

автордың кітабын онлайн тегін оқу Искусственный интеллект и компьютерное зрение. Реальные проекты на Python, Keras и TensorFlow
Переводчик А. Киселев
Анирад Коул, Сиддха Ганджу, Мехер Казам
Искусственный интеллект и компьютерное зрение. Реальные проекты на Python, Keras и TensorFlow. — СПб.: Питер, 2022.
ISBN 978-5-4461-1840-3
© ООО Издательство "Питер", 2022
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Вступление
Мы переживаем возрождение интереса к искусственному интеллекту (ИИ). Вероятно, поэтому вы листаете эту книгу. Есть множество книг о глубоком обучении, и возникает резонный вопрос: с какой целью эта книга вообще появилась? Ответим на него чуть ниже.
Занимаясь глубоким обучением с 2013 года (разрабатывая продукты в Microsoft, NVIDIA, Amazon и Square), мы стали свидетелями значительных изменений в этой сфере. Непрекращающиеся исследования были данностью, а отсутствие зрелого инструментария — правдой жизни.
Продолжая расти и перенимая опыт сообщества, мы обратили внимание, что нет каких-либо четких указаний на то, как превратить исследования в конечный продукт для обычных пользователей, которые взаимодействуют с веб-браузером, смартфоном или краевым (edge) устройством. В поисках тайных знаний мы бесконечно экспериментировали, читали блоги, обсуждали проблемы на GitHub и Stack Overflow, а также переписывались с авторами пакетов и ловили случайные инсайты. Многие книги по большей части фокусировались на теории или на особенностях использования конкретных инструментов. Лучшее, на что мы могли рассчитывать с такими книгами, — это построить игрушечную модель.
Чтобы заполнить пробел между теорией и практикой, мы с самого начала стали говорить о возможности перехода от исследований ИИ к его практическому применению. Мы старались дать мотивирующие примеры, а также показать различные уровни сложности в зависимости от уровня навыков (от любителя до инженера масштаба Google) и усилий, затраченных на внедрение глубокого обучения в продакшен. Все это было ценно и для новичков, и для экспертов.
К счастью, со временем ландшафт стал доступным для новичков, и появилось больше инструментов. Отличные онлайн-площадки, например Fast.ai и DeepLearning.ai, упростили подход к приемам обучения моделей ИИ. На рынке появились книги по основам глубокого обучения с использованием TensorFlow и PyTorch. Но даже несмотря на все это, между теорией и практикой оставалась пропасть. Мы решили восполнить этот пробел. Так и появилась эта книга.
Простым и доступным языком, на примере реальных интересных проектов в сфере компьютерного зрения книга описывает простые классификаторы, не предполагая наличия у читателя знаний о машинном обучении и ИИ. Затем сложность проектов постепенно увеличивается, повышается их точность и скорость, открывается возможность масштабировать их до обслуживания миллионов пользователей на широком спектре оборудования и программного обеспечения. И наконец, описывается пример использования обучения с подкреплением для создания миниатюрного беспилотного автомобиля.
Почти каждая глава начинается с мотивирующего примера и вопросов, которые могут возникнуть в процессе поиска решения. Потом описываются различные подходы к решению, с разным уровнем сложности и требуемых усилий. Если вы ищете быстрое решение, то просто прочтите несколько первых страниц каждой главы — и все. Тем же, кто хочет получить более глубокое понимание предмета, следует прочитать всю главу и изучить примеры. Во-первых, они довольно интересные. Во-вторых, они показывают, как специалисты в сфере ИИ применяют идеи, описываемые в главе, для создания реальных продуктов.
Мы также обсудим проблемы, с которыми сталкиваются практики и профессионалы глубокого обучения при создании реальных приложений с использованием облачных систем, браузеров, мобильных и краевых устройств. В этой книге мы собрали ряд практических советов и приемов, а также уроков из реальной жизни, чтобы побудить читателей создавать приложения, которые смогут сделать чей-то день немного лучше.
Разработчикам
Скорее всего, вы опытный программист. Даже если вы не знакомы с Python, мы надеемся, что с легкостью освоите его и сможете приступить к работе в кратчайшие сроки. Но мы не предполагаем у вас наличие какого-либо опыта в области машинного обучения и искусственного интеллекта. Мы поможем обрести вам эти знания и уверены, что вы извлечете пользу, узнав из этой книги:
• как создавать продукты c ИИ, ориентированные на пользователя;
• как быстро обучать модели;
• как минимизировать усилия и объем кода, нужные для создания прототипа;
• как сделать модели более производительными и энергоэффективными;
• как внедрять и масштабировать модели глубокого обучения, а также оценивать связанные с этим затраты;
• как применять ИИ на практике на примере более 40 реальных проектов;
• в каких направлениях развиваются знания о глубоком обучении;
• об обобщенных приемах, которые предлагают новые фреймворки (например, PyTorch), предметных областях (например, здравоохранение, робототехника), видах входной информации (например, видео, аудио, текст) и задачах (например, сегментация изображений, обучение с одного раза).
Специалистам по данным
Возможно, вы уже хорошо разбираетесь в машинном обучении и знаете, как работать с моделями глубокого обучения. Тогда у нас хорошие новости. Вы сможете еще больше обогатить набор своих навыков и углубить знания в этой области, которые позволят создавать настоящие продукты. Эта книга расскажет вам, как эффективнее решать повседневные задачи, а также:
• как ускорить обучение, в том числе в кластерах с множеством нод;
• как развить интуицию, нужную для разработки и отладки моделей, включая настройку гиперпараметров для значительного повышения их точности;
• как работает модель, как выявить предвзятость в данных, а также как автоматически подобрать лучшие гиперпараметры и архитектуру модели с помощью AutoML;
• даст советы и приемы от других практиков, в том числе касающиеся быстрого сбора данных, организации экспериментов, обмена моделями с другими специалистами во всем мире и получения самой свежей информации о лучших доступных моделях для вашей задачи;
• как использовать инструменты для развертывания и масштабирования своей лучшей модели для реальных пользователей, и даже автоматически (без участия DevOps-команды).
Студентам
Сейчас самое время подумать о будущей карьере в области ИИ — это следующая революционная технология после появления интернета и смартфонов. Здесь уже достигнуты большие успехи, но многое еще предстоит открыть. Надеемся, что эта книга станет для вас первым шагом к карьере в области ИИ и, что еще лучше, к развитию более глубоких теоретических знаний. Самое замечательное, что не нужно тратить много денег на покупку дорогостоящего оборудования — можно тренироваться на мощном оборудовании совершенно бесплатно, пользуясь лишь браузером (спасибо, Google Colab!). Надеемся, что с помощью этой книги вы:
• начнете карьеру в области ИИ, познакомившись с пакетом интересных проектов;
• обретете знания и навыки, которые помогут подготовиться к стажировке и устройству на работу;
• дадите волю своему творчеству, создавая забавные приложения, например автопилот для автомобиля;
• станете чемпионом состязания «AI for Good» (ИИ во имя добра) и используете свой творческий потенциал для решения насущных проблем, с которыми сталкивается человечество.
Преподавателям
Надеемся, что эта книга поможет разнообразить ваш курс забавными проектами из реального мира. Мы подробно рассматриваем каждый этап пайплайна глубокого обучения, а также эффективные и действенные методы выполнения каждого этапа. Все проекты, представленные в книге, могут пригодиться для совместной или индивидуальной работы в течение семестра. А еще мы подготовили презентации на https://github.com/PracticalDL/Practical-Deep-Learning-Book, которые можно брать для занятий.
Энтузиастам робототехники
Робототехника — это увлекательно. Если вы энтузиаст робототехники, то не нужно убеждать вас в том, что наделение роботов интеллектом — неминуемый шаг. Все функциональные аппаратные платформы: Raspberry Pi, NVIDIA Jetson Nano, Google Coral, Intel Movidius, PYNQ-Z2 и другие — помогают внедрению инноваций в области робототехники. По мере развития промышленной революции 4.0 некоторые из этих платформ будут становиться все более актуальными и повсеместными. Из этой книги вы узнаете:
• как создать и обучить ИИ, а затем довести его до совершенства;
• как тестировать и сравнивать краевые устройства по производительности, размеру, мощности, энергоэффективности и стоимости;
• как выбрать оптимальный алгоритм ИИ и устройство для конкретной задачи;
• как другие производители создают творческих роботов и машины;
• как добиться дальнейшего прогресса в этой области и показать достижения.
Обзор глав
Глава 1. Обзор ландшафта искусственного интеллекта
Посмотрим, как менялся ландшафт ИИ с 1950-х годов до наших дней. Поговорим о компонентах идеального рецепта глубокого обучения. Познакомимся с общепринятой терминологией и известными датасетами, а также заглянем в мир ответственного ИИ.
Глава 2. Что на картинке: классификация изображений с помощью Keras
Погрузимся в мир классификации изображений, написав лишь пять строк кода, использующего Keras. Затем с помощью тепловых карт узнаем, на что обращают внимание нейронные сети, делая свои прогнозы. А на десерт ознакомимся с любопытной историей Франсуа Шолле, создателя Keras. Она покажет, какое влияние может оказать всего один человек.
Глава 3. Кошки против собак: перенос обучения с помощью Keras в 30 строках кода
В этой главе рассмотрим прием переноса обучения и задействуем ранее обученную сеть в новой задаче классификации, чтобы за считанные минуты получить высочайшую точность. Затем изучим результаты, чтобы оценить качество классификации. Попутно создадим пайплайн машинного обучения, который с небольшими изменениями будет использоваться во всей книге. В качестве бонуса узнаем от Джереми Ховарда, соучредителя fast.ai, о том, как сотни тысяч студентов используют перенос обучения, чтобы начать свой путь в ИИ.
Глава 4. Создание механизма обратного поиска изображений. Эмбеддинги
Вдохновившись примером Google Reverse Image Search, изучим эмбеддинги, представления признаков изображений, и покажем, как реализовать обратный поиск похожих изображений в десяти строках кода. А затем начнется самое интересное: изучив различные стратегии и алгоритмы, мы ускорим работу этой системы, чтобы она анализировала миллионы изображений и отыскивала похожие за микросекунды.
Глава 5. От новичка до мастера прогнозирования: увеличение точности сверточной нейронной сети
В этой главе изучим стратегии увеличения точности классификатора с помощью TensorBoard, What-If Tool, tfexplain, TensorFlow Datasets, AutoKeras и AutoAugment. И немного поэкспериментируем, чтобы выработать интуитивное представление о том, какие параметры могут влиять на качество работы вашей задачи ИИ.
Глава 6. Увеличение скорости и эффективности TensorFlow: удобный чек-лист
В этой главе увеличим скорость обучения и прогнозирования, пройдясь по чек-листу из 30 трюков, которые помогут устранить неэффективные действия и максимально использовать возможности текущего оборудования.
Глава 7. Практические инструменты, советы и приемы
Здесь сгруппируем практические знания и навыки, начиная от установки, сбора данных, управления экспериментами, визуализации и слежения за современными исследованиями до изучения дальнейших возможностей развития теоретических основ глубокого обучения.
Глава 8. Облачные API для компьютерного зрения: установка и запуск за 15 минут
Работайте не 12 часов, а головой. В этой главе мы покажем, как за 15 минут приступить к использованию возможностей облачных платформ ИИ, предлагаемых Google, Microsoft, Amazon, IBM и Clarifai. Для задач, неразрешимых для существующих API, используем специальные сервисы классификации. С их помощью, не прибегая к программированию, обучим облачные классификаторы, а затем сравним их друг с другом. Увидев победителя, вы, скорее всего, немало удивитесь.
Глава 9. Масштабируемый инференс в облаке с помощью TensorFlow Serving и KubeFlow
В этой главе мы перенесем нашу обученную модель из облака на уровень клиента для масштабирования обслуживания запросов от нескольких сотен до миллионов. Здесь мы познакомимся с Flask, Google Cloud ML Engine, TensorFlow Serving и KubeFlow и проанализируем усилия, сценарии и затраты.
Глава 10. ИИ в браузере с TensorFlow.js и ml5.js
Любой человек, использующий компьютер или смартфон, всегда имеет доступ к браузеру. Охватите всех этих пользователей с помощью библиотек глубокого обучения, работающих в браузере, таких как TensorFlow.js и ml5.js. Приглашенный автор Зайд Аляфеи (Zaid Alyafeai) познакомит нас с оценкой позы тела, применением генеративно-состязательных сетей, преобразованием изображений с помощью Pix2Pix и многими другими задачами, выполняемыми не на сервере, а в самом браузере. В качестве бонуса вы узнаете от ключевых участников о том, как развивались проекты TensorFlow.js и ml5.js.
Глава 11. Классификация объектов в реальном времени в iOS с Core ML
Изучим ландшафт глубокого обучения на мобильных устройствах, уделив особое внимание экосистеме Apple с Core ML. Проведем сравнительный анализ моделей на разных моделях iPhone, рассмотрим стратегии уменьшения размеров приложений и их энергопотребления, а также изучим динамическое развертывание моделей, обучение на устройстве и приемы создания профессиональных приложений.
Глава 12. Not Hotdog на iOS с Core ML и Create ML
Приложение Not Hotdog из сериала HBO «Кремниевая долина» — это аналог «Hello World» в сфере мобильного ИИ. Воздадим ему должное и сделаем свою версию, и не одним или двумя, а тремя разными способами.
Глава 13. Шазам для еды: разработка приложений для Android с помощью TensorFlow Lite и ML Kit
В этой главе перенесем ИИ на Android, использовав TensorFlow Lite. Затем рассмотрим кроссплатформенную разработку с помощью ML Kit (основанного на TensorFlow Lite) и Fritz и изучим полный жизненный цикл разработки на примере самосовершенствующегося приложения с ИИ. Попутно рассмотрим управление версиями моделей, A/B-тестирование, оценку успешности, динамическое обновление, оптимизацию модели и другие темы. А в качестве бонуса Пит Уорден (Pete Warden), техлид проекта Mobile and Embedded TensorFlow, расскажет о своем богатом опыте по внедрению ИИ в краевые устройства.
Глава 14. Создание приложения Purrfect Cat Locator с помощью TensorFlow Object Detection API
Здесь мы изучим четыре метода обнаружения объектов на изображениях, познакомимся с эволюцией приемов обнаружения объектов, проанализируем компромиссы между скоростью и точностью и заложим основы для исследований в подсчете численности толпы, распознавании лиц и беспилотных автомобилей.
Глава 15. Как стать творцом: ИИ в краевых устройствах
Приглашенный автор Сэм Стеркваль (Sam Sterckval) занимается реализацией моделей глубокого обучения для устройства с низким энергопотреблением. Он покажет несколько встраиваемых устройств с поддержкой ИИ, имеющих разную вычислительную мощность и стоимость, включая Raspberry Pi, NVIDIA Jetson Nano, Google Coral, Intel Movidius и PYNQ-Z2 FPGA, и приоткроет двери для проектов в сфере робототехники и умных устройств. Бонус: узнайте от команды NVIDIA Jetson Nano о том, как можно самостоятельно собрать робота!
Глава 16. Моделирование беспилотного автомобиля методом сквозного глубокого обучения с использованием Keras
Приглашенные авторы Адитья Шарма (Aditya Sharma) и Митчелл Сприн (Mitchell Spryn) расскажут об обучении виртуального автомобиля в фотореалистичной среде моделирования Microsoft AirSim, управляя им вручную и обучая модель ИИ воспроизводить его поведение. Попутно рассмотрим ряд идей, используемых в индустрии беспилотных автомобилей.
Глава 17. Создание беспилотного автомобиля менее чем за час: обучение с подкреплением с помощью AWS DeepRacer
Перейдем от виртуального мира к физическому — приглашенный автор Сунил Маллья (Sunil Mallya) покажет, как всего за час можно собрать и обучить миниатюрный автомобиль AWS DeepRacer. С помощью обучения с подкреплением автомобиль научится самостоятельно водить, штрафуя себя за ошибки и добиваясь максимального успеха. Узнаем, как применить эти знания в гонках от Olympics of AI Driving до RoboRace (с использованием полноразмерных беспилотных автомобилей). А в финале Анима Анандкумар (Anima Anandkumar) из NVIDIA и Крис Андерсон (Chris Anderson), основатель DIY Robocars, расскажут, куда движется индустрия беспилотных автомобилей.
Условные обозначения
В этой книге приняты следующие условные обозначения:
Курсив
Используется для обозначения новых терминов, адресов URL и электронной почты, имен файлов и расширений имен файлов.
Моноширинный
Применяется для оформления листингов программ и программных элементов внутри обычного текста, таких как имена переменных и функций, баз данных, типов данных, переменных окружения, инструкций и ключевых слов.

