

автордың кітабын онлайн тегін оқу Искусство программирования на R. Погружение в большие данные
Переводчик Е. Матвеев
Технический редактор А. Бульченко
Литературный редактор А. Бульченко
Художник В. Мостипан
Корректоры С. Беляева, Н. Викторова
Верстка Л. Егорова
Норман Мэтлофф
Искусство программирования на R. Погружение в большие данные. — СПб.: Питер, 2021.
ISBN 978-5-4461-1101-5
© ООО Издательство "Питер", 2021
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Отзывы о книге
«Если вы захотите освоить язык R и стать компетентным программистом на R, то <...> вам не найти лучшего пособия, чем “Искусство программирования на R. Погружение в большие данные” Нормана Мэтлоффа».
— Джозеф Рикерт (Joseph Rickert, Revolution Analytics)
«Я порекомендую эту книгу каждому, кто хочет изучить R, особенно людям, которые разбираются в программировании лучше, чем в статистике».
— Джон Д. Кук (John D. Cook), «The Endeavor»
«Превосходно от первой до последней страницы. Достаточно глубоко, чтобы даже опытные пользователи R узнали для себя что-то полезное ближе к концу книги».
— Джон Грэм-Камминг (John Graham-Cumming)
«Если вы серьезно относитесь к изучению R <...> книга “Искусство программирования на R” будет вам безусловно полезна».
— Паоло Сонего (Paolo Sonego), «One R Tip A Day»
«Упрощает картину для тех, кто хочет строить численные модели на основании статистического анализа. Серьезный материал как для уже программирующих на R, так и для начинающих».
— Хэнк Кэмпбелл (Hank Campbell), «Science 2.0»
«Если вы хотите заниматься программированием в области статистики, я рекомендую купить эту книгу».
— Брайан Белл (Bryan Bell), «Math And More»
«Книга по программированию на R, которая начинается с основ. Если вы хотя бы отдаленно представляете, что такое программирование, книга “Искусство программирования на R” вам пригодится. Я оставлю ее на своей полке».
— Нейтан Яо (Nathan Yau), Flowingdata.Com, автор книги «Visualize This»
Благодарности
В основу этой книги легло множество полезных источников.
В первую очередь я должен поблагодарить научного редактора Хэдли Уикхэма (Hadley Wickham), известного благодаря ggplot2 и plyr. Я порекомендовал Хэдли издательству «No Starch Press» из-за его опыта в разработке этих и других популярных пакетов R в CRAN — репозитории кода R, опубликованного пользователями. Как и ожидалось, многие комментарии Хэдли привели к улучшению текста, особенно комментарии в отношении конкретных примеров кода, часто начинавшиеся словами: «Интересно, а что, если написать это вот так…» В некоторых случаях эти комментарии привели к тому, что пример с одной-двумя версиями кода в итоге демонстрировал два, три, а иногда даже четыре разных способа достижения цели написания кода. Это позволило сравнить преимущества и недостатки разных решений, что, как я полагаю, будет поучительно для читателя.
Я очень благодарен Джиму Порзаку (Jim Porzak), соучредителю группы «Bay Area useR Group» (BARUG, http://www.bay-r.org/), за его постоянную поддержку во время моей работы над книгой. И раз уж речь зашла о BARUG, я должен поблагодарить Джима и другого соучредителя, Майка Дрисколла (Mike Driscoll), за создание этого живого форума, стимулирующего творческую деятельность. После знакомства с людьми, рассказывавшими в BARUG о возможностях R, у меня всегда было чувство, что эта книга была достойным проектом.
Группа BARUG также получала финансовую поддержку от Revolution Analytics; Дэвид Смит (David Smith) и Джо Рикерт (Joe Rickert) из этой компании посвятили ей бесчисленные часы, свою творческую энергию и идеи.
Джей Эмерсон (Jay Emerson) и Майк Кейн (Mike Kane), авторы признанного пакета bigmemory в CRAN, прочитали раннюю версию главы 16, посвященной параллельному программированию на R, и сделали ряд полезных замечаний.
Джон Чемберс (John Chambers) (создатель языка S, «предка» R) и Мартин Морган (Martin Morgan) поделились советами, касающимися внутреннего устройства R; эти советы очень пригодились мне при обсуждении проблем быстродействия R в главе 14.
В разделе 7.8.4 рассматривается тема, вызывающая ожесточенные споры в сообществе программирования, — использование глобальных переменных. Чтобы представить широкий спектр точек зрения, я воспользовался мнением нескольких людей, среди которых я хочу отметить участника базовой группы R Томаса Ламли (Thomas Lumley) и своего коллегу по Калифорнийскому университету в Дейвисе Шона Дейвиса (Sean Davis). Разумеется, это вовсе не означает, что мы разделяем их мнение в этом разделе книги, но их комментарии были весьма полезными.
