

автордың кітабын онлайн тегін оқу Глубокое обучение с fastai и PyTorch: минимум формул, минимум кода, максимум эффективности
Перевод Д. Брайт
Джереми Ховард, Сильвейн Гуггер
Глубокое обучение с fastai и PyTorch: минимум формул, минимум кода, максимум эффективности. — СПб.: Питер, 2022.
ISBN 978-5-4461-1475-7
© ООО Издательство "Питер", 2022
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Отзывы о книге
Если вам нужен гайд, который проведет вас от первых исследований до передовых рубежей в сфере глубокого обучения, эта книга для вас. Не только доктора наук могут наслаждаться преимуществами глубокого обучения — вы тоже можете использовать его для решения рабочих задач.
Хэл Вариан (Hal Varian), заслуженный профессор Калифорнийского университета в Беркли, главный экономист Google
Сегодня искусственный интеллект активно развивается в области глубокого обучения, поэтому настало время разобраться в принципах его работы. Данная книга позволяет сделать это даже непосвященным. Авторы смогли в упрощенном виде передать то, что иные сочли бы очень сложным.
Эрик Тополь (Eric Topol), автор книги Deep Medicine, профессор Scripps Research
Джереми и Сильвейн приглашают вас в интерактивное путешествие, где каждую строчку кода вы сможете выполнить на своем ноутбуке. Это будет путешествие по долинам потерь и пикам производительности. Приправленная остроумными шутками, эта книга поражает балансом изложения глубоких технических принципов и непринужденной манеры разговора. Она даст вам эталонные практические инструменты и реальные примеры для их использования. Независимо от того, новичок вы или опытный разработчик, книга позволит ускорить ваше обучение и постичь не только вершины, но и глубины машинного обучения.
Себастьян Рудер (Sebastian Ruder), ученый-исследователь Deepmind
Джереми Ховард и Сильвейн Гуггер написали удивительную книгу — она прокладывает мост между областью ИИ и всем миром. Эта работа — исключительно содержательное и проницательное, но одновременно и понятное пособие по глубокому обучению для всех, кто интересуется этой областью.
Энтони Чанг (Anthony Chang), директор по информационным технологиям, детская больница округа Оранж
Как освоить глубокое обучение и не завязнуть в его деталях? Как быстро разобраться в его принципах, тонкостях и технических приемах с помощью примеров и кода? Все ответы здесь. Не пропустите новый источник практического глубокого обучения.
Орен Эциони (Oren Etzioni), профессор Вашингтонского университета, исполнительный директор, Институт ИИ Аллена
Эта книга — редкая жемчужина, тщательно проработанный и высокоэффективный учебный продукт, отточенный несколькими годами повторений не на одной тысяче студентов, одним из которых являюсь и я. Курс Fast.ai чудесным образом изменил мою жизнь и, без сомнений, может сделать то же самое для вас.
Джейсон Антик (Jason Antic), создатель DeOldify
Данная книга уже в первых главах учит эффективно использовать глубокое обучение. После этого в ней тщательно, но на доступном уровне рассматриваются внутренние процессы моделей машинного обучения и фреймворков. Хотел бы я иметь под рукой такую книгу, когда только начинал осваивать машинное обучение!
Эммануэль Амейсен (Emmanuel Ameisen), автор приложений на основе машинного обучения
«Глубокое обучение — для всех» — утверждается в первой главе. Подобное заявление можно встретить и в других книгах, но здесь оно раскрывается в полной мере. Авторы обладают обширными знаниями и при этом способны доступно донести их людям, знакомым с программированием, но не имеющим опыта в машинном обучении. Сначала даются примеры, и только затем рассматривается теория. Для большинства людей это наилучший способ обучения. Здесь вы найдете приложения глубокого обучения для области компьютерного зрения, обработки естественного языка и табличных данных, а также ознакомитесь с такой важной темой, как этика данных, которой так не хватает многим книгам. Материал представляет собой один из лучших ресурсов для программиста, изучающего глубокое обучение.
Питер Норвиг (Peter Norvig), директор по исследованиям Google
Гуггер и Ховард создали идеальный источник знаний для тех, кто хоть немного знаком с программированием. Благодаря практическому подходу и предварительно написанному коду они отлично раскрывают тему глубокого обучения. Больше не нужно мучиться с теоремами и доказательствами абстрактных понятий. Уже в первой главе вы создадите свою модель глубокого обучения, а к концу книги сможете читать и понимать раздел «Методы» любой научной работы по глубокому обучению.
Кертис Ланглотц (Curtis Langlotz), директор центра использования искусственного интеллекта для медицины и обработки изображений, Стэнфордский университет
Эта книга проливает свет на самый черный из всех черных ящиков — глубокое обучение. Она позволяет начать активно экспериментировать с кодом, используя возможности Python. Глубоко затрагиваются этические последствия применения ИИ. Авторы показывают, как не допустить появления антиутопии.
Гийом Шасло (Guillaume Chaslot), сотрудник Mozilla
Меня часто спрашивают, как начать осваивать глубокое обучение. Я же всегда указываю на fastai. Эта книга решает, казалось бы, невыполнимую задачу, выступая понятным руководством для сложного предмета. При этом она полна передовых открытий, которые, без сомнения, оценят даже опытные разработчики.
Кристин Пейн (Christine Payne), специалист OpenAI
Чрезвычайно практичная и доступная книга, которая поможет быстро начать создавать собственные проекты. Это очень понятное и легко читаемое руководство по практическому глубокому обучению, которое окажется полезным для всех: от начинающих программистов до руководителей и менеджеров проектов. Такую книгу я мечтала иметь много лет назад!
Кэрол Райли (Carol Reiley), президент-учредитель и председатель Drive.ai
Компетентность Джереми и Сильвейна в области глубокого обучения, их практичный подход, а также участие в открытых проектах сделали их ключевыми фигурами в сообществе PyTorch. Книга является продолжением работы, которую ее авторы совместно с сообществом fast.ai делают для повышения доступности машинного обучения, что в дальнейшем окажет серьезное влияние на всю сферу ИИ.
Джером Песенти (Jerome Pesenti), вице-президент подразделения ИИ в Facebook
Сегодня глубокое обучение — одна из наиболее важных технологий. С ее помощью были достигнуты многие прорывы в сфере ИИ. Глубокое обучение больше не является областью, доступной только для ученых. Эта книга, основанная на популярном курсе fast.ai, делает глубокое обучение ближе всем тем, кто имеет опыт программирования. Обучение строится по целостному принципу, с помощью практических примеров и интерактивного сайта. Кстати, для кандидатов наук здесь тоже найдется много интересного.
Григорий Пятецкий-Шапиро (Gregory Piatetsky-Shapiro), президент KDnuggets
Эта книга — продолжение курса fast.ai, который я неустанно рекомендовал всем на протяжении нескольких лет. Она превратит вас из новичка в опытного практика буквально за считаные месяцы. Наконец-то появилось что-то стоящее!
Луи Монье (Louis Monier), учредитель Altavista; бывший глава Airbnb AI Lab
Рекомендуем эту книгу! В ней описаны продвинутые фреймворки, позволяющие без лишней суеты проработать реальные задачи ИИ и автоматизации. В итоге у вас остается время для часто игнорируемых тем, таких как безопасный перенос моделей в продакшен и этика данных.
Джон Маунт (John Mount) и Нина Зумель (Nina Zumel), авторы книги Practical Data Science with R
Эта книга предназначена для программистов и подойдет даже тем, у кого нет ученой степени. Хоть я и обладаю такой степенью, но я не программист. Так почему же меня попросили оценить ее? Думаю, чтобы я рассказал вам, что она чертовски крута!
Прочитав первые две страницы первой главы, вы узнаете, как с помощью всего четырех строк кода и менее одной минуты вычислений получить эталонную сеть, способную отличать кошек от собак. Во второй главе вы перейдете от модели в продакшен, узнав, как быстро разместить приложение в вебе, не прибегая к HTML или JavaScript и не имея собственного сервера.
Эта книга как луковица. Вы получаете полноценный пакет с наилучшими возможными настройками. Если потребуется что-то переделать, то вы просто снимаете внешний слой. Нужны дополнительные настройки? Можно продолжить снимать оболочки. Еще? Углубляйтесь до уровня использования только PyTorch. На всем 600-страничном путешествии вас будут направлять три голоса, предлагая свою точку зрения.
Альфредо Канциани (Alfredo Canziani), профессор Нью-Йоркского университета NYU
Это доступная и построенная на принципе диалога книга, которая рассказывает об основах и понятиях глубокого обучения. Авторы с самого начала приводят практические примеры, а теорию — по мере необходимости. Практик может начать знакомство с миром глубокого обучения на примерах в первой половине книги, а глубокие принципы откроются уже во второй части. И наконец-то все мифы будут окончательно развеяны.
Джош Паттерсон (Josh Patterson), Patterson Consulting
Введение
Глубокое обучение (deep learning, DL) — новая мощная технология, и мы считаем, что ее следует использовать в разных дисциплинах. Эксперты, скорее всего, найдут новые возможности ее применения, и нам хотелось бы, чтобы специалисты различного профиля также включились в процесс обучения.
По этой причине и не только Джереми принял участие в создании fast.ai, организации, которая стремится сделать глубокое обучение доступным с помощью бесплатных онлайн-курсов и ПО. Сильвейн — инженер-исследователь в Hugging Face. До этого он занимал должность ученого-исследователя в fast.ai, а также преподавал математику и computer science по программе подготовки студентов к поступлению в элитные университеты Франции. Мы вместе написали эту книгу, чтобы помочь как можно большему числу людей начать использовать глубокое обучение.
Для кого эта книга
Если вы новичок в области глубокого и машинного обучения, эта книга для вас. Но желательно уметь писать код на Python.

Если же код вы раньше не писали, то и это не проблема. Первые три главы написаны так, чтобы руководители, менеджеры по продукту и другие специалисты без труда поняли наиболее важные аспекты глубокого обучения. Встречая в тексте отрывки кода, просматривайте их, чтобы сформировать интуитивное понимание его работы. Мы же будем объяснять код строка за строкой. В этом случае не так важен синтаксис, как высокоуровневое понимание.
Если вы уверенно себя чувствуете в глубоком обучении, то все равно найдете в книге много полезного. Мы покажем, как добиваться высоких результатов, и познакомим вас с новейшими передовыми техниками. Вы увидите, что для этого не требуется глубокое знание математики. Нужны лишь здравый смысл и упорство.
Что нужно знать
Единственное (желательное) требование — умение писать код (года опыта будет достаточно), лучше всего на Python, а также знание математики из курса старших классов. Даже если вы ее подзабыли, мы поможем освежить знания. Отличным вспомогательным ресурсом послужит Khan Academy (https://www.khanacademy.org/).
Мы не говорим, что в глубоком обучении нет математики сложнее той, что изучают в старшей школе, но мы дадим вам основы, которые понадобятся для понимания рассматриваемых тем (или направим на нужные ресурсы).
Начнем с общей картины и постепенно будем углубляться, поэтому время от времени вам может потребоваться изучить дополнительные темы (программирование чего-либо или математику). Это нормально — именно так мы и будем строить работу. Читайте книгу и изучайте дополнительные ресурсы по мере необходимости.