Так выделяются советы и предложения.

Так обозначаются советы, предложения и примечания общего характера.

Так обозначаются предупреждения и предостережения.
Использование исходного кода примеров
Вспомогательные материалы (примеры кода, упражнения и т.д.) доступны для загрузки по адресу https://github.com/PracticalDL/Practical-Deep-Learning-Book. Если у вас возникнут вопросы технического характера по использованию примеров кода, направляйте их по электронной почте на адрес PracticalDLBook@gmail.com.
В общем случае все примеры кода из книги вы можете использовать в своих программах и в документации. Вам не нужно обращаться в издательство за разрешением, если вы не собираетесь воспроизводить существенные части программного кода. Если вы разрабатываете программу и используете в ней несколько фрагментов кода из книги, вам не нужно обращаться за разрешением. Но для продажи или распространения примеров из книги вам потребуется разрешение от издательства O’Reilly. Вы можете отвечать на вопросы, цитируя данную книгу или примеры из нее, но для включения существенных объемов программного кода из книги в документацию вашего продукта потребуется разрешение.
Мы рекомендуем, но не требуем добавлять ссылку на первоисточник при цитировании. Под ссылкой на первоисточник мы подразумеваем указание авторов, издательства и ISBN.
За получением разрешения на использование значительных объемов программного кода из книги обращайтесь по адресу permissions@oreilly.com.
Благодарности
Коллективные благодарности
Мы хотели бы поблагодарить следующих людей за неоценимую помощь в работе над этой книгой. Без них она была бы невозможна.
Книга появилась на свет благодаря усилиям нашего редактора Николь Таше (Nicole Taché). Она болела за нас и на каждом этапе давала ценные рекомендации. Николь помогла правильно расставить приоритеты, отобрать материал (хотите верьте, хотите нет, но изначально книга была намного больше) и не сбиться с пути. Она была первым читателем, и поэтому нам было важно, чтобы Николь было понятно содержание несмотря на то, что она новичок в ИИ. Мы безмерно благодарны ей за поддержку.
Хотим поблагодарить и остальную часть команды O’Reilly, в том числе выпускающего редактора Кристофера Фоше (Christopher Faucher), который без устали трудился, чтобы эта книга вовремя попала в типографию. Мы также благодарны редактору Бобу Расселу (Bob Russell), который поразил нас своей молниеносной скоростью правки и вниманием к деталям. Он заставил нас осознать, насколько важно уделять внимание грамматике английского языка в школьном курсе (хотя он и опоздал на несколько лет). Хотим также поблагодарить Рэйчел Румелиотис (Rachel Roumeliotis), вице-президента по контент-стратегии, и Оливию Макдональд (Olivia MacDonald), главного редактора по развитию, за веру в проект и постоянную поддержку.
Мы безмерно признательны нашим приглашенным авторам, которые согласились поделиться опытом. Адитья Шарма (Aditya Sharma) и Митчелл Сприн (Mitchell Spryn) из Microsoft показали, что нашу любовь к гоночным видеоиграм можно использовать для обучения беспилотных автомобилей, управляя ими в среде моделирования AirSim. Сунил Малля (Sunil Mallya) из Amazon показал, как перенести эти знания в физический мир, показав на примере, что достаточно одного часа, чтобы собрать миниатюрный беспилотный автомобиль (AWS DeepRacer) и научить его ездить по треку с помощью обучения с подкреплением. Сэм Стеркваль (Sam Sterckval) из Edgise подвел итог огромному разнообразию встраиваемого оборудования для реализации ИИ, доступного на рынке, так что теперь мы можем принять участие в разработке проекта по робототехнике. И наконец, Зайд Аляфеи (Zaid Alyafeai) из Университета имени короля Фахда показал, что браузеры вполне способны поддерживать серьезные интерактивные модели ИИ (с помощью TensorFlow.js и ml5js).
Свой нынешний вид книга приобрела благодаря оперативной обратной связи наших замечательных научных редакторов, которые кропотливо изучали проекты, указывали на технические неточности и давали рекомендации по улучшению изложения идей. Благодаря их отзывам (и постоянно меняющемуся TensorFlow API) мы заново переписали почти всю книгу после выхода черновой версии. Благодарим Маргарет Мейнард-Рид (Margaret Maynard-Reid), эксперта по машинному обучению из Google. Возможно, вы знакомы с ней заочно, если читали документацию для TensorFlow. Благодарим Пако Натана (Paco Nathan), более 35 лет работающего в индустрии в Derwin Inc. и познакомившего Анирудха с миром публичных выступлений, Энди Петрелла (Andy Petrella), CEO и основателя Kensu и создателя SparkNotebook, чьи технические идеи соответствуют его репутации, и Никхиту Коула (Nikhita Koul), старшего научного сотрудника в Adobe, который предлагал новые улучшения после каждой итерации чтения черновика. Фактически он прочитал несколько тысяч страниц, и благодаря ему книга стала намного доступнее. Нам очень помогли рецензенты, обладающие богатым опытом в конкретных областях, будь то ИИ в браузере, разработка мобильных приложений или создание беспилотных автомобилей. Вот поглавный список рецензентов:
• глава 1: Дхарини Чандрасекаран (Dharini Chandrasekaran), Шерин Томас (Sherin Thomas);
• глава 2: Анудж Шарма (Anuj Sharma), Чарльз Козиерок (Charles Kozierok), Манодж Парихар (Manoj Parihar), Панкеш Бамотра (Pankesh Bamotra), Пранав Кант (Pranav Kant);
• глава 3: Анудж Шарма, Чарльз Козиерок, Манодж Парихар, Панкеш Бамотра, Пранав Кант;
• глава 4: Анудж Шарма, Манодж Парихар, Панкеш Бамотра, Пранав Кант;
• глава 6: Габриэль Ибагон (Gabriel Ibagon), Иржи Симса (Jiri Simsa), Макс Кац (Max Katz), Панкеш Бамотра;
• глава 7: Панкеш Бамотра;
• глава 8: Дипеш Аггарвал (Deepesh Aggarwal);
• глава 9: Панкеш Бамотра;
• глава 10: Бретт Берли (Brett Burley), Лоран Денуэ (Laurent Denoue), Манрадж Сингх (Manraj Singh);
• глава 11: Дэвид Апгар (David Apgar), Джеймс Уэбб (James Webb);
• глава 12: Дэвид Апгар;
• глава 13: Джесси Уилсон (Jesse Wilson), Салман Гадит (Salman Gadit);
• глава 14: Акшит Арора (Akshit Arora), Пранав Кант, Рохит Танеджа (Rohit Taneja), Ронай Ак (Ronay Ak);
• глава 15: Гертруи Ван Ломмель (Geertrui Van Lommel), Джок Декуббер (Joke Decubber), Жульен Де Кок (Jolien De Cock), Марианна Ван Ломмель (Marianne Van Lommel), Сэм Хендрикс (Sam Hendrickx);
• глава 16: Дарио Салищик (Dario Salischiker), Курт Нибур (Kurt Niebuhr), Мэтью Чан (Matthew Chan), Правин Паланисами (Praveen Palanisamy);
• глава 17: Киртеш Гарг (Kirtesh Garg), Ларри Пизетт (Larry Pizette), Пьер Дюма (Pierre Dumas), Рикардо Суэйрас (Ricardo Sueiras), Сеголен Десертин-Панхард (Segolene Dessertine-panhard), Шри Элапролу (Sri Elaprolu), Тацуя Араи (Tatsuya Arai).
Во многих главах есть врезки «От создателя», в которых известные специалисты из мира ИИ приоткрывают дверь в свой мир и рассказывают, как и почему они создавали проекты, принесшие им известность. Мы благодарны Франсуа Шолле (François Chollet), Джереми Ховарду (Jeremy Howard), Питу Уордену (Pete Warden), Аниме Анандкумар (Anima Anandkumar), Крису Андерсону (Chris Anderson), Шанкину Каю (Shanqing Cai), Дэниелу Смилкову (Daniel Smilkov), Кристобалю Валенсуэле (Cristobal Valenzuela), Дэниелу Шиффману (Daniel Shiffman), Харту Вулери (Hart Woolery), Дэну Абдинуру (Dan Abdinoor), Читоку Ято (Chitoku Yato), Джону Уэлшу (John Welsh) и Дэнни Атсмо (Danny Atsmo).
Личные благодарности
Хочу поблагодарить свою семью — Арбинда, Сароджу и Никхиту, которые дали мне все, чтобы я мог заниматься моими увлечениями. Спасибо всем специалистам и исследователям из Microsoft, Aira и Yahoo, которые поддерживали меня и помогали воплощать идеи в прототипы и продукты. Не успехи, а трудности научили нас многому на этом пути. И эти трудности стали основной великолепного материала для этой книги в таком объеме, что можно было бы написать еще 250 страниц! Спасибо академическим сообществам университетов Карнеги — Меллона, Далхаузи и Тапара: вы научили меня многому (и не только тому, от чего зависел мой средний балл). Спасибо сообществу слепых и слабовидящих — вы ежедневно вдохновляли меня на работу в области ИИ, показывая, что возможности людей, вооруженных правильными инструментами, действительно безграничны.
Анирад
Мой дедушка, сам автор, однажды сказал мне: «Писать книги труднее, чем можно подумать, но это приносит больше удовольствия, чем можно представить». Бесконечно благодарен своим бабушке и дедушке, семье, маме, папе и Шрие за то, что подталкивали меня на поиск знаний и помогли стать тем, кто я есть. Спасибо моим замечательным коллегам и наставникам из университета Карнеги — Меллона, CERN, NASA FDL, Deep Vision, NITH и NVIDIA, которые были со мной все это время. Я в большом долгу перед ними за знания и развитие научного темперамента. Хотел бы выразить благодарность своим друзьям, которые, надеюсь, еще не забыли меня, поскольку в последнее время я был очень занят. Огромное спасибо вам за невероятное терпение. Надеюсь, снова увижу вас всех. Огромное спасибо моим товарищам, которые самоотверженно рецензировали главы книги и давали обратную связь — без вас книга не сложилась бы.
Сиддха
Я в неоплатном долгу перед своими родителями Раджагопалом и Лакшми за их бесконечную любовь и поддержку, а также за стремление обеспечить мне хорошую жизнь и дать хорошее образование. Я благодарен своим профессорам из университета Флориды и национального технологического института Висвесварая, которые учили меня и способствовали моей специализации в области информатики. Я благодарен своей девушке Джулии Таннер, которой почти два года приходилось терпеть бесконечные звонки по Skype по ночам и выходным, а также мои ужасные шутки (часть из которых, к сожалению, попала в эту книгу). Хотел бы также отметить своего замечательного руководителя Джоэла Кустку, поддерживавшего меня, пока я работал над этой книгой. Большой привет всем моим друзьям, которые проявили невероятное понимание, когда я не мог уделять им времени столько, сколько им хотелось бы.
Мехер
И последнее, но не менее важное: спасибо создателям Grammarly! Благодаря вам люди с неважными оценками по английскому могут стать публикуемыми авторами.
Глава 1. Обзор ландшафта искусственного интеллекта
Ниже приводится фрагмент из фундаментальной статьи доктора Мэй Карсон (May Carson; рис. 1.1) об изменении роли искусственного интеллекта (ИИ) в жизни человека в XXI веке:
Искусственныйинтеллект часто называют электричеством XXI века. Со временем программы искусственного интеллекта смогут управлять всеми видами промышленной деятельности (включая здравоохранение), разрабатывать медицинские устройства и создавать новые типы продуктов и услуг, включая роботов и автомобили. Многие организации уже работают над такими программами искусственного интеллекта, способными выполнять свою работу и, что особенно важно, не допускать ошибок или опасных происшествий. Организациям нужен ИИ, но они также понимают, что ИИ подходит не для всех сфер человеческой деятельности.
Мы провели обширные исследования, чтобы выяснить, что нужно для работы искусственного интеллекта с использованием этих методов и политик, и пришли к важному выводу: количество денег, затрачиваемых на программы ИИ на одного человека в год, сравнимо с суммой, затрачиваемой на их исследование, создание и производство. Это кажется очевидным, но в действительности не совсем так.
Прежде всего системы искусственного интеллекта нуждаются в поддержке и обслуживании. А чтобы быть по-настоящему надежными, им нужны люди, обладающие знаниями и навыками управления такими системами и способные помогать им решать некоторые задачи. Для организаций очень важно иметь в своем штате таких сотрудников, помогающих искусственному интеллекту в его работе. Также важно понимать людей, которые делают эту работу, особенно если ИИ сложнее людей. Например, люди особенно часто работают на должностях, где важно обладать передовыми знаниями, но не требуется владеть навыками работы с системами, которые необходимо создавать и поддерживать.

