

автордың кітабын онлайн тегін оқу Настольная книга 1С:Эксперта по технологическим вопросам. Издание 2
Е. В. Филиппов
Настольная книга 1С:Эксперта по технологическим вопросам
Издание 2
Настольная книга 1С:Эксперта по технологическим вопросам
Издание 2
Электронная книга в формате ePub; ISBN 978-5-9677-2474-9.
Версия издания от 08.09.2015.
Электронный аналог издания "Настольная книга 1С:Эксперта по технологическим вопросам"
(ISBN 978-5-9677-2354-4, М.: ООО "1С-Паблишинг", 2015; артикул печатной книги по прайс-листу фирмы "1С": 4601546118530;
по вопросам приобретения печатных изданий издательства "1С-Паблишинг" обращайтесь к партнеру "1С",
обслуживающему вашу организацию, или к другим партнерам фирмы "1С").
«Настольная книга 1С:Эксперта по технологическим вопросам» посвящена теории и практике решения проблем производительности и параллельности в информационных системах на платформе «1С:Предприятие 8». В работе приводятся теоретические сведения, необходимые для понимания основных механизмов, обеспечивающих функционирование платформы «1С:Предприятие 8» и СУБД как многоуровневой многопользовательской системы.
Кроме этого, дается алгоритм основного бизнес-процесса расследования проблем и приводятся практические приемы решения конкретных прикладных задач: описывается развертывание, настройка и использование инструментов для воспроизведения и расследования, а также возможные способы исправления, применяемые, когда причины проблем найдены.
При работе был учтен опыт подготовки сотрудников на аттестацию 1С:Эксперт по технологическим вопросам: в книге собраны необходимые для подготовки к аттестации материалы и методики.
Также в книгу вошли методики, наработанные автором за длительный срок решения практических проблем производительности и параллельности. В значительной степени это методики профилактики, регулярного контроля и ранней диагностики.
Во втором издании скорректированы неточности в теоретической части и в инструкциях, а также добавлены новые материалы.
Для 1С:Экспертов по технологическим вопросам, для сотрудников ИТ-служб заказчика (ИТ-директоров, системных администраторов, методистов, администраторов СУБД), а также для сотрудников фирм-1С:Франчайзи: внедренцев, разработчиков, руководителей проектов.
© ООО «1С-Паблишинг», 2015
© Оформление. ООО «1С-Паблишинг», 2015
Все права защищены.
Материалы предназначены для личного индивидуального использования приобретателем.
Запрещено тиражирование, распространение материалов, предоставление доступа по сети к материалам без письменного разрешения правообладателей.
Разрешено копирование фрагментов программного кода для использования в разрабатываемых прикладных решениях.
Фирма "1С"
123056, Москва, а/я 64, Селезневская ул., 21.
Тел.: (495) 737-92-57, факс: (495) 681-44-07.
1c@1c.ru, http://www.1c.ru/
Издательство ООО "1С-Паблишинг"
127434, Москва, Дмитровское ш., д. 9.
Тел.: (495) 681-02-21, факс: (495) 681-44-07.
publishing@1c.ru, http://books.1c.ru/
Глава 1. Поднимемся на крыльцо, откроем дверь
Широкое распространение информационных систем на платформе «1С:Предприятие» неизбежно поставило вопрос повышения технологического качества работы этих систем. Связано это и с естественным ростом информационных систем вместе с ростом предприятий, их использующих, и с усложнением учета, которое становится возможным по мере вовлечения в информационную систему новых участков, и с ростом баз, происходящим в течение жизни информационных систем. И однажды эти количественные и качественные изменения могут вызвать (и вызывают) у людей, обслуживающих эти системы, проблему: новый уровень информационной системы требует, во-первых, изменения подхода к принципиальным схемам работы и к их технической реализации, а во-вторых, нового уровня обслуживания.
На практике, однако, оказывается, что изменения подхода как к схемам и их воплощениям в виде решений, так и к обслуживанию могут запаздывать. В итоге в уже вполне больших и серьезных системах встречаются механизмы, которые выглядят как сколоченное из досок крыльцо для дачного домика в качестве входа в многоэтажный бизнес-центр.
И ведь нельзя сказать, что дощатое крыльцо – это заведомо некачественная или негодная вещь, отнюдь нет. Оно вполне может быть сделано с любовью и сделано руками мастера: красиво, ровно, аккуратно, с украшениями. Вот только его объективные технические характеристики (ограниченная пропускная способность, низкая износостойкость и ограничения по массе и габаритам для проносимого по нему груза) не позволяют его рассматривать и использовать иначе, чем для маленького домика.
И наоборот, шикарный стеклянный фасад с вращающимися или автоматическими дверями на дачных участках найти сложно: дорогое удовольствие, как в установке, так и в обслуживании.
Понятно, что и уровень обслуживания сложных механизмов должен быть другой: деревянную дверь вполне можно обслуживать только по факту возникновения проблем (смазывать петли), а у вращающихся или автоматических дверей состав и стоимость работ намного больше и определяется заводом-изготовителем.
Дверь и крыльцо однако находятся у всех на виду. А механизмы информационных систем прямому восприятию на первый взгляд недоступны, и, к сожалению, нередка ситуация, когда кто-то начинает думать, как решить проблемы качества работы системы, только если эти проблемы уже стоят в полный рост в виде недовольных пользователей.
Первоначально данная работа задумывалась именно как способ объяснить, что на самом деле работу систем на платформе «1С:Предприятие» можно видеть так же отчетливо, как входную дверь и очередь на вход, причем для этого не требуется никаких особых платных инструментов: все встроено в штатные механизмы. Эта идея в книге осталась, см. раздел 5.6.Ежедневный мониторинг
Однако стало необходимо объяснить, что стоит за полученными при мониторинге показателями и что с ними делать дальше. Это потребовало в относительно полном объеме собрать и изложить материал, который требуется для подготовки 1С:Эксперта по технологическим вопросам. И постараться изложить не только сам материал, но и подход к его использованию, потому что эта информация раскидана по многим источникам.
Тем, кто уже аттестовался как 1С:Эксперт по технологическим вопросам, известен замкнутый круг: чтобы правильно воспринять теорию, нужен правильный подход, но. чтобы использовать подход, нужно владеть теорией. Чтобы усвоить знания, нужен опыт, но. чтобы получить опыт, нужны знания.