На ранней стадии работы проекта я опубликовал очень приблизительный (и далеко не полный) черновик книги для открытого обсуждения. Со мной поделились своим полезным мнением Рамон Диас-Уриарте (Ramon Diaz-Uriarte), Барбара Ф. Ла Скала (Barbara F. La Scala), Джейсон Ляо (Jason Liao) и мой старый друг Майк Хэннон (Mike Hannon). Моя дочь Лаура, студентка инженерной специальности, прочитала отдельные части ранних набросков глав и поделилась полезными советами, которые позволили мне улучшить книгу. Моим собственным проектам CRAN и другим исследованиям в области R (которые послужили основой для примеров книги) принесли пользу советы, обратная связь и/или поддержка многих людей; прежде всего это были Марк Бравингтон (Mark Bravington), Стивен Эглен (Stephen Eglen), Дирк Эдделбуэт (Dirk Eddelbuett), Джей Эмерсон (Jay Emerson), Майк Кейн (Mike Kane), Гэри Кинг (Gary King), Дункан Мердок (Duncan Murdoch) и Джо Рикерт (Joe Rickert).
Участник базовой группы R Дункан Темпл Лэнг (Duncan Temple Lang) работает в той же организации, что и я, — Калифорнийском университете в Дейвисе. Хотя мы работаем на разных факультетах и общались не так уж много, эта книга кое-чем обязана его присутствию в университетском городке. Он помог сформировать в Калифорнийском университете культуру R, что помогло мне оправдать большие затраты времени на работу над книгой на моем факультете.
Это мой второй проект в издательстве «No Starch Press». Как только я решил написать эту книгу, я обратился в «No Starch Press», потому что мне нравится неформальный стиль, высокая практичность и доступность их продуктов. Спасибо Биллу Поллоку (Bill Pollock) за утверждение проекта, сотрудникам издательства Кейт Фенчер (Keith Fancher) и Элисон Лоу (Alison Law), а также внештатному редактору Мэрилин Смит (Marilyn Smith).
Наконец, я хочу поблагодарить двух прекрасных, умных и интересных женщин — мою жену Гэмис и упоминавшуюся выше Лауру. Они обе спокойно принимали мой ответ «Я пишу книгу по R» каждый раз, когда спрашивали, почему я так погружен в работу.
Введение
R — язык сценариев для обработки и анализа статистических данных. Он создавался по образцу статистического языка S, разработанного в компании AT&T (и в основном совместим с ним). Название S (от «Statistics») было аллюзией на другой язык программирования с однобуквенным именем, разработанный в AT&T, — знаменитый язык C. Позднее технология S была продана меньшей компании, которая добавила графический интерфейс (GUI) и назвала полученный продукт S-Plus.
Язык R стал более популярным, чем S или S-Plus, потому что он распространялся бесплатно, а в его разработке участвовало больше людей. R также иногда называют GNU S, чтобы намекнуть на специфику проекта. (GNU Project — огромная коллекция продуктов с открытым исходным кодом.)
Зачем использовать R в статистических вычислениях?
Как говорят жители Кантона: yauh peng, yauh leng, что означает «недорого и красиво». Лучше спросить: зачем использовать что-то другое?
R обладает целым рядом достоинств:
• R представляет собой открытую реализацию признанного статистического языка S, а платформа R/S стала фактическим стандартом среди профессиональных статистиков.
• По своей мощи он сравним с коммерческими продуктами (а часто и превосходит их в большинстве практических аспектов — разнообразии поддерживаемых операций, программируемости, средствах графического вывода информации и т.д.).
• Доступны версии для операционных систем Windows, Mac и Linux.
• R не ограничивается выполнением статистических операций — это язык программирования общего назначения, который может использоваться для автоматизации анализа данных и создания новых функций, расширяющих возможности языка.
• R обладает возможностями, присущими объектно-ориентированным и функциональным языкам программирования.
• Система сохраняет данные между сеансами, поэтому вам не придется перезагружать их снова и снова. Также сохраняется история команд.
• Так как R распространяется с открытым исходным кодом, вы сможете легко получить помощь от сообщества пользователей. Кроме того, новые функции создаются пользователями, многие из которых являются известными специалистами в области статистики.
Хочу сразу предупредить, что обычно для ввода команд R пользователь вводит текст в окне терминала, а не работает с мышью в графическом интерфейсе; большинство пользователей R графический интерфейс не используют. Это не означает, что R не обладает графическими возможностями. Напротив, в R имеются средства для построения чрезвычайно полезных и эффектных графических изображений, но они используются для вывода результатов работы системы (например, диаграмм), а не для пользовательского ввода.
Если вы решительно не можете обойтись без графического интерфейса, выберите одну из бесплатных графических оболочек, созданных для R. Несколько примеров таких продуктов — с открытым кодом или бесплатных:
• RStudio, http://www.rstudio.org/;
• StatET, http://www.walware.de/goto/statet/;
• ESS (Emacs Speaks Statistics), http://ess.r-project.org/;
• R Commander: Джон Фокс (John Fox), «The R Commander: A Basic-Statistics Graphical Interface to R», Journal of Statistical Software 14, №9 (2005):1–42;
• JGR (Java GUI for R), http://cran.r-project.org/web/packages/JGR/index.html.
Первые три продукта — RStudio, StatET и ESS — представляют собой интегрированные среды разработки (IDE), предназначенные скорее для программирования. StatET и ESS предоставляют программисту R средства разработки в известных средах Eclipse и ESS соответственно.