Рис. 1.1. Доктор Мэй Карсон
Извинения
А теперь признаемся: все, что мы написали выше в этой главе, — фейк. Буквально все! Весь текст (кроме первого предложения, которое мы написали в качестве затравки) был сгенерирован с помощью модели GPT-2, созданной Адамом Кингом (Adam King), на сайте TalkToTransformer.com. Имя автора цитаты мы сгенерировали с помощью генератора имен «Nado Name Generator» на сайте Onitools.moe. Вы думаете, что уж фотография автора точно должна быть настоящей, да? А вот и нет! Изображение взято с сайта ThisPersonDoesNotExist.com, где при каждом его посещении генерируются фотографии несуществующих людей с помощью генеративно-состязательных сетей (Generative Adversarial Networks, GAN).
Мы сомневались, правильно ли начинать книгу с мистификации, но при этом хотели показать современное состояние ИИ, когда вы, наш читатель, меньше всего этого ожидали. Вообще, способности ИИ удивляют, ошеломляют, а иногда даже пугают. Тот факт, что он в состоянии с нуля создать более осмысленный и красноречивый текст, чем некоторые мировые лидеры, говорит сам за себя.
Однако есть кое-что, чего ИИ не сможет унаследовать от нас, — нашу способность веселиться. Надеемся, что эти первые три фейковых абзаца будут самыми cкучными во всей книге. В конце концов, мы не хотим, чтобы про нас сказали, что авторы скучнее машины.
Настоящее вступление
Наверняка каждый может вспомнить какое-либо поразительное выступление иллюзиониста, вызвавшее вопрос: «Как, черт возьми, он это сделал?!» А возникал ли у вас такой вопрос, когда в новостях говорили о применении ИИ? В этой книге мы хотим вооружить вас знаниями и инструментами, которые позволят не только понять устройство ИИ, но и создать что-нибудь свое.
Шаг за шагом мы разберем устройство реальных приложений, использующих технологии ИИ, и покажем, как их создавать на самых разных платформах — от облака до браузера, от смартфонов до встраиваемых систем. Закончим же высшим достижением ИИ на сегодняшний день: беспилотными автомобилями.
Большинство глав начинается с описания мотивирующей задачи, за которым следует пошаговое создание комплексного решения. С первых глав мы будем развивать навыки, нужные для создания мозга ИИ. Но это только полдела. Истинная ценность ИИ — создание полезных приложений. И речь не об игрушечных прототипах. Мы хотим, чтобы вы создали софт, который люди смогут применять с пользой для себя. Отсюда и слова «реальные проекты» в названии книги. Поэтому мы обсудим различные доступные варианты и выберем наиболее подходящие, исходя из таких параметров, как производительность, энергопотребление, масштабируемость, надежность и конфиденциальность.
В первой главе мы отступим на шаг назад, чтобы оценить этот момент в истории ИИ. Мы узнаем, что такое искусственный интеллект, особенно в контексте глубокого обучения, и рассмотрим последовательность событий, благодаря которым глубокое обучение стало одной из самых революционных областей технического прогресса в начале XXI века. Мы также изучим основные компоненты, лежащие в основе законченного решения глубокого обучения, а в следующих главах займемся практикой.
Начнем же наше путешествие с фундаментального вопроса.
Что такое ИИ?
В этой книге мы часто используем термины «искусственный интеллект», «машинное обучение» и «глубокое обучение», иногда как синонимы. Но, строго говоря, они имеют разные значения, и вот краткое описание каждого из них (также рис. 1.2):
Искусственный интеллект
Позволяет машинам имитировать поведение человека. Известный пример ИИ — IBM Deep Blue.
Машинное обучение
Раздел ИИ, в котором машины используют статистические методы для самообучения на основе имеющейся информации. Цель МО — научить машину действовать, опираясь на данные, полученные в прошлом. Если вы смотрели телешоу Jeopardy!, в котором IBM Watson побеждает Кена Дженнингса (Ken Jennings) и Бреда Раттера (Brad Rutter), то видели машинное обучение в действии. Более наглядный пример: когда в следующий раз в ваш почтовый ящик не попадет спам, поблагодарите за это машинное обучение.
Глубокое обучение
Это подраздел МО, в котором глубокие многослойные нейронные сети используются для прогнозирования — например, в области компьютерного зрения, распознавания речи, анализа естественного языка и т.д.
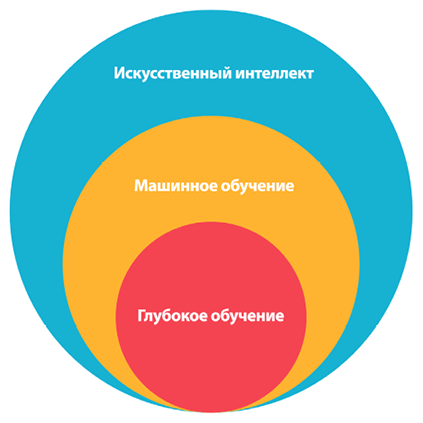
Рис. 1.2. Связь между ИИ, машинным обучением и глубоким обучением
В этой книге основное внимание уделяется глубокому обучению.
Мотивирующие примеры
А теперь к делу. Что побудило нас написать эту книгу? А зачем вы потратили свои кровно заработанные деньги1 на ее покупку? Наша мотивация проста и понятна: вовлечь как можно больше людей в мир ИИ. А тот факт, что вы читаете эту книгу, означает, что половина работы сделана.
Чтобы по-настоящему заинтересовать вас, представим несколько ярких примеров уже достигнутых возможностей ИИ:
• «DeepMind’s AI agents conquer human pros at StarCraft II» («Агенты ИИ от компании DeepMind побеждают опытных игроков в StarCraft II»): The Verge, 2019.
• «AI-Generated Art Sells for Nearly Half a Million Dollars at Christie’s» («Картина, созданная искусственным интеллектом, продана на аукционе Christie’s почти за полмиллиона долларов»): AdWeek, 2018.
• «AI Beats Radiologists in Detecting Lung Cancer» («ИИ превзошел радиологов в обнаружении рака легких»): American Journal of Managed Care, 2019.
• «Boston Dynamics Atlas Robot Can Do Parkour» («Робот Atlas, созданный компанией Boston Dynamics, может заниматься паркуром»): ExtremeTech, 2018.
• «Facebook, Carnegie Mellon build first AI that beats pros in 6-player poker» («Facebook и Университет Карнеги — Меллона создали первый ИИ, превзошедший профессиональных игроков в покер на шесть игроков»): Facebook, 2019.
• «Blind users can now explore photos by touch with Microsoft’s Seeing AI» («С помощью Microsoft Seeing AI слепые пользователи теперь смогут просматривать фотографии на ощупь»): Tech-Crunch, 2019.
• «IBM’s Watson supercomputer defeats humans in final Jeopardy match» («Суперкомпьютер IBM Watson победил человека в финальном матче Jeopardy»): Venture Beat, 2011.
• «Google’s ML-Jam challenges musicians to improvise and collaborate with AI» («Система машинного обучения ML-Jam, созданная в Google, предлагает музыкантам импровизировать и играть с ИИ»): VentureBeat, 2019.
• «Mastering the Game of Go without Human Knowledge» («Нейросеть AlphaGo Zero, созданная в DeepMind, научилась играть в го за 3 дня»): Nature, 2017.
• «Chinese AI Beats Doctors in Diagnosing Brain Tumors» («Китайский ИИ превзошел врачей в диагностике опухолей головного мозга»): Popular Mechanics, 2018.
• «Two new planets discovered using artificial intelligence» («С помощью ИИ обнаружены две новые планеты»): Phys.org, 2019.
• «Nvidia’s latest AI software turns rough doodles into realistic landscapes» («Новейшее программное обеспечение ИИ, созданное в Nvidia, превращает наброски в реалистичные пейзажи»): The Verge, 2019.
Эти примеры реализации ИИ послужат нам Полярной звездой. Уровень перечисленных достижений сопоставим с победами на Олимпийских играх. Но кроме них в мире есть множество приложений, решающих практические задачи, которые можно сравнить с гонкой на 5 км. Разработка этих приложений не требует многолетнего обучения, но доставляет разработчикам огромное удовлетворение, когда они пересекают финишную черту. Мы хотим научить вас проходить эту дистанцию в 5 км.
Мы намеренно уделяем внимание широте обсуждаемых вопросов. Область ИИ меняется очень быстро, поэтому мы хотим вооружить вас правильным мышлением и набором инструментов. Помимо решения отдельных задач, посмотрим, как разные, казалось бы, никак не связанные между собой задачи имеют фундаментальные совпадения, которые можно использовать в своих интересах. Например, для распознавания речи используются сверточные нейронные сети (Convolutional Neural Networks, CNN), которые одновременно являются основой современного компьютерного зрения. Мы затронем практические аспекты нескольких областей, чтобы вы могли быстро пройти 80 % пути в решении реальных задач. Если мы заинтересовали вас, чтобы вы решили пройти еще 15 % пути, то будем считать нашу цель достигнутой. Как часто говорят, мы хотим демократизировать ИИ.
Важно отметить, что значительный прогресс в области ИИ, который трудно переоценить, произошел только в последние несколько лет. Чтобы показать, как далеко мы продвинулись, вот вам пример: пять лет назад требовалось иметь степень Ph.D., только чтобы войти в эту индустрию. Пять лет спустя не понадобится Ph.D., даже чтобы написать целую книгу по этой теме. (Серьезно, проверьте наши профили!) Современные приложения глубокого обучения кажутся удивительными, но появились они не на пустом месте. Они стоят на плечах многих гигантов отрасли, которые десятилетиями раздвигали границы. И чтобы по достоинству оценить значение этого времени, нужно заглянуть в прошлое.
Краткая история ИИ
Итак, наша Вселенная существовала в виде горячей и бесконечно плотной точки. Потом почти 14 миллиардов лет назад началось расширение и... Так, стоп! Не будем углубляться в прошлое так далеко. На самом деле первые семена ИИ были посажены всего 70 лет назад. В 1950 году Алан Тьюринг (Alan Turing) в своей работе «Вычислительные машины и разум» впервые задал вопрос: могут ли машины мыслить? Это положило начало более широкой философской дискуссии о разумности и о том, что значит быть человеком. Означает ли это способность сочинять музыку под воздействием собственных мыслей и эмоций? Тьюринг счел такой подход слишком ограниченным и предложил тест: если человек не может отличить машину от другого человека, то имеет ли это значение? ИИ, способный имитировать человека, по сути, является человеком.
Захватывающее начало
Термин «искусственный интеллект» был придуман Джоном Маккарти (John McCarthy) в 1956 году в рамках летнего исследовательского проекта Дартмута (Dartmouth Summer Research Project). В то время настоящих компьютеров еще не было, поэтому особенно примечательно, что участники проекта обсуждали такие футуристические темы, как языковое моделирование, самосовершенствующиеся машины, абстракции на основе сенсорных данных и многое другое. Конечно, обсуждения носили сугубо теоретический характер. Но это был первый случай, когда ИИ стал областью исследований, а не отдельным проектом.
Статья Фрэнка Розенблатта (Frank Rosenblatt) «Perceptron: A Perceiving and Recognizing Automaton», опубликованная в 1957 году, заложила основы глубоких нейронных сетей. Он предположил возможность построить электронную или электромеханическую систему, способную научиться распознавать сходство между образцами оптической, электрической или тональной информации и которая будет функционировать подобно человеческому мозгу. Вместо модели на основе правил (стандартной для алгоритмов того времени) он предложил использовать статистические модели прогнозирования.