Все примеры кода доступны онлайн в виде блокнотов Jupyter (в главе 1 мы расскажем, что это). Это интерактивная версия книги, где можно выполнять код и экспериментировать с ним. Дополнительно об этом можно прочитать на сайте книги (https://book.fast.ai/). Там же содержится актуальная информация о настройке различных инструментов и дополнительные главы.
Чему вы научитесь
Прочитав эту книгу, вы будете знать следующее.
• Как обучать модели, достигающие эталонных результатов:
• в компьютерном зрении, включая распознавание изображений (например, классификацию фотографий домашних животных по породам), а также локализацию изображений и обнаружение (например, поиск животных на изображении);
• в обработке естественного языка (NLP), включая классификацию документов (например, анализ тональности) и языковое моделирование;
• в обработке табличных данных (например, прогнозировании продаж) с категориальными, непрерывными и смешанными данными, включая временной ряд;
• в совместной фильтрации (например, рекомендации фильмов).
• Как преобразовывать модели в веб-приложения.
• Почему и как работают модели глубокого обучения, а также как на основе этих знаний повысить точность, скорость и надежность таких моделей.
• Как работают новейшие техники глубокого обучения, наиболее актуальные в практических задачах.
• Как читать исследовательские работы по глубокому обучению.
• Как реализовывать алгоритмы глубокого обучения с нуля.
• Как анализировать этические последствия вашей работы, чтобы в итоге она позволила сделать мир лучше и не могла быть использована во вред.
Полный перечень в содержании, но для краткого представления мы приведем несколько техник, которые рассмотрим (не переживайте, если слова кажутся непонятными, — скоро вы все узнаете):
• аффинные функции и нелинейности;
• параметры и активации;
• случайная инициализация и трансфертное обучение (transfer learning);
• SGD, Momentum, Adam и другие оптимизаторы;
• свертки;
• пакетная нормализация;
• дропаут;
• увеличение (аугментация) данных;
• уменьшение весов;
• архитектуры ResNet и DenseNet;
• классификация и регрессия изображений;
• вложения;
• рекуррентные нейронные сети (RNN);
• сегментация;
• U-Net
• и многое другое!

В конце каждой главы вы найдете тест. Он поможет закрепить полученные знания — если (мы надеемся!) вы сможете ответить на все вопросы. Кстати, один из рецензентов книги (спасибо, Фред!) сказал, что предпочитает начинать главу именно с вопросника, чтобы сразу понимать, на что обращать внимание.
Предисловие
Глубокое обучение весьма быстро стало популярной методикой, которая решает и автоматизирует задачи в области компьютерного зрения, робототехники, здравоохранения, физики, биологии и т.д. К приятным особенностям глубокого обучения можно отнести его сравнительную простоту. Есть много софта, благодаря которому буквально за несколько недель можно понять основы и освоить необходимые техники.
Здесь открывается целый мир творчества. Вы используете полученные знания для решения задач с данными, наблюдая, как машина справляется с этими задачами за вас. Затем вы приближаетесь к новому этапу, когда, создав модель глубокого обучения, понимаете, что работает она не так, как вы рассчитывали. И дальше вы начинаете искать и изучать новейшие исследования в глубоком обучении.
Эта область охватывает невероятный объем знаний — теорию и великое множество техник и инструментов, стоящих за ней. Надо признать, что люди склонны объяснять простое сложным языком. Ученые используют в своих работах непонятные слова и математические выражения, и кажется, что ни посты, ни туториалы не освещают нужную информацию доступным образом. Инженеры и программисты предполагают, что вы уже знаете, как работают GPU, и разбираетесь в малоизвестных инструментах.
Именно здесь закрадывается мысль, что неплохо бы иметь наставника или друга, которому можно задать вопросы. Кого-то, кто уже бывал в похожей ситуации и знает и инструменты, и математику, кто сможет рассказать о наилучших исследованиях, эталонных техниках и продвинутых инженерных решениях, до смешного упрощая задачу. Я был в похожей ситуации около десяти лет назад, когда только начинал знакомиться с машинным обучением (machine learning, ML). Несколько лет я с трудом понимал работы, где была математика. Меня окружали хорошие наставники, которые здорово помогали, но чтобы начать уверенно использовать машинное и глубокое обучение, потребовались годы. Это послужило мотивом принять участие в разработке PyTorch, фреймворка, делающего глубокое обучение доступным.
Джереми Говард и Сильвейн тоже были на вашем месте. Они начали осваивать и применять глубокое обучение, не являясь учеными или инженерами в области ML. Как и я, Джереми и Сильвейн учились несколько лет и в итоге стали не только экспертами, но и лидерами. Но в отличие от меня, они делали все возможное, чтобы в будущем другим людям не пришлось идти по такому же сложному пути. Они разработали отличный курс под названием fast.ai, который делает передовые техники глубокого обучения доступными для тех, кто умеет программировать. Сотни тысяч желающих окончили этот курс, став отличными практиками.
В книге Джереми и Сильвейн используют простые слова и поясняют каждое понятие, доступно описывая передовые техники глубокого обучения и эталонные исследования.
Вас познакомят с последними достижениями в области компьютерного зрения, научат обработке естественного языка и дадут основы математики. Но на этом веселье не заканчивается — ведь затем вам покажут, как реализовать ваши идеи в продакшене. Пускай сообщество fast.ai, объединяющее тысячи практиков онлайн, станет вашей семьей, где все люди могут обсуждать и находить решения любых проблем.
Я очень рад, что вы взялись за эту книгу, и надеюсь, она вдохновит вас на правильное использование глубокого обучения, независимо от области решаемой задачи.
Сумит Чинтала (Soumith Chintala), соавтор PyTorch
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
На веб-сайте издательства www.piter.com вы найдете подробную информацию о наших книгах.
Часть I. Глубокое обучение на практике
Глава 1. Путешествие в мир глубокого обучения
Приветствуем вас и хотим поблагодарить за возможность попутешествовать с вами по миру глубокого обучения, как бы далеко вы в нем ни зашли. Поговорим сначала немного о том, что вас ждет на страницах книги, представим основные принципы, стоящие за глубоким обучением, и обучим нашу первую модель для различных задач. Неважно, есть ли у вас опыт работы в технической сфере (но если есть, то замечательно), — эту книгу мы написали понятным для широкой аудитории языком.
Глубокое обучение для всех
Многие предполагают, что для успеха в глубоком обучении нужны разные труднодоступные материалы. Но как вы увидите позже, это ошибочное мнение. В табл. 1.1 перечислено то, что вам совершенно не понадобится для достижения успеха.
Таблица 1.1. Что НЕ нужно для глубокого обучения
| Миф |
Правда |
| Много математики |
Программы старших классов школы достаточно |
| Много данных |
Мы встречали рекордные результаты с использованием <50 элементов данных |
| Дорогое оборудование |
Все необходимое для работы вы можете получить бесплатно |
Глубокое обучение — это компьютерная методика для извлечения и преобразования данных. Область ее использования простирается от распознавания человеческой речи до классификации образов животных. Делается это через несколько слоев нейронных сетей, каждый из которых получает вводные от предыдущего и постепенно их уточняет. Слои обучаются через алгоритмы, которые минимизируют ошибки и одновременно повышают точность. Таким образом сеть учится выполнять конкретные задачи. В следующем разделе мы подробно рассмотрим алгоритмы обучения.
В глубоком обучении кроется мощь, гибкость и простота. Именно поэтому мы верим, что его следует применять во многих дисциплинах, включая гуманитарные и технические науки, искусство, медицину, финансы и многое другое. Вот вам личный пример: несмотря на отсутствие опыта в медицине, Джереми организовал Entilic — компанию, использующую алгоритмы глубокого обучения для постановки диагнозов. Спустя всего несколько месяцев после запуска компании было объявлено, что используемые алгоритмы способны обнаруживать злокачественные опухоли точнее, чем рентгенологи (https://oreil.ly/aTwdE).
Вот список лишь некоторых из множества задач, для которых глубокое обучение или использующие его методы являются лучшими в мире.
Обработка естественного языка (NLP)
Ответы на вопросы; распознавание речи; классификация документов; обнаружение имен, дат и т.п. в документах; поиск статей, содержащих определенное понятие.
Компьютерное зрение
Интерпретация снимков со спутников и дронов (например, для предупреждения стихийных бедствий), распознавание лиц, захват изображений, чтение дорожных знаков, обнаружение автономными транспортными средствами пешеходов и других транспортных средств.
Медицина
Обнаружение аномалий на радиологических снимках, включая КТ, МРТ и рентген; подсчет признаков патологий на слайдах; измерение признаков в ультразвуке; диагностирование диабетической ретинопатии.
Биология
Свертывание белков; классификация белков; ряд задач геномики, включая секвенирование «опухоль — норма» и классификацию клинически значимых генетических мутаций; классификация клеток; анализ белков и белковых взаимодействий.
Создание изображений
Раскрашивание изображений, увеличение их разрешения, удаление шума, преобразование изображений в произведения искусства, оформленные в стиле известных художников.
Системы рекомендаций
Веб-поиск, рекомендации, создание домашней страницы.
Игры
Шахматы, го, большинство видеоигр от Atari, разные стратегии в реальном времени.
Робототехника
Обработка сложных для обнаружения объектов (например, прозрачных, блестящих, с отсутствием текстур) или тех, которые сложно захватить.
Другие сферы
Финансовое и логистическое прогнозирование, перевод текста в речь и многое другое…
Хотя глубокое обучение и находит столь разнообразное применение, в основе практически всех его решений лежит один инновационный тип модели: нейронная сеть.
Но нейросети не настолько новы. И чтобы во всем разобраться, начнем с небольшого исторического экскурса.
Нейронные сети: краткая история
В 1943 году нейрофизиолог Уоррен Маккаллок (Warren McCulloch) и логик Уолтер Питтс (Walter Pitts) занялись разработкой математической модели искусственного нейрона. В работе «Логическое исчисление идей, относящихся к нервной активности» они заявили следующее:
Из-за взаимодействия нейронов, характеризуемого как «все или никто», нейронные события и отношения между ними можно трактовать через логику высказываний. Выяснилось, что поведение каждой сети можно описать в этих терминах.
Маккаллок и Питтс поняли, что упрощенную модель реального нейрона можно представить с помощью простого сложения и определения порога (рис. 1.1). Питтс был самоучкой и к 12 годам уже получил предложение учиться в Кэмбриджском университете у великого Бертранда Рассела. Он отказался, как и от всех остальных предложений о присвоении ученых степеней и руководящих должностей, которые получал в течение жизни. Большая часть его выдающихся работ была создана им во времена, когда у него даже не было собственного жилья. Несмотря на отсутствие официально признанного положения и увеличивающуюся социальную изоляцию Питтса, его работа с Маккаллоком серьезно заинтересовала психолога Фрэнка Розенблатта (Frank Rosenblatt).
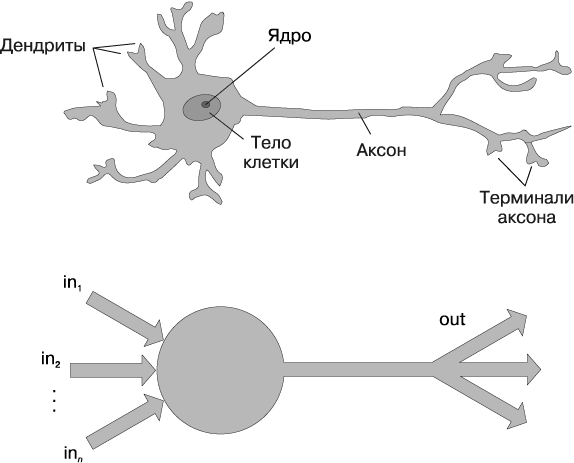
Рис. 1.1. Естественный и искусственный нейроны
Розенблатт усовершенствовал искусственный нейрон, чтобы тот смог обучаться. Более того, он работал над созданием первого устройства, использующего эти принципы: перцептрона «Марк-1». В своей работе The Design of an Intelligent Automaton Розенблатт писал об этом так: «Мы готовимся узреть рождение такой машины — машины, способной воспринимать, распознавать и идентифицировать свое окружение, не требуя какого-либо обучения или контроля со стороны человека». Перцептрон был создан и мог успешно распознавать простые формы.
Профессор Массачусетского технологического института (MIT) Марвин Мински (Marvin Minsky) (который в школе учился в одном классе с Розенблаттом!) совместно с Сеймуром Папертом (Seymour Papert) написал книгу Perceptrons (MIT Press), в которой рассказывалось об изобретении Розенблатта. В этой книге они показали, что один слой таких устройств не способен изучить простые, но критически важные функции, например XOR. Кроме этого, они показали, что устранить эти ограничения можно через использование нескольких слоев устройств. К сожалению, широко были приняты только первые из этих выводов, и в итоге глобальное научное сообщество практически полностью прекратило изучение нейронных сетей на последующие 20 лет.
Наиболее же значительным трудом в этой области за последние 50 лет стала многотомная работа Parallel Distributed Processing (PDP) («Параллельная распределенная обработка»), написанная Дэвидом Румельхартом (David Rumelhart), Джеймсом Макклиландом (James McClelland) и исследовательской группой PDP. Она была издана MIT Press в 1986 году. В первой главе высказывается та же идея, о которой когда-то говорил Розенблатт:
Люди умнее современных компьютеров, потому что человеческий мозг использует базовую вычислительную архитектуру, а она больше подходит для решения задач по обработке естественной информации, в которых люди так хороши… Мы создадим вычислительную структуру для моделирования когнитивного процесса, которая превзойдет другие структуры и окажется более приближенной к модели вычисления, характерной для мозга.
В качестве предпосылки PDP подразумевает, что принцип работы традиционных компьютерных программ отличается от принципа работы головного мозга, в связи с чем эти программы (на тот момент) плохо справлялись с задачами, которые мозг решал легко (например, распознавание объектов на картинках). Авторы заявляли, что подход PDP был «ближе других структур» к модели функционирования человеческого мозга, вследствие чего он сможет лучше справляться с такими задачами.
В действительности подход, заложенный в PDP, очень похож на используемый в современных нейронных сетях. Согласно той книге для параллельной распределенной обработки требовалось следующее:
• набор блоков обработки;
• состояние активации;
• функция вывода для каждого блока;
• паттерн связей между блоками;
• правило распространения для распространения шаблонов активности через сеть взаимосвязей;
• правило активации для объединения вводов, влияющих на блок, с текущим состоянием этого блока, чтобы можно было генерировать его вывод;
• правило обучения, согласно которому модели связей изменяются в процессе получения опыта;
• среда, в которой система должна функционировать.
В этой книге мы увидим, что современные нейронные сети отвечают всем перечисленным требованиям.
В 1980-х большинство моделей создавались со вторым слоем нейронов, что помогало избежать проблемы, выявленной Мински и Папертом (это была их «модель связей между нейронами» для использования предыдущей структуры). Нейронные сети действительно широко использовались на протяжении 80-х и 90-х годов прошлого века в реальных практических проектах. Тем не менее недопонимание теоретических сложностей в очередной раз привело к замедлению развития области. Считалось, что добавления всего одного дополнительного слоя нейронов должно хватать, чтобы такие сети могли аппроксимировать любую математическую функцию, но на практике эти сети зачастую оказывались слишком большими и медленными для эффективного использования.
И хотя исследователи еще 30 лет назад показали, что для получения хорошей практической производительности необходимо использовать больше нейронных слоев, этот принцип был широко принят и начал применяться только в течение последнего десятилетия. Нейронные сети наконец-то приближаются к реализации собственного потенциала. К этому привело развитие компьютерного оборудования, позволившего использовать большее число слоев, а также повышение доступности данных и доработка алгоритмических приемов, что в совокупности упростило и ускорило обучение нейронных сетей. Теперь мы получили то, что обещал нам Розенблатт: «машину, способную воспринимать, узнавать и идентифицировать окружение без какого-либо обучения или контроля со стороны человека».
Именно такие программы вы и будете учиться создавать по мере прочтения данной книги. Но сначала, раз уж мы собираемся провести вместе много времени, познакомимся поближе…
Кто мы
Мы — это Сильвейн и Джереми, ваши гиды в предстоящем путешествии. Надеемся, что вы сочтете нас подходящими на эту роль.
Джереми использует и преподает машинное обучение на протяжении почти 30 лет. Применять нейронные сети он начал 25 лет назад. За все это время он курировал многие компании и проекты, использующие в своей основе ML. К его достижениям можно отнести основание первой компании Enlitic, занимающейся глубоким обучением в сфере медицины, а также деятельность на посту президента и научного руководителя в Kaggle — крупнейшем мировом сообществе машинного обучения. Совместно с доктором Рейчел Томас (Rachel Thomas) он основал fast.ai, организацию, разработавшую учебный курс, на котором основывается данная книга.
Во врезках вы будете встречать наши комментарии:

