

автордың кітабын онлайн тегін оқу Kafka Streams в действии. Приложения и микросервисы для работы в реальном времени
Научный редактор И. Пальти
Переводчик И. Пальти
Технические редакторы Н. Гринчик, Е. Рафалюк-Бузовская
Литературный редактор Е. Рафалюк-Бузовская
Художник Н. Гринчик
Корректоры Е. Павлович, Т. Радецкая
Верстка Г. Блинов
Билл Беджек
Kafka Streams в действии. Приложения и микросервисы для работы в реальном времени. — СПб.: Питер, 2021.
ISBN 978-5-4461-1201-2
© ООО Издательство "Питер", 2021
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Предисловие
Я считаю, что в будущем архитектуры, ориентированные на потоки событий и обработку их в режиме реального времени, будут встречаться повсеместно. Технически продвинутые компании, например Netflix, Uber, Goldman Sachs, Bloomberg и др., уже настроили масштабную работу подобных больших платформ потоковой обработки событий. Как бы громко это ни прозвучало, но я считаю, что появление потоковой обработки и событийно-управляемых архитектур повлияет на модель использования компаниями данных так же сильно, как повлияли в свое время реляционные базы данных.
Событийно-ориентированный образ мыслей и создание событийно-управляемых приложений, ориентированных на потоковую обработку, требует определенной смены мировоззрения от тех, кто привык к приложениям в стиле «запрос/ответ» и к реляционным базам данных. Именно тут и пригодится книга Kafka Streams.
Потоковая обработка влечет фундаментальный переход от командно-ориентированного мышления к мышлению событийно-ориентированному — это перемена, позволяющая создавать быстро реагирующие, событийно-управляемые, расширяемые, гибкие приложения для работы в режиме реального времени. С точки зрения бизнеса событийно-ориентированное мышление открывает организациям дорогу к принятию решений и операциям в реальном времени с учетом контекста. С точки зрения технологии событийно-ориентированное мышление дает возможность создания более автономных и расцепленных приложений и, следовательно, адаптивно масштабируемых и расширяемых систем.
В обоих случаях конечной целью является увеличение скорости адаптации (agility) — как для бизнеса, так и для облегчающих его задачи технологий. В основе событийно-ориентированной архитектуры лежит внедрение событийно-ориентированного мышления в масштабах всей организации. А технологией, делающей возможным этот переход, выступает потоковая обработка.
Kafka Streams — нативная библиотека потоковой обработки Apache Kafka, предназначенная для создания событийно-управляемых приложений на языке Java. Kafka Streams позволяет приложениям выполнять сложные преобразования потоков данных, причем автоматически обеспечивает их отказоустойчивость и прозрачность, а также адаптивное распределение по экземплярам приложения. С момента ее появления в 2016 году, в версии 0.10 Apache Kafka, множество компаний начало промышленную эксплуатацию Kafka Streams, включая Pinterest, «Нью-Йорк Таймс», Rabobank, LINE.
Наша цель относительно Kafka Streams и KSQL — упростить потоковую обработку до такой степени, чтобы создание событийно-управляемых приложений, реагирующих на события, стало естественным и не пришлось использовать тяжеловесные фреймворки для обработки больших данных. В нашей модели основной сущностью является не код, выполняющий обработку, а потоки данных в Kafka.
Руководство Kafka Streams — прекрасный способ изучить библиотеку Kafka Streams, а также понять, почему она представляет собой ключевое средство создания событийно-ориентированных приложений. Надеюсь, вы получите от прочтения этой книги не меньшее удовольствие, чем я!
Ния Нархид (Neha Narkhede), соучредитель и технический директор компании Confluent, одна из создателей Apache Kafka
Введение
В бытность разработчиком программного обеспечения мне посчастливилось работать с современным ПО над интересными проектами. Поначалу я работал как над клиентскими, так и над серверными приложениями, но обнаружил, что мне больше нравится взаимодействовать исключительно с прикладной частью, так что этим я и занялся. Со временем я перешел к распределенным системам, начиная с Hadoop (тогда еще версии до 1.0). В очередном новом проекте я столкнулся с платформой Kafka. Сначала меня поразила простота работы с ней, а также ее возможности и гибкость. С каждым разом я находил все новые способы интеграции Kafka в процесс доставки данных проекта. Написание генераторов и потребителей оказалось элементарной задачей, а качество системы благодаря Kafka значительно улучшилось.
Затем я узнал о Kafka Streams. Я сразу сообразил: «Зачем мне лишний кластер для чтения данных из Kafka и немедленной их записи обратно?» Внимательно посмотрев на доступные API, я нашел все, что только нужно было для потоковой обработки: соединения, ассоциативные массивы, операции свертки и группировки. Но что важнее, подход Kafka Streams к добавлению состояния превосходил все решения, с которыми мне только приходилось работать.
Мне всегда нравилось объяснять что-то другим просто и понятно. Так что, когда появилась возможность написать о Kafka Streams, я знал, что эта сложная работа стоит того. Я надеюсь, что мой труд принесет свои плоды и в данной книге мне удастся продемонстрировать, что Kafka Streams — простой и в то же время изящный и эффективный способ осуществления потоковой обработки.
Благодарности
Прежде всего мне хотелось бы поблагодарить свою жену Бет и выразить ей признательность за всю поддержку, которую она мне оказывала в процессе написания книги. Написание книги — задача, занимающая немало времени, и без ее содействия мне никогда бы это не удалось. Бет, ты потрясающая, и я очень рад, что ты — моя жена. Я хотел бы также поблагодарить моих детей, которые терпеливо переносили сидение папы в офисе все выходные напролет, удовлетворяясь туманным ответом «скоро» на вопрос о том, когда же я закончу.