В области коммерческих предложений еще одну IDE предлагает Revolution Analytics, обслуживающая компания R (http://www.revolutionanalytics.com/). Так как R является языком программирования, а не набором разрозненных команд, вы можете объединять команды в цепочку; при этом выходные данные одной команды используются в качестве входных данных другой (эта возможность хорошо знакома пользователям Linux, привыкшим объединять команды оболочки при помощи каналов, или конвейеров (pipes)). Механизм объединения функций R обладает огромной гибкостью, и при правильном использовании он весьма мощен. Простой пример: возьмем следующую (составную) команду:
nrow(subset(x03,z == 1))
Сначала функция subset() получает кадр данных x03 и извлекает все записи, у которых переменная z равна 1. При этом создается новый кадр данных, который затем передается функции nrow(). Эта функция подсчитывает количество строк в кадре. В итоге команда выдает количество строк, для которых z = 1, в исходном кадре данных.
Ранее упоминались термины «объектно-ориентированное программирование» и «функциональное программирование». Эти темы сейчас широко обсуждаются специалистами в области теории вычислений. Несмотря на то что другим читателям эти термины могут быть незнакомы, они актуальны для всех, кто применяет R для программирования статистических вычислений. В следующем разделе предоставляются краткие обзоры этих тем.
Объектно-ориентированное программирование
Преимущества объектно-ориентированного программирования проще пояснить на конкретном примере. Возьмем статистическую регрессию. При проведении регрессионного анализа с использованием других статистических пакетов (например, SAS или SPSS) на экран выводится огромный объем информации. Напротив, при вызове регрессионной функции lm() в R функция возвращает объект, содержащий все результаты — оценки коэффициентов, их стандартные погрешности, остатки и т.д. Вам остается выбрать (на программном уровне), какие части извлечь из объекта.
Вы увидите, что подход R существенно упрощает программирование — отчасти потому, что он обеспечивает определенное единообразие работы с данными. Это однообразие происходит от того факта, что R является полиморфным языком; другими словами, одна функция может использоваться для разных типов входных данных, для которых выбирается подходящий способ обработки. Такие функции называются обобщенными (программистам C++ знакома похожая концепция виртуальных функций).
Например, возьмем функцию plot(). Если вызвать ее для списка чисел, вы получите простой график. Но если вызвать ее для выходных данных регрессионного анализа, вы получите набор графиков, представляющих различные аспекты анализа. Собственно, функция plot() может использоваться практически с любым объектом, создаваемым в R. И это удобно — ведь вам как пользователю придется запоминать меньше команд!
Функциональное программирование
Как характерно для языков функционального программирования, в программировании на R часто встречается тема предотвращения явного программирования итераций. Вместо того чтобы программировать циклы, вы при помощи функциональных средств R выражаете итеративное поведение неявно. В результате можно получить код, который выполняется намного эффективнее, ведь при обработке больших наборов данных в R затраты времени могут быть весьма значительными.
Как вы вскоре увидите, природа функционального программирования языка R обладает рядом преимуществ:
• более четкий и компактный код;
• возможность многократного ускорения выполнения кода;
• снижение затрат времени на отладку из-за упрощения кода;
• упрощение перехода на параллельное программирование.
Для кого написана эта книга?
Многие пользователи используют R для конкретных задач — тут построить гистограмму, там провести регрессионный анализ или выполнить другие отдельные операции, связанные со статистической обработкой данных. Но эта книга написана для тех, кто хочет разрабатывать программное обеспечение на R. Навыки программирования предполагаемых читателей этой книги могут лежать в широком спектре — от профессиональной квалификации до «Я проходил курс программирования в колледже», но ключевой целью является написание кода R для конкретных целей. (Глубокое знание статистики в общем случае не обязательно.)
Несколько примеров читателей, которые могли бы извлечь пользу из этой книги:
• Аналитик (допустим, работающий в больнице или в правительственном учреждении), которому приходится регулярно выдавать статистические отчеты и разрабатывать программы для этой цели.
• Научный работник, занимающийся разработкой статистической методологии — новой или объединяющей существующие методы в интегрированные процедуры. Методологию нужно закодировать, чтобы она могла использоваться в сообществе исследователей.
• Специалисты по маркетингу, судебному сопровождению, журналистике, издательскому делу и т.д., занимающиеся разработкой кода для построения сложных графических представлений данных.
• Профессиональные программисты с опытом разработки программного обеспечения, назначенные в проекты, связанные со статистическим анализом.
• Студенты, изучающие статистику и обработку данных.
Таким образом, эта книга не является справочником по бесчисленным статистическим методам замечательного пакета R. На самом деле она посвящена программированию и в ней рассматриваются вопросы программирования, редко встречающиеся в других книгах о R. Даже основополагающие темы рассматриваются под углом программирования. Несколько примеров такого подхода:
• В этой книге встречаются разделы «Расширенные примеры». Обычно в них представлены полные функции общего назначения вместо изолированных фрагментов кода, основанных на конкретных данных. Более того, некоторые из этих функций могут пригодиться в вашей повседневной работе с R. Изучая эти примеры, вы не только узнаете, как работают конкретные конструкции R, но и научитесь объединять их в полезные программы. Во многих случаях я привожу описания альтернативных решений и отвечаю на вопрос: «Почему это было сделано именно так?»