Всем привет! Меня зовут Джереми! Возможно, вам будет интересно узнать, что у меня нет формального технического образования. Я отучился на бакалавра философии и более серьезных ученых степеней не получал. Мне было гораздо интереснее заниматься практическими задачами, чем изучать теорию, поэтому в студенческие годы я на полную ставку работал в консалтинговой фирме McKinsey and Company. Если вы тоже предпочитаете заниматься делом, а не тратить годы, изучая абстрактные концепции, то поймете, о чем я говорю. Не пропускайте мои комментарии — в них вы найдете информацию, предназначенную для тех, кто не имеет глубокого математического или технического бэкграунда, то есть для таких же людей, как я сам.
Сильвейн же хорошо понимает суть технического образования. Он написал десять учебников по математике, охватывающих всю продвинутую программу изучения математики во Франции!

В отличие от Джереми, я не тратил годы на программирование и применение алгоритмов машинного обучения. Напротив, я лишь недавно познакомился со сферой ML, просматривая видеокурсы Джереми по программе fast.ai. Так что если вы тоже не открывали терминал и не писали инструкции в командной строке, то мы найдем общий язык. В моих врезках представлена информация для тех, кто хорошо ориентируется в математике или имеет техническое образование, но не имеет реального опыта программирования.
Курс fast.ai прошли сотни тысяч студентов со всего мира. Сильвейн же, по мнению Джереми, выделялся среди всех встречавшихся ему за годы обучения студентов, в связи с чем он в итоге стал сначала сотрудником fast.ai, а затем в соавторстве с Джереми написал библиотеку ПО fastai.
В нашем дуэте представлено лучшее от обоих миров: эксперт в математике и эксперт в программировании и машинном обучении, которые при этом знают, каково это — не разбираться в математике или в написании кода.
Любой, кто смотрел спортивные передачи, знает, что если действия команды комментируют двое, то им нужен третий участник для «особых комментариев». Таким комментатором будет Алексис Галлахер (Alexis Gallagher). У Алексиса очень разнообразный опыт: он занимался исследованиями в области математической биологии, писал киносценарии, был исполнителем-импровизатором, консультантом в фирме McKinskey (как и Джереми!), программировал на Swift и даже занимал должность технического директора.

