Глава 11 |
| Бустинг |
Двойное назначение |
Глава 11 |
| Случайный лес |
Двойное назначение |
Глава 11 |
Для того чтобы использовать машинное обучение в реальном проекте, вам необходимо определить, какая из четырех задач обучения лежит в основе вашего проекта: классификация, числовое прогнозирование, обнаружение закономерностей или кластеризация. От этой задачи и будет зависеть выбор алгоритма. Например, если требуется обнаружение закономерностей, то вы, скорее всего, примените ассоциативные правила. Если же задача требует кластеризации, то, вероятно, будет использоваться алгоритм k-средних, а для числового прогнозирования — регрессионный анализ или регрессионные деревья.
Для классификации нужно потратить дополнительное время на исследование, чтобы выбрать соответствующий классификатор для данной задачи обучения. В таких случаях полезно рассмотреть различия между алгоритмами, которые станут очевидными только при углубленном изучении каждого классификатора. Например, в рамках задач классификации деревья решений позволяют построить понятные модели, в то время как модели нейронных сетей, как известно, трудны для интерпретации. При разработке модели кредитоспособности это может быть важным моментом, поскольку закон часто требует, чтобы заявитель был уведомлен о причинах отказа в выдаче ему кредита. Даже если нейронная сеть лучше прогнозирует вероятность неуплаты по кредиту, но при этом ее прогнозы невозможно объяснить, в данном случае она бесполезна.
Чтобы вам легче было определиться в выборе алгоритма, в каждой главе перечислены основные плюсы и минусы конкретного алгоритма обучения. Вы увидите, что иногда эти характеристики позволяют однозначно исключить из рассмотрения некоторые модели, однако во многих случаях выбор алгоритма является произвольным. Если это произойдет, не бойтесь использовать любой алгоритм, который считаете более удобным. В других случаях, когда главная цель — точность прогнозирования, может потребоваться протестировать несколько моделей и выбрать ту из них, которая подходит лучше всего, или же использовать алгоритм метаобучения, который объединяет в себе несколько разных обучаемых моделей, чтобы задействовать сильные стороны каждой из них.
Машинное обучение с использованием R
Многие алгоритмы, необходимые для машинного обучения, не входят в базовую инсталляцию R. Однако они доступны благодаря обширному сообществу экспертов, которые свободно делятся результатами своей работы. Эти алгоритмы следует установить вручную поверх базовой инсталляции R. Благодаря тому что R является бесплатным программным обеспечением с открытым исходным кодом, вам не придется платить за эту дополнительную функциональность.
Набор функций R, свободно распространяемых между пользователями, называется пакетом. Для каждого алгоритма ML, описанного в книге, существуют бесплатные пакеты. В сущности, данная книга охватывает лишь небольшую часть существующих пакетов машинного обучения на R.
Если вас интересует более подробная информация об R-пакетах, обратитесь к списку Comprehensive R Archive Network (CRAN) — это всемирная коллекция сайтов и FTP-ресурсов, где представлены последние версии программного обеспечения и пакеты для R. Если вы получили программное обеспечение R путем скачивания, то, скорее всего, оно скачано с сайта CRAN, который доступен по адресу http://cran.r-project.org/index.html.
Если у вас еще не установлен R, то на сайте CRAN вы также найдете инструкции по его установке и информацию о том, куда обратиться при возникновении проблем.
Ссылка Packages в левой части веб-страницы CRAN ведет на страницу, где можно просмотреть список пакетов в алфавитном порядке или отсортировать их по дате публикации. На момент написания этой книги было доступно в общей сложности 13 904 пакета — вдвое больше, чем на момент написания второго издания, и более чем втрое — со времени выхода первого издания! Очевидно, что R-сообщество процветает, и эта тенденция не замедляется!
Ссылка Task Views, расположенная в левой части веб-страницы CRAN, ведет к списку пакетов, отсортированному по темам. Описание задач машинного обучения с перечислением пакетов, представленных в этой книге (и многих других), вы найдете по адресу https://CRAN.R-project.org/view=MachineLearning.