• Материал излагается с учетом восприятия программиста. Например, при описании кадров данных я не только утверждаю, что кадр данных в R представляет собой список, но и указываю на последствия этого факта с точки зрения программирования. Также в тексте R сравнивается с другими языками там, где это может быть полезно (для читателей, владеющих этими языками).
• Отладка играет важнейшую роль в программировании на любом языке, однако в большинстве книг о R эта тема практически не упоминается. В этой книге я посвятил средствам отладки целую главу, воспользовался принципом «расширенных примеров» и представил полностью проработанные демонстрации того, как происходит отладка программ в реальности.
• В наши дни многоядерные компьютеры появились во всех домах, а программирование графических процессоров (GPU) производит незаметную революцию в области научных вычислений. Все больше приложений R требует очень больших объемов вычислений, и параллельная обработка стала актуальной для программистов на R. В книге этой теме посвящена целая глава, в которой помимо описания механики также приводятся расширенные примеры.
• Отдельная глава рассказывает о том, как использовать информацию о внутренней реализации и других аспектах R для ускорения работы кода R.
• Одна из глав посвящена интерфейсу R с другими языками программирования, такими как C и Python. И снова особое внимание уделяется расширенным примерам и рекомендациям по выполнению отладки.
Немного о себе
Я пришел в мир R несколько необычно.
После написания диссертации по абстрактной теории вероятностей я провел ранние годы своей карьеры на должности профессора статистики — за преподаванием, научными исследованиями и консультациями по статистической методологии. Я был одним из дюжины профессоров Калифорнийского университета в Дейвисе, основавших там факультет статистики.
Позднее я перешел на факультет Computer Science в том же университете, где прошла большая часть моей карьеры. Я занимался исследованиями в области параллельного программирования, анализа веб-трафика, глубокого анализа данных, производительности дисковой системы и во многих других областях. Большая часть моей преподавательской и исследовательской работы была связана со статистикой.
Таким образом, я могу рассматривать ситуацию как с точки зрения опытного специалиста по компьютерным технологиям, так и с точки зрения статистика и ученого-исследователя в области статистики. Надеюсь, такое сочетание позволит этой книге заполнить пробел в литературе и сделает ее более ценной для вас, уважаемый читатель.
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу comp@piter.com (издательство «Питер», компьютерная редакция). Мы будем рады узнать ваше мнение!
На веб-сайте издательства www.piter.com вы найдете подробную информацию о наших книгах.
1. Первые шаги
R — чрезвычайно универсальный язык программирования с открытым исходным кодом, предназначенный для статистических расчетов и анализа данных. Он широко применяется во всех областях, в которых нам приходится иметь дело с данными, — в бизнесе, промышленности, управлении, медицине, мире науки и т.д.
В этой главе содержится краткий вводный курс по языку R: как его запустить, что он может делать и какие файлы использует. Приведенной информации достаточно ровно для того, чтобы вы могли понять примеры в следующих главах, где будут приведены подробности.
Возможно, язык R уже установлен в вашей системе, если ваш работодатель или университет предоставляет его своим пользователям. Если нет — вы найдете инструкции по установке в приложении А.
1.1. Как запустить R
R работает в двух режимах: интерактивном и пакетном (batch). На практике чаще используется интерактивный режим. В этом режиме вы вводите команды, R выводит результаты, вы вводите новые команды, и т.д. С другой стороны, пакетный режим обходится без взаимодействия с пользователем. Он может пригодиться для повседневной работы (например, если программа должна запускаться периодически — скажем, раз в сутки), потому что процесс можно автоматизировать.
1.1.1. Интерактивный режим
В системах Linux или Mac для запуска сеанса R введите команду R в приглашении командной строки в окне терминала. На машинах с Windows R запускается при помощи соответствующего значка.
На экран выводится приветствие и приглашение R — знак >. Экран выглядит примерно так:
R version 2.10.0 (2009-10-26)
Copyright (C) 2009 The R Foundation for Statistical Computing
ISBN 3-900051-07-0
...
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
>
Теперь все готово к выполнению команд R. Окно, в котором выводится вся эта информация, называется консолью R.
Короткий пример: возьмем стандартное нормальное распределение (с математическим ожиданием 0 и дисперсией 1). Если случайная переменная X имеет такое распределение, то ее значения сосредоточены вокруг центра 0 — одни из них положительны, другие отрицательны, а в среднем сумма равна 0. Теперь создадим новую случайную переменную Y = |X|. Так как мы вычисляем абсолютное значение, значения Y не будут сосредоточены вокруг 0 и математическое ожидание Y будет положительным.
Определим математическое ожидание Y. Наш подход будет основан на смоделированных случайных данных с распределением N(0,1).
> mean(abs(rnorm(100)))
[1] 0.7194236
Этот код генерирует 100 случайных переменных, находит их абсолютные значения, а затем вычисляет для них среднюю величину.