Я решил, что пришло время узнать об этих ваших искусственных интеллектах. Перепробовал я очень многое… Но на самом деле у меня нет опыта разработки моделей ML. И все же… Насколько это может быть сложно? По ходу книги я собираюсь учиться вместе с вами. Заглядывайте в мои комментарии — здесь вас ждут подсказки, которые пригодились мне самому на моем пути. Надеюсь, что и для вас они окажутся полезны.
Как изучать глубокое обучение
Профессор Гарварда Дэвид Перкинс, написавший книгу Making Learning Whole, имеет богатейший опыт преподавания. Основная его идея состоит в обучении с помощью целостного подхода. Это означает, что если вы учите людей играть в бейсбол, то сначала ведете их на матч или на площадку для игры. Вы не учите их, как наматывать шпагат, чтобы сделать бейсбольный мяч с нуля, и не рассказываете о физических свойствах или коэффициентах трения мяча о биту.
Пол Локхарт (Paul Lockhart), доктор математических наук Колумбийского университета, бывший профессор Университета Брауна, а также учитель математики полного курса, в своем известном эссе A Mathematician’s Lament («Плач математика», https://oreil.ly/yNimZ) рисует мрачный мир, где музыке и искусству обучают так же, как математике. Детям не разрешается слушать музыку или играть, пока они не проведут более десяти лет за освоением нотной грамоты и теории, бесконечно перенося на уроках ноты в другую тональность. В художественном же классе студенты изучают краски и кисти, но рисовать им разрешается только после поступления в колледж. Звучит абсурдно, не так ли? А ведь именно так преподают математику: мы требуем, чтобы студенты годами занимались механическим запоминанием и изучением сухих, разрозненных основ, которые, как мы их заверяем, пригодятся в дальнейшем, когда многие из них уже просто бросят изучение этого предмета.
К сожалению, именно с этого и начинаются многие обучающие программы по глубокому обучению: в них учащихся просят выучить матрицы и теоремы Тейлора для аппроксимации функций потерь, не приводя никаких рабочих примеров кода. Мы не против теории аппроксимации. Мы ее любим — Сильвейн даже преподавал ее в колледже, но мы не считаем, что это лучшая отправная точка для знакомства с глубоким обучением.
В глубоком обучении очень важно регулярно корректировать модель, чтобы она с каждым разом все лучше выполняла поставленную задачу. Вот тогда вы и начинаете изучать соответствующую теорию. Но для начала у вас должна быть модель. Почти всему мы учим на реальных примерах. По мере создания этих примеров мы будем постепенно углубляться и покажем, как совершенствовать свои проекты. Шаг за шагом вы будете изучать необходимые теоретические основы в соответствующем контексте и понимать, что и как работает.
Итак, мы обязуемся, что на протяжении книги будем следовать этим принципам.
Целостный подход обучения
Начнем с того, что покажем, как использовать завершенную рабочую эталонную сеть глубокого обучения для решения реальных задач с помощью простых, но наглядных инструментов. Затем постепенно мы будем все глубже и глубже вникать в то, как создаются эти инструменты, как создаются инструменты для создания инструментов и т.д.
Обучение только на примерах
Мы не будем жонглировать алгебраическими символами, а дадим вам контекст и цель, которые можно понять интуитивно.
Максимальное упрощение
Мы провели годы за разработкой инструментов и преподаванием методов, которые делают некогда сложные темы простыми.
Устранение барьеров
Глубокое обучение до этого времени было областью для избранных. Мы делаем ее открытой и даем возможность поработать в ней каждому.
Сложнейшая часть глубокого обучения при использовании на практике: откуда вам знать, что данных достаточно, что они находятся в нужном формате, правильно ли обучается ваша модель и что делать, если неправильно? Именно поэтому мы делаем ставку на обучение в процессе работы. Как и в случае с базовыми навыками в науке о данных, в глубоком обучении вы совершенствуетесь только через практический опыт. Попытки тратить чересчур много времени на теорию могут привести к обратным результатам. Главное — просто заниматься написанием кода и стараться решать задачи: теория придет позже, когда у вас уже будет контекст и мотивация.
Иногда вам будет тяжело, местами вы будете застревать, но не сдавайтесь! Возвращайтесь к той части книги, в которой полностью разобрались, а затем не спеша продолжайте читать с этого места в поиске первого непонятного момента. Затем постарайтесь самостоятельно поэкспериментировать с кодом, погуглите дополнительные уроки по возникшему вопросу — это поможет найти иной угол обзора и разобраться. Абсолютно нормально, что при первом прочтении некоторые моменты, особенно код, будут непонятны. Иногда бывает сложно понять материал последовательно, не забегая вперед. Бывает, что все встает на свои места, когда вы получаете больше контекста из последующего материала, показывающего более общую картину. Поэтому если вы вдруг застрянете в каком-то разделе, то попробуйте перейти дальше, отметив, что к этому разделу нужно вернуться позднее.
Чтобы достичь успеха в области глубокого обучения, не требуется особая академическая подготовка. Многие важнейшие прорывы в исследованиях и самой индустрии были сделаны людьми, не имеющими ученых степеней. Например, можно привести работу Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks (https://oreil.ly/JV6rL) — один из наиболее влиятельных трудов последнего десятилетия, который был процитирован более 5000 раз. А написал его Алек Рэдфорд (Alec Radford) еще в годы своего студенчества. Илон Маск — генеральный директор компании Tesla, решающей чрезвычайно сложные задачи по созданию беспилотных машин, говорит (https://oreil.ly/nQCmO):
Ученая степень точно не требуется. Важно лишь глубокое понимание ИИ и способность реализовывать нейронные сети так, чтобы они были действительно полезны (и последнее — очень трудно). При этом неважно, окончили вы вообще среднюю школу или нет.
Для достижения успеха вам нужно будет применять полученные в этой книге знания в собственных проектах и упорно продолжать делать свое дело.
Ваши проекты и мышление
Не так важно, хотите ли вы определять болезни растений по фотографиям их листьев, генерировать узоры для вязания, диагностировать туберкулез по рентгеновскому снимку, мы поможем начать использовать глубокое обучение для решения насущных задач максимально быстро (с помощью предварительно обученных другими моделей), а затем будем постепенно углубляться в подробности процесса. После прочтения следующей главы вы узнаете, как использовать глубокое обучение для решения своих задач с эталонной точностью. (Если вам не терпится поскорее приступить к работе с кодом, смело переходите к ней.) Есть миф, что для работы с глубоким обучением требуются огромные вычислительные ресурсы и наборы данных объемом как у Google, но это совершенно не так.
Какие же задачи подходят для хороших тестовых примеров? Можно обучить модель различать картины Пикассо и Моне или выбирать фотографии дочери, а не сына. Это помогает сосредоточиться на ваших увлечениях и пристрастиях — выбор четырех или пяти небольших проектов вместо стремления решить одну огромную суперзадачу упростит начало изучения данной области. Поскольку в этом деле очень легко застрять, излишнее рвение на ранних этапах может дать обратный эффект. Но когда вы уже освоите основы, можете нацеливаться на решение более серьезных задач.

Глубокое обучение можно использовать для решения почти любой задачи. Например, моим первым стартапом была компания FastMail, запущенная в 1999 году. Она предоставляла расширенные сервисы электронной почты (кстати, она работает и по сей день). В 2002 году, стремясь улучшить качество сортировки писем и защиты пользователей от спама, я настроил ее на использование простейшей формы глубокого обучения, а именно однослойных нейронных сетей.
Как правило, люди, успешно справляющиеся с глубоким обучением, отличаются любопытством. Покойный физик Ричард Фейнман — пример того, кто, по нашему мнению, преуспел бы в глубоком обучении: в основу его работы над движением субатомных частиц легло увлеченное наблюдение за колеблющимися в воздухе тарелками для игры в фрисби.
А теперь сфокусируемся на том, что конкретно вы будете изучать, и начнем с софта.
ПО: PyTorch, fastai и Jupyter (почему это важно)
Мы завершили сотни проектов машинного обучения, используя десятки разных пакетов и множество языков программирования. В fast.ai мы подготовили онлайн-курсы с помощью большинства из основных пакетов ML и DL. После того как в 2017 году появился PyTorch, мы провели более тысячи часов за его тестированием, прежде чем решили, что будем использовать этот пакет в будущих курсах, разработке ПО и исследованиях. С тех пор PyTorch стал самой быстро растущей библиотекой глубокого обучения, которая уже применяется в большинстве исследовательских работ, представленных на престижных конференциях. По большому счету, это главный показатель используемости в индустрии, потому что эти работы в итоге применяются в коммерческих продуктах и сервисах. Мы выяснили, что PyTorch — это наиболее гибкая и выразительная библиотека для глубокого обучения. Она не жертвует скоростью ради простоты, обеспечивая и то и другое.
PyTorch лучше всего работает как базовая библиотека низкого уровня, предоставляющая основные операции для высокоуровневой функциональности. fastai же — это наиболее популярная библиотека для добавления этой высокоуровневой функциональности поверх PyTorch. Кроме того, она отлично подходит для целей этой книги, потому что уникальным образом предоставляет глубокую многослойную архитектуру ПО (об этом многослойном API есть даже научная статья (https://oreil.ly/Uo3GR)). По мере освоения глубокого обучения мы будем также погружаться в слои fastai. Эта книга рассказывает о ее второй версии, являющейся полностью переработанным вариантом со множеством уникальных возможностей.
Не имеет значения, какое ПО вы изучите, — для переключения с одной библиотеки на другую требуется всего несколько дней. По-настоящему же важным является изучение основ глубокого обучения и его техник. Мы сосредоточимся на коде, который максимально отчетливо выражает необходимые для освоения принципы. При объяснении высокоуровневых принципов мы будем использовать высокоуровневый код fastai. Там же, где будет рассказываться о низкоуровневых принципах, будем использовать низкоуровневый PyTorch или даже чистый код на Python.
Хотя может показаться, что новые библиотеки глубокого обучения появляются достаточно часто, вам нужно быть готовыми к существенному росту темпа изменений в ближайшие месяцы и годы. Поскольку все больше людей приходят в эту область, они будут привносить свои навыки и идеи, стремясь разработать больше новых продуктов. Следует понимать, что какие бы конкретные библиотеки и ПО вы ни изучали сегодня, они устареют буквально через год или два. Только подумайте о количестве изменений в библиотеках и наборах технологий, которые постоянно происходят в мире веб-программирования, — гораздо более зрелой и медленно растущей области, чем глубокое обучение. Мы твердо уверены, что при освоении этой сферы нужно уделять внимание как пониманию и применению ее основных техник, так и развитию способности быстро осваивать новые техники с инструментами по мере их появления.
К концу книги вы поймете практически весь код, лежащий внутри fastai (и большую часть PyTorch тоже), потому что в каждой главе мы будем уходить все глубже и глубже, показывая вам, что именно происходит при построении и обучении моделей. Это означает, что вы освоите наиболее важные практики, используемые в современном глубоком обучении. При этом вы узнаете не только о способах их использования, но и о принципах их работы. Если затем вы захотите использовать эти подходы в другом фреймворке, то для этого у вас уже будут необходимые знания.
Поскольку написание кода и эксперименты — это важнейшая часть освоения глубокого обучения, потребуется хорошая платформа для работы с кодом. Наиболее популярная — Jupyter (https://jupyter.org/). Именно ее мы и будем использовать в книге. Мы покажем, как с ее помощью обучать модели и экспериментировать с ними, рассмотрим каждый этап конвейера предварительной обработки данных и разработки модели. Jupyter неспроста считается самым популярным инструментом для научной работы с данными в Python. Он мощный, гибкий и легкий в использовании. Уверены, вы его полюбите!
Давайте же посмотрим его в деле, обучив нашу первую модель.
Ваша первая модель
Мы уже говорили, что сначала научим вас создавать что-либо, а потом расскажем, как это работает. Мы начнем с обучения классификатора изображений распознаванию кошек и собак. Для обучения этой модели и экспериментов с ней вам понадобится сделать кое-какую начальную настройку. Не волнуйтесь, это совсем не сложно.