В этой книге мы снова и снова будем повторять термин «нейронная сеть». Что это такое? Это упрощенная модель человеческого мозга. Как и в мозге, в ней есть нейроны, которые активируются, встретив что-то знакомое. Различные нейроны соединены друг с другом связями (напоминающими синапсы в нашем мозгу), которые помогают информации перетекать от одного нейрона к другому.
На рис. 1.3 пример простейшей нейронной сети: перцептрон. Математически перцептрон можно выразить так:
выход = f(x1, x2, x3) = x1 w1 + x2 w2 + x3 w3 + b.
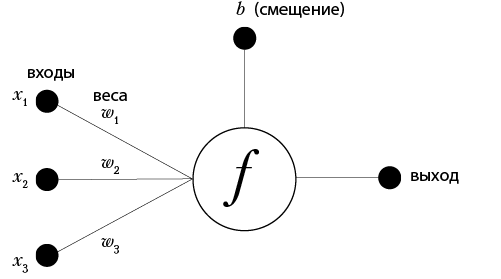
Рис. 1.3. Пример перцептрона
В 1965 году Ивахненко (Ivakhnenko) и Лапа (Lapa) представили первую действующую нейронную сеть в своей статье «Group Method of Data Handling — A Rival Method of Stochastic Approximation», ссылаясь на которую многие, несмотря на некоторые разногласия, считают Ивахненко отцом глубокого обучения.
Примерно в это же время были сделаны смелые прогнозы относительно способностей машин. Перевод с одного языка на другой, распознавание речи и многое другое будут выполняться машинами лучше, чем людьми. Эти прогнозы взволновали правительства по всему миру, и они начали финансировать подобные проекты. Золотая лихорадка началась в конце 1950-х годов и продолжалась до середины 1970-х.
Холодные и мрачные дни
За эти годы в исследования были инвестированы миллионы долларов, и появились первые действующие системы. Но многие из первоначальных пророчеств оказались нереалистичными. Машины распознавали речь только при определенном произношении и только для ограниченного набора слов. Машинный перевод с одного языка на другой содержал множество ошибок и обходился намного дороже, чем перевод, выполненный человеком. Перцептроны (по сути, однослойные нейронные сети) очень скоро уперлись в предел надежности прогнозирования. Это ограничивало их применение для решения большинства практических задач. Проблема в том, что перцептроны — линейные функции, тогда как в реальных задачах для точного прогнозирования часто нужен нелинейный классификатор. Представьте, что вы пытаетесь аппроксимировать кривую линию прямой!
А что происходит, когда вы обещаете слишком много, но не выполняете обещаний? Правильно: теряете финансирование. Управление перспективных исследовательских проектов Министерства обороны США (Defense Advanced Research Project Agency), широко известное как DARPA (да-да, это те самые люди, которые создали сеть ARPANET, ставшую потом интернетом), профинансировало множество оригинальных проектов в США. Но отсутствие результатов за почти два десятилетия вызвало охлаждение интереса. Было легче высадить человека на Луну, чем получить пригодный к употреблению распознаватель речи!
Точно так же в 1974 году, по другую сторону Атлантики, был опубликован отчет Лайтхилла (Lighthill Report), в котором говорилось: «Универсальный робот — это мираж». Представьте, что вы в 1974 году, живете в Великобритании и наблюдаете, как авторитеты информатики обсуждают в телепередачах BBC оправданность затрат на исследования ИИ. В итоге исследования были остановлены сначала в Соединенном Королевстве, а затем и во всем мире, из-за чего рухнули карьеры многих перспективных ученых. Эта фаза утраты веры в ИИ длилась около двух десятилетий и стала известна как «зима ИИ». Эх, если бы Нед Старк был в то время поблизости и смог бы предупредить их!
Проблеск надежды
Но даже в те ненастные дни в области ИИ продолжалась работа. Конечно, перцептроны, будучи линейными функциями, имели ограниченные возможности. А можно ли исправить этот недостаток? Например, связать перцептроны в сеть так, чтобы выходы одних соединялись с входами других, то есть построить многослойную нейронную сеть, как показано на рис. 1.4. Чем больше слоев, тем глубже будет изучаться нелинейность, что приведет к созданию более точных прогнозов. Остается только решить: как обучать такую сеть? И тут на сцену выходит Джеффри Хинтон (Geoffrey Hinton) с коллегами. В 1986 году они опубликовали статью «Learning representations by back-propagating errors» с описанием метода под названием обратное распространение ошибки. Как он работает? Сеть делает прогноз, смотрит, насколько он далек от реальности, и распространяет величину ошибки по сети в обратном направлении, чтобы учиться ее исправлять. Этот процесс повторяется, пока ошибка не станет несущественной. Простая, но мощная идея. Термин «обратное распространение ошибки» будет часто использоваться в этой книге.
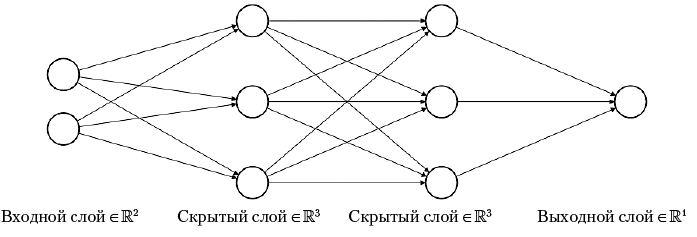
Рис. 1.4. Пример многослойной нейронной сети (изображение заимствовано из статьи)
В 1989 году Джордж Кибенко (George Cybenko) представил первое доказательство универсальной аппроксимационной теоремы (Universal Approximation Theorem), утверждающей, что нейронная сеть с единственным скрытым слоем теоретически способна смоделировать любую задачу. Это означает способность нейронных сетей превзойти (по крайней мере, теоретически) любой другой подход к машинному обучению. И, черт возьми, они могут даже имитировать человеческий мозг! Но все это только на бумаге. Размеры таких сетей ограничены возможностями реального мира. Частично эти ограничения можно преодолеть, создав несколько скрытых слоев и обучив такую сеть... Стоп! А как же обратное распространение ошибки?
Что касается практического воплощения, то в 1986 году команда из университета Карнеги — Меллона построила первое в истории беспилотное транспортное средство NavLab 1 (рис. 1.5). Первоначально для управления рулем в нем использовалась однослойная нейронная сеть. В итоге в рамках этого проекта в 1995 году был создан автомобиль NavLab 5. Во время демонстрации он самостоятельно проехал почти 50 миль из 2850-мильного пробега из Питтсбурга в Сан-Диего. NavLab получил водительские права еще до того, как родились многие инженеры Tesla!

Рис. 1.5. Беспилотный автомобиль NavLab 1 1986 года во всей своей красе (изображение взято по адресу http://www.cs.cmu.edu/Groups/ahs/navlab_list.html)
Еще один примечательный пример из 1980-х: почтовой службе США (United States Postal Service, USPS) потребовалось наладить автоматическую сортировку почтовых отправлений по индексам получателей. Поскольку большая часть писем всегда писалась от руки, оптическое распознавание символов оказалось бессильно. Чтобы решить эту задачу, Ян ЛеКун (Yann LeCun) с коллегами использовал набор рукописных образцов из Национального института стандартов и технологий (National Institute of Standards and Technology, NIST), чтобы показать способность нейронных сетей распознавать рукописные цифры. Они опубликовали результаты в своей статье «Backpropagation Applied to Handwritten Zip Code Recognition». Созданная ими сеть LeNet несколько десятков лет использовалась почтовой службой США для автоматического сканирования и сортировки почты. Пример особенно примечателен, потому что это была первая сверточная сеть, нашедшая практическое применение на производстве. Позднее, в 1990-х годах, банки начали использовать усовершенствованную версию этой сети под названием LeNet-5 для чтения рукописных цифр на чеках. Так была заложена основа современного компьютерного зрения.

Те из вас, кто читал о датасете MNIST, возможно, заметили связь с только что упомянутым институтом NIST. Дело в том, что датасет MNIST фактически включает подмножество изображений из исходного датасета NIST, к которым были применены некоторые модификации (modifications — «M» в MNIST), чтобы упростить процесс обучения и тестирования нейронной сети. Модификации, часть из которых видны на рис. 1.6, заключались в изменении размеров изображений до 28 × 28 пикселей, центрировании цифр в этой области, сглаживании и т.д.