Здесь [1] означает, что первый элемент в этой строке вывода равен 1. В данном случае вывод состоит только из одной строки (и одного элемента), поэтому эта информация избыточна. Она становится полезной при чтении длинного вывода с множеством элементов, распределенных по многим строкам. Например, если бы в выводе было две строки по шесть элементов в каждой, то вторая строка была бы снабжена пометкой [7].
> rnorm(10)
[1] -0.6427784 -1.0416696 -1.4020476 -0.6718250 -0.9590894 -0.8684650
[7] -0.5974668 0.6877001 1.3577618 -2.2794378
Здесь выходные данные состоят из 10 значений, и метка [7] во второй строке позволяет быстро увидеть, что 0,6877001, например, является восьмым элементом вывода.
Команды R также можно сохранить в файле. По соглашению файлы с кодом R имеют суффикс .R или .r. Если создать файл с именем z.R, то его содержимое можно будет выполнить следующей командой:
> source("z.R")
1.1.2. Пакетный режим
В некоторых ситуациях бывает удобно автоматизировать сеансы R. Например, можно запускать сценарий R для построения графика, вместо того чтобы вручную запускать R и выполнять сценарий самостоятельно. В таком случае R работает в пакетном режиме.
Например, включим код построения графика в файл с именем z.R и следующим содержимым:
pdf("xh.pdf") # Выбрать выходной файл
hist(rnorm(100)) # Сгенерировать 100 переменных N(0,1)
# и построить гистограмму
dev.off() # Закрыть выходной файл
За символом # следуют комментарии. Интерпретатор R их игнорирует. Комментарии напоминают нам и другим разработчикам, что именно делает код, в удобочитаемом формате.
Разберем шаг за шагом, что же происходит в этом коде:
• Мы вызываем функцию pdf(), чтобы сообщить R, что создаваемый график должен быть сохранен в PDF-файле xh.pdf.
• Вызов функции rnorm() (от «random normal», то есть «случайное нормальное») генерирует 100 случайных переменных с распределением N(0,1).
• Для сгенерированных переменных вызывается функция hist(), которая строит гистограмму полученных данных.
• Вызов dev.off() закрывает используемое графическое «устройство» — в данном случае файл xh.pdf. Эта операция приводит к фактической записи файла на диск.
Этот код может быть выполнен автоматически, без входа в интерактивный режим R. Запустите R командой оболочки операционной системы (например, из приглашения $, обычно используемого в системах Linux):
$ R CMD BATCH z.R
Чтобы убедиться в том, что команда была успешно выполнена, откройте сохраненную гистограмму в программе просмотра PDF-файлов (это будет очень простая гистограмма, но R также позволяет строить достаточно сложные разновидности).
1.2. Первый сеанс R
Создайте простой набор данных (в терминологии R — вектор), состоящий из чисел 1, 2 и 4, и присвойте ему имя x:
> x <- c(1,2,4)
Стандартным оператором присваивания в R является оператор <-. Также можно использовать оператор =, но лучше этого не делать, так как он не будет работать в некоторых специфических ситуациях. Обратите внимание: с переменными не связываются никакие фиксированные типы. Здесь вектор был присвоен переменной x, но позднее ему может быть присвоено значение другого типа. Векторы и другие типы будут рассматриваться в разделе 1.4.
Имя c означает конкатенацию (concatenate). В данном случае конкатенация выполняется с числами 1, 2 и 4. Точнее говоря, мы выполняем конкатенацию трех одноэлементных векторов, каждый из которых содержит одно из этих чисел. Дело в том, что любое число также рассматривается как вектор с одним элементом.
Теперь можно выполнить следующую команду:
> q <- c(x,x,8)
которая присваивает q значение (1,2,4,1,2,4,8) (да, включая дубликаты).
А теперь убедимся в том, что данные действительно хранятся в x. Чтобы вывести вектор на экран, просто введите его имя. При вводе любого имени переменной (или в более широком смысле — любого выражения) в интерактивном режиме R выведет значение этой переменной (или выражения). Эта особенность известна программистам, знакомым с другими языками (например, Python). В нашем примере это выглядит так:
> x
[1]124
Да, все верно — x состоит из чисел 1, 2 и 4.
Для обращения к отдельным элементам вектора используется синтаксис []. Например, третий элемент x выводится следующей командой:
> x[3]
[1] 4
Как и в других языках, селектор (в данном случае 3) называется индексом. Программистам, знакомым с языками из семейства ALGOL (включая C и C++), стоит учитывать, что индексирование элементов векторов R начинается с 1, а не с 0.
Сегментация — одна из важнейших операций с векторами. Пример:
> x <- c(1,2,4)
> x[2:3]
[1]24
Выражение x[2:3] обозначает подвектор x, состоящий из элементов с 2 по 3 (в данном случае элементы со значениями 2 и 4.)