Далее я благодарю Гочжена Вана (Guozhang Wang), Маттиаса Сакса (Matthias Sax), Дэмиана Гая (Damian Guy) и Ино Терезку (Eno Thereska) — основных разработчиков библиотеки Kafka Streams. Без их гениальных озарений и упорного труда библиотека Kafka Streams просто не появилась бы и у меня не было бы возможности написать об этом революционном инструменте.
Я благодарю моего редактора из издательства «Мэннинг», Фрэнсис Лефковиц (Frances Lefkowitz), чьи советы эксперта и бесконечное терпение превратили написание данной книги почти в развлечение. Я также благодарен Джону Хайдаку (John Hyaduck) за меткие технические замечания и Валентину Креттазу (Valentin Crettaz), техническому корректору, за великолепную работу по анализу исходного кода. Кроме того, я говорю спасибо рецензентам, благодаря которым читатели этой книги получили продукт намного лучшего качества, за их непростую работу и бесценные отзывы — это Александер Кутмос (Alexander Koutmos), Боян Джуркович (Bojan Djurkovic), Дилан Скотт (Dylan Scott), Hamish Dickson (Хэмиш Диксон), Джеймс Фроннхофер (James Frohnhofer), Джим Мэнтили (Jim Manthely), Хосе Сан Лиандро (Jose San Leandro), Кэрри Коич (Kerry Koitzsch), Ласло Хегедюш (La'szlo' Hegedu..s), Мэтт Беланже (Matt Belanger), Мишель Аддучи (Michele Adduci), Николас Уайтхед (Nicholas Whitehead), Рикардо Хорхе Перейра Мано (Ricardo Jorge Pereira Mano), Робин Коу (Robin Coe), Сумант Тамбе (Sumant Tambe) и Венката Марапу (Venkata Marrapu).
Наконец, я хотел бы поблагодарить всех разработчиков фреймворка Kafka за создание столь превосходного программного продукта, особенно Джея Крепса (Jay Kreps), Нию Нархид (Neha Narkhede) и Дзюна Рао (Jun Rao), не только за саму идею Kafka в первую очередь, но и за основание компании Confluent — потрясающего и вдохновляющего места для работы.
Об этой книге
Я написал книгу Kafka Streams, чтобы познакомить вас с Kafka Streams и, в меньшей степени, вообще научить применять потоковую обработку. Я писал эту книгу с точки зрения парного программирования, представляя, что сижу рядом с вами, пока вы пишете код и изучаете API. Мы начнем с создания простого приложения и будем добавлять в него новый функционал по мере погружения в Kafka Streams. Вы узнаете, как выполнять тестирование и мониторинг, и, наконец, мы завершим книгу созданием продвинутого приложения Kafka Streams.
Кому стоит прочитать эту книгу
Эта книга подойдет для любого разработчика, который хочет разобраться в потоковой обработке. Понимание распределенного программирования поможет лучше изучить Kafka и Kafka Streams. Было бы неплохо знать и сам фреймворк Kafka, но это не обязательно: я расскажу вам все, что нужно. Опытные разработчики Kafka, как и новички, благодаря этой книге освоят создание интересных приложений для потоковой обработки с помощью библиотеки Kafka Streams. Java-разработчики среднего и высокого уровня, уже привычные к таким понятиям, как сериализация, научатся применять свои навыки для создания приложений Kafka Streams. Исходный код книги написан на Java 8 и существенно использует синтаксис лямбда-выражений Java 8, так что умение работать с лямбда-функциями (даже на другом языке программирования) вам пригодится.
Структура издания
Книга состоит из четырех частей, разбитых на девять глав. Часть I познакомит вас с ментальной моделью библиотеки Kafka Streams, чтобы дать комплексное представление о ее функционировании. В этих главах также приводятся основы Kafka для тех, кто ничего о ней не знает или хотел бы освежить свои знания.
• Глава 1 описывает историю вопроса: как и почему потоковая обработка стала необходимым элементом широкомасштабной обработки данных в режиме реального времени. В ней также приводится ментальная модель Kafka Streams. Вместо демонстрации кода я просто опишу в ней, как работает Kafka Streams.
• Глава 2 — руководство для разработчиков, еще не имевших дела с Kafka. Те, у кого уже есть опыт работы с ней, могут эту главу пропустить и перейти непосредственно к Kafka Streams.
В части II я расскажу о Kafka Streams: начну с основ API и постепенно перейду к более продвинутым возможностям.
• В главе 3 вы найдете приложение типа Hello World, а далее и более реалистичный пример: разработку приложения для вымышленного розничного торговца, включая продвинутые возможности.
• В главе 4 обсуждается понятие состояния и объясняется, почему оно иногда необходимо для потоковых приложений. Вы узнаете из нее про реализации хранилищ состояния, а также выполнение соединений в Kafka Streams.
• Глава 5 посвящена дуализму таблиц и потоков, в ней вы познакомитесь с новым понятием: интерфейсом KTable. Если KStream представляет собой поток событий, то KTable — это поток взаимосвязанных событий или поток, предназначенный для обновления записей.
• В главе 6 мы углубимся в низкоуровневый API узлов-обработчиков (Processor API). До сих пор вы имели дело с высокоуровневым предметно-ориентированным языком (Domain Specific Language, DSL), а здесь научитесь использовать API узлов обработки на случай, если вам понадобится писать адаптированные к конкретной задаче части приложения.
В части III мы перейдем от разработки приложений Kafka Streams к управлению библиотекой Kafka Streams.
• Глава 7 рассказывает о тестировании приложений Kafka Streams. Вы научитесь тестировать топологию приложения в целом, осуществлять модульное тестирование отдельного узла обработки, а также использовать встроенный брокер для комплексных тестов.
• Глава 8 охватывает вопросы мониторинга приложений Kafka Streams с целью как оценки времени обработки записей, так и обнаружения потенциальных узких мест.