Проблема стоит даже не в сборе информации, а в отсутствии системного подхода к ее усвоению и применению. А ему учат в единственном месте: на специализированном курсе в «1С».
На практике эта проблема решается тем, что специалисты посещают курс несколько раз и выходят из замкнутого круга, набрав требуемые знания и опыт и усвоив правильный подход к решению проблемы. Все бы ничего, но долго. А до этого момента новичок при решении практических задач оказывается беспомощным и реально самостоятельно работать не может.
Поэтому в нашей работе сделана попытка объединить вместе и правильный процесс подхода к решению проблем, и теорию, и инструкции по работе с инструментами, и практические методики по отработанным ситуациям. Только все вместе это может дать цельную картину, необходимую для правильного понимания и успешного решения возникающих проблем.
Об авторе
Филиппов Евгений Валерьевич
Имеет высшее техническое образование. В 2009 году первым провел успешное нагрузочное тестирование, в ходе которого в одной базе «1С:Предприятия» работало 1 000 пользователей, и экспериментально подтвердил работоспособность такой информационной системы. Работая в компаниях «Трейд Софт», а затем «1С:Первый БИТ», участвовал не менее чем в десяти проектах ЦКТП. В период подготовки второго издания руководил компанией «Центр технологической экспертизы Аксиома», специализировавшейся на проведении работ по нагрузочному тестированию и оптимизации производительности решений на платформе «1С:Предприятие». Ведет активную деятельность в направлении разработки механизмов и методик, которые снижают стоимость проведения таких работ и делают эти работы доступными для массового рынка. Проводит обучающие семинары и вебинары для сотрудников своей компании, партнеров и представителей клиентов.
Замечания и предложения по данной книге принимаются на адрес publishing@1c.ru.
Благодарности
Автор выражает благодарность А. Н. Арламенкову, А. А. Долгову, А. В. Звонилову, А. Р. Зорину, И. Н. Костяковой, Н. А. Моисеенко, А. Н. Морозову, С. Г. Нуралиеву, К. В. Рупасову, И. И. Русаковой, П. А. Скловскому за поддержку и помощь, оказанную на разных этапах создания книги.
Глава 2. Основной подход к решению проблем
2.1.Мы работаем только с проблемами
Для начала хотелось бы уточнить, какие именно задачи решают 1С:Эксперты по технологическим вопросам. Иногда случается, что задачи, которые нам присылают, формулируются так: провести аудит нашей системы управления торговлей, оценить:
- Быстродействие системы. Анализ аппаратных и программных средств, поиск узких мест. Рекомендации по увеличению быстродействия.
- Степень соответствия программного кода стандартам «1С». Возможно, дать рекомендации по исправлению, с расчетом стоимости работ.
- Степень востребованности доработок функционала в системе.
- Оптимальность реализации написанного функционала с точки зрения методологии (оптимальность бизнес-процессов) и с точки зрения программирования. Дать рекомендации по оптимизации.
Дать рекомендации по развитию системы; в ближайшей перспективе планируется подключение баз пятнадцати филиалов.
Можно высказать ряд догадок [1], откуда именно берется подобная постановка задач, однако есть смысл сказать сразу: задача в подобной постановке решена быть не может. Хотя бы просто потому, что в ней не задано ни начальное, ни конечное состояние системы, ни само пространство состояний. Давать же рекомендации по переходу из одного неизвестного состояния в другое неизвестное состояние в пространстве неопределенной размерности, а также оценивать стоимость работ по такому переходу как-то затруднительно, потому что потом за свои рекомендации придется отвечать.
Тем не менее, если люди к вам обратились, значит, определенная потребность в ваших работах есть, и надо как-то выяснить, что именно их к вам привело и какую задачу нужно решить на самом деле.
Для этого надо определить:
- пространство состояний системы,
- текущее состояние и мнение заказчика о нем,
- желаемое состояние и мнение о нем.
Обычно бывает, что задача сводится к двум вариантам:
- Работающая система. Заказчик обратился к вам, потому что текущее состояние системы его не устраивает. Это можно переформулировать так: пользователи, работающие в базе, сталкиваются с какими-либо проблемами.
- Существенно изменяемая или проектируемая система. Заказчик обратился к вам, потому что у него есть ожидания, что после некоторых изменений в системе пользователи, работающие в базе, начнут сталкиваться с какими-либо проблемами. Текущее состояние системы его устраивает, но сама система находится на пороге изменений либо уже изменяется.
В обоих случаях существует важный объект, называемый проблемой. Введение этого объекта позволяет определить пространство состояний системы и задать количественные характеристики, определяющие желательные и нежелательные состояния.
Существует частный случай варианта 1.
У нас все медленно работает. Сколько стоит посмотреть и исправить?
Хотя пространство состояний определено (это время выполнения каких-то операций) и текущее состояние обозначено как нежелательное, для такого варианта бывает характерно, что по разным причинам более подробной детализации получить не удается. В таком случае, если требуется назвать сроки и стоимость работ, лучше договориться об экспресс-диагностике (см. раздел 4.22.Бизнес-процесс общей диагностики) и уже по итогам анализа данных, полученных о системе, попробовать самостоятельно сформулировать проблемы, требующие решения.
Итак, что такое проблемы. Это те симптомы, которые видит (или потенциально увидит, если речь об изменениях системы) пользователь и которые определяют для него текущее состояние системы как нежелательное. К ним относятся:
- медленная работа,
- зависания,
- сообщения об ошибках.
Это означает, например, что участок кода, при написании которого никто и не думал ни о каких стандартах и при написании которого оптимизировали затраты на его создание, а не время его выполнения, совершенно не обязательно надо дорабатывать, потому что может иметь место следующее:
- Этот код работает всегда с очень малым объемом данных и поэтому всегда выполняется быстро. Поясню: очень плохой код может выполняться за 0,1 с. Если его оптимизировать, он станет выполняться в 10 раз быстрее, т. е. за 0,01 с. Но поскольку абсолютное значение в 0,1 с мало само по себе, то такой код, скорее всего, оптимизировать не надо, даже если он написан совершенно ужасно.