Математическое ожидание и среднеквадратическое отклонение для нашего набора данных легко вычисляются следующим образом:
> mean(x)
[1] 2.333333
> sd(x)
[1] 1.527525
Этот фрагмент снова демонстрирует, что при вводе выражения на экран выводится его значение. В первой строке выражением является вызов функции mean(x). Возвращаемое значение этой функции выводится автоматически, вызывать функцию R print() для этого не обязательно.
Если вычисленное математическое ожидание нужно сохранить в переменной (вместо того, чтобы просто вывести его на экран), выполните следующую команду:
> y <- mean(x)
Как и прежде, убедимся в том, что y действительно содержит математическое ожидание x:
> y
[1] 2.333333
И снова в команды можно включать комментарии после символа #:
> y # Вывести значение y
[1] 2.333333
Комментарии особенно полезны для документирования программного кода, но в интерактивных сеансах они тоже пригодятся, поскольку R сохраняет историю команд (см. раздел 1.6). Если вы сохраните сеанс и загрузите его в будущем, комментарии помогут вспомнить, чем вы занимались.
Наконец, давайте сделаем что-нибудь с одним из внутренних наборов данных R (эти наборы предназначены для демонстраций). Чтобы получить список таких наборов, введите следующую команду:
> data()
Один из наборов данных с именем Nile содержит данные о течении Нила. Вычислим математическое ожидание и среднеквадратическое отклонение для этого набора данных:
> mean(Nile)
[1] 919.35
> sd(Nile)
[1] 169.2275
Также можно вывести гистограмму этих данных:
> hist(Nile)
На экране появляется окно с гистограммой (рис. 1.1). Диаграмма содержит минимум декоративных элементов, но R предоставляет массу возможностей для оформления вывода. Например, вы можете изменить количество групп при помощи переменной breaks. Вызов hist(z,breaks=12) выведет гистограмму набора данных z с разбиением на 12 групп. Также можно создавать более удобные метки, использовать цвета и вносить много других изменений для создания более информативных и привлекательных диаграмм. Когда у вас появится опыт работы с R, вы сможете строить сложные, яркие графики и диаграммы невероятной красоты.
Итак, первое пятиминутное знакомство с R подошло к концу. Закройте R вызовом функции q() (также это можно сделать нажатием клавиш Ctrl+D в Linux или Cmd+D на Mac):
> q()
Save workspace image? [y/n/c]: n
Последний запрос предлагает сохранить переменные, чтобы вы смогли продолжить работу позднее. Если подтвердить сохранение (y), то все объекты
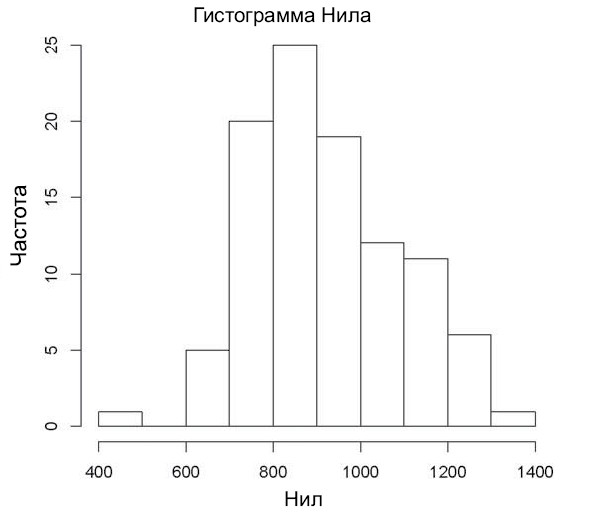
Рис. 1.1. Данные течения Нила (минимальное оформление)
будут автоматически загружены при следующем запуске R. Эта возможность очень важна, особенно при работе с большими или многочисленными наборами данных. Ответ y также сохраняет историю команд сеанса. Сохранение рабочего пространства и истории команд более подробно рассматривается в разделе 1.6.
1.3. Знакомство с функциями
Как и в большинстве языков программирования, суть программирования на R сводится к написанию функций. Функция представляет собой набор команд, который получает входные данные, использует их для вычисления других значений и возвращает результат.
В качестве простого примера определим функцию с именем oddcount(), предназначенную для подсчета нечетных чисел в целочисленном векторе. Обычно разработчик пишет код функции в текстовом редакторе и сохраняет его в файле, но в примере на скорую руку мы введем его строку за строкой в интерактивном режиме R. Затем функция будет вызвана в паре тестовых примеров.
# Подсчитывает количество нечетных целых чисел в x
> oddcount <- function(x) {
+ k <- 0 # Присвоить k значение 0
+ for (n in x) {
+ if (n %% 2 == 1) k <- k+1 # %% — оператор вычисления остатка
+ }
+ return(k)
+ }
> oddcount(c(1,3,5))
[1] 3
> oddcount(c(1,2,3,7,9))
[1] 4
Сначала мы сообщаем R, что хотим определить функцию с именем oddcount с одним аргументом x. Левая фигурная скобка обозначает начало тела функции. Мы записываем по одной команде R на строку.
Пока тело функции не будет завершено, R напоминает вам о том, что функция еще определяется; для этого обычное приглашение > заменяется приглашением +. (Хотя на самом деле + — признак продолжения строки, а не приглашение для нового ввода.) После того как будет введена правая фигурная скобка, завершающая тело функции, R возвращается к стандартному приглашению >.