Не пропускайте этап настройки, даже если сперва он покажется пугающим, особенно если у вас мало или совсем нет опыта в работе с терминалом или командной строкой. Большая часть из всего этого необязательна, и вы увидите, что простейшие серверы можно настроить с помощью обычного браузера. Но для успешного обучения параллельно с книгой нужно пробовать экспериментировать.
Настройка сервера глубокого обучения на GPU
Для работы вам понадобится доступ к компьютеру с NVIDIA GPU (к сожалению, другие производители GPU не полностью поддерживаются основными библиотеками глубокого обучения). Но мы не призываем вас покупать именно такое устройство. Даже если оно у вас уже есть, мы пока не предлагаем его использовать. Для настройки компьютера потребуется время и силы, а сейчас вам нужно все их сосредоточить на освоении глубокого обучения. Поэтому мы предлагаем вам арендовать компьютер, где все необходимое уже установлено и готово к работе.

Иначе называется графическим адаптером, или видеокартой. Особый вид процессора, который может обрабатывать тысячи отдельных задач одновременно. Разработан, в частности, для отображения 3D-сред в видеоиграх. Выполняемые им базовые задачи очень похожи на те, с которыми работают нейросети, в связи с чем GPU может обучать нейросети в сотни раз быстрее обычного CPU. GPU установлен в каждом современном компьютере, но лишь в некоторых используется подходящий для глубокого обучения.
Предпочтительные GPU-cерверы будут со временем меняться, так как компании появляются и исчезают, и цены тоже не стоят на месте. Мы поддерживаем актуальность списка рекомендуемых вариантов на сайте книги (https://book.fast.ai), так что можете перейти туда прямо сейчас и выполнить инструкции для подключения к предпочтительному GPU-серверу глубокого обучения. Не волнуйтесь: потребуется всего около двух минут, чтобы выполнить настройку для большинства платформ. При этом в ряде случаев даже не придется платить или использовать кредитную карту.

Внесу свою лепту: прислушайтесь к этому совету! Если вы любите компьютеры, то наверняка захотите настроить собственный. Будьте осторожны! Это реально, но сильно затягивает и отвлекает. Неспроста мы не назвали эту книгу «Все, что вы хотели знать об администрировании системы Ubuntu, установке драйверов Nvidia, apt-get, conda, pip и конфигурации Jupyter Notebook». Собрав и развернув производственную инфраструктуру ML на работе, я могу гарантировать, что она справляется со своей задачей, но при этом не связана с моделированием, как обслуживание самолета не связано с управлением его полетом.
Каждый представленный на сайте вариант содержит руководство, проследовав которому вы увидите экран как на рис. 1.2.
Рис. 1.2. Начальное представление Jupyter Notebook
Теперь вы готовы к запуску своего первого блокнота Jupyter!

Элемент ПО, позволяющий включать форматированный текст, код, изображения, видео и многое другое в один интерактивный документ. Благодаря своему широкому использованию и невероятному влиянию на многие академические области и индустрию, Jupyter получил высочайшую награду ACM Software System. Блокноты Jupyter наиболее активно используются специалистами по работе с данными для разработки моделей глубокого обучения и взаимодействия с ними.
Запуск первого блокнота
Блокноты пронумерованы по главам в том же порядке, в каком представлены в книге. Итак, первым в списке вы увидите блокнот, который нужно использовать сейчас. С его помощью вы обучите модель, способную распознавать фотографии собак и кошек. Для этого вам потребуется загрузить датасет собак и кошек, с помощью которого вы и обучите модель.
Датасет (набор данных) — это просто куча данных, которыми могут быть изображения, электронные письма, финансовые показатели, звуки или что угодно другое. Существует множество бесплатных датасетов, подходящих для обучения моделей. Одни из них созданы учеными для использования в исследованиях, другие сделаны доступными для конкурсов (среди ученых, изучающих данные, проводятся турниры, в которых участники соревнуются, чья модель окажется наиболее точной), а третьи являются побочными продуктами других процессов, например подготовки финансовой отчетности.

Есть два каталога, в которых находятся разные версии блокнотов. Каталог full содержит блокноты, использованные для создания этой книги. В них прописано все содержание и выводы. Пустая версия содержит те же заголовки и ячейки кода, но все выводы и содержание из них удалены. После прочтения раздела книги мы рекомендуем закрывать ее и прорабатывать именно пустые блокноты, чтобы проверить, удастся ли вам выяснить, что покажет каждая ячейка, прежде чем вы ее выполните. Также старайтесь вспомнить, что тот или иной код демонстрирует.
Откройте блокнот, просто щелкнув на нем. В открытом виде он будет выглядеть примерно так, как показано на рис. 1.3 (обратите внимание, что могут быть небольшие отличия в зависимости от платформы, но можно не обращать на них внимания).
Блокнот состоит из ячеек, которые делятся на два основных вида:
• содержащие форматированный текст, изображения и т.д. Они созданы с помощью языка разметки Markdown, о котором вы можете прочесть в приложении А;
• включающие код, который можно выполнить, вследствие чего вывод тут же отобразится внизу (им может быть простой текст, таблицы, изображения, анимация, звуки или даже интерактивные приложения).
Блокноты Jupyter могут находиться в одном из двух режимов: режим редактирования или режим команд. В первом режиме при наборе с клавиатуры знаки вводятся в ячейки обычным способом. А вот в режиме команд вы уже не увидите мигающего курсора, и у каждой клавиши на клавиатуре будет своя функция.
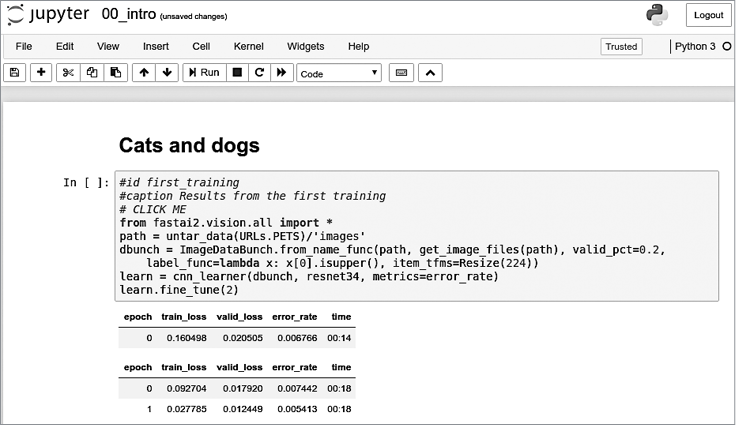
Рис. 1.3. Блокнот Jupyter
Прежде чем продолжить, нажмите клавишу Esc для перехода в режим команд (если вы уже находитесь в этом режиме, ничего не произойдет, поэтому нажмите на всякий случай). Вызвать полный список доступных функций можно нажатием клавиши H. Для выхода из этого вспомогательного экрана нажмите Esc. Обратите внимание, что в отличие от большинства программ в этом режиме выполнение команд не требует удержания Ctrl, Alt и т.п. — вы просто нажимаете нужную буквенную клавишу.
Скопировать ячейку можно нажатием клавиши С (сначала потребуется щелкнуть на этой ячейке, после чего она будет выделена рамкой; если она еще не выбрана, выберите ее). Для вставки скопированной ячейки нажмите клавишу V.
Щелкните на ячейке, начинающейся со строки # CLICK ME, чтобы выбрать ее. Первый знак в этой строке указывает, что далее следует комментарий Python, поэтому при выполнении ячейки он игнорируется. Остальная часть ячейки — это, как ни странно, полноценная система для создания и обучения эталонной модели, которая будет распознавать кошек и собак. Итак, приступим к ее обучению! Для этого просто нажмите Shift+Enter или кнопку Play на панели инструментов. Затем подождите несколько минут, в течение которых произойдет следующее.
1. Из коллекции датасетов fast.ai на используемый вами GPU-сервер будет загружен, а затем извлечен датасет под названием Oxford-IIIT Pet Dataset (https://oreil.ly/c_4Bv), содержащий 7349 изображений кошек и собак 37 пород.
2. Из интернета будет загружена предварительно обученная на 1,3 млн изображений модель.
3. Эта модель будет скорректирована с помощью последних достижений в технологии переноса обучения (transfer learning) для получения модели, распознающей собак и кошек.
Первые два шага выполняются только один раз на GPU-сервере. Если вы выполните ячейку повторно, она использует уже загруженные датасет и модель. Заглянем в содержимое ячейки и ее результаты (табл. 1.2):
# CLICK ME
from fastai.vision.all import *
path = untar_data(URLs.PETS)/'images'
def is_cat(x): return x[0].isupper()
dls = ImageDataLoaders.from_name_func(
path, get_image_files(path), valid_pct=0.2, seed=42,
label_func=is_cat, item_tfms=Resize(224))
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(1)
Таблица 1.2. Результаты первого обучения
| epoch |
train_loss |
valid_loss |
error_rate |
time |
| 0 |
0.169390 |
0.021388 |
0.005413 |
00:14 |
| epoch |
train_loss |
valid_loss |
error_rate |
time |
| 0 |
0.058748 |
0.009240 |
0.002706 |
00:19 |
Возможно, ваши результаты будут другими. На обучение влияет множество небольших произвольных вариаций. Однако в этом примере частота ошибок (error rate) обычно не превышает 0.02.