- Этот код никогда не вызывается или вызывается раз в год.
- Любой другой пример, почему совершенно неоптимальный, в спешке написанный код может не создавать пользователям никаких проблем. Увидев такой код, совершенно не надо начинать его оптимизировать просто по факту его выявления.
То, что пользователь «видит» проблемы, не обязательно означает, что он «жалуется» на них. Желание жаловаться является субъективным, подвержено изменениям и формализации не поддается, а это означает, что «наличие жалоб» в качестве формальной границы, отделяющей желательное состояние системы от нежелательного, не годится совершенно.
И хотя очень многие службы поддержки на практике используют количество обращений и жалоб в качестве одного из основных показателей своей деятельности, качественный мониторинг проблем при таком подходе весьма затруднителен.
Поэтому надо понять, что проблема – это симптом, который пользователь видит. А реагирует он на него или нет – нас не интересует, так как система содержит средства, позволяющие нам наблюдать эти же симптомы. Нас интересует, вышли ли некоторые объективно измеряемые характеристики этого симптома из зоны желательных значений или нет, а получать эти сведения можно и без привлечения пользователей.
Однако, несмотря на наше стремление определить пространство состояний исключительно в объективно измеряемых показателях, этого сделать не удается. Есть две вещи, определяющие размерность и границы пространства состояний, являющиеся по определению субъективными, поскольку они не измеряются, а назначаются человеком:
- важность проблемы: количеством важных проблем определяется размерность пространства состояний, относительная важность (приоритет) определяет порядок осей координат этого пространства;
- разделение количественных значений характеристик на желательные и нежелательные (а также в некоторой степени желательные, если допускается нечеткость подмножеств): этим определяются границы областей пространства состояний, в которых мы будем работать.
Несмотря на такую субъективность и, возможно, нечеткость, существует единственный разумный способ формализовать важность и желательность – зафиксировать список важных проблем, их относительную важность (приоритеты) и желательные значения количественно измеряемых показателей этих проблем в договоре.
Если важная проблема возникает вследствие превышения допустимого значения длительности выполнения системой некоторого действия, такое действие называют ключевой операцией.
То есть, говоря наоборот: ключевая операция – это операция (действие) системы, у которой количественной характеристикой, определяющей наступление нежелательного состояния, является время выполнения этой операции, и наступление этого нежелательного состояния является важной проблемой.
Обычно ключевая операция – это однократное нажатие пользователем какой-то кнопки на форме или выбор пункта меню, а время выполнения – это время, за которое система это нажатие отрабатывает. Иногда разные кнопки могут интерпретироваться как одна и та же ключевая операция (но обычно при этом системой выполняются одни и те же действия: проведение документа, формирование отчета, открытие формы и т. п.).
Когда таких действий выполнено много, имеет смысл как-то сворачивать в число совокупность всех полученных значений длительности их выполнения (получать интегральную характеристику). Фирмой «1С» в качестве способа такой свертки применяется методика APDEX.
Подробнее о понятии ключевой операции и интегральной характеристике APDEX см. главу «Теория», разделы 3.1.Ключевые операции и 3.2.Методика APDEX.
Если важная проблема возникает вследствие реакции системы, не позволяющей продолжить выполнение действия (единичной или некоторого количества за период), такую реакцию системы называют критичной ошибкой.
То есть, говоря наоборот: критичная ошибка – это операция (действие) системы, у которой количественной характеристикой, определяющей наступление нежелательного состояния, является фактическое количество таких действий за период, и наступление этого нежелательного состояния является важной проблемой.
О критичных ошибках подробнее см. главу «Теория», раздел 3.3.Критичные ошибки.
Все проблемы таким образом оказываются поделенными на два класса, и обычно в договорах по повышению технологического качества информационных систем «1С» их выделяют как:
- коэффициент производительности: значение показателя APDEX, являющееся сверткой времени выполнения ключевых операций;
- количество критичных ошибок, обычно за какой-то период, к которым относят:
- ошибки блокировок;
- системные ошибки;
- ошибки защиты;
- падение кластера серверов «1С:Предприятия»;
- зависание кластера серверов «1С:Предприятия».
Надо отметить, что часть критичных ошибок в проектной документации на создание центров обработки данных и в других похожих задачах интерпретируется как устойчивость системы, а также как процент доступности системы. Что это и как осуществляется расчет таких показателей, см. главу «Теория», раздел 3.14.Планы запросов.
Также следует обратить внимание на то, что при работах по оптимизации системы и при работах по повышению технологического качества системы не уделяется внимания несистемным, функциональным и прикладным ошибкам, в т. ч.:
- синтаксическим ошибкам кода;
- неправильной, с точки зрения пользователя, реакции системы без сообщения об ошибке (при нажатии кнопки не заполняется табличная часть);
- неправильным расчетам (НДС считает 17 % вместо 18 %) и т. п.
Связано это с тем, что такие ошибки относятся к другим областям знаний и обычно требуют от сотрудника несколько (а иногда и существенно) иных знаний и умений, чем те, которые предъявляются к 1С:Экспертам по технологическим вопросам.
В итоге в договор должен попасть список ключевых операций и критичных ошибок, формально определяющий пространство состояний системы. Критерий включения в список – важность возникающей проблемы и ее практическая значимость.
По каждому из компонентов списка должно быть указано целевое состояние, в которое надо привести этот компонент:
- приемлемая стабильность.
- целевое значение APDEX для каждой из ключевых операций.
В совокупности это даст целевое состояние всей системы.
Существует опасность задать слишком большой список ключевых операций. Это может привести к следующему: обычное время решения одной проблемы – дня три; 20 проблем = 60 рабочих дней – это 3 месяца. С учетом того, что при работах по оптимизации существует необходимость устанавливать мораторий на внесение изменений в определенную область конфигурации (а если операций много, то на всю конфигурацию), устранение даже 20 проблем потребует трехмесячного моратория на доработки функционала. В реальности даже такой срок предоставить никто не может, не говоря уже о большем.
Поэтому список ключевых операций надо ограничивать, и совершенно точно нет смысла включать в него свыше 20 позиций. Впоследствии (после завершения оптимизации этих 20 операций) можно будет составить новый список из следующих по приоритету операций.