Рис. 1.6. Выборка рукописных цифр из датасета MNIST
Другие исследователи тоже продолжили свои работы, в том числе Юрген Шмидхубер (Jürgen Schmidhuber), предложивший сети с долгой краткосрочной памятью (Long Short-Term Memory, LSTM) с многообещающими перспективами для распознавания рукописного текста и речи.
Несмотря на существенное развитие теории, результаты тогда нельзя было показать на практике, главным образом из-за дороговизны вычислительного оборудования и сложности его масштабирования для решения более крупных задач. Даже если каким-то чудом оборудование оказывалось доступным, собрать данные, позволяющие полностью реализовать его потенциал, было очень нелегко. В конце концов, развитие интернета все еще находилось на этапе коммутируемого доступа. Метод опорных векторов (Support Vector Machine, SVM) — метод машинного обучения, разработанный для задач классификации в 1995 году — был быстрее и давал достаточно хорошие результаты на меньших объемах данных, а потому выглядел предпочтительнее.
В результате ИИ и глубокое обучение заработали плохую репутацию. Аспирантов предостерегали от проведения исследований в области глубокого обучения, потому что именно в этой области «многие умные ученые закончили свою карьеру». Люди и компании, работающие в этой области, стали использовать альтернативные обозначения и термины, такие как информатика, когнитивные системы, интеллектуальные агенты, машинное обучение и другие, чтобы отмежеваться от слов «искусственный интеллект». Похоже на то, как Министерство войны США (Department of War) было переименовано в Министерство обороны (Department of Defense), чтобы название было менее пугающим.
Как глубокое обучение вошло в моду
К счастью для нас, 2000-е принесли высокоскоростной интернет, смартфоны с камерами, видеоигры, Flickr и Creative Commons (что дало возможность легально использовать фотографии, созданные другими людьми). Огромное количество людей получили возможность быстро делать фотографии с помощью карманного устройства, а затем мгновенно выгружать их. Океан данных наполнялся, и постепенно стали появляться возможности искупаться в нем. В результате такого счастливого стечения обстоятельств и упорного труда Фей-Фей Ли (Fei-Fei Li, в ту пору трудившейся в Принстонском университете) и ее коллег появился датасет ImageNet с 14 миллионами изображений.
Тогда же серьезного уровня достигли компьютерные и консольные игры. Геймерам нужна была все более качественная графика. Это, в свою очередь, подтолкнуло производителей графических процессоров (Graphics Processing Unit, GPU), например NVIDIA, совершенствовать свое оборудование. При этом важно помнить, что GPU чертовски хороши в матричных операциях. Почему? Потому что этого требует математика. В компьютерной графике распространены такие задачи, как перемещение объектов, вращение объектов, изменение их формы, регулировка их освещения и т.д., и во всех этих задачах используются матричные операции. И GPU стали специализироваться на них. А знаете, где еще требуется масса матричных вычислений? В нейронных сетях. Это одно большое счастливое совпадение.
После создания ImageNet в 2010 году был организован ежегодный конкурс ImageNet Large Scale Visual Recognition Challenge (ILSVRC), побуждавший исследователей разрабатывать более совершенные методы классификации данных из этого набора. Исследователям было предложено подмножество, разделенное на 1000 категорий и включавшее примерно 1,2 миллиона изображений. Первые пять мест заняли современные на тот момент методы компьютерного зрения, такие как масштабно-инвариантное преобразование признаков (Scale-Invariant Feature Transform, SIFT) и метод опорных векторов (SVM). Они дали 28 % (в 2010-м) и 25 % (в 2011-м) ошибок (то есть если метод ошибался в одном случае из пяти, он считался точным). А затем наступил 2012 год, и в таблице лидеров появилась запись с уровнем ошибок почти в два раза ниже — до 16 %. Эту заявку подали Алекс Крижевский (Alex Krizhevsky), Илья Суцкевер (Ilya Sutskever, который позднее основал OpenAI) и Джеффри Хинтон (Geoffrey Hinton) из университета Торонто. Это была сверточная нейронная сеть (Convolutional Neural Network, CNN) под названием AlexNet, построенная по образу и подобию LeNet-5. Даже всего с восемью слоями AlexNet имела 60 миллионов параметров и 650 000 нейронов, что дало модель с размером 240 Мбайт. Ее обучали неделю с помощью двух GPU NVIDIA. Это событие прозвучало как гром среди ясного неба, доказав потенциал CNN, после чего дело сдвинулось с мертвой точки и наступила современная эра глубокого обучения.
На рис. 1.7 показан количественный прогресс, достигнутый сверточными сетями за последнее десятилетие. С момента появления глубокого обучения в 2012 году количество ошибок классификации среди победителей конкурса ImageNet LSVRC каждый год снижалось на 40 %. По мере того как сверточные сети становились все глубже, ошибка уменьшалась.
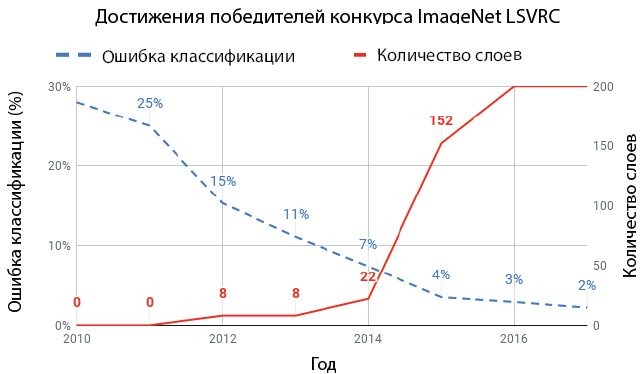
Рис. 1.7. Прогресс победителей конкурса ImageNet LSVRC
Имейте в виду, что история ИИ здесь значительно сокращена, а некоторые детали опущены. Но, по сути, именно это сочетание — появление больших объемов доступных данных, развитие GPU и создание более совершенных методов — привело нас к эре глубокого обучения. Прогресс распространяется и на новые сферы. Как показано в табл. 1.1, то, что раньше считалось научной фантастикой, теперь стало реальностью.
Таблица 1.1. Наиболее значимые этапы эпохи глубокого обучения
| 2012 |
Нейронная сеть, созданная командой Google Brain, начинает распознавать кошек в видеороликах на YouTube |
| 2013 |
Исследователи начинают применять глубокое обучение для решения множества задач. word2vec привносит контекст в слова и фразы, делая еще один шаг в сторону понимания их смысла. Уровень ошибок при распознавании речи снизился на 25 % |
| 2014 |
Изобретены генеративно-состязательные сети (Generative Adversarial Network, GAN). Skype переводит речь в режиме реального времени. Чат-бот Юджина Густмана (Eugene Goostman) преодолевает тест Тьюринга. Изобретена модель «последовательность в последовательность» нейронных сетей. Преобразование изображений в предложения с их кратким описанием |
| 2015 |
Обученная 1000-слойная сеть Microsoft ResNet превзошла человека в распознавании изображений. Deep Speech 2, созданная в Baidu, продемонстрировала возможность сквозного (end-to-end) распознавания речи. Gmail запустила услугу интеллектуального ответа Smart Reply. YOLO (You Only Look Once) обнаруживает объекты в масштабе реального времени. Visual Question Answering позволяет задавать вопросы на основе изображений |
| 2016 |
AlphaGo побеждает профессиональных игроков в го. Google WaveNets помогает создавать реалистичные звуки. Microsoft достигает человеческого уровня в распознавании разговорной речи |
| 2017 |
AlphaGo Zero самостоятельно обучается игре в го за 3 дня. Capsule Nets исправляет недостатки в сверточной сети. Представлен тензорный процессор (Tensor Processing Unit, TPU). Калифорния разрешает продажу беспилотных автомобилей. Pix2Pix обретает возможность генерировать изображения из набросков |
| 2018 |
ИИ превосходит людей в проектировании ИИ, благодаря методам поиска нейронной архитектуры Neural Architecture Search. Демонстрационная версия Google Duplex может бронировать столики в ресторане от нашего имени. Deep Fakes заменяет одно лицо другим в видео. Нейронная сеть BERT компании Google помогает людям переводить с одного языка на другой. Созданы комплекты тестов DawnBench и MLPerf для проверки качества обучения искусственного интеллекта |
| 2019 |
OpenAI Five сокрушает чемпионов мира в игре Dota2. StyleGan создает фотореалистичные изображения. OpenAI GPT-2 генерирует реалистичные отрывки текста. Fujitsu обучает ImageNet за 75 секунд. Microsoft инвестирует миллиард долларов в OpenAI |
Получив представление об истории развития ИИ и глубокого обучения, вы должны понимать, почему этот момент времени важен. Важно осознавать, насколько быстро движется прогресс в этой области. Но, как мы уже видели, так было не всегда.
По словам двух пионеров этой области, еще в 1960-х годах они прогнозировали срок появления настоящего компьютерного зрения как «этим летом». Они ошиблись всего на полвека! Да, быть футуристом непросто. Исследование Александра Висснера-Гросса (Alexander Wissner-Gross) показало, что между появлением алгоритма и прорывом, к которому ведет этот алгоритм, в среднем проходило 18 лет. С другой стороны, аналогичный разрыв между появлением датасета и прорывом, которого он помог достичь, составлял в среднем всего три года! Возьмите любое открытие, сделанное в последние десять лет, и вы увидите, что датасет, позволивший сделать это открытие, скорее всего, стал доступен всего за несколько лет до этого.
Очевидно, что нехватка данных была ограничивающим фактором. Это показывает, насколько велика роль хорошего датасета в глубоком обучении. Однако данные — не единственный фактор. Рассмотрим другие составляющие, образующие основу идеального решения глубокого обучения.
Рецепт идеального решения задачи глубокого обучения
Прежде чем приступить к приготовлению блюд, Гордон Рамзи2 проверяет наличие всех ингредиентов. То же относится к решению задач с помощью глубокого обучения (рис. 1.8). И вот ваш набор ингредиентов для глубокого обучения:
Датасет + Модель + Фреймворк + Оборудование = Решение задачи глубокого обучения
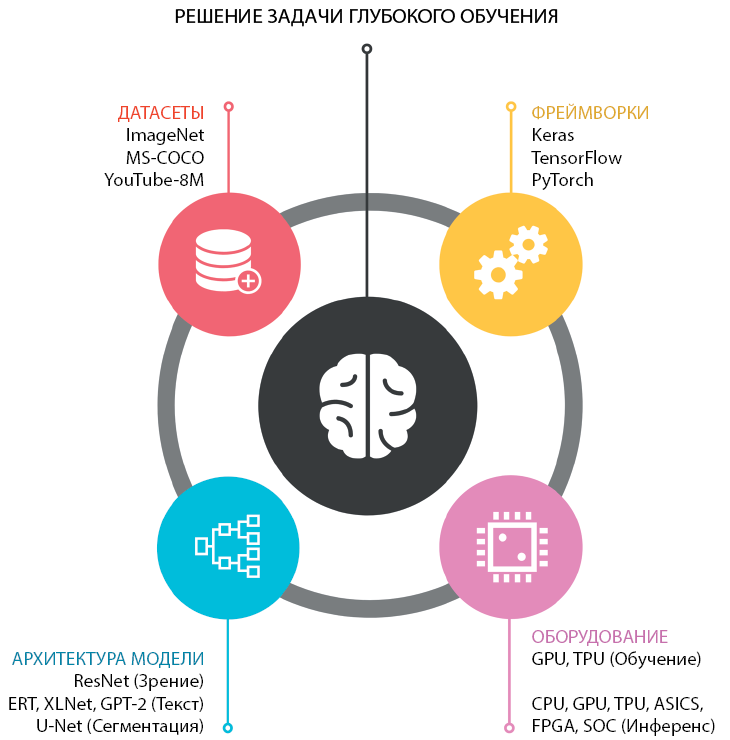
Рис. 1.8. Ингредиенты для идеального решения задачи глубокого обучения
Рассмотрим каждый из них поближе.
Датасеты
Как моряк Попай страстно жаждет шпинат, так глубокое обучение страстно жаждет данных — много данных. Для выявления значимых закономерностей, которые помогают делать надежные прогнозы, нужны огромные объемы данных. В 1980-х и 1990-х годах нормой считалось традиционное машинное обучение, использовавшее сотни или тысячи образцов. Глубокие нейронные сети, построенные с нуля, напротив, требуют намного больше данных даже для типовых задач прогнозирования. Но в этом есть свой плюс — прогнозы получаются гораздо точнее.
Сейчас мы наблюдаем взрывной рост накопления данных: каждый день создаются квинтиллионы байтов данных — изображений, текста, видео, информации от датчиков и многого другого. Но чтобы использовать эти данные, нужны метки. Чтобы создать классификатор настроений, отделяющий положительные отзывы на Amazon от отрицательных, нужны тысячи таких отзывов с присвоенными им метками настроения. Чтобы обучить систему сегментации лица для Snapchat, нужны тысячи изображений, на которых точно отмечено расположение глаз, губ, носа и т.д. Чтобы обучить беспилотный автомобиль, нужны фрагменты видео, на которых показаны реакции человека-водителя на дорожную обстановку и его воздействие на органы управления автомобилем — тормоза, акселератор, рулевое колесо и т.д. Эти метки выступают в роли учителя нашего ИИ, и размеченные данные гораздо ценнее неразмеченных.
Создание меток может обходиться очень дорого. Неудивительно, что есть целая индустрия, которая занимается поиском исполнителей для решения задач разметки. Каждая метка стоит от нескольких центов до нескольких долларов, в зависимости от времени, потраченного исполнителем. Например, во время разработки датасета Microsoft COCO (Common Objects in Context — обычные объекты в контексте) требовалось примерно три секунды, чтобы присвоить метку с названием каждому объекту на изображении; примерно 30 секунд, чтобы определить ограничивающую рамку вокруг каждого объекта, и 79 секунд, чтобы обрисовать контур каждого объекта. Теперь представьте, что эти операции нужно произвести с сотнями тысяч изображений, и вы поймете, какие средства были вложены в создание некоторых из наиболее крупных датасетов. Отдельные компании, занимающиеся разметкой, — Appen и Scale.AI, уже оцениваются более чем в миллиард долларов каждая.
На нашем счете может не быть миллиона долларов. Но, к счастью для нас, в этой революции глубокого обучения произошло два хороших события.
• Крупные компании и университеты щедро поделились с нами, обнародовав гигантские наборы размеченных данных.
• Был разработан метод под названием «перенос обучения» (transfer learning), который позволяет настраивать модели с использованием небольших датасетов, насчитывающих всего несколько сотен образцов, при условии, что эти модели предварительно были обучены на более крупных наборах, аналогичных текущему. Мы неоднократно использовали этот метод в книге, в том числе в главе 5, где экспериментально доказали, что этот прием способен обеспечить достойное качество даже при наличии всего нескольких десятков обучающих образцов. Возможность переноса обучения развенчивает миф о том, что для обучения хорошей модели необходимы большие данные. Добро пожаловать в мир крошечных данных!
В табл. 1.2 перечислены некоторые из популярных датасетов для различных задач глубокого обучения.
Таблица 1.2. Общедоступные датасеты
| Тип данных |
Название |
Описание |
| Изображения |
Open Images V4 (Google) |
Девять миллионов изображений в 19 700 категориях. 1,74 миллиона изображений в 600 категориях (ограничивающие рамки, bounding boxes) |
| Microsoft COCO |
330 000 изображений объектов в 80 категориях. Ограничивающие рамки, сегментация и по пять подписей к каждому изображению |
|
| Видео |
YouTube-8M |
6,1 миллиона видео, 3862 категории, 2,6 миллиарда аудиовизуальных признаков. По 3 метки на видео. 1,53 ТБ случайно выбранных видео |
| Видео, изображения |
BDD100K (Калифорнийский университет в Беркли) |
100 000 видеороликов о вождении с суммарной продолжительностью более 1100 часов. 100 000 изображений с ограничивающими рамками в 10 категориях. 100 000 изображений с разметкой полос движения. 100 000 изображений с сегментацией дорожных областей. 10 000 изображений с пиксельной сегментацией экземпляров |
| Waymo Open Dataset |
3000 сцен вождения с суммарной продолжительностью 16,7 часа, 600 000 кадров, примерно 25 миллионов ограничивающих 3-мерных рамок и 22 миллиона 2-мерных рамок |
|
| Текст |
SQuAD |
150 000 материалов из Википедии со смысловыми метками |
| Yelp Reviews |
Пять миллионов отзывов на Yelp |
|
| Спутниковые данные |
Landsat Data |
Несколько миллионов спутниковых изображений поверхности Земли (с шириной и высотой в 100 морских миль) в восьми спектральных диапазонах (с пространственным разрешением от 15 до 60 метров) |
| Аудио |
Google AudioSet |
2 084 320 10-секундных аудиозаписей с YouTube в 632 категориях |
| LibriSpeech |
1000 часов английской речи |
Архитектура модели
Модель — это просто функция. Она принимает один или несколько входных параметров и возвращает результат. Входными данными могут быть текст, изображения, аудио, видео или что-то еще, а результатом является прогноз. Хорошей считается модель, прогнозы которой достаточно точно соответствуют ожидаемой реальности. Точность модели, обученной на некотором датасете, является основным определяющим фактором ее пригодности для реального использования. Для большинства это все, что нужно знать о моделях глубокого обучения. Но если заглянуть внутрь модели, взору откроется множество интересных деталей (рис. 1.9).

Рис. 1.9. Черный ящик модели глубокого обучения
Внутри модели находится граф, состоящий из вершин и ребер. Вершины — это математические операции, а ребра представляют потоки данных между узлами. Другими словами, если выход одной вершины связать со входом одной или нескольких других вершин, то эти связи между вершинами будут представлены ребрами. Структура графа определяет потенциальную точность, скорость, количество потребляемых ресурсов (память, продолжительность вычислений и электроэнергия), а также тип входных данных, которые она может обрабатывать.
Расположение вершин и ребер определяется архитектурой модели. По сути, это план здания. Но кроме плана нужно еще само здание. Обучение — это строительство здания с помощью плана. Обучение модели происходит многократным выполнением нескольких этапов: 1) на вход подаются исходные данные; 2) извлекаются выходные данные; 3) определяется, насколько прогноз далек от ожидаемой реальности (то есть от меток, связанных с данными); затем 4) величина ошибки распространяется через модель в обратном направлении, чтобы она могла исправить себя. Этот процесс обучения повторяется снова и снова, пока не будет достигнут удовлетворительный уровень прогнозирования.
Результатом обучения является набор чисел (также известных как веса), которые присваиваются каждой из вершин. Эти веса являются необходимыми параметрами вершин в графе, обеспечивающими правильную обработку входных данных. Перед началом обучения весам обычно присваиваются случайные значения. Целью процесса обучения фактически является постепенная настройка значений этих весов, пока они не обеспечат получение удовлетворительных прогнозов.
Чтобы лучше понять, как работают веса, рассмотрим следующий датасет с двумя входами и одним выходом:
Таблица 1.3. Пример датасета
| вход1 |
вход2 |
выход |
| 1 |
6 |
20 |
| 2 |
5 |
19 |
| 3 |
4 |
18 |
| 4 |
3 |
17 |
| 5 |
2 |
16 |
| 6 |
1 |
15 |
Применив методы линейной алгебры (или посчитав в уме), мы можем прийти к выводу, что этому датасету соответствует следующее уравнение:
выход = f(вход1, вход2) = 2 × вход1 + 3 × вход2.
В данном случае веса равны 2 и 3. Глубокая нейронная сеть имеет миллионы таких весовых параметров.
Разные типы используемых вершин определяют разные виды архитектур моделей, каждая из которых лучше подходит для входных данных определенного типа. Например, для анализа изображения и звука обычно используются сверточные нейронные сети (CNN), а для обработки текста — рекуррентные нейронные сети (RNN) и сети с долгой краткосрочной памятью (LSTM).
В общем случае обучение одной из таких моделей с нуля может потребовать довольно много времени, возможно, недели. К счастью, многие исследователи уже проделали всю тяжелую работу по обучению своих моделей на универсальных датасетах (например, ImageNet) и сделали их доступными для всех. Благодаря этому можно взять эти модели и настроить их для своего конкретного датасета. Этот процесс называется переносом обучения (transfer learning) и подходит для большинства практических потребностей.
По сравнению с обучением с нуля перенос обучения дает двойное преимущество: значительно сокращается время обучения (от нескольких минут до часов вместо недель), и он дает хорошие результаты даже при использовании относительно небольшого датасета (от сотен до тысяч образцов вместо миллионов). В табл. 1.4 перечислены некоторые примеры известных архитектур моделей.
Таблица 1.4. Примеры известных архитектур моделей
| Задача |
Примеры архитектур моделей |
| Классификация изображений |
ResNet-152 (2015), MobileNet (2017) |
| Классификация текста |
BERT (2018), XLNet (2019) |
| Сегментация изображений |
U-Net (2015), DeepLabv3 (2018) |
| Преобразование изображений |
Pix2Pix (2017) |
| Распознавание объектов |
YOLO9000 (2016), Mask R-CNN (2017) |
| Генерация речи |
WaveNet (2016) |
Для всех моделей, перечисленных в табл. 1.4, опубликованы показатели точности на эталонных датасетах (например, для моделей классификации — на наборе ImageNet, для моделей распознавания объектов — на наборе MS COCO). Кроме того, разные архитектуры имеют свои характерные требования к ресурсам (размер модели в мегабайтах или требование к производительности в виде количества операций с плавающей запятой в секунду — floating-point operations in second, FLOPS).
Подробнее о переносе обучения поговорим в следующих главах, а сейчас познакомимся с доступными фреймворками и сервисами глубокого обучения.