Часть IV завершает эту книгу, в ней мы займемся разработкой продвинутого приложения на основе Kafka Streams.
• Глава 9 рассказывает об интеграции существующих источников данных с Kafka Streams с помощью фреймворка Kafka Connect. Вы узнаете, как включать таблицы базы данных в потоковое приложение, а затем и как использовать интерактивные запросы для создания визуализаций и приложений — информационных панелей на основе проходящих через Kafka Streams данных без необходимости применения реляционных баз данных. В этой главе вы также познакомитесь с механизмом KSQL, благодаря которому с помощью Kafka можно выполнять непрерывные запросы без написания кода, используя один SQL.
О коде
Эта книга содержит множество примеров исходного кода как в пронумерованных листингах, так и внутри обычного текста. В обоих случаях исходный код отформатирован с помощью такого моноширинного шрифта, чтобы можно было отличить его от обычного текста.
Во многих случаях исходный код был переформатирован: добавлены разрывы строк и изменены отступы, чтобы оптимально использовать место на странице. В редких случаях даже этого было недостаточно и листинги содержат символы продолжения строки (![]()
Наконец, важно отметить, что многие из примеров кода несамодостаточны и содержат лишь фрагменты кода, наиболее важные для обсуждаемого вопроса. Все примеры из книги в их изначальном виде можно найти в прилагаемом к данной книге исходном коде. Он находится на GitHub по адресу https://github.com/bbejeck/kafka-streams-in-action или на сайте издательства: http://www.manning.com/books/kafka-streams-in-action.
Исходный код для книги представляет собой комплексный проект, использующий утилиту сборки Gradle (https://gradle.org). Этот проект можно импортировать в среды разработки IntelliJ или Eclipse с помощью соответствующих команд. Полные инструкции по применению исходного кода и навигации по нему можно найти в прилагаемом файле README.md.
Другие онлайн-ресурсы
• Документация по фреймворку Apache Kafka: https://kafka.apache.org/.
• Документация по платформе Confluent: https://docs.confluent.io/current.
• Документация по библиотеке Kafka Streams: https://docs.confluent.io/current/streams/index.html#kafka-streams.
• Документация по движку KSQL: https://docs.confluent.io/current/ksql.html#ksql.
Об авторе

Билл Беджек (Bill Bejeck) — участник проекта Kafka, работает в компании Confluent, в команде разработчиков Kafka Streams. Разработкой программного обеспечения он занимается более 13 лет, шесть из которых посвятил исключительно прикладной части, а именно обработке больших объемов данных. Билл также работал в командах, занимающихся вводом и обработкой данных, где использовал Kafka для повышения качества информационных потоков, отправляемых конечным потребителям. Билл — автор книги Getting Started with Google Guava (издательство Packt). Кроме того, он регулярно ведет блог «Беспорядочные размышления о написании кода» (http://codingjunkie.net/).
Часть I. Знакомство с Kafka Streams
В части I этой книги мы поговорим об эре больших данных: как она началась, когда появилась необходимость обрабатывать большие объемы данных и постепенно выросла до принципа потоковой обработки — обработки данных по мере их доступности. Мы также обсудим, что представляет собой библиотека Kafka Streams, и я покажу вам ментальную модель ее функционирования, без какого-либо кода, чтобы вы могли сконцентрироваться на общей картине происходящего. Мы также вкратце рассмотрим платформу Kafka, чтобы ввести вас в курс работы с ней.
1. Добро пожаловать в Kafka Streams
В этой главе:
• как большие данные повлияли на программирование;
• как работает потоковая обработка и зачем она нужна;
• знакомство с Kafka Streams;
• задачи, решаемые Kafka Streams.
С помощью этой книги вы научитесь использовать Kafka Streams для решения насущных проблем ваших потоковых приложений. Мы рассмотрим в ней компоненты Kafka Streams, начиная от простейших операций извлечения, преобразования и загрузки (extract, transform and load, ETL) и до сложных преобразований и соединений записей. После ее прочтения вы сможете легко решать подобные сложные задачи в своих потоковых приложениях.
Прежде чем углубиться в Kafka Streams, мы коротко рассмотрим историю обработки больших данных. По мере описания нами задач и их решений вы наглядно увидите, как возникла необходимость в Kafka, а затем и Kafka Streams. Давайте посмотрим, как началась эра больших данных и что привело к появлению Kafka Streams.
1.1. Движение больших данных, и как оно повлияло на программирование
Современное программирование начало бурно расти с появлением фреймворков и технологий больших данных. Конечно, разработка приложений на стороне клиента тоже подверглась изменениям, и число мобильных приложений также резко выросло. Но вне зависимости от размеров рынка мобильных устройств или развития технологий клиентских приложений неизменным остается одно: с каждым днем приходится обрабатывать все больше и больше данных. А по мере роста объемов данных с такой же скоростью растут потребности в их анализе и использовании в своих интересах.
Однако далеко не всегда достаточно возможности обрабатывать большие объемы данных крупными фрагментами (пакетной обработки). У организаций все чаще возникает необходимость обрабатывать данные по мере поступления (потоковой обработки). Библиотека Kafka Streams дает возможность обработки записей по событиям — это самый передовой подход к потоковой обработке. Обработка по событиям (per-event processing) означает, что каждая запись обрабатывается сразу же, как только оказывается доступна, никакой группировки данных в небольшие пакеты (микропакетирования) не нужно.
примечание
Когда потребности обработки данных стали совершенно явственными, была разработана новая стратегия — микропакетирование (microbatching). Как понятно из названия, оно представляет собой просто пакетную обработку, но с меньшими объемами данных. Благодаря снижению размера пакета микропакетирование позволяет иногда получать результаты быстрее, но это все равно пакетная обработка, хотя и с более короткими промежутками времени. Это не настоящая обработка по событиям.