Установка R-пакетов
Несмотря на обширный набор доступных расширений R, благодаря формату пакета его установка и использование практически не требуют усилий. Чтобы продемонстрировать использование пакетов, мы установим и загрузим пакет RWeka, разработанный Куртом Хорником (Kurt Hornik), Кристианом Бухтой (Christian Buchta) и Акимом Зайлисом (Achim Zeileis), — подробнее об этом пакете читайте в публикации Open-Source Machine Learning: R Meets Weka, Computational Statistics, Vol. 24, p. 225–232. Пакет RWeka предоставляет набор функций, которые открывают для R доступ к алгоритмам машинного обучения, входящим в состав программного пакета Weka, написанного на Java и разработанного Иеном Х. Уиттеном (Ian H. Witten) и Эйбом Франком (Eibe Frank). Подробнее о пакете Weka читайте здесь: http://www.cs.waikato.ac.nz/~ml/weka/.
Для того чтобы использовать пакет RWeka, вам нужно установить Java, если это еще не сделано (на многих компьютерах Java устанавливается по умолчанию). Java — это бесплатный набор инструментов программирования, который позволяет использовать кросс-платформенные приложения, такие как Weka. Подробнее о Java читайте здесь: http://www.java.com. Там же вы сможете загрузить Java для вашей системы.
Самый прямой способ установки пакета — с помощью функции install.packages(). Для того чтобы установить пакет RWeka, просто введите в командной строке R следующую команду:
> install.packages("RWeka")
Среда R подключится к CRAN и загрузит пакет в формате, соответствующем вашей операционной системе. Некоторые пакеты, такие как RWeka, прежде чем их можно будет использовать, требуют установки дополнительных пакетов. Это так называемые зависимости. По умолчанию установщик автоматически загрузит и установит все зависимости.
При первой установке R-пакета установщик может попросить вас выбрать зеркало CRAN. В таком случае выберите ближайшее от вас зеркало. Этим вы обеспечите самую высокую скорость загрузки.
Параметры установки, предлагаемые по умолчанию, подходят для большинства систем. Однако иногда требуется установить пакет в другое место. Например, если у вас нет полномочий пользователя root или администратора, то вам может потребоваться выбрать другой путь установки. Это можно сделать с помощью параметра lib следующим образом:
> install.packages("RWeka", lib = "/path/to/library")
Функция установки также предоставляет дополнительные параметры для установки из локального файла, из заданного источника или для использования экспериментальных версий. Чтобы узнать больше об этих параметрах в файле справки, можно ввести следующую команду:
> ?install.packages
Вообще, вопросительный знак может использоваться для получения справки о любой R-функции. Для этого просто введите ?, а затем название функции.
Загрузка и выгрузка R-пакетов
Для того чтобы сэкономить память, R не загружает по умолчанию все установленные пакеты. Их загружают пользователи по мере необходимости с помощью функции library().
Из-за названия функции library() некоторые ошибочно считают, что термины «библиотека» и «пакет» являются взаимозаменяемыми. Однако, строго говоря, библиотека — это место, где установлены пакеты, а не сам пакет.
Для того чтобы загрузить ранее установленный пакет RWeka, введите следующую команду:
> library(RWeka)
Кроме RWeka, в следующих главах будут использоваться еще несколько R-пакетов. Инструкции по установке этих дополнительных пакетов будут приводиться по мере необходимости.
Для того чтобы выгрузить R-пакет, используется функция detach(). Например, чтобы выгрузить пакет RWeka, введите следующую команду:
> detach("package:RWeka", unload = TRUE)
При этом освободятся все ресурсы, используемые пакетом.
Установка RStudio
Перед началом работы с R настоятельно рекомендую также установить приложение RStudio с открытым исходным кодом. RStudio — это дополнительный интерфейс к R, включающий в себя функциональные возможности, которые значительно упрощают работу с R-кодом, делают ее более удобной и интерактивной (рис. 1.10). Приложение RStudio доступно бесплатно по адресу https://www.rstudio.com/.