Когда в 2015 году Кайминг Хе (Kaiming He) с коллегами придумал 152-слойную архитектуру ResNet — это был настоящий подвиг для того времени, учитывая, что предыдущая самая большая модель GoogLeNet состояла из 22 слоев — у всех возник только один вопрос: «Почему не 153 слоя?» Как оказывается, Каймингу просто не хватило памяти, доступной графическому процессору.
Фреймворки
Есть несколько библиотек глубокого обучения. Кроме того, есть фреймворки, специализирующиеся на использовании обученных моделей для прогнозирования (или инференса) и оптимизации их использования в приложениях.
Как это часто случается с софтом в целом, многие библиотеки появлялись и исчезали: Torch (2002), Theano (2007), Caffe (2013), Microsoft Cognitive Toolkit (2015), Caffe2 (2017) — и ландшафт постоянно менялся. Но уроки не проходили даром, и последующие библиотеки получались все более простыми в использовании, более мощными, более производительными и вызывающими интерес как у новичков, так и у экспертов. В табл. 1.5 перечислены некоторые из популярных библиотек.
Таблица 1.5. Популярные фреймворки глубокого обучения
| Фреймворк |
Основное назначение |
Типичная целевая платформа |
| TensorFlow (включая Keras) |
Обучение |
Настольные компьютеры, серверы |
| PyTorch |
Обучение |
Настольные компьютеры, серверы |
| MXNet |
Обучение |
Настольные компьютеры, серверы |
| TensorFlow Serving |
Прогнозирование |
Серверы |
| TensorFlow Lite |
Прогнозирование |
Мобильные и встраиваемые устройства |
| TensorFlow.js |
Прогнозирование |
Браузеры |
| ml5.js |
Прогнозирование |
Браузеры |
| Core ML |
Прогнозирование |
Устройства компании Apple |
| Xnor AI2GO |
Прогнозирование |
Встраиваемые устройства |
TensorFlow
В 2011 году в Google Brain была разработана библиотека глубокого обучения DistBelief для внутренних исследований и разработок. Она обучала сеть Inception (победительницу конкурса ImageNet Large Scale Visual Recognition Challenge 2014 года), а также улучшала качество распознавания речи в продуктах Google. Эта библиотека была тесно связана с инфраструктурой Google, имела запутанные настройки, и ею было очень сложно поделиться вне Google. Осознав ограничения, сотрудники Google приступили к созданию распределенного фреймворка МО второго поколения, который должен был получиться универсальным, масштабируемым, высокопроизводительным и переносимым на многие аппаратные платформы. И, что самое приятное, он имел открытый исходный код. В Google этот фреймворк назвали TensorFlow и объявили о его релизе в ноябре 2015 года.
В TensorFlow были реализованы многие из вышеупомянутых обещаний и сквозной процесс от разработки до развертывания. Фреймворк стал очень популярным. Сейчас у него 164 тысячи звезд на GitHub, и это не предел. Но по мере распространения пользователи справедливо критиковали TensorFlow за недостаточную простоту в использовании. Даже родилась шутка: TensorFlow была создана инженерами Google для инженеров Google, и если вы умеете использовать TensorFlow, то достаточно умны, чтобы работать в Google.
Но Google — не единственная компания, игравшая на этом поле. По правде говоря, даже в 2015 году считалось, что работа с библиотеками глубокого обучения — это не самое приятное занятие. Более того, даже простая установка некоторых из этих фреймворков заставляла людей рвать на себе волосы. (Пользователи Caffe тут? Согласны? Узнали?)
Keras
В ответ на трудности, с которыми приходилось сталкиваться практикам глубокого обучения, в марте 2015 года Франсуа Шолле (François Chollet) выпустил библиотеку с открытым исходным кодом Keras, изменившую мир. Это решение внезапно сделало глубокое обучение доступным для новичков. Keras имела простой и понятный интерфейс и стала использоваться в других библиотеках глубокого обучения в роли внутренней вычислительной инфраструктуры. Первоначально основанная на Theano, Keras способствовала быстрому созданию прототипов и сокращала количество строк кода. Позднее ее абстракции были распространены на другие фреймворки — Cognitive Toolkit, MXNet, PlaidML и, да, TensorFlow.
PyTorch
Примерно в то же время, в начале 2016 года, в Facebook был запушен проект PyTorch, инженеры которого столкнулись с ограничениями TensorFlow. Библиотека PyTorch изначально поддерживала конструкции Python и инструменты отладки Python, что обеспечило ей большую гибкость и простоту в использовании и быстро сделало ее фаворитом среди исследователей ИИ. Это вторая по величине сквозная (end-to-end) система глубокого обучения. Также в Facebook была создана библиотека Caffe2, позволяющая использовать модели PyTorch и развертывать их в производственной среде для обслуживания более миллиарда пользователей. В отличие от PyTorch, которая в основном предназначалась для исследований, Caffe2 применялась в основном в продакшене. В 2018 году Caffe2 вошла в состав PyTorch и был создан полноценный фреймворк.
Постоянно развивающийся ландшафт
Если бы эта история закончилась с появлением простых и удобных библиотек Keras и PyTorch, в подзаголовке этой книги не было бы слова «TensorFlow». В команде TensorFlow осознали, что если они действительно хотят расширить возможности инструмента и демократизировать ИИ, то нужно упростить инструмент. Поэтому объявление об официальном включении Keras в состав TensorFlow стало долгожданной новостью. Это объединение позволило разработчикам использовать Keras для определения моделей и их обучения, а ядро TensorFlow — для организации высокопроизводительного пайплайна обработки данных, включая распределенное обучение и экосистему развертывания. Это был брак, заключенный на небесах. А еще версия TensorFlow 2.0 (выпущенная в 2019 году) включала поддержку собственных конструкций Python и режима «немедленного выполнения» (eager execution), хорошо знакомых по PyTorch.
При наличии нескольких конкурирующих фреймворков неизбежно встает вопрос о переносимости. Представьте, что появилась исследовательская статья, сопровождающаяся примером обученной модели PyTorch. Если вы не используете PyTorch, то для проверки этой модели придется заново реализовать и обучить ее. Разработчикам нравится возможность свободно делиться моделями и не ограничиваться какой-то конкретной экосистемой.
Первое время многие разработчики писали библиотеки для преобразования моделей из одного формата в другой. Это было простое решение, но оно привело к росту количества инструментов преобразования в геометрической прогрессии и нехватке официальной поддержки из-за огромного их числа. Чтобы решить эту проблему, Microsoft, Facebook и другие основные игроки в этой отрасли поддержали создание проекта Open Neural Network Exchange (ONNX), в рамках которого была разработана спецификация общего формата моделей, который получил официальную поддержку в ряде популярных библиотек. Также были созданы инструменты преобразования для библиотек, которые изначально не поддерживали этот формат. В результате разработчики получили возможность обучать модели в одной среде и использовать их для прогнозирования в другой.
Кроме этих фреймворков есть также несколько систем с графическим пользовательским интерфейсом, позволяющих обучать модели, не написав ни строчки кода. Используя прием переноса обучения, они создают обученные модели в нескольких форматах, которые можно использовать для прогнозирования. Используя интерфейсы «наведи и щелкни», даже ваша бабушка сможет обучать нейронные сети.
Таблица 1.6. Популярные инструменты с графическим интерфейсом для обучения моделей
| Служба |
Платформа |
| Microsoft CustomVision.AI |
На веб-основе |
| Google AutoML |
На веб-основе |
| Clarifai |
На веб-основе |
| IBM Visual Recognition |
На веб-основе |
| Apple Create ML |
macOS |
| NVIDIA DIGITS |
Настольные компьютеры |
| Runway ML |
Настольные компьютеры |
Так почему же для этой книги в качестве основных фреймворков мы выбрали TensorFlow и Keras? Учитывая доступность огромного объема информации, включая документацию, ответы на вопросы на Stack Overflow, онлайн-курсы, обширное сообщество участников, поддержку платформ и устройств, распространение в отрасли и, да, количество доступных вакансий (в США на 2019 год число вакансий, связанных с TensorFlow, примерно в три раза больше числа вакансий, связанных с PyTorch), можно утверждать, что сейчас TensorFlow и Keras заняли доминирующие позиции. И определенно имело смысл выбрать эту комбинацию. Тем не менее методы, обсуждаемые в книге, можно распространить и на другие библиотеки. Вам не придется тратить много времени на освоение новых фреймворков, если потребуется. Если вы действительно решите уйти в компанию, где используется только PyTorch, то не сомневайтесь и действуйте.
Оборудование
В 1848 году, когда Джеймс Маршалл обнаружил золото в Калифорнии, эта новость распространилась по США как лесной пожар. Сотни тысяч людей отправились туда на добычу богатств. Это явление стало известно как Калифорнийская золотая лихорадка. Первопроходцы смогли отхватить приличный кусок, но опоздавшим повезло меньше. Лихорадка продолжалась много лет. Сможете ли вы угадать, кто за все это время заработал больше всего денег? Производители лопат!
Компании, предлагающие услуги облачных вычислений, и производители оборудования — это производители лопат XXI века. Не верите? Посмотрите, как выросли в цене акции Microsoft и NVIDIA за последнее десятилетие. Единственное отличие настоящего времени от 1848 года — ошеломляющее количество доступных лопат.
При нынешнем разнообразии доступного оборудования важно сделать правильный выбор с учетом ограничений ресурсов, задержек, бюджета, конфиденциальности и юридических требований приложения.
Обычно на этапе прогнозирования пользователь ожидает получить ответ. Это накладывает ограничения на тип оборудования, которое можно использовать, а также на его расположение. Например, Snapchat не может работать в облаке из-за задержек в сети. Кроме того, приложение должно работать практически в масштабе реального времени, чтобы соответствовать ожиданиям пользователя, и определяет минимальные требования к количеству кадров, обрабатываемых в секунду (обычно > 15). При этом фотография, выгруженная в Google Photos, не требует немедленной классификации. Задержка в несколько секунд или даже минут вполне допустима.
С другой стороны, обучение занимает намного больше времени, от нескольких минут до часов или даже дней. В зависимости от сценария использования истинная ценность высокопроизводительного оборудования заключается в возможности ускорить эксперименты и выполнить больше итераций. Для чего-то более серьезного, чем простые нейросети, производительность оборудования может иметь огромное значение. Как правило, графические процессоры ускоряют работу в 10–15 раз по сравнению с обычными процессорами, имеют гораздо более высокую производительность на ватт и сокращают время ожидания завершения эксперимента с нескольких дней до нескольких часов. Эту разницу легко представить, сравнив продолжительность просмотра документального фильма о Гранд-Каньоне (два часа) с продолжительностью поездки в Гранд-Каньон (четыре дня).
Ниже описывается несколько основных категорий оборудования на выбор и то, как они обычно характеризуются (см. также рис. 1.10):
Центральный процессор (Central Processing Unit, CPU)
Дешевизна, универсальность, низкое быстродействие. Например, Intel Core i9-9900K.
Графический процессор (GPU)
Высокая пропускная способность, пригодность для пакетной обработки с высокой степенью распараллеливания задач, дороговизна. Например, NVIDIA GeForce RTX 2080 Ti.
Программируемая логическая интегральная схема (Field-Programmable Gate Array, FPGA)
Высокое быстродействие, низкое энергопотребление, возможность перепрограммирования для нестандартных решений, дороговизна. В числе известных производителей FPGA можно назвать: Xilinx, Lattice Semiconductor, Altera (Intel). Благодаря возможности настройки для обучения любой модели ИИ, большая часть ИИ в Microsoft Bing обучается на интегральных схемах FPGA.
Специализированная интегральная схема (Application-Specific Integrated Circuit, ASIC)
Специализированная микросхема. Чрезвычайно дорогостоящая в проектировании, но дешевая при массовом производстве. Так же как в фармацевтической промышленности, первое изделие стоит дорого из-за затрат на научно-исследовательские и конструкторские работы. Массовое производство обходится относительно недорого. Вот некоторые конкретные примеры:
TPU
Специализированные интегральные схемы, предназначенные для работы с нейронными сетями, доступны только в Google Cloud.
Краевой (edge) TPU
Крошечная микросхема, меньше центовой монеты, но дает значительный прирост в производительности инференса.
Нейронный процессор (Neural Processing Unit, NPU)
Часто используется производителями смартфонов в виде отдельной микросхемы для ускорения прогнозирования с использованием нейронной сети.
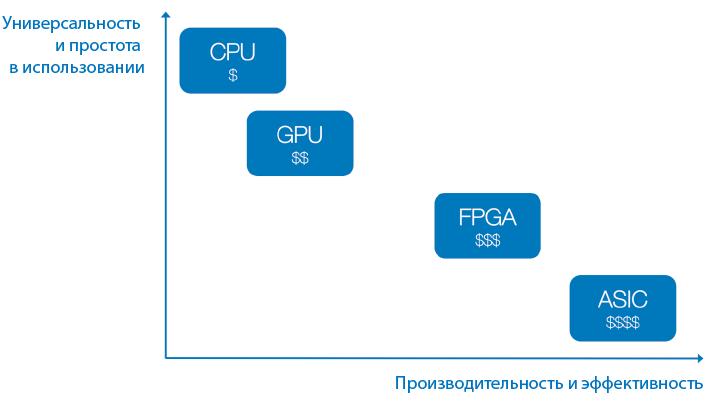
Рис. 1.10. Сравнение разных типов оборудования по универсальности, производительности и стоимости
Перечислим типичные сценарии использования оборудования каждого типа:
• Начало обучения → CPU.
• Обучение больших сетей → GPU и TPU.
• Прогнозирование на смартфонах → мобильный CPU, GPU, процессор для цифровой обработки сигналов (Digital Signal Processor, DSP), NPU.
• Носимые устройства (например, умные очки, умные часы) → краевые TPU, NPU .
• Встраиваемые реализации ИИ (например, беспилотные летательные аппараты, автономные инвалидные коляски) → ускорители, такие как Google Coral, Intel Movidius с Raspberry Pi, или графические процессоры, такие как NVIDIA Jetson Nano, вплоть до микроконтроллеров (MCU) за 15 долларов для обнаружения активирующих слов в интеллектуальных колонках.
Многие из этих сценариев мы рассмотрим позже.
Ответственный ИИ
После знакомства с потенциальными возможностями ИИ можно питать большие надежды на расширение наших способностей, повышение продуктивности и получение сверхспособностей.
Но с широкими возможностями приходит большая ответственность.
Насколько ИИ может помочь человечеству, настолько же он может навредить ему, если разрабатывать его без осознания важности и должного внимания (намеренно или нет). Здесь нет вины ИИ — вся ответственность лежит на разработчиках.
Рассмотрим несколько инцидентов последних лет.
«____ якобы может определить, являетесь ли вы террористом, просто проанализировав ваше лицо» (рис. 1.11): Computer World, 2016;
«ИИ отправляет людей в тюрьму и... ошибается»: MIT Tech Review, 2019;
«____ суперкомпьютер рекомендовал “небезопасные и ошибочные” методы лечения рака, свидетельствуют внутренние документы»: STAT News, 2018;
«____ создал инструмент искусственного интеллекта для найма людей, но ему пришлось отказаться от него из-за дискриминации женщин»: Business Insider, 2018;
«____ исследование искусственного интеллекта: ведущие системы распознавания объектов отдают предпочтение людям с большими деньгами»: 2019;
«____ изображения чернокожих людей подписывал как “горилла”» USA Today, 2015. «Два года спустя ____ решили проблему “расистского алгоритма”, удалив подпись “горилла” из классификатора изображений»: Boing Boing, 2018;
«____ отключили своего нового бота ИИ после того, как пользователи Twitter обучили его расизму»: TechCrunch, 2016
«ИИ по ошибке оштрафовал известную предпринимательницу за переход на красный свет, приняв портрет на проезжавшем автобусе за реального человека.»: Caixin Global, 2018;
«____ отказаться от контракта с Пентагоном в области ИИ после возражений сотрудников делать “бизнес на войне”»: Washington Post, 2018;
«Беспилотный автомобиль-убийца Uber “заметил пешехода за шесть секунд до того, как наехал на него и убил”»: The Sun, 2018.
Возможно, вы сможете заполнить пробелы в этом списке. Вот несколько вариантов: Amazon, Microsoft, Google, IBM и Uber. Добавьте их, а мы подождем.