1.1.1. Возникновение больших данных
Интернет начал всерьез влиять на нашу повседневную жизнь в середине 1990-х. С тех пор благодаря сетевой связи у нас появился беспрецедентный доступ к информации и возможность общения с кем угодно, в любой точке мира. Но побочным продуктом этой всей сетевой связи оказалась генерация колоссальных объемов данных.
Для наших целей можно считать, что эра больших данных началась в 1998 году, когда Сергей Брин (Sergey Brin) и Ларри Пейдж (Larry Page) создали компанию Google. Брин и Пейдж разработали новый способ ранжирования веб-страниц для поиска — алгоритм PageRank. Если не вдаваться в подробности, алгоритм PageRank оценивает сайт по количеству и качеству указывающих на него ссылок. При этом предполагается, что чем важнее или значимее веб-страница, тем больше сайтов будет на нее ссылаться.
Рисунок 1.1 наглядно иллюстрирует алгоритм PageRank.
• Сайт А — наиболее важный, поскольку на него указывает большинство ссылок.
• Сайт Б тоже довольно важен. Хотя на него указывает меньше ссылок, но среди них — важный сайт (A).
• Сайт В менее важен, чем A или Б. На сайт В указывает больше ссылок, чем на B, но их качество ниже.
• На сайты внизу рисунка (от Г до И) никакие ссылки не указывают, что делает их наименее ценными.
Алгоритм PageRank на рисунке сильно упрощен, но этого достаточно, чтобы получить основное представление о его работе.
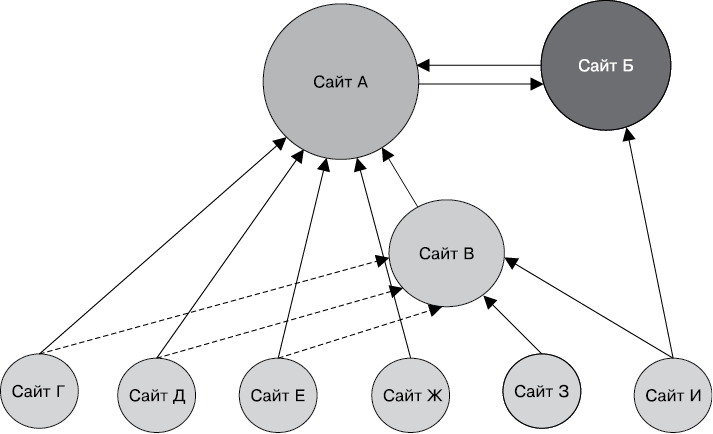
Рис. 1.1. Алгоритм PageRank в действии. Круги означают сайты, самые большие — те, на которые указывает больше ссылок с других сайтов
На то время алгоритм PageRank был поистине революционным подходом. До той поры поиски в Интернете чаще всего возвращали результаты на основе булевой логики. Если сайт содержал все искомые ключевые слова или большинство из них, то оказывался в результатах поиска вне зависимости от качества контента. Но для работы алгоритма PageRank в масштабах всего контента Интернета необходим был другой подход — традиционные подходы к работе с данными были слишком медленными. Чтобы выжить и развиваться, Google необходимо было быстро (где «быстро» — понятие относительное) индексировать весь этот контент и предоставить аудитории качественные результаты.
И компания Google разработала еще один революционный подход для обработки всех этих данных — парадигму MapReduce («отображение — свертка»). Парадигма MapReduce не только дала Google возможность выполнить всю необходимую работу, но и нечаянно породила целую новую отрасль вычислений.
1.1.2. Важнейшие понятия парадигмы MapReduce
Функции отображения (map) и свертки (reduce) не были чем-то новым на момент разработки компанией Google MapReduce. Уникальным в подходе Google было применение этих простых принципов в колоссальных масштабах на множестве машин.
По сути, MapReduce берет начало в функциональном программировании. Функция отображения получает на входе данные и отображает их во что-то без изменения исходных данных. Вот простой пример на языке Java 8, в котором объект LocalDate отображается в сообщение типа String, причем исходный объект LocalDate остается неизменным:
Function<LocalDate, String> addDate =
(date) -> "The Day of the week is " + date.getDayOfWeek();
Хотя и очень простой, этот короткий пример достаточен для демонстрации функции отображения.
С другой стороны, функция свертки принимает на входе несколько параметров и свертывает их в единое (или по крайней мере меньшее по размеру) значение. Хороший пример свертки — сложение всех значений из набора чисел.
Для выполнения свертки набора чисел сначала необходимо задать начальное значение. В данном случае мы возьмем 0 (нейтральный по отношению к операции сложения элемент). Следующий шаг состоит в сложении этого начального значения с первым элементом списка. Функция свертки повторяет данный процесс до тех пор, пока не достигнет последнего значения, в результате чего получается одно число.
Ниже приведены шаги свертки объекта List<Integer>, содержащего значения 1, 2 и 3:

Как вы можете видеть, функция свертки сворачивает результаты для большей компактности. Как и в функции отображения, исходный список чисел остается неизменным.
Следующий пример демонстрирует реализацию простой функции свертки с помощью лямбда-функций Java 8:
List<Integer> numbers = Arrays.asList(1, 2, 3);
int sum = numbers.reduce(0, (i, j) -> i + j );
Наша книга посвящена не MapReduce, так что на этом мы завершим обсуждение данного побочного вопроса. Но какие-то из основных концепций, появившихся в парадигме MapReduce (и позднее реализованные в Hadoop, исходная версия которого, с открытым исходным кодом, была основана на официальном описании MapReduce от Google), применяются в Kafka Streams:
• распределение данных по кластеру так, чтобы процесс обработки хорошо масштабировался;
• использование пар «ключ/значение» и секций для группировки распределенных данных;
• вместо избегания сбоев — подготовка к ним с помощью репликации.