После определения функции мы получаем результаты двух вызовов oddcount(). Так как вектор (1,3,5) содержит три нечетных числа, вызов oddcount(c(1,3,5)) возвращает значение 3. В векторе (1,2,3,7,9) четыре нечетных числа, поэтому второй вызов возвращает 4.
Обратите внимание: оператор вычисления остатка в R имеет вид %%, как указано в комментарии. Например, при целочисленном делении 38 на 7 остаток равен 3:
>38 %% 7
[1] 3
А теперь посмотрим, что произойдет при выполнении следующего кода:
for (n in x) {
if(n %% 2 == 1) k <- k+1
}
Сначала n присваивается значение x[1], после чего переменная проверяется на четность. Если значение нечетно (как в данном случае), то переменная-счетчик k увеличивается на 1. Затем n присваивается x[2], значение проверяется на четность и т.д.
Кстати говоря, у программистов C/C++ может появиться желание записать этот цикл в следующем виде:
for (i in 1:length(x)) {
if (x[i] %% 2 == 1) k <- k+1
}
Здесь length(x) — количество элементов в x. Предположим, вектор содержит 25 элементов. Запись 1:length(x) означает 1:25, что, в свою очередь, означает 1, 2, 3, ..., 25. Такой код будет работать (если только длина x не равна 0), но один из главных принципов программирования на R гласит, что следует обходиться без циклов, если это возможно, а если нет, то циклы должны быть простыми. Взглянем еще раз на исходную формулу:
for (n in x) {
if(n %% 2 == 1) k <- k+1
}
Она проще и элегантнее, потому что не требует использования функции length() и индексирования массива.
В конце кода функции располагается команда return():
return(k)
Функция возвращает вычисленное значение k тому коду, из которого она была вызвана. Впрочем, следующая простая запись тоже работает:
k
При отсутствии явного вызова return() функции R возвращают последнее вычисленное значение. Тем не менее такой подход следует использовать с осторожностью, как будет показано в разделе 7.4.1.
В терминологии языков программирования x называется формальным аргументом (или формальным параметром) функции oddcount(). В первом вызове функции из предыдущего примера c(1,3,5) называется фактическим аргументом. Эти термины указывают на тот факт, что x в определении функции представляет собой условное имя, представляющее значение, а c(1, 3, 5) определяет само значение, использованное в вычислениях. Аналогичным образом во втором вызове функции c(1,2,3,7,9) является фактическим аргументом.
1.3.1. Область видимости переменной
Переменная, видимая только в теле функции, называется локальной по отношению к этой функции. В oddcount() k и n являются локальными переменными. Они пропадают после того, как функция вернет управление:
> oddcount(c(1,2,3,7,9))
[1] 4
> n
Error: object 'n' not found
Важно понимать, что формальные параметры в функции R являются локальными переменным. Предположим, программа содержит следующий вызов функции:
> z <- c(2,6,7)
> oddcount(z)
Теперь допустим, что код oddcount() изменяет x. Переменная z при этом не изменится. После вызова oddcount() z будет содержать то же значение, что и прежде. Чтобы вычислить результат вызова функции, R копирует каждый фактический аргумент в соответствующую переменную локального параметра, и изменения в этой переменной не будут видны за пределами функции. Правила области видимости будут более подробно рассмотрены в главе 7.
Переменные, созданные за пределами функций, являются глобальными; они также доступны внутри функций. Пример:
> f <- function(x) return(x+y)
> y<-3
> f(5)
[1] 8
Здесь y является глобальной переменной.
Запись нового значения в глобальную переменную осуществляется оператором суперприсваивания R <<-. Эта тема также обсуждается в главе 7.
1.3.2. Аргументы по умолчанию
В R также часто используются аргументы по умолчанию. Возьмем определение функции следующего вида:
> g <- function(x,y=2,z=T) { ... }
Здесь формальный аргумент y будет инициализирован 2, если программист не укажет значение y при вызове. Аналогичным образом z будет присвоено значение TRUE.
А теперь возьмем следующий вызов:
> g(12,z=FALSE)
Здесь значение 12 — фактический аргумент для x, для y принимается значение по умолчанию, но значение по умолчанию для z переопределяется — переменной присваивается FALSE. Предыдущий пример также показывает, что, как и во многих языках программирования, в R существует логический тип (то есть тип с логическими значениями TRUE и FALSE).
ПРИМЕЧАНИЕ
R позволяет сокращать TRUE и FALSE до T и F. Тем не менее вы можете отказаться от сокращения этих значений во избежание проблем, если в программе используются переменные с именами T или F.
1.4. Важнейшие структуры данных R
В R поддерживаются разнообразные структуры данных. Здесь мы кратко опишем несколько наиболее часто используемых структур, чтобы дать вам представление о возможностях R перед тем, как углубляться в подробности. Вы хотя бы увидите несколько содержательных примеров даже при том, что с полным описанием придется подождать.