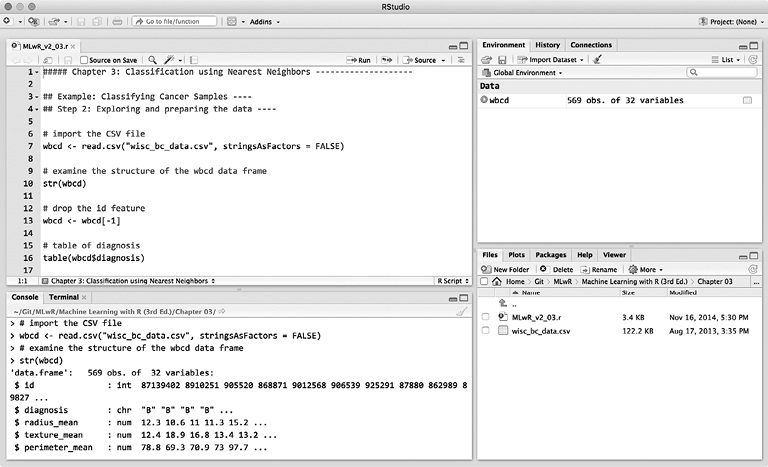
Рис. 1.10. Графическая среда RStudio делает использование R проще и удобнее
Интерфейс RStudio включает в себя встроенный редактор кода, консоль командной строки R, браузер файлов и браузер объектов R. Синтаксические конструкции кода R автоматически выделяются цветом, а результаты выполнения кода, диаграммы и графики отображаются непосредственно в среде, что значительно упрощает отслеживание длинных или сложных операторов и программ. Более продвинутые функции позволяют управлять R-проектами и пакетами; обеспечивают интеграцию с инструментами контроля исходного кода и контроля версий, такими как Git и Subversion; помогают управлять подключением к базе данных; обеспечивают преобразование результатов работы R-кода в форматы HTML, PDF и Microsoft Word.
Наличие RStudio — главная причина, по которой R сегодня является лучшим выбором для специалистов по обработке данных. Эта среда объединяет в себе возможности программирования R и огромную библиотеку R-пакетов машинного обучения и статистики, характеризующихся простотой использования и установки. Эта среда не просто идеальна для изучения R — она будет развиваться вместе с вами, по мере того как вы будете изучать более сложную функциональность языка.
Резюме
Машинное обучение появилось на стыке статистики, управления базами данных и информатики. Это мощный инструмент, способный находить полезную информацию среди больших объемов данных. Тем не менее, как следует из этой главы, необходимо соблюдать осторожность, чтобы избежать распространенных злоупотреблений ML при решении практических задач.
В основе процесса обучения — абстрагирование данных с преобразованием их в структурированное представление и обобщение структуры с преобразованием в действие, полезность которого затем можно оценить. На практике обучаемая машина использует данные, содержащие примеры и признаки изучаемой концепции, а затем объединяет эти данные в модель, которая используется для прогнозирующих или описательных целей. Эти цели могут быть сгруппированы в задачи, такие как классификация, числовое прогнозирование, обнаружение закономерностей и кластеризация. Среди множества возможных методов нужный алгоритм машинного обучения выбирается в зависимости от входных данных и задачи обучения.
Язык R обеспечивает поддержку ML c помощью пакетов, созданных R-сообществом. Эти мощные инструменты доступны для бесплатной загрузки. Такие пакеты будут представлены в каждой главе книги по мере необходимости.
В следующей главе речь пойдет об основных командах R, которые используются для управления данными и подготовки данных к машинному обучению. У вас может возникнуть желание пропустить эту главу и перейти сразу к практическому применению, однако опыт показывает, что более 80 % времени, затрачиваемого на типичные проекты ML, посвящается этапу подготовки данных, также известному как «выпас данных». Постепенно вы научитесь делать это эффективно, и тогда затраченные усилия окупятся.
1 Этот и другие аспекты обеспечения кибербезопасности систем с машинным обучением раскрыты в книге: Уорр К. «Надежность нейронных сетей: укрепляем устойчивость ИИ к обману». — СПб.: Питер, 2020.
2 Впрочем, поскольку алгоритмы машинного обучения основаны на формировании статистической, а не логической модели, зачастую человек не способен понять (выделить слово), хоть и может увидеть процесс обработки отдельной порции данных (единицы анализа).
Впрочем, поскольку алгоритмы машинного обучения основаны на формировании статистической, а не логической модели, зачастую человек не способен понять (выделить слово), хоть и может увидеть процесс обработки отдельной порции данных (единицы анализа).