В следующих разделах мы обсудим эти концепции в общих словах. Обратите на них внимание, поскольку они еще не раз будут встречаться в данной книге.
Распределение данных по кластеру для лучшей масштабируемости
Работа с объемами данных порядка 5 Тбайт (5000 Гбайт) может оказаться для отдельной машины непосильной задачей. Но такую проблему можно минимизировать, разбив данные и воспользовавшись несколькими дополнительными машинами, чтобы каждая обрабатывала посильный ей объем данных. Это ясно видно из табл. 1.1.
Таблица 1.1. Как разбиение 5 Тбайт на части повышает пропускную способность обработки
| Количество машин |
Объем обрабатываемых каждым сервером данных, Гбайт |
| 10 |
500 |
| 100 |
50 |
| 1000 |
5 |
| 5000 |
1 |
Как можно видеть из приведенной таблицы, вероятно, сначала объемы данных, которые нужно обработать, будут совершенно «неподъемны», но за счет распределения нагрузки по дополнительным серверам эти сложности можно устранить. Один гигабайт данных в последней строке таблицы — вполне посильный для обработки на обычном ноутбуке объем данных.
Это первая ключевая концепция MapReduce: за счет распределения нагрузки по кластеру машин можно превратить непомерные объемы данных во вполне доступные для обработки.
Использование пар «ключ/значение» и секций для группировки распределенных данных
Пара «ключ/значение» — простая структура данных с большими возможностями. В предыдущем разделе вы видели, какое значение может иметь распределение большого объема данных по кластеру машин. Распределение данных решает задачу обработки, но при этом возникает задача сбора распределенных данных обратно.
Для перегруппировки распределенных данных можно воспользоваться ключами из пар «ключ/значение» для секционирования данных. Термин «секционирование» подразумевает группировку, но я имею в виду группировку не по одинаковым ключам, а по ключам с одним хеш-кодом. Для разбиения данных на секции по ключу можно применить следующую формулу:
int partition = key.hashCode() % numberOfPartitions;
Рисунок 1.2 демонстрирует использование функции хеширования для получения данных по различным олимпийским видам спорта, хранящихся на отдельных серверах, и группировки их по секциям для различных видов спорта.

Рис. 1.2. Группировка записей по ключу по секциям. Хотя записи берутся с различных серверов, они все равно оказываются в соответствующих секциях
Все данные хранятся в виде пар «ключ/значение». На рисунке под ключами находятся названия событий, а значение представляет собой результат отдельного спортсмена.
Секционирование — важная концепция, в следующих главах вы увидите ее подробные примеры.
Готовимся к сбоям с помощью репликации
Еще один ключевой компонент MapReduce — файловая система Google (Google File System, GFS). Подобно тому как Hadoop — реализация MapReduce с открытым исходным кодом, так и файловая система Hadoop (Hadoop File System, HDFS) — реализация GFS с открытым исходным кодом.
Если не вдаваться в подробности, то как GFS, так и HDFS разбивают данные на блоки и распределяют эти блоки по кластеру. Но одна из неотъемлемых частей GFS/HDFS — их подход к обработке отказов серверов и дисков. Вместо того чтобы пытаться предотвращать сбои, фреймворк учитывает их возможность с помощью репликации блоков данных по кластеру (по умолчанию коэффициент репликации равен 3).
Благодаря репликации блоков данных на различных серверах больше не нужно бояться, что отказ дисков или даже сервера в целом приведет к простою в работе. Репликация данных критически важна для обеспечения отказоустойчивости распределенных приложений, которая, в свою очередь, необходима для их успешной работы. Далее мы увидим, как работает репликация в Kafka Streams.
1.1.3. Одной пакетной обработки недостаточно
Мода на Hadoop охватила мир обработки данных подобно лесному пожару. Он дал возможность обрабатывать огромные объемы данных отказоустойчивым образом с помощью стандартного аппаратного обеспечения (а значит, экономя средства). Но использование Hadoop/MapReduce, по сути, пакетный процесс, так что приходится собирать большие объемы данных, обрабатывать их, а затем сохранять результаты для дальнейшего применения. Пакетная обработка идеально подходит для алгоритмов, подобных PageRank, поскольку все равно нельзя принимать решения о ценности ресурсов в масштабах всего Интернета на основе наблюдения за переходами пользователей по ссылкам в режиме реального времени.
Но в коммерческой сфере все сильнее требуются как можно более оперативные ответы на такие важные вопросы, как:
• какие тенденции существуют в настоящий момент;
• сколько неудачных попыток входа в систему было сделано за последние 10 минут;
• насколько востребована пользователями только что выпущенная возможность?
Потребность в ином решении задачи была очевидна, и этим решением стала потоковая обработка.
1.2. Знакомство с потоковой обработкой
Существует много различных определений потоковой обработки. В этой книге я называю потоковой обработкой (stream processing) работу с данными по мере поступления их в систему. Определение можно уточнить, сказав, что потоковая обработка — способность оперировать бесконечным потоком данных по мере их движения посредством непрерывных вычислений без необходимости их сбора или сохранения для того, чтобы на них отреагировать.
На рис. 1.3 показан поток данных, где каждый круг на прямой отражает состояние данных в какой-либо момент времени. Информационный поток непрерывен, поскольку данные при потоковой обработке ничем не ограничены.

Рис. 1.3. Эта «жемчужная» диаграмма — упрощенное представление потоковой обработки. Каждый круг соответствует какой-либо информации или происходящему в конкретный момент времени событию. Количество событий ничем не ограничено, и они перетекают слева направо
Кому требуется потоковая обработка? Всем, кому нужна своевременная реакция на наблюдаемое событие. Рассмотрим несколько примеров.