Целевое состояние, которое мы описанным выше образом формализовали, определяет требования к производительности, доступности и работоспособности системы, которым она должна удовлетворять либо в ее нынешнем состоянии, либо с учетом ее планируемых изменений.
[1] Было высказано пожелание писать более конкретно и четко. К сожалению, когда приходится принимать решения в условиях высокой неопределенности и нечеткой постановки задачи, возможности что-либо конкретизировать практически не бывает; такая возможность появляется, только когда задача уже формализована.
2.2.Как измерять, как получать цифры
Как отмечалось в предыдущем разделе, работы по оптимизации производительности или повышению технологического качества работы системы могут быть инициированы:
- на работающей системе;
- на перспективной системе, к которой можно отнести как проектируемую систему, так и существующую систему, для которой запланированы изменения.
В обоих случаях методика замеров одинакова. Замерять надо:
- время выполнения ключевых операций с указанием, что за операция выполнялась;
- количество критичных ошибок в разрезе того, что это за ошибки:
- ошибки блокировок;
- системные ошибки;
- ошибки защиты;
- падение кластера серверов «1С:Предприятия»;
- зависание кластера серверов «1С:Предприятия».
Удобным способом получения длительности выполнения ключевых операций и их интегральных оценок по шкале APDEX является встраивание подсистемы «Оценка производительности» из состава Библиотеки стандартных подсистем «1С». Как ее встроить, см. главу «Инструкции», раздел 4.7.Замеры производительности.
Ошибки блокировок, системные ошибки и ошибки защиты можно считать по технологическому журналу. Как организовать сбор технологического журнала и его анализ, см. главу «Инструкции», разделы 4.5.Как включить технологический журнал «1С» и как его можно разбирать и 4.6.Общий подход к анализу технологического журнала «1С». Этот алгоритм планируется встраивать в Центр контроля качества (ЦКК).
Аварийные завершения процессов кластера серверов «1С:Предприятия» можно считать по дампам, образующимся при падении процессов при включенной специальной настройке. Общий подход – см. главу «Инструкции», раздел 4.9.Сбор статистики дампов (общий принцип). Рекомендуется, однако, использовать ЦКК, в него уже встроены подсчет дампов и их группировка по офсетам.
Зависание кластера серверов «1С:Предприятия» нужно отслеживать с помощью ЦКК. Вручную факт зависания можно отследить только непосредственно наблюдая его симптомы (процессы кластера находятся в памяти, но ни на какие запросы пользователей кластер не отвечает и новые клиентские соединения создавать не дает). Понятно, что такой метод ни полноты картины, ни удобства не обеспечивает.
Если речь идет о комплексе с одной базой, то всю собранную статистику можно объединять вручную. Однако если речь идет о комплексе с большим количеством баз и с интенсивным потоком событий, ручное формирование сводной статистики может превратиться в трудоемкую операцию, и в таком случае существенное облегчение может быть получено за счет использования ЦКК для автоматизации сбора всей статистики. О принципах работы ЦКК см. главу «Инструкции», разделы 4.10.Работа с ЦКК. Общие принципы, стандартные возможности, первичная настройка и 4.11.Работа с ЦКК. Настройка собственных контрольных процедур.
В случае перспективной системы вместо построения теоретических умозаключений будет значительно эффективнее согласовать и создать модель базы, которая должна получиться в первые месяцы работы системы. Затем на оборудовании заказчика или на арендованном оборудовании в этой базе нужно запустить нагрузочный тест с учетом прогнозируемой интенсивности ввода документов, после чего посмотреть на результаты и сделать выводы.
О том, как организуются нагрузочные тесты, см. главу «Инструкции», раздел 4.21.Нагрузочные тесты.
Для получения статистики перспективной системы применяется тот же состав замеров и методика их организации, что и для работающей системы. При этом надо понимать, что если нагрузочный тест не проведен заранее силами роботов, то это же нагрузочное тестирование все равно пойдет в первые же дни эксплуатации созданной (или измененной) системы. Только это тестирование пойдет уже на живых пользователях в ходе реальной работы, и еще неизвестно, какое из тестирований по факту обойдется дороже. Если все же принято решение о нагрузочном тестировании на людях, это также не меняет ни состава, ни методики организации замеров.
Данные, полученные в ходе измерений, как показатели APDEX, так и количество критичных ошибок, надо сравнить с целевыми требованиями и переходить к решению проблем.
По падениям и непонятным ошибкам, оцененным как критичные, необходимо обращаться в фирму «1С»: либо в техподдержку, либо через участие в проекте ЦКТП.
По задачам оптимизации ключевых операций последовательность действий определяется как движение по «незеленым» строчкам в списке полученных показателей APDEX, начиная с операции, имеющей наивысший приоритет.
2.3.Как устроена система
Действие пользователя, предусматривающее чтение данных из базы или запись их в базу, вызывает некоторую последовательность команд.
Эти команды и связанные с ними данные должны пройти приблизительно следующий маршрут, сначала в прямом направлении, а затем в обратном:
- клиент:
- код на языке «1С», выполняющийся на клиенте,
- платформа «1С:Предприятие» (клиентское приложение),
- ОС,
- оборудование.
- сеть,
- сервер «1С»:
- код на языке «1С», выполняющийся на сервере,
- платформа «1С:Предприятие» (серверные процессы),
- ОС и софт виртуальной машины (если есть),
- ОС физической машины,
- оборудование,
- сеть,
- сервер СУБД:
- сами запросы,
- СУБД,
- ОС и софт виртуальной машины (если есть),
- ОС физической машины,
- оборудование.
По приведенной выше схеме видно, что система является многоуровневой, и в расходах времени на операцию принимают участие все накладные расходы на всех уровнях, в обе стороны.
Чтобы понять, о чем речь, можно сопоставить такой схеме схему поездки в сетевой гипермаркет. Причем нет особой разницы: идет чтение или идет запись – и то, и другое одинаково описывается с помощью такого сопоставления.
Туда:
- дом:
- найти ключи,
- лифт,
- дорога:
- дойти до автомобиля,
- автомобиль (дорога туда),
- магазин:
- найти тележку,
- траволатор,
- стеллажи,
- касса.