На рис. 1.4 процесс обучения представлен в виде четырех отдельных составляющих, однако они организованы таким образом лишь в иллюстративных целях. На самом деле весь учебный процесс неразрывно связан. У людей обучение происходит на подсознательном уровне. Мы вспоминаем, обобщаем, делаем выводы и интуитивные прогнозы в пределах границ нашего разума, и поскольку этот процесс скрыт, то любые различия между людьми относятся к неопределенному понятию субъективности. Компьютеры, наоборот, выполняют эти процессы явно2, и, поскольку весь процесс прозрачен, полученные знания можно исследовать, передавать, использовать в последующих действиях и рассматривать как науку о данных.
Этот и другие аспекты обеспечения кибербезопасности систем с машинным обучением раскрыты в книге: Уорр К. «Надежность нейронных сетей: укрепляем устойчивость ИИ к обману». — СПб.: Питер, 2020.
Наконец, важно отметить, что, по мере того как алгоритмы машинного обучения становятся все более важными в нашей повседневной жизни, у недобросовестных людей появляется соблазн воспользоваться ими в корыстных целях. Иногда злоумышленники хотят лишь сломать алгоритмы ради забавы или дурной славы, организовав что-то вроде «бомбардировки Google» — обмана системы ранжирования страниц Google методом толоки (англ. crowdsourced method). В других случаях результат может быть более драматичным. Актуальный пример — недавняя волна так называемых ложных новостей и вмешательство в выборы путем манипулирования алгоритмами, которые показывали рекламу и давали рекомендации в соответствии с личностными характеристиками пользователя. Чтобы избежать предоставления таких возможностей посторонним лицам, при создании систем машинного обучения важно учитывать, как на эти алгоритмы может повлиять определенный человек или группа людей1.
2. Управление данными и их интерпретация
Первым этапом любого проекта машинного обучения выступает управление данными и их интерпретация. Возможно, это не так приятно, как создание и развертывание моделей — этапы, на которых вы начинаете видеть плоды своего труда, — однако неразумно игнорировать столь важную подготовительную работу.
Любой обучающий алгоритм хорош ровно настолько, насколько хороши его входные данные, а входные данные зачастую являются сложными, неупорядоченными, разбросанными по нескольким источникам, представленными в разных форматах. Поэтому часто бывает так, что большая часть усилий, затрачиваемых на проект ML, направлена на подготовку и исследование данных.
В этой главе описано три подхода к подготовке данных (data preparation). В первом разделе будут рассмотрены основные структуры данных, которые используются в языке R для хранения данных. Вы близко познакомитесь с этими структурами, когда будете создавать наборы данных и манипулировать ими. Второй раздел является практическим — в нем описано несколько функций, которые используются для ввода и извлечения данных в R. В третьем разделе показаны методы интерпретации данных на примере реального набора данных.
В этой главе рассмотрены следующие темы:
• применение основных структур данных R для хранения и обработки информации;
• простые функции для ввода данных в R из распространенных исходных форматов;
• типичные методы для интерпретации и визуализации сложных данных.
То, как данные представлены в R, будет определять, как с ними нужно работать, поэтому полезно изучить структуры данных R, прежде чем приступать непосредственно к их подготовке. Однако если вы уже знакомы с программированием на языке R, то смело переходите к разделу, посвященному предварительной обработке данных.
Структуры данных R
В разных языках программирования существует множество типов структур данных, каждая из которых имеет свои сильные и слабые стороны и подходит для определенного круга задач. Поскольку R — это язык программирования, широко применяемый для статистического поиска закономерностей, используемые им структуры данных разработаны именно для этого типа задач.
Структуры данных R, наиболее часто встречающиеся в машинном обучении, — это векторы (vectors), факторы (factors), списки (lists), массивы (arrays), матрицы (matrices) и таблицы (фреймы) данных (data frames). Каждая из этих структур адаптирована к конкретной задаче управления данными, поэтому важно понять, как они будут взаимодействовать в вашем R-проекте. В следующих разделах мы рассмотрим сходства этих структур данных и различия между ними.
Векторы
Основной структурой данных в R является вектор. В нем хранится упорядоченное множество значений, называемых элементами. Вектор может содержать любое количество элементов. Однако все элементы вектора должны быть одного типа; например, вектор не может содержать и цифры, и текст. Тип вектора v определяется с помощью команды typeof(v).