Когда имеет смысл использовать потоковую обработку, а когда — нет. Как и любое техническое решение, потоковая обработка не подходит на все случаи жизни. Оптимальный сценарий использования для потоковой обработки — тот, где необходимо быстро реагировать на поступающие данные или уведомить об их поступлении. Вот несколько примеров.
• Мошенничество с платежными картами. Владелец платежной карты может не заметить ее кражи, но путем анализа покупок и сравнения их с устоявшимися паттернами (местоположение, общий характер потребительских расходов) можно заметить кражу платежной карты и оповестить ее владельца.
• Обнаружение атак. Благодаря анализу файлов журналов приложения после проникновения в систему можно предотвратить будущие атаки и повысить уровень безопасности, но это не отменяет критической важности мониторинга аномального поведения в реальном времени.
• Финансовый сектор. Для принятия удачных решений о покупке или продаже брокерам и потребителям необходимо иметь возможность отслеживать рыночные цены и тенденции в режиме реального времени.
С другой стороны, потоковая обработка подходит не для всех предметных областей. Для удачных прогнозов будущего поведения, например, необходимо обработать большое количество данных по длительному промежутку времени, чтобы исключить аномалии и выявить паттерны и тенденции. В следующих областях разумнее анализировать данные за длительный промежуток времени, а не только текущие.
• Экономическое прогнозирование. Для точного прогноза, например, тенденций процентной ставки на рынке недвижимости необходимо собрать данные о множестве переменных за длительный период времени.
• Изменения школьных программ обучения. Только через один или два семестра администрация школы сможет оценить, достигли ли своей цели изменения программы обучения.
Важно помнить следующее: потоковая обработка — оптимальный подход для случая, когда выдать уведомление или предпринять какие-либо действия необходимо сразу же при поступлении данных. Если же требуется углубленный анализ или сбор большого архива данных для дальнейшего анализа, возможно, потоковая обработка не то, что вам требуется. Теперь посмотрим на конкретный пример потоковой обработки.
1.3. Обработка транзакции покупки товара
Начнем с применения общего подхода потоковой обработки к примеру с продажей товаров в розницу. А затем рассмотрим использование Kafka Streams для реализации потокового приложения.
Допустим, Джейн Доу едет с работы домой и вспоминает, что забыла купить зубную пасту. Она останавливается у магазина ZMart и заходит внутрь, берет зубную пасту и направляется к кассе для оплаты. Кассир спрашивает ее, член ли она ZClub, и сканирует ее карту участника. Теперь информация о том, что Джейн — член клуба постоянных покупателей, включена в транзакцию покупки товара.
После отображения суммы покупки Джейн передает кассиру свою дебетовую карту. Кассир проводит картой по терминалу и отдает Джейн чек. Выйдя из магазина, Джейн проверяет электронный почтовый ящик и обнаруживает там сообщение от ZMart с благодарностью за приверженность их магазину и различные купоны на скидки, которые можно использовать при следующем визите.
Эта транзакция — обычное событие, о котором покупатель не задумывается, но вы наверняка видите, какое изобилие информации в нем содержится, и благодаря ей ZMart может работать более эффективно и лучше обслуживать покупателей. Перенесемся в прошлое и посмотрим, как данная транзакция стала возможной.
1.3.1. Рассматриваем вариант с потоковой обработкой
Допустим, вы ведущий разработчик отдела ZMart, занимающегося потоковыми данными. ZMart — сеть розничных гипермаркетов, разбросанных по стране. Дела у ZMart идут отлично, ежегодные доходы превышают $1 млрд. Вы собираетесь провести интеллектуальный анализ данных о транзакциях компании, чтобы повысить эффективность бизнеса. Вы знаете, что объемы данных продаж колоссальны, так что реализуемая технология должна работать быстро и хорошо масштабироваться, чтобы справиться с ними.
Вы решаете воспользоваться потоковой обработкой, поскольку некоторые коммерческие решения лучше принимать по горячим следам, сразу после транзакции, чтобы не упустить возможностей. Если данные собраны, ждать многие часы для принятия решений нет смысла. Вы проводите совещание с руководством и командой разработчиков и вырабатываете следующие четыре основных требования, необходимых для успеха проекта потоковой обработки.
• Защита персональной информации. Прежде всего ZMart ценит свои отношения с покупателями. При всей нынешней шумихе вокруг соблюдения конфиденциальности информации первоочередная задача — защитить персональную информацию покупателей, а главное — номера их платежных карт. Как бы ни использовалась информация о транзакциях, рисковать раскрытием информации о платежных картах покупателей недопустимо.
• Поощрение покупателей. При новой программе поощрения покупателей зарабатываемые покупателями бонусы зависят от количества потраченных на определенные товары денег. Необходимо быстро оповещать покупателей о получении бонусов, ведь мы хотим, чтобы они вернулись за следующими покупками! Опять же при этом требуется соответствующий мониторинг действий. Помните, как Джейн получила сообщение по электронной почте сразу же после выхода из магазина? Именно так все и должно работать.
• Данные о продажах. Компания ZMart не отказалась бы усовершенствовать свою стратегию рекламы и продаж. В частности, ее руководителям хотелось бы отслеживать продажи по областям, чтобы выяснить, какие товары популярнее в определенных частях страны. Цель — таргетинг продаж и организация рекламных акций по наиболее продаваемым в конкретных областях страны товарам.
• Хранилище. Все записи о продажах должны храниться во внешнем центре хранения для ретроспективного и ситуативного анализа.
Эти требования сами по себе довольно просты, но как реализовать их применительно к отдельной транзакции покупки, такой как у Джейн Доу?