В зависимости от скорости вашей нейросети для загрузки предварительно обученной модели и датасета может потребоваться несколько минут. Само же выполнение может занять около минуты. Нередко для обучения моделей из этой книги нужно несколько минут, столько же потребуется и для ваших, поэтому есть смысл найти этому времени хорошее применение, чтобы не тратить его впустую. Например, перейти к чтению следующего раздела, пока модель обучается, или открыть еще один блокнот и поэкспериментировать с кодом.
Эта книга была написана в блокнотах Jupyter
Мы написали эту книгу, используя блокноты Jupyter, поэтому почти для каждого графика, таблицы и вычислений мы будем приводить точный код, с помощью которого вы сможете их повторить. По этой же причине вы очень часто будете видеть код сразу за таблицей, картинкой или просто текстом. Весь этот код можно найти на сайте книги (https://book.fast.ai/) и самостоятельно поэкспериментировать с выполнением и изменением каждого примера.
Вы только что видели, как в книге выглядит ячейка, выводящая таблицу. А вот пример ячейки, выводящей текст:
1+1
2
Jupyter всегда выводит или показывает результат последней строки (если таковая присутствует). Например, вот образец ячейки, выводящей изображение:
img = PILImage.create('images/chapter1_cat_example.jpg')
img.to_thumb(192)

Как же нам узнать, что модель работает хорошо? В последнем столбце таблицы указана частота ошибок, то есть доля неверно распознанных изображений. Частота ошибок служит в качестве метрики — полноценной и интуитивно понятной меры качества модели. В данном случае видно, что модель близка к идеалу, даже несмотря на то, что время обучения составило всего несколько секунд (без учета времени на загрузку датасета и предварительно обученной модели). В действительности еще десять лет назад такой точности не удавалось достичь никому.
В завершение убедимся, что эта модель на самом деле работает. Сделайте фото собаки или кошки. Если рядом с вами нет этих животных, то просто скачайте изображение из Google. Теперь выполните ячейку с определенным uploader. Это выведет кнопку для выбора изображения, которое требуется классифицировать.
uploader = widgets.FileUpload()
uploader
![]()
Теперь можете передать загруженный файл в модель. Убедитесь, что это отчетливый снимок собаки или кошки, а не рисунок, мультфильм или нечто подобное. Блокнот сообщит вам, узнает ли он на снимке собаку или кошку и насколько он уверен в своем выборе. Надеемся, что ваша модель отлично справится с задачей:
img = PILImage.create(uploader.data[0])
is_cat,_,probs = learn.predict(img)
print(f"Is this a cat?: {is_cat}.")
print(f"Probability it's a cat: {probs[1].item():.6f}")
Is this a cat?: True.
Probability it's a cat: 0.999986
Поздравляем вас с созданием первого классификатора!
Но что это значит? Что вы на самом деле сделали? А теперь несколько отвлечемся и взглянем на картину обобщенно.
Что такое машинное обучение
Ваш классификатор — это модель глубокого обучения. Как уже говорилось, такие модели используют нейронные сети, которые ведут свою историю от 50-х годов и только недавно раскрыли свой мощный потенциал благодаря последним прорывам в их исследовании.
Не менее важной деталью контекста является и то, что глубокое обучение — это всего лишь новая область, относящаяся к более общей дисциплине: машинному обучению. Для понимания сути происходящего в процессе обучения вашей модели классификации вам не нужно понимать само глубокое обучение. Достаточно увидеть, что ваша модель и процесс ее обучения выражают принципы, характерные для машинного обучения в целом.
Так что в этом разделе мы расскажем именно о машинном обучении. Мы познакомим вас с его ключевыми понятиями и проследим их до момента первого появления в научном эссе.
Машинное обучение, как и обычное программирование, — это способ заставить компьютеры выполнять поставленную задачу. Но как же нам использовать стандартное программирование для выполнения только что решенной нами задачи: распознавания собак и кошек по фотографиям? Нам понадобилось бы прописать для компьютера точные шаги, необходимые для ее решения.
Обычно при написании программы несложно указать такие шаги для выполнения нужных действий. Мы просто представляем себе, какие шаги нужно проделать, если решать задачу самим, а затем переводим их в код. Например, можно написать функцию, сортирующую список. Как правило, для такой задачи мы пишем функцию, структура которой изображена на рис. 1.4, где входные данные могут быть представлены неупорядоченным списком, а результаты — упорядоченным.

Рис. 1.4. Стандартная программа
Но для распознавания объектов на фото сделать это уже не так просто. Какие мы в таком случае предпринимаем шаги для распознавания? Мы не знаем этого, потому что весь процесс происходит у нас в голове неосознанно!
Еще на заре вычислительных технологий в 1949 году исследователь из IBM по имени Артур Сэмюэл (Arthur Samuel) начал разрабатывать иной подход к постановке компьютерам задач, который он назвал машинным обучением. В своем классическом эссе 1962 года Artificial Intelligence: A Frontier of Automation («Искусственный интеллект: передовая автоматизации») он писал:
Программирование компьютера для подобных вычислений — тяжелая задача. И не по причине сложности самого компьютера, а из-за необходимости прописывать ежеминутные шаги процесса в исчерпывающих подробностях. Любой программист вам скажет, что компьютеры — это не гигантские мозги, а гигантские тупицы.
Его основной идеей было, что вместо того, чтобы сообщать компьютеру конкретные шаги решения задачи, ему нужно показывать примеры ее решения, позволяя определить, как ее решить, самому. Такой способ оказался очень эффективным: к 1961 году его программа игры в шашки обучилась до такой степени, что победила чемпиона Коннектикута! Вот как он описывал свою идею (из того же эссе):
Предположим, мы организуем некоторые автоматические средства проверки эффективности любого текущего назначения веса с позиции фактической производительности и предоставим механизм изменения назначения веса для максимального увеличения этой производительности. Нам не нужно углубляться в детали такой процедуры, чтобы увидеть, что она полностью автоматизирована, и понять, что машина, запрограммированная таким образом, будет «учиться» на собственном опыте.
В этом коротком заявлении кроется ряд важнейших принципов:
• идея «назначения веса»;
• то, что каждое назначение веса имеет определенную «фактическую производительность»;
• необходимость наличия «автоматических средств» тестирования этой производительности;
• потребность в «механизме» (то есть еще одном автоматическом процессе) для повышения производительности через изменение назначений веса.
Рассмотрим все эти принципы по очереди, чтобы увидеть, как они соотносятся друг с другом на практике. Для начала нам нужно понять, что Сэмюэл подразумевал под назначением веса.
Веса — это просто переменные, и их назначение — присвоение им конкретных значений. Входные данные программы — значения, которые она обрабатывает с целью получения их результатов: например, получая на входе пиксели изображения и возвращая в виде результата классификацию dog. Назначения весов программы — это уже другие значения, которые определяют, как программа будет выполняться.
Поскольку они влияют на выполнение программы, в некотором смысле их можно назвать другим видом входных данных. Учитывая это, мы изменим рис. 1.4 и получим рис. 1.5.

Рис. 1.5. Программа, использующая назначение весов
Мы изменили имя блока с программа на модель, чтобы следовать современной терминологии и отразить модель как особый вид программы: тот, что может решать много разных задач, количество и разнообразие которых зависит от весов. Ее можно реализовать многими способами. Например, в программе шашек Сэмюэла разные значения весов приводили к использованию различных стратегий игры.
(Кстати, то, что Сэмюэл называл «весами», теперь принято называть параметрами модели, а термин «веса» выделен для конкретного типа этих параметров.)
Затем Сэмюэл сказал, что нам нужны автоматические средства тестирования эффективности любого текущего назначения веса с позиции фактической производительности. В случае программы, играющей в шашки, «фактическая производительность» модели отражалась бы тем, как хорошо она играет. При этом вы могли бы автоматически тестировать производительность двух моделей, настроив их играть друг против друга и наблюдая, какая из них обычно выигрывает.
Наконец, он говорит, что нам нужен механизм изменения распределения веса для максимального повышения производительности. Например, мы можем посмотреть на разницу в весах между побеждающей и проигрывающей моделью, а затем немного скорректировать эти веса для выигрыша.
Теперь мы можем понять, почему он сказал, что такая процедура может быть сделана полностью автоматической и… машина, запрограммированная таким образом, будет «учиться» на собственном опыте. Как только коррекция весов станет автоматической, обучение также станет полностью автоматическим. В этом случае уже не нам придется обучать модель, подстраивая ее веса вручную, а автоматизированному механизму, который произведет ее тонкую настройку на основе производительности.
На рис. 1.6 показана полная картина идеи Сэмюэла по обучению модели ML.

Рис. 1.6. Обучение модели ML
Обратите внимание на различие между результатами модели (например, ходами в шашках) и ее производительностью (например, выигрывает ли она игру или насколько быстро она ее выигрывает).
Также заметьте, что когда обучение модели завершено (то есть мы утвердили одно наилучшее итоговое назначение веса), тогда уже можно рассматривать веса как часть модели, поскольку дальше мы их не изменяем.
Следовательно, схема фактического использования модели после завершения ее обучения выглядит, как показано на рис. 1.7.

Рис. 1.7. Использование обученной модели как программы
Теперь она идентична начальной схеме на рис. 1.4, только слово программа заменено на модель. Это важное заключение: обученную модель можно рассматривать как стандартную компьютерную программу.

Обучение программ, подразумевающее самообучение компьютера на собственном опыте, а не ручное программирование всех отдельных шагов.
Что такое нейронная сеть
Не так уж сложно представить, как может выглядеть модель для программы по обучению игре в шашки. В ней может быть прописано несколько стратегий игры и определенный механизм поиска, после чего с помощью весов может выбираться определенная стратегия, область доски для выполнения поиска и т.д. Однако уже гораздо сложнее представить модель для распознавания изображений, понимания текста или многих других интересных задач.
Для этого нам понадобится определенная функция, которая будет достаточно гибкой, чтобы использоваться для решения любой поставленной задачи простым изменением весов. Удивительно, но такая функция есть! Это нейронная сеть, которую мы уже обсуждали. Таким образом, если рассматривать нейросеть как математическую функцию, то она оказывается чрезвычайно гибкой функцией, регулируемой весами. Математическое доказательство, известное как теорема об универсальной аппроксимации, показывает, что эта функция теоретически может решать любую задачу, достигая любого уровня точности. Факт такой гибкости нейросетей показывает, что на практике они часто оказываются подходящим видом модели, и вы можете сосредоточить свои усилия на их обучении, то есть на поиске удачных назначений веса.
Как же будет выглядеть этот процесс? Можно представить, что потребуется найти новый «механизм» для автоматического обновления веса для каждой задачи. Но это было бы очень утомительно. Нам же здесь нужен абсолютно общий способ обновления весов нейронной сети, чтобы она совершенствовалась при выполнении любой поставленной задачи. Удобно, что такой способ тоже есть!
Он называется стохастическим градиентным спуском (SGD). Подробности работы нейросети и SGD мы увидим в главе 4, где также рассмотрим теорему об универсальной аппроксимации. Сейчас же мы обратимся к словам самого Сэмюэла: «Не нужно углубляться в детали этой процедуры, чтобы увидеть, что ее можно сделать полностью автоматической, и понять, что машина, запрограммированная таким образом, будет “учиться” на собственном опыте».