В машинном обучении обычно используются следующие типы векторов: integer (числа без десятичных знаков), double (числа со значениями после запятой), character (текстовые данные) и logical (принимающие значения TRUE или FALSE). Есть также два специальных значения: NA — отсутствующее (пропущенное или недоступное) значение и NULL — нет значения (пустое множество). Два последних значения могут показаться синонимичными, однако на самом деле они различаются. Значение NA является заполнителем для чего-либо другого, и поэтому его длина равна единице, а значение NULL — действительно пустое, и его длина равна нулю.
Некоторые функции R возвращают векторы типа integer и double как numeric, в то время как другие функции различают эти два типа. В результате все векторы double относятся к типу numeric, однако не все векторы numeric имеют тип double.
Вводить большое количество данных вручную утомительно, однако простые векторы можно создавать с помощью функции объединения c(). Вектору также можно присвоить имя с помощью оператора <-. Это оператор присваивания языка R, используемый практически так же, как оператор = во многих других языках программирования.
Для примера построим набор векторов, содержащих данные о трех пациентах. Мы создадим символьный вектор с названием subject_name для хранения имен трех пациентов, числовой вектор temperature для хранения температуры тела каждого из пациентов (в градусах Фаренгейта) и логический вектор с названием flu_status для хранения диагноза каждого пациента (TRUE, если у него грипп, и FALSE — если нет). Эти три вектора выглядят так, как показано в следующем фрагменте кода:
> subject_name <- c("John Doe", "Jane Doe", "Steve Graves")
> temperature <- c(98.1, 98.6, 101.4)
> flu_status <- c(FALSE, FALSE, TRUE)
Значения в R-векторах сохраняют свою последовательность. Поэтому для получения доступа к данным каждого пациента можно использовать его положение в наборе, начиная с 1, и указывать это число в квадратных скобках ([ и ]) после имени вектора. Например, чтобы получить значение температуры для пациентки Джейн Доу, второй в списке, достаточно ввести:
> temperature[2]
[1] 98.6
В языке R есть множество методов извлечения данных из векторов. Так, с помощью оператора двоеточия можно получить диапазон значений. Например, чтобы получить температуру тела второго и третьего пациентов, введите следующее:
> temperature[2:3]
[1] 98.6 101.4
Чтобы исключить элемент, нужно указать его номер со знаком «минус». Так, для исключения данных о температуре второго пациента введите:
> temperature[-2]
[1] 98.1 101.4
Иногда полезно указать логический вектор, каждый элемент которого говорит о том, следует ли включать во множество результатов соответствующий элемент. Например, чтобы включить два первых показания температуры, но исключить третье, введите следующее:
> temperature[c(TRUE, TRUE, FALSE)]
[1] 98.1 98.6
Как вскоре будет видно, вектор является основой для многих других структур данных R. Поэтому знание различных векторных операций имеет решающее значение для работы с данными в R.
Как загрузить пример кода
Примеры кода доступны через GitHub по адресу https://github.com/dataspelunking/MLwR/. Здесь вы найдете последнюю версию кода на R, а также обсуждение ошибок и общедоступную вики-страницу. Добро пожаловать в сообщество!
Факторы
Как вы, вероятно, помните из главы 1, номинальные признаки представляют собой характеристику с категориями значений. Для хранения номинальных данных можно использовать вектор символов, однако в R есть структура данных, специально предназначенная для этой цели. Фактор — это особый случай вектора, который нужен исключительно для представления категориальных или порядковых переменных. В медицинском наборе данных, который мы создаем, можно использовать фактор для указания пола пациента, для этого есть две категории: мужчины и женщины.
Зачем использовать факторы, а не векторы символов? Одним из преимуществ факторов является то, что метки категорий сохраняются только один раз. Вместо сохранения слов MALE, MALE и FEMALE компьютер сохранит числа 1, 1 и 2, что позволит сократить объем памяти, необходимый для хранения значений. Кроме того, разные алгоритмы ML по-разному обрабатывают номинальные и числовые функции. Кодирование категориальных переменных как факторов гарантирует, что R будет обрабатывать категориальные данные надлежащим образом.
Не следует использовать фактор для символьных векторов, которые в действительности не являются категориальными. Так, если вектор хранит в основном уникальные значения, такие как имена или идентификационные коды, сохраните его как символьный вектор.