Рис. 1.11. Стартап, утверждающий, что способен классифицировать людей по строению лица (High IQ — высокий IQ; Academic Reseahcher — ученый-исследователь; Proffesional Poker Player — профессиональный игрок в покер; Terrorist — террорист)
Мы опустили названия компаний по одной простой причине: проблема не в конкретном человеке или компании. Эта проблема касается каждого. И хотя ошибки прошлого могут не отражать современного состояния дел, мы должны усвоить урок и постараться не повторять тех же ошибок. И самое приятное, что многие уроки действительно были усвоены.
Мы как разработчики, дизайнеры и архитекторы ИИ обязаны мыслить не только техническими категориями. Ниже приводятся несколько примеров проблем, которые имеют отношение к любой решаемой нами задаче (связанной или не связанной с ИИ). Они не должны отходить на задний план.
Предвзятость
Часто, осознанно или нет, мы привносим в работу собственную предвзятость — результат влияния множества факторов, включая окружающую среду, воспитание, культурные нормы и даже нашу внутреннюю природу. В конце концов, ИИ и датасеты, на которых он основан, создавались не в вакууме, а людьми со своими предубеждениями. Компьютеры не имеют собственных предубеждений, они лишь отражают и усиливают существующие.
Приведем пример из первых дней существования приложения для YouTube, когда разработчики заметили, что примерно 10 % выгруженных видео перевернуты вверх ногами. Возможно, если бы это число было ниже, скажем, 1 %, то проблему можно было бы списать на ошибки пользователей. Но 10 % — это слишком большое число, чтобы его игнорировать. А вы знаете, кто составляет 10 % населения? Левши! Они держат телефоны во время съемки перевернутыми по сравнению с правшами. Но инженеры YouTube не учли этот аспект во время разработки и тестирования своего мобильного приложения, поэтому все видео выгружались на сервер YouTube в одинаковой ориентации, как для левшей, так и для правшей.
Эту проблему можно было обнаружить гораздо раньше, если бы в команде разработчиков был хоть один левша. Этот простой пример демонстрирует важность многообразия. Праворукость или леворукость — это всего лишь одна маленькая особенность человека. Есть множество других факторов, определяющих индивидуальность. Такие факторы, как пол, цвет кожи, экономическое положение, ограничения по здоровью, страна происхождения, особенности речи или даже что-то столь тривиальное, как длина волос, могут определять результаты, меняющие жизнь человека, в том числе и обработку их алгоритмами.
В глоссарии Google по машинному обучению (https://developers.google.com/machine-learning/glossary) перечислено несколько форм предвзятости, которые могут повлиять на пайплайн машинного обучения. Вот лишь некоторые из них:
Предвзятость выборки
Датасет не отражает реальное распределение и смещен в сторону подмножества категорий. Например, во многих виртуальных помощниках и домашних интеллектуальных колонках некоторые акценты языка представлены чрезмерно, в то время как другие вообще не включены в обучающий датасет, из-за чего большие группы населения мира остаются неохваченными.
Предвзятость выборки также может произойти из-за схожих понятий. Например, Google Translate при переводе таких предложений, как «She is a doctor. He is a nurse» (Она доктор. Он медбрат), на гендерно-нейтральный язык, скажем, турецкий, а затем обратно, меняет пол, как показано на рис. 1.12. Вероятно, это связано с тем, что датасет содержит большую выборку образцов словосочетаний, включающих мужские местоимения со словом «доктор» и женские со словом «медсестра»3.
Неявная предвзятость
Этот вид предвзятости обусловлен неявными предположениями, которые мы делаем, когда видим что-то. Обратите внимание на выделенный фрагмент на рис. 1.13. Любой, увидев его, мог бы с большой долей уверенности предположить, что здесь зебра. Фактически, учитывая, насколько сети, обученные на наборе ImageNet, склонны придавать значение текстурам, большинство из них классифицируют даже полное изображение как зебру. Но мы-то знаем, что это изображение дивана, обитого тканью с зебровидным рисунком.
Рис. 1.12. Google Translate отражает внутреннюю смещенность в данных (по состоянию на сентябрь 2019)