Не волнуйтесь: ни SGD, ни нейронные сети не представляют математической сложности. Обе эти технологии практически полностью опираются на использование только сложения и умножения (но эти операции они производят в изобилии!). Обычно в ответ на разъяснение этих подробностей наши студенты с удивлением спрашивают: «И это все?»
Короче говоря, нейросеть — это конкретный вид модели ML, которая как раз соответствует изначальной концепции Сэмюэла. Особенность таких сетей в их повышенной гибкости, которая позволяет им решать необычайно широкий спектр задач простым нахождением подходящих весов. Это мощный инструмент, потому что стохастический градиентный спуск предоставляет нам способ находить значения этих весов автоматически.
Теперь уменьшим масштаб и вернемся к нашей задаче по классификации изображений с помощью схемы Сэмюэла.
Входными данными у нас являются изображения, а весами — веса в нейронной сети. Наша модель — это нейронная сеть, а результаты — значения, которые она вычисляет, например dog или cat.
А что насчет следующего элемента: автоматического средства тестирования эффективности любого текущего назначения веса с позиции производительности? Определить «фактическую производительность» достаточно легко: можно просто определить производительность нашей модели как точность ее прогнозирования правильных ответов.
Если все это объединить и предположить, что SGD является механизмом для обновления назначений весов, то становится очевидно, что классификатор изображений — это модель машинного обучения, как и предполагал Сэмюэл.
Немного терминологии глубокого обучения
Сэмюэл работал в 1960-е годы, и терминология с тех пор изменилась. Далее приведены современные термины глубокого обучения для всех рассмотренных нами элементов.
• Функциональная форма модели называется архитектурой (но будьте внимательны: иногда люди используют термин модель как синоним архитектуры, поэтому может возникнуть путаница).
• Веса теперь называются параметрами.
• Прогнозы вычисляются на основе независимой переменной, которой являются данные, не включающие метки.
• Результаты модели называются прогнозами.
• Потери — мера производительности.
• Потери зависят не только от прогнозов, но и от верности меток (также называемых целями или зависимыми переменными), например dog или cat.
На рис. 1.8 изображена обновленная схема с рис. 1.6 после внесения изменений.
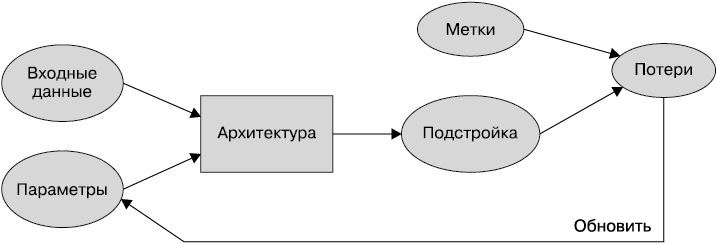
Рис. 1.8. Подробный цикл обучения
Характерные для ML ограничения
На основе этой схемы можно сделать фундаментальные выводы.
• Модель нельзя создать без данных.
• Модель может научиться работать только с шаблонами, найденными в используемых для ее обучения входных данных.
• Такой подход к обучению создает только прогнозы, но не рекомендуемые действия.
• Недостаточно иметь только образцы входных данных. Для этих данных также необходимы метки (например, картинок собак и кошек недостаточно для обучения модели; для каждой из них нужна метка, поясняющая, на какой из них собака, а на какой — кошка).
Исходя из наблюдений, мы заметили, что большинство организаций, заявляющих о недостатке данных, имеют в виду, что недостает именно маркированных данных. Если какая-либо организация заинтересована в выполнении какой-то задачи с помощью модели, то скорее всего, у них уже есть некоторые входные данные, в отношении которых они собираются применять эту модель. Кроме того, они наверняка уже выполняли эту задачу каким-то другим способом (например, вручную или с помощью эвристической программы), следовательно, от этих процессов у них тоже остались данные. Например, в практической радиологии наверняка будет архив медицинских снимков (поскольку они сохраняются для отслеживания изменений состояния пациентов), но эти снимки могут не иметь структурированных меток, содержащих список диагнозов или вмешательств (так как радиологи обычно создают отчеты в произвольной форме, а не структурированными данными). Мы будем много говорить о подходах к маркировке данных, потому что для глубокого обучения этот аспект очень важен.
Поскольку такие виды моделей ML могут только делать прогнозы (то есть стараться воспроизвести метки), это может привести к существенному разрыву между целями организации и возможностями модели. Например, вы узнаете, как создавать рекомендательную систему, способную прогнозировать, какие товары может приобрести пользователь. Эта система часто используется в коммерции, например, для настройки показа товаров на главной странице исходя из их популярности. Однако такая модель обычно создается на основе изучения пользователя и его истории покупок (входные данные), а также того, что он собирался купить или что просматривал (метки). Это означает, что модель с большей вероятностью сообщит вам о товарах, которые у пользователя уже есть или о которых он уже знает, а не о новых, которые могли бы его реально заинтересовать. Это противоположно тому, что делает, например, эксперт в книжном магазине, который задает вопросы для выяснения вашего вкуса и уже затем рассказывает об авторах или сериях, о которых вы никогда не слышали.
Еще один важный нюанс можно заметить при рассмотрении того, как модель взаимодействует со средой. В результате этого взаимодействия могут создаваться петли обратной связи.
1. Предиктивная полицейская модель создается на основе данных о местах прошлых арестов. На практике это скорее предсказывает не преступление, а арест, что отчасти отражается в смещениях, наблюдаемых в текущей работе полиции.
2. Полицейские могут использовать эту модель для выбора приоритетных мест наблюдения, что, естественно, приводит к повышению числа арестов в этих местах.
3. Данные об этих дополнительных арестах в дальнейшем будут использоваться для повторного обучения будущих версий модели.
Это пример положительной петли обратной связи: чем больше используется модель, тем более необъективными становятся данные, что приводит ко все большему искажению модели, и т.д.
Петли обратной связи могут также создавать проблемы в коммерческой сфере. К примеру, рекомендательная система видео может быть смещена в сторону рекомендации контента, популярного среди наиболее активных зрителей (например, любителей теорий заговоров и экстремистов), что приводит к повышению просмотра этими пользователями аналогичных видеоматериалов, в связи с чем такие материалы рекомендуются все больше и больше. Мы рассмотрим эту тему подробнее в главе 3.
Теперь, когда вы ознакомились с теорией, пора вернуться к нашему примеру кода и детальнее проанализировать элементы, соответствующие только что описанным процессам.
Как работает наш распознаватель изображений
Давайте проанализируем, как с описанными идеями соотносится код нашего распознавателя изображений. Мы поместим строчки в отдельные ячейки и посмотрим, что каждая из них делает (мы пока не будем объяснять каждую деталь каждого параметра, но опишем самые важные части, а подробности оставим на потом). Первая строка импортирует библиотеку fastai.vision целиком:
from fastai.vision.all import *
В итоге мы получаем все функции и классы, которые потребуются для создания моделей компьютерного зрения.

Многие Python-программисты советуют избегать импорта всей библиотеки, подобной этой (используя синтаксис import *), потому что в крупных проектах это может вызвать проблемы. Однако для интерактивной работы, как, например, с блокнотом Jupyter, это подходит отлично. Библиотека fastai специально спроектирована для поддержки подобного вида интерактивного использования и импортирует в вашу среду только необходимые элементы.
Вторая строка загружает на ваш сервер стандартный датасет из коллекции fast.ai (https://course.fast.ai/datasets) (если он не загружался ранее), извлекает его (если он еще не извлекался) и возвращает объект Path с путем к месту извлечения:
path = untar_data(URLs.PETS)/'images'

Во время обучения в fast.ai да и по сей день я многое узнаю о продуктивных практиках написания кода. Библиотека fastai и блокноты fast.ai содержат множество маленьких приемов, которые помогли мне повысить свои навыки программирования. В качестве примера можно даже обратить внимание на то, что библиотека fastai возвращает не просто строку, содержащую путь к датасету, но целый объект Path. Это очень полезный класс из стандартной библиотеки Python 3, который существенно упрощает доступ к файлам и каталогам. Если вы с ним еще не сталкивались, то обязательно ознакомьтесь с соответствующей документацией или руководством и попробуйте его в деле. Имейте в виду, что сайт книги предоставляет ссылки на рекомендуемые материалы для каждой главы. Я продолжу обращать ваше внимание на советы по программированию, которые сам нашел полезными, по мере их появления в книге.
В третьей строке мы определяем функцию is_cat, которая ставит метки кошек на основе правила имени файла, предоставленного создателями датасета:
def is_cat(x): return x[0].isupper()
Мы используем эту функцию в четвертой строке, которая сообщает fastai о нашем датасете и его структуре:
dls = ImageDataLoaders.from_name_func(
path, get_image_files(path), valid_pct=0.2, seed=42,
label_func=is_cat, item_tfms=Resize(224))
Существуют различные классы, предназначенные для разных видов датасетов и задач, но здесь мы используем ImageDataLoaders. Первая часть имени класса обычно указывает на тип ваших данных, например image (изображение) или text (текст).
Еще один важный элемент информации, который нам нужно сообщить fastai, — это способ получения меток из датасета. Датасеты компьютерного зрения обычно структурированы так, что метка для изображения является частью имени файла или пути: чаще всего имени родительского каталога. fastai предлагает ряд стандартизированных методов разметки и возможности написания собственных. Здесь мы даем fastai команду использовать функцию is_cat, которую только что написали.
В завершение мы определяем нужные элементы Transforms. Transform содержит код, который автоматически применяется в процессе обучения. fastai включает множество предопределенных Transforms, а добавить новые так же просто, как создать функцию Python. Существует два их вида: item_tfms применяются к каждому элементу (в данном случае размер каждого элемента изменяется до квадрата размером 224 пикселя), а batch_tfms применяются сразу к набору элементов с помощью GPU, что делает их особенно быстрыми (в книге мы увидим много таких примеров).
Почему именно 224 пикселя? Так сложилось исторически — старые предварительно обученные модели требуют именно такой размер, но вы можете передать любой. Если этот размер увеличить, то зачастую вы получите модель с лучшими результатами (поскольку она сможет фокусироваться на большем числе деталей), но в итоге понизится скорость и увеличится потребление памяти. При понижении размера произойдет обратное.
Датасет домашних животных содержит 7390 картинок собак и кошек, относящихся к 37 породам. Каждое изображение размечено на основе имени его файла: например, файл great_pyrenees_173.jpg — это 173-й образец изображения пиренейской горной собаки в датасете. Имена файлов начинаются с верхнего регистра, если на их изображении кошка, и с нижнего регистра в любом другом случае. Нам нужно указать fastai, как получать метки из имен файлов, для чего мы используем вызов from_name_func (это означает, что метки можно извлекать, применяя к ним функцию) и передаем is_cat, которая принимает значение True, если первая буква написана в верхнем регистре (то есть на изображении кошка).