Для того чтобы создать фактор из символьного вектора, просто примените функцию factor(), например:
> gender <- factor(c("MALE", "FEMALE", "MALE"))
> gender
[1] MALE FEMALE MALE
Levels: FEMALE MALE
Обратите внимание, что при отображении фактора gender выводится дополнительная информация о его уровнях. Уровни (levels) представляют собой множество возможных категорий, которые может принимать фактор, в данном случае MALE и FEMALE.
Создавая факторы, можно добавлять в них дополнительные уровни, которые могут быть не представлены в исходных данных. Предположим, мы создали еще один фактор для группы крови, как показано в следующем примере:
> blood <- factor(c("O", "AB", "A"),
levels = c("A", "B", "AB", "O"))
> blood
[1] O AB A
Levels: A B AB O
Определив фактор blood, с помощью параметра levels мы указали дополнительный вектор, состоящий из четырех возможных групп крови. Несмотря на то что данные включают в себя только группы крови O, AB и A, в факторе blood, как показывают результаты, сохраняются все четыре типа. Сохранение дополнительного уровня позволит добавлять пациентов с другой группой крови. Это также гарантирует, что, если бы мы создали таблицу групп крови, мы бы знали, что тип B существует, несмотря на его отсутствие в наших исходных данных.
Фактор как структура данных дает возможность включать информацию о последовательности категорий номинальных переменных, что позволяет создавать порядковые признаки. Например, предположим, что у нас есть данные о выраженности симптомов у пациента, закодированные в порядке возрастания степени тяжести — от легкой до умеренной или тяжелой. Мы указываем наличие порядковых данных, предоставляя уровни фактора в желаемой последовательности, перечисляя их в порядке возрастания — от самого низкого до самого высокого — и присваивая параметру ordered значение TRUE, как показано ниже:
> symptoms <- factor(c("SEVERE", "MILD", "MODERATE"),
levels = c("MILD", "MODERATE", "SEVERE"),
ordered = TRUE)
Полученный в результате фактор symptoms теперь включает в себя информацию о требуемом порядке. В отличие от предыдущих факторов уровни этого фактора разделены символами < для обозначения последовательности от MILD до SEVERE:
> symptoms
[1] SEVERE MILD MODERATE
Levels: MILD < MODERATE < SEVERE
Полезным свойством упорядоченных факторов является то, что для них логические тесты работают так, как требуется. Например, можно проверить, насколько выражены симптомы каждого пациента — серьезнее ли они, чем умеренные:
> symptoms > "MODERATE"
[1] TRUE FALSE FALSE
Алгоритмы машинного обучения, способные моделировать упорядоченные данные, ожидают на входе упорядоченные факторы, поэтому обязательно представляйте данные соответствующим образом.
Списки
Список — это структура данных, очень похожая на вектор тем, что она тоже используется для хранения упорядоченного множества элементов. Однако если для вектора требуется, чтобы все его элементы были одинакового типа, то список позволяет собирать разные типы данных. Благодаря такой гибкости списки часто используются для хранения различных типов входных и выходных данных, а также параметров конфигурации для моделей машинного обучения.
Для того чтобы продемонстрировать списки, рассмотрим построенный нами набор данных о трех пациентах, который хранится в шести векторах. Если мы хотим отобразить все данные для первого пациента, то нам нужно ввести пять R-команд:
> subject_name[1]
[1] "John Doe"
> temperature[1]
[1] 98.1
> flu_status[1]
[1] FALSE
> gender[1]
[1] MALE
Levels: FEMALE MALE
> blood[1]
[1] O
Levels: A B AB O
> symptoms[1]
[1] SEVERE
Levels: MILD < MODERATE < SEVERE
Чтобы иметь возможность исследовать данные о пациенте повторно, не вводя заново эти команды, можно использовать список. Он позволяет сгруппировать все значения в один объект, который можно использовать повторно.
Подобно тому как вектор создается с помощью функции c(), список создается с помощью функции list(), как показано в следующем примере. Единственное заметное различие заключается в том, что при создании списка каждому компоненту в последовательности должно быть присвоено имя. Имена необязательны, однако их наличие впоследствии позволит получить доступ к значениям по имени, а не по порядковому номеру. Для того чтобы создать список с именованными компонентами для всех данных первого пациента, введите следующую команду:
> subject1 <- list(fullname = subject_name[1],
temperature = temperature[1],
flu_status = flu_status[1],



