Обратно:
- магазин:
- траволатор,
- погрузить сумки в автомобиль,
- дорога:
- автомобиль (дорога обратно),
- донести сумки до лифта, возможно, за несколько заходов,
- дом:
- лифт,
- отпереть дверь, зайти домой.
Такая схема годится, потому что и организация движения, и организация розничной торговли, и система на платформе «1С:Предприятие» по своей сущности являются системами массового обслуживания. Для простоты будем считать, что все автомобили, которые едут по дороге, едут либо в этот магазин, либо из него, и таким образом снимем необходимость других допущений.
Рассмотрение систем на платформе «1С:Предприятие» с помощью аппарата теории массового обслуживания еще ждет своего исследователя. Одним из практических аспектов такого исследования могла бы стать замена нагрузочных тестов для некоторых целей имитационным моделированием (нагрузочный тест хотя и проводится с помощью средств вычислительной техники, представляет собой все-таки натурный эксперимент, хотя и с заменой живых пользователей «роботами»).
Как отмечалось ранее, на каждом из уровней системы существуют определенные накладные расходы на выполнение команд (действий, требований). Совокупность этих расходов определяет суммарное время выполнения операции. Расходы, происходящие на каждом из уровней, определяются:
- Собственно свойствами уровня (более скоростной автомобиль может доехать до магазина быстрее).
- Свойствами выполняемых действий (от количества товаров в тележке зависит время обслуживания на кассе).
- Потерями времени на ожидание (очередь в кассу и пробка на дороге сводят на нет весь выигрыш времени, полученный от использования скоростного автомобиля и небольшого количества покупок).
Первые два фактора приводят к проблемам, называемым проблемами производительности. Эти проблемы возникают, даже если система в указанный момент времени обслуживает только одну операцию.
Третий фактор приводит к проблемам, называемым проблемами параллельности. Эти проблемы возникают только тогда, когда в системе одновременно выполняется более одной операции.
Существует характерная особенность систем, в которых есть проблемы параллельности. Она заключается в том, что в условиях установившегося входного потока пропускная способность системы определяется пропускной способностью ее самого медленного уровня. Такой уровень называется «узким местом» или «бутылочным горлышком» (bottle neck). В рассматриваемом классе систем (у всех действий единая точка входа, например, все автомобили, которые едут по дороге, едут либо в этот магазин, либо из него) это «бутылочное горлышко» всегда одно. Так же, как на дороге, на уровнях, находящихся после этого «бутылочного горлышка», всегда будет иметь место характерный спад загрузки: если покупатели толпятся в овощном отделе, на кассах будет свободно; если в системе выстроилась очередь из блокировок, оборудование сервера СУБД будет простаивать.
2.4.Бизнес-процесс решения проблем по ключевым операциям
Выше рассматривалась схема взаимодействия с заказчиком. Подводя итог написанному выше, ее можно представить так:
- Получить список жалоб.
- По списку жалоб составить список ключевых операций (ограниченное количество).
- По списку ключевых операций совместно с заказчиком назначить целевое время и приоритеты.
- Пока идет согласование по п. 3 (это не всегда быстро), можно подключить и настроить ЦУП, но он не понадобится до этапа 8.
- По списку ключевых операций встроить замеры в базу, получить результаты.
- Сравнить результаты с целевым временем. Операции с плохим фактическим временем относительно целевого (с плохим APDEX) следует начинать разбирать в порядке убывания приоритета.
- По каждой операции найти наиболее типичное действие (по гистограмме найти интервал времени, в который попало наибольшее количество замеров).
- Для этого действия провести анализ, выяснить, что это за действие (как – описано в этом разделе ниже).
- Понять, с какой проблемой имеем дело, что придется делать, и оценить трудоемкость решения.
- Оформить результаты по п. 7 и 8 в виде отчета, согласовать с заказчиком дальнейшие действия.
- Воплотить рекомендации в жизнь, сравнить результаты с целевым временем.
Теперь более подробно рассмотрим алгоритм анализа (п. 7, 8) и оценки трудоемкости (п. 9) из списка выше.
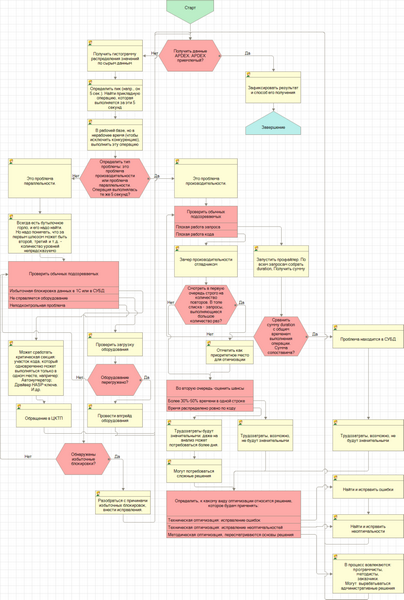
Рис. 2.4.1. Схема бизнес-процесса решения проблем по ключевым операциям
На рис. 2.4.1 приведена схема бизнес-процесса решения проблем по ключевым операциям. Ключевым пунктом схемы является вопрос: имеем мы дело с проблемой производительности или проблемой параллельности.
Чтобы подготовить ответ на этот вопрос, нужно найти наиболее типичного представителя действий, выполненных по ключевой операции, для которой требуется улучшать APDEX, и в нерабочее время его выполнить. Дело в том, что если для этой же операции ориентироваться на наихудших представителей, список причин, вызывающих проблемы, может оказаться другим. Чтобы этого наиболее типичного представителя найти, для ключевой операции, по которой требуется улучшать APDEX, нужно:
- по данным замеров построить гистограмму [2] распределения частот попаданий значений времени в интервалы (количество и границы интервалов определяются сообразно фактическим данным), написание программного кода построения такой гистограммы трудностей вызвать не должно;
- определить интервал, в который частота попадания максимальна;
- подобрать действие [3] по этой ключевой операции, длительность выполнения которого по данным замеров соответствует этому интервалу.
Выполнив именно это действие (например, проведя этот же документ) в тех же самых условиях, под тем же самым пользователем, но в нерабочее время, и сопоставив время выполнения этого действия с исходным временем, мы сразу сможем установить: происходили ли при выполнении этого же действия в рабочее время ожидания в очередях. Если они были, то время выполнения в нерабочее время будет гораздо меньше, чем в рабочее, и мы имеем дело с проблемой параллельности. Если же время выполнения осталось примерно то же самое, то мы имеем дело с проблемой производительности.