Классификация и регрессия в машинном обучении имеют очень специфичные значения. Они описывают два основных типа модели, которые мы будем изучать на протяжении книги. Классификационнаямодель — это та, которая старается прогнозировать класс или категорию, то есть делает прогноз из числа дискретных вероятностей, таких как dog или cat. Регрессионная модель — это та, которая старается прогнозировать одну или несколько численных величин, таких как температура или локация. Некоторые используют слово регрессия в отношении конкретного вида модели, называемой моделью линейной регрессии. Это плохая практика, и мы такую терминологию использовать в книге не будем.
Самый важный параметр здесь — это valid_pct=0.2. Он говорит о том, что fastai должен удержать 20 % данных и вообще не использовать их для обучения модели. Эти 20 % данных называются контрольной выборкой. Оставшиеся же 80 % называются обучающей выборкой. Контрольная выборка используется для измерения точности модели. По умолчанию эти 20 % выбираются произвольно. Параметр seed=42 при каждом выполнении кода устанавливает для случайного начального числа одно и то же значение, и каждый раз мы получаем одинаковую контрольную выборку. Таким образом, если мы изменим нашу модель и повторно ее обучим, то мы будем знать, что любые отличия вызваны изменениями в модели, а не использованием другой контрольной выборки.
fastai будет всегда показывать точность вашей модели, используя только контрольную выборку, но не обучающую. Это критически важно, потому что если вы обучаете достаточно большую модель достаточно длительное время, то в итоге она запомнит метку каждого элемента вашего датасета! В результате получится бесполезная модель — нам важно, чтобы она работала на ранее не встречавшихся изображениях. Именно эту цель мы будем преследовать при каждом обучении модели: она должна быть эффективной только для будущих данных, которые встретит после своего обучения.
Даже когда ваша модель еще не полностью запомнила все данные, на ранних этапах обучения она может запомнить их конкретные части. Следовательно, чем дольше процесс обучения, тем выше точность в отношении обучающей выборки. Точность в отношении контрольной выборки тоже будет какое-то время увеличиваться, но в итоге уменьшится, так как модель будет запоминать обучающую выборку, вместо того чтобы находить базовые обобщаемые шаблоны в данных. Когда такое происходит, мы говорим, что модель переобучилась.
На рис. 1.9 показано, что происходит, если переборщить. Для демонстрации мы использовали упрощенный пример, где применяется только один параметр и немного произвольно сгенерированных на основе функции x**2 данных. Несмотря на то что прогнозы в переобученной модели точны в отношении данных возле наблюдаемых точек, эта точность утрачивается при выходе за их диапазон.
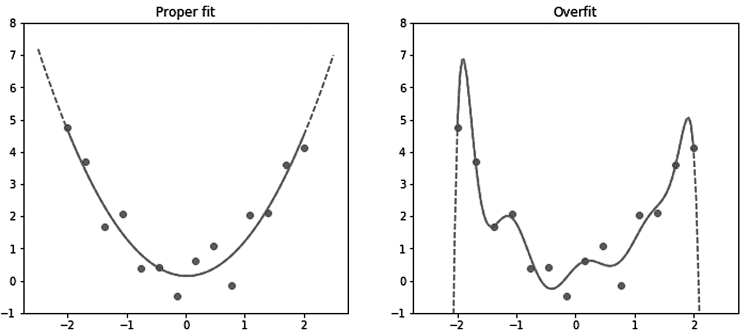
Рис. 1.9. Пример переобучения
Переобучение — это наиболее важная и сложная задача для всех практиков ML и алгоритмов. Как вы позднее увидите, легко создать модель, которая отлично справляется с составлением прогнозов только для тех данных, на которых она обучалась, но при этом куда сложнее делать точные прогнозы для данных, с которыми модель ранее не встречалась. Конечно же, именно такие данные и будут иметь значение на практике. Например, если вы создаете классификатор рукописных цифр (а мы скоро его создадим!) и используете для распознавания написанных на чеках чисел, то вы никогда не увидите таких чисел, на которых модель обучалась, ведь на каждом чеке будут как минимум небольшие вариации написания.
В этой книге мы рассмотрим много методов, позволяющих избежать переобучения. Однако использовать эти методы следует только после того, как вы убедитесь, что переобучение действительно имеет место (то есть если в процессе обучения вы наблюдаете ухудшение контрольной точности). Мы часто видим, что люди используют техники избегания переобучения, даже когда у них достаточно данных, чтобы этого не делать. В итоге их модель получается менее точной, чем могла бы быть.
Пятая строка кода, обучающего наш распознаватель изображений, дает fastai команду создать сверточную нейронную сеть (CNN) и указывает, какую архитектуру применять (то есть какой вид модели создать), на каких данных мы собираемся проводить обучение и какую метрику использовать:
learn = cnn_learner(dls, resnet34, metrics=error_rate)

При обучении модели у вас всегда должна быть и обучающая выборка, и контрольная. Точность нужно измерять только с помощью контрольной. Если вы будете производить обучение слишком долго при недостаточном количестве данных, то обнаружите, что точность модели начнет ухудшаться, что и называется переобучением. fastai по умолчанию устанавливает valid_pct на 0.2, поэтому, даже если вы забудете это сделать, библиотека создаст контрольную выборку за вас!
Почему CNN? Это эталонный подход к созданию моделей компьютерного обучения. Позднее мы с вами подробно познакомимся с этим видом нейронных сетей, структура которых основана на принципе работы системы зрения человека.
В книге мы познакомим вас со множеством доступных в fastai архитектур, а также покажем, как создавать собственную. Но чаще всего выбор архитектуры не будет являться важной частью глубокого обучения. Эту тему больше любят обсуждать ученые умы, но на практике тратить на них много времени не придется. Есть стандартные архитектуры, которые подойдут для большинства ситуаций, и в конкретном случае мы используем ResNet, о которой будем говорить очень много. Для многих датасетов и задач она оказывается не только быстрой, но и точной. В resnet34 число 34 указывает на число слоев в этой версии архитектуры (другие возможные варианты включают 18, 50, 101 и 152). Модели, использующие архитектуры с большим числом слоев, дольше обучаются и более подвержены переобучению (то есть вы не можете выполнять обучение определенное количество эпох до того, как точность в отношении контрольной выборки начнет падать). С другой стороны, при использовании большего объема данных они могут быть немного точнее.
Что такое метрика? Метрика — это функция, измеряющая качество прогнозов модели при использовании контрольной выборки, результаты которой выводятся в конце каждой эпохи обучения. В нашем случае мы используем error_rate — функцию, предоставляемую fastai, которая делает именно то, о чем говорит ее название: сообщает вам процент неверно классифицированных изображений контрольной выборки. Еще одной распространенной метрикой для классификации является accuracy (которая вычисляется как 1.0 – error_rate). fastai предлагает гораздо больше вариантов метрик, которые мы также еще будем рассматривать.
Метрика может вызвать ассоциацию с потерями, но между ними есть важное отличие. Потери — это способ определения «показателя производительности», который обучающая система сможет использовать для автоматического обновления весов. Другими словами, для потерь хорошим вариантом будет тот, который удобно использовать стохастическому градиентному спуску. Метрика же определяется для оценки человеком, поэтому хорошая метрика — это та, которую легко понять вам и которая максимально близка к тому, что ваша модель должна делать. Иногда вы можете решить, что функция потерь — это подходящая метрика, но это не обязательно так.
cnn_learner помимо прочего содержит параметр pretrained, который по умолчанию равен True (поэтому используется в данном случае, несмотря на то что мы его не указывали), что устанавливает значения весов вашей модели на те, которые уже были обучены экспертами для распознавания тысячи разных категорий среди 1,3 миллиона фотоснимков (при использовании известного датасета ImageNet (http://www.image-net.org/)). Модель, которая использует веса, обученные на другом датасете, называется предварительно обученной моделью. Вам следует использовать такой вид модели, так как это означает, что еще до знакомства с вашими данными она уже будет обладать рядом возможностей. И как вы увидите, в модели глубокого обучения многие из этих возможностей окажутся нужны независимо от деталей вашего проекта. Например, части предварительно обученных моделей будут обрабатывать границы, градиент и определение цвета, что необходимо для многих задач.
При использовании предварительно обученной модели cnn_learner удаляет последний слой, поскольку он всегда специально настроен для исходной задачи обучения (то есть классификации датасета ImageNet), и заменяет его одним или несколькими новыми слоями подходящего размера с произвольными весами для датасета, с которым работаете уже вы. Последняя часть модели называется головой.
Использование предварительно обученной модели — важнейший метод из имеющихся, который позволяет нам обучать более точные модели быстрее, используя при этом меньше данных, с меньшими затратами времени и денег. Может показаться, что использование предварительно обученных моделей является наиболее исследуемой областью в академическом глубоком обучении… Но это совершенно не так! Значимость таких моделей практически не признается и не учитывается в большинстве курсов и книг, а также редко рассматривается в академических трудах. На момент написания этой книги, а именно в первой половине 2020 года, ситуация только начинает меняться, но для существенных изменений потребуется какое-то время. Поэтому будьте внимательны: большинство людей, с которыми вы можете заговорить на эту тему, вероятно, будут недооценивать ваши достижения в глубоком обучении с помощью небольшого объема ресурсов, так как сами будут плохо разбираться в применении предварительно обученных моделей.
Использование таких моделей для задач, отличных от тех, для которых модель тренировалась изначально, называется transfer learning, то есть переносом обучения. К сожалению, из-за недостаточной изученности этой техники предварительно обученные модели доступны лишь для ограниченного числа областей. Например, в медицине таких моделей доступно очень мало, что усложняет использование переноса обучения в этой сфере. Кроме того, пока недостаточно ясно, как использовать эту технику для таких задач, как анализ временных рядов.

Использование предварительно обученной модели для задачи, отличающейся от той, для которой модель обучалась изначально.
Шестая строка нашего кода сообщает fastai, как тонко настраивать модель:
learn.fine_tune(1)
Как мы уже говорили, архитектура описывает только шаблон для математической функции, но по факту ничего не делает, пока мы не предоставим значения для миллионов содержащихся в ней параметров.
Это ключевой момент в глубоком обучении — определение того, как настроить параметры модели так, чтобы она решала поставленную задачу. Для тонкой настройки модели нам нужно предоставить хотя бы один элемент информации: сколько раз просматривать каждое изображение (указать так называемое число эпох). Выбор числа эпох будет сильно зависеть от того, сколько у вас есть времени и сколько его фактически потребуется для тонкой настройки модели. Если вы выберете слишком маленькое число, то всегда сможете обучить модель позднее.
Но почему метод называется fine_tune, а не fit? В fastai есть метод под названием fit, который действительно тонко настраивает модель (то есть просматривает изображения обучающей выборки несколько раз, каждый раз обновляя параметры, чтобы максимально приблизить прогнозы к целевым меткам). Но в данном случае мы начали с предварительно обученной модели и не хотим отказываться от всех тех возможностей, которые у нее уже есть. Как вы узнаете из этой книги, есть ряд полезных приемов для адаптации предварительно обученной модели к новому датасету, и этот процесс называется тонкой настройкой (fine-tuning).

Техника переноса обучения, которая обновляет параметры предварительно обученной модели, обучая ее дополнительное количество эпох с помощью зад



