1.3.2. Представление требований в виде графа
Предыдущие требования можно легко представить в виде ориентированного ациклического графа (directed acyclic graph, DAG). Момент завершения покупателем транзакции на кассе является узлом-источником всего графа. Требования ZMart становятся узлами-потомками главного узла-источника (рис. 1.4).
Далее необходимо разобраться, как отобразить транзакцию покупки на граф требований.
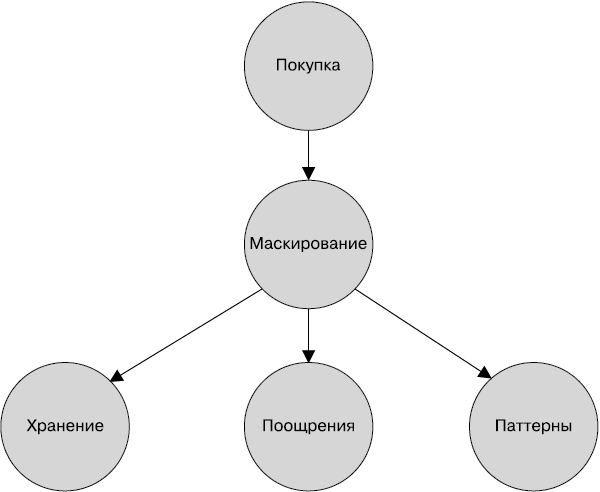
Рис. 1.4. Бизнес-требования к потоковому приложению в виде ориентированного ациклического графа. Каждая вершина соответствует требованию, а ребра отражают движение данных по графу
1.4. Транзакция покупки с другой точки зрения
В этом разделе мы пройдемся по этапам покупки и посмотрим, как они соотносятся, без особых подробностей, с графом требований с рис. 1.4. В следующем разделе мы выясним, как применить для данного процесса библиотеку Kafka Streams.
1.4.1. Узел-источник
Узел-источник графа (рис. 1.5) — место, в котором приложение потребляет транзакцию покупки. Этот узел служит источником информации о транзакциях покупок, проходящей по графу.
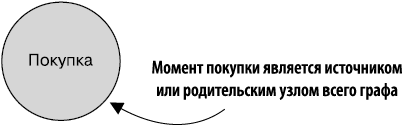
Рис. 1.5. Простое начало графа транзакций покупок. Данный узел является источником первичной информации о транзакциях покупок, которая будет перемещаться по графу
1.4.2. Узел маскирования номеров платежных карт
В дочернем узле источника графа происходит маскирование номеров платежных карт (рис. 1.6). Это первая вершина (узел) графа, отражающая бизнес-требования, и единственная получающая первичные данные о продажах из узла-источника, что делает ее, по сути, источником для остальных соединенных с ней узлов.
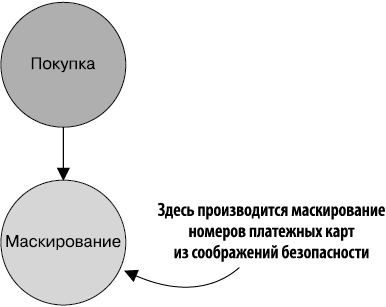
Рис. 1.6. Первый из узлов графа, отражающих бизнес-требования. Данный узел отвечает за маскирование номеров платежных карт, он единственный, кто получает первичные данные о продажах из узла-источника, что делает его, по существу, источником для остальных соединенных с ним узлов
При операции маскирования платежных карт делается копия данных с последующим преобразованием всех цифр номера в x, за исключением четырех последних. В данных во всех остальных частях графа поле номера платежной карты будет иметь вид xxxx-xxxx-xxxx-1122.
1.4.3. Узел паттернов
Узел «Паттерны» (рис. 1.7) извлекает соответствующую информацию с целью выяснения, в каких местах страны покупатели приобретают товары. Вместо копирования данных узел паттернов извлекает товар, дату и почтовый индекс (ZIP) продажи и создает новый объект с этими полями.
1.4.4. Узел поощрений
Следующий дочерний узел в процессе — сумматор бонусов (рис. 1.8). У компании ZMart есть программа поощрения покупателей, в соответствии с которой за приобретенные в ее магазинах товары покупателям начисляются бонусы. Роль данного узла состоит в извлечении потраченной клиентом суммы (в долларах) и его идентификатора и создании затем нового объекта, содержащего эти два поля.
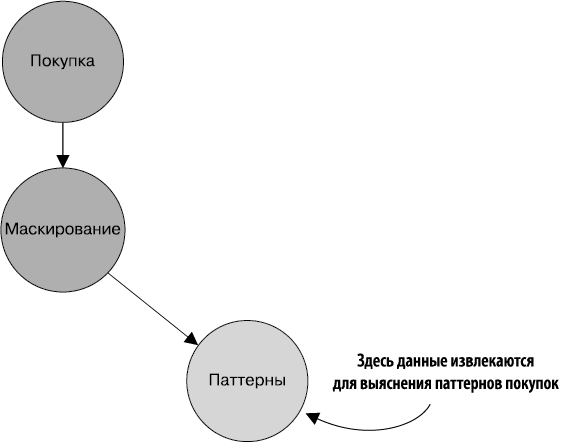
Рис. 1.7. Узел паттернов потребляет информацию о продажах из узла маскирования и преобразует ее в запись, указывающую, когда покупатель приобрел товар, и содержащую почтовый индекс места, где была завершена транзакция
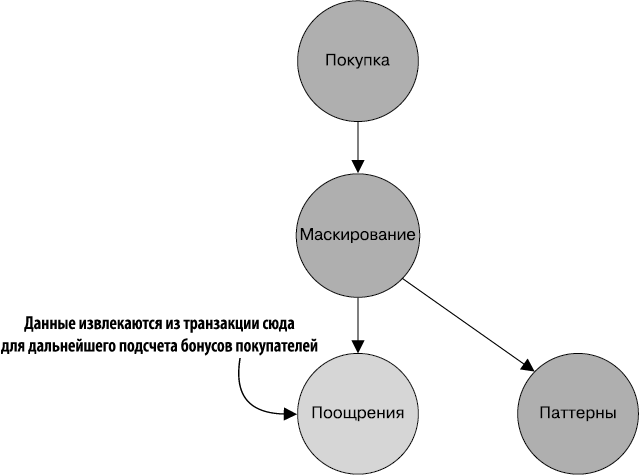
Рис. 1.8. Узел поощрений отвечает за потребление записей о продажах из узла маскирования и преобразование их в записи, содержащие общую сумму покупки и идентификатор покупателя
1.4.5. Узел хранения
Последний из дочерних узлов записывает данные о покупке в NoSQL-хранилище данных для дальнейшего анализа (рис. 1.9).