Рис. 1.13. Диван, обитый тканью с зебровидным рисунком; фотография Глена Эдельсона (Glen Edelson; https://www.flickr.com/photos/glenirah/2781264490)
Предвзятость в освещении информации
Иногда самые громкие голоса в комнате становятся самыми резкими и доминируют в разговоре. При беглом взгляде на Twitter может показаться, что наступил конец света, хотя на самом деле большинство людей не сидят в Twitter и заняты обычными делами. К сожалению, обыденное не продается.
Предвзятость внутри/вне группы
Комментатор из Восточной Азии может взглянуть на изображение статуи Свободы и присвоить ей метки, такие как «Америка» или «США», тогда как комментатор из США может сделать более подробные метки — «Нью-Йорк» или «Остров Свободы». Такова природа человека — видеть свои нюансы, в то время как другие видят что-то более обобщенное. Все это тоже отражается в наших датасетах.
Прозрачность и объяснимость
Представьте, что в конце 1800-х годов Карл Бенц сказал вам, что изобрел четырехколесное устройство, на котором можно перемещаться быстрее, чем на чем-либо еще. Только он понятия не имеет, как это устройство работает. Он только знает, что оно заправляется легковоспламеняющейся жидкостью, которая взрывается внутри и толкает устройство вперед. Что заставляет устройство двигаться? Что заставляет его останавливаться? Почему человек, сидящий внутри, не сгорает? У него нет ответов на эти вопросы. И наверное, вы тогда не захотели бы садиться в эту штуковину.
Именно так можно описать положение дел в сфере ИИ. Раньше в традиционном машинном обучении специалистам по данным приходилось вручную отбирать признаки (переменные для прогнозирования), на основе которых затем обучалась модель. Этот процесс ручного отбора, хотя и обременительный, давал больше контроля и понимания, как выполняется прогноз. В глубоком обучении, напротив, признаки отбираются автоматически. Специалисты по данным создают модели, вводят в них большие объемы данных, и эти модели каким-то образом дают надежные прогнозы, по крайней мере в большинстве случаев. Но человек не знает точно, как работает модель, какие признаки она приняла во внимание, при каких обстоятельствах модель работает эффективно и, что особенно важно, при каких обстоятельствах она не работает. Такой подход, вероятно, приемлем, когда Netflix выдает рекомендации, основываясь на том, что мы просматривали раньше (хотя мы более чем уверены, что где-то в их коде есть строчка recommendations.append("StrangerThings"). Но сейчас ИИ используется гораздо шире, не только для подбора рекомендуемых фильмов. Полиция и судебная система начинают полагаться на алгоритмы, чтобы решить, представляет ли кто-то из подозреваемых риск для общества и следует ли задерживать его до суда. На карту поставлены жизни и свобода многих людей. Мы просто не должны отдавать важные решения на откуп бездушному черному ящику. К счастью, эту ситуацию можно изменить, вкладывая средства в «объяснимый ИИ», когда модель не только дает прогнозы, но и показывает, какие факторы заставили ее принять то или иное решение, чтобы выявлять имеющиеся ограничения.
Кроме того, городские власти (например, Нью-Йорка) начинают раскрывать свои алгоритмы перед общественностью, признавая право жителей знать, какие алгоритмы используются для принятия жизненно важных решений и как они работают. Это позволяет экспертам проводить исследования и аудит, государственным учреждениям повышать уровень компетенции и точнее оценивать каждую добавляемую ими систему и открывает перед гражданами возможность оспорить решения, принятые алгоритмом.
Воспроизводимость
Научные исследования получают широкое признание сообщества, только когда воспроизводимы. Любой человек, изучающий такую научную работу, может воспроизвести условия теста и получить те же результаты. Не имея возможности воспроизвести результаты, полученные моделью в прошлом, мы не сможем привлечь ее к принятию ответственных решений в будущем. Если нет воспроизводимости, то исследования уязвимы для подделки результатов (p-hacking), когда параметры эксперимента подгоняются под желаемые результаты. Для исследователей чрезвычайно важно тщательно задокументировать условия эксперимента, включая датасеты, контрольные тесты и алгоритмы, и до проведения эксперимента объявить, какую гипотезу они будут проверять. Доверие к институтам и так не особенно высоко, и исследования, оторванные от реальности, но поднявшие шум в СМИ, могут еще больше подорвать это доверие. Традиционно воспроизведение исследовательских экспериментов считалось черной магией из-за отсутствия описания многих деталей реализации. Но ситуация начинает постепенно исправляться благодаря тому, что исследователи переходят на использование общедоступных эталонных тестов (вместо своих, специально подготовленных датасетов) и открывают исходный код, который использовался в исследованиях. Сообщество может использовать этот код, доказать, что он работает, усовершенствовать его и тем самым способствовать новым инновациям.
Устойчивость
Есть целая область исследований однопиксельных (one-pixel) атак на сверточные нейронные сети. Суть в том, чтобы найти и изменить единственный пиксель в изображении и тем самым заставить сверточную сеть классифицировать измененное изображение как нечто совершенно иное. Например, изменение одного пикселя на изображении яблока может привести к тому, что сеть классифицирует его как собаку. На прогнозы может влиять множество других факторов: шум, условия освещения, ракурс камеры и многое другое, которые не влияют на способность человека правильно воспринимать изображения. Это особенно актуально для беспилотных автомобилей, потому что злоумышленник может добавить на улице какие-то объекты, которые видит машина, и заставить ее принимать неправильные решения. Так, например, исследователи из лаборатории Keen Security Lab в компании Tencent воспользовались уязвимостью в Tesla AutoPilot, разместив на дороге небольшие наклейки и заставив автомобиль выехать на встречную полосу. Чтобы мы могли доверять ИИ, он должен быть устойчивым, способным противостоять постороннему шуму, незначительным отклонениям и преднамеренным манипуляциям.
Конфиденциальность
В стремлении создать еще более совершенный ИИ компании собирают большие объемы данных. К сожалению, иногда они выходят за рамки дозволенного и собирают информации больше, чем надо для решения поставленной задачи. Компания может полагать, что использует собираемые данные только во благо. Но что, если ее приобретет другая компания, у которой нет этических границ в отношении использования данных? Информация о потребителе может быть использована в целях, выходящих за рамки первоначально намеченных. Кроме того, данные, собранные в одном месте, выглядят привлекательной целью для хакеров, которые крадут персональные данные и продают их на черном рынке преступным организациям. Более того, многие правительства уже зашли слишком далеко, пытаясь отследить каждого человека.
Все это противоречит общепризнанному праву человека на неприкосновенность частной жизни. Потребители хотят знать, какие данные о них собираются, кто имеет к ним доступ, как эти данные используются, какие механизмы для отказа от сбора данных существуют, а также как удалить данные о них, которые уже были собраны.
Как разработчики мы должны со всей ответственностью подходить к сбору данных и спрашивать себя, все ли собираемые данные действительно нужны. Чтобы свести сбор данных к необходимому минимуму, мы могли бы использовать методы машинного обучения с поддержкой конфиденциальности, например федеративное обучение (используется в Google Keyboard), которые позволяют обучать сети на устройствах пользователей без того, чтобы отправлять какие-либо персональные данные на сервер.
Оказывается, что во многих инцидентах из начала этого раздела именно негативный общественный резонанс привел к массовому осознанию этих проблем, вызвал глобальный сдвиг в мышлении и стал причиной стремления поставить ИИ под контроль, чтобы предотвратить повторение чего-то подобного в будущем. Мы должны и впредь требовать от самих себя, ученых, ведущих производителей и политиков отчета за каждую ошибку и быстро их исправлять. Каждое решение и действие могут создать прецедент на десятилетия вперед. Сфера применения ИИ постоянно расширяется, поэтому мы должны объединиться, чтобы поставить сложные вопросы и найти на них ответы, если хотим снизить потенциальный вред и получить максимальную пользу.
Итоги
В этой главе мы изучили ландшафт удивительного мира ИИ и глубокого обучения. Познакомились с историей развития ИИ от скромных начинаний, через многообещающие периоды и мрачные зимы ИИ и до возрождения в наши дни. Попутно ответили на вопрос, почему на этот раз все складывается иначе. Затем посмотрели, какие компоненты нужны для создания решения глубокого обучения, включая датасеты, архитектуры моделей, фреймворки и оборудование. Теперь мы готовы приступить к исследованиям, которые ждут нас в следующих главах. Надеемся, вам понравится остальная часть книги.
Часто задаваемые вопросы
1. Я только начинаю изучать эту тему. Можно ли обойтись без больших затрат на покупку мощного оборудования?
К счастью для вас, вы можете обойтись даже простым браузером. Сотрудники Google Colab (рис. 1.14) любезно согласились предоставить вычислительное время мощных графических процессоров бесплатно (до 12 часов за раз). Этого вполне достаточно, чтобы опробовать сценарии из нашего репозитория в GitHub. По мере совершенствования, когда начнете проводить больше экспериментов (особенно если будете заниматься этим профессионально или использовать большие датасеты), вы сможете получить доступ к графическому процессору, арендовав его в облаке (Microsoft Azure, Amazon Web Services, Google Cloud Platform и др.) или купив соответствующее оборудование. Но берегитесь счетов за электричество!
2. Colab — это хорошо, но у меня уже есть мощный компьютер, который я купил, чтобы играть в <вставьте название видеоигры>. Как мне настроить свое локальное окружение?
В идеале желательно использовать Linux, но Windows и macOS тоже подойдут. Для примеров в большинстве случаев вам понадобятся:
• Python 3 и доступ к PIP;
• пакет Tensorflow или Tensorflow-gpu из PIP (версии 2 или выше);
• библиотека Pillow.
Нам нравятся чистота и автономность, поэтому советуем использовать поддержку виртуальных окружений в Python. Устанавливайте пакеты и запускайте сценарии или блокноты (Jupiter Notebook) в виртуальном окружении. Ознакомьтесь с инструкциям по установке.
Если у вас нет графического процессора, то на этом подготовку своего окружения можно считать законченной.
Рис. 1.14. Скриншот с блокнотом из GitHub, открытым в Colab (в браузере Chrome)
Если у вас есть графический процессор NVIDIA, то установите соответствующие драйверы, затем библиотеку CUDA, затем библиотеку cuDNN, затем пакет Tensorflow-gpu. Для пользователей Ubuntu есть более простое решение, чем установка всех этих пакетов и библиотек вручную с риском ошибиться, от чего не застрахованы даже самые лучшие из нас: просто установите все нужное одной командой с помощью Lambda Stack (https://lambdalabs.com/lambda-stack-deep-learning-software).
Также нужные пакеты можно установить с помощью Anaconda Distribution. Это решение одинаково хорошо подходит для Windows, Mac и Linux.
3. Где найти код примеров из книги?
По адресу https://github.com/PracticalDL/Practical-Deep-Learning-Book.
4. Каковы минимальные требования для чтения этой книги?
Степень Ph.D. в математическом анализе, статистическом анализе, вариационных автокодировщиках, исследовании операций и т.д. совершенно не требуется для чтения этой книги (признайтесь, что уже напряглись). Для усвоения материала важны базовые навыки программирования, знакомство с Python, здоровое любопытство и чувство юмора. Некоторое понимание особенностей разработки мобильных приложений (на Swift или Kotlin) не будет лишним, но мы постарались сделать наши примеры самодостаточными и довольно простыми для развертывания, чтобы с этим могли справиться даже те, кто раньше никогда не писал мобильных приложений.
5. Какие фреймворки будут использоваться?
Keras + TensorFlow для обучения. Постепенно, глава за главой, мы рассмотрим различные фреймворки для инференса.
6. Стану ли я экспертом, когда закончу читать эту книгу?
Следуя инструкциям, вы овладеете широким кругом знаний и умений — от обучения до инференса и приемов увеличения производительности. Несмотря на то что эта книга в первую очередь посвящена компьютерному зрению, полученные здесь знания можно применить в других областях, например для анализа текста, речи и т.д.
7. Что за кот упоминался выше в этой главе?
Это кот Мехера по кличке Вейдер. В этой книге он будет сниматься в нескольких эпизодах. Не переживайте: он уже подписал согласие на использование его изображений.
8. Как с вами связаться?
Пишите нам по адресу practicaldlbook@gmail.com, присылайте свои вопросы, замечания и т.д. Или пишите в Твиттер: @practicaldlbook.
1 Если вы скачали эту книгу с пиратского сайта, то разочаровали нас.
2 Гордон Джеймс Рамзи (Gordon James Ramsay; родился 8 ноября 1966 года) — британский шеф-повар. Его рестораны удостоены 16 звезд Мишлен. Его фирменный ресторан Restaurant Gordon Ramsay в Лондоне имеет три звезды Мишлен. Популярный ведущий британских телешоу. — Примеч. пер.
3 В английском и турецком языках нет деления «медсестра/медбрат», есть одно слово «nurse» (hemşire в турецком), обозначающее сотрудника из числа младшего медицинского персонала. — Примеч. пер.
Прежде чем приступить к приготовлению блюд, Гордон Рамзи2 проверяет наличие всех ингредиентов. То же относится к решению задач с помощью глубокого обучения (рис. 1.8). И вот ваш набор ингредиентов для глубокого обучения:
В английском и турецком языках нет деления «медсестра/медбрат», есть одно слово «nurse» (hemşire в турецком), обозначающее сотрудника из числа младшего медицинского персонала. — Примеч. пер.
А теперь к делу. Что побудило нас написать эту книгу? А зачем вы потратили свои кровно заработанные деньги1 на ее покупку? Наша мотивация проста и понятна: вовлечь как можно больше людей в мир ИИ. А тот факт, что вы читаете эту книгу, означает, что половина работы сделана.
Гордон Джеймс Рамзи (Gordon James Ramsay; родился 8 ноября 1966 года) — британский шеф-повар. Его рестораны удостоены 16 звезд Мишлен. Его фирменный ресторан Restaurant Gordon Ramsay в Лондоне имеет три звезды Мишлен. Популярный ведущий британских телешоу. — Примеч. пер.
Если вы скачали эту книгу с пиратского сайта, то разочаровали нас.
Предвзятость выборки также может произойти из-за схожих понятий. Например, Google Translate при переводе таких предложений, как «She is a doctor. He is a nurse» (Она доктор. Он медбрат), на гендерно-нейтральный язык, скажем, турецкий, а затем обратно, меняет пол, как показано на рис. 1.12. Вероятно, это связано с тем, что датасет содержит большую выборку образцов словосочетаний, включающих мужские местоимения со словом «доктор» и женские со словом «медсестра»3.
Глава 2. Что на картинке: классификация изображений с помощью Keras
Наверняка в литературе по глубокому обучению вы наталкивались на академические объяснения со страшными математическими формулами. Не переживайте! В этой книге мы упростили вхождение в практику глубокого обучения и взяли за основу пример классификации изображений, где всего несколько строк кода.
В этой главе познакомимся c фреймворком Keras, обсудим его место в мире глубокого обучения, а затем используем для классификации нескольких изображений современные классификаторы. Изучим работу этих классификаторов с помощью тепловых карт и реализуем забавный проект, где будем классифицировать объекты в видео.
Вспомните раздел «Рецепт идеального решения задачи глубокого обучения» в главе 1, где говорилось, что нужны четыре ингредиента: оборудование, датасет, фреймворк и модель. Давайте посмотрим, какую роль играет каждый из них в этой главе.
• Начнем с простого: оборудование. Для запуска примеров из этой главы достаточно даже недорогого ноутбука. Кроме того, код из этой главы можно запустить, открыв блокнот из GitHub в Colab. Почти в два клика.
• На первом этапе мы не будем обучать нейронную сеть, поэтому датасет не понадобится (кроме нескольких образцов фотографий для тестирования).
• Следующий компонент — фреймворк. В названии этой главы есть слово Keras — так что используем этот фреймворк. Обучать модели в Keras мы будем на протяжении большей части книги.
• Один из подходов к решению задач глубокого обучения — получить датасет, написать модель и обучающий ее код, потратить много времени и энергии (как человеческой, так и электрической) на обучение модели, а затем использовать ее для прогнозирования. Но как мы сказали, мы собираемся облегчить вхождение в глубокое обучение, и поэтому будем использовать предварительно обученную модель. В конце концов, исследователи пролили много крови, пота и слез на обучение и публикацию многих стандартных моделей, которые теперь доступны всем желающим. Используем одну из наиболее известных моделей — ResNet-50, младшую сестру модели ResNet-152, победившей в конкурсе Imagenet Large Scale Visual Recognition Challenge (ILSVRC) в 2015 году.
В этой главе будет некоторый код. Как известно, лучший способ обучения — это обучение на практике. Но, может быть, вам будет интересно познакомиться с теоретическими основами. Они будут рассматриваться в последующих главах — там мы углубимся в изучение сверточных нейронных сетей, взяв за основу эту главу.
От создателя
Изначально я создавал Keras для собственного использования. На тот момент, в конце 2014 — начале 2015 года, не было надежных и удобных фреймворков глубокого обучения с мощной поддержкой рекуррентных и сверточных сетей. В то время у меня не было мысли демократизировать глубокое обучение, я просто создавал удобный для себя инструмент. Но со временем увидел, что многие осваивают глубокое обучение с помощью Keras и используют его для решения самых разных задач, о существовании которых я даже не подозревал. Я был удивлен и восхищен, и это заставило меня осознать, что глубокое обучение можно применить в гораздо большем количестве областей, чем известно исследователям машинного обучения. Людей, которым эти технологии могли бы быть полезны, оказалось так много, что я решил позаботиться о максимальной доступности глубокого обучения. Единственный способ раскрыть возможности ИИ в полной мере — сделать его широкодоступным. Сейчас интерфейс Keras в TensorFlow 2.0 объединяет возможности глубокого обучения с целым спектром действительно эффективных и удобных рабочих процессов, подходящих для воплощения разных проектов, от исследовательских до прикладных, включая развертывание. С нетерпением жду возможности увидеть, что вы построите с его помощью!
Франсуа Шолле — создатель Keras, специалист по искусственному интеллекту, автор книги «Deep Learning with Python»4
Введение в Keras
Фреймворк Keras появился в 2015 году как более простой в использовании по сравнению с другими библиотеками слой абстракции, открывший новые возможности для быстрого прототипирования. Его появление сделало кривую обучения новичков в глубоком обучении намного менее крутой. В то же время этот фреймворк помог экспертам в глубоком обучении повысить продуктивность и позволил быстро повторять эксперименты. Фактически большинство команд-победителей на Kaggle.com (где проводятся соревнования по обработке данных) использовали Keras. Наконец, в 2017 году полная реализация Keras была включена непосредственно в TensorFlow, что позволило объединить высокую масштабируемость, производительность и обширную экосистему TensorFlow с простотой Keras. В интернете можно встретить версию Keras для TensorFlow с названием tf.keras.
Весь код, который мы напишем в главах 2 и 3, будет использовать Keras, включая стандартные функции для чтения файлов, манипулирования изображениями и т.д. Мы сделаем это в первую очередь для простоты обучения. В главе 5 мы постепенно начнем напрямую использовать другие встроенные и высокопроизводительные функции TensorFlow для большей гибкости и контроля.
Классификация изображений
С точки зрения непрофессионала, задача классификации изображений отвечает на вопрос: что изображено на этой картинке или фотографии? Например, «здесь изображен объект X с такой-то вероятностью», где X — одна из предопределенных категорий объектов. Если вероятность выше минимального порога, то, скорее всего, изображение содержит один или несколько экземпляров X.
Простой пайплайн классификации изображений состоит из следующих этапов:
1. Загрузка изображения.
2. Масштабирование до предопределенных размеров, например 224 × 224 пикселя.
3. Нормализация значений пикселей в диапазон [0,1] или [–1,1].
4. Выбор предварительно обученной модели.
5. Ввод подготовленного изображения в модель и получение списка категорий с их вероятностями.
6. Вывод нескольких наиболее вероятных категорий.

В репозитории GitHub (https://github.com/PracticalDL/Practical-Deep-Learning-Book/) перейдите в папку code/chapter-2. Все дальнейшие этапы подробно описаны и реализованы в блокноте Jupyter 1-predict-class.ipynb.
Сначала импортируем нужные модули из пакетов Keras и Python:
import tensorflow as tf
from tf.keras.applications.resnet50 import preprocess_input, decode_predictions
from tf.keras.preprocessing import image
import numpy as np
import matplotlib.pyplot as plt
Затем загрузим и отобразим изображение, которое будем классифицировать (рис. 2.1):
img_path = "../../sample-images/cat.jpg"
img = image.load_img(img_path, target_size=(224, 224))
plt.imshow(img)
plt.show()

Рис. 2.1. Содержимое входного файла
Да, это кот (хотя имя файла как бы намекает на это). И в идеале наша модель должна распознать кота на этом изображении.
Краткая справка
Прежде чем углубиться в процесс обработки изображений, было бы неплохо посмотреть, как изображения хранят информацию. В общем случае изображение — это множество пикселей, расположенных в прямоугольной сетке. В зависимости от типа изображения каждый пиксель может содержать от 1 до 4 частей (также известных как компоненты, или каналы). Эти компоненты определяют интенсивности красного, зеленого и синего цветов (Red Green Blue, RGB). Обычно каждый компонент представлен 8-битным числом, поэтому их значения находятся в диапазоне от 0 до 255 (то есть 28 – 1).
Прежде чем ввести изображение в Keras, нужно преобразовать его в стандартный формат. Это связано с тем, что предварительно обученные модели ожидают получить на входе данные определенного размера. В нашем случае мы должны привести изображение к стандартному размеру 224 × 224 пикселя.
Большинство моделей глубокого обучения предполагают ввод целого пакета изображений. Но как быть, если есть только одно изображение? Создать пакет с одним изображением! Для этого нужно создать массив с единственным элементом. Это можно также представить как увеличение количества измерений — с трех (три канала) до четырех (дополнительное измерение для длины самого массива).
Если что-то непонятно, представьте такую ситуацию: объект, представляющий пакет из 64 изо



