Чтобы было понятнее, можно вернуться к аналогии с автомобилем и гипермаркетом. Едем на той же машине в тот же магазин, но ночью. Если приехали намного быстрее, чем днем, то днем была пробка, следовательно, нужно устранять ее причины (строить развязку). Если приехали примерно за то же время, то мы ездим на «запорожце» – нужно менять его на «порше».
Определив, с какой проблемой имеем дело, можно четко установить план дальнейших действий. Сначала рассмотрим, что делать с проблемой производительности.
У проблем производительности есть два обычных подозреваемых:
- плохая работа запроса,
- плохая работа кода.
Прочие подозреваемые описаны в главе «Методики», разделы 5.2.Требования с диска ИТС, применяемые при проверке на 1С:Совместимо!, влияющие на производительность–5.5.Приемы конфигурирования, приводящие к проблемам. Методики их поимки, см., например, «Инструкции», раздел 4.22.Бизнес-процесс общей диагностики и «Методики», раздел 5.6.Ежедневный мониторинг.
Обоих обычных подозреваемых надо проверить.
Плохая работа запроса для СУБД MS SQL проверяется так: включив профайлер SQL Server, выполняем ключевую операцию еще раз и собираем длительности всех запросов, выполнявшихся во время его работы (показатель duration). Инструкцию, как это сделать и как получить их сумму, см. в главе «Инструкции», раздел 4.13.Работа в профайлере. Как получить сумму duration. Если сумма duration близка ко времени выполнения всей операции, можно однозначно делать вывод, что потери времени происходят в СУБД. Дальнейшее исправление состоит в определении неоптимальностей и их устранении (см., например, главу «Инструкции» раздел 4.20.Работа в конфигураторе. Исправление запросов). Для измерения длительности запроса в других СУБД (не MS SQL Server) рекомендуется использовать технологический журнал «1С».
Плохая работа кода проверяется так: включив замер на отладчике (см. главу «Инструкции», раздел 4.7.Замеры производительности), выполняем действие еще раз (отладка на сервере должна быть включена). Получаем таблицу, содержащую строки кода, количество их выполнений и время выполнения (как абсолютное, так и в процентном отношении к общему). Следует учесть, что замер отладчиком показывает именно работу кода конфигурации, а не общее время операции, включающее в себя также и платформенные вызовы.
Первое, на что надо смотреть, сколько раз выполнялись строки кода, входящие в топ по времени выполнения. Если эти строки содержат запросы к базе через объектную модель или на языке запросов и эти строки выполнялись много раз, то эти участки кода надо иметь в виду как приоритетные для исправления: запрос в цикле – это способ программирования, который всегда дает проигрыш во времени выполнения кода.
Второе, на что надо смотреть, есть ли строки кода, выполнение которых заняло существенную часть от общего времени. Это позволяет оценить шансы в борьбе за повышение производительности. Если такие строки есть, то шансы можно оценивать как очень хорошие. Если же таких строк нет и, например, на первом месте находится строка, выполнение которой занимает 3–5 % от общего времени, то понятно, что уменьшение времени выполнения этой строки даже до нуля даст прирост в те же самые 3–5 %. Поскольку речь может идти о том, чтобы ускорить выполнение операций в разы, шансы на это будут совершенно призрачны.
Далее надо оценить и согласовать трудозатраты, требующиеся на решение проблемы.
Основанием для оценок трудоемкости решения проблемы будут служить полученные сведения. Если проблема находится в СУБД или есть строки кода, имеющие высокую относительную длительность выполнения, то, как правило, проблема может быть решена техническими средствами и решена довольно быстро: пары часов обычно хватает, чтобы с ней разобраться. Как и что можно исправить, см. главу «Инструкции», раздел 4.20.Работа в конфигураторе. Исправление запросов и главу «Методики и дополнительная информация», разделы 5.2.Требования с диска ИТС, применяемые при проверке на 1С:Совместимо!, влияющие на производительность и 5.5.Приемы конфигурирования, приводящие к проблемам.
Если же все строки кода имеют малую относительную длительность, а строк много, то длительность работ серьезно возрастает: только на то, чтобы провести анализ ситуации, может уйти день работы. По итогам анализа может быть установлено, что проблема не имеет технического решения, и потребуются сложные методические или даже административные решения, с пересмотром основ конфигурации, с вовлечением в процесс программистов-разработчиков, методистов и заказчиков.
Для решения проблем параллельности, как указывалось ранее, всегда надо найти «бутылочное горлышко». Однако надо понимать, что за одним «горлышком» может быть целый каскад следующих «горлышек», и, вообще говоря, количество уровней может быть непредсказуемым. Поэтому, встретившись с проблемами параллельности, оценку трудозатрат надо давать с учетом этой особенности таких задач.
Обычные подозреваемые:
- избыточная блокировка данных в «1С» или в СУБД. Подробности по блокировкам см. в главе «Теория», разделы 3.6.Транзакции. Уровни изоляции транзакций. Явные и неявные транзакции. Вложенные транзакции. Откат транзакций–3.10.Эскалация блокировок;
- не справляется оборудование. Как организовать замер загрузки оборудования и интерпретировать значения, см. в главе «Инструкции», раздел 4.1.Как настроить сбор информации о загрузке оборудования и как оценить эту загрузку.
Может, однако, случиться и такое, что сработает критическая секция (участок кода, который одновременно может выполняться только в одном месте), например:
- автонумератор,
- драйвер HASP-ключа и др.
Такая проблема классифицируется как неподконтрольная проблема. В таких ситуациях, с одной стороны, нет никаких средств диагностики, с другой – видно, что это проблема параллельности. При обнаружении такой проблемы неизбежным и правильным вариантом решения является обращение за помощью в ЦКТП.
В заключение надо сказать, что и в ходе работ по решению проблем производительности, и в ходе работ по решению проблем параллельности вам могут встретиться задачи, для решения которых не хватит средств диагностики и опыта. В случае необходимости применения методических или административных способов решения проблем вам может не хватить авторитета. В случае работы над проектом, который выполняет ваша же компания, у вас может не быть возможности для независимой оценки, либо заказчик может не верить в то, что ваша оценка независима. В случаях работы в рискованных финансовых или технических условиях вам может не хватить уверенности из-за отсутствия страховки.