Мы проследили пример транзакции продажи по всему графу требований ZMart. Посмотрим теперь, как с помощью Kafka Streams преобразовать этот граф в полнофункциональное потоковое приложение.
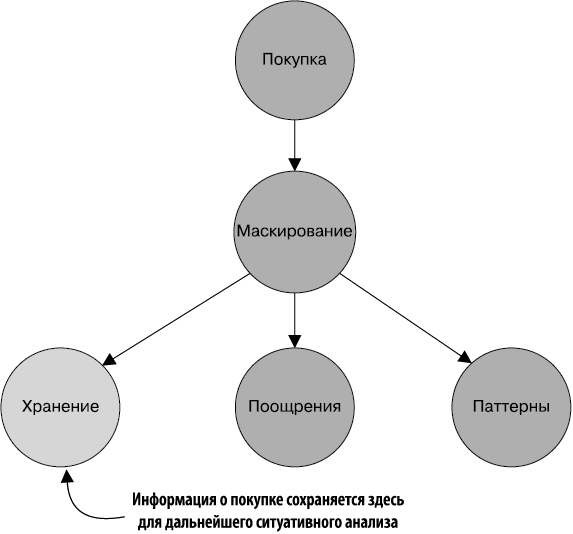
Рис. 1.9. Узел хранилища также потребляет записи из узла маскирования. Эти записи не преобразуются в другой формат, а сохраняются в NoSQL-хранилище данных для дальнейшего ситуативного анализа
1.5. Kafka Streams как граф узлов обработки
Kafka Streams — библиотека, позволяющая выполнять обработку записей по мере поступления каждого события. С ее помощью можно обрабатывать данные при их поступлении без группировки в микропакеты. Каждая запись обрабатывается сразу же, как только оказывается доступна.
Большинство целей компании ZMart чувствительны ко времени в том смысле, что действия необходимо предпринимать при первой же возможности. В идеале сбор информации должен производиться при появлении событий. Кроме того, магазинов ZMart в стране несколько, так что все записи о транзакциях следует сосредоточить в едином потоке данных для анализа. Именно поэтому библиотека Kafka Streams оптимальна для наших целей. Kafka Streams дает возможность обрабатывать записи по мере их поступления, обеспечивая требуемое низкое значение задержки.
В Kafka Streams необходимо задать топологию обрабатывающих узлов (я буду попеременно использовать как термин (узел-)обработчик (processor), так и термин (обрабатывающий) узел (node)). Источником для одного или нескольких узлов будет топик Kafka, причем можно добавлять дополнительные узлы, которые будут считаться дочерними (если вы плохо представляете себе, что такое топик Kafka, не волнуйтесь, я объясню все в главе 2). Любой дочерний узел может задавать свои дочерние узлы. Каждый из узлов обработки выполняет назначенную задачу, после чего переправляет запись каждому из своих дочерних узлов. Процесс выполнения заданий и последующей отправки данных дочерним узлам продолжается до тех пор, пока все дочерние узлы не выполнят свои задачи.
Не напоминает ли вам этот процесс что-либо? Должен напоминать, поскольку он схож с вышеприведенным преобразованием бизнес-требований ZMart в граф узлов обработки. Kafka Streams работает путем обхода графа типа DAG (то есть топологии узлов обработки).
Начнем мы с источника (родительского узла с одним или несколькими дочерними). Данные всегда перемещаются от родительского к дочерним узлам, и никогда — наоборот. У каждого дочернего узла могут быть, в свою очередь, свои дочерние узлы и т.д.
Записи перемещаются «вглубь» графа. Важные следствия такого подхода: каждая запись (пара «ключ/значение») полностью обрабатывается всем графом, прежде чем начинается перемещение следующей записи по топологии. А поскольку все записи проходят при обработке «вглубь» всего DAG, нет необходимости встраивать в Kafka Streams контроль обратного потока данных.
Определение
Существует несколько определений контроля обратного потока данных (backpressure), но тут мы обозначим это понятие как необходимость ограничения потока данных посредством буферизации или механизма блокирования. Контроль обратного потока данных необходим тогда, когда источник (source) генерирует данные быстрее, чем сток (sink) может их получать и обрабатывать.
Благодаря способности связывать или соединять цепочкой несколько узлов обработки можно быстро создавать сложную логику с сохранением относительной простоты отдельных компонентов. Именно при подобном объединении узлов обработки проявляются вся мощь и сложность Kafka Streams.
Определение
Топология — способ организации частей системы и соединения их друг с другом. Говоря о топологии Kafka Streams, я подразумеваю преобразование данных посредством их пропускания через один или несколько узлов обработки.
| Kafka Streams и Kafka Как вы могли догадаться по названию, библиотека Kafka Streams — надстройка над фреймворком Kafka. В этой |



