1.4.1. Векторы
Векторный тип в действительности занимает важнейшее место в R. Трудно представить себе код R (и даже интерактивный сеанс), в котором бы не использовались векторы.
Все элементы вектора должны иметь один тип данных (или режим — mode). Например, вектор может содержать три символьные строки (режим character) или три целых числа, но не одно целое число и две символьные строки.
Векторы более подробно рассматриваются в главе 2.
1.4.1.1. Скаляры
Скаляры (то есть отдельные числа) не существуют в R. Как упоминалось ранее, то, что на первый взгляд кажется отдельным числом, в действительности является вектором из одного элемента.
Пример:
> x < -8
> x
[1] 8
Напомню: [1] означает, что следующая строка чисел начинается с элемента 1 вектора — в данном случае x[1]. Как видите, R действительно интерпретирует x как вектор, хотя и состоящий всего из одного элемента.
1.4.2. Символьные строки
Символьные строки в действительности являются одноэлементными векторами с элементами символьного (не числового) типа:
> x <- c(5,12,13)
> x
[1] 51213
> length(x)
[1] 3
> mode(x)
[1] "numeric"
> y <- "abc"
> y
[1] "abc"
> length(y)
[1] 1
> mode(y)
[1] "character"
> z <- c("abc","29 88")
> length(z)
[1] 2
> mode(z)
[1] "character"
В первом примере создается вектор x с числовыми элементами (режим numeric). Затем создаются два вектора с символьными элементами (режим character): вектор y содержит одну строку, а z — две строки.
R содержит различные функции для работы со строками. Многие из них предназначены для объединения или разбора строк, как две следующие функции:
> u <- paste("abc","de","f") # Конкатенация строк
> u
[1] "abc de f"
> v <- strsplit(u," ") # Разбиение строки по пробелам
> v
[[1]]
[1] "abc" "de" "f"
Строки более подробно описаны в главе 11.
1.4.3. Матрицы
Концепция матрицы в R не отличается от традиционного математического понятия: этим термином обозначается прямоугольный массив чисел. Технически матрица представляет собой вектор, но с двумя дополнительными атрибутами: количеством строк и количеством столбцов. Пример работы с матрицей:
> m <- rbind(c(1,4),c(2,2))
> m
[,1] [,2]
[1,] 1 4
[2,] 2 2
> m %*% c(1,1)
[,1]
[1,] 5
[2,] 4
Сначала для построения матрицы из двух векторов, представляющих строки, используется функция rbind() (от Row Bind), а затем результат сохраняется в m. (Соответствующая функция cbind() объединяет несколько столбцов в матрицу.) Затем в командной строке вводится только имя переменной; как вы уже знаете, при этом выводится текущее значение переменной. По нему можно проверить, что была построена именно та матрица, которая вам нужна. Наконец, мы вычисляем матричную производительность вектора (1,1) и m. Оператор умножения матриц, знакомый вам из курса линейной алгебры, в R имеет вид %*%.
Матрицы индексируются по двум индексам; это делается почти так же, как в C/C++, хотя индексы начинаются с 1, а не с 0.
> m[1,2]
[1] 4
> m[2,2]
[1] 2
В R предусмотрена исключительно полезная возможность извлечения подматриц (по аналогии с извлечением подвекторов из векторов). Пример:
> m[1,] # строка 1
[1] 1 4
> m[,2] # столбец 2
[1] 4 2
О матрицах более подробно поговорим в главе 3.
1.4.4. Списки
По аналогии с векторами R списки R являются контейнерами для значений, однако они могут содержать элементы с разными типами данных. (Программисты C/C++ заметят аналогию со структурами языка C.) Для обращения к элементам списков используются составные имена, которые в R записываются со знаком $. Простой пример:
> x <- list(u=2, v="abc")
> x
$u
[1] 2
$v
[1] "abc"
> x$u
[1] 2
Выражение x$u обозначает компонент u списка x. Последний содержит еще один компонент с именем v.
Одно из стандартных применений списков — объединение нескольких значений в один пакет, который возвращается функцией. Это особенно удобно для статических функций, которые могут возвращать сложные результаты. Возьмем базовую функцию построения гистограмм R hist(), упомянутую в разделе 1.2. Функция вызывалась для встроенного в R набора данных течения Нила:
> hist(Nile)
Вызов строил диаграмму, но hist() также возвращает значение, которое можно сохранить:
> hn <- hist(Nile)
Что хранится в hn? Давайте посмотрим:
> print(hn)
$breaks
[1] 400 500 600 700 800 900 1000 1100 1200 1300 1400
$counts
[1]105202519121161
$intensities
[1] 9.999998e-05 0.000000e+00 5.000000e-04 2.000000e-03 2.500000e-03
[6] 1.900000e-03 1.200000e-03 1.100000e-03 6.000000e-04 1.000000e-04
$density
[1] 9.999998e-05 0.000000e+00 5.000000e-04 2.000000e-03 2.500000e-03
[6] 1.900000e-03 1.200000e-03 1.100000e-03 6.000000e-04 1.000000e-04
$mids
[1] 450 550 650 750 850 950 1050 1150 1250 1350



