Во всех этих случаях обращение в ЦКТП является правильным и может обеспечить успех проекта, а иногда и просто его спасти.
[2] В текущей версии подсистемы ОП гистограмма строится автоматически.
[3] При использовании подсистемы «Оценка производительности», если ключевая операция связана с транзакцией, это можно точно определить имеющимися средствами. Регистр сведений «Замеры времени» содержит реквизит «Имя пользователя» и данные о времени начала замера. Нужно найти по журналу регистрации, что пользователь в это время делал, и в нем по полю «Представление данных» определить, например, что это был за документ (номер и дату). Если ключевая операция с транзакцией не связана (например, ключевая операция – это выполнение отчета или открытие формы), обычно просто достаточно знать, под каким пользователем это действие выполнялось. Но если этого недостаточно, надо вместе с началом замера вносить в журнал регистрации данные, необходимые для понимания особенностей выполняемой операции.
Глава 3.Теория
3.1.Ключевые операции
Ключевая операция (КО) – это операция (действие) системы, у которой количественной характеристикой, определяющей наступление нежелательного состояния, является время выполнения этой операции, и наступление этого нежелательного состояния является важной проблемой.
На практике под ключевой операцией понимают действия системы после однократного нажатия пользователем какой-либо кнопки на форме или выбора пункта меню.
С единственной оговоркой [4] можно утверждать следующее:
- ключевая операция всегда начинается на клиенте;
- ключевая операция не может состоять из нескольких интерактивных действий пользователя, потому что мы оптимизируем только систему, а не работу пользователей;
- ключевая операция всегда заканчивается на клиенте. То есть мы не можем разбить на несколько КО действие, которое является единым с точки зрения пользователя. В этом нет смысла, т. к. требования к частям операции не могут быть определены (пользователю все равно).
Обычно нежелательность состояния рассматривается с точки зрения пользователя: проблема – это симптом, который видит пользователь, и в данном случае это недостаточно быстрое выполнение системой какой-либо важной для него операции.
Перед началом выполнения работ по оптимизации список ключевых операций должен быть составлен и зафиксирован. Размер списка не должен быть большим: разбор даже несложных проблем по каждой ключевой операции требует времени, и работы по списку из 20 операций точно займут не менее двух-трех месяцев.
Каждой ключевой операции должно быть назначено (пользователем) целевое время Т, а также приоритет.
Целевое время – это время, за которое, с точки зрения пользователя, всегда должна выполняться ключевая операция, чтобы он считал работу системы отличной. Пользователь имеет право выразить завышенные ожидания, и тогда его надо письменно предупредить, что, возможно, вы вернетесь к этому разговору (см. рис. 3.1.1).
Приоритет обычно определяется исходя из того,, насколько проблема, вызываемая недостаточно быстрым выполнением действий системы, важна для пользователя. На практике при такой формулировке пользователь говорит: «Мне все проблемы важны одинаково» – и ставит всем одинаковый приоритет (как вариант выделяет несколько групп с разными приоритетами).
На самом деле приоритет – это то, в каком порядке вы будете заниматься решением проблем пользователя. Поэтому заказчику так и надо сказать: «Оптимизацией будет заниматься один человек (это наиболее распространенный случай), поэтому он все равно будет решать задачи не параллельно, а последовательно. Пожалуйста, укажите, в каком порядке ему заниматься решением задач, если по итогам замеров окажется, что по всем операциям производительность недостаточно хороша».
В договоре обычно указывается следующее (см. рис. 3.1.1):
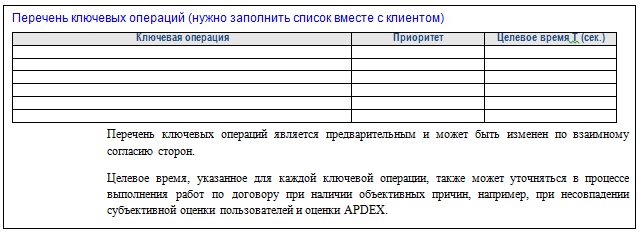
Рис. 3.1.1. Список ключевых операций и дополнительные пояснения к ним, обычно включаемые в договор
После согласования списка ключевых операций замеры времени надо встроить в конфигурацию. Удобный способ это сделать – использовать подсистему «Оценка производительности» из состава Библиотеки стандартных подсистем «1С». Описание см. в главе «Инструкции», раздел 4.7.Замеры производительности.
[4] Оговорка заключается в том, что при проведении нагрузочных тестов в качестве ключевых операций может выступать как раз время выполнения действий на сервере, потому что организовать это проще и дешевле. Это имеет право на существование, если достоверно установлено, что вызов кода обработкой с сервера, а не имитацией выполнения действия на клиенте, не исказит результатов. Например, вам надо удостовериться, что с точки зрения решаемой задачи допустимо вместо нажатия кнопки ОК на форме использовать вызов ДокументОбъект.Записать(...) сразу с сервера.
3.2.Методика APDEX
Когда ключевая операция выполняется много раз, имеет смысл как-то сворачивать в число совокупность всех значений (получать интегральную характеристику) времени ее выполнения.
И глядя с противоположной стороны, собранные замеры всегда имеет смысл рассматривать на достаточно большой выборке – не менее 100 замеров.
Агрегировать можно по-разному: максимум, минимум, среднее, сумма, взвешенная сумма, методы математической статистики, методика APDEX. Не очень важно, как именно вы агрегируете или сворачиваете показатели. Важно, чтобы ваш заказчик понимал, в чем эта свертка заключается и почему она корректна.
Фирма «1С» считает, что удобной и корректной является методика APDEX. Эта методика используется в составе подсистемы «Оценка производительности» из Библиотеки стандартных подсистем. Подробную информацию об этой методике можно найти в Интернете (на английском языке): http://apdex.org/index.html, http://en.wikipedia.org/wiki/Apdex.
Смысл методики таков: если какое-то действие должно выполниться за T секунд и оно выполняется за эти T секунд или быстрее, оно считается успешно выполненным. Если оно выполняется несколько дольше – от Т до 4Т, оно считается наполовину успешным. Если оно выполняется очень долго – свыше 4Т, оно считается неуспешным.
Если действия выполнялись неоднократно (N раз), далее достаточно подсчитать успешно выполненные действия (пусть их будет NS), подсчитать наполовину успешные (пусть их будет NT).
Число (NS + NT /2) / N показывает отношение успешных и наполовину успешных действий к общему количеству действий.
Что такое Т и 4Т, с точки зрения пользователя:
- Т – это время, которое пользователя полностью удовлетворяет;
- 4Т – это время, которое пользователя не удовлетворяет, но он дождался получения результата;
- больше 4Т – пользователь не дождался получения результата, то есть операция вообще не выполнена.
В таблице 3.2.1 показано, какие качественные значения соответствуют количественным значениям показателей APDEX.
Таблица 3.2.1. Соответствие качественных оценок значениям APDEX
| Шкала APDEX | ||
|---|---|---|
| Значение | Оценка | |
| от | до | |
| 0.00 | 0.50 | неприемлемо |
| 0.50 | 0.70 | очень плохо |
| 0.70 | 0.85 | плохо (в некоторых интерпретациях – удовлетворительно) |
| 0.85 | 0.94 | хорошо |
| 0.94 | 1.00 | отлично |
В случае 100-кратного выполнения [5] действия на практике это выглядит так, как показано в таблице 3.2.2.
Таблица 3.2.2. Примеры комбинаций N, NS и NT для 100-кратного выполнения действия и соответствующие им оценки APDEX (показаны комбинации для нижней границы диапазона, соответствующего оценке)
| (NS + NT /2) / N | Оценка | NS (успешных) | NT (наполовину успешных) | N – NS – NT (не уложившихся в 4Т) |
|---|---|---|---|---|
| 0,94 – 1 | отлично | 94 | 0 | 6 |
| 0,94 – 1 | отлично | 88 | 12 | 0 |
| 0,85 – 0,93 | хорошо | 85 | 0 | 15 |
| 0,85 – 0,93 | хорошо | 70 | 30 | 0 |
| 0,70 – 0,84 | плохо | 70 | 0 | 30 |
| 0,70 – 0,84 | плохо | 40 | 60 | 0 |
| 0,50 – 0,69 | очень плохо | 50 | 0 | 50 |
| 0,50 – 0,69 | очень плохо | 0 | 100 | 0 |
| 0,00 – 0,49 | неприемлемо | Все, что еще хуже, чем две предыдущие строки | ||
Заказчики не сразу принимают такую схему, но для массовых замеров она действительно хороша, так как учитывает не двоичную логику результата (уложились/не уложились), а более сложную (уложились полностью/уложились в рамках допустимого/не уложились).
Соответствие качественной оценки «хорошо» значению показателя 0,85 и выше – это для бизнеса, т. к. решаются его задачи. При этом некоторые операции выполняются долго или не выполняются вообще (пользователи «страдают» [6]). Но, поскольку может оказаться дешевле оплачивать «страдания» пользователей, чем оптимизировать систему до 1,00, это приемлемо с точки зрения бизнеса.
Повторим еще раз: можно использовать любой подходящий для вашей ситуации способ свертки [7], лишь бы у вас с заказчиком по этому поводу было единое мнение. Если вы идете по пути встраивания подсистемы «Оценка производительности» из Библиотеки стандартных подсистем, то по сырым данным регистра сведений «Замеры времени» вы можете самостоятельно построить любую подходящую функцию, позволяющую яснее представить результат себе и заказчику. Свертка по методике APDEX в этой подсистеме, однако, уже реализована, и это еще один хороший повод пользоваться именно ей.
Существует обратная задача – получить целевое время по заданному значению APDEX, если заказчик затрудняется это целевое время назвать.
На практике, правда, в такой постановке эта задача встречается редко: список ключевых операций согласовывается до встраивания замеров в базу, а предлагаемая методика основывается на том, что замеры в базу уже встроены. Более вероятен вариант – использовать этот подход при необходимости переназначения и повторного согласования целевого времени, изначально заданного чересчур жестко.
Задачу необязательно решать вручную. В подсистему ОП встроен механизм автоматического подбора времени Т под заданное значение APDEX.
Если же требуется все-таки ручное решение, то порядок действий должен быть таким:
- Получить у заинтересованных пользователей субъективную оценку производительности этой операции в терминах APDEX: Неприемлемо, Очень плохо, Плохо, Хорошо, Отлично. Установить значение APDEX, равное середине диапазона: соответственно, 0,25, 0,6, 0,775, 0,9, 0,95.
- Собрать информацию – сколько на самом деле выполняется эта операция в системе.
- Подобрать такое значение T, чтобы APDEX, рассчитанный для него, был примерно равен значению, назначенному в п. 1. В случае использования подсистемы «Оценка производительности» из БСП это можно делать непосредственно в режиме исполнения.
- Проверить правильность полученного значения Т, если подбор осуществлялся каким-то другим способом.
- Продолжать получать значение APDEX для данной операции, исходя из нового времени Т, убедиться в том, что получаемая оценка APDEX соответствует субъективной оценке заказчика (в том числе если имело место переназначение и повторное согласование целевого времени).
[7] Но только не в том случае, если вы работаете с «1С» по проекту ЦКТП – тогда использование именно методики APDEX будет обязательным.
[6] Почему «страдания» заключено в кавычки, и что страдает на самом деле, см. раздел 6.1.
[5] Как говорилось выше, для получения необходимой точности нужно не менее 100 замеров. Если речь идет не о частых, а о редких или даже единичных событиях большой длительности (например, о выполнении каких-то регламентных операций), то описанный подход не годится: очень велика становится разница, выполняется операция, скажем, 2 часа или же 8. Если такая ключевая операция находится в числе прочих (коротких и частых), то надо смотреть по ситуации, что с ней делать. Можно считать для нее APDEX просто для сохранения единого подхода к замерам, соответственно подобрав целевое время, но можно сразу выделять ее в отдельную задачу, с результатом в виде достижения обозначенного времени выполнения.



















